
An Evaluation of Multilingual Offensive Language Identification Methods for the Languages of India



Abstract
:1. Introduction
- We applied cross-lingual contextual word embeddings to offensive language identification in six different spoken in India from two language families, Indo-Aryan and Dravidian.
- We analyzed the feasibility of training a single multilingual model that is able to generalize to multiple languages from different language families.
- We evaluated the influence of language similarity and typology in cross-lingual offensive language identification by training models using only similar languages.
- We explored the possibility of using zero-shot and few-shot learning methods for offensive language identification in low-resource languages to address data scarcity with a particular emphasis on language combination.
Motivation
2. Related Work
Offensive Language Identification in Languages from India
3. Data
4. Architecture
5. Experimental Setup
5.1. Running Configurations
5.2. Evaluation Method
6. Results
6.1. Multilingual Offensive Language Identification
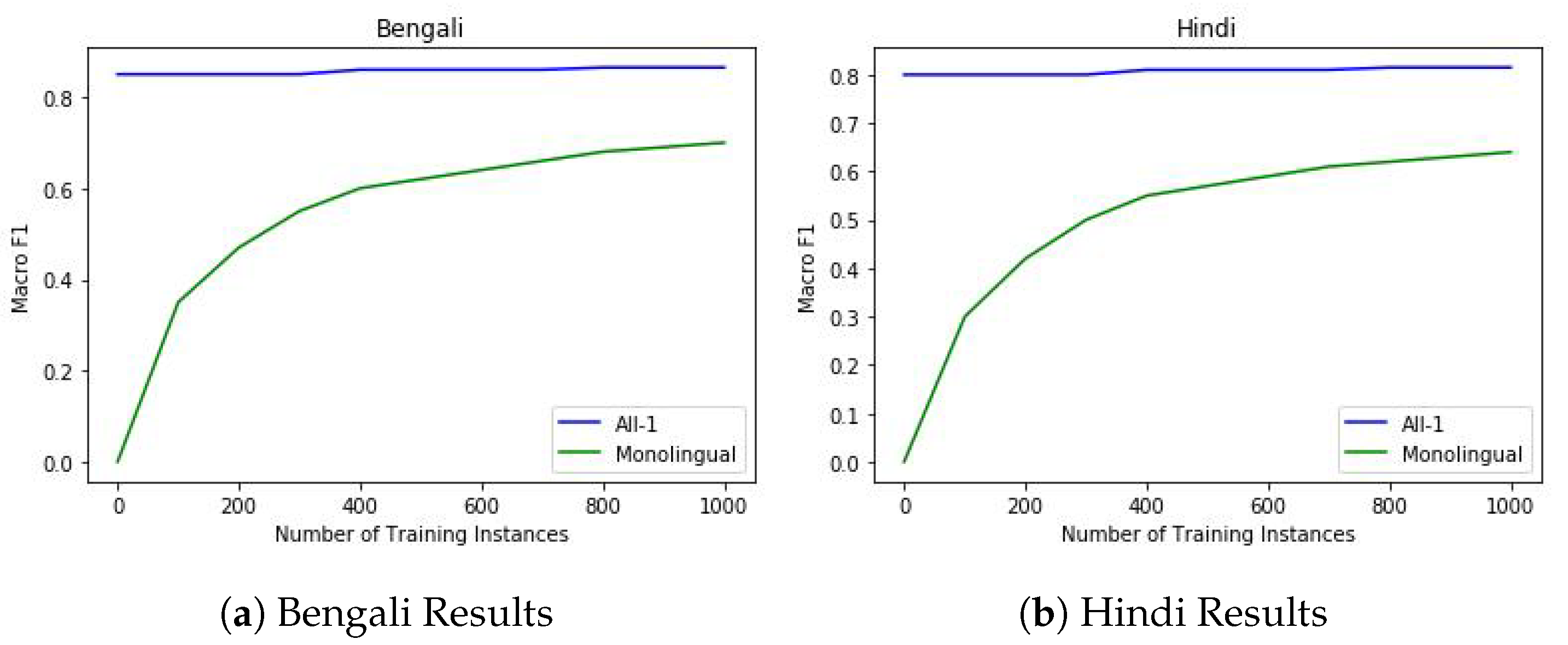
6.2. Zero-Shot Offensive Language Identification
- Performing zero-shot learning for a code-switched dataset is better when the trained model is based on English or that particular language. For example, zero-shot results on Hindi–English are better when you perform transfer learning from Hindi or English rather than a completely different language such as Bengali or Urdu.
- A model trained on code-mixed data on a particular language is better for zero-shot learning in not code-mixed data in that particular language. For example, performing zero-shot learning from Hindi–English to Hindi is better than performing zero-shot learning from Bengali to Hindi.
- Performing zero-shot learning is better inside the language groups. For example, performing zero-shot learning from Hindi to Urdu is better than performing zero-shot learning from Hindi to English–Tamil or English—Kannada since both Hindi and Urdu belong to the same language pair.
6.3. Few-Shot Offensive Language Identification
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, R.; Ojha, A.K.; Malmasi, S.; Zampieri, M. Evaluating Aggression Identification in Social Media. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 16 May 2020; pp. 1–5. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval). In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 75–86. [Google Scholar] [CrossRef] [Green Version]
- Basile, V.; Bosco, C.; Fersini, E.; Nozza, D.; Patti, V.; Rangel Pardo, F.M.; Rosso, P.; Sanguinetti, M. SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 54–63. [Google Scholar] [CrossRef] [Green Version]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the Type and Target of Offensive Posts in Social Media. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 1415–1420. [Google Scholar] [CrossRef] [Green Version]
- Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Zampieri, M.; Nakov, P. SOLID: A Large-Scale Semi-Supervised Dataset for Offensive Language Identification. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 17 July 2021; pp. 915–928. [Google Scholar] [CrossRef]
- Ghadery, E.; Moens, M.F. LIIR at SemEval-2020 Task 12: A Cross-Lingual Augmentation Approach for Multilingual Offensive Language Identification. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Online, 12–13 December 2020; pp. 2073–2079. [Google Scholar]
- Pamungkas, E.W.; Patti, V. Cross-domain and Cross-lingual Abusive Language Detection: A Hybrid Approach with Deep Learning and a Multilingual Lexicon. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, Florence, Italy, 29–31 July 2019; pp. 363–370. [Google Scholar] [CrossRef]
- Ranasinghe, T.; Zampieri, M. Multilingual Offensive Language Identification with Cross-lingual Embeddings. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5838–5844. [Google Scholar] [CrossRef]
- Sai, S.; Sharma, Y. Towards Offensive Language Identification for Dravidian Languages. In Proceedings of the First Workshop on Speech and Language Technologies for Dravidian Languages, Kyiv, Ukraine, 19–20 April 2021; pp. 18–27. [Google Scholar]
- Hettiarachchi, H.; Adedoyin-Olowe, M.; Bhogal, J.; Gaber, M.M. Embed2Detect: Temporally clustered embedded words for event detection in social media. Mach. Learn. 2021. [Google Scholar] [CrossRef]
- Akbar, S.Z.; Panda, A.; Kukreti, D.; Meena, A.; Pal, J. Misinformation as a Window into Prejudice: COVID-19 and the Information Environment in India. Proc. ACM Hum.-Comput. Interact. 2021, 4. [Google Scholar] [CrossRef]
- Sharma, I. Contextualising Hate Speech: A Study of India And Malaysia. Millenn. J. Int. Stud. 2019, 15, 133–144. [Google Scholar] [CrossRef]
- Ranasinghe, T.; Zampieri, M. Multilingual Offensive Language Identification for Low-resource Languages. arXiv 2021, arXiv:2105.05996. [Google Scholar]
- Ranasinghe, T.; Zampieri, M. MUDES: Multilingual Detection of Offensive Spans. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations, Online, 8–9 June 2021; pp. 144–152. [Google Scholar] [CrossRef]
- Solorio, T.; Blair, E.; Maharjan, S.; Bethard, S.; Diab, M.; Ghoneim, M.; Hawwari, A.; AlGhamdi, F.; Hirschberg, J.; Chang, A.; et al. Overview for the First Shared Task on Language Identification in Code-Switched Data. In Proceedings of the First Workshop on Computational Approaches to Code Switching, Doha, Qatar, 25 October 2014; pp. 62–72. [Google Scholar] [CrossRef] [Green Version]
- Mubarak, H.; Darwish, K.; Magdy, W. Abusive Language Detection on Arabic Social Media. In Proceedings of the First Workshop on Abusive Language, Vancouver, BC, Canada, 4 August 2017; pp. 52–56. [Google Scholar] [CrossRef] [Green Version]
- Vidgen, B.; Derczynski, L. Directions in abusive language training data, a systematic review: Garbage in, garbage out. PLoS ONE 2021, 15, e0243300. [Google Scholar] [CrossRef]
- Kumar, R.; Ojha, A.K.; Malmasi, S.; Zampieri, M. Benchmarking Aggression Identification in Social Media. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; pp. 1–11. [Google Scholar]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.C.; Carvalho, J.P.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Malmasi, S.; Zampieri, M. Detecting Hate Speech in Social Media. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP 2017, Varna, Bulgaria, 2–8 September 2017; pp. 467–472. [Google Scholar] [CrossRef]
- Malmasi, S.; Zampieri, M. Challenges in Discriminating Profanity from Hate Speech. J. Exp. Theor. Artif. Intell. 2018, 30, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Röttger, P.; Vidgen, B.; Nguyen, D.; Waseem, Z.; Margetts, H.; Pierrehumbert, J. HateCheck: Functional Tests for Hate Speech Detection Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 17 July 2021; pp. 41–58. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Ranasinghe, T.; Zampieri, M.; Hettiarachchi, H. BRUMS at HASOC 2019: Deep Learning Models for Multilingual Hate Speech and Offensive Language Identification. In Proceedings of the 11th Forum for Information Retrieval, Kolkata, India, 12–15 December 2019. [Google Scholar]
- Mandl, T.; Modha, S.; Kumar M, A.; Chakravarthi, B.R. Overview of the HASOC Track at FIRE 2020: Hate Speech and Offensive Language Identification in Tamil, Malayalam, Hindi, English and German. In Proceedings of the FIRE 2020: Forum for Information Retrieval Evaluation, Hyderabad, India, 16–20 December 2020; pp. 29–32. [Google Scholar] [CrossRef]
- Mubarak, H.; Rashed, A.; Darwish, K.; Samih, Y.; Abdelali, A. Arabic Offensive Language on Twitter: Analysis and Experiments. In Proceedings of the Sixth Arabic Natural Language Processing Workshop (Virtual), Kyiv, Ukraine, 19 April 2021; pp. 126–135. [Google Scholar]
- Pitenis, Z.; Zampieri, M.; Ranasinghe, T. Offensive Language Identification in Greek. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 5113–5119. [Google Scholar]
- Çöltekin, Ç. A Corpus of Turkish Offensive Language on Social Media. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6174–6184. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Risch, J.; Krestel, R. Bagging BERT Models for Robust Aggression Identification. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 16 May 2020; pp. 55–61. [Google Scholar]
- Mandl, T.; Modha, S.; Majumder, P.; Patel, D.; Dave, M.; Mandlia, C.; Patel, A. Overview of the HASOC Track at FIRE 2019: Hate Speech and Offensive Content Identification in Indo-European Languages. In Proceedings of the 11th Forum for Information Retrieval Evaluation, Kolkata, India, 12–15 December 2019; pp. 14–17. [Google Scholar] [CrossRef]
- Chakravarthi, B.R.; Priyadharshini, R.; Jose, N.; Mandl, T.; Kumaresan, P.K.; Ponnusamy, R.; Hariharan, R.L.; McCrae, J.P.; Sherly, E. Findings of the Shared Task on Offensive Language Identification in Tamil, Malayalam, and Kannada. In Proceedings of the First Workshop on Speech and Language Technologies for Dravidian Languages, Kyiv, Ukraine, 19 April 2021; pp. 133–145. [Google Scholar]
- Chakravarthi, B.R.; Mihaela, G.; Ionescu, R.T.; Jauhiainen, H.; Jauhiainen, T.; Lindén, K.; Ljubešić, N.; Partanen, N.; Priyadharshini, R.; Purschke, C.; et al. Findings of the VarDial Evaluation Campaign 2021. In Proceedings of the Eighth Workshop on NLP for Similar Languages, Varieties and Dialects, Kiyv, Ukraine, 20 April 2021; pp. 1–11. [Google Scholar]
- Saha, D.; Paharia, N.; Chakraborty, D.; Saha, P.; Mukherjee, A. Hate-Alert@DravidianLangTech-EACL2021: Ensembling strategies for Transformer-based Offensive language Detection. In Proceedings of the First Workshop on Speech and Language Technologies for Dravidian Languages, Kyiv, Ukraine, 19 April 2021; pp. 270–276. [Google Scholar]
- Kedia, K.; Nandy, A. indicnlp@kgp at DravidianLangTech-EACL2021: Offensive Language Identification in Dravidian Languages. In Proceedings of the First Workshop on Speech and Language Technologies for Dravidian Languages, Kyiv, Ukraine, 19 April 2021; pp. 330–335. [Google Scholar]
- Balouchzahi, F.; Aparna, B.K.; Shashirekha, H.L. MUCS@DravidianLangTech-EACL2021:COOLI-Code-Mixing Offensive Language Identification. In Proceedings of the First Workshop on Speech and Language Technologies for Dravidian Languages, Kyiv, Ukraine, 19 April 2021; pp. 323–329. [Google Scholar]
- Kakwani, D.; Kunchukuttan, A.; Golla, S.; Gokul, N.C.; Bhattacharyya, A.; Khapra, M.M.; Kumar, P. IndicNLPSuite: Monolingual Corpora, Evaluation Benchmarks and Pre-trained Multilingual Language Models for Indian Languages. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4948–4961. [Google Scholar] [CrossRef]
- Ranasinghe, T.; Gupte, S.; Zampieri, M.; Nwogu, I. WLV-RIT at HASOC-Dravidian-CodeMix-FIRE2020: Offensive Language Identification in Code-switched YouTube Comments. In Proceedings of the 12th Forum for Information Retrieval, Hyderabad, India, 16–20 December 2020. [Google Scholar]
- Bhattacharya, S.; Singh, S.; Kumar, R.; Bansal, A.; Bhagat, A.; Dawer, Y.; Lahiri, B.; Ojha, A.K. Developing a Multilingual Annotated Corpus of Misogyny and Aggression. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 16 May 2020; pp. 158–168. [Google Scholar]
- Bohra, A.; Vijay, D.; Singh, V.; Akhtar, S.S.; Shrivastava, M. A Dataset of Hindi-English Code-Mixed Social Media Text for Hate Speech Detection. In Proceedings of the Second Workshop on Computational Modeling of People’s Opinions, Personality, and Emotions in Social Media, New Orleans, LA, USA, 6 June 2018; pp. 36–41. [Google Scholar] [CrossRef] [Green Version]
- Hande, A.; Priyadharshini, R.; Chakravarthi, B.R. KanCMD: Kannada CodeMixed Dataset for Sentiment Analysis and Offensive Language Detection. In Proceedings of the Third Workshop on Computational Modeling of People’s Opinions, Personality, and Emotion’s in Social Media, Online, 13 December 2020; pp. 54–63. [Google Scholar]
- Chakravarthi, B.R.; Muralidaran, V.; Priyadharshini, R.; McCrae, J.P. Corpus Creation for Sentiment Analysis in Code-Mixed Tamil-English Text. In Proceedings of the 1st Joint Workshop on Spoken Language Technologies for Under-resourced languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL), Marseille, France, 11 May 2020; pp. 202–210. [Google Scholar]
- Akhter, M.P.; Jiangbin, Z.; Naqvi, I.R.; Abdelmajeed, M.; Sadiq, M.T. Automatic Detection of Offensive Language for Urdu and Roman Urdu. IEEE Access 2020, 8, 91213–91226. [Google Scholar] [CrossRef]
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual is Multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4996–5001. [Google Scholar] [CrossRef] [Green Version]
- Uyangodage, L.; Ranasinghe, T.; Hettiarachchi, H. Transformers to Fight the COVID-19 Infodemic. In Proceedings of the Fourth Workshop on NLP for Internet Freedom: Censorship, Disinformation, and Propaganda, Online, 6 June 2021; pp. 130–135. [Google Scholar] [CrossRef]
- K, K.; Wang, Z.; Mayhew, S.; Roth, D. Cross-Lingual Ability of Multilingual BERT: An Empirical Study. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 1 May–26 April 2020. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? Chinese Computational Linguistics; Sun, M., Huang, X., Ji, H., Liu, Z., Liu, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 194–206. [Google Scholar]
- Ranasinghe, T.; Hettiarachchi, H. BRUMS at SemEval-2020 Task 12: Transformer Based Multilingual Offensive Language Identification in Social Media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation (Online), Barcelona, Spain, 12–13 December 2020; pp. 1906–1915. [Google Scholar]
- Hettiarachchi, H.; Ranasinghe, T. InfoMiner at WNUT-2020 Task 2: Transformer-based Covid-19 Informative Tweet Extraction. In Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020), Online, 19 November 2020; pp. 359–365. [Google Scholar] [CrossRef]
- Zampieri, M.; Nakov, P.; Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Mubarak, H.; Derczynski, L.; Pitenis, Z.; Çöltekin, Ç. SemEval-2020 Task 12: Multilingual Offensive Language Identification in Social Media (OffensEval 2020). In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Online, 12–13 December 2020; pp. 1425–1447. [Google Scholar]
- Wiedemann, G.; Yimam, S.M.; Biemann, C. UHH-LT at SemEval-2020 Task 12: Fine-Tuning of Pre-Trained Transformer Networks for Offensive Language Detection. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Online, 12–13 December 2020; pp. 1638–1644. [Google Scholar]
- Bashar, M.A.; Nayak, R. QutNocturnal@ HASOC’19: CNN for hate speech and offensive content identification in Hindi language. In Proceedings of the 11th Forum for Information Retrieval, Kolkata, India, 12–15 December 2019. [Google Scholar]
- Sai, S.; Sharma, Y. Siva@HASOC-Dravidian-CodeMix-FIRE-2020: Multilingual Offensive Speech Detection in Code-mixed and Romanized Text. In Proceedings of the 12th Forum for Information Retrieval, Hyderabad, India, 16–20 December 2020. [Google Scholar]
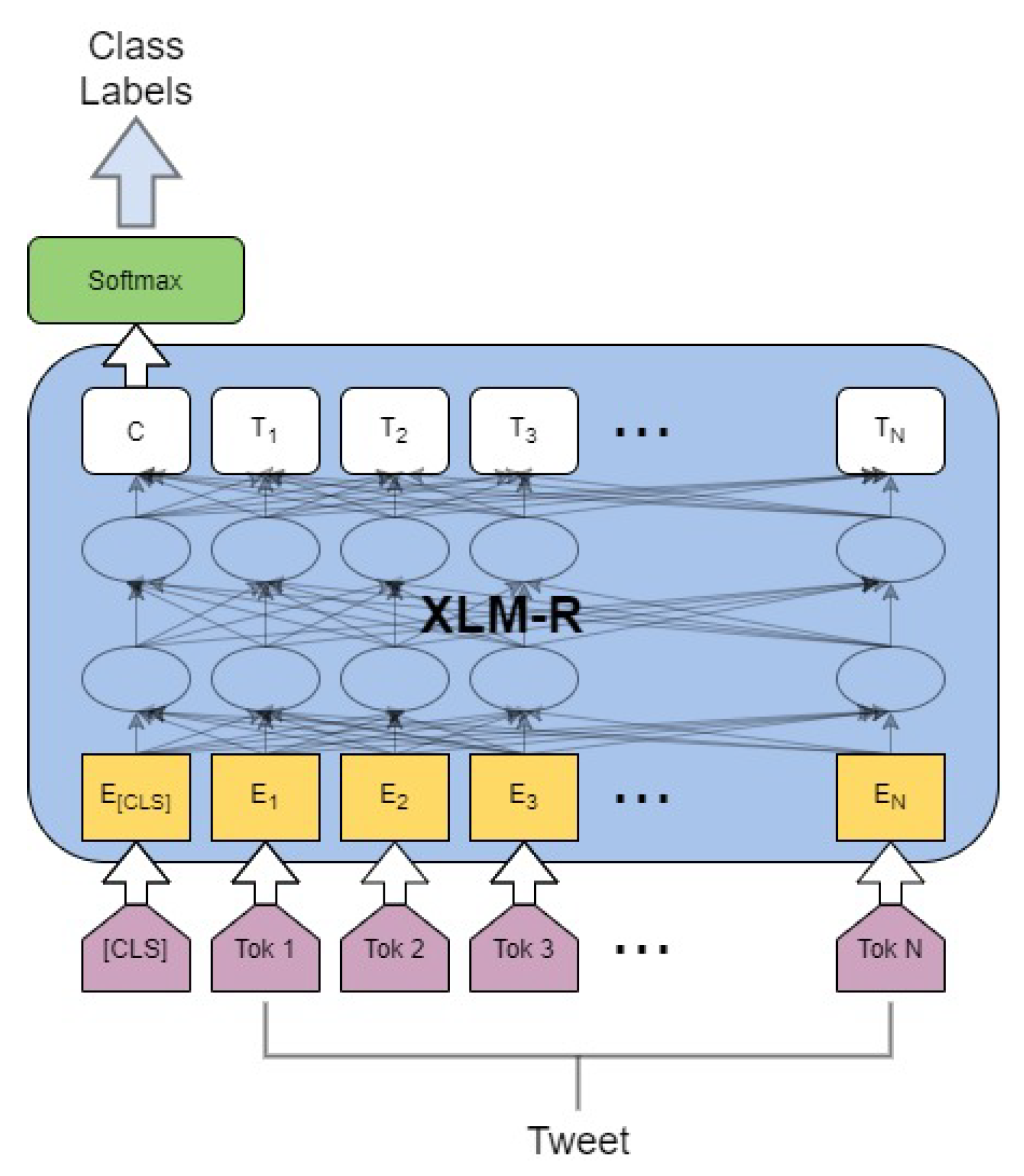

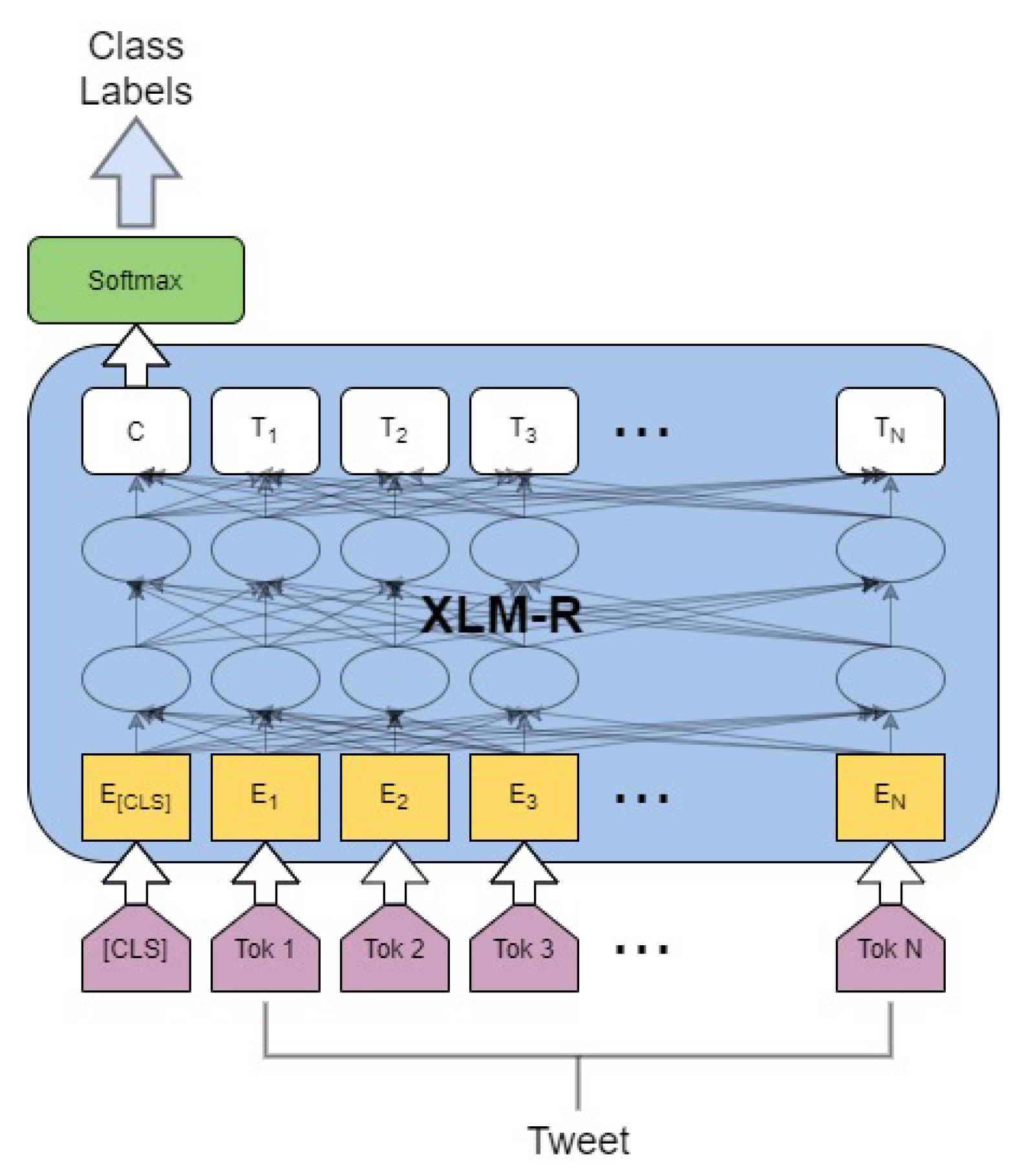{kind=link}
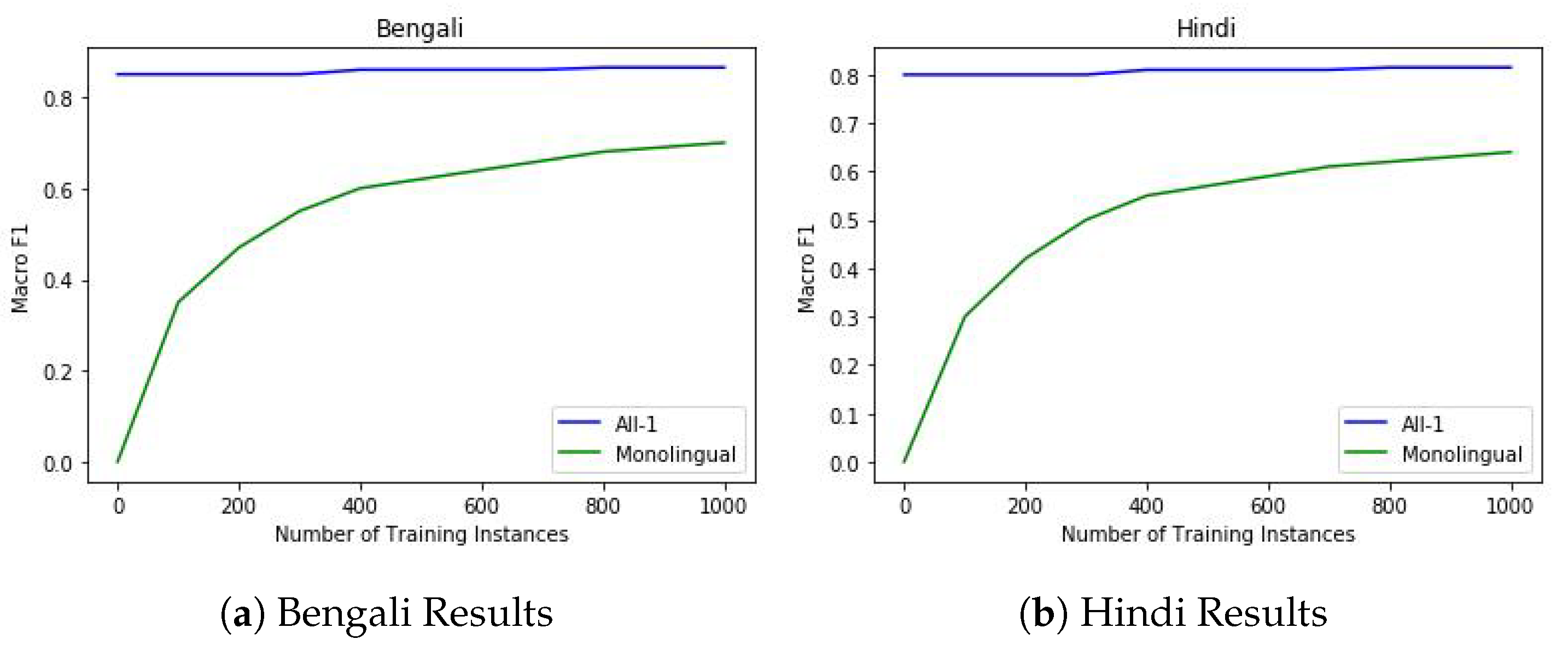{kind=link}
| Language | I | S | Labels | Family |
|---|---|---|---|---|
| English [4] | 14,100 | T | offensive, non-offensive | |
| Bengali [39] | 4000 | Y | overtly aggressive, covertly aggressive, non-aggressive | Indo-Aryan |
| Hindi [31] | 8000 | T | hate offensive, non-hate-offensive | Indo-Aryan |
| Hindi–English [40] | 4114 | T | hate Speech, normal Speech | Indo-Aryan |
| Kannada–English [41] | 7671 | Y | Non-offensive, Offensive-untargeted, Offensive Targeted-Insult | Dravidian |
| Malayalam–English [25] | 4000 | T | offensive, not offensive | Dravidian |
| Tamil–English [42] | 8000 | Y | not-offensive, offensive-untargeted, offensive Targeted-Insult | Dravidian |
| Urdu [43] | 2171 | T | offensive, non-offensive | Indo-Aryan |
| Urdu–English [43] | 10,000 | T | offensive, non-offensive | Indo-Aryan |
| Parameter | Value |
|---|---|
| learning rate ‡ | |
| number of epochs ‡ | 3 |
| adam epsilon | |
| warmup ration | 0.1 |
| warmup steps | 0 |
| max grad norm | 1.0 |
| max seq. length | 120 |
| gradient accumulation steps | 1 |
| Language | Model | Macro F1 |
|---|---|---|
| English | Wiedemann et al. [52] | 0.9204 |
| XLM-R | 0.9123 | |
| Zampieri et al. [4] | 0.8000 | |
| Majority Baseline | 0.4193 | |
| Bashar and Nayak [53] | 0.8149 | |
| Hindi | XLM-R | 0.8061 |
| Majority Baseline [31] | 0.3510 | |
| XLM-R | 0.7782 | |
| Hindi–English | Bohra et al. [40] | 0.7170 |
| Majority Baseline [40] | 0.4542 | |
| Sai and Sharma [54] | 0.9504 | |
| Malayalam–English | XLM-R [38] | 0.9332 |
| Majority Baseline [25] | 0.7652 | |
| Akhter et al. [43] | 0.9591 | |
| Urdu | XLM-R | 0.9503 |
| Majority Baseline | 0.5000 | |
| Akhter et al. [43] | 0.9901 | |
| Urdu–English | XLM-R | 0.9891 |
| Majority Baseline | 0.4842 |
| Train Language(s) | Bengali | English | Hindi | Hindi–English | Kannada–English | Malayalam–English | Tamil–English | Urdu | Urdu–English | |
|---|---|---|---|---|---|---|---|---|---|---|
| I | Bengali | 0.8751 | (−0.09) | (−0.07) | (−0.09) | (−0.10) | (−0.10) | (−0.09) | (−0.07) | (−0.07) |
| English | (−0.12) | 0.9123 | (−0.11) | (−0.08) | (−0.07) | (−0.07) | (−0.08) | (−0.11) | (−0.07) | |
| Hindi | (−0.07) | (−0.10) | 0.8061 | (−0.03) | (−0.08) | (−0.08) | (−0.09) | (−0.04) | (−0.05) | |
| Hindi–English | (−0.11) | (−0.05) | (−0.04) | 0.7782 | (−0.06) | (−0.06) | (−0.07) | (−0.05) | (−0.05) | |
| Kannada–English | (−0.12) | (−0.06) | (−0.11) | (−0.08) | 0.8153 | (−0.06) | (−0.06) | (−0.11) | (−0.09) | |
| Malayalam–English | (−0.13) | (−0.07) | (−0.12) | (−0.08) | (−0.07) | 0.9332 | (−0.07) | (0.11) | (−0.08) | |
| Tamil–English | (−0.04) | (−0.08) | (−0.10) | (−0.09) | (−0.16) | (−0.01) | 0.8334 | (−0.15) | (−0.14) | |
| Urdu | (−0.09) | (−0.09) | (−0.08) | (−0.09) | (−0.14) | (−0.12) | (−0.11) | 0.9503 | (−0.04) | |
| Urdu–English | (−0.09) | (−0.05) | (−0.08) | (−0.07) | (−0.12) | (−0.11) | (−0.13) | (−0.03) | 0.9891 | |
| II | Language Group | 0.8892 | NA | 0.8334 | 0.7981 | 0.8341 | 0.9487 | 0.8568 | 0.9698 | 0.9911 |
| III | All-1 | (−0.02) | (−0.02) | (−0.02) | (−0.02) | (−0.02) | (−0.02) | (−0.02) | (−0.02) | (−0.03) |
| All | 0.8853 | 0.9120 | 0.8225 | 0.7882 | 0.8201 | 0.9412 | 0.8452 | 0.9661 | 0.9900 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ranasinghe, T.; Zampieri, M. An Evaluation of Multilingual Offensive Language Identification Methods for the Languages of India. Information 2021, 12, 306. https://doi.org/10.3390/info12080306
Ranasinghe T, Zampieri M. An Evaluation of Multilingual Offensive Language Identification Methods for the Languages of India. Information. 2021; 12(8):306. https://doi.org/10.3390/info12080306
Chicago/Turabian StyleRanasinghe, Tharindu, and Marcos Zampieri. 2021. "An Evaluation of Multilingual Offensive Language Identification Methods for the Languages of India" Information 12, no. 8: 306. https://doi.org/10.3390/info12080306
APA StyleRanasinghe, T., & Zampieri, M. (2021). An Evaluation of Multilingual Offensive Language Identification Methods for the Languages of India. Information, 12(8), 306. https://doi.org/10.3390/info12080306