
A 2D Convolutional Gating Mechanism for Mandarin Streaming Speech Recognition


Abstract
:1. Introduction
- 1.
- We combine convolutional networks with LSTM as the Encoder of Transducer to build a low-latency streaming speech recognition model. These convolutional networks are built in the form of VGG2 [24] networks, which are the first two layers of VGG16, a deep convolutional network architecture. Additionally, the maximum pooling layer is retained to reduce the frame rate, which improves the training efficiency.
- 2.
- We introduce a two-dimensional (2D) convolutional gating mechanism inside VGG2, called gated-VGG2, which controls what information will flow into LSTM. The gating mechanism employs half of the channel features that are generated by the convolutional network to form gate states acting on the other half of the channel features, so that twice the channel information can be learned, which improves the performance of the model.
- 3.
- There are no temporal dependencies in the gating mechanism, so that our model is easy to train in parallel.
2. Related Works
3. Transducer
3.1. RNN-Transducer
3.2. Training
4. Extension to Gated-VGG2 RNN-T
4.1. Convolutional Network
4.2. Activation Function
4.3. Max Pooling Layer
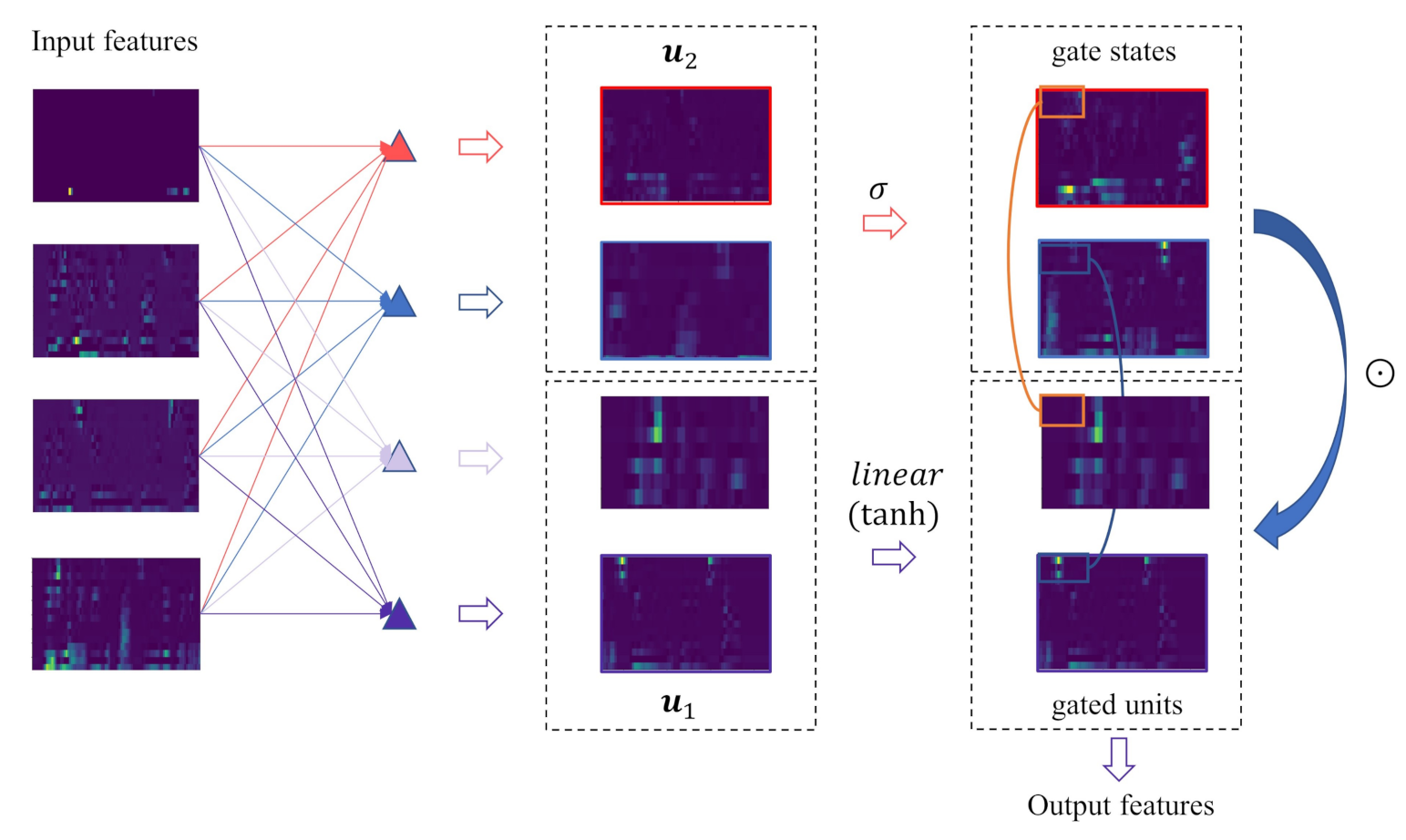
4.4. 2D Convolutional Gating Mechanism
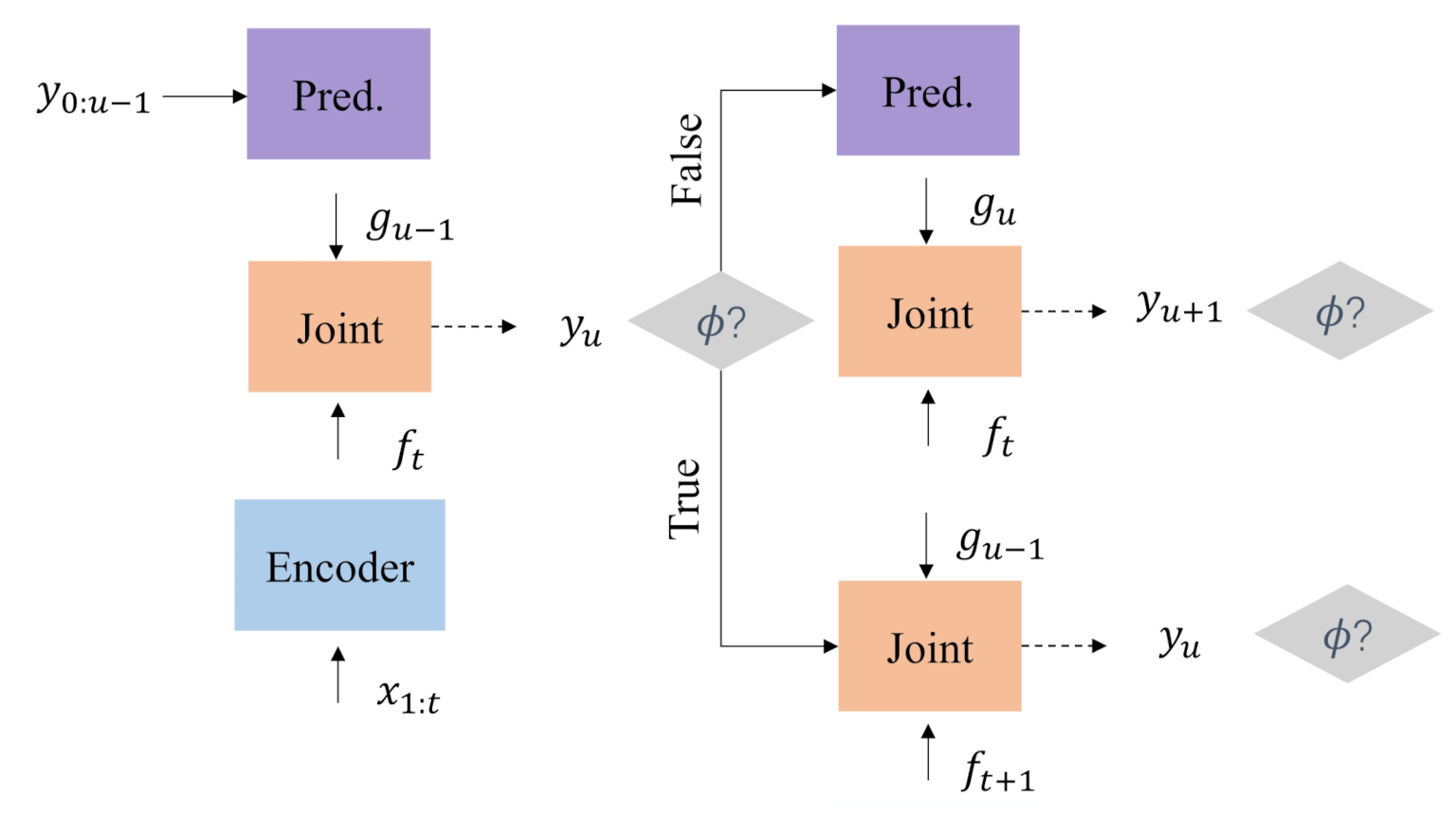
5. Latency
6. Experiment
6.1. Corpus
6.2. Hyperparameter Setting
6.3. Performance
6.3.1. Gating Mechanism
6.3.2. Beam Search
6.3.3. End-to-End Model
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Selfridge, E.; Arizmendi, I.; Heeman, P.A.; Williams, J.D. Stability and accuracy in incremental speech recognition. In Proceedings of the SIGDIAL 2011 Conference, Portland, OR, USA, 17–18 June 2011; pp. 110–119. [Google Scholar]
- Arivazhagan, N.; Cherry, C.; Te, I.; Macherey, W.; Baljekar, P.; Foster, G. Re-translation strategies for long form, simultaneous, spoken language translation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7919–7923. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-Attention Based End-to-End Speech Recognition Using Multi-Task Learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4835–4839. [Google Scholar]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Zhang, W.; et al. A Comparative Study on Transformer vs RNN in Speech Applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Sentosa, Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Pang, R.; et al. Conformer: Convolution-Augmented Transformer for Speech Recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Emiru, E.D.; Xiong, S.; Li, Y.; Fesseha, A.; Diallo, M. Improving Amharic Speech Recognition System Using Connectionist Temporal Classification with Attention Model and Phoneme-Based Byte-Pair-Encodings. Information 2021, 12, 62. [Google Scholar] [CrossRef]
- Sepp, H.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Sak, H.; Shannon, M.; Rao, K.; Beaufays, F. Recurrent Neural Aligner: An Encoder-Decoder Neural Network Model for Sequence to Sequence Mapping. In Proceedings of the Interspeech 2017: Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 1298–1302. [Google Scholar]
- Jaitly, N.; Sussillo, D.; Le, Q.V.; Vinyals, O.; Sutskever, I.; Bengio, S. A Neural Transducer. arXiv 2016, arXiv:1511.04868. [Google Scholar]
- Graves, A. Sequence Transduction with Recurrent Neural Networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–30 May 2013; pp. 6645–6649. [Google Scholar]
- Rao, K.; Sak, H.; Prabhavalkar, R. Exploring Architectures, Data and Units For Streaming End-to-End Speech Recognition with RNN-Transducer. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 193–199. [Google Scholar]
- He, Y.; Sainath, T.N.; Prabhavalkar, R.; McGraw, I.; Alvarez, R.; Zhao, D.; Rybach, D.; Kannan, A.; Wu, Y.; Gruenstein, A.; et al. Streaming End-to-End Speech Recognition for Mobile Devices. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6381–6385. [Google Scholar]
- Yeh, C.F.; Mahadeokar, J.; Kalgaonkar, K.; Wang, Y.; Le, D.; Jain, M.; Schubert, K.; Fuegen, C.; Seltzer, M.L. Transformer transducer: End-to-end speech recognition with self-attention. arXiv 2019, arXiv:1910.12977. [Google Scholar]
- Zhang, Q.; Lu, H.; Sak, H.; Tripathi, A.; McDermott, E.; Koo, S.; Kumar, S. Transformer transducer: A streamable speech recognition model with transformer encoders and rnn-t loss. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the ICLR 2015: International Conference on Learning Representations 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, Y.; Li, X.; Yang, Y.; Anwar, A.; Dong, R. Hybrid System Combination Framework for Uyghur–Chinese Machine Translation. Information 2021, 12, 98. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lu, Z.; Pu, H.; Wang, F.; Hu, Z.; Wang, L. The Expressive Power of Neural Networks: A View from the Width. arXiv 2017, arXiv:1709.02540. [Google Scholar]
- Bu, H.; Du, J.; Na, X.; Wu, B.; Zheng, H. AISHELL-1: An Open-Source Mandarin Speech Corpus and a Speech Recognition Baseline. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Korea, 1–3 November 2017; pp. 1–5. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Mohamed, A.; Okhonko, D.; Zettlemoyer, L. Transformers with convolutional context for ASR. arXiv 2019, arXiv:1904.11660. [Google Scholar]
- Huang, W.; Hu, W.; Yeung, Y.; Chen, X. Conv-Transformer Transducer: Low Latency, Low Frame Rate, Streamable End-to-End Speech Recognition. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 5001–5005. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. arXiv 2017, arXiv:1612.08083. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. In Proceedings of the ICLR 2014: International Conference on Learning Representations (ICLR) 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Matthew, Z. ADADELTA: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701v1. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.E.Y.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. arXiv 2018, arXiv:1804.00015. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AISHELL-1 | Duration | Speaker | Utterance |
|---|---|---|---|
| train | 150 h | 340 | 120,098 |
| validation | 10 h | 40 | 14,326 |
| test | 5 h | 20 | 7176 |
| BiLSTM | LSTM | VGG2 | Gated-VGG2 | Transformer |
|---|---|---|---|---|
| 4× BiLSTM | 5× LSTM | Conv3-64 | Conv3-64 | 12× Transformer |
| = 640 | = 1024 | Conv3-64 | Conv3-64 | d = 512, h = 4, u = 2048 |
| maxpool | maxpool | |||
| Conv3-128 | Conv3-256 | |||
| Conv3-128 | Conv3-256 | |||
| maxpool | maxpool |
| Gating Mechanism | CER(Test) | Sub. | Del. | Ins. |
|---|---|---|---|---|
| GTU | 12.9 | 11.9 | 0.7 | 0.3 |
| GLU | 13.1 | 12.1 | 0.7 | 0.3 |
| Encoder | CER(Test) | Sub. | Del. | Ins. |
|---|---|---|---|---|
| BiLSTM | 13.2 | 12.3 | 0.6 | 0.3 |
| LSTM | 17.2 | 15.3 | 1.4 | 0.5 |
| + VGG2 | 13.4 | 12.4 | 0.7 | 0.3 |
| + Gated (ours) | 12.9 | 11.9 | 0.7 | 0.3 |
| Encoder | Latency | CER(Test) | Sub. | Del. | Ins. |
|---|---|---|---|---|---|
| gated-VGG2 LSTM | 60 ms | 12.9 | 11.9 | 0.7 | 0.3 |
| VGG2-Transformer [15] | |||||
| Full attention | INF | 11.4 | 10.0 | 1.1 | 0.3 |
| unidirectional | 60 ms | 19.9 | 18.6 | 1.0 | 0.3 |
| Lookahead 1 | 540 ms | 16.9 | 15.8 | 0.8 | 0.3 |
| Lookahead 2 | 1020 ms | 14.6 | 13.5 | 0.8 | 0.3 |
| Lookahead 3 | 1500 ms | 13.0 | 12.0 | 0.7 | 0.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Zhao, C. A 2D Convolutional Gating Mechanism for Mandarin Streaming Speech Recognition. Information 2021, 12, 165. https://doi.org/10.3390/info12040165
Wang X, Zhao C. A 2D Convolutional Gating Mechanism for Mandarin Streaming Speech Recognition. Information. 2021; 12(4):165. https://doi.org/10.3390/info12040165
Chicago/Turabian StyleWang, Xintong, and Chuangang Zhao. 2021. "A 2D Convolutional Gating Mechanism for Mandarin Streaming Speech Recognition" Information 12, no. 4: 165. https://doi.org/10.3390/info12040165
APA StyleWang, X., & Zhao, C. (2021). A 2D Convolutional Gating Mechanism for Mandarin Streaming Speech Recognition. Information, 12(4), 165. https://doi.org/10.3390/info12040165