
Information Retrieval and Knowledge Organization: A Perspective from the Philosophy of Science


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. The Field of Knowledge Organization (KO)
- (1)
- the practical classification and indexing of books and other kinds of documents in libraries and bibliographical databases;
- (2)
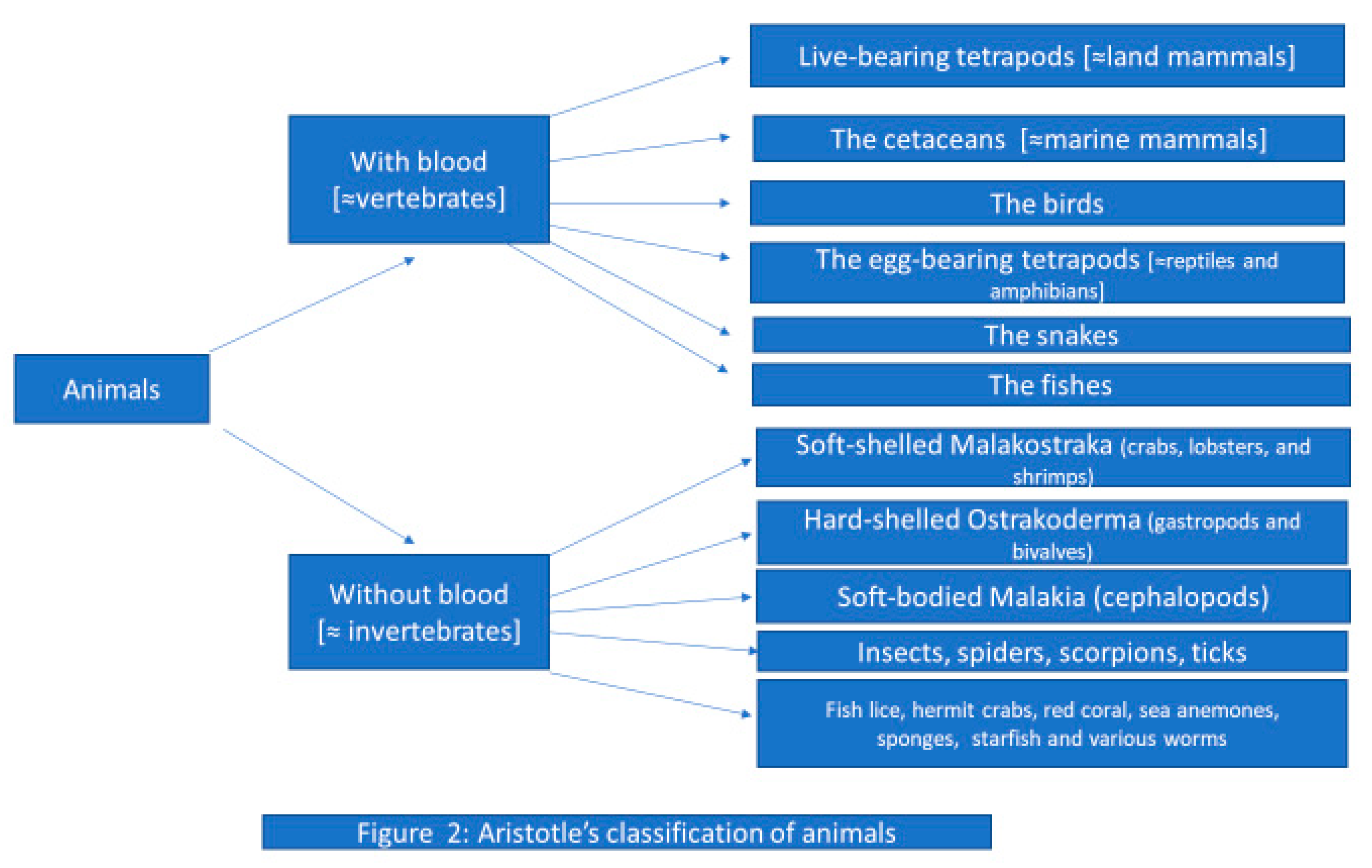
- philosophical principles, including Aristotle’s logic and Francis Bacon’s classification of knowledge, among many others; (The reader should be warned, however, that there are many misunderstandings about philosophical issues, including Aristotle’s role in classification. What is commonly attributed to Aristotle is a myth (see, e.g., [6], Chapter 2: “The Aristotelian Framework”).
- (3)
- scientific and scholarly contributions, including, for example, the contributions of Aristotle, Carl Linnaeus, Charles Darwin and many other scientists to the classification of living organisms and all other things in the world;
- (4)
- developments in information technology (IT), such as databases, communication networks and social media.
- To consider KO an intuitive process that does not need deeper justification. The original classification of journals in the citation indexes published by the Institute for Scientific Information, for example, was just intuitive (cf., [7], p. 602). In practice, many KO activities have been driven by this view: you simply start constructing a classification and stop when it seems to suit the purpose. A criticism of this perspective may state that any classification is always serving some interests at the expense of other interests, and if unanalyzed, it cannot be optimized for the purpose it is going to serve (cf., [8]). Of course, this view challenges the whole idea of KO as a needed field of study.
- To claim that since only the individual user knows their own “information need”, they are the only person qualified to set principles of what should be found in IR and how documents should be indexed or classified. This is the view underlying user-oriented and cognitive approaches in information science and KO and is discussed a little in the present article and more detailed in [9].
- To say that the best way, both economically and qualitatively, is to base KO on user tagging or related “social technologies”, implying that a deeper theoretical understanding of KO is unnecessary. User tagging is by some both seen as “democratic” and economically preferrable, while there are also critical voices (for a discussion, see [10]).
- To claim that KO is basically a technological problem, that, for example, when enough computer power and optimal algorithms are available, the problems of IR will be solved without a deeper theoretical understanding of KO. A version of this view is that the principles underlying systems such as Google are sufficient. This view dominates the IR tradition in computer science and shall be discussed further in Section 2. (Computer science is, however, also dominating in knowledge representation and ontology development; therefore, a simple dichotomy between knowledge organization and computer science cannot be made.)
3. Challenges from IR
- (a)
- If you type in a sentence, such as: “It seems to be based on the problematic assumption that relations between concepts are a priori”, Google will retrieve the one article (and its possible copies and versions) that contains this exact sentence. This exact match is obtained because the search applies proximity operators and thereby can retrieve documents identical to the query. This is not, however, what is generally understood by “exact match” techniques (or “set-retrieval”), which were defined by [20] (p. 284):
- (b)
- If you type in a number of terms such as “concepts”, “relations” and “a priori” from the example in point (a), Google will make a so-called “best match” search (also called “partial match”, “relevance ranking” or “weighted retrieval”) and retrieve millions of documents in a ranked order according to some principles, which are more or less business secrets. (The one article retrieved in point (a) is not among the top results).
- (c)
- It is well known that Google also uses a kind of popularity measure; the more in-links a certain document has, the greater the weight it is given and the higher it is listed in the ranked order shown to the user. This is often, if not in most cases, working very well because people often want the same as the majority. However, in searching for rare diseases, for example, this has proven a bad principle because rare diseases are, by definition, not a majority issue (for empirical demonstration of the failure of this principle for IR about rare diseases, see [37,38].
- (d)
- The fourth major principle in search engines is personalization; Google can identify users’ IP address and thereby their physical location as well as their search history on Google, and may adapt, not just the advertisements, but also the so-called “organic results” in the ranked list presented to the user. This provides an element of subjectivity and randomness into the search and harms the ability to make conscious search strategies. It is also a double-edged sword; sometimes, it works well, but other times, you may want to eliminate this element, you may want more objective searches, you may have changed interests, or you may be searching on behalf of others. This is why the focus on past search interests may be harmful rather than fruitful.
- (1)
- (2)
- selecting high-quality sources (e.g., journals with high impact factors); (See [18], Section 6 about the quality of indexed documents. Some citation indexes such as the Web of Science cover more limited amounts of indexed sources (based on journal impact factors), compared to, for example, Google Scholar, and use this to argue for a higher quality in the retrieved documents. This is, however, an open hypothesis, which seems to have been challenged by [39], who found that important papers are more and more published in non-elite journals. For a criticism of the journal impact factor, see, for example, [40]).
- (3)
- selecting documents based on principles used in so-called evidence-based research (e.g., studies based on double blind clinical trials); In evidence-based medicine (or evidence-based practice in general, EBP) the trustworthiness of claims about the effectiveness of a given treatment are classified according to the quality of the research methods employed. Explicit norms should be made for investigations that are most relevant, and a hierarchy of the value of different kinds of research methods as evidence should be made (where randomized controlled trials are considered to be a high level of evidence, while, for example, evidence from expert committee reports is considered to be a low level of evidence). There has been criticism of such views, and there is an example of two different systematic reviews based on this procedure that provide very different conclusions (cf., [41]). Regarding IR, the EBP model provides clear criteria for prioritizing information sources, although, as already said, they are not uncontroversial.
- (4)
- Selecting documents based on their influence measures, e.g., their number of citations, in general or within some specifications (e.g., papers highly cited within leading journals in the field).
- (5)
- basing IR on quality KOS (such as our thought experiment with Swedish cities). In addition to such KOS, it is necessary that each document is assigned to the most relevant classes in the KOS, which is not a trivial issue, but depends both on the specific qualifications by the indexer and by the indexing philosophy used by the system, e.g., the operationalization of the concept “subject” (cf., [32]). (Ref. [42] Section 5.2, put forward the hypothesis, that indexing done by MEDLINE, one of the most important bibliographical databases in the world, may be based on principles that are too mechanical.)
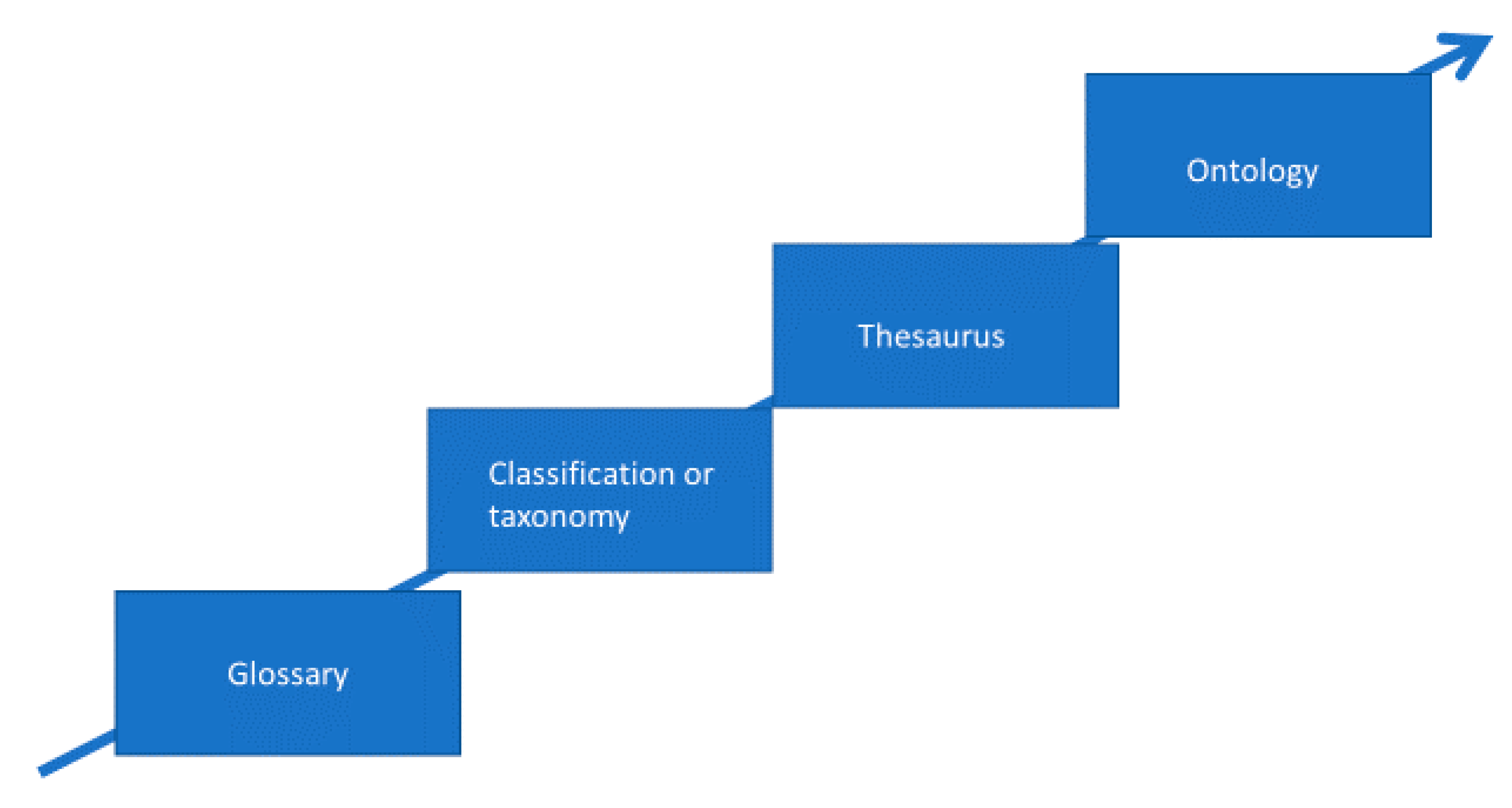
4. Knowledge Organization Systems (KOS) and the Semantic Staircase
4.1. Classification Systems
4.2. Thesauri
4.3. Ontologies
- is_a
- part_of
- located_in
- contained_in
- adjacent_to
- transformation_of
- derives_ from
- preceded_by
- has_participant
- has_agent
4.4. The Semantic Staircase
5. Concept Theory and Realism
5.1. Challenges from “Smithian Realism”
- Universals have an observer-independent objective existence; they are invariants of reality.
- Bad ontologies are those whose general terms lack a relation to corresponding universals in reality, and thereby also to corresponding instances.
- Good ontologies are representations of reality. A good ontology must be based on universals instead of concepts.
5.2. What Are Concepts?
5.3. Does a KOS Need to Contain Universals and Symbolic Structures in Addition to Concepts?
- Concept [74] (p. 301–302): “Concepts are categories that are expressed by linguistic expressions and which are represented as meanings in someone’s mind. Concepts are a result of common intentionality which is based on communication and society (Searle, 1995) [92]”. (Ref. [74] (p. 302, footnote 7): “The mental representation of a concept allows us to understand a linguistic expression. Concepts are outside of individual minds, but they are anchored, on the one hand, in individual minds by the concepts’ mental representation, and on the other hand, in society as a result of communication and usage of language”.)
- Category [74] (p. 301): “Categories are entities that are expressed by predicative terms of a formal or natural language that can be predicated of other entities. […]. We distinguish at least three kinds of categories: universals, concepts, and symbol structures. We hold that any reasonable foundational ontology must include these three types of categories”.(It is difficult to understand Herre’s difference between categories and concepts. Both categories and concepts may be expressed by linguistic expressions and predicative terms and may be represented in somebody’s mind. Ref. [93] wrote: “Categories are hard to describe, and even harder to define. This is in part a consequence of their complicated history, and in part because category theory must grapple with vexed questions concerning the relation between linguistic or conceptual categories on the one hand, and objective reality on the other”. Concepts and categories are often defined in ways that make them synonyms, but categories may also, and probably better, be used about the highest kinds or genera, such as Aristotle’s 10 categories: substance, quantity, quality, relation, place, date, posture, state, action, and passion. This way of understanding categories has its own philosophical history (see, e.g., [94]). For more detail about the relation to Ranganathan’s categories in KO, see [95])
- Symbol/symbol structure [74] (p. 302): “Symbols are signs or texts that can be instantiated by tokens. There is a close relation between these three kinds of categories: a universal is captured by a concept which is individually grasped by a mental representation, and the concept and its representation is denoted by a symbol structure being an expression of a language. Texts and symbolic structures may be communicated by their instances that a[re] physical tokens”. Further (p. 304): “One must distinguish between symbols and tokens. Only tokens, being physical instances of symbols, can be perceived and transmitted through space and time”.Ref. [96] (p. 120): “Tokens are said to instantiate types: they exemplify, embody, manifest, fall under, belong to types; they’re occurrences, instances, members of types. Tokens are treated as individuals, singles, particulars, substances, objects; they’re concrete, real, material. Types, on the other hand, are like sorts, kinds, forms, properties, classes, sets, universals; they’re said to be abstract, ideal, immaterial.”
- Universal [74] (p. 301): “Universals are constituents of the real world, they are associated to invariants of the spatio-temporal real world, they are something abstract that is in the things”.
- (1)
- It seems unnecessary to define categories and concepts as entities that are expressed by terms or linguistic expression. We might conversely say that concepts may be expressed by words, and that concepts that have a linguistic or symbolic expression are lexicalized. Ref. [97] (p. 237) wrote that WordNet introduced the non-lexicalized concept “wheeled vehicle”: “The argument is that people distinguish between the category of wheeled vehicles and vehicles moving on runners independently of whether this distinction is lexically encoded in their language”.
- (2)
- As already presented in Section 4.1, there is a discussion in the ontological literature between a realistic position that rejects concepts as units for KOS and another realist position (like Herre and the present author), which defends concepts as units in KOS. Herre’s statement that concepts are “represented as meanings in someone’s mind” may, however, make it more difficult to see his position as representing realism (although his argument is partly saved by his addition that concepts are a result of a common intentionality, that they are social). We shall return to this problem about realism in Section 5.4.
- (3)
- Herre finds that ontologies/KOS must include universals, but his position on this point seems not to be crystal clear. On the one hand, he writes [74] (p. 305): “In sum, the nodes in an ontology are labeled by terms that denote concepts. Some of these concepts, notably natural concepts, are related to invariants of material reality”. This is in line with the semiotic triangle and in accordance with the view expressed by the present author. However, he [74] (pp. 326–327) also speaks of facts, defined as “The simplest combinations of relators and relata”. Perhaps Herre’s view is opposed to that of [98] (p. 4): “In hermeneutics, we defend the idea that there are no pure facts. Behind every interpretation lies another interpretation. We never reach an understanding of anything that is not an interpretation”. If we follow this view, it seems that universals are not elements in ontologies since we can only know them as interpretations and concepts. This is further discussed in Section 5.4.
5.4. Pragmatic Realism
6. Conclusions
- Go to a given domain,
- Look at how it is classified according to contemporary knowledge (including different views),
- Discuss the basis, the epistemological assumptions and which interests are served by proposed classifications,
- Suggest a motivated classification.
Funding
Acknowledgments
Conflicts of Interest
References
- Anderson, J.D.; José, P.-C. Information Retrieval Design: Principles and Options for Infor-mation Description, Organization, Display and Access in Information Retrieval Databases, Digital Libraries, Catalogs, and Indexes; Ometeca Institute: St. Petersburg, FL, USA, 2005. [Google Scholar]
- Salaba, A. Knowledge Organization Requirements in LIS Graduate Programs. Knowl. Organ. Interf. 2020, 17, 384–393. [Google Scholar] [CrossRef]
- Salton, G. Letter to the Editor. A New Horizon for Information Science? J. Am. J. Inf. Sci. 1996, 47, 333. [Google Scholar] [CrossRef]
- Hjørland, B. Is classification necessary after Google? J. Doc. 2012, 68, 299–317. [Google Scholar] [CrossRef]
- Bliss, H.E. The Organization of Knowledge in Libraries and the Subject Approach to Books; Henry Holt: New York, NY, USA, 1933. [Google Scholar]
- Richards, R.A. Biological Classification: A Philosophical Introduction; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Leydesdorff, L. Can scientific journals be classified in terms of aggregated journal-journal citation relations using the Journal Citation Reports? J. Am. Soc. Inf. Sci. Technol. 2006, 57, 601–613. [Google Scholar] [CrossRef]
- Hjørland, B. Political Versus Apolitical Epistemologies in Knowledge Organization. Knowl. Organ. 2020, 47, 461–485. [Google Scholar] [CrossRef]
- Hjørland, B. User-based and Cognitive Approaches to Knowledge Organization: A Theoretical Analysis of the Research Literature. KO Knowl. Organ. 2013, 40, 11–27. [Google Scholar] [CrossRef]
- Rafferty, P. Tagging. Knowl. Organ. 2018, 45, 500–516. [Google Scholar] [CrossRef]
- Hjørland, B. The foundation of the concept of relevance. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 217–237. [Google Scholar] [CrossRef]
- Hjørland, B. Domain Analysis. Knowl. Organ. 2017, 44, 436–464. [Google Scholar] [CrossRef]
- Warner, J. Human Information Retrieval; The MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Hjørland, B. Classical Databases and Knowledge Organization: A Case for Boolean Retrieval and Human Decision-making During Searches. J. Assoc. Inf. Sci. Technol. 2015, 66, 1559–1575. [Google Scholar] [CrossRef]
- Plato. 380 B.C.E. Meno. Translated by Benjamin Jowett. Available online: https://www.gutenberg.org/files/1643/1643-h/1643-h.htm#link2H_4_0003 (accessed on 17 March 2021).
- Swanson, D.R. Undiscovered Public Knowledge. Libr. Q. 1986, 56, 103–118. [Google Scholar] [CrossRef]
- Hjørland, B. Citation analysis: A social and dynamic approach to knowledge organization. Inf. Process. Manag. 2013, 49, 1313–1325. [Google Scholar] [CrossRef]
- Araújo, P.C.D.; Castanha, R.C.G.; Hjørland, B. Citation Indexing and Indexes. Knowl. Organ. 2021, 48, 58–87.
- Hjørland, B.; Nielsen, L.K. Subject Access Points in Electronic Retrieval. Annu. Rev. Inf. Sci. Technol. 2001, 35, 249–298. [Google Scholar]
- Turtle, H.R.; Croft, W.B. A Comparison of Text Retrieval Models. Comput. J. 1992, 35, 279–290. [Google Scholar] [CrossRef]
- Fiorini, N.; Canese, K.; Starchenko, G.; Kireev, E.; Kim, W.; Miller, V.; Osipov, M.; Kholodov, M.; Ismagilov, R.; Mohan, S.; et al. Best Match: New relevance search for PubMed. PLoS Biol. 2018, 16, e2005343. [Google Scholar] [CrossRef]
- Sampson, M.; Nama, N.; O’Hearn, K.; Murto, K.; Nasr, A.; Katz, S.L.; Macartney, G.; Momoli, F.; McNally, J.D. Creating enriched training sets of eligible studies for large systematic reviews: The utility of PubMed’s Best Match algorithm. Int. J. Technol. Assess. Health Care 2021, 37, 1–6. [Google Scholar] [CrossRef]
- Harter, S.P. Online Information Retrieval: Concepts, Principles, and Techniques; Academic Press: New York, NY, USA, 1986. [Google Scholar]
- Frei, H.-P.; Qiu, Y. Effectiveness of Weighted Searching in an Operational IR Environment. In Information Retrieval ’93, von der Modellierung zur Anwendung; Proceedings der 1. Tagung Information Retrieval ’93; Universität Verlag Konstanz: Konstanz, Germany, 1993; pp. 41–54. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.56.7021&rep=rep1&type=pdf (accessed on 17 March 2021).
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval: The Concepts and Technology behind Search, 2nd ed.; Addison Wesley: New York, NY, USA, 2011. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. An Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009; Available online: http://nlp.stanford.edu/IR-book/pdf/irbookonlinereading.pdf (accessed on 17 March 2021).
- Roelleke, T. Information Retrieval Models: Foundations and Relationships. Synth. Lect. Inf. Concepts Retr. Serv. 2013, 5, 1–163. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.-S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Robertson, S.E.; Jones, K.S. Relevance weighting of search terms. J. Am. Soc. Inf. Sci. 1976, 27, 129–146. [Google Scholar] [CrossRef]
- Robertson, S.E. The State of Information Retrieval. ISKO-UK. 2008. Available online: https://web.archive.org/web/20190512123726/http://event-archive.iskouk.org/sites/default/files/robertson.pdf (accessed on 17 March 2021).
- Hjørland, B. Epistemology and the socio-cognitive perspective in information science. J. Am. Soc. Inf. Sci. Technol. 2002, 53, 257–270. [Google Scholar] [CrossRef]
- Hjørland, B. Subject (of Documents). Knowl. Organ. 2017, 44, 55–64. [Google Scholar] [CrossRef]
- Paris, L.A.H.; Tibbo, H.R. Freestyle vs. Boolean: A Comparison of Partial and Exact Match Retrieval Systems. Inf. Process. Manag. 1998, 34, 175–190. [Google Scholar] [CrossRef]
- Robertson, S.E.; Thompson, C.L. Weighted Searching: The CIRT Experiment. In Lnformatics 10: Prospects for Intelligent Retrieval, Proceedings of the Conference Jointly Sponsored by Aslib, the Aslib Informatics Group and the Information Retrieval Specialist Group of the British Computer Society, King’s College, Cambridge, UK, 21–23 March 1989; Karen, S.J., Ed.; Aslib: London, UK, 1990; pp. 153–165. [Google Scholar]
- Belkin, N.J.; Croft, W.C. Retrieval Techniques. Annu. Rev. Inf. Sci. Technol. 1987, 22, 109–145. [Google Scholar]
- Robertson, S.E. Salton Award Lecture on theoretical argument in information retrieval. ACM Sigir Forum 2000, 34, 1–10. [Google Scholar] [CrossRef]
- Dragusin, R.; Petcu, P.; Lioma, C.; Larsen, B.; Jørgensen, H.L.; Cox, I.J.; Hansen, L.K.; Ingwersen, P.; Winther, O. FindZebra: A search engine for rare diseases. Int. J. Med Inform. 2013, 82, 528–538. [Google Scholar] [CrossRef]
- Dragusin, R.; Petcu, P.; Lioma, C.; Larsen, B.; Jørgensen, H.L.; Cox, I.J.; Hansen, L.K.; Ingwersen, P.; Winther, O. Specialized tools are needed when searching the web for rare disease diagnoses. Rare Dis. (AustinTex.) 2013, 1, e25001. [Google Scholar] [CrossRef][Green Version]
- Acharya, A.; Verstak, A.; Suzuki, H.; Henderson, S.; Iakhiaev, M.; Lin, C.C.Y.; Shetty, N. Rise of the Rest: The Growing Impact of Non-Elite Journals. arXiv 2014. Available online: http://arxiv.org/pdf/1410.2217v1.pdf (accessed on 17 March 2021).
- Picard, C.-F.; Durocher, S.; Gendron, Y. Desingularization and Dequalification: A Foray Into Ranking Production and Utilization Processes. Eur. Acc. Rev. 2019, 28, 737–765. [Google Scholar] [CrossRef]
- Hjørland, B. Evidence-based practice: An analysis based on the philosophy of science. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 1301–1310. [Google Scholar] [CrossRef]
- Lardera, M.; Hjørland, B. Keyword. In ISKO Encyclopedia of Knowledge Organization; Hjørland, B., Gnoli, C., Eds.; International Organization of Knowledge Organization (ISKO): Toronto, ON, Canada, 2020; Available online: https://www.isko.org/cyclo/keyword (accessed on 17 March 2021).
- Mazzocchi, F. Knowledge organization system (KOS). Knowl. Organ. 2018, 45, 54–78. [Google Scholar] [CrossRef]
- Olensky, M. Semantic Interoperability in Europeana: An Examination of CIDOC CRM in Digital Cultural Heritage Documentation. Bull. IEEE Tech. Comm. Digit. Libr. 2010, 6. Available online: https://web.archive.org/web/20130620181231/https://www.ieee-tcdl.org/Bulletin/v6n2/Olensky/olensky.html (accessed on 17 March 2021).
- Blake, J. Some Issues in the Classification of Zoology. Knowl. Organ. 2011, 38, 463–472. [Google Scholar]
- ISO 25964-1: 2011 (E). Information and Documentation—Thesauri and Interoperability with Other Vocabularies—Part 1: Thesauri for Information Retrieval; International Organization for Standardization: Geneva, Switzerland, 2011. [Google Scholar]
- UNESCO Thesaurus. Available online: http://vocabularies.unesco.org/browser/thesaurus/en/ (accessed on 17 March 2021).
- Wächter, T.; Alexopoulou, D.; Dietze, H.; Hakenberg, J.; Schroeder, M. Searching Biomedical Literature with Anatomy Ontologies. Anatomy Ontologies for Bioinformatics; Springer: London, UK, 2008; Volume 6, pp. 177–194. [Google Scholar]
- The Foundational Model of Anatomy ontology (FMA). Available online: http://sig.biostr.washington.edu/projects/fm/AboutFM.html (accessed on 17 March 2021).
- Aitchison, J.; Gilchrist, A.; Bawden, D. Thesaurus Construction and Use: A Practical Manual, 4th ed.; Aslib: London, UK, 2000. [Google Scholar]
- Svenonius, E. Definitional Approaches in the Design of Classification and Thesauri and Their Implications for Retrieval and Automatic Classification. In Knowledge Organization for Information Retrieval; McIlwaine, I.C., Ed.; International Federation for Information and Documentation: The Hague, The Netherlands, 1997; pp. 12–16. [Google Scholar]
- Hudson, M. Preparing Terminological Definitions for Indexing and Retrieval Thesauri: A Model. Adv. Knowl. Organ. 1996, 5, 363–369. [Google Scholar]
- Gruber, T.R. A Translation Approach to Portable Ontology Specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Genesereth, M.R.; Nilsson, N.J. Logical Foundations of Artificial Intelligence; Morgan Kaufmann: Los Altos, CA, USA, 1987. [Google Scholar]
- Colomb, R.M. Ontology and the Semantic Web; IOS Press: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Soergel, D.; Lauser, B.; Liang, A.; Fisseha, F.; Keizer, J.; Katz, S. Reengineering Thesauri for New Application: The AGROVOC Example. J. Digit. Inf. 2004, 4. Available online: https://journals.tdl.org/jodi/index.php/jodi/article/view/112/111 (accessed on 17 March 2021).
- Ali, N.M.; Khan, H.A.; Amy, Y.; Then, H.; Ching, C.V.; Gaur, M.; Dhillon, S.K. Fish Ontology framework for taxonomy-based fish recognition. PeerJ 2017, 5, e3811. [Google Scholar] [CrossRef] [PubMed]
- Rosse, C.; Mejino, J.L.V. The Foundational Model of Anatomy Ontology. In Anatomy Ontologies for Bioinformatics: Principles and Practice; Albert, B., Duncan, D., Richard, B., Eds.; Springer: London, UK, 2008; pp. 59–117. [Google Scholar]
- Smith, B.; Ceusters, W.; Klagges, B.; Köhler, J.; Kumar, A.; Lomax, J.; Mungall, C.; Neuhaus, F.; Rector, A.L.; Rosse, C. Relations in biomedical ontologies. Genome Biol. 2005, 6, R46. [Google Scholar] [CrossRef] [PubMed]
- Blunauer, A.; Pellegrini, T. Semantic Web und Semantische Technologien: Zentrale Begriffe und Unterscheidungen. In Tassilo Pellegrini and Andreas Blumauer; Springer: Berlin, Germany, 2006; pp. 9–25. [Google Scholar]
- Obrst, L. Ontological Architectures. Theory and Applications of Ontology: Computer Applications; Springer: Dordrecht, The Netherlands, 2010; pp. 27–66. [Google Scholar]
- Garshol, L.M. Metadata? Thesauri? Taxonomies? Topic Maps! Making Sense of It All. J. Inform. Sci. 2004, 30, 378–391. [Google Scholar] [CrossRef]
- Aitchison, J. A Classification as a Source for a Thesaurus: The Bibliographic Classification of H. E. Bliss as a source of Thesaurus Terms and Structure. J. Doc. 1986, 42, 160–181. [Google Scholar] [CrossRef]
- Temmerman, R. Questioning the univocity ideal. The difference between socio-cognitive Terminology and traditional Terminology. Hermes J. Lang. Commun. Bus. 1997, 18, 51–90. Available online: https://tidsskrift.dk/her/article/view/25412/22333 (accessed on 17 March 2021). [CrossRef]
- Van Deemter, K. Not Exactly: In Praise of Vagueness; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Svenonius, E. The Epistemological Foundations of Knowledge Representations. Libr. Trends 2004, 52, 571–587. [Google Scholar]
- Hjørland, B. Are Relations in Thesauri ‘Context-Free, Definitional, and True in all Possible Worlds’? J. Assoc. Inf. Sci. Technol. 2015, 66, 1367–1373. [Google Scholar] [CrossRef]
- Fidel, R. Searchers’ Selection of Search Keys: II. Controlled Vocabulary or Free-Text Searching. J Am Soc Inform Sci. 1991, 42, 501–514. [Google Scholar] [CrossRef]
- Dahlberg, I. Brief Communication: Concepts and Terms—ISKO’s Major Challenge. Knowl. Organ. 2009, 36, 169–177. [Google Scholar] [CrossRef]
- Hjørland, B. Fundamentals of Knowledge Organization. Knowl. Organ. 2003, 30, 87–111. [Google Scholar]
- Sowa, J.F. Conceptual Structures: Information Processing in Mind and Machine; Addison-Wesley: Reading, MA, USA, 1984. [Google Scholar]
- Patel, A.; Jain, S.; Shandilya, S.K. Data of Semantic Web as Unit of Knowledge. J. Web Eng. 2019, 17, 647–674. [Google Scholar] [CrossRef]
- Machado, L.; Simões, G.; Gnoli, C.; Souza, R. Can an Ontologically-Oriented KO Do Without Concepts? Knowl. Organ. Interf. 2020, 17, 502–506. [Google Scholar] [CrossRef]
- Herre, H. General Formal Ontology (GFO): A Foundational Ontology for Conceptual Modelling. In Theory and Applications of Ontology: Computer Applications; Roberto, P., Michael, H., Achilles, K., Eds.; Springer: Dordrecht, The Netherlands, 2010; pp. 297–345. [Google Scholar] [CrossRef]
- Smith, B. Beyond Concepts: Ontology as Reality Representation. In Proceedings of the FOIS 2004. International Conference on Formal Ontology and Information Systems, Turin, Italy, 4–6 November 2004; Achille, C.V., Laure, V., Eds.; IOS Press: Amsterdam, The Netherlands, 2004; Available online: https://www.researchgate.net/publication/244107491_Beyond_Concepts_Ontology_as_Reality_Representation (accessed on 7 February 2021).
- Smith, B.; Ceusters, W. Ontology as the Core Discipline of Biomedical Informatics. In Compu-ting, Philosophy, and Cognitive Science: The Nexus and the Liminal; Susan, A.J.S., Gordana, D.C., Eds.; Cambridge Scholars Press: Newcastle, UK, 2007; pp. 104–122. [Google Scholar]
- Arp, R.; Smith, B.; Spear, A.D. Building Ontologies with Basic Formal Ontology; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Leclercq, H. Europe: Term for Many Concepts. Int. Classif. 1978, 5, 156–162. [Google Scholar] [CrossRef]
- Smith, B.; Ceusters, W. Ontological realism: A methodology for coordinated evolution of scientific ontologies. Appl. Ontol. 2010, 5, 139–188. [Google Scholar] [CrossRef]
- Leonelli, S. Data-Centric Biology: A Philosophical Study; University of Chicago Press: Chicago, IL, USA, 2016. [Google Scholar]
- Ogden, C.K.; Richards, I.A. The Meaning of Meaning: A Study of the Influence of Language Upon Thought and of the Science of Symbolism; Routledge & Kegan Paul: London, UK, 1923. [Google Scholar]
- Sowa, J.F. Ontology, Metadata, and Semiotics. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2000; Volume 1867, pp. 55–81. [Google Scholar]
- Hjelmslev, H. Omkring Sprogteoriens Grundlæggelse; B. Lunos bogtrykkeri: Copenhagen, Denmark, 1943. [Google Scholar]
- Kuhn, T.S. The Structure of Scientific Revolutions; University of Chicago Press: Chicago, IL, USA, 1962. [Google Scholar]
- Thagard, P. Conceptual Change. In Encyclopedia of Cognitive Science; Nadel, L., Ed.; Macmillan: London, UK, 2003; Volume 1, pp. 666–670. Available online: http://cogsci.uwaterloo.ca/Articles/conc.change.pdf (accessed on 17 February 2021).
- Del Hoyo, J.; Elliott, A.; Sargatal, J.V. (Eds.) Handbook of the Birds of the World; Lynx Edicions: Barcelona, Spain, 1997; Volume 1. [Google Scholar]
- Fjeldså, J. Avian Classification in Flux. In Handbook of the Birds of the World; Lynx Edicions: Barcelona, Spain, 2013; Special Volume 17, pp. 77–146. [Google Scholar]
- Mayr, E.; Bock, W.J. Provisional Classifications v Standard Avian Sequences: Heuristics and Communication in Ornithology. IBIS 1994, 136, 12–18. [Google Scholar] [CrossRef]
- Sibley, C.; Ahlquist, J.E. Phylogeny and Classification of Birds: A Study in Molecular Evolution; Yale University Press: New Haven, CT, USA, 1990. [Google Scholar]
- Hjørland, B. Concept Theory. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 1519–1536. [Google Scholar] [CrossRef]
- Biagetti, M.T. Ontologies (as Knowledge Organization Systems). ISKO Encycl. Knowl. Organ. 2020. Available online: https://www.isko.org/cyclo/ontologies (accessed on 17 March 2021).
- Searle, J. The Construction of Social Reality; Free Press: New York, NY, USA, 1995. [Google Scholar]
- Wardy, R. Categories. In Routledge Encyclopedia of Philosophy; Edward, C., Ed.; Routledge: London, UK, 1998; Volume 1–10. [Google Scholar]
- Thomasson, A. Categories. In The Stanford Encyclopedia of Philosophy; Edward, N.Z., Ed.; 2019; Available online: https://plato.stanford.edu/archives/sum2019/entries/categories/ (accessed on 17 March 2021).
- Moss, W.R. Categories and Relations: Origins of Two Classification Theories. Am. Doc. 1964, 15, 296–301. [Google Scholar] [CrossRef]
- Furner, J. Type–Token Theory and Bibliometrics. In Theories of Informetrics and Scholarly Communication; De Gruyter Saur: Berlin, Germany, 2016; pp. 119–147. [Google Scholar]
- Fellbaum, C. WordNet. In Theory and Applications of Ontology: Computer Applications; Springer: Dordrecht, The Netherlands, 2010; pp. 231–243. [Google Scholar]
- Caputo, J.D. Hermeneutics: Facts and Interpretation in the Age of Information; Penguin: London, UK, 2018. [Google Scholar]
- Soergel, D. WordNet [Book Review]. D-Lib Mag. 1998, 4, 1–7. Available online: http://www.dlib.org/dlib/october98/10bookreview.html (accessed on 17 March 2021).
- Barnes, B.; Bloor, D.; Henry, J. Scientific Knowledge: A Sociological Analysis; The University of Chicago Press: Chicago, IL, USA, 1996. [Google Scholar]
- Kuhn, T.S. Reflections on My Critics. In Criticism and the Growth of Knowledge; Lakatos, I., Musgrave, A., Eds.; Cambridge University Press: Cambridge, UK, 1970; pp. 231–278. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hjørland, B. Information Retrieval and Knowledge Organization: A Perspective from the Philosophy of Science. Information 2021, 12, 135. https://doi.org/10.3390/info12030135
Hjørland B. Information Retrieval and Knowledge Organization: A Perspective from the Philosophy of Science. Information. 2021; 12(3):135. https://doi.org/10.3390/info12030135
Chicago/Turabian StyleHjørland, Birger. 2021. "Information Retrieval and Knowledge Organization: A Perspective from the Philosophy of Science" Information 12, no. 3: 135. https://doi.org/10.3390/info12030135
APA StyleHjørland, B. (2021). Information Retrieval and Knowledge Organization: A Perspective from the Philosophy of Science. Information, 12(3), 135. https://doi.org/10.3390/info12030135