
Combine-Net: An Improved Filter Pruning Algorithm


Abstract
:1. Introduction
2. Related Work
2.1. Lightweight Neural Network
2.2. Quantization
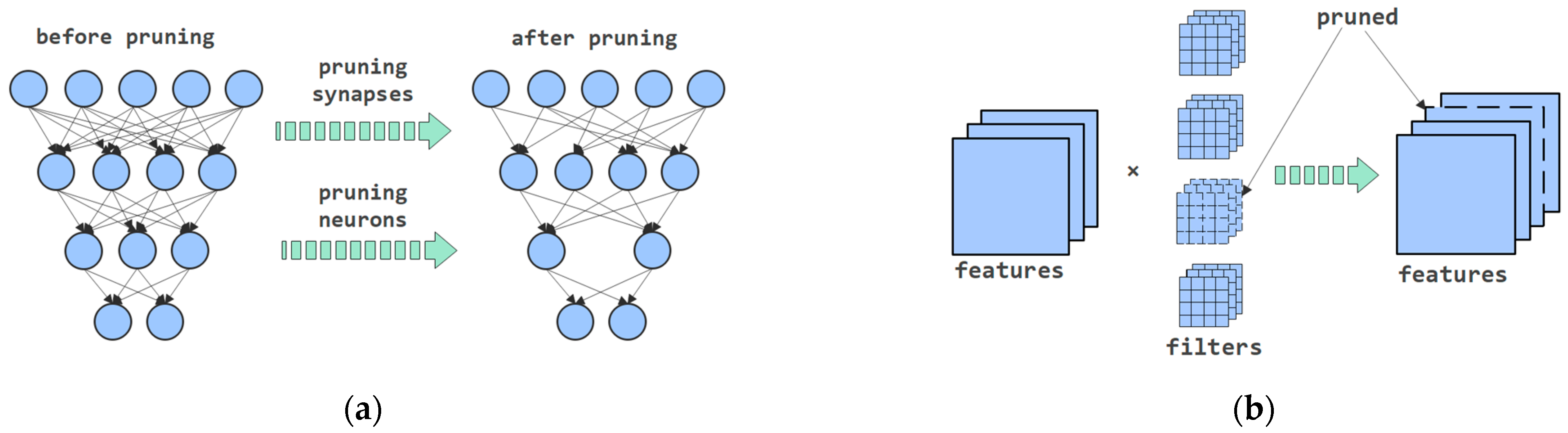
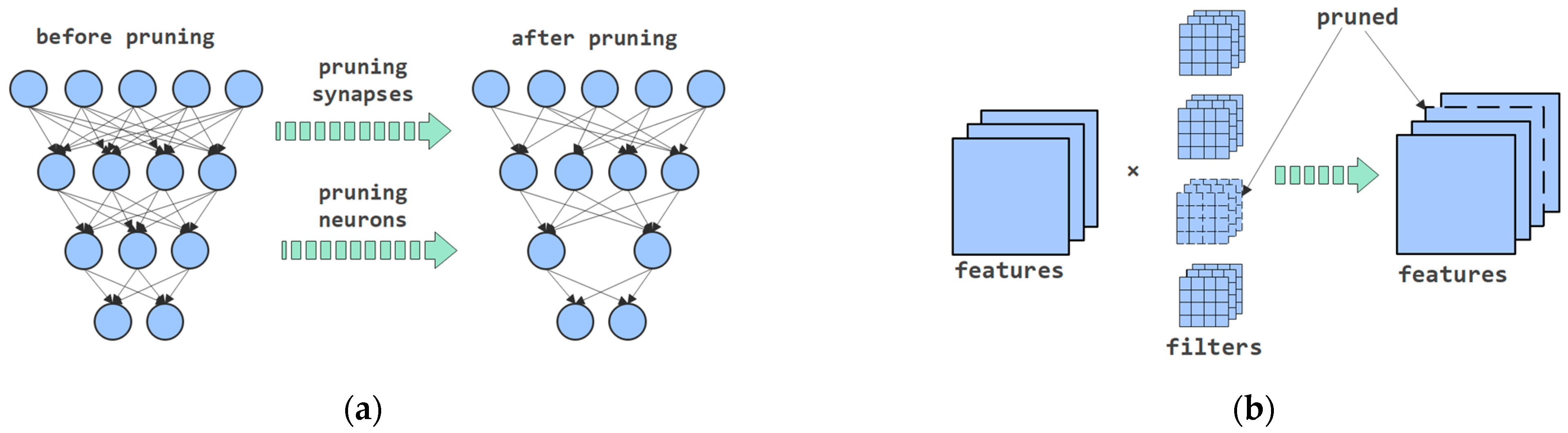
2.3. Pruning
- One-shot pruning followed by retraining: this method is fast but cannot ensure that the accuracy of the pruned model is as stable as the original one.
- Iterative pruning and retraining: the idea is to prune and retrain layer by layer, which ensures higher accuracy but needs more time. Combine-Net’s pruning process follows this idea.
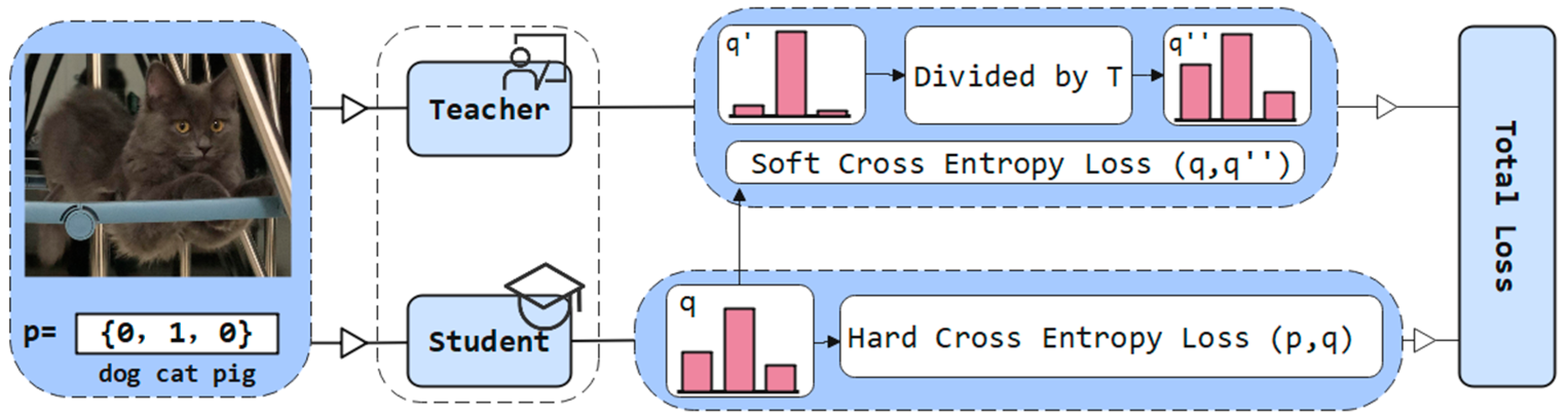
2.4. Knowledge Distillation
3. Methods Overview
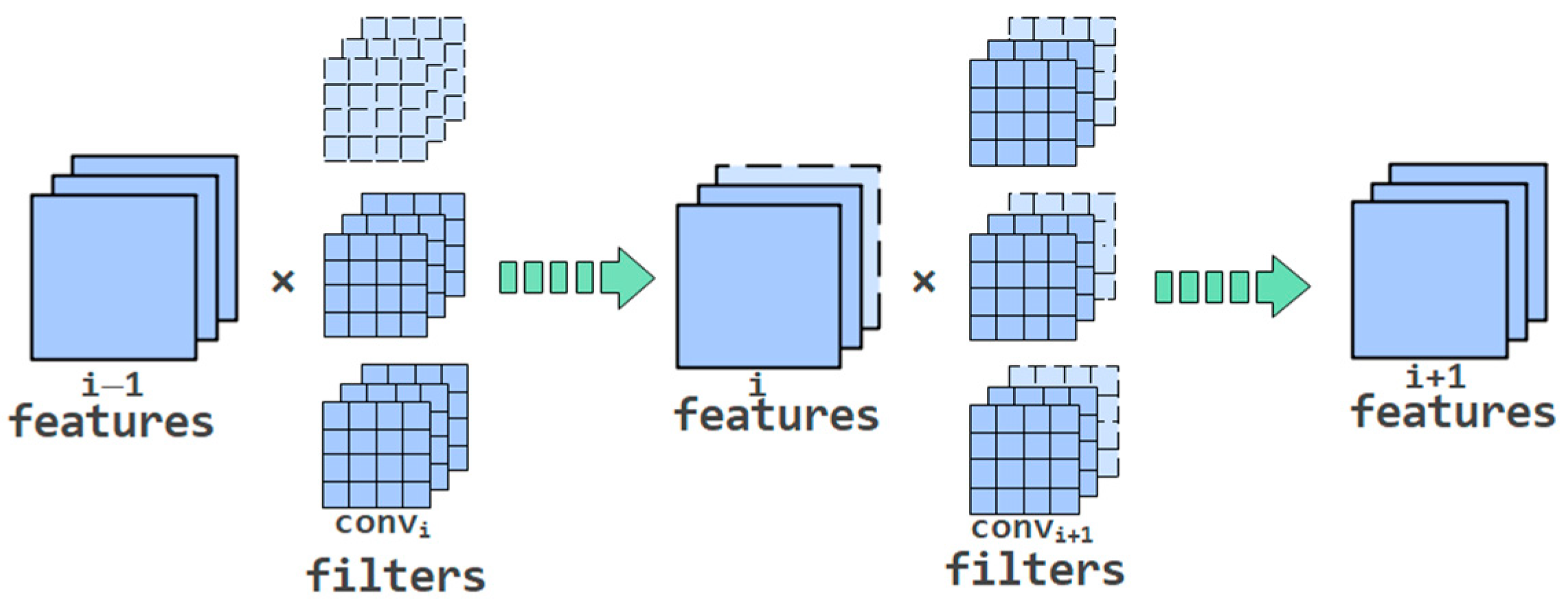
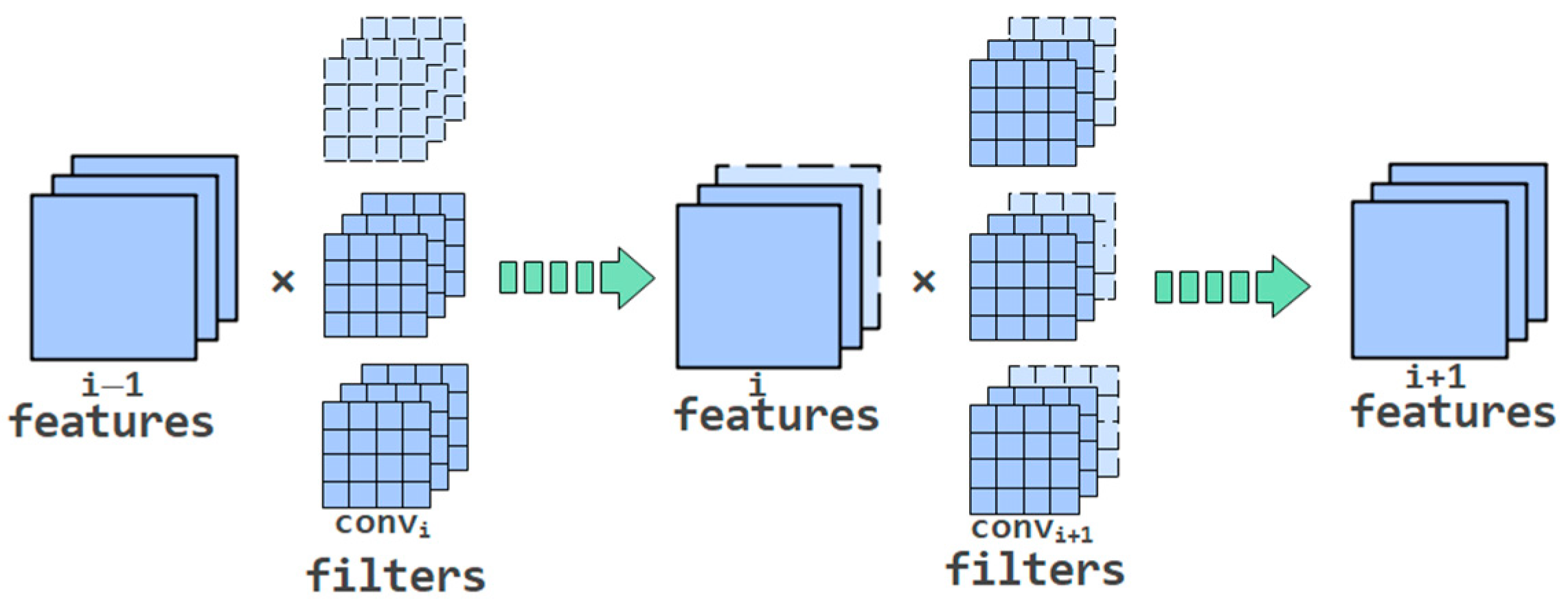
3.1. Pruning Method
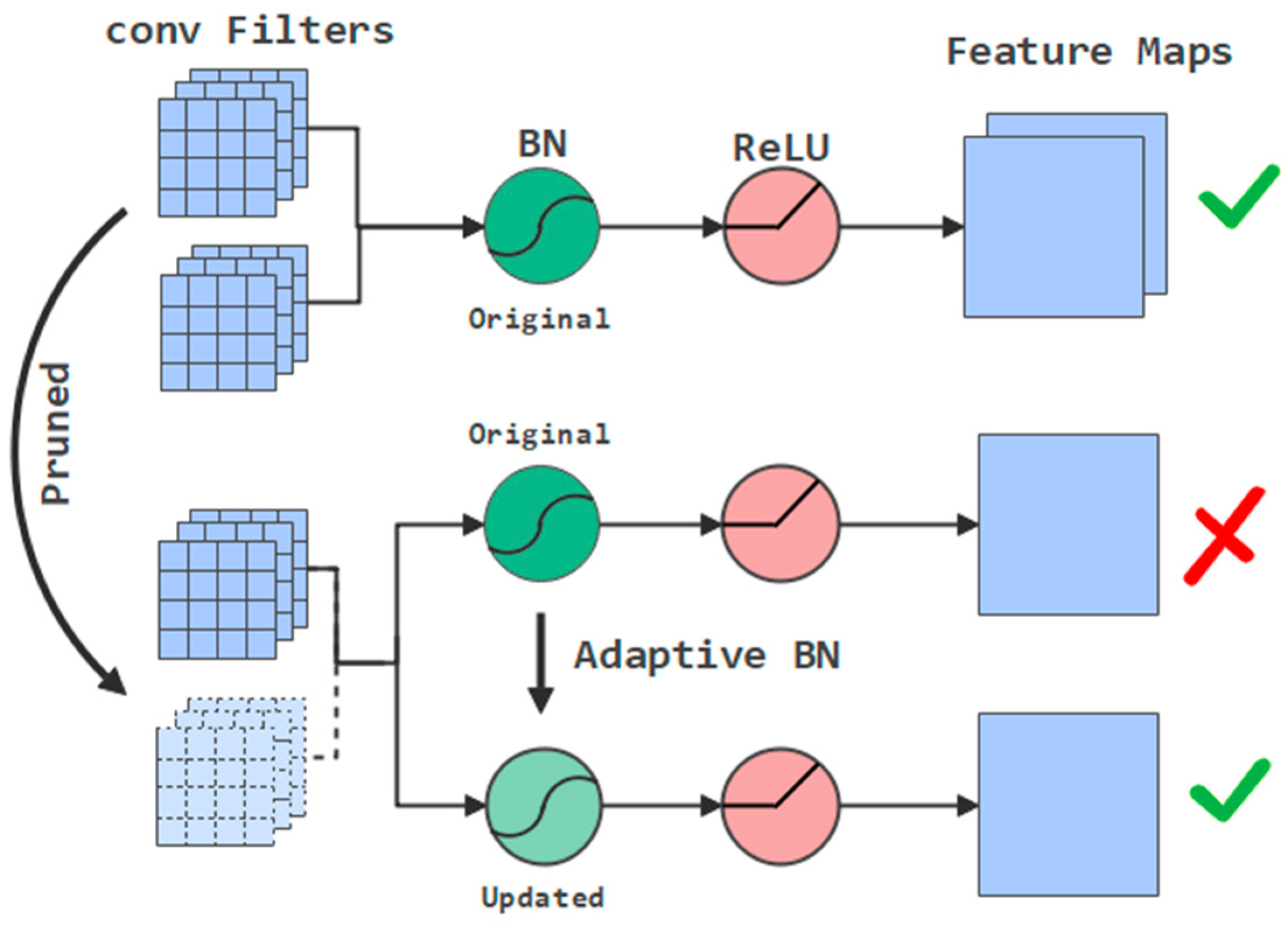
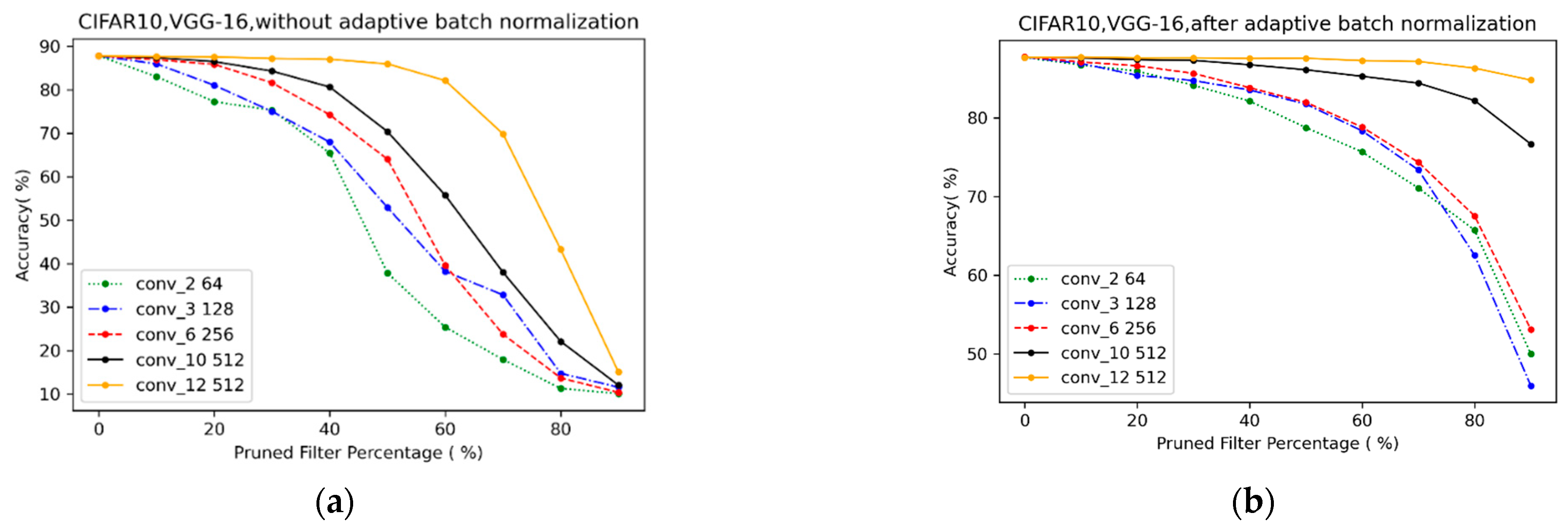
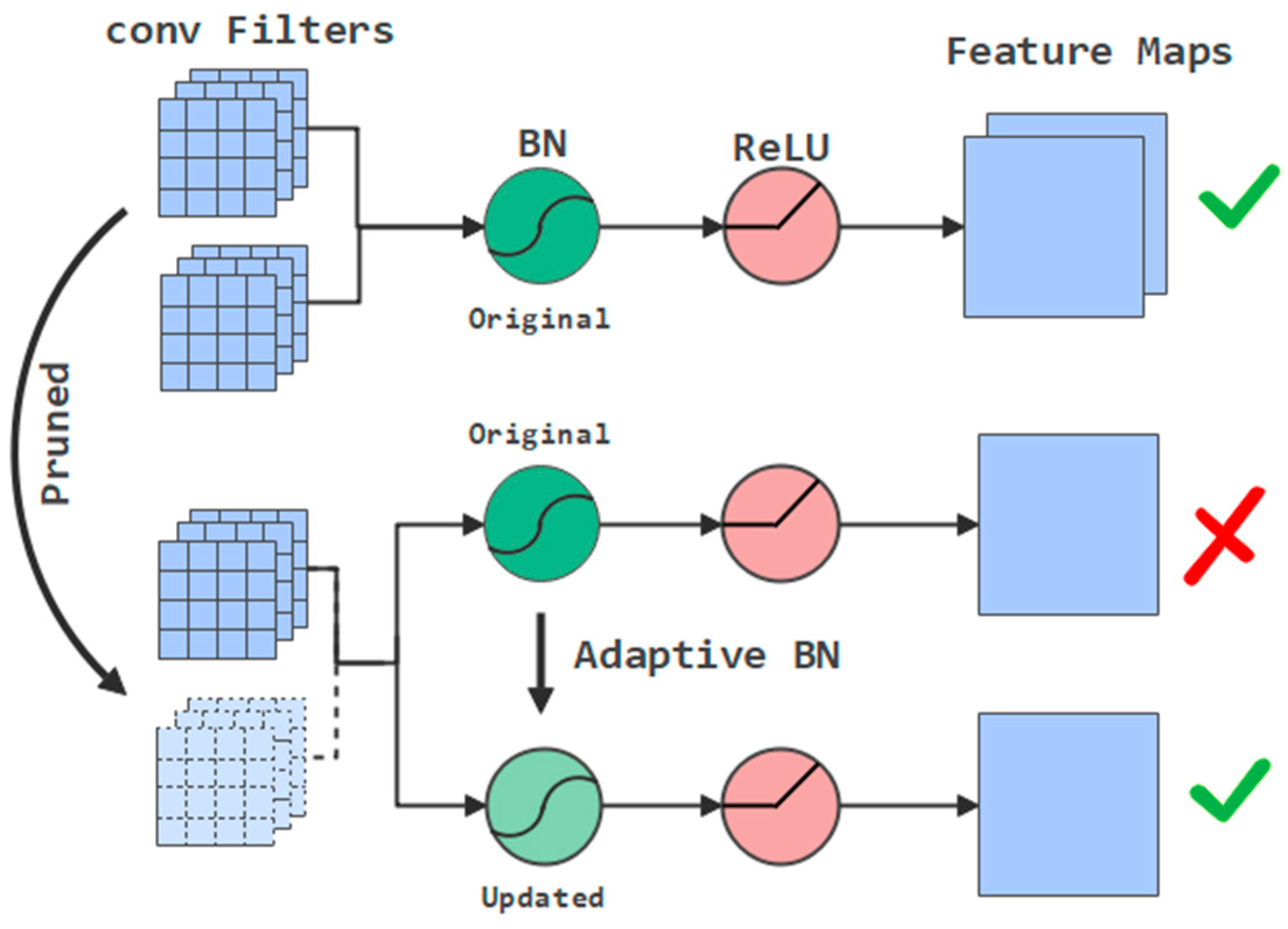
3.1.1. Fast and Accurate Evaluation with Adaptive BN
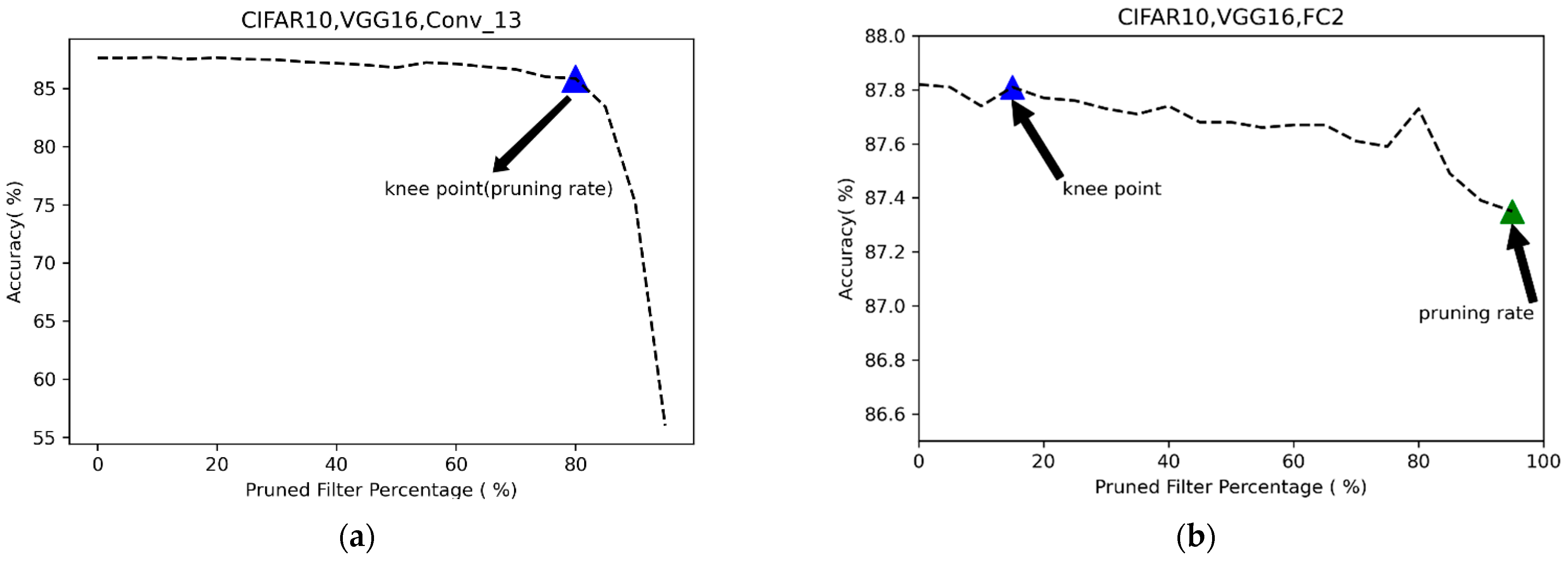
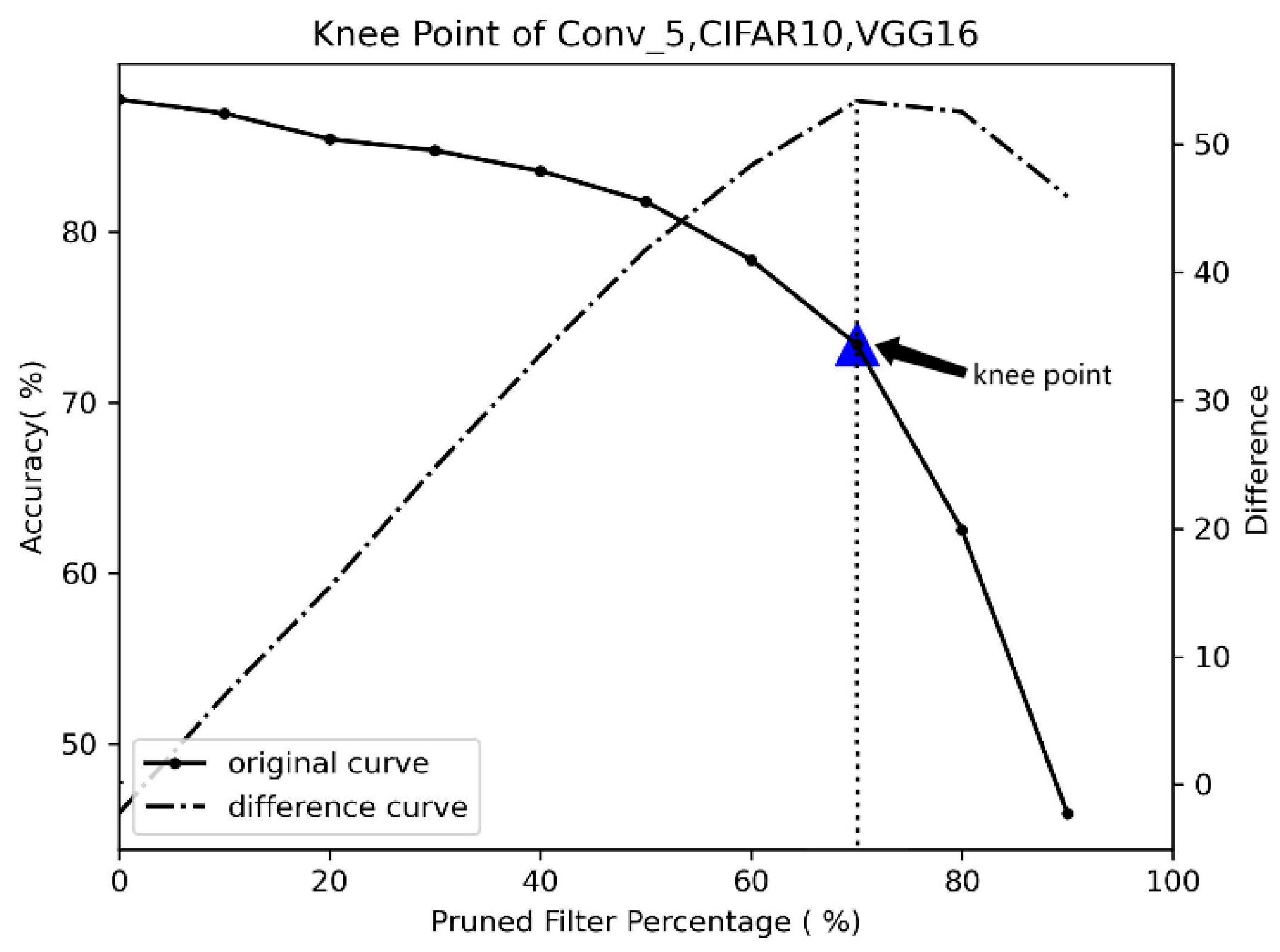
3.1.2. Determination of the Appropriate Pruning Rate by Kneedle
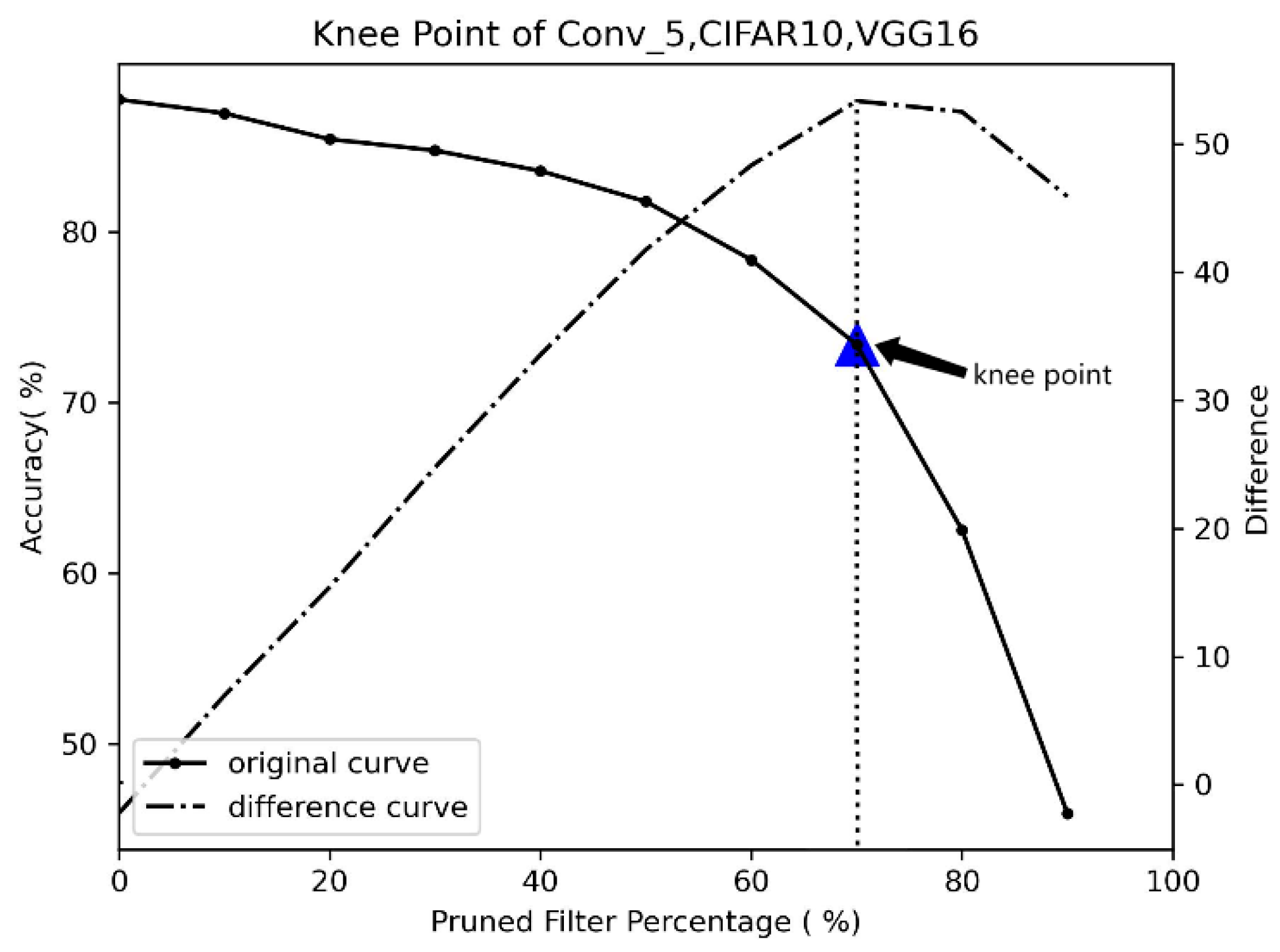
3.1.3. How to Confirm the Knee Point
| Algorithm 1 Using the Kneedle Algorithm to Determine the Pruning Rate. |
| 1: Input: The number of neural network’s layers: Lay_Num; Pre pruning rate of each layer r%; The accuracy rate corresponding to the pre pruning rate: acc%; |
| 2: Output: True pruning rate of each layer: R%; |
| 3: for i = 1 to Lay_Num do |
| 4: # Smooth the curve. |
| 5: Smooth (ri, acci); |
| 6: # Calculate the position of the knee point. |
| 7: Ri = Calculate_Knee_Point (ri, acci); |
| 8: # Verify the rationality of the knee point. |
| 9: Ri = Vertify_Knee_Point (ri, acci); |
| 10: end for |
| 11: return R; |
- The algorithm is relatively more objective and does not require subjective experience as a basis for judgment.
- The algorithm determines the pruning rate faster and does not require experimentation to accumulate expertise.
- The algorithm is highly applicable and suitable for determining the pruning rate of any model.
- This algorithm meets the needs of different precisions. The pruning rate is more accurate when the data are denser.
3.2. Retraining Method
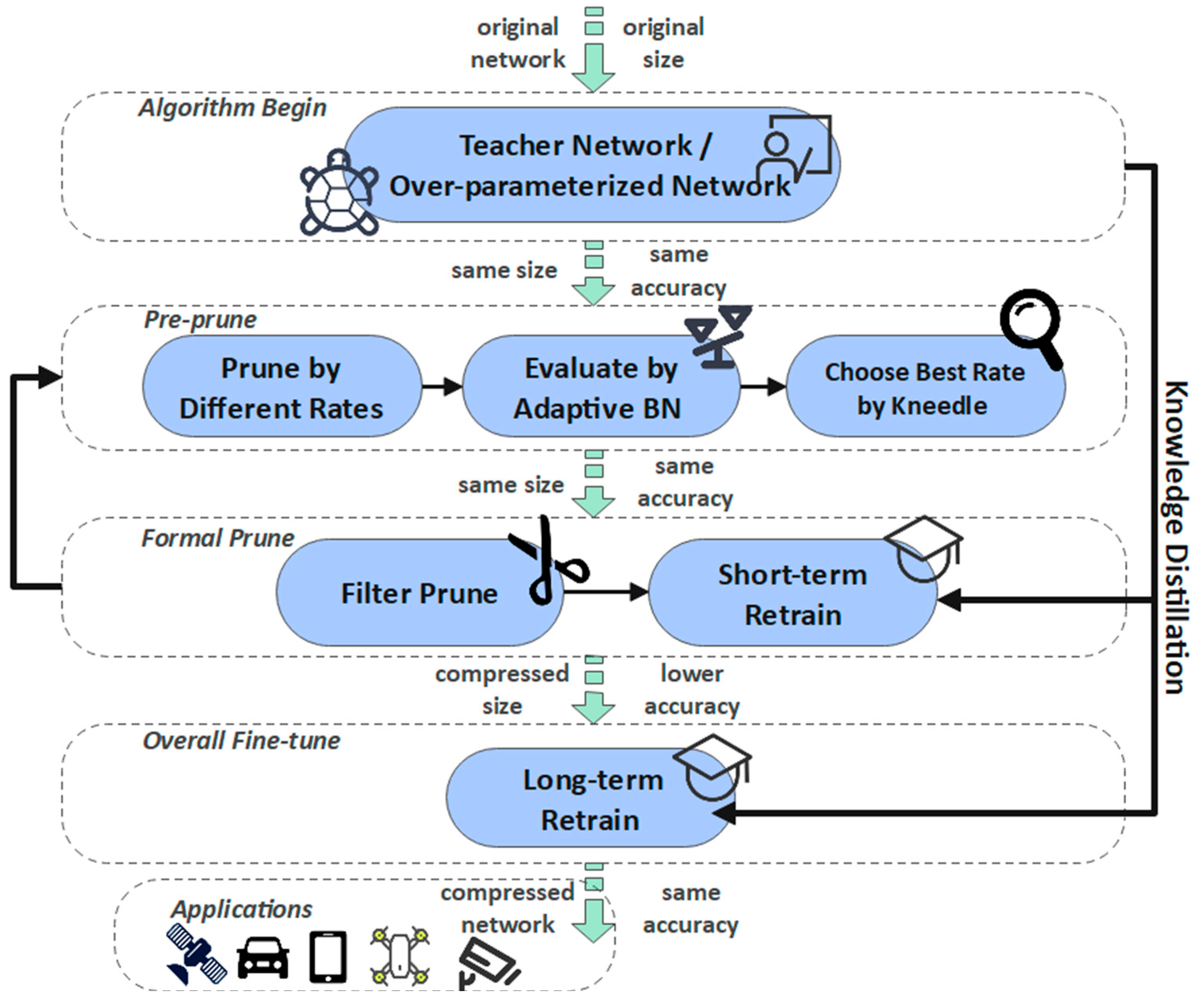
3.3. General Method
- A pre-trained and over-parameterized network needs to be obtained first, as not only a pruning object but also a teacher network, to guide the retraining of the sub-network.
- Start pruning layer by layer: the convolution layers or full connection layers that need to be pruned should be pre-cut according to different proportions. After that, evaluate these sub-nets fine or not by Adaptive BN. Finally, the best pruning rate is determined by the Kneedle algorithm. Then, the formal pruning is carried out.
- After each layer of pruning, the precision is slightly restored through a few rounds of retraining. The concrete method of retraining is to use knowledge distillation to distill dark knowledge from the pre-training network to guide the sub-network learning. Being layer-by-layer pruned and retrained, the parameterized model is compressed into a compact sub-network. Finally, restore the global accuracy of the model by multiple rounds of retraining.
4. Experiment
4.1. Proper Pruning Rate Improves Algorithm Efficiency
4.1.1. Significant Effect of Adaptive BN in Pruning Evaluation
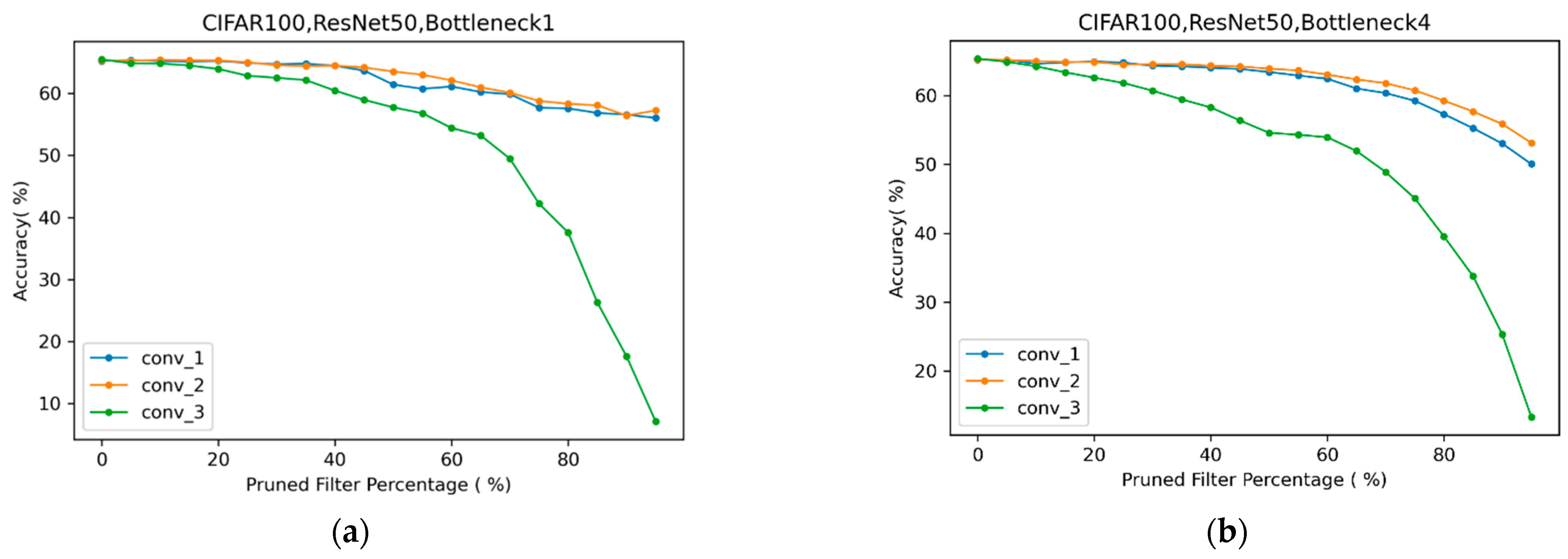
4.1.2. Choose the Best Pruning Rate by Kneedle
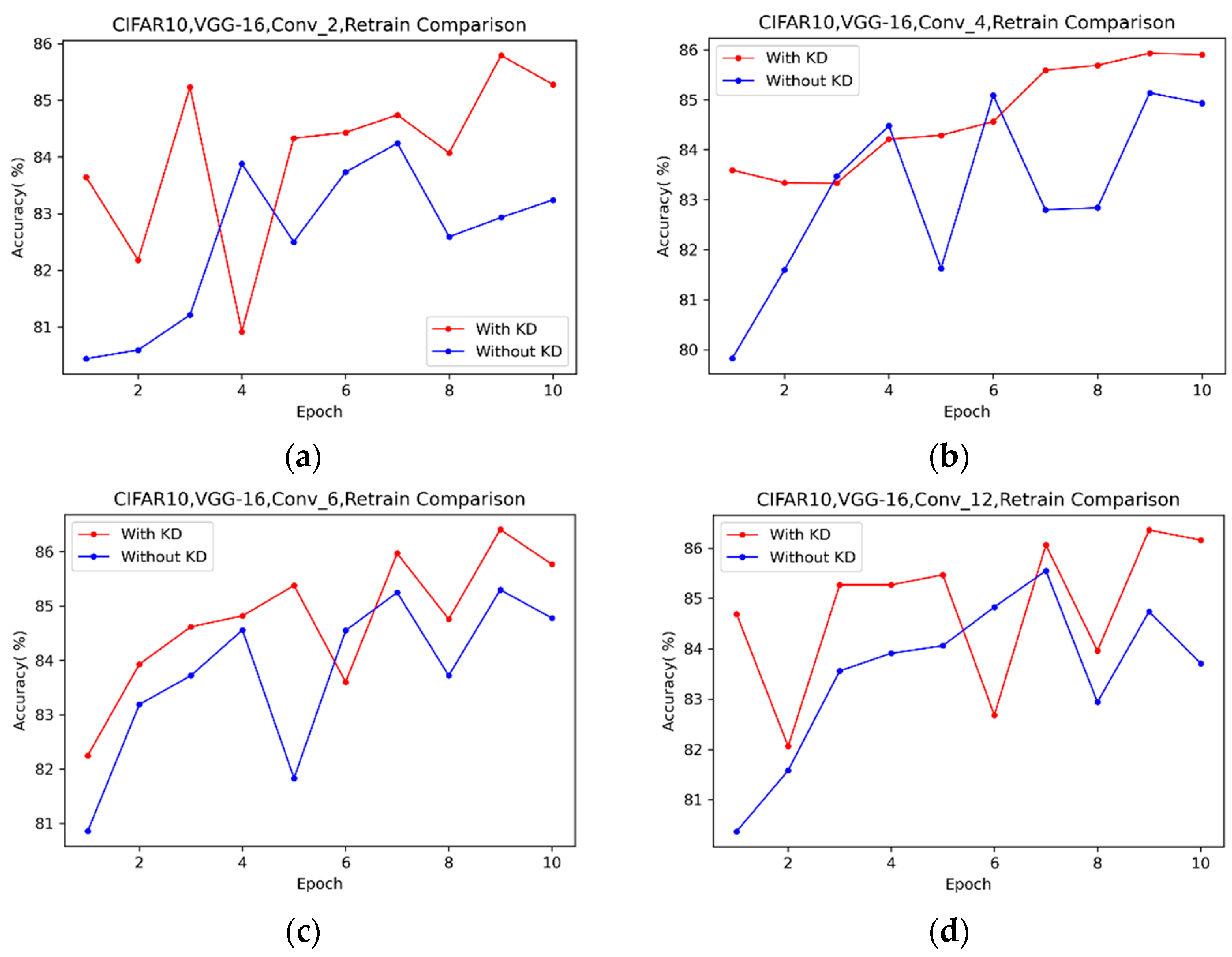
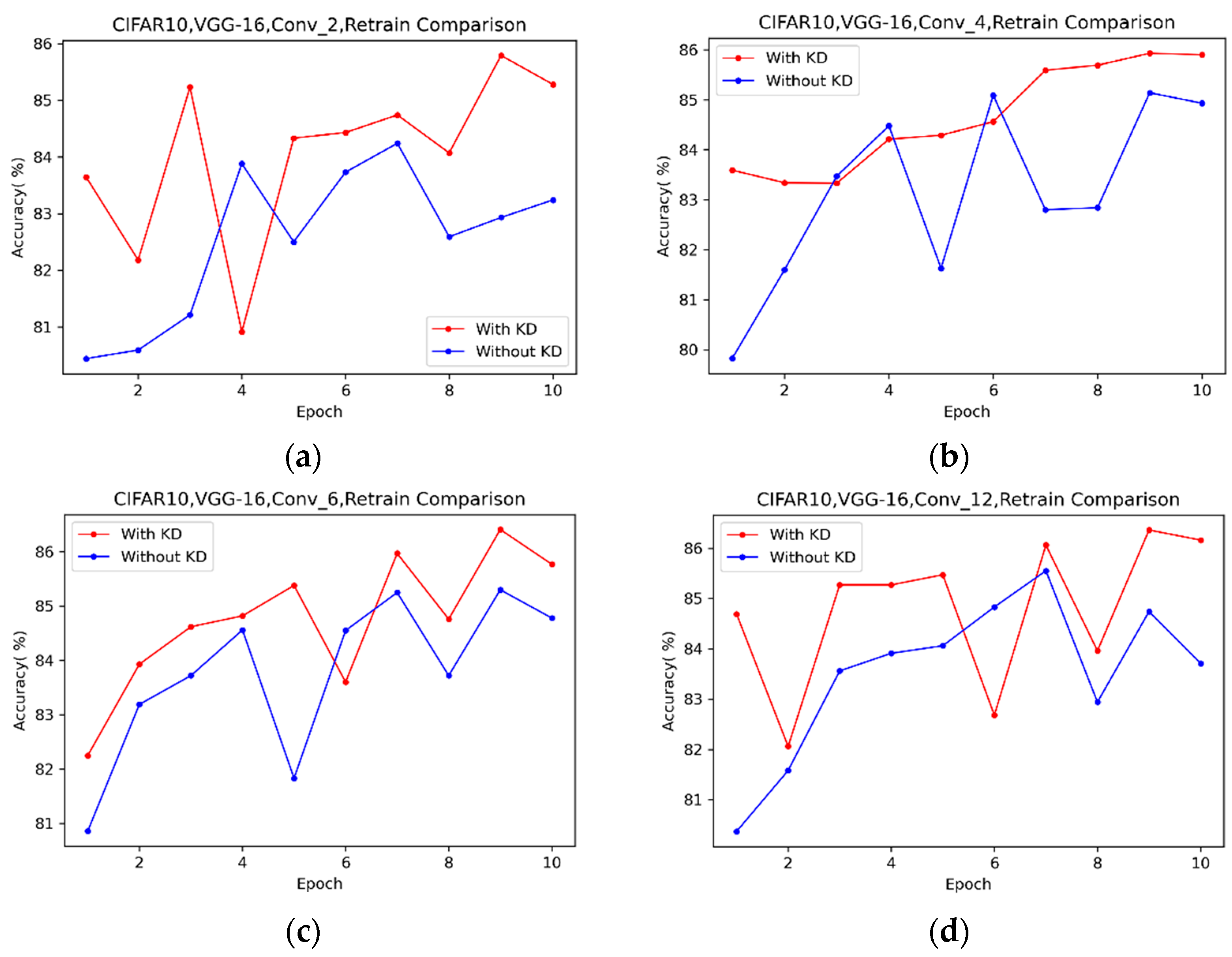
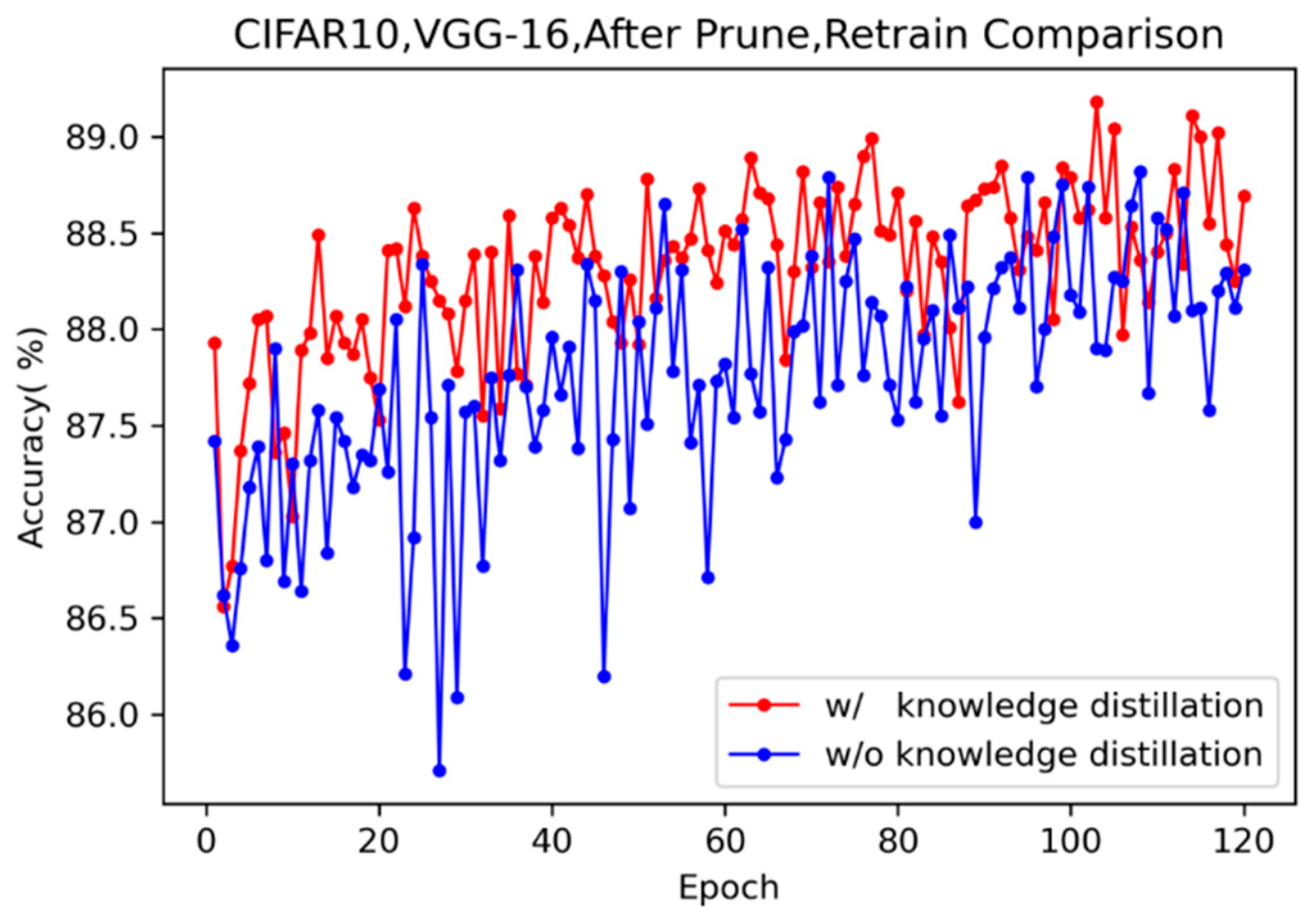
4.2. Efficient Retraining with Knowledge Distillation
4.2.1. Short-Term Effects
4.2.2. Long-Term Effects
4.3. Evaluate the Effect of Combine-Net’s Improvements
4.3.1. VGG16 on CIFAR 10
4.3.2. ResNet34 on CIFAR10
4.3.3. ResNet50 on CIFAR100
5. Discussion
6. Conclusions
- Analyzing the relationship between model structure and pruning rate.
- Providing recommended pruning rates for different model structures.
- Looking for a method to replace the greedy algorithm of layer-by-layer pruning.
- Extending the algorithm to unstructured pruning and verifying Combine-Net’s universality and robustness.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Amato, G.; Carrara, F.; Falchi, F.; Gennaro, C.; Meghini, C.; Vairo, C. Deep learning for decentralized parking lot occupancy detection. Expert Syst. Appl. 2017, 72, 327–334. [Google Scholar] [CrossRef]
- Li, Y.; Chen, F.; Sun, Z.; Ji, J.; Jia, W.; Wang, Z. A Smart Binaural Hearing Aid Architecture Leveraging a Smartphone APP with Deep-Learning Speech Enhancement. IEEE Access 2020, 8, 56798–56810. [Google Scholar] [CrossRef]
- Xu, C.; Mao, Y. An Improved Traffic Congestion Monitoring System Based on Federated Learning. Information 2020, 11, 365. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Hu, H.; Peng, R.; Tai, Y.W.; Tang, C.K. Network trimming: A data-driven neuron pruning approach towards efficient deep architectures. arXiv 2016, arXiv:1607.03250. [Google Scholar]
- Li, B.; Wu, B.; Su, J.; Wang, G. Eagleeye: Fast sub-net evaluation for efficient neural network pruning. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 639–654. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- Denil, M.; Shakibi, B.; Dinh, L.; Ranzato, M.A.; De Freitas, N. Predicting parameters in deep learning. arXiv 2013, arXiv:1306.0543. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Courbariaux, M.; Bengio, Y.; David, J.P. Binaryconnect: Training deep neural networks with binary weights during propagations. arXiv 2015, arXiv:1511.00363. [Google Scholar]
- Fang, B.; Zeng, X.; Zhang, M. Nestdnn: Resource-aware multi-tenant on-device deep learning for continuous mobile vision. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 115–127. [Google Scholar]
- He, Y.; Kang, G.; Dong, X.; Fu, Y.; Yang, Y. Soft filter pruning for accelerating deep convolutional neural networks. arXiv 2018, arXiv:1808.06866. [Google Scholar]
- Li, H. Exploring Knowledge Distillation of Deep Neural Nets for Efficient Hardware Solutions. CS230 Report. 2018. Available online: https://github.com/peterliht/knowledge-distillation-pytorch (accessed on 23 June 2020).
- Luo, J.H.; Wu, J. An entropy-based pruning method for cnn compression. arXiv 2017, arXiv:1706.05791. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Satopaa, V.; Albrecht, J.; Irwin, D.; Raghavan, B. Finding a “kneedle” in a haystack: Detecting knee points in system behavior. In Proceedings of the 2011 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011; pp. 166–171. [Google Scholar]
- Chen, L.; Chen, Y.; Xi, J.; Le, X. Knowledge from the original network: Restore a better pruned network with knowledge distillation. Complex Intell. Syst. 2021, 1–10. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Original Maps | Pruning Rate Used in [5] | Determine Pruning Rate by Kneedle | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Maps Remained | Pruning Rate | Mean of Top-1 Acc. | Std of Top-1 Acc. | Maps Remained | Pruning Rate | Mean of Top-1 Acc. | Std of Top-1 Acc. | ||
| Conv_1 | 64 | 32 | 50% | 85.34% | 0.46% | 52 | 20% | 85.62% | 0.41% |
| Conv_2 | 64 | 64 | 0% | —— | —— | 16 | 75% | 84.28% | 0.38% |
| Conv_3 | 128 | 128 | 0% | —— | —— | 52 | 60% | 84.71% | 0.24% |
| Conv_4 | 128 | 128 | 0% | —— | —— | 52 | 60% | 85.06% | 0.22% |
| Conv_5 | 256 | 256 | 0% | —— | —— | 77 | 70% | 85.30% | 0.45% |
| Conv_6 | 256 | 256 | 0% | —— | —— | 103 | 60% | 84.46% | 0.46% |
| Conv_7 | 256 | 256 | 0% | —— | —— | 90 | 65% | 84.99% | 0.23% |
| Conv_8 | 512 | 256 | 50% | 84.99% | 0.57% | 154 | 70% | 85.40% | 0.24% |
| Conv_9 | 512 | 256 | 50% | 85.42% | 0.17% | 154 | 70% | 85.10% | 0.10% |
| Conv_10 | 512 | 256 | 50% | 85.88% | 0.35% | 154 | 70% | 85.68% | 0.24% |
| Conv_11 | 512 | 256 | 50% | 85.74% | 0.18% | 154 | 70% | 85.91% | 0.20% |
| Conv_12 | 512 | 256 | 50% | 86.08% | 0.18% | 128 | 75% | 85.82% | 0.10% |
| Conv_13 | 512 | 256 | 50% | 85.88% | 0.21% | 103 | 80% | 85.66% | 0.36% |
| Model | Top-1 Acc. | Top-5 Acc. | Parameters (M) | Pruned | GMacs | Pruned | Size (MB) |
|---|---|---|---|---|---|---|---|
| VGG16 ON CIFAR10 | 87.82% | 99.55% | 33.639 | 0.304 | 128.4 | ||
| VGG16-Pruned | 89.17% | 99.62% | 1.376 | 95.91% | 0.049 | 83.88% | 5.9 |
| VGG16-Pruned In [5] | 88.98% | 96.63% | 22.137 | 34.19% | 0.225 | 25.99% | 88.3 |
| ResNet34 ON CIFAR10 | 88.16% | 99.5% | 21.29 | 0.075 | 81.4 | ||
| ResNet34-Pruned | 87.72% | 94.97% | 1.462 | 93% | 0.035 | 53.33% | 5.7 |
| ResNet50 ON CIFAR100 | 65.48% | 87.49% | 23.713 | 0.084 | 90.8 | ||
| ResNet50-Pruned | 66.08% | 87.84% | 6.843 | 71.14% | 0.049 | 41.67% | 26.4 |
| Layer Type | Pre-Trained Model | Pruned Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Maps | Params (M) | GMacs | Maps Remained | Pruning Rate | Top-1 Acc. | Top-5 Acc. | Params (M) | GMacs | |
| Conv_1 | 64 | 0.002 | 0.002 | 52 | 20% | 86.38% | 99.54% | 0.001 | 0.001 |
| Conv_2 | 64 | 0.037 | 0.038 | 32 | 50% | 87% | 99.34% | 0.015 | 0.015 |
| Conv_3 | 128 | 0.074 | 0.019 | 58 | 55% | 86.32% | 99.22% | 0.017 | 0.004 |
| Conv_4 | 128 | 0.148 | 0.038 | 45 | 65% | 86.39% | 99.43% | 0.024 | 0.006 |
| Conv_5 | 256 | 0.295 | 0.019 | 103 | 60% | 85.84% | 99.34% | 0.042 | 0.003 |
| Conv_6 | 256 | 0.59 | 0.038 | 77 | 70% | 85.98% | 99.31% | 0.071 | 0.005 |
| Conv_7 | 256 | 0.59 | 0.038 | 90 | 65% | 86.31% | 99.42% | 0.062 | 0.004 |
| Conv_8 | 512 | 1.18 | 0.019 | 154 | 70% | 86.31% | 99.43% | 0.125 | 0.002 |
| Conv_9 | 512 | 2.36 | 0.038 | 128 | 75% | 86.43% | 99.36% | 0.178 | 0.003 |
| Conv_10 | 512 | 2.36 | 0.009 | 154 | 70% | 86.73% | 99.32% | 0.178 | 0.003 |
| Conv_11 | 512 | 2.36 | 0.009 | 128 | 75% | 86.89% | 99.39% | 0.178 | 0.001 |
| Conv_12 | 512 | 2.36 | 0.009 | 180 | 65% | 87.17% | 99.44% | 0.208 | 0.001 |
| Conv_13 | 512 | 2.36 | 0.009 | 128 | 75% | 86.98% | 99.48% | 0.207 | 0.001 |
| Linear_1 | 512 | 2.101 | 0.002 | 128 | 75% | 86.78% | 99.26% | 0.026 | <0.001 |
| Linear_2 | 4096 | 16.781 | 0.017 | 205 | 95% | 87.08% | 99.01% | 0.042 | <0.001 |
| Linear_3 | 10 | 0.041 | <0.001 | 10 | 0% | —— | —— | 0.002 | <0.001 |
| Total | 33.639 | 0.304 | 1.376 | 0.049 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, G.; Zhang, W. Combine-Net: An Improved Filter Pruning Algorithm. Information 2021, 12, 264. https://doi.org/10.3390/info12070264
Wang J, Li G, Zhang W. Combine-Net: An Improved Filter Pruning Algorithm. Information. 2021; 12(7):264. https://doi.org/10.3390/info12070264
Chicago/Turabian StyleWang, Jinghan, Guangyue Li, and Wenzhao Zhang. 2021. "Combine-Net: An Improved Filter Pruning Algorithm" Information 12, no. 7: 264. https://doi.org/10.3390/info12070264
APA StyleWang, J., Li, G., & Zhang, W. (2021). Combine-Net: An Improved Filter Pruning Algorithm. Information, 12(7), 264. https://doi.org/10.3390/info12070264