
Measuring Terminology Consistency in Translated Corpora: Implementation of the Herfindahl-Hirshman Index


Abstract
1. Introduction
2. Related Work
3. Research
3.1. Dataset
- i.
- Croatian-English parallel corpus (1991–2009)—Croatian legislative texts translated into English by 39 translators, as in Gašpar (2013) [45];
- ii.
- Canon Law corpus (1983)—English and Croatian versions of the Latin original text of The Code of Canon Law (CCL), available at http://www.arcc-catholic-rights.net/code_of_canon_law_1983.htm, accessed on 29 October 2021; https://zrno.wordpress.com/teoloske-teme/crkveni-dokumenti/zakonik-kanonskog-prava-1983/, accessed on 29 October 2021; the Croatian version was translated by 18 translators, as in Zec (2011) [46];
- iii.
- EU legislation corpus (2013–)—English and Croatian versions of the EU legislation, comprising legislative texts (reports, protocols, agreements, regulations, working documents) from 2013, available at http://eur-lex.europa.eu/homepage.html, accessed on 29 October 2021.
3.2. Methods and Tools
3.3. HHI
4. Results and Discussion
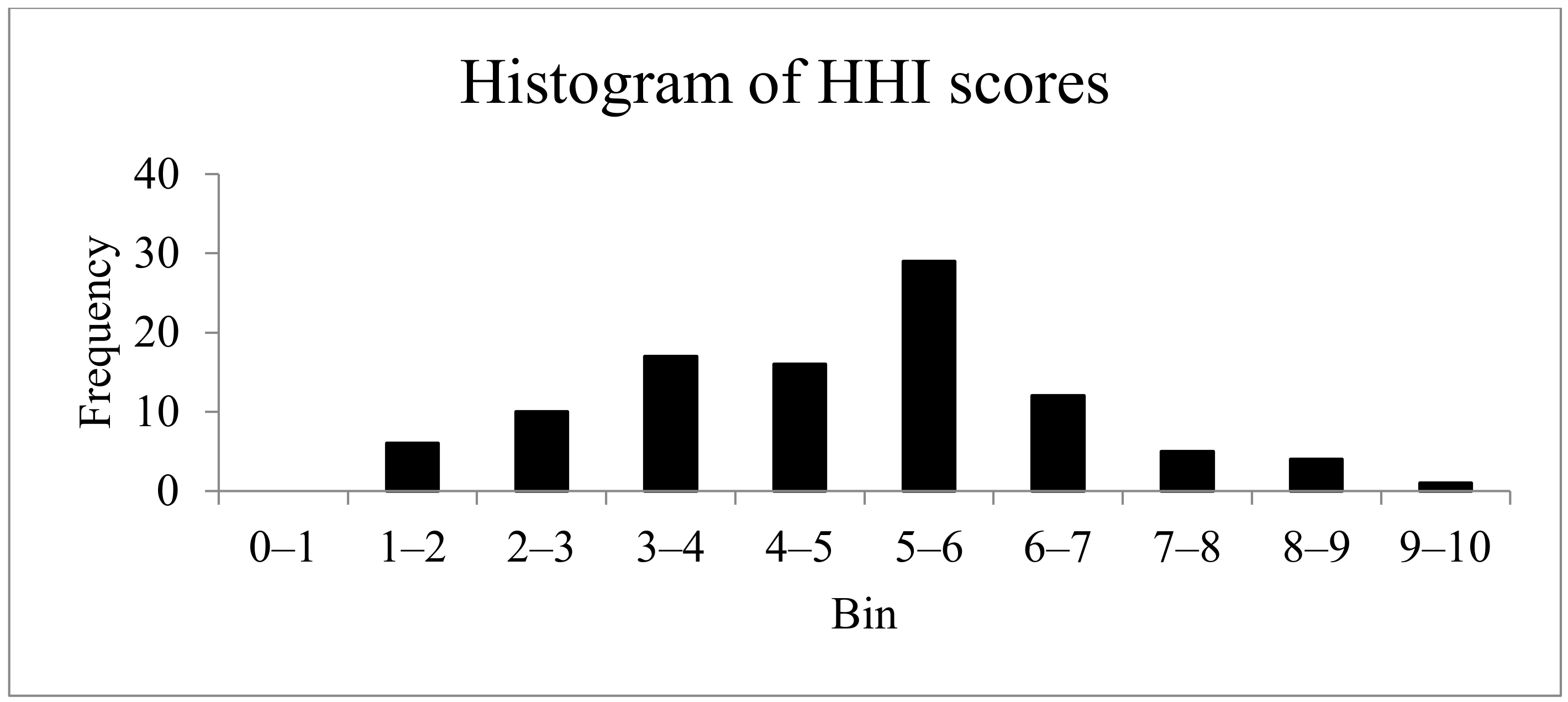
4.1. HHI for Croatian–English Parallel Corpus
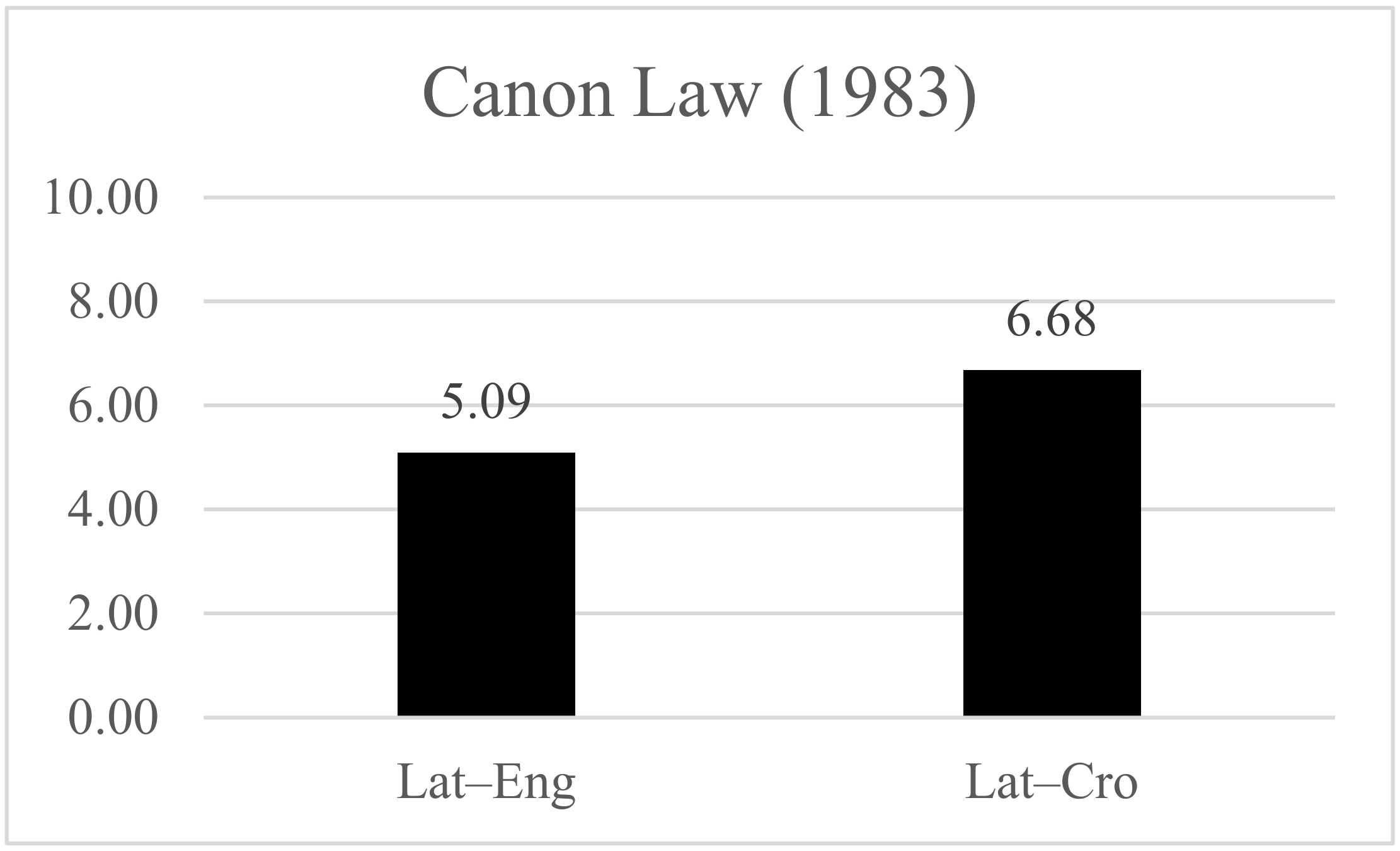
4.2. HHI for Canon Law Sample Corpus
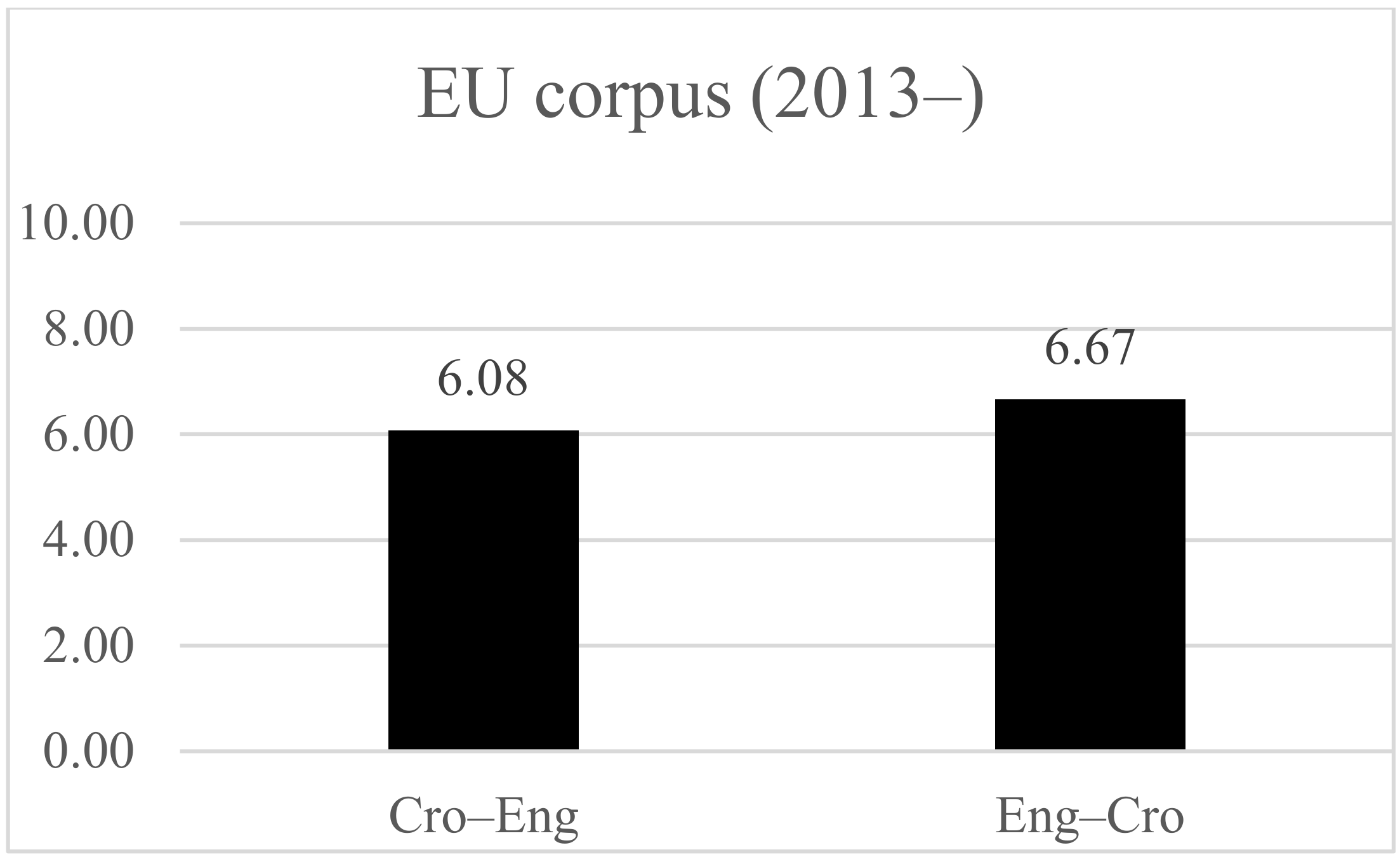
4.3. HHI for EU Legislation Sample Subcorpus
- -
- Eng. general provisions/Cro. opće odredbe, opći akti, uvodne odredbe;
- -
- Eng. in accordance with/Cro. sukladno, u skladu s, prema;
- -
- Eng. authorized representative/Cro. predstavnik, zastupnik, osoba ovlaštena za zastupanje, opunomoćenik;
- -
- Cro. žalba protiv rješenja/Eng. appeal against the ruling, appeal lodged against a decision, appeal against the decision;
- -
- Cro. rješenje iz stavka/Eng. decision referred to in/under paragraph, notice referred to in paragraph, ruling from paragraph, decision from paragraph, rules referred to in paragraph, formal decision from paragraph,
- -
- Cro. laici/Eng. lay members, laymen, lay people, lay persons, etc.
- -
- Eng. public institution/Cro. javna ustanova,
- -
- Eng. religious community/Cro. vjerska zajednica,
- -
- Eng. rights and freedoms/Cro. prava i slobode,
- -
- Eng. legal person/Cro. pravna osoba,
- -
- Eng. official seal/Cro. službeni pečat.
4.4. Analysis of the Overall Term Structure
4.5. Diachronic Analysis of the Croatian–English Parallel Corpus
- 10 documents created from 1991 to 2005 (before the publication of the Croatian Style Guide) and 10 documents from 2006 to 2009 (including 2006).
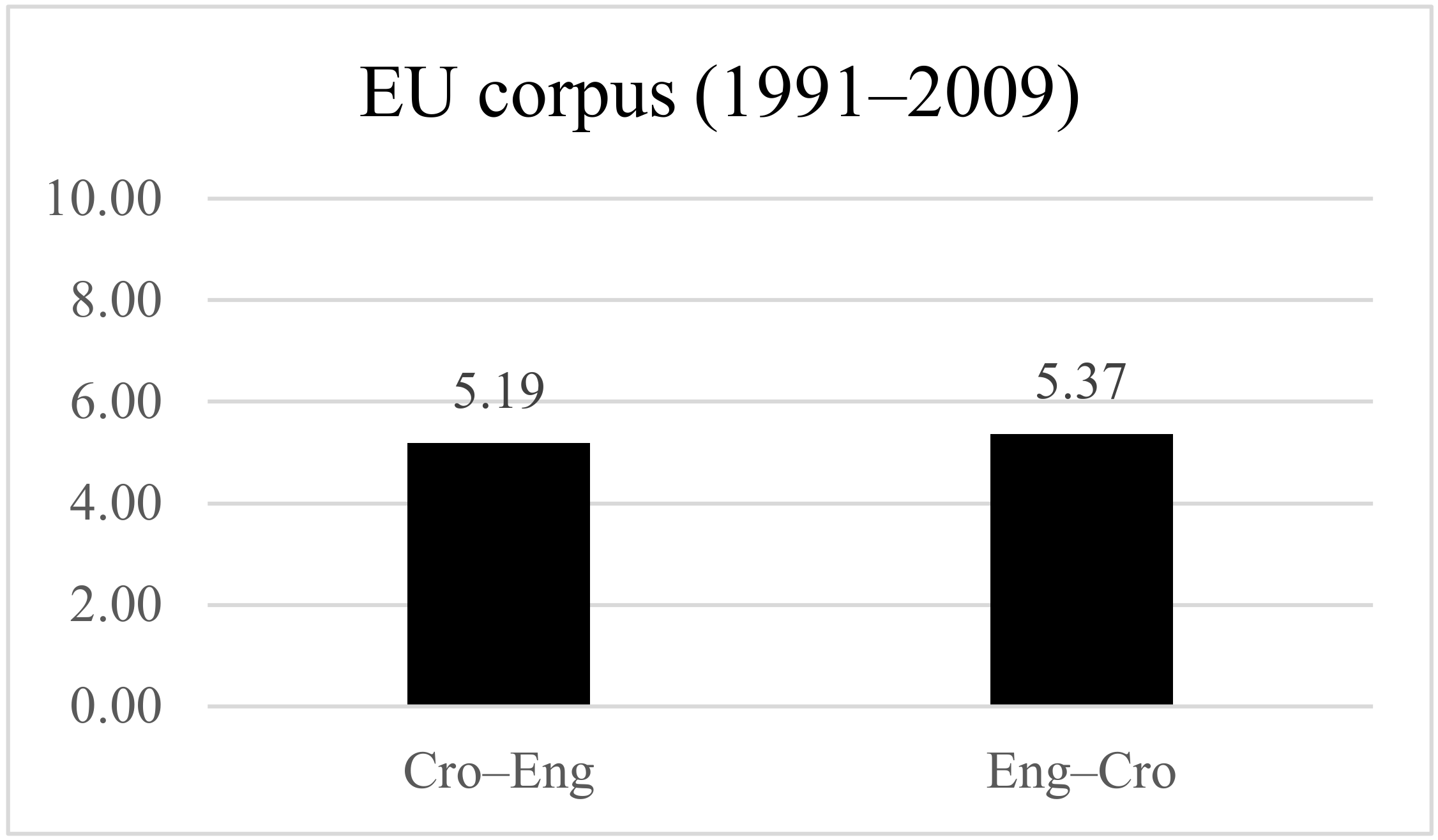
- The average HHI for the 100 terms of the entire corpus (1991–2009) was 4.81 for Croatian–English.
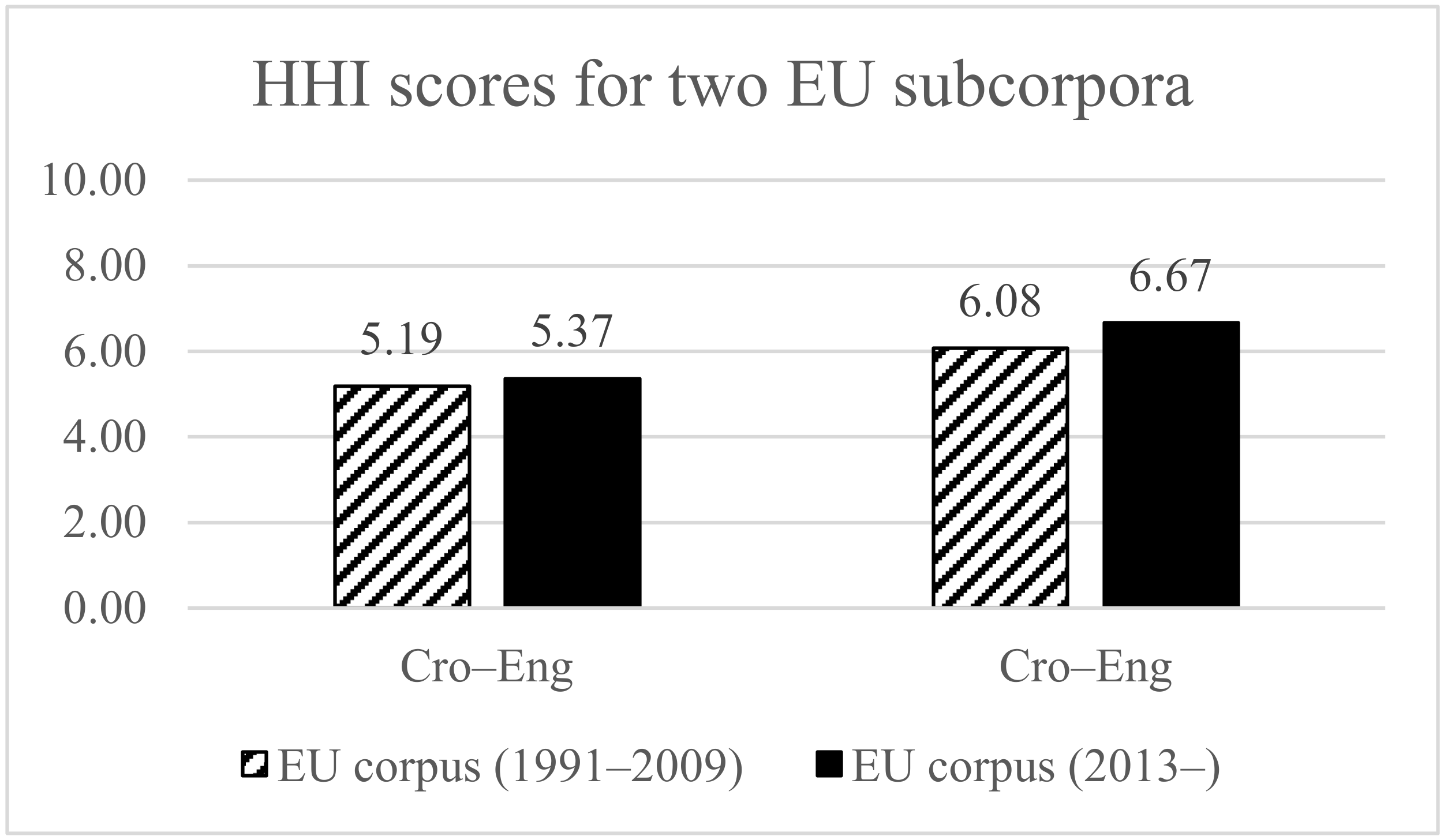
- The average HHI for 15 terms for 10 documents (1991–2005) translated from Croatian into English, before the Croatian Style Guide publication was 5.19.
- The average HHI for the same set of 15 term candidates, for 10 documents (2006–2009) after the Croatian Manual publication (2005) was 5.37.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guillou, L. Analysing Lexical Consistency in Translation. In Proceedings of the Workshop on Discourse in Machine Translation, Sofia, Bulgaria, 9 August 2013; pp. 10–18. [Google Scholar]
- Ninova, G.; Nazarenko, A.; Hamon, T.; Szulman, S. Comment Mesurer La Couverture D’une Ressource Terminologique Pour Un Corpus; ATALA: Dourdan, France, 2005; pp. 293–302. [Google Scholar]
- Bloomquist, M.S.; Powell, J.; Masand, R.P.; Dhall, D.; Karamchandani, D.M.; Jain, S. Lack of uniformity in reporting autoimmune gastritis among a diverse group of pathologists. Ann. Diagn. Pathol. 2021, 56, 151840. [Google Scholar] [CrossRef] [PubMed]
- Keloth, V.K.; Geller, J.; Chen, Y.; Xu, J. Extending import detection algorithms for concept import from two to three biomedical terminologies. BMC Med. Informatics Decis. Mak. 2020, 20, 1–11. [Google Scholar] [CrossRef] [PubMed]
- McAleavy, T. Interoperability and standardization: Lessons from the fruit-bowl. Disaster Prev. Manag. Int. J. 2021, 30, 480–493. [Google Scholar] [CrossRef]
- Christensen, L.L.W.; Madsen, B.N. A Danish terminological ontology of incident management in the field of disaster management. J. Contingencies Crisis Manag. 2020, 28, 466–478. [Google Scholar] [CrossRef]
- Gottfried, T. Sozialmedizinische Beurteilung im Rahmen der Rehabilitation. Orthopäde 2021, 50, 11. [Google Scholar] [CrossRef]
- Pettinicchio, D.; Maroto, M. Who Counts? Measuring Disability Cross-Nationally in Census Data. J. Surv. Stat. Methodol. 2021, 9, 257–284. [Google Scholar] [CrossRef]
- Pozzo, B. Looking for a Consistent Terminology in European Contract Law. Lang. Cult. Meditatio 2020, 7. [Google Scholar] [CrossRef]
- Komissarov, M.; Donetsk State University of Internal Affairs; Komissarova, N. Terminology of Criminal Law. Law J. Donbass 2021, 75. [Google Scholar] [CrossRef]
- Kizil, M. Terms of designation of persons in juridical terminology of British and American Variants of the English language. Res. Bull. Ser. Philol. Sci. 2021, 1, 231–235. [Google Scholar] [CrossRef]
- Zhilina, N.Y.; Lukyanchikova, E.F.; Kovalenko, D.V.; Mironuk, I.V.; Prokhorova, M.L. Terminological description of extremism in international acts and national criminal laws. Linguistics Cult. Rev. 2021, 5, 942–949. [Google Scholar] [CrossRef]
- European Commission, Directorate-General for Translation. Quantifying Quality Costs and the Cost of Poor Quality in Translation: Quality Efforts and the Consequences of Poor Quality in the European Commission’s Directorate-General for Translation, Publications Office. 2012. Available online: https://data.europa.eu/doi/10.2782/44381 (accessed on 29 October 2021).
- Seljan, S.; Baretić, M.; Kučiš, V. Information Retrieval and Terminology Extraction in Online Resources for Patients with Diabetes. Coll. Antropol. 2014, 38, 705–710, PMID: 25145011. Available online: https://pubmed.ncbi.nlm.nih.gov/25145011/ (accessed on 29 October 2021). [PubMed]
- Krauss, P.; Touré, V.; Gnodtke, K.; Crameri, K.; Österle, S. DCC Terminology Service—An Automated CI/CD Pipeline for Converting Clinical and Biomedical Terminologies in Graph Format for the Swiss Personalized Health Network. Appl. Sci. 2021, 11, 11311. [Google Scholar] [CrossRef]
- Kachlik, D.; Varga, I.; Báča, V.; Musil, V. Variant Anatomy and Its Terminology. Medicina 2020, 56, 713. [Google Scholar] [CrossRef]
- Barnett, K.A. Medical Terminology. In Practical Imaging Informatics; Springer: Singapore, 2021; pp. 15–23. [Google Scholar]
- Marshall, D.; Bano, F.; Banas, K. A meaty issue: The effect of meat-related label terminology on the willingness to eat vegetarian foods. Food Qual. Preference 2022, 96, 104413. [Google Scholar] [CrossRef]
- Watson, L.; Falconer, L.; Dale, T.; Telfer, T.C. ‘Offshore’ salmon aquaculture and identifying the needs for environmental regulation. Aquaculture 2021, 546, 737342. [Google Scholar] [CrossRef]
- Rampasso, A.S.; O’Grady, P.M. Standardized terminology and visual atlas of the external morphology and terminalia for the genus Scaptomyza (Diptera: Drosophilidae). Fly 2022, 16, 37–61. [Google Scholar] [CrossRef]
- Lanza, C.; Folino, A.; Pasceri, E.; Perri, A. Lexicon of pandemics: A semantic analysis of the Spanish flu and the COVID-19 timeframe terminology. J. Doc. 2021. [Google Scholar] [CrossRef]
- Baumüller, J.; Sopp, K. Double materiality and the shift from non-financial to European sustainability reporting: Review, outlook and implications. J. Appl. Account. Res. 2021. ahead-of-print. [Google Scholar] [CrossRef]
- Drouin, P.; Francœur, A.; Humbley, J.; Picton, A. Multiple Perspectives on Terminological Variation; John Benjamins: Amsterdam, The Netherlands, 2017. [Google Scholar] [CrossRef]
- Araúz, P.L.; García, M.C. Term and translation variation of multiword terms. MonTi Monogr. De Traducción E Interpret. 2002, (special issue 6), 210–247. [Google Scholar] [CrossRef]
- Ramos, F.P. Translating legal terminology and phraseology: Between inter-systemic incongruity and multilingual harmonization. Perspectives 2021, 29, 175–183. [Google Scholar] [CrossRef]
- Kerremans, K. Comparative Study of Terminological Variation in Specialised Translation. Reconceptualizing LSP. XVII Eur. LSP Symp. 2010, 2009, 1–14. [Google Scholar]
- Condamines, A. Variations in terminology. Terminology 2010, 16, 30–50. [Google Scholar] [CrossRef]
- Candel-Mora M, Á.; Carrió Pastor, M. Corpus Analysis: A Pragmatic perspective on term Variation. RESLA. Rev. Española De Lingüística Apl. 2012, 25, 33–50. [Google Scholar]
- Thomas, I.; Atanassova, I. Towards the Enrichment of Terminological Resources by Scientific Corpora Analysis. Electron. Lexicogr. 21st Century: Link. Lex. Data Digit. Age. 2015, pp. 136–151. Available online: https://elex.link/elex2015/proceedings/eLex_2015_09_Thomas+Atanassova.pdf (accessed on 29 October 2021).
- Wehrli, E.; Seretan, V.; Nerima, L.; Russo, L. Collocations in a Rule-Based MT System: A Case Study Evaluation of Their Translation Adequacy. In Proceedings of the 13th Annual conference of the European Association for Machine Translation, Barcelona, Spain, 14–15 May 2009; pp. 128–135. [Google Scholar]
- Kockaert, H.; Vanallemeersch, T.; Steurs, F. Term-based context extraction in legal terminology: A case study in Belgium. Terminol. Et Corpora 2008, 4, 153–162. [Google Scholar]
- Gromann, D.; Declerck, T. Terminology Harmonization in Industry Classification Standards. In Proceedings of the CHAT: The 2nd Workshop on the Creation; Harmonization and Application of Terminology Resources, Madrid, Spain, 22 June 2012; pp. 19–26. [Google Scholar]
- Hamon, T.; Grabar, N. Extraction of ingredient names from recipes by combining linguistic annotations and CRF selection. In Proceedings of the 5th International Workshop on Multimedia for Cooking & Eating Activities-CEA ’13; ACM: New York, NY, USA, 2013; pp. 63–68. [Google Scholar]
- Grabar, N.; Hamon, T. Automatic Extraction of Layman Names for Technical Medical Terms. In Proceedings of the 2014 IEEE International Conference on Healthcare Informatics, Verona, Italy, 5–17 September 2014; pp. 310–319. [Google Scholar]
- Garcia, E.M.; Creus, C.; España-Bonet, C.; Màrquez, L. Using Word Embeddings to Enforce Document-Level Lexical Consistency in Machine Translation. Prague Bull. Math. Linguist. 2017, 108, 85–96. [Google Scholar] [CrossRef][Green Version]
- Seljan, S. Quality Assurance (QA) of Terminology in a Translation Quality Management System (QMS) in the Business Environment. In Translation Services in the Digital World: A Sneak Peek into the (Near) Future; European Parliament: Strasbourg, France, 2018. [Google Scholar] [CrossRef]
- Alwazna, R.Y. The Efficacy of the Integrative Model Proposed by Prieto Ramos (2014) in Surmounting Terminological Problems of Arabic-English Legal Translation. Int. J. Semiot. Law-Rev. Int. De Sémiotique Jurid. 2014, 2021, 1–16. [Google Scholar] [CrossRef]
- Ramuedzisi, L.; Van Huyssteen, L.; Mandende, I.P. An enhanced terminology development and management approach for South African languages. S. Afr. J. Afr. Lang. 2019, 39, 263–272. [Google Scholar] [CrossRef]
- Kwong, O.Y. User-driven assessment of commercial term extractors. Terminology 2021, 27, 179–218. [Google Scholar] [CrossRef]
- Brozović, M.; Sever Mališ, S.; Novak, A. The consistency and complexity of accounting terminology in Croatian higher education system. Ekon. Pregl. 2019, 70, 496–518. [Google Scholar] [CrossRef]
- Mattila, H.E.S. Observing Eurolects: Corpus Analysis of Linguistic Variation in EU Law; John Benjamins: Amsterdam, The Netherlands, 2018. [Google Scholar] [CrossRef]
- Condamines, A. Nouvelles perspectives pour la terminologie textuelle. In Terminology and Discourse; Altmanova, J., Centrella, M., Russo, K.E., Eds.; Peter Lang: Bern, Switzerland, 2018. [Google Scholar] [CrossRef]
- Lapshinova-Koltunski, E. Variation in translation: Evidence from corpora. In New Directions in Corpus-Based Translation Studies; Fantinuoli, C., Zanettin, F., Eds.; Language Science Press: Berlin, Germany, 2015; pp. 93–114. [Google Scholar]
- Seljan, S.; Škof Erdelja, N.; Kučiš, V.; Dunđer, I.; Pejić Bach, M. Quality Assurance in Computer-Assisted Translation in Business Environments. In Natural Language Processing for Global and Local Business; IGI Global Publisher of Timely Knowledge: Hershey, PA, USA, 2021; pp. 242–270. [Google Scholar] [CrossRef]
- Gašpar, A. Računalno Potpomognuta Provjera Terminološke Dosljednosti Prijevoda Hrvatskog Zakonodavstva Na Engleski Jezik. Ph.D. Thesis, University of Zagreb, Zagreb, Croatia, 2013. [Google Scholar]
- Zec, S. Crkva u Hrvatskoj i crkveno parvo. Bogosl. Smotra 2011, 81, 267–290. [Google Scholar]
- Itagaki, M.; Aikawa, T.; He, X. Automatic Validation of Terminology Translation Consistency with Statistical Method. Proc. MT Summit XI 2007, 269–274. [Google Scholar]
- Gašpar, A. Corpus-based Bilingual Terminology Extraction. In Multidisciplinary Approaches to Multilingualism. Proc. from CALS Conference; Peter Lang: Bern, Switzerland, 2015; pp. 303–318. [Google Scholar]
- Novak, J. Priručnik Za Prevođenje Pravnih Propisa Republike Hrvatske Na Engleski Jezik; MVPEI: Zagreb, Croatia, 2006. [Google Scholar]
- Gašpar, A. Multiterm Database Quality Assessment. In Human Language Technologies as Challenge for Computer Science and Linguistics; Springer: Poznań, Poland, 2013; pp. 183–187. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parallel Corpora | English | Croatian | ||||
|---|---|---|---|---|---|---|
| Pages | Tokens | Paragraphs | Pages | Tokens | Paragraphs | |
| Cro-Eng (1991–2009) | 1595 | 635,792 | 28,526 | 1356 | 506,338 | 25,416 |
| Canon Law (1983) | 119 | 123,875 | 5272 | 279 | 99,109 | 3639 |
| EU legislation (2013) | 160 | 81,413 | 2248 | 163 | 75,222 | 2447 |
| Total | 1874 | 841,080 | 36,046 | 1798 | 680,669 | 31,502 |
| Language Pair | Corpus Size | # Validated Extracted Terms | # Selected Terms | |
|---|---|---|---|---|
| Cro–Eng (1991–2009) | Cro–Eng parallel | 1,142,130 | 10,000 | 100 Cro |
| Canon Law (1983) | Eng and Cro (from Latin) | 222,984 | 290 | 25 Cro 25 Eng |
| EU legislation (2013) | Cro-Eng parallel | 156,635 | 598 | 15 Cro 15 Eng |
| Source Language Term | Terminology Variants | Frequency | |
|---|---|---|---|
| stečajno vijeće | insolvency tribunal | 61 | Ct = 4.73 |
| bankruptcy tribunal | 31 | ||
| bankruptcy council | 7 | ||
| bankruptcy chamber | 11 |
| Corpus | # Terms for HHI | HHI ≥ 5 | Av. HHI for Target Language |
|---|---|---|---|
| Cro–Eng (1991–2009) | 100 Cro | Ct (57Eng) ≥ 5 | Ct (100Eng) = 4.81 |
| Canon Law (1983) | 25 Cro 25 Eng | Ct (14Eng) ≥ 5 Ct (15Cro) ≥ 5 | Ct (25Eng) = 5.09 Ct (25Cro) = 6.68 |
| EU corpus (2013) | 25 Cro 25 Eng | Ct (9Eng) ≥ 5 Ct (12Cro) ≥ 5 | Ct (25Eng) = 6.08 Ct (25Cro) = 6.67 |
| 10 docs. 1991–2005 10 docs. 2006–2009 | 15 Cro 15 Cro | Ct (8Eng) ≥ 5 Ct (12Eng) ≥ 5 | Ct (15Eng) = 5.19 Ct (15Eng) = 5.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gašpar, A.; Seljan, S.; Kučiš, V. Measuring Terminology Consistency in Translated Corpora: Implementation of the Herfindahl-Hirshman Index. Information 2022, 13, 43. https://doi.org/10.3390/info13020043
Gašpar A, Seljan S, Kučiš V. Measuring Terminology Consistency in Translated Corpora: Implementation of the Herfindahl-Hirshman Index. Information. 2022; 13(2):43. https://doi.org/10.3390/info13020043
Chicago/Turabian StyleGašpar, Angelina, Sanja Seljan, and Vlasta Kučiš. 2022. "Measuring Terminology Consistency in Translated Corpora: Implementation of the Herfindahl-Hirshman Index" Information 13, no. 2: 43. https://doi.org/10.3390/info13020043
APA StyleGašpar, A., Seljan, S., & Kučiš, V. (2022). Measuring Terminology Consistency in Translated Corpora: Implementation of the Herfindahl-Hirshman Index. Information, 13(2), 43. https://doi.org/10.3390/info13020043