
Evaluating the Impact of Integrating Similar Translations into Neural Machine Translation


Abstract
:1. Introduction
2. Research Background
2.1. TM–MT Integration
2.2. Quality Assessment of MT
2.2.1. Automatic Quality Assessment
2.2.2. Manual Quality Assessment
3. The Current Study
- RQ1: How does the quality of NFR output compare to that of a baseline NMT system in terms of (a) semantic, syntactic and lexical similarity to a reference translation, as measured by automated quality metrics; and (b) the types and number of edit operations required to transform the MT output into the reference translation?
- RQ2: What types of and how many translation errors do the NFR and the baseline NMT system make? To what extent are the error profiles of the two systems different?
- RQ3: How do fuzzy matches in NFR influence the MT output, i.e., how often do tokens in fuzzy matches appear in NFR output and in the reference translations and to what extent are these tokens aligned to tokens in the source sentence?
- RQ4: Which factors influence NFR quality and to what extent can these factors explain the variation in quality differences between the NFR and the baseline NMT system?
4. Methodology
4.1. Data
- The distribution of the number of sentences in different FM ranges (based on the similarity between the input sentence and the sentence retrieved from the TM; see Section 4.2) was similar in both data sets;
- The subset contained an equal number of sentences with different source lengths (i.e., short sentences of length 1–10 tokens, medium of length 11–25 and long with a length over 25 tokens) per FM range;
- Segments consisting (almost exclusively) of chemical formulas, numbers or abbreviations were excluded.
4.2. NMT Systems
4.3. Automated Quality Estimation
4.3.1. Metrics
4.3.2. TER Edit Operations
4.4. Manual Error Analysis
4.4.1. Error Taxonomy
4.4.2. Procedure
4.4.3. Inter-Annotator Agreement
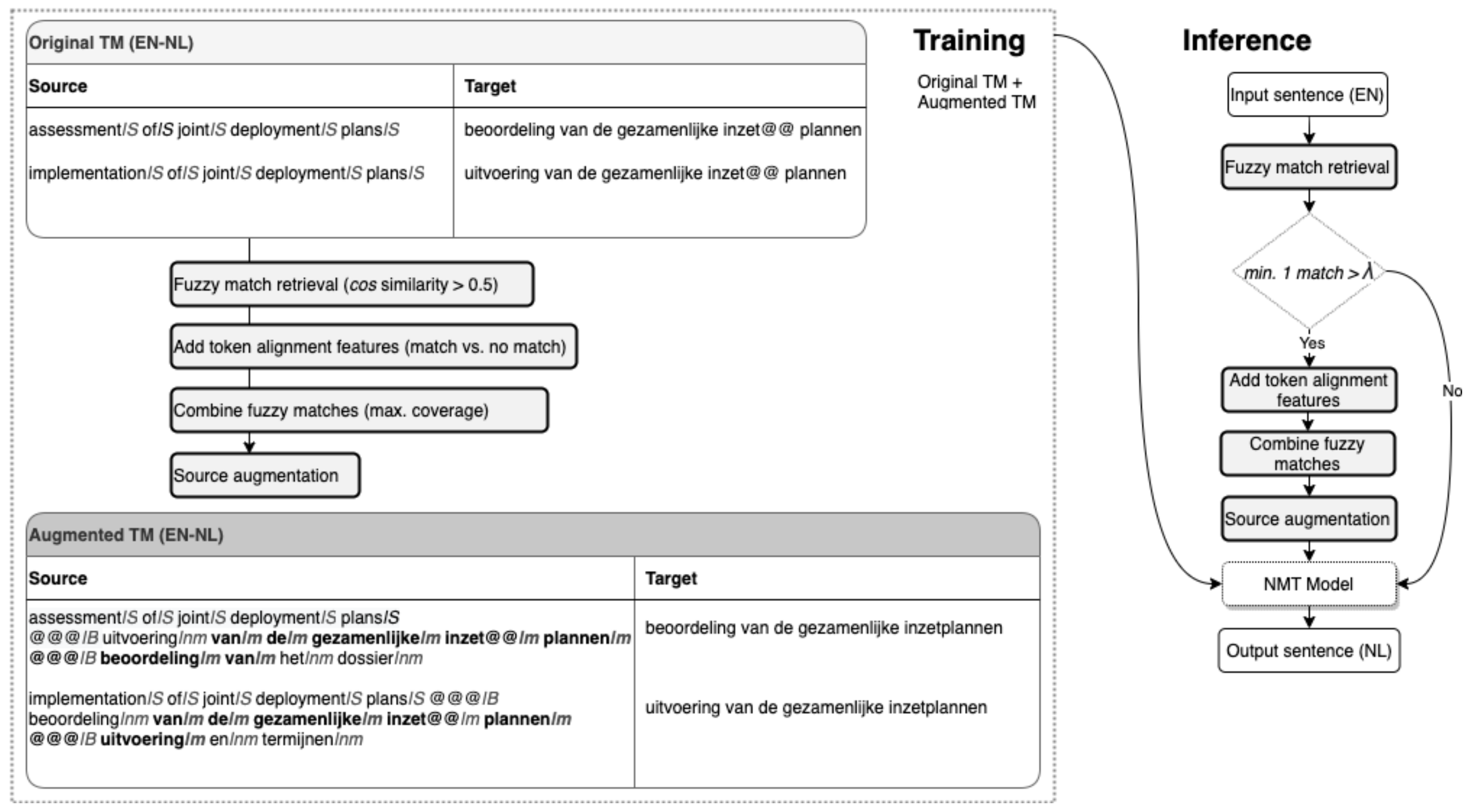
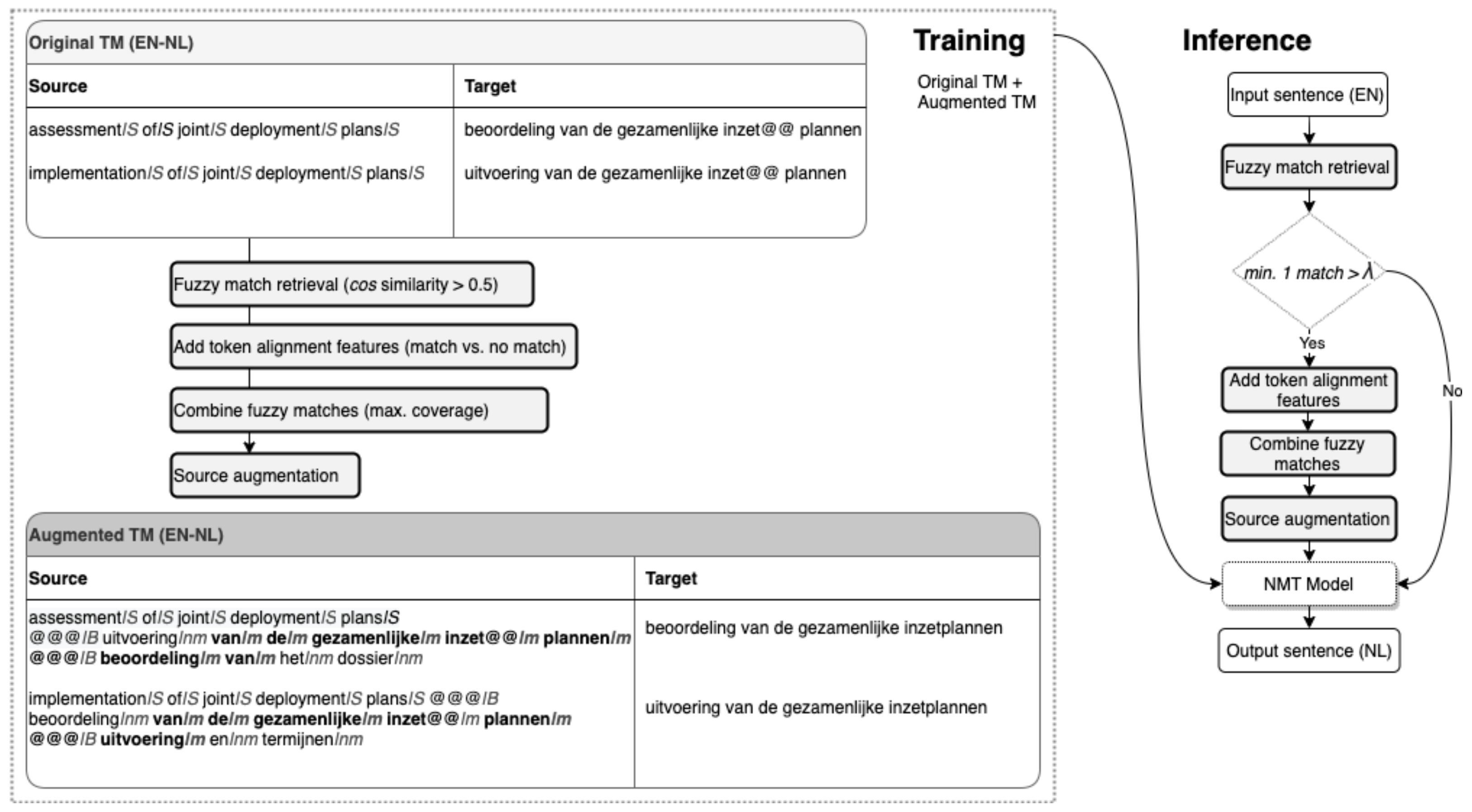
4.5. Fuzzy Match Analysis in NFR
4.6. Features and Statistical Models
5. Results
5.1. Automated Quality Assessment
5.1.1. Semantic, Syntactic and Lexical Similarity
5.1.2. Edit Operations
5.2. Fine-Grained Error Analysis
5.3. Impact of Data Augmentation
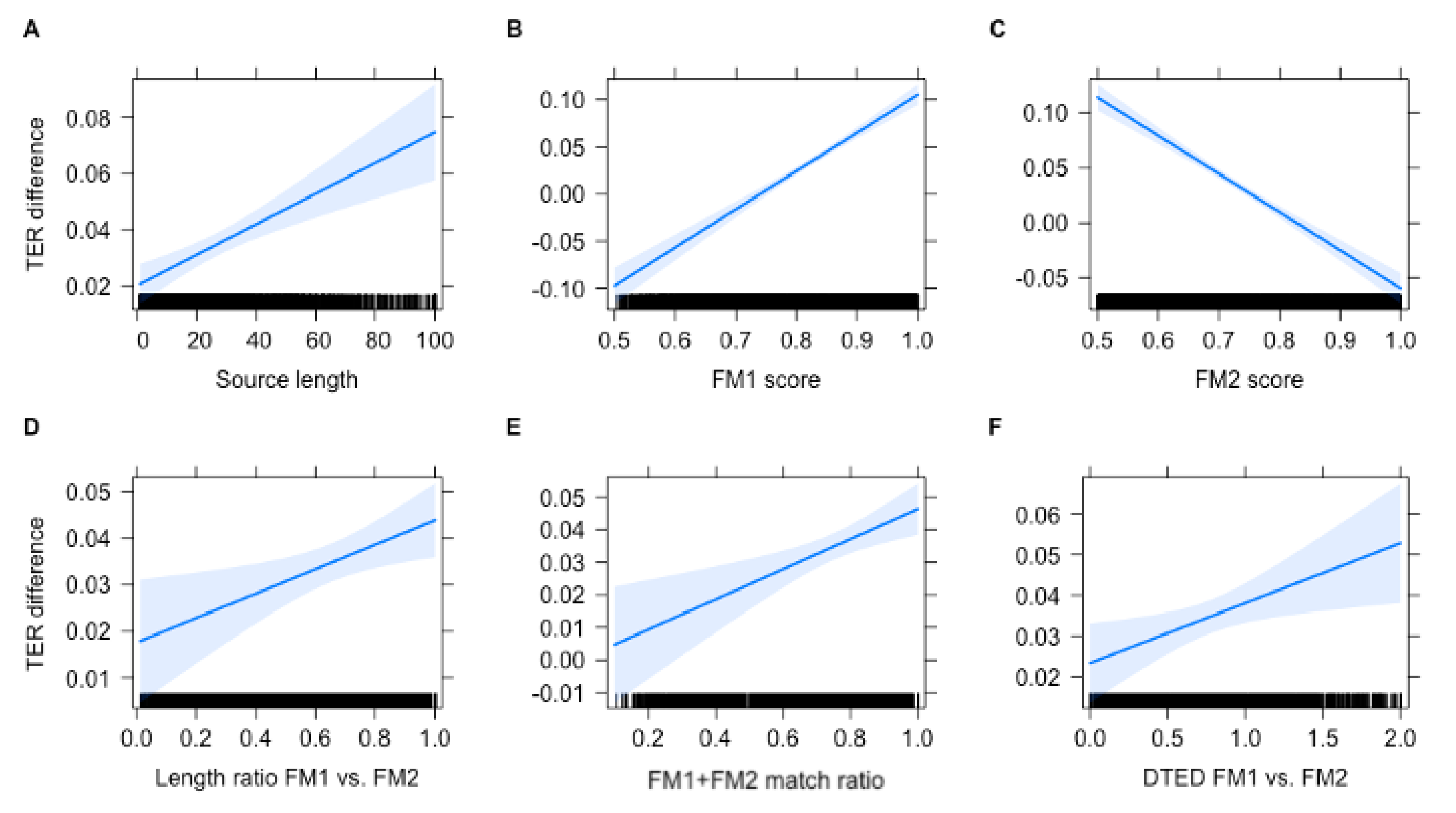
5.4. Variables Influencing MT Quality
- Vocabulary frequency: Percentages of tokens in the input sentence that belonged to the 99%, 90% and 75% least frequent tokens in the source side of the training set (% Q99, % Q90 and % Q75).
- Length: Length of the source sentence in number of tokens (Source), length ratio of FMs to source sentence (FM1/source and FM2/source) and to each other (FM2/FM1).
- FM similarity: Fuzzy match scores as measured by their cosine similarity to the source sentence (FM1 score and FM2 score), percentage of match tokens in fuzzy matches (% m/FM1 and % m/FM2) and the ratio of total unique match tokens from FM1 and FM2 combined, relative to the length of the source sentence (total_m/source).
- Syntax: Syntactic similarity between the source sentence and the fuzzy matches (Source vs. FM1, Source vs. FM2 and FM1 vs. FM2), measured by DTED.
6. Discussion
6.1. Findings and Implications
6.1.1. RQ1: Automated Quality Evaluation and Required Edits
6.1.2. RQ2: Error Profiles
6.1.3. RQ3: Impact of Fuzzy Matches
6.1.4. RQ4: Factors Influencing NFR Quality
6.2. Limitations
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CAT | computer-assisted translation |
| FM | fuzzy match |
| NFR | neural fuzzy repair |
| NMT | neural machine translation |
| MT | machine translation |
| TM | translation memory |
Appendix A. Details of Automated Quality Metrics
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BLEU ↑ | METEOR ↑ | TER ↓ | chrF ↓ | BERTScore ↑ | COMET ↑ | DTED ↓ | |
|---|---|---|---|---|---|---|---|
| Baseline NMT | 45.02 | 66.37 | 38.53 | 67.90 | 89.86 | 71.13 | 36.23 |
| NFR | 54.73 | 72.60 | 32.55 | 73.59 | 91.47 | 74.39 | 33.19 |
| S. Significance | *** | *** | *** | *** | *** | * | – |
| All | 50–59% | 60–69% | 70–79% | 80–89% | 90–99% | |
|---|---|---|---|---|---|---|
| Baseline NMT | 45.02 | 35.02 | 38.29 | 41.74 | 46.26 | 56.96 |
| NFR | 54.73 | 35.66 | 39.43 | 48.06 | 58.56 | 72.51 |
| Diff. NFR-NMT | +9.71 | +0.64 | +1.14 | +6.32 | +12.30 | +15.55 |
| % sentences | %100 | %10 | %20 | %20 | %25 | %25 |
| Annotator 1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Token Level | Sentence Level | ||||||||
| Baseline NMT | NFR | Baseline NMT | NFR | ||||||
| Yes | No | Yes | No | Yes | No | Yes | No | ||
| Annotator 2 | Yes | 147 | 167 | 178 | 179 | 60 | 29 | 76 | 30 |
| No | 104 | 5205 | 113 | 5242 | 18 | 193 | 11 | 183 | |
| FM 50–59 | FM 60–69 | FM 70–79 | FM 80–89 | FM 90–99 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BASE | NFR | BASE | NFR | BASE | NFR | BASE | NFR | BASE | NFR | |
| INS (Cont) | 555 | 537 | 1093 | 1126 | 997 | 993 | 823 | 702 | 1255 | 852 |
| INS (Func) | 591 | 565 | 1274 | 1283 | 1113 | 1062 | 960 | 882 | 1560 | 1147 |
| INS (Oth) | 97 | 93 | 177 | 187 | 198 | 205 | 193 | 217 | 444 | 384 |
| DEL (Cont) | 350 | 359 | 790 | 777 | 610 | 573 | 535 | 434 | 760 | 517 |
| DEL (Func) | 419 | 402 | 827 | 868 | 763 | 707 | 615 | 479 | 968 | 623 |
| DEL (Oth) | 52 | 36 | 93 | 98 | 103 | 83 | 77 | 72 | 150 | 140 |
| SUB (Cont) | 1729 | 1742 | 3274 | 3189 | 2623 | 2358 | 1842 | 1397 | 2693 | 1361 |
| SUB (Func) | 1124 | 1091 | 2219 | 2205 | 1776 | 1639 | 1379 | 1027 | 1963 | 1015 |
| SUB (Oth) | 83 | 109 | 192 | 193 | 190 | 192 | 148 | 118 | 299 | 212 |
| SHIFT-TOK (Cont) | 308 | 302 | 818 | 821 | 713 | 663 | 518 | 416 | 883 | 438 |
| SHIFT-TOK (Func) | 477 | 489 | 1201 | 1172 | 986 | 861 | 726 | 540 | 1140 | 517 |
| SHIFT-TOK (Oth) | 33 | 30 | 102 | 101 | 95 | 101 | 95 | 64 | 89 | 55 |
| SHIFT-GROUP | 234 | 244 | 590 | 585 | 499 | 454 | 359 | 289 | 563 | 249 |
| Data | NFR Better | Baseline NMT Better | Tie |
|---|---|---|---|
| All | 36.5% | 21.1% | 42.4% |
| 50–59% | 40.2% | 35.4% | 24.5% |
| 60–69% | 35.7% | 36.8% | 27.4% |
| 70–79% | 39.5% | 26.9% | 33.6% |
| 80–89% | 38.1% | 17.9% | 44% |
| 90–99% | 34.1% | 11.1% | 54.9% |
References
- Castilho, S.; Doherty, S.; Gaspari, F.; Moorkens, J. Approaches to human and machine translation quality assessment. In Translation Quality Assessment; Springer: Cham, Switzerland, 2018; pp. 9–38. [Google Scholar]
- Way, A. Quality expectations of machine translation. In Translation Quality Assessment; Springer: Cham, Switzerland, 2018; pp. 159–178. [Google Scholar]
- Bulte, B.; Tezcan, A. Neural Fuzzy Repair: Integrating Fuzzy Matches into Neural Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1800–1809. [Google Scholar] [CrossRef]
- Tezcan, A.; Bulté, B.; Vanroy, B. Towards a Better Integration of Fuzzy Matches in Neural Machine Translation through Data Augmentation. Informatics 2021, 8, 7. [Google Scholar] [CrossRef]
- Xu, J.; Crego, J.; Senellart, J. Boosting Neural Machine Translation with Similar Translations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1580–1590. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef] [Green Version]
- Popović, M.; Lommel, A.; Burchardt, A.; Avramidis, E.; Uszkoreit, H. Relations between different types of post-editing operations, cognitive effort and temporal effort. In Proceedings of the 17th Annual Conference of the European Association for Machine Translation, Dubrovnik, Croatia, 16–18 June 2014; pp. 191–198. [Google Scholar]
- Drugan, J.; Strandvik, I.; Vuorinen, E. Translation quality, quality management and agency: Principles and practice in the European Union institutions. In Translation Quality Assessment; Springer: Cham, Switzerland, 2018; pp. 39–68. [Google Scholar]
- Reinke, U. State of the art in translation memory technology. In Language Technologies for a Multilingual Europe; Rehm, G., Stein, D., Sasaki, F., Witt, A., Eds.; Language Science Press: Berlin, Germany, 2018; Chapter 5; pp. 55–84. [Google Scholar] [CrossRef]
- Levenshtein, V. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Bloodgood, M.; Strauss, B. Translation Memory Retrieval Methods. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; Association for Computational Linguistics: Gothenburg, Sweden, 2014; pp. 202–210. [Google Scholar] [CrossRef] [Green Version]
- Baldwin, T. The hare and the tortoise: Speed and accuracy in translation retrieval. Mach. Transl. 2009, 23, 195–240. [Google Scholar] [CrossRef]
- Ranasinghe, T.; Orasan, C.; Mitkov, R. Intelligent Translation Memory Matching and Retrieval with Sentence Encoders. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; European Association for Machine Translation: Lisboa, Portugal, 2020; pp. 175–184. [Google Scholar]
- Vanallemeersch, T.; Vandeghinste, V. Assessing linguistically aware fuzzy matching in translation memories. In Proceedings of the 18th Annual Conference of the European Association for Machine Translation, Antalya, Turkey, 11–13 May 2015; EAMT: Antalya, Turkey, 2015; pp. 153–160. [Google Scholar]
- Koponen, M. Is machine translation post-editing worth the effort? A survey of research into post-editing and effort. J. Spec. Transl. 2016, 25, 131–148. [Google Scholar]
- Rossi, C.; Chevrot, J.P. Uses and perceptions of Machine Translation at the European Commission. J. Spec. Transl. 2019, 31, 177–200. [Google Scholar]
- Stefaniak, K. Evaluating the usefulness of neural machine translation for the Polish translators in the European Commission. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; European Association for Machine Translation: Lisboa, Portugal, 2020; pp. 263–269. [Google Scholar]
- Simard, M.; Isabelle, P. Phrase-based machine translation in a computer-assisted translation environment. In Proceedings of the MT Summit XII, Ottawa, ON, Canada, 26–30 August 2009; AMTA: Ottawa, ON, Canada, 2009; pp. 120–127. [Google Scholar]
- Moorkens, J.; O’Brien, S. Assessing user interface needs of post-editors of machine translation. In Human Issues in Translation Technology: The IATIS Yearbook; Taylor & Francis: Abingdon, UK, 2016; pp. 109–130. [Google Scholar]
- Sánchez-Gijón, P.; Moorkens, J.; Way, A. Post-editing neural machine translation versus translation memory segments. Mach. Transl. 2019, 33, 31–59. [Google Scholar] [CrossRef]
- Bulté, B.; Vanallemeersch, T.; Vandeghinste, V. M3TRA: Integrating TM and MT for professional translators. In Proceedings of the 21st Annual Conference of the European Association for Machine Translation, Alicante, Spain, 28–30 May 2018; EAMT: Alicante, Spain, 2018; pp. 69–78. [Google Scholar]
- Koehn, P.; Senellart, J. Convergence of Translation Memory and Statistical Machine Translation. In Proceedings of the AMTA Workshop on MT Research and the Translation Industry, Denver, CO, USA, 31 October–4 November 2010; Association for Machine Translation in the Americas: Denver, CO, USA, 2010; pp. 21–31. [Google Scholar]
- Kranias, L.; Samiotou, A. Automatic Translation Memory Fuzzy Match Post-Editing: A Step Beyond Traditional TM/MT Integration. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04), Lisbon, Portugal, 26–28 May 2004; European Language Resources Association (ELRA): Lisbon, Portugal, 2004; pp. 331–334. [Google Scholar]
- Ortega, J.E.; Forcada, M.L.; Sanchez-Martinez, F. Fuzzy-match repair guided by quality estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, S.; Zhang, A.; Wang, D.; Abel, A. Memory-augmented Neural Machine Translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 1390–1399. [Google Scholar] [CrossRef]
- He, Q.; Huang, G.; Cui, Q.; Li, L.; Liu, L. Fast and accurate neural machine translation with translation memory. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 3170–3180. [Google Scholar]
- Khandelwal, U.; Fan, A.; Jurafsky, D.; Zettlemoyer, L.; Lewis, M. Nearest neighbor machine translation. arXiv 2020, arXiv:2010.00710. [Google Scholar]
- Zhang, J.; Utiyama, M.; Sumita, E.; Neubig, G.; Nakamura, S. Guiding Neural Machine Translation with Retrieved Translation Pieces. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 1325–1335. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 30th Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems Foundation: Long Beach, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Hokamp, C.; Liu, Q. Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1535–1546. [Google Scholar] [CrossRef] [Green Version]
- Dabre, R.; Cromieres, F.; Kurohashi, S. Enabling multi-source neural machine translation by concatenating source sentences in multiple languages. arXiv 2017, arXiv:1702.06135. [Google Scholar]
- Hossain, N.; Ghazvininejad, M.; Zettlemoyer, L. Simple and Effective Retrieve-Edit-Rerank Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2532–2538. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, X.; Zhang, H.; Sun, H.; Liu, X. Retrieval-based neural source code summarization. In Proceedings of the 2020 IEEE/ACM 42nd International Conference on Software Engineering (ICSE), Online, 24 June–16 July 2020; pp. 1385–1397. [Google Scholar]
- Li, Z.; Specia, L. Improving Neural Machine Translation Robustness via Data Augmentation: Beyond Back-Translation. In Proceedings of the 5th Workshop on Noisy User-Generated Text, Hong Kong, China, 4 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 328–336. [Google Scholar] [CrossRef]
- Banar, N.; Daelemans, W.; Kestemont, M. Neural machine translation of artwork titles using iconclass codes. In Proceedings of the the 4th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, Online, 12 December 2020; pp. 42–51. [Google Scholar]
- Cai, D.; Wang, Y.; Li, H.; Lam, W.; Liu, L. Neural machine translation with monolingual translation memory. arXiv 2021, arXiv:2105.11269. [Google Scholar]
- Hutchins, W.J.; Somers, H.L. An introduction to Machine Translation; Academic Press London: London, UK, 1992. [Google Scholar]
- Harris, K.; Burchardt, A.; Rehm, G.; Specia, L. Technology Landscape for Quality Evaluation: Combining the Needs of Research and Industry. In Proceedings of the LREC Workshop on Translation Evaluation, Portorož, Slovenia, 24 May 2016; pp. 50–54. [Google Scholar]
- Koby, G.; Fields, P.; Hague, D.; Lommel, A.; Melby, A. Defining translation quality. Revista tradumàtica Traducció i Tecnologies de la Informació i la Comunicació 2014, 12, 413–420. [Google Scholar] [CrossRef] [Green Version]
- Toury, G. The nature and role of norms in translation. Descr. Transl. Stud. Beyond 1995, 4, 53–69. [Google Scholar]
- White, J. Approaches to black box MT evaluation. In Proceedings of the Machine Translation Summit V, Luxembourg, 10–13 July 1995. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; Association for Computational Linguistics: Ann Arbor, MI, USA, 2005; pp. 65–72. [Google Scholar]
- Doddington, G. Automatic Evaluation of Machine Translation Quality Using N-Gram Co-Occurrence Statistics. In Proceedings of the Second International Conference on Human Language Technology Research, San Francisco, CA, USA, 24–27 March 2002; pp. 138–145. [Google Scholar]
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 17–18 September 2015; pp. 392–395. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A study of translation edit rate with targeted human annotation. In Proceedings of the 2006 Conference of the Association for Machine Translation in the Americas, Cambridge, MA, USA, 8–12 August 2006; AMTA: Cambridge, MA, USA, 2006; pp. 223–231. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.; Artzi, Y. BERTScore: Evaluating text generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Rei, R.; Stewart, C.; Farinha, A.; Lavie, A. COMET: A neural framework for MT evaluation. arXiv 2020, arXiv:2009.09025. [Google Scholar]
- Feng, Y.; Xie, W.; Gu, S.; Shao, C.; Zhang, W.; Yang, Z.; Yu, D. Modeling fluency and faithfulness for diverse neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 59–66. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- McCaffery, M.; Nederhof, M.J. DTED: Evaluation of machine translation structure using dependency parsing and tree edit distance. In Proceedings of the First Conference on Machine Translation, Berlin, Germany, 11–12 August 2016; pp. 491–498. [Google Scholar]
- Specia, L.; Raj, D.; Turchi, M. Machine translation evaluation versus quality estimation. Mach. Transl. 2010, 24, 39–50. [Google Scholar] [CrossRef]
- Mathur, N.; Wei, J.; Freitag, M.; Ma, Q.; Bojar, O. Results of the WMT20 metrics shared task. In Proceedings of the Fifth Conference on Machine Translation, Association for Computational Linguistics, Online, 19–20 November 2020; pp. 688–725. [Google Scholar]
- Kocmi, T.; Federmann, C.; Grundkiewicz, R.; Junczys-Dowmunt, M.; Matsushita, H.; Menezes, A. To ship or not to ship: An extensive evaluation of automatic metrics for machine translation. arXiv 2021, arXiv:2107.10821. [Google Scholar]
- Freitag, M.; Rei, R.; Mathur, N.; Lo, C.; Stewart, C.; Foster, G.; Lavie, A.; Bojar, O. Results of the WMT21 Metrics Shared Task: Evaluating Metrics with Expert-based Human Evaluations on TED and News Domain. In Proceedings of the Sixth Conference on Machine Translation, Association for Computational Linguistics, Online, 10–11 November 2021. [Google Scholar]
- Callison-Burch, C.; Fordyce, C.; Koehn, P.; Monz, C.; Schroeder, J. Further meta-evaluation of machine translation. In Proceedings of the Third Workshop on Statistical Machine Translation, Columbus, OH, USA, 19 June 2008; pp. 70–106. [Google Scholar]
- Graham, Y.; Baldwin, T.; Moffat, A.; Zobel, J. Continuous measurement scales in human evaluation of machine translation. In Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Columbus, OH, USA, 19 June 2013; pp. 33–41. [Google Scholar]
- Bentivogli, L.; Cettolo, M.; Federico, M.; Federmann, C. Machine translation human evaluation: An investigation of evaluation based on post-editing and its relation with direct assessment. In Proceedings of the 15th International Workshop on Spoken Language Translation, Bruges, Belgium, 29–30 October 2018; pp. 62–69. [Google Scholar]
- Sanchez-Torron, M.; Koehn, P. Machine Translation Quality and Post-Editor Productivity. In Proceedings of the Conference of the Association for Machine Translation in the Americas (AMTA) Vol. 1: MT Researchers’ Track, Austin, TX, USA, 28 October–1 November 2016; Association for Machine Translation in the Americas (AMTA): Austin, TX, USA, 2016; pp. 16–26. [Google Scholar]
- Läubli, S.; Fishel, M.; Massey, G.; Ehrensberger-Dow, M.; Volk, M.; O’Brien, S.; Simard, M.; Specia, L. Assessing post-editing efficiency in a realistic translation environment. In Proceedings of the MT Summit XIV Workshop on Post-editing Technology and Practice, Nice, France, 3 September 2013; pp. 83–91. [Google Scholar]
- Daems, J. A translation Robot for Each Translator?: A Comparative Study of Manual Translation and Post-Editing of Machine Translations: Process, Quality and Translator Attitude. Ph.D. Thesis, Ghent University, Ghent, Belgium, 2016. [Google Scholar]
- Vilar, D.; Xu, J.; D’Haro, L.F.; Ney, H. Error Analysis of Statistical Machine Translation Output. In Proceedings of the International Conference on Language Resources and Evaluation (LREC), Genoa, Italy, 22–28 May 2006; pp. 697–702. [Google Scholar]
- Avramidis, E.; Koehn, P. Enriching morphologically poor languages for statistical machine translation. In Proceedings of the Association for Computer Linguistics (ACL), Columbus, OH, USA, 15–20 June 2008; pp. 763–770. [Google Scholar]
- Farrús, M.; Costa-Jussa, M.; Marino, J.; Poch, M.; Hernández, A.; Henríquez, C.; Fonollosa, J. Overcoming statistical machine translation limitations: Error analysis and proposed solutions for the Catalan–Spanish language pair. Lang. Resour. Eval. 2011, 45, 181–208. [Google Scholar] [CrossRef] [Green Version]
- Costa, A.; Ling, W.; Luís, T.; Correia, R.; Coheur, L. A linguistically motivated taxonomy for Machine Translation error analysis. Mach. Transl. 2015, 29, 127–161. [Google Scholar] [CrossRef] [Green Version]
- Lommel, A.; Burchardt, A.; Uszkoreit, H. Multidimensional Quality Metrics (MQM): A Framework for Declaring and Describing Translation Quality Metrics. Tradumàtica 2014, 12, 455–463. [Google Scholar] [CrossRef] [Green Version]
- Tezcan, A.; Hoste, V.; Macken, L. SCATE taxonomy and corpus of machine translation errors. Trends E-tools Resour. Transl. Interpret. 2017, 32, 219–244. [Google Scholar]
- Klubička, F.; Toral, A.; Sánchez-Cartagena, V. Fine-grained human evaluation of neural versus phrase-based machine translation. arXiv 2017, arXiv:1706.04389. [Google Scholar]
- Lommel, A.; Popović, M.; Burchardt, A. Assessing Inter-Annotator Agreement for Translation Error Annotation. In Proceedings of the International Conference on Language Resources and Evaluation (LREC), Workshop on Automatic and Manual Metrics for Operational Translation Evaluation, Reykjavik, Iceland, 26 May 2014. [Google Scholar]
- Tezcan, A.; Daems, J.; Macken, L. When a ‘sport’ is a person and other issues for NMT of novels. In Proceedings of the Qualities of Literary Machine Translation, Florence, Italy, 19 August 2019; European Association for Machine Translation: Dublin, Ireland, 2019; pp. 40–49. [Google Scholar]
- Vardaro, J.; Schaeffer, M.; Hansen-Schirra, S. Translation quality and error recognition in professional neural machine translation post-editing. In Informatics; Multidisciplinary Digital Publishing Institute: Basel, Switzerland, 2019; Volume 6, p. 41. [Google Scholar]
- Hayakawa, T.; Arase, Y. Fine-Grained Error Analysis on English-to-Japanese Machine Translation in the Medical Domain. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisbon, Portugal, 3–5 November 2020; pp. 155–164. [Google Scholar]
- Läubli, S.; Sennrich, R.; Volk, M. Has Machine Translation Achieved Human Parity? A Case for Document-level Evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2–4 November 2018; pp. 4791–4796. [Google Scholar]
- Macken, L.; Prou, D.; Tezcan, A. Quantifying the effect of machine translation in a high-quality human translation production process. Informatics 2020, 7, 12. [Google Scholar] [CrossRef] [Green Version]
- Steinberger, R.; Eisele, A.; Klocek, S.; Pilos, S.; Schlüter, P. DGT-TM: A freely available Translation Memory in 22 languages. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; European Language Resources Association (ELRA): Istanbul, Turkey, 2012; pp. 454–459. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open Source Toolkit for Statistical Machine Translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 177–180. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. OpenNMT: Open-source toolkit for neural machine translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 528–540. [Google Scholar] [CrossRef]
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. IEEE Trans. Big Data 2019, 7, 535–547. [Google Scholar] [CrossRef] [Green Version]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 1715–1725. [Google Scholar] [CrossRef]
- Och, F.J.; Ney, H. A Systematic Comparison of Various Statistical Alignment Models. Comput. Linguist. 2003, 29, 19–51. [Google Scholar] [CrossRef]
- Pawlik, M.; Augsten, N. Efficient computation of the tree edit distance. ACM Trans. Database Syst. 2015, 40, 1–40. [Google Scholar] [CrossRef]
- Koponen, M.; Aziz, W.; Ramos, L.; Specia, L. Post-editing time as a measure of cognitive effort. In Proceedings of the Association for Computer Linguistics (ACL), Workshop on Post-Editing Technology and Practice, San Diego, CA, USA, 28 October–1 November 2012; pp. 11–20. [Google Scholar]
- Koponen, M. Comparing human perceptions of post-editing effort with post-editing operations. In Proceedings of the Seventh Workshop on Statistical Machine Translation, Montreal, QC, Canada, 7–8 June 2012; pp. 181–190. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor universal: Language specific translation evaluation for any target language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 26–27 June 2014; pp. 376–380. [Google Scholar]
- Nivre, J.; De Marneffe, M.C.; Ginter, F.; Goldberg, Y.; Hajic, J.; Manning, C.D.; McDonald, R.; Petrov, S.; Pyysalo, S.; Silveira, N.; et al. Universal dependencies v1: A multilingual treebank collection. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Miyazaki, Japan, 23–28 May 2016; pp. 1659–1666. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. arXiv 2020, arXiv:2003.07082. [Google Scholar]
- Fonteyne, M.; Tezcan, A.; Macken, L. Literary Machine Translation under the Magnifying Glass: Assessing the Quality of an NMT-Translated Detective Novel on Document Level. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 7–12 May 2020; pp. 3790–3798. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2020. [Google Scholar]
- Ripley, B.; Venables, B.; Bates, D.; Hornik, K.; Gebhardt, A.; Firth, D. Package ‘Mass’. Available online: https://cran.r-project.org/web/packages/MASS/index.html (accessed on 20 October 2021).
- Akaike, H. Information theory and an extension of the maximum likelihood principle. In Proceeding of the Second International Symposium on Information Theory, Tsahkadsor, Armenia, U.S.S.R., 2–8 September 1971; Akademiai Kiado: Armenia, U.S.S.R., 1973; pp. 267–281. [Google Scholar]
- Federico, M.; Cattelan, A.; Trombetti, M. Measuring user productivity in machine translation enhanced computer assisted translation. In Proceedings of the 2012 Conference of the Association for Machine Translation in the Americas, San Diego, CA, USA, 28 October–1 November 2012; pp. 44–56. [Google Scholar]
- Zouhar, V.; Vojtěchová, T.; Bojar, O. WMT20 document-level markable error exploration. In Proceedings of the Fifth Conference on Machine Translation, Online, 19–20 November 2020; pp. 371–380. [Google Scholar]
- Tezcan, A.; Hoste, V.; Macken, L. Estimating post-editing time using a gold-standard set of machine translation errors. Comput. Speech Lang. 2019, 55, 120–144. [Google Scholar] [CrossRef]
- Federico, M.; Negri, M.; Bentivogli, L.; Turchi, M. Assessing the impact of translation errors on machine translation quality with mixed-effects models. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1643–1653. [Google Scholar]
- Daems, J.; Vandepitte, S.; Hartsuiker, R.; Macken, L. Identifying the machine translation error types with the greatest impact on post-editing effort. Front. Front. Psychol. 2017, 8, 1282. [Google Scholar] [CrossRef] [Green Version]



| 50–59% | 60–69% | 70–79% | 80–89% | 90–99% | All | ||
|---|---|---|---|---|---|---|---|
| Test set | Sentences | 459 | 1012 | 1012 | 1192 | 2514 | 6207 |
| % of total | 7.4% | 16.3% | 16.3% | 19.2% | 40.5% | ||
| Subset | Sentences | 30 | 60 | 60 | 75 | 75 | 300 |
| % of total | 10% | 20% | 20% | 25% | 25% |
| Metric | Method | Unit | Quality Dimension Targeted |
|---|---|---|---|
| BLEU | N-gram precision | Token string | Exact lexical overlap |
| METEOR | N-gram precision | Token string | Lexical overlap (with morphological and lexical variation) |
| TER | Edit distance | Token string | Minimum number of edits (technical PE effort) |
| chrF | N-gram F-score | Character string | Exact sub-word level overlap |
| BERTScore | Vector similarity | Token embedding | Semantic similarity |
| COMET | Vector similarity | Sentence embedding | Semantic similarity (predicting human quality ratings) |
| DTED | Edit distance | Token dep. label | Syntactic similarity |
| Token Level | Sentence Level | |
|---|---|---|
| Baseline NMT | 0.495 | 0.611 |
| NFR | 0.522 | 0.688 |
| Baseline NMT | NFR | |
|---|---|---|
| Level 1 | ||
| Accuracy vs. Fluency | 0.978 | 1 |
| Level 2 | ||
| Accuracy | 0.902 | 0.935 |
| Fluency | 0.804 | 0.860 |
| Level 3 | ||
| Accuracy → Mistranslation | 0.596 | 0.763 |
| Fluency → Style and Register | 1 | 1 |
| Vocabulary frequency |
|---|
| % of frequent/rare words in source sentence |
| Sentence length |
| Length of source sentence |
| Length ratios of source sentence, FM1 and FM2 |
| FM similarity |
| FM scores |
| Ratio of match/no-match tokens in FMs |
| Syntax |
| DTED between sources, FM1 and FM2 |
| BLEU ↑ | METEOR ↑ | TER ↓ | chrF ↑ | BERTScore ↑ | COMET ↑ | DTED ↓ | |
|---|---|---|---|---|---|---|---|
| TM | 44.49 | 56.10 | 60.26 | 59.67 | 84.86 | 14.46 | 63.09 |
| Baseline NMT | 58.87 | 75.53 | 29.66 | 75.52 | 92.56 | 78.33 | 29.76 |
| NFR | 66.07 | 79.45 | 25.25 | 79.33 | 93.49 | 81.79 | 26.33 |
| NMT vs. NFR | |||||||
| Absolute diff. | +7.20 | +3.02 | −4.41 | +3.81 | +0.93 | +3.46 | +3.43 |
| Relative diff. | +12.23% | +5.19% | −14.87% | +5.05% | +1.00% | +4.42% | +11.53% |
| Z-score diff. | +0.157 | +0.124 | −0.125 | +0.155 | +0.134 | +0.077 | −0.108 |
| All | 50–59% | 60–69% | 70–79% | 80–89% | 90–99% | |
|---|---|---|---|---|---|---|
| TM | 44.49 | 5.18 | 10.77 | 23.52 | 43.99 | 75.25 |
| Baseline NMT | 58.87 | 34.64 | 42.94 | 50.24 | 59.09 | 74.64 |
| NFR | 66.07 | 35.97 | 43.63 | 53.93 | 67.29 | 85.24 |
| METEOR ↑ | TER ↓ | chrF ↑ | BERTScore ↑ | COMET ↑ | DTED ↓ | |
|---|---|---|---|---|---|---|
| METEOR | 1 | −0.811 | 0.923 | 0.902 | 0.747 | −0.661 |
| TER | −0.852 | 1 | −0.781 | −0.806 | −0.693 | 0.838 |
| chrF | 0.916 | −0.818 | 1 | 0.934 | 0.797 | −0.646 |
| BERTScore | 0.890 | −0.831 | 0.929 | 1 | 0.824 | −0.728 |
| COMET | 0.739 | −0.695 | 0.796 | 0.820 | 1 | −0.608 |
| DTED | −0.648 | 0.801 | −0.637 | −0.723 | −0.591 | 1 |
| Baseline NMT | NFR | NMT vs. NFR | ||||
|---|---|---|---|---|---|---|
| Total | /Sent | Total | /Sent | % Difference | ||
| Insertions | Content words | 4747 | 0.76 | 4239 | 0.68 | −10.70 |
| Function words | 5527 | 0.89 | 4966 | 0.80 | −10.15 | |
| Other | 1114 | 0.18 | 1089 | 0.18 | −2.24 | |
| Total | 11,388 | 1.83 | 10,294 | 1.66 | −9.61 | |
| Deletions | Content words | 3063 | 0.49 | 2677 | 0.43 | −12.60 |
| Function words | 3609 | 0.58 | 3102 | 0.50 | −14.05 | |
| Other | 475 | 0.08 | 431 | 0.07 | −9.26 | |
| Total | 7147 | 1.15 | 6210 | 1.00 | −13.11 | |
| Substitutions | Content words | 12,258 | 1.97 | 10,146 | 1.63 | −17.23 |
| Function words | 8511 | 1.37 | 7030 | 1.13 | −17.40 | |
| Other | 919 | 0.15 | 832 | 0.13 | −9.47 | |
| Total | 21,688 | 3.49 | 18,008 | 2.90 | −16.97 | |
| Token shifts | Content words | 3253 | 0.52 | 2651 | 0.43 | −18.51 |
| Function words | 4552 | 0.73 | 3610 | 0.58 | −20.69 | |
| Other | 415 | 0.07 | 352 | 0.06 | −15.18 | |
| Total | 8220 | 1.32 | 6613 | 1.07 | −19.55 | |
| Total token-level edits | 48,443 | 7.80 | 41,125 | 6.62 | −15.10 | |
| Group shifts | 2255 | 0.36 | 1832 | 0.30 | −18.76 | |
| Baseline NMT | NFR | |
|---|---|---|
| Number of errors | 199 | 199 |
| Number of erroneous tokens | 395 | 442 |
| % of erroneous tokens | 7.0% | 7.9% |
| Number of sentences with error(s) | 120 | 123 |
| % of sentences with error(s) | 40% | 41% |
| BASE | NFR | BASE | NFR | ||
|---|---|---|---|---|---|
| FLUENCY | 89 | 71 | ACCURACY | 110 | 128 |
| • Coherence | 20 | 11 | • Mistranslation | 58 | 57 |
| ○ Logical problem | 18 | 9 | ○ Multiword expression | 10 | 5 |
| ○ Co-reference | — | — | ○ Semantically unrelated | 12 | 27 |
| ○ Cultural reference | — | — | ○ Word sense | 14 | 8 |
| ○ Verb tense | 2 | 2 | ○ Part-of-speech | 2 | 1 |
| ○ Inconsistency | — | — | ○ Partial | — | — |
| • Grammar and Syntax | 8 | 15 | ○ Other | 20 | 16 |
| ○ Extra word | 2 | 1 | • Omission | 36 | 40 |
| ○ Missing word | 2 | 6 | • Addition | 8 | 25 |
| ○ Multi-word syntax | — | — | • Do-not-translate | — | — |
| ○ Word order | 2 | 2 | • Untranslated | 2 | — |
| ○ Word form | 2 | 6 | • Mechanical | 4 | 5 |
| ○ Other | — | — | ○ Capitalization | — | — |
| • Lexicon | 29 | 12 | ○ Punctuation | 4 | 5 |
| ○ Lexical choice | 17 | 9 | ○ Other | — | — |
| ○ Non-existing/Foreign | 7 | 1 | • Other | 2 | 1 |
| ○ Wrong preposition | 5 | 2 | |||
| • Orthography | 2 | 4 | |||
| ○ Punctuation | 2 | 1 | |||
| ○ Capitalization | — | — | |||
| ○ Spelling | — | 3 | |||
| ○ Other | — | — | |||
| • Style and Register | 30 | 29 | |||
| ○ Disfluent | 26 | 26 | |||
| ○ Register | 1 | 1 | |||
| ○ Repetition | 3 | 2 | |||
| ○ Untranslated | — | — |
| Full Test Set | 50–59% | 90–99% | ||
|---|---|---|---|---|
| NFR | Baseline NMT | NFR | NFR | |
| Fuzzy match 1 | ||||
| % m/FM1 | 62.2 | — | 26.6 | 82.7 |
| % m-pass | 88.4 | 82.6 | 74.5 | 95.8 |
| % m-pass-REF | 69.5 | 66.6 | 59.5 | 77.4 |
| % nm/FM1 | 37.8 | — | 73.4 | 17.3 |
| % nm-pass | 36.5 | 31.9 | 23.5 | 45.8 |
| % nm-pass-REF | 29.6 | 27.3 | 17.4 | 38.7 |
| Fuzzy match 2 | ||||
| % m/FM2 | 46.8 | — | 22.8 | 63.7 |
| % m-pass | 82.1 | 80.2 | 69.8 | 89.0 |
| % m-pass-REF | 66.4 | 65.4 | 54.0 | 74.7 |
| % nm/FM2 | 53.2 | — | 77.2 | 36.3 |
| % nm-pass | 26.8 | 25.7 | 11.5 | 32.5 |
| % nm-pass-REF | 23.1 | 22.3 | 16.6 | 29.1 |
| NFR Better | Baseline Better | T Test | |||||
|---|---|---|---|---|---|---|---|
| (n = 1310) | (n = 579) | ||||||
| Mean | SD | Mean | SD | t | p | d | |
| Vocabulary frequency | |||||||
| % Q99 | 45.7 | 16.9 | 48.5 | 19.7 | 3.13 | 0.002 | 0.16 |
| % Q90 | 18.5 | 14.3 | 19.7 | 16.7 | 1.54 | 0.123 | 0.08 |
| % Q75 | 8.3 | 9.4 | 8.8 | 10.8 | 0.99 | 0.323 | 0.05 |
| Length | |||||||
| Source | 30.2 | 20.4 | 25.5 | 19.8 | −4.64 | <0.001 | 0.23 |
| FM1/source | 1.14 | 0.57 | 1.14 | 0.71 | 0.16 | 0.875 | 0.00 |
| FM2/source | 1.53 | 1.41 | 1.67 | 1.45 | 1.95 | 0.051 | 0.10 |
| FM2/FM1 | 1.47 | 1.16 | 1.17 | 1.70 | 1.25 | 0.213 | 0.22 |
| FM similarity | |||||||
| FM1 score | 84.3 | 13.1 | 76.0 | 14.4 | −12.27 | <0.001 | 0.61 |
| % m/FM1 | 65.9 | 26.2 | 53.8 | 29.2 | −8.91 | <0.001 | 0.45 |
| FM2 score | 69.1 | 14.5 | 65.8 | 15.0 | −4.53 | <0.001 | 0.23 |
| % m/FM2 | 41.7 | 26.8 | 38.1 | 26.4 | −2.68 | 0.007 | 0.14 |
| total_m/source | 87.1 | 28.9 | 77.9 | 42.4 | −5.48 | <0.001 | 0.27 |
| Syntax—DTED | |||||||
| Source vs. FM1 | 0.86 | 0.42 | 0.84 | 0.48 | −0.37 | 0.709 | 0.04 |
| Source vs. FM2 | 1.23 | 1.01 | 1.46 | 2.17 | 1.44 | 0.151 | 0.16 |
| FM1 vs. FM2 | 1.09 | 1.22 | 0.85 | 0.55 | −2.50 | 0.013 | 0.22 |
| Parameter | b | S.E. | t | p | |
|---|---|---|---|---|---|
| (Intercept) | −12.3 | 1.71 | −7.24 | <0.001 *** | |
| Length source | 0.055 | 0.012 | 0.065 | 4.72 | <0.001 *** |
| Length FM1/FM2 | 2.62 | 1.00 | 0.041 | 2.62 | 0.009 ** |
| FM1 score | 40.41 | 2.94 | 0.323 | 13.76 | <0.001 *** |
| FM2 score | −34.74 | 2.50 | −0.302 | −13.87 | <0.001 *** |
| total_m/source | 4.63 | 1.37 | 0.060 | 3.38 | <0.001 *** |
| DTED FM1 vs. FM2 | 1.48 | 0.59 | 0.041 | 2.52 | 0.012 * |
| System | All Errors | Fluency | Accuracy |
|---|---|---|---|
| Baseline NMT | 17 (8.5%) | 6 (6.7%) | 11 (10%) |
| NFR | 36 (18.1%) | 9 (12.6%) | 27 (21.1%) |
| Segment | |
|---|---|
| Source (EN) | Furthermore, the importers and the retailers will not be substantially |
| affected | |
| Baseline NMT (NL) | Bovendien zullen de importeurs en detailhandelaren geen grote gevolgen |
| ondervinden | |
| NFR (NL) | Bovendien zullen de importeurs en detailhandelaren geen ernstige gevolgen |
| van de maatregelen ondervinden | |
| Reference (NL) | Bovendien zullen de importeurs en kleinhandelaren geen ernstige gevolgen |
| van de maatregelen ondervinden |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tezcan, A.; Bulté, B. Evaluating the Impact of Integrating Similar Translations into Neural Machine Translation. Information 2022, 13, 19. https://doi.org/10.3390/info13010019
Tezcan A, Bulté B. Evaluating the Impact of Integrating Similar Translations into Neural Machine Translation. Information. 2022; 13(1):19. https://doi.org/10.3390/info13010019
Chicago/Turabian StyleTezcan, Arda, and Bram Bulté. 2022. "Evaluating the Impact of Integrating Similar Translations into Neural Machine Translation" Information 13, no. 1: 19. https://doi.org/10.3390/info13010019
APA StyleTezcan, A., & Bulté, B. (2022). Evaluating the Impact of Integrating Similar Translations into Neural Machine Translation. Information, 13(1), 19. https://doi.org/10.3390/info13010019