
Detecting Learning Patterns in Tertiary Education Using K-Means Clustering


Abstract
:1. Introduction
1.1. Work Done
1.2. Contribution
1.3. Paper Organisation
2. Proposed Model for Students Performance Evaluation
2.1. Distribution Entry


2.2. Compute Each Distribution Parameter
- Current mean: this is to determine the expected mark for the student, and this can be used to determine whether a student may have pass or fail marks.
- Current standard deviation: it would determine how far the student’s mark may be different from their current average marks. This would help in showing improving or lowering students.
2.3. Distribution Clustering
2.4. Migration Analysis
3. Experimental Results
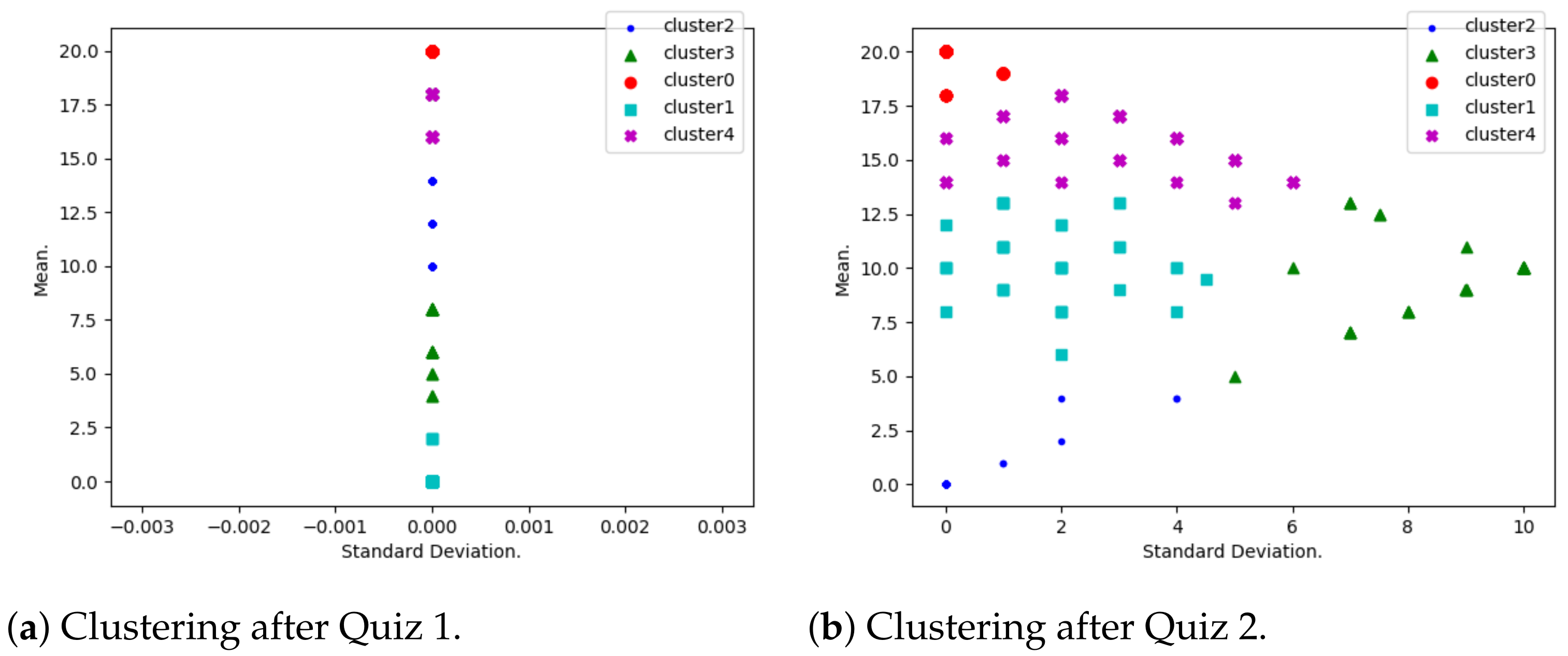
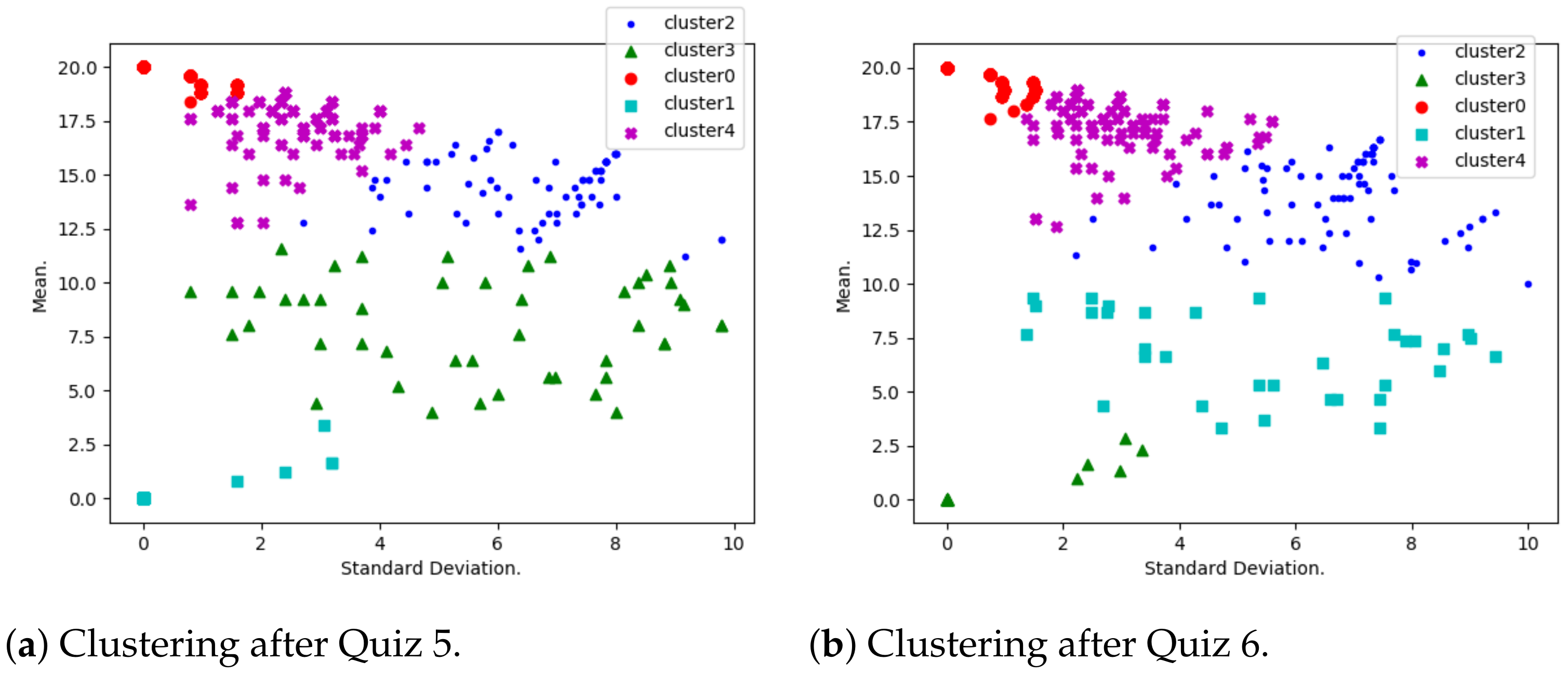
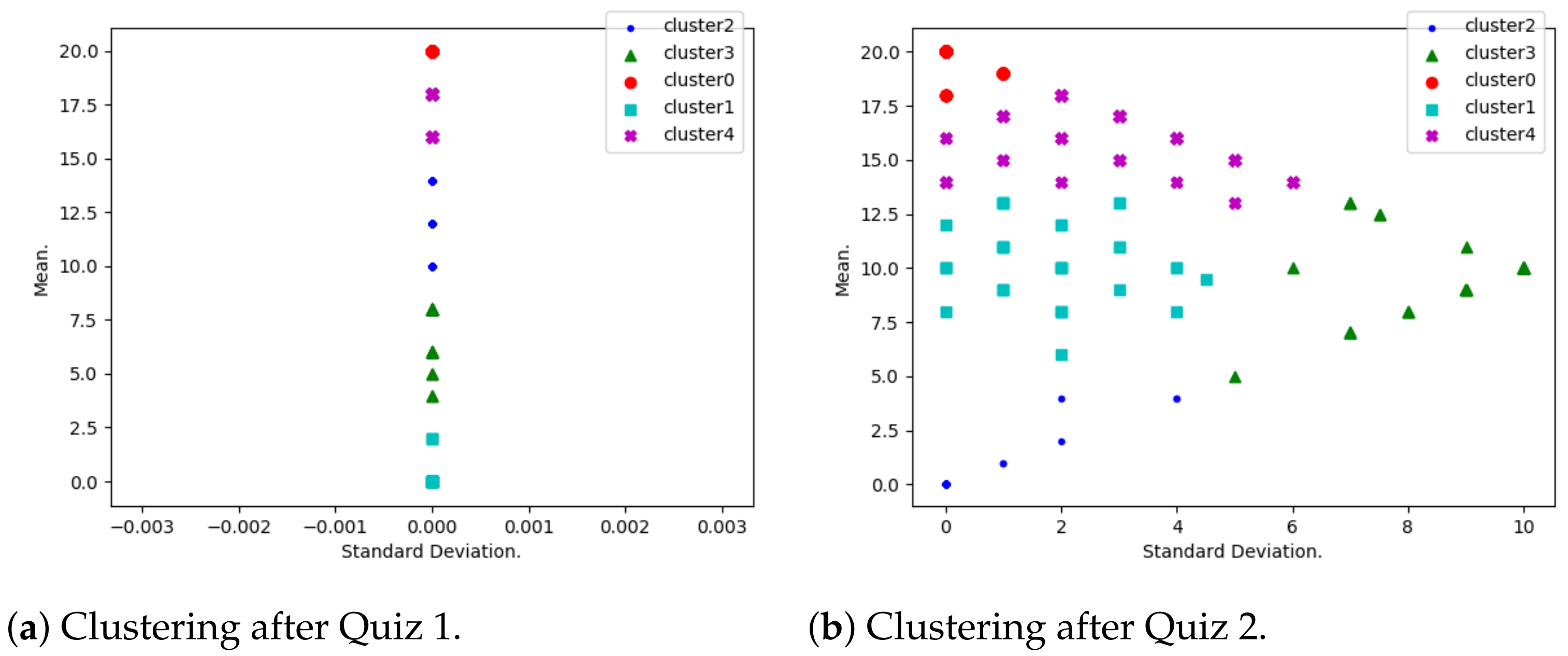
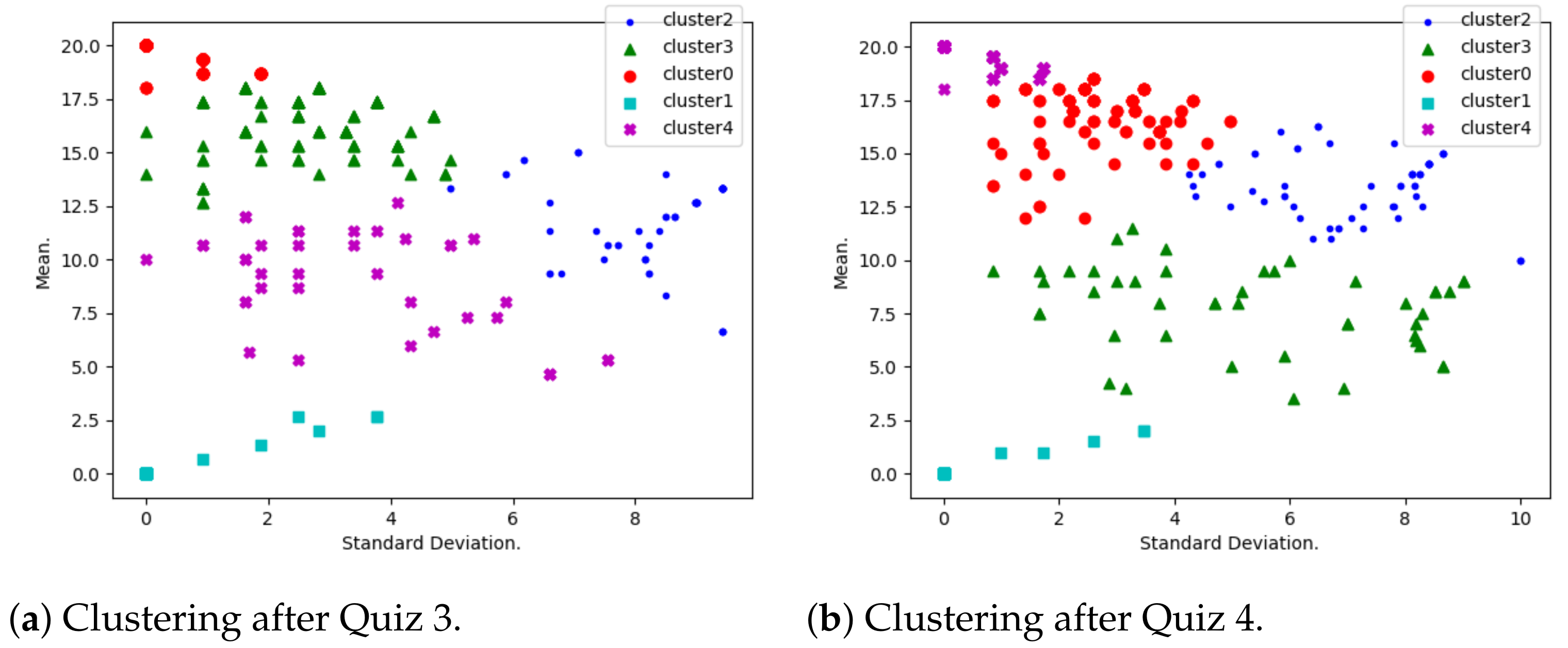
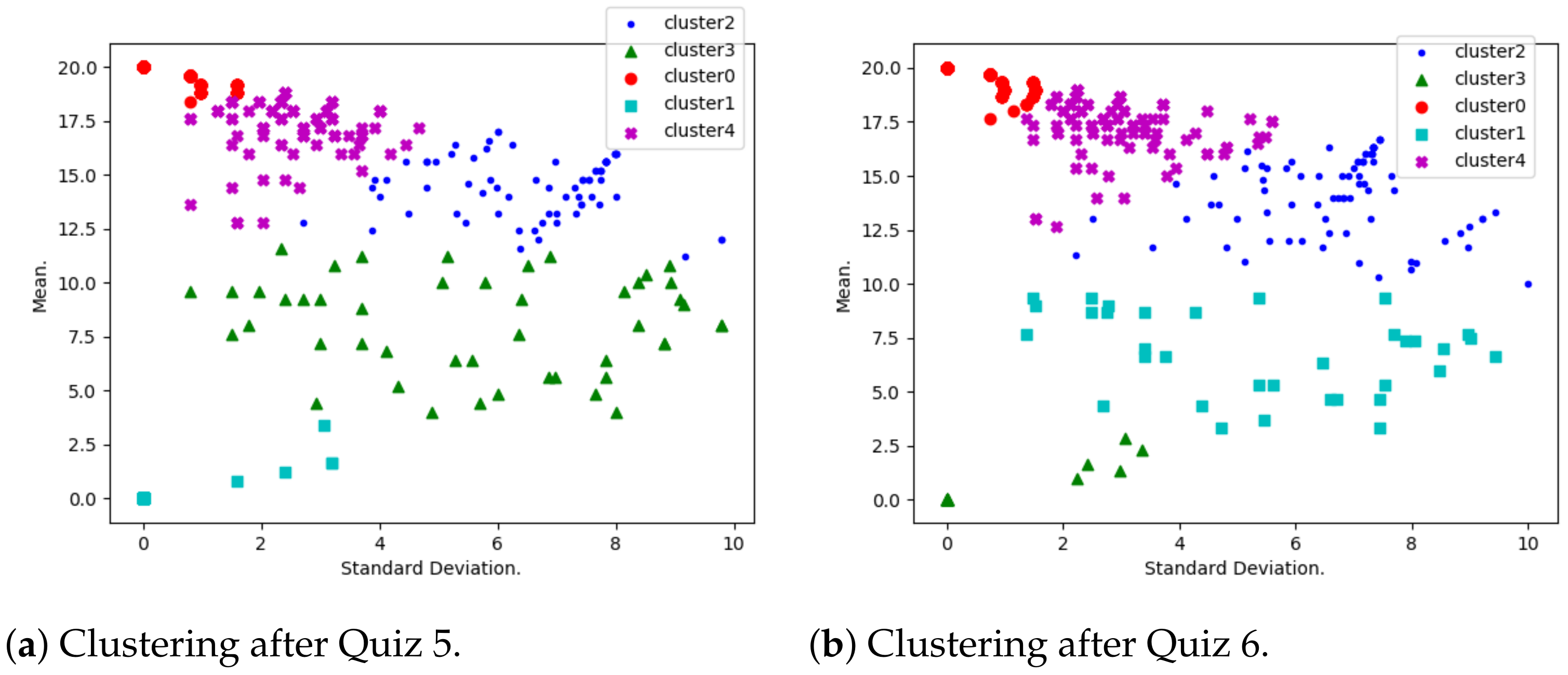
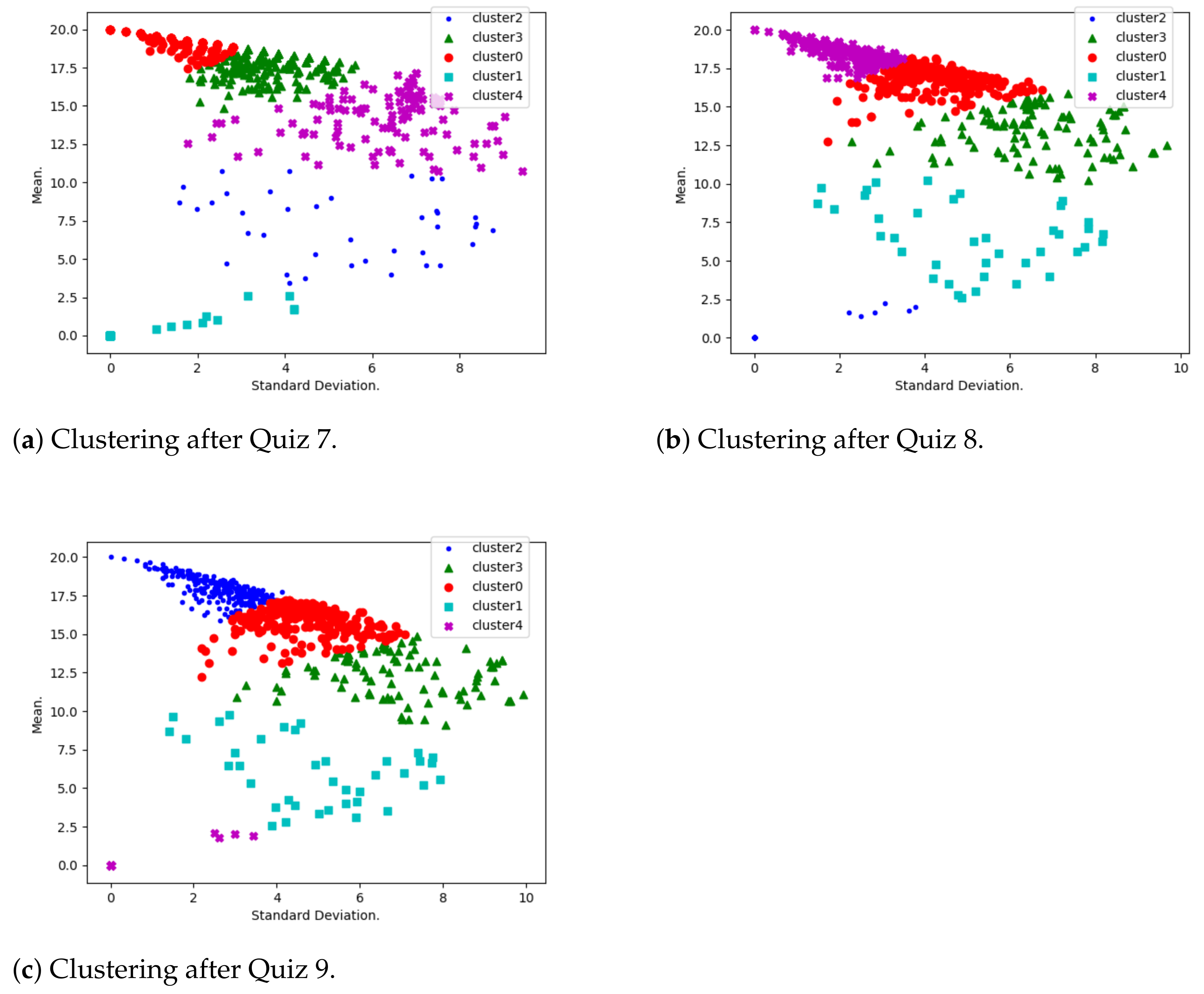
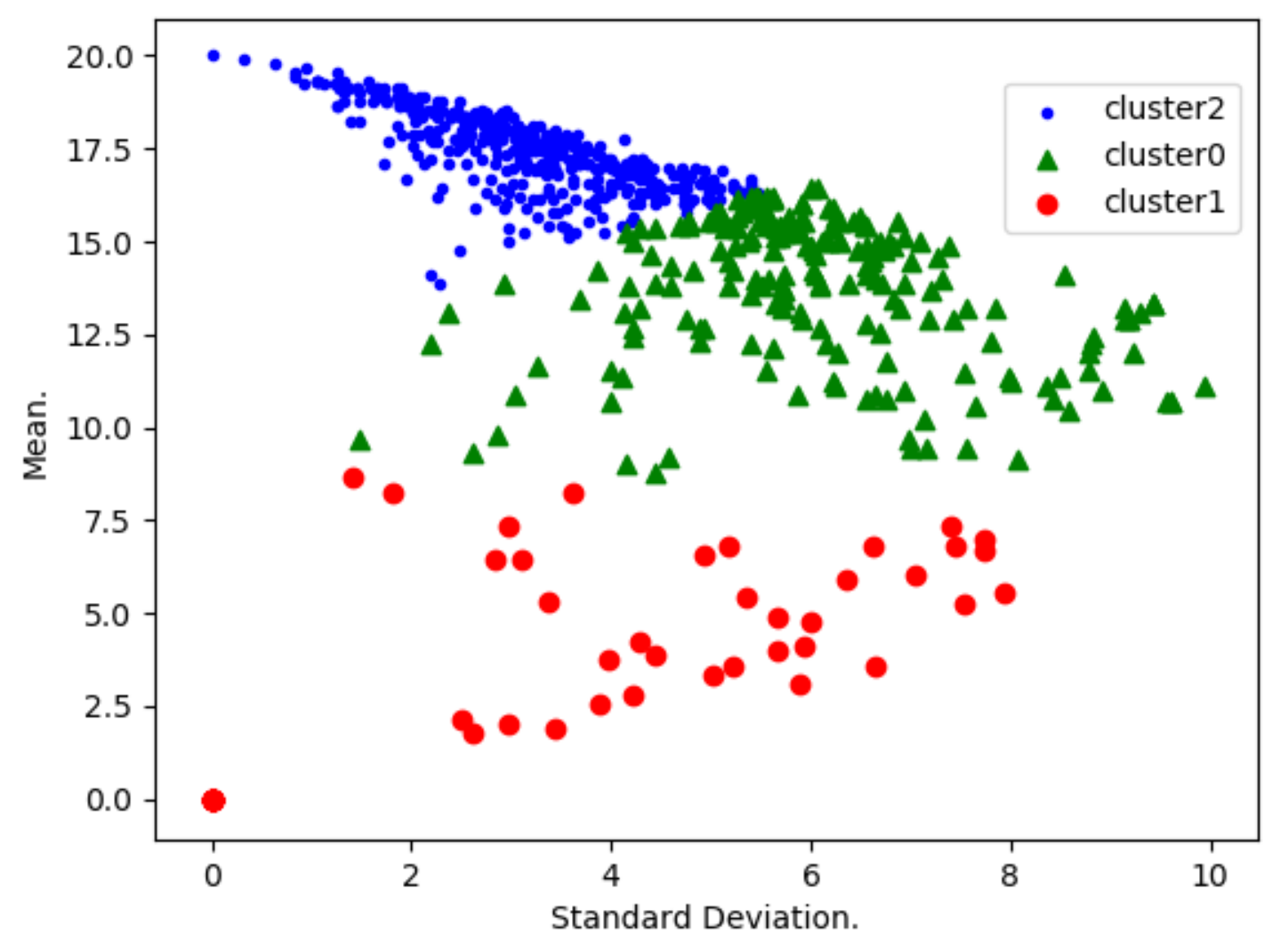
- Performance evolution. A K-means algorithm has been used to group students according to their mean and standard deviation.As shown by Table 3, several default values have been considered for the Python-Sklearn function “sklearn.cluster.KMeans”. The considered number of cluster is first 5 (with a silhouette score calculated to be 0.39) and later 3 (with a silhouette score calculated to be 0.58). Many clusters reflect a situation where few critical students need to be isolated, and a smaller number of clusters reflects a situation where more critical students need to be isolated.When using K-means, it is a common practice to use optimum number K of clusters (see [28,29] for example). This number is determined by minimizing a cost function, and a great example of such a function is the Silhouette Score, which is expressed in terms of the considered independent parameters. However, in this study, the optimal number K truly depends on various parameters (other than the mean and standard deviation used in this study), such as demographic and historical ones. This is why we believe that the optimum number of clusters, in this context, needs to be determined in future research.Students with a highest mean and least standard deviation are considered to be consistently motivated; those with a lowest mean and least standard deviation are the ones who are consistently discouraged. High standard deviation shows that the corresponding students have diverse marks, due to either encouragement or discouragement.
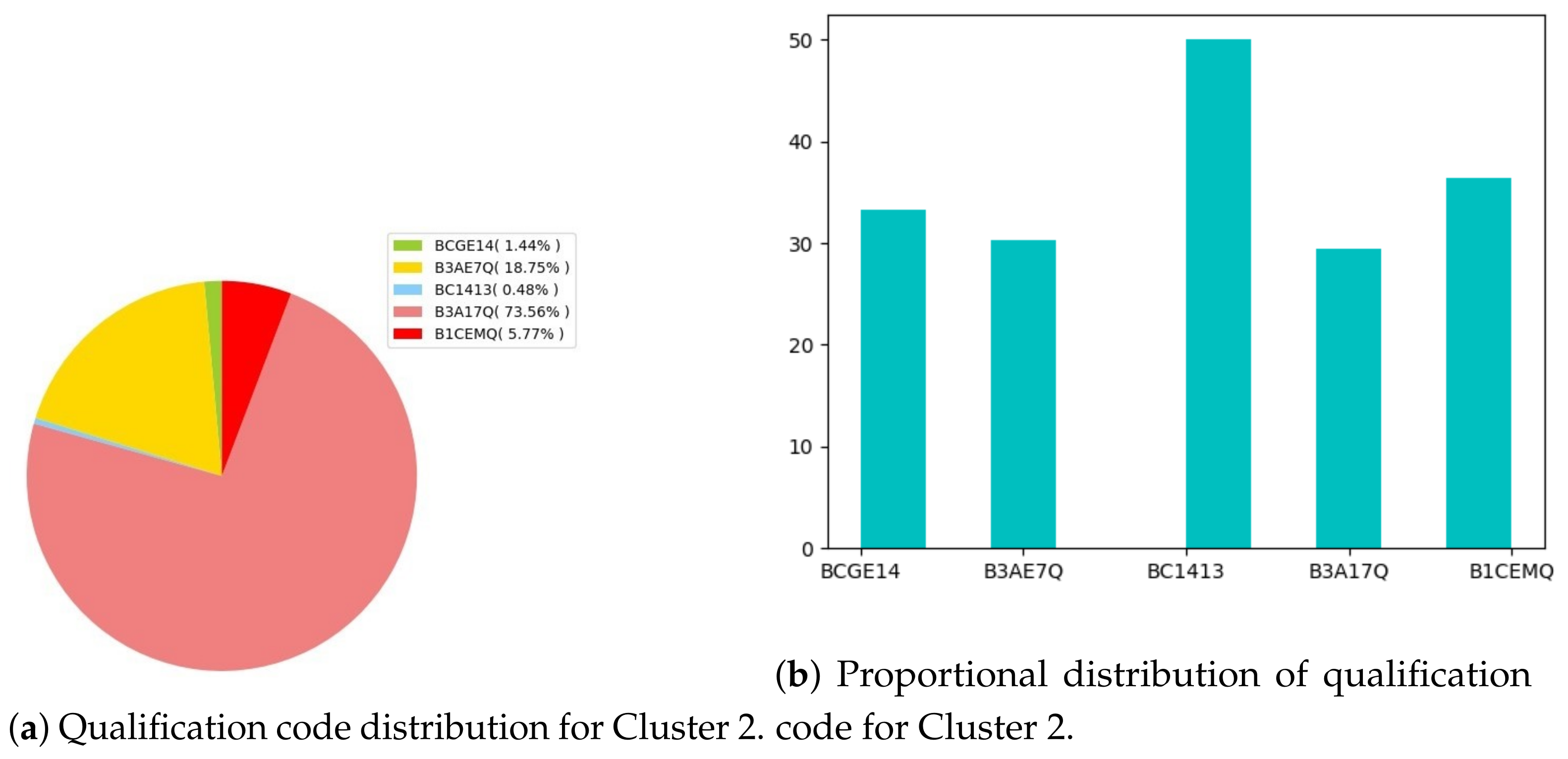
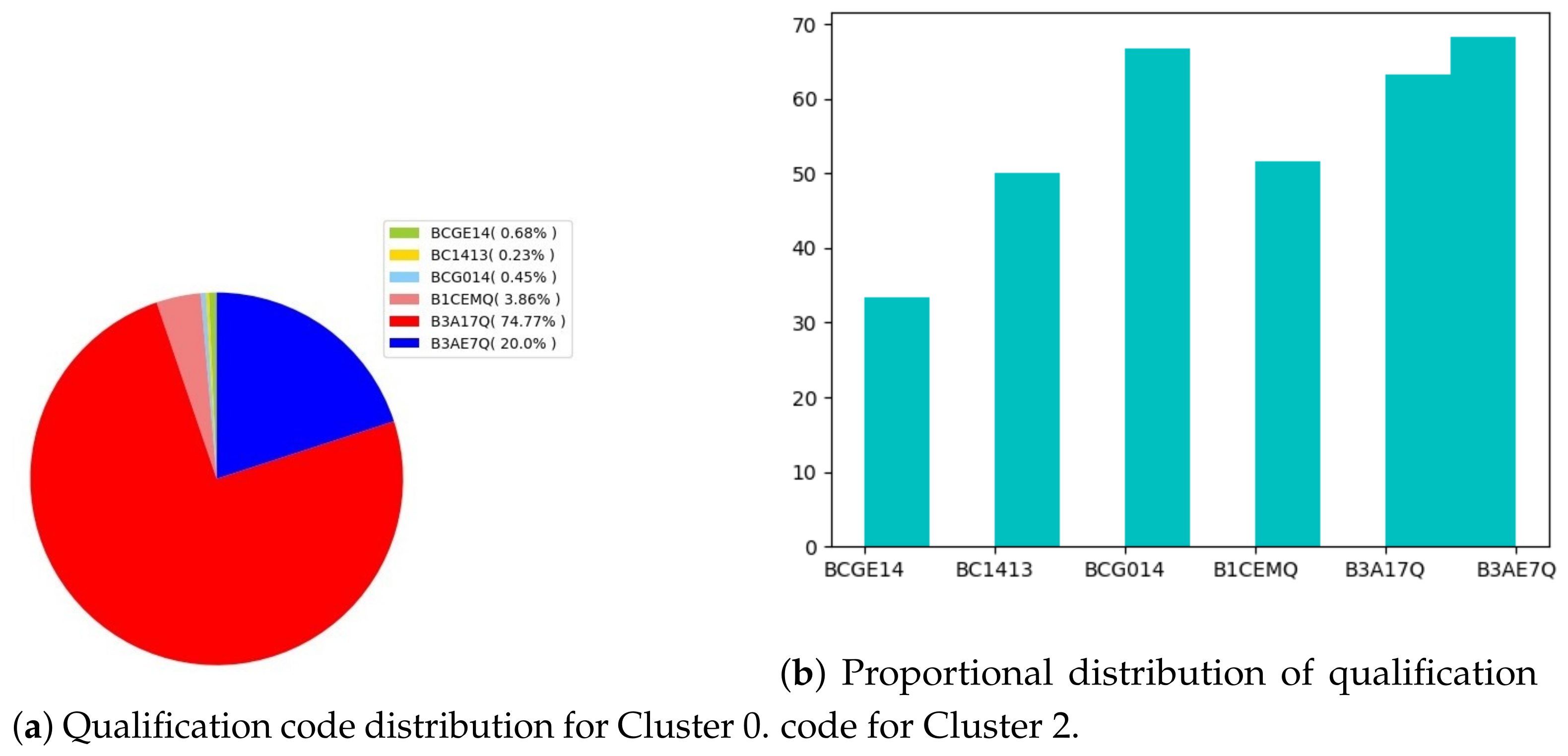
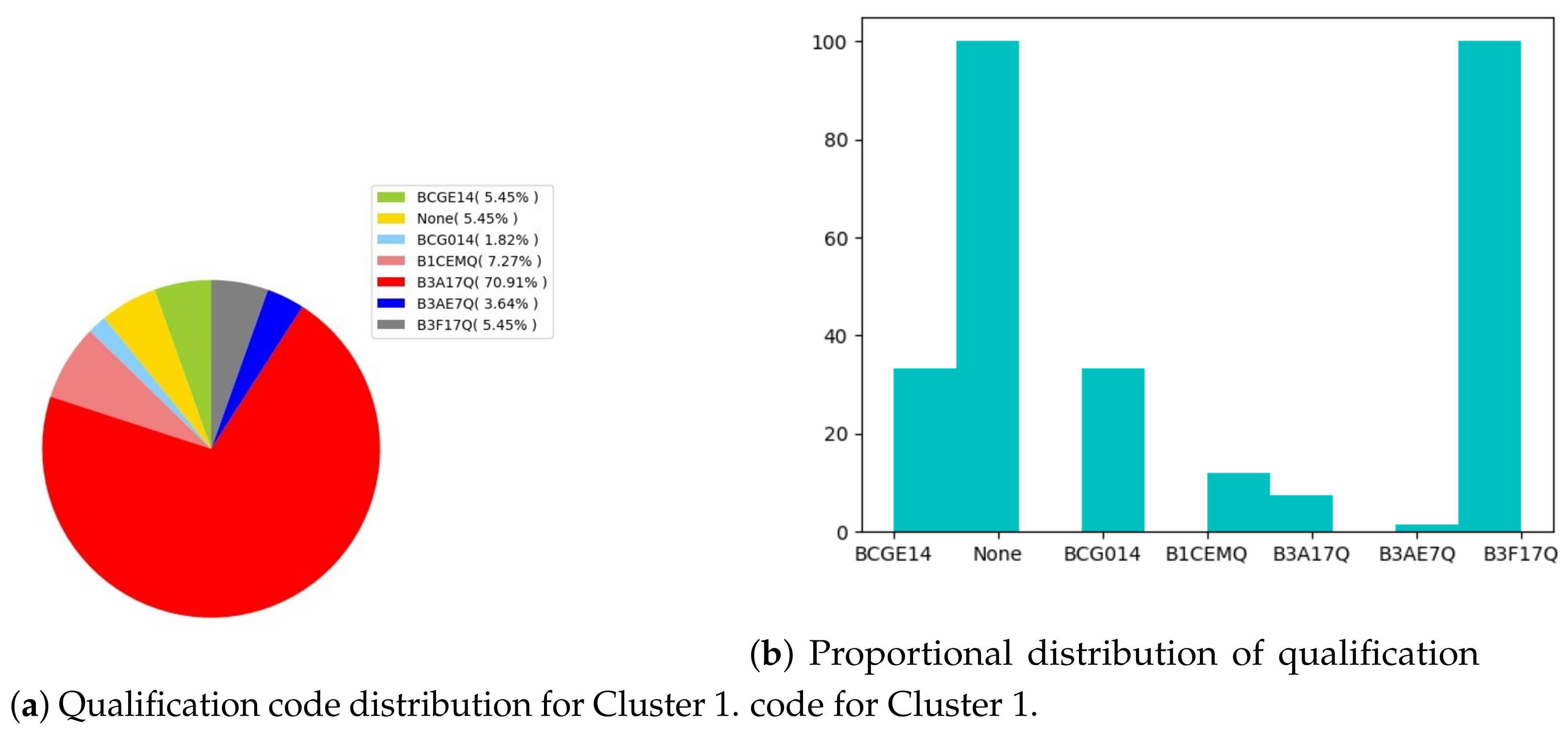
- Performance distribution. At this stage, students have been grouped into five performance clusters. For each of the clusters, qualification codes have been interpreted. These are
- ▸
- B1CEMQ: Bachelor of Commerce in Entrepreneurial Management.
- ▸
- B3A17Q: Bachelor of Commerce in Accounting.
- ▸
- B3AE7Q: Extended Bachelor of Commerce in Accounting.
- ▸
- B3F17Q: Bachelor of Commerce in Finance.
- ▸
- BC1413: Bachelor of Commerce in Entrepreneurial. Management (qualification phasing out).
- ▸
- BCG014: Bachelor of Commerce in Accounting (qualification phasing out).
- ▸
- BCGE14: Extended Bachelor of Commerce in Accounting (qualification phasing out).
- ▸
- None: no information shown.
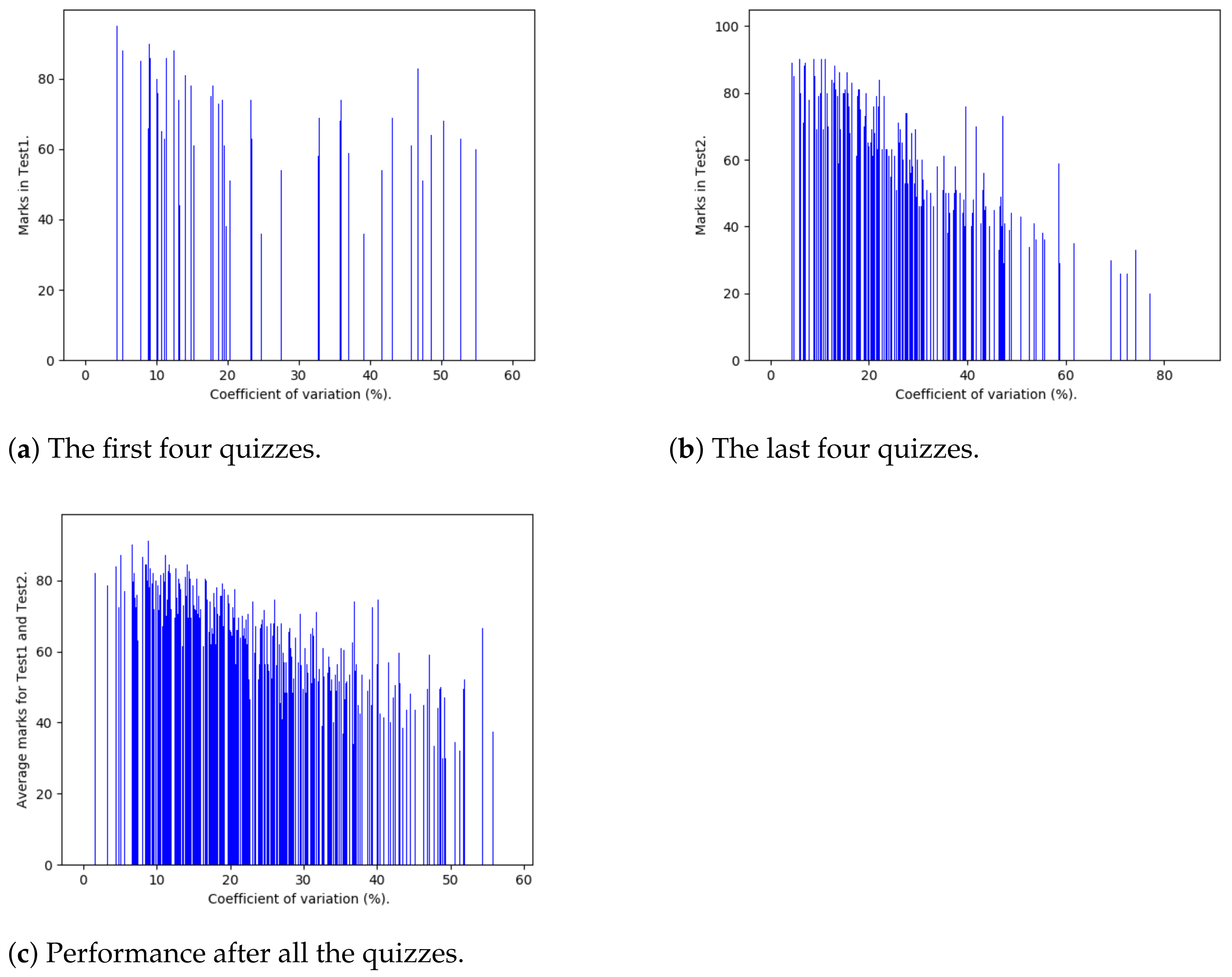
- Consistency. We study the relevance of the quizzes-based performance and succeeding in written tests, for fully engaged students. Test 1 has been written after the first four quizzes and Test 2 after the next/last four. Here, the coefficient of variation has been employed to measure each student’s performance based on a series of marks obtained in the considered quizzes.
3.1. Performance Evolution
3.2. Performance Distribution
3.3. Consistency
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Schwab, K. The Fourth Industrial Revolution; Currency: Danvers, MA, USA, 2017. [Google Scholar]
- Mohamed, A. UNESCO Rallies International Organizations, Civil Society and Private Sector Partners in a Broad Coalition to Ensure# LearningNeverStops. 2020. Available online: https://en.unesco.org/news/unesco-rallies-international-organizations-civil-society-and-private-sector-partners-broad (accessed on 20 November 2021).
- Wanner, T.; Palmer, E. Personalising learning: Exploring student and teacher perceptions about flexible learning and assessment in a flipped university course. Comput. Educ. 2015, 88, 354–369. [Google Scholar] [CrossRef]
- Fan, J.Y.; Wang, Y.H.; Chao, L.F.; Jane, S.W.; Hsu, L.L. Performance evaluation of nursing students following competency-based education. Nurse Educ. Today 2015, 35, 97–103. [Google Scholar] [CrossRef]
- Anema, M.; McCoy, J. Competency Based Nursing Education: Guide to Achieving Outstanding Learner Outcomes; Springer Publishing Company: New York, NY, USA, 2009. [Google Scholar]
- Milanowski, A. The relationship between teacher performance evaluation scores and student achievement: Evidence from Cincinnati. Peabody J. Educ. 2004, 79, 33–53. [Google Scholar] [CrossRef]
- Gokmen, G.; Akinci, T.Ç.; Tektaş, M.; Onat, N.; Kocyigit, G.; Tektaş, N. Evaluation of student performance in laboratory applications using fuzzy logic. Procedia-Soc. Behav. Sci. 2010, 2, 902–909. [Google Scholar] [CrossRef] [Green Version]
- Yen, J.; Langari, R.; Zadeh, L.A. Industrial Applications of Fuzzy Logic and Intelligent Systems; IEEE Press: New York, NY, USA, 1995. [Google Scholar]
- Cheung, L.L.; Kan, A.C. Evaluation of factors related to student performance in a distance-learning business communication course. J. Educ. Bus. 2002, 77, 257–263. [Google Scholar] [CrossRef]
- Pulito, A.R.; Donnelly, M.B.; Plymale, M. Factors in faculty evaluation of medical students’ performance. Med Educ. 2007, 41, 667–675. [Google Scholar] [CrossRef]
- Mortada, L.; Bolbol, J.; Kadry, S. Factors Affecting Students’ Performance a Case of Private Colleges in Lebanon. J. Math. Stat. Anal. 2018, 1, 105. [Google Scholar]
- Moubayed, A.; Injadat, M.; Shami, A.; Lutfiyya, H. Student engagement level in an e-learning environment: Clustering using k-means. Am. J. Distance Educ. 2020, 34, 137–156. [Google Scholar] [CrossRef]
- Kuo, R.; Krahn, T.; Chang, M. Behaviour Analytics-A Moodle Plug-in to Visualize Students’ Learning Patterns. In Proceedings of the International Conference on Intelligent Tutoring Systems, Virtual Event, 7–11 June 2021; Springer: Cham, Switzerland, 2021; pp. 232–238. [Google Scholar]
- Li, X.; Zhang, Y.; Cheng, H.; Zhou, F.; Yin, B. An Unsupervised Ensemble Clustering Approach for the Analysis of Student Behavioral Patterns. IEEE Access 2021, 9, 7076–7091. [Google Scholar] [CrossRef]
- Elbattah, M.; Molloy, O.; Zeigler, B.P. Designing care pathways using simulation modeling and machine learning. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 1452–1463. [Google Scholar]
- Elbattah, M.; Molloy, O. Data-Driven patient segmentation using K-Means clustering: The case of hip fracture care in Ireland. In Proceedings of the Australasian Computer Science Week Multiconference, Geelong, Australia, 30 January–3 February 2017; pp. 1–8. [Google Scholar]
- Wang, G.; Kwok, S.W.H. Using K-Means Clustering Method with Doc2Vec to Understand the Twitter Users’ Opinions on COVID-19 Vaccination. In Proceedings of the 2021 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), Athens, Greece, 27–30 July 2021; pp. 1–4. [Google Scholar]
- Cortez, P.; Silva, A.M.G. Using data mining to predict secondary school student performance. In Proceedings of the 5th Annual Future Business Technology Conference, Porto, Portugal, 9–11 April 2008. [Google Scholar]
- Osmanbegovic, E.; Suljic, M. Data mining approach for predicting student performance. Econ. Rev. J. Econ. Bus. 2012, 10, 3–12. [Google Scholar]
- Kabakchieva, D. Predicting student performance by using data mining methods for classification. Cybern. Inf. Technol. 2013, 13, 61–72. [Google Scholar] [CrossRef]
- Ramesh, V.; Parkavi, P.; Ramar, K. Predicting student performance: A statistical and data mining approach. Int. J. Comput. Appl. 2013, 63, 35–39. [Google Scholar] [CrossRef]
- Kabakchieva, D. Student performance prediction by using data mining classification algorithms. Int. J. Comput. Sci. Manag. Res. 2012, 1, 686–690. [Google Scholar]
- Mengash, H.A. Using data mining techniques to predict student performance to support decision making in university admission systems. IEEE Access 2020, 8, 55462–55470. [Google Scholar] [CrossRef]
- Sánchez-Ruiz, L.M.; Moll-López, S.; Moraño-Fernández, J.A.; Roselló, M.D. Dynamical continuous discrete assessment of competencies achievement: An approach to continuous assessment. Mathematics 2021, 9, 2082. [Google Scholar] [CrossRef]
- Kim, D.J.; Choi, S.H.; Lee, Y.; Lim, W. Secondary Teacher Candidates’ Mathematical Modeling Task Design and Revision. Mathematics 2021, 9, 2933. [Google Scholar] [CrossRef]
- Lenkauskaitė, J.; Bubnys, R.; Masiliauskienė, E.; Malinauskienė, D. Participation in the Assessment Processes in Problem-Based Learning: Experiences of the Students of Social Sciences in Lithuania. Educ. Sci. 2021, 11, 678. [Google Scholar] [CrossRef]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Tuyishimire, E.; Bagula, A.; Ismail, A. Clustered data muling in the internet of things in motion. Sensors 2019, 19, 484. [Google Scholar] [CrossRef] [Green Version]
- Tuyishimire, E.; Bagula, B.A.; Ismail, A. Optimal clustering for efficient data muling in the internet-of-things in motion. In International Symposium on Ubiquitous Networking; Springer: Cham, Switzerland, 2018; pp. 359–371. [Google Scholar]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [Green Version]
- Barnes, T. The Q-matrix method: Mining student response data for knowledge. In American Association for Artificial Intelligence 2005 Educational Data Mining Workshop; AAAI Press: Pittsburgh, PA, USA, 2005; pp. 1–8. [Google Scholar]
- McKinney, W. pandas: A foundational Python library for data analysis and statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Oliphant, T.E. A Guide to NumPy; Trelgol Publishing: New York, NY, USA, 2006; Volume 1. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Student | Quiz 1 | Quiz 2 | Mean | Standard Deviation |
|---|---|---|---|---|
| A | 8 | 2 | 5 | 3 |
| B | 5 | 5 | 5 | 0 |
| C | 4 | 6 | 5 | 1 |
| Name and Citation | Role |
|---|---|
| Pandas [32] and Numpy [33] | Data handling |
| Scikit-Learn [34] | Data clustering |
| Matplotlib [35] | Data visualisation |
| Parameter Name | Parameter Value |
|---|---|
| 5 or 3 | |
| ‘k-means++’ | |
| 10 | |
| 300 | |
| 0.0001 | |
| ‘auto’ | |
| 0 | |
| None | |
| True | |
| None | |
| ‘auto’ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tuyishimire, E.; Mabuto, W.; Gatabazi, P.; Bayisingize, S. Detecting Learning Patterns in Tertiary Education Using K-Means Clustering. Information 2022, 13, 94. https://doi.org/10.3390/info13020094
Tuyishimire E, Mabuto W, Gatabazi P, Bayisingize S. Detecting Learning Patterns in Tertiary Education Using K-Means Clustering. Information. 2022; 13(2):94. https://doi.org/10.3390/info13020094
Chicago/Turabian StyleTuyishimire, Emmanuel, Wadzanai Mabuto, Paul Gatabazi, and Sylvie Bayisingize. 2022. "Detecting Learning Patterns in Tertiary Education Using K-Means Clustering" Information 13, no. 2: 94. https://doi.org/10.3390/info13020094
APA StyleTuyishimire, E., Mabuto, W., Gatabazi, P., & Bayisingize, S. (2022). Detecting Learning Patterns in Tertiary Education Using K-Means Clustering. Information, 13(2), 94. https://doi.org/10.3390/info13020094