
Multi-Objective Optimization of a Task-Scheduling Algorithm for a Secure Cloud

 ,
,
Abstract
:1. Introduction
- We build a secure cloud task-scheduling model that combined with the power information system, which defines the relevant attributes of the scheduling model, the risk level of business traffic and the objective function of task scheduling.
- We combine the AFSA with the secure cloud task-scheduling model and propose a Multi-objective optimal scheduling algorithm MOOAFSA. During algorithm optimization, multi-objective optimization is carried out with execution time, cost and load balance as evaluation indexes so as to obtain the relatively optimal secure cloud task-scheduling strategy under current conditions.
- At the same time, we test some classical heuristic algorithms to build task-scheduling strategies in a secure cloud environment, evaluating our proposed strategy model in terms of convergence speed, task completion time, execution cost, and load balancing.
2. Related Work
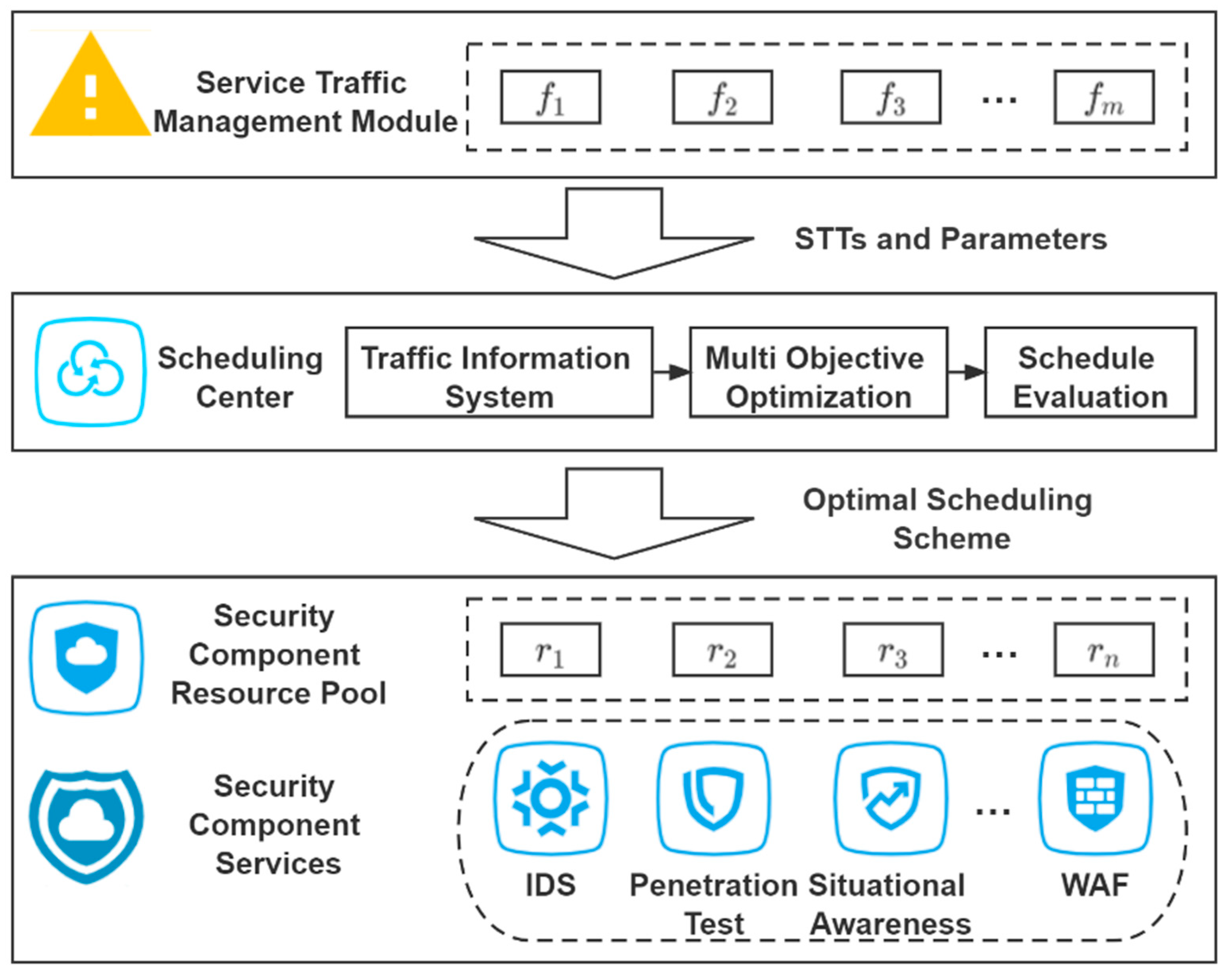
3. Scheduling Models
3.1. Model Definition
3.2. Objective Function
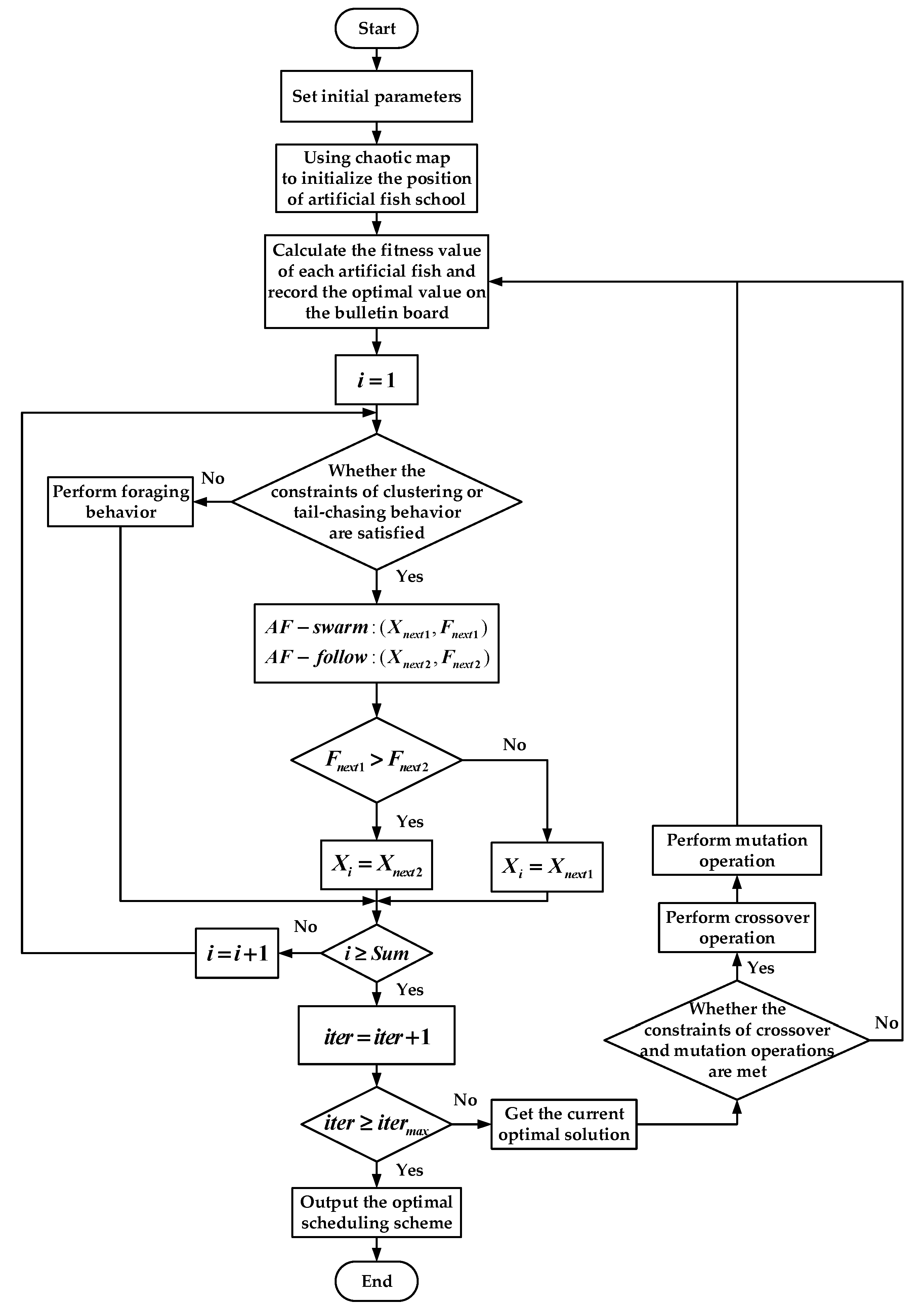
4. Proposed Algorithms
4.1. Enhanced Chaotic Tent Mapping
| Algorithm 1. Enhanced chaotic mapping initializes artificial fish |
| Input: an m-dimensional vector, . |
| Output: the initial population . |
| Process: |
|
4.2. Enhanced Step Size and View
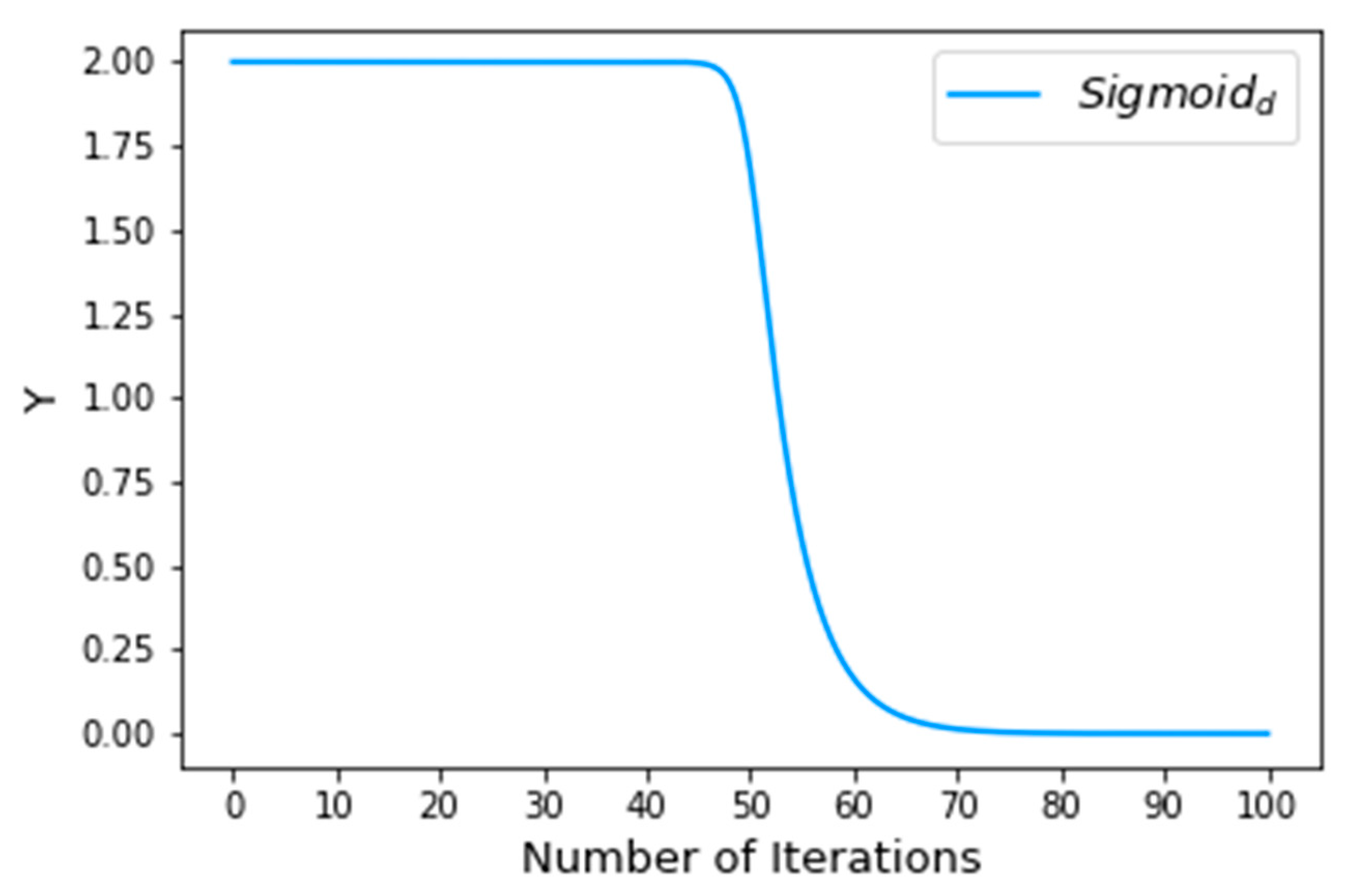
4.3. Adaptive Weight Factor
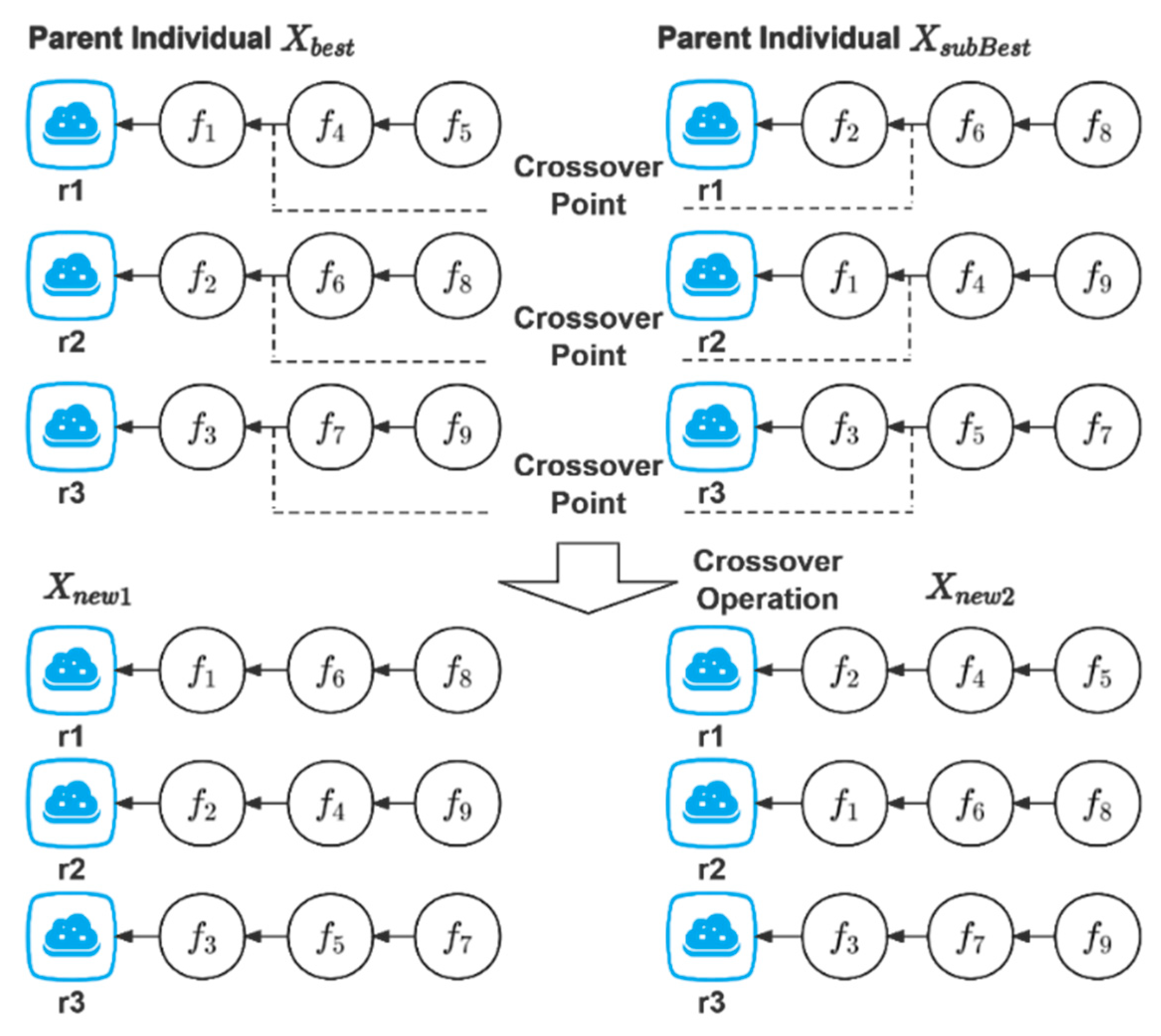
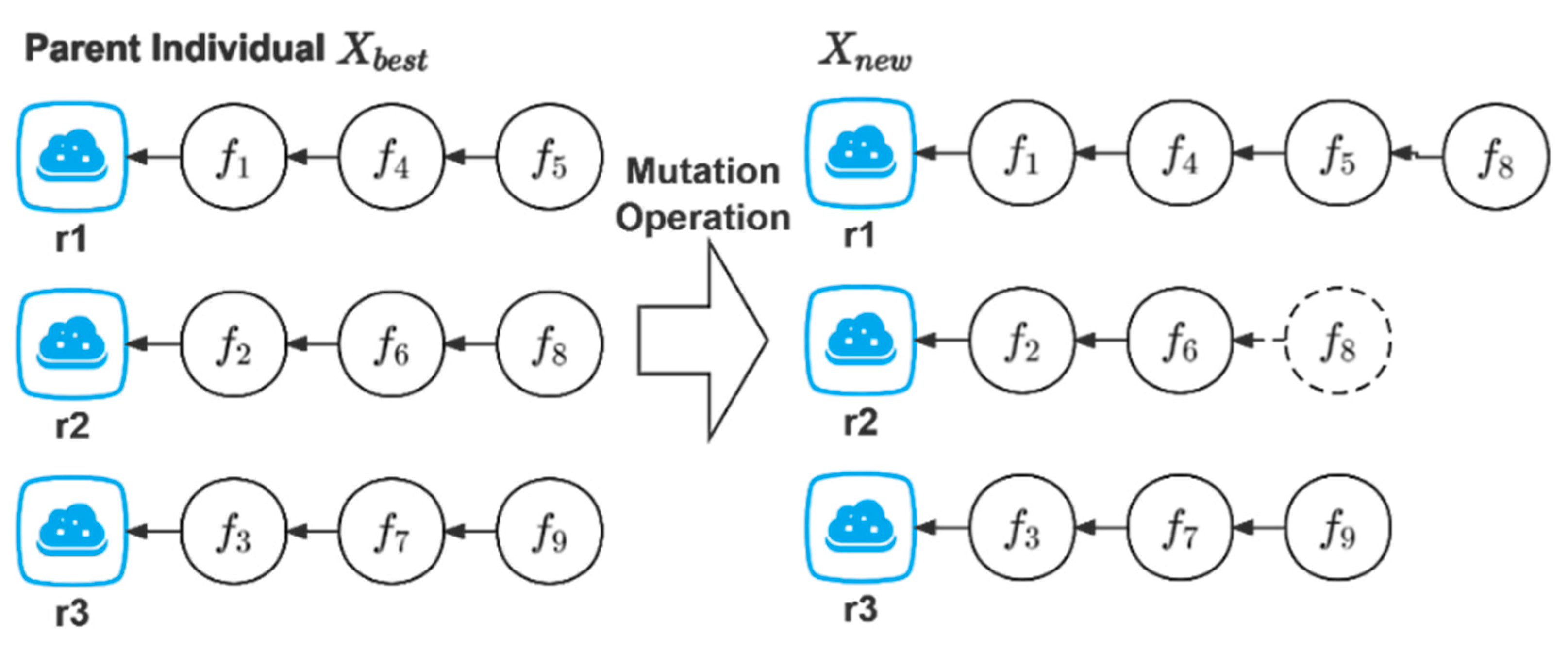
4.4. Crossover and Mutation
| Algorithm 2. Crossover operation |
| Input: the current population and . |
| Output: the new population . |
| Process: |
|
| Algorithm 3. Mutation operation |
| Input: the new population , and . |
| Output: the new population . |
| Process: |
|
4.5. Coding
4.6. Algorithm Process
| Algorithm 4. MOOAFSA |
| Input: randomly generate a random vector of size , . |
| Output: the optimal scheduling scheme. |
| Process: |
|
5. Performance Validation
5.1. Experimental Environment and Parameter Setting
5.2. Experimental Results
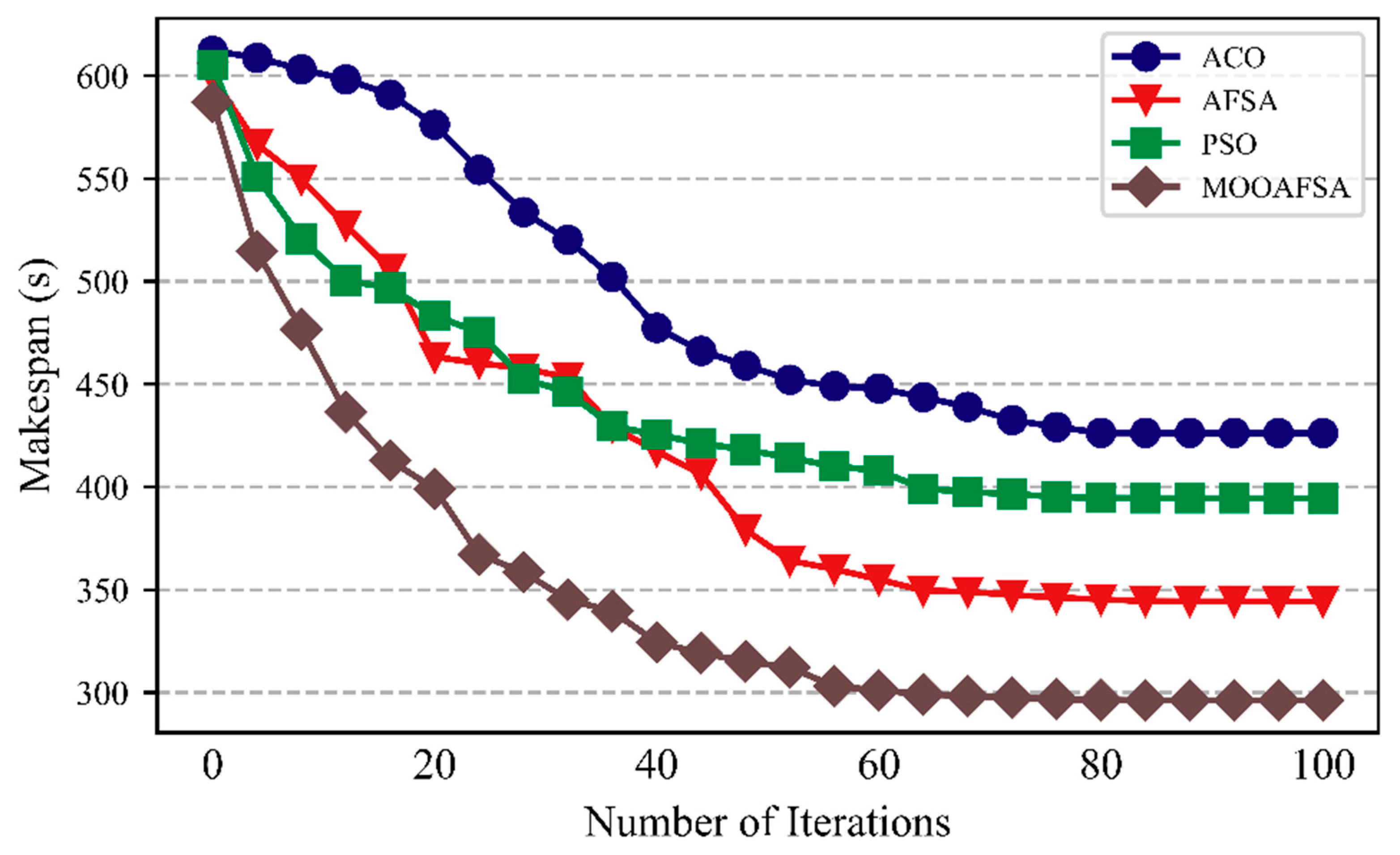
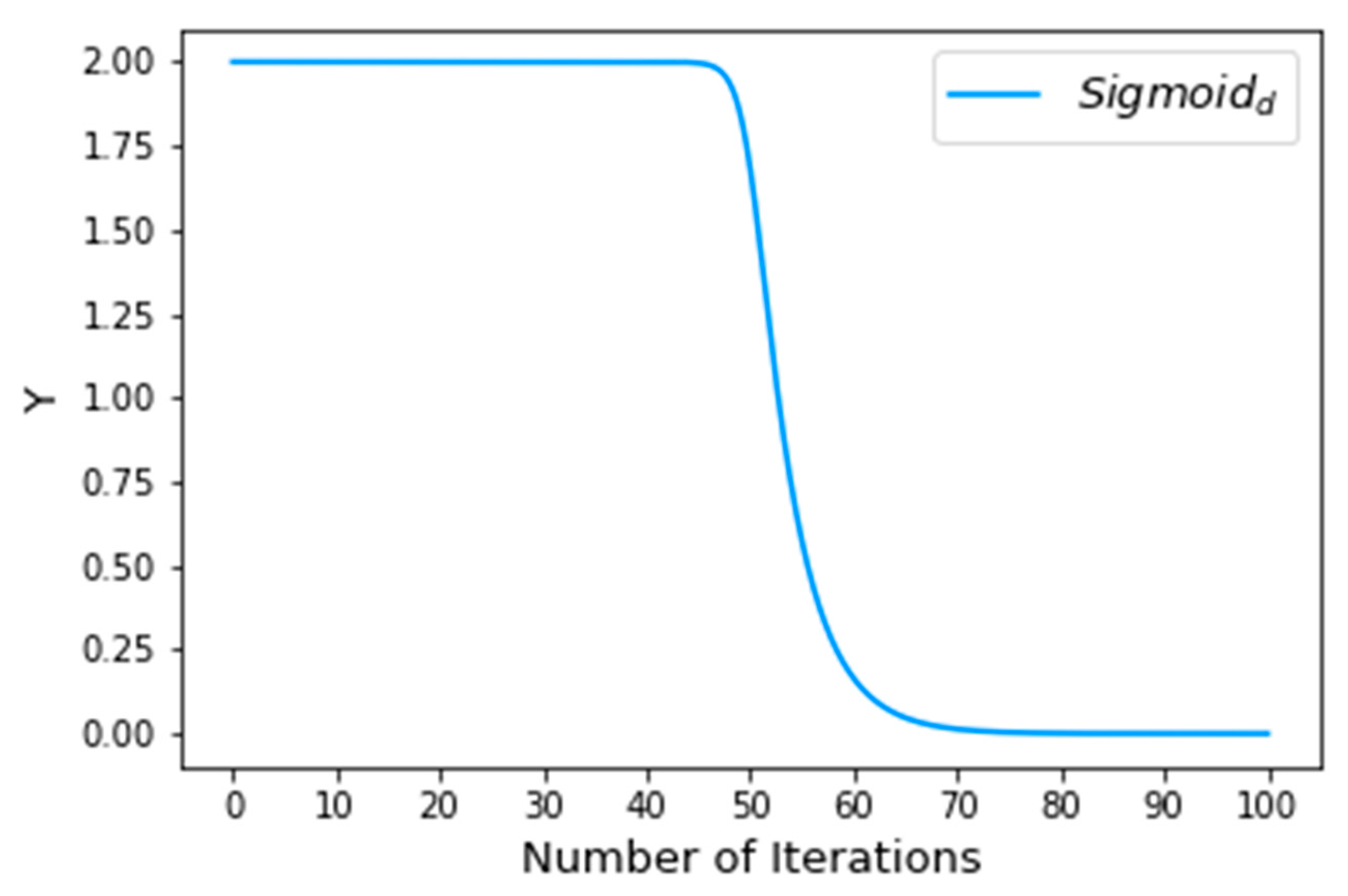
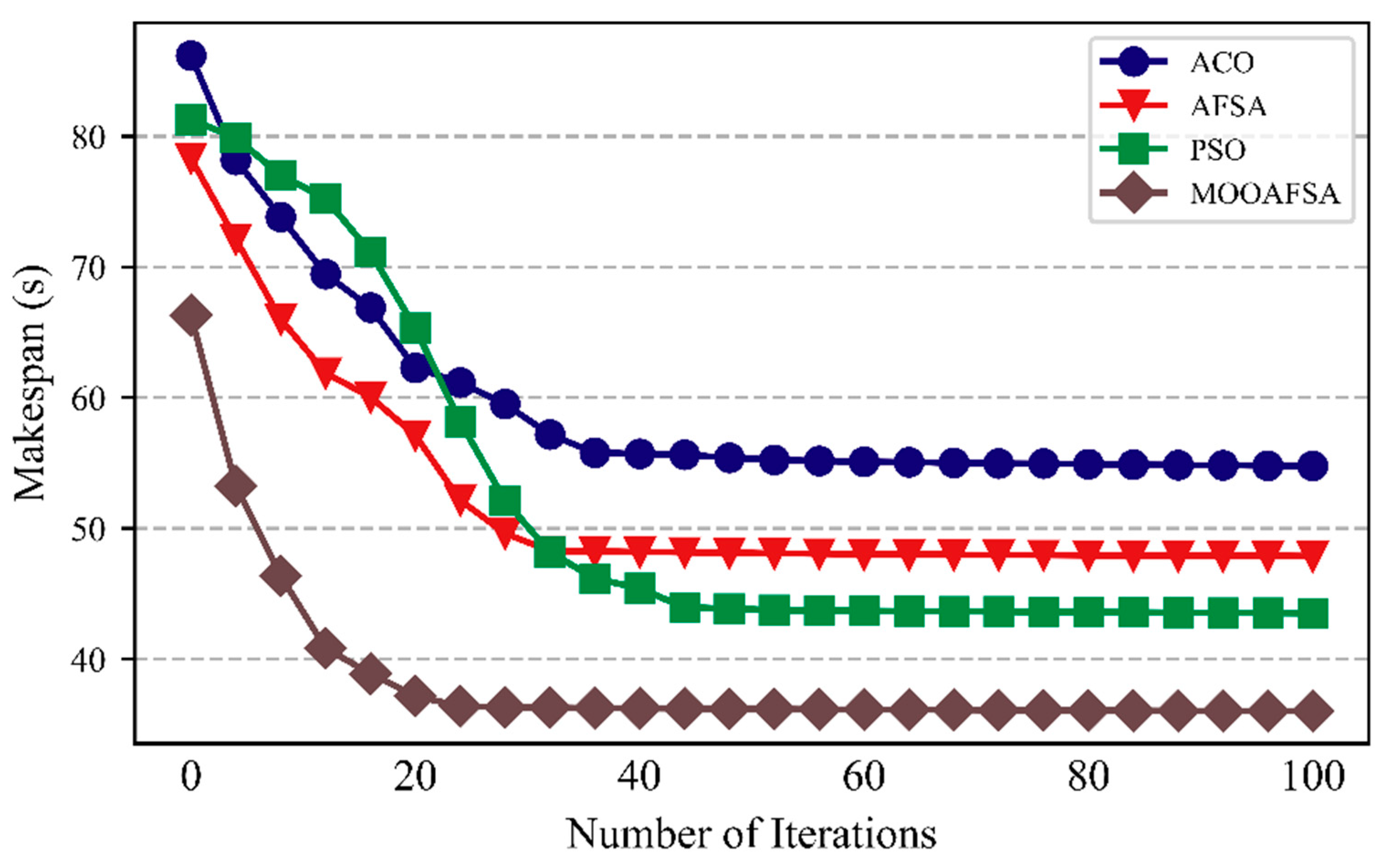
5.2.1. Rate of Convergence
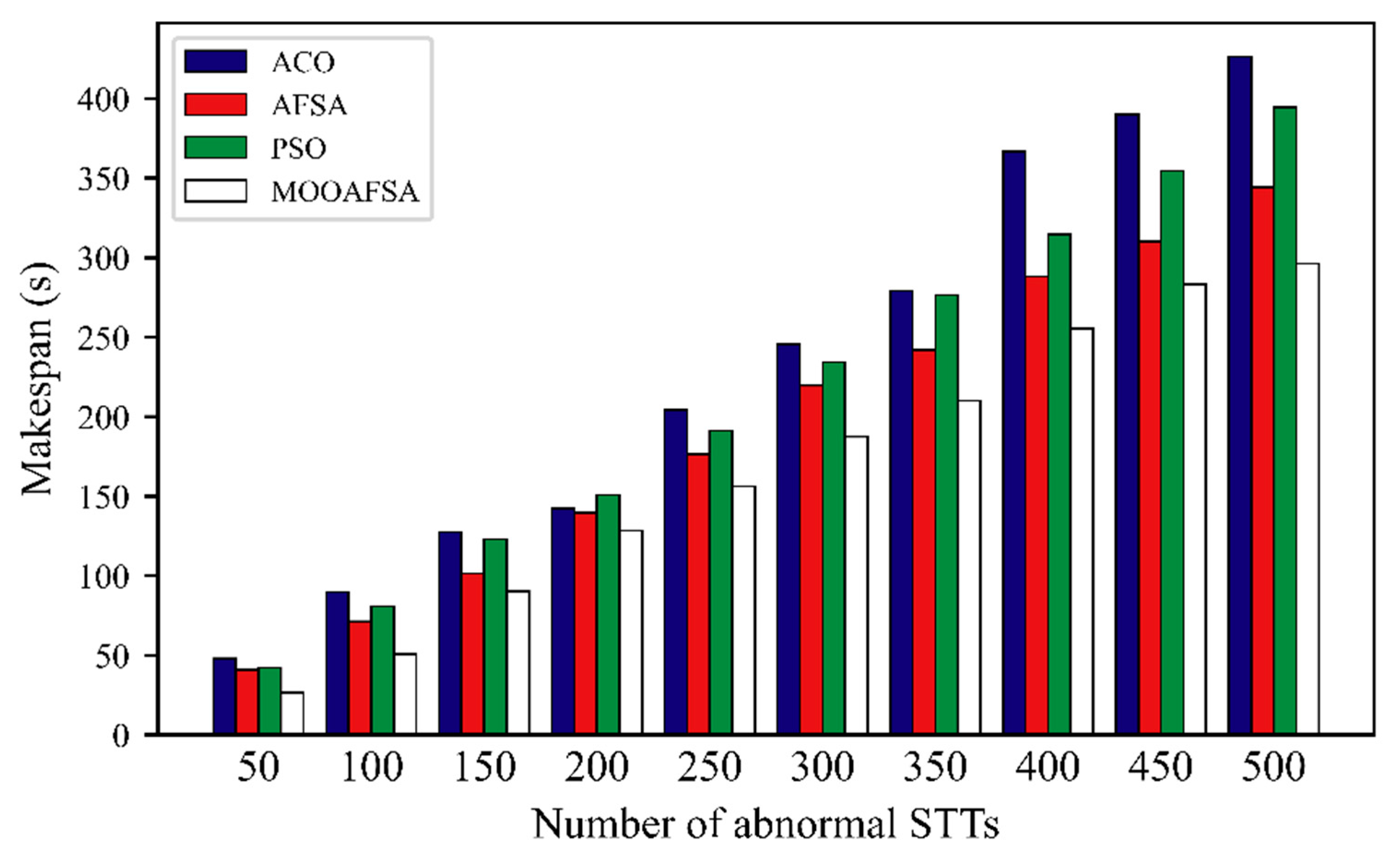
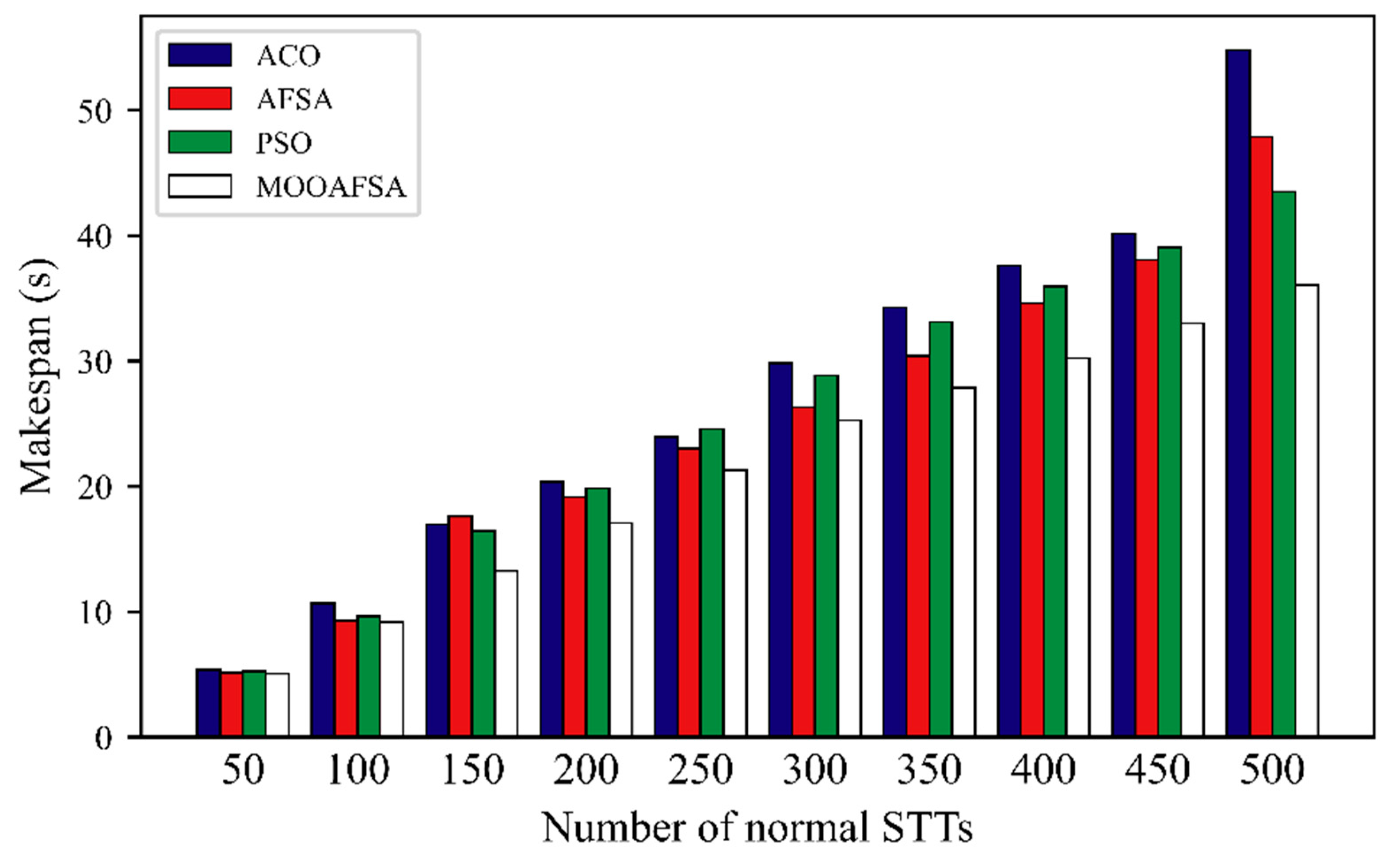
5.2.2. Completion Time
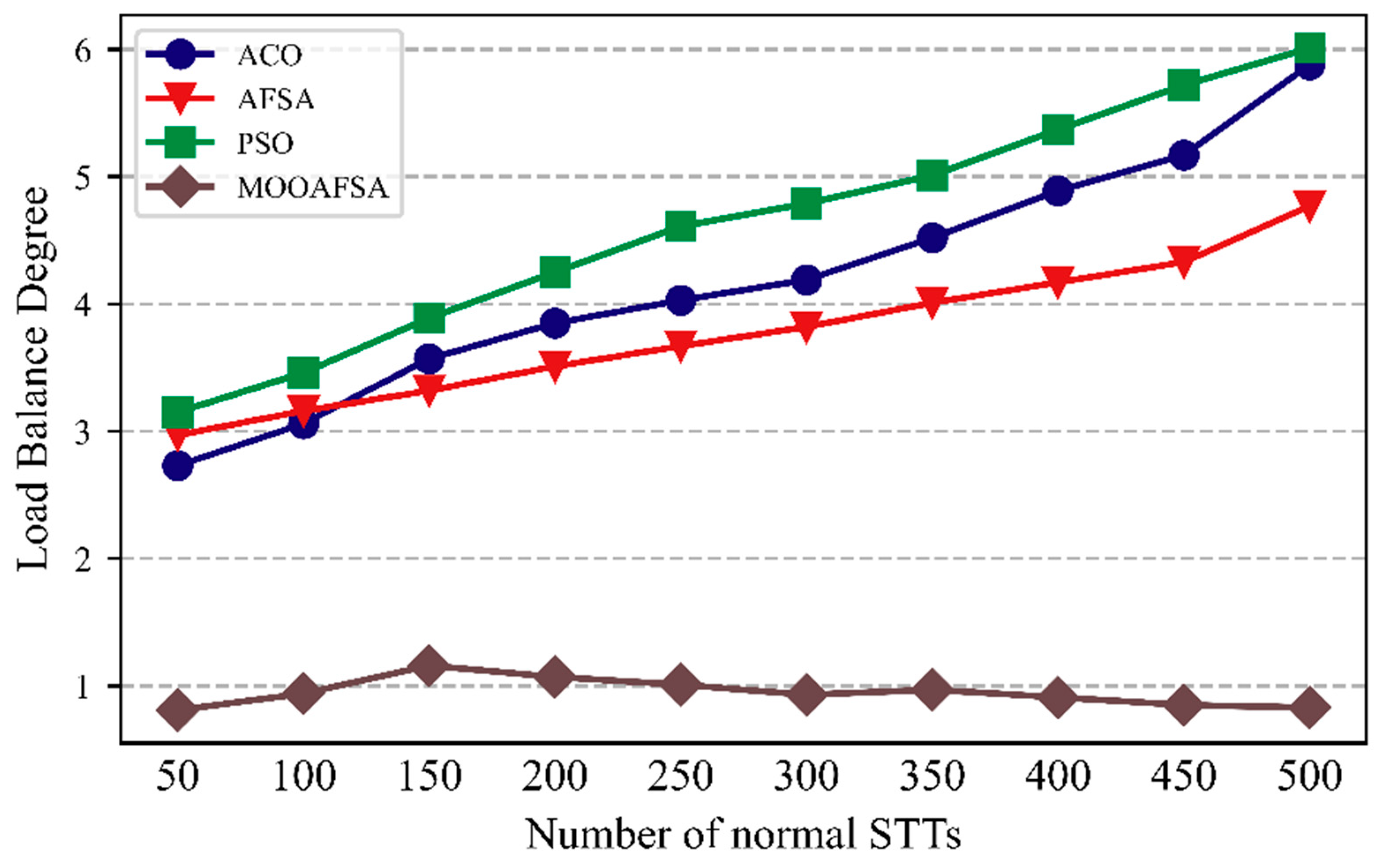
5.2.3. Load Balancing
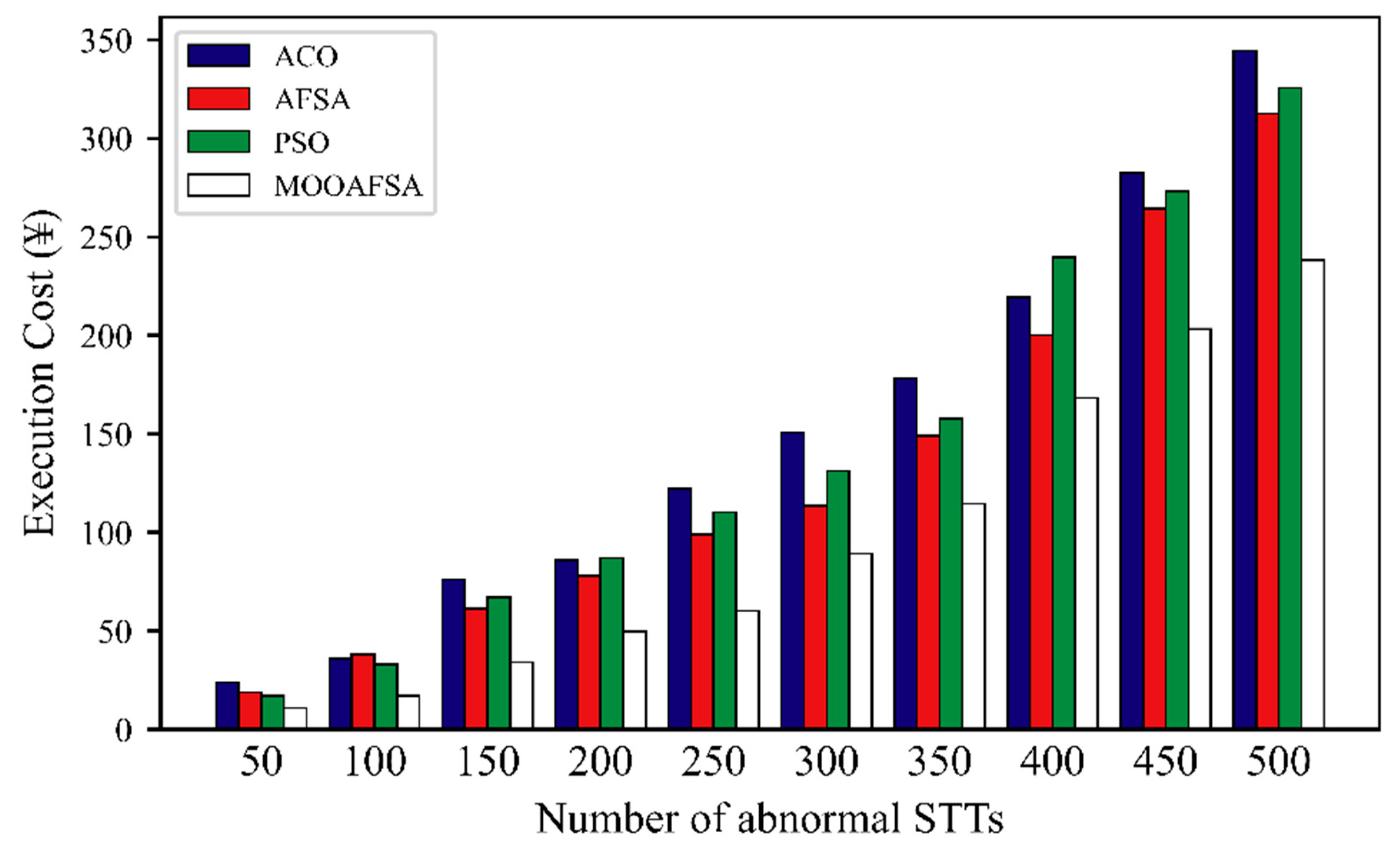
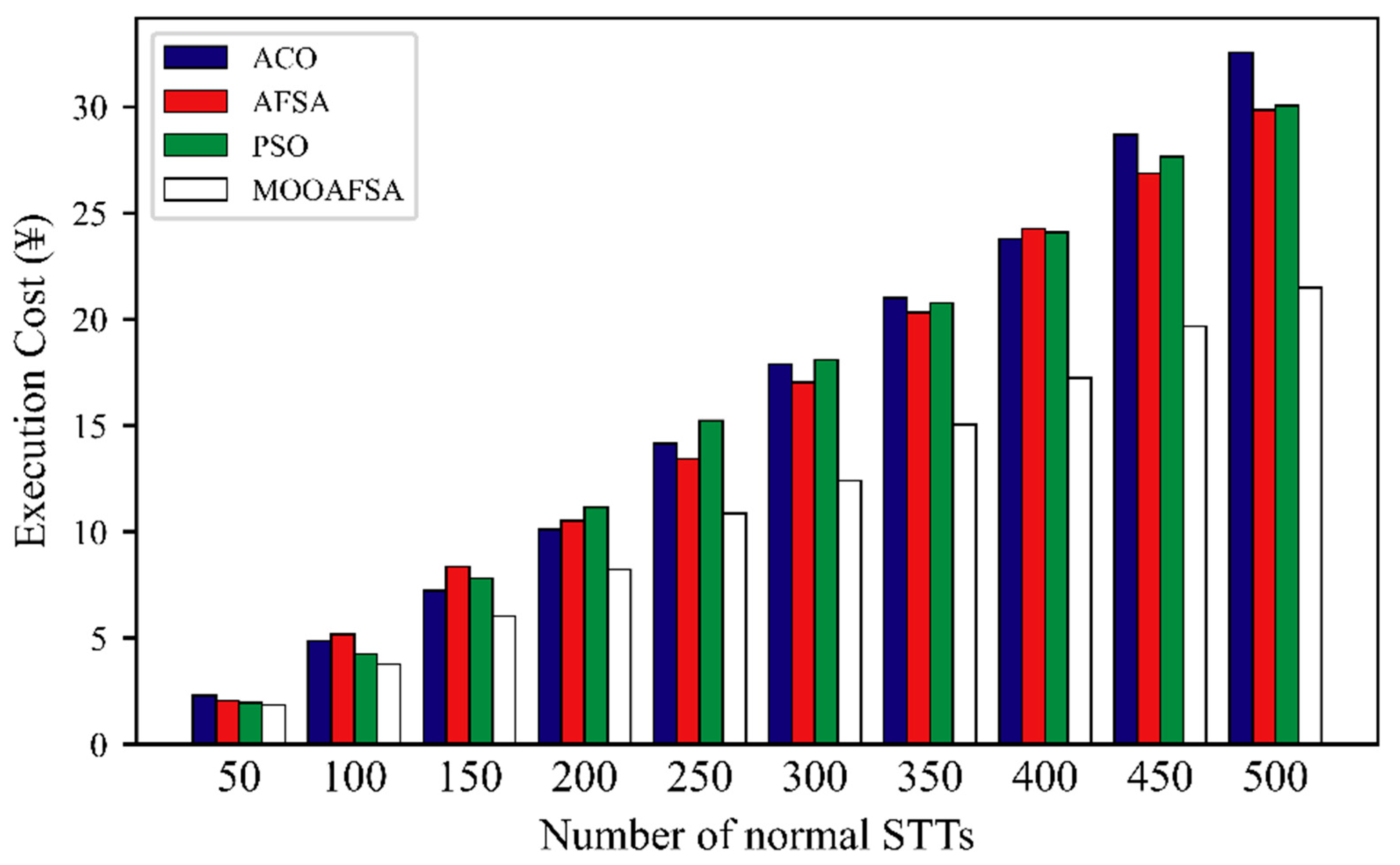
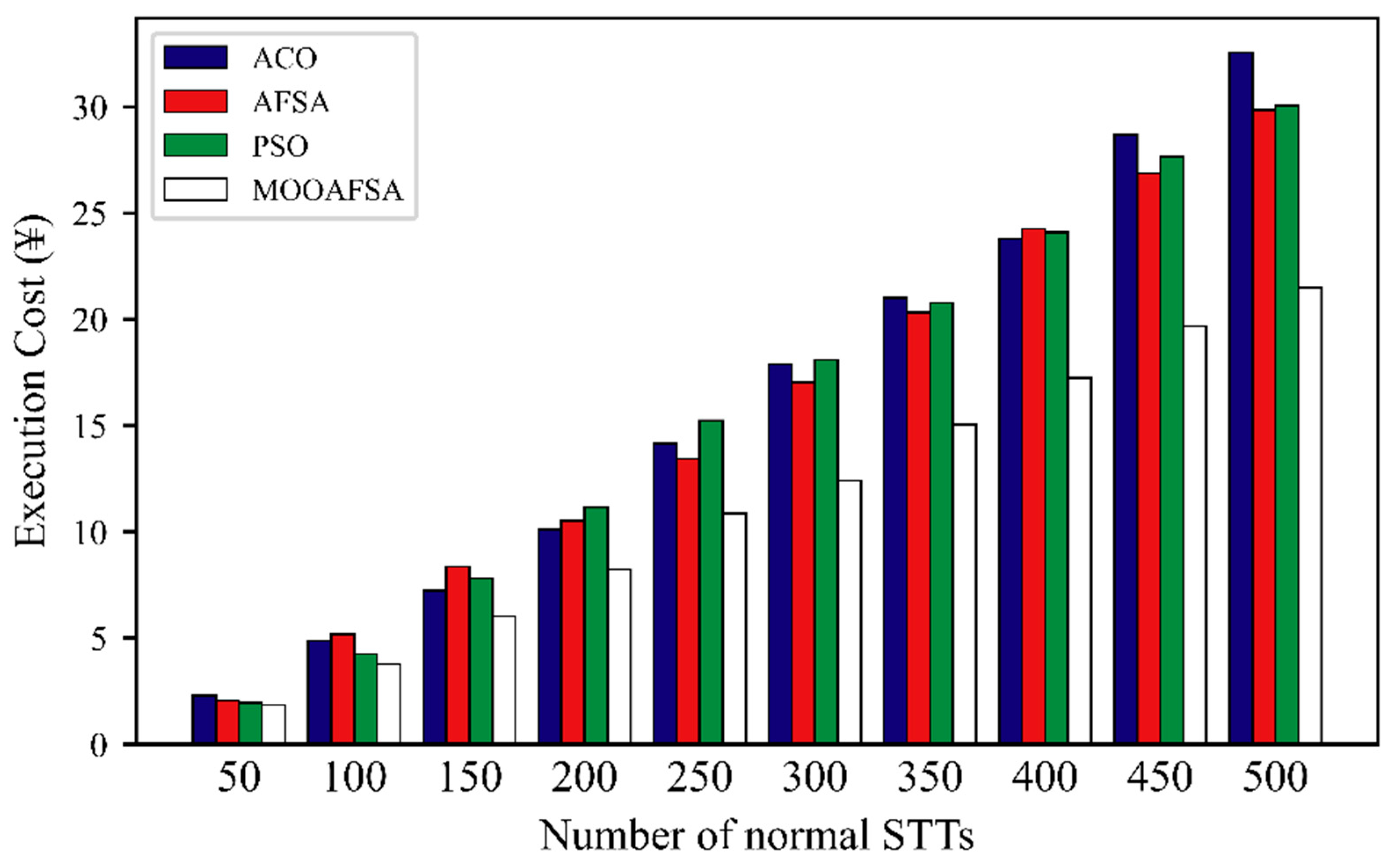
5.2.4. Execution Cost
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, X.; Zhang, S.; Litvinov, E. Practical Design and Implementation of Cloud Computing for Power System Planning Studies. Smart Grid. IEEE Trans. Smart Grid 2018, 10, 2301–2311. [Google Scholar] [CrossRef]
- Anushree, B.; Arul Xavier, V.M. Comparative Analysis of Latest Task Scheduling Techniques in Cloud Computing environment. In Proceedings of the Second International Conference on Computing Methodologies and Communication (ICCMC 2018), Erode, India, 15–16 February 2018; pp. 608–611. [Google Scholar]
- Han, P.; Du, C.; Chen, J. A DEA Based Hybrid Algorithm for Bi-objective Task Scheduling in Cloud Computing. In Proceedings of the 5th IEEE International Conference on Cloud Computing and Intelligence Systems (CCIS 2018), Nanjing, China, 23–25 November 2018; pp. 63–67. [Google Scholar]
- Li, X.L.; Qian, J.X. Studies on artificial fish swarm optimization algorithm based on decomposition and coordination techniques. J. Circuits Syst. 2003, 1, 1–6. [Google Scholar]
- Qi, B.; Xiong, L.; Wang, L.; Chen, Z.; Huang, L. A Weights and Improved Adaptive Artificial Fish Swarm Algorithm for Path Planning. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 1698–1702. [Google Scholar]
- Xin-yue, L.; Kai-yao, Y.; Dong-min, X. The Research on the Coordinated Control System of PID Neural Network Based on Artificial Fish Swarm Algorithm. In Proceedings of the Chinese Control and Decision Conference (CCDC 2016), Yinchuan, China, 28–30 May 2016; pp. 3065–3068. [Google Scholar]
- Fu, M.; Fei, T.; Zhang, L.; Li, H. Research on Location Optimization of Low-Carbon Cold Chain Logistics Distribution Center by FWA-Artificial Fish Swarm Algorithm. In Proceedings of the International Conference on Communications, Information System and Computer Engineering (CISCE 2021), Beijing, China, 14–16 May 2021; pp. 529–533. [Google Scholar]
- Chiang, M.L.; Hsieh, H.C.; Tsai, W.C.; Ke, M.C. An improved task scheduling and load balancing algorithm under the heterogeneous cloud computing network. In Proceedings of the 2017 IEEE 8th International Conference on Awareness Science and Technology (iCAST), Taichung, Taiwan, 8–10 November 2017; pp. 290–295. [Google Scholar]
- Panda, S.K.; Jana, P.K. SLA-based task scheduling algorithms for heterogeneous multi-cloud environment. J. Supercomput. 2017, 73, 2730–2762. [Google Scholar] [CrossRef]
- Mao, H.; Schwarzkopf, M.; Venkatakrishnan, S.B.; Meng, Z.; Alizadeh, M. Learning Scheduling Algorithms for Data Processing Clusters. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 270–288. [Google Scholar]
- Adhikari, M.; Nandy, S.; Amgoth, T. Meta heuristic-based task deployment mechanism for load balancing in IaaS cloud. J. Netw. Comput. Appl. 2019, 128, 64–77. [Google Scholar] [CrossRef]
- Narayanan, D.; Santhanam, K.; Kazhamiaka, F.; Phanishayee, A.; Zaharia, M. Heterogeneity-Aware Cluster Scheduling Policies for Deep Learning Workloads. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation, Banff, AB, Canada, 4–6 November 2020; pp. 481–498. [Google Scholar]
- Ding, D.; Fan, X.; Zhao, Y.; Kang, K.; Yin, Q.; Zeng, J. Q-learning based dynamic task scheduling for energy-efficient cloud computing. Future Gener. Comput. Syst. 2020, 108, 361–371. [Google Scholar] [CrossRef]
- Devaraj, A.F.S.; Elhoseny, M.; Dhanasekaran, S.; Lydia, E.L.; Shankar, K. Hybridization of firefly and Improved Multi-Objective Particle Swarm Optimization algorithm for energy efficient load balancing in Cloud Computing environments. J. Parallel Distrib. Comput. 2020, 142, 36–45. [Google Scholar] [CrossRef]
- Li, J.Q.; Han, Y.Q. A hybrid multi-objective artificial bee colony algorithm for flexible task scheduling problems in cloud computing system. Clust. Comput. 2020, 23, 2483–2499. [Google Scholar] [CrossRef]
- Domanal, S.G.; Guddeti, R.M.R.; Buyya, R. A hybrid bio-inspired algorithm for scheduling and resource management in cloud environment. IEEE Trans. Serv. Comput. 2020, 13, 3–15. [Google Scholar] [CrossRef]
- Mondal, S.S.; Sheoran, N.; Mitra, S. Scheduling of time-varying workloads using reinforcement learning. In AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2021; Volume 35, pp. 9000–9008. [Google Scholar]
- Teylo, L.; Arantes, L.; Sens, P.; Drummond, L. A dynamic task scheduler tolerant to multiple hibernations in cloud environments. Clust. Comput. 2021, 24, 1051–1073. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A. A novel hybrid antlion optimization algorithm for multi-objective task scheduling problems in cloud computing environments. Clust. Comput. 2021, 24, 205–223. [Google Scholar] [CrossRef]
- Shelke, M.P.K.; Sontakke, M.S.; Gawande, A.D. Intrusion detection system for cloud computing. Int. J. Sci. Technol. Res. 2012, 1, 67–71. [Google Scholar]
- Casola, V.; De Benedictis, A.; Rak, M.; Villano, U. Towards automated penetration testing for cloud applications. In Proceedings of the 2018 IEEE 27th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Paris, France, 27–29 June 2018; pp. 24–29. [Google Scholar]
- Lingkang, Z.; Yuwei, L.; Xue, J. Detection of Abnormal Data Flow at Network Boundary of Renewable Energy Power System. In Proceedings of the 2020 IEEE 3rd International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 20–22 November 2020; pp. 309–312. [Google Scholar]
- Gao, Z.; Zhao, J.; Li, S.; Hu, R. The Improved Equilibrium Optimization Algorithm with Tent Map. In Proceedings of the 5th International Conference on Computer and Communication Systems (ICCCS 2020), Shanghai, China, 15–18 May 2020; pp. 343–346. [Google Scholar]
- Gao, Z.; Zhao, J.; Hu, Y.; Chen, H. The Improved Harris Hawk Optimization Algorithm with the Tent Map. In Proceedings of the 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE 2019), Xiamen, China, 18–20 October 2019; pp. 336–339. [Google Scholar]
- Rani, E.; Kaur, H. Study on fundamental usage of CloudSim simulator and algorithms of resource allocation in cloud computing. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–7. [Google Scholar]
- Duan, H.; Ma, G.; Liu, S. Experimental study of the adjustable parameters in basic ant colony optimization algorithm. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; pp. 149–156. [Google Scholar]
- Jiang, M.; Luo, Y.P.; Yang, S.Y. Stochastic convergence analysis and parameter selection of the standard particle swarm optimization algorithm. Inf. Process. Lett. 2007, 102, 8–16. [Google Scholar] [CrossRef]
- Wu, C.; Toosi, A.N.; Buyya, R.; Ramamohanarao, K. Hedonic Pricing of Cloud Computing Services. IEEE Trans. Cloud Comput. 2021, 9, 182–196. [Google Scholar] [CrossRef] [Green Version]
- Kandpal, M.; Patel, K. Pricing Model for Revenue Generation using Recurrent Neural Network for Cloud Service Provider. In Proceedings of the 3rd International Conference on Trends in Electronics and Informatics (ICOEI 2019), Tirunelveli, India, 23–25 April 2019; pp. 988–992. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Algorithm | Indicator | Advantage |
|---|---|---|---|---|
| [8] | 2017 | AMS | Makespan Load balancing | AWS can obtain good task completion time and achieve load balancing in cloud computing network. |
| [9] | 2017 | SLA-MCT SLA-Min-Min | Makespan Resource Utilization Cost | The proposed algorithm achieves a proper balance between manufacturing time and service gain cost. |
| [10] | 2019 | Decima | Makespan | Decima can help improve resource utilization by automatically learning highly efficient, workload-specific scheduling policies. Decima’s policies are particularly effective during periods of high cluster load. |
| [11] | 2019 | LB-RC | Makespan Execution cost Load balancing | LB-RC algorithm can reduce the execution time and completion time of tasks while meeting deadlines, and maintain the load balance of resources. |
| [12] | 2020 | Gavel | Makespan Throughput Average job completion time Fairness | Gavel uses a decoupled round-based scheduling mechanism to ensure that the computed optimal allocation is realized. Gavel’s heterogeneity-aware policies improve end objectives both on a physical and simulated cluster. |
| [13] | 2020 | QEEC | Average response time Energy consumption | Maximizing the service capability of each virtual machine can effectively reduce the energy consumption in the cloud environment. |
| [14] | 2020 | FIMPSO | Makespan Load balancing Throughput Resource Utilization | FIMPSO achieved effective average load for making and enhanced the essential measures like proper resource usage and response time of the tasks. |
| [15] | 2020 | LABC | Makespan Fitness value Average calculation time | LABC algorithm has strong development ability and local search ability. |
| [16] | 2020 | HYBRID Bio-Inspired | Makespan Load balancing Response time Resource Utilization | HYBRID Bio-Inspired algorithm realizes resource load balancing, reduces execution time and improves resource utilization. |
| [17] | 2021 | TVW-RL | Resource Utilization Resource Fragmentation Resource Overshoot | TVW-RL improves resource utilization, reduces resource fragments and the number of machines used. |
| [18] | 2021 | HADS | Monetary costs | HADS can minimize the monetary costs of bag-of-tasks, respecting the application’s deadline and avoiding temporal failures. |
| [19] | 2021 | MALO | Makespan Load balancing Response time | For large search space, MALO has faster convergence speed and is suitable for large-scale scheduling problems. |
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| The length of the STT | The size of the STT before execution | ||
| The size of the STT after execution | The type of the STT | ||
| The risk level of the STT | The computing capacity of the VSCR | ||
| The bandwidth of the VSCR | The running memory of the VSCR | ||
| The number of CPUs of the VSCR | The storage size of the VSCR | ||
| Time consumed by VSCR to execute STT | Assignment relation between STT and VSCR | ||
| Transfer time of STT on VSCR | Time consumed by VSCR to complete STT | ||
| Unit computation cost | Unit bandwidth cost | ||
| Unit memory cost | Unit storage cost | ||
| Performance of VSCR | Load on VSCR | ||
| Average load on all VSCRs | System load evaluation metrics | ||
| The category of the VSCR |
| Type | Harm |
|---|---|
| Traditional network attacks [22] | For example, distributed denial of service attack (DDoS). It can make use of some defects of network protocol and operating system to carry out network attack, fill the server with a large number of information to be replied, consume network bandwidth or system resources, and cause the network or system to be overloaded and paralyzed to stop providing normal network services. |
| Invisible penetration and scanning [22] | This kind of attack means that the attacker initiates an intrusion from outside the target network in order to steal or destroy important assets in the target network. During this period, the attacker continues to use several vulnerabilities in the target network to invade and finally complete a series of attacks on the target. |
| Hide disguised communications [22] | It is a kind of antagonism network attack, using the hidden means of invasion, and its network communication is disguised as or concealed in the normal legal network data flow to avoid terminal level and network level of safety inspection in order to reside for a long time and can control the victim host or device, achieve the goal of continuing to steal information or long-term control using. |
| Attack aimed at application layer vulnerabilities [22] | Hackers send disguised data requests to users for loopholes in the application layer so as to achieve the purpose of illegal data theft, illegal data tampering, system paralysis and other attacks. |
| Parameter | Value | Advantages | Disadvantages |
|---|---|---|---|
| Step size | Too high | There are fewer iterations and convergence is faster. | Optimization accuracy is not high, and oscillations can occur outside a certain range (the number of iterations increases, and the convergence is slower). |
| Too low | Optimization accuracy is improved. | There are more iterations, convergence is slow, and it may easily fall into a local optimum. | |
| Field of view | Too wide | Global search capability is enhanced and the convergence is faster. | Optimization accuracy is low. |
| Too narrow | Local search ability is enhanced and optimization accuracy is improved. | Convergence is slow. |
| Experiment | Object | Number |
|---|---|---|
| Experiment 1 | VSCR | 15 |
| Abnormal STTs | 50–500 | |
| Experiment 2 | VSCR | 15 |
| Normal STTs | 50–500 |
| Object | Parameter | Value |
|---|---|---|
| VSCR | Processing speed (MIPS): | 200–500 |
| Bandwidth (Mb/s): | 50–200 | |
| Memory (GB): | 2–16 | |
| Number of CPU cores: | 2–8 | |
| Storage capacity (GB): | 50–200 | |
| Category: | 1–8 | |
| STT | Length of the STT (MI): | 2000–6000 |
| Pre-execution size (MB): | 200–300 | |
| Post-execution size (MB): | 200–300 | |
| Category: | 1–8 | |
| Risk level: | 1–4 |
| Algorithm | Parameter | Value |
|---|---|---|
| AFSA, MOOAFSA | Number of attempts: | 3 |
| Step length: | 2.5 | |
| Field of vision: | 3.5 | |
| Crowding factor: | 2 | |
| Threshold: | 5 | |
| MOOAFSA | Computing power weight: | 0.75 |
| Bandwidth size weight: | 0.25 | |
| ACO | Information heuristic factor: | 2.5 |
| Expectation heuristic factor: | 5.5 | |
| Information volatile factor: | 0.35 | |
| Pheromone increment: | 100 | |
| PSO | Learning factor 1: | 1.5 |
| Learning factor 2: | 2 | |
| Inertial factor: | 0.9 | |
| ACO, PSO, AFSA, MOOAFSA | Number of iterations: | 100 |
| Population size: | 40 |
| Resource Type | Unit Pricing | Unit Price |
|---|---|---|
| CPU | CNY per core per hour | 0.46 |
| RAM | CNY per GB per hour | 0.04 |
| Bandwidth | CNY per Mbps per hour | 0.03 |
| Disk | CNY per GB per hour | 0.008 |
| Number of VSCRs | Number of STTs | STT Completion Time (s) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Abnormal | Normal | ||||||||
| ACO | AFSA | PSO | MOOAFSA | ACO | AFSA | PSO | MOOAFSA | ||
| 15 | 50 | 47.84 | 41.01 | 42.37 | 26.72 | 5.36 | 5.12 | 5.24 | 5.06 |
| 100 | 89.63 | 71.32 | 80.91 | 50.83 | 10.68 | 9.30 | 9.63 | 9.18 | |
| 150 | 127.46 | 101.58 | 123.12 | 90.12 | 16.98 | 17.63 | 16.42 | 13.25 | |
| 200 | 142.50 | 139.55 | 151.01 | 128.38 | 20.35 | 19.14 | 19.87 | 17.09 | |
| 250 | 204.43 | 176.66 | 191.31 | 156.27 | 23.97 | 23.01 | 24.58 | 21.32 | |
| 300 | 245.75 | 219.78 | 234.43 | 187.49 | 29.83 | 26.32 | 28.87 | 25.27 | |
| 350 | 279.37 | 241.89 | 276.53 | 210.12 | 34.29 | 30.41 | 33.12 | 27.89 | |
| 400 | 366.94 | 288.26 | 314.57 | 255.48 | 37.61 | 34.59 | 35.97 | 30.21 | |
| 450 | 389.96 | 310.25 | 354.69 | 283.37 | 40.16 | 38.09 | 39.05 | 32.99 | |
| 500 | 426.24 | 344.31 | 394.48 | 296.22 | 54.78 | 47.89 | 43.52 | 36.04 | |
| Number of VSCRs | Number of STTs | Load Balance Degree | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Abnormal | Normal | ||||||||
| ACO | AFSA | PSO | MOOAFSA | ACO | AFSA | PSO | MOOAFSA | ||
| 15 | 50 | 3.12 | 3.53 | 4.51 | 1.04 | 2.73 | 2.97 | 3.15 | 0.81 |
| 100 | 3.65 | 3.31 | 4.48 | 1.95 | 3.06 | 3.16 | 3.46 | 0.94 | |
| 150 | 4.24 | 3.62 | 5.17 | 1.72 | 3.57 | 3.32 | 3.89 | 1.16 | |
| 200 | 5.31 | 3.98 | 5.83 | 1.84 | 3.85 | 3.51 | 4.25 | 1.07 | |
| 250 | 5.88 | 4.11 | 5.92 | 1.73 | 4.03 | 3.67 | 4.61 | 1.01 | |
| 300 | 6.67 | 4.56 | 5.98 | 1.32 | 4.19 | 3.82 | 4.79 | 0.93 | |
| 350 | 7.49 | 5.23 | 6.89 | 1.23 | 4.52 | 4.01 | 5.01 | 0.97 | |
| 400 | 8.02 | 5.99 | 7.53 | 1.30 | 4.89 | 4.17 | 5.37 | 0.91 | |
| 450 | 8.87 | 6.83 | 8.60 | 1.21 | 5.17 | 4.33 | 5.72 | 0.85 | |
| 500 | 10.26 | 7.95 | 9.89 | 1.18 | 5.88 | 4.77 | 6.01 | 0.83 | |
| Number of VSCRs | Number of STTs | Execution Cost (¥) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Abnormal | Normal | ||||||||
| ACO | AFSA | PSO | MOOAFSA | ACO | AFSA | PSO | MOOAFSA | ||
| 15 | 50 | 24.01 | 18.96 | 16.98 | 11.10 | 2.31 | 2.05 | 1.96 | 1.85 |
| 100 | 36.12 | 38.04 | 33.02 | 17.01 | 4.87 | 5.19 | 4.26 | 3.78 | |
| 150 | 76.22 | 61.42 | 67.21 | 34.13 | 7.23 | 8.36 | 7.81 | 6.03 | |
| 200 | 85.88 | 78.12 | 87.16 | 49.79 | 10.12 | 10.51 | 11.16 | 8.24 | |
| 250 | 122.14 | 98.93 | 110.20 | 60.32 | 14.15 | 13.44 | 15.23 | 10.87 | |
| 300 | 150.67 | 113.42 | 131.12 | 89.27 | 17.88 | 17.03 | 18.09 | 12.42 | |
| 350 | 178.20 | 148.96 | 157.63 | 114.56 | 21.02 | 20.31 | 20.76 | 15.06 | |
| 400 | 219.21 | 200.16 | 239.64 | 168.23 | 23.78 | 24.26 | 24.09 | 17.24 | |
| 450 | 282.42 | 264.33 | 273.15 | 203.17 | 28.67 | 26.87 | 27.64 | 19.66 | |
| 500 | 344.25 | 312.56 | 325.47 | 238.17 | 32.54 | 29.84 | 30.06 | 21.48 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Fan, Q.; Dang, F.; Jiang, Y.; Wang, H.; Li, S.; Zhang, X. Multi-Objective Optimization of a Task-Scheduling Algorithm for a Secure Cloud. Information 2022, 13, 92. https://doi.org/10.3390/info13020092
Li W, Fan Q, Dang F, Jiang Y, Wang H, Li S, Zhang X. Multi-Objective Optimization of a Task-Scheduling Algorithm for a Secure Cloud. Information. 2022; 13(2):92. https://doi.org/10.3390/info13020092
Chicago/Turabian StyleLi, Wei, Qi Fan, Fangfang Dang, Yuan Jiang, Haomin Wang, Shuai Li, and Xiaoliang Zhang. 2022. "Multi-Objective Optimization of a Task-Scheduling Algorithm for a Secure Cloud" Information 13, no. 2: 92. https://doi.org/10.3390/info13020092
APA StyleLi, W., Fan, Q., Dang, F., Jiang, Y., Wang, H., Li, S., & Zhang, X. (2022). Multi-Objective Optimization of a Task-Scheduling Algorithm for a Secure Cloud. Information, 13(2), 92. https://doi.org/10.3390/info13020092