
Short-Term Load Forecasting Based on the Transformer Model

 , ,
, , 


Abstract
:1. Introduction
2. Literature Review
3. Materials and Methodology
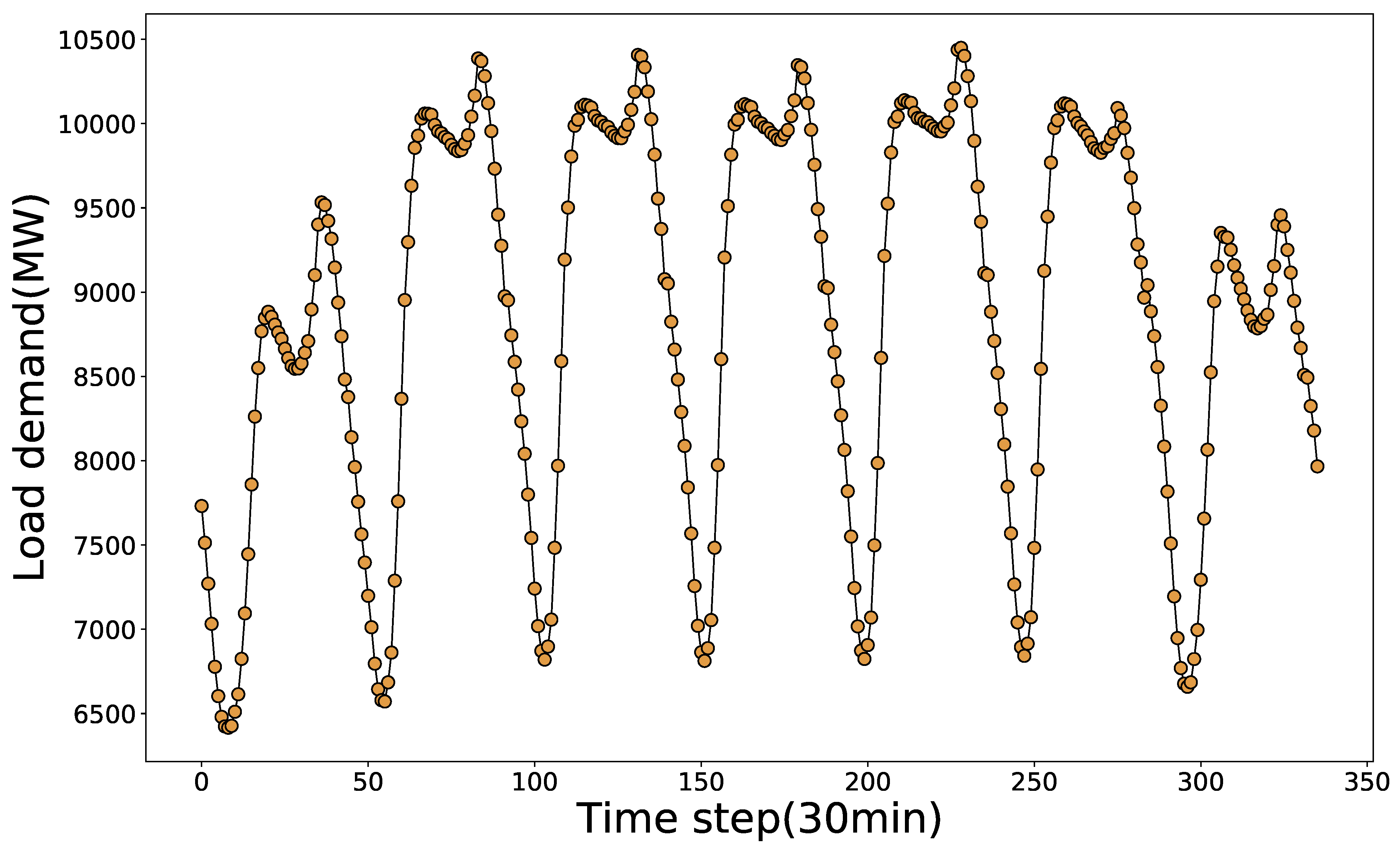
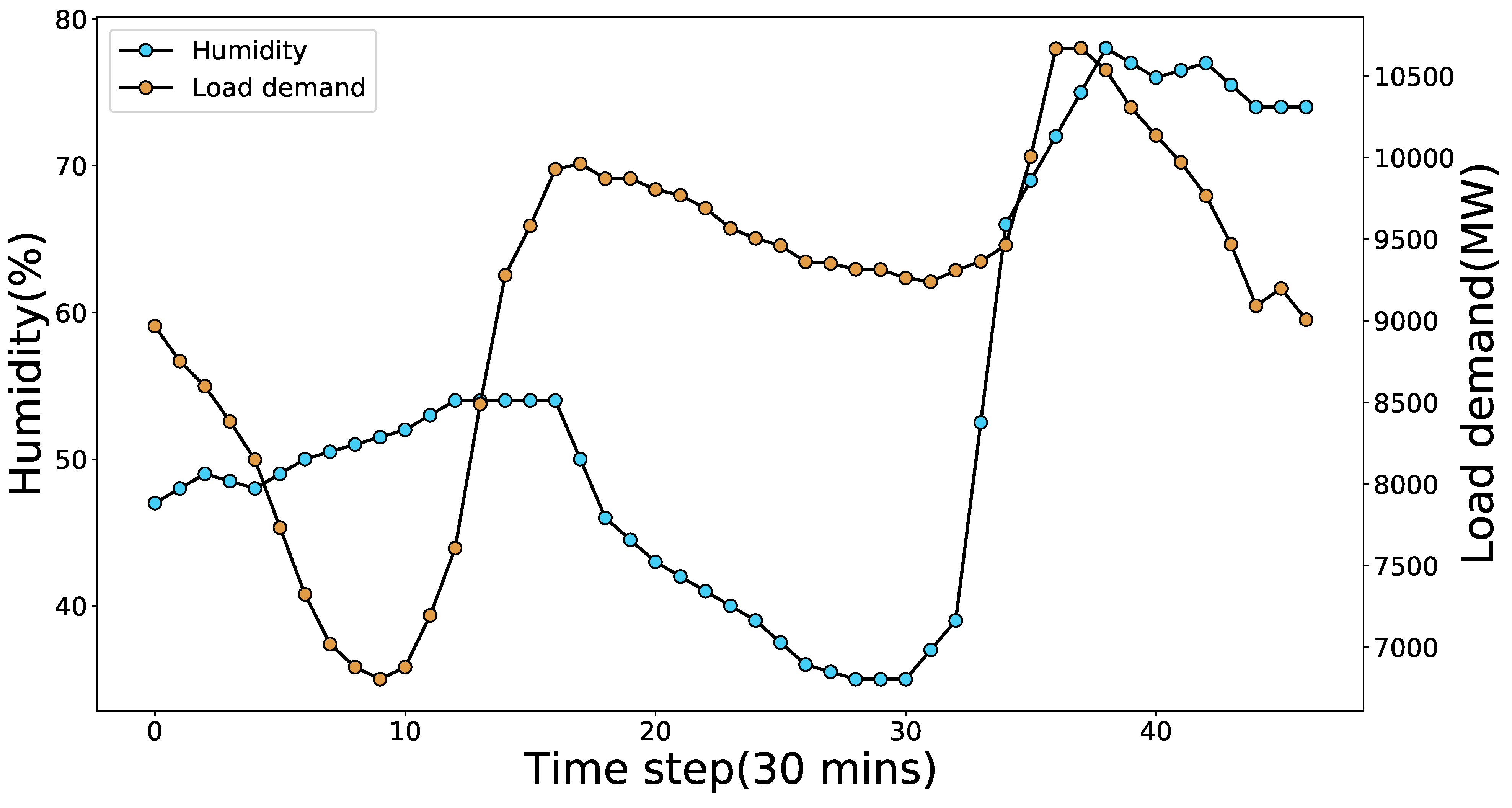
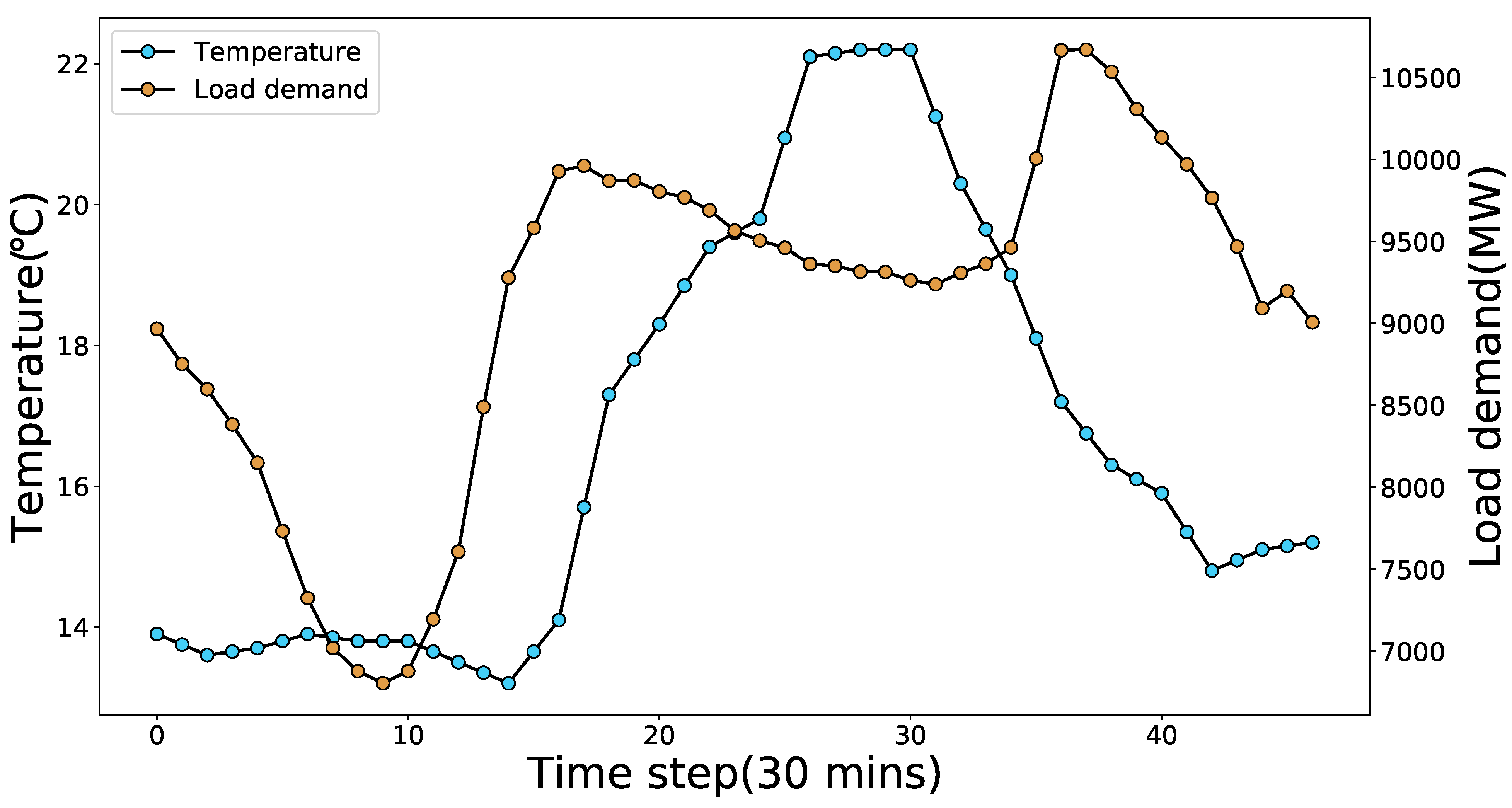
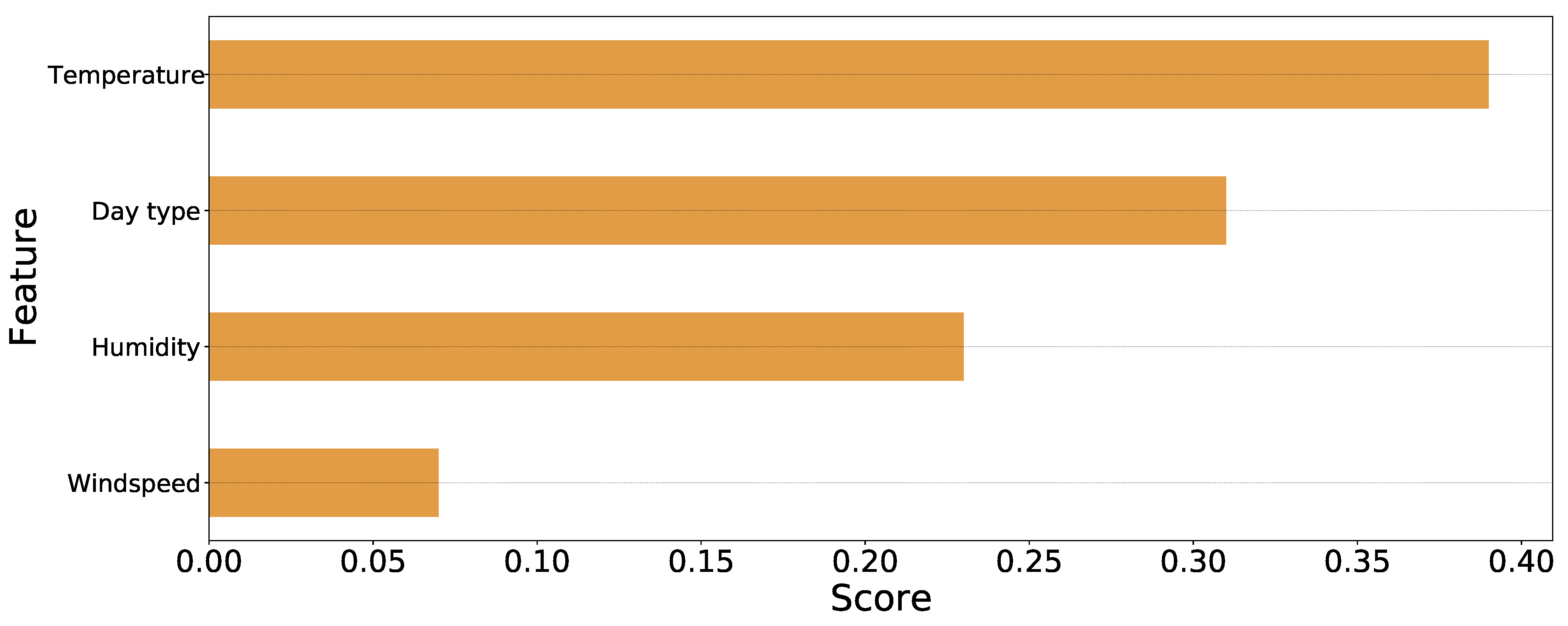
3.1. Data Collection
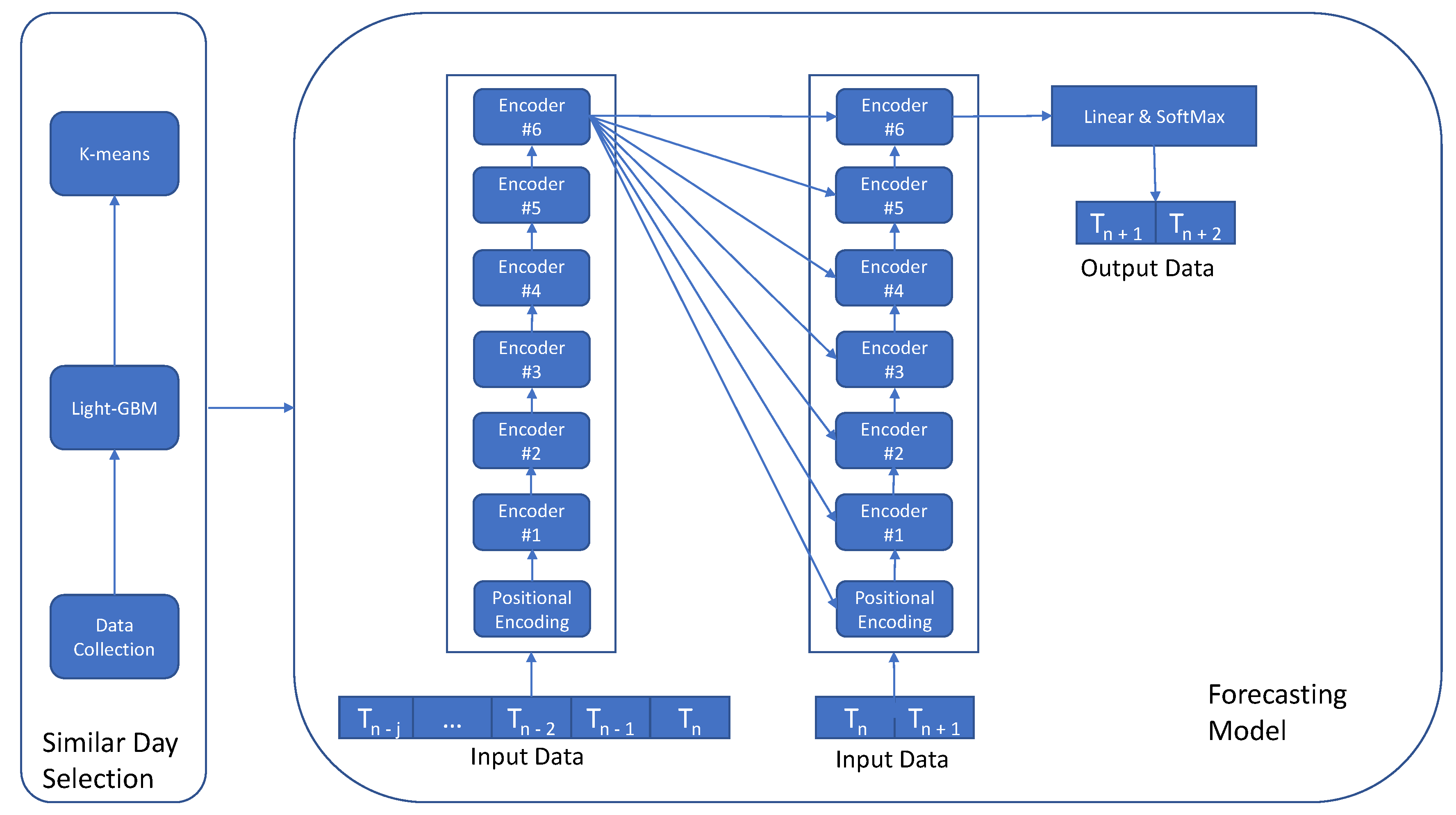
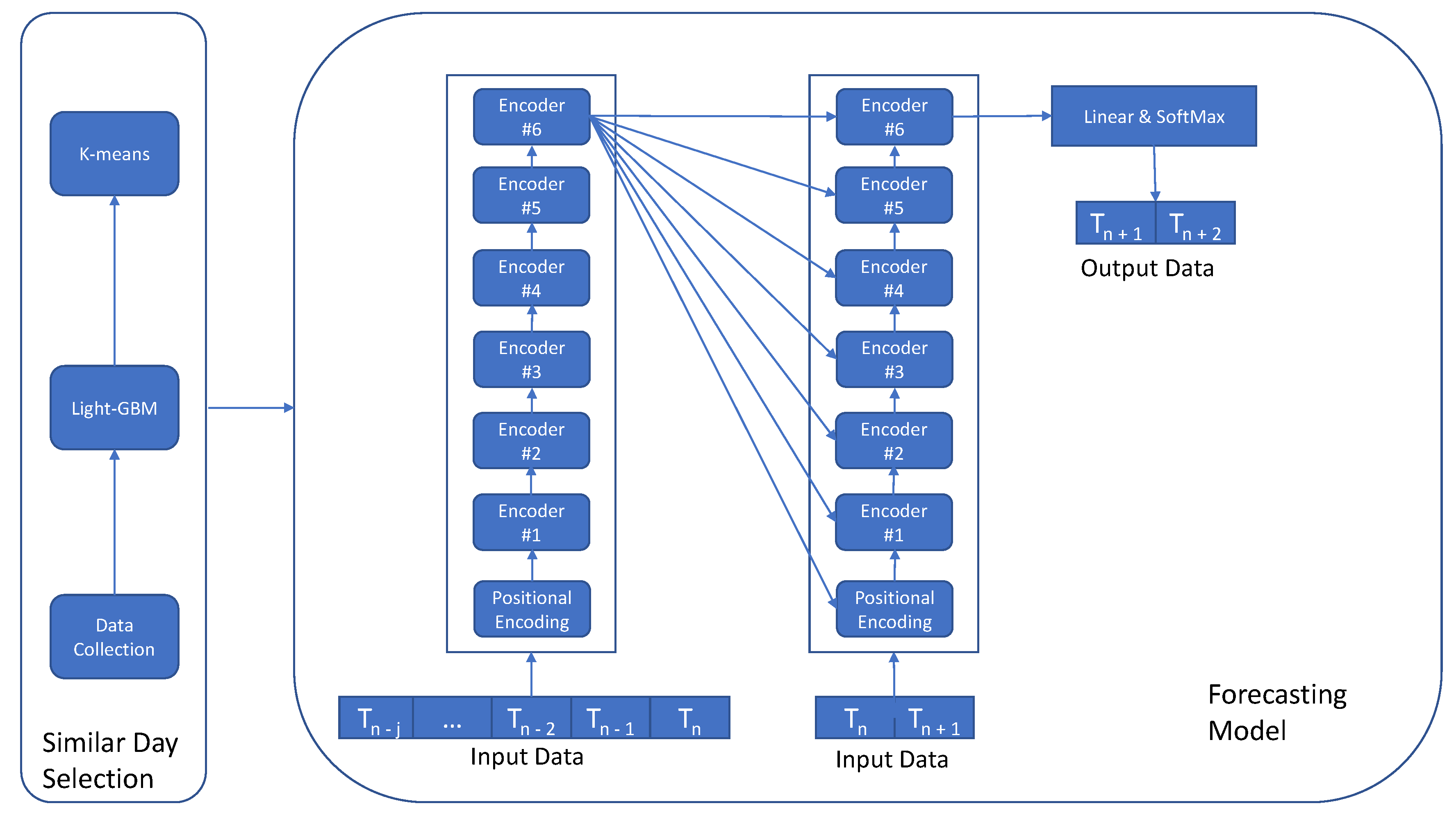
3.2. Problem Description and Model Overview
3.3. Similar Day Selection
3.3.1. LightGBM
3.3.2. k-Means
| Algorithm 1. k-means Clustering |
| input: Dataset: , cluster number: K, maximum iteration , The weight parameter set: |
| output: Cluster set: |
| Normalise the data set; |
| Select the forecasting day as the first cluster centre ; |
 |
| return C; |
3.4. Forecasting Model
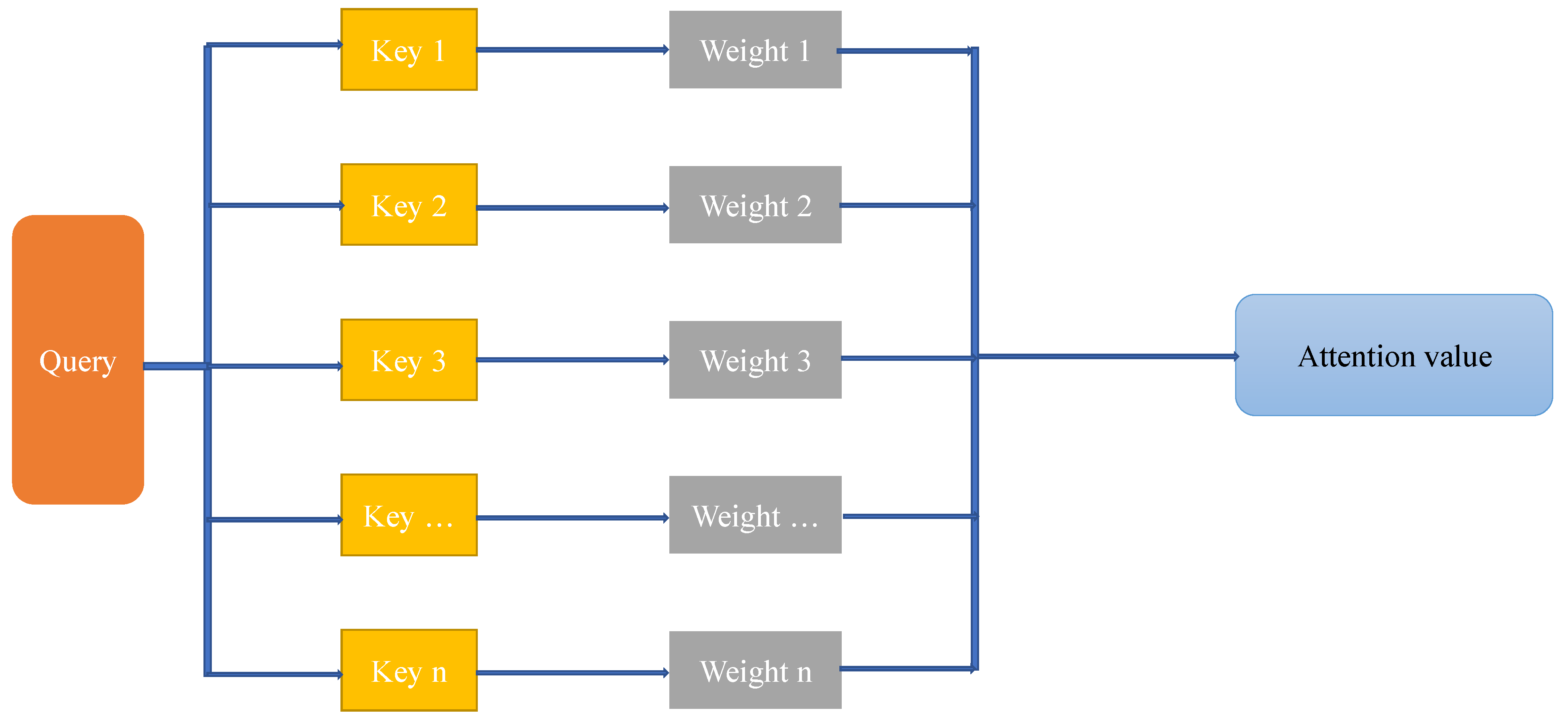
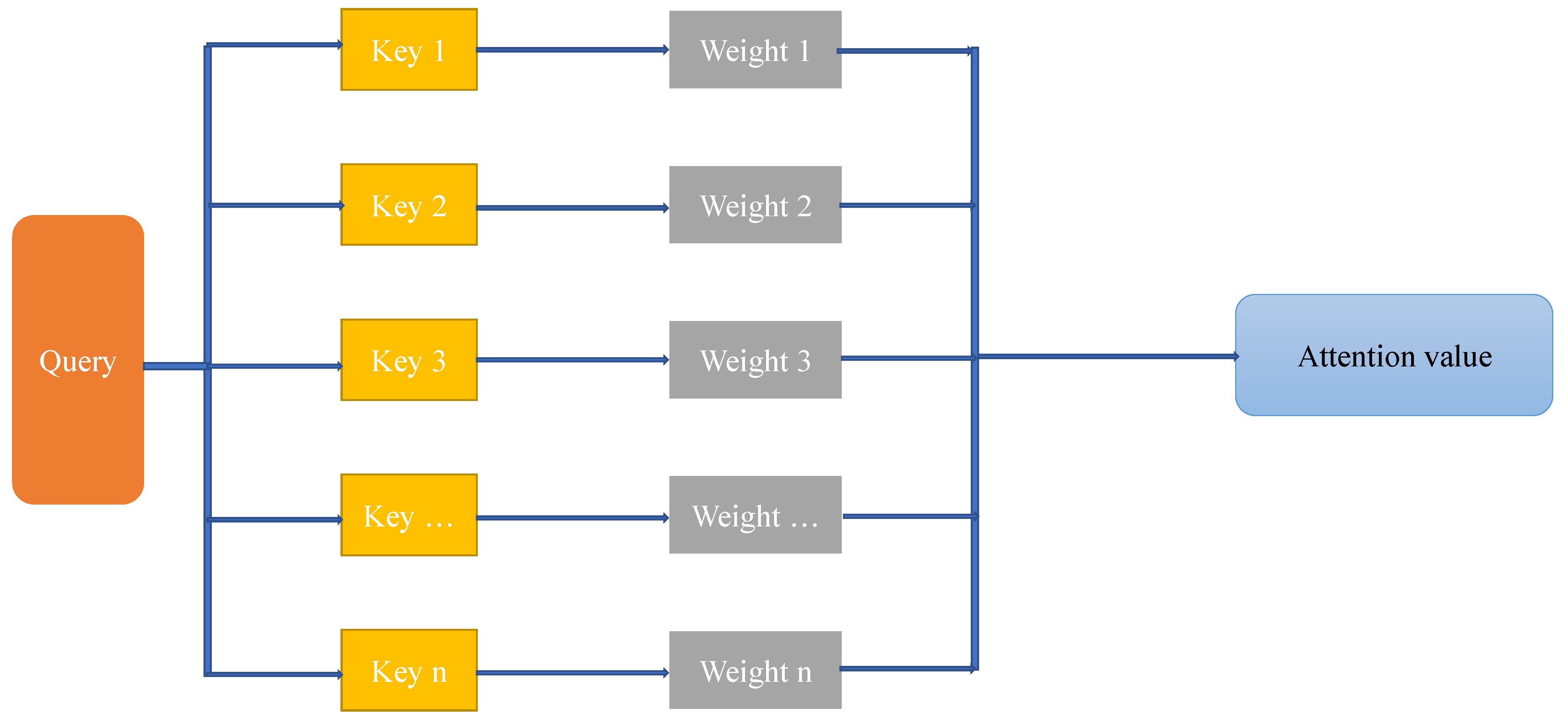
3.4.1. Attention Mechanism
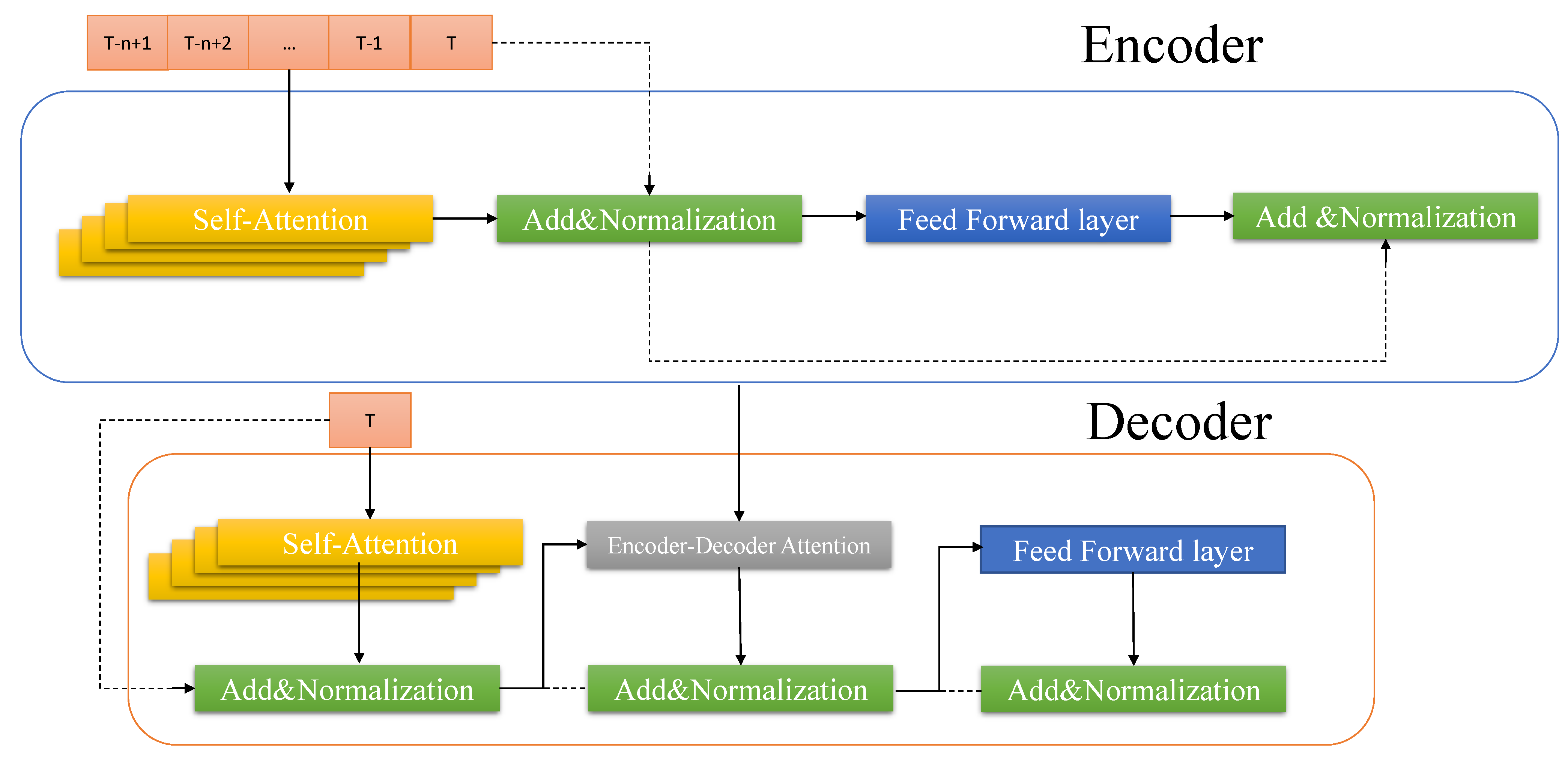
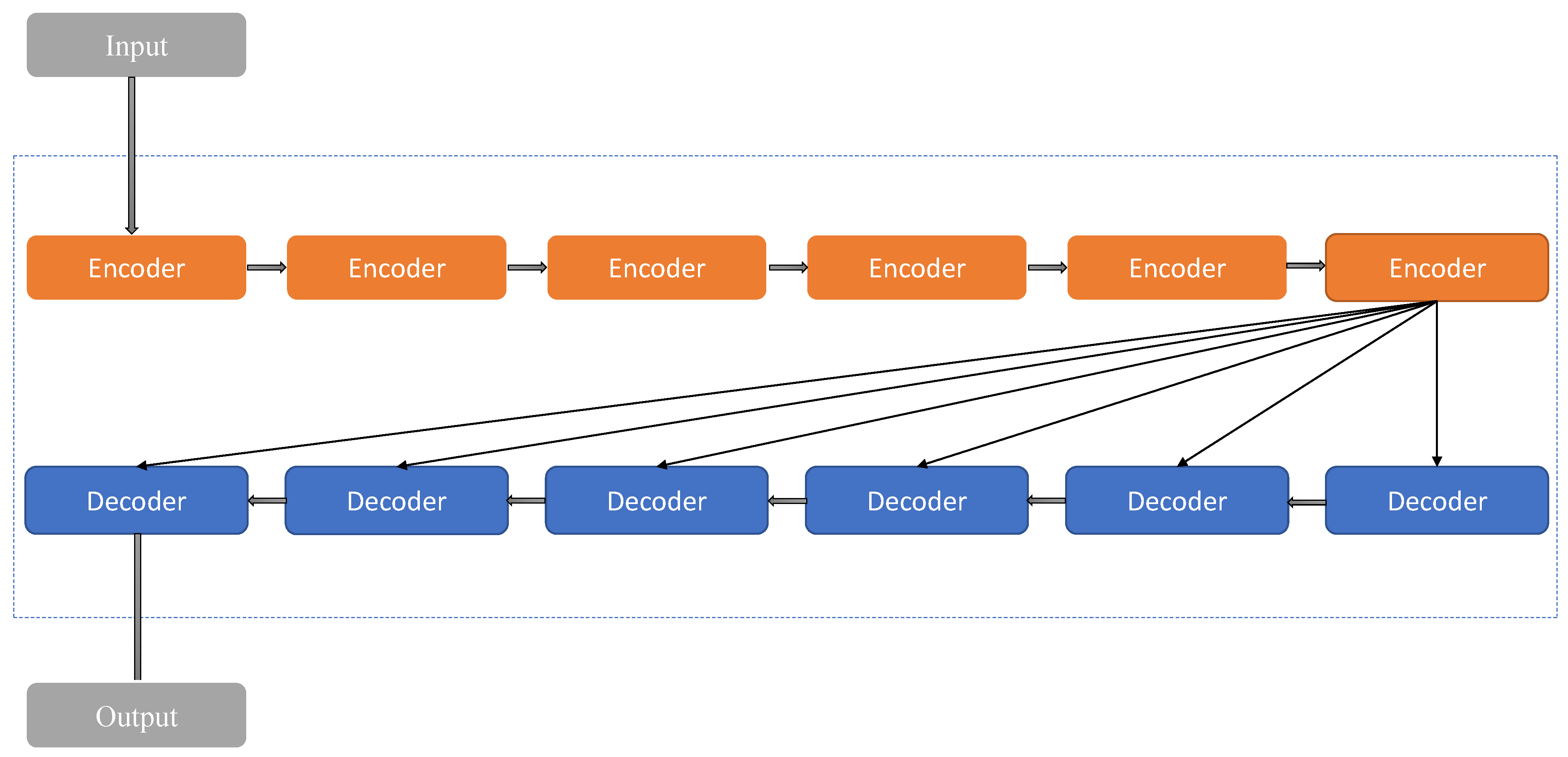
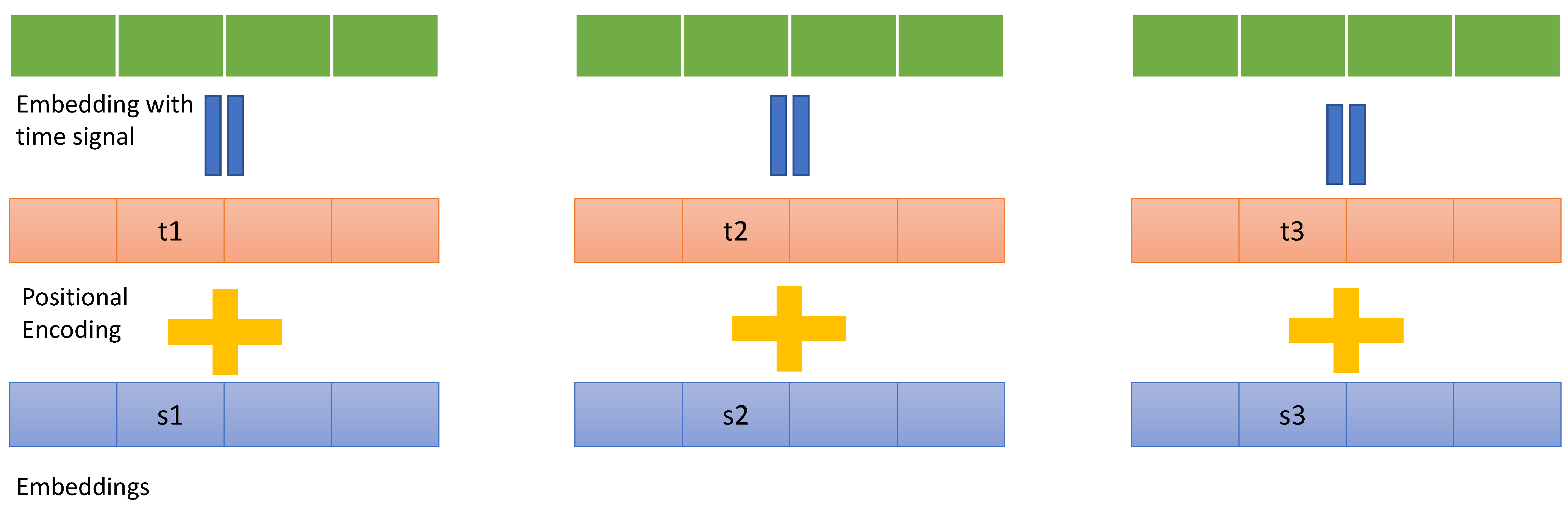
3.4.2. Transformer-Based Model
3.5. Baseline Model
3.5.1. Recurrent Neural Network
3.5.2. Long Short-Term Memory
4. Experiment
4.1. Evaluation Metrics
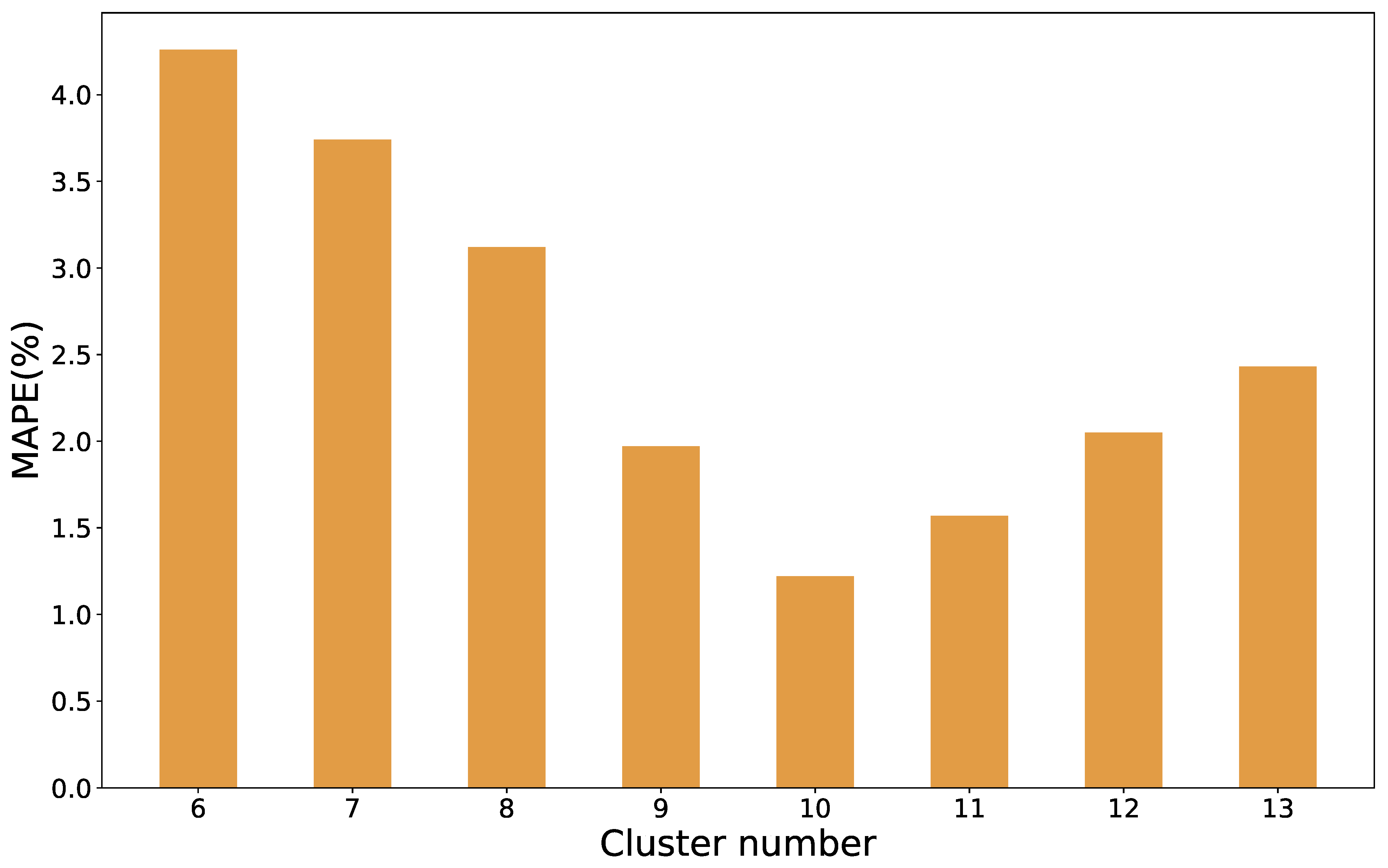
4.2. Comparison of Various k-Values
4.3. Evaluation of the Effective of Future Weighted
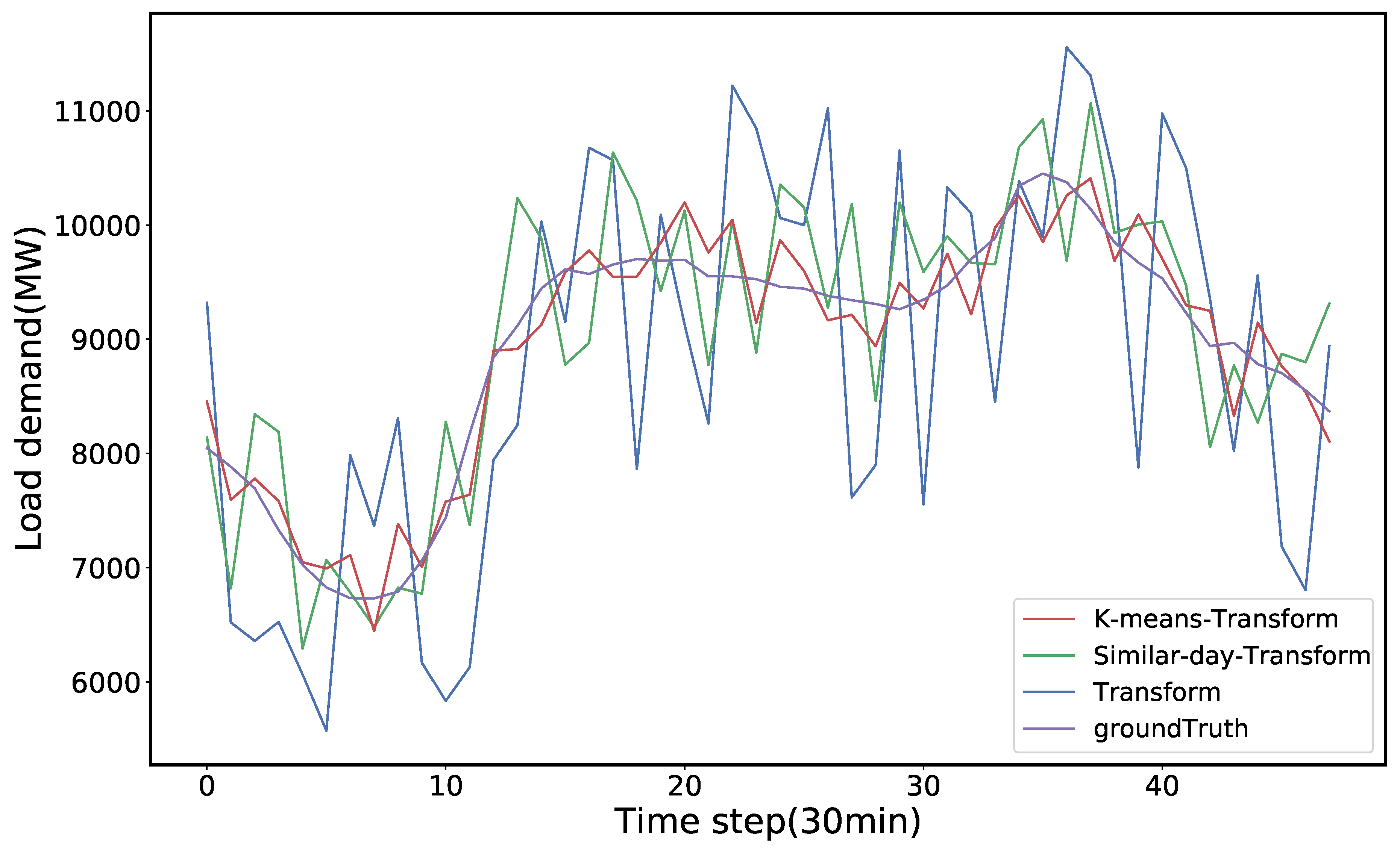
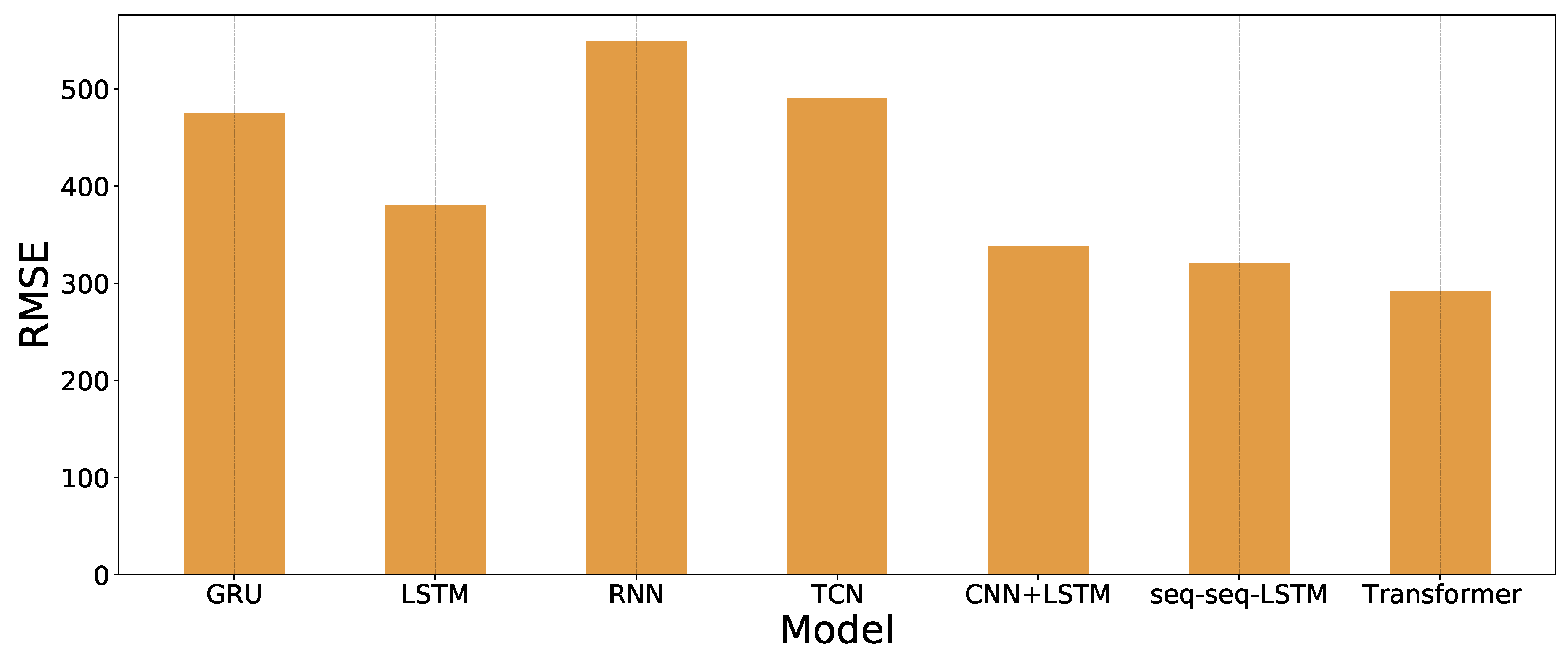
4.4. Forecasting Result
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Heinemann, G.T.; Nordmian, D.A.; Plant, E.C. The Relationship Between Summer Weather and Summer Loads—A Regression Analysis. IEEE Trans. Power Appar. Syst. 1966, PAS-85, 1144–1154. [Google Scholar] [CrossRef]
- Samuel, I.A.; Adetiba, E.; Odigwe, I.A.; Felly-Njoku, F.C. A comparative study of regression analysis and artificial neural network methods for medium-term load forecasting. Indian J. Sci. Technol. 2017, 10, 1–7. [Google Scholar] [CrossRef]
- Hobbs, B.F.; Jitprapaikulsarn, S.; Konda, S.; Chankong, V.; Loparo, K.A.; Maratukulam, D.J. Analysis of the value for unit commitment of improved load forecasts. IEEE Trans. Power Syst. 1999, 14, 1342–1348. [Google Scholar] [CrossRef]
- Kalekar, P.S. Time series forecasting using holt-winters exponential smoothing. Kanwal Rekhi Sch. Inf. Technol. 2004, 4329008, 1–13. [Google Scholar]
- Che, J.; Wang, J. Short-term electricity prices forecasting based on support vector regression and auto-regressive integrated moving average modeling. Energy Convers. Manag. 2010, 51, 1911–1917. [Google Scholar] [CrossRef]
- Ye, N.; Liu, Y.; Wang, Y. Short-term power load forecasting based on SVM. In Proceedings of the World Automation Congress 2012, Puerto Vallarta, Mexico, 24–28 June 2012; pp. 47–51. [Google Scholar]
- Ranaweera, D.; Hubele, N.; Karady, G. Fuzzy logic for short term load forecasting. Int. J. Electr. Power Energy Syst. 1996, 18, 215–222. [Google Scholar] [CrossRef]
- Badri, A.; Ameli, Z.; Birjandi, A.M. Application of artificial neural networks and fuzzy logic methods for short term load forecasting. Energy Procedia 2012, 14, 1883–1888. [Google Scholar] [CrossRef] [Green Version]
- Amber, K.; Aslam, M.; Hussain, S. Electricity consumption forecasting models for administration buildings of the UK higher education sector. Energy Build. 2015, 90, 127–136. [Google Scholar] [CrossRef]
- Song, K.B.; Baek, Y.S.; Hong, D.H.; Jang, G. Short-term load forecasting for the holidays using fuzzy linear regression method. IEEE Trans. Power Syst. 2005, 20, 96–101. [Google Scholar] [CrossRef]
- Amral, N.; Ozveren, C.S.; King, D. Short term load forecasting using Multiple Linear Regression. In Proceedings of the 2007 42nd International Universities Power Engineering Conference, Brighton, UK, 4–6 September 2007; pp. 1192–1198. [Google Scholar] [CrossRef]
- Silva, G.C.; Silva, J.L.R.; Lisboa, A.C.; Vieira, D.A.G.; Saldanha, R.R. Advanced fuzzy time series applied to short term load forecasting. In Proceedings of the 2017 IEEE Latin American Conference on Computational Intelligence, (LA-CCI), Arequipa, Peru, 8–10 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Adika, C.O.; Wang, L. Short term energy consumption prediction using bio-inspired fuzzy systems. In Proceedings of the 2012 North American Power Symposium (NAPS), Champaign, IL, USA, 9–11 September 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Zhang, M.-G. Short-term load forecasting based on support vector machines regression. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 7, pp. 4310–4314. [Google Scholar] [CrossRef] [Green Version]
- Amin, M.A.A.; Hoque, M.A. Comparison of ARIMA and SVM for Short-term Load Forecasting. In Proceedings of the 2019 9th Annual Information Technology, Electromechanical Engineering and Microelectronics Conference (IEMECON), Jaipur, India, 13–15 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Xiao, Z.; Ye, S.J.; Zhong, B.; Sun, C.X. BP neural network with rough set for short term load forecasting. Expert Syst. Appl. 2009, 36, 273–279. [Google Scholar] [CrossRef]
- Bin, H.; Zu, Y.X.; Zhang, C. A forecasting method of short-term electric power load based on BP neural network. Appl. Mech. Mater. 2014, 538, 247–250. [Google Scholar] [CrossRef]
- Chen, S.T.; Yu, D.C.; Moghaddamjo, A.R. Weather sensitive short-term load forecasting using nonfully connected artificial neural network. IEEE Trans. Power Syst. 1992, 7, 1098–1105. [Google Scholar] [CrossRef]
- Chen, K.; Chen, K.; Wang, Q.; He, Z.; Hu, J.; He, J. Short-Term Load Forecasting With Deep Residual Networks. IEEE Trans. Smart Grid 2019, 10, 3943–3952. [Google Scholar] [CrossRef] [Green Version]
- Lara-Benítez, P.; Carranza-García, M.; Luna-Romera, J.M.; Riquelme, J.C. Temporal convolutional networks applied to energy-related time series forecasting. Appl. Sci. 2020, 10, 2322. [Google Scholar] [CrossRef] [Green Version]
- Amarasinghe, K.; Marino, D.L.; Manic, M. Deep neural networks for energy load forecasting. In Proceedings of the 2017 IEEE 26th International Symposium on Industrial Electronics (ISIE), Edinburgh, UK, 19–21 June 2017; pp. 1483–1488. [Google Scholar] [CrossRef]
- Siddarameshwara, N.; Yelamali, A.; Byahatti, K. Electricity Short Term Load Forecasting Using Elman Recurrent Neural Network. In Proceedings of the 2010 International Conference on Advances in Recent Technologies in Communication and Computing, Kottayam, India, 16–17 October 2010; pp. 351–354. [Google Scholar] [CrossRef]
- Marvuglia, A.; Messineo, A. Using recurrent artificial neural networks to forecast household electricity consumption. Energy Procedia 2012, 14, 45–55. [Google Scholar] [CrossRef] [Green Version]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Zheng, J.; Xu, C.; Zhang, Z.; Li, X. Electric load forecasting in smart grids using Long-Short-Term-Memory based Recurrent Neural Network. In Proceedings of the 2017 51st Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Cheng, Y.; Xu, C.; Mashima, D.; Thing, V.L.; Wu, Y. PowerLSTM: Power demand forecasting using long short-term memory neural network. In Proceedings of the International Conference on Advanced Data Mining and Applications, Singapore, 5–6 November 2017; pp. 727–740. [Google Scholar]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Optimal deep learning lstm model for electric load forecasting using feature selection and genetic algorithm: Comparison with machine learning approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Liu, M.; Bao, Z.; Zhang, S. Short-term load forecasting with multi-source data using gated recurrent unit neural networks. Energies 2018, 11, 1138. [Google Scholar] [CrossRef] [Green Version]
- Stollenga, M.F.; Byeon, W.; Liwicki, M.; Schmidhuber, J. Parallel multi-dimensional LSTM, with application to fast biomedical volumetric image segmentation. arXiv 2015, arXiv:1506.07452. [Google Scholar]
- He, W. Load forecasting via deep neural networks. Procedia Comput. Sci. 2017, 122, 308–314. [Google Scholar] [CrossRef]
- Tian, C.; Ma, J.; Zhang, C.; Zhan, P. A deep neural network model for short-term load forecast based on long short-term memory network and convolutional neural network. Energies 2018, 11, 3493. [Google Scholar] [CrossRef] [Green Version]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building energy load forecasting using Deep Neural Networks. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 7046–7051. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Jan | Feb | Mar | Apr | May | June | July | Aug | Sep | Oct | Nov | Dec | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GRU | 2.78 | 2.65 | 2.74 | 3.54 | 3.17 | 3.69 | 2.93 | 3.02 | 3.45 | 2.71 | 3.16 | 2.98 | 3.06 |
| LSTM | 1.81 | 1.93 | 2.02 | 1.65 | 1.78 | 1.76 | 1.86 | 1.63 | 1.69 | 1.79 | 2.15 | 1.91 | 1.93 |
| RNN | 4.65 | 3.89 | 4.28 | 3.94 | 4.58 | 4.33 | 3.85 | 3.62 | 4.76 | 3.90 | 4.13 | 4.28 | 4.18 |
| TCN | 1.97 | 2.27 | 2.02 | 1.92 | 1.76 | 2.12 | 2.06 | 1.82 | 1.95 | 2.04 | 1.94 | 1.89 | 1.98 |
| CNN + LSTM | 1.65 | 1.72 | 1.68 | 1.49 | 1.52 | 1.57 | 1.62 | 1.53 | 1.48 | 1.74 | 1.46 | 1.55 | 1.58 |
| seq2seq-LSTM | 1.29 | 1.35 | 1.39 | 1.32 | 1.28 | 1.21 | 1.31 | 1.19 | 1.24 | 1.36 | 1.31 | 1.25 | 1.29 |
| Transformer | 1.23 | 1.46 | 1.15 | 0.93 | 1.09 | 1.13 | 1.26 | 1.12 | 1.07 | 1.18 | 0.96 | 1.02 | 1.13 |
| Compared Models | p-Value |
|---|---|
| Our proposed model vs. RNN | 0.0086 |
| Our proposed model vs. LSTM | 0.0145 |
| Our proposed model vs. GRU | 0.0001 |
| Our proposed model vs. TCN | 0.0197 |
| Our proposed model vs. CNN + LSTM | 0.0284 |
| Our proposed model vs. seq2seq-LSTM | 0.0336 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Xia, C.; Chi, L.; Chang, X.; Li, W.; Yang, T.; Zomaya, A.Y. Short-Term Load Forecasting Based on the Transformer Model. Information 2021, 12, 516. https://doi.org/10.3390/info12120516
Zhao Z, Xia C, Chi L, Chang X, Li W, Yang T, Zomaya AY. Short-Term Load Forecasting Based on the Transformer Model. Information. 2021; 12(12):516. https://doi.org/10.3390/info12120516
Chicago/Turabian StyleZhao, Zezheng, Chunqiu Xia, Lian Chi, Xiaomin Chang, Wei Li, Ting Yang, and Albert Y. Zomaya. 2021. "Short-Term Load Forecasting Based on the Transformer Model" Information 12, no. 12: 516. https://doi.org/10.3390/info12120516
APA StyleZhao, Z., Xia, C., Chi, L., Chang, X., Li, W., Yang, T., & Zomaya, A. Y. (2021). Short-Term Load Forecasting Based on the Transformer Model. Information, 12(12), 516. https://doi.org/10.3390/info12120516