
Lexical Diversity in Statistical and Neural Machine Translation


Abstract
:1. Introduction
1.1. Related Work
1.2. Motivations
2. Materials and Methods
2.1. Data and Tools
2.2. Analyzing Lexical Diversity
3. Results
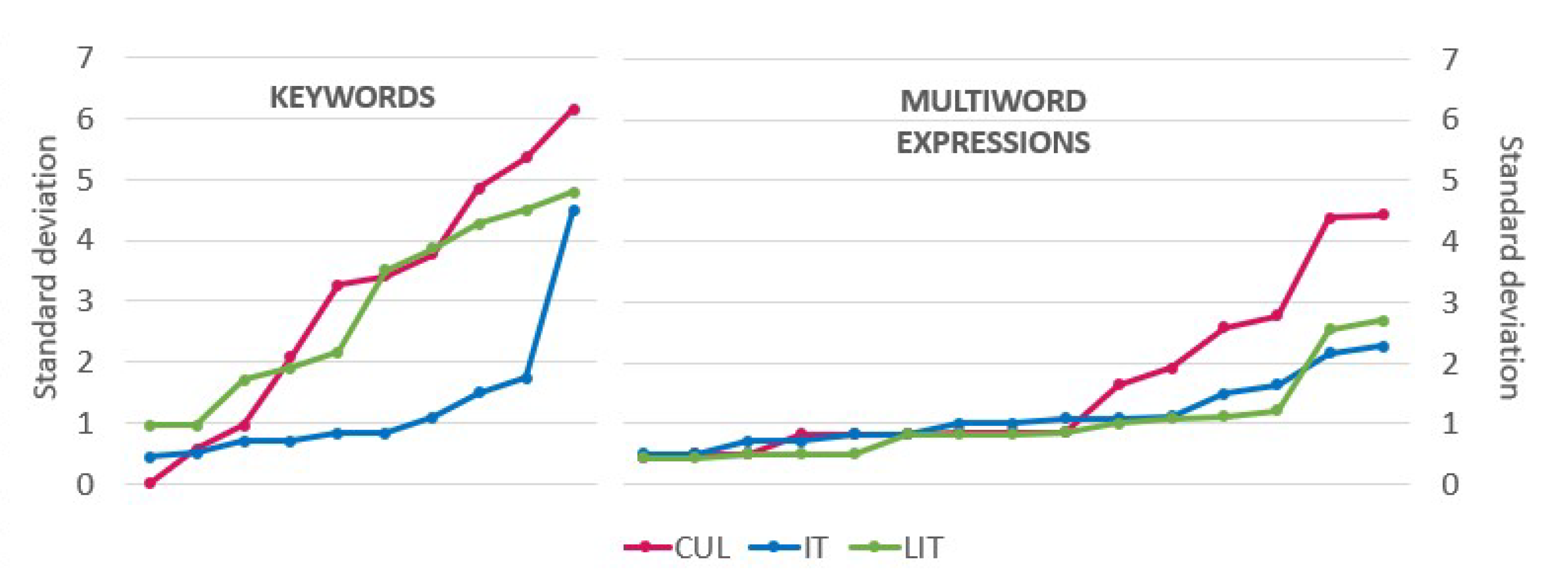
3.1. TTR
3.2. MTLD
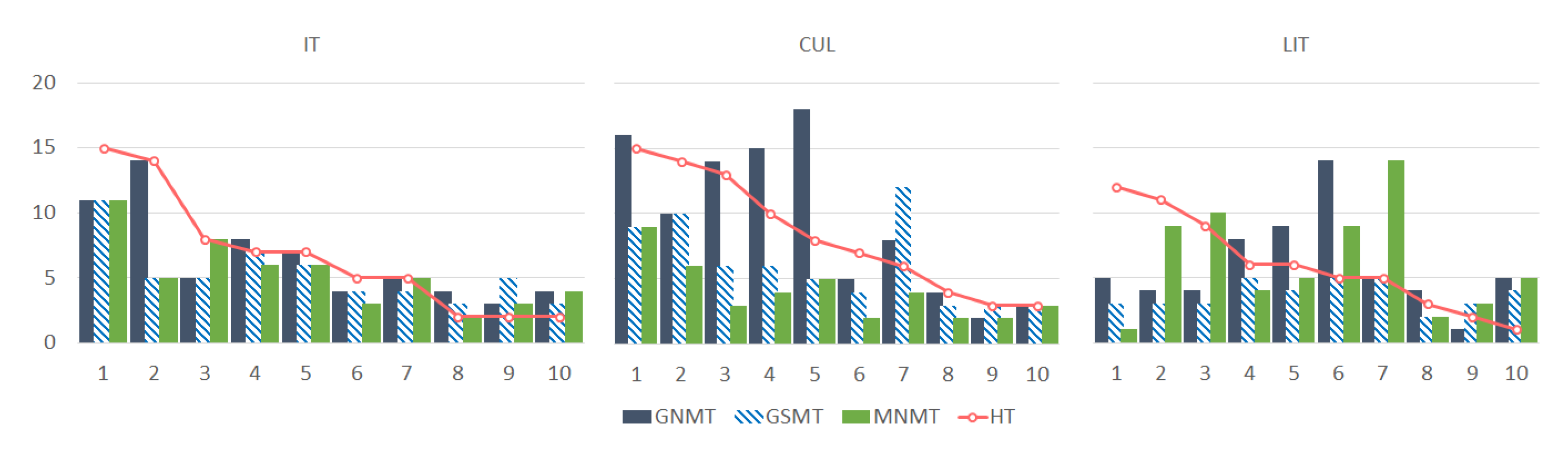
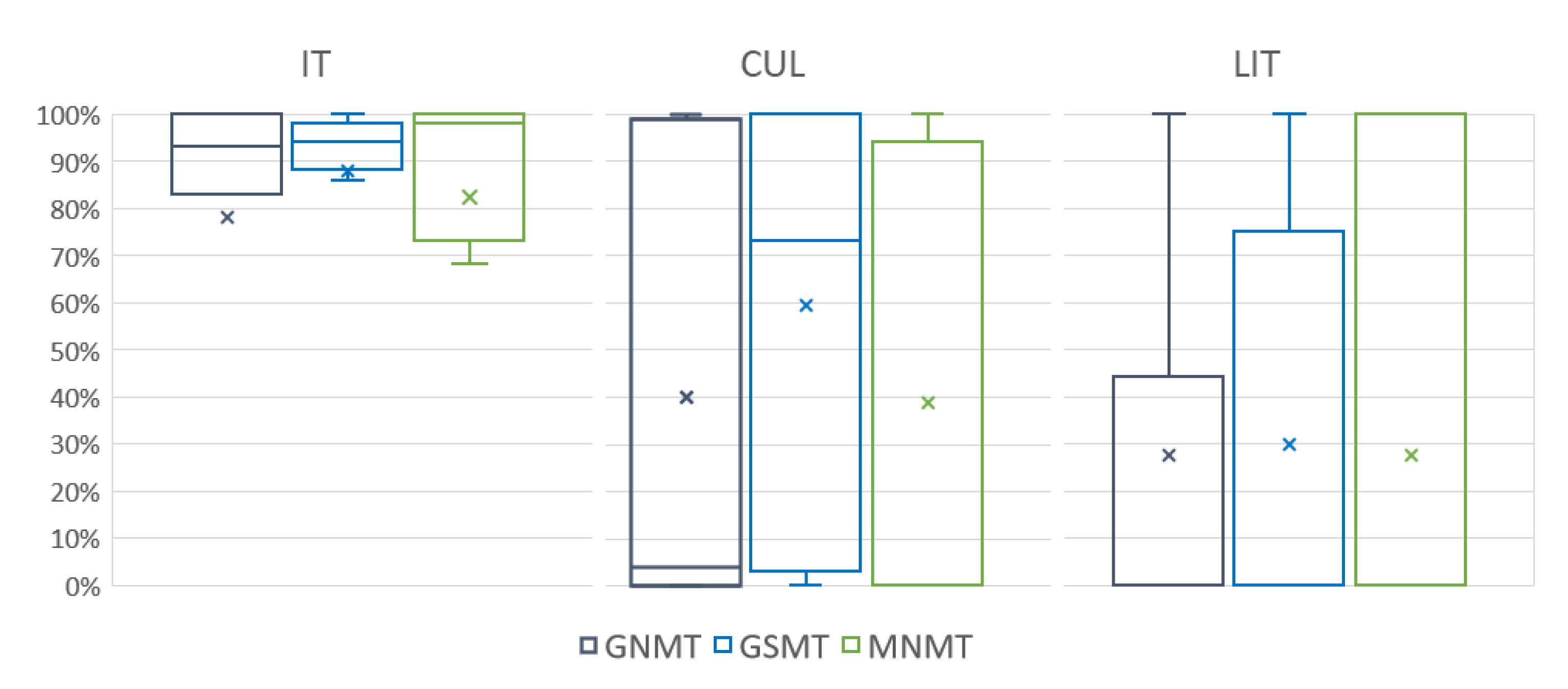
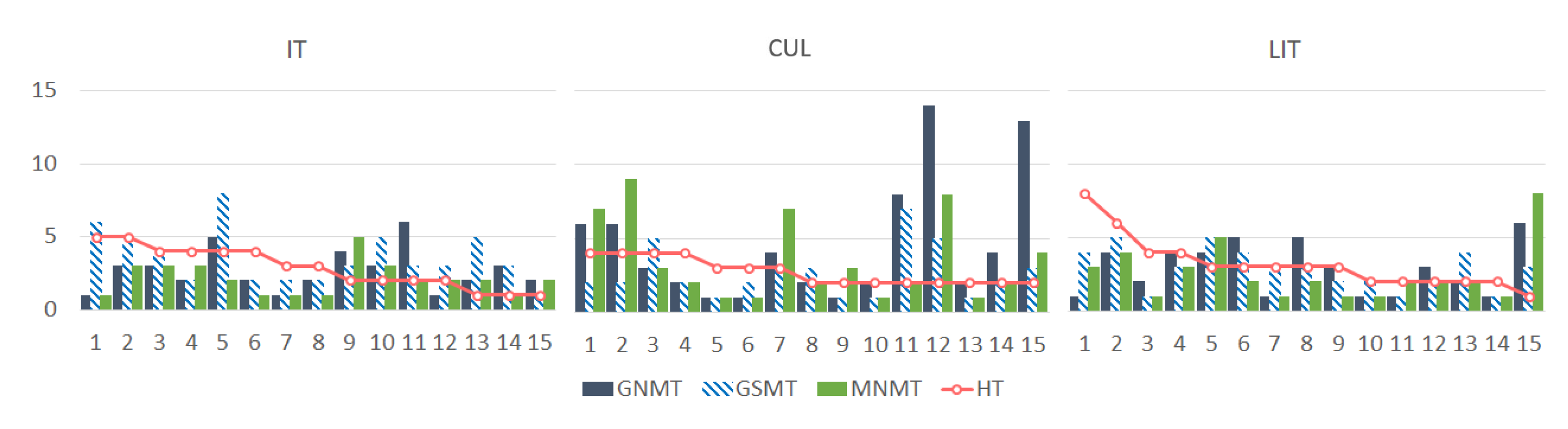
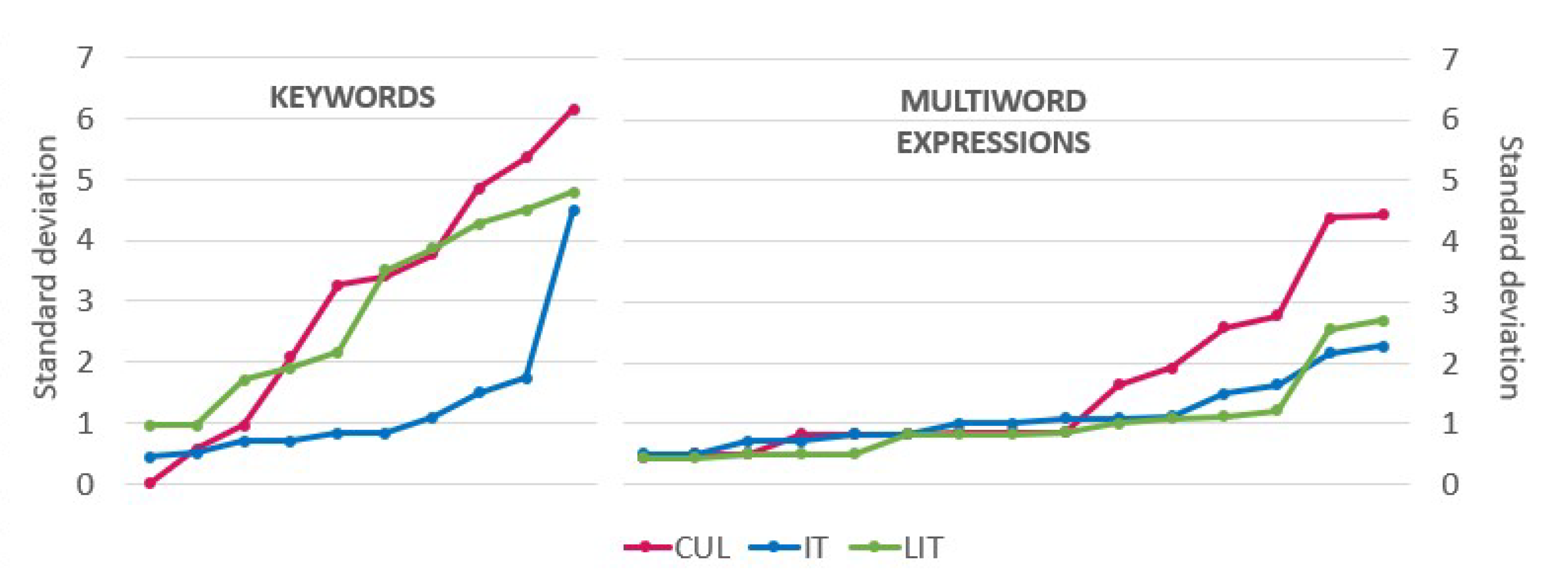
3.3. Diversity of Translations of Keywords and Multi-Word Expressions
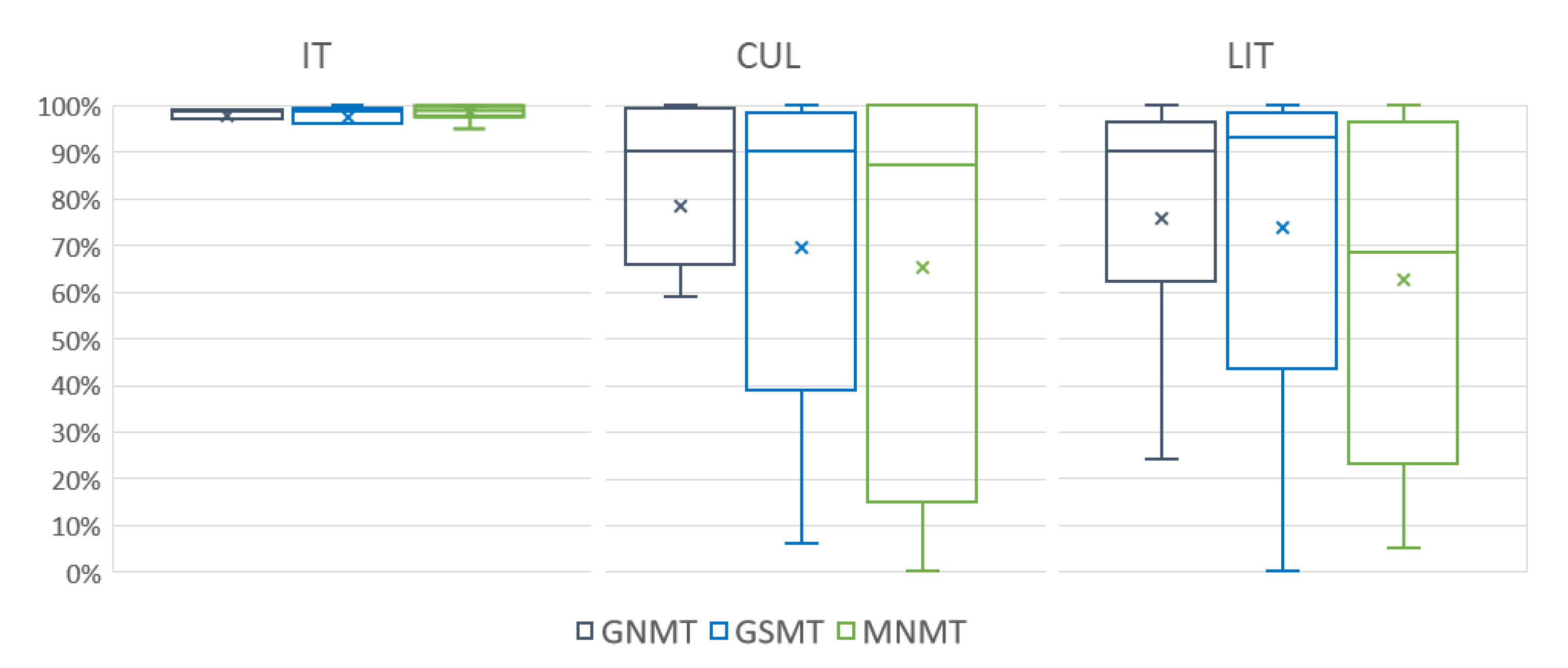
3.4. Agreement of Machine and Human Translations
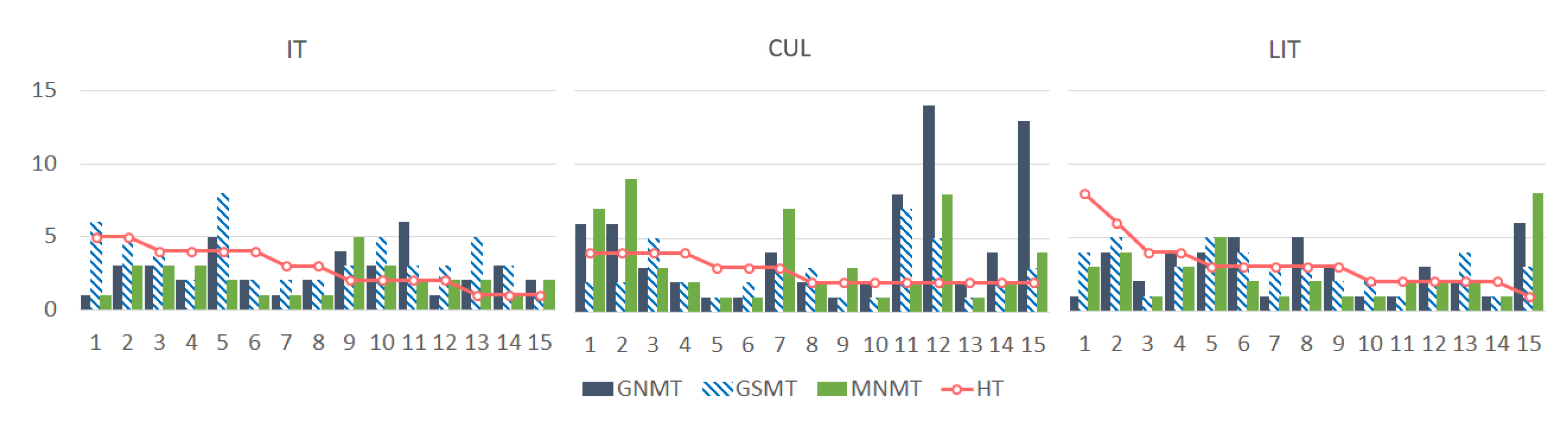
3.5. A Closer Look at Translation Diversity
3.5.1. Google’s Phrase-Based Statistical Model
3.5.2. Google’s Neural Model
3.5.3. Microsoft’s Neural Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MT | Machine translation |
| HT | Human translation |
| NMT | Neural machine translation |
| SMT | Statistical (phrase-based) machine translation |
| GSMT | Google’s statistical (phrase-based) translation system |
| GNMT | Google’s neural translation system |
| MNMT | Microsoft’s neural translation system |
| IT | Information technology |
| CUL | Culinary arts |
| LIT | Literature |
| TTR | Type-token ratio |
| MTLD | Measure of textual lexical diversity |
| POS | Part of speech |
| KW | Keyword |
| MWE | Multi-word expression |
References
- Hassan, H.; Aue, A.; Chen, C.; Chowdhary, V.; Clark, J.; Federmann, C.; Huang, X.; Junczys-Dowmunt, M.; Lewis, W.; Li, M.; et al. Achieving Human Parity on Automatic Chinese to English News Translation. arXiv 2018, arXiv:1803.05567. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadephia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Castilho, S.; Moorkens, J.; Gaspari, F.; Calixto, I.; Tinsley, J.; Way, A. Is Neural Machine Translation the New State of the Art? Prague Bull. Math. Linguist. 2017, 108, 109–120. [Google Scholar] [CrossRef] [Green Version]
- Shterionov, D.; Superbo, R.; Nagle, P.; Casanellas, L.; O’Dowd, T.; Way, A. Human versus automatic quality evaluation of NMT and PBSMT. Mach. Transl. 2018, 32, 217–235. [Google Scholar] [CrossRef]
- Vanmassenhove, E.; Shterionov, D.; Way, A. Lost in Translation: Loss and Decay of Linguistic Richness in Machine Translation. Proceedings of Machine Translation Summit XVII Volume 1: Research Track, Dublin, Ireland, 19–23 August 2019; pp. 222–232. [Google Scholar]
- Vanmassenhove, E.; Shterionov, D.S.; Gwilliam, M. Machine Translationese: Effects of Algorithmic Bias on Linguistic Complexity in Machine Translation. arXiv 2021, arXiv:2102.00287. [Google Scholar]
- Roberts, N.; Liang, D.; Neubig, G.; Lipton, Z.C. Decoding and Diversity in Machine Translation. arXiv 2020, arXiv:cs.CL/2011.13477. [Google Scholar]
- Farrell, M. Machine Translation Markers in Post-Edited Machine Translation Output. In Proceedings of the 40th Conference Translating and the Computer, London, UK, 15–16 November 2018; pp. 50–59. [Google Scholar]
- Baker, M.; Francis, G.; Tognini-Bonelli, E. Corpus Linguistics and Translation Studies: Implications and Applications. In Text and Technology: In Honour of John Sinclair; John Benjamins Publishing Company: Amsterdam, The Netherlands, 1993. [Google Scholar]
- Toral, A. Post-editese: An Exacerbated Translationese. In Proceedings of the Machine Translation Summit XVII, Dublin, Ireland, 19–23 August 2019; pp. 273–281. [Google Scholar]
- Castilho, S.; Resende, N.; Mitkov, R. What Influences the Features of Post-Editese? A Preliminary Study. In Proceedings of the Human-Informed Translation and Interpreting Technology Workshop (HiT-IT 2019), Varna, Bulgaria, 5–6 September 2019; pp. 19–27. [Google Scholar] [CrossRef]
- De Clercq, O.; De Sutter, G.; Loock, R.; Cappelle, B.; Plevoets, K. Uncovering Machine Translationese Using Corpus Analysis Techniques to Distinguish between Original and Machine-Translated French. Transl. Q. 2021, 101, 21–45. [Google Scholar]
- Čulo, O.; Nitzke, J. Patterns of Terminological Variation in Post-editing and of Cognate Use in Machine Translation in Contrast to Human Translation. In Proceedings of the 19th Annual Conference of the European Association for Machine Translation, Riga, Latvia, 30 May–1 June 2016; pp. 106–114. [Google Scholar]
- Arcan, M. A Comparison of Statistical and Neural Machine Translation for Slovene, Serbian and Croatian. In Proceedings of the Conference on Language Technologies & Digital Humanities, Ljubljana, Slovenia, 20–21 September 2018. [Google Scholar]
- Gregor Donaj, M.S.M. Prehod iz statističnega strojnega prevajanja na prevajanje z nevronskimi omrežji za jezikovni par slovenščina-angleščina. In Proceedings of the Conference on Language Technologies & Digital Humanities, Ljubljana, Slovenia, 20–21 September 2018. [Google Scholar]
- Vintar, Š. Terminology Translation Accuracy in Statistical versus Neural MT: An Evaluation for the English-Slovene Language Pair. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; Du, J., Arcan, M., Liu, Q., Isahara, H., Eds.; European Language Resources Association (ELRA): Paris, France, 2018. [Google Scholar]
- LASERJET PRO 300 COLOR MFP/LASERJET PRO 400 COLOR MFP User Guide. 2011. Available online: http://h10032.www1.hp.com/ctg/Manual/c02666267.pdf (accessed on 3 March 2020).
- LASERJET PRO 300 COLOR MFP/LASERJET PRO 400 COLOR MFP Uporabniški Priročnik. 2011. Available online: http://h10032.www1.hp.com/ctg/Manual/c02666724.pdf (accessed on 3 March 2020).
- LASERJET PRO 300 COLOR MFP/LASERJET PRO 400 COLOR MFP Installation Guide. 2011. Available online: http://h10032.www1.hp.com/ctg/Manual/c02843075.pdf (accessed on 3 March 2020).
- LASERJET PRO 300 COLOR MFP/LASERJET PRO 400 COLOR MFP Priročnik za Namestitev. 2011. Available online: http://h10032.www1.hp.com/ctg/Manual/c02843079.pdf (accessed on 3 March 2020).
- Blashford-Snell, V. The Cooking Book; Dorling Kindersley: London, UK, 2008. [Google Scholar]
- Blashford-Snell, V. Dobra Kuha; Mladinska Knjiga: Ljubljana, Slovenia, 2012. [Google Scholar]
- James, J. Practice Makes Perfect; Berkley Sensation: New York, NY, USA, 2009. [Google Scholar]
- James, J. Osem let skomin; Hiša knjig, Založba KMŠ: Maribor, Slovenia, 2014. [Google Scholar]
- Kilgarriff, A.; Baisa, V.; Bušta, J.; Jakubíček, M.; Kovář, V.; Michelfeit, J.; Rychlý, P.; Suchomel, V. The Sketch Engine: Ten years on. Lexicography 2014, 1, 7–36. [Google Scholar] [CrossRef] [Green Version]
- McCarthy, P.M. An Assessment of the Range and Usefulness of Lexical Diversity Measures and the Potential of the Measure of Textual, Lexical Diversity (MTLD). Ph.D. Thesis, The University of Memphis, Memphis, TN, USA, 2005. [Google Scholar]
- Mccarthy, P.; Jarvis, S. MTLD, vocd-D, and HD-D: A validation study of sophisticated approaches to lexical diversity assessment. Behav. Res. Methods 2010, 42, 381–392. [Google Scholar] [CrossRef] [PubMed]
- Fergadiotis, G.; Wright, H.; West, T. Measuring Lexical Diversity in Narrative Discourse of People with Aphasia. Am. J. Speech-Lang. Pathol./Am. Speech-Lang. Assoc. 2013, 22, S397–S408. [Google Scholar] [CrossRef] [Green Version]
- Kyle, K. Lexical Diversity. 2020. Available online: https://github.com/kristopherkyle/lexical_diversity (accessed on 1 June 2020).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| English Original | Slovenian Translation | |||
|---|---|---|---|---|
| Domain | Title | Words | Title | Words |
| Information technology (IT) | LASERJET PRO 300 COLOR MFP / LASERJET PRO 400 COLOR MFP User Guide and Installation Guide | 50,146 | LASERJET PRO 300 COLOR MFP / LASERJET PRO 400 COLOR MFP Uporabniški priročnik and Priročnik za namestitev | 45,206 |
| Culinary Arts (CUL) | The Cooking Book | 127,853 | Dobra kuha | 107,373 |
| Literature (LIT) | Practice Makes Perfect | 76,951 | Osem let skomin | 72,604 |
| Corpus | HT | GNMT | GSMT | MNMT |
|---|---|---|---|---|
| IT | 13.07% | 13.54% | 13.50% | 13.40% |
| CUL | 7.76% | 9.58% | 8.50% | 7.57% |
| LIT | 15.41% | 16.59% | 14.94% | 16.06% |
| Corpus | HT | GNMT | GSMT | MNMT |
|---|---|---|---|---|
| IT | 84.53 | 86.74 | 91.66 | 86.46 |
| CUL | 164.22 | 196.80 | 187.58 | 162.93 |
| LIT | 148.38 | 158.66 | 177.53 | 175.94 |
| Corpus | Keywords | Multi-Word expressions |
|---|---|---|
| IT | fax, cartridge, touch, print (NOUN), setup, tray, button, print (VERB), menu, printer | print cartridge, control panel, setup menu, setup button, ok button, document feeder, printer driver, software program, fax number, fax button, scanner glass, wireless network, phone line, print quality, recommended action |
| CUL | tbsp, stir, pan, pepper, saucepan, boil, chop, simmer, tsp | frying pan, olive oil, baking tray, cling film, lemon juice, medium heat, low heat, food processor, kitchen paper, large saucepan, black pepper, cold water, greaseproof paper, large bowl, wire rack |
| LIT | deposition, gesture, glance, nod, grin, desk, peer, briefcase, courtroom, sigh | making partner, general counsel, voice mail, front door, partnership decision, spare suit, litigation group, opening statement, cocktail hour, class action, suit jacket, law school, coffee shop, partnership spot, deposition transcript |
| Corpus | Translation Unit | GNMT | GSMT | MNMT |
|---|---|---|---|---|
| IT | KW | 97.9% | 97.3% | 98.6% |
| CUL | KW | 78.5% | 69.4% | 65.1% |
| LIT | KW | 75.7% | 73.9% | 62.4% |
| IT | MWE | 78.1% | 87.7% | 82.2% |
| CUL | MWE | 40.0% | 59.2% | 38.5% |
| LIT | MWE | 27.6% | 29.8% | 27.5% |
| HT | Occurrences | GSMT | Occurrences |
|---|---|---|---|
| sesekljan | 322 | sesekljan | 310 |
| sesekljati | 44 | sesekljati | 31 |
| ELLIPSIS | 16 | narezan | 17 |
| narezati | 6 | nasekljan | 17 |
| narezan | 4 | narezati | 6 |
| nastrgan | 1 | rezan | 3 |
| chop | 3 | ||
| nasekljati | 2 | ||
| sekljanje | 1 | ||
| zrezan | 1 | ||
| ELLIPSIS | 1 | ||
| sekanje | 1 |
| HT | Occurrences | GSMT | Occurrences |
|---|---|---|---|
| nadzorna plošča | 140 | nadzorna plošča | 136 |
| nadzorni | 1 | ||
| nadzoren […] plošče | 1 | ||
| plošča […] nadzorni | 1 | ||
| plošča […] kontrole | 1 |
| HT | Occurrences | GNMT | Occurrences |
|---|---|---|---|
| zaslišanje | 37 | odlaganje | 23 |
| izjave prič | 2 | depozit | 5 |
| izjave | 2 | izjava | 3 |
| izjave na zapisnik | 2 | ELLIPSIS | 2 |
| ELLIPSIS | 1 | naloga | 2 |
| “privednik” | 1 | ||
| deponiranje | 1 | ||
| odpust | 1 | ||
| odstopil | 1 | ||
| odložiti | 1 | ||
| nanos | 1 | ||
| dejanje | 1 | ||
| izjava (odložiti izjavo) | 1 | ||
| odlog | 1 |
| HT | Occurrences | GNMT | Occurrences |
|---|---|---|---|
| multipraktik | 102 | kuhalnik hrane | 52 |
| strojček | 3 | predelovalec hrane | 21 |
| obdelovalec hrane | 7 | ||
| kuhalnik | 5 | ||
| hranilnik | 5 | ||
| predelava hrane | 3 | ||
| živilski procesor | 2 | ||
| posodo za kuhanje hrane | 2 | ||
| predelovalnik hrane | 2 | ||
| procesor za hrano | 2 | ||
| živilski predelovalec | 1 | ||
| paradižnik | 1 | ||
| pralni stroj | 1 | ||
| predelava za hrano | 1 |
| HT | Occurrences | GNMT | Occurrences |
|---|---|---|---|
| nasmehniti se | 20 | zbrusiti se | 13 |
| zarežati se | 8 | “zasiti” se | 7 |
| zasmejati se | 7 | “zgriniti” se | 3 |
| smehljati se | 2 | režati (se) | 2 |
| sam pri sebi se smehljati | 1 | nasmehniti (se) | 2 |
| grinned | 2 | ||
| grinning | 2 | ||
| nasmejati (se) | 1 | ||
| “Cerenje” | 1 | ||
| zasmećen | 1 | ||
| ELLIPSIS | 1 | ||
| “zasoviti” se | 1 | ||
| “zmelje” | 1 | ||
| zgrniti se | 1 |
| HT | Occurrences | MNMT | Occurrences |
|---|---|---|---|
| skupinska tožba | 8 | razredom ukrepanje | 1 |
| razred dejanje | 1 | ||
| skupinska tožba | 1 | ||
| dejavnosti | 1 | ||
| razred akcijske | 1 | ||
| ukrep () razred | 1 | ||
| razreda ukrep | 1 | ||
| akcijski | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brglez, M.; Vintar, Š. Lexical Diversity in Statistical and Neural Machine Translation. Information 2022, 13, 93. https://doi.org/10.3390/info13020093
Brglez M, Vintar Š. Lexical Diversity in Statistical and Neural Machine Translation. Information. 2022; 13(2):93. https://doi.org/10.3390/info13020093
Chicago/Turabian StyleBrglez, Mojca, and Špela Vintar. 2022. "Lexical Diversity in Statistical and Neural Machine Translation" Information 13, no. 2: 93. https://doi.org/10.3390/info13020093
APA StyleBrglez, M., & Vintar, Š. (2022). Lexical Diversity in Statistical and Neural Machine Translation. Information, 13(2), 93. https://doi.org/10.3390/info13020093