
Text Classification Based on Convolutional Neural Networks and Word Embedding for Low-Resource Languages: Tigrinya

 ,
, 
 ,
,  and
and
Abstract
1. Introduction
- We develop a dataset that contains 30,000 text documents labeled in six categories.
- We develop an unsupervised corpus that contains more than six million words to support CNN embedding.
- This work allows an immediate comparison of current state-of-the-art text classification techniques in the context of the Tigrinya language.
- Finally, we evaluate the CNN classification accuracy with word2vec and FastText models and compare classifier performance with various machine learning techniques.
2. Background and Related Works
2.1. Previous Attempts for Tigrinya Natural Language Processing
2.2. Text Classification
2.3. Word Embeddings
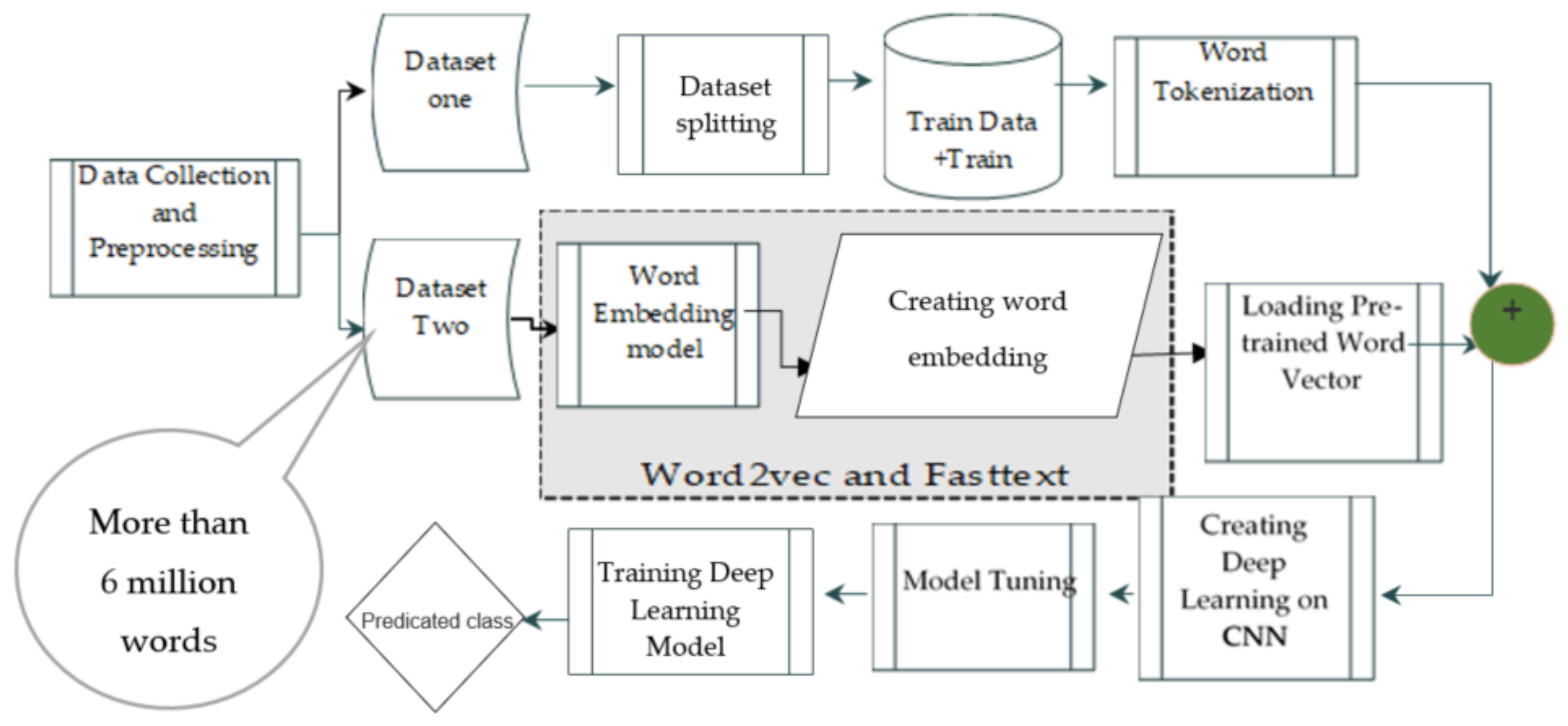
3. Research Methods and Dataset Construction
Research Methods
4. Dataset Construction and CNN Architecture
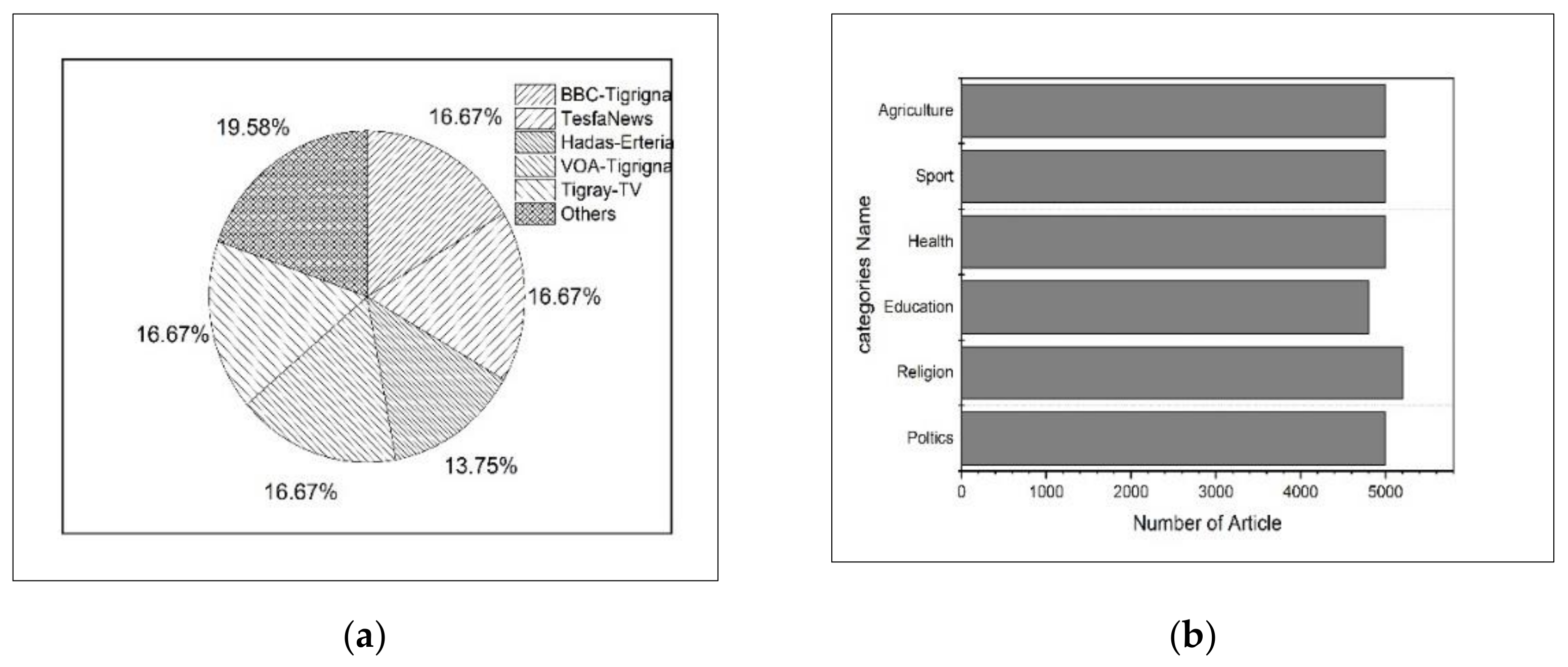
4.1. Single-Label Tigrinya News Articles Dataset
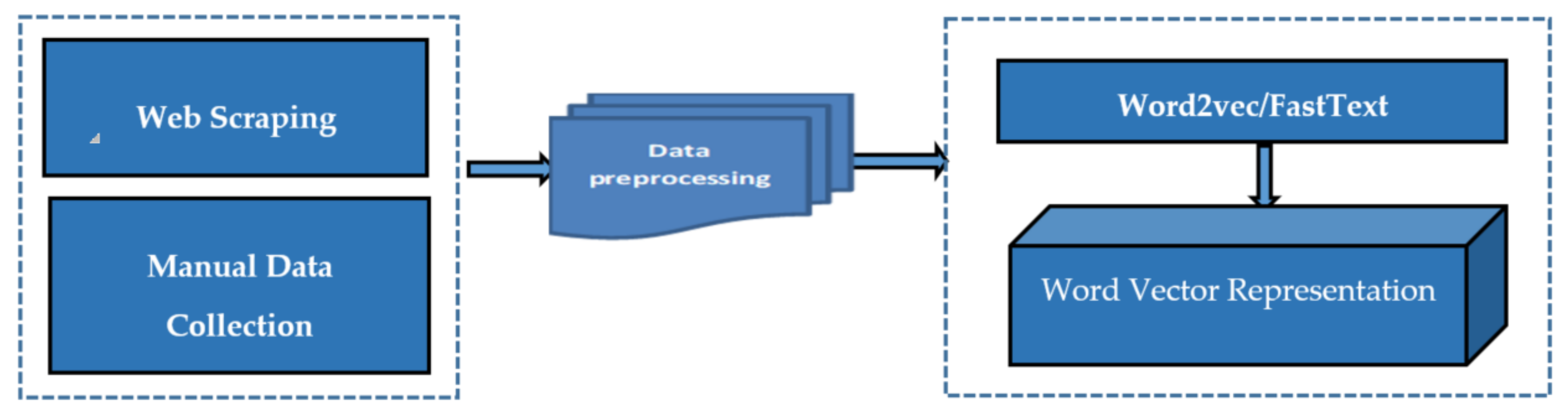
4.1.1. Tigrinya Corpus Collection and Preparation
4.1.2. Data Preprocessing
- Removing stop words using Python, Figure 6 shows an example of common stop words;
- Tokenizing the texts using Python;
- Removing URLs and links to websites that started with “www.*” or “http://*”;
- Removing typing errors;
- Removing non-Tigrinya characters;
- We avoided normalization since it can affect word meanings, for example, the verb “eat” in English is equivalently translated to the Tigrinya form “በልዐ/bele”, and adding the prefix “ke/ክእ” changes the word to “kebele/ክእበልዐ”, meaning to “let me eat”;
- Furthermore, we also prepared a list for mapping known abbreviations into counterpart meanings, e.g., abbreviated “(bet t/t (ቤት ት/ቲ)” means “school/ትምህርቲ ቤት” and abbreviated “betf/di (ቤት ፍ/ዲ)” means “justice office/ቤት ፍርዲ”.
4.1.3. Basic CNN Architecture
Sequence Embedding Layer
Convolutional Layer
Pooling Layer
Fully Connected Layer
Softmax Function
5. Experiment and Discussion
5.1. CNN Parameter Values
5.2. Comparison with Traditional Models
5.3. Comparison of Pretrained Word2vec with CNN-Based Models
5.4. Comparison of FastText Pretrained on CNN-Based Models
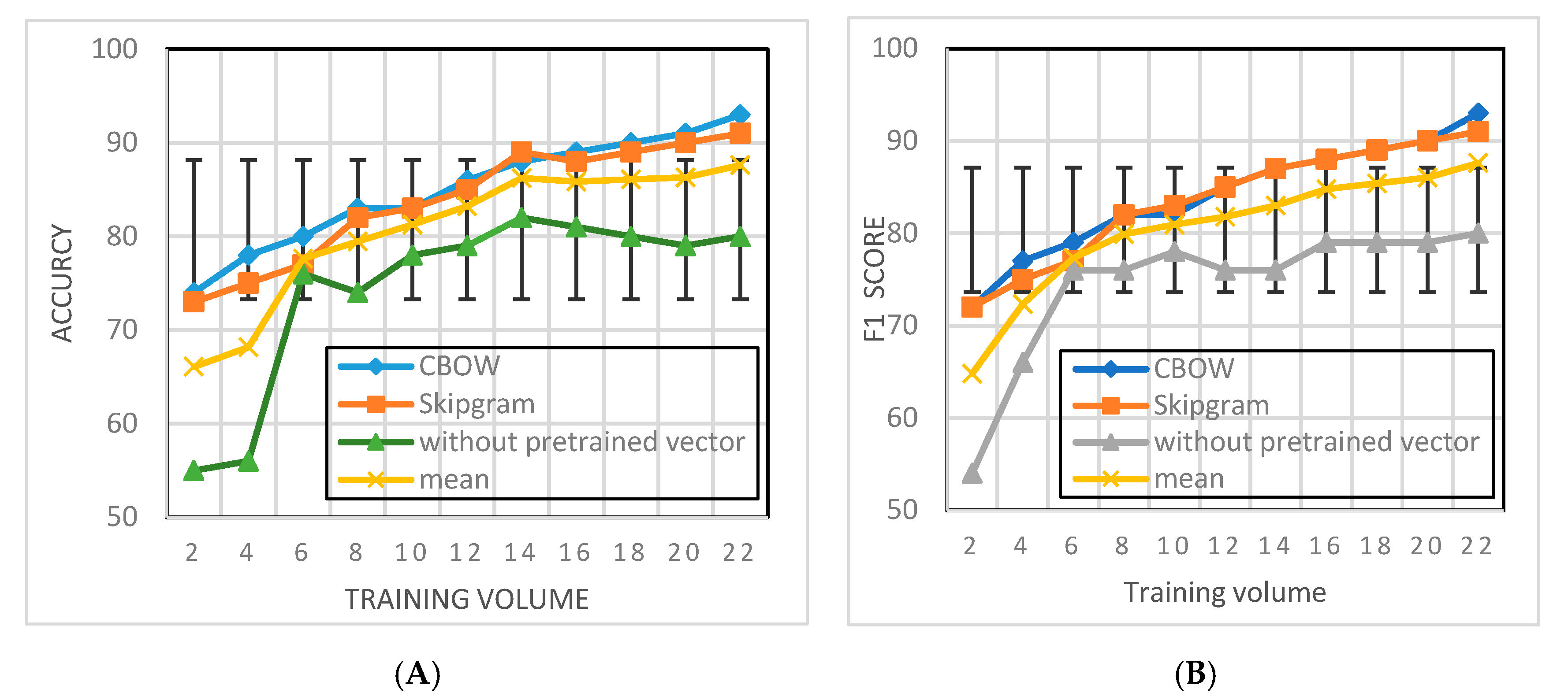
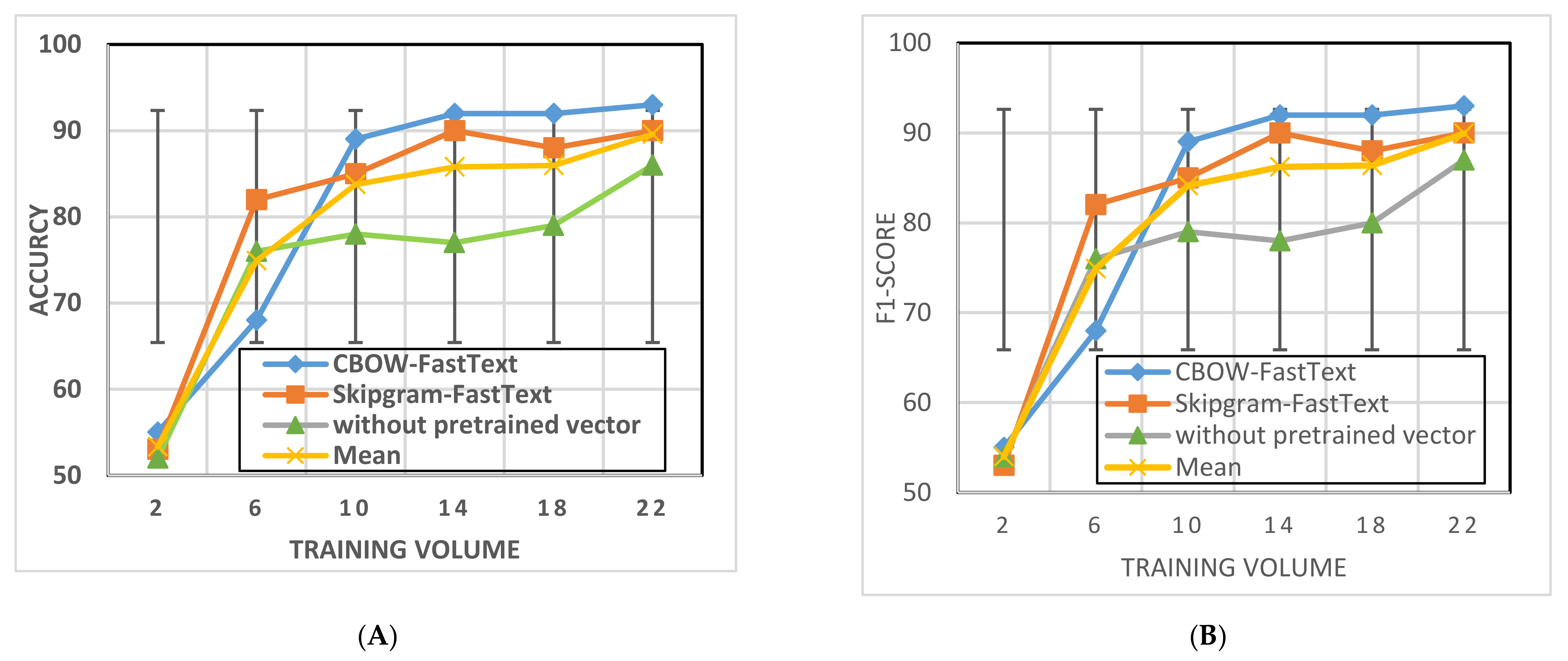
5.5. Comparison of CBOW Results Word2vec and FastText
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviation
| CNN | Convolutional neural network |
| TF-IDF | Term frequency-inverse document frequency |
| NLP | Natural language processing |
| ML | Machine learning |
| CBOW | Continuous bag of words |
| ReLU | Rectified linear unit |
| SVM | Support vector machine |
| NB | Naïve Bayes |
| KNN | K-nearest neighbor |
| BOW | Bag-of-words |
| PWV | Pretrained word vector |
Appendix A

References
- Al-Ayyoub, M.; Khamaiseh, A.A.; Jararweh, Y.; Al-Kabi, M.N. A comprehensive survey of arabic sentiment analysis. Inf. Process. Manag. 2019, 56, 320–342. [Google Scholar] [CrossRef]
- Negash, A. The Origin and Development of Tigrinya Language Publications (1886-1991) Volume One. 2016. Available online: https://scholarcommons.scu.edu/cgi/viewcontent.cgi?article=1130&context=library (accessed on 20 January 2021).
- Osman, O.; Mikami, Y. Stemming Tigrinya words for information retrieval. In Proceedings of the COLING 2012: Demonstration Papers, Mumbai, India, 1 December 2012; pp. 345–352. Available online: https://www.aclweb.org/anthology/C12-3043 (accessed on 20 January 2021).
- Tedla, Y.K.; Yamamoto, K.; Marasinghe, A. Nagaoka Tigrinya Corpus: Design and Development of Part-of-speech Tagged Corpus. Int. J. Comput. Appl. 2016, 146, 33–41. [Google Scholar] [CrossRef]
- Tedla, Y.K. Tigrinya Morphological Segmentation with Bidirectional Long Short-Term Memory Neural Networks and its Effect on English-Tigrinya Machine Translation; Nagaoka University of Technology: Niigata, Japan, 2018. [Google Scholar]
- Tedla, Y.; Yamamoto, K. Analyzing word embeddings and improving POS tagger of tigrinya. In Proceedings of the 2017 International Conference on Asian Language Processing (IALP), Singapore, 5–7 December 2017; pp. 115–118. [Google Scholar] [CrossRef]
- Tedla, Y.; Yamamoto, K. The effect of shallow segmentation on English-Tigrinya statistical machine translation. In Proceedings of the 2016 International Conference on Asian Language Processing (IALP), Tainan, Taiwan, 21–23 November 2016; pp. 79–82. [Google Scholar] [CrossRef]
- Stats, I.W. Available online: https://www.internetworldstats.com/ (accessed on 10 September 2020).
- Kalchbrenner, N.; Blunsom, P.J. Recurrent convolutional neural networks for discourse compositionality. arXiv 2013, arXiv:1306.3584. [Google Scholar]
- Jiang, M.; Liang, Y.; Feng, X.; Fan, X.; Pei, Z.; Xue, Y.; Guan, R.J.N.C. Text classification based on deep belief network and softmax regression. Neural. Comput. Appl. 2018, 29, 61–70. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P.J. A convolutional neural network for modelling sentences. Neural. Comput. 2014. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Lai, S.; Liu, K.; He, S.; Zhao, J.J.I.I.S. How to generate a good word embedding. IEEE Intell. Syst. 2016, 31, 5–14. [Google Scholar] [CrossRef]
- T. S. International, in Tigrinya at Ethnologue, Ethnologue. 2020. Available online: http://www.ethnologue.com/18/language/tir/ (accessed on 3 March 2020).
- Mebrahtu, M. Unsupervised Machine Learning Approach for Tigrigna Word Sense Disambiguation. Ph.D. Thesis, Assosa University, Assosa, Ethiopia, 2017. [Google Scholar]
- Abate, S.T.; Tachbelie, M.Y.; Schultz, T. Deep Neural Networks Based Automatic Speech Recognition for Four Ethiopian Languages. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8274–8278. [Google Scholar]
- Littell, P.; McCoy, T.; Han, N.-R.; Rijhwani, S.; Sheikh, Z.; Mortensen, D.R.; Mitamura, T.; Levin, L. Parser combinators for Tigrinya and Oromo morphology. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Fisseha, Y. Development of Stemming Algorithm for Tigrigna Text; Addis Ababa University: Addis Ababa, Ethiopia, 2011. [Google Scholar]
- Reda, M. Unsupervised Machine Learning Approach for Tigrigna Word Sense Disambiguation. Philosophy 2018, 9. [Google Scholar]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Wallach, H.M. Topic modeling: Beyond bag-of-words. In Proceedings of the 23rd international conference on Machine learning, Haifa, Israel, 21–25 June 2010; pp. 977–984. [Google Scholar]
- Gauging, D.M.J.S. Similarity with n-grams: Language-independent categorization of text. Science 1995, 267, 843–848. [Google Scholar]
- Joachims, T.A. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. Available online: https://apps.dtic.mil/docs/citations/ADA307731 (accessed on 20 January 2021).
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In AAAI-98 Workshop on Learning for Text Categorization; Citeseer: Princeton, NJ, USA, 1998; Volume 752, pp. 41–48. [Google Scholar]
- Trstenjak, B.; Mikac, S.; Donko, D.J.P.E. KNN with TF-IDF based framework for text categorization. Procedia Eng. 2014, 69, 1356–1364. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar]
- Yun-tao, Z.; Ling, G.; Yong-cheng, W. An improved TF-IDF approach for text classification. J. Zhejiang Univ. Sci. A 2005, 6, 49–55. [Google Scholar]
- Johnson, R.; Zhang, T. Semi-supervised convolutional neural networks for text categorization via region embedding. Adv. Neural Inf. Process. Syst. 2015, 28, 919–927. [Google Scholar]
- Johnson, R.; Zhang, T. Supervised and semi-supervised text categorization using LSTM for region embeddings. arXiv 2016, arXiv:1602.02373. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B.; Discovery, K. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. Available online: https://arxiv.org/abs/1509.01626 (accessed on 20 January 2021).
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Menlo Park, CA, USA, 25–30 January 2015. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Parwez, M.A.; Abulaish, M.J.I.A. Multi-label classification of microblogging texts using convolution neural network. IEEE Access 2019, 7, 68678–68691. [Google Scholar] [CrossRef]
- Tang, D.; Wei, F.; Qin, B.; Yang, N.; Liu, T.; Zhou, M.; Engineering, D. Sentiment embeddings with applications to sentiment analysis. IEEE Trans. Knowl. Data Eng. 2015, 28, 496–509. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Wang, X.; Jiang, W.; Luo, Z. Combination of convolutional and recurrent neural network for sentiment analysis of short texts. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–17 December 2016; pp. 2428–2437. [Google Scholar]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. 2016. Available online: https://openreview.net/forum?id=SyK00v5xx (accessed on 20 January 2021).
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. Fasttext. zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Peng, H.; Song, Y.; Roth, D. Event detection and co-reference with minimal supervision. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 392–402. [Google Scholar]
- Kulkarni, A.; Shivananda, A. Converting text to features. In Natural Language Processing Recipes; Springer: Berlin/Heidelberg, Germany, 2019; pp. 67–96. [Google Scholar] [CrossRef]
- Řehůřek, R. Models.Word2vec–Deep Learning with Word2vec. Available online: https://radimrehurek.com/gensim/models/word2vec.html (accessed on 16 February 2017).
- Liu, J.; Chang, W.-C.; Wu, Y.; Yang, Y. Deep learning for extreme multi-label text classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 115–124. [Google Scholar] [PubMed]
- Zhang, Y.; Wallace, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Main Application | Sentences/Tokens | Year |
|---|---|---|---|
| Fisseha [20] | Stemming algorithm | 690,000 | 2011 |
| Reda et al. [21] | Unsupervised ML word sense disambiguation | 190,000 | 2018 |
| Osman et al. [3] | Stemming Tigrinya words | 164,634 | 2012 |
| Yemane et al. [6] | Post tagging for Tigrinya | 72,000 | 2016 |
| Training Instances | Validation Instances | Category (Class Labels) | Length (Maximum) | Words (Average) | Vocabulary Size |
|---|---|---|---|---|---|
| 30,000 | 6000 | 6 | 1000 | 235 | 51,000 |
| Number of documents | 111,082 |
| Number of sentences | 17,000 |
| Number of words (vocabulary) | 6,002,034 |
| Number of unique words | 368,453 |
| Parameter | Value |
|---|---|
| Word embedding size | 100 |
| Window size (filter size) | 2, 3, 4, and 5 |
| Number of filters for each size | 100 |
| Dropout probability at the embedding layer | 0.15 |
| Parameter | Value |
|---|---|
| Epochs | 20 |
| Learning rate | 0.001 |
| Regularization rate | 0.025 |
| CNN dropout probability | 0.2 |
| Optimization | Adam |
| Classifier | Training Accuracy | Validation Accuracy |
|---|---|---|
| Naïve Byes | 0.9287 | 0.8658 |
| Random Forest | 0.9307 | 0.8356 |
| SVM | 0.9503 | 0.8452 |
| Decision tree | 0.9663 | 0.8123 |
| CNN without embedding | 0.9335 | 0.9141 |
| Pretrained Vector | Model with Pretrained | Accuracy | F1 Score | Time for Training (S) | Training Volume | Epochs |
|---|---|---|---|---|---|---|
| Word2vec | CNN + CBOW | 0.9341 | 0.9151 | 2000 | 24 | 20 |
| CNN + skip-gram | 0.9147 | 0.9161 | 1865 | 24 | 17 | |
| CNN + without pretrained | 0.7905 | 0.7809 | 900 | 16 | 13 | |
| FastText | CNN + CBOW | 0.9041 | 0.9054 | 1980 | 24 | 20 |
| CNN + skip-gram | 0.8975 | 0.8909 | 1723 | 24 | 20 | |
| CNN + without pretrained | 0.7941 | 0.7951 | 868 | 16 | 14 |
| Category | Pretrained Word2vec (CBOW) | Pretrained FastText (CBOW) | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| Agriculture | 0.8807 | 0.8834 | 0.8820 | 0.8607 | 0.8624 | 0.8615 |
| Sport | 0.9301 | 0.9312 | 0.9306 | 0.9202 | 0.9214 | 0.9206 |
| Health | 0.9212 | 0.9234 | 0.9222 | 0.9201 | 0.9202 | 0.9202 |
| Education | 0.9231 | 0.9311 | 0.9270 | 0.9031 | 0.9311 | 0.9168 |
| Politics | 0.9105 | 0.9151 | 0.9127 | 0.9105 | 0.9151 | 0.9127 |
| Religion | 0.9201 | 0.9113 | 0.9156 | 0.9001 | 0.9013 | 0.9006 |
| Average | 0.9438 | 0.9425 | 0.9150 | 0.9438 | 0.9425 | 0.9054 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fesseha, A.; Xiong, S.; Emiru, E.D.; Diallo, M.; Dahou, A. Text Classification Based on Convolutional Neural Networks and Word Embedding for Low-Resource Languages: Tigrinya. Information 2021, 12, 52. https://doi.org/10.3390/info12020052
Fesseha A, Xiong S, Emiru ED, Diallo M, Dahou A. Text Classification Based on Convolutional Neural Networks and Word Embedding for Low-Resource Languages: Tigrinya. Information. 2021; 12(2):52. https://doi.org/10.3390/info12020052
Chicago/Turabian StyleFesseha, Awet, Shengwu Xiong, Eshete Derb Emiru, Moussa Diallo, and Abdelghani Dahou. 2021. "Text Classification Based on Convolutional Neural Networks and Word Embedding for Low-Resource Languages: Tigrinya" Information 12, no. 2: 52. https://doi.org/10.3390/info12020052
APA StyleFesseha, A., Xiong, S., Emiru, E. D., Diallo, M., & Dahou, A. (2021). Text Classification Based on Convolutional Neural Networks and Word Embedding for Low-Resource Languages: Tigrinya. Information, 12(2), 52. https://doi.org/10.3390/info12020052