

Image-Based Approach to Intrusion Detection in Cyber-Physical Objects

Abstract
1. Introduction
- An approach to the preprocessing of the network data in PCAP format into images;
- An evaluation of the impacts of different settings of the image generation procedure on the efficiency of the analysis models, namely, ResNet34 and MobileNetV3-small, that are used in the feature extraction mode, as well as the CNN constructed by the authors.
2. Related Work
- 1.
- Extraction of the numerical and nominal features from the PCAP packets.
- 2.
- Transformation of the numerical and nominal features to image.
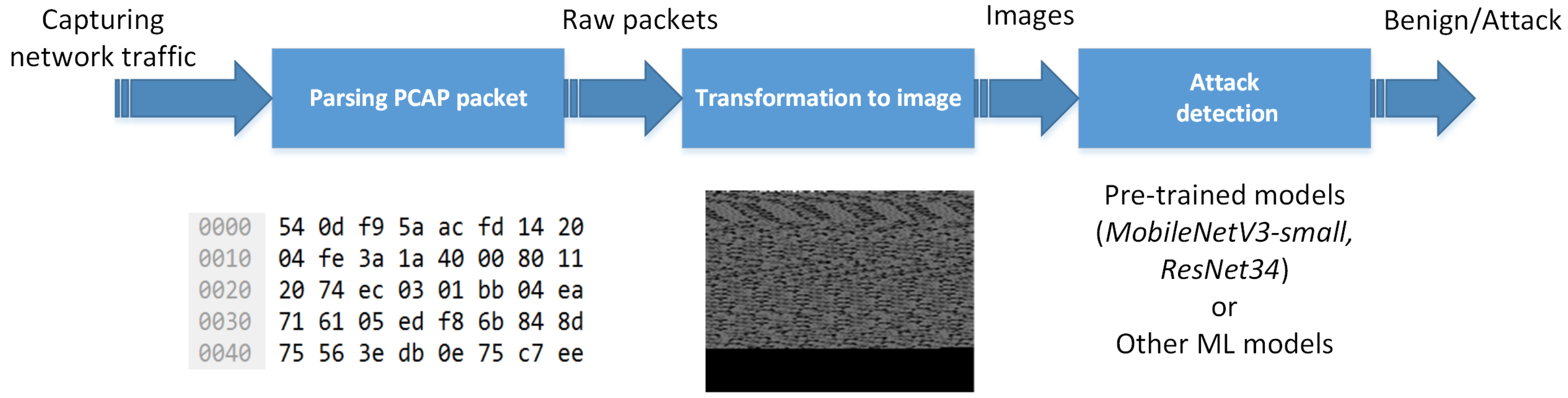
3. A Proposed Approach to Image-Based Feature Extraction
- 1.
- An extraction of the raw (binary) packets from the PCAP files.
- 2.
- A transformation of each packet into a grayscale image.
- 3.
- An attack detection based on the analysis of the images.
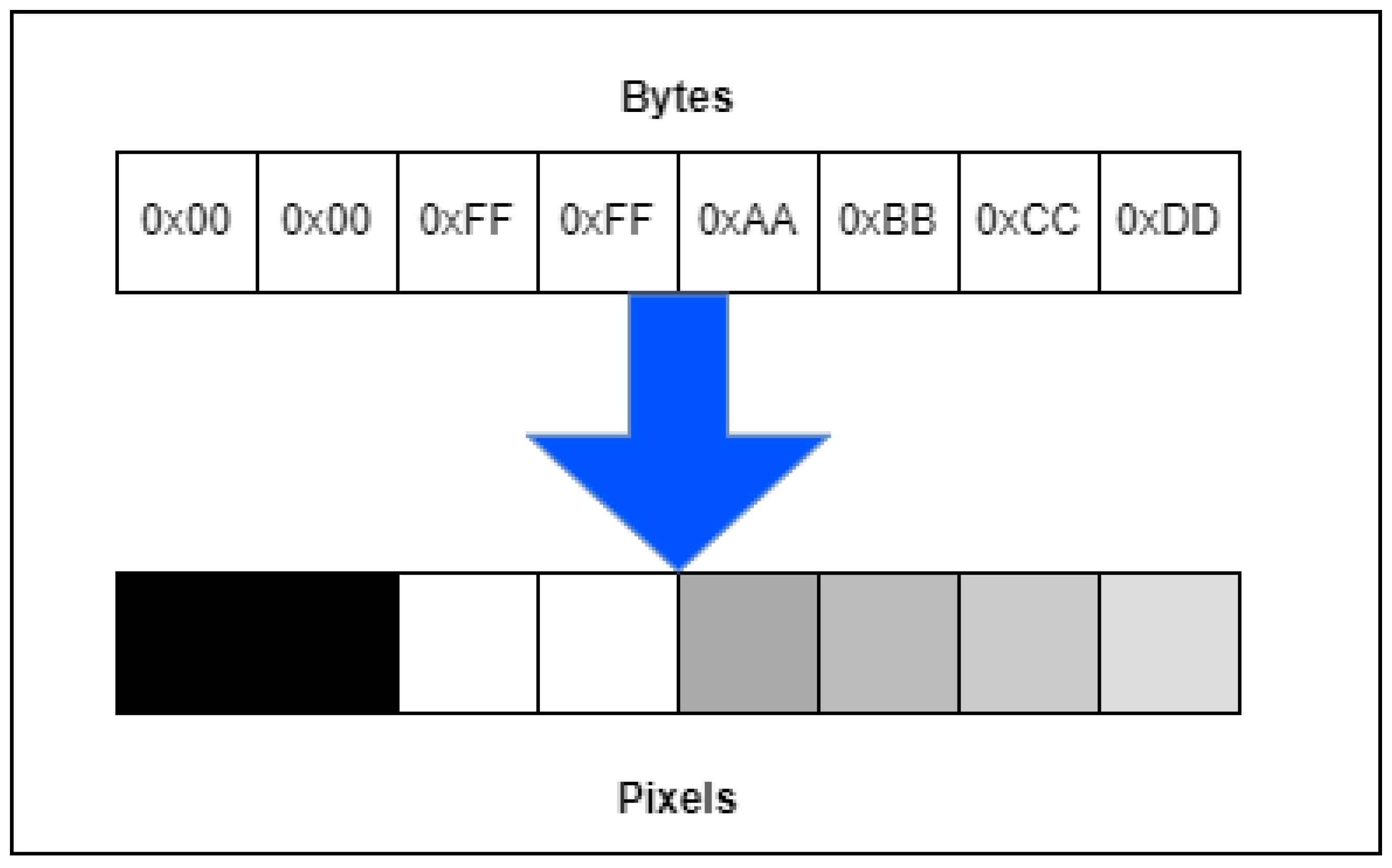
- 1.
- To define a width and a height of the matrix, i.e., size of an image to be generated.
- 2.
- To select a way how pixels are filled during the image generation.
- . The pixel matrix is filled up row by row. This is the most widely used approach.
- . The filling of the pixel matrix is started from the center and continues in a spiral form. This technique is suitable for square matrices.
- –. This type of image construction is suggested in [49]. The pixels are filled up in the zigzag form. The underlying idea of such a layout relates to the fact that when the image size is greater than the length of the packet, the majority of pixels will be padded with zeros, however, the zig–zag filling of the pixel matrix with further discrete cosine transform can preserve and enforce existing patterns in low frequency part of the frequency domain.
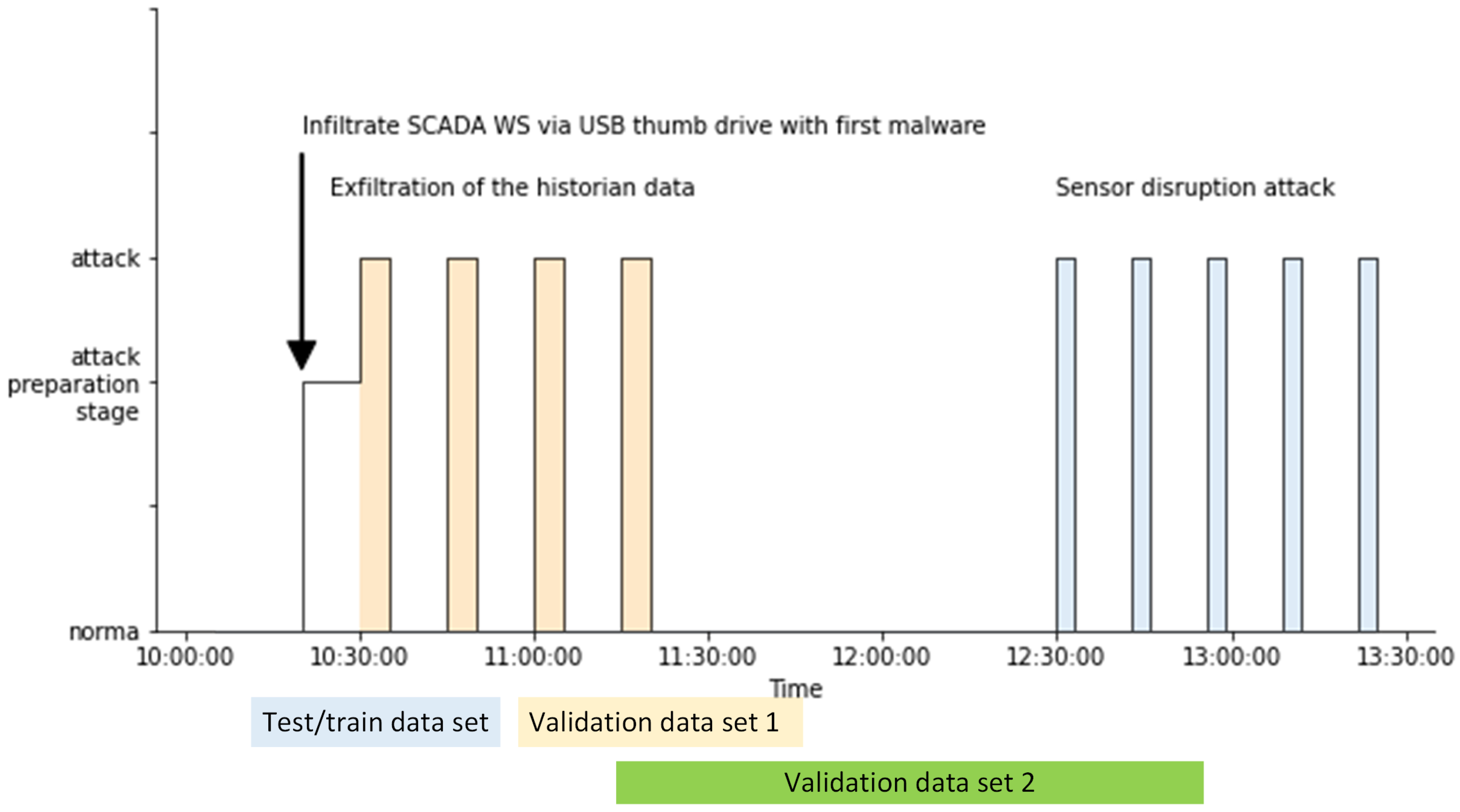
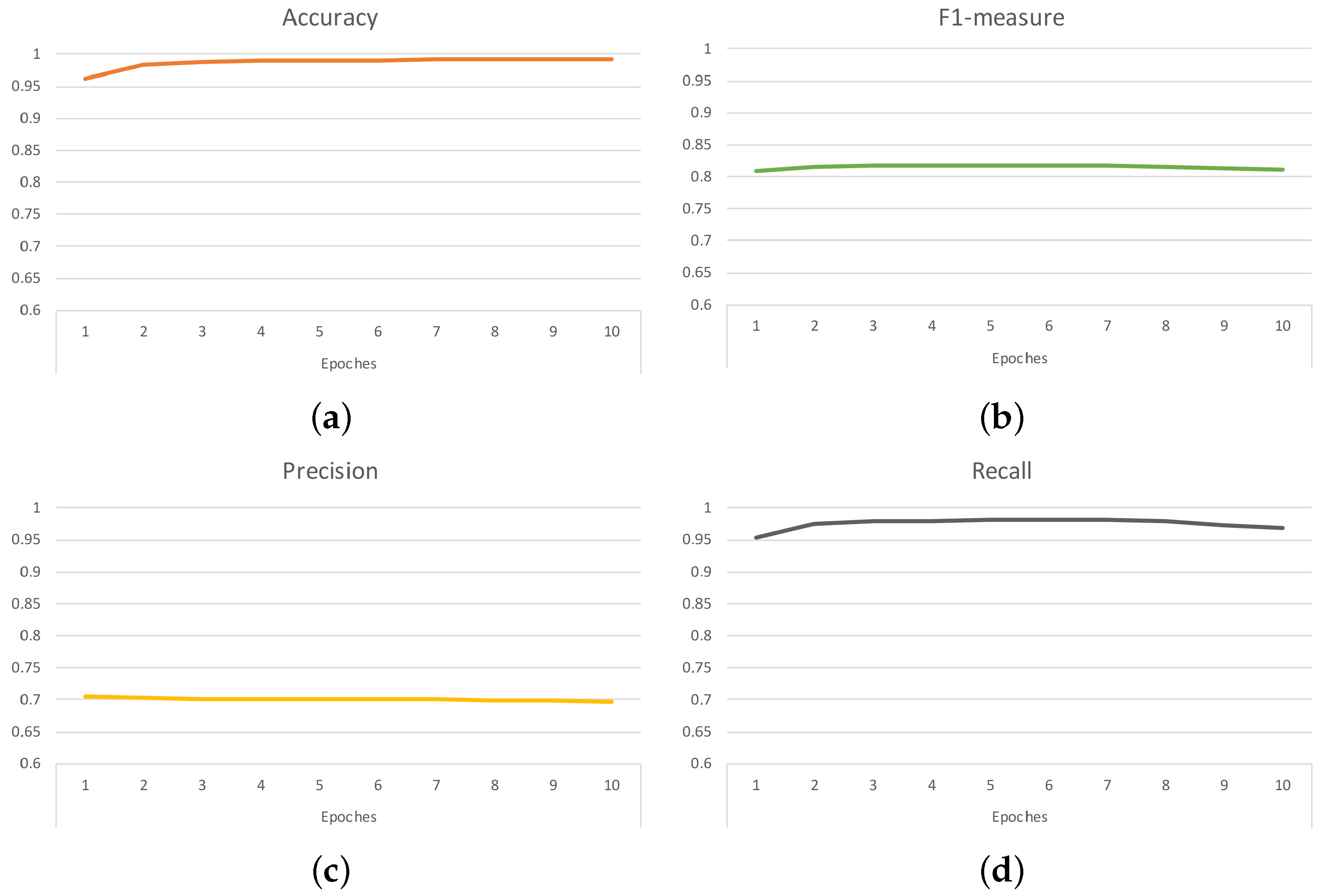
4. Experiments and Discussion
- Number of epochs: 7;
- Optimizer: SGD (Stochastic gradient descent);
- Loss function: CrossEntropyLoss;
- Learning rate: 0.001;
- Batch size: 16.
- 1 input layer;
- 3 convolutional layers;
- 3 max pooling layers;
- 1 flatten layer;
- 1 dense layer;
- 1 output layer.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FLOPs | Floating Point Operations |
References
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Debnath, B.; O’Brient, M.; Kumar, S.; Behera, A. Attention-Driven Body Pose Encoding for Human Activity Recognition. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5897–5904. [Google Scholar] [CrossRef]
- Sharma, A.; Vans, E.; Shigemizu, D.; Boroevich, K.; Tsunoda, T. DeepInsight: A methodology to transform a non-image data to an image for convolution neural network architecture. Sci. Rep. 2019, 9, 11399. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. A Transfer Learning with Deep Neural Network Approach for Network Intrusion Detection. Int. J. Intell. Comput. Res. 2021, 12, 1087–1095. [Google Scholar]
- Noever, D.A.; Noever, S.E.M. Image Classifiers for Network Intrusions. arXiv 2021, arXiv:2103.07765. [Google Scholar]
- Wu, P.; Guo, H.; Buckland, R. A Transfer Learning Approach for Network Intrusion Detection. In Proceedings of the 2019 IEEE 4th International Conference on Big Data Analytics (ICBDA), Suzhou, China, 15–18 March 2019; pp. 281–285. [Google Scholar] [CrossRef]
- Branitskiy, A.; Kotenko, I. Analysis and Classification of Methods for Network Attack Detection. SPIIRAS Proc. 2016, 2, 207. [Google Scholar] [CrossRef]
- Alrabaee, S.; Karbab, E.B.; Wang, L.; Debbabi, M. BinEye: Towards Efficient Binary Authorship Characterization Using Deep Learning. In Proceedings of the Computer Security—ESORICS 2019; Sako, K., Schneider, S., Ryan, P.Y.A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 47–67. [Google Scholar]
- Kaur, R.; Ning, Y.; Gonzalez, H.; Stakhanova, N. Unmasking Android obfuscation tools using spatial analysis. In Proceedings of the 2018 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, Ireland, 28–30 August 2018; pp. 1–10. [Google Scholar]
- Rong, C.; Gou, G.; Cui, M.; Xiong, G.; Li, Z.; Guo, L. TransNet: Unseen Malware Variants Detection Using Deep Transfer Learning. In Proceedings of the Security and Privacy in Communication Networks; Park, N., Sun, K., Foresti, S., Butler, K., Saxena, N., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 84–101. [Google Scholar]
- Wang, F.; Chai, G.; Li, Q.; Wang, C. An Efficient Deep Unsupervised Domain Adaptation for Unknown Malware Detection. Symmetry 2022, 14, 296. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Golubev, S.; Novikova, E. Image-based Intrusion Detection in Network Traffic. In Proceedings of the Intelligent Distributed Computing XV; Braubach, L., Jander, K., Bădic, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Zhu, W. On the model-checking-based IDS. arXiv 2018, arXiv:1806.09337. [Google Scholar]
- Kruegel, C.; Toth, T. Using Decision Trees to Improve Signature-Based Intrusion Detection. In Proceedings of the Recent Advances in Intrusion Detection; Vigna, G., Kruegel, C., Jonsson, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 173–191. [Google Scholar]
- Chen, W.H.; Hsu, S.H.; Shen, H.P. Application of SVM and ANN for intrusion detection. Comput. Oper. Res. 2005, 32, 2617–2634. [Google Scholar] [CrossRef]
- Heckerman, D. A Tutorial on Learning with Bayesian Networks. In Innovations in Bayesian Networks: Theory and Applications; Holmes, D.E., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 33–82. [Google Scholar] [CrossRef]
- Barbará, D.; Wu, N.; Jajodia, S. Detecting Novel Network Intrusions Using Bayes Estimators. In Proceedings of the 2001 SIAM International Conference on Data Mining (SDM), Chicago, IL, USA, 5–7 April 2001; pp. 1–17. [Google Scholar]
- Mukkamala, S.; Sung, A.H.; Abraham, A.; Ramos, V. Intrusion Detection Systems Using Adaptive Regression Spines. In Proceedings of the Enterprise Information Systems VI; Seruca, I., Cordeiro, J., Hammoudi, S., Filipe, J., Eds.; Springer: Dordrecht, The Netherlands, 2006; pp. 211–218. [Google Scholar]
- Ranjan, R.; Sahoo, G. A New Clustering Approach for Anomaly Intrusion Detection. Int. J. Data Min. Knowl. Manag. Process. 2014, 4, 29–38. [Google Scholar] [CrossRef]
- Wang, Y. A multinomial logistic regression modeling approach for anomaly intrusion detection. Comput. Secur. 2005, 24, 662–674. [Google Scholar] [CrossRef]
- Sheth, H.; Shah, B.; Yagnik, S.B. A Survey on RBF Neural Network for Intrusion Detection System. Int. J. Eng. Res. Appl. 2014, 4, 17–22. [Google Scholar]
- Sammany, M.; Sharawi, M.; El-beltagy, M.; Saroit, I. Artificial Neural Networks Architecture For Intrusion Detection Systems and Classification of Attacks. In Proceedings of the 5th International Conference INFO2007, Cairo University, Giza, Egypt, 24–26 March 2007. [Google Scholar]
- Lu, W.; Traore, I. Detecting New Forms of Network Intrusion Using Genetic Programming. In Proceedings of the Congress on Evolutionary Computation, Canberra, Australia, 8–12 December 2003; IEEE-Press: Piscataway, NJ, USA, 2004; Volume 20, pp. 2165–2172. [Google Scholar] [CrossRef]
- Mahendiran, A.; Appusamy, R. A Survey on Intrusion Detection System Using Fuzzy Logic. Int. J. Control Theory Appl. 2016, 9, 7517–7522. [Google Scholar]
- Powers, S.T.; He, J. A hybrid artificial immune system and Self Organising Map for network intrusion detection. Inf. Sci. 2008, 178, 3024–3042. [Google Scholar] [CrossRef]
- Barford, P.; Kline, J.; Plonka, D.; Ron, A. A signal analysis of network traffic anomalies. In Proceedings of the IMW’02, Marseille, France, 6–8 November 2002. [Google Scholar]
- Denning, D. An Intrusion-Detection Model. IEEE Trans. Softw. Eng. 1987, SE-13, 222–232. [Google Scholar] [CrossRef]
- Gu, Y.; Mccallum, A.; Towsley, D. Detecting Anomalies in Network Traffic Using Maximum Entropy Estimation; USENIX Association: Berkeley, CA, USA, 2005; pp. 345–350. [Google Scholar] [CrossRef]
- Dymora, P.; Mazurek, M. Network Anomaly Detection Based on the Statistical Self-similarity Factor. Lect. Notes Electr. Eng. 2015, 324, 271–287. [Google Scholar] [CrossRef]
- Lee, K.; Kim, J.; Kwon, K.H.; Han, Y.; Kim, S. DDoS attack detection method using cluster analysis. Expert Syst. Appl. 2008, 34, 1659–1665. [Google Scholar] [CrossRef]
- Bazgir, O.; Zhang, R.; Dhruba, S.R.; Rahman, R.; Ghosh, S.; Pal, R. Representation of features as images with neighborhood dependencies for compatibility with convolutional neural networks. Nat. Commun. 2020, 11, 4391. [Google Scholar] [CrossRef]
- Su, R.; Liu, X.; Wei, L.; Zou, Q. Deep-Resp-Forest: A deep forest model to predict anti-cancer drug response. Methods 2019, 166, 91–102. [Google Scholar] [CrossRef] [PubMed]
- Lim, J.; Ryu, S.; Park, K.; Choe, Y.J.; Ham, J.; Kim, W.Y. Predicting drug-target interaction using a novel graph neural network with 3D structure-embedded graph representation. J. Chem. Inf. Model. 2019, 59, 3981–3988. [Google Scholar] [CrossRef]
- NCI60 Drug Response Data Set. Available online: https://dtp.cancer.gov/databases_tools/bulk_data.htm (accessed on 1 November 2022).
- Drug Sensitivity in Cancer (GDSC) Data Set. Available online: https://www.cancerrxgene.org/downloads/bulk_download (accessed on 1 November 2022).
- Zhu, Y.; Brettin, T.; Xia, F.; Partin, A.; Shukla, M.; Yoo, H.; Evrard, Y.; Doroshow, J.; Stevens, R. Converting tabular data into images for deep learning with convolutional neural networks. Sci. Rep. 2021, 11, 11325. [Google Scholar] [CrossRef] [PubMed]
- Cancer Therapeutics Response Portal v2 (CTRP). Available online: https://portals.broadinstitute.org/ctrp.v2.1/ (accessed on 1 November 2022).
- Masum, M.; Shahriar, H. TL-NID: Deep Neural Network with Transfer Learning for Network Intrusion Detection. In Proceedings of the 15th International Conference for Internet Technology and Secured Transactions (ICITST), London, UK, 8–10 December 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Wang, W.; Wang, Z.; Zhou, Z.; Deng, H.; Zhao, W.; Wang, C.; Guo, Y. Anomaly detection of industrial control systems based on transfer learning. Tsinghua Sci. Technol. 2021, 26, 821–832. [Google Scholar] [CrossRef]
- Zhao, J.; Shetty, S.; Pan, J.W.; Kamhoua, C.; Kwiat, K. Transfer learning for detecting unknown network attacks. Int. J. Comput. Vision 2019, 2019, 1. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- NSL-KDD Data Set. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 1 November 2022).
- Manjula, P.; Sankaralingam, B.P. An effective network intrusion detection and classification system for securing WSN using VGG-19 and hybrid deep neural network techniques. J. Intell. Fuzzy Syst. 2022, 43, 6419–6432. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Park, S.; Kim, M.; Lee, S. Anomaly Detection for HTTP Using Convolutional Autoencoders. IEEE Access 2018, 6, 70884–70901. [Google Scholar] [CrossRef]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware Images: Visualization and Automatic Classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 20 July 2011; Association for Computing Machinery: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, J.; Zhou, Y.; Han, L.; Lin, J. A Multiple-Layer Representation Learning Model for Network-Based Attack Detection. IEEE Access 2019, 7, 91992–92008. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Goh, J.; Adepu, S.; Junejo, K.N.; Mathur, A. A Dataset to Support Research in the Design of Secure Water Treatment Systems. In Proceedings of the Critical Information Infrastructures Security, Lucca, Italy, 8–13 October 2017; Havarneanu, G., Setola, R., Nassopoulos, H., Wolthusen, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 88–99. [Google Scholar]
- PyTorch Model Hub. Available online: https://pytorch.org/vision/stable/models.html (accessed on 1 November 2022).
- Suresh, C.; Singh, S.; Saini, R.; Saini, A.K. A Comparative Analysis of Image Scaling Algorithms. Int. J. Image Graph. Signal Process. 2013, 5, 55–62. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Zhao, Q.; Geng, G.; Yan, Z. Detection of DNS DDoS Attacks with Random Forest Algorithm on Spark. Procedia Comput. Sci. 2018, 134, 310–315. [Google Scholar] [CrossRef]
- Resende, P.A.A.; Drummond, A.C. A Survey of Random Forest Based Methods for Intrusion Detection Systems. ACM Comput. Surv. 2018, 51, 1–38. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
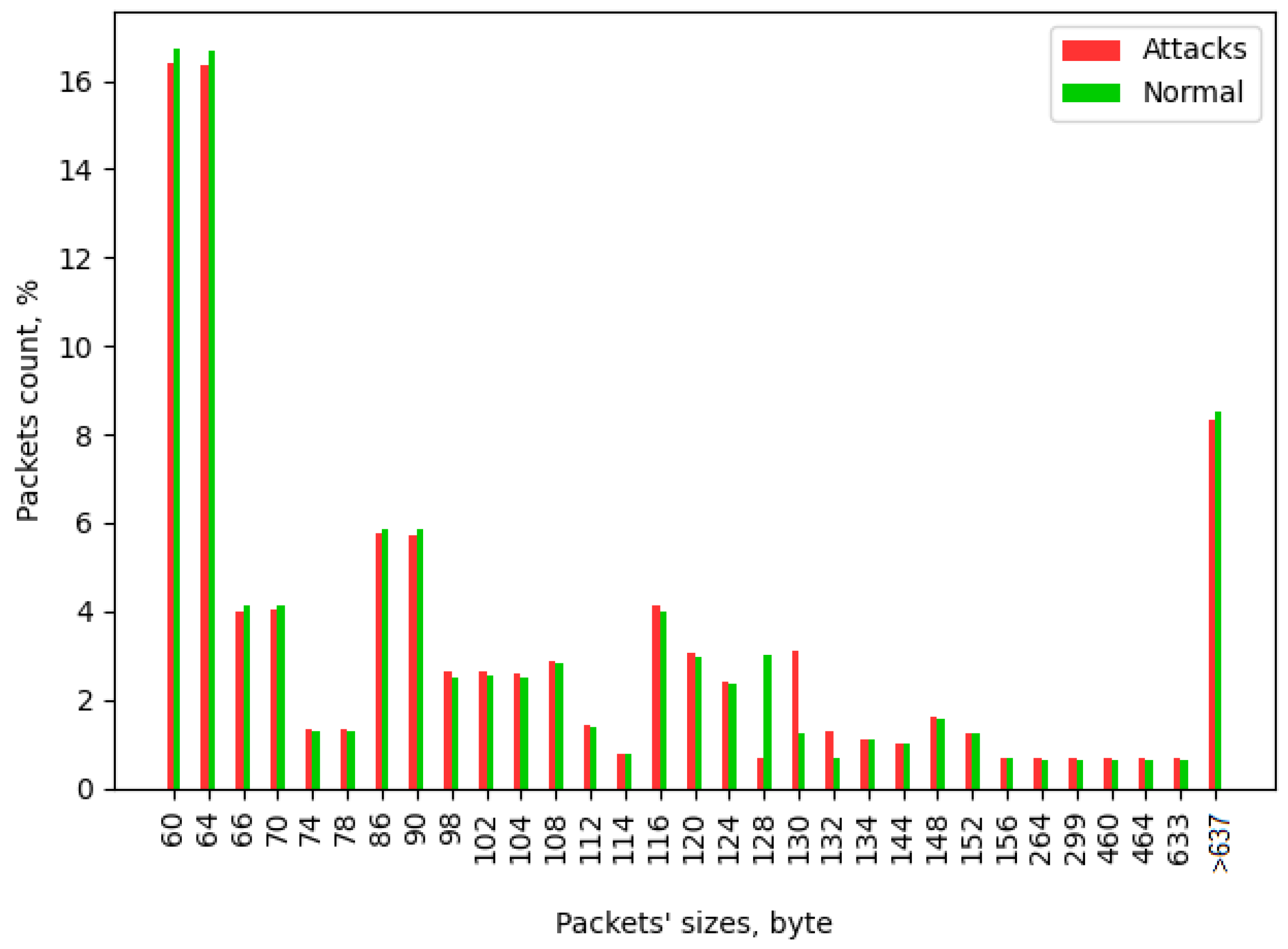
| Packet Type | Mode | Median | 80 Percentile | 99 Percentile | Min | Max |
|---|---|---|---|---|---|---|
| Normal | 64 | 90 | 128 | 633 | 60 | 19,034 |
| Attack | 64 | 86 | 128 | 633 | 60 | 14,888 |
| Pre-Trained Model | Input Image Size | Top-1 Accuracy | Top-5 Accuracy | FLOPs (Millions) | Num. of Trained Parameters |
|---|---|---|---|---|---|
| ResNet34 [12] | 224 × 224 | 73.31 | 91.42 | 21.8 | 1026 |
| MobileNetv3-small [50] | 224 × 224 | 67.67 | 87.40 | 2.5 | 2050 |
| Pre-Trained Model | Pixel Layout Scheme | Accuracy | Precision | Recall | F1-Measure |
|---|---|---|---|---|---|
| ResNet34 [40] | linear | 0.56 | 0.51 | 0.51 | 0.49 |
| spiral | 0.59 | 0.53 | 0.52 | 0.51 | |
| zig-zag | 0.64 | 0.55 | 0.57 | 0.57 | |
| MobileNetv3-small [41] | linear | 0.54 | 0.49 | 0.47 | 0.48 |
| spiral | 0.52 | 0.49 | 0.5 | 0.48 | |
| zig-zag | 0.56 | 0.5 | 0.52 | 0.44 |
| Size of the Test Dataset | Image Size | Metric Used to Define Image Size | Accuracy |
|---|---|---|---|
| 1 million | 10 × 10 | Median (and mode) | 0.99 |
| 26 × 26 | 99 Percentile | 0.99 | |
| 138 × 138 | Maximum size | 0.99 | |
| 10 millions | 138 × 138 | Maximum size | 0.99 |
| Validation Dataset | F1-Measure | Precision | Recall |
|---|---|---|---|
| Validation dataset 1 | 0.78 | 0.64 | 0.98 |
| Validation dataset 2 (with novel attack type) | 0.75 | 0.62 | 0.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golubev, S.; Novikova, E.; Fedorchenko, E. Image-Based Approach to Intrusion Detection in Cyber-Physical Objects. Information 2022, 13, 553. https://doi.org/10.3390/info13120553
Golubev S, Novikova E, Fedorchenko E. Image-Based Approach to Intrusion Detection in Cyber-Physical Objects. Information. 2022; 13(12):553. https://doi.org/10.3390/info13120553
Chicago/Turabian StyleGolubev, Sergey, Evgenia Novikova, and Elena Fedorchenko. 2022. "Image-Based Approach to Intrusion Detection in Cyber-Physical Objects" Information 13, no. 12: 553. https://doi.org/10.3390/info13120553
APA StyleGolubev, S., Novikova, E., & Fedorchenko, E. (2022). Image-Based Approach to Intrusion Detection in Cyber-Physical Objects. Information, 13(12), 553. https://doi.org/10.3390/info13120553