
HEVC Based Frame Interleaved Coding Technique for Stereo and Multi-View Videos




Abstract
1. Introduction
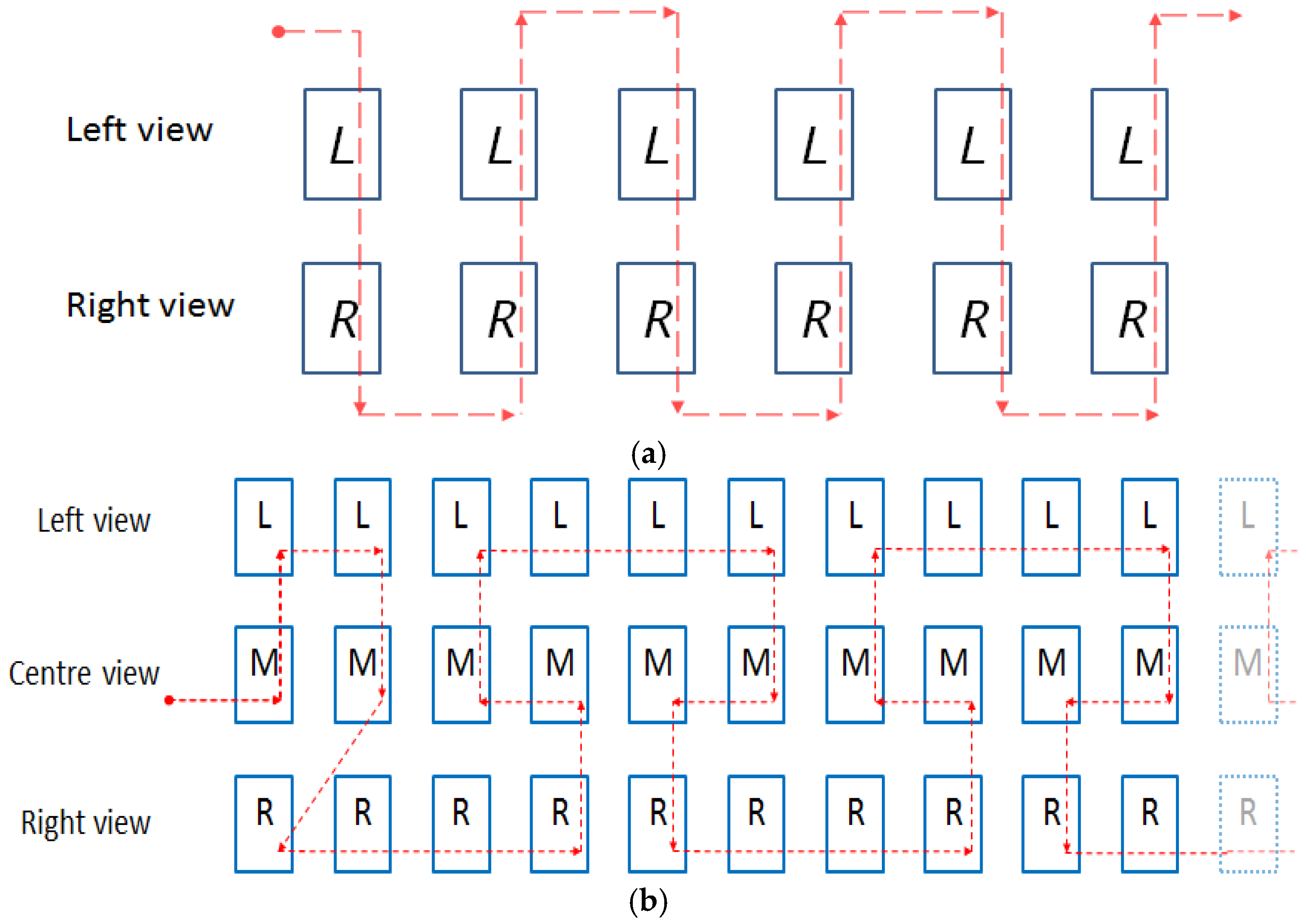
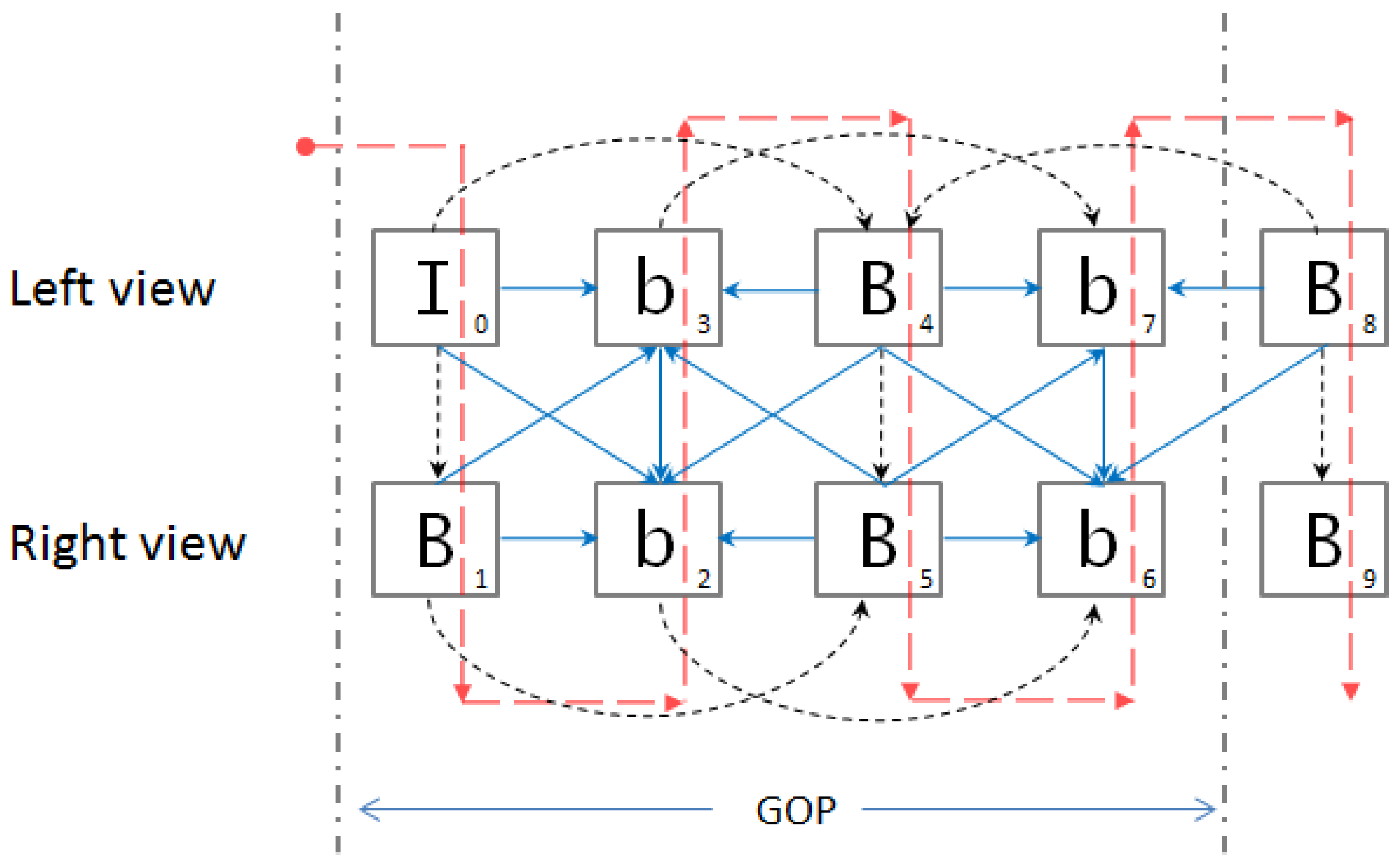
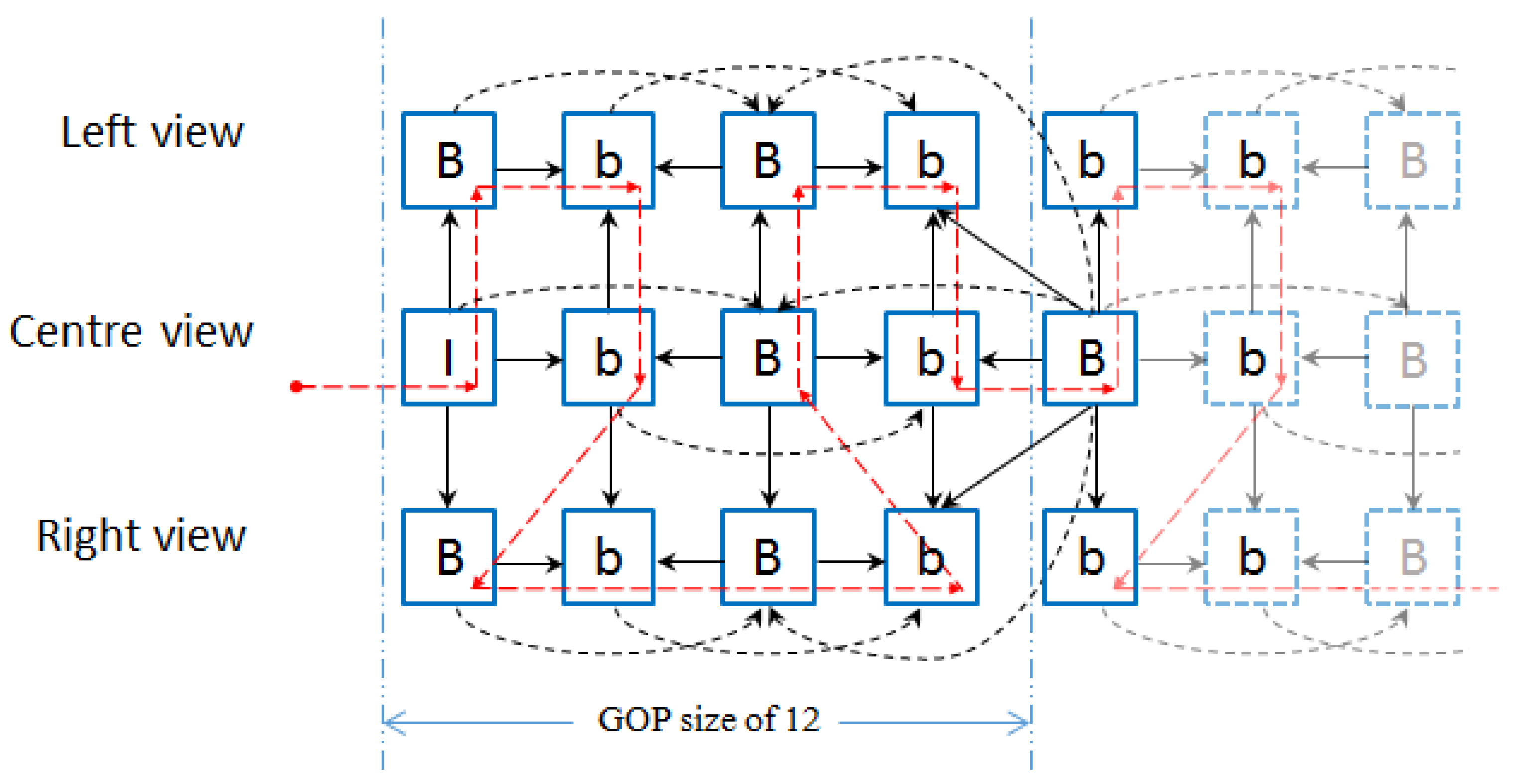
2. HEVC Based Frame Interleaved Stereo and Multiview Video Coding Technique
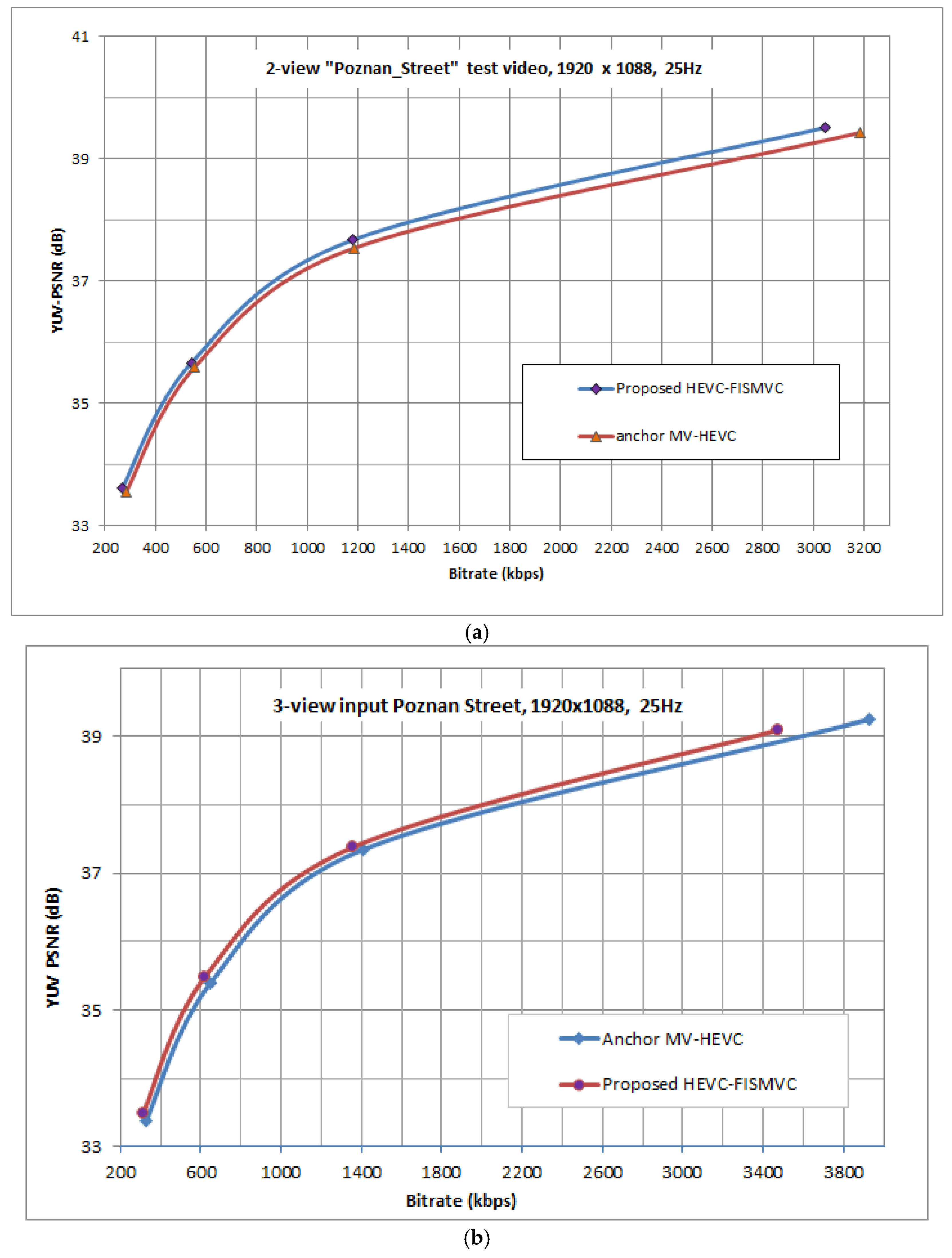
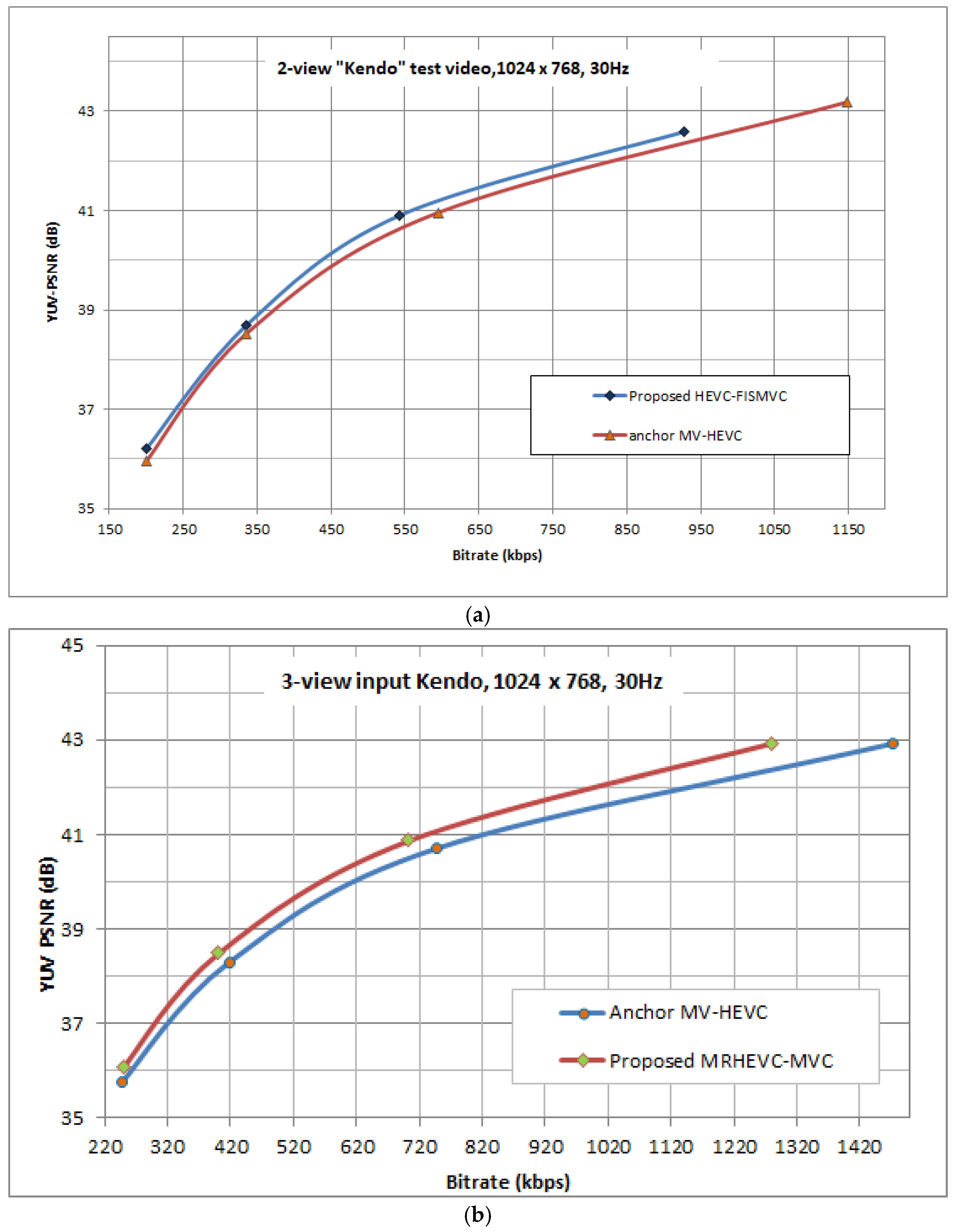
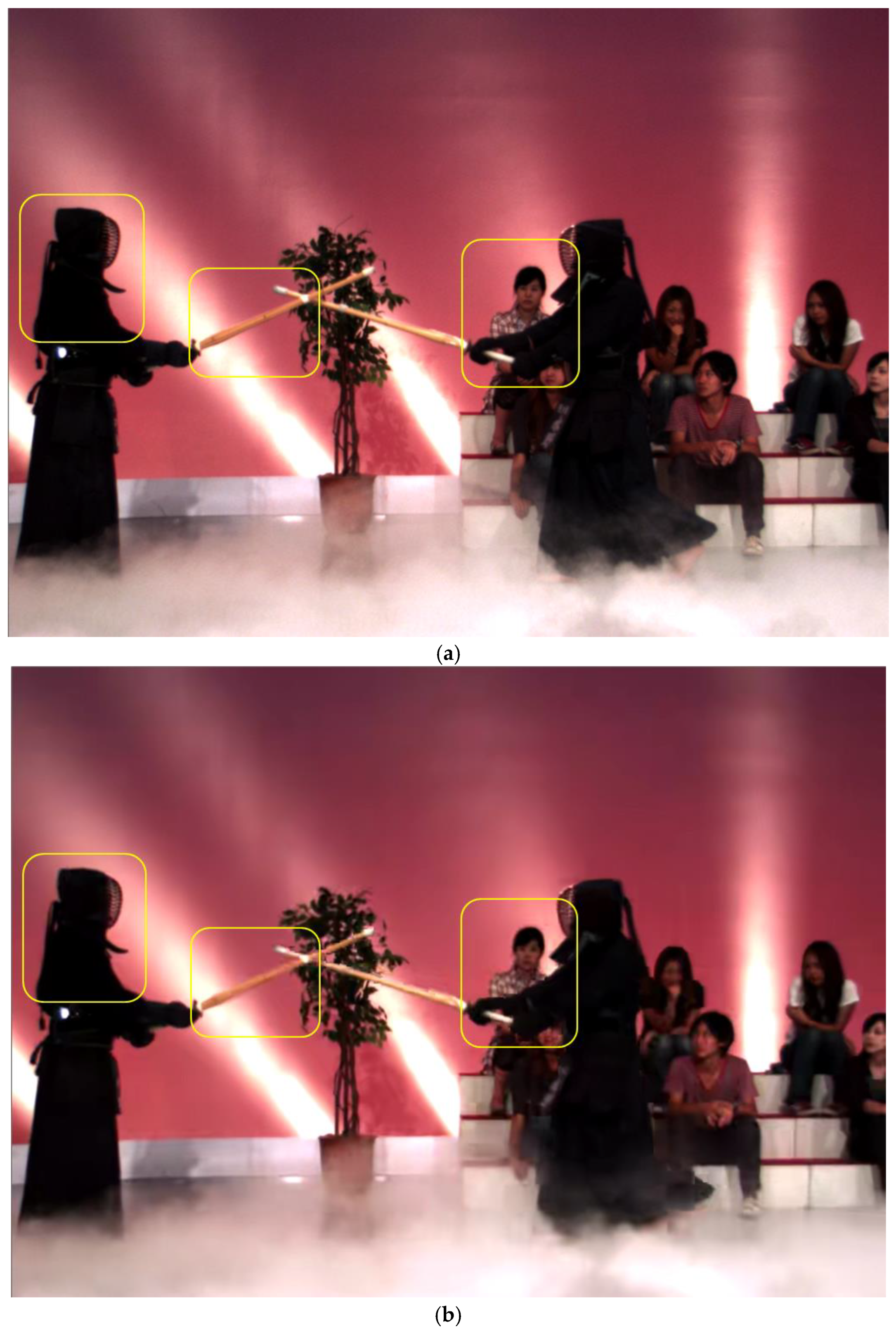
3. Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, Y.; Wang, Y.K.; Ugur, K.; Hannuksela, M.M.; Lainema, J.; Gabbouj, M. The emerging MVC standard for 3D video services. EURASIP J. Adv. Signal Process. 2008, 2009, 1–13. [Google Scholar] [CrossRef]
- Urey, H.; Chellappan, K.V.; Erden, E.; Surman, P. State of the Art in Stereoscopic and Autostereoscopic Displays. Proc. IEEE 2011, 99, 540–555. [Google Scholar] [CrossRef]
- Merkle, P.; Müller, K.; Wiegand, T. 3D video: Acquisition, coding, and display. IEEE Trans. Consum. Electron. 2010, 56, 946–950. [Google Scholar] [CrossRef]
- Perkins, M.G. Data compression of stereopairs. IEEE Trans. Commun. 1992, 40, 684–696. [Google Scholar] [CrossRef]
- Vetro, A.; Wiegand, T.; Sullivan, G.J. Overview of the stereo and multiview video coding extensions of the H. 264/MPEG-4 AVC standard. Proc. IEEE 2011, 99, 626–642. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- Information Technology-Coding of Audio-Visual Objects-Part 10: Advanced Video Coding, Amendment 1: Constrained Baseline Profile, Stereo High Profile and Frame Packing Arrangement SEI Message, Document N10707, ISO/IEC JTC 1/SC 29/WG 11 (MPEG). 2007. Available online: https://www.iso.org/standard/75400.html (accessed on 15 July 2020).
- “High Efficiency Video Coding,” ITU-T Recommendation H.265 and ISO/IEC 23008-2, April 2013 (and subsequent editions). Available online: https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-H.265-201304-S!!PDF-E&type=items (accessed on 15 July 2020).
- Hurst, W.; Withington, A.; Kolivand, H. Virtual conference design: Features and obstacles. Multimed. Tools Appl. 2022, 81, 16901–16919. [Google Scholar] [CrossRef] [PubMed]
- Tang, D.; Zhang, L. Audio and Video Mixing Method to Enhance WebRTC. IEEE Access 2020, 8, 67228–67241. [Google Scholar] [CrossRef]
- Gandam, A.; Sidhu, J.-S. Fuzzy Based Adaptive Deblocking Filters at Low-Bitrate HEVC Videos for Communication Networks. J. Comput. Mater. Contin. 2021, 66, 3045–3063. [Google Scholar] [CrossRef]
- Malekzadeh, M. Perceptual service-level QoE and network-level QoS control model for mobile video transmission. Telecommun. Syst. 2021, 77, 523–541. [Google Scholar] [CrossRef]
- Luo, Y.; Song, L.; Xie, R.; Luo, C. View-Dependent Omnidirectional Video Encapsulation Using Multiple Tracks. In Proceedings of the 2017 International Conference on Virtual Reality and Visualization (ICVRV), Zhengzhou, China, 21–22 October 2017; pp. 421–422. [Google Scholar]
- Lee, J.; Kim, S.-H.; Jeong, S.Y.; Choi, J.S.; Kang, D.-W.; Jung, K.-H.; Kim, J. A Stereoscopic 3-D Broadcasting System Using Fixed and Mobile Hybrid Delivery and the Quality Assessment of the Mixed Resolution Stereoscopic Video. IEEE Trans. Broadcast. 2015, 61, 222–237. [Google Scholar] [CrossRef]
- Joachimiak, M.; Hannuksela, M.; Gabbouj, M. View synthesis quality mapping for depth-based super resolution on mixed resolution 3D video. In Proceedings of the 2014 3DTV-Conference: The True Vision—Capture, Transmission and Display of 3D Video (3DTV-CON), Budapest, Hungary, 2–4 July 2014; pp. 1–4. [Google Scholar]
- Mallik, B.; Sheikh-Akbari, A.; Kor, A.-L. HEVC Based Mixed-Resolution Stereo Video Codec. IEEE Access 2018, 6, 52691–52702. [Google Scholar] [CrossRef]
- Mallik, B.; Sheikh-Akbari, A. HEVC Based Multi-view Video Codec Using Frame Interleaving Technique. In Proceedings of the 2016 9th International Conference on Developments in eSystems Engineering (DeSE), Liverpool, UK, 31 August–2 September 2016; pp. 181–185. [Google Scholar]
- Mallik, B.; Sheikh-Akbari, A.; Bagheri-Zadeh, P. HEVC based stereo video codec. In Proceedings of the 2nd IET International Conference on Intelligent Signal Processing 2015 (ISP), London, UK, 1–2 December 2015; pp. 1–6. [Google Scholar]
- Merkle, P.; Smolic, A.; Muller, K.; Wiegand, T. Efficient prediction structures for multiview video coding. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1461–1473. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.; Sohn, K. Fast Disparity and Motion Estimation for Multi-view Video Coding. IEEE Trans. Consum. Electron. 2007, 53, 712–719. [Google Scholar] [CrossRef]
- Shen, L.; Liu, Z.; Liu, S.; Zhang, Z.; An, P. Selective Disparity Estimation and Variable Size Motion Estimation Based on Motion Homogeneity for Multi-View Coding. IEEE Trans. Broadcast. 2009, 55, 761–766. [Google Scholar] [CrossRef]
- Li, S.; Hou, C.; Ying, Y.; Song, X.; Yang, L. Stereoscopic video compression based on H. 264 MVC. In Proceedings of the 2nd International IEEE Congress on Image and Signal Processing, CISP 2009, Tianjin, China, 17–19 October 2009; pp. 1–5. [Google Scholar]
- Hewage, C.T.E.R.; Karim, H.A.; Worrall, S.; Dogan, S.; Kondoz, A.M. Comparison of stereo video coding support in MPEG-4 MAC, H.264/AVC and H. 264/SVC. In Proceedings of the IET Visual Information Engineering-VIE07, London, UK, 25–27 July 2007. [Google Scholar]
- Gürler, C.G.; Bağci, K.T.; Tekalp, A.M. Adaptive stereoscopic 3D video streaming. In Proceedings of the 17th IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 2409–2412. [Google Scholar]
- Saygili, G.; Gurler, C.G.; Tekalp, A.M. Evaluation of Asymmetric Stereo Video Coding and Rate Scaling for Adaptive 3D Video Streaming. IEEE Trans. Broadcast. 2011, 57, 593–601. [Google Scholar] [CrossRef]
- Sansli, D.B.; Ugur, K.; Hannuksela, M.M.; Gabbouj, M. Interview motion vector prediction in multiview HEVC. In Proceedings of the 3DTV-Conference: The True Vision Capture, Transmission and Display of 3D Video, 2014. 3DTV-CON, Budapest, Hungary, 2–4 July 2014; pp. 1–4. [Google Scholar]
- Van Wallendael, G.; van Leuven, S.; de Cock, J.; Bruls, F.; van de Walle, R. 3D video compression based on high efficiency video coding. IEEE Trans. Consum. Electron. 2012, 58, 137–145. [Google Scholar] [CrossRef]
- Stankowski, J.; Domanski, M.; Stankiewicz, O.; Konieczny, J.; Siast, J.; Wegner, K. Extensions of the HEVC technology for efficient multiview video coding. In Proceedings of the 19th IEEE International Conference on Image Processing, ICIP 2012, Orlando, FL, USA, 3 September–3 October 2012; pp. 225–228. [Google Scholar]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Boyce, J.M.; Chen, Y.; Ohm, J.-R.; Segall, C.A.; Vetro, A. Standardized Extensions of High Efficiency Video Coding (HEVC). IEEE J. Sel. Top. Signal Process. 2013, 7, 1001–1016. [Google Scholar] [CrossRef]
- Paramkusam, A.V.; Reddy, V.S.K. An efficient multi-layer reference frame motion estimation for video coding. J. Real-Time Image Process. 2014, 11, 645–661. [Google Scholar] [CrossRef]
- Bouyagoub, S.; Akbari, A.S.; Bull, D.; Canagarajah, N. Impact of camera separation on performance of H. 264/AVC-based stereoscopic video codec. IET Electron. Lett. 2010, 46, 345–346. [Google Scholar] [CrossRef]
- Sheikh-Akbari, A.; Said, H.; Moniri, M. Effect of inter-camera angles on the performance of an H. 264/AVC based multi-view video codec. In Proceedings of the 2012 Picture Coding Symposium, Krakow, Poland, 7–9 May 2012; pp. 109–112. [Google Scholar]
- Muller, K.; Vetro, A. “Common Test Conditions of 3DV Core Experiments,” in ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, JCT3V G1100. 2014, pp. 1–7. Available online: https://www.itu.int/wftp3/av-arch/jct3v-site/2014_03_H_Valencia/JCT3V-H_Notes_d7.doc (accessed on 10 June 2020).
- Schwarz, H.; Schierl, T.; Marpe, D. Block Structure and Parallelism. In High Efficiency Video Coding (HEVC): Algorithms and Architectures, Integrated Circuit and Systems; Springer: New York, NY, USA, 2014; Chapter 3; pp. 49–90. [Google Scholar]
- Bjontegaard, G. Calculation of Average PSNR Differences between RD Curves. In ITU-T SG 16, VCEG-M33. 2001, pp. 1–4. Available online: https://www.itu.int/wftp3/av-arch/video-site/0104_Aus/VCEG-M33.doc (accessed on 16 November 2022).
- Bjontegaard, G. Improvements of the BD-PSNR Model. In ITUT SG 16, VCEG-AI11. 2008, pp. 1–2. Available online: https://www.itu.int/wftp3/av-arch/video-site/1707_Tor/VCEG-BD04-v1.doc (accessed on 16 November 2022).
- Senzaki, K. BD-PSNR/Rate Computation Tool for Five Data Points. In ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, JCTVC-B055. 2010, pp. 1–3. Available online: https://www.itu.int/wftp3/av-arch/JCTVC-site/2010_07_B_Geneva/JCTVC-B055.doc (accessed on 16 November 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| NumberOfLayers | 1 |
| NumberOfViewId | 1 |
| VpsNumLayerSets | 1 |
| OutputLayerSetIdx | 0 |
| LayerIdsInAddOutputLayerSet_0 | 0 |
| GOP Size: 2-view scenario | 8 |
| GOP Size: 3-view scenario | 12 |
| Intra Period | 24 |
| QP | 25, 30, 35, 40 |
| BD-PSNR (dB) | |||
|---|---|---|---|
| Sequence | BD-PSNR Y | BD-PSNR U | BD-PSNR V |
| Poznan_Street | 0.293725 | 0.092543 | 0.035271 |
| Kendo | 0.165743 | 0.015274 | 0.021561 |
| Newspaper1 | 0.216158 | 0.037409 | 0.017538 |
| Average | 0.225208 | 0.048408 | 0.024790 |
| BD-PSNR (dB) | |||
|---|---|---|---|
| Sequence | BD-PSNR Y | BD-PSNR U | BD-PSNR V |
| Poznan_Street | 0.317251 | 0.071045 | 0.032501 |
| Kendo | 0.154372 | 0.015274 | 0.074198 |
| Newspaper1 | 0.274381 | 0.037409 | 0.058016 |
| Average | 0.248668 | 0.041242 | 0.164715 |
| BD-Rate (kbps) | |||
|---|---|---|---|
| Sequence | BD-Rate Y | BD-Rate U | BD-Rate V |
| Poznan_Street | −3.72356 | −0.76472 | −0.43817 |
| Kendo | −2.17652 | −0.84175 | −1.15233 |
| Newspaper1 | −3.65218 | −0.85279 | −0.97857 |
| Average | −3.184086 | −0.819732 | −0.856492 |
| BD-Rate (kbps) | |||
|---|---|---|---|
| Sequence | BD-Rate Y | BD-Rate U | BD-Rate V |
| Poznan_Street | −3.013856 | −0.943276 | −0.06723 |
| Kendo | −1.854732 | −0.087431 | −0.075832 |
| Newspaper1 | −2.714531 | −0.274352 | −0.004951 |
| Average | −2.527706 | −0.435019 | −0.049337 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mallik, B.; Sheikh-Akbari, A.; Bagheri Zadeh, P.; Al-Majeed, S. HEVC Based Frame Interleaved Coding Technique for Stereo and Multi-View Videos. Information 2022, 13, 554. https://doi.org/10.3390/info13120554
Mallik B, Sheikh-Akbari A, Bagheri Zadeh P, Al-Majeed S. HEVC Based Frame Interleaved Coding Technique for Stereo and Multi-View Videos. Information. 2022; 13(12):554. https://doi.org/10.3390/info13120554
Chicago/Turabian StyleMallik, Bruhanth, Akbar Sheikh-Akbari, Pooneh Bagheri Zadeh, and Salah Al-Majeed. 2022. "HEVC Based Frame Interleaved Coding Technique for Stereo and Multi-View Videos" Information 13, no. 12: 554. https://doi.org/10.3390/info13120554
APA StyleMallik, B., Sheikh-Akbari, A., Bagheri Zadeh, P., & Al-Majeed, S. (2022). HEVC Based Frame Interleaved Coding Technique for Stereo and Multi-View Videos. Information, 13(12), 554. https://doi.org/10.3390/info13120554