
Emergent Robotic Personality Traits via Agent-Based Simulation of Abstract Social Environments

Abstract
1. Introduction
1.1. Overview
“The different theories often seek to explain different aspects of the overall phenomenon of affect. Consequently, developing an overall theory for affect/emotion modeling would require reconciling not just the theories themselves, narrowly construed, but also their architectural assumptions. This aim, however, resembles the early dreams of strong AI, and its disillusions.”
1.2. Approach
1.3. Background
1.3.1. Robotic Personalities
1.3.2. Agent-Based Modeling and Emotion
1.3.3. Human–Robot Interaction
2. Materials and Methods
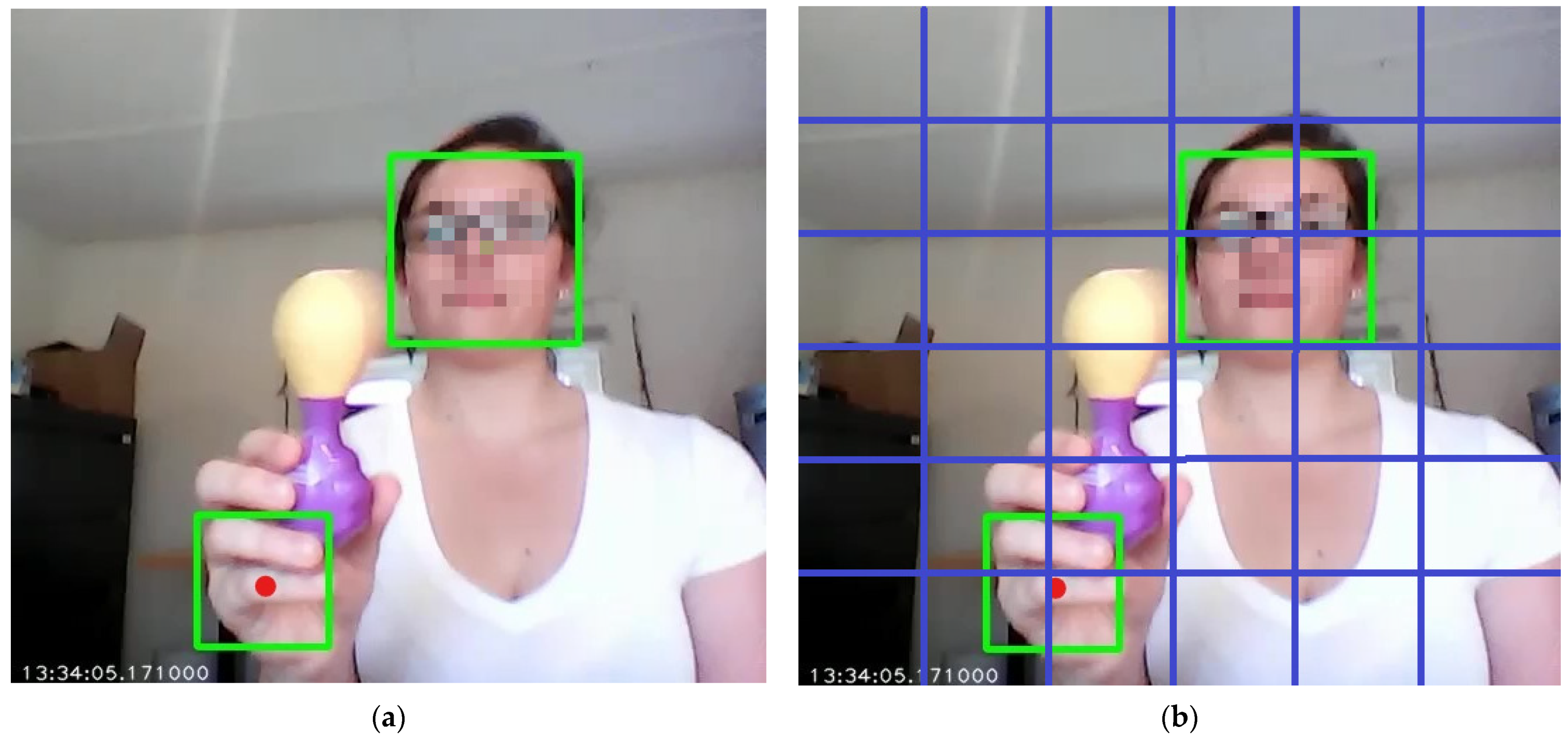
2.1. Prior Work on Robotic Faces
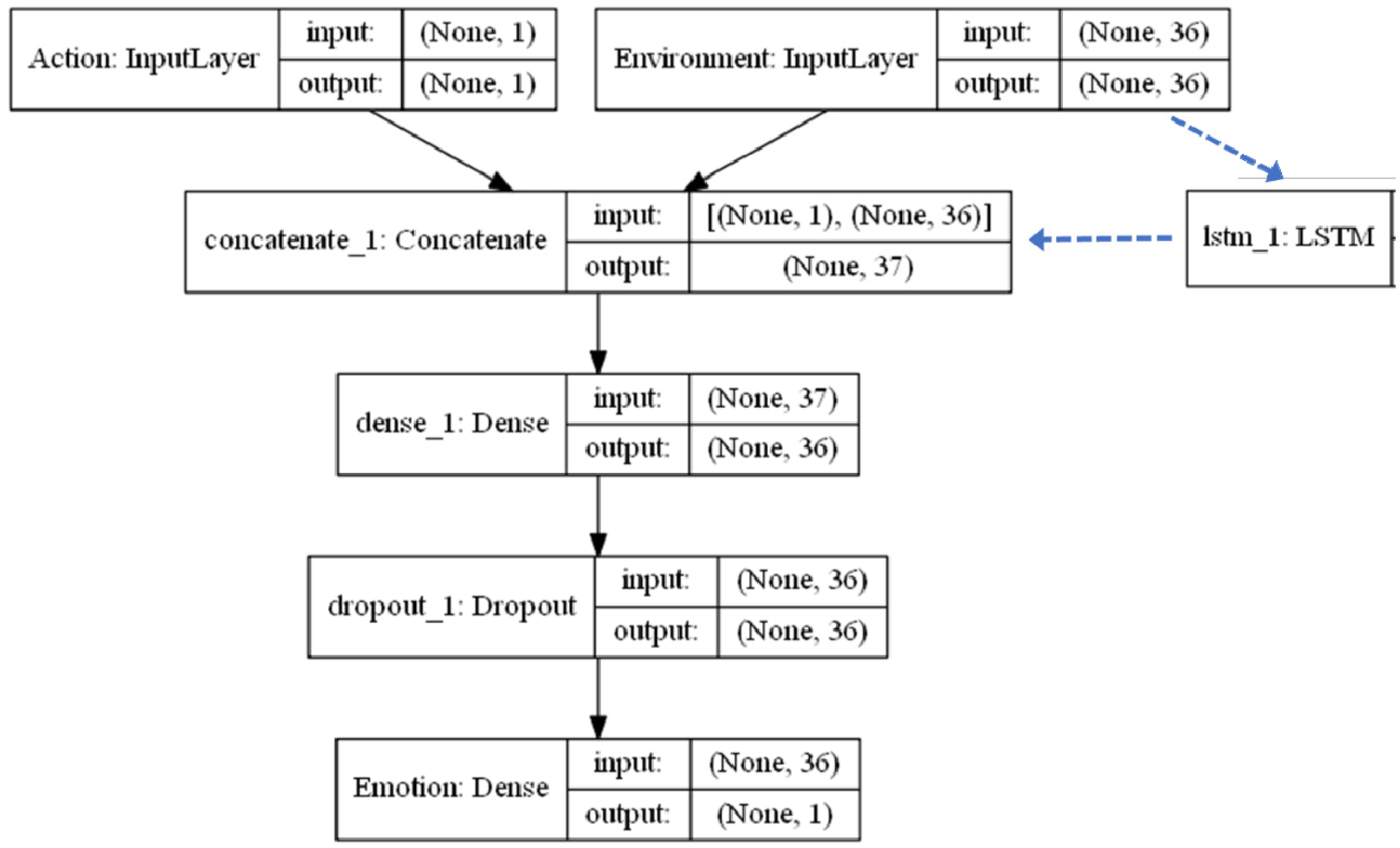
2.2. Simulation Architecture
- Environment congruent response;
- Environment incongruent response;
- Environment random response;
- Environment congruent some percentage of time (25%, 50%, 75%), else random;
- Environment congruent after persistence (same agent action 3 times);
- Environment congruent above thresholds (e.g., >0.7 or <0.3).
2.3. Experimental Design
3. Results
3.1. Main Results
3.2. Effects of Environmental Noise
3.3. Extending the Maximum Iteration Limit
3.4. Algorithmic Analysis
4. Discussion
4.1. Summary of Key Findings
- Altering the environment, while holding the robot agent constant, can alter the robot’s behavior and learning patterns (Table 2). In particular, certain environments were notably better in producing stable behavioral learning convergence, whereas others produced only chaotic behavior. This appears to support our primary hypothesis from Section 1.2.
- For congruent response environments, it is better to utilize global information. For incongruent response environments, it is better to use more local information near the focal point of the visual field. This can be seen in the interaction patterns between the environmental perception and environmental setup parameters in Table 2. In layman’s terms, one could perhaps think of this as a greater necessity of minimizing distractions in incongruent environments.
- The robot agent was much more effective at learning how to respond using environmental deltas (difference of the current state from the previous state), rather than the absolute environmental states themselves (current information only), as shown in Table 2. In other words, a Markovian approach seemed more effective.
- These effects are dependent on the robot agent having some sort of “goal”, even just a simple goal like maximizing their positive emotion level (Table A1).
- In terms of neural networks, MLPs in general performed better than RNNs. This should be taken with caution, however. That may or may not be true, however, in more complex sensory environments.
- Environmental noise has a direct effect on this. Too much noise in the environmental response (e.g., measurement noise from its own sensors) disrupts the agent’s ability to achieve stable learning convergence (Table 6). Accounting for environmental noise appears to be an important component for modeling agent learning in a social environment.
- Extending the maximum iteration steps to a higher limit did not appear to alter the above patterns (Table 7).
4.2. HRI Implications
4.3. Limitations
4.4. Future Work
- Implementing the Simulation Model on the Physical Robotic Face: Since the agent-based simulation is based on data from actual robotic face HRI interaction experiments, it could be ported back to the physical robot for future HRI studies to compare the simulation with physical reality.
- Exploring Other Neural Network Architectures: In particular, as the main sensory mode here is visual, it could be interesting to explore the use of convolutional neural networks, especially with the full-scale visual images. In the same sense, adding autoencoders may be useful to compress information in more complex sensory environments.
- Exploring Other Environmental Setups: This might entail adding additional variables to define the environment, or exploring larger state spaces or action spaces. More complex variations of congruence/incongruence could be implemented. Additionally, other types of agent goals could be modeled.
- Learned Attention Parameters: The parameters of the attentional mechanism could be learned from interaction with the environment, rather than static pre-scripted settings used here.
- Exploring Instinctive Behaviors: This could be accomplished by differentially “weighting” the connections between certain actions and affective states at the start of training, by heavily weighting them closer to 1. The weights are currently initialized all the same.
- Exploring the Effects of Cognitive Dissonance: This could be defined as when the difference between the predicted next emotion and actual next emotion exceeds some threshold. In other words, when the agent expects the environment to respond in one way, but it instead responds completely differently.
- Conscious vs. Automatic Response Mechanisms: As mentioned in the introduction, the simulation described here could be expanded to explore something akin to behavior-based approaches [8,9], but geared toward personality traits. This relates to the ongoing debate strong vs. weak AI, and whether overtly engineered systems capable of “conscious thought” are necessary for intelligent behavior [64].
- Failure Response: A critical issue in real-world interactive systems is the ability to respond to “failures” that cause the system to crash, such as some event outside the bounds of expected behavior occurring [73]. For example, this was a major challenge for the robotic face art museum deployment shown in Figure 1 during unconstrained human–robot interaction. Patterns of convergence/deconvergence in social simulations may shed light on this issue.
- Approach/Avoidance Behaviors: As mentioned in Section 4.2, similar simplified models for robot control have been developed for approach/avoidance in a number of studies [69,70]. One potentially interesting alternative to the convergence-based metric we used here would be a performance metric based on exhibited approach/avoidance behaviors relative to some simulated social stimuli.
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agent Goal Type | Env Learn Type | NN Type | Environment Setup | Env Perception | Init Error | Final Error | Converge Step | Deconverge Cnt | Program RunTime |
|---|---|---|---|---|---|---|---|---|---|
| None | States | MLP | Incongruent | Global | 0.60687 | 0.00100 | 990.2 | 132.7 | 1.51 |
| None | States | MLP | Incongruent | Local | 0.80881 | 0.00186 | 997.6 | 171.3 | 1.47 |
| None | States | MLP | Congruent | Global | 0.50813 | 0.00611 | 996.5 | 132.5 | 1.50 |
| None | States | MLP | Congruent | Local | 0.61027 | 0.00260 | 998.4 | 137.3 | 1.47 |
| None | States | MLP | Random | Global | 0.70943 | 0.00137 | 992.8 | 130.9 | 1.50 |
| None | States | MLP | Random | Local | 0.83843 | 0.00237 | 996.8 | 153.5 | 1.47 |
| None | States | RNN | Incongruent | Global | 0.22351 | 0.00031 | 980.4 | 65.3 | 20.66 |
| None | States | RNN | Incongruent | Local | 0.35286 | 0.00118 | 998.5 | 193.4 | 20.62 |
| None | States | RNN | Congruent | Global | 0.33759 | 0.00408 | 993.9 | 111.2 | 20.64 |
| None | States | RNN | Congruent | Local | 0.34856 | 0.00671 | 997.5 | 128.3 | 20.64 |
| None | States | RNN | Random | Global | 0.23767 | 0.00052 | 978.1 | 76.8 | 20.67 |
| None | States | RNN | Random | Local | 0.34436 | 0.00180 | 998.0 | 184.5 | 20.67 |
| None | Deltas | MLP | Incongruent | Global | 0.35786 | 0.00114 | 994.8 | 146.6 | 1.50 |
| None | Deltas | MLP | Incongruent | Local | 0.26401 | 0.00304 | 998.7 | 153.6 | 1.48 |
| None | Deltas | MLP | Congruent | Global | 0.40878 | 0.00170 | 996.7 | 132.0 | 1.50 |
| None | Deltas | MLP | Congruent | Local | 0.22136 | 0.00838 | 996.1 | 138.3 | 1.48 |
| None | Deltas | MLP | Random | Global | 0.31946 | 0.00113 | 997.1 | 144.4 | 1.49 |
| None | Deltas | MLP | Random | Local | 0.27330 | 0.00259 | 999.4 | 154.3 | 1.48 |
| None | Deltas | RNN | Incongruent | Global | 0.34608 | 0.00310 | 994.5 | 135.2 | 20.66 |
| None | Deltas | RNN | Incongruent | Local | 0.30158 | 0.00143 | 997.4 | 178.3 | 20.67 |
| None | Deltas | RNN | Congruent | Global | 0.24657 | 0.00077 | 994.9 | 111.5 | 20.72 |
| None | Deltas | RNN | Congruent | Local | 0.26918 | 0.00891 | 996.3 | 132.4 | 20.63 |
| None | Deltas | RNN | Random | Global | 0.34087 | 0.00046 | 989.6 | 129.2 | 20.68 |
| None | Deltas | RNN | Random | Local | 0.26489 | 0.00281 | 999.3 | 186.3 | 20.57 |
| Diff Neutral | States | MLP | Incongruent | Global | 1.05690 | 0.00259 | 981.8 | 124.1 | 1.50 |
| Diff Neutral | States | MLP | Incongruent | Local | 0.95328 | 0.00895 | 975.3 | 102.6 | 1.46 |
| Diff Neutral | States | MLP | Congruent | Global | 0.62204 | 0.00335 | 998.3 | 118.6 | 1.48 |
| Diff Neutral | States | MLP | Congruent | Local | 0.69515 | 0.01212 | 998.8 | 102.5 | 1.46 |
| Diff Neutral | States | MLP | Random | Global | 1.01896 | 0.00138 | 995.6 | 137.7 | 1.49 |
| Diff Neutral | States | MLP | Random | Local | 1.12872 | 0.00155 | 997.8 | 158.1 | 1.47 |
| Diff Neutral | States | RNN | Incongruent | Global | 0.42703 | 0.00315 | 994.5 | 111.8 | 20.67 |
| Diff Neutral | States | RNN | Incongruent | Local | 0.73010 | 0.00413 | 997.3 | 141.3 | 20.64 |
| Diff Neutral | States | RNN | Congruent | Global | 0.63140 | 0.00480 | 997.7 | 119.9 | 20.70 |
| Diff Neutral | States | RNN | Congruent | Local | 0.49112 | 0.00277 | 998.0 | 130.6 | 20.65 |
| Diff Neutral | States | RNN | Random | Global | 0.49125 | 0.00047 | 983.7 | 84.1 | 20.66 |
| Diff Neutral | States | RNN | Random | Local | 0.45876 | 0.00099 | 998.0 | 192.8 | 20.69 |
| Diff Neutral | Deltas | MLP | Incongruent | Global | 0.62197 | 0.00027 | 956.5 | 61.3 | 1.49 |
| Diff Neutral | Deltas | MLP | Incongruent | Local | 0.55085 | 0.00091 | 975.4 | 56.7 | 1.46 |
| Diff Neutral | Deltas | MLP | Congruent | Global | 0.55478 | 0.00187 | 981.6 | 53.1 | 1.49 |
| Diff Neutral | Deltas | MLP | Congruent | Local | 0.92185 | 0.00182 | 980.5 | 50.8 | 1.46 |
| Diff Neutral | Deltas | MLP | Random | Global | 0.76580 | 0.00121 | 995.9 | 142.0 | 1.49 |
| Diff Neutral | Deltas | MLP | Random | Local | 0.67409 | 0.00378 | 999.0 | 137.1 | 1.47 |
| Diff Neutral | Deltas | RNN | Incongruent | Global | 0.51839 | 0.00395 | 983.6 | 123.1 | 20.67 |
| Diff Neutral | Deltas | RNN | Incongruent | Local | 0.46090 | 0.00613 | 997.6 | 128.9 | 20.64 |
| Diff Neutral | Deltas | RNN | Congruent | Global | 0.59646 | 0.00454 | 996.2 | 146.2 | 20.81 |
| Diff Neutral | Deltas | RNN | Congruent | Local | 0.52317 | 0.00321 | 998.6 | 134.2 | 20.63 |
| Diff Neutral | Deltas | RNN | Random | Global | 0.41503 | 0.00085 | 995.0 | 137.0 | 20.70 |
| Diff Neutral | Deltas | RNN | Random | Local | 0.45784 | 0.00240 | 999.7 | 177.1 | 20.63 |
| Max Pos | States | MLP | Incongruent | Global | 0.93260 | 0.00050 | 692.2 | 103.0 | 1.49 |
| Max Pos | States | MLP | Incongruent | Local | 0.81140 | 0.00090 | 806.5 | 114.3 | 1.47 |
| Max Pos | States | MLP | Congruent | Global | 0.74902 | 0.00158 | 848.2 | 125.8 | 1.50 |
| Max Pos | States | MLP | Congruent | Local | 0.61600 | 0.00252 | 919.2 | 140.8 | 1.47 |
| Max Pos | States | MLP | Random | Global | 1.07642 | 0.00212 | 996.7 | 161.1 | 1.50 |
| Max Pos | States | MLP | Random | Local | 0.77879 | 0.00235 | 998.4 | 161.5 | 1.47 |
| Max Pos | States | RNN | Incongruent | Global | 0.25909 | 0.00020 | 908.5 | 94.9 | 20.59 |
| Max Pos | States | RNN | Incongruent | Local | 0.29707 | 0.00020 | 847.5 | 111.3 | 140.73 |
| Max Pos | States | RNN | Congruent | Global | 0.29620 | 0.00046 | 837.9 | 93.4 | 20.66 |
| Max Pos | States | RNN | Congruent | Local | 0.45748 | 0.00055 | 851.1 | 112.2 | 20.56 |
| Max Pos | States | RNN | Random | Global | 0.31244 | 0.00059 | 988.6 | 109.2 | 20.70 |
| Max Pos | States | RNN | Random | Local | 0.31294 | 0.00149 | 998.7 | 189.2 | 20.64 |
| Max Pos | Deltas | MLP | Incongruent | Global | 0.38212 | 0.00174 | 623.0 | 89.5 | 1.49 |
| Max Pos | Deltas | MLP | Incongruent | Local | 0.29870 | 0.00440 | 421.3 | 28.3 | 1.47 |
| Max Pos | Deltas | MLP | Congruent | Global | 0.27035 | 0.00038 | 481.6 | 45.4 | 1.49 |
| Max Pos | Deltas | MLP | Congruent | Local | 0.42274 | 0.01899 | 663.2 | 64.9 | 1.46 |
| Max Pos | Deltas | MLP | Random | Global | 0.25289 | 0.00311 | 999.4 | 164.9 | 1.50 |
| Max Pos | Deltas | MLP | Random | Local | 0.28992 | 0.01572 | 999.6 | 118.4 | 1.47 |
| Max Pos | Deltas | RNN | Incongruent | Global | 0.26123 | 0.00058 | 821.3 | 110.2 | 20.55 |
| Max Pos | Deltas | RNN | Incongruent | Local | 0.32758 | 0.00077 | 777.0 | 118.8 | 20.49 |
| Max Pos | Deltas | RNN | Congruent | Global | 0.37378 | 0.00292 | 757.8 | 100.3 | 20.55 |
| Max Pos | Deltas | RNN | Congruent | Local | 0.35068 | 0.00079 | 881.2 | 122.2 | 20.49 |
| Max Pos | Deltas | RNN | Random | Global | 0.45440 | 0.00126 | 997.9 | 166.4 | 20.57 |
| Max Pos | Deltas | RNN | Random | Local | 0.43835 | 0.00340 | 999.5 | 166.9 | 20.50 |
References
- Dexter, J.P.; Prabakaran, S.; Gunawardena, J. A complex hierarchy of avoidance behaviors in a single-cell eukaryote. Curr. Biol. 2019, 29, 4323–4329. [Google Scholar] [CrossRef]
- Robert, L. Personality in the human robot interaction literature: A review and brief critique. In Proceedings of the 24th Americas Conference on Information Systems, New Orleans, LA, USA, 16–18 August 2018; pp. 16–18. [Google Scholar]
- Calvo, R.; D’Mello, S.; Gratch, J.; Kappas, A.; Lisetti, C.; Hudlicka, E. Why and how to build emotion-based agent architectures. In The Oxford Handbook of Affective Computing; Oxford University Press: New York, NY, USA, 2015; p. 94. [Google Scholar]
- Bennett, C.C.; Šabanović, S. Deriving minimal features for human-like facial expressions in robotic faces. Int. J. Soc. Robot. 2014, 6, 367–381. [Google Scholar] [CrossRef]
- Bennett, C.C.; Šabanović, S. The effects of culture and context on perceptions of robotic facial expressions. Interact. Stud. 2015, 16, 272–302. [Google Scholar] [CrossRef]
- Bennett, C.C. Robotic Faces: Exploring Dynamical Patterns of Social Interaction between Humans and Robots. Ph.D. Thesis, Indiana University, Bloomington, IN, USA, May 2015. [Google Scholar]
- Hönemann, A.; Bennett, C.; Wagner, P.; Sabanovic, S. Audio-visual synthesized attitudes presented by the German speaking robot SMiRAE. In Proceedings of the 15th International Conference on Auditory-Visual Speech Processing, Melbourne, Australia, 10–11 August 2019. [Google Scholar]
- Brooks, R.A. From earwigs to humans. Robot. Auton. Syst. 1997, 20, 291–304. [Google Scholar] [CrossRef]
- Sun, R. Cognition and Multi-Agent Interaction: From Cognitive Modeling to Social Simulation; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Masterson, J.F. The Search for the Real Self: Unmasking the Personality Disorders of Our Age; Taylor & Francis: New York, NY, USA, 1988. [Google Scholar]
- Lieb, K.; Zanarini, M.C.; Schmahl, C.; Linehan, M.M.; Bohus, M. Borderline personality disorder. Lancet 2004, 364, 453–461. [Google Scholar] [CrossRef]
- Ortony, A.; Clore, G.L.; Collins, A.J. The Cognitive Structure of Emotions; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Scherer, K.R.; Schorr, A.; Johnstone, T. Appraisal Processes in Emotion: Theory, Methods, Research; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Murphy, R.; Lisetti, C.; Tardif, R.; Irish, L.; Gage, A. Emotion-based control of cooperating heterogeneous mobile robots. IEEE Trans. Robot. Autom. 2002, 18, 744–757. [Google Scholar] [CrossRef]
- Tonkin, M.; Vitale, J.; Herse, S.; Williams, M.A.; Judge, W.; Wang, X. Design methodology for the UX of HRI: A field study of a commercial social robot at an airport. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), Chicago, IL, USA, 5–8 March 2018; pp. 407–415. [Google Scholar]
- Cruz-Maya, A.; Tapus, A. Influence of user’s personality on task execution when reminded by a robot. In Proceedings of the International Conference on Social Robotics (ICSR), Kansas City, MO, USA, 1–3 November 2016; pp. 829–838. [Google Scholar]
- Gockley, R.; Mataric, M.J. Encouraging physical therapy compliance with a hands-Off mobile robot. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), Salt Lake City, UT, USA, 2–3 March 2006; pp. 150–155. [Google Scholar]
- Kimoto, M.; Iio, T.; Shiomi, M.; Tanev, I.; Shimohara, K.; Hagita, N. Relationship between personality and robots’ interaction strategies in object reference conversations. In Proceedings of the Second International Conference on Electronics and Software Science (ICESS2016), Takamatsu, Japan, 14–16 November 2016; pp. 128–136. [Google Scholar]
- Lee, K.M.; Peng, W.; Jin, S.-A.; Yan, C. Can robots manifest personality?: An empirical test of personality recognition, social responses, and social presence in human–robot interaction. J. Commun. 2006, 56, 754–772. [Google Scholar] [CrossRef]
- Looije, R.; Neerincx, M.A.; Cnossen, F. Persuasive robotic assistant for health self-management of older adults: Design and evaluation of social behaviors. Int. J. Hum. Comput. Stud. 2010, 68, 386–397. [Google Scholar] [CrossRef]
- Park, E.; Jin, D.; Del Pobil, A.P. The law of attraction in human-robot interaction. Int. J. Adv. Robot. Syst. 2012, 9, 35. [Google Scholar] [CrossRef]
- Sandoval, E.B.; Brandstetter, J.; Obaid, M.; Bartneck, C. Reciprocity in human-robot interaction: A quantitative approach through the prisoner’s dilemma and the ultimatum game. Int. J. Soc. Robot. 2016, 8, 303–317. [Google Scholar] [CrossRef]
- Bartneck, D.; Kulic, E.; Croft, M.; Zoghbi, S. Measurement instruments for the anthropomorphism, animacy, likeability, per-ceived intelligence, and perceived safety of robots. Int. J. Soc. Robot. 2009, 1, 71–81. [Google Scholar] [CrossRef]
- Santamaria, T.; Nathan-Roberts, D. Personality measurement and design in human-robot interaction: A systematic and critical review. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2017, 61, 853–857. [Google Scholar] [CrossRef]
- Grollman, D.H. Avoiding the content treadmill for robot personalities. Int. J. Soc. Robot. 2017, 10, 225–234. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Unmasking the Face: A Guide to Recognizing Emotions from Facial Clues; Malor Books: Los Altos, CA, USA, 2003. [Google Scholar]
- Russell, J.A.; Fernández-Dols, J.M. The Psychology of Facial Expression; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Breazeal, C. Emotion and sociable humanoid robots. Int. J. Hum. Comput. Stud. 2003, 59, 119–155. [Google Scholar] [CrossRef]
- Han, M.-J.; Lin, C.-H.; Song, K.-T. Robotic emotional expression generation based on mood transition and personality model. IEEE Trans. Cybern. 2012, 43, 1290–1303. [Google Scholar] [CrossRef] [PubMed]
- Ilies, R.; Judge, T.A. Understanding the dynamic relationships among personality, mood, and job satisfaction: A field experience sampling study. Organ. Behav. Hum. Decis. Process. 2002, 89, 1119–1139. [Google Scholar] [CrossRef]
- Meyer, G.J.; Shack, J.R. Structural convergence of mood and personality: Evidence for old and new directions. J. Personal. Soc. Psychol. 1989, 57, 691. [Google Scholar] [CrossRef]
- Van Steenbergen, H.; Band, G.P.; Hommel, B. In the mood for adaptation: How affect regulates conflict-driven control. Psychol. Sci. 2010, 21, 1629–1634. [Google Scholar] [CrossRef] [PubMed]
- Ivanovic, M.; Budimac, Z.; Radovanovic, M.; Kurbalija, V.; Dai, W.; Bădică, C.; Colhon, M.; Ninkovic, S.; Mitrovic, D. Emotional agents—state of the art and applications. Comput. Sci. Inf. Syst. 2015, 12, 1121–1148. [Google Scholar] [CrossRef]
- Bosse, T.; Duell, R.; Memon, Z.A.; Treur, J.; Van Der Wal, C.N. Agent-based modeling of emotion contagion in groups. Cogn. Comput. 2014, 7, 111–136. [Google Scholar] [CrossRef]
- Evers, E.; De Vries, H.; Spruijt, B.M.; Sterck, E.H.M. The EMO-Model: An agent-based model of primate social behavior regulated by two emotional dimensions, anxiety-FEAR and satisfaction-LIKE. PLoS ONE 2014, 9, e87955. [Google Scholar] [CrossRef]
- Shen, Z.; Miao, C. An Emotional Agent in Virtual Learning Environment. In Transactions on Edutainment IV; Springer: Berlin/Heidelberg, Germany, 2010; pp. 22–33. [Google Scholar]
- Puică, M.A.; Florea, A.M. Emotional belief-desire-intention agent model: Previous work and proposed architecture. Int. J. Adv. Res. Artif. Intell. 2013, 2, 1–8. [Google Scholar]
- Bosse, T.; De Lange, F.P. Development of Virtual Agents with a Theory of Emotion Regulation. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Sydney, Australia, 9–12 December 2008; Volume 2, pp. 461–468. [Google Scholar]
- Gratch, J. The social psychology of human-agent interaction. In Proceedings of the 7th International Conference on Human-Agent Interaction (HAI), Kyoto, Japan, 6–10 October 2019; p. 1. [Google Scholar]
- MacDorman, K.F.; Chattopadhyay, D. Reducing consistency in human realism increases the uncanny valley effect; increasing category uncertainty does not. Cognition 2016, 146, 190–205. [Google Scholar] [CrossRef]
- Dang, T.H.H.; Hutzler, G.; Hoppenot, P. Emotion Modeling for Intelligent Agents—Towards a Unifying Framework. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Lyon, France, 22–27 August 2011; Volume 3, pp. 70–73. [Google Scholar]
- Laird, J.E. The Soar Cognitive Architecture; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Šabanović, S. Robots in society, society in robots. Int. J. Soc. Robot. 2010, 2, 439–450. [Google Scholar] [CrossRef]
- Sabanovic, S.; Michalowski, M.; Simmons, R. Robots in the wild: Observing human-robot social interaction outside the lab. In Proceedings of the 9th IEEE International Workshop on Advanced Motion Control, Istanbul, Turkey, 27–29 March 2006; pp. 596–601. [Google Scholar] [CrossRef]
- Jung, M.; Hinds, P. Robots in the wild: A time for more robust theories of human-robot interaction. ACM Trans. Hum. Robot. Interact. 2018, 7, 2. [Google Scholar] [CrossRef]
- Cass, A.G.; Striegnitz, K.; Webb, N.; Yu, V. Exposing real-world challenges using HRI in the wild. In Proceedings of the 4th Workshop on Public Space Human-Robot Interaction at the International Conference on Human-Computer Interaction with Mobile Devices and Services, Barcelona, Spain, 3 September 2018. [Google Scholar]
- Šabanović, S.; Bennett, C.C.; Lee, H.R. Towards culturally robust robots: A critical social perspective on robotics and culture. In Proceedings of the HRI Workshop on Culture-Aware Robotics, Bielefeld, Germany, 3–6 March 2014. [Google Scholar]
- Schneider, D.; Lam, R.; Bayliss, A.P.; Dux, P.E. Cognitive load disrupts implicit theory-of-mind processing. Psychol. Sci. 2012, 23, 842–847. [Google Scholar] [CrossRef]
- Spunt, R.P.; Lieberman, M.D. The busy social brain: Evidence for automaticity and control in the neural systems supporting social cognition and action understanding. Psychol. Sci. 2013, 24, 80–86. [Google Scholar] [CrossRef]
- Paas, F.; Van Gog, T.; Sweller, J. Cognitive load theory: New conceptualizations, specifications, and integrated research perspectives. Educ. Psychol. Rev. 2010, 22, 115–121. [Google Scholar] [CrossRef]
- Smith, S.M.; Petty, R.E. Personality moderators of mood congruency effects on cognition: The role of self-esteem and negative mood regulation. J. Personal. Soc. Psychol. 1995, 68, 1092. [Google Scholar] [CrossRef]
- Robins, B.; Dautenhahn, K.; Te Boekhorst, R.; Nehaniv, C.L. Behaviour delay and robot expressiveness in child-robot inter-actions: A user study on interaction kinesics. In Proceedings of the ACM/IEEE international conference on Human robot Iinteraction (HRI), Amsterdam, The Netherlands, 12–15 March 2008; pp. 17–24. [Google Scholar]
- Barsalou, L.W.; Breazeal, C.; Smith, L.B. Cognition as coordinated non-cognition. Cogn. Process. 2007, 8, 79–91. [Google Scholar] [CrossRef]
- Beer, R.D. Dynamical approaches to cognitive science. Trends Cogn. Sci. 2000, 4, 91–99. [Google Scholar] [CrossRef]
- Vallacher, R.R.; Read, S.J.; Nowak, A. The dynamical perspective in personality and social psychology. Pers. Soc. Psychol. Rev. 2002, 6, 264–273. [Google Scholar] [CrossRef]
- Kastner, S.; De Weerd, P.; Desimone, R.; Ungerleider, L.G. Mechanisms of directed attention in the human extrastriate cortex as revealed by functional MRI. Science 1998, 282, 108–111. [Google Scholar] [CrossRef] [PubMed]
- Land, M.F.; Nilsson, D.E. Animal Eyes; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Movellan, J.R.; Tanaka, F.; Fortenberry, B.; Aisaka, K. The RUBI/QRIO project: Origins, principles, and first steps. In Proceedings of the IEEE International Conference on Development and Learning (ICDL), Osaka, Japan, 19–21 July 2005; pp. 80–86. [Google Scholar]
- Bennett, C.C.; Hauser, K. Artificial intelligence framework for simulating clinical decision-making: A Markov decision process approach. Artif. Intell. Med. 2013, 57, 9–19. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley and Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Shannon, C.E. The mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Clark, A. Whatever next? Predictive brains, situated agents, and the future of cognitive science. Behav. Brain Sci. 2013, 36, 181–204. [Google Scholar] [CrossRef]
- Hosoya, T.; Baccus, S.A.; Meister, M. Dynamic predictive coding by the retina. Nature 2005, 436, 71–77. [Google Scholar] [CrossRef]
- Broz, F.; Nehaniv, C.L.; Kose, H.; Dautenhahn, K. Interaction histories and short-term memory: Enactive development of turn-taking behaviours in a childlike humanoid robot. Philosophies 2019, 4, 26. [Google Scholar] [CrossRef]
- Bashir, F.I.; Khokhar, A.A.; Schonfeld, D. Object trajectory-based activity classification and recognition using hidden Markov Models. IEEE Trans. Image Process. 2007, 16, 1912–1919. [Google Scholar] [CrossRef]
- Xia, L.; Chen, C.-C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Lones, J.; Lewis, M.; Cañamero, L.; Lewis, M. Hormonal modulation of interaction between autonomous agents. In Proceedings of the 4th International Conference on Development and Learning and on Epigenetic Robotics, Genoa, Italy, 13–16 October 2014; pp. 402–407. [Google Scholar]
- Belkaid, M.; Cuperlier, N.; Gaussier, P. Emotional modulation of peripersonal space as a way to represent reachable and comfort areas. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 353–359. [Google Scholar]
- Grant, B.F.; Chou, S.P.; Goldstein, R.B.; Huang, B.; Stinson, F.S.; Saha, T.D.; Smith, S.M.; Dawson, D.A.; Pulay, A.J.; Pickering, R.P.; et al. Prevalence, correlates, disability, and comorbidity of DSM-IV Borderline Personality Disorder: Results from the Wave 2 National Epidemiologic Survey on Alcohol and Related Conditions. J. Clin. Psychiatry 2008, 69, 533–545. [Google Scholar] [CrossRef]
- Fonagy, P. Attachment and Borderline Personality Disorder. J. Am. Psychoanal. Assoc. 2000, 48, 1129–1146. [Google Scholar] [CrossRef]
- Honi, S.; Oron-Gilad, T. Understanding and resolving failures in human-robot interaction: Literature review and model development. Front. Psychol. 2018, 9, 861. [Google Scholar] [CrossRef]




| Type | Parameter | Programming Code Variable Name | Brief Definition | Possible Values | Varied in Simulation |
|---|---|---|---|---|---|
| Agent | Affective State | emot | Agent’s internal affective state | 0–1 scale | |
| Agent | Agent Goal Type | agent_goal_type | Flag to control type of agent goal | Discrete | Y |
| Agent | Actions | action_list | Possible agent actions | Discrete | |
| Environment | Env Setup | congruent_switch | Determines how environment responds | Discrete | Y |
| Environment | Env Step Size | env_step_size | How quickly environment responds | 0–1 scale | |
| Environment | Env Noise | env_noise | How much stochastic noise there is in env response | 0–1 scale | Y |
| Environment | Env State | states | Represents strength of stimuli (for each point in env grid) | 0–1 scale | |
| Environment | Env Deltas | deltas | Change in env state from previous time to next | 0–1 scale | |
| Perception | Env Learning Type | env_learn_type | Controls how agent learns from sensory info | Discrete | Y |
| Perception | Env Perception Model | local_switch | Whether agent uses only local or global sensory info | Discrete | Y |
| Attention | Attention Decay Rate | att_decay_rate | Controls the rate of attentional decay | Infinite | |
| Attention | Attention Span | att_span | Timer delay before attentional decay kicks in | Infinite | |
| Attention | Dulling Threshold | dull_thresh | Threshold of env change triggering attentional decay | 0–1 scale | |
| Neural Net | NN Type | nn_type | Determines type of neural net to use | Discrete | Y |
| General | Max Iteration Count | max_iter | Maximum number of iterations for simulation | Infinite |
| Env Learn Type | NN Type | Environment Setup | Env Perception | Init Error | Final Error | Converge Step | Deconverge Cnt | Program RunTime |
|---|---|---|---|---|---|---|---|---|
| States | MLP | Incongruent | Global | 0.93260 | 0.00050 | 692.2 | 103.0 | 1.49 |
| Local | 0.81140 | 0.00090 | 806.5 | 114.3 | 1.47 | |||
| Congruent | Global | 0.74902 | 0.00158 | 848.2 | 125.8 | 1.50 | ||
| Local | 0.61600 | 0.00252 | 919.2 | 140.8 | 1.47 | |||
| Random | Global | 1.07642 | 0.00212 | 996.7 | 161.1 | 1.50 | ||
| Local | 0.77879 | 0.00235 | 998.4 | 161.5 | 1.47 | |||
| RNN | Incongruent | Global | 0.25909 | 0.00020 | 908.5 | 94.9 | 20.59 | |
| Local | 0.29707 | 0.00020 | 847.5 | 111.3 | 140.73 | |||
| Congruent | Global | 0.29620 | 0.00046 | 837.9 | 93.4 | 20.66 | ||
| Local | 0.45748 | 0.00055 | 851.1 | 112.2 | 20.56 | |||
| Random | Global | 0.31244 | 0.00059 | 988.6 | 109.2 | 20.70 | ||
| Local | 0.31294 | 0.00149 | 998.7 | 189.2 | 20.64 | |||
| Deltas | MLP | Incongruent | Global | 0.38212 | 0.00174 | 623.0 | 89.5 | 1.49 |
| Local | 0.29870 | 0.00440 | 421.3 | 28.3 | 1.47 | |||
| Congruent | Global | 0.27035 | 0.00038 | 481.6 | 45.4 | 1.49 | ||
| Local | 0.42274 | 0.01899 | 663.2 | 64.9 | 1.46 | |||
| Random | Global | 0.25289 | 0.00311 | 999.4 | 164.9 | 1.50 | ||
| Local | 0.28992 | 0.01572 | 999.6 | 118.4 | 1.47 | |||
| RNN | Incongruent | Global | 0.26123 | 0.00058 | 821.3 | 110.2 | 20.55 | |
| Local | 0.32758 | 0.00077 | 777.0 | 118.8 | 20.49 | |||
| Congruent | Global | 0.37378 | 0.00292 | 757.8 | 100.3 | 20.55 | ||
| Local | 0.35068 | 0.00079 | 881.2 | 122.2 | 20.49 | |||
| Random | Global | 0.45440 | 0.00126 | 997.9 | 166.4 | 20.57 | ||
| Local | 0.43835 | 0.00340 | 999.5 | 166.9 | 20.50 |
| Parameter | Values | Converge Step | Deconverge Cnt |
|---|---|---|---|
| Env Learn Type | States | 891.1 | 126.4 |
| Delta | 785.2 | 108.0 | |
| NN Type | MLP | 787.4 | 109.8 |
| RNN | 888.9 | 124.6 | |
| Environment Setup | Incongruent | 737.2 | 96.3 |
| Congruent | 780.0 | 100.6 | |
| Env Perception | Global | 829.4 | 113.7 |
| Local | 846.9 | 120.7 |
| Parameter | Df | Sum Sq | Mean Sq | F Value | Pr (>F) | Sign. Level | |
|---|---|---|---|---|---|---|---|
| Main Effects | |||||||
| Env.Learn.Type | 1 | 201,8136 | 201,8136 | 23.75 | <0.001 | *** | |
| NN.Type | 1 | 1,853,289 | 1,853,289 | 21.81 | <0.001 | *** | |
| Congruent.Switch | 1 | 8,122,924 | 8,122,924 | 95.58 | <0.001 | *** | |
| Local.Switch | 1 | 55,178 | 55,178 | 0.65 | 0.421 | ||
| Interaction Effects | |||||||
| Env.Learn.Type:NN.Type | 1 | 957,834 | 957,834 | 11.27 | <0.001 | *** | |
| Env.Learn.Type:Congruent.Switch | 1 | 735,081 | 735,081 | 8.65 | 0.003 | ** | |
| NN.Type:Congruent.Switch | 1 | 1,262,596 | 1,262,596 | 14.86 | <0.001 | *** | |
| Env.Learn.Type:Local.Switch | 1 | 9776 | 9776 | 0.12 | 0.735 | ||
| NN.Type:Local.Switch | 1 | 19,313 | 19,313 | 0.23 | 0.634 | ||
| Congruent.Switch:Local.Switch | 1 | 79,877 | 79,877 | 0.94 | 0.333 | ||
| Env.Learn.Type:NN.Type:Congruent.Switch | 1 | 15,8268 | 15,8268 | 1.86 | 0.173 | ||
| Env.Learn.Type:NN.Type:Local.Switch | 1 | 132,167 | 132,167 | 1.56 | 0.213 | ||
| Env.Learn.Type:Congruent.Switch:Local.Switch | 1 | 156,891 | 156,891 | 1.85 | 0.175 | ||
| NN.Type:Congruent.Switch:Local.Switch | 1 | 1442 | 1442 | 0.02 | 0.896 | ||
| Env.Learn.Type:NN.Type:Congruent.Switch:Local.Switch | 1 | 216,495 | 216,495 | 2.55 | 0.111 | ||
| Residuals | 704 | 59,831,846 | 84,988 | ||||
| Parameter | Df | Sum Sq | Mean Sq | F value | Pr (>F) | Sign. Level | |
|---|---|---|---|---|---|---|---|
| Main Effects | |||||||
| Env.Learn.Type | 1 | 60,830 | 60,830 | 27.78 | <0.001 | *** | |
| NN.Type | 1 | 39,043 | 39,043 | 17.83 | <0.001 | *** | |
| Congruent.Switch | 1 | 409,326 | 409,326 | 186.93 | <0.001 | *** | |
| Local.Switch | 1 | 8946 | 8946 | 4.09 | 0.044 | * | |
| Interaction Effects | |||||||
| Env.Learn.Type:NN.Type | 1 | 170,755 | 170,755 | 77.98 | <0.001 | *** | |
| Env.Learn.Type:Congruent.Switch | 1 | 9819 | 9819 | 4.48 | 0.035 | * | |
| NN.Type:Congruent.Switch | 1 | 10,370 | 10,370 | 4.74 | 0.030 | * | |
| Env.Learn.Type:Local.Switch | 1 | 49,601 | 49,601 | 22.65 | <0.001 | *** | |
| NN.Type:Local.Switch | 1 | 53,941 | 53,941 | 24.63 | <0.001 | *** | |
| Congruent.Switch:Local.Switch | 1 | 6593 | 6593 | 3.01 | 0.083 | ||
| Env.Learn.Type:NN.Type:Congruent.Switch | 1 | 4326 | 4326 | 1.98 | 0.160 | ||
| Env.Learn.Type:NN.Type:Local.Switch | 1 | 1181 | 1181 | 0.54 | 0.463 | ||
| Env.Learn.Type:Congruent.Switch:Local.Switch | 1 | 4008 | 4008 | 1.83 | 0.177 | ||
| NN.Type:Congruent.Switch:Local.Switch | 1 | 5038 | 5038 | 2.30 | 0.130 | ||
| Env.Learn.Type:NN.Type:Congruent.Switch:Local.Switch | 1 | 17,751 | 17,751 | 8.11 | 0.005 | ** | |
| Residuals | 704 | 1,541,569 | 2190 | ||||
| Env Learn Type | NN Type | Environment Setup | Env Perception | Env Noise | Init Error | Final Error | Converge Step | Deconverge Cnt | Program RunTime |
|---|---|---|---|---|---|---|---|---|---|
| Deltas | MLP | Incongruent | Local | 0% | 0.38467 | 0.01003 | 401.9 | 30.4 | 1.72 |
| 2% | 0.41105 | 0.01057 | 441.5 | 31.0 | 2.49 | ||||
| 4% | 0.29869 | 0.00141 | 452.4 | 36.1 | 3.31 | ||||
| 6% | 0.40636 | 0.00310 | 540.2 | 43.4 | 4.02 | ||||
| 8% | 0.31083 | 0.00050 | 529.7 | 56.4 | 4.62 | ||||
| 10% | 0.36615 | 0.00212 | 540.1 | 51.2 | 5.50 | ||||
| 12% | 0.33988 | 0.00223 | 557.8 | 46.8 | 6.22 | ||||
| 14% | 0.32184 | 0.01261 | 997.7 | 90.2 | 7.21 | ||||
| 16% | 0.34944 | 0.00567 | 998.7 | 106.2 | 8.04 | ||||
| 18% | 0.39220 | 0.00869 | 999.0 | 105.7 | 8.64 | ||||
| 20% | 0.39526 | 0.01029 | 997.8 | 116.4 | 9.50 | ||||
| 25% | 0.29403 | 0.01630 | 999.9 | 117.4 | 10.30 | ||||
| 30% | 0.28652 | 0.01482 | 999.3 | 114.5 | 11.15 | ||||
| Deltas | MLP | Congruent | Global | 0% | 0.38020 | 0.00908 | 552.3 | 51.3 | 2.09 |
| 2% | 0.31174 | 0.00068 | 448.4 | 41.3 | 2.83 | ||||
| 4% | 0.27282 | 0.00695 | 459.9 | 42.6 | 3.61 | ||||
| 6% | 0.51272 | 0.00131 | 477.4 | 44.6 | 4.46 | ||||
| 8% | 0.32698 | 0.01602 | 624.6 | 64.6 | 5.11 | ||||
| 10% | 0.28824 | 0.00155 | 551.6 | 51.8 | 5.82 | ||||
| 12% | 0.42805 | 0.00704 | 620.2 | 58.3 | 6.61 | ||||
| 14% | 0.29626 | 0.00981 | 992.8 | 97.0 | 7.58 | ||||
| 16% | 0.43348 | 0.02487 | 997.8 | 106.8 | 8.17 | ||||
| 18% | 0.27201 | 0.01394 | 996.4 | 109.0 | 9.19 | ||||
| 20% | 0.27935 | 0.02050 | 997.3 | 115.4 | 9.89 | ||||
| 25% | 0.30008 | 0.05376 | 997.7 | 114.3 | 10.81 | ||||
| 30% | 0.30225 | 0.04410 | 995.5 | 118.4 | 11.62 |
| Env Learn Type | NN Type | Environment Setup | Env Perception | Init Error | Final Error | Converge Step | Deconverge Cnt | Program RunTime |
|---|---|---|---|---|---|---|---|---|
| Deltas | MLP | Incongruent | Local | 0.23043 | 0.00002 | 1437.2 | 176.2 | 12.42 |
| MLP | Congruent | Global | 0.38931 | 0.00002 | 1122.5 | 120.5 | 13.53 | |
| Deltas | RNN | Incongruent | Local | 0.32601 | 0.00129 | 6198.7 | 908.3 | 230.76 |
| RNN | Congruent | Global | 0.38887 | 0.00012 | 6107.4 | 697.5 | 227.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bennett, C.C. Emergent Robotic Personality Traits via Agent-Based Simulation of Abstract Social Environments. Information 2021, 12, 103. https://doi.org/10.3390/info12030103
Bennett CC. Emergent Robotic Personality Traits via Agent-Based Simulation of Abstract Social Environments. Information. 2021; 12(3):103. https://doi.org/10.3390/info12030103
Chicago/Turabian StyleBennett, Casey C. 2021. "Emergent Robotic Personality Traits via Agent-Based Simulation of Abstract Social Environments" Information 12, no. 3: 103. https://doi.org/10.3390/info12030103
APA StyleBennett, C. C. (2021). Emergent Robotic Personality Traits via Agent-Based Simulation of Abstract Social Environments. Information, 12(3), 103. https://doi.org/10.3390/info12030103