
Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic



Abstract
1. Introduction
- The building and annotating of large Arabic emotion and symptom corpora from Twitter.
- Developing a system for monitoring people’s emotions and link these emotions with tweets that mention any of the COVID-19 pandemic symptoms.
2. Related Work
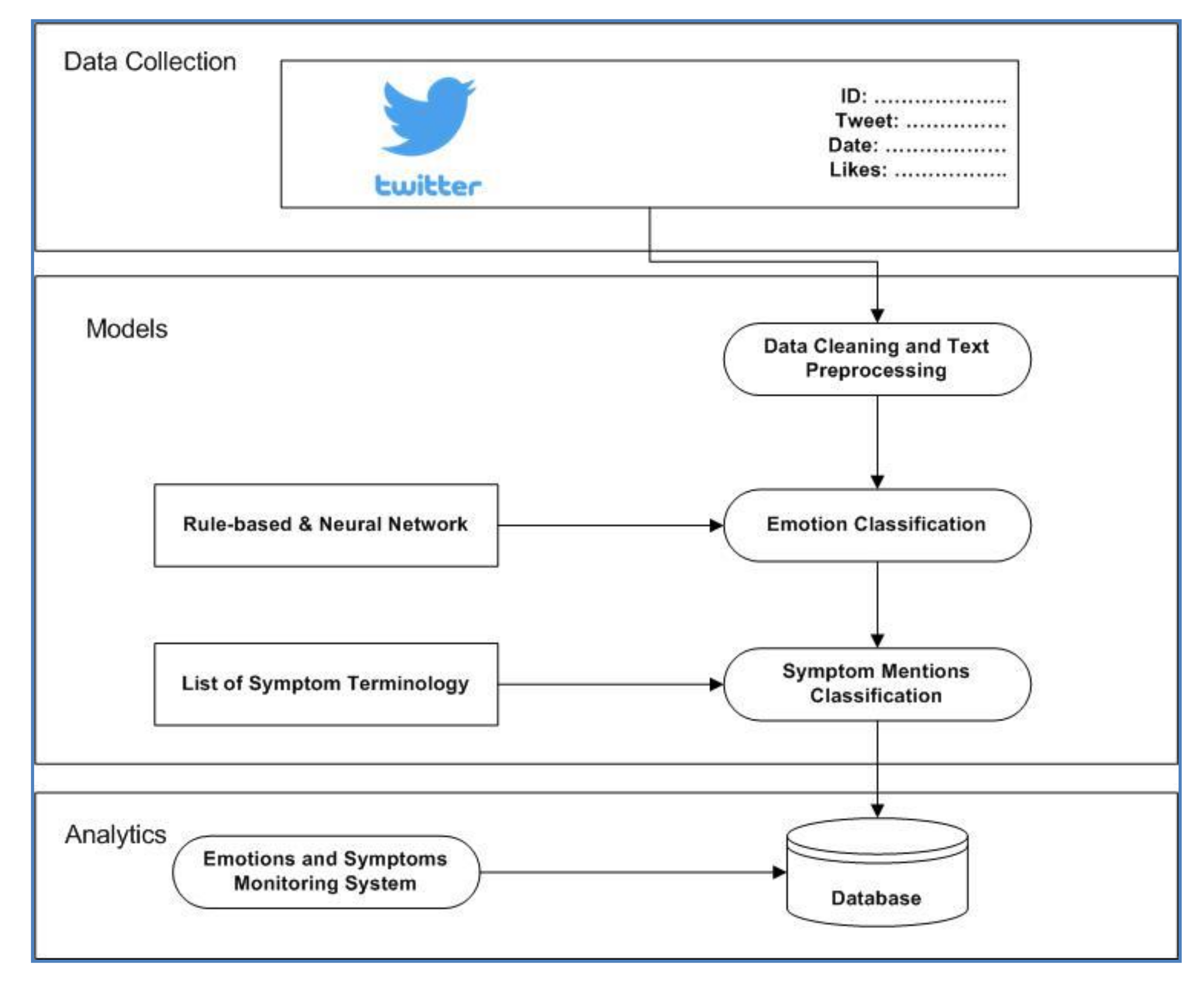
3. Methodology
3.1. Data Collection
3.2. Corpus Statistics
- There was a total of 51,448 hashtags on that day.
- There was a total of 4819 unique hashtags on that day.
- By observing the top hashtags, we found that most of them were from Saudi Arabia where there was the imposition of closing shops and then issuing a curfew in large cities of the Kingdom.
- One day before that date, the Saudi government suspended all domestic flights, buses, taxis, and trains for 14 days.
3.3. Data Preprocessing
3.4. Emotion Tweets Annotation
3.4.1. Rule-based Emotion Annotation
3.4.2. Automatic Emotion Annotation
| Algorithm 1 Automatic Emotion Annotation Algorithm |
| Data: (LabeledData (300K Tweets), UnlabeledData (5.2M Tweets)) Result: NewLabeledData TrainingSet = LabeledData; UnlabeledData = UnlabeledData; NewLabeledData; ThresholdValue = 0.8 //training fastText model on TrainingSet fastTextModel = TrainClassifier (TrainingSet); while (t ≤ UnlabeledData.size()) do //predict most likely emotion classes of t from fastTextModel emotionClass = fastTextModel.predict(UnlabeledData(t)); //predict most likely emotion probabilities of t from fastTextModel emotionClassProbability = fastTextModel.predict-prob(UnlabeledData(t)); if (emotionClassProbability ≥ ThresholdV alue) then NewLabeledData.Add(t and emotionClass); End end |
3.5. Symptom Tweets Annotation
- Fever
- Tiredness
- Dry cough
- Loss of smell or taste
- Pains and aches
- Headache
- Sore throat
- Diarrhea
- Conjunctivitis
- Rash on skin
- Discoloration of fingers or toes
- Difficulty breathing or shortness of breath
- Chest pain or pressure
- Loss of speech or movement
3.6. Deep Learning Architecture
3.6.1. Embedding Layer
3.6.2. LSTM Layer
3.6.3. Dropout Layer
3.6.4. Fully Connected Layer
3.6.5. Loss Layer
4. Experiments
4.1. Dataset
4.2. Experimental Setup
4.3. Evaluation Metrices
4.4. Emotion Classification Results
4.4.1. Rule-Based Classification Results
4.4.2. Automatic Classification Results
4.5. Symptom Classification Results
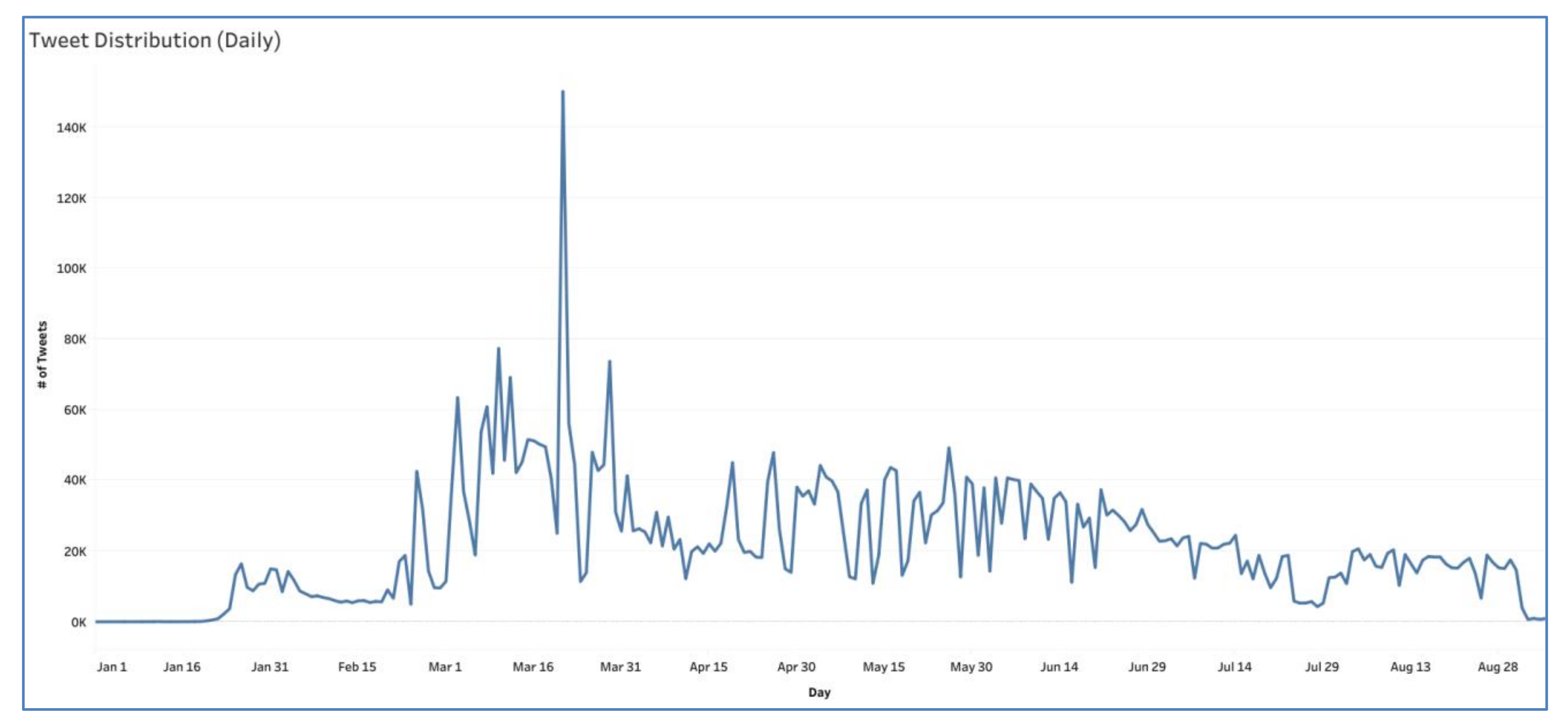
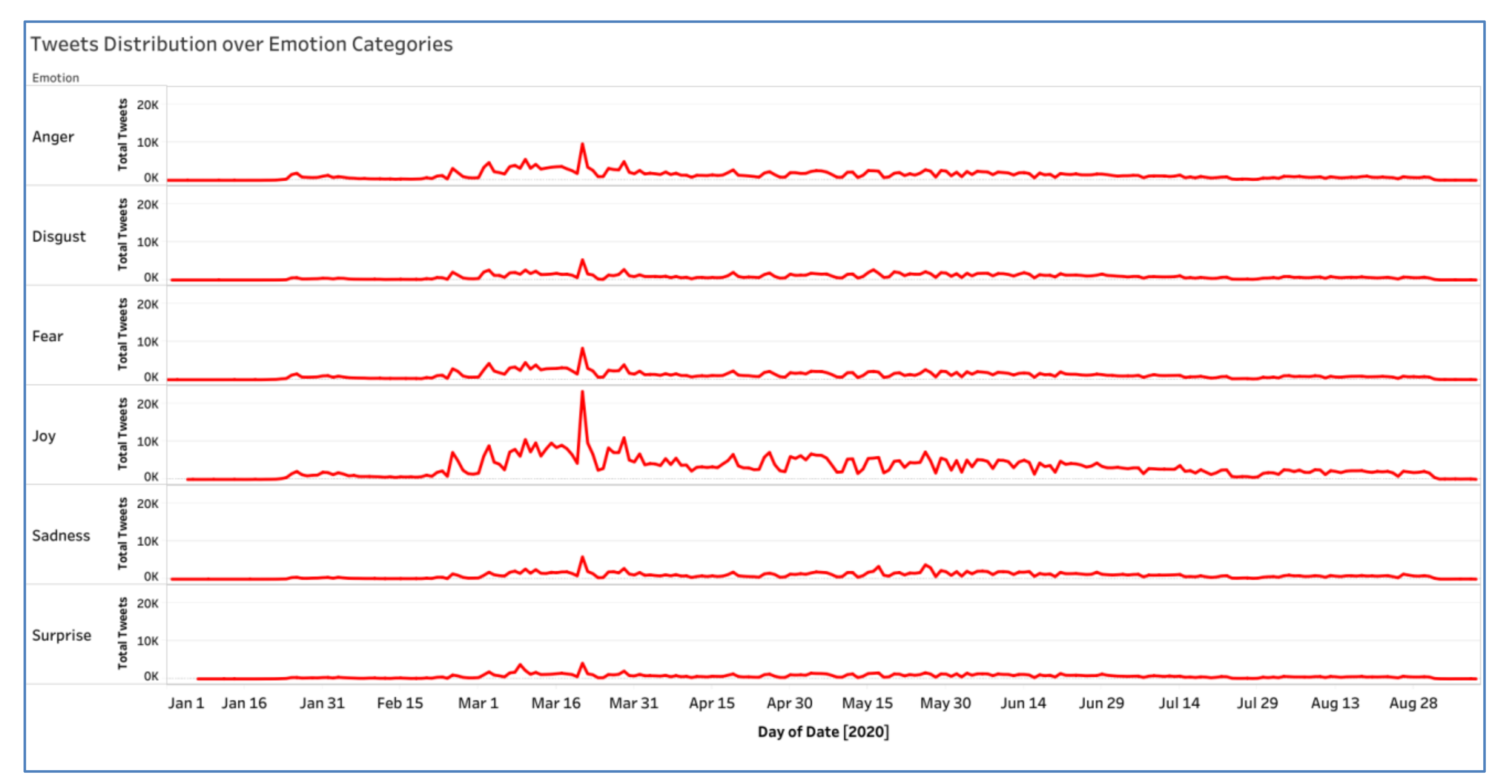
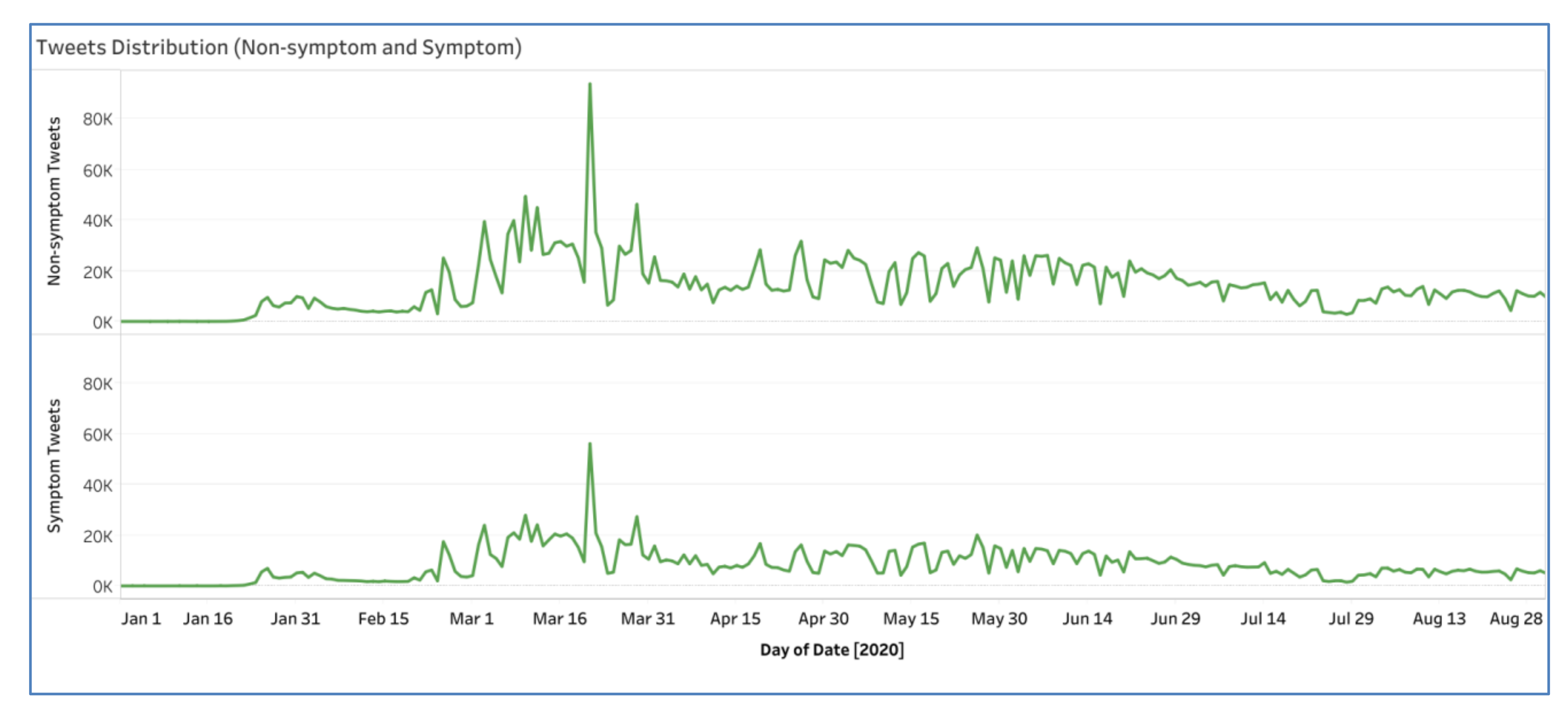
4.6. Monitoring System
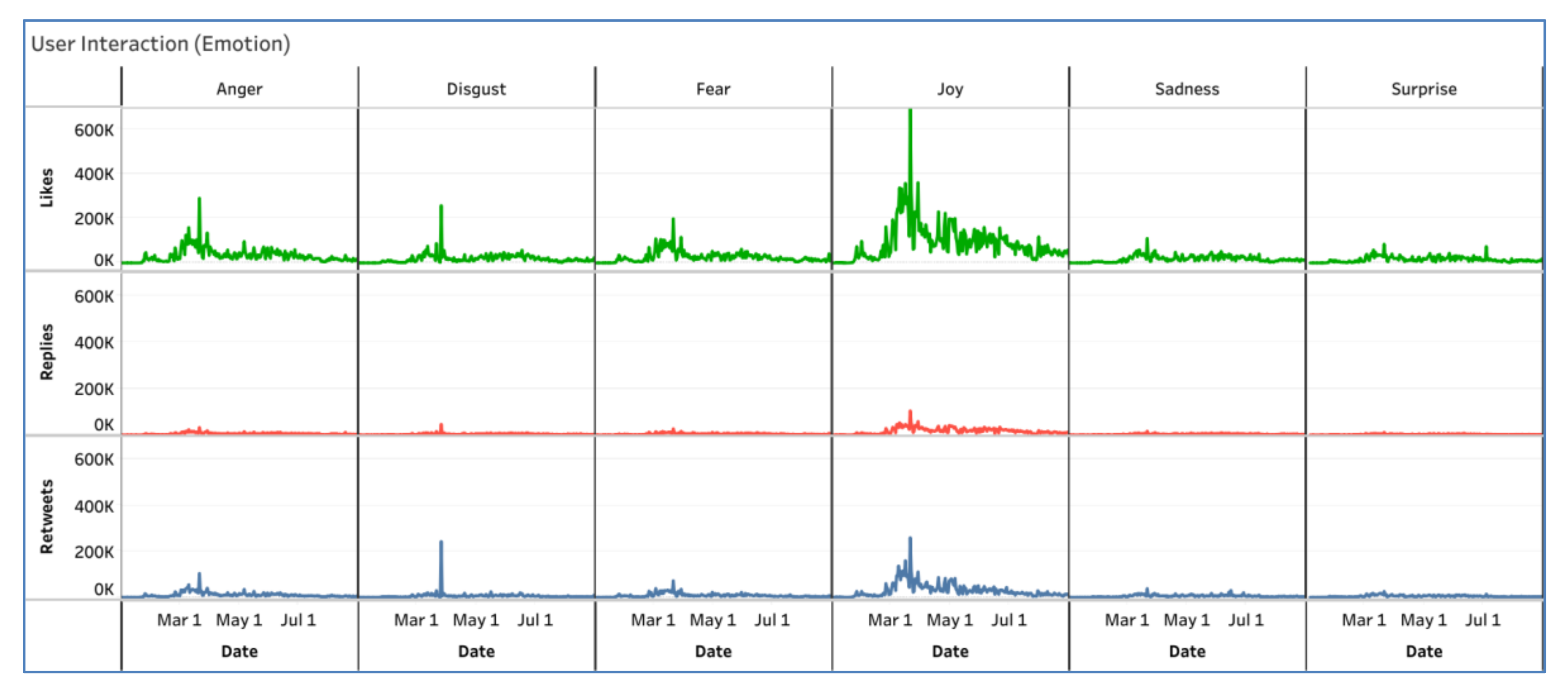
4.6.1. Monitoring Emotion Distribution
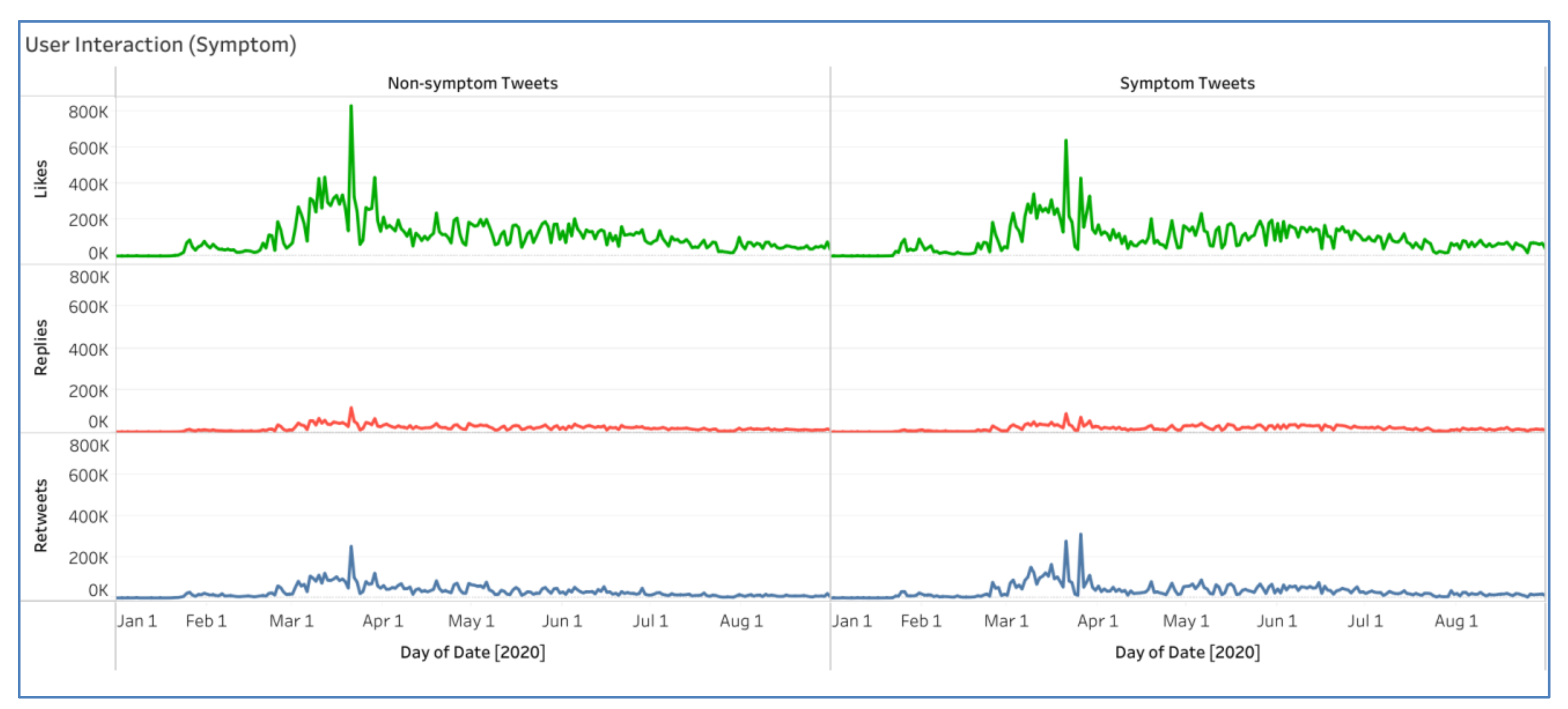
4.6.2. Monitoring Symptom Distribution
4.6.3. Monitoring User Interactions
5. Use Cases
- What do people fear?
- Why are people angry?
- What are the symptoms that cause people anxiety and fear?
5.1. Anger Emotion Tweets
- An increase in COVID-19-infected people due to the outbreak of the corona virus epidemic.
- The call to stay at home to curb the spread of the epidemic.
- Wars continuing despite the spread of the epidemic in some countries, such as Yemen.
- Anger and accusations of China spreading the virus.
- The possibility of death from infection with the virus and neglect of governments.
- The carelessness of people during the time of the pandemic.
- Anger over China’s deliberate transmission of the pandemic to Muslims.
- The risk of transmitting the pandemic via arrivals from Iran.
5.2. Fear Emotion Tweets
- The government’s role in fighting the epidemic.
- The collapse of countries’ economies due to the closure of borders.
- The fear of infection and death from the virus and praying to God to raise the epidemic.
- Fear of the long stay-at-home quarantine.
5.3. Symptom Tweets
- Discussion about disease and treatment.
- Discussion about ways to prevent corona.
- Prayers for healing for the COVID-19-infected people.
- Exposure to some symptoms of infection with the corona virus, such as the throat.
6. Discussion and Limitation
7. Conclusion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kanitkar, T. The COVID-19 lockdown in India: Impacts on the economy and the power sector. Glob. Transit. 2020, 2, 150–156. [Google Scholar] [CrossRef]
- Iadecola, C.; Anrather, J.; Kamel, H. Effects of COVID-19 on the Nervous System. Cell 2020, 183, 16–27.e1. [Google Scholar] [CrossRef]
- Weinberger, D.M.; Chen, J.; Cohen, T.; Crawford, F.W.; Mostashari, F.; Olson, D.; Pitzer, V.E.; Reich, N.G.; Russi, M.; Simonsen, L.; et al. Estimation of Excess Deaths Associated With the COVID-19 Pandemic in the United States, March to May 2020. JAMA Intern. Med. 2020, 180, 1336–1344. [Google Scholar] [CrossRef] [PubMed]
- Alyami, M.; Henning, M.; Krägeloh, C.U.; Alyami, H. Psychometric Evaluation of the Arabic Version of the Fear of COVID-19 Scale. Int. J. Ment. Heal. Addict. 2020, 1–14. [Google Scholar] [CrossRef]
- Al-Musharaf, S. Prevalence and Predictors of Emotional Eating among Healthy Young Saudi Women during the COVID-19 Pandemic. Nutrients 2020, 12, 2923. [Google Scholar] [CrossRef]
- Olimat, S.N. COVID-19 Pandemic: Euphemism and Dysphemism in Jordanian Arabic. GEMA Online J. Lang. Stud. 2020, 20, 268–290. [Google Scholar] [CrossRef]
- Essam, B.A.; Abdo, M.S. How Do Arab Tweeters Perceive the COVID-19 Pandemic? J. Psycholinguist. Res. 2020, 1–15. [Google Scholar] [CrossRef]
- Mavragani, A. Tracking COVID-19 in Europe: Infodemiology Approach. JMIR Public Heal. Surveill. 2020, 6, e18941. [Google Scholar] [CrossRef]
- Sousa-Pinto, B. Assessment of the Impact of Media Coverage on COVID-19–Related Google Trends Data: Infodemiology Study. J. Med. Int. Res. 2020, 22, e19611. [Google Scholar] [CrossRef]
- Rajan, A.; Sharaf, R.; Brown, R.S.; Sharaiha, R.Z.; Lebwohl, B.; Mahadev, S. Association of Search Query Interest in Gastrointestinal Symptoms With COVID-19 Diagnosis in the United States: Infodemiology Study. JMIR Public Heal. Surveill. 2020, 6, e19354. [Google Scholar] [CrossRef]
- Hernández-García, I.; Giménez-Júlvez, T. Assessment of health information about COVID-19 prevention on the internet: Infodemiological study. JMIR Public Health Surveill. 2020, 6, e18717. [Google Scholar] [CrossRef]
- Ahmed, W.; Bath, P.A.; DeMartini, G. Chapter 4: Using Twitter as a Data Source: An Overview of Ethical, Legal, and Methodological Challenges. In Virtue Ethics in the Conduct and Governance of Social Science Research; Emerald Publishing Limited: Bingley, UK, 2017. [Google Scholar]
- McClellan, C.; Ali, M.M.; Mutter, R.; Kroutil, L.; Landwehr, J. Using social media to monitor mental health discussions − evidence from Twitter. J. Am. Med. Inf. Assoc. 2017, 24, 496–502. [Google Scholar] [CrossRef]
- Sinnenberg, L.E.; DiSilvestro, C.L.; Mancheno, C.; Dailey, K.; Tufts, C.; Buttenheim, A.M.; Barg, F.; Ungar, L.; Schwartz, H.; Brown, D.; et al. Twitter as a Potential Data Source for Cardiovascular Disease Research. JAMA Cardiol. 2016, 1, 1032–1036. [Google Scholar] [CrossRef] [PubMed]
- Mai, E.; Hranac, R. Twitter interactions as a data source for transportation incidents. In Proceedings of the Transportation Research Board 92nd Annual Meeting, Washington, DC, USA, 13–17 January 2013. [Google Scholar]
- Nakhasi, A.; Bell, S.G.; Passarella, R.J.; Paul, M.J.; Dredze, M.; Pronovost, P.J. The Potential of Twitter as a Data Source for Patient Safety. J. Patient Saf. 2019, 15, e32–e35. [Google Scholar] [CrossRef] [PubMed]
- Nawaz, H.; Ali, T.; Al-laith, A.; Ahmad, I.; Tharanidharan, S.; Nazar, S.K.A. Sentimental Analysis of Social Media to Find Out Customer Opinion. In Proceedings of the International Conference on Intelligent Technologies and Applications, Bahawalpur, Pakistan, 23–25 October 2018. [Google Scholar]
- Shivhare, S.N.; Khethawat, S. Emotion detection from text. arXiv 2012, arXiv:1205.4944. [Google Scholar]
- Chun, S.A.; Li, A.C.-Y.; Toliyat, A.; Geller, J. Tracking Citizen’s Concerns during COVID-19 Pandemic. In Proceedings of the The 21st Annual International Conference on Digital Government Research, Seoul, Korea, 15–19 June 2020; Association for Computing Machinery (ACM): New York, NY, USA, 2020. [Google Scholar]
- Park, H.W.; Park, S.; Chong, M. Conversations and Medical News Frames on Twitter: Infodemiological Study on COVID-19 in South Korea. J. Med Internet Res. 2020, 22, e18897. [Google Scholar] [CrossRef]
- Guntuku, S.C.; Sherman, G.; Stokes, D.C.; Agarwal, A.K.; Seltzer, E.; Merchant, R.M.; Ungar, L.H. Tracking Mental Health and Symptom Mentions on Twitter During COVID-19. J. Gen. Intern. Med. 2020, 35, 2798–2800. [Google Scholar] [CrossRef]
- Mathur, K.P.; Vaidya, S. Emotional Analysis using Twitter Data during Pandemic Situation: COVID-19. In Proceedings of the 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020. [Google Scholar]
- Almouzini, S.; Khemakhem, M.; Alageel, A. Detecting Arabic Depressed Users from Twitter Data. Procedia Comput. Sci. 2019, 163, 257–265. [Google Scholar] [CrossRef]
- Mukhtar, S. Pakistanis’ mental health during the COVID-19. Asian J. Psychiatry 2020. [Google Scholar] [CrossRef] [PubMed]
- Su, Y.; Xue, J.; Liu, X.; Wu, P.; Chen, J.; Chen, C.; Liu, T.; Gong, W.; Zhu, T. Examining the Impact of COVID-19 Lockdown in Wuhan and Lombardy: A Psycholinguistic Analysis on Weibo and Twitter. Int. J. Environ. Res. Public Heal. 2020, 17, 4552. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top Concerns of Tweeters During the COVID-19 Pandemic: Infoveillance Study. J. Med Internet Res. 2020, 22, e19016. [Google Scholar] [CrossRef]
- Lwin, M.O.; Lu, J.; Sheldenkar, A.; Schulz, P.J.; Shin, W.; Gupta, R.; Yang, Y. Global Sentiments Surrounding the COVID-19 Pandemic on Twitter: Analysis of Twitter Trends. JMIR Public Heal. Surveill. 2020, 6, e19447. [Google Scholar] [CrossRef]
- Gupta, R.K.; Vishwanath, A.; Yang, Y. COVID-19 Twitter Dataset with Latent Topics, Sentiments and Emotions Attributes. Arxiv 2020, arXiv:2007.06954, 2020. [Google Scholar]
- Zhang, Y. Monitoring Depression Trend on Twitter during the COVID-19 Pandemic. arXiv 2020, arXiv:2007.00228, 2020. [Google Scholar]
- Dimple, C.; Parul, G.; Payal, G. COVID-19 pandemic lockdown: An emotional health perspective of Indians on Twitter. Int. J. Soc. Psychiatry 2020. [Google Scholar] [CrossRef]
- Galbraith, N.; Boyda, D.; McFeeters, D.; Hassan, T. The mental health of doctors during the COVID-19 pandemic. BJPsych Bull. 2020, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Han, B.; Jiang, R.; Huang, Y.; Ma, C.; Wen, J.; Zhang, T.; Wang, Y.; Chen, H.; Ma, Y. Mental health status of doctors and nurses during COVID-19 epidemic in China. 2020. preprint; SSRN 3551329. [Google Scholar] [CrossRef]
- Spoorthy, M.S.; Pratapa, S.K.; Mahant, S. Mental health problems faced by healthcare workers due to the COVID-19 pandemic–A review. Asian J. Psychiatry 2020, 51, 102119. [Google Scholar] [CrossRef]
- Di Tella, M.; Romeo, A.; Benfante, A.; Castelli, L. Mental health of healthcare workers during the COVID -19 pandemic in Italy. J. Eval. Clin. Pr. 2020, 26, 1583–1587. [Google Scholar] [CrossRef] [PubMed]
- Alanazi, E.; Alashaikh, A.; AlQurashi, S.; Alanazi, A. Identifying and Ranking Common COVID-19 Symptoms From Tweets in Arabic: Content Analysis. J. Med. Internet Res. 2020, 22, e21329. [Google Scholar] [CrossRef]
- Alkouz, B.; Al Aghbari, Z. Analysis and prediction of influenza in the UAE based on Arabic tweets. In Proceedings of the 2018 IEEE 3rd International Conference on Big Data Analysis (ICBDA), Shanghai, China, 9–12 March 2018. [Google Scholar]
- Saad, M.K. Mining Documents and Sentiments in Cross-Lingual Context. Mining Documents and Sentiments in Cross-Lingual Context; Université de Lorraine: Nancy, France, 2015. [Google Scholar]
- Sutton, J.N.; Palen, L.; Shklovski, I. Backchannels on the front lines: Emergency uses of social media in the 2007. In Southern California Wildfires; University of Colorado: Boulder, CO, USA, 2008. [Google Scholar]
- Al-Laith, A.; Shahbaz, M. Tracking sentiment towards news entities from arabic news on social media. Futur. Gener. Comput. Syst. 2021. [Google Scholar] [CrossRef]
- Giachanou, A.; Mele, I.; Crestani, F. Explaining sentiment spikes in twitter. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016. [Google Scholar]
- Alves, A.L.F. A spatial and temporal sentiment analysis approach applied to Twitter microtexts. J. Inf. Data Manag. 2015, 6, 118. [Google Scholar]
- Chaabani, Y.; Toujani, R.; Akaichi, J. Sentiment analysis method for tracking touristics reviews in social media network. In Proceedings of the International Conference on Intelligent Interactive Multimedia Systems and Services, Gold Coast, Australia, 20–22 May 2018. [Google Scholar]
- Contractor, D. Tracking political elections on social media: Applications and experience. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Bai, H.; Yu, G. A Weibo-based approach to disaster informatics: Incidents monitor in post-disaster situation via Weibo text negative sentiment analysis. Nat. Hazards 2016, 83, 1177–1196. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. # | Hashtag | Translation | Sr. # | Hashtag | Translation |
|---|---|---|---|---|---|
| 1 | #كورونا | #Coronavirus | 9 | #كورونا_قطر | #corona_Qatar |
| 2 | #كورونا_المستجد | #new_corona | 10 | #كورونا_الاردن | #corona_Jordan |
| 3 | #كورونا_الجديد | #new_corona | 11 | #كورونا_السعودية | #corona_Saudi_Arabia |
| 4 | #الحجر_الصحي | #Quarantine | 12 | #كورونا_الكويت | #corona_Kuwait |
| 5 | #الحجر_المنزلي | #Quarantine | 13 | #كورونا_لبنان | #corona_Lebanon |
| 6 | #خليك_في_البيت | #Stay_home | 14 | #كورونا البحرين | #corona_Bahrain |
| 7 | #كورونا_العراق | #corona_Iraq | 15 | #كورونا_مصر | #corona_Egypt |
| 8 | #كورونا_ايران | #corona_Iran | 16 | #كورونا_اليمن | #corona_Yemen |
| Sr. # | Account | Title | Total Tweets | Is Verified? | Followers |
|---|---|---|---|---|---|
| 1 | @corona_news | اخبار كورونا فيروس | 11,952 | No | 15.6K |
| 2 | @aawsat_news | صحيفة الشرق الاوسط | 11,579 | Yes | 4.3M |
| 3 | @aljawazatksa | الجوازات السعودية | 10,043 | Yes | 1.6M |
| 4 | @newssnapnet | NewsSnap | 6837 | No | 3.1K |
| 5 | @menafnarabic | MENAFN.com Arabic | 6447 | No | 1.3K |
| 6 | @newsemaratyah | اخبار الامارات UAE NEWS | 5954 | Yes | 185.5K |
| 7 | @aljoman_center | مركز الجُمان | 5669 | Yes | 20.6K |
| 8 | @misrtalateen | صحيفة مصر تلاتين | 5324 | No | 1K |
| 9 | @alahram | الأهرامAlAhram | 5238 | Yes | 5.6M |
| 10 | @alahramgate | بوابة الأهرام | 5213 | Yes | 158.8K |
| 11 | @rtarabic | RTARABIC | 5181 | Yes | 5.3M |
| 12 | @alainbrk | العين الإخبارية - عاجل | 4926 | Yes | 71.8K |
| 13 | @alroeya | صحيفة الرؤية | 4818 | Yes | 748.9K |
| 14 | @kuna_ar | كـــــــــــونا KUNA | 4417 | Yes | 993K |
| 15 | @libanhuit | Liban8 | 4192 | Yes | 19.2K |
| 16 | @alghadtv | قناة الغد | 4011 | Yes | 153.3K |
| 17 | @arabi21news | عربي21 | 4002 | Yes | 919.3K |
| 18 | @ch23news | Channel 23 | 3916 | No | 5.5K |
| 19 | @newselmostaqbal | المستقبل | 3778 | No | 486 |
| 20 | @emaratalyoum | الإمارات اليوم | 3741 | Yes | 2.2M |
| Emotion | Arabic Words/Phrase |
|---|---|
| Anger | 748 |
| Disgust | 155 |
| Fear | 425 |
| Joy | 1156 |
| Sadness | 522 |
| Surprise | 201 |
| Total | 3207 |
| Title | Number |
|---|---|
| Total Tweets | 5,499,318 |
| Total Words | 100,788,175 |
| Unique Words | 2,657,173 |
| Unique Users | 1,402,874 |
| Average Words per Tweet | 18.3 |
| Anger | Disgust | Fear | Joy | Sadness | Surprise | |
|---|---|---|---|---|---|---|
| Anger | 40 | 3 | 2 | 1 | 1 | 3 |
| Disgust | 4 | 38 | 2 | 2 | 3 | 1 |
| Fear | 1 | 4 | 41 | 3 | 1 | 0 |
| Joy | 2 | 2 | 0 | 44 | 1 | 1 |
| Sadness | 2 | 1 | 1 | 3 | 42 | 1 |
| Surprise | 1 | 1 | 1 | 3 | 1 | 43 |
| # | Class | Precision | Recall | F1 Score |
|---|---|---|---|---|
| 1 | Anger | 0.80 | 0.80 | 0.80 |
| 2 | Disgust | 0.76 | 0.78 | 0.77 |
| 3 | Fear | 0.82 | 0.87 | 0.85 |
| 4 | Joy | 0.88 | 0.79 | 0.83 |
| 5 | Sadness | 0.84 | 0.86 | 0.85 |
| 6 | Surprise | 0.86 | 0.88 | 0.87 |
| Average | 0.826 | 0.83 | 0.828 | |
| Sr. # | Emotion | Threshold (90%) | Threshold (80%) | Threshold (70%) |
|---|---|---|---|---|
| 1 | Anger | 213,189 | 297,781 | 381,629 |
| 2 | Disgust | 206,025 | 330,530 | 417,140 |
| 3 | Fear | 231,869 | 326,931 | 421,748 |
| 4 | Joy | 241,264 | 283,606 | 406,080 |
| 5 | Sadness | 197,406 | 280,685 | 358,142 |
| 6 | Surprise | 119,198 | 151,022 | 185,202 |
| Total Tweets | 1,208,951 | 1,670,555 | 2,169,941 | |
| Deep Learning Classifier | Accuracy | F1-Score (Macro Avg) | F1-Score (Weighted Avg) |
|---|---|---|---|
| LSTM | 0.75 | 0.75 | 0.75 |
| # | Type | Number of Tweets | % |
|---|---|---|---|
| 1 | Symptom Tweets | 2,034,748 | 37% |
| 2 | Non-symptom Tweets | 3,464,570 | 63% |
| Total Tweets | 5,499,318 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Laith, A.; Alenezi, M. Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic. Information 2021, 12, 86. https://doi.org/10.3390/info12020086
Al-Laith A, Alenezi M. Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic. Information. 2021; 12(2):86. https://doi.org/10.3390/info12020086
Chicago/Turabian StyleAl-Laith, Ali, and Mamdouh Alenezi. 2021. "Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic" Information 12, no. 2: 86. https://doi.org/10.3390/info12020086
APA StyleAl-Laith, A., & Alenezi, M. (2021). Monitoring People’s Emotions and Symptoms from Arabic Tweets during the COVID-19 Pandemic. Information, 12(2), 86. https://doi.org/10.3390/info12020086