4.1. Outlier Identification in DA Simulations
For a given angle, at times the stable amplitude may differ considerably from seed to seed, resulting in a spread of stable amplitudes over seeds. Outliers may be present in this distribution, which may have an impact on (and, to a lesser extent, ). The cause of such outliers may be due to the excitation of particular resonances as a result of the distribution of nonlinear magnetic errors, which is highly seed-dependent. It is also clear that outliers possibly represent realizations of the magnetic field errors that generate an unlikely (because it is non-typical) value of the DA, which might be removed from the analysis of the numerical data in view of the computation of . For these reasons, ML techniques have been applied to the results of large-scale DA simulations in order to flag the presence of outliers, which can then be dealt with appropriately.
There are, however, a number of points that should be considered carefully in order to devise the most appropriate approach to this problem. Indeed, the key point is to ensure that the flagged outliers are genuine, and not members of a particular cluster of DA amplitudes. Therefore, the outlier detection is performed through the following procedure. First, for each angle
j the
values for that angle and for the different seeds are re-scaled between the minimum and maximum values. Therefore, there is only one feature, namely the re-scaled
values for a given angle. Then two types of ML approaches have been investigated, in order to detect outliers automatically. In the SL approach, the goal of outlier detection is treated as a classification problem, and a Support Vector Machine (SVM) algorithm [
32] is used to discriminate between normal and abnormal points. The Radial Basis Function (RBF) kernel [
33] with a penalty factor
C of unity has been identified as the best hyperparameter for the SVM model following a hyperparameter optimization using grid search.
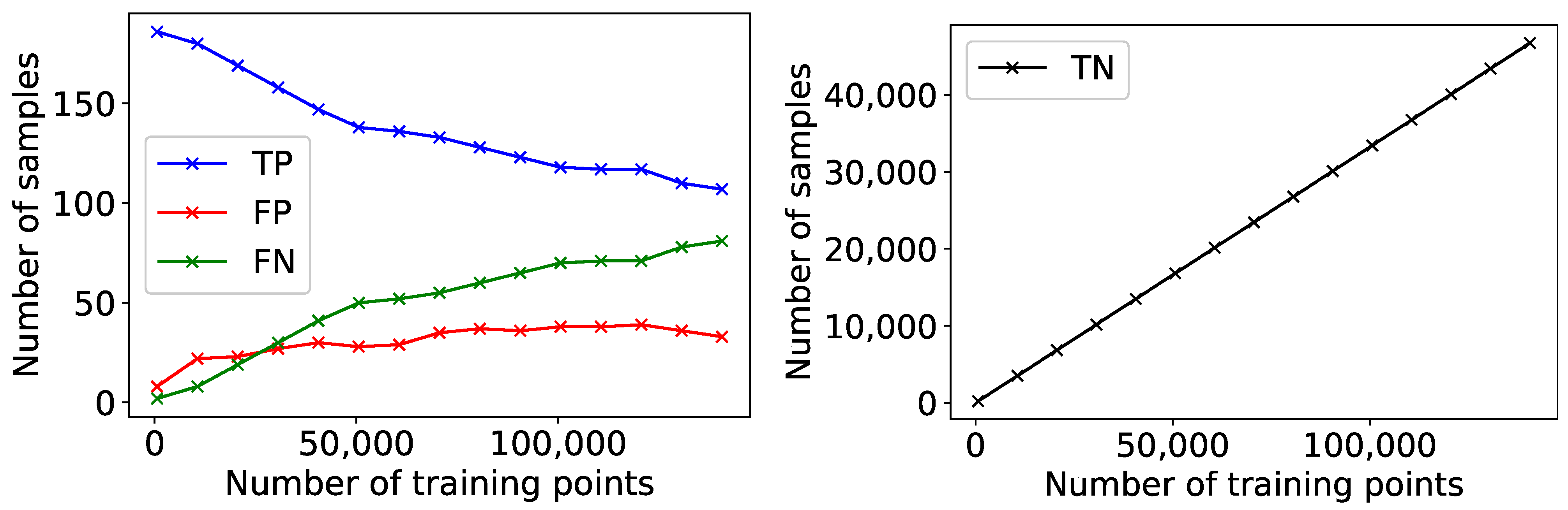
To further examine the performance of the model, a learning curve was obtained. This allows to determine the model performance as a function of the number of training points used, and is shown in
Figure 3. The ground truth corresponding to the training points has been generated by manually selecting the points that according to human judgement corresponded to outliers. Each point in the curves represents the number of True Negatives (TN), True Positives (TP), False Negatives (FN), and False Positives (FP) obtained on a test data set whose size corresponds to 25% of the overall data set available, which is made up of some thousands of numerical simulations of DA for both the LHC and HL-LHC rings, when the model is trained on all anomalous points plus a certain increasing number of normal points. A TP is a ground-truth anomalous point, which was correctly predicted as being anomalous. The results show that when the training data set is approximately balanced between abnormal and normal points, the number of TP is quite high, while the FP and FN are low. However, as the data set skews towards an increasing majority of normal points, the model achieves a lower performance. This is understandable given the assumption of balance in the SVM algorithm.
Two UL approaches for detecting anomalies on an angle-by-angle basis have been considered, too. The first algorithm is the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) [
34]. DBSCAN is a density-based, non-parametric algorithm, which groups points based on local density of samples. The points that are not assigned to any cluster after applying the algorithm are automatically considered to be outliers. The second algorithm is the Local Outlier Factor (LOF) [
35] method. LOF also uses the concept of local density, but directly computes an outlier score per point. Locality is provided by the
K nearest neighbors, whose distance is used to estimate the density. By comparing the local density of an object to the local densities of its neighbors, it is possible to identify regions of similar density. Therefore, it is clear that points that have a substantially lower density than their neighbors are to be considered as outliers.
For the UL approach, 75% of the data set was used for training and 25% was used for validation. As a result of hyperparameter optimization through a grid search, the following is a list of the hyperparameters determined for each method:
DBSCAN: eps = 1 (the maximum distance between two samples for one to be considered as in the neighborhood of the other); min_samples = 3 (the number of samples, or total weight, in a neighborhood for a point to be considered as a core point, including the point itself);
LOF: n_neighbors = 58 (the number of neighbors used to measure the local deviation of density of a given sample with respect to the same neighbors); contamination = 0.001 (the expected fraction of outliers in the data set).
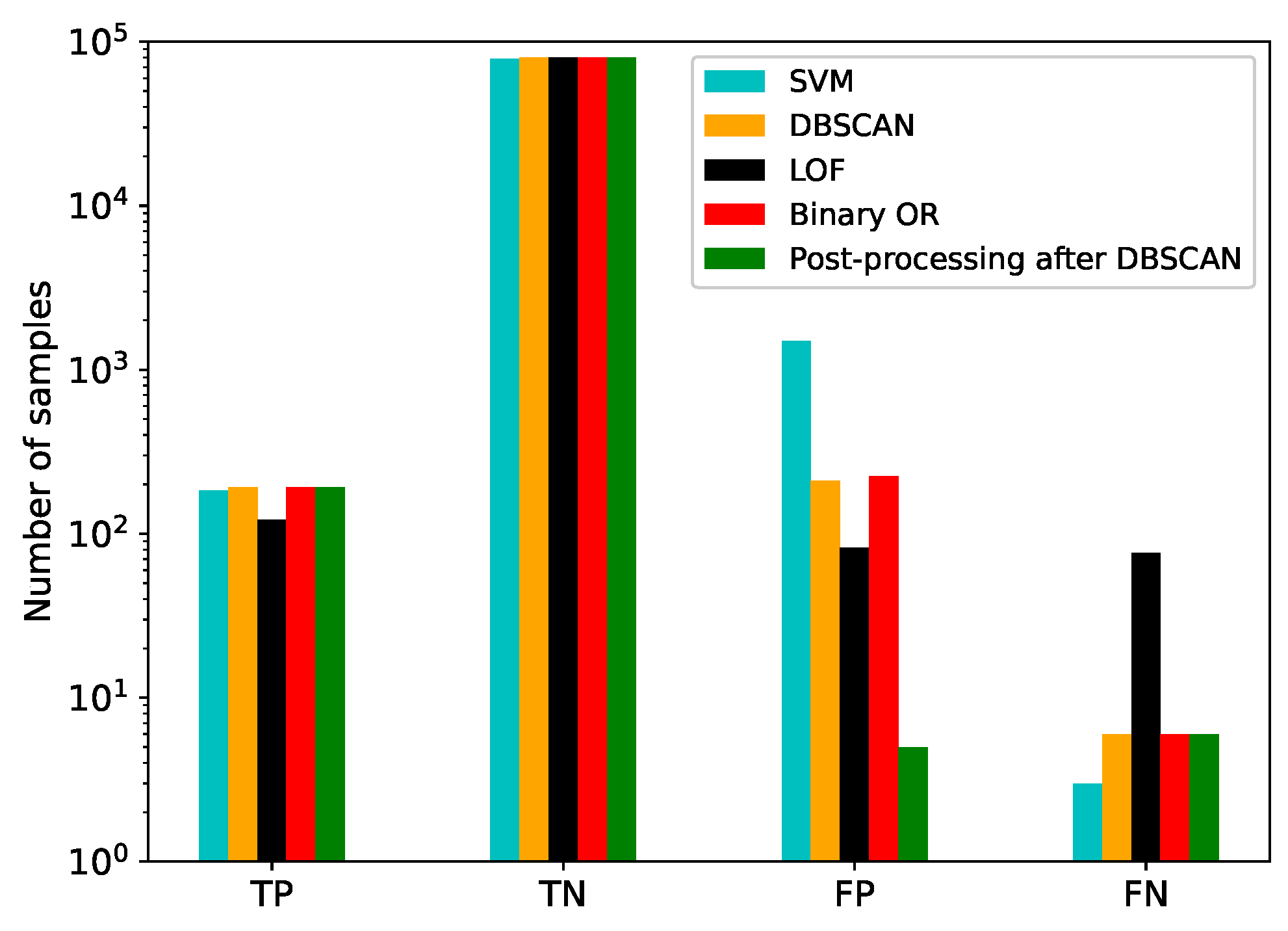
A comparison between the performance of the SVM, DBSCAN, and LOF algorithms is shown in
Figure 4. The Python-based scikit-learn [
36] implementation of these three algorithms was used. The labels determined by the DBSCAN and LOF algorithms were also combined through a binary OR operation to produce a fourth set of labels. A further fifth set of labels was created following an initial labelling by DBSCAN by removing false positives through a statistical method to determine whether this approach would add to the robustness of the original prediction. For a point, being originally flagged by DBSCAN as an outlier, to be considered as a true outlier, three additional criteria should be fulfilled: the distance from the mean should be at least
(where mean and standard deviation are only calculated over the normal points); the distance to the nearest normal point should be greater than
, in absolute units, and the distance to the nearest regular point should be greater than
of the total spread of the regular points. This post-processing is performed iteratively, starting at the minimum (maximum) point and moving outwards (inwards), recalculating the statistical variables of the regular points at every step. The values of these thresholds are chosen empirically to ensure that false positives that are due to dense clusters are correctly filtered out.
The results show that the unsupervised learning methods perform better than SVM by an order of magnitude in terms of false positives; however they are worse in terms of false negatives, especially in the case of LOF. The method of post-processing following DBSCAN clearly contributes to reducing the number of false positives, while maintaining the TP and FN rates.
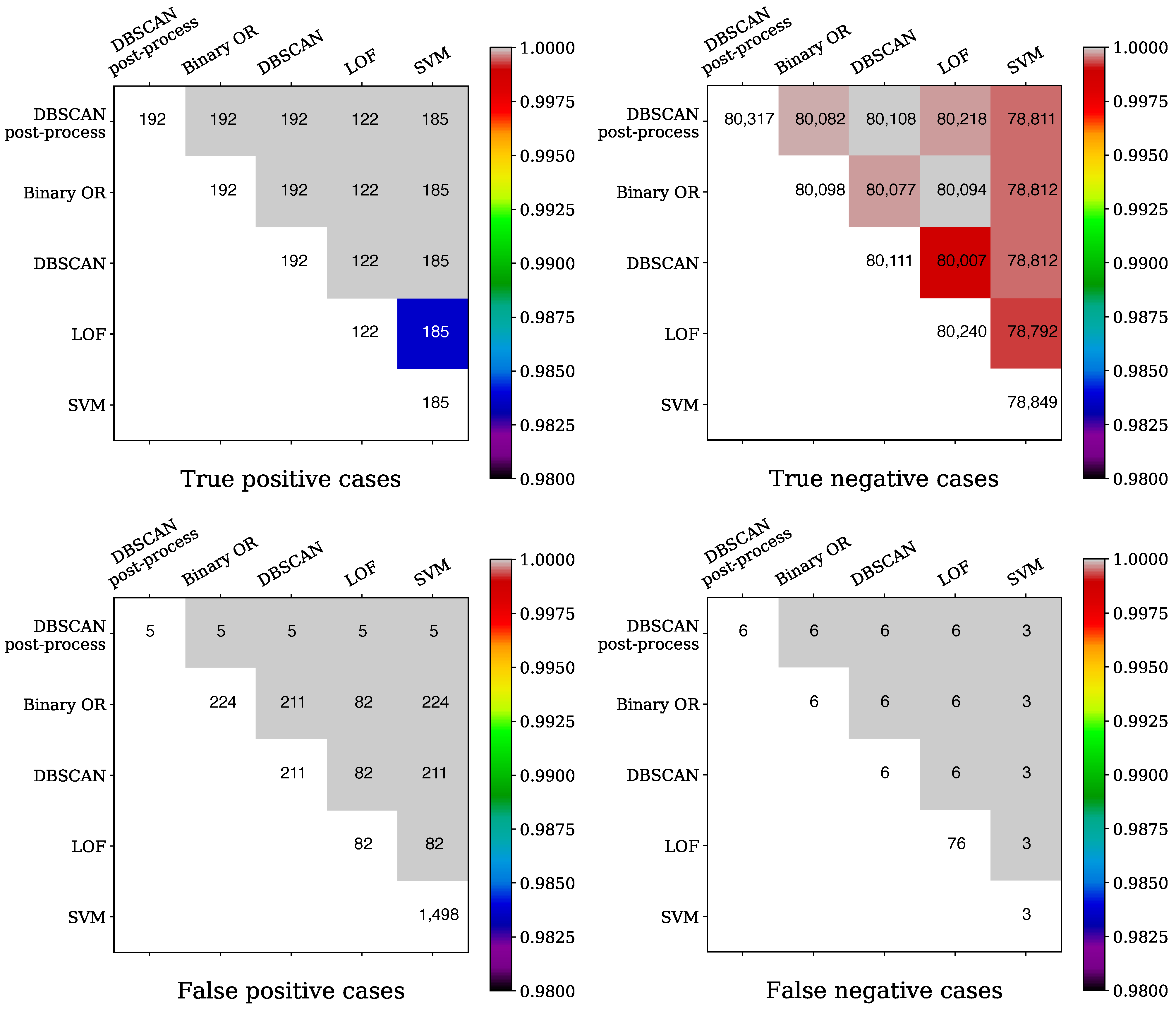
Additional detail on the impact of the post-processing is visible in
Figure 5, in which the number of events for the various methods applied, and the size of the intersection of the events between pairs of methods, is shown for the four classes of TP, TN, FP, and FN cases.
Each heat map reports along the diagonal the number of events for each method of a given class, i.e., TP, TF, FP, and FN. In the upper triangular part of the matrix, the number of events in the intersection between the methods taken in pairs is shown; the color used is selected by normalizing the number of events in the intersection by the minimum of the events for the considered pair of methods. The level of TP cases is very similar for most of the methods, whereas differences are observed concerning the TN cases, and there the post-processing ensures that the higher score of TN cases is reached. As far as the FP and FN cases are concerned, it is clear that the post-processing provides the least number of events for FP cases, which is a very important feature. Similarly, FN cases are minimized by the post-processing, although the same number is obtained by the binary OR or plain DBSCAN. SVN scored excellently in FN, but was rather poor in the other three classes. All in all, the proposed post-processing of the DBSCAN clearly outperformed the other methods and provided a level of FP and FN cases that is perfectly adequate for our needs.
4.2. Digression: Accelerator Physics Considerations from Outlier Identification in DA Simulations
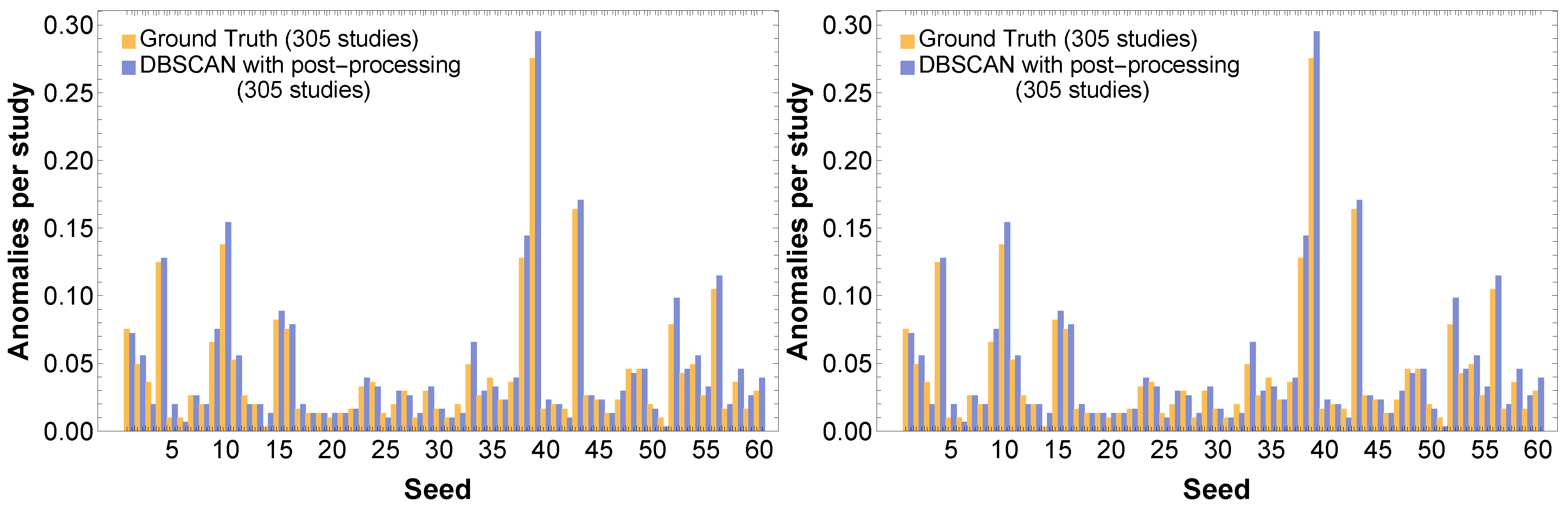
It is very useful to investigate the dependence of the number of outliers on the value of the angular variable and on the seed number. A comparison between the ground-truth and predicted anomalies (using post-processing following DBSCAN) is shown in
Figure 6, where it can be seen that the anomaly profiles for both seeds and angles are similar between the ground-truth and the predictions. The peculiar profile of outliers as a function of seed is worth noting, featuring three clusters with a very large number of outliers. As far as the anomalies distribution as a function of angle is concerned, there is a tendency towards a larger number of outliers for angles close to
. It is worth stressing that there are outliers affecting the lower-amplitude part of the distribution or
(outliers from below) or the higher-amplitude part (outliers from above). The analyses performed indicate that the number of outliers from below and those from above are essentially equal, totaling 2882 and 2847 cases, respectively.
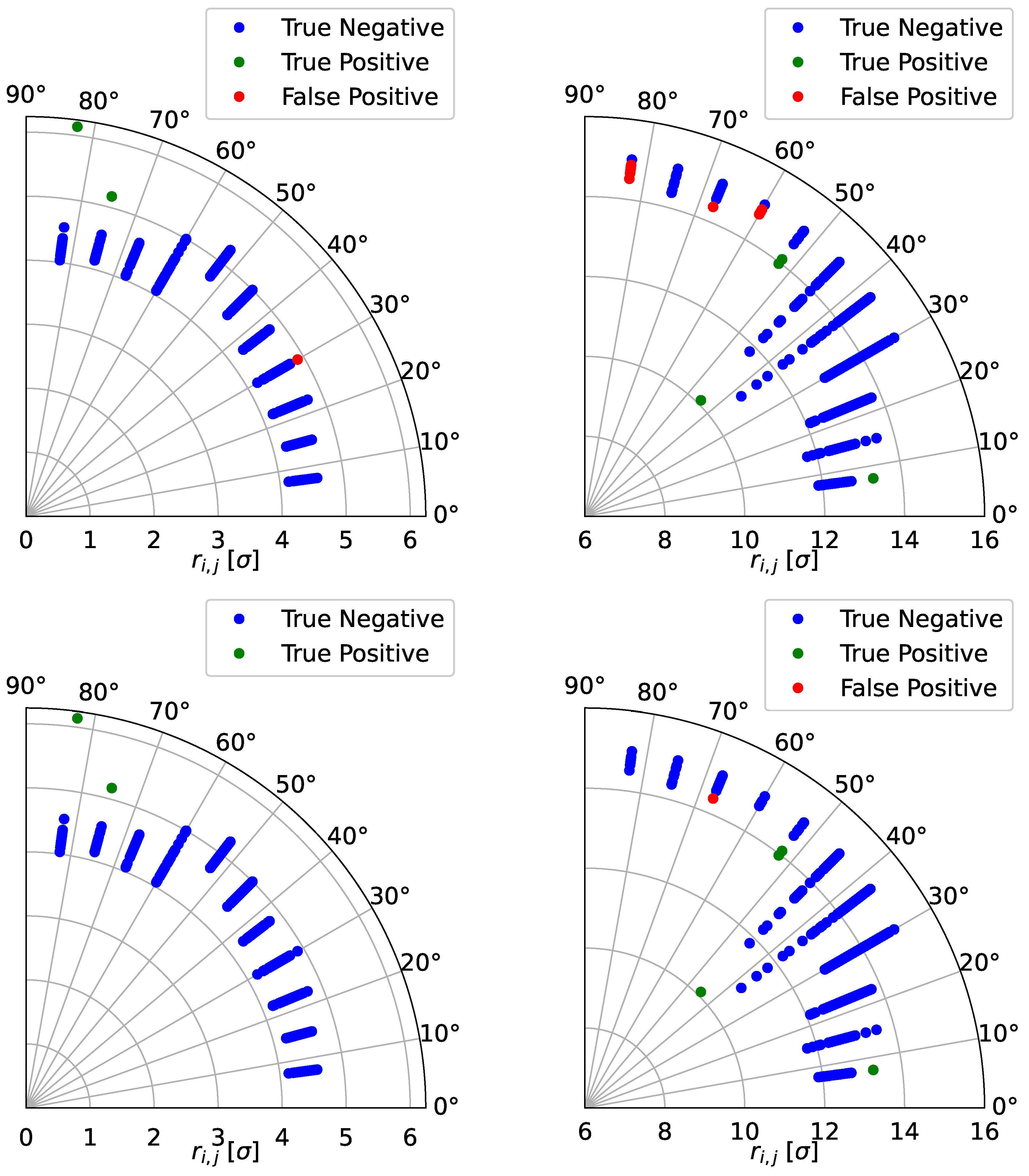
Two examples of the classification of outliers from normal points obtained by means of the post-processing following the DBSCAN method are shown in
Figure 2.
It should be noted that the dynamics governing the DA can be very different as a function of the angle ; hence, even when the neighboring points are similar in amplitude, the spotted outlier might be a genuine one. Obviously, particular care needs to be taken in these cases before drawing any conclusions, and additional investigations might be advisable.
It is clear that the previous analysis provides useful insight into the underlying physics. Indeed, it is interesting to consider how the outliers are distributed over seeds and angles for the various configurations that make up the huge data set to which the analysis has been applied. The main cases covered by the numerical simulations can be categorized according to: accelerator (LHC or HL-LHC); beam energy (injection, 450 GeV, or top energy, 7 TeV); circulating beam (Beam 1, rotating clockwise, or Beam 2, rotating counter-clockwise); optical configuration of the accelerator (nominal [
20] or ATS [
37] for the LHC, and V1.0, V1.3, V1.4 for the HL-LHC); and the strength of the octupole magnets that are used to stabilize the beams against collective effects. In
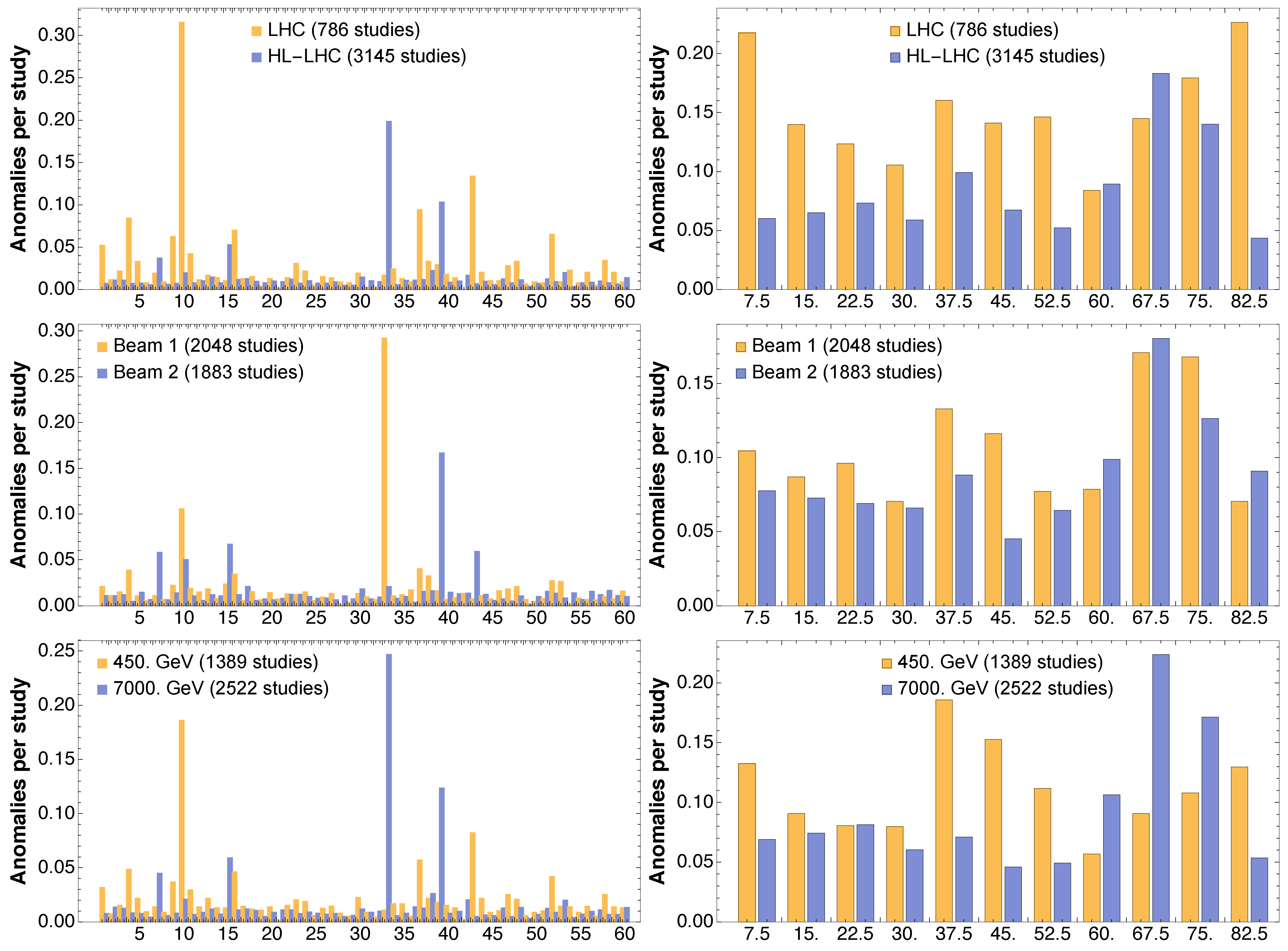
Figure 7, a collection of results of the obtained distributions of outliers vs. seed and angle are shown for several configurations probed with the numerical simulations.
The LHC and HL-LHC feature a different distribution of outliers, the first being affected by a number of outliers that are mildly dependent on the angles and special seed 10, whereas the latter features a mild increase of outliers towards a large angle and special seeds 33 and 39. While the two counter-rotating beams do not feature a meaningful differences in the distribution of outliers as a function of angle, with a sort of peak around 70 degrees, we can pinpoint the high number of anomalies for seed 33 to Beam 1 and those for seed 39 to Beam 2. On the other hand, the situation in terms of outliers when considering the injection or the collision energies is a bit different, inasmuch that at collision energy the distribution of anomalies is skewed towards larger angles. Note also that different seeds present anomalies depending on the value of the beam energy. Here it is worth mentioning that the overall data set is skewed towards HL-LHC cases, which, in turn, feature mainly collision-energy cases. On the other hand, the LHC cases refer mainly to the injection energy case. This explains some of the similarities in the behavior of anomalies as a function of the ring considered and on the beam energy.
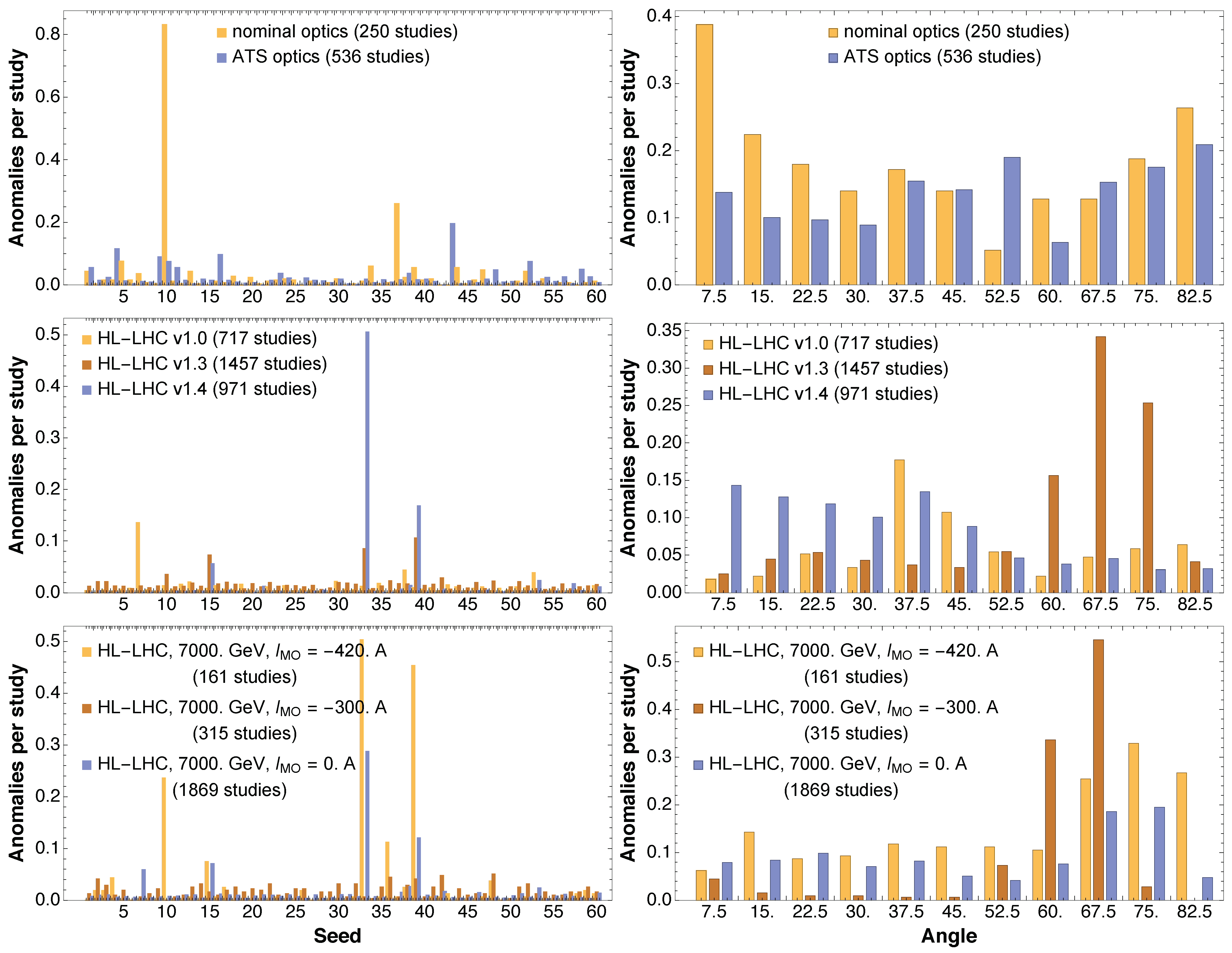
In terms of optical configuration used for the LHC, the nominal one features a special seed 10, and outliers towards low angle values. On the other hand, ATS shows essentially no anomalous seeds and a very small number of anomalies as a function of angle.
The situation concerning different ring layouts and optics versions that are being studied for the HL-LHC shows an interesting evolution in terms of the appearance of anomalous seeds as of version V1.3. This is also combined with a change in terms of distribution of outliers as a function of angle. Indeed, while version V1.0 features outliers mainly in the middle range of angles, version V1.3 is characterized by outliers towards the high range of angles. The situation then changes with version V1.4, where an increase of outliers is observed towards the low range of angles. Interestingly enough, the presence of strong octupoles used to stabilize the beams has an adverse effect in terms of anomalous seeds and outliers vs. angle. In fact, a clear increase of anomalies can be observed with increasing, in absolute value, current in the Landau octupoles. This feature appears in conjunction with an increased number of anomalies for large values of angles.
It is worth stressing that the observed features of the distribution of outliers for LHC and HL-LHC will be carefully considered to shed some light on the underlying beam dynamics phenomena that are responsible for their generation.
4.3. Fitting the DA as a Function of Number of Turns
Another domain where ML techniques have been applied, with the hope that they can bring improvements, is the modeling of the DA as a function of the number of turns. In
Section 3, the concept of DA has been introduced and briefly discussed; it can be estimated by means of numerical simulations that are performed for a given number of turns
. The main observation is that the DA tends to shrink with time, which is logical as by increasing the number of turns even initial conditions with a low-amplitude might turn increase it, either slowly or more abruptly, due to the presence of nonlinear effects. The second fundamental observation is that the variation of the DA with the turn number can be described with rather simple functional forms (see, e.g., Equation (12)) that feature a very limited number of free parameters.
The approach pursued by our research consists of fitting one of the scaling laws to the numerical data and performing extrapolation over the number of turns
N so as to make predictions of the DA value for
that would be inaccessible to numerical simulations, because of the excessive computing time needed. We stress once more that the concept of DA at turn number
N can be linked with that of beam intensity at the same time
N [
28]. This means that the knowledge of the evolution of the DA, i.e., a rather abstract quantity, can be directly linked to the evolution of the beam intensity in a circular particle accelerator, which is a fundamental physical observable. This approach has been already successfully applied in experimental studies [
38] and intense efforts are devoted to refine and promote the proposed strategy.
A detailed analysis has been presented in Reference [
24], where the extrapolation error has been considered as a key figure of merit to qualify the models describing the DA evolution. The key improvement that can be brought to the DA modeling by ML is to improve the extrapolation error. However, it is generally believed that ML has serious limitations in providing efficient answers to extrapolation problems. Therefore, the devised approach is based on a different strategy. It consists in training a Gaussian Process (GP) (see, e.g., [
39]) on the available DA evolution data to generate synthetic, though realistic, points that are used to increase the overall density of points, which are then used to create the model. In this way, ML is used to provide interpolated points, which is a task that can be dealt with very efficiently. This considerably improves the extrapolation capabilities of the fitted model as the results of our studies indicate clearly. In
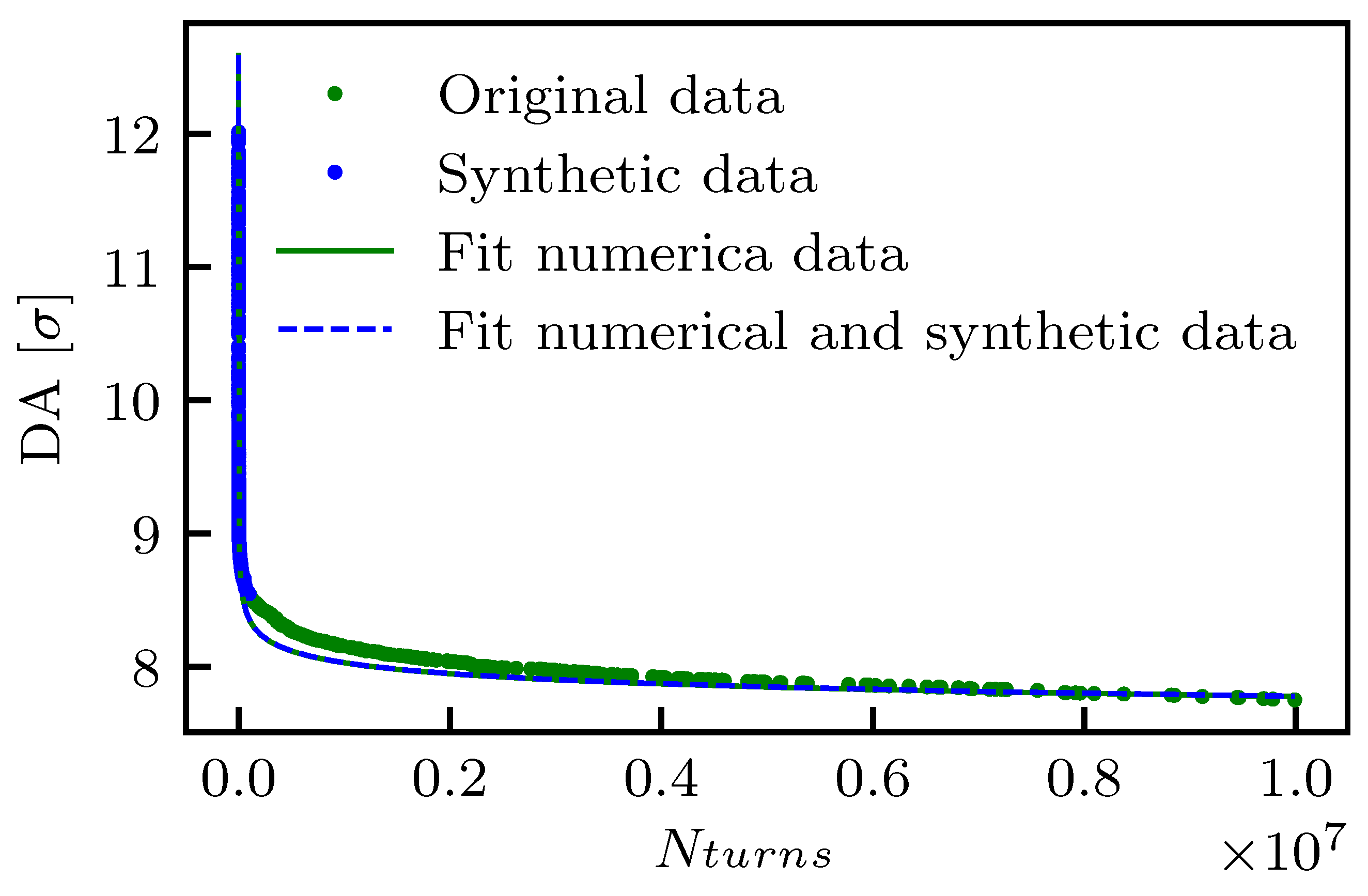
Figure 8 an example of the proposed fit based on the DA model (14b) with three parameters and with the addition of synthetic points determined by means of a GP is shown for reference. In this specific case, the original fit approach and that based on the GP provide very similar results.
Out of the large pool of several thousands of DA simulations performed for LHC and HL-LHC, a single study with
has been selected at random and 50 values of turns
have been distributed uniformly between
and
. The corresponding values
have been generated by means of the GP and then a fit of the DA data (numerical plus synthetic points) was performed using model (14b), and this procedure was repeated
times, each time computing the Mean Square Error (MSE)
. Note that, indeed, two variants have been tested, namely using three fit parameters (
), or two (
), in which
was expressed as a function of
according to Equation (
15). It is worth mentioning that whenever the GP is used, the MSE of the fitted model is computed disregarding the synthetic points, i.e., using only the points obtained from the DA simulations. In this way, we can perform a fair comparison between the MSE for the original fit and that performed with the help of GP.
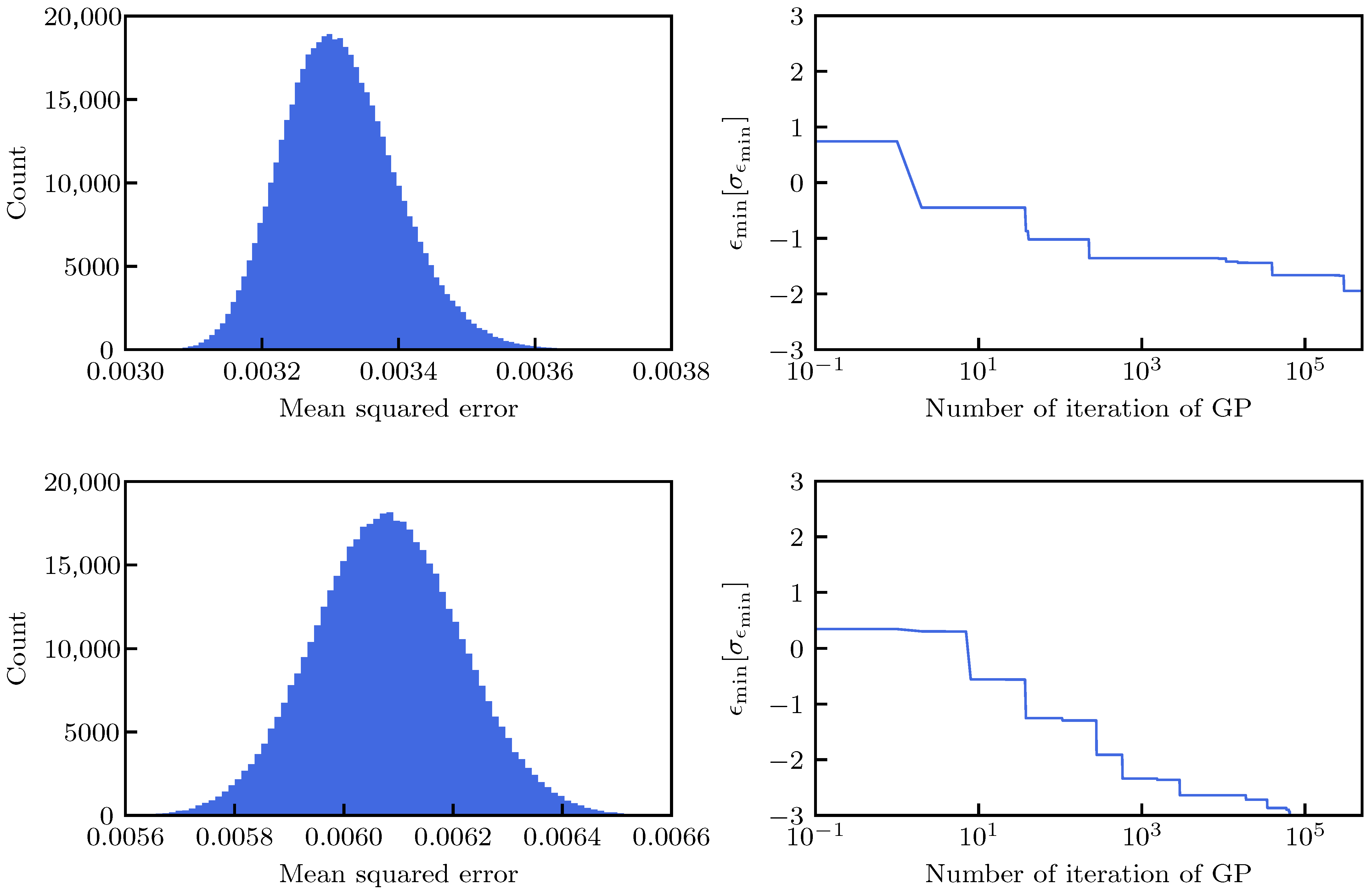
The resulting distribution of the MSE is shown in
Figure 9 (left) for the case of the three-(top) and two-parameter (bottom) fit.
The shape of the MSE distribution for the three-parameter fit is located closer to zero and its width is smaller than the corresponding distribution for the two-parameter fit. The former is logical as a model with more parameters that has more possibility to tune and typically will have a better MSE, while the latter implies that the iterative application of the GP can provide a larger improvement in the MSE in the case of the two-parameter fit. It is worth noting that while the MSE distribution for the three-parameter fit is right-skewed, that for the two-parameter fit is left-skewed.
In the right-hand plots of
Figure 9, the behavior of the following quantity is shown:
which is the minimum, over the iterations of the GP process, expressed as its normalized distance to the average MSE. The average MSE,
, and its variance,
, used to express
, are calculated over the full set of
iterations and are reported in
Table 1. The initial value
is not particularly meaningful, whereas the variation can be used as an estimate of the rate of improvement of the MSE with the number of iterations of the GP. Another interesting variable to investigate is the relative gain, w.r.t the original fit, of the minimum MSE after
i iterations:
which is also reported in
Table 1. For both fit types, i.e., with two or three parameters, a number of iterations of about
would seem to induce a sizeable reduction of the MSE. However, looking at
, it becomes clear that going from
to
iterations only induces an extra gain of around 1% (even considering that
doubles in case of the two-parameter fit). This can be explained by observing that
is already multiple
units away from the MSE of the original fit. Knowing this, and taking into consideration that in the case of analyses of a large set of DA simulations a trade-off between CPU time and final value of MSE needs to be found, we consider a value of around
GP iterations to be sufficient.
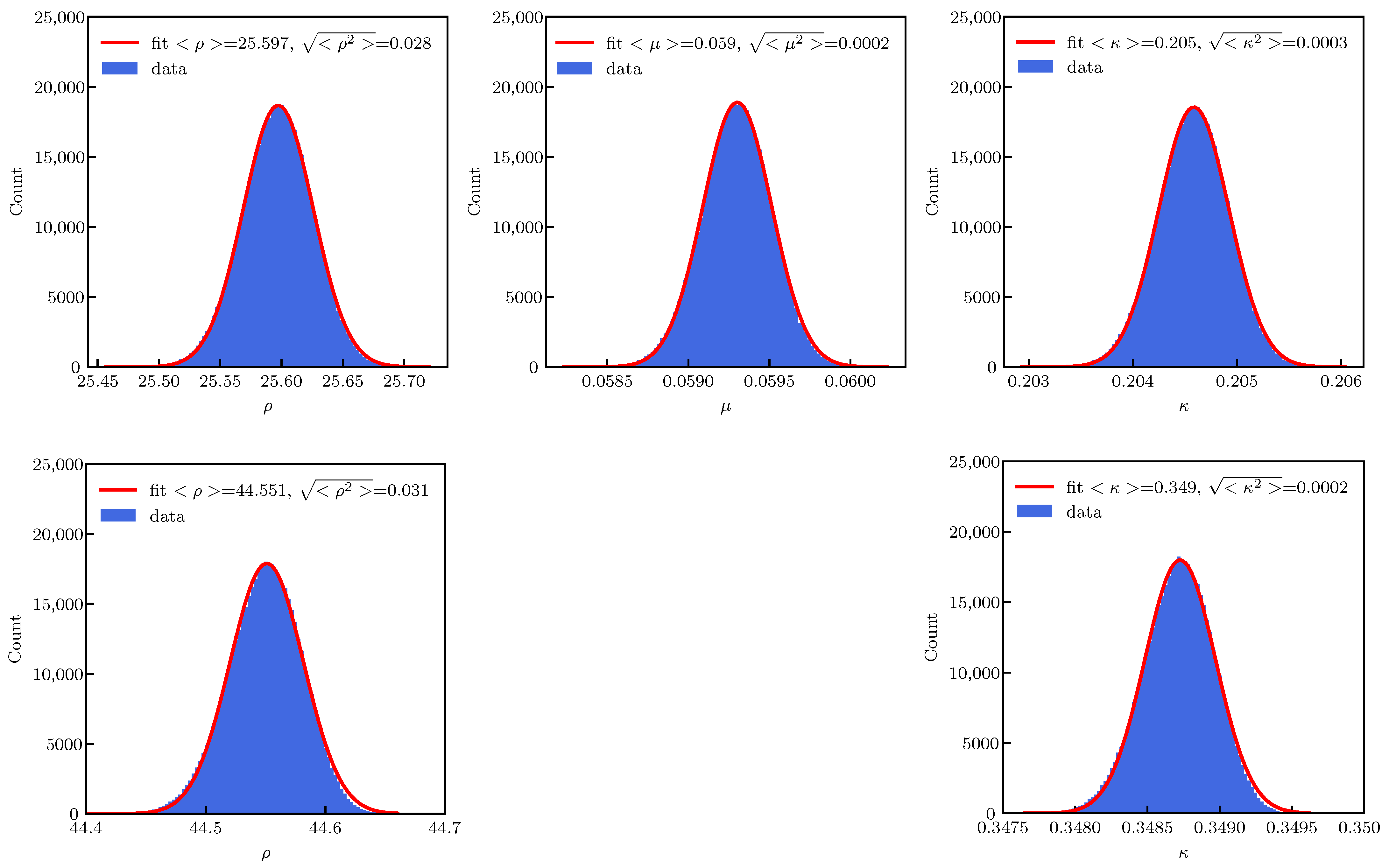
The distribution of the parameters describing the DA evolution with time is shown in
Figure 10 for the three- (top) and two-parameter (bottom) cases.
Gaussian fits to the model parameters are provided for reference, and while these fits are in excellent agreement with the numerical data for the three-parameter case, slight asymmetries of the parameter distributions are visible for the two-parameter case. Although the mean values of the common fit parameters, i.e., and , are different for the two types of fits, the absolute values of their RMS values are very similar.
As mentioned earlier, the main use of the DA models is to provide an accurate tool to extrapolate DA beyond a number of turns N that is currently feasible with the CPU power available to our numerical simulations. Therefore, it is essential to probe the accuracy of the prediction of the fitted model. To this aim, a set of six DA simulations performed using a LHC lattice at injection energy and with a maximum number of turns of (note that the standard value of turns is , when beam–beam effects are neglected but magnetic fields errors are included, or when beam–beam effect are included and the magnetic field errors are neglected). The large number of turns simulated, which accounts for only 889 s of beam revolutions in the ring with respect to several hours of a typical fill, allow the accuracy of the prediction power of the DA model to be probed accurately. This is done by setting the value of the maximum number of turns of the numerical data that are used to fit the DA model. Such a model is then used to extrapolate the DA up to turns, and the MSE is evaluated over the full set of numerical data up to turns. All of this is repeated by varying . The same procedure is applied when the GP is used to improve the quality of the fitted model. In this case, 75 additional points are uniformly distributed between when , and the number of synthetic points is linearly increased to reach 750 when . Once more, we recall that the synthetic points are not considered when computing the MSE for the GP-based fit, which ensures a fair comparison between the MSE of the original and GP-based fits. Also in this application of the GP-based fit, the GP part is repeated 200 times and the minimum MSE error over the 200 iterations is used. Lastly, all of these protocols are repeated for the three- and two-parameter fit of the DA model.
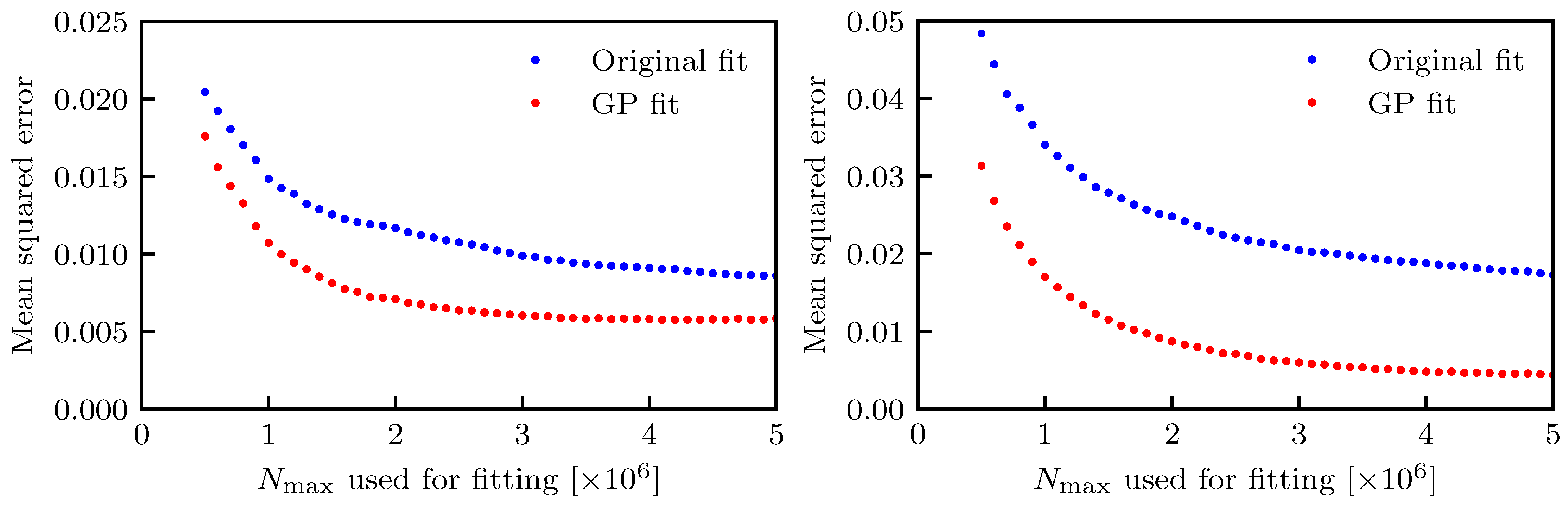
The results are shown in
Figure 11, where the case of three- and two-parameters fit are shown in the left and right plots, respectively.
The metrics used to quantify the performance in terms of extrapolation could have been the determination of the difference between the DA value at turns computed from numerical simulations and that obtained from the fitted DA models. However, it has been chosen to apply the MSE computed over the entire set of points from the tracking simulations. Indeed, this approach is much more robust, as it estimates the fit performance by using the information carried by the full set of points, rather than a single point.
The key point is that the MSE for the GP-based fit is always better than that of the corresponding original fit, which clearly indicates the success of the proposed approach. Some sort of saturation in the decrease of the MSE is visible for for the three-parameter fit, which indicates that the numerical simulations carried out up until any of the turn numbers in that interval allow a reliable extrapolation up to turns. No qualitative difference was observed for the two types of fits: as expected, the initial MSE value was larger for the case of two- with respect to the case of three-parameter fit. However, the MSE decreased steadily as a function of , and the MSE for the GP-based fit reached a final comparable value no matter the value of the number of free fit parameters. In fact, as previously mentioned, the GP was more efficient in improving the two- than the three-parameter fit, as the MSE for was reduced from (original fit) to (GP fit) for the two-parameter case (a reduction of 74%), whereas a reduction from (original fit) to (GP fit) for the three-parameter case (a reduction of 32%) was observed.
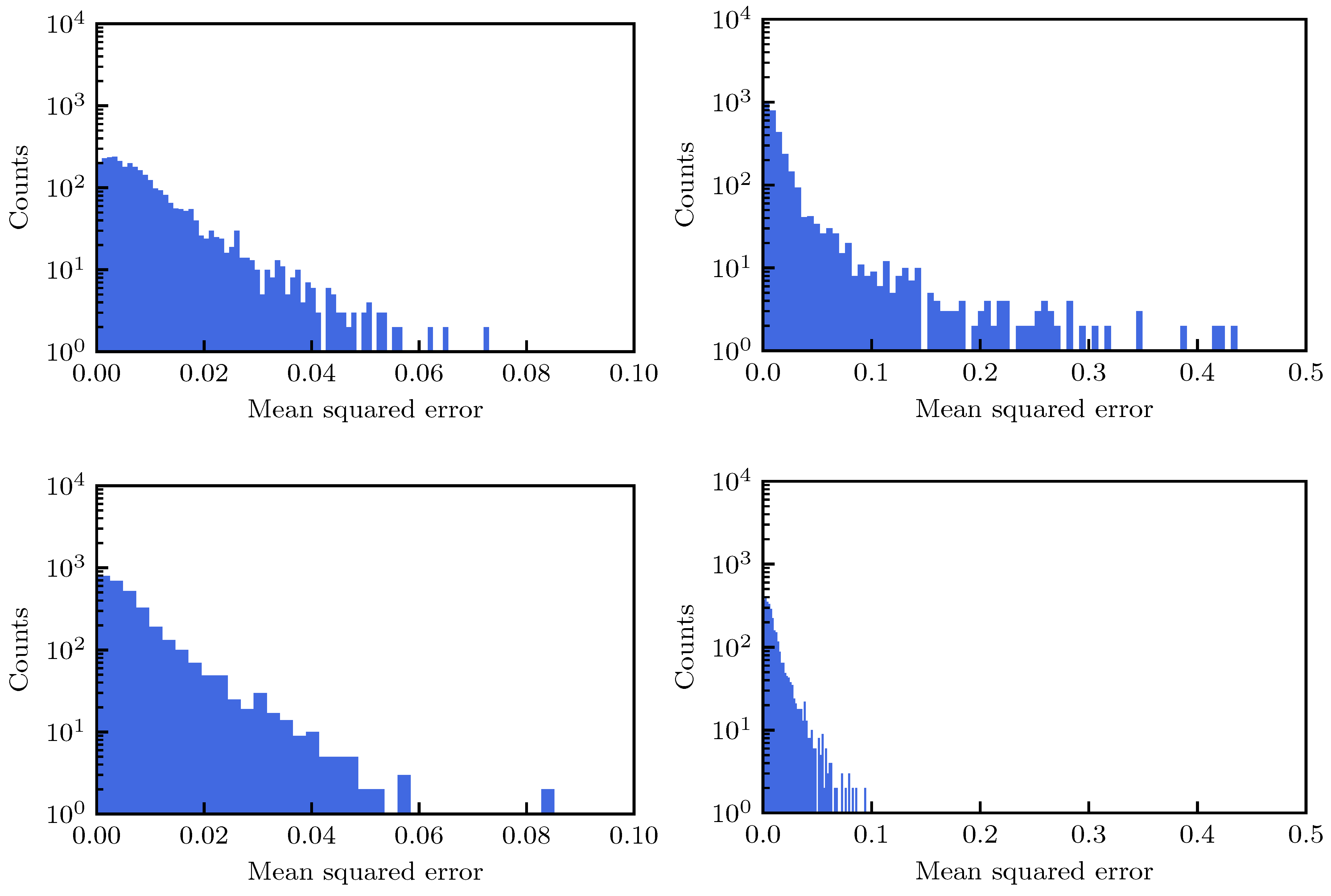
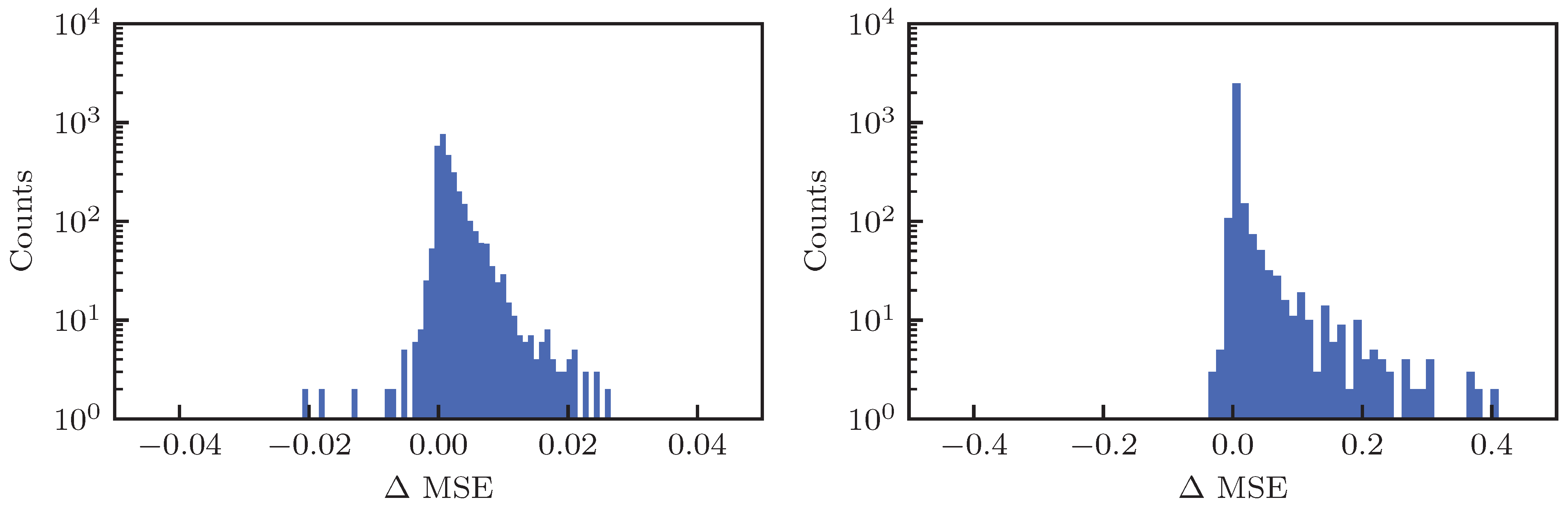
As a last investigation, the behavior of the proposed method based on ML was probed on a large set of DA simulations, corresponding to 3090 cases of the LHC lattice at injection energy for various configurations of the strength of the octupoles and values of the linear chromaticity. The fits were performed using
and then extrapolating the fitted function up until
turns and evaluating the MSE. Whenever the GP was used, 50 iterations were applied (this number is slightly sub-optimal, but it was chosen as a trade-off between the improvement achieved by the iterations of the GP and the CPU time required by this study (the generation of the plots shown in
Figure 12 took several hours) and in addition to the MSE for each fit type, the difference of MSE values, i.e.,
was considered to provide an easy comparison between the two approaches. As in the previous studies, both three- and two-parameter DA models were used and the summary plots are shown in
Figure 12.
The results for the three-parameter fit are reported in the left column, whereas those for the two-parameter fit are reported in the right one. In the first and second rows the distribution of the MSE for the original fit and for that with GP are shown, respectively; whereas in the third row the distribution of
is reported. Globally, the MSE for the three-parameter fit is smaller than that of the two-parameter fit, and the fit with GP has a better performance in terms of MSE than the original one. This is clearly visible for the two-parameter fit, but is also the case for the three-parameter variant. This can be appreciated in
Table 2, where some statistical parameters of the distributions are reported: the improvement in terms of MSE distribution brought by the GP is clear, and very much visible, in particular for the two-parameter fit.
As far as the distribution of is concerned, its positive part shows how many DA simulations have been improved by means of the GP fit, wheres the negative part shows the case in which the GP fit has worsened the DA model. Although there are some DA simulations for which the GP fit produced a slight worsening, it is worth mentioning that this set corresponds to 13% and 8% for the three- and two-parameter fits, respectively. It is exactly for this reason that one should not use a single iteration of the GP process as a means to improve the fit. As mentioned before, a value of around iterations seems appropriate to improve the fitting quality overall.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}