
Visual Active Learning for Labeling: A Case for Soundscape Ecology Data


Abstract
:1. Introduction
- Proposal, implementation, and testing of a Visual Active Learning strategy for labeling and application of such strategy to soundscape ecology data;
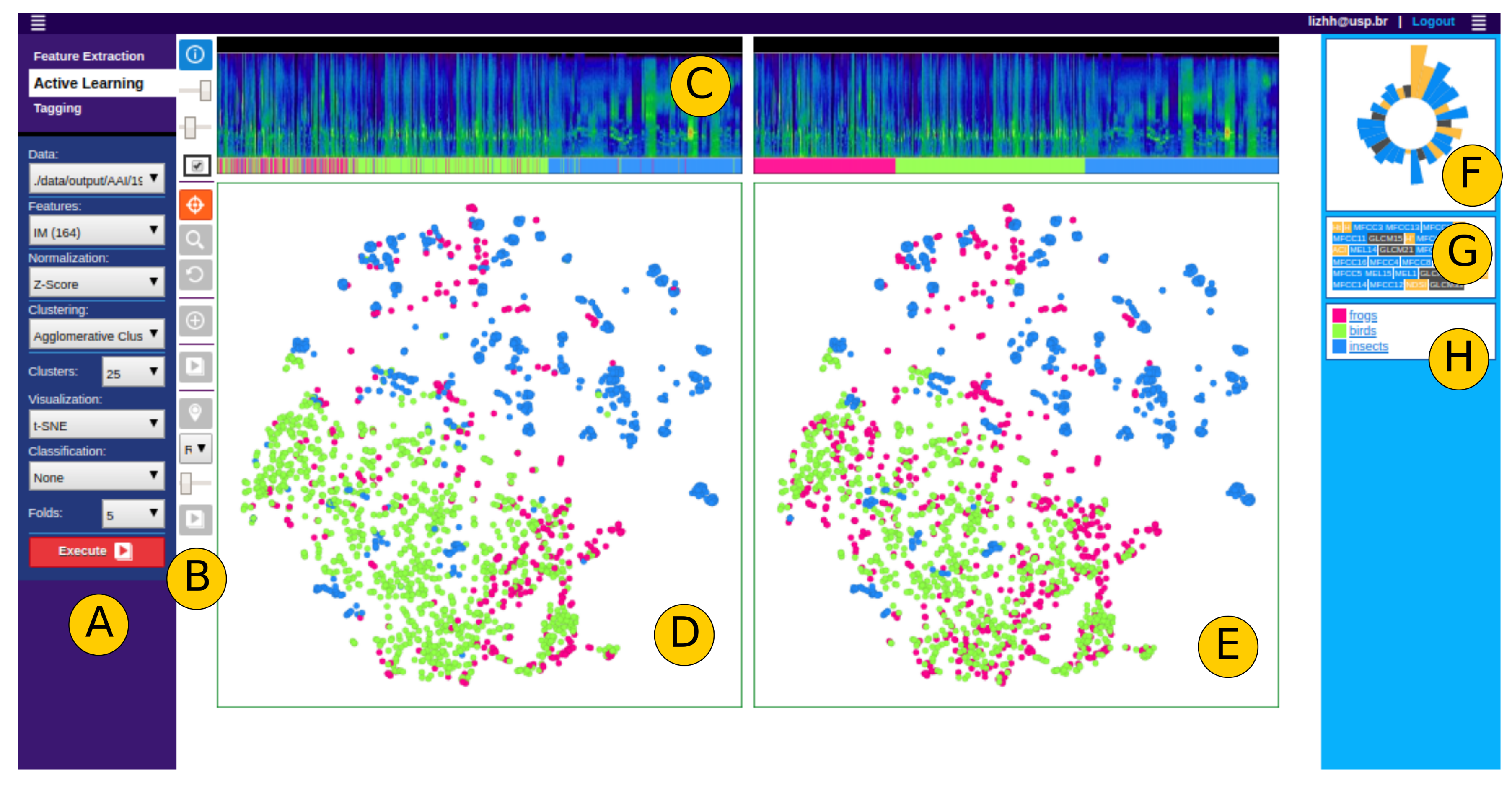
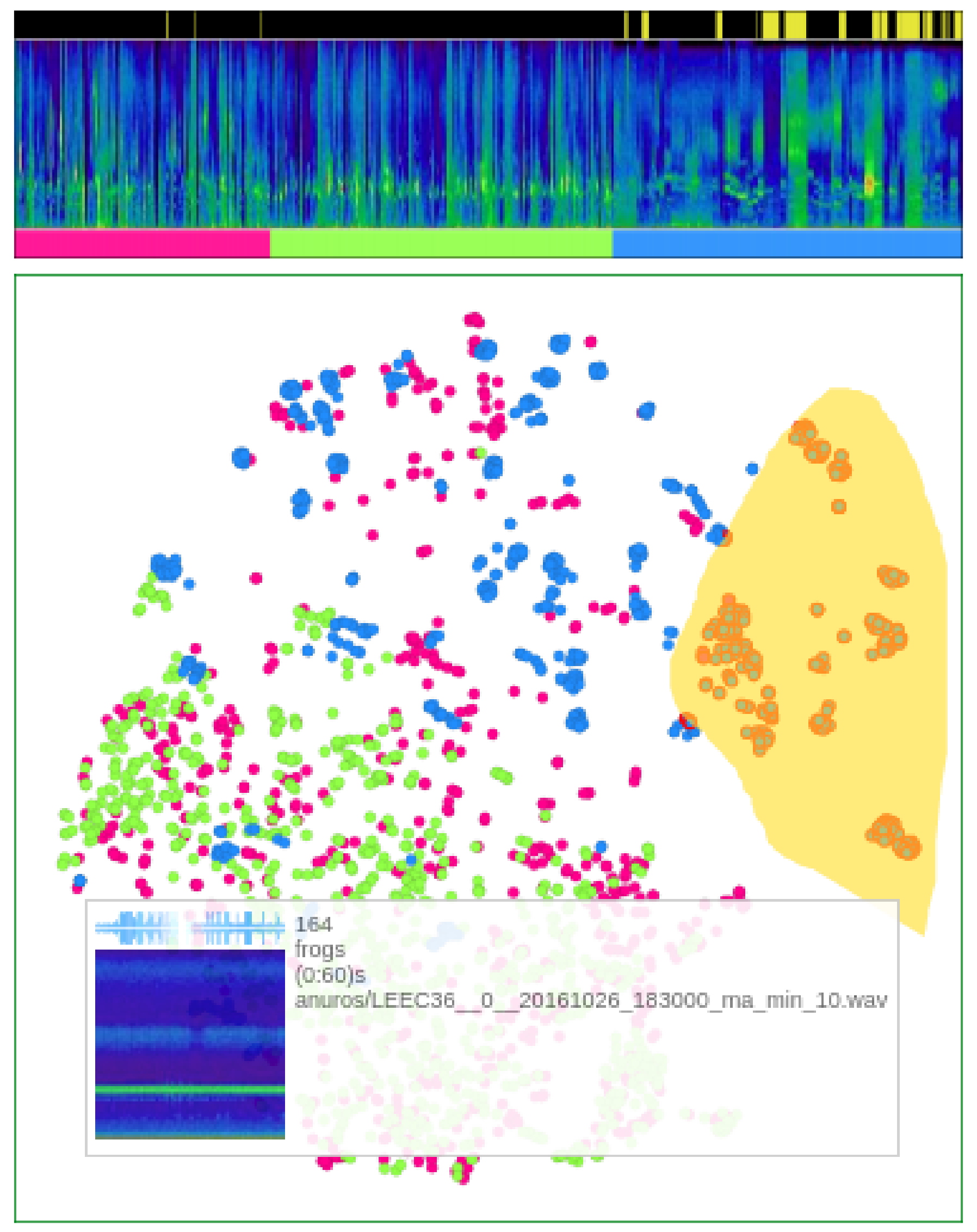
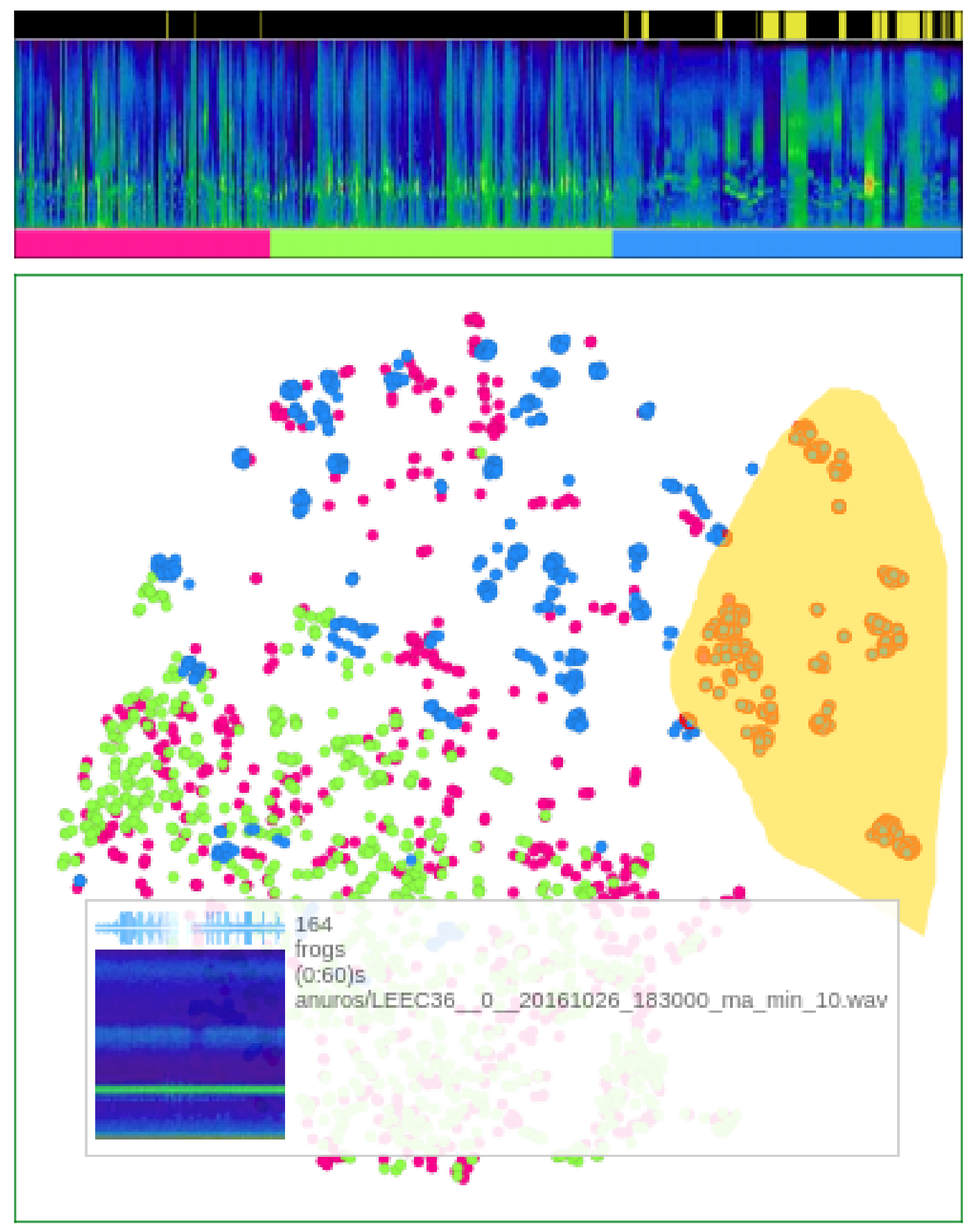
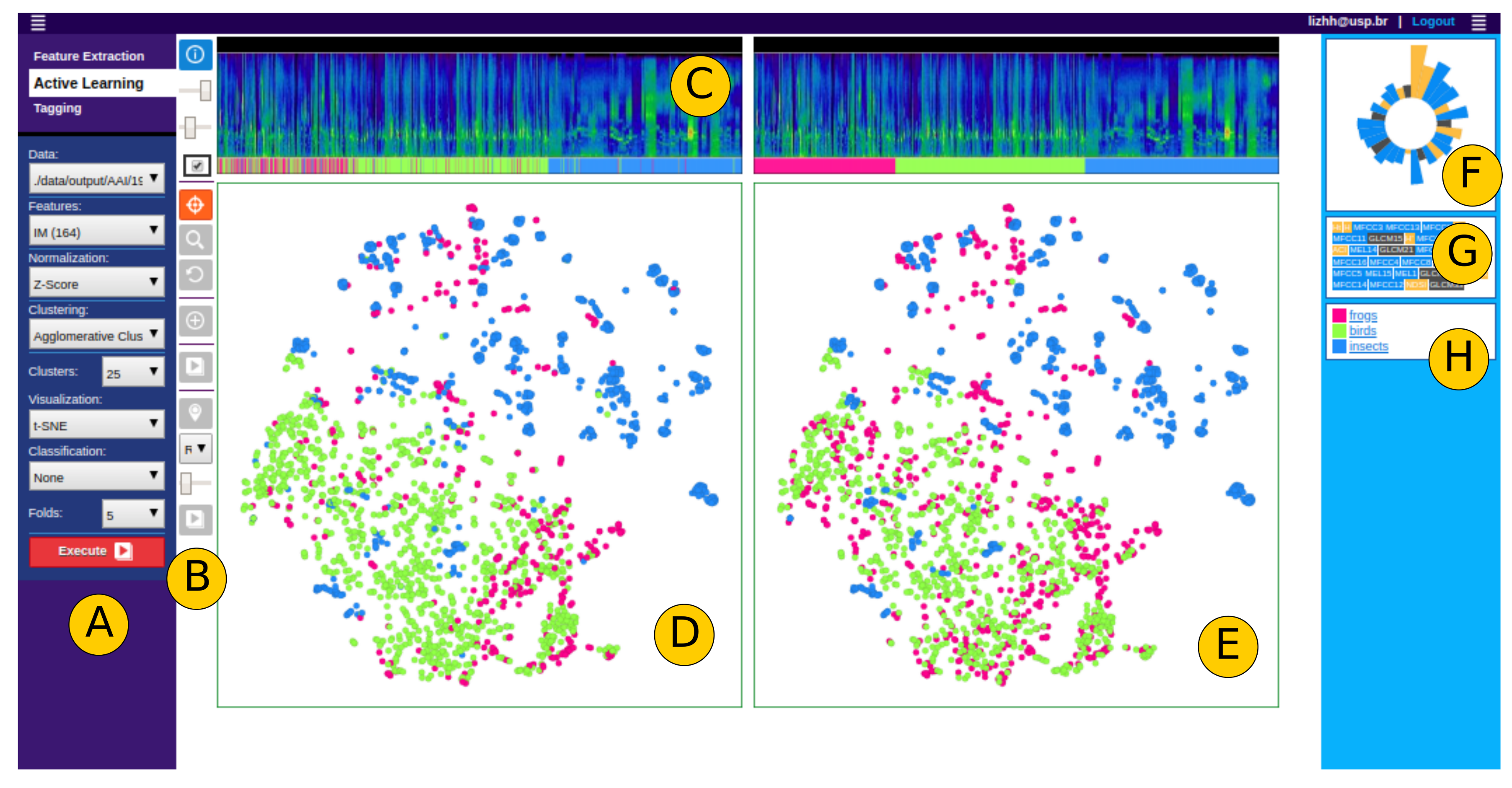
- Anchoring the process of user centered labeling through visualization by multidimensional projections. Anchoring data detailing in visualizations of summarized data; in the case of our sample application that is done by the proposal of “Time Line Spectrogram” (TLS) visualizations (Figure 3).
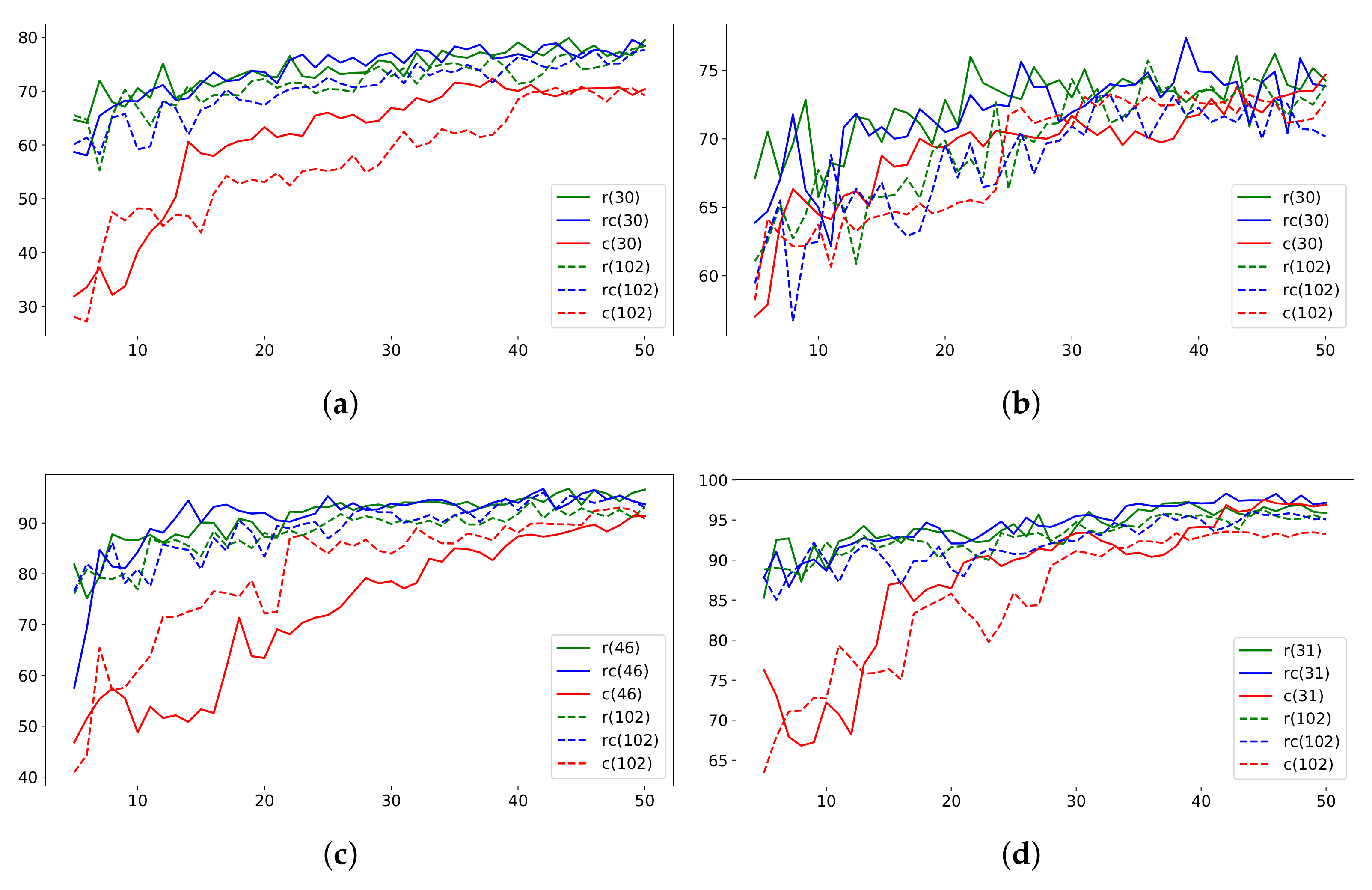
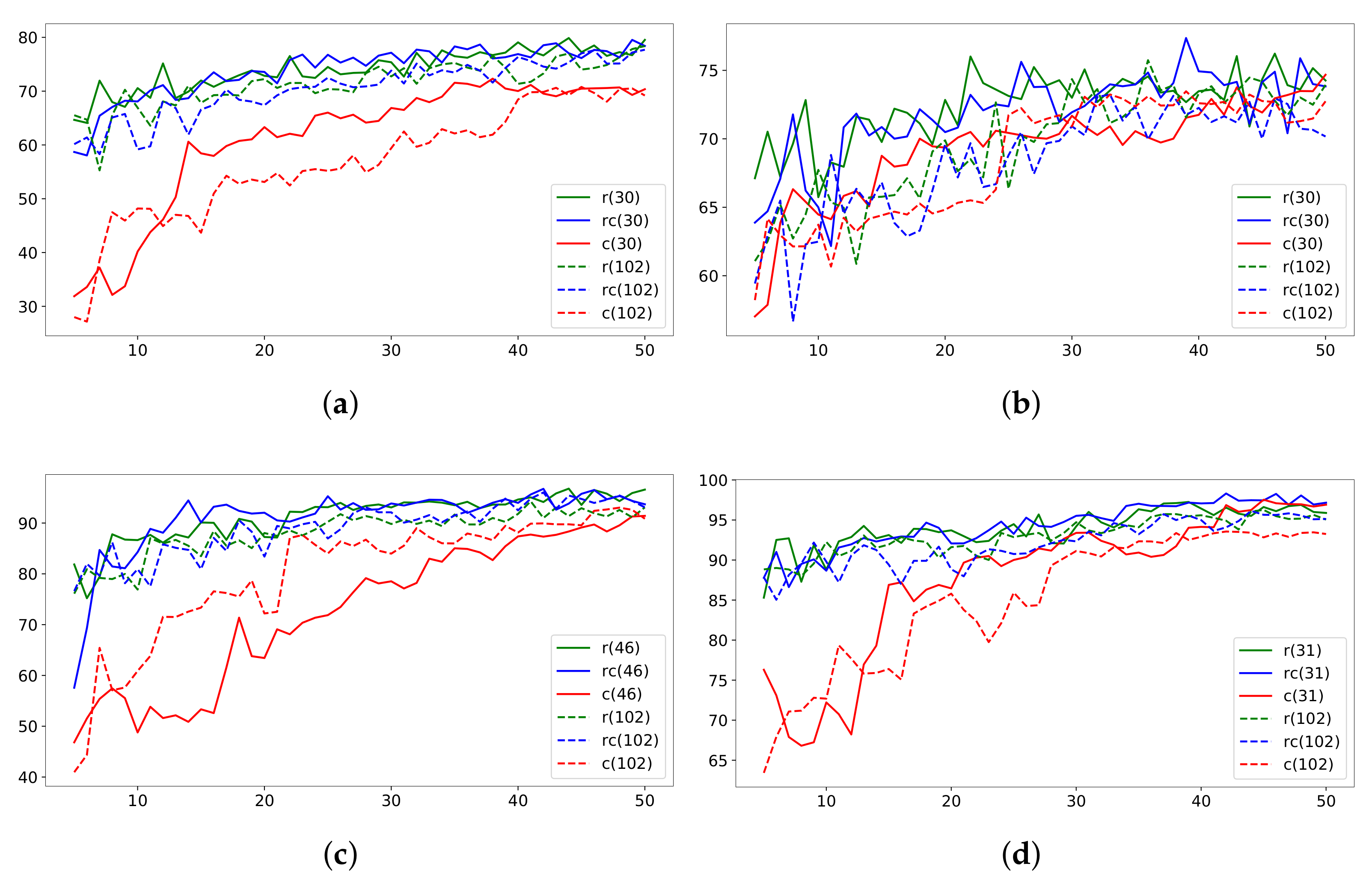
- New sampling strategies incorporated in the process of Active Learning for labeling, and their evaluation (Figure 4) using this strategy, we demonstrate reduced annotation costs (Table 1);
- Presentation of extensive experimental results that demonstrate the relevance of the proposed methods (Figures 3–5 and Table 1).
2. Background
2.1. Visualization in Active Learning and Labeling
2.2. Labeling of Sound Data
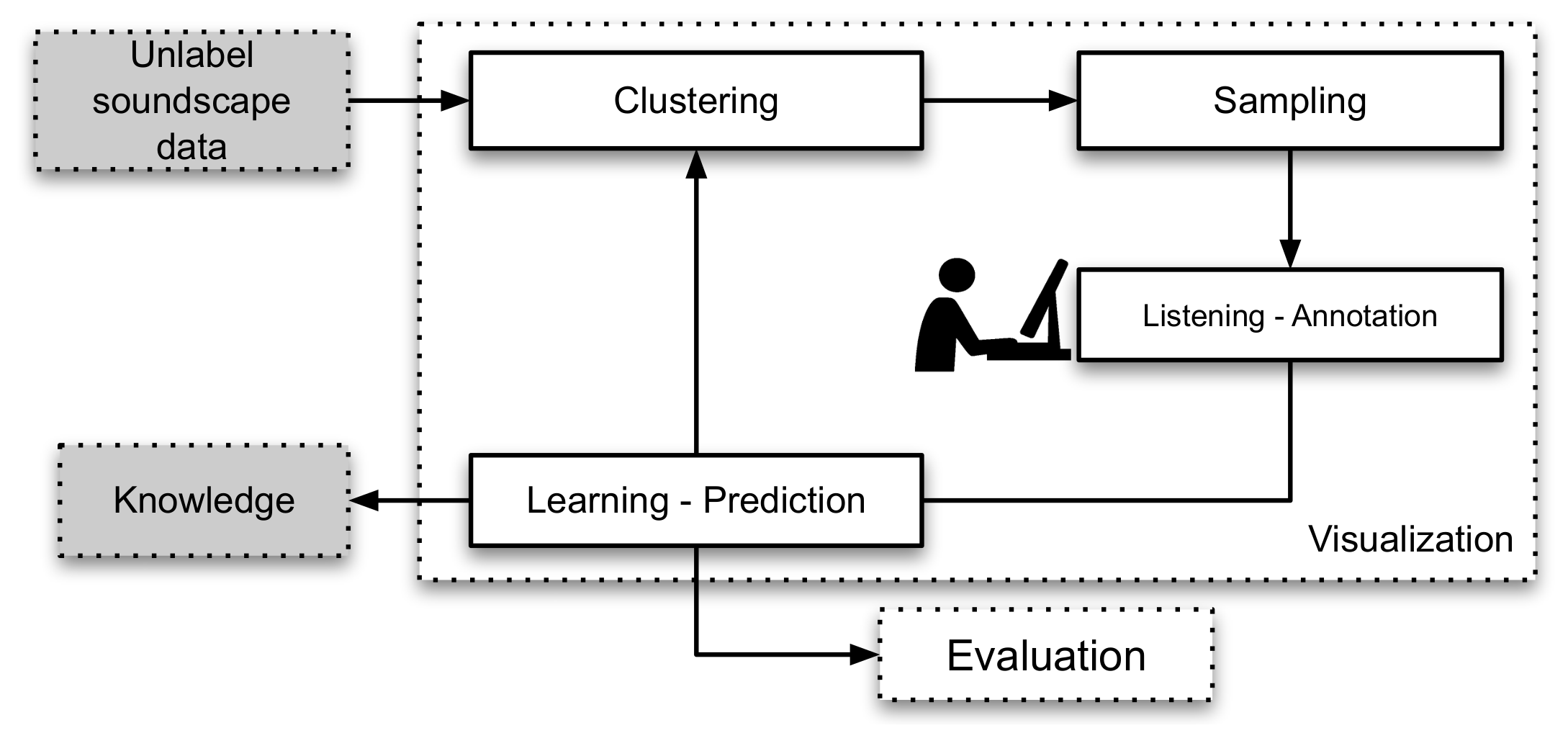
3. The Labeling Method
| Algorithm 1: Graph building. |
 |
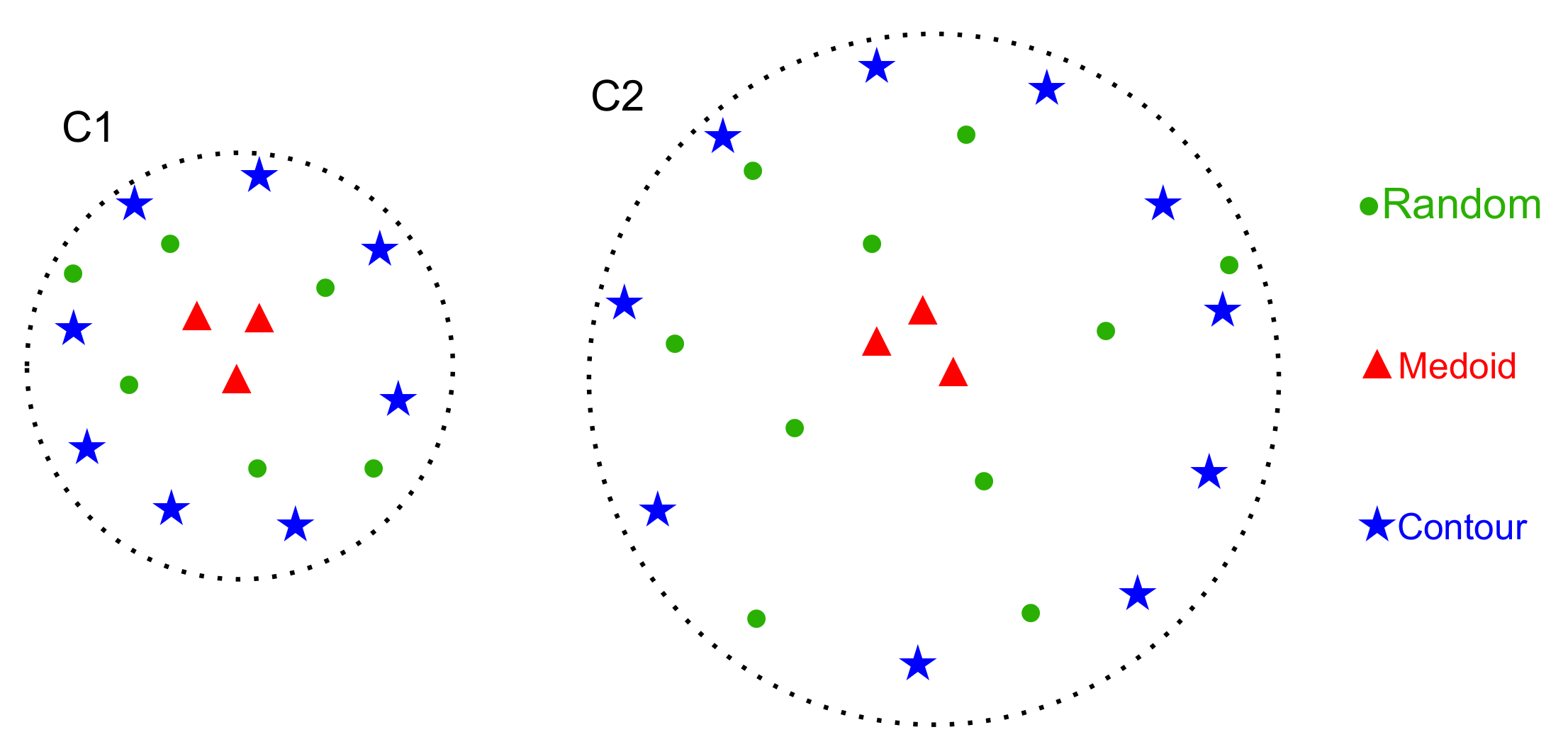
3.1. Clustering
3.2. Sampling
3.3. Annotation
3.4. Learning-Prediction
- (i)
- Learning: Model training. In this case, the model to be used is Random Forest Classifier (RFC).
- (ii)
- Prediction: After the learning, labels of the instances other than the samples are predicted. Then, by examining the results using the same visualizations, and the criteria of the application, the steps of the proposed method can be repeated starting from the Clustering step (Section 3.1).
3.5. Validation
3.6. Visualization
4. Data Description and Case Study
Data Availability and Bioethics
5. Results and Discussion
5.1. Clustering and Sampling Analysis
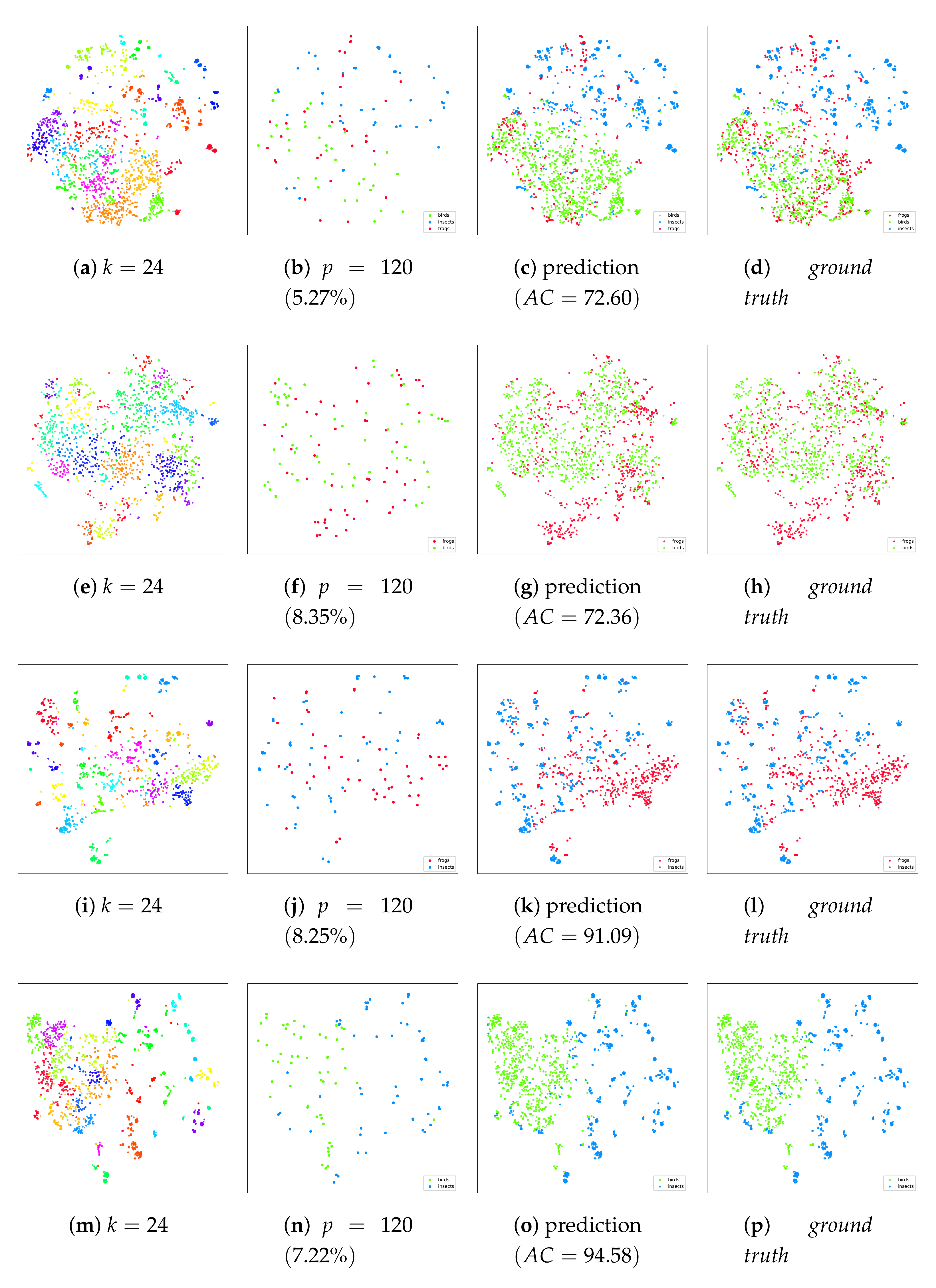
5.2. Visual Analysis via Projections
6. Conclusions, Future Work, and Opportunities
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Overview of the Visual Active Learning Framework for Soundscape Ecology
References
- Settles, B. Active Learning Literature Survey. In Computer Sciences Technical Report 1648; University of Wisconsin–Madison: Madison, WI, USA, 2009. [Google Scholar]
- Piczak, K.J. ESC: Dataset for Environmental Sound Classification. In Proceedings of the 23rd ACM International Conference on Multimedia (MM ’15); Association for Computing Machinery: New York, NY, USA, 2015; pp. 1015–1018. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A Survey of Active Learning Algorithms for Supervised Remote Sensing Image Classification. IEEE J. Sel. Top. Signal Process. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Pereira-Santos, D.; Prudêncio, R.B.C.; de Carvalho, A.C. Empirical investigation of active learning strategies. Neurocomputing 2019, 326–327, 15–27. [Google Scholar] [CrossRef]
- Riccardi, G.; Hakkani-Tur, D. Active learning: Theory and applications to automatic speech recognition. IEEE Trans. Speech Audio Process. 2005, 13, 504–511. [Google Scholar] [CrossRef]
- Kapoor, A.; Horvitz, E.; Basu, S. Selective Supervision: Guiding Supervised Learning with Decision-Theoretic Active Learning. In Proceedings of the 20th International Joint Conference on Artifical Intelligence (IJCAI’07); Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2007; pp. 877–882. [Google Scholar]
- Moskovitch, R.; Nissim, N.; Stopel, D.; Feher, C.; Englert, R.; Elovici, Y. Improving the Detection of Unknown Computer Worms Activity Using Active Learning. In KI 2007: Advances in Artificial Intelligence; Hertzberg, J., Beetz, M., Englert, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 489–493. [Google Scholar]
- Hu, R. Active Learning for Text Classification. Ph.D. Thesis, Technological University Dublin, Dublin, Ireland, 2011. [Google Scholar] [CrossRef]
- Abdelwahab, M.; Busso, C. Active Learning for Speech Emotion Recognition Using Deep Neural Network. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 1–7. [Google Scholar]
- Mandel, M.I.; Poliner, G.E.; Ellis, D.P. Support Vector Machine Active Learning for Music Retrieval. Multimed. Syst. 2006, 12, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Xin, D.; Ma, L.; Liu, J.; Macke, S.; Song, S.; Parameswaran, A. Accelerating Human-in-the-loop Machine Learning: Challenges and opportunities. In Conjunction with the 2018 ACM SIGMOD/PODS Conference (DEEM 2018), 15 June 2018, Proceedings of the 2nd Workshop on Data Management for End-To-End Machine Learning; Association for Computing Machinery, Inc.: New York, NY, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Liao, H.; Chen, L.; Song, Y.; Ming, H. Visualization-Based Active Learning for Video Annotation. IEEE Trans. Multimed. 2016, 18, 2196–2205. [Google Scholar] [CrossRef]
- Limberg, C.; Krieger, K.; Wersing, H.; Ritter, H. Active Learning for Image Recognition Using a Visualization-Based User Interface. In Artificial Neural Networks and Machine Learning—ICANN 2019: Deep Learning; Tetko, I.V., Kůrková, V., Karpov, P., Theis, F., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 495–506. [Google Scholar]
- Maijala, P.; Shuyang, Z.; Heittola, T.; Virtanen, T. Environmental noise monitoring using source classification in sensors. Appl. Acoust. 2018, 129, 258–267. [Google Scholar] [CrossRef]
- Servick, K. Eavesdropping on Ecosystems. Science 2014, 343, 834–837. [Google Scholar] [CrossRef] [PubMed]
- Farina, A.; Pieretti, N.; Piccioli, L. The soundscape methodology for long-term bird monitoring: A Mediterranean Europe case-study. Ecol. Inform. 2011, 6, 354–363. [Google Scholar] [CrossRef]
- Farina, A.; Pieretti, N. Sonic environment and vegetation structure: A methodological approach for a soundscape analysis of a Mediterranean maqui. Ecol. Inform. 2014, 21, 120–132. [Google Scholar] [CrossRef]
- Putland, R.; Mensinger, A. Exploring the soundscape of small freshwater lakes. Ecol. Inform. 2020, 55, 101018. [Google Scholar] [CrossRef]
- Kasten, E.P.; Gage, S.H.; Fox, J.; Joo, W. The remote environmental assessment laboratory’s acoustic library: An archive for studying soundscape ecology. Ecol. Inform. 2012, 12, 50–67. [Google Scholar] [CrossRef]
- LeBien, J.G.; Zhong, M.; Campos-Cerqueira, M.; Velev, J.; Dodhia, R.; Ferres, J.; Aide, T. A pipeline for identification of bird and frog species in tropical soundscape recordings using a convolutional neural network. Ecol. Inform. 2020, 59, 101113. [Google Scholar] [CrossRef]
- Pijanowski, B.C.; Farina, A.; Gage, S.H.; Dumyahn, S.L.; Krause, B.L. What is soundscape ecology? An introduction and overview of an emerging new science. Landsc. Ecol. 2011, 26, 1213–1232. [Google Scholar] [CrossRef]
- Scarpelli, M.D.; Ribeiro, M.C.; Teixeira, F.Z.; Young, R.J.; Teixeira, C.P. Gaps in terrestrial soundscape research: It’s time to focus on tropical wildlife. Sci. Total. Environ. 2020, 707, 135403. [Google Scholar] [CrossRef]
- Hu, W.; Bulusu, N.; Chou, C.T.; Jha, S.; Taylor, A.; Tran, V.N. Design and Evaluation of a Hybrid Sensor Network for Cane Toad Monitoring. ACM Trans. Sen. Netw. 2009, 5, 4:1–4:28. [Google Scholar] [CrossRef]
- Joo, W.; Gage, S.H.; Kasten, E.P. Analysis and interpretation of variability in soundscapes along an urban-rural gradient. Landsc. Urban Plan. 2011, 103, 259–276. [Google Scholar] [CrossRef]
- Parks, S.E.; Miksis-Olds, J.L.; Denes, S.L. Assessing marine ecosystem acoustic diversity across ocean basins. Ecol. Inform. 2014, 21, 81–88. [Google Scholar] [CrossRef]
- Sueur, J.; Farina, A. Ecoacoustics: the Ecological Investigation and Interpretation of Environmental Sound. Biosemiotics 2015, 8, 493–502. [Google Scholar] [CrossRef]
- Bellisario, K.; Broadhead, T.; Savage, D.; Zhao, Z.; Omrani, H.; Zhang, S.; Springer, J.; Pijanowski, B. Contributions of MIR to soundscape ecology. Part 3: Tagging and classifying audio features using a multi-labeling k-nearest neighbor approach. Ecol. Inform. 2019, 51, 103–111. [Google Scholar] [CrossRef]
- Abramson, Y.; Freund, Y. SEmi-automatic VIsuaL LEarning (SEVILLE): A tutorial on active learning for visual object recognition. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; p. 11. [Google Scholar]
- Turtinen, M.; Pietikänien, M. Labeling of Textured Data with Co-Training and Active Learning. Proc. Workshop on Texture Analysis and Synthesis. 2005, pp. 137–142. Available online: https://core.ac.uk/display/20963071 (accessed on 22 June 2021).
- Lecerf, L.; Chidlovskii, B. Visalix: A web application for visual data analysis and clustering. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, Paris, France, 29 June–1 July 2009. [Google Scholar]
- Namee, B.M.; Hu, R.; Delany, S.J. Inside the Selection Box: Visualising active learning selection strategies. nips2010. 2010, p. 15. Available online: https://cseweb.ucsd.edu/~lvdmaaten/workshops/nips2010/papers/namee.pdf (accessed on 22 June 2021).
- Huang, L.; Matwin, S.; de Carvalho, E.J.; Minghim, R. Active Learning with Visualization for Text Data. In Proceedings of the 2017 ACM Workshop on Exploratory Search and Interactive Data Analytics (ESIDA ’17); Association for Computing Machinery: New York, NY, USA, 2017; pp. 69–74. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Ristin, M.; Guillaumin, M.; Gall, J.; Van Gool, L. Incremental Learning of Random Forests for Large-Scale Image Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 490–503. [Google Scholar] [CrossRef] [PubMed]
- Tasar, O.; Tarabalka, Y.; Alliez, P. Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2019, 12, 3524–3537. [Google Scholar] [CrossRef] [Green Version]
- Shin, G.; Yooun, H.; Shin, D.; Shin, D. Incremental Learning Method for Cyber Intelligence, Surveillance, and Reconnaissance in Closed Military Network Using Converged IT Techniques. Soft Comput. 2018, 22, 6835–6844. [Google Scholar] [CrossRef]
- Hilasaca, L.M.H.; Gaspar, L.P.; Ribeiro, M.C.; Minghim, R. Visualization and categorization of ecological acoustic events based on discriminant features. Ecol. Indic. 2021, 107316. [Google Scholar] [CrossRef]
- Han, W.; Coutinho, E.; Ruan, H.; Li, H.; Schuller, B.; Yu, X.; Zhu, X. Semi-Supervised Active Learning for Sound Classification in Hybrid Learning Environments. PLoS ONE 2016, 11, 1–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shuyang, Z.; Heittola, T.; Virtanen, T. Active learning for sound event classification by clustering unlabeled data. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 751–755. [Google Scholar] [CrossRef]
- Salamon, J.; Jacoby, C.; Bello, J.P. A Dataset and Taxonomy for Urban Sound Research. In Proceedings of the 22nd ACM International Conference on Multimedia (MM ‘14); Association for Computing Machinery: New York, NY, USA, 2014; pp. 1041–1044. [Google Scholar] [CrossRef]
- Shuyang, Z.; Heittola, T.; Virtanen, T. An Active Learning Method Using Clustering and Committee-Based Sample Selection for Sound Event Classification. In Proceedings of the 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), Tokyo, Japan, 17–20 September 2018; pp. 116–120. [Google Scholar] [CrossRef]
- Kholghi, M.; Phillips, Y.; Towsey, M.; Sitbon, L.; Roe, P. Active learning for classifying long-duration audio recordings of the environment. Methods Ecol. Evol. 2018, 9, 1948–1958. [Google Scholar] [CrossRef]
- Shuyang, Z.; Heittola, T.; Virtanen, T. Active Learning for Sound Event Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2895–2905. [Google Scholar] [CrossRef]
- Wang, Y.; Mendez Mendez, A.E.; Cartwright, M.; Bello, J.P. Active Learning for Efficient Audio Annotation and Classification with a Large Amount of Unlabeled Data. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 880–884. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (p) | (%) | (r) | (m) | (c) | () | () | () | () | (p) | (%) | (r) | (m) | (c) | () | () | () | () | (p) | (%) | (r) | (m) | (c) | () | () | () | () | |
| 5 | 25 | 1.10 | 62.79 | 58.30 | 32.50 | 59.64 | 47.38 | 58.53 | 62.79 | 50 | 2.20 | 64.66 | 64.12 | 31.88 | 60.66 | 58.69 | 53.84 | 58.15 | 103 | 4.52 | 67.25 | 62.79 | 34.64 | 66.65 | 62.93 | 55.24 | 57.41 |
| 6 | 30 | 1.32 | 65.24 | 62.44 | 31.51 | 60.21 | 43.21 | 59.28 | 60.17 | 60 | 2.64 | 64.10 | 63.78 | 33.60 | 62.07 | 58.05 | 52.64 | 58.37 | 112 | 4.92 | 64.43 | 63.74 | 40.05 | 67.48 | 69.24 | 55.66 | 57.14 |
| 7 | 35 | 1.54 | 71.19 | 61.46 | 38.85 | 67.53 | 59.28 | 62.36 | 62.62 | 70 | 3.07 | 71.95 | 60.67 | 37.20 | 66.38 | 65.43 | 57.59 | 63.25 | 119 | 5.23 | 72.85 | 63.30 | 37.26 | 68.40 | 67.98 | 55.28 | 61.03 |
| 8 | 40 | 1.76 | 65.62 | 61.42 | 37.82 | 65.53 | 59.10 | 64.68 | 64.33 | 80 | 3.51 | 67.96 | 62.90 | 32.13 | 64.54 | 67.05 | 60.31 | 61.72 | 126 | 5.53 | 67.55 | 63.69 | 39.01 | 68.62 | 68.06 | 61.13 | 64.53 |
| 9 | 45 | 1.98 | 60.26 | 64.61 | 40.14 | 62.46 | 64.25 | 66.71 | 66.58 | 90 | 3.95 | 67.08 | 64.61 | 33.74 | 68.54 | 68.22 | 65.11 | 65.57 | 136 | 5.97 | 69.87 | 64.27 | 41.71 | 71.18 | 63.80 | 64.83 | 66.14 |
| 10 | 50 | 2.20 | 63.36 | 64.89 | 43.65 | 62.73 | 66.91 | 67.85 | 67.49 | 100 | 4.39 | 70.56 | 64.17 | 40.19 | 66.65 | 68.08 | 67.98 | 65.55 | 142 | 6.24 | 71.52 | 65.43 | 48.01 | 73.40 | 71.05 | 68.99 | 68.29 |
| 11 | 55 | 2.42 | 64.13 | 62.15 | 46.98 | 65.84 | 67.96 | 66.61 | 65.98 | 110 | 4.83 | 68.76 | 63.54 | 43.79 | 68.94 | 70.14 | 67.74 | 65.39 | 149 | 6.54 | 73.50 | 64.29 | 43.70 | 71.95 | 69.41 | 69.08 | 66.17 |
| 12 | 60 | 2.64 | 70.55 | 60.62 | 45.20 | 67.34 | 68.20 | 63.78 | 65.31 | 120 | 5.27 | 75.15 | 62.87 | 46.13 | 64.72 | 71.12 | 67.45 | 64.86 | 155 | 6.81 | 76.48 | 64.89 | 49.62 | 69.32 | 72.20 | 67.86 | 66.21 |
| 13 | 65 | 2.85 | 67.18 | 61.35 | 44.71 | 66.59 | 60.67 | 64.87 | 67.09 | 130 | 5.71 | 68.70 | 62.55 | 50.30 | 67.54 | 68.37 | 68.70 | 65.16 | 160 | 7.03 | 70.00 | 64.38 | 60.23 | 68.02 | 70.15 | 69.25 | 66.98 |
| 14 | 70 | 3.07 | 69.87 | 60.17 | 58.13 | 67.20 | 66.38 | 65.84 | 65.29 | 140 | 6.15 | 69.91 | 62.56 | 60.60 | 68.79 | 68.69 | 68.65 | 64.25 | 166 | 7.29 | 73.14 | 62.72 | 59.02 | 66.51 | 76.69 | 70.82 | 67.69 |
| 15 | 75 | 3.29 | 68.94 | 61.22 | 54.13 | 66.17 | 65.67 | 63.40 | 63.90 | 150 | 6.59 | 71.98 | 59.71 | 58.44 | 68.97 | 71.37 | 69.44 | 65.26 | 171 | 7.51 | 72.98 | 62.68 | 58.97 | 70.85 | 73.12 | 69.94 | 67.57 |
| 16 | 80 | 3.51 | 66.64 | 61.36 | 56.94 | 66.18 | 67.59 | 64.54 | 63.31 | 160 | 7.03 | 70.81 | 62.21 | 57.96 | 67.45 | 73.50 | 69.49 | 67.60 | 177 | 7.77 | 70.48 | 64.38 | 60.86 | 71.10 | 75.24 | 69.95 | 69.14 |
| 17 | 85 | 3.73 | 67.38 | 62.55 | 61.82 | 69.21 | 68.48 | 67.47 | 65.88 | 170 | 7.47 | 71.95 | 62.70 | 59.80 | 68.15 | 71.86 | 71.29 | 67.68 | 180 | 7.91 | 73.72 | 63.61 | 57.51 | 71.01 | 73.06 | 71.44 | 69.19 |
| 18 | 90 | 3.95 | 66.94 | 62.87 | 59.35 | 68.27 | 67.86 | 68.77 | 64.29 | 180 | 7.91 | 72.96 | 63.09 | 60.75 | 71.63 | 72.10 | 71.39 | 68.43 | 187 | 8.21 | 73.25 | 64.31 | 62.54 | 67.13 | 72.87 | 70.29 | 68.04 |
| 19 | 95 | 4.17 | 69.43 | 62.74 | 61.18 | 67.51 | 68.65 | 68.70 | 66.68 | 190 | 8.34 | 73.84 | 63.44 | 61.04 | 70.96 | 73.74 | 71.01 | 68.28 | 190 | 8.34 | 74.89 | 65.26 | 62.48 | 71.35 | 72.40 | 70.29 | 69.38 |
| 20 | 100 | 4.39 | 70.56 | 63.30 | 57.83 | 67.98 | 63.99 | 69.13 | 68.26 | 200 | 8.78 | 72.85 | 64.52 | 63.31 | 72.22 | 73.57 | 73.18 | 72.32 | 196 | 8.61 | 72.80 | 64.44 | 62.09 | 70.98 | 74.20 | 72.03 | 70.40 |
| 21 | 105 | 4.61 | 67.50 | 63.49 | 61.60 | 66.44 | 69.11 | 69.20 | 66.85 | 210 | 9.22 | 72.57 | 64.25 | 61.44 | 71.02 | 71.46 | 73.39 | 72.18 | 202 | 8.87 | 70.80 | 64.00 | 58.31 | 69.54 | 73.78 | 72.96 | 71.28 |
| 22 | 110 | 4.83 | 69.59 | 62.67 | 64.28 | 67.10 | 68.90 | 68.44 | 67.01 | 220 | 9.66 | 76.52 | 63.93 | 62.08 | 71.66 | 75.79 | 71.85 | 69.42 | 205 | 9.00 | 73.94 | 64.43 | 57.77 | 72.39 | 75.87 | 71.43 | 69.88 |
| 23 | 115 | 5.05 | 69.29 | 61.89 | 62.86 | 65.54 | 70.40 | 68.13 | 65.82 | 230 | 10.10 | 72.74 | 62.77 | 61.65 | 71.18 | 76.80 | 72.79 | 71.52 | 208 | 9.13 | 72.21 | 64.52 | 58.05 | 71.53 | 73.66 | 71.58 | 71.00 |
| 24 | 120 | 5.27 | 70.47 | 62.31 | 63.65 | 67.22 | 72.60 | 68.47 | 66.34 | 240 | 10.54 | 72.46 | 63.48 | 65.44 | 71.18 | 74.37 | 73.10 | 71.28 | 213 | 9.35 | 74.13 | 64.58 | 63.81 | 71.32 | 75.53 | 72.29 | 70.69 |
| 25 | 125 | 5.49 | 71.28 | 63.48 | 64.92 | 64.78 | 69.56 | 68.77 | 67.80 | 250 | 10.98 | 74.49 | 65.02 | 66.01 | 70.35 | 76.76 | 72.72 | 71.88 | 216 | 9.49 | 73.70 | 64.68 | 60.89 | 69.00 | 76.71 | 72.68 | 72.97 |
| 26 | 130 | 5.71 | 71.50 | 64.28 | 62.23 | 69.21 | 71.63 | 70.42 | 67.26 | 260 | 11.42 | 73.13 | 66.83 | 64.95 | 70.70 | 75.31 | 74.62 | 73.33 | 220 | 9.66 | 73.94 | 66.80 | 61.84 | 69.52 | 75.55 | 73.65 | 71.46 |
| 27 | 135 | 5.93 | 71.99 | 64.43 | 61.06 | 67.04 | 69.33 | 69.09 | 66.29 | 270 | 11.86 | 73.39 | 66.72 | 65.62 | 70.30 | 76.23 | 73.59 | 71.10 | 227 | 9.97 | 72.59 | 65.66 | 61.41 | 72.73 | 74.54 | 73.07 | 71.41 |
| 28 | 140 | 6.15 | 71.31 | 64.16 | 60.93 | 69.35 | 69.07 | 70.47 | 67.01 | 280 | 12.30 | 73.46 | 66.80 | 64.15 | 73.56 | 74.71 | 73.86 | 71.71 | 230 | 10.10 | 72.50 | 66.05 | 62.29 | 72.69 | 74.50 | 73.82 | 70.35 |
| 29 | 145 | 6.37 | 73.26 | 64.59 | 58.72 | 65.95 | 71.62 | 70.73 | 67.68 | 290 | 12.74 | 75.74 | 66.53 | 64.47 | 73.28 | 76.60 | 73.73 | 71.97 | 235 | 10.32 | 75.37 | 64.84 | 62.10 | 69.59 | 75.81 | 72.97 | 70.23 |
| 30 | 150 | 6.59 | 73.25 | 64.27 | 64.17 | 67.47 | 72.21 | 69.25 | 68.36 | 300 | 13.18 | 75.37 | 66.26 | 66.87 | 70.97 | 77.14 | 74.00 | 73.88 | 237 | 10.41 | 73.48 | 66.96 | 63.43 | 71.27 | 74.85 | 71.76 | 69.56 |
| 31 | 155 | 6.81 | 72.01 | 63.81 | 64.14 | 69.93 | 74.46 | 70.45 | 68.94 | 310 | 13.61 | 72.70 | 67.16 | 66.50 | 71.73 | 75.19 | 73.97 | 73.84 | 241 | 10.58 | 73.04 | 66.70 | 65.28 | 72.59 | 73.04 | 73.43 | 71.41 |
| 32 | 160 | 7.03 | 73.36 | 64.67 | 66.23 | 69.44 | 71.99 | 70.29 | 68.63 | 320 | 14.05 | 77.11 | 67.25 | 68.73 | 72.15 | 77.72 | 73.89 | 72.84 | 245 | 10.76 | 75.84 | 67.47 | 64.22 | 73.13 | 76.28 | 73.38 | 72.59 |
| 33 | 165 | 7.25 | 72.02 | 65.34 | 65.53 | 66.76 | 74.76 | 70.74 | 69.74 | 330 | 14.49 | 74.47 | 67.28 | 67.95 | 72.37 | 77.40 | 75.30 | 74.65 | 249 | 10.94 | 74.51 | 66.96 | 67.50 | 71.65 | 72.68 | 73.82 | 73.67 |
| 34 | 170 | 7.47 | 72.95 | 65.54 | 67.44 | 70.72 | 76.70 | 70.00 | 70.53 | 340 | 14.93 | 77.59 | 66.91 | 68.97 | 71.66 | 75.32 | 75.12 | 74.57 | 254 | 11.16 | 75.43 | 66.58 | 69.25 | 72.96 | 78.25 | 72.66 | 72.86 |
| 35 | 175 | 7.69 | 74.41 | 65.08 | 67.98 | 72.36 | 72.84 | 69.36 | 69.89 | 350 | 15.37 | 76.49 | 68.19 | 71.56 | 74.26 | 78.31 | 75.30 | 74.13 | 257 | 11.29 | 74.60 | 67.67 | 70.25 | 74.01 | 75.54 | 74.50 | 71.63 |
| 36 | 180 | 7.91 | 72.53 | 64.43 | 68.14 | 72.25 | 71.20 | 70.15 | 69.19 | 360 | 15.81 | 76.21 | 66.82 | 71.36 | 72.98 | 77.78 | 75.59 | 75.14 | 260 | 11.42 | 73.67 | 67.48 | 71.00 | 70.90 | 77.94 | 73.28 | 70.80 |
| 37 | 185 | 8.12 | 75.05 | 66.68 | 66.30 | 72.28 | 75.00 | 71.94 | 70.98 | 370 | 16.25 | 77.24 | 69.01 | 70.79 | 74.04 | 78.66 | 75.62 | 74.99 | 262 | 11.51 | 75.88 | 68.44 | 73.15 | 73.10 | 75.93 | 73.40 | 72.16 |
| 38 | 190 | 8.34 | 75.13 | 64.64 | 66.94 | 71.63 | 73.26 | 71.73 | 70.92 | 380 | 16.69 | 76.70 | 68.90 | 72.32 | 75.28 | 76.07 | 75.12 | 75.18 | 264 | 11.59 | 74.42 | 68.21 | 71.98 | 75.56 | 74.96 | 72.78 | 72.48 |
| 39 | 195 | 8.56 | 73.15 | 64.94 | 66.71 | 74.02 | 75.22 | 71.85 | 71.66 | 390 | 17.13 | 77.16 | 68.73 | 70.48 | 74.03 | 76.31 | 74.46 | 74.31 | 268 | 11.77 | 75.96 | 68.19 | 70.68 | 72.62 | 77.20 | 72.32 | 71.38 |
| 40 | 200 | 8.78 | 73.95 | 64.28 | 67.60 | 75.16 | 75.16 | 71.98 | 71.27 | 399 | 17.52 | 79.07 | 68.00 | 70.02 | 73.48 | 76.89 | 74.81 | 73.54 | 271 | 11.90 | 77.52 | 66.15 | 71.44 | 75.62 | 74.63 | 72.78 | 72.38 |
| 41 | 205 | 9.00 | 71.72 | 64.29 | 67.37 | 71.09 | 76.11 | 72.10 | 70.24 | 409 | 17.96 | 77.46 | 67.93 | 71.15 | 75.54 | 76.28 | 74.20 | 74.57 | 274 | 12.03 | 75.09 | 67.30 | 70.00 | 72.74 | 74.84 | 73.34 | 71.24 |
| 42 | 210 | 9.22 | 71.60 | 64.97 | 65.99 | 70.39 | 76.15 | 72.09 | 70.16 | 419 | 18.40 | 76.64 | 69.05 | 69.54 | 71.91 | 78.53 | 74.87 | 74.49 | 277 | 12.17 | 74.35 | 67.95 | 68.75 | 72.60 | 77.60 | 75.30 | 71.85 |
| 43 | 215 | 9.44 | 75.46 | 66.25 | 66.88 | 72.41 | 75.56 | 71.92 | 69.95 | 429 | 18.84 | 78.35 | 68.72 | 69.05 | 72.73 | 78.90 | 74.57 | 73.76 | 280 | 12.30 | 74.81 | 67.80 | 70.36 | 74.01 | 77.52 | 73.86 | 70.56 |
| 44 | 220 | 9.66 | 75.21 | 66.65 | 67.87 | 72.78 | 73.36 | 71.90 | 70.12 | 439 | 19.28 | 79.87 | 68.99 | 69.91 | 75.57 | 77.04 | 74.92 | 75.20 | 283 | 12.43 | 77.03 | 67.30 | 69.41 | 72.92 | 75.63 | 74.02 | 72.77 |
| 45 | 225 | 9.88 | 74.22 | 65.98 | 69.01 | 71.30 | 73.68 | 72.95 | 70.04 | 449 | 19.72 | 77.24 | 68.54 | 70.46 | 72.92 | 76.15 | 75.44 | 75.00 | 286 | 12.56 | 73.93 | 67.40 | 71.52 | 73.73 | 76.34 | 74.23 | 71.52 |
| 46 | 230 | 10.10 | 75.38 | 65.51 | 69.47 | 74.26 | 76.50 | 71.81 | 70.21 | 459 | 20.16 | 78.49 | 68.04 | 70.52 | 77.06 | 77.67 | 74.70 | 74.51 | 288 | 12.65 | 76.62 | 67.67 | 70.29 | 73.81 | 74.56 | 74.76 | 72.40 |
| 47 | 235 | 10.32 | 73.90 | 65.38 | 69.83 | 70.96 | 75.17 | 71.35 | 69.60 | 469 | 20.60 | 76.55 | 68.36 | 70.58 | 75.28 | 77.43 | 75.77 | 74.51 | 290 | 12.74 | 74.94 | 67.04 | 71.36 | 74.13 | 75.84 | 72.97 | 71.62 |
| 48 | 240 | 10.54 | 75.75 | 65.93 | 68.53 | 71.87 | 75.11 | 72.12 | 70.36 | 479 | 21.04 | 77.25 | 68.91 | 70.69 | 74.53 | 76.25 | 75.36 | 74.10 | 293 | 12.87 | 76.41 | 66.99 | 71.07 | 73.74 | 75.35 | 74.90 | 72.18 |
| 49 | 245 | 10.76 | 75.69 | 66.19 | 69.14 | 72.15 | 77.46 | 72.44 | 70.39 | 489 | 21.48 | 76.68 | 68.40 | 69.30 | 74.55 | 79.53 | 77.46 | 75.86 | 296 | 13.00 | 75.42 | 66.33 | 72.34 | 75.42 | 76.73 | 75.27 | 72.69 |
| 50 | 250 | 10.98 | 73.06 | 67.00 | 68.18 | 74.10 | 74.99 | 72.72 | 71.15 | 499 | 21.91 | 79.53 | 70.13 | 70.36 | 75.70 | 78.40 | 76.43 | 76.11 | 300 | 13.18 | 76.53 | 67.17 | 70.21 | 73.60 | 77.79 | 74.51 | 72.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hilasaca, L.H.; Ribeiro, M.C.; Minghim, R. Visual Active Learning for Labeling: A Case for Soundscape Ecology Data. Information 2021, 12, 265. https://doi.org/10.3390/info12070265
Hilasaca LH, Ribeiro MC, Minghim R. Visual Active Learning for Labeling: A Case for Soundscape Ecology Data. Information. 2021; 12(7):265. https://doi.org/10.3390/info12070265
Chicago/Turabian StyleHilasaca, Liz Huancapaza, Milton Cezar Ribeiro, and Rosane Minghim. 2021. "Visual Active Learning for Labeling: A Case for Soundscape Ecology Data" Information 12, no. 7: 265. https://doi.org/10.3390/info12070265
APA StyleHilasaca, L. H., Ribeiro, M. C., & Minghim, R. (2021). Visual Active Learning for Labeling: A Case for Soundscape Ecology Data. Information, 12(7), 265. https://doi.org/10.3390/info12070265