
Performance Study on Extractive Text Summarization Using BERT Models



Abstract
:1. Introduction
1.1. Data Pre-Processing Phase
- (1)
- Removal of noise data found in the document;
- (2)
- Sentence and word tokenization;
- (3)
- Removal of punctuation marks;
- (4)
- Removal of stop words to remove frequently occurring words, such as (a), (an), (the), etc.;
- (5)
- Word stemming, which is the removal of suffixes and prefixes;
- (6)
- Word lemmatization, which is the transformation of a word to its base structure, such as transforming the word “playing” to “play”;
- (7)
- Part-of-speech tagging.
1.2. Algorithmic Processing Phase
1.3. Post-Processing Phase
2. Literature Review
2.1. Summarization Approaches
- Sentence Content Relevance Metric;
- Sentence Novelty Metric;
- Sentence Position Relevance Metric.
2.2. ROUGE Evaluation Algorithm
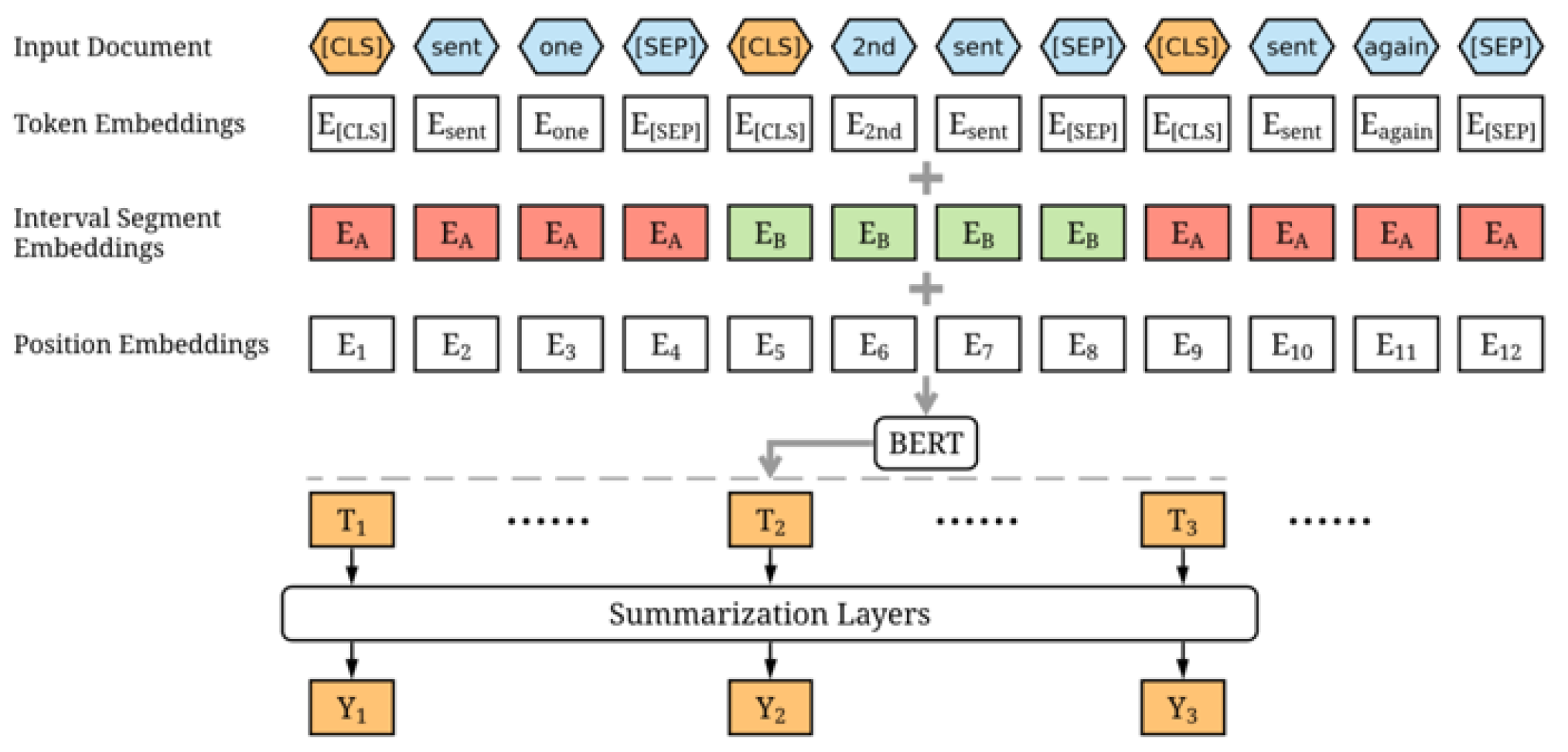
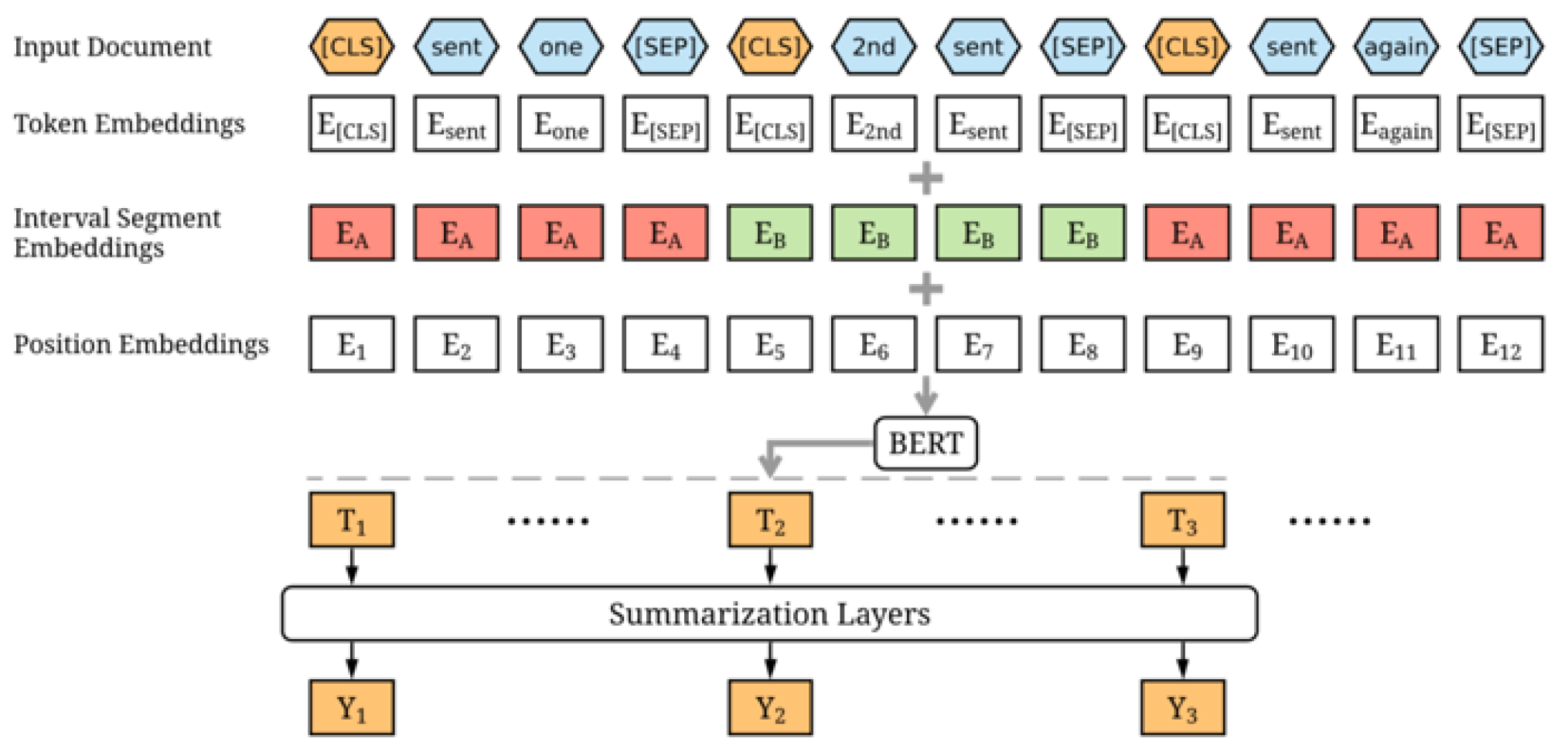
3. Methodology
3.1. Experiment: Exploring DistilBERT Model
- The token-type embeddings and the pooler are moved;
- The number of layers is reduced by a factor of 2.
3.2. Experiment: Exploring SqueezeBERT Model
4. Experiments & Results
4.1. Training Fine-Tuned DistilBERT Summarizer
4.2. Training Fine-Tuned SqueezeBERT Summarizer
5. Conclusions
5.1. Experiment Conclusions
5.2. Contribution
5.3. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2016, 47, 1–66. [Google Scholar] [CrossRef]
- Nallapati, R.; Zhai, F.; Zhou, B. Summarunner: A Recurrent Neural Network-Based Sequence Model for Extractive Summarization of Documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3075–3081. [Google Scholar]
- Hovy, E.; Lin, C.Y. Automated Text Summarization in SUMMARIST; MIT Press: Cambridge, MA, USA, 1999; pp. 81–94. [Google Scholar]
- Luhn, H.P. The Automatic Creation of Literature Abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef] [Green Version]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the Empirical Methods on Natural Language Processing, Barcelona, Spain, 1 July 2004; pp. 404–411. [Google Scholar]
- Erkan, G.; Radev, D.R. LexRank: Graph-based Lexical Centrality as Salience in Text Summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Steinberger, J.; Jezek, K. Using Latent Semantic Analysis in Text Summarization and Summary Evaluation. In Proceedings of the 7th International Conference on Information System Implementation and Modeling, New York, NY, USA, 23–24 April 2004; pp. 93–100. [Google Scholar]
- Nenkova, A.; Vanderwende, L. The Impact of Frequency on Summarization. In Technical Report, Microsoft Research (MSR-TR-2005-101); Columbia University: New York, NY, USA, 2005. [Google Scholar]
- Cheng, J.; Lapata, M. Neural Summarization by Extracting Sentences and Words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. EdgeSumm: Graph-based framework for automatic text summarization. Inf. Process. Manag. 2020, 57, 102264. [Google Scholar] [CrossRef]
- Lin, C.Y. Rouge: A Package for Automatic Evaluation Of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out (WAS 2004), Barcelona, Spain, 25–26 July 2004; pp. 25–26. [Google Scholar]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. arXiv 2019, arXiv:1908.08345. [Google Scholar]
- Zhong, M.; Liu, P.; Chen, Y.; Wang, D.; Qiu, X.; Huang, X. Extractive Summarization as Text Matching. ACL Anthology. 2020. Available online: https://www.aclweb.org/anthology/2020.acl-main.552/ (accessed on 9 August 2021).
- Joshi, A.; Fidalgo, E.; Alegre, E.; Fernández-Robles, L. SummCoder: An unsupervised framework for extractive text summarization based on deep auto-encoders. Expert Syst. Appl. 2019, 129, 200–215. [Google Scholar] [CrossRef]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient knowledge distillation for bert model compression. arXiv 2019, arXiv:1908.09355. [Google Scholar]
- Iandola, F.N.; Shaw, A.E.; Krishna, R.; Keutzer, K.W. SqueezeBERT: What Can Computer Vision Teach NLP about Efficient Neural Networks? arXiv 2020, arXiv:2006.11316. [Google Scholar]
- VSanh, i.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2020, arXiv:1910.0110v4. Available online: https://arxiv.org/pdf/1910.01108v4.pdf (accessed on 12 July 2021).
- Dong, Y.; Shen, Y.; Crawford, E.; van Hoof, H.; Cheung, J.C.K. Banditsum: Extractive summarization as a contextual bandit. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Bucila, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Philadelphia, PA, USA, 20–23 August 2006. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UH, USA, 18–22 June 2018. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: Alexnet-level accuracy with 50× fewer parameters and <0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-Art Natural Language Processing. arXiv.org. 2020. Available online: https://arxiv.org/abs/1910.03771 (accessed on 6 November 2021).
- Zafrir, O.; Boudoukh, G.; Izsak, P.; Wasserblat, M. Q8BERT: Quantized 8bit bert. arXiv 2019, arXiv:1910.06188. [Google Scholar]
- Sanh, V.; Wolf, T.; Rush, A.M. Movement pruning: Adaptive sparsity by fine-tuning. arXiv 2020, arXiv:2005.07683. [Google Scholar]

{kind=link}
| DistilBERT Summarizer | Average R Average P Average F | ||
|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | |
| Model at 10,000 | 0.54046 | 0.24811 | 0.49321 |
| 0.37102 | 0.17079 | 0.33920 | |
| 0.42535 | 0.19527 | 0.38856 | |
| Model at 20,000 | 0.52756 | 0.24105 | 0.48198 |
| 0.37355 | 0.17152 | 0.34193 | |
| 0.42238 | 0.19324 | 0.38631 | |
| Model at 30,000 | 0.50242 | 0.22208 | 0.45819 |
| 0.36837 | 0.16356 | 0.33656 | |
| 0.41015 | 0.18153 | 0.37443 | |
| BERT Models | ROUGE Scores | Params | ||
|---|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | ||
| BERT-base | 43.23 | 20.24 | 39.63 | 120.5 M |
| DistilBERT | 42.54 | 19.53 | 38.86 | 77.4 M |
| SqueezeBERT Summarizer | Average R Average P Average F | ||
|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | |
| Model at 10,000 | 0.52760 | 0.24278 | 0.48227 |
| 0.37796 | 0.17427 | 0.34612 | |
| 0.42538 | 0.19563 | 0.38922 | |
| Model at 20,000 | 0.50638 | 0.22715 | 0.46294 |
| 0.37708 | 0.16975 | 0.34537 | |
| 0.41699 | 0.18717 | 0.38162 | |
| Model at 30,000 | 0.48312 | 0.20655 | 0.43988 |
| 0.36130 | 0.15517 | 0.32963 | |
| 0.39832 | 0.17044 | 0.36306 | |
| BERT Models | ROUGE Scores | Params | ||
|---|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | ||
| BERT-base | 43.23 | 20.24 | 39.63 | 120.5 M |
| SqueezeBERT | 42.54 | 19.56 | 38.92 | 62.13 M |
| BERT Models | ROUGE Scores | Params | ||
|---|---|---|---|---|
| ROUGE-1 | ROUGE-2 | ROUGE-L | ||
| BERT-base | 43.23 | 20.24 | 39.63 | 120.5 M |
| DistilBERT | 42.54 | 19.53 | 38.86 | 77.4 M |
| SqueezeBERT | 42.54 | 19.56 | 38.92 | 62.13 M |
| Performance Retention % ROUGE-1 | Performance Retention % ROUGE-2 | Performance Retention % ROUGE-L | Parameters Reduction % | |
|---|---|---|---|---|
| DistilBERT | 98.4 | 96.49 | 98.05 | 35.77 |
| SqueezeBERT | 98.4 | 96.64 | 98.2 | 48.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdel-Salam, S.; Rafea, A. Performance Study on Extractive Text Summarization Using BERT Models. Information 2022, 13, 67. https://doi.org/10.3390/info13020067
Abdel-Salam S, Rafea A. Performance Study on Extractive Text Summarization Using BERT Models. Information. 2022; 13(2):67. https://doi.org/10.3390/info13020067
Chicago/Turabian StyleAbdel-Salam, Shehab, and Ahmed Rafea. 2022. "Performance Study on Extractive Text Summarization Using BERT Models" Information 13, no. 2: 67. https://doi.org/10.3390/info13020067
APA StyleAbdel-Salam, S., & Rafea, A. (2022). Performance Study on Extractive Text Summarization Using BERT Models. Information, 13(2), 67. https://doi.org/10.3390/info13020067