
Translation Alignment with Ugarit


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (i)
- (ii)
- (iii)
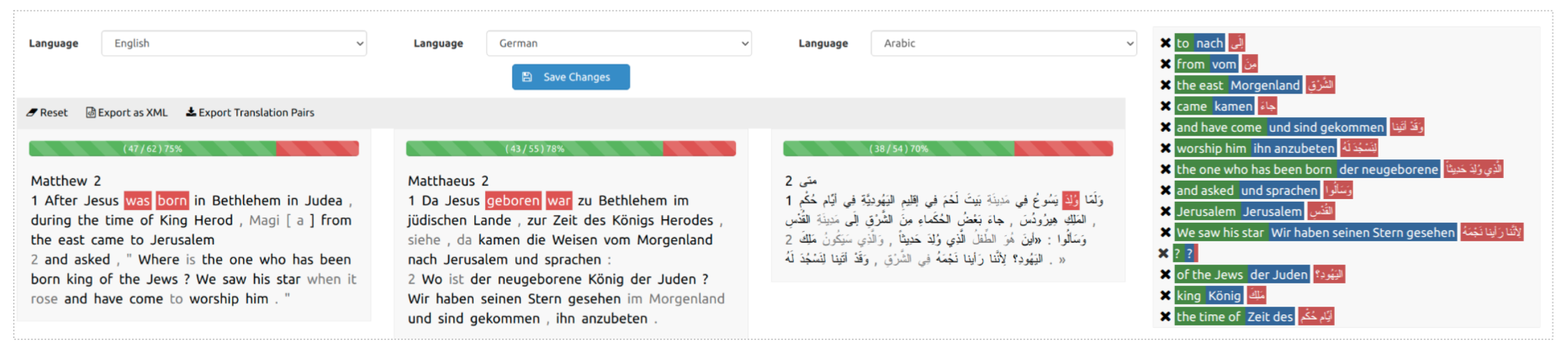
- The texts are placed side-by-side. Annotators can select the source words and their translation correspondents with mouse clicks.
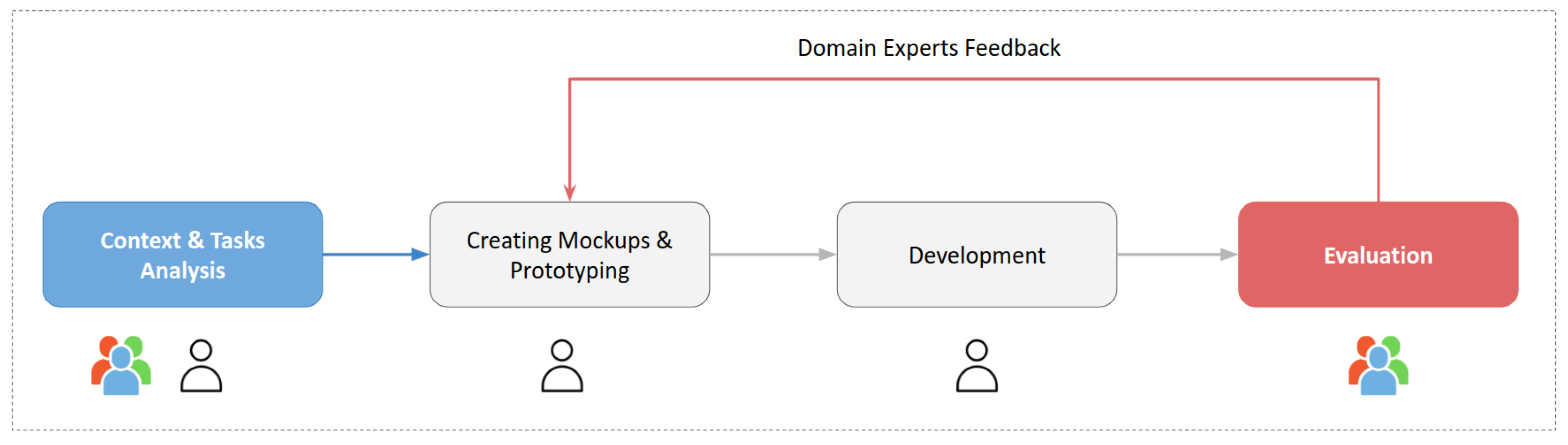
2. Development Process
3. Alignment Workflow
Alignment Guidelines
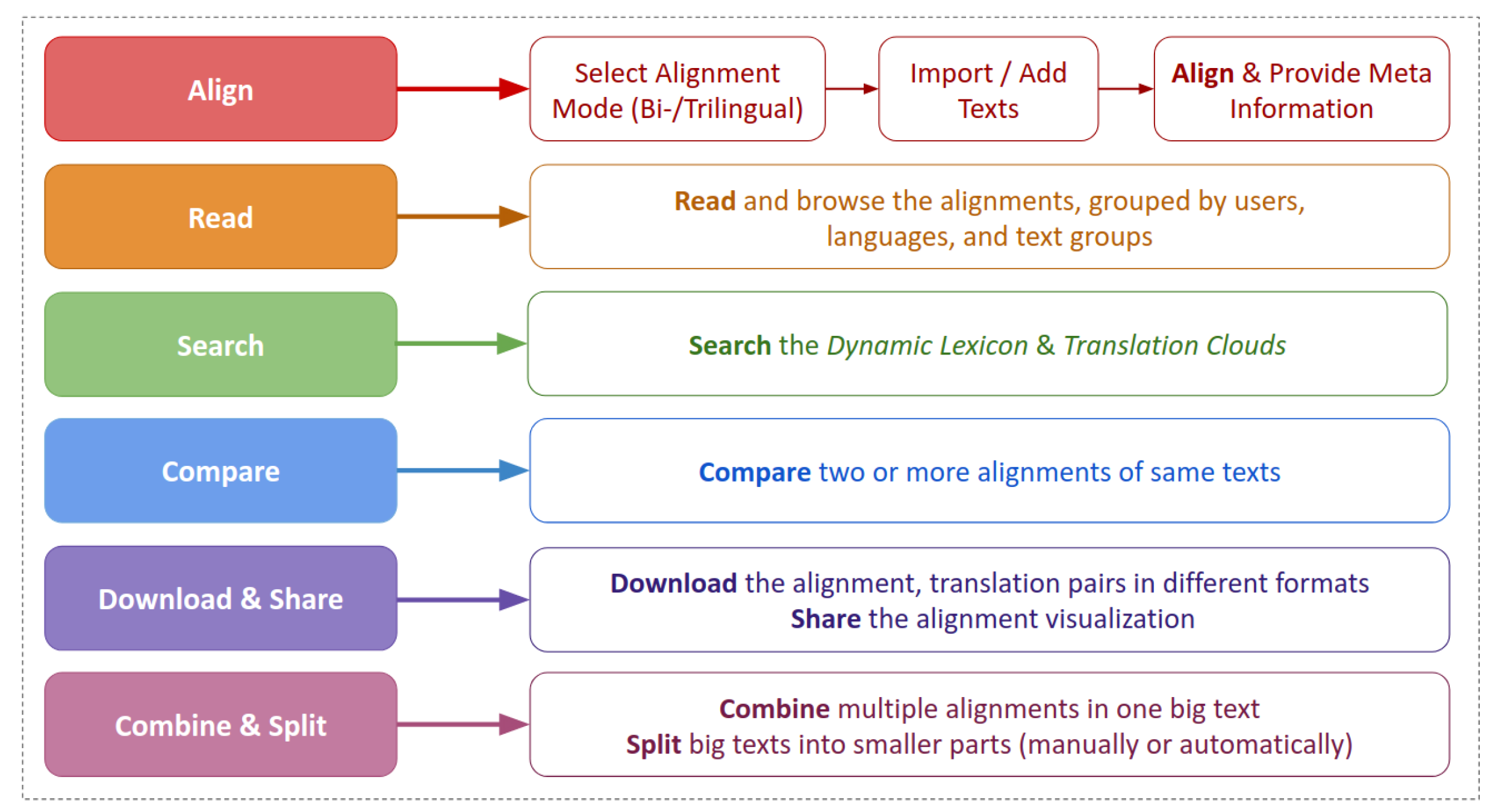
4. Visualization Techniques
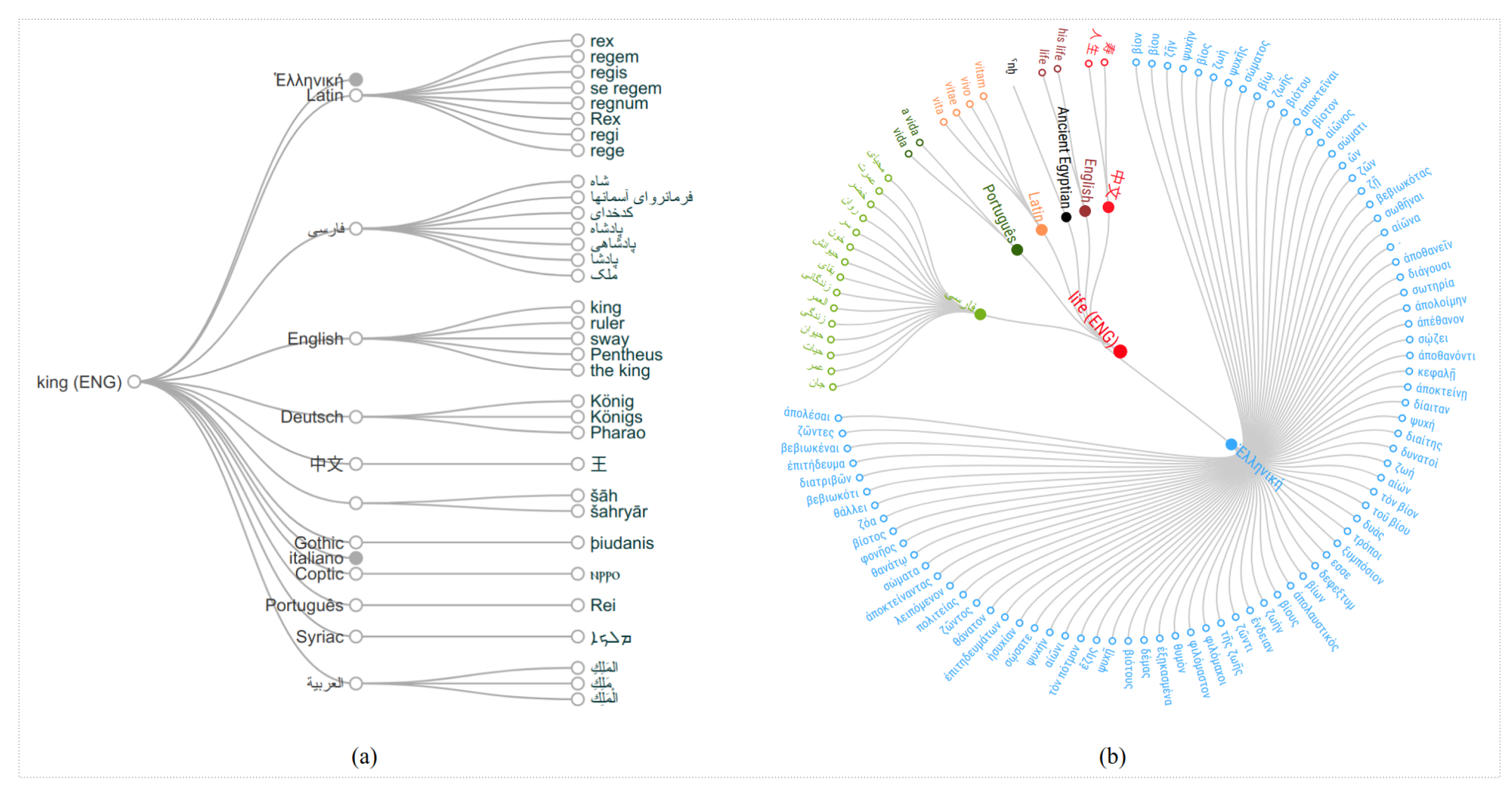
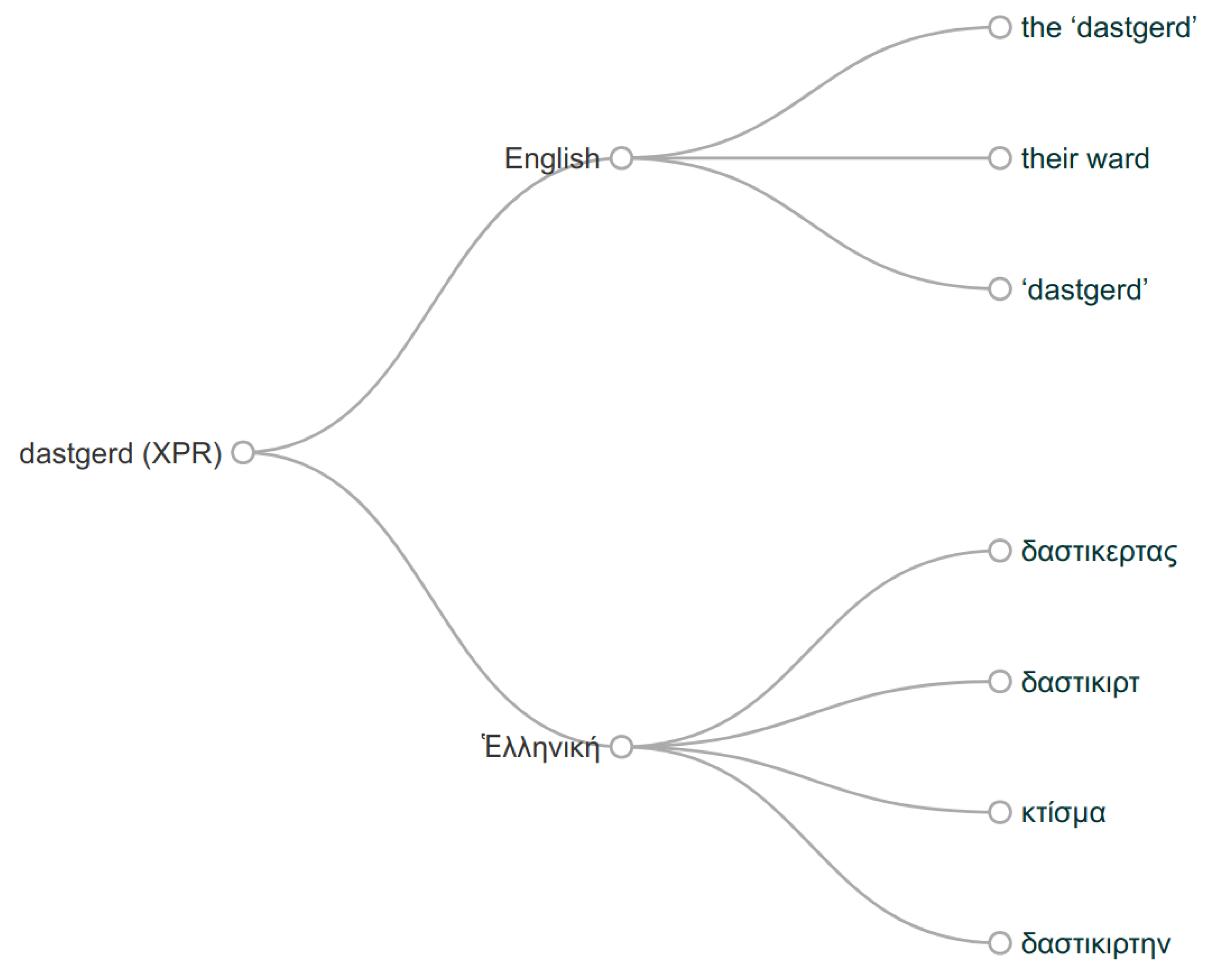
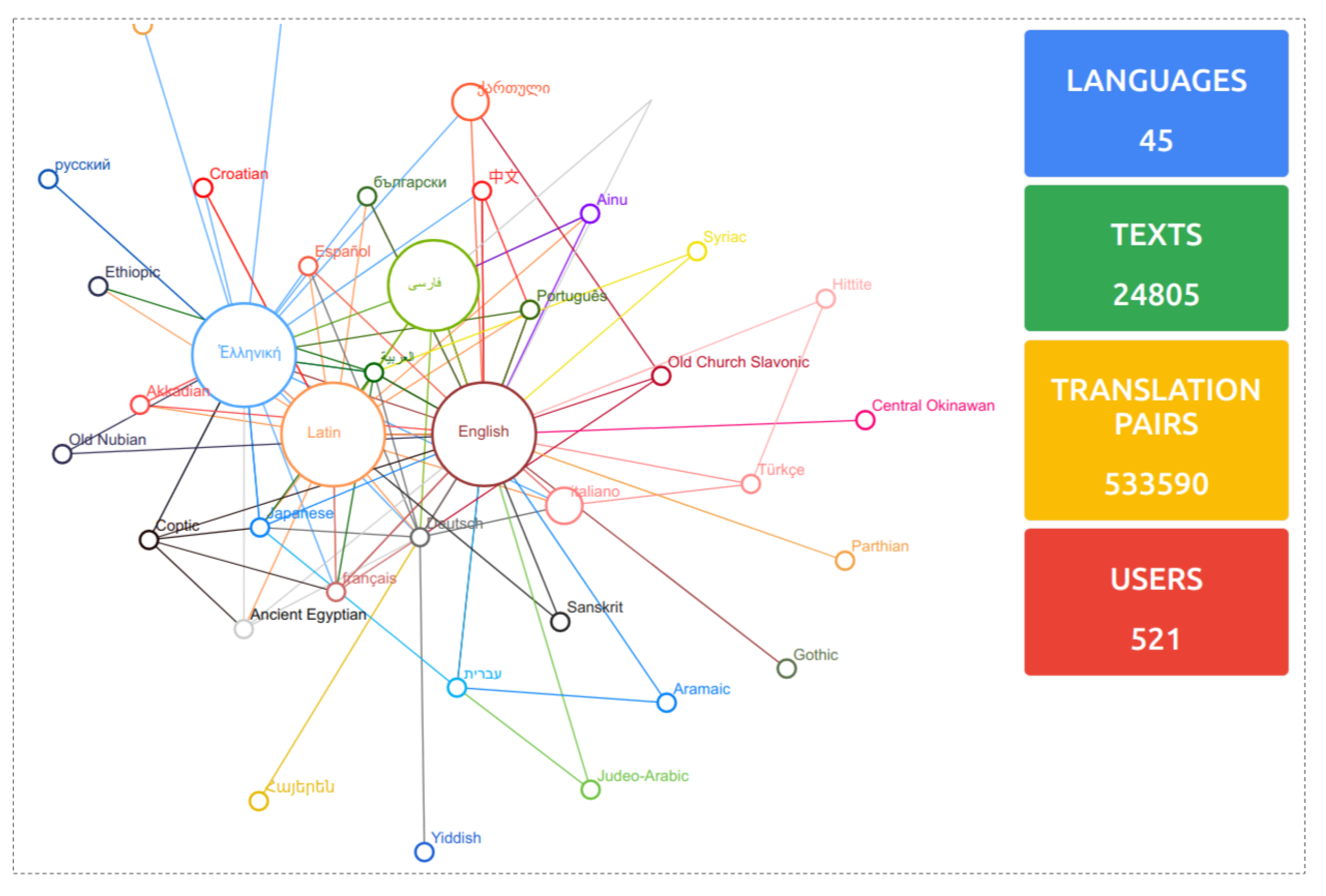
4.1. Languages Graph
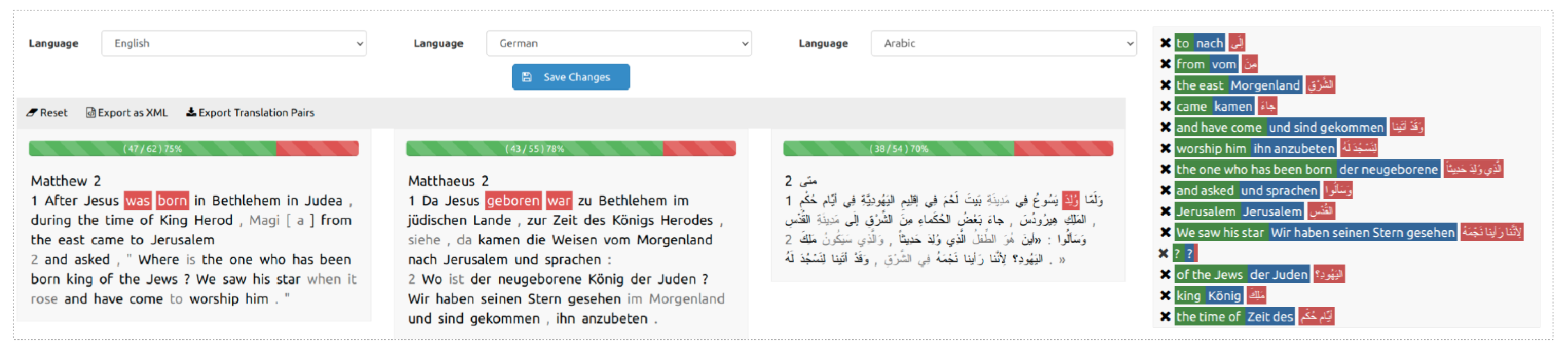
4.2. Aligned Texts
- -
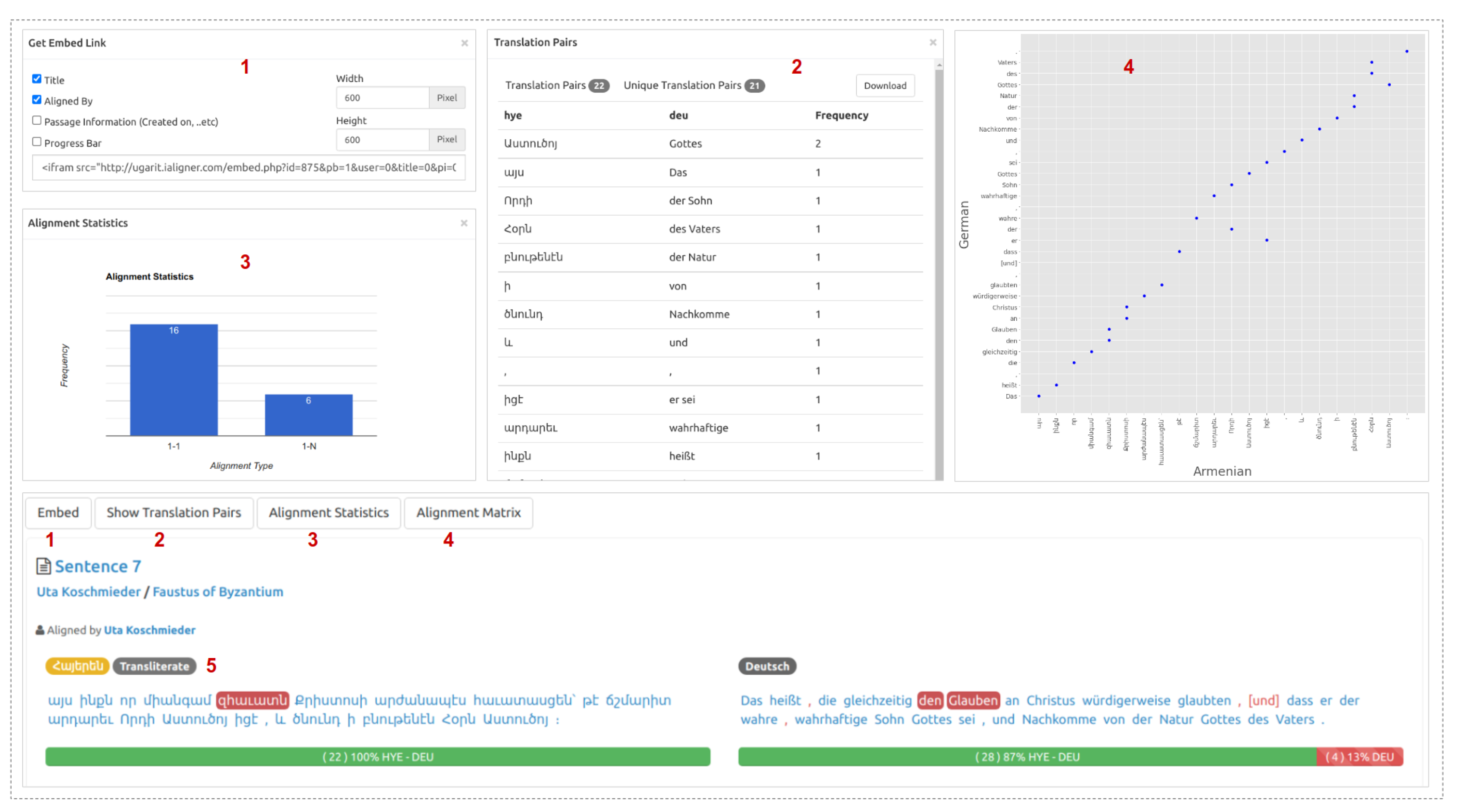
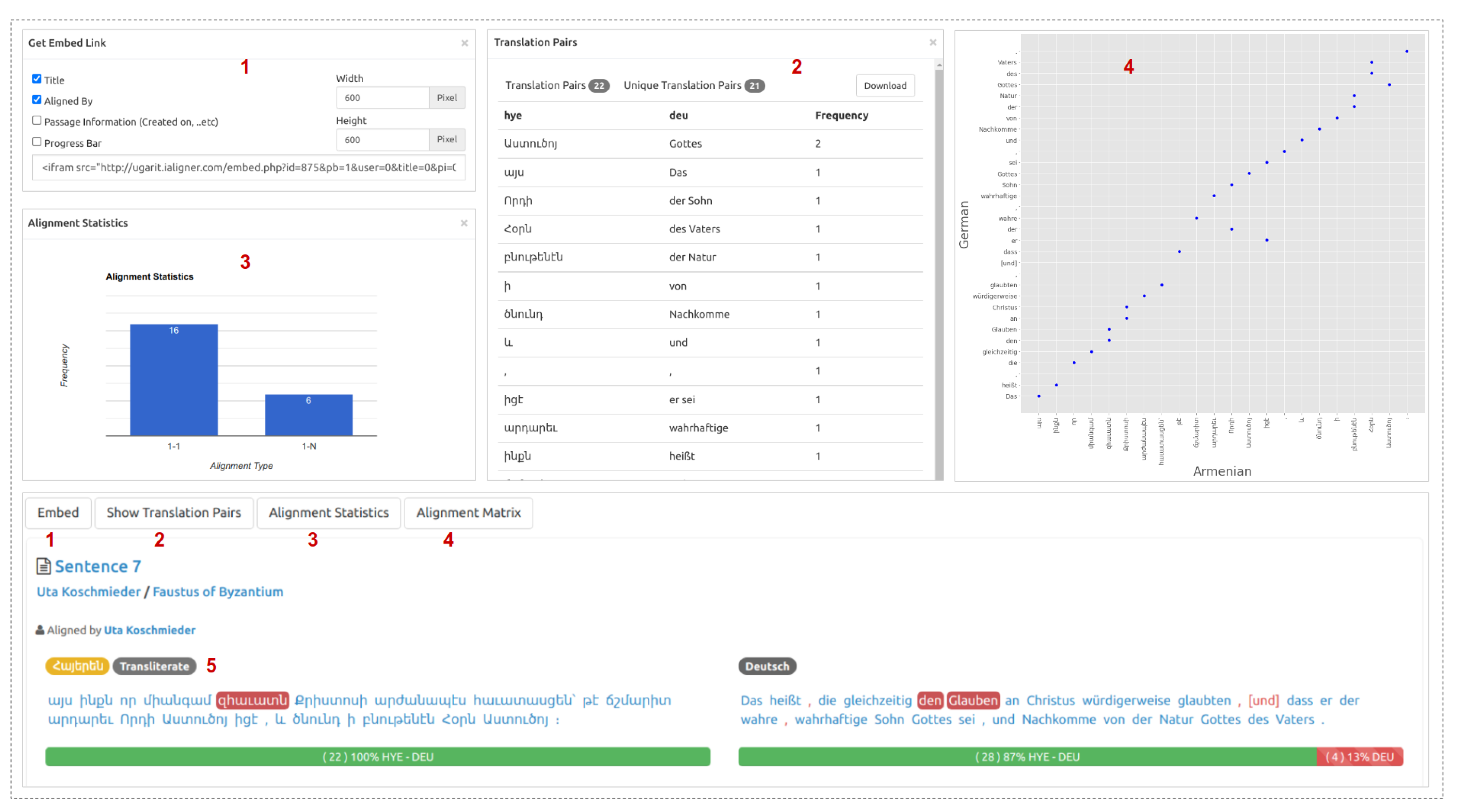
- Embed: This option allows users to generate a link that can be used to share and embed the visualization of their alignments on any blog or website. Furthermore, and users can select which components can be included in the embedded text (progress bar, title, annotator info, text info) (Figure 6(1)).
- -
- Translation Pairs: This option shows an aggregated list of the translation pairs extracted from the aligned text, users can download them in JSON format (Figure 6(2)).
- -
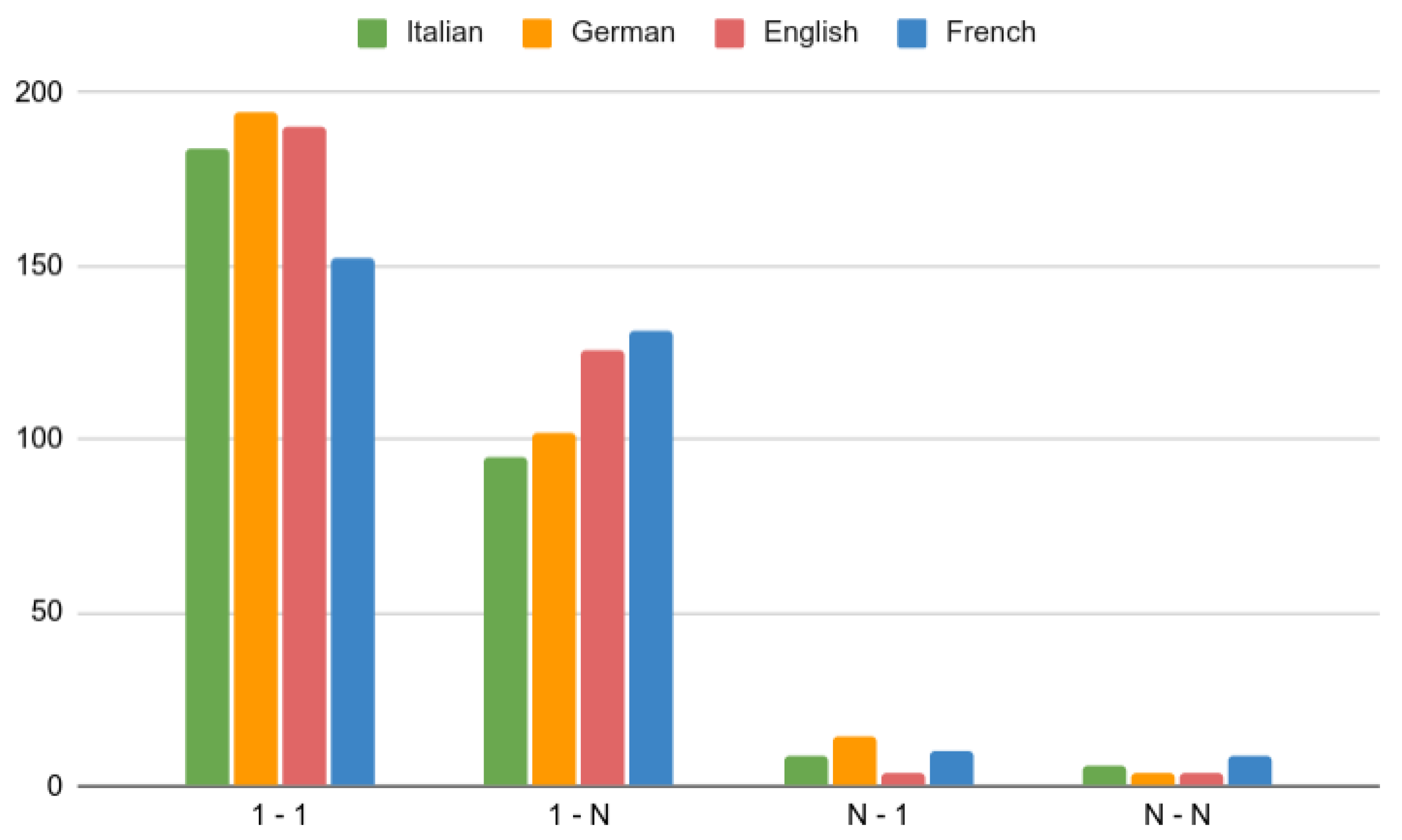
- Alignment Statistics: This option shows statistics of the different alignment categories. This chart provides valuable information on the alignment quality, user’s language knowledge, and the relation between the aligned languages (Figure 6(3)).
- -
- Alignment Matrix: with this option, users can view the alignment in the form of a grid: the source text tokens are located on the horizontal axis, and the translation tokens are located on the vertical axis. The blue dots represent alignment between the corresponding column and row tokens. The diagonal dots indicate one-to-one alignments, whereas the vertical ones indicate the one-to-many (Figure 6(4)).
- -
- Transliteration: Ugarit contains texts in various languages with different alphabets. For better readability, especially for new language learners, Ugarit offers an automatic transliteration for non-Latin alphabets languages, which is visible when the pointer hovers the aligned word. This feature is currently available for Greek, Arabic, Persian, Armenian, and Georgian (Figure 6(5)).
- -
- Combine/Split Aligned Texts: Ugarit enables users to merge multiple aligned texts into one bigger text. It also lets users split a long aligned text into smaller units (sentences/paragraphs). This feature is beneficial since annotators prefer to align long paragraphs over short ones to avoid copying and pasting them multiple times. On the other hand, splitting long aligned text is useful when users want to create shorter aligned units that can be used later to train or evaluate machine translation or translation alignments models.
4.3. Translation Pairs & the Dynamic Lexicon
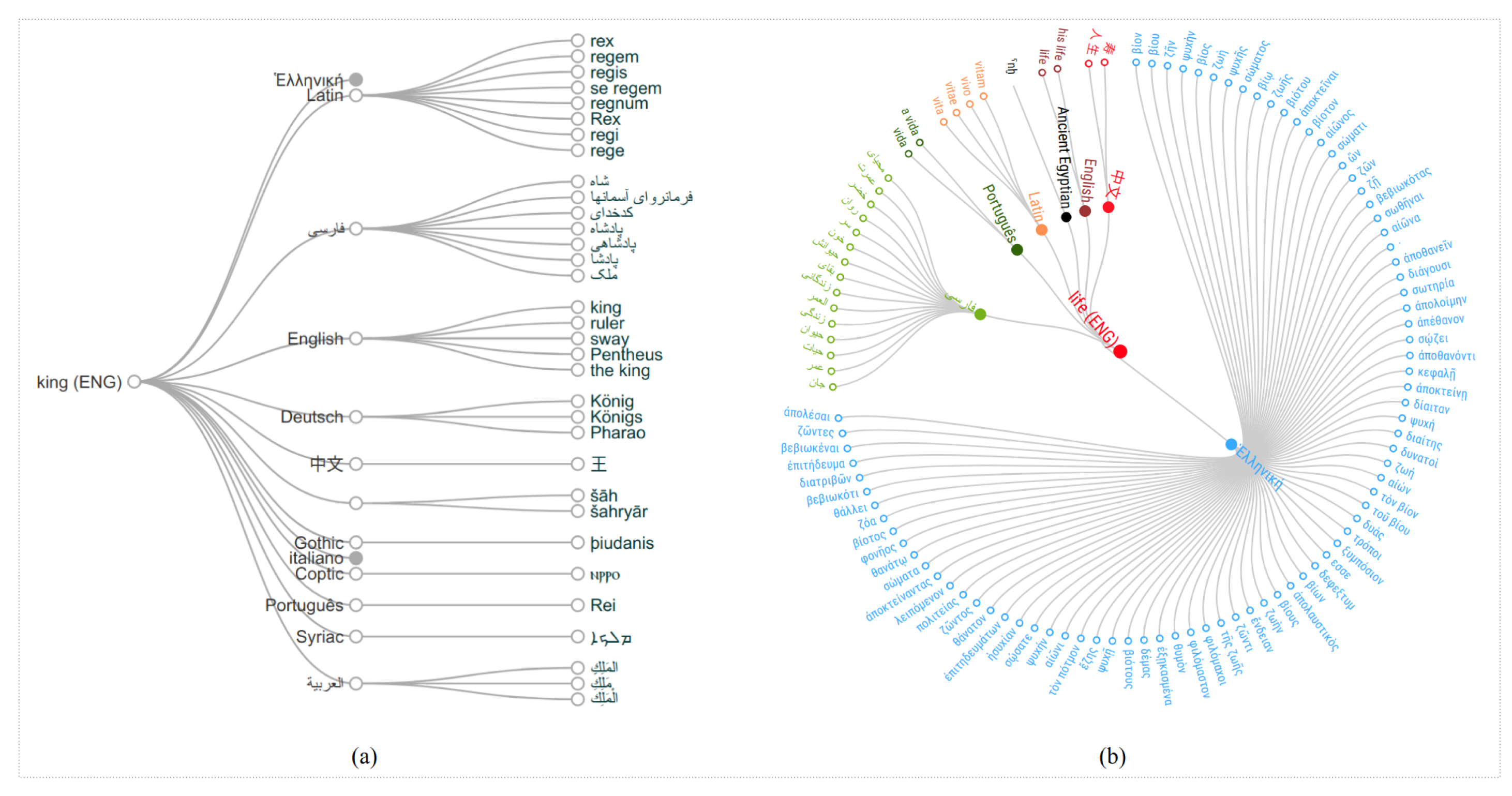
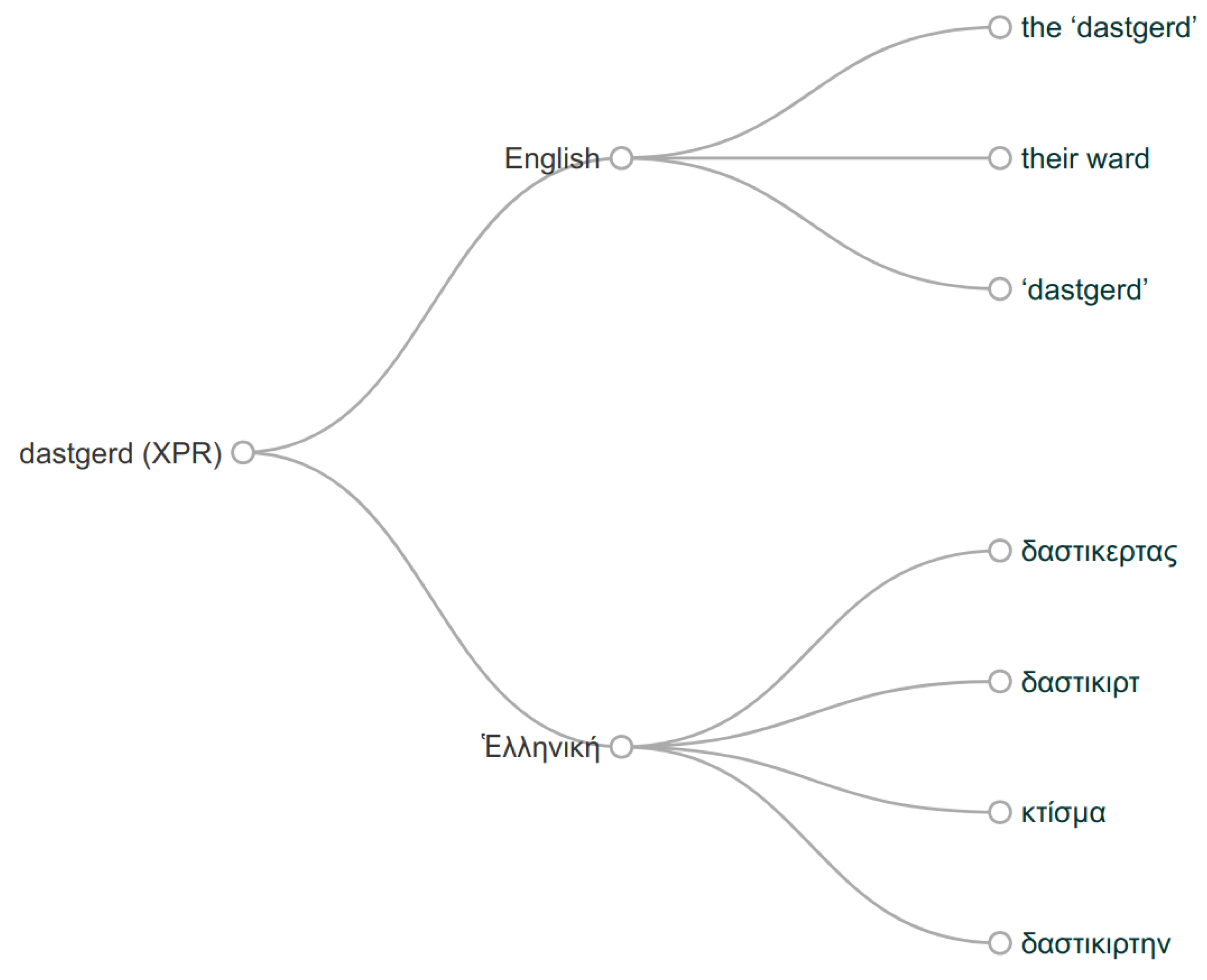
5. Translations Graph
Translation Clouds
6. Ugarit in Research and Pedagogy
7. Future Work
- -
- User roles: the next version of Ugarit will offer different user roles such as expert, instructor, student, which would help create accurate training data by considering the alignments created by experts and instructors, since they are supposed to produce correct and precise alignments. In contrast, students in the learning phase could make some alignment mistakes, and these mistakes should not affect the accuracy of the dynamic lexicon and training datasets;
- -
- Teaching: Further, experts and instructors will be able to create groups, add students to the groups, and create assignments. Instructors can upload these assignments in the form of plain parallel texts; students will be asked to align them with deadlines, with the possibility of uploading the correct alignment to allow the system to evaluate the assignments automatically and give notes to every student;
- -
- Alignments sharing and exporting: in the current version of Ugarit, users can export their results in XML format only. The next version will offer other formats such as JSON and CSV to facilitate the reuse of the alignment in other applications or for other purposes;
- -
- Automatic alignment: we are currently developing an automatic alignment system and planning to offer an automatic alignment option for texts in specific languages, such as Ancient Greek–English and Latin–English, or at least supporting the users with alignment suggestions to reduce the time required to align long texts;
- -
- Collaborative alignment: in the current version, users can only align their texts; however, the next version will provide an option for the collaborative alignment of long texts where multiple users can work on the same text.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kay, M.; Röscheisen, M. Text-Translation Alignment. Comput. Linguist. 1993, 19, 121–142. [Google Scholar]
- DeNero, J.; Klein, D. Tailoring word alignments to syntactic machine translation. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 25–27 June 2007; pp. 17–24. [Google Scholar]
- David, Y.; Grace, N.; Richard, W. Inducing multilingual text analysis tools via robust projection across aligned corpora. In Proceedings of the First International Conference on Human Language Technology Research, San Diego, CA, USA, 18–21 March 2001; pp. 1–8. [Google Scholar]
- Padó, S.; Lapata, M. Cross-lingual annotation projection for semantic roles. J. Artif. Intell. Res. 2009, 36, 307–340. [Google Scholar] [CrossRef]
- Durrani, N.; Koehn, P. Improving machine translation via triangulation and transliteration. In Proceedings of the 17th Annual Conference of the European Association for Machine Translation, Dubrovnik, Croatia, 16–18 June 2014; pp. 71–78. [Google Scholar]
- Wu, D.; Xia, X. Learning an English-Chinese lexicon from a parallel corpus. In Proceedings of the First Conference of the Association for Machine Translation in the Americas, Cuernavaca, Mexico, 10–14 October 1994. [Google Scholar]
- Yousef, T.; Berti, M. The digital fragmenta historicorum graecorum and the ancient greek-latin dynamic lexicon. In Corpus-Based Research in the Humanities (CRH); Institute of Computer Science: Warsaw, Poland, 2015; p. 117. [Google Scholar]
- Brown, P.F.; Cocke, J.; Della-Pietra, S.A.; Della-Pietra, V.J.; Jelinek, F.; Lafferty, J.D.; Mercer, R.L.; Rossin, P. A statistical approach to machine translation. Comput. Linguist. 1990, 16, 76–85. [Google Scholar]
- Gale, W.A.; Church, K.W. A program for aligning sentences in bilingual corpora. In Proceedings of the 29th Annual Meeting of the Association of Computational Linguistics (ACL), Berkeley, CA, USA, 18–21 June 1991. [Google Scholar]
- Moore, R.C. Fast and Accurate Sentence Alignment of Bilingual Corpora. In Machine Translation: From Research to Real Users, 5th Conference of the Association for Machine Translation in the Americas, AMTA 2002 Tiburon, CA, USA, 6–12 October 2002, Proceedings; Richardson, S.D., Ed.; Springer: Berlin, Heidelberg, 2002; Volume 2499. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Jalili Sabet, M.; Dufter, P.; Yvon, F.; Schütze, H. SimAlign: High Quality Word Alignments Without Parallel Training Data Using Static and Contextualized Embeddings. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Online, 2020; pp. 1627–1643. [Google Scholar] [CrossRef]
- Dou, Z.Y.; Neubig, G. Word Alignment by Fine-tuning Embeddings on Parallel Corpora. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume; Association for Computational Linguistics: Online, 19–23 April 2021; pp. 2112–2128. [Google Scholar]
- Bojar, O.; Prokopová, M. Czech-English Word Alignment. In Proceedings of the LREC, Genoa, Italy, 22–28 May 2006; pp. 1236–1239. [Google Scholar]
- Graça, J.; Pardal, J.P.; Coheur, L.; Caseiro, D. Building a Golden Collection of Parallel Multi-Language Word Alignment. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08); European Language Resources Association (ELRA): Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Mareček, D. Automatic Alignment of Tectogrammatical Trees from Czech-English Parallel Corpus. Master’s Thesis, Charles University, Prague, Czech Republic, 2008. [Google Scholar]
- De Pauw, G.; Wagacha, P.W.; de Schryver, G.M. The SAWA corpus: A parallel corpus English-Swahili. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, Workshop on ’Language Technologies for African Languages’; Association for Computational Linguistics: Athens, Greece, 30 March 2009; pp. 9–16. [Google Scholar]
- Holmqvist, M.; Ahrenberg, L. A Gold Standard for English-Swedish Word Alignment. In Proceedings of the 18th Nordic Conference of Computational Linguistics (NODALIDA 2011), Riga, Latvia, 11–13 May 2011; Northern European Association for Language Technology (NEALT): Riga, Latvia, 2011; pp. 106–113. [Google Scholar]
- Melamed, I.D. Manual Annotation of Translational Equivalence: The Blinker Project. arXiv 1998, arXiv:cmp-lg/9805005. [Google Scholar]
- Grimes, S.; Li, X.; Bies, A.; Kulick, S.; Ma, X.; Strassel, S. Creating Arabic-English Parallel Word-Aligned Treebank Corpora at LDC; European Language Resources Association (ELRA): Valletta, Malta, 2010. [Google Scholar]
- Benner, D. A Tool for a High-Carat Gold-Standard Word Alignment. In Proceedings of the 8thWorkshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (LaTeCH), Gothenburg, Sweden, 26 April 2014; pp. 80–85. [Google Scholar]
- Caseli, H.M.; Feltrim, V.D.; Nunes, M.G.V. TagAlign: Uma Ferramenta de Pré-Processamento de Textos; Série de Relatórios do NILC. NILC-TR-02-09 Junho; NILC: Berkeley, CA, USA, 2002. [Google Scholar]
- Germann, U. Yawat: Yet another word alignment tool. In Proceedings of the ACL-08: HLT Demo Session, Columbus, OH, USA, 10 January 2008; pp. 20–23. [Google Scholar]
- Almas, B.; Beaulieu, M.C. Developing a New Integrated Editing Platform for Source Documents in Classics. Lit. Linguist. Comput. 2013, 28, 493–503. [Google Scholar] [CrossRef]
- Gilmanov, T.; Scrivner, O.; Kübler, S. SWIFT Aligner, A Multifunctional Tool for Parallel Corpora: Visualization, Word Alignment, and (Morpho)-Syntactic Cross-Language Transfer. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2014; pp. 2913–2919. [Google Scholar]
- Barreiro, A.; Raposo, F.; Luís, T. CLUE-Aligner: An alignment tool to annotate pairs of paraphrastic and translation units. In Proceedings of the 10th Language Resources and Evaluation Conference (LREC), Portorož, Slovenia, 23–28 May 2016; pp. 7–13. [Google Scholar]
- Almas, B.; Berti, M. Perseids Collaborative Platform for Annotating Text Re-Uses of Fragmentary Authors. In Proceedings of the 1st International Workshop on Collaborative Annotations in Shared Environment: Metadata, Vocabularies and Techniques in the Digital Humanities, DH-CASE ’13, Florence, Italy, 10 September 2013; Association for Computing Machinery: Florence, Italy, 2013. [Google Scholar] [CrossRef]
- Callison-Burch, C.; Talbot, D.; Osborne, M. Statistical Machine Translation with Word- and Sentence-Aligned Parallel Corpora. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), Barcelona, Spain, 21–26 July 2014; pp. 175–182. [Google Scholar] [CrossRef]
- Yousef, T.; Janicke, S. A Survey of Text Alignment Visualization. IEEE Trans. Vis. Comput. Graph. 2021, 27, 1149–1159. [Google Scholar] [CrossRef] [PubMed]
- Jänicke, S.; Franzini, G.; Cheema, M.F.; Scheuermann, G. Visual text analysis in digital humanities. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2017; Volume 36, pp. 226–250. [Google Scholar]
- Bamman, D.; Crane, G. Measuring Historical Word Sense Variation. In Proceedings of the 11th Annual International ACM/IEEE Joint Conference on Digital Libraries; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1–10. [Google Scholar] [CrossRef] [Green Version]
- Palladino, C.; Foradi, M.; Yousef, T. Translation Alignment for Historical Language Learning: A Case Study. Digit. Humanit. Q. 2021, 15. Available online: https://www.proquest.com/openview/e048d32e8e991c67282c3fbda5c1f0d4/1?pq-origsite=gscholar=5124193 (accessed on 4 November 2021).
- Neves, M.; Leser, U. A survey on annotation tools for the biomedical literature. Brief. Bioinform. 2014, 15, 327–340. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ide, N. Introduction: The Handbook of Linguistic Annotation. In Handbook of Linguistic Annotation; Ide, N., Pustejovsky, J., Eds.; Springer: Dordrecht, The Netherlands, 2017; pp. 1–18. [Google Scholar] [CrossRef]
- Finlayson, M.A.; Erjavec, T. Overview of annotation creation: Processes and tools. In Handbook of Linguistic Annotation; Springer: Berlin/Heidelberg, Germany, 2017; pp. 167–191. [Google Scholar]
- Burghardt, M. Usability Recommendations for Annotation Tools. In Proceedings of the Sixth Linguistic Annotation Workshop; Association for Computational Linguistics: Jeju, Korea, 12–13 July 2012; pp. 104–112. [Google Scholar]
- Burghardt, M. Engineering Annotation Usability—Toward Usability Patterns for Linguistic Annotation Tools. Ph.D. Thesis, University of Regensburg, Regensburg, Germany, 2014. [Google Scholar]
- Petrillo, M.; Baycroft, J. Introduction to Manual Annotation; Fairview Research: Haven, CT, USA, 2010. [Google Scholar]
- Babeu, A. The Perseus Catalog: Of FRBR, Finding Aids, Linked Data, and Open Greek and Latin; Berti, M., Ed.; Digital Classical Philology: Ancient Greek and Latin in the Digital Revolution; De Gruyter Saur: Berlin, Germany; Boston, MA, USA, 2019; pp. 53–72. [Google Scholar] [CrossRef]
- Li, J.J.; Kim, D.I.; Lee, J.H. Annotation Guidelines for Chinese-Korean Word Alignment. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08); European Language Resources Association (ELRA): Marrakech, Morocco, 26 May 2008. [Google Scholar]
- Kholidy, H.A.; Chatterjee, N. Towards developing an Arabic word alignment annotation tool with some Arabic alignment guidelines. In Proceedings of the 2010 10th International Conference on Intelligent Systems Design and Applications, Cairo, Egypt, 29 November–1 December 2010; pp. 778–783. [Google Scholar] [CrossRef]
- Ács, J. Pivot-based multilingual dictionary building using Wiktionary. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14); European Language Resources Association (ELRA): Reykjavik, Iceland, 26–31 May 2014; pp. 1938–1942. [Google Scholar]
- Database, N.G. Graph Modeling Guidelines. 2019. Available online: http://neo4j.com/developer/guide-data-modeling (accessed on 2 November 2019).
- Palladino, C. Reading Texts in Digital Environments: Applications of Translation Alignment for Classical Language Learning. J. Interact. Technol. Pedagog. 2020, 18, 724–731. [Google Scholar]
- Palladino, C.; Yousef, T. We Want to Learn All Languages! Digital Classicist Seminar London. 2021. Available online: https://www.youtube.com/watch?v=R2Ms6yAMZss (accessed on 27 October 2021).
- Shamsian, F. Digital Classics and Learning Greek in Iran, Sunoikisis Digital Classics. Thursday, 14 May 2020. Available online: https://www.youtube.com/watch?v=ernL2sRGJ-U (accessed on 27 October 2021).
- The Digital Rosetta Stone Project. 2019. Available online: https://rosetta-stone.dh.uni-leipzig.de/ (accessed on 2 November 2019).
- Shukhoshvili, M. Methodology of Translation Alignment of Georgian Text of Plato’s “Theaetetus”. Int. J. Lang. Linguist. 2017, 4, 63–69. [Google Scholar]
- Foradi, M.; Palladino, C.; Shamsian, F. Confronting Complexity of Babel in a Global and Digital Age. In DH2019: Digital Humanities Conference, Book of Abstracts; Utrecht University: Utrecht, The Netherlands, 2019; pp. 127–138. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yousef, T.; Palladino, C.; Shamsian, F.; Foradi, M. Translation Alignment with Ugarit. Information 2022, 13, 65. https://doi.org/10.3390/info13020065
Yousef T, Palladino C, Shamsian F, Foradi M. Translation Alignment with Ugarit. Information. 2022; 13(2):65. https://doi.org/10.3390/info13020065
Chicago/Turabian StyleYousef, Tariq, Chiara Palladino, Farnoosh Shamsian, and Maryam Foradi. 2022. "Translation Alignment with Ugarit" Information 13, no. 2: 65. https://doi.org/10.3390/info13020065
APA StyleYousef, T., Palladino, C., Shamsian, F., & Foradi, M. (2022). Translation Alignment with Ugarit. Information, 13(2), 65. https://doi.org/10.3390/info13020065