
Fast, Efficient and Flexible Particle Accelerator Optimisation Using Densely Connected and Invertible Neural Networks


Abstract
:1. Introduction
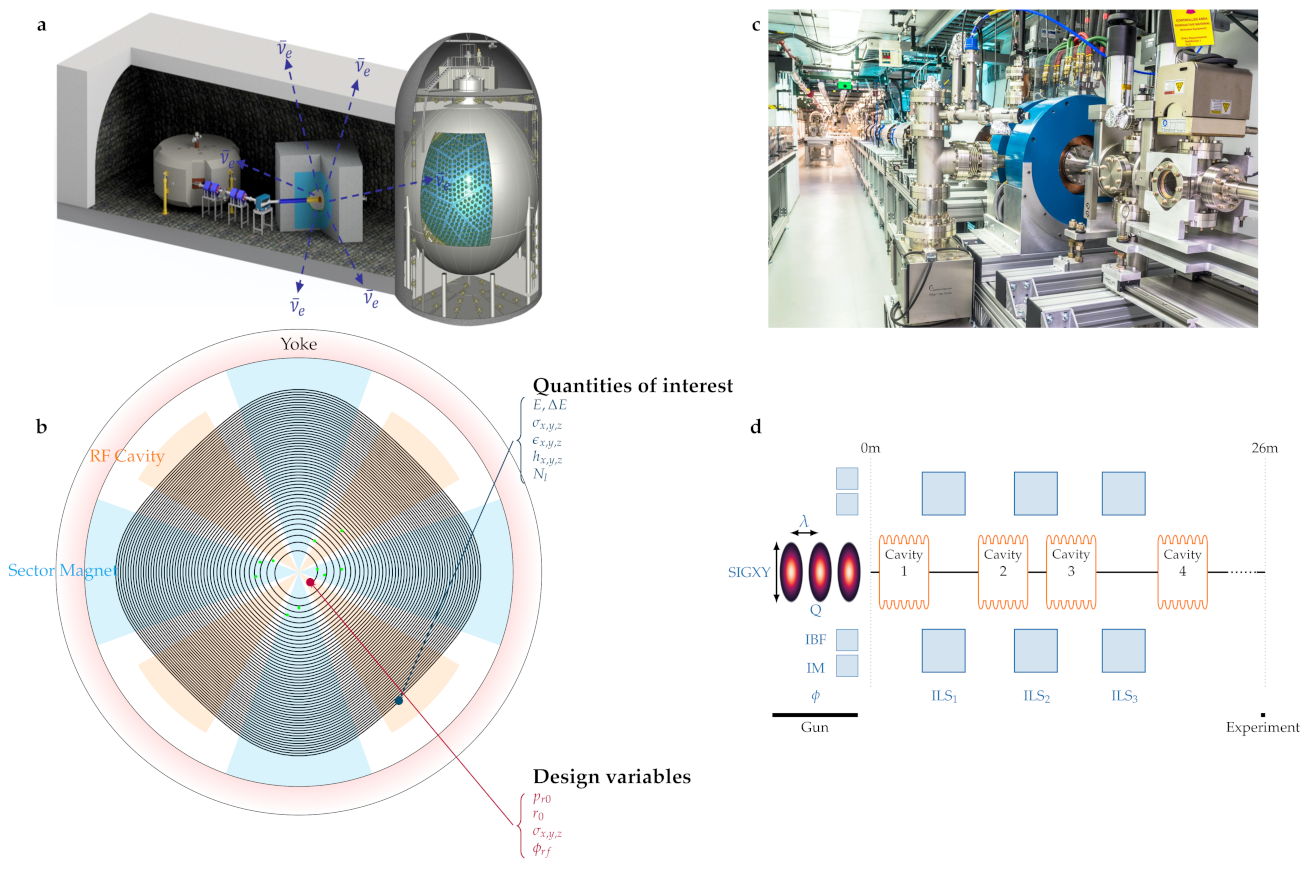
1.1. Physics Models and Datasets
1.2. Specifics of the Argonne Wakefield Accelerator Model
1.3. Specifics of the IsoDAR Cyclotron Model
2. Results
2.1. Forward and Invertible Models
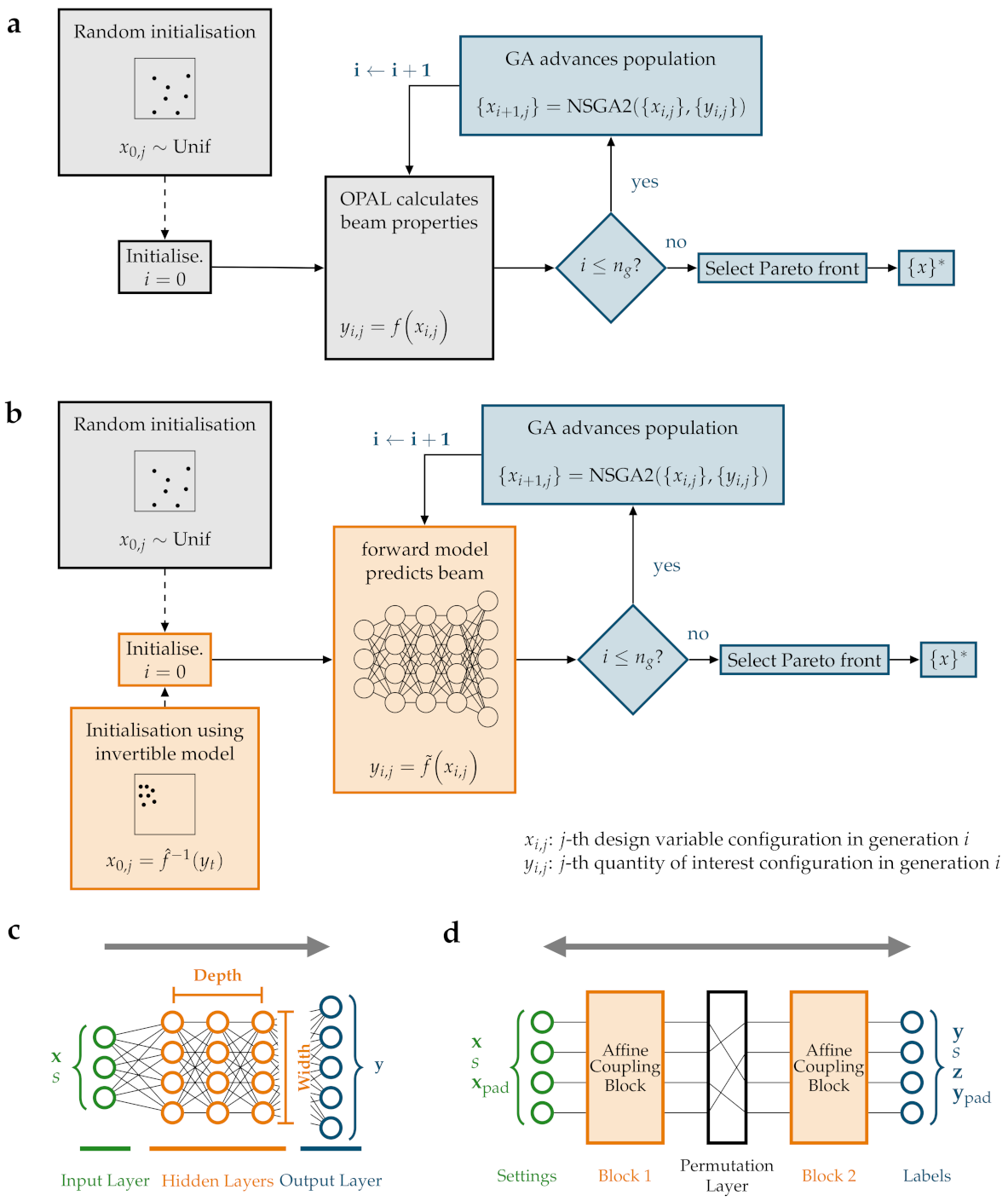
2.2. Multi-Objective Optimisation
2.3. Performance Metrics for the Optimisations
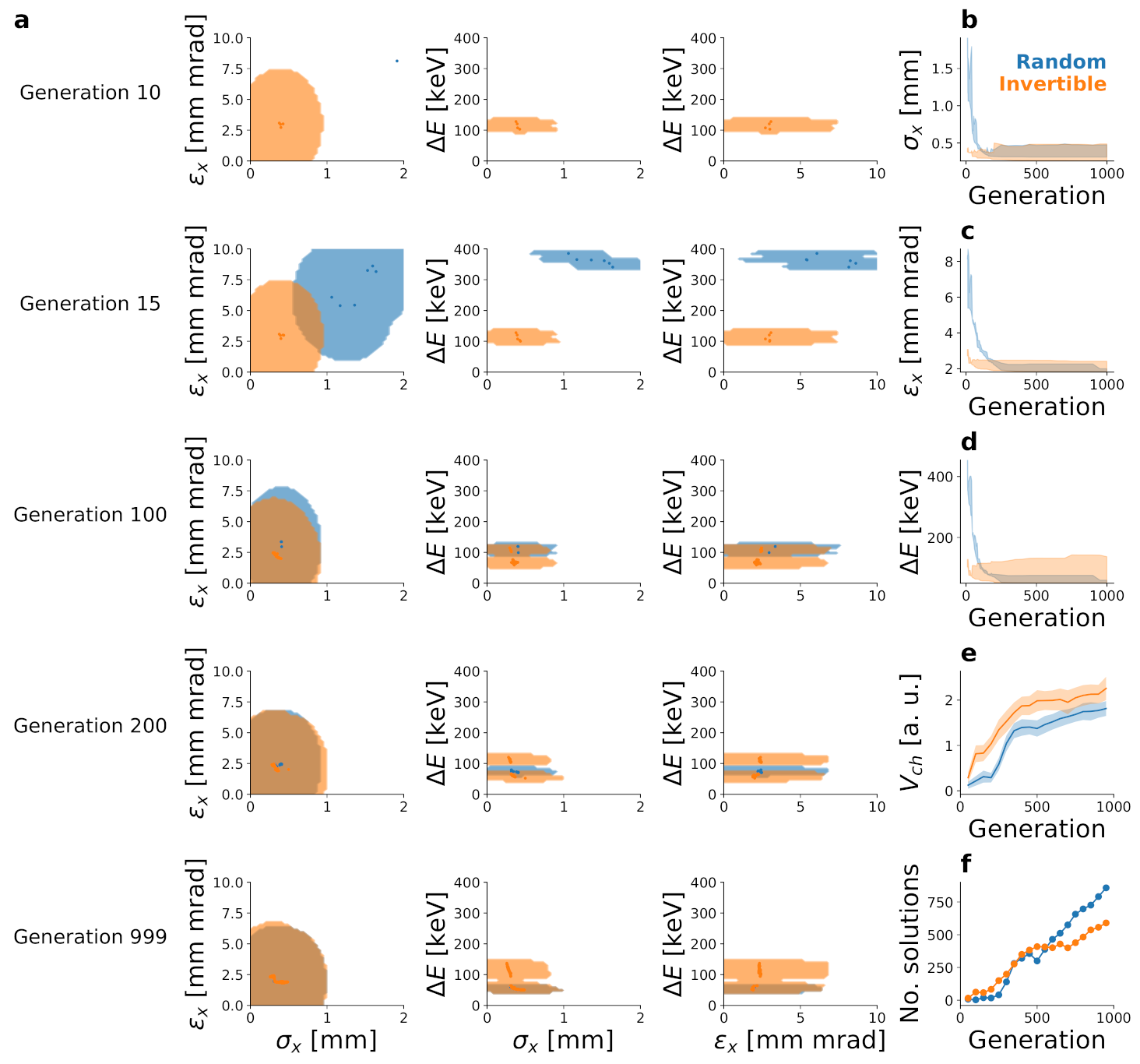
2.4. Multi-Objective Optimisation for AWA
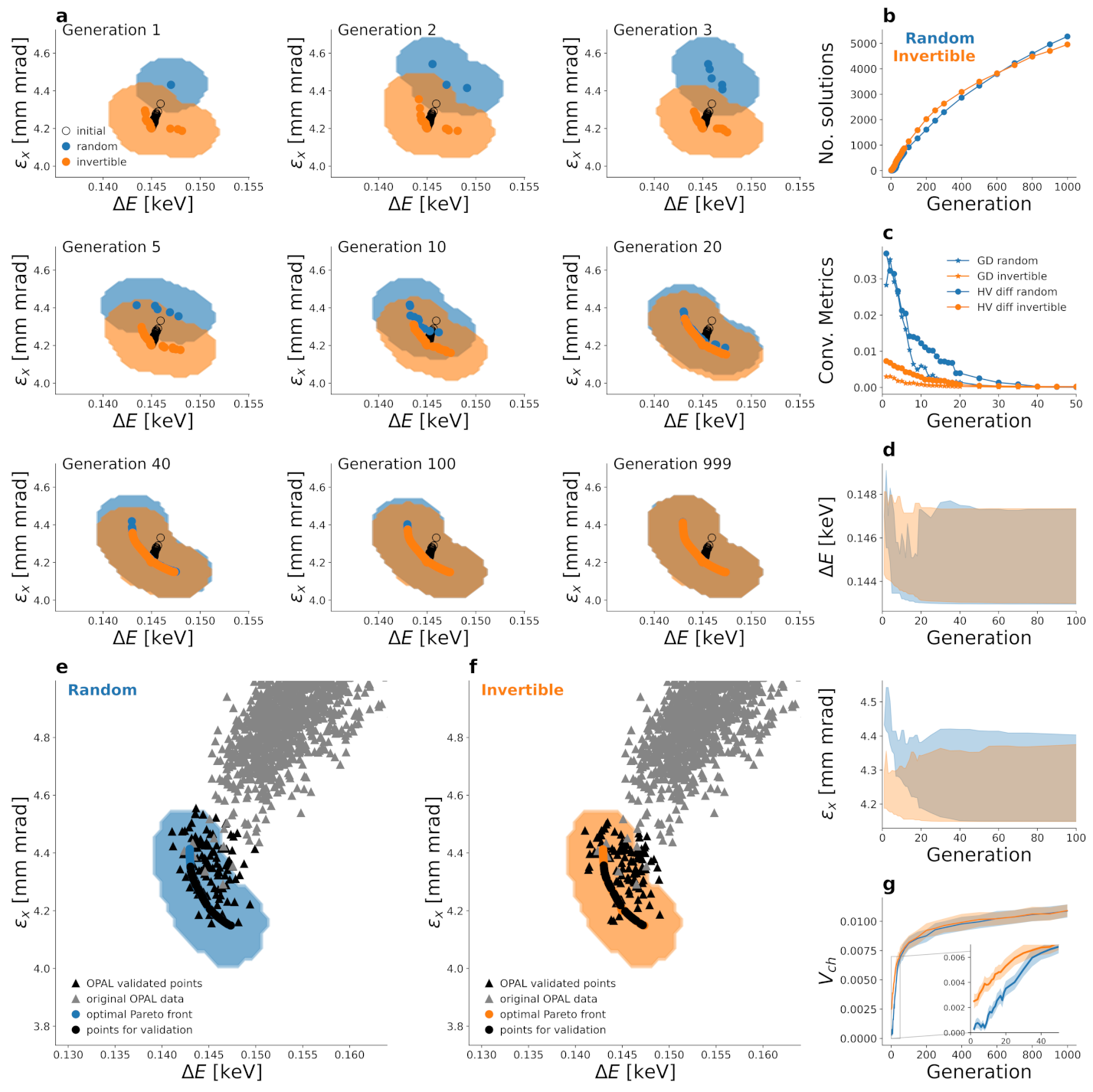
2.5. Multi-Objective Optimisation for IsoDAR
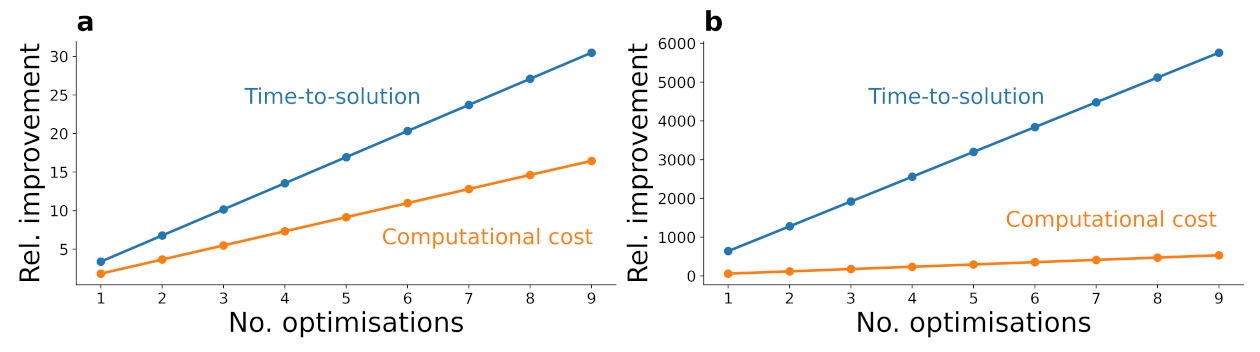
2.6. Computational Advantages
3. Methods
3.1. Forward Model
3.2. Invertible Model
4. Discussion and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
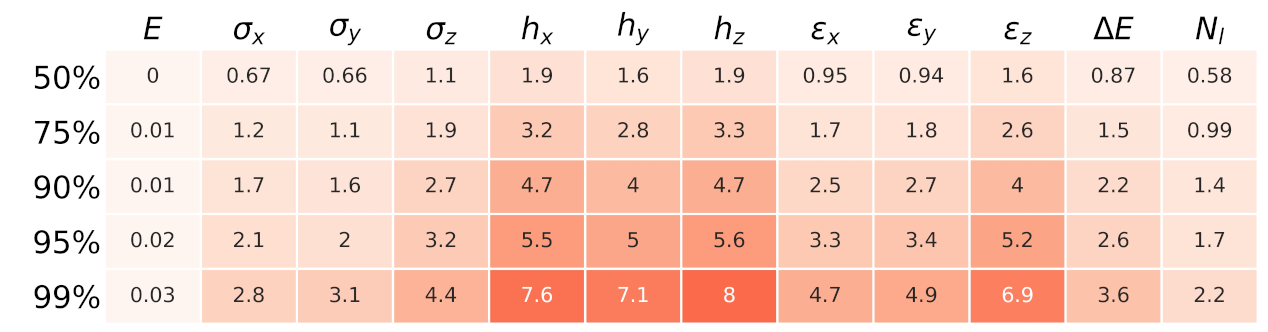
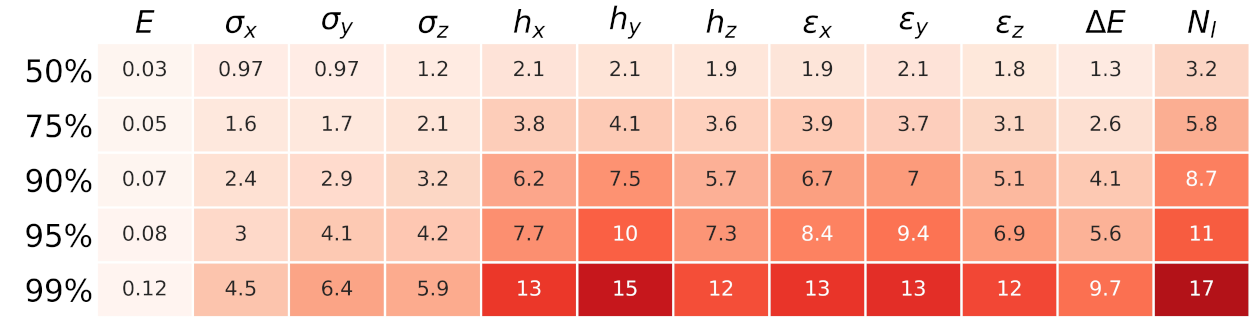
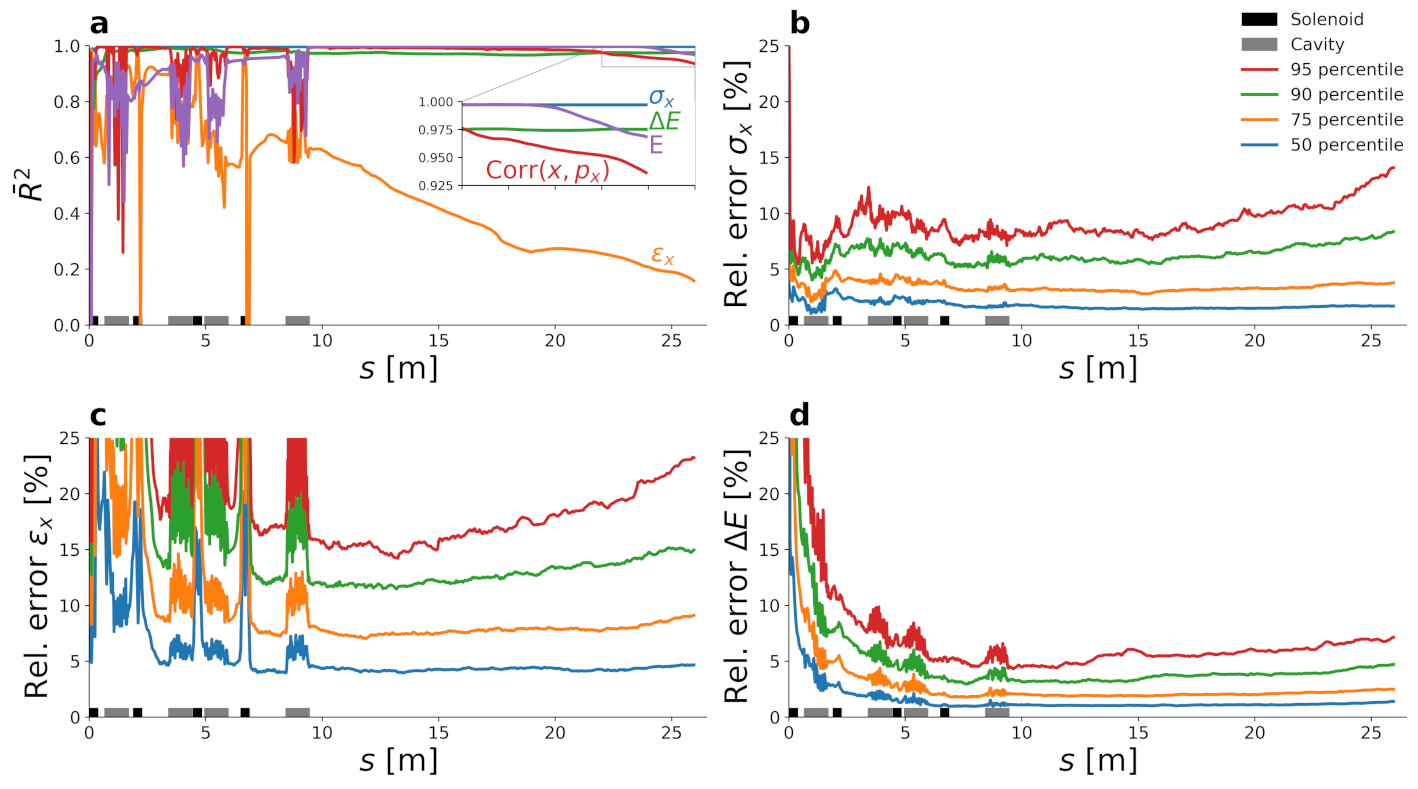
Appendix A. Predicted Quantities and Model Fidelity
Appendix A.1. Performance Metrics
Appendix A.2. IsoDAR Model Fidelity

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| E | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| forward | 1.0 | 0.97 | 0.96 | 0.85 | 0.9 | 0.95 | 0.86 | 0.99 | 0.99 | 0.82 | 0.98 | 1.0 |
| inv FP | 0.97 | 0.92 | 0.91 | 0.75 | 0.84 | 0.88 | 0.81 | 0.93 | 0.95 | 0.69 | 0.94 | 0.9 |
| inv IP | 0.96 | 0.94 | 0.88 | 0.77 | 0.83 | 0.82 | 0.77 | 0.91 | 0.91 | 0.65 | 0.91 | 0.79 |
Appendix A.3. Model Summary
| AWA | IsoDAR | |||
|---|---|---|---|---|
| Forward | Invertible | Forward | Invertible | |
| E (MeV) | ✓ | ✓ | ✓ | ✓ |
| (MeV) | ✓ | ✓ | ✓ | ✓ |
| (m) | ✓ | ✓ | ✓ | ✓ |
| (mm mrad) | ✓ | ✓ | ✓ | ✓ |
| ✓ | x | x | x | |
| (m | x | x | ✓ | ✓ |
| (mm mrad) | x | x | ✓ | ✓ |
| x | x | ✓ | ✓ | |
| x | x | ✓ | ✓ | |
Appendix B. Parameter Ranges Used in the Optimisation
| Bound | IBF (A) | IM (A) | (°) | ILS1 (A) | ILS2 (A) | ILS3 (A) | Q (nC) | (ps) | SIGXY (mm) |
|---|---|---|---|---|---|---|---|---|---|
| Lower | 450 | 100 | −50 | 0 | 0 | 0 | 0.3 | 0.3 | 1.5 |
| Upper | 550 | 260 | 10 | 250 | 200 | 200 | 5 | 2 | 12.5 |
| Bound | () | (mm) | (°) | (mm) | (mm) | (mm) |
|---|---|---|---|---|---|---|
| Lower | 0.002254 | 115.9 | 283.0 | 0.95 | 2.85 | 4.75 |
| Upper | 0.002346 | 119.9 | 287.0 | 1.05 | 3.15 | 5.25 |
| E | |||||
|---|---|---|---|---|---|
| 112.0 MeV | 2.4 mm | 2.1 mm | 1.5 mm | 4.5 | 3.6 |
| 3.4 | 4.2 mm mrad | 4.5 mm mrad | 2.1 mm mrad | 146.2 keV | 7090.0 |
| E | s | |||||
|---|---|---|---|---|---|---|
| 47.5 MeV | 2 mm | 2 mm | 3 mm mrad | 3 mm mrad | 60 keV | 13.7 m |
Appendix C. Model Parameters
| AWA | IsoDAR | |||
|---|---|---|---|---|
| Forward | Invertible | Forward | Invertible | |
| Modelled region | (entire machine) | EOM | EOM | |
| Preprocessing | Scale to | QuantileScaler Scale to | Scale to | Scale to |
| Preprocessing | Shift to be positive Apply Scale to | Clip Scale to | Scale to | Scale to |
| Dimension of the latent space | - | 1 | - | 1 |
| Nominal Dimension | - | 12 | - | 14 |
| Distribution of the latent space | - | Unif(-1, 1) | - | Unif(−1, 1) |
| Loss function | MAE | (Equation (1)) with weights: | MSE | (Equation (1)) with weights: = 1 |
| Training algorithm | Adam | Adam | Adam | Adam |
| Learning rate | ||||
| Batch size | 256 | 256 | 256 | 8 |
| Number of epochs | 56 | 15 | 5000 | 30 |
| Architecture | ||||
| Activation of hidden neurons | ReLU | ReLU | tanh | ReLU |
| Number of trainable parameters | 1,512,618 | 688,192 | 33,932 | 91,340 |
| CPU cores for training | 12 | 12 | 1 | 1 |
| Time for training | 49 h | 31 h | 1 h | 1 h |
Appendix D. Computational Details
Appendix D.1. Hardware
Appendix D.2. Implementation
Appendix D.3. Speedup Calculation
| Algorithm A1: Optimisation using surrogate models. |
 |
| Algorithm A2: Biased initialisation using the invertible surrogate model. |
 |
| Quantity | Symbol | AWA | IsoDAR |
|---|---|---|---|
| Time for one OPAL evaluation | 10 min | 1.8 h | |
| Time to train one forward model | 49 h | 1 h | |
| Time to predict one machine with the surrogate | 21 ms | 26 μs | |
| Number of unique machine settings in the dataset | n | 21.000 | 5.000 |
| Number of hyperparameters to try | 100 | 120 | |
| Number of CPU cores per OPAL evaluation | 4 | 1 | |
| Number of CPU cores to train and evaluate the surrogate | 12 | 1 | |
| Number of generations | 1.000 | 1.000 | |
| Number of individuals per generation | 200 | 300 |
References
- Shiltsev, V. Particle beams behind physics discoveries. Phys. Today 2020, 73, 32. [Google Scholar] [CrossRef] [Green Version]
- No final frontier. Nat. Rev. Phys. 2019, 1, 231. [CrossRef] [Green Version]
- Adelmann, A.; Calvo, P.; Frey, M.; Gsell, A.; Locans, U.; Metzger-Kraus, C.; Neveu, N.; Rogers, C.; Russell, S.; Sheehy, S.; et al. OPAL a Versatile Tool for Charged Particle Accelerator Simulations. arXiv 2019, arXiv:1905.06654. [Google Scholar]
- Emery, L. Global Optimization of Damping Ring Designs using a Multi-objective Evolutionary Algorithm. In Proceedings of the Particle Accelerator Conference, Knoxville, TN, USA, 16–20 May 2005; p. 2962. [Google Scholar]
- Gulliford, C.; Bartnik, A.; Bazarov, I.; Maxson, J. Multiobjective optimization design of an rf gun based electron diffraction beam line. Phys. Rev. Accel. Beams 2017, 20, 033401. [Google Scholar] [CrossRef] [Green Version]
- Neveu, N.; Spentzouris, L.; Adelmann, A.; Ineichen, Y.; Kolano, A.; Metzger-Kraus, C.; Bekas, C.; Curioni, A.; Arbenz, P. Parallel general purpose multiobjective optimization framework with application to electron beam dynamics. Phys. Rev. Accel. Beams 2019, 22, 054602. [Google Scholar] [CrossRef] [Green Version]
- Frey, M.; Snuverink, J.; Baumgarten, C.; Adelmann, A. Matching of turn pattern measurements for cyclotrons using multiobjective optimization. Phys. Rev. Accel. Beams 2019, 22, 064602. [Google Scholar] [CrossRef] [Green Version]
- Kranjčević, M.; Gorgi Zadeh, S.; Adelmann, A.; Arbenz, P.; van Rienen, U. Constrained multiobjective shape optimization of superconducting rf cavities considering robustness against geometric perturbations. Phys. Rev. Accel. Beams 2019, 22, 122001. [Google Scholar] [CrossRef] [Green Version]
- Edelen, A.; Neveu, N.; Frey, M.; Huber, Y.; Mayes, C.; Adelmann, A. Machine learning for orders of magnitude speedup in multiobjective optimization of particle accelerator systems. Phys. Rev. Accel. Beams 2020, 23, 044601. [Google Scholar] [CrossRef] [Green Version]
- Scheinker, A.; Hirlaender, S.; Velotti, F.M.; Gessner, S.; Della Porta, G.Z.; Kain, V.; Goddard, B.; Ramjiawan, R. Online multi-objective particle accelerator optimization of the AWAKE electron beam line for simultaneous emittance and orbit control. AIP Adv. 2020, 10, 055320. [Google Scholar] [CrossRef]
- Jalas, S.; Kirchen, M.; Messner, P.; Winkler, P.; Hübner, L.; Dirkwinkel, J.; Schnepp, M.; Lehe, R.; Maier, A.R. Bayesian Optimization of a Laser-Plasma Accelerator. Phys. Rev. Lett. 2021, 126, 104801. [Google Scholar] [CrossRef]
- Power, J. Advanced Acceleration Concepts at the Argonne Wakefield Accelerator Facility. APS Division of Physics of Beams Annual Newsletter. 2018; p. 21. Available online: https://www.anl.gov/awa (accessed on 2 July 2021).
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output from a Computer Code. Technometrics 1979, 21, 239. [Google Scholar] [CrossRef]
- Bungau, A.; Adelmann, A.; Alonso, J.R.; Barletta, W.; Barlow, R.; Bartoszek, L.; Calabretta, L.; Calanna, A.; Campo, D.; Conrad, J.M.; et al. Proposal for an Electron Antineutrino Disappearance Search Using High-Rate 8Li Production and Decay. Phys. Rev. Lett. 2012, 109, 141802. [Google Scholar] [CrossRef] [PubMed]
- Waites, L.H.; Alonso, J.R.; Conrad, J. IsoDAR: A cyclotron-based neutrino source with applications to medical isotope production. AIP Conf. Proc. 2019, 2160, 040001. [Google Scholar] [CrossRef]
- Alonso, J.R.; Barlow, R.; Conrad, J.M.; Waites, L.H. Medical isotope production with the IsoDAR cyclotron. Nat. Rev. Phys. 2019, 1, 533–535. [Google Scholar] [CrossRef] [Green Version]
- Bazarov, I.V.; Sinclair, C.K. Multivariate optimization of a high brightness dc gun photoinjector. Phys. Rev. ST Accel. Beams 2005, 8, 034202. [Google Scholar] [CrossRef] [Green Version]
- Veldhuizen, V.; Allen, D. Multiobjective Evolutionary Algorithms: Classifications, Analyses, and New Innovations; Technical Report, Evolutionary Computation; Air Force Institute of Technology: Dayton, OH, USA, 1999. [Google Scholar]
- Fonseca, C.M.; Paquete, L.; Lopez-Ibanez, M. An Improved Dimension-Sweep Algorithm for the Hypervolume Indicator. In Proceedings of the 2006 IEEE International Conference on Evolutionary Computation, Vancouver, BC, Canada, 16–21 July 2006; pp. 1157–1163. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 16 June 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 3 August 2021).
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A Research Platform for Distributed Model Selection and Training. arXiv 2018, arXiv:1807.05118. [Google Scholar]
- Ardizzone, L.; Kruse, J.; Wirkert, S.; Rahner, D.; Pellegrini, E.W.; Klessen, R.S.; Maier-Hein, L.; Rother, C.; Köthe, U. Analyzing Inverse Problems with Invertible Neural Networks. arXiv 2018, arXiv:1808.04730v3. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Abs, M.; Adelmann, A.; Alonso, J.R.; Axani, S.; Barletta, W.A.; Barlow, R.; Bartoszek, L.; Bungau, A.; Calabretta, L.; Calanna, A.; et al. IsoDAR@ KamLAND: A Conceptual Design Report for the Technical Facility. arXiv 2015, arXiv:1511.05130. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Blank, J.; Deb, K. Pymoo: Multi-Objective Optimization in Python. IEEE Access 2020, 8, 89497–89509. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bellotti, R.; Boiger, R.; Adelmann, A. Fast, Efficient and Flexible Particle Accelerator Optimisation Using Densely Connected and Invertible Neural Networks. Information 2021, 12, 351. https://doi.org/10.3390/info12090351
Bellotti R, Boiger R, Adelmann A. Fast, Efficient and Flexible Particle Accelerator Optimisation Using Densely Connected and Invertible Neural Networks. Information. 2021; 12(9):351. https://doi.org/10.3390/info12090351
Chicago/Turabian StyleBellotti, Renato, Romana Boiger, and Andreas Adelmann. 2021. "Fast, Efficient and Flexible Particle Accelerator Optimisation Using Densely Connected and Invertible Neural Networks" Information 12, no. 9: 351. https://doi.org/10.3390/info12090351
APA StyleBellotti, R., Boiger, R., & Adelmann, A. (2021). Fast, Efficient and Flexible Particle Accelerator Optimisation Using Densely Connected and Invertible Neural Networks. Information, 12(9), 351. https://doi.org/10.3390/info12090351