
Data Quality Barriers for Transparency in Public Procurement


 ,
,  ,
,
Abstract
:1. Introduction
- Data heterogeneity including structured data (e.g., statistics and financial records) as well as unstructured data (e.g., text and social media content) sources in various languages with their own vocabulary and formats, such as PDFs, APIs, CSVs, and databases;
- Transforming this large and heterogeneous set of data sources into an interconnected knowledge organisation structure using standardised vocabularies and sustainable knowledge integration and sharing approaches, which could be analysed in depth to detect patterns and anomalies.
- (a)
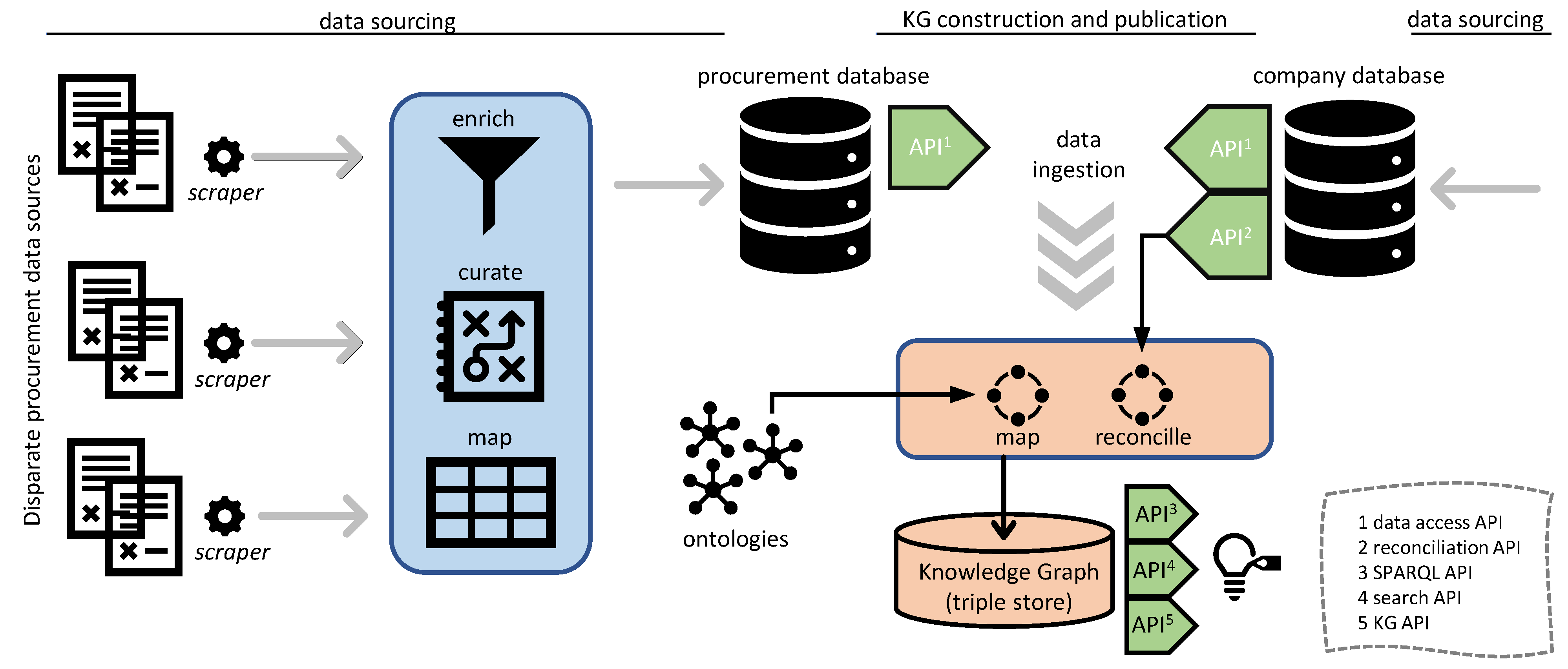
- Data sourcing: gathering, enriching, and curating (i.e., including classification according to common vocabularies, resolving mismatches at schema level, and deduplication) procurement data across EU countries from several different primary sources;
- (b)
- Tackling with heterogeneity: data mapping, transformation, and publication with respect to common vocabularies and standards and entity reconciliation for linking data sets through common, but originally disconnected, entities;
- (c)
- Cross-lingual matching and pattern mining: matching contracts and company profiles across multiple languages and identifying spending patterns across data sets from different sources.
2. Related Work
2.1. Public Procurement Transparency Initiatives
2.2. Procurement Platforms
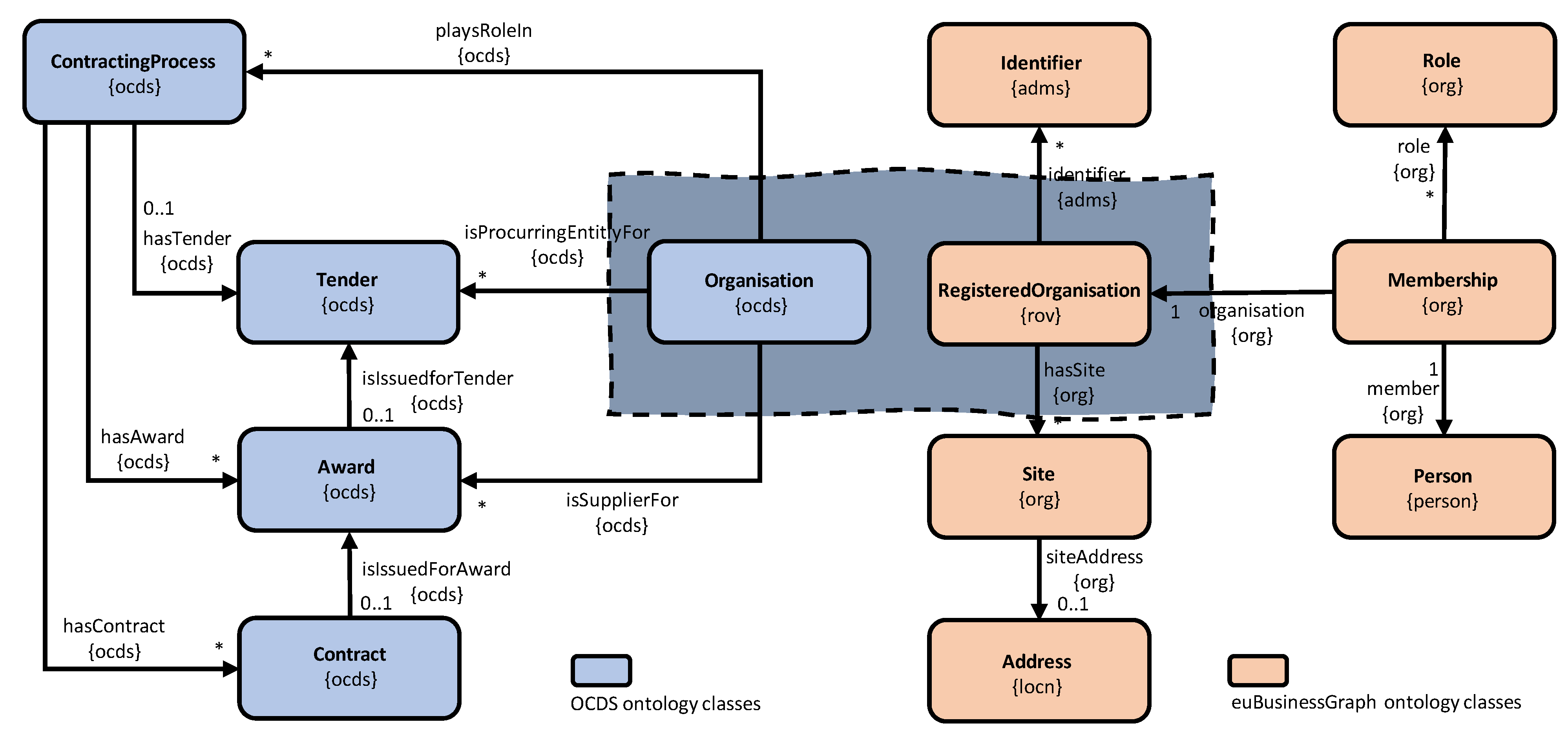
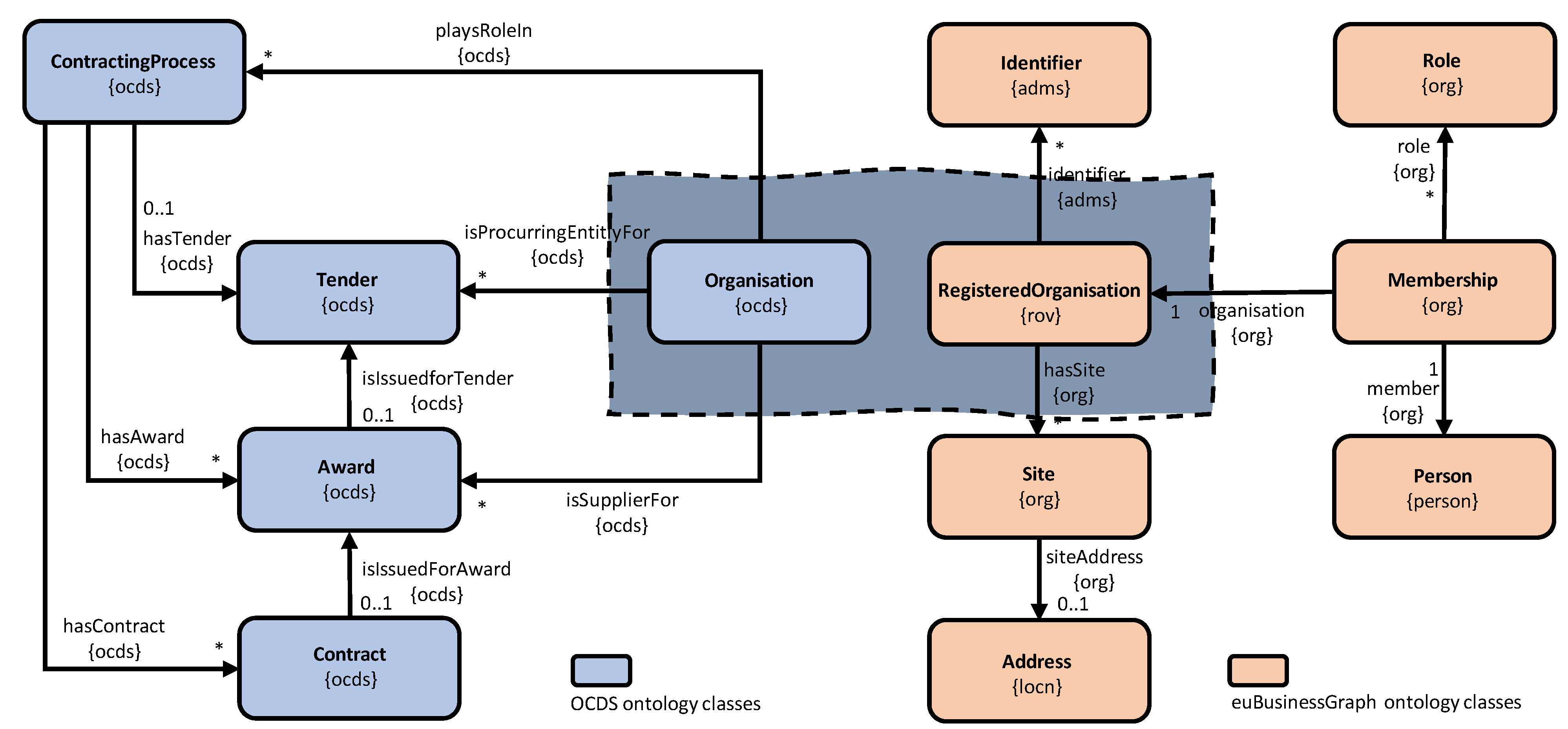
2.3. Procurement Data Models and Ontologies
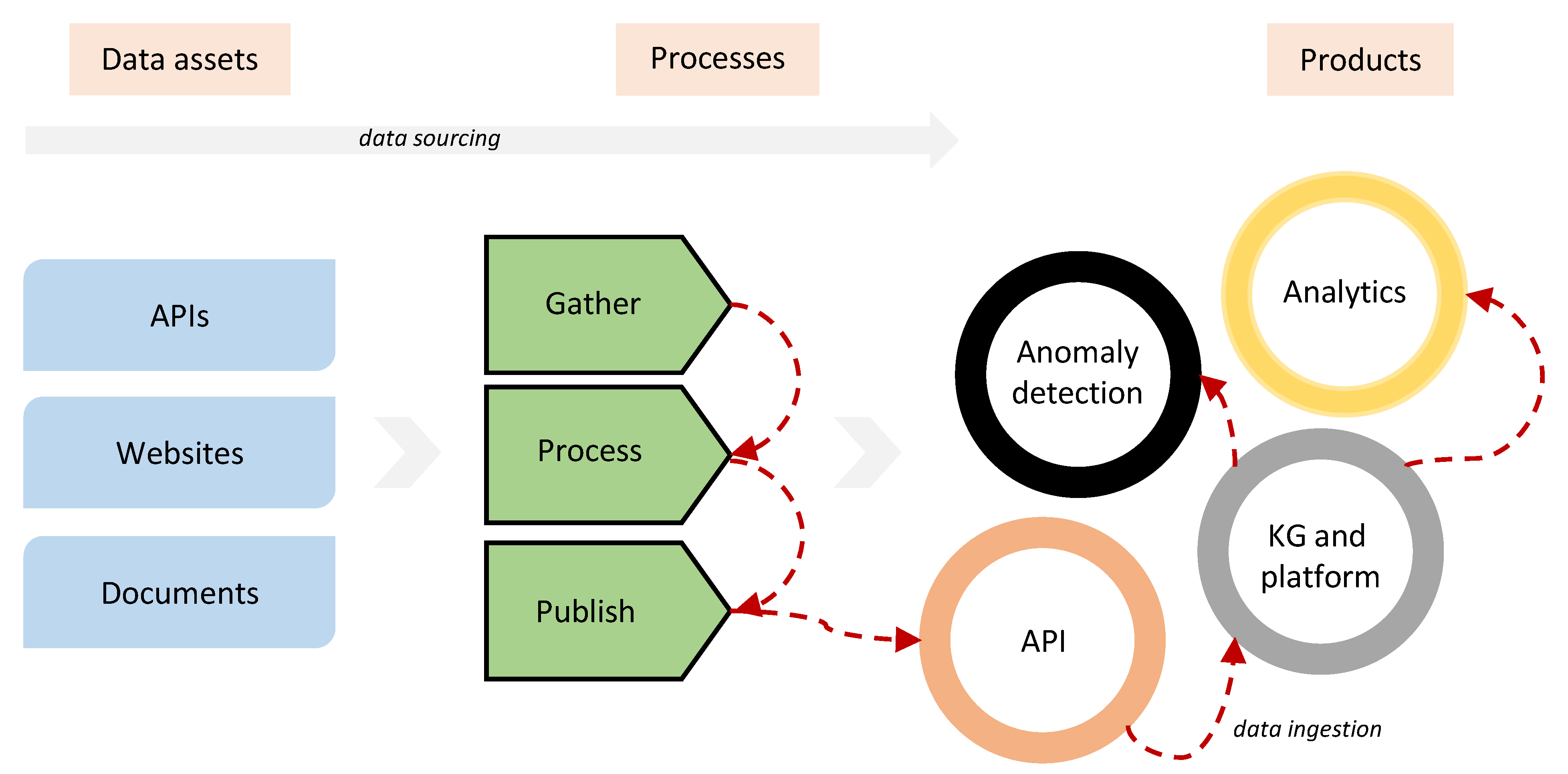
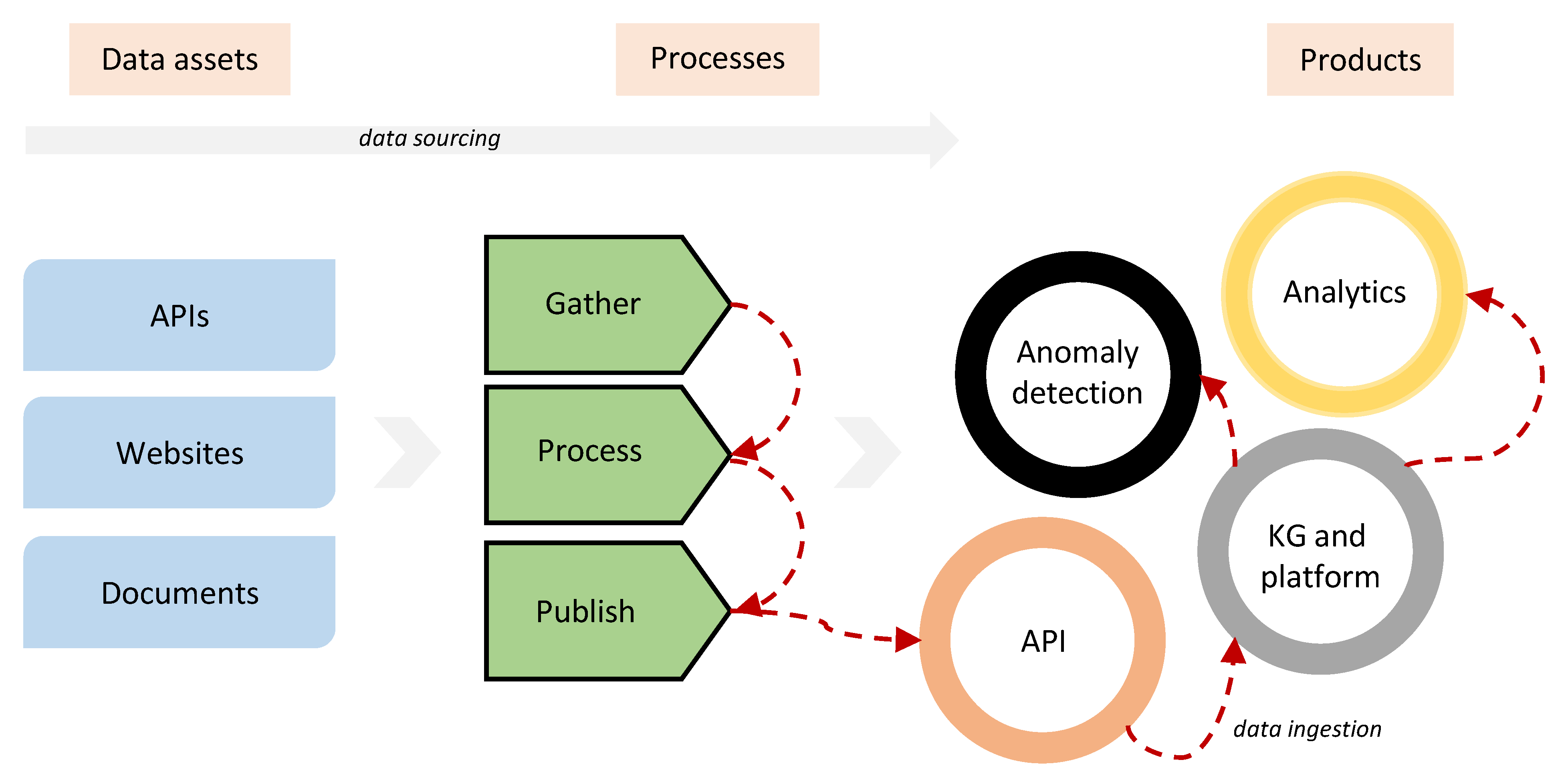
3. Procurement Data Sourcing
3.1. Data Sourcing Process
- A minimum number of fields need to be present in a record for it to be a viable record. For instance, a buyer name, a title, and a tender deadline date are required for tenders.
- Relative fields need to be structured. This is particularly important for date fields, and source strings must be able to be mapped to a date for us to use them.
- The record needs to include viable data, e.g., which is the deadline date later than the current date. This allows us to provide only data that can be used by data consumers.
- Every record is checked for OCDS compliance; this permits errors that may occur as a result of changes to the underlying HTML code when data are scraped.
3.2. Data Curation
3.2.1. Missing Data
3.2.2. Duplicates
3.2.3. Poorly Formed Data
3.2.4. Erroneous Data
3.2.5. Absent Data
3.3. Data Enrichment
4. Knowledge Graph Construction and Publication
- 1.
- A KG API: This is a REST-based API exposing URIs for the resources available in the KG (e.g., awards and contracts) and includes functionalities such as authentication and authorisation, pagination, and sorting. The KG API is mainly meant for programmers and developers who are not familiar with Semantic Web technologies. KG API is available online (https://tbfy.github.io/knowledge-graph-API (accessed on 19 February 2022)) along with an explanatory video (https://www.youtube.com/watch?v=Iyq_mUPWAaA (accessed on 19 February 2022)).
- 2.
- A SPARQL end-point: This is an end-point present over HTTP and receives and processes SPARQL protocol requests. It is primarily meant for executing ad-hoc queries over the KG and is not constrained with certain resources such as KG API. The SPARQL end-point is available online (http://data.tbfy.eu/sparql (accessed on 19 February 2022)) along with a third party GUI (http://yasgui.tbfy.eu (accessed on 19 February 2022)).
- 3.
- A Search API: This API allows exploring large multilingual document collections of public procurement data through a REST-based API as well as searching for similar documents given a document or even given a text. The Search API is available online (http://tbfy.librairy.linkeddata.es/search-api (accessed on 19 February 2022)) along with an explanatory video (https://www.youtube.com/watch?v=djnLBZOHphw (accessed on 19 February 2022)).
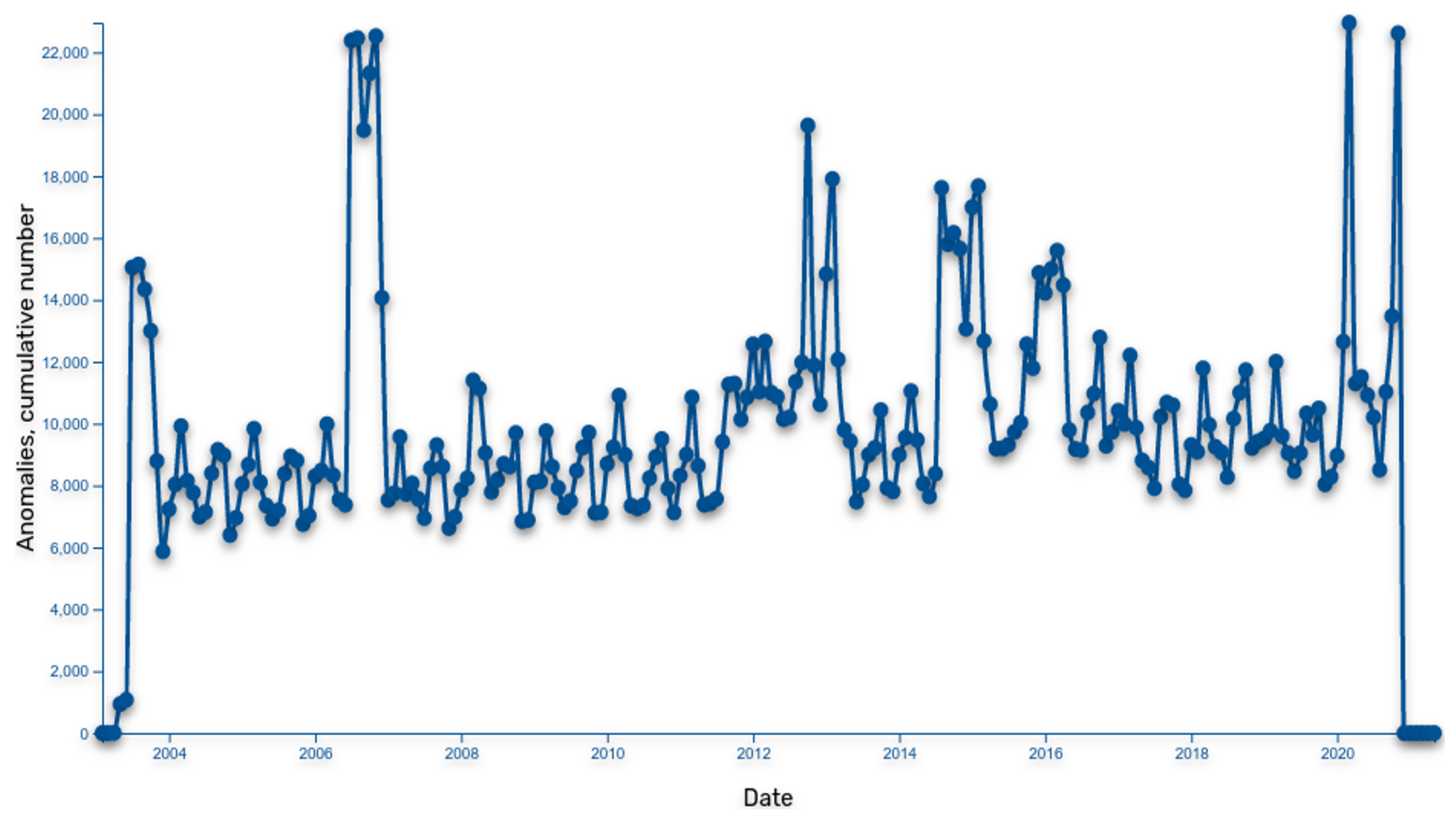
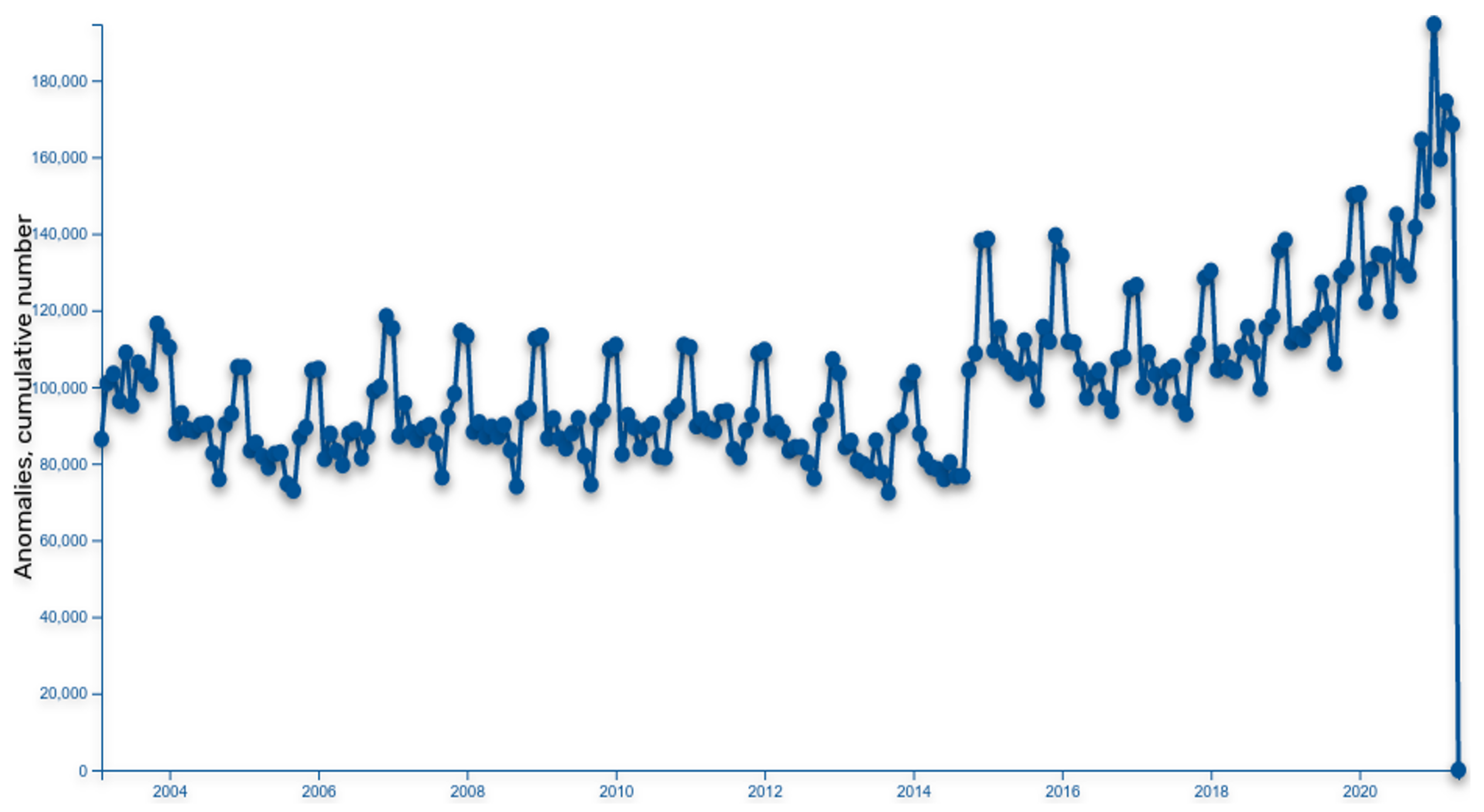
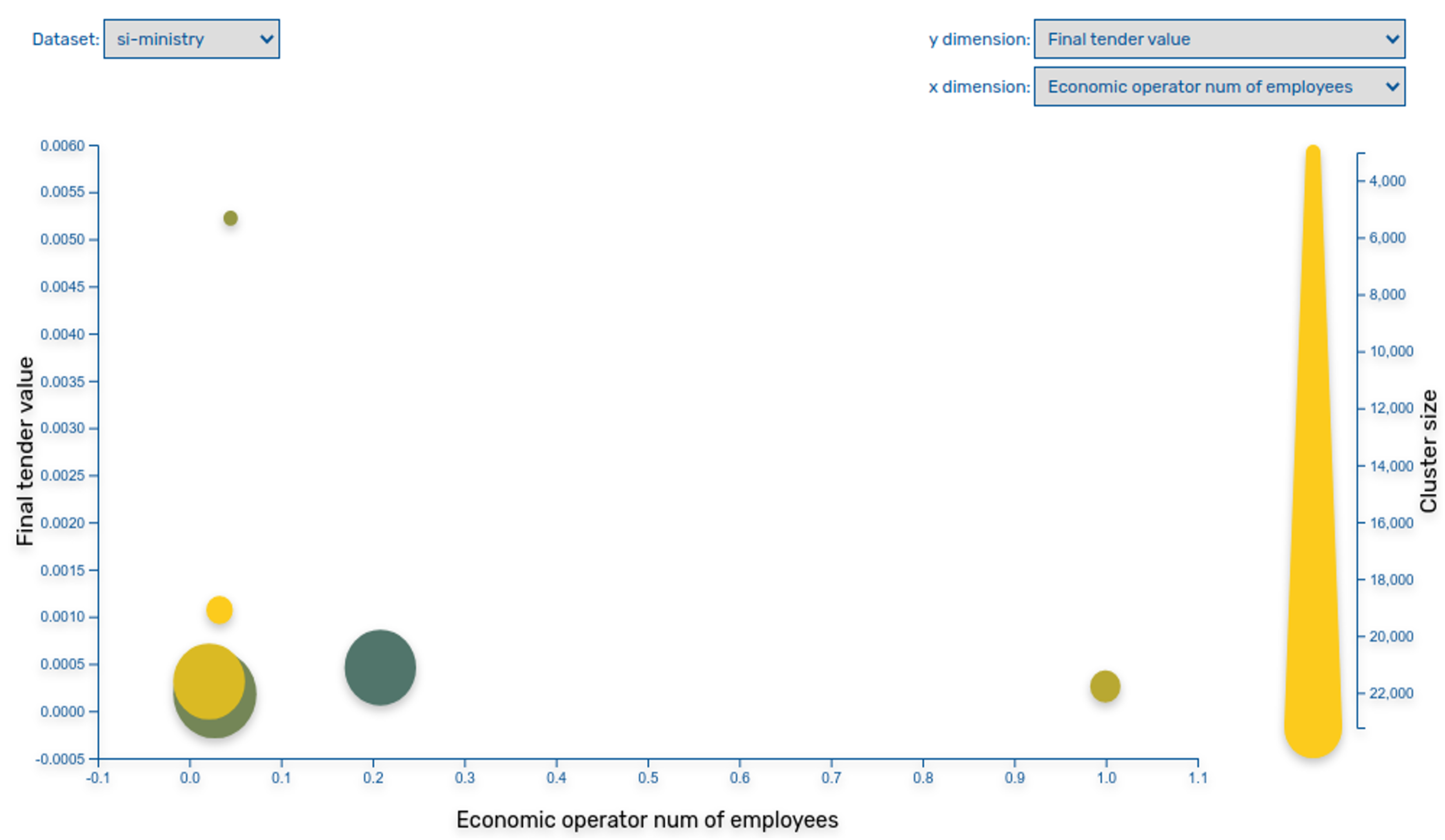
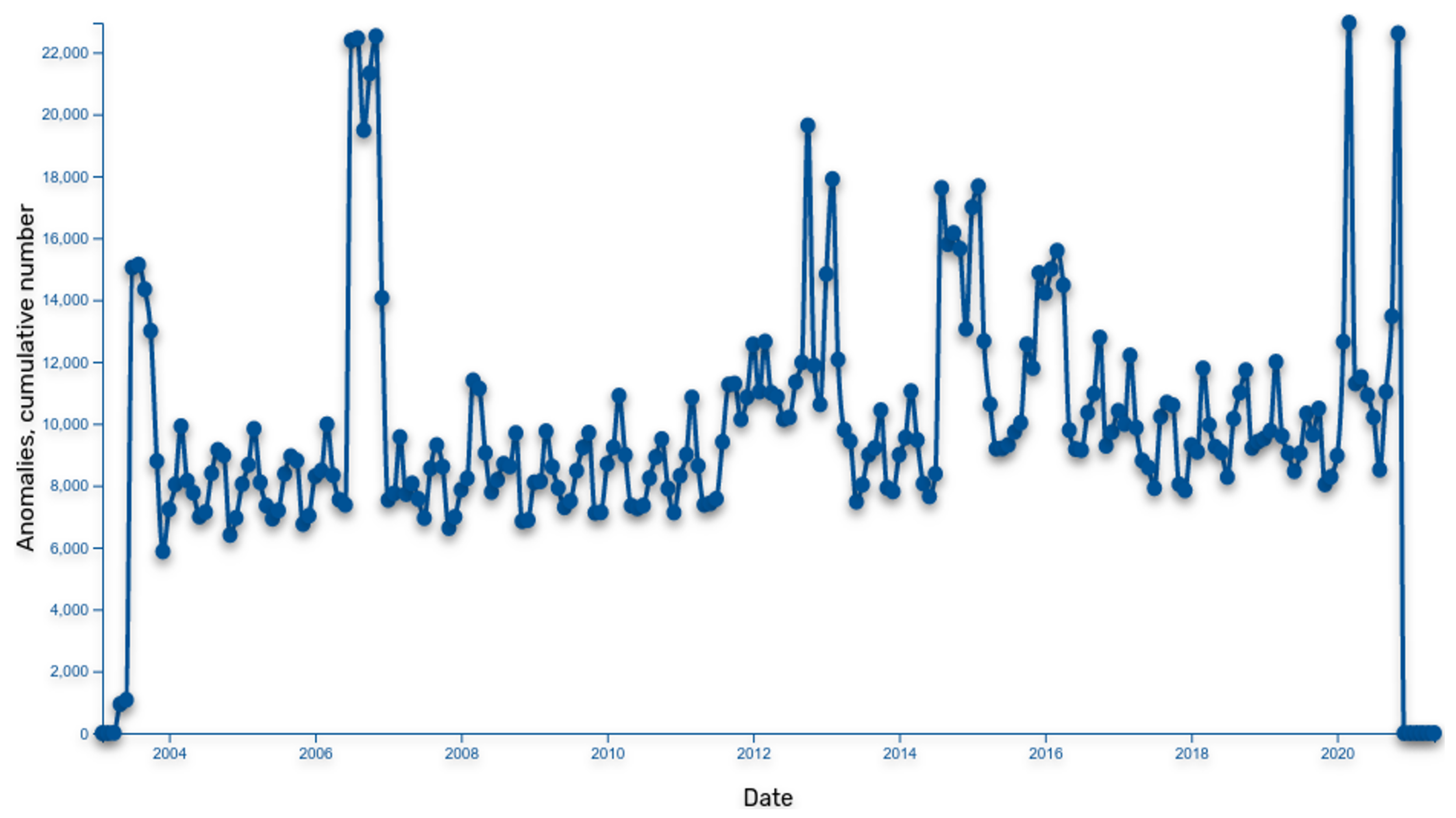
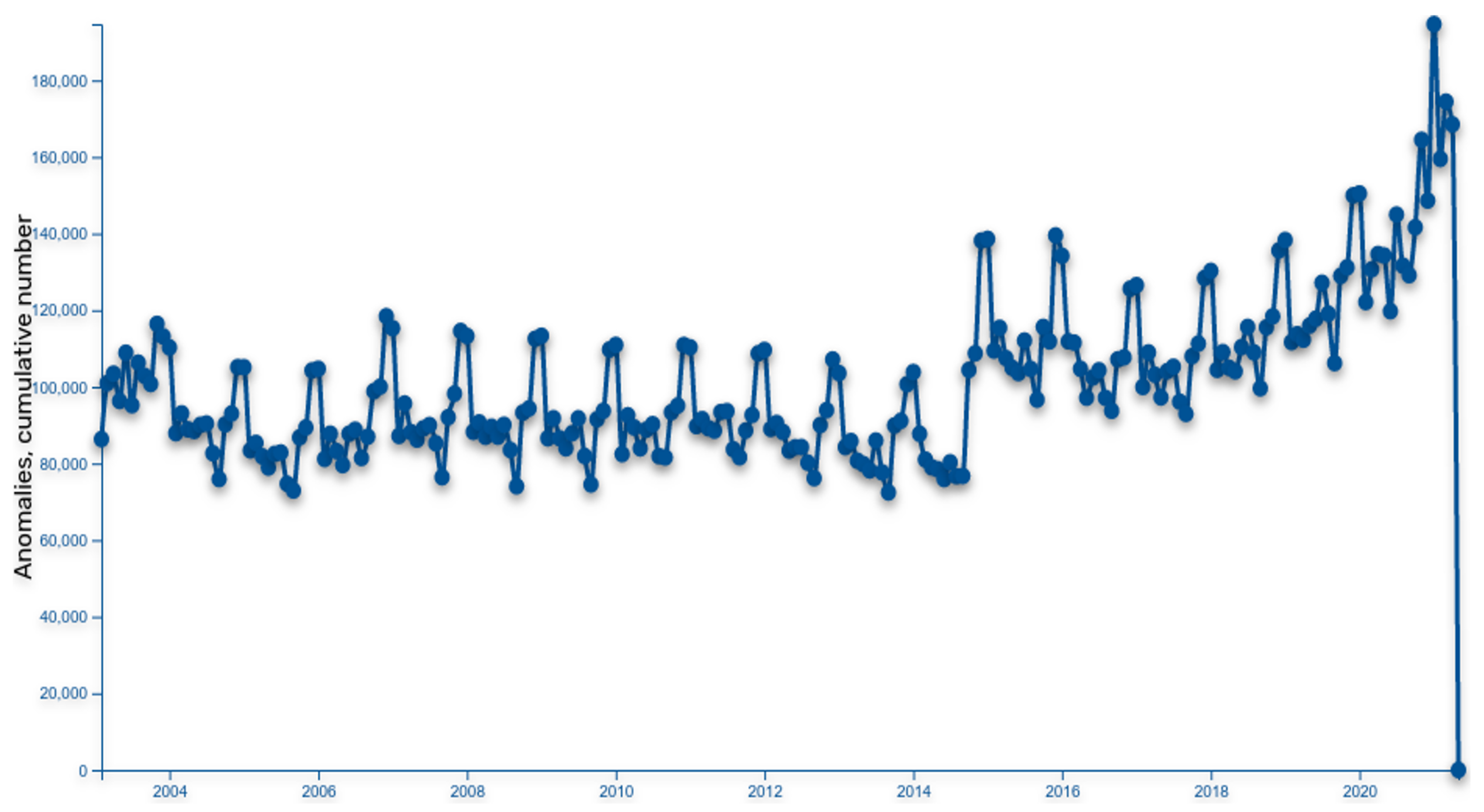
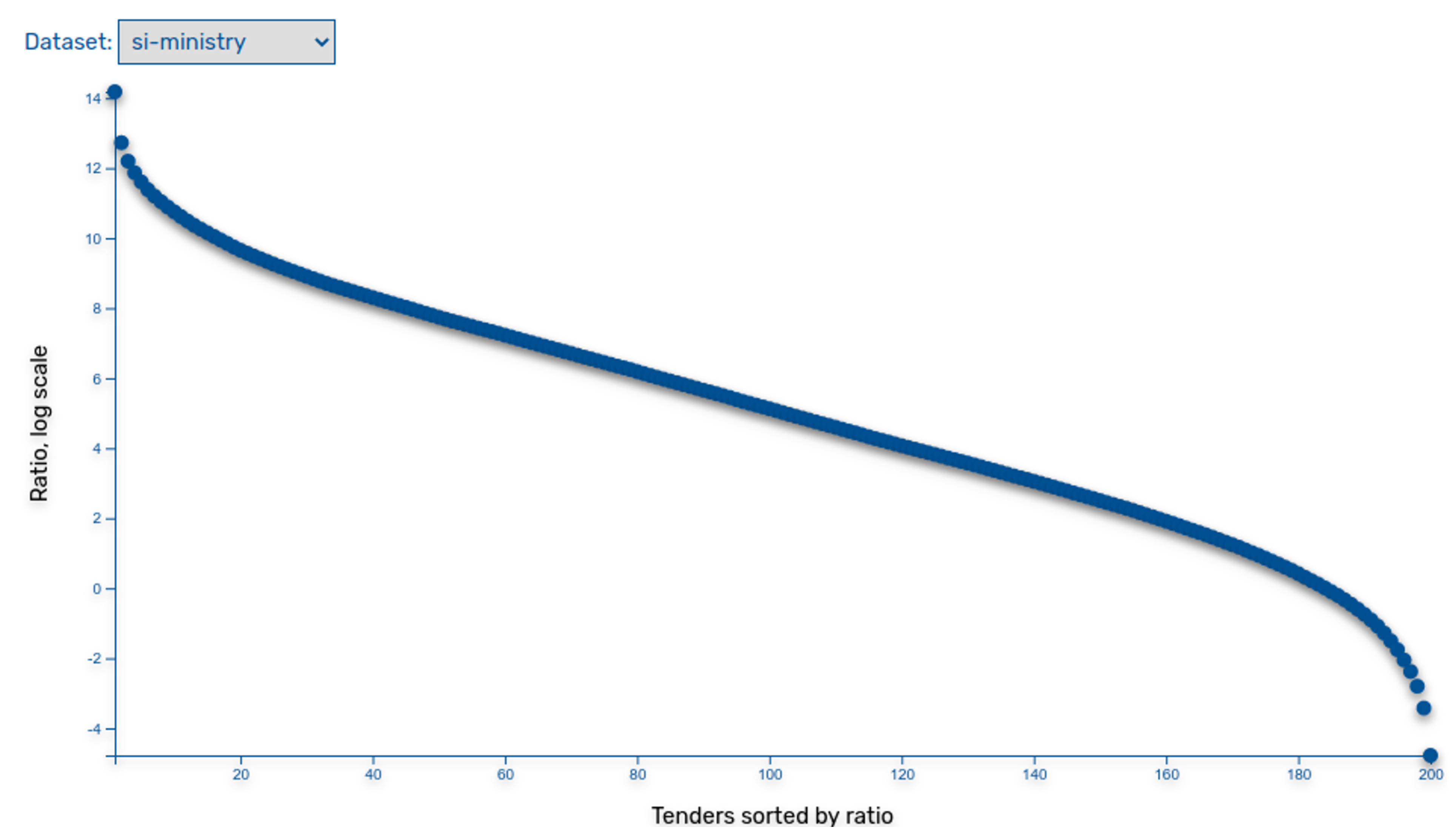
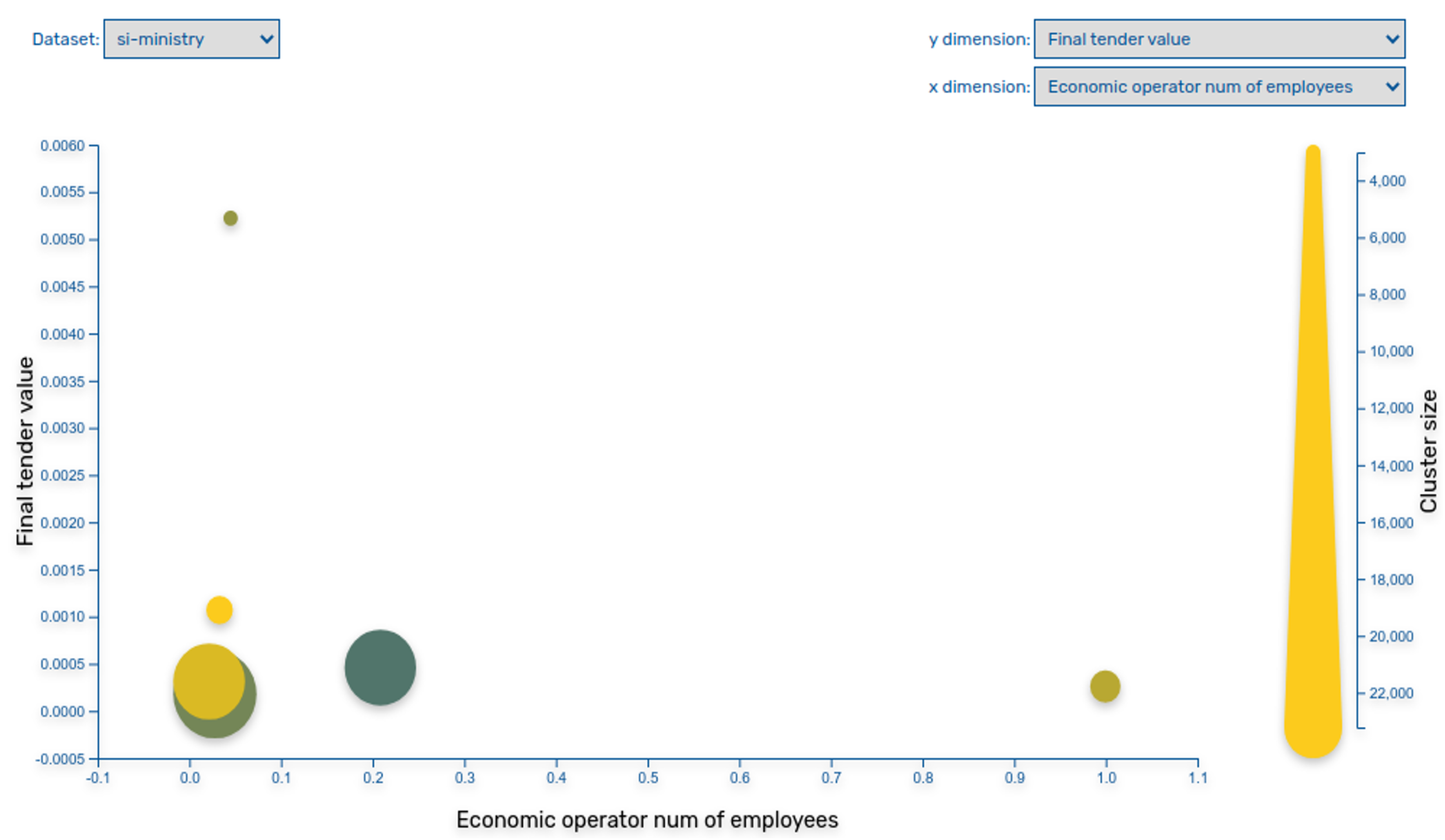
5. Using Public Procurement Data for Anomaly Detection
- 1.
- Average Deviation Anomaly: This method summarises financial transactions between two entities and find the most deviating ones. The method was applied on all entities as well as on entities grouped based on company classifiers (e.g., construction-oriented companies and IT-oriented companies).
- 2.
- Clusters: The method organises transaction sums into an optimal number of clusters and define deviations within each cluster separately. Therefore, this method performs data clustering in order to determine the best arrangement of values into different classes. The method seeks to minimise each class’s average deviation from the class mean and at the same time it is maximising each class’s deviation from the means of the other groups. The method clusters data in a manner that it reduces variance within classes and maximise variance between classes.
- 3.
- Periods: This method defines a financial transaction as a base relation between two entities (public sector entity and business entity). Based on this, relation periods (when relation started or ended) are detected and starting/ending periods are accumulated on a timeline. Based on cumulative relation period extremes, deviations are detected, and entities are listed as part of identified extremes.
- 4.
- Derivatives: This method analyses the biggest changes within two entities and transactional relation in a given period. If a change is identified as an anomaly, it is added to the cumulative anomaly graph. Once the cumulative anomaly graph is defined (based on all transactions jumps between the two entities), the extremes are identified, and anomalous companies are identified. The goal of this method is to find companies showing the greatest changes in transaction relations.
- 5.
- Cumulatives: In this method’s approach, we first define transaction sums for all related entities and normalise sums with the total transactions sum. In such manner, this method defines a comparison baseline. Then, it takes transactions between entities and sums them into a predefined number of periods. For each period partial sums weights are compared to baseline weights, and the anomalies are identified. The more anomalous a company behaves, the higher it ranks on the anomalous list. The purpose of the method is to identify the greatest changes within the series of accumulated periods.
6. Recommendations for Publishing Procurement Data
- Make your public procurement data available in a structured format and according to existing standards
- Include identifiers of all the tenderers that participate in a contracting process
- Include identifiers of the departments and suborganisations that act as tenderers
- Include identifiers of the participating organisations in joint ventures’ data
- All notices and steps associated to a contracting process should be linked with the same identifier
- Link invoices (and results) to the public procurement process to which they belong
- The text of all documents used in a contracting process should be available for further processing and linked to their corresponding contracting process
- Provide commonly agreed visualisations of public contracting data
- Provide answers to the most common questions made by citizens and organisations
- Use your own public procurement data internally (e.g., as a data backend in your transparency portal)
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- OECD Principles for Integrity in Public Procurement; Technical Report; Organisation for Economic Co-Operation and Development: Paris, France, 2009.
- Safarov, I.; Meijer, A.; Grimmelikhuijsen, S. Utilization of open government data: A systematic literature review of types, conditions, effects and users. Inf. Polity 2017, 22, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Ruijer, E.; Evelijn, M. Researching the democratic impact of open government data: A systematic literature review. Inf. Polity 2017, 22, 233–250. [Google Scholar] [CrossRef]
- Futia, G.; Melandri, A.; Vetrò, A.; Morando, F.; Martin, J.C.D. Removing Barriers to Transparency: A Case Study on the Use of Semantic Technologies to Tackle Procurement Data Inconsistency. In Proceedings of the 14th International Conference on the Semantic Web (ESWC), Portorož, Slovenia, 28 May–1 June 2017; Volume10249, pp. 623–637. [Google Scholar] [CrossRef]
- Espinoza-Arias, P.; Fernández Ruíz, M.J.; Morlán-Plo, V.; Notivol-Bezares, R.; Corcho, Ó. The Zaragoza’s Knowledge Graph: Open Data to Harness the City Knowledge. Information 2020, 11, 129. [Google Scholar] [CrossRef] [Green Version]
- Janssen, M.; Charalabidis, Y.; Zuiderwijk, A. Benefits, Adoption Barriers and Myths of Open Data and Open Government. Inf. Syst. Manag. 2012, 29, 258–268. [Google Scholar] [CrossRef] [Green Version]
- Lourenço, R.P. An analysis of open government portals: A perspective of transparency for accountability. Gov. Inf. Q. 2015, 32, 323–332. [Google Scholar] [CrossRef]
- Muñoz-Soro, J.F.; Esteban, G.; Corcho, Ó.; Serón, F.J. PPROC, an ontology for transparency in public procurement. Semant. Web 2016, 7, 295–309. [Google Scholar] [CrossRef] [Green Version]
- Bobowski, S.; Gola, J.; Szydło, W. Access to Public Procurement Contracts in EU: Perspective of SMEs. In Proceedings of the 20th Eurasia Business and Economics Society Conference (EBES 2017), Vienna, Austria, 28–30 September 2018; pp. 89–103. [Google Scholar] [CrossRef]
- Soylu, A.; Corcho, Ó.; Elvesæter, B.; Badenes-Olmedo, C.; Blount, T.; Martínez, F.Y.; Kovacic, M.; Posinkovic, M.; Makgill, I.; Taggart, C.; et al. TheyBuyForYou Platform and Knowledge Graph: Expanding Horizons in Public Procurement with Open Linked Data. Semant. Web 2022, 13, 265–291. [Google Scholar] [CrossRef]
- Soylu, A.; Corcho, Ó.; Elvesæter, B.; Badenes-Olmedo, C.; Martínez, F.Y.; Kovacic, M.; Posinkovic, M.; Makgill, I.; Taggart, C.; Simperl, E.; et al. Enhancing Public Procurement in the European Union Through Constructing and Exploiting an Integrated Knowledge Graph. In Proceedings of the 19th International Semantic Web Conference (ISWC 2020), Athens, Greece, 2–6 November 2020; Volume 12507, pp. 430–446. [Google Scholar] [CrossRef]
- Yan, J.; Wang, C.; Cheng, W.; Gao, M.; Zhou, A. A Retrospective of Knowledge Graphs. Front. Comput. Sci. 2018, 12, 55–74. [Google Scholar] [CrossRef]
- Mountantonakis, M.; Tzitzikas, Y. Large-Scale Semantic Integration of Linked Data: A Survey. ACM Comput. Surv. 2019, 52, 1–40. [Google Scholar] [CrossRef]
- Hitzler, P. A Review of the Semantic Web Field. Commun. ACM 2021, 64, 76–83. [Google Scholar] [CrossRef]
- Guarino, N.; Oberle, D.; Staab, S. What Is an Ontology? In Handbook on Ontologies; Staab, S., Studer, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–17. [Google Scholar] [CrossRef]
- Distinto, I.; d’Aquin, M.; Motta, E. LOTED2: An ontology of European public procurement notices. Semant. Web 2016, 7, 267–293. [Google Scholar] [CrossRef] [Green Version]
- Nečaský, M.; Klímek, J.; Mynarz, J.; Knap, T.; Svátek, V.; Stárka, J. Linked data support for filing public contracts. Comput. Ind. 2014, 65, 862–877. [Google Scholar] [CrossRef]
- Álvarez Rodríguez, J.M.; Gayo, J.E.L.; Cifuentes, F.; Hérnandez, G.; Sánchez, C.; Luna, J.A.G. Towards a Pan-European E-Procurement Platform to Aggregate, Publish and Search Public Procurement Notices Powered by Linked Open Data: The Moldeas Approach. Int. J. Softw. Eng. Knowl. Eng. 2012, 22, 365–384. [Google Scholar] [CrossRef]
- Miroslav, M.; Miloš, M.; Štavljanin, V.; Božo, D.; Đorđe, L. Semantic technologies on the mission: Preventing corruption in public procurement. Comput. Ind. 2014, 65, 878–890. [Google Scholar] [CrossRef]
- Csáki, C.; Prier, E. Quality Issues of Public Procurement Open Data. In Proceedings of the 7th International Conference on Electronic Government and the Information Systems Perspective (EGOVIS 2018), Regensburg, Germany, 3–5 September 2018; Volume 11032, pp. 177–191. [Google Scholar] [CrossRef]
- Kharlamov, E.; Jiménez-Ruiz, E.; Pinkel, C.; Rezk, M.; Skjæveland, M.G.; Soylu, A.; Xiao, G.; Zheleznyakov, D.; Giese, M.; Horrocks, I.; et al. Optique: Ontology-Based Data Access Platform. In Proceedings of the ISWC 2015 Posters & Demonstrations Track Co-Located with the 14th International Semantic Web Conference (ISWC-2015), Monterey, CA, USA, 11–15 October 2015; Volume 1486. [Google Scholar]
- Kharlamov, E.; Mailis, T.P.; Bereta, K.; Bilidas, D.; Brandt, S.; Jiménez-Ruiz, E.; Lamparter, S.; Neuenstadt, C.; Özçep, Ö.L.; Soylu, A.; et al. A semantic approach to polystores. In Proceedings of the International Conference on Big Data (BigData 2016), Washington, DC, USA, 5–8 December 2016; pp. 2565–2573. [Google Scholar] [CrossRef]
- Corcho, O.; Priyatna, F.; Chaves-Fraga, D. Towards a new generation of ontology based data access. Semant. Web 2020, 11, 153–160. [Google Scholar] [CrossRef]
- Soylu, A.; Elvesæter, B.; Turk, P.; Roman, D.; Corcho, Ó.; Simperl, E.; Konstantinidis, G.; Lech, T.C. Towards an Ontology for Public Procurement Based on the Open Contracting Data Standard. In Proceedings of the 18th IFIP WG 6.11 Conference on e-Business, e-Services, and e-Society (I3E 2019), Trondheim, Norway, 18–20 September 2019; Volume 11701, pp. 230–237. [Google Scholar] [CrossRef]
- Roman, D.; Alexiev, V.; Paniagua, J.; Elvesæter, B.; Zernichow, B.M.V.; Soylu, A.; Simeonov, B.; Taggart, C. The euBusinessGraph Ontology: A Lightweight Ontology for Harmonizing Basic Company Information. Semant. Web 2022, 13, 41–68. [Google Scholar] [CrossRef]
- Dimou, A.; Sande, M.V.; Colpaert, P.; Verborgh, R.; Mannens, E.; de Walle, R.V. RML: A Generic Language for Integrated RDF Mappings of Heterogeneous Data. In Proceedings of the Workshop on Linked Data on the Web Co-Located with the 23rd International World Wide Web Conference, Seoul, Korea, 7–11 April 2014; Volume 1184. [Google Scholar]
- Lyra, M.S.; Pinheiro, F.L.; Bacao, F. Public Procurement Fraud Detection: A Review Using Network Analysis. In Proceedings of the Tenth International Conference on Complex Networks and Their Applications (COMPLEX NETWORKS 2021), Madrid, Spain, 30 November–2 December 2022; Volume 1015, pp. 116–129. [Google Scholar] [CrossRef]
- García Rodríguez, M.J.; Rodríguez-Montequín, V.; Ballesteros-Pérez, P.; Love, P.E.; Signor, R. Collusion detection in public procurement auctions with machine learning algorithms. Autom. Constr. 2022, 133, 104047. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Sources by Continent | Count of Sources |
|---|---|
| Global | 10 |
| Africa | 16 |
| Asia | 29 |
| Europe | 569 |
| North America | 44 |
| Oceania | 3 |
| South America | 14 |
| Grand total | 685 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soylu, A.; Corcho, Ó.; Elvesæter, B.; Badenes-Olmedo, C.; Yedro-Martínez, F.; Kovacic, M.; Posinkovic, M.; Medvešček, M.; Makgill, I.; Taggart, C.; et al. Data Quality Barriers for Transparency in Public Procurement. Information 2022, 13, 99. https://doi.org/10.3390/info13020099
Soylu A, Corcho Ó, Elvesæter B, Badenes-Olmedo C, Yedro-Martínez F, Kovacic M, Posinkovic M, Medvešček M, Makgill I, Taggart C, et al. Data Quality Barriers for Transparency in Public Procurement. Information. 2022; 13(2):99. https://doi.org/10.3390/info13020099
Chicago/Turabian StyleSoylu, Ahmet, Óscar Corcho, Brian Elvesæter, Carlos Badenes-Olmedo, Francisco Yedro-Martínez, Matej Kovacic, Matej Posinkovic, Mitja Medvešček, Ian Makgill, Chris Taggart, and et al. 2022. "Data Quality Barriers for Transparency in Public Procurement" Information 13, no. 2: 99. https://doi.org/10.3390/info13020099
APA StyleSoylu, A., Corcho, Ó., Elvesæter, B., Badenes-Olmedo, C., Yedro-Martínez, F., Kovacic, M., Posinkovic, M., Medvešček, M., Makgill, I., Taggart, C., Simperl, E., Lech, T. C., & Roman, D. (2022). Data Quality Barriers for Transparency in Public Procurement. Information, 13(2), 99. https://doi.org/10.3390/info13020099