
System Design to Utilize Domain Expertise for Visual Exploratory Data Analysis †



Abstract
1. Introduction
- We recommend views that do not necessarily show statistically prominent data from the dataset (e.g., anomalies) but those views that contain insights from the perspective of a domain expert.
- We recommend coherent sequences of interactions (i.e., a sequence of consecutive views) to provide more context to an insight compared to recommendation of single independent views.
2. Problem Description
3. Related Work
3.1. Systems to Ease the Visualization of Data
3.2. Systems to Recommend Statistically Interesting Views on Datasets
3.3. Systems to Recommend Statistically Relevant Next Steps during EDA
3.4. Systems to Track and View Interaction Data
3.5. Recommender Systems
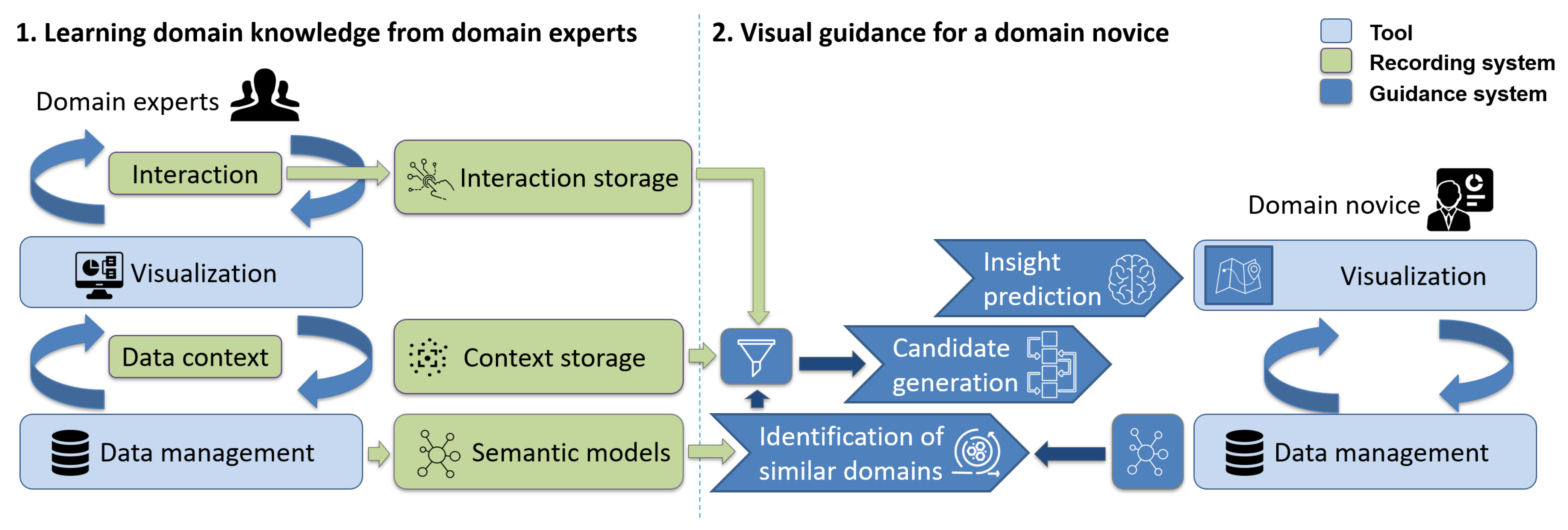
4. Using Machine Learning and Analytic Provenance for Guided Visual Exploratory Data Analysis
4.1. System Workflow
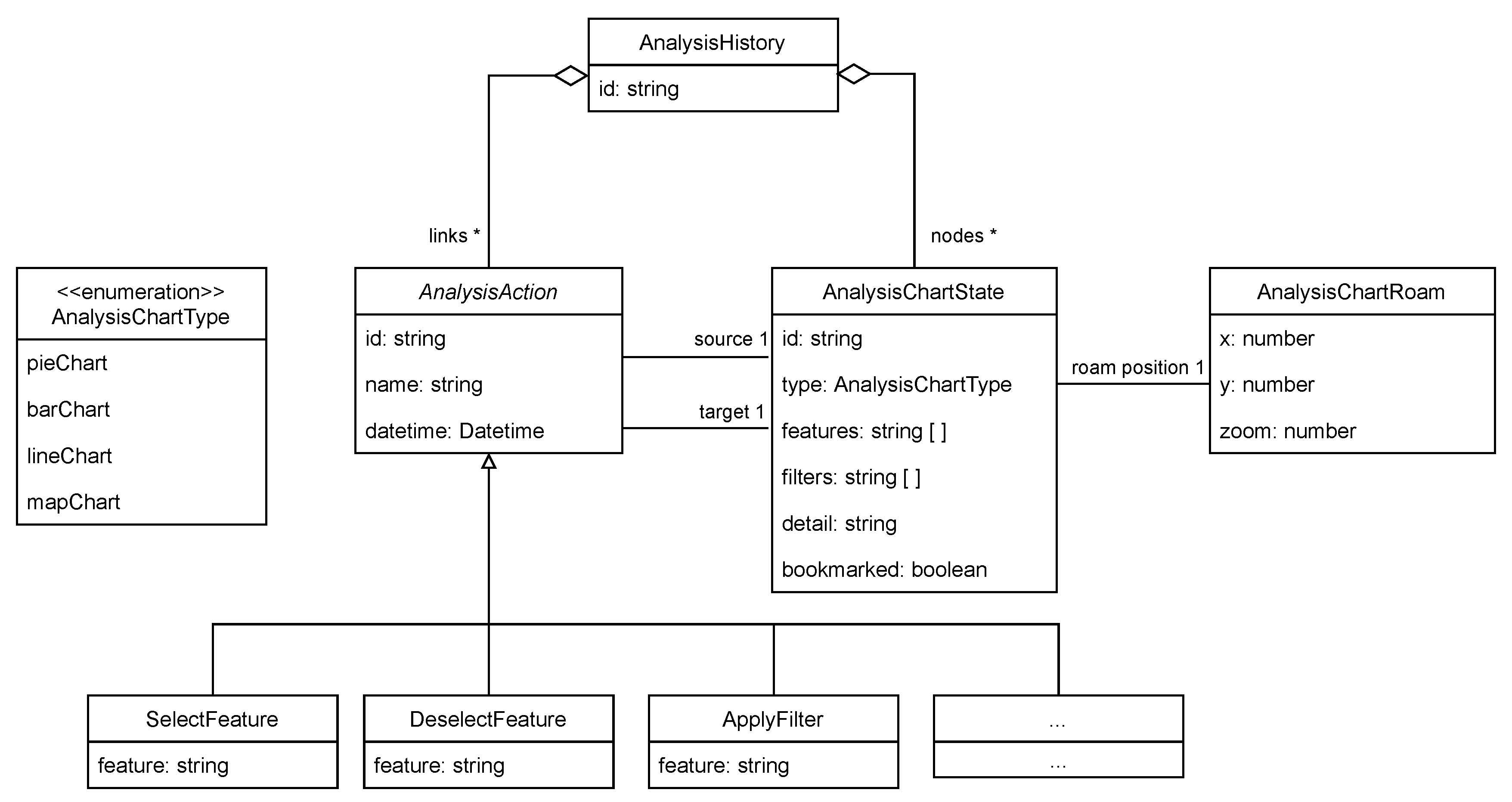
4.2. Record EDA Sessions: How to Record EDA Sessions and Context?
4.3. Evaluate EDA Sessions: How to Measure Insight?
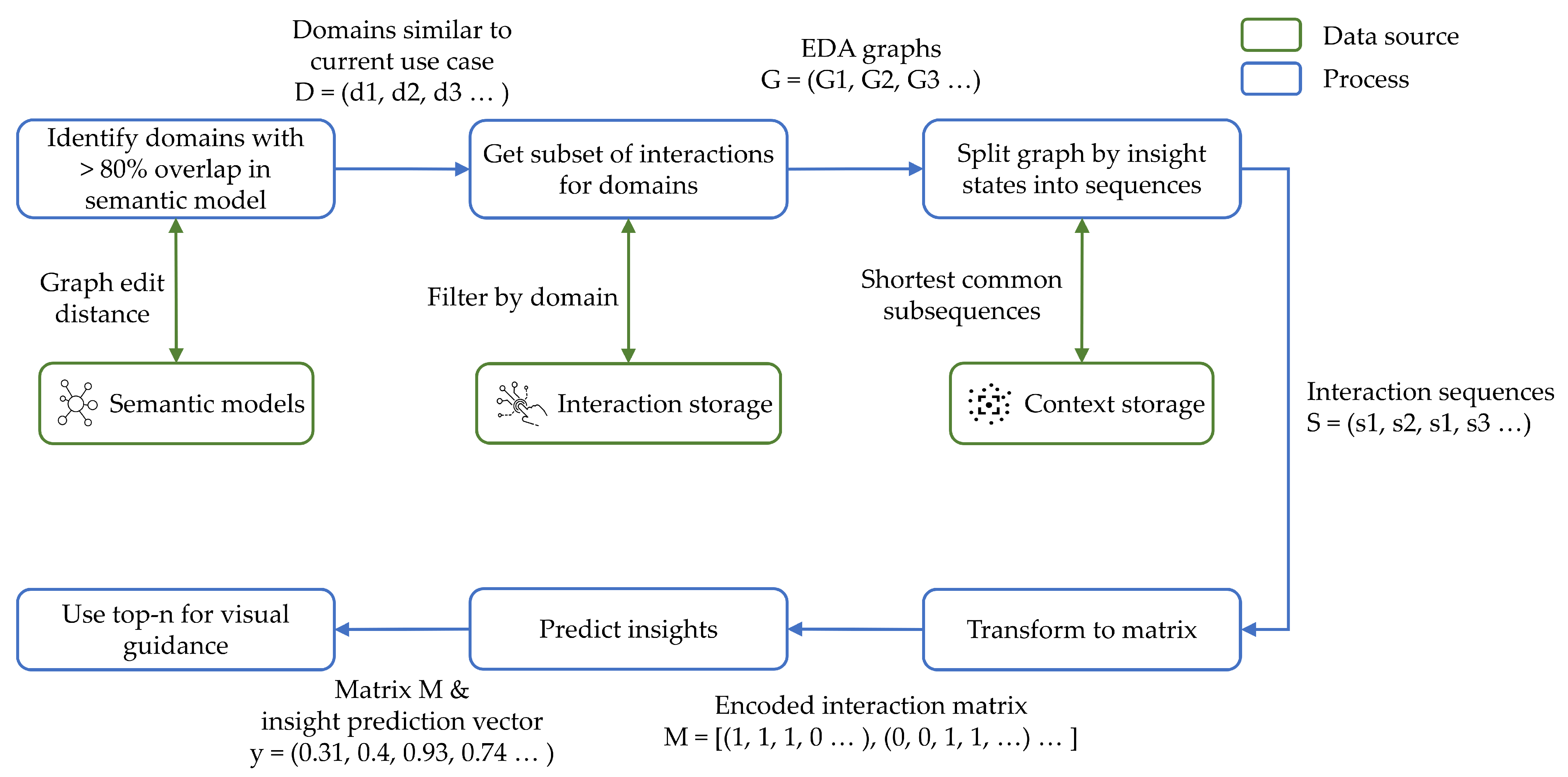
4.4. Gather Recommendation Data: How to Identify a Suitable Subset of Historical EDA Data for New Use Cases?
4.5. Provide Recommendations: How to Generate Good EDA Recommendations?
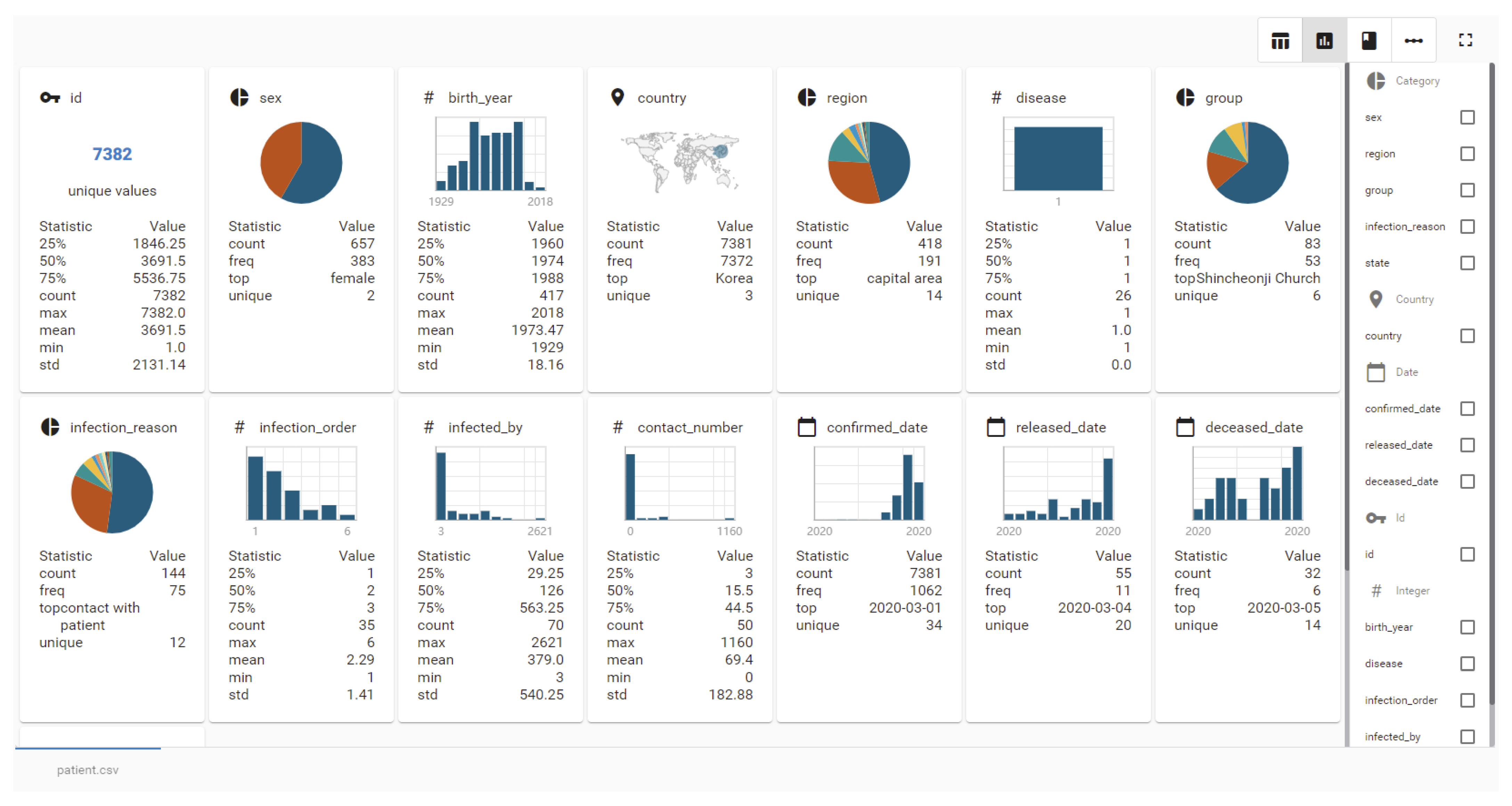
4.6. Proof of Concept System
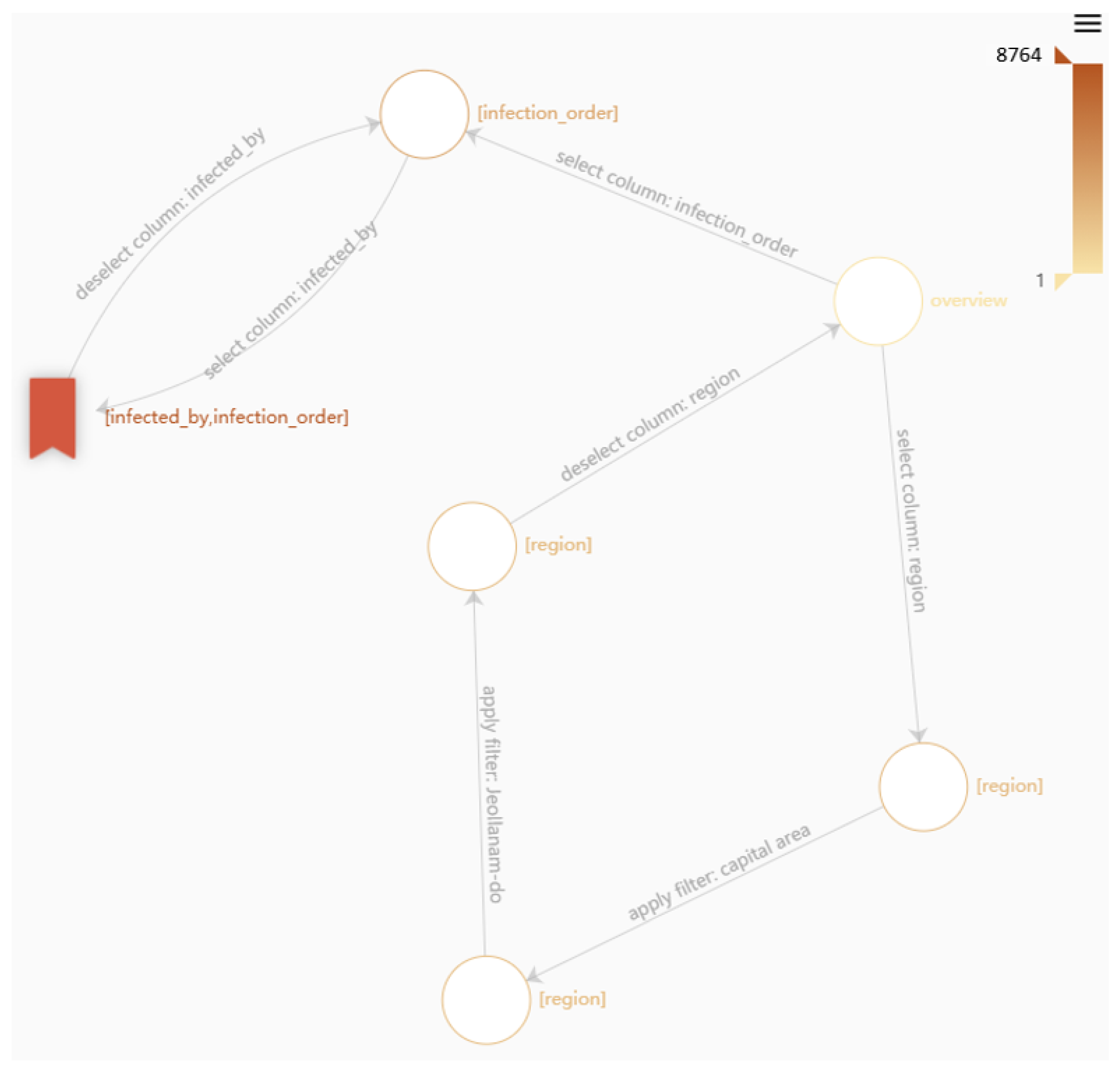
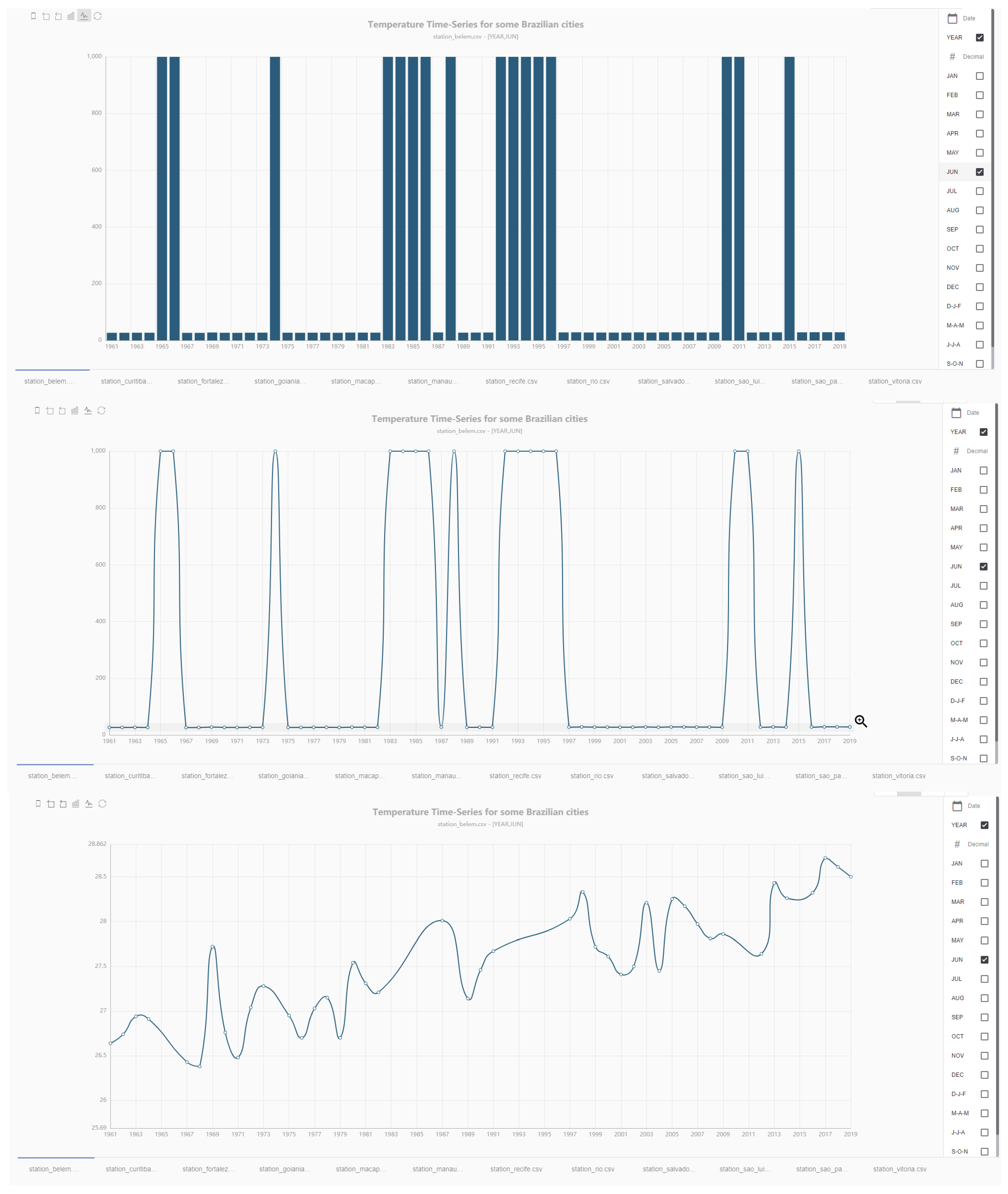
4.7. Exemplary Use Case
5. Critical Reflection and Research Opportunities
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VA | Visual Analytics |
| EDA | Exploratory Data Analysis |
| MLP | Multilayer Perceptron |
References
- Grinstein, G.G. Harnessing the Human in Knowledge Discovery; KDD: Washington, DC, USA, 1996; pp. 384–385. [Google Scholar]
- Dimitriadou, K.; Papaemmanouil, O.; Diao, Y. Explore-by-example: An automatic query steering framework for interactive data exploration. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 517–528. [Google Scholar]
- Langer, T.; Meisen, T. Towards Utilizing Domain Expertise for Exploratory Data Analysis. In Proceedings of the 12th International Symposium on Visual Information Communication and Interaction, Shanghai, China, 23–25 September 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Milo, T.; Somech, A. Next-step suggestions for modern interactive data analysis platforms. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 576–585. [Google Scholar]
- Wasay, A.; Athanassoulis, M.; Idreos, S. Queriosity: Automated Data Exploration. In Proceedings of the 2015 IEEE International Congress on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 716–719. [Google Scholar]
- El, O.B.; Milo, T.; Somech, A. Towards Autonomous, Hands-Free Data Exploration; CIDR: Klagenfurt, Germany, 2020. [Google Scholar]
- McCue, C. Chapter 2—Domain Expertise. In Data Mining and Predictive Analysis, 2nd ed.; McCue, C., Ed.; Butterworth-Heinemann: Boston, MA, USA, 2015; pp. 25–30. [Google Scholar]
- Sacha, D.; Stoffel, A.; Stoffel, F.; Kwon, B.C.; Ellis, G.; Keim, D.A. Knowledge generation model for visual analytics. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1604–1613. [Google Scholar] [CrossRef]
- Insight. In Cambridge Dictionary; Cambridge University Press: New York, NY, USA, 2020.
- Microsoft. Power BI. Available online: https://powerbi.microsoft.com/ (accessed on 10 August 2020).
- Tableau Software. Tableau. Available online: https://www.tableau.com/ (accessed on 10 August 2020).
- QlikTech. Qlik. Available online: https://www.qlik.com/ (accessed on 10 August 2020).
- Behrisch, M.; Streeb, D.; Stoffel, F.; Seebacher, D.; Matejek, B.; Weber, S.H.; Mittelstaedt, S.; Pfister, H.; Keim, D. Commercial visual analytics systems-advances in the big data analytics field. IEEE Trans. Vis. Comput. Graph. 2018, 25, 3011–3031. [Google Scholar] [CrossRef]
- Batch, A.; Elmqvist, N. The Interactive Visualization Gap in Initial Exploratory Data Analysis. IEEE Trans. Vis. Comput. Graph. 2018, 24, 278–287. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Moritz, D.; Anand, A.; Mackinlay, J.; Howe, B.; Heer, J. Voyager: Exploratory analysis via faceted browsing of visualization recommendations. IEEE Trans. Vis. Comput. Graph. 2015, 22, 649–658. [Google Scholar] [CrossRef] [PubMed]
- Demiralp, Ç.; Haas, P.J.; Parthasarathy, S.; Pedapati, T. Foresight: Recommending visual insights. arXiv 2017, arXiv:1707.03877. [Google Scholar] [CrossRef]
- Tang, B.; Han, S.; Yiu, M.L.; Ding, R.; Zhang, D. Extracting Top-K Insights from Multi-Dimensional Data. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1509–1524. [Google Scholar]
- Vartak, M.; Rahman, S.; Madden, S.; Parameswaran, A.; Polyzotis, N. SeeDB: Efficient Data-driven Visualization Recommendations to Support Visual Analytics. In Proceedings of the 41th International Conference on Very Large Data Bases (VLDB) Endowment, Waikoloa, HI, USA, 31 August–4 September 2015; pp. 2182–2193. [Google Scholar]
- Srinivasan, A.; Drucker, S.M.; Endert, A.; Stasko, J. Augmenting visualizations with interactive data facts to facilitate interpretation and communication. IEEE Trans. Vis. Comput. Graph. 2018, 25, 672–681. [Google Scholar] [CrossRef] [PubMed]
- Eirinaki, M.; Abraham, S.; Polyzotis, N.; Shaikh, N. Querie: Collaborative database exploration. IEEE Trans. Knowl. Data Eng. 2013, 26, 1778–1790. [Google Scholar] [CrossRef]
- Dimitriadou, K.; Papaemmanouil, O.; Diao, Y. AIDE: An active learning-based approach for interactive data exploration. IEEE Trans. Knowl. Data Eng. 2016, 28, 2842–2856. [Google Scholar] [CrossRef]
- Huang, E.; Peng, L.; Palma, L.D.; Abdelkafi, A.; Liu, A.; Diao, Y. Optimization for Active Learning-Based Interactive Database Exploration. In Proceedings of the 44th International Conference on Very Large Data Bases (VLDB) Endowment, Rio de Janeiro, Brazil, 9 May 2018; pp. 71–84. [Google Scholar]
- Qu, Y.; Furnas, G.W. Model-driven Formative Evaluation of Exploratory Search: A Study Under a Sensemaking Framework. Inf. Process. Manag. 2008, 44, 534–555. [Google Scholar] [CrossRef]
- Mohseni, S.; Pena, A.M.; Ragan, E.D. ProvThreads: Analytic Provenance Visualization and Segmentation. arXiv 2018, arXiv:1801.05469. [Google Scholar]
- Endert, A.; Fiaux, P.; North, C. Semantic interaction for sensemaking: Inferring analytical reasoning for model steering. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2879–2888. [Google Scholar] [CrossRef]
- Feng, M.; Deng, C.; Peck, E.M.; Harrison, L. HindSight: Encouraging Exploration through Direct Encoding of Personal Interaction History. IEEE Trans. Vis. Comput. Graph. 2017, 23, 351–360. [Google Scholar] [CrossRef]
- Gotz, D.; When, Z.; Lu, J.; Kissa, P.; Cao, N.; Qian, W.H.; Liu, S.X.; Zhou, M.X. HARVEST: An intelligent visual analytic tool for the masses. In Proceedings of the 1st International Workshop on Intelligent Visual Interfaces for Text Analysis, Hong Kong, China, 22–26 February 2010; pp. 1–4. [Google Scholar]
- Camisetty, A.; Chandurkar, C.; Sun, M.; Koop, D. Enhancing Web-based Analytics Applications through Provenance. IEEE Trans. Vis. Comput. Graph. 2019. [Google Scholar] [CrossRef]
- Nguyen, P.H.; Xu, K.; Wheat, A.; Wong, B.W.; Attfield, S.; Fields, B. Sensepath: Understanding the sensemaking process through analytic provenance. IEEE Trans. Vis. Comput. Graph. 2015, 22, 41–50. [Google Scholar] [CrossRef] [PubMed]
- Brown, E.T.; Yarlagadda, S.; Cook, K.A.; Chang, R.; Endert, A. Modelspace: Visualizing the trails of data models in visual analytics systems. In Proceedings of the Machine Learning from User Interaction for Visualization and Analytics Workshop at IEEE VIS, Paris, France, 22 October 2018. [Google Scholar]
- Boukhelifa, N.; Bezerianos, A.; Trelea, I.C.; Perrot, N.M.; Lutton, E. An exploratory study on visual exploration of model simulations by multiple types of experts. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Scotland, UK, 4–9 May 2019; pp. 1–14. [Google Scholar]
- Barczewski, A.; Bezerianos, A.; Boukhelifa, N. How Domain Experts Structure Their Exploratory Data Analysis: Towards a Machine-Learned Storyline. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–8. [Google Scholar]
- Caruccio, L.; Deufemia, V.; Polese, G. Understanding user intent on the web through interaction mining. J. Vis. Lang. Comput. 2015, 31, 230–236. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to recommender systems handbook. In Recommender Systems Handbook; Springer: New York, NY, USA, 2011; pp. 1–35. [Google Scholar]
- Jannach, D.; Zanker, M.; Felfernig, A.; Friedrich, G. Recommender Systems: An Introduction; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 191–198. [Google Scholar]
- Chirigati, F.; Doraiswamy, H.; Damoulas, T.; Freire, J. Data Polygamy: The Many-Many Relationships Among Urban Spatio-Temporal Data Sets. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June–1 July 2016; ACM: New York, NY, USA, 2016; pp. 1011–1025. [Google Scholar]
- Pomp, A.; Paulus, A.; Jeschke, S.; Meisen, T. Enabling Semantics in Enterprises. In Proceedings of the International Conference on Enterprise Information Systems, Porto, Portugal, 26–29 April 2017; Springer: New York, NY, USA, 2017; pp. 428–450. [Google Scholar]
- Zhang, K.; Shasha, D. Simple fast algorithms for the editing distance between trees and related problems. SIAM J. Comput. 1989, 18, 1245–1262. [Google Scholar] [CrossRef]
- Needham, M.; Hodler, A.E. Graph Algorithms: Practical Examples in Apache Spark and Neo4j; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019; p. 256. [Google Scholar]
- Hirschberg, D.S. Algorithms for the longest common subsequence problem. J. ACM 1977, 24, 664–675. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Abedjan, Z.; Golab, L.; Naumann, F. Profiling relational data: A survey. VLDB J. 2015, 24, 557–581. [Google Scholar] [CrossRef]
- Po, L.; Bikakis, N.; Desimoni, F.; Papastefanatos, G. Linked Data Visualization: Techniques, Tools, and Big Data. Synth. Lect. Semant. Web Theory Technol. 2020, 10, 1–157. [Google Scholar] [CrossRef]
- Ceneda, D.; Gschwandtner, T.; May, T.; Miksch, S.; Schulz, H.; Streit, M.; Tominski, C. Characterizing Guidance in Visual Analytics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 111–120. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Type | Interaction | Parameters | Description |
|---|---|---|---|
| Meta | Initial | Marks the beginning of a new analysis session. | |
| End session | Marks the end of the current analysis session. | ||
| Analysis | Select feature | Feature | A request to add a feature to the visualization. |
| Deselect feature | Feature | A request to remove a feature from the visualization. | |
| Select chart type | Chart type | Request to visualize selected data with given chart type. | |
| Apply filter | Feature, filter range | A request to reduce the data of a feature to a given filter range. | |
| Remove filter | Feature, filter | A request to remove filter range for given feature. | |
| Roam | Roam range (x, y, zoom) | Request to change view to given x and y coordinates, and zoom in to given zoom level. | |
| Details | Data point | Request to view the details for a selected data point. | |
| Insight | Add view to final report | A request to add the current view to the final report to indicate that the user has reached a milestone on the exploration path. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Langer, T.; Meisen, T. System Design to Utilize Domain Expertise for Visual Exploratory Data Analysis. Information 2021, 12, 140. https://doi.org/10.3390/info12040140
Langer T, Meisen T. System Design to Utilize Domain Expertise for Visual Exploratory Data Analysis. Information. 2021; 12(4):140. https://doi.org/10.3390/info12040140
Chicago/Turabian StyleLanger, Tristan, and Tobias Meisen. 2021. "System Design to Utilize Domain Expertise for Visual Exploratory Data Analysis" Information 12, no. 4: 140. https://doi.org/10.3390/info12040140
APA StyleLanger, T., & Meisen, T. (2021). System Design to Utilize Domain Expertise for Visual Exploratory Data Analysis. Information, 12(4), 140. https://doi.org/10.3390/info12040140