Abstract
Morphologically derivative languages form words by fusing stems and suffixes, stems are important to be extracted in order to make cross lingual alignment and knowledge transfer. As there are phonetic harmony and disharmony when linguistic particles are combined, both phonetic and morphological changes need to be analyzed. This paper proposes a multilingual stemming method that learns morpho-phonetic changes automatically based on character based embedding and sequential modeling. Firstly, the character feature embedding at the sentence level is used as input, and the BiLSTM model is used to obtain the forward and reverse context sequence, and the attention mechanism is added to this model for weight learning, and the global feature information is extracted to capture the stem and affix boundaries; finally CRF model is used to learn more information from sequence features to describe context information more effectively. In order to verify the effectiveness of the above model, the model in this paper is compared with the traditional model on two different data sets of three derivative languages: Uyghur, Kazakh and Kirghiz. The experimental results show that the model in this paper has the best stemming effect on multilingual sentence-level datasets, which leads to more effective stemming. In addition, the proposed model outperforms other traditional models, and fully consider the data characteristics, and has certain advantages with less human intervention.
1. Introduction
Nowadays, people obtain and share all kinds of information through the Internet such as multilingual information of popular and unpopular languages. In order to dissolve the linguistic barriers, people are researching on cross-lingual information processing and knowledge transferring. And the stems and terms are the only basic important particles which can be aligned between language and provide reliable knowledge bases for cross language learning and machine translation.
Minority languages such as Uyghur, Kazakh and Kirghiz languages in Northwest China have a similar morphology. But there are certain differences and noise in word formations as a result of personalized expressions, that required a lot of manual works in previous research [1]. These languages are typical derivative languages with various forms of word formation. So the low quality and scarcity of linguistic resources are the big problems. Data collected from the Internet is noisy and uncertain [2]. Although the writing forms of Uyghur, Kazakh and Kirghiz languages appear to be similar, there are still some differences. Due to these uncertainties, making a unified language independent tool is quite difficult. What these three languages have in common is that the text characters are similar [3]. In order to reduce the polyphony of each letter in the three languages and to remove the ambiguity, this paper normalizes Uyghur, Kazakh, and Kirghiz language texts and transcribed in Roman alphabets. This paper proposes a multilingual stemming model based on bidirectional LSTM, attention mechanism and CRF. The stemming model uses a bidirectional LSTM to learn long-range dependencies between inputs from texts in three languages, Uyghur, Kazakh, and Kirghiz, and extract better features. In addition, an attention mechanism is introduced to calculate the attention probability distribution, weight it, and then send it to the CRF layer to obtain the corresponding annotation sequence, thereby improving the performance of multilingual derivative language stemming. Our contributions can be summarized as follows:
- In this paper, we propose a stemming model that integrates sentence context and character features. In order to study the impact of context information on the model in this paper, the model is tested on sentence-level and word-level datasets. Effective It solves the problem that the sticky language stemming task is difficult to deal with sentence-level corpus with contextual information.
- Based on the BiLSTM-CRF model, we introduce an attention mechanism to improve it, compare it with the traditional model, and comprehensively consider the data characteristics, thus verifying the effectiveness of the model in this paper.
- Regarding the role of stemming in the fields of cross-language alignment and knowledge transfer, in this paper we propose a multilingual stemming method that automatically learns morphological phonetic inflections based on character embeddings and sequence models. Firstly, the characteristics of the dataset were analyzed, and letters were normalized for three agglutinative languages such as Uyghur, Kazakh and Kirghiz, and then a comparative experiment was conducted on the same dataset with two distribution forms of these three derivative languages. In addition, the proposed model is compared with traditional models and achieves better performance on stemming research.
2. Related Work
Stemming itself is to segment each word in the text, and separate the stem and affix to obtain the stem itself. Stemming can obtain effective and meaningful language features, and reduce the repetition rate and feature bits of information.
In 2007, Majumder [4] proposed a clustering-based stemming algorithm, which does not need to master too many language rules. In 2008, Chrupala et al. [5] used the maximum entropy classification model for stem extraction on three languages, namely Romanian, Spanish and Polish, and the algorithm obtained better accuracy for sequence labeling of these three morphologically rich languages.used the maximum entropy classification model for stem extraction in three languages, and the algorithm obtained better accuracy for sequence labeling of these three morphologically rich languages.
In 2015, Muller et al. [6] proposed a CRF-based stemming method, and its performance surpassed other traditional methods. With the wide application of neural networks in the field of natural language, it has been widely used in morphological analysis tasks. Lots of progress. In 2018, Bergmanis and Goldwater et al. [7] proposed a neural network framework. The framework includes an encoder and a decoder, the input is a word sequence of characters, and the output is a sequence of morphological labels. In 2019, Malayviya et al. [8] dealt with morphological analysis through sequence annotation, specifically using a character-level sequence annotation model of the attention mechanism, and produced a significant improvement in the performance of sequence annotation on morphological analysis.
In the stemming research of derivative languages, Sediyegvl, et al. [9] used the N-gram model to perform stem extraction for Uyghur language. Under the premise of using the N-gram model, the stemming accuracy rate extracted by part-of-speech features reaches 95.19%, and the fusion of part-of-speech features and contextual stemming information together improves the accuracy rate by 96.60%. The experimental results show that context and part-of-speech features play a certain role in stemming. Ulan, et al. [10] starts from the Kazakh stem affix connection point, combines its word formation rules and statistical model characteristics, uses N-gram language model for stem extraction, and achieves an accuracy rate of 72.34%. However, the disadvantage of this model is that it cannot avoid encountering some unregistered words (OOV), which directly affects the stemming effect. Halidanmu, et al. [11] proposed a Uyghur language morphological segmentation method on bidirectional threshold recurrent unit neural network, and solved the problem of data sparsity. This experiment shows that ambiguity resolution can be effectively solved by making full use of context information, and the method surpasses several mainstream statistical methods in performance. M, Ablimit, et al. [12] developed a sentence-level multilingual morphological processing tool. The tool provides sentence-level morpheme extraction, uses parallel corpora to train a statistical model, and achieves 98% accuracy in morpheme segmentation. The experimental results show that the parallel corpus helps to improve the stemming effect. Wumaierjiang, et al. [13] used the Lovins algorithm, the conditional random field (CRF) model and the gated recurrent unit (BiGRU) network respectively, and conducted a comparative experiment on the research of stem extraction through a series of processing on two different data sets. The experimental results show that the method based on sequence tagging is relatively more effective than the method based on rule-based stemming, but the independence between words in the data makes it difficult to learn more information. Sardar, et al. [14] takes into account the morphological analysis characteristics of Kazakh, and performs stem extraction on Kazakh. Based on it, Kazakh texts are text-classified by convolutional neural network (CNN) using word2vec-TFIDF fused feature representation. The experimental results show that the text classification effect based on the stem unit through deep learning has a significant contrast with the traditional text classification effect, and the classification accuracy is improved by 95.39%.
3. Methods
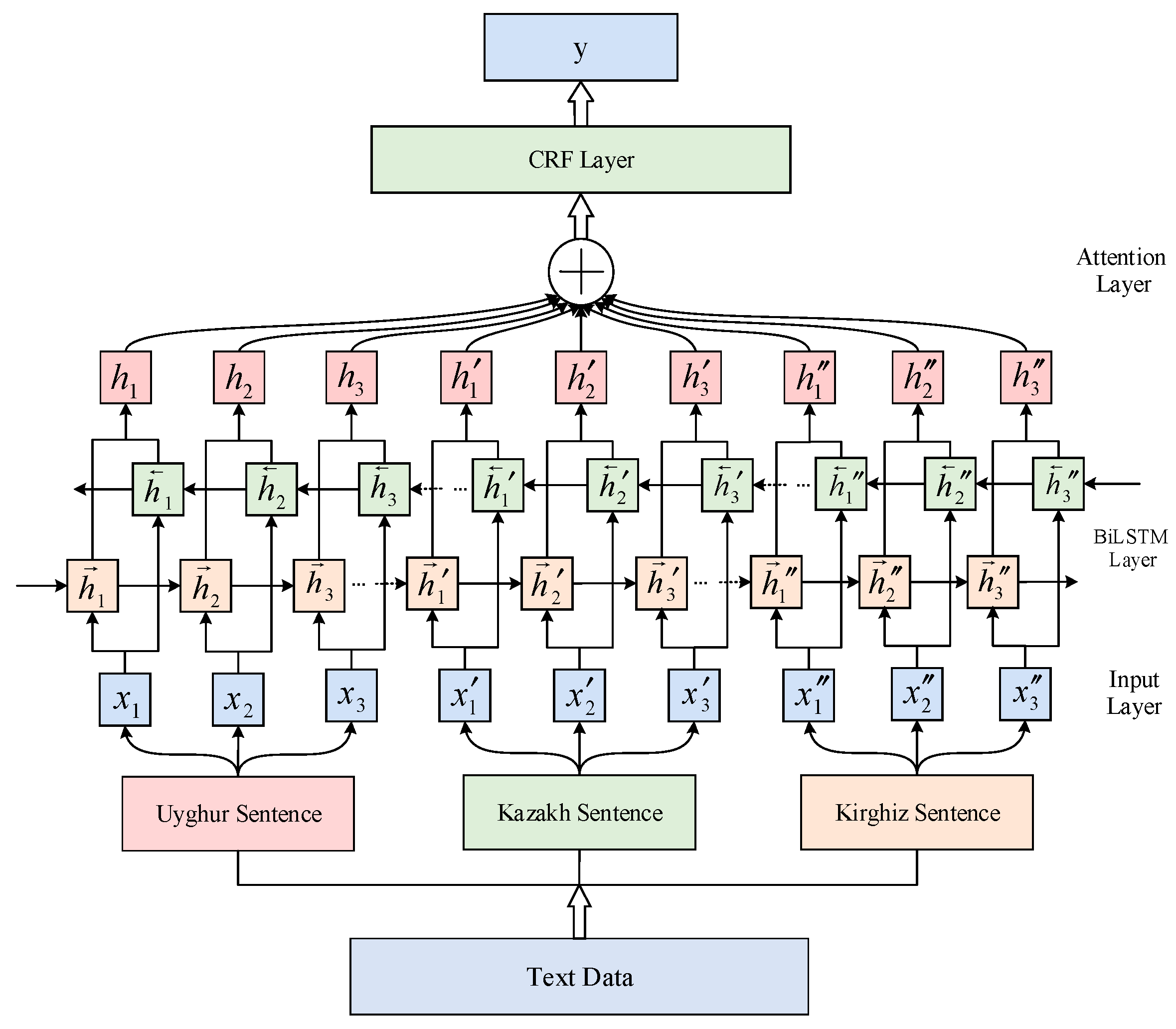
This paper proposes a multilingual stem extraction model based on BiLSTM-Attention-CRF for Uyghur, Kazakh, and Kirghiz languages, which is mainly composed of preprocessing layer, sentence-level character embedding layer, BiLSTM layer, Attention layer and CRF layer. The overall framework is shown in Figure 1. First, take sentence-level text data in three languages as input, manually segment the stem and affix parts in the multilingual text, and then segment them into character string and annotations, then feed their feature embedding to the BiLSTM layer, and BiLSTM, learns the dependencies between particles to obtain contextual features. The output of BiLSTM is used as the input of the Attention layer to obtain the global feature information in the multilingual text, and then it is sent to the CRF layer. Finally, the annotation sequences corresponding to the three languages are obtained through CRF. Multilingual stemming research with longer contexts can make full use of resources, provide reliable semantic and syntactic information, and effectively reduce ambiguity in languages.
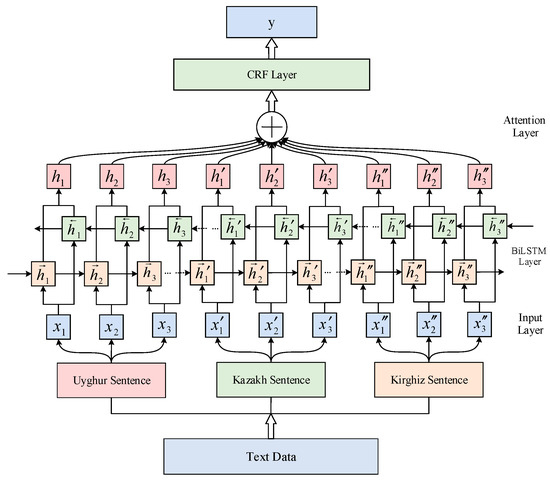
Figure 1.
The overall framework of the model. This framework is mainly composed of input layer, BiLSTM layer, Attention layer and CRF layer.
3.1. Stemming in Derivative Languages
Table 1 below is a comparison table of the Uyghur, Kazakh and Kirghiz letters corresponding to the Latin letters. This paper uses 33 Latin letters to represent the Uyghur alphabet, and 30 Latin letters to represent the Kazakh and Kirghiz alphabets.

Table 1.
Uyghur-Kazakh-Kirghiz language alphabetical chart.
In Uyghur, Kazakh and Kirghiz languages, sentences are composed of separate words. Morphologically, words in these three languages can be derived by adding some suffixes to a stem. In the process, changes such as phonetic harmony will occur and are directly reflected in the text. The stem itself can also be a word, expressing the inherent meaning of the word, while affixes have powerful role in a sentence, but have no meaning independently. There are derivational suffixes and inflectional suffixes [15]. The derivational suffixes can make a new stem while the inflectional suffixes only change the grammatical function. And these three languages possess more than 120 suffixes and their thousands of combinations. Table 2 is an example of word formation and configuration suffixes in three languages. As shown in this table, for the Uyghur word “yazGucisi”, the stem “yaz” (write) and the derivational suffix “Guci” form “yazGuci” (author), and then the inflectional suffix “si” forms “yazGucisi” (author’s third-person form). For the Kazakh word “sabaqtastar”, the stem “sabaq” (course) and the derivational suffix “tas” form “sabaqtas” (class + mate), and then connect the inflectional suffix “tar” to form “sabaqtastar” (class + mate + s). For the Kirghiz word “qoycular”, the stem “qoy” (sheep) and the derivational suffix “cu” form “qoycu” (herd + er), and then connect the inflectional suffix “lar” to form “qoycular” (herd + er + s).
Table 2.
Examples of multilingual suffix types.
In previous work, most of the researches basically used a single language for stemming, and did not progress to multilanguage stemming for these low resource languages. In addition, the traditional stemming methods are stemming words through suffixes and some morphological rules, which has ambiguity and uncertainty. And it is more difficult to determine the stem with multiple meanings, because the semantic information at the sentence level is ignored. In the following example, the Uyghur word “alma” appears in two sentences at the same time but has different meanings. For example, “alma” means “apple” in the first sentence, and “don’t take” in the second sentence. The Kazakh word “at” means “horse” in the first sentence and “throw” in the second sentence. The Kirghiz word “qoy” means “sheep” in the first sentence, and “put” in the second sentence. These ambiguous words can also be briefly described through Table 3.
Table 3.
Examples of multilingual ambiguous words.
- Uyghur Sentence1: u bazardin alma setiwaldi.
- Sentence2: qAlAmni qoluNGa alma.
- Kazakh Sentence1: ol at menep jater.
- Sentence2: topte bEre qaray at.
- Kirghiz Sentence1: al nArsAni bul jArgA qoy.
- Sentence2: bizdin OydU qoy bar.
There is usually some ambiguity in the segmentation process. The following is an example of Uyghur words. In the example the Uyghur words “tepix” and “berix” are words with two meanings. They can be divided into two sets of stems on the basis of these two senses. The stems of “tepix” are “tAp” (kick) and “tap” (find), and the stems of “berix” are “bar” (go) and “bAr” (give). The two words have different meanings in different context.
tepix(kick\earn) = tAp(kick) + ix = tap(find) + ix
berix(go\give) = bar(go) + ix = bAr(give) + ix
Stemming plays a key role in natural language processing research, and it is widely used in various NLP tasks. Stemming can obtain effective and meaningful language features, and reduce the lexicon size [14,16], as shown in the following examples:
(Uyghur sentence) vAllikkA vAllikni qoxsaq vAllikniN vikki hAssigA tAN bolidu.
(after split) vAllik + kA vAllik + ni qox + saq vAllik + niN vikki hAssi + gA tAN bol + idu.
(after split) vAllik + kA vAllik + ni qox + saq vAllik + niN vikki hAssi + gA tAN bol + idu.
(Kazakh sentence) ElwgE Elwde qossa ElwdeN Eke EsEsenE tEN bolade.
(after splitting) Elw + gE Elw + de qos + sa Elw + deN Eke EsE + se + nE tEN bol + a + de.
(after splitting) Elw + gE Elw + de qos + sa Elw + deN Eke EsE + se + nE tEN bol + a + de.
(Kirghiz sentence) AlOOgU AlOOnO qoxso AlOOnOn Aki AssAsinA tAN bolot.
(After segmentation) AlOO + gU AlOO + nO qox + so AlOO + nOn Aki AssA + si + nA tAN bol + ot.
(After segmentation) AlOO + gU AlOO + nO qox + so AlOO + nOn Aki AssA + si + nA tAN bol + ot.
The sentences in the above three languages have the same meaning (Add fifty to fifty equals double fifty). The sentences in each language are composed of eight words. By performing morpheme segmentation and stem extraction, the three words in each laguage can be divided into one stem and three suffixes. Their stems (underlined words) are connected by three suffixes (bold words) to form three words, as shown in Table 4. So, dividing words into morpheme sequences can alleviate the data sparsity problem.
Table 4.
Uyghur-Kazakh-Kirghiz language word variants.
It is extremely important to consider contextual information at the sentence level. Sentence-based reliable stemming can correctly predict stems and terms in noisy environments, providing an efficient approach for many aspects of multilingual natural language processing [17]. This paper proposes to use bidirectional LSTM, attention mechanism and conditional random field for sentence-level analysis by fusing character-level embedding and contextual information. Since the data in this paper is based on sentences, each sentence component will be affected by the contextual semantic relationship, so this method can effectively utilize the contextual information.
3.2. BiLSTM Layer
So far, there are many types of neural networks, and each type has its own characteristics. Recurrent Neural Networks (RNN) have a very good sequential signal learning ability, and remember previous events. The LSTM structure was introduced by the literature [18] and is regarded as a deformed structure developed from RNN. RNN usually has the problem of gradient disappearance or gradient explosion. In order to solve its shortcomings, LSTM is generated by adding additional memory units on the basis of RNN.
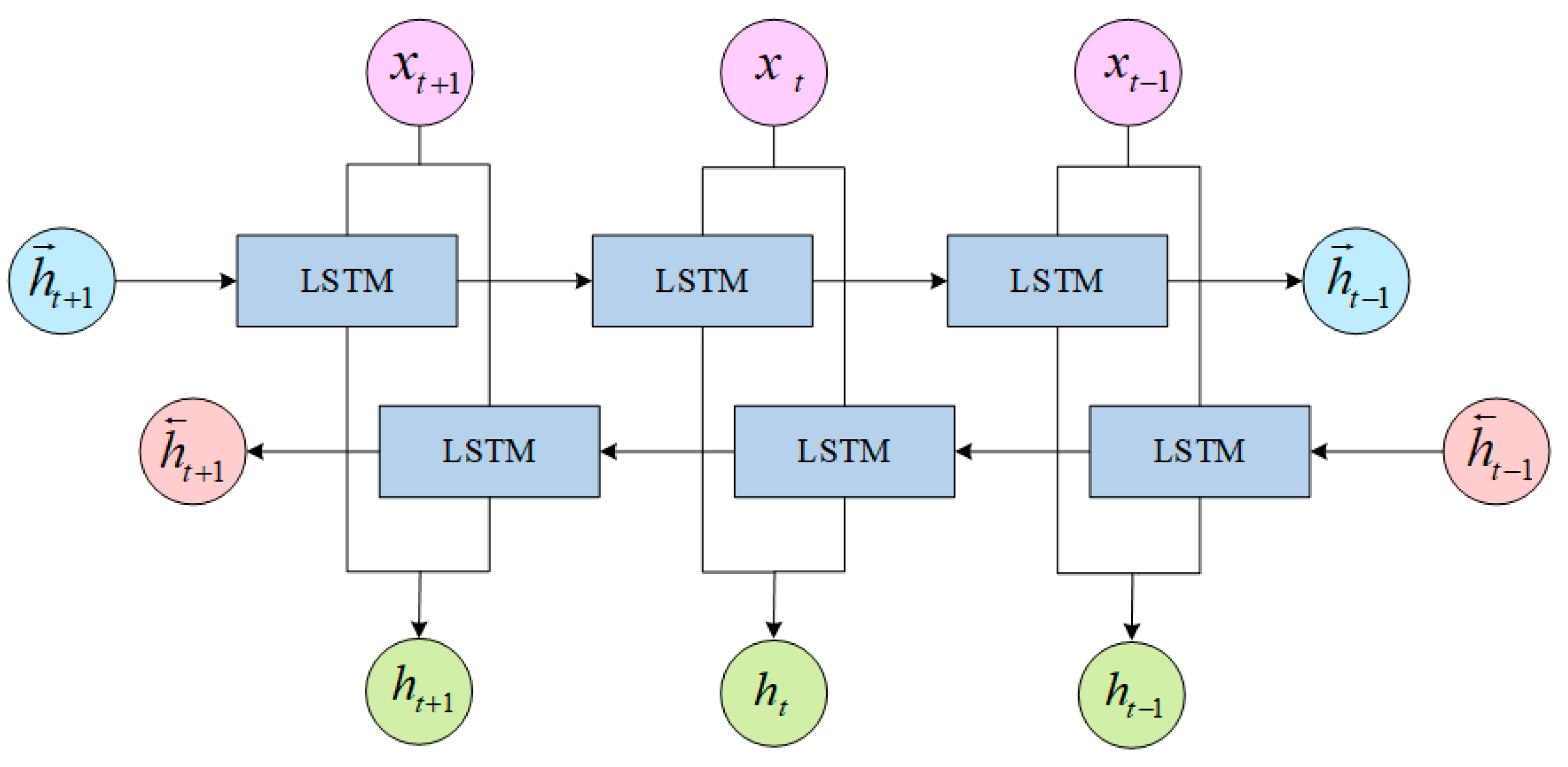
LSTM can only capture the above information of the input sequence, but cannot capture the context information. BiLSTM is proposed based on LSTM optimization. It is actually composed of two LSTM networks, one is the forward input LSTM, and the other is the reverse input LSTM. Their parameters are independent, and the output is also do not interfere with each other. The BiLSTM network structure is shown in Figure 2.
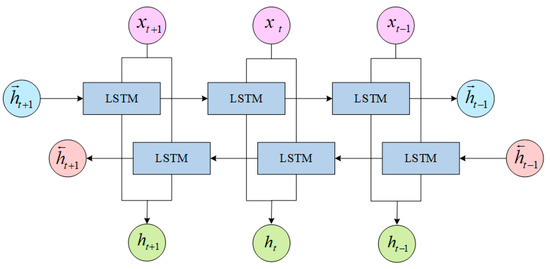
Figure 2.
BiLSTM Structure.
In the figure, represent the input embedding data, is the hidden state of forward LSTM and backward LSTM, and represents the hidden information about the past and future at time t. The embedding text enters BiLSTM for contextual semantic feature extraction, which simultaneously processes contextual information and can obtain historical information and future information respectively. In order to obtain more context dependencies, this paper will use the characteristics of bidirectional LSTM as the starting point for model training, and obtain context information from the generated forward and backward semantic information.
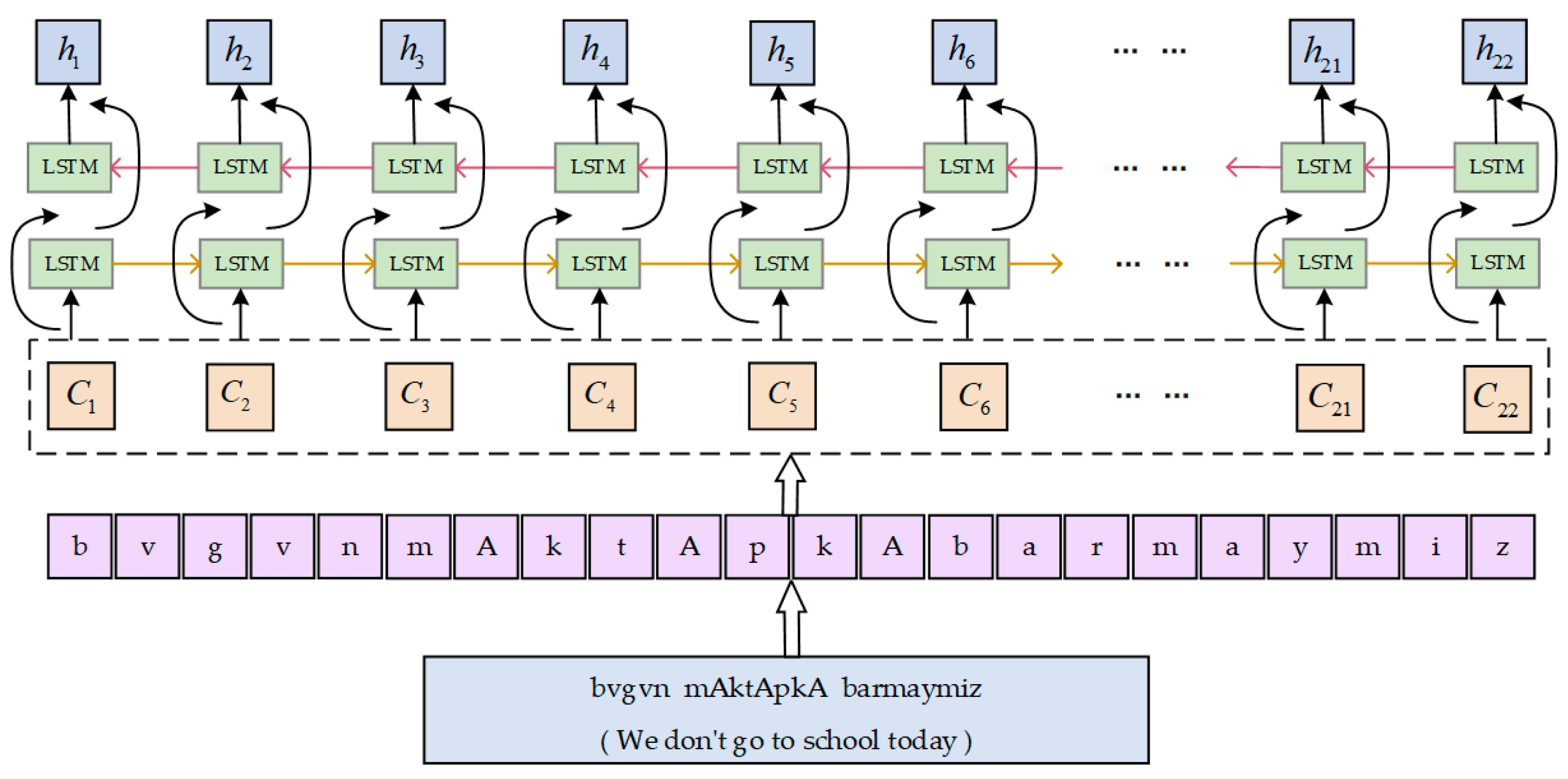
Figure 3 below is the process of the BiLSTM layer handling the derivative language, suppose we enter a three-word sentence with 22 letters in it. The feature of the character sequence is obtained after encoding by forward and backward LSTM using their character-level context vectors first. The represents the hidden layer vector containing the context information of the phoneme sequence ci produced by BiLSTM.
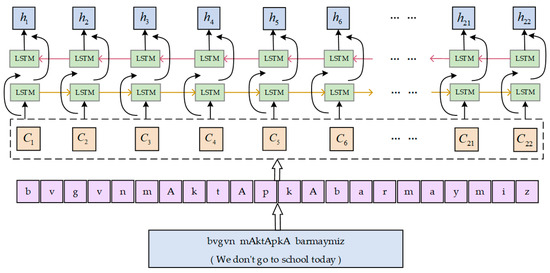
Figure 3.
BiLSTM layer handles the derivative language process.
3.3. Attention Layer
Attention Mechanism (AM) was first proposed by BahandAu et al. [19] and is one of the most valuable breakthroughs in deep learning research. The attention mechanism calculates the probability distribution of attention to reflect the correlation between input and output, and optimizes the neural network model. The attention mechanism assigns different weights to the semantic encoding of the text before and after, in order to more accurately distinguish the stem and affix information in the text, so as to improve the effect of stem extraction.
For sentence-level morphological analysis, words in a sentence and characters in a word have different effects on stemming. In order to distinguish the key features among them, the text features present in them are further extracted by introducing an attention layer. Attention models are used to represent the connections between sentences, words, characters and outputs. The learning of attention weights is realized by adding a feedforward network to the structure of the original network structure.
Among them, is the attention weight, is the hidden state value of the encoder, is a weighted sum of each output state , and the attention weight generated by the model is assigned to the corresponding hidden layer state, so that the attention weight plays a role. After introducing the attention layer in the text model, train it along with the BiLSTM model.
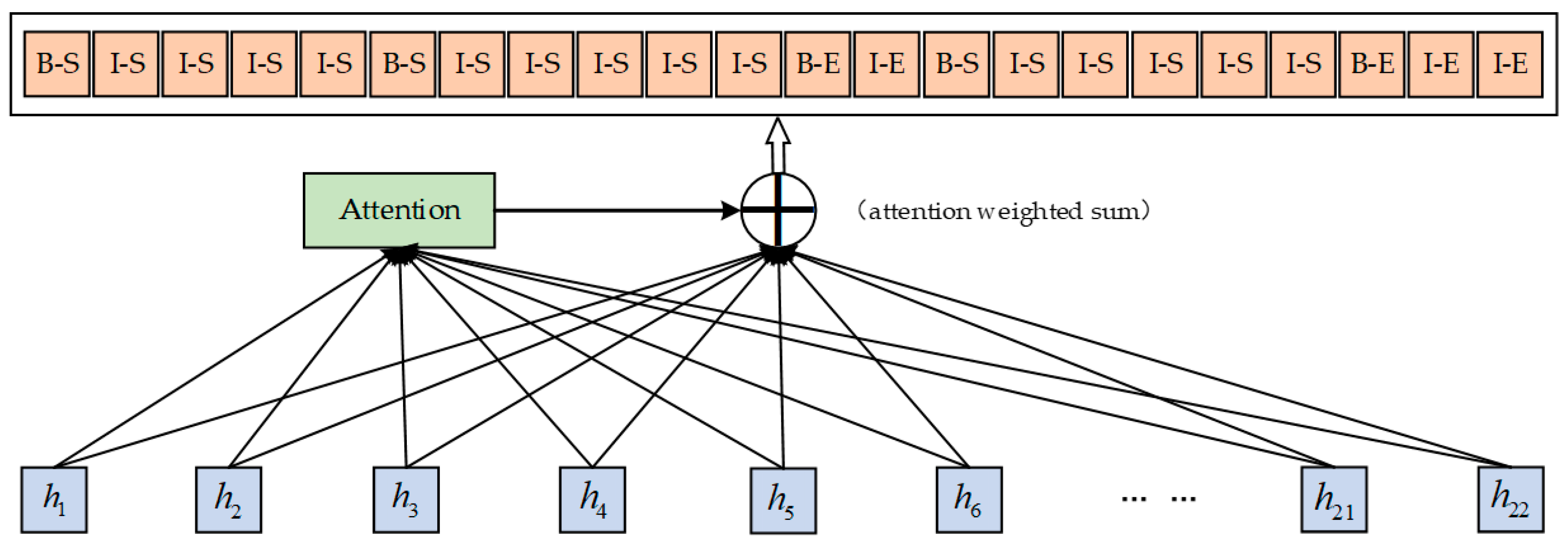
As shown in Figure 4, after adding the Attention layer to the BiLSTM model, we pass the output feature vectors of BiLSTM, the attention first calculates their weights, and then weights all the feature vectors. Attention captures the relationship between stems and affixes in the input sequence (sentence), calculates the alignment probability between the input sentence and the label, and highlights the boundaries of stems and affixes.
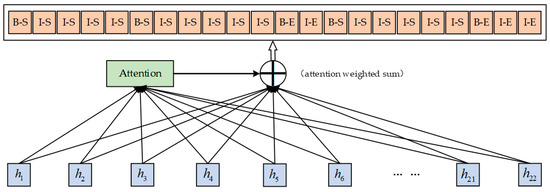
Figure 4.
Attention layer handles the derivative language process.
3.4. CRF Layer
Condition Random Field, referred to as CRF for short, is a condition that combines the advantages of Hidden Markov Model (HMM) and Maximum Entropy Model (ME) [20] to label and segment the input sequence probabilistic model. BiLSTM only considers context information and cannot consider the dependencies between adjacent labels, while CRF can consider the dependencies between labels to obtain an optimal sequence, and can solve the shortcomings of BiLSTM. Character, word and sentence context features are fused by CRF.
In neural network models, the Softmax function is usually used for classification prediction, which has a close logical relationship with CRF sequence labeling [21]. The combined model of BiLSTM, attention mechanism and CRF adopted in this paper can deal with the dependencies existing between the context and adjacent labels, and effectively deal with the problem of sequence labeling. The CRF layer is the last layer of the neural network architecture. Its input is the output of the attention layer, and it is used as an input to comprehensively measure the relationship between the outputs through the transition score matrix and the emission score matrix, and finally get the most The optimal output sequence can significantly improve the effect of stemming. The CRF layer normalizes the global features to obtain the global optimum.
CRF can effectively solve the dependency problem between tags. In this paper, the {B, I, O, E, S} annotation method is used in the stem extraction research. That is, the output includes 7 labels {B-S, I-S, B-E, I-E, O}. Using the BiLSTM model alone cannot pay attention to the plausibility of the transformation relationship between the output labels. For example, “B-S” tags cannot be directly followed by “B-E” or “I-E”, and tags ending with “E” cannot be preceded by “O”. CRF can effectively solve this problem.
4. Experiment
4.1. Datasets
The dataset used in this paper is composed of 20,000 Uyghur sentences and 2500 Kazakh and Kirghiz sentences each crawled from the official website People’s Daily Online (people.com.cn). The dataset crawled from Renmin.com in this paper contains data from February to October 2021, with specific subsets of five categories: education, life, sports, tourism, and health. We divide the text of each language into train set, test set and development (dev) set in a ratio of 8:1:1. The specific data statistics are shown in Table 5 and Table 6.
Table 5.
Experimental data statistics. The Uy-Kz-Kr data set in the table is the corpus collected in Uyghur, Kazakh and Kirghiz languages, which is the multilingual data set of the experiment in this paper.
Table 6.
Multilingual dataset data distribution. The table is the data distribution after statistics of words, morphemes and characters in the multilingual data set Uy-Kz-Kr.
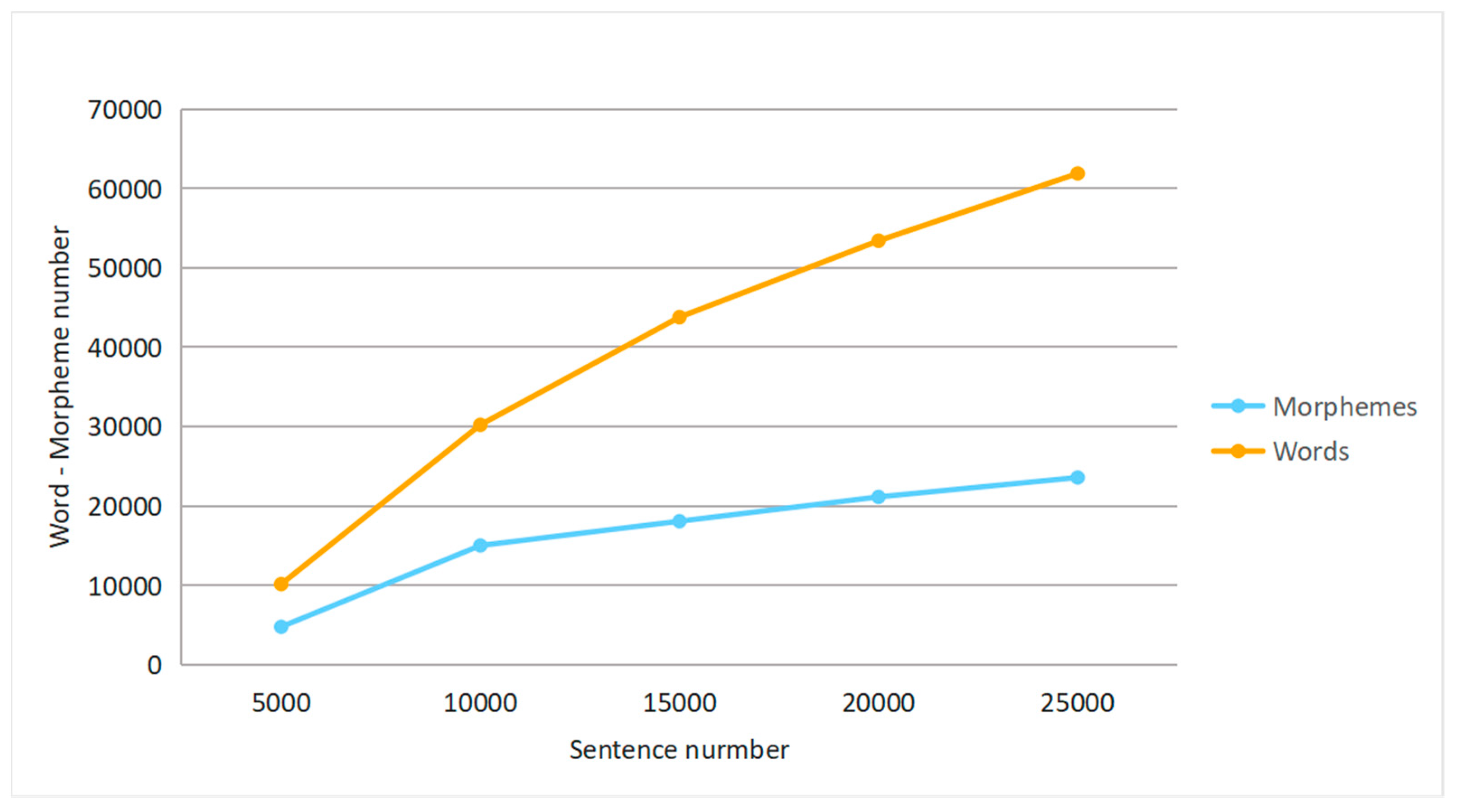
First, perform stem and affix segmentation on all sentence components in the multilingual data, so as to process the subsequent data labeling work. Figure 5 is the result of statistics of morphemes (stems and affixes) and words in all sentences included in the experimental data of this paper. The data in the figure does not contain repeated words and morphemes.
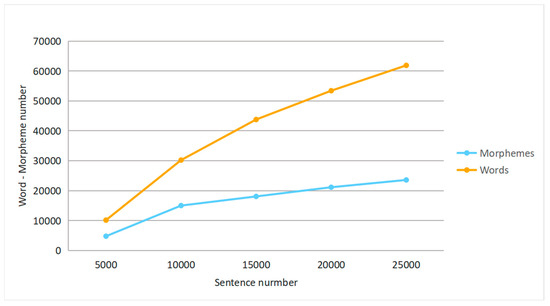
Figure 5.
Statistical distribution of multilingual corpus. After the multilingual dataset is composed of three languages, the statistics of words and morphemes in every 5000, 10,000, 15,000, 20,000 and 25,000 sentences are performed.
4.2. Experimental Preprocessing
4.2.1. Char Normalization
Although the written forms of Uyghur, Kazakh and Kirghiz languages appear to be similar, there are certain differences. Therefore, in order to reduce the multiple codes of each letter in the three languages and facilitate processing, we perform letter conversion on the multilingual text data. Table 7 is an example of encoding the Uyghur, Kazakh and Kirghiz letters to the Latin alphabet, showing some examples of different encoding schemes. Each Uyghur, Kazakh, and Kirghiz alphabet in the experimental data in this paper can be represented by different encodings. Our job is to build a code map that normalizes all the different codes into uniform Latin characters. This code normalization is important for multilingual text processing.
Table 7.
Multilingual phoneme mapping.
4.2.2. Data Tagging
When labeling characters (multilingual text letters), we use the BIOES sequence labeling method to label stems and affixes. When defining the tag set, in order to represent the context more comprehensively and effectively, the stem affix part is subdivided into units of characters, and the three languages are represented by the tag set {B-S, I-S, B-E, I-E, O}. The stem affix label for each character contained in the sentence. Among them:
- B-S: Stem first character
- I-S: Stem non-first character
- B-E: Affix first character
- I-E: Affix non-first character
- O: Non-morpheme character (number)
The CRF layer learns more information from the input sequence to describe the context information more effectively. We train the model on a multilingual text training set so that the model can discriminate and classify the input, thereby improving the effect of the overall model.
4.3. Experiment Settings
4.3.1. Data Distribution
To further verify the validity of the multilingual dataset in this paper, We adopted two data distribution methods. The first distribution method is to use the texts of three languages, such as Uyghur, Kazakh and Kirghiz languages, to form the training set, test set and validation set of multilingual texts in the order of sentences in these three languages. The second distribution method is to evenly distribute the sentences in the three languages according to the proportion of the data in the three languages to form the multilingual text training set, test set and validation set, as shown in Table 8. Among them, UyS1…UyS16000 represent the variables corresponding to the 16,000 sentences contained in the Uyghur training set, KzS1…KzS2000 represent the variables corresponding to the 2000 sentences contained in the Kazakh training set, and KrS1…KrS2000 represent the corresponding 2000 sentences contained in the Kirghiz training set Sentence variables. UyS1…UyS2000 represent the variables corresponding to the 2000 sentences contained in the Uyghur test set and the validation set respectively, KzS1…KzS250 correspond to the variables of the 250 sentences contained in the Kazakh test set and the validation set respectively, KrS1…KrS250 correspond to the variables of the 250 sentences contained in the Kirghiz test set and the validation set respectively.
Table 8.
Data distribution type.
4.3.2. Evaluation Indicators
The indicators in this paper involve P (accuracy rate), R (recall rate) and F1 (average value). The specific calculation formulae of the three indicators are as follows, where represents the number of correctly extracted morphemes, and represents the total number of morphemes extracted. represents the total number of words in the multilingual corpus.
4.4. Results
We use the model in this paper to perform stem extraction for multilingual datasets with two assignments, and perform corresponding ablation experiments, as shown in Table 9. It can be seen from the results that the stem extraction results obtained on the neural network model using different data allocation forms of the multilingual dataset are obviously different. The stem extraction effect of the dataset (Data type 2) that evenly distributes the sentences of the three languages is better than that of the dataset (Data type1: all sentences in Uyghur first, all sentences in Kazakh and Kirghiz after) is better for stemming. It can be seen that evenly distributing multilingual datasets plays a big role in stemming.
Table 9.
Stemming results for different data distribution types.
To verify the effect of different test sets on the model in this paper, we use the Uyghur, Kazakh and Kirghiz languages test sets that contain separately and the test set containing three languages to perform stem extraction, and also on different test sets. Ablation experiments were performed as shown in Table 10. As can be seen from the table, the stemming performance obtained with the test set of a single language is inferior to the stemming performance obtained with the test set containing three languages.
Table 10.
Stemming results obtained on different test sets.
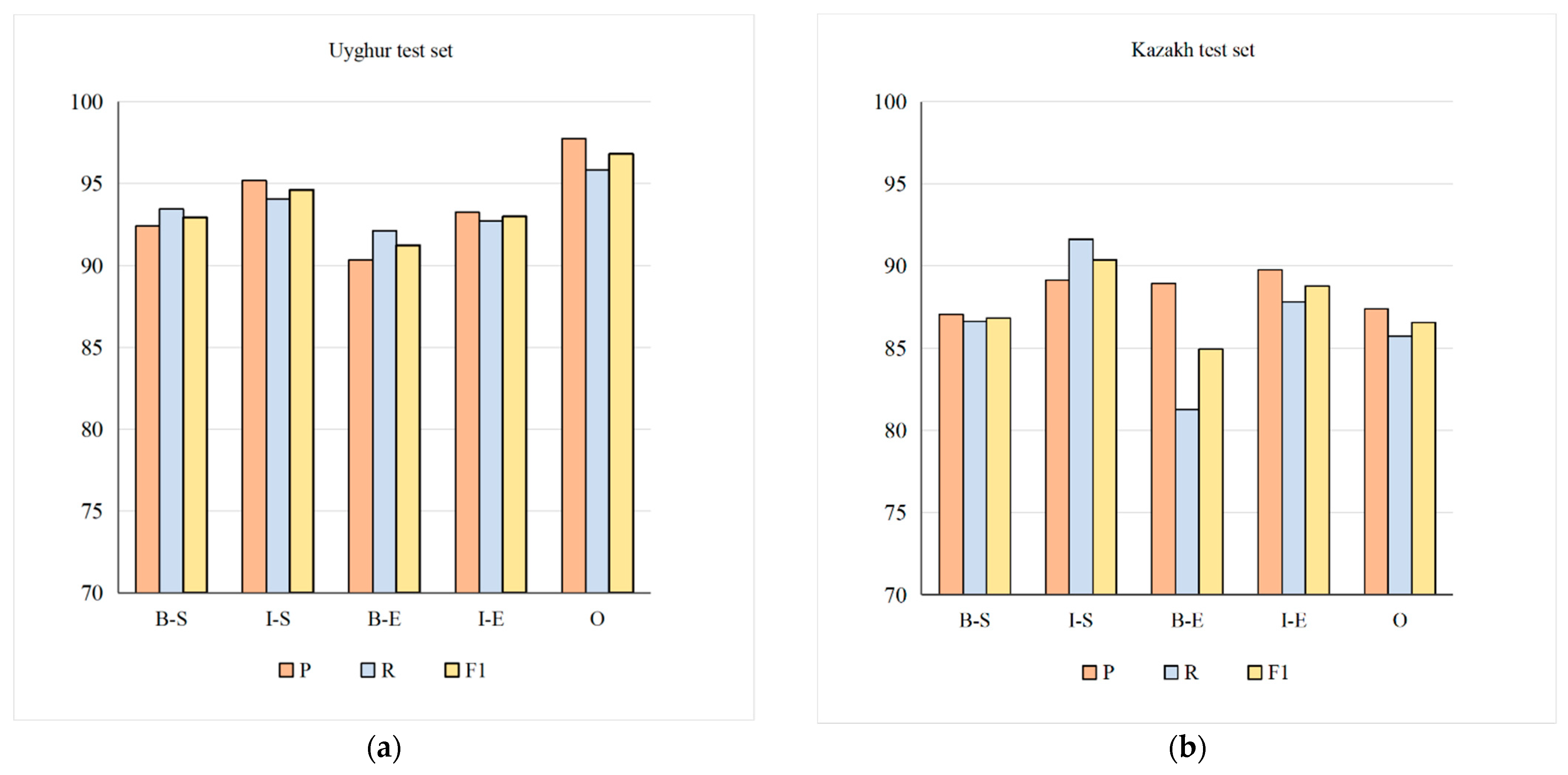
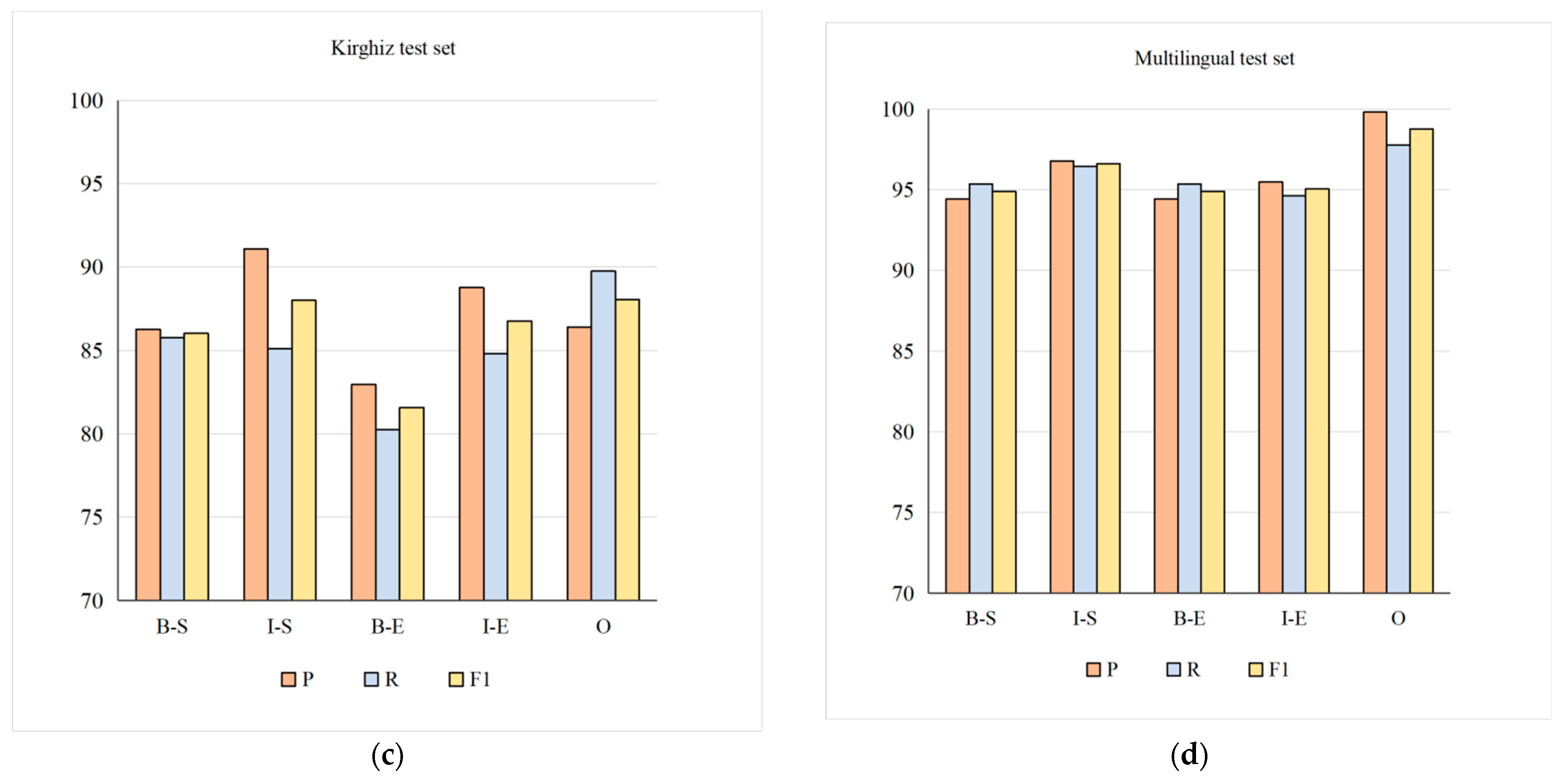
According to the sequence labels defined in this paper, when testing, the effects of extracting stem and affix parts in multilingual data are shown in Figure 6. As can be seen from the figure, on the same training set, the morpheme extracted using the test data set containing three languages performs best, and it correctly identifies and extracts the first stem character (B-S), stem non-first character (I-S), affix first character (B-E), affix non-first character (I-E) and non-morpheme character (O) results are shown in the following figure. On the whole, since affixes contain prefixes and suffixes, although the number of prefixes is small, it is relatively difficult to identify prefixes, so the recognition rate of affixes is slightly lower than that of stems. The proportion of numbers in the data is very small, and the numbers refer to ten numbers from 0 to 9, so it has the highest recognition rate.
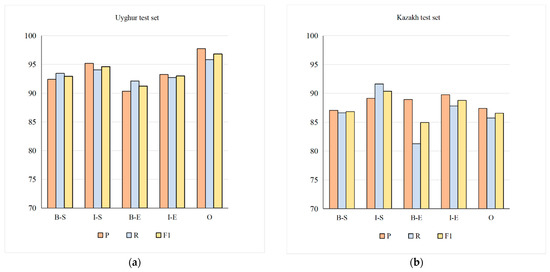
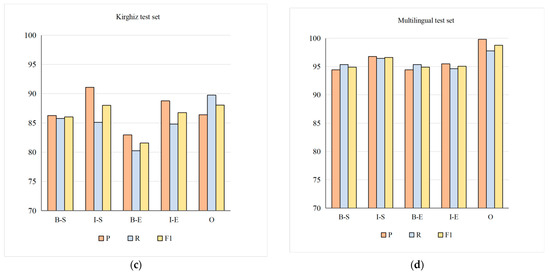
Figure 6.
Stem and affix recognition rates on different test set. (a) is the extraction result of the test set containing only Uyghur sentences. (b)is the extraction result of the test set containing Kazakh sentences alone. (c) is the test set containing the extraction results of Kirghiz sentences alone. (d) is the test set Figure 1 is the extraction result Contains extraction results in three languages at the same time.
In order to verify the validity of the BiLSTM-Attention-CRF model proposed in this paper, this paper selects the Uyghur word-level morphological segmentation corpus (THUUyMorph) [22] provided by Tsinghua University and the manually constructed multilingual dataset as the research object, using different models such as BiLSTM, BiLSTM-CRF and BiLSTM-Attention-CRF to conduct ablation experiments, and compare their stemming effects on different datasets. Table 11 shows the data distribution of the THUUyMoprh dataset in terms of words. The results of ablation experiments on different datasets are shown in Table 12:
Table 11.
Data distribution of the THUUyMoprh dataset.
Table 12.
Ablation experiments on different datasets.
From the experimental results, it can be seen that the stemming effect of two different types of data sets extracted by the neural network model is quite different. THUUyMorph is a dataset made up of individual Uyghur words without sentence context information. Multilingual dataset is a sentence-level dataset collected for the purpose of this paper. When using word-level data sets, the stemming effects of the three models are almost the same, but we can see that the BiLSTM-Attention-CRF proposed in this paper can still play some role in word-level data sets. For sentence-level data sets, the stemming effect of BiLSTM-Attention-CRF model is very obvious.
The multilingual sentence corpus constructed and adopted in this paper is beneficial to the neural network model to learn more information. Through the BiLSTM model, the multilingual sentence-level corpus is used to obtain the forward and reverse context sequence features. On the basis of the BiLSTM model, an attention mechanism layer is added to perform weight learning on multilingual data, making full use of the long-distance and global feature information between multiple languages, so that the stem extraction performance is better.
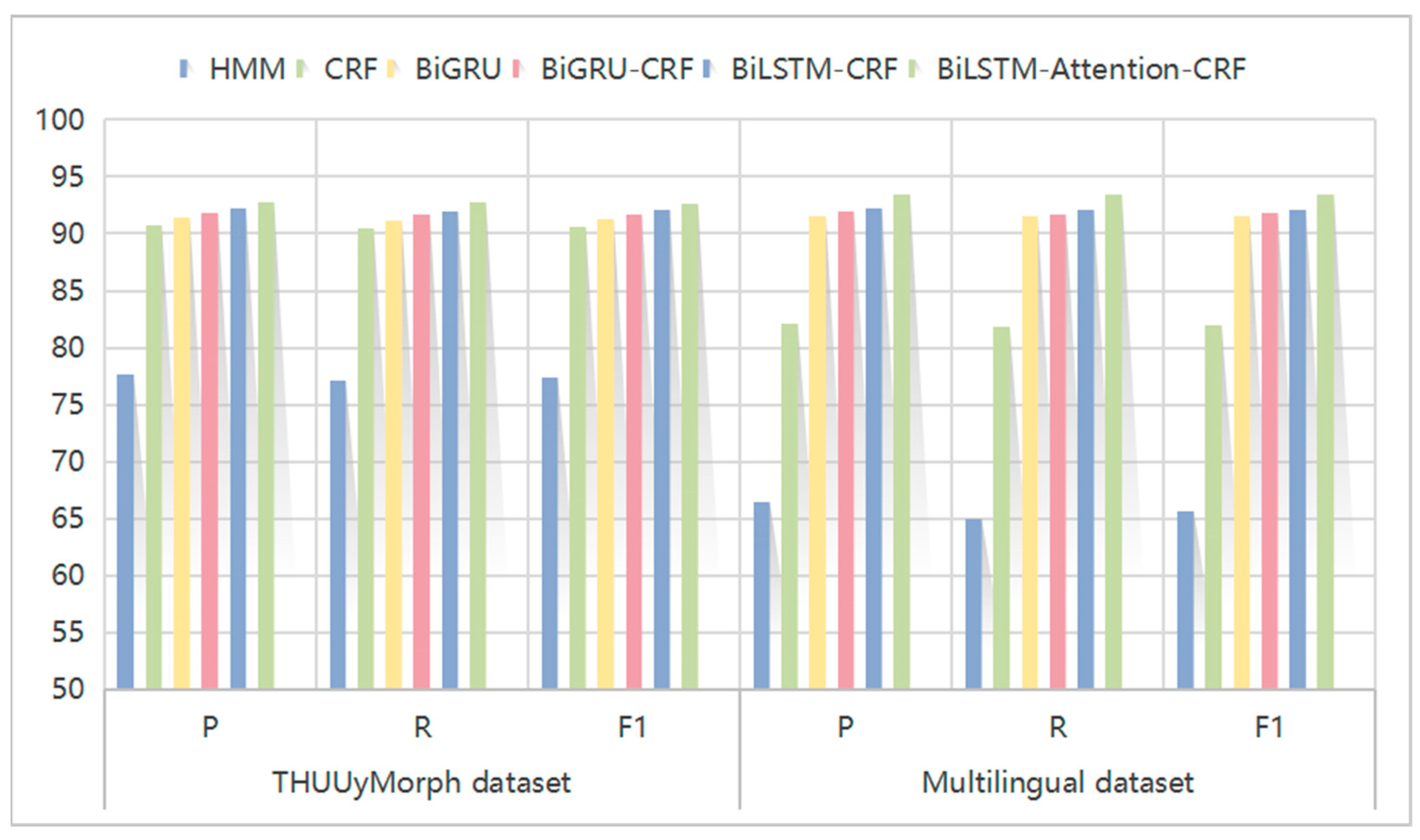
In order to verify the performance of the traditional model and the neural network model proposed in this paper on the task of stemming, the model in this paper is compared with the statistical models HMM, CRF and several common neural network models. In the comparison process, the multilingual text dataset constructed in this paper and the Uyghur word-level morphological segmentation corpus THUUyMorph dataset are used for stemming. The results of the comparison experiment are shown in Figure 7.
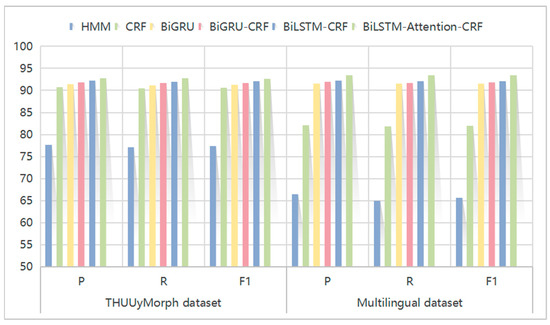
Figure 7.
Comparative experiment. This is the result of stemming using traditional and neural network methods through different datasets.
As can be seen from the Figure 7, whether it is a word-level dataset or a sentence-level dataset, the stem extraction effect of the neural network model is much better than that of the traditional HMM and CRF models. If further analysis is performed, the effect of the BiLSTM-Attention-CRF model is better than that of BiGRU and BiGRU-CRF on two different datasets, and it can be considered that the stem extraction effect of the model in this paper is the best. If the two datasets are further compared, the effect of the sentence-based multilingual dataset is more obvious.
5. Conclusions and Future Works
For common agglutinative NLP tasks, stemming research is a very critical step. However, for multilingual agglutinative stemming research, character embedding representation is too simple to effectively process data with contextual information. Based on a large number of high-quality multilingual sentence-level corpora, this paper proposes a neural network-based multilingual stemming model that fuses character and context features. When a bidirectional LSTM is employed, the data sparsity problem in multilingual texts can be alleviated by continuous representation. In this paper, the multilingual stemming task is regarded as a sequence labeling problem, and stemming is performed through different models using two different datasets. Experimental results show that the model proposed in this paper is more effective for stemming on multilingual datasets with sentence context. At the same time, this paper compares the stemming effect of the traditional model and the neural network model on two different datasets. It can be seen from the comparison results that the BiLSTM-Attention-CRF model outperforms other models, especially on sentence-level-based datasets. All in all, contextual analysis at the sentence level can not only reduce ambiguity, but also segment difficult words for further analysis. We can randomly use the specific data of any one of these three languages to achieve the purpose of text information processing. This paper does not delve into the problem of phonetic inflection in agglutinative languages even most them are automatically solved. In future research, try to consider more features between multiple languages, learn more morphological relationships, and further improve the effect of multilingual stemming.
Due to the limited amount of data, this paper does not introduce newer neural network models and pre-training models with better performance, and we will further study this aspect in the future. Therefore, in future research, try to consider more features between multiple languages, learn more morphological relationships, strive to capture more agglutinative text data sets, and try to add some pre-training models such as Transformer. In addition, in agglutinative languages, when stems are connected with affixes, some letters later in the stem will have the problem of phonetic inflection, but this paper does not delve into this problem in agglutinative languages. Therefore, in the future, we will try to consider more features between more agglutinative languages, learn more morphological relationships, further improve the stemming effect, and transfer them to more low-resource languages with similar language families.
Author Contributions
Conceptualization, G.I. and M.A.; methodology, G.I. and M.A.; software, G.I.; validation, M.A. and A.H.; formal analysis, G.I. and M.A.; investigation, G.I., M.A., A.H. and H.Y.; resources, M.A., A.H. and H.Y.; data curation, H.Y.; writing—original draft preparation, G.I.; writing—review and editing, M.A. and A.H.; visualization, M.A. and H.Y.; supervision, M.A. and A.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Strengthening Plan of National Defense Science and Technology Foundation of China grant number 2021-JCJQ-JJ-0059 and Natural Science Foundation of China grant number U2003207.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This study uses public datasets to compare with the datasets collected in this paper. These public dataset can be found here: https://github.com/halidanmu//THUUMS (accessed on 26 December 2021).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ablimit, M.; Parhat, A.; Hamdulla, T.; Zheng, F. A multilingual language processing tool for Uyghur, Kazak and Kirghiz. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 737–740. [Google Scholar]
- Ablimit, M.; Kawahara, T.; Pattar, A.; Hamdulla, A. Stem-Affix based Uyghur Morphological Analyzer. Int. J. Future Gener. Commun. Netw. 2016, 9, 59–72. [Google Scholar] [CrossRef]
- Abmitl, M.; Pattar, A.; Hamdulla, A. Multilayer structure based lexiconoptimization for language modeling. Tsinghua Univ. (Sci. Technol.) 2017, 57, 257–263. [Google Scholar]
- Majumder, P.; Mitra, M.; Parui, S.K. YASS: Yet another suffix stripper. ACM Trans. Inf. Syst. 2007, 25, 409–420. [Google Scholar] [CrossRef]
- Chrupala, G.; Dinu, G.; Genabith, J.V. Learning morphology with Morfette. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2008, Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Thomas, M.; Cotterell, R.; Fraser, A. Joint Lemmatization and Morphological Tagging with Lemming. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Bergmanis, T.; Kann, K.; Schütze, H. Training Data Augmentation for Low-Resource Morphological Inflection. In Proceedings of the CoNLL SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection, Vancouver, BC, Canada, 3–4 August 2017. [Google Scholar]
- Malaviya, C.; Wu, S.; Ctterell, R. A Simple Joint Model for Improved Contextual Neural Lemmatization. arXiv 2019, arXiv:1904.02306. [Google Scholar]
- Sediyegvl, E.; Xiang, L.; Zong, C.; Akbar, P.; Askar, H. A Multi-Strategy Approach to Uyghur Stemming. J. Chin. Inf. Process. 2015, 29, 204–210. [Google Scholar]
- Ulan, N.; Rahmotola, M.; Aska, H. The Method of Kazakh Word Lemmatization Based on N-gram Model. Comput. Knowl. Technol. 2017, 13, 160–162. [Google Scholar]
- Abudukelimu, H.; Cheng, Y.; Liu, Y.; Sun, M. Uyghur morphological segmentation with bidirectional GRU neural networks. J. Tsinghua Univ. (Sci. Technol.) 2017, 57, 1–6. [Google Scholar]
- Ablimit, M.; Parhat, A.; Hamdulla, T.; Zheng, F. Multilingual Stemming and Term extraction for Uyghur, Kazak and Kirghiz. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 587–590. [Google Scholar]
- Wumaierjiang, M.; Gulinigeer, A.; Maihemuti, M.; Kahaerjiang, A.; Tuergen, Y. A Comparative Study of Uzbek Stemming Algorithms. J. Chin. Inf. Processing 2020, 34, 45–50. [Google Scholar]
- Sardar, P.; Mijit, A.; Askar, H. Kazakh Short Text Classification Based on Stem Unit and Convolutional Neural Network. J. Chin. Comput. Syst. 2020, 41, 1627–1633. [Google Scholar]
- Mukaddam, I.; Sardar, P.; Askar, H. A Multilingual Morpheme Segmentation Tool. Video Eng. 2020, 44, 46–51. [Google Scholar]
- Wu, S.; Qian, Q.; Hu, T. Comparative Analysis of Methods and Tools for Word Stemming. Libr. Inf. Serv. 2012, 56, 109–115. [Google Scholar]
- Parhat, S.; Gao, T.; Ablimit, M. A morpheme sequence and convolutional neural network based Kazakh text classification. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J.S. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bahdanau, D.; Cho, K.; Bengio, Y.D. Neural machine translation by jointly learning to align and translate. arXiv 2015, arXiv:1409.0473. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; The Mit Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Zhang, T.; Zhang, J. Across-domain Chinese word segmentation model based on feature transfer. J. Commun. Univ. China (Sci. Technol.) 2021, 28, 41–45. [Google Scholar]
- Halidanmu, A.; Sun, M.; Liu, Y.; Abudukelimu, A. THUUyMorph:An Uyghur Morpheme Segmentation Corpus. J. Chin. Inf. Process. 2018, 32, 81–86. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).