1. Introduction
It is common for the real world to have a lot of optimization problems that are complex, large-scale, and NP-Hard. A lot of these problems not only contain constraints and objectives, but also have their modeling constantly changing. Unfortunately, it is hard for a universal method to provide a solution.
Nowadays, more and more artificial intelligence methods (e.g., heuristics and metaheuristics) are used to solve such problems in many different domains, such as online learning [
1], multi-objective optimization [
1,
2], scheduling [
3], transportation [
4], medicine [
5], data classification [
6], etc. Many issues can theoretically be solved by searching through a large number of possible answers intelligently. For the metaheuristic algorithm, the search can begin with some type of guessing and then gradually refine the guesses until no further refinement is possible. The process of this can be seen as a blind climb: we start our search at a random point on the mountain and then, by jumping or stepping, keep moving upward until we reach the top.
The particle swarm optimization algorithm [
7], a classical metaheuristic, has proven to be very effective in many fields [
8,
9,
10]; it is a method for optimizing a problem by iteratively improving a candidate solution relative to a given measure of quality. During PSO, each particle has a velocity and position, and the optimization problem is transformed into several optimization functions, called fitness functions. Each particle records its own best value and updates the swarm’s best value.
In order to solve increasingly complex optimization problems, a useful method is parallel PSO. The parallelization solutions include Hadoop MapReduce, MATLAB parallel computing toolbox, CUDA, R Parallel package, Julia: Parallel for and MapReduce, OpenGL, OpenCL, OpenMP with C++ and Rcpp, Parallel computing module in python, MPI, HPF, PVM, POSIX threads, and Java threads on SMP machines [
11].
Previous papers [
12,
13] have implemented MapReduce parallel PSO, which proved to be very effective in training a radial basis function (RBF) network and enlarging the swarm population and problem dimension sizes.
In this study, we used Apache Beam to implement parallelized PSO, as it is an open-source unified model for defining both batch and streaming data-parallel processing pipelines [
14]. In the experiment, we used Apache Beam to parallelize the PSO algorithm (BPSO) and compare it with the running time and results of MapReduce parallel PSO (MRPSO).
In
Section 2, we introduce the details of the PSO algorithm. In
Section 3, we introduce the basic concepts of Apache Beam, WordCount programming examples, and the advantages of Apache Beam. In
Section 4, we introduce, in detail, the algorithm ideas and steps of Apache Beam PSO. In
Section 5, we compare BPSO with MRPSO on four benchmark functions, namely Sphere, Generalized Griewank, Generalized Rastrigin, and Rosenbrock functions, by varying the number and dimensionality of particles. The experiments show that BPSO can run faster and obtain better results than MRPSO under the same conditions. Finally, we summarize the paper and give directions for future work in
Section 6.
4. Apache Beam PSO (BPSO)
First, we need to convert the standard PSO serialization process to parallelization. In standard PSO, after initialization, each particle changes its speed and position, and then calculates their fitness value and updates the most well-known position of the individual. In this process, each particle can be executed independently.
Considering the above process, we designed a BPSO with Map-Element function, as shown in Function 1. First, the particle object was initialized by a line of string. Second, we used (1) and (2) to update the velocity and position of the particle. Third, we compared the updated fitness through the new position and updated the individual best position of the particle. Since we wanted all particles to be in the solution space, when the position and velocity of any particle were out of range, we initialized the particles in the solution space. Finally, we used the message of each neighborhood ID and particle to send out key-value pairs (including particle ID, neighbors, current position, current fitness, speed, personal best position, personal best fitness, swarm’s best position, and swarm’s best fitness [
12], as shown in
Figure 2) to their neighbors if we found a better position.
| Function 1 BPSO Map-Element |
| Function map_element(line): |
| |
| //Initialize the particle according to each line: |
| particle p = Particle(line) |
| |
| //Update and limit position and velocity |
| particle.update_velocity_position(p); |
| particle.limit_velocity_position(p); |
| |
| //Compare fitness and update personal best position and fitness |
| If is_better(p.personal_best_position, p.position): |
| p.personal_best_position = p.position; |
| p.personal_best_value = p.fitness; |
| |
| //Compare the best fitness: |
| If is_better(p.swarm_best_fitness, p.personal_best_fitness): |
| p.swarm_best_position = p.personal_best_position; |
| p.swarm_best_value = p.personal_best_value; |
| |
| //Send messages to neighbors: |
| for i in p.neighborhood: |
| output(p.neighborhood[i], p.message); |
| output (p.id, p.message); |
In serial PSO, when any particle finds a better position, the best position of the swarm is updated. However, in a parallel model such as Apache Beam, each particle is a subset of a PCollection, and it must send messages to others through communication. Therefore, we designed the BPSO Combine-Grouped-Values as Function 2.
Before this operation, we used GroupByKey (an Apache Beam transformation similar to the Shuffle stage of MapReduce) to collect all the values associated with each unique key. As Function 2 said, initially we used variables to record the particles whose id is the key and store the best position and fitness of the swarm. Second, we queried the list of values to find the best position and fitness and find the particle that matches the corresponding key. Third, we output the message of the best particle.
In this process, each particle initializes and updates its personal best position. If a particle finds a better position than the individual best position, then it updates the individual best position and compares this position with the swarm’s best position.. Then it sends a message with the neighbor ID. When other particles receive this message, they use this information to update the personal and swarm’s best position. With the sharing of information, particle swarms gather near the optimal value to complete the search for the optimal value.
Different from the traditional PSO algorithm, the standard PSO algorithm [
17] uses a ring topology and only communicates between the left and right neighbors instead of all particles. As the communication between particles decreases, the algorithm runs more efficiently and the communication cost is lower.
| Function 2 BPSO Combine-Grouped-Values |
| Function combine_grouped-values(key,value_list): |
| particle = None |
| swarm_best_position = None |
| swarm_best_fitness = Double.MAX_VALUE |
| |
| //Iterate through the list of all values to find the best position: |
| for v in value_list: |
| temp = Particle(v) |
| |
| //Find the particle corresponding to the key: |
| if temp.id == key: |
| p = temp |
| |
| //Update the best position of the particle swarm: |
| if is_better(temp.personal_best_position, swarm_best_position): |
| swarm_best_position = temp.personal_best_position |
| swarm_best_fitness = temp.personal_best_fitness |
| |
| //Update the best position of the particle swarm of particles and output |
| p.swarm_best_position = swarm_best_position |
| p.swarm_best_fitness = swarm_best_fitness |
| output (p.message) |
Author Contributions
Investigation, J.L.; methodology, J.L. and T.Z.; experiment, J.L.; supervision, T.Z. and Z.L.; validation, J.L., Y.Z. and T.Z.; writing—original draft, J.L.; writing—review and editing, T.Z., Y.Z. and Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China (No. 62006110) and the Natural Science Foundation of Hunan Province (No. 2019JJ50499).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Acknowledgments
The first author (Liu Jie) thanks Wenjuan Chen for her support and company.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhao, H.; Zhang, C. An Online-Learning-Based Evolutionary Many-Objective Algorithm. Inf. Sci. 2020, 509, 1–21. [Google Scholar] [CrossRef]
- Biswas, D.K.; Panja, S.C.; Guha, S. Multi Objective Optimization Method by PSO. Procedia Mater. Sci. 2014, 6, 1815–1822. [Google Scholar] [CrossRef] [Green Version]
- Dulebenets, M.A.; Pasha, J.; Abioye, O.F.; Kavoosi, M.; Ozguven, E.E.; Moses, R.; Boot, W.R.; Sando, T. Exact and Heuristic Solution Algorithms for Efficient Emergency Evacuation in Areas with Vulnerable Populations. Int. J. Disaster Risk Reduct. 2019, 39, 101114. [Google Scholar] [CrossRef]
- Estevez, J.; Graña, M. Robust control tuning by PSO of aerial robots hose transportation. In Proceedings of the International Work—Conference on the Interplay between Natural and Artificial Computation, Elche, Spain, 1–5 June 2015; pp. 291–300. [Google Scholar]
- D’Angelo, G.; Pilla, R.; Tascini, C.; Rampone, S. A Proposal for Distinguishing between Bacterial and Viral Meningitis Using Genetic Programming and Decision Trees. Soft Comput. 2019, 23, 11775–11791. [Google Scholar] [CrossRef]
- Dubey, A.K.; Kumar, A.; Agrawal, R. An Efficient ACO-PSO-Based Framework for Data Classification and Preprocessing in Big Data. Evol. Intel. 2021, 14, 909–922. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Perth, WA, Australia, 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Houssein, E.H.; Gad, A.G.; Hussain, K.; Suganthan, P.N. Major advances in particle swarm optimization: Theory, analysis, and application. Swarm Evol. Comput. 2021, 63, 100868. [Google Scholar] [CrossRef]
- Jain, N.K.; Nangia, U.; Jain, J. A Review of Particle Swarm Optimization. J. Inst. Eng. India Ser. B 2018, 99, 407–411. [Google Scholar] [CrossRef]
- Eberhart; Shi, Y. Particle Swarm Optimization: Developments, Applications and Resources. In Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No.01TH8546), Seoul, Korea, 27–30 May 2001; IEEE: Seoul, Korea, 2001; Volume 1, pp. 81–86. [Google Scholar]
- Lalwani, S.; Sharma, H.; Satapathy, S.C.; Deep, K.; Bansal, J.C. A Survey on Parallel Particle Swarm Optimization Algorithms. Arab. J. Sci. Eng. 2019, 44, 2899–2923. [Google Scholar] [CrossRef]
- McNabb, A.W.; Monson, C.K.; Seppi, K.D. Parallel Pso Using Mapreduce. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 7–14. [Google Scholar]
- Mehrjoo, S.; Dehghanian, S. Mapreduce based particle swarm optimization for large scale problems. In Proceedings of the 3rd International Conference on Artificial Intelligence and Computer Science, Penang, Malaysia, 12–13 October 2015; pp. 12–13. [Google Scholar]
- Beam Overview. Available online: https://beam.apache.org/get-started/beam-overview/ (accessed on 7 January 2022).
- Shi, Y.; Eberhart, R. A Modified Particle Swarm Optimizer. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No.98TH8360), Anchorage, AK, USA, 4–9 May 1998; IEEE: Anchorage, AK, USA, 1998; pp. 69–73. [Google Scholar]
- Kennedy, J. The Particle Swarm: Social Adaptation of Knowledge. In Proceedings of the 1997 IEEE International Conference on Evolutionary Computation (ICEC ’97), Indianapolis, IN, USA, 13–16 April 1997; IEEE: Indianapolis, IN, USA, 1997; pp. 303–308. [Google Scholar]
- Bratton, D.; Kennedy, J. Defining a standard for particle swarm optimization. In Proceedings of the 2007 IEEE Swarm Intelligence Symposium, Honolulu, HI, USA, 1–5 April 2007; pp. 120–127. [Google Scholar]
- Sherar, M.; Zulkernine, F. Particle Swarm Optimization for Large-Scale Clustering on Apache Spark. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; IEEE: Honolulu, HI, USA, 2017; pp. 1–8. [Google Scholar]
- Cui, L. Parallel Pso in Spark. Master’s Thesis, University of Stavanger, Stavanger, Norway, 2014. [Google Scholar]
- GitHub—Apache/Beam: Apache Beam Is a Unified Programming Model for Batch and Streaming. Available online: https://github.com/apache/beam (accessed on 7 January 2022).
- MapReduce—Wikipedia. Available online: https://en.wikipedia.org/wiki/MapReduce#Lack_of_novelty (accessed on 7 January 2022).
- Beam Programming Guide. Available online: https://beam.apache.org/documentation/programming-guide/#requirements-for-writing-user-code-for-beam-transforms (accessed on 11 February 2022).
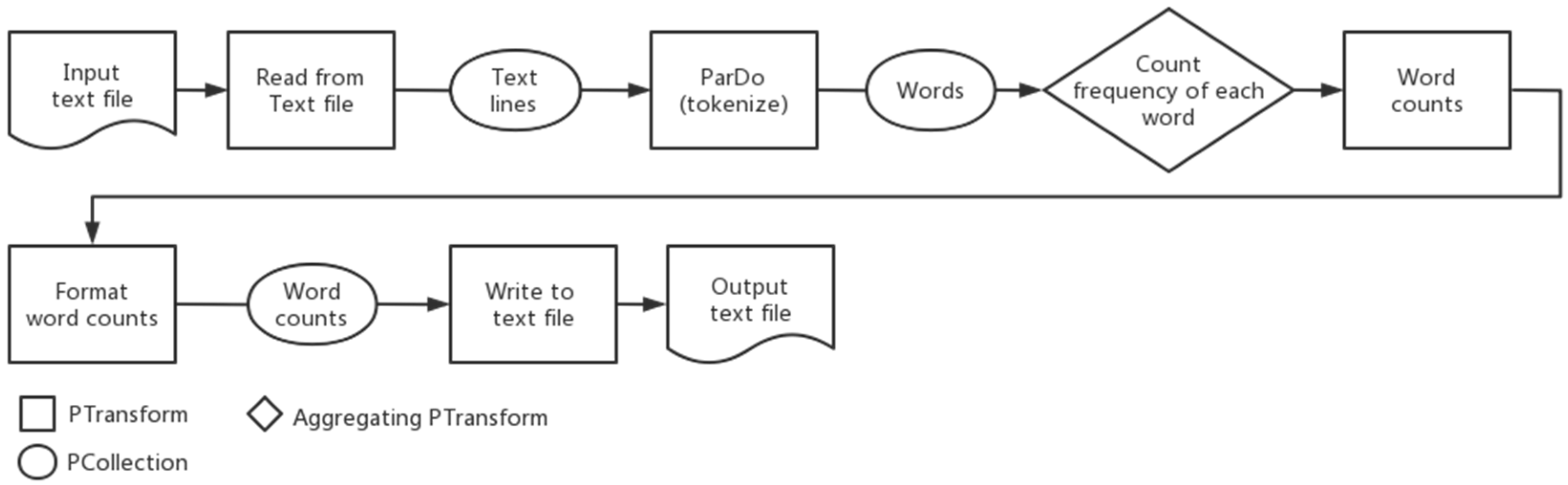
Figure 1.
Apache Beam WordCount pipeline data flow.
Figure 2.
Message of particle 3 (fitness function, sphere function; dimension, 2).
Figure 3.
Running time and swarm population.
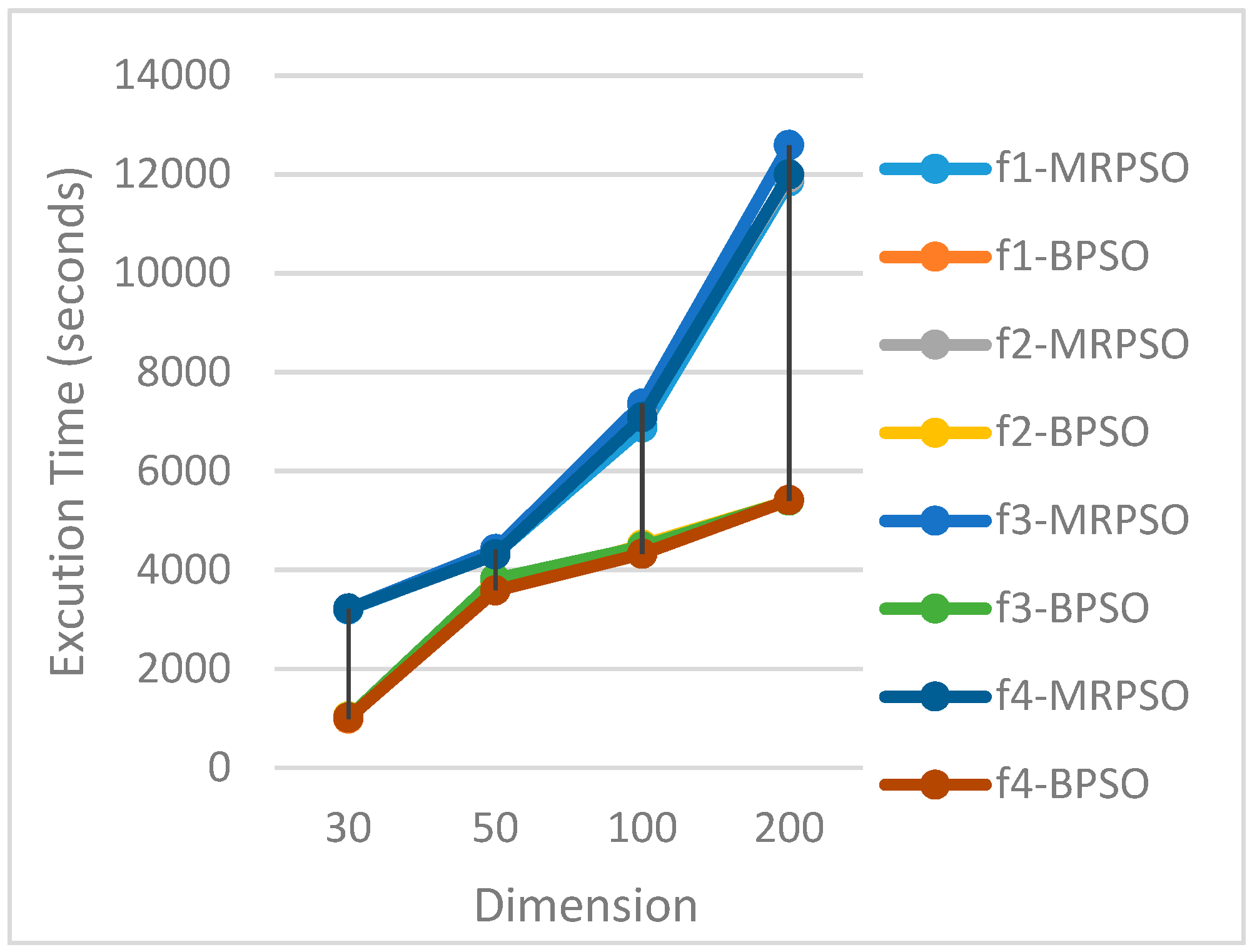
Figure 4.
Running time and dimensions.
Table 1.
Benchmark function.
| Equation | Name | Bounds |
|---|
| Sphere/Parabola | |
| Generalized Griewank | |
| Generalized Rastrigin | |
| Rosenbrock function | |
Table 2.
MRPSO and BPSO running time and speedup on .
| N | MRPSO Time | BPSO Time | Speedup |
|---|
| 100 | 1198.49 | 436.08 | 2.75 |
| 500 | 1192.87 | 578.18 | 2.06 |
| 1000 | 2189.19 | 740.49 | 2.96 |
| 2000 | 3197.82 | 988.38 | 3.24 |
Table 3.
MRPSO and BPSO running time and speedup on .
| N | MRPSO Time | BPSO Time | Speedup |
|---|
| 100 | 1206.55 | 438.46 | 2.75 |
| 500 | 1213.93 | 637.24 | 1.90 |
| 1000 | 2212.14 | 776.57 | 2.85 |
| 2000 | 3209.24 | 1031.51 | 3.11 |
Table 4.
MRPSO and BPSO running time and speedup on .
| N | MRPSO Time | BPSO Time | Speedup |
|---|
| 100 | 1210.64 | 446.73 | 2.71 |
| 500 | 1209.00 | 616.24 | 1.96 |
| 1000 | 2209.92 | 770.61 | 2.87 |
| 2000 | 3210.92 | 1013.85 | 3.17 |
Table 5.
MRPSO and BPSO running time and speedup on .
| N | MRPSO Time | BPSO Time | Speedup |
|---|
| 100 | 1203.08 | 450.84 | 2.67 |
| 500 | 1209.39 | 620.17 | 1.95 |
| 1000 | 2208.28 | 769.74 | 2.87 |
| 2000 | 3215.17 | 1008.69 | 3.19 |
Table 6.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| N | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 100 | 128.14 | 133.96 |
| 500 | 9.37 | 2.46 |
| 1000 | 7.09 | 0.68 |
| 2000 | 5.60 | 0.41 |
Table 7.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| N | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 100 | 2.48 | 2.92 |
| 500 | 1.09 | 1.02 |
| 1000 | 1.05 | 1.00 |
| 2000 | 1.05 | 1.00 |
Table 8.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| N | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 100 | 92.79 | 96.45 |
| 500 | 93.16 | 43.86 |
| 1000 | 56.40 | 35.90 |
| 2000 | 60.67 | 21.58 |
Table 9.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| N | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 100 | 208.13 | 214.30 |
| 500 | 42.30 | 32.92 |
| 1000 | 40.48 | 29.94 |
| 2000 | 37.67 | 27.43 |
Table 10.
MRPSO and BPSO running time and speedup on .
| D | MRPSO Time | BPSO Time | Speedup |
|---|
| 30 | 3197.82 | 988.38 | 3.24 |
| 50 | 4327.67 | 3760.29 | 1.15 |
| 100 | 6877.07 | 4462.22 | 1.54 |
| 200 | 11,858.53 | 5398.02 | 2.20 |
Table 11.
MRPSO and BPSO running time and speedup on .
| D | MRPSO Time | BPSO Time | Speedup |
|---|
| 30 | 3209.24 | 1031.51 | 3.11 |
| 50 | 4399.53 | 3641.00 | 1.21 |
| 100 | 7155.96 | 4508.83 | 1.59 |
| 200 | 11,937.03 | 5395.53 | 2.21 |
Table 12.
MRPSO and BPSO running time and speedup on .
| D | MRPSO Time | BPSO Time | Speedup |
|---|
| 30 | 3210.92 | 1013.85 | 3.17 |
| 50 | 4414.91 | 3819.42 | 1.16 |
| 100 | 7360.37 | 4470.32 | 1.65 |
| 200 | 12,593.52 | 5396.43 | 2.33 |
Table 13.
MRPSO and BPSO running time and speedup on .
| D | MRPSO Time | BPSO Time | Speedup |
|---|
| 30 | 3215.17 | 1008.69 | 3.19 |
| 50 | 4309.39 | 3582.94 | 1.20 |
| 100 | 7086.78 | 4323.71 | 1.64 |
| 200 | 11,995.85 | 5412.74 | 2.22 |
Table 14.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| D | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 30 | 5.60 | 0.41 |
| 50 | 49.47 | 19.62 |
| 100 | 345.25 | 226.72 |
| 200 | 1184.81 | 1065.62 |
Table 15.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| D | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 30 | 1.05 | 1.00 |
| 50 | 1.50 | 1.19 |
| 100 | 4.34 | 3.30 |
| 200 | 11.93 | 10.37 |
Table 16.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| D | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 30 | 92.79 | 21.58 |
| 50 | 135.50 | 101.66 |
| 100 | 456.46 | 332.56 |
| 200 | 948.23 | 909.30 |
Table 17.
Mean of the particle best-fit values in MRPSO and BPSO on . The bold numbers refers to the better results.
| D | MRPSO Fitness Value | BPSO Fitness Value |
|---|
| 30 | 37.67 | 27.43 |
| 50 | 134.10 | 90.79 |
| 100 | 505.26 | 400.99 |
| 200 | 1438.01 | 1291.71 |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




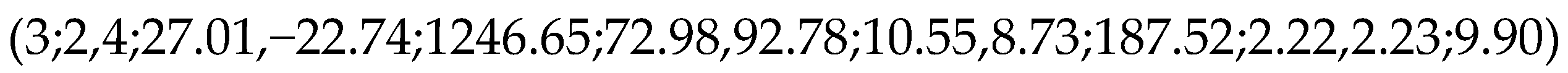


{kind=link}
{kind=link}
{kind=link}
{kind=link}