
MEduKG: A Deep-Learning-Based Approach for Multi-Modal Educational Knowledge Graph Construction


Abstract
:1. Introduction
- We propose a model to automatically construct a multi-modal educational knowledge graph, and we provide a way for speech fusion to incorporate and refine the knowledge graph by treating speech as an entity;
- We propose a lexicon-based BERT model for educational concept recognition by combining the BiLSTM-CRF model that can better identify educational concepts. For relation extraction, in order to better combine the domain information, we combine the location information of the entity with BERT to dig out the implicit relationships between these entities;
- We take computer courses as an example to verify the scalability and feasibility of our work. In addition, the empirical results show that our proposed approach performs competitively better than the state-of-the-art models in entity recognition and in relation extraction.
2. Related Work
2.1. Educational Knowledge Graph Construction
2.2. Named Entity Recognition
2.3. Relation Extraction
3. Methods
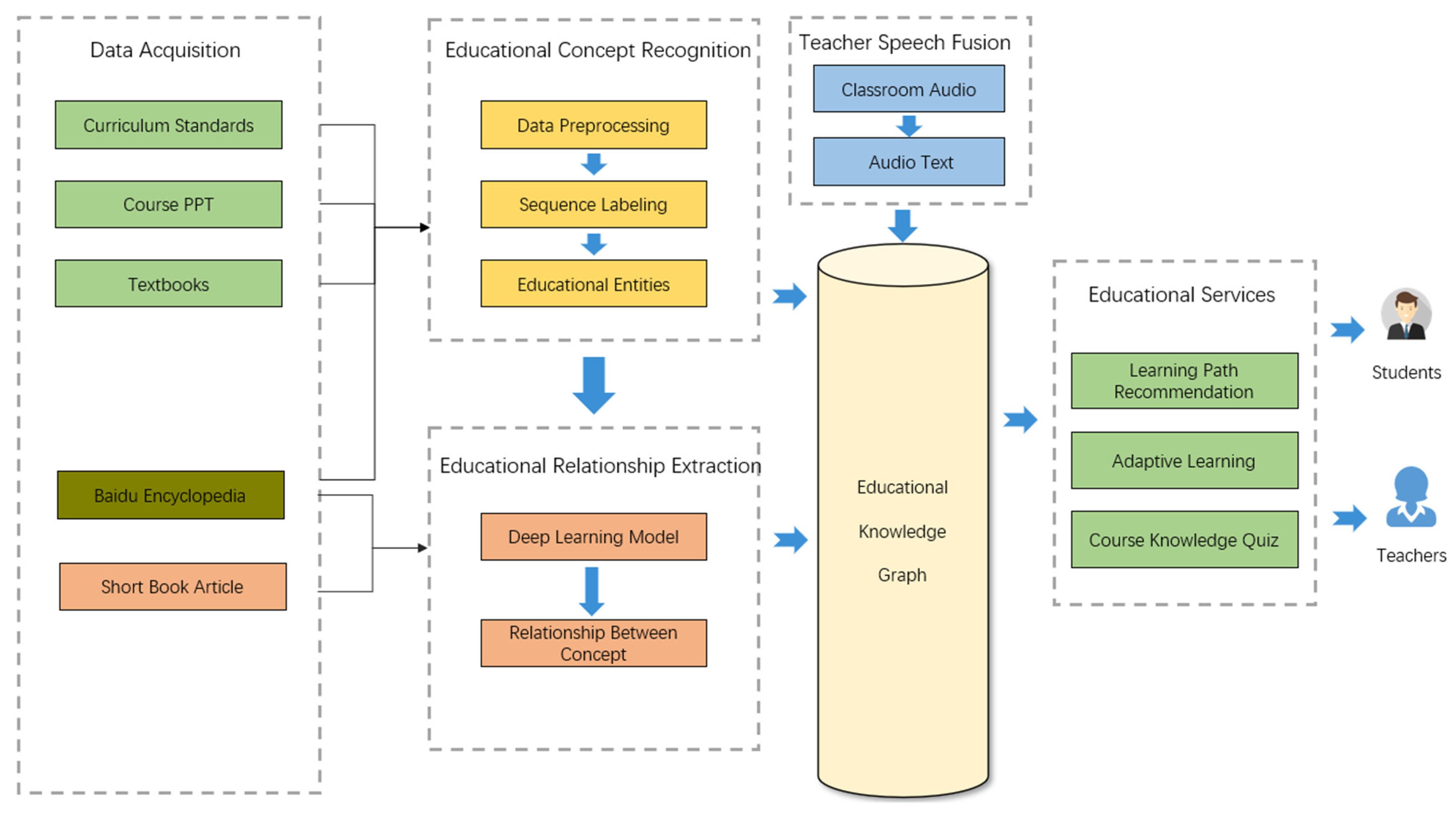
3.1. Framework Overview
- Educational Concept Recognition Module: The main goal of this module is to extract teaching concepts or educational entities in a specified course. Online education resources include Baidu entries and Jianshu articles. Offline education resources usually include course outlines, PowerPoints, and teaching courses. The lexicon enhancement method is used to pre-process the data, and then combine a fine-tuned BERT model to extract the educational concepts. The final outputs of this module are the extracted concepts, which are the basis for the construction of the knowledge graph;
- Educational Relation Extraction Module: The main goal of this module is to associate the extracted educational concepts to help learners clarify the relationship between knowledge concepts. Vocabulary information is still important for relation classification. This module uses the acquired entities for vocabulary labeling and combines itself with the BERT model to distinguish the potential relationships between educational concepts;
- Teacher Speech Fusion Module: The teacher’s voice is also an important resource in the field of education. The main goal of this module is to fuse real classroom teacher speech as a kind of entity into the text-based education knowledge graph. The module mainly uses Mel Frequency Cepstral Coefficients (MFCC) to extract speech feature variables and performs the Fourier transform. HMM is used to obtain speech text and calculate similarity. Teacher speech is matched with text entities.
3.2. Educational Concepts Recognition
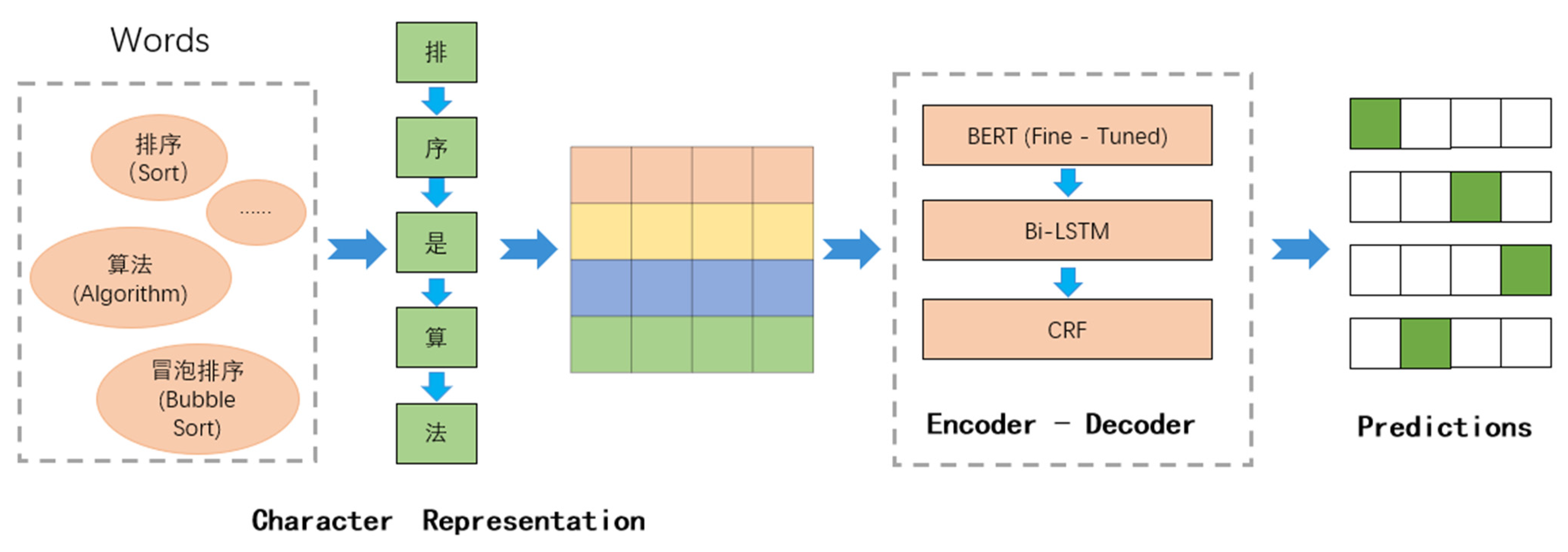
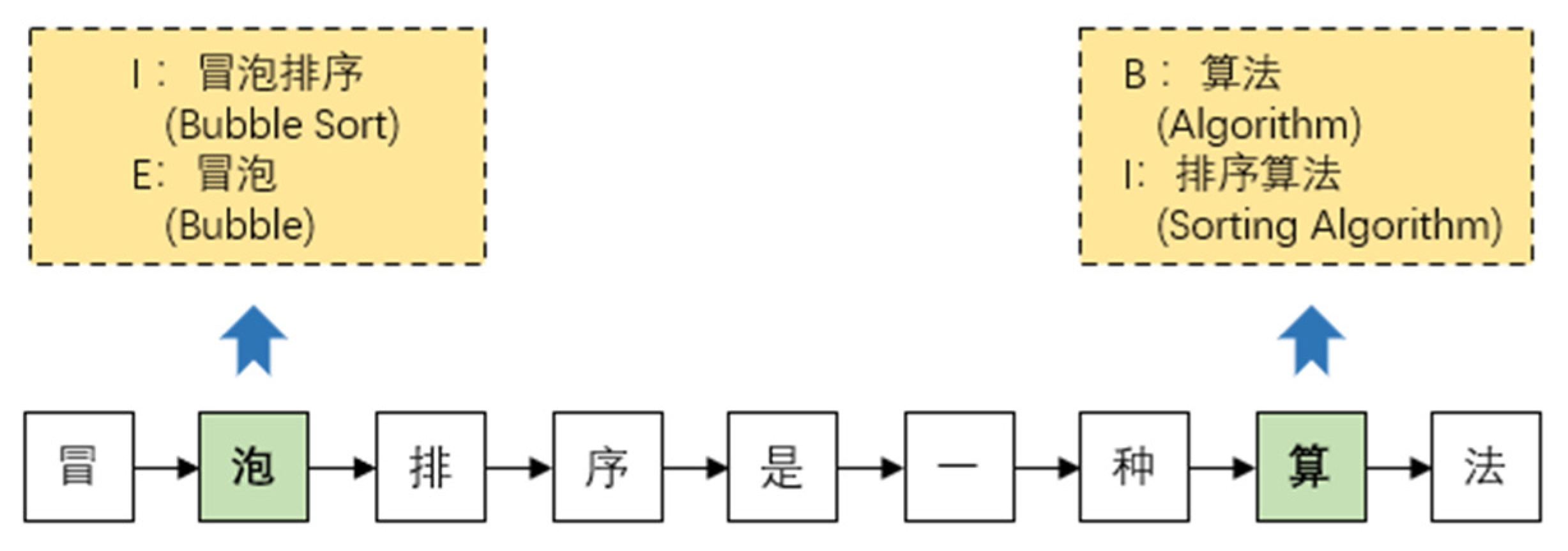
3.2.1. Character Representation
3.2.2. Fine-Tuned BERT
3.2.3. BiLSTM Encoder
3.2.4. CRF Decoder
3.3. Educational Relation Extraction
3.4. Teacher Speech Fusion Module
4. Results and Discussion
4.1. Experiment Settings
4.1.1. Dataset
4.1.2. Data Preprocessing
4.1.3. Evaluation Metrics
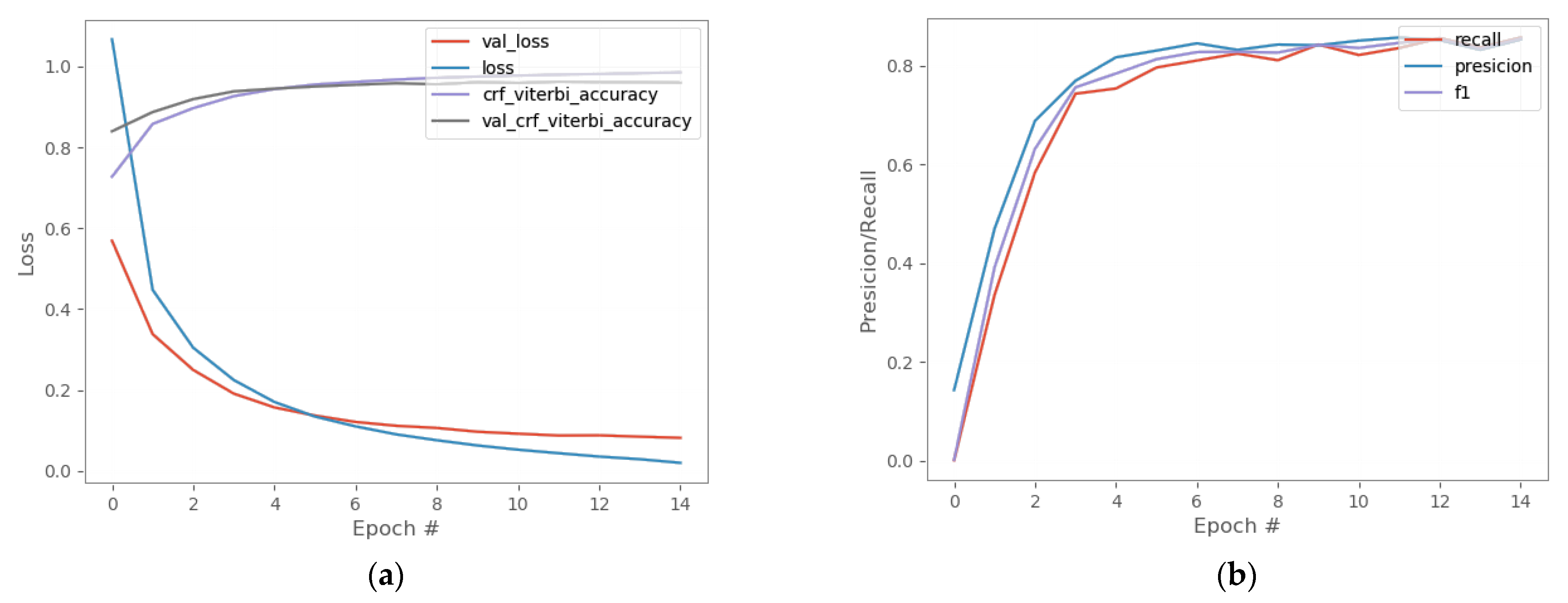
4.2. Experiment Results on Entity Recognition
4.2.1. Model Comparison
4.2.2. Parameter Sensitivity Analysis
4.3. Empirical Results on Relation Extraction
4.4. Visual Display of Knowledge Graph
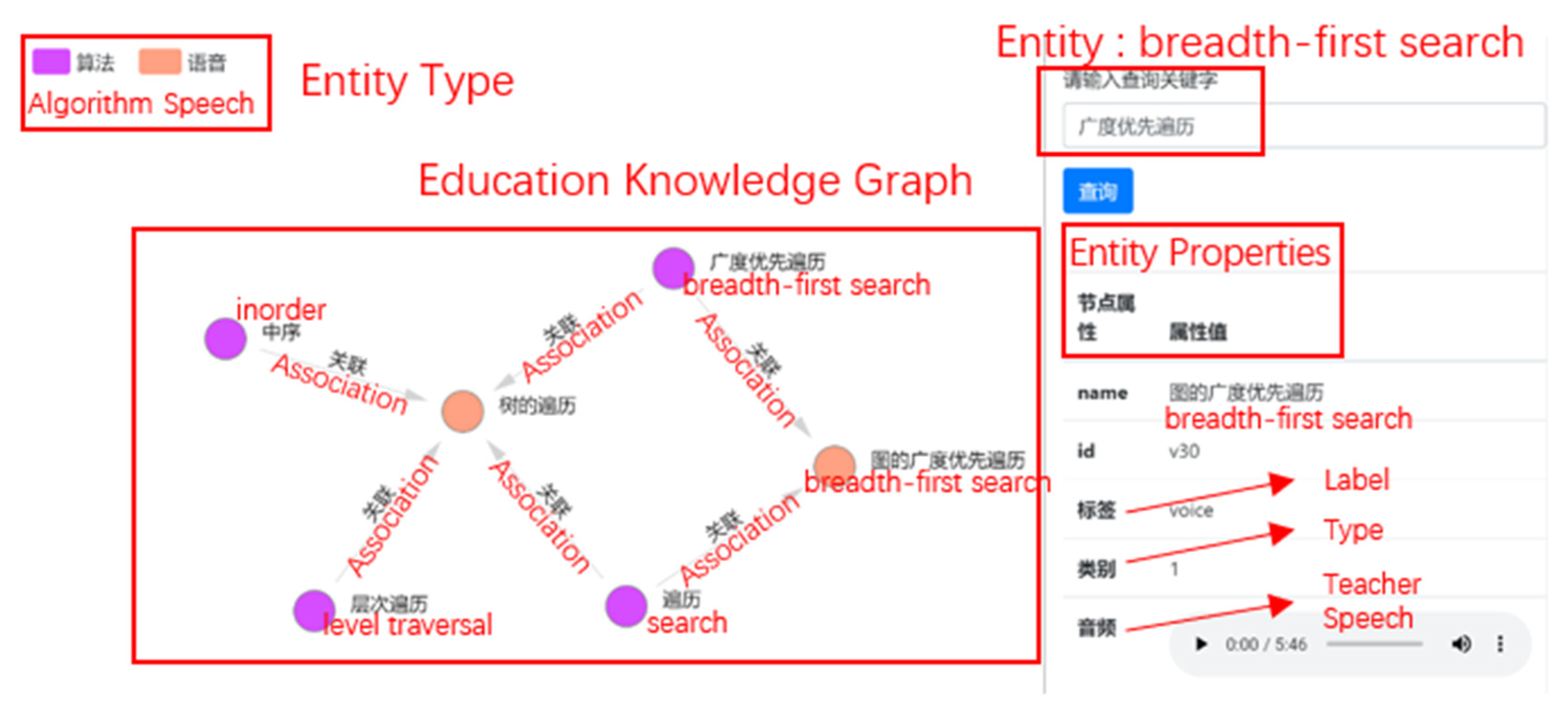
4.4.1. Course Knowledge Concept Query Module
4.4.2. Multi-Modal Concept Display Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Martín, A.C.; Alario-Hoyos, C.; Kloos, C.D. Smart Education: A Review and Future Research Directions. Proceedings 2019, 31, 57. [Google Scholar] [CrossRef] [Green Version]
- D’Mello, S.K.; Olney, A.M.; Blanchard, N.; Samei, B.; Sun, X.; Ward, B.; Kelly, S. Multimodal Capture of Teacher-Student Interactions for Automated Dialogic Analysis in Live Classrooms. In ICMI’15, Proceedings of the 2015 ACM on International Conference on Multimodal Interaction; Association for Computing Machinery: New York, NY, USA, 2015; pp. 557–566. [Google Scholar]
- Suresh, A.; Sumner, T.; Jacobs, J.; Foland, B.; Ward, W. Automating Analysis and Feedback to Improve Mathematics Teachers’ Classroom Discourse. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; 2019; Volume 33, pp. 9721–9728. [Google Scholar]
- Anand, R.; Ottmar, E.; Crouch, J.L.; Whitehill, J. Toward Automated Classroom Observation: Predicting Positive and Negative Climate. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Heiko, P. Towards Profiling Knowledge Graphs. In Proceedings of the PROFILES@ISWC, Vienna, Austria, 22 October 2017. [Google Scholar]
- Wang, S.; Liang, C.; Wu, Z.; Williams, K.; Pursel, B.; Brautigam, B.; Saul, S.; Williams, H.; Bowen, K.; Giles, C.L. Concept Hierarchy Extraction from Textbooks. In Proceedings of the DocEng’15—ACM Symposium on Document Engineering 2015, Lusanne, Switzerland, 8–11 September 2015. [Google Scholar]
- Lu, W.; Zhou, Y.; Yu, J.; Jia, C. Concept Extraction and Prerequisite Relation Learning from Educational Data. Proc. Conf. AAAI Artif. Intell. 2019, 33, 9678–9685. [Google Scholar] [CrossRef]
- Hu, J.; Zheng, L.; Xu, B. An Approach of Ontology Based Knowledge Base Construction for Chinese K12 Education. In Proceedings of the 2016 First International Conference on Multimedia and Image Processing (ICMIP), Bandar Seri Begawan, Brunei, 1–3 June 2016; pp. 83–88. [Google Scholar]
- Liu, H.; Ma, W.; Yang, Y.; Carbonell, J.G. Learning Concept Graphs from Online Educational Data. J. Artif. Intell. Res. 2016, 55, 1059–1090. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.; Yu, L.; Zheng, V.W.; Chen, X.; Li, X. An Automatic Knowledge Graph Construction System for K-12 Education. In Proceedings of the Fifth Annual ACM Conference on Learning at Scale 2018, London, UK, 26–28 June 2018. [Google Scholar]
- Biega, J.A.; Kuzey, E.; Suchanek, F.M. Inside YAGO2s: A Transparent Information Extraction Architecture. In Proceedings of the 22nd International Conference on World Wide Web—WWW’13 Companion, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 325–328. [Google Scholar]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia—A crystallization point for the Web of Data. J. Web Semant. 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Fredo, E.; Günther, M.; Krötzsch, M.; Mendez, J.; Vrandečić, D. Introducing Wikidata to the Linked Data Web; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Liu, S.; Yang, H.; Li, J.; Kolmanič, S. Preliminary Study on the Knowledge Graph Construction of Chinese Ancient History and Culture. Information 2020, 11, 186. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.; Zhang, Y. Automatic Construction of Subject Knowledge Graph based on Educational Big Data. In Proceedings of the ICBDE’20—3rd International Conference on Big Data and Education, London, UK, 1–3 April 2020. [Google Scholar]
- Yang, Y.; Liu, H.; Carbonell, J.G.; Ma, W. Concept Graph Learning from Educational Data. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015. [Google Scholar]
- Senthilkumar, R.D. Concept Maps in Teaching Physics Concepts Applied to Engineering Education: An Explorative Study at The Middle East College, Sultanate of Oman. In Proceedings of the 2017 IEEE Global Engineering Education Conference, EDUCON 2017, Athens, Greece, 25–28 April 2017; pp. 107–110. [Google Scholar]
- Chen, L.; Ye, L.; Wu, Z.; Pursel, B.; Lee, C.G. Recovering Concept Prerequisite Relations from University Course Dependencies. Proc. AAAI Conf. Artif. Intell. 2017, 31, 10550. [Google Scholar]
- Kai, S.; Liu, Y.; Guo, Z.; Wang, C. Visualization for Knowledge Graph Based on Education Data. Int. J. Softw. Inform. 2017, 10, 3. [Google Scholar]
- Zheng, Y.; Liu, R.; Hou, J. The Construction of High Educational Knowledge Graph Based on MOOC. In Proceedings of the 2017 IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference, ITNEC, Chengdu, China, 15–17 December 2017; pp. 260–263. [Google Scholar]
- Dang, F.; Tang, J.-T.; Pang, K.; Wang, T.; Li, S.; Li, X. Constructing an Educational Knowledge Graph with Concepts Linked to Wikipedia. J. Comput. Sci. Technol. 2021, 36, 1200–1211. [Google Scholar] [CrossRef]
- Yao, S.; Wang, R.; Sun, S.; Bu, D.; Liu, J. Joint Embedding Learning of Educational Knowledge Graphs. arXiv 2019, arXiv:1911.08776. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. NAACL. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. arXiv 2018, arXiv:1910.11470. [Google Scholar]
- Nadeau, D.; Sekine, S. A Survey of Named Entity Recognition and Classification. Lingvist. Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Fu, G.; Kit, C.; Webster, J.J. A Morpheme-based Lexical Chunking System for Chinese. Int. Conf. Mach. Learn. Cybern. 2008, 5, 2455–2460. [Google Scholar]
- Wang, Y.; Wang, L.; Rastegar-Mojarad, M.; Moon, S.; Shen, F.; Afzal, N.; Liu, S.; Zeng, Y.; Mehrabi, S.; Sohn, S.; et al. Clinical information extraction applications: A literature review. J. Biomed. Inform. 2018, 77, 34–49. [Google Scholar] [CrossRef]
- Sutton, C.; McCallum, A. An Introduction to Conditional Random Fields. Found. Trends Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P.P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Zhiheng, H.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Yann, D.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. Proc. Mach. Learn. Res. 2017, 70, 933–941. [Google Scholar]
- Hang, Y.; Deng, B.; Li, X.; Qiu, X. TENER: Adapting Transformer Encoder for Named Entity Recognition. arXiv 2019, arXiv:1911.04474. [Google Scholar]
- Hui, C.; Lin, Z.; Ding, G.; Lou, J.-G.; Zhang, Y.; Börje, F.K. GRN: Gated Relation Network to Enhance Convolutional Neural Network for Named Entity Recognition. arXiv 2019, arXiv:1907.05611. [Google Scholar]
- Zhu, Y.; Wang, G.; Börje, F.K. CAN-NER: Convolutional Attention Network for Chinese Named Entity Recognition. arXiv 2019, arXiv:1904.02141. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. NAACL. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Karthik, N. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Aydar, M.; Ozge, B.; Özbay, F. Neural Relation Extraction: A Survey. arXiv 2020, arXiv:2007.04247. [Google Scholar]
- Vu, N.T.; Adel, H.; Gupta, P.; Schütze, H. Combining Recurrent and Convolutional Neural Networks for Relation Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: San Diego, CA, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Ganjam, K.; Jain, N.; Lundin, J.; White, R.; Lin, J. An Insight Extraction System on BioMedical Literature with Deep Neural Networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks; EMNLP: Lisbon, Portugal, 2015. [Google Scholar]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional Long Short-Term Memory Networks for Relation Classification; Fujitsu Research and Development Center: Beijing, China, 2015. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. arXiv 2018, arXiv:1809.10185. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. arXiv 2019, arXiv:abs/1906.07510. [Google Scholar]
- Fu, T.-J.; Li, P.-H.; Ma, W.-Y. GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction; Association for Computational Linguistics: Florence, Italy, 2019. [Google Scholar]
- Wu, S.; He, Y. Enriching Pre-trained Language Model with Entity Information for Relation Classification. arXiv 2019, arXiv:1905.08284. [Google Scholar]
- Li, C.; Ye, T. Downstream Model Design of Pre-trained Language Model for Relation Extraction Task. arXiv 2020, arXiv:2004.03786. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | 排序是一种算法 (Sorting Is an Algorithm) |
|---|---|
| Word Segmentation | 排序 是 一种 算法 |
| Original Mask | 排[M] 是 一种 [M]法 |
| Current Mask | [M][M] 是 一种 [M][M] |
| Relation Type | Relation Definition |
|---|---|
| Inclusion Relationship | Knowledge point A contains knowledge point B, and knowledge point B is the refinement of knowledge point A |
| Precursor Relationship | Knowledge point A must be learned before learning knowledge point B |
| Identity Relationship | Knowledge point A and knowledge point B are different descriptions of the same knowledge |
| Sister Relationship | Knowledge point A and knowledge point B have the same parent knowledge point C, and there is no learning sequence |
| Correlation Relationship | Knowledge point A and knowledge point B do not conform to the previous relationships, although they are still relevant |
| Method | P | R | F1 |
|---|---|---|---|
| BiLSTM-CRF | 80.04% | 82.07% | 81.06% |
| BERT-BiLSTM-CRF | 80.34% | 85.49% | 82.83% |
| EduBERT-BiLSTM-CRF | 85.32% | 85.72% | 85.52% |
| Learning Rate | F1 |
|---|---|
| 0.01 | 82.43% |
| 0.001 | 83.97% |
| 0.0001 | 85.61% |
| Dropout | F1 |
|---|---|
| 0.1 | 84.92% |
| 0.3 | 85.31% |
| 0.5 | 85.78% |
| 0.7 | 85.12% |
| 0.9 | 84.72% |
| Method | Acc | P | R | F1 |
|---|---|---|---|---|
| BiLSTM | 64.94% | 67.49% | 81.68% | 73.91% |
| CNN | 70.92% | 76.25% | 79.81% | 77.99% |
| PCNN | 73.80% | 76.33% | 81.45% | 78.80% |
| Lexicon + R-BERT | 75.26% | 76.38% | 84.85% | 80.39% |
| Dropout | F1 |
|---|---|
| 0.1 | 79.14% |
| 0.3 | 79.87% |
| 0.5 | 80.39% |
| 0.7 | 79.92% |
| 0.9 | 78.67% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, N.; Shen, Q.; Song, R.; Chi, Y.; Xu, H. MEduKG: A Deep-Learning-Based Approach for Multi-Modal Educational Knowledge Graph Construction. Information 2022, 13, 91. https://doi.org/10.3390/info13020091
Li N, Shen Q, Song R, Chi Y, Xu H. MEduKG: A Deep-Learning-Based Approach for Multi-Modal Educational Knowledge Graph Construction. Information. 2022; 13(2):91. https://doi.org/10.3390/info13020091
Chicago/Turabian StyleLi, Nan, Qiang Shen, Rui Song, Yang Chi, and Hao Xu. 2022. "MEduKG: A Deep-Learning-Based Approach for Multi-Modal Educational Knowledge Graph Construction" Information 13, no. 2: 91. https://doi.org/10.3390/info13020091
APA StyleLi, N., Shen, Q., Song, R., Chi, Y., & Xu, H. (2022). MEduKG: A Deep-Learning-Based Approach for Multi-Modal Educational Knowledge Graph Construction. Information, 13(2), 91. https://doi.org/10.3390/info13020091