
RDFsim: Similarity-Based Browsing over DBpedia Using Embeddings




Abstract
:1. Introduction
2. Related Work
2.1. Access Systems over RDF
2.2. Semantic Similarity Methods (Focus on RDF Knowledge Graph Embeddings)
2.2.1. Semantic Similarity in Knowledge Bases
2.2.2. RDF Knowledge Graph Embeddings
2.3. The Positioning and Novelty of RDFsim
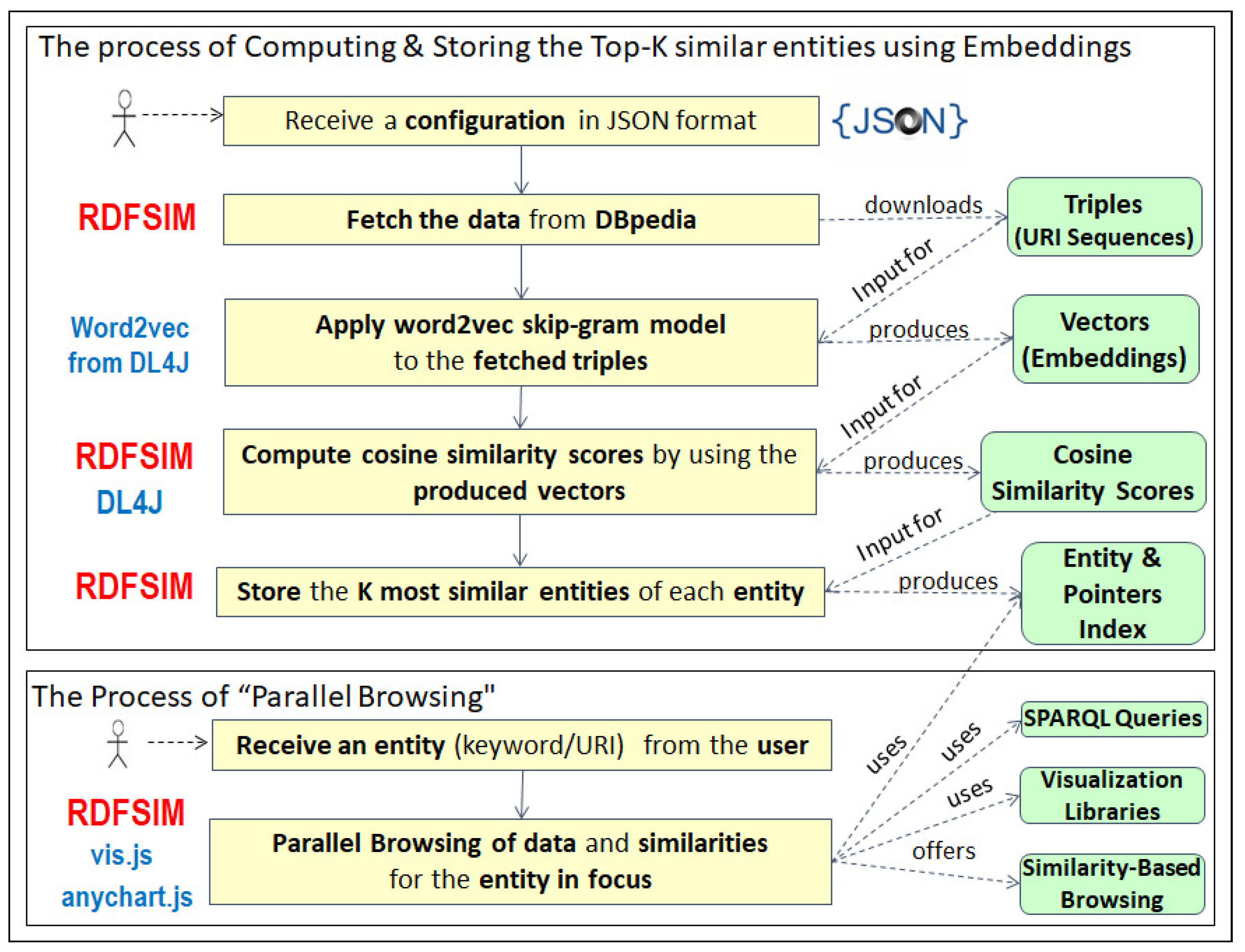
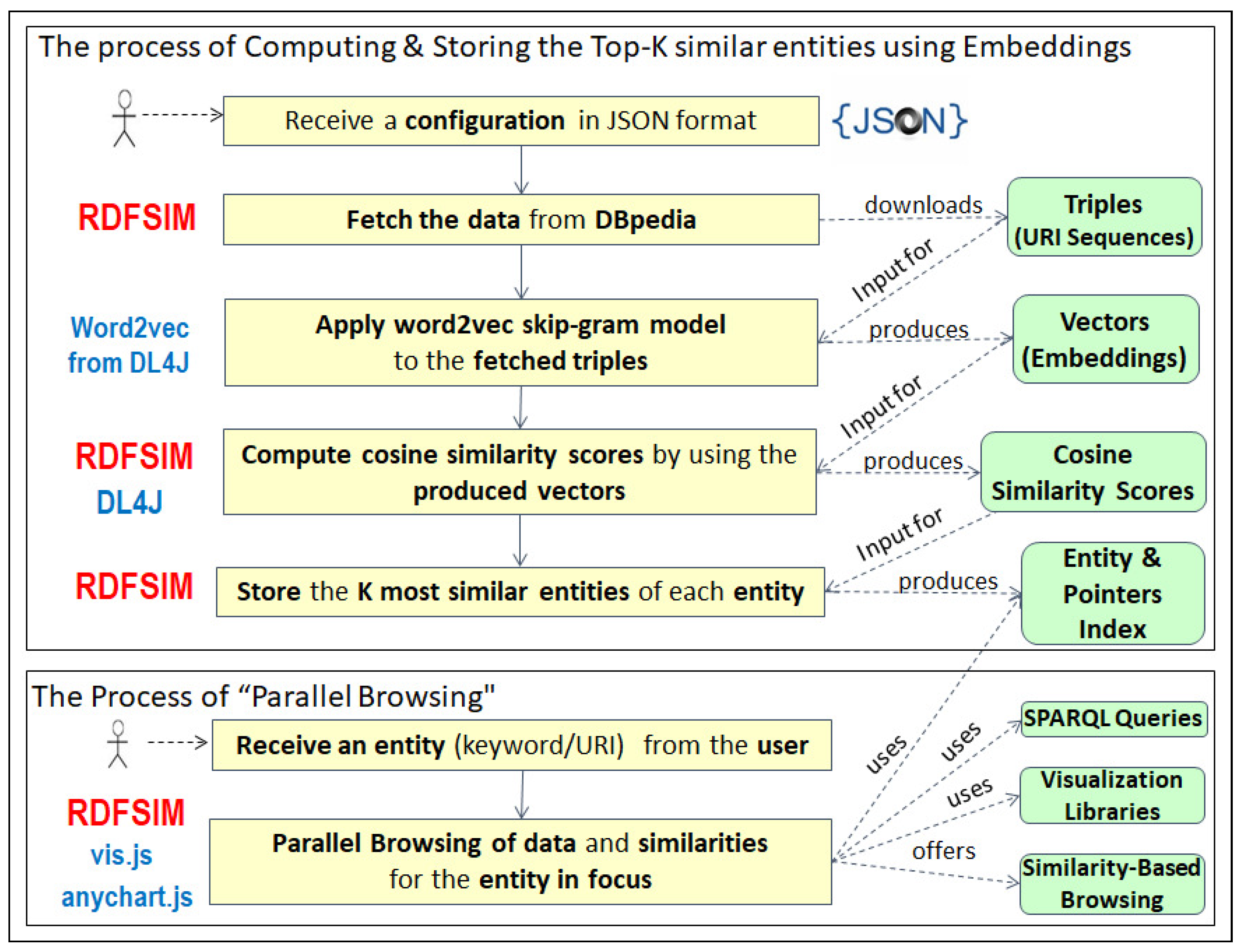
3. The Process of Computing and Storing the Top-K Similar Entities Using Embeddings
| Algorithm 1: Creating the Entity and the Pointers Index, by using the embeddings created from the data of a SPARQL query to DBpedia. |
| Input: Input query q for downloading the triples from DBpedia SPARQL endpoint Output: The entity Index containing for each entity its prefix, its URI and its top-K similar entities, and the pointers index /* Step A. Download the triples by using the input query q */ 1 /* Step B. Create the embeddings (vectors) for the URIs of the fetched triples by using word2vec */ 2 // Step C. Create the Indexes by using the produced vectors 3 // Read each URI of for creating the Entity Index 4 forall do 5 // The top-K most similar entities to wrt score 6 // Store the above information to the index 7 8 // Create the Pointers Index by using the Entity Index 9 10 Return , |
3.1. Step A. Configuration and Data Fetching

3.2. Step B. Production of Embeddings for the Fetched Data and Computation of Similar Entities
3.2.1. Step B1. Computation of URI Embeddings
3.2.2. Step B2. Production of Vectors for the URIs and Computation of Similar Entities
3.3. Step C. The Indexing Process
3.4. How Can the Process Be Adjusted to Other Datasets or Similarity Methods?
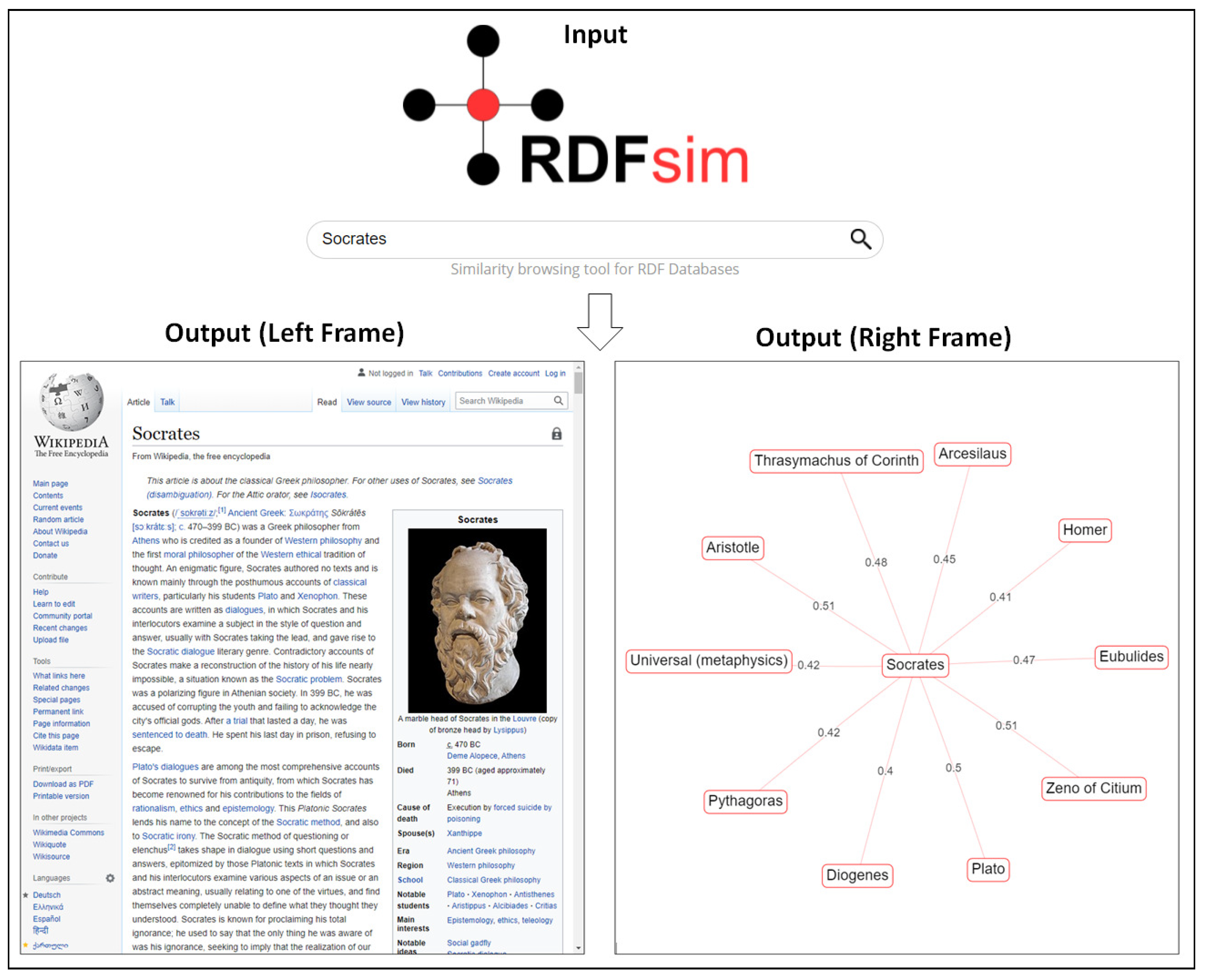
4. The Process of “Parallel Browsing”
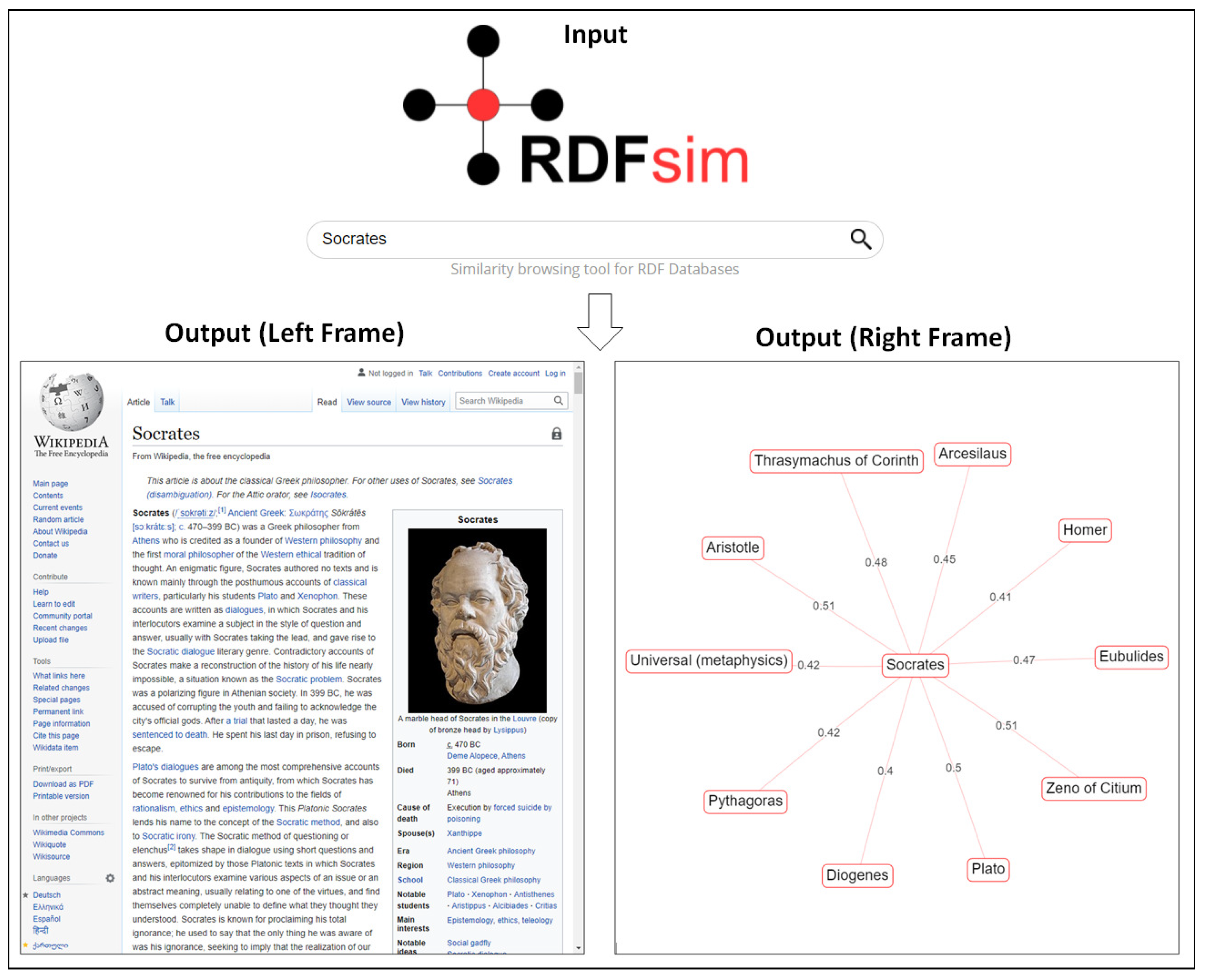
4.1. Landing Page and Finding the First Entity
4.2. The Frames of “Parallel Browsing”
4.3. Constructing the Browsing Frames
4.3.1. Finding the Selected Entity in the Index
4.3.2. Constructing the Left Frame of RDFsim Web Page
4.3.3. Constructing the Right Frame of RDFsim Web Page
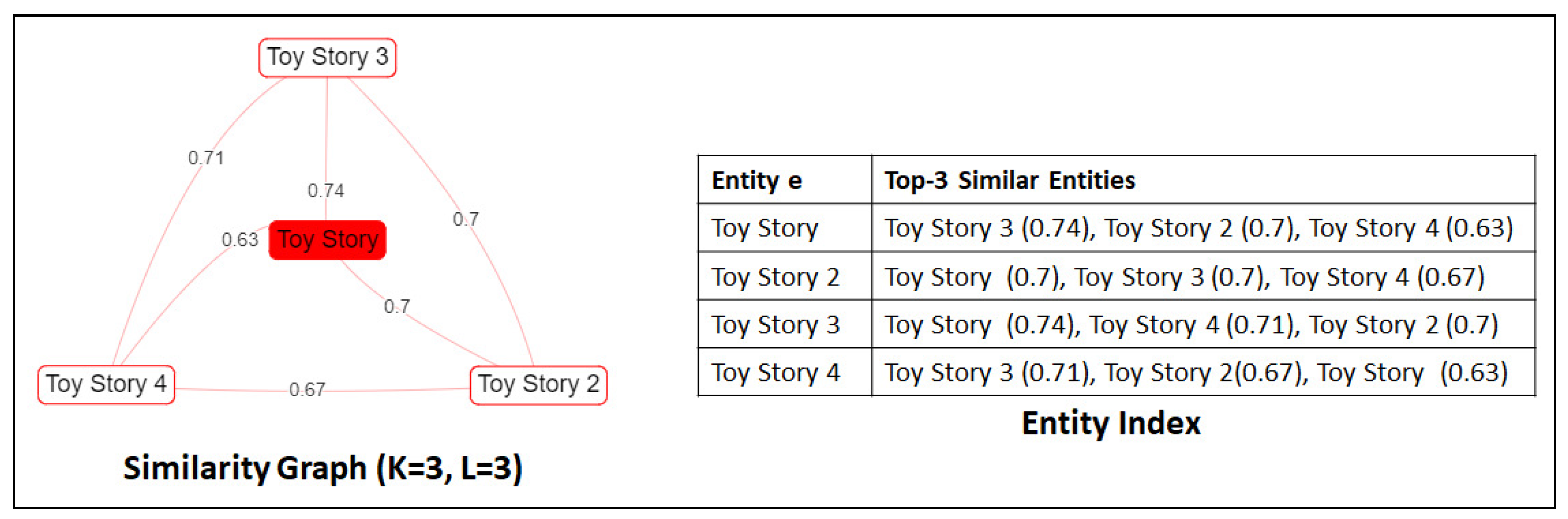
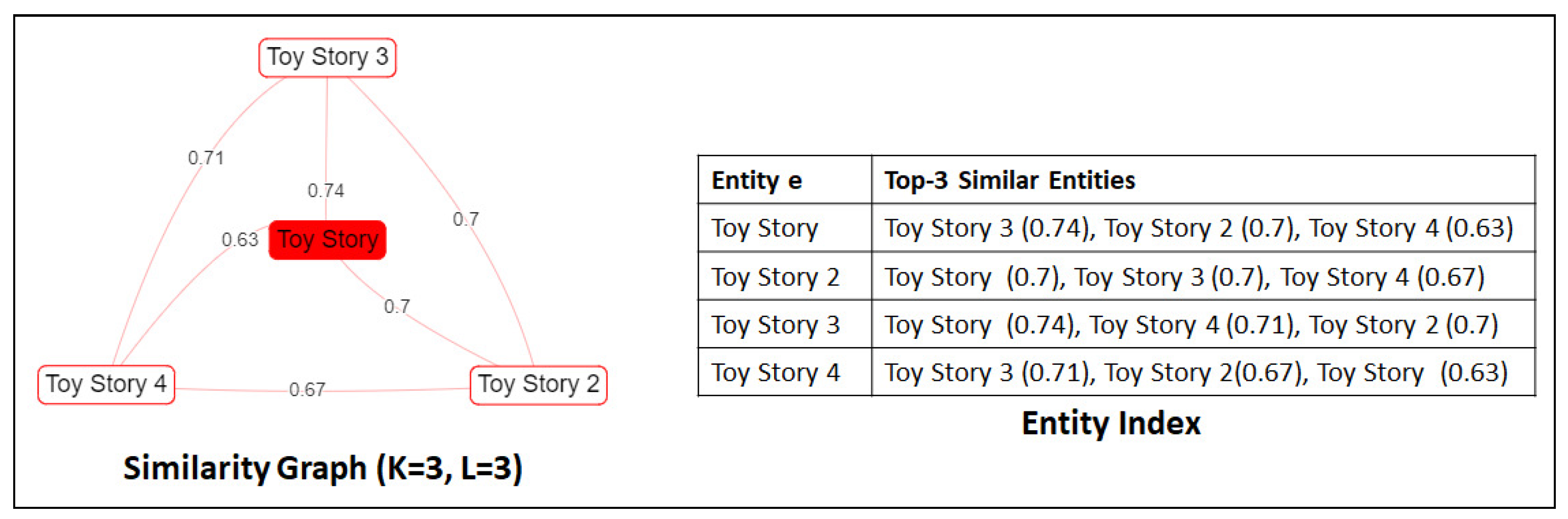
| Algorithm 2: Creating the similarity graph G for the selected entity . |
| Input: Entity , depth L, number of similars K, Entity Index Output: The similarity graph starting G from entity e by using specific L and K // Initialize Graph 1 2 , 3 4 } 5 6 // Add the selected entity as the first node 7 8 // Follow a BFS-like approach 9 while and do 10 // Traverse each node e of the current 11 forall do 12 /* Traverse the top-K to similar entities of v and create the corresponding nodes/edges (if they do not exist) */ 13 forall do 14 if then 15 16 17 18 else if then 19 20 21 Return G |
4.4. Implementation and Current Online Version of RDFsim
5. Evaluation
5.1. Comparison with Related Systems
5.2. Efficiency and Similarity Measurements
5.2.1. Datasets and Indexes of RDFsim
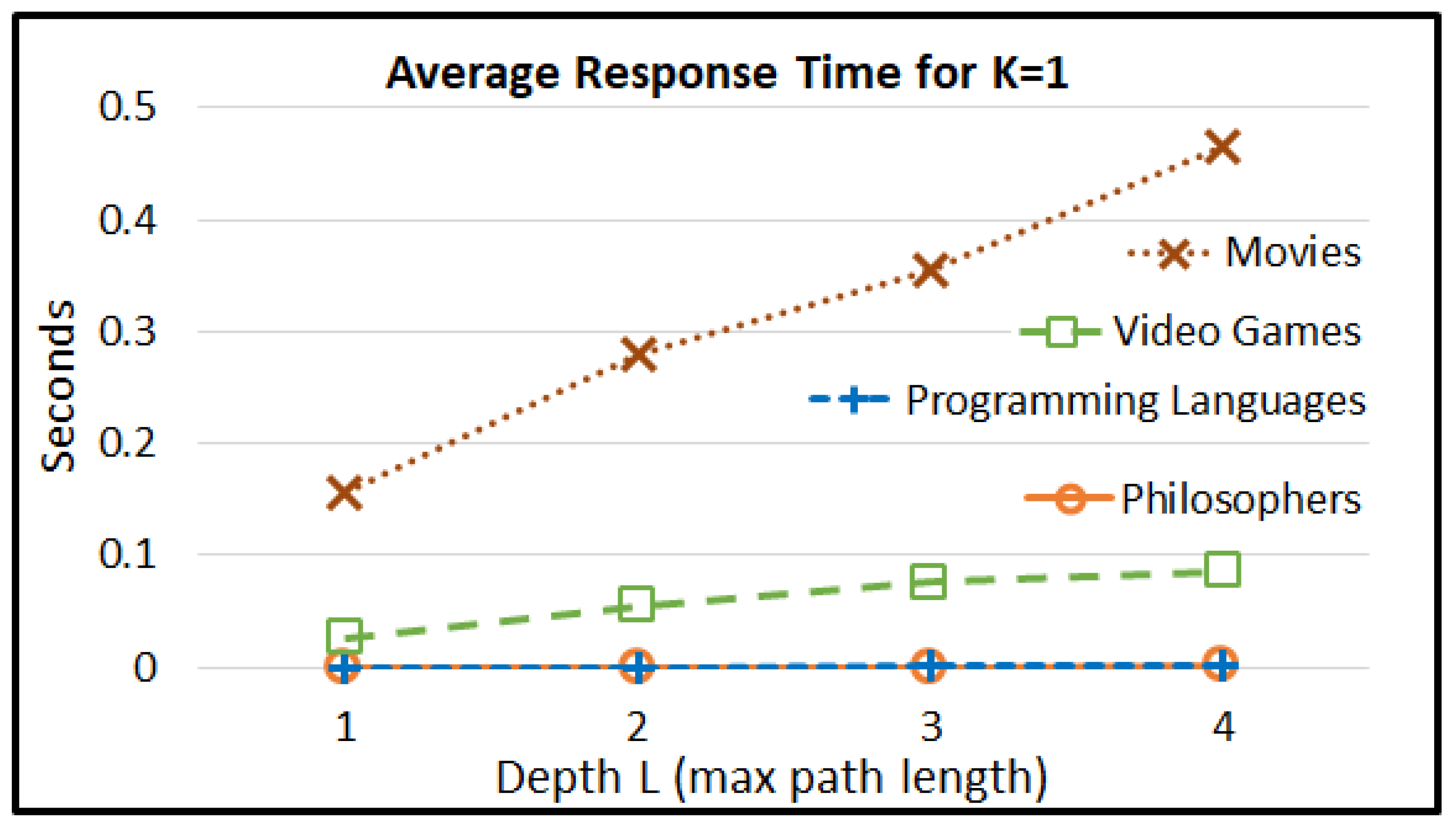
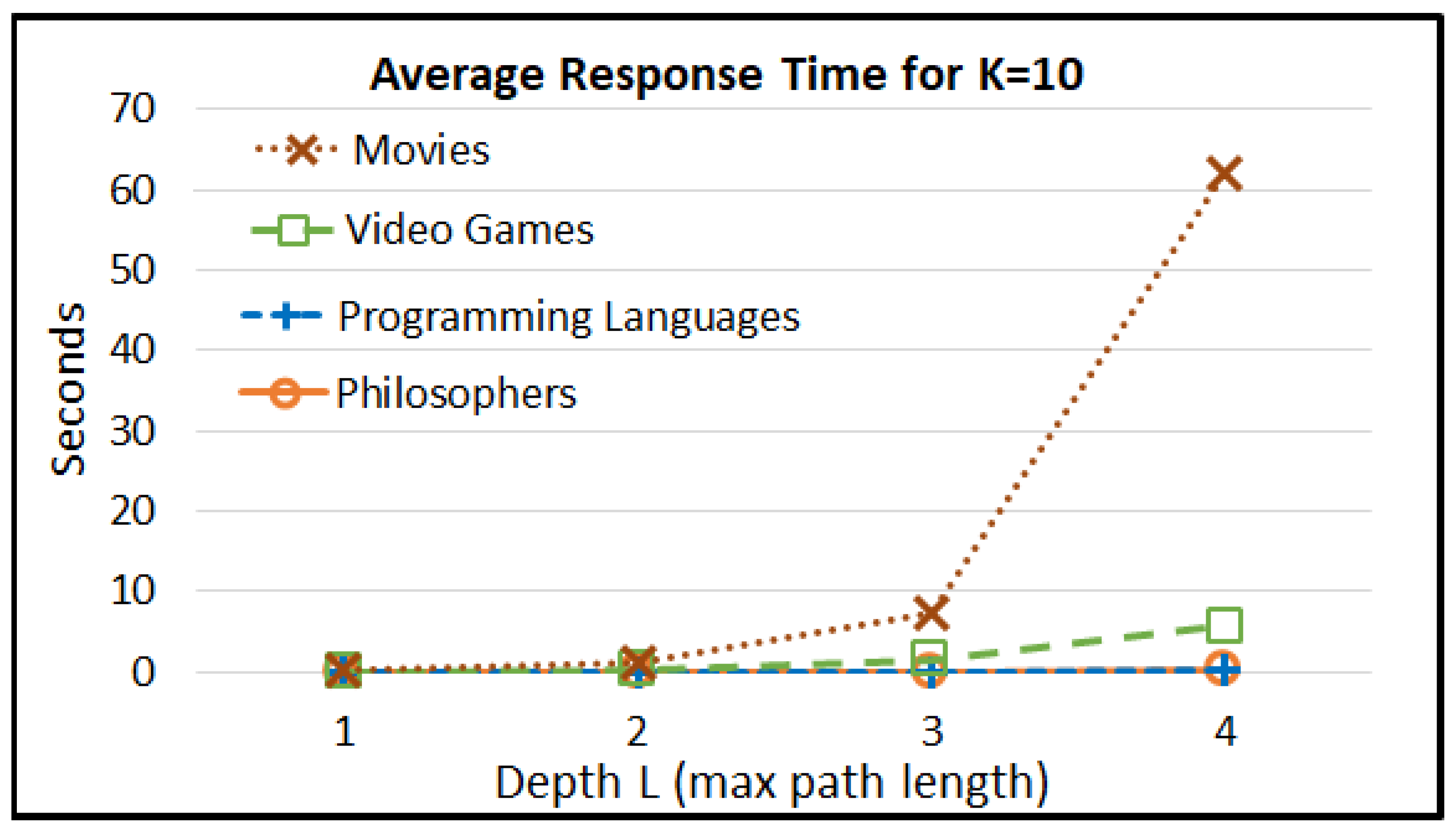
5.2.2. Efficiency Measurements
5.2.3. Indicative Measurements for the Results of the Embeddings
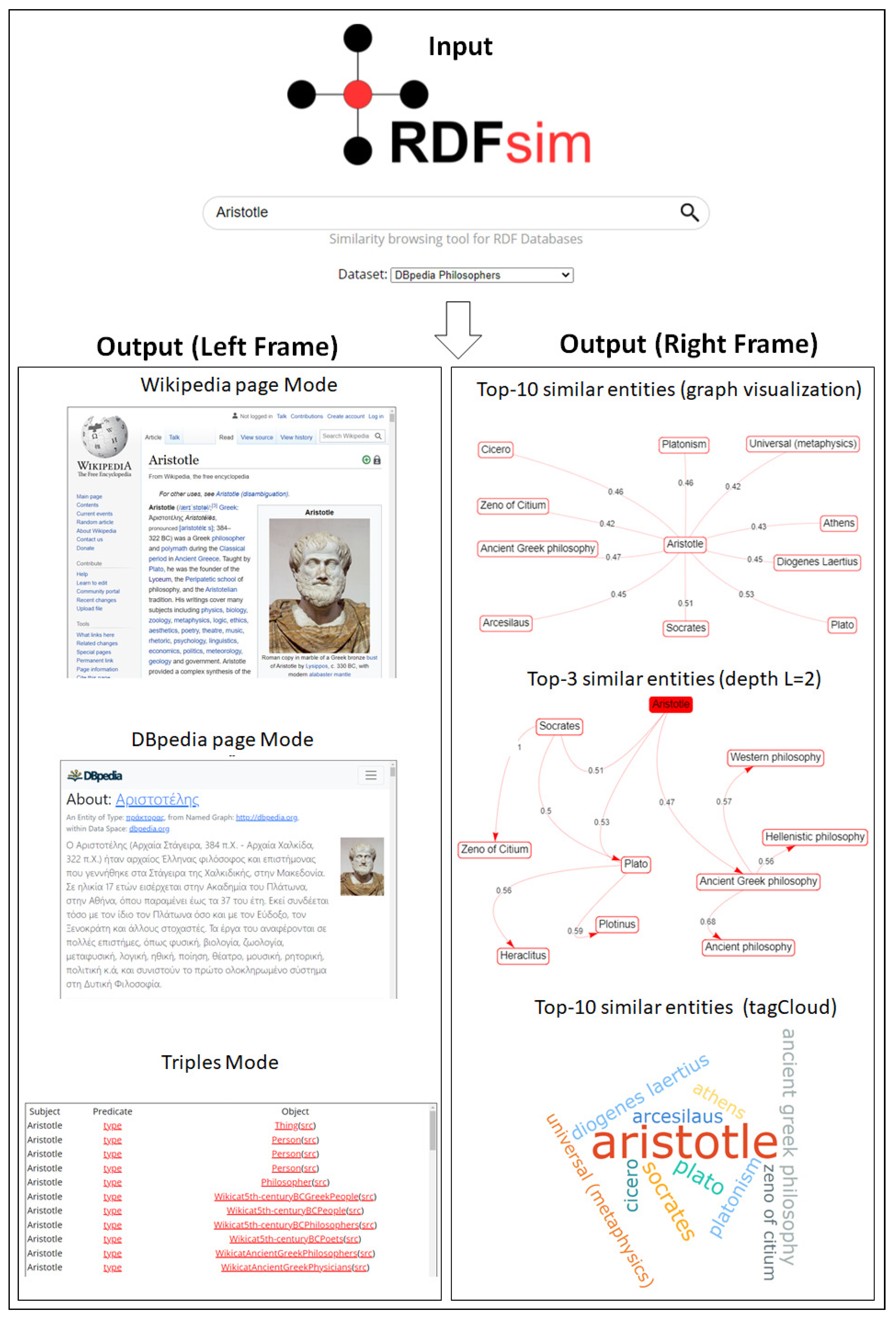
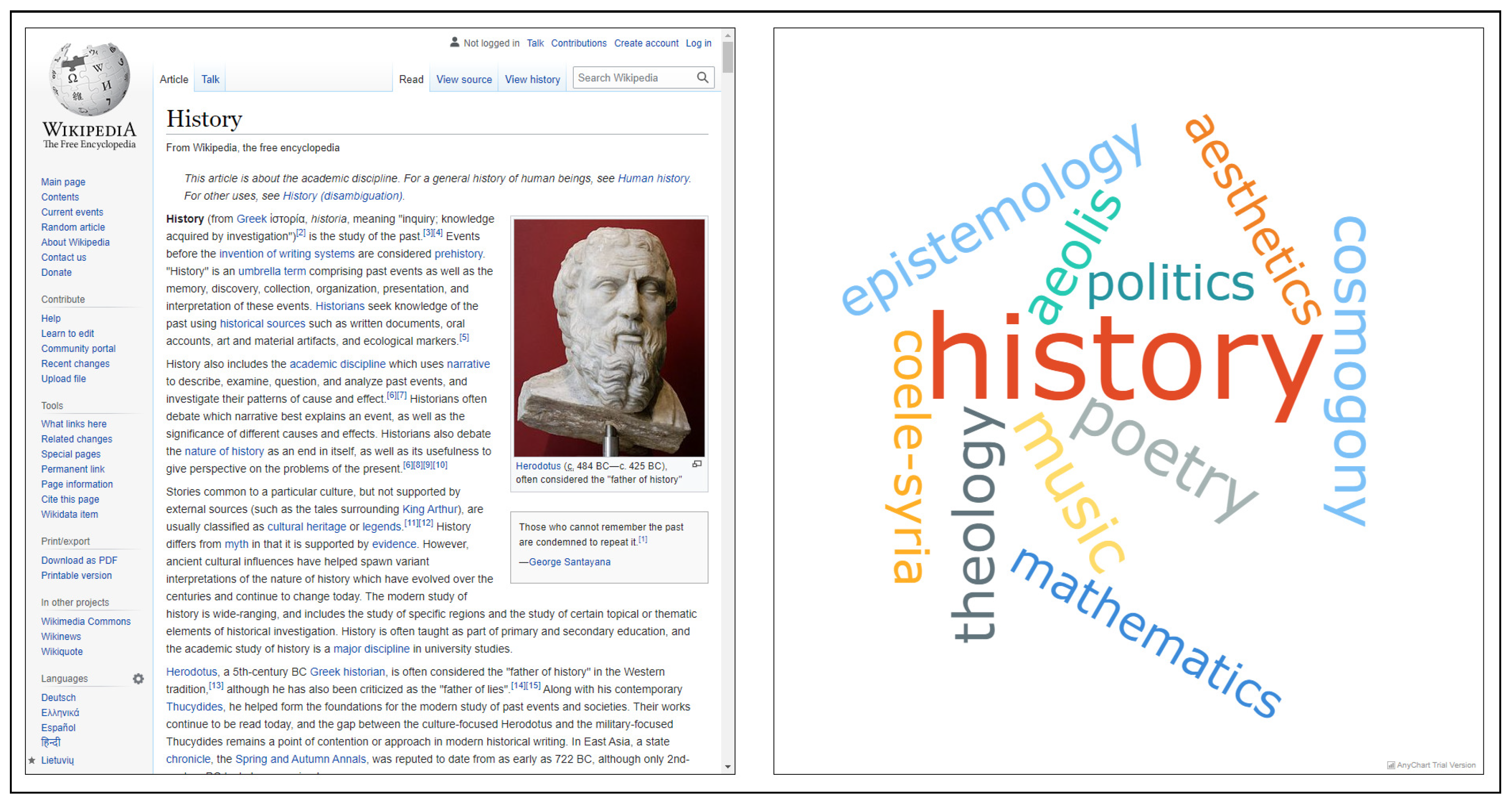
6. Use Cases
6.1. Use Case 1. “Parallel Browsing” of the Entity in Focus
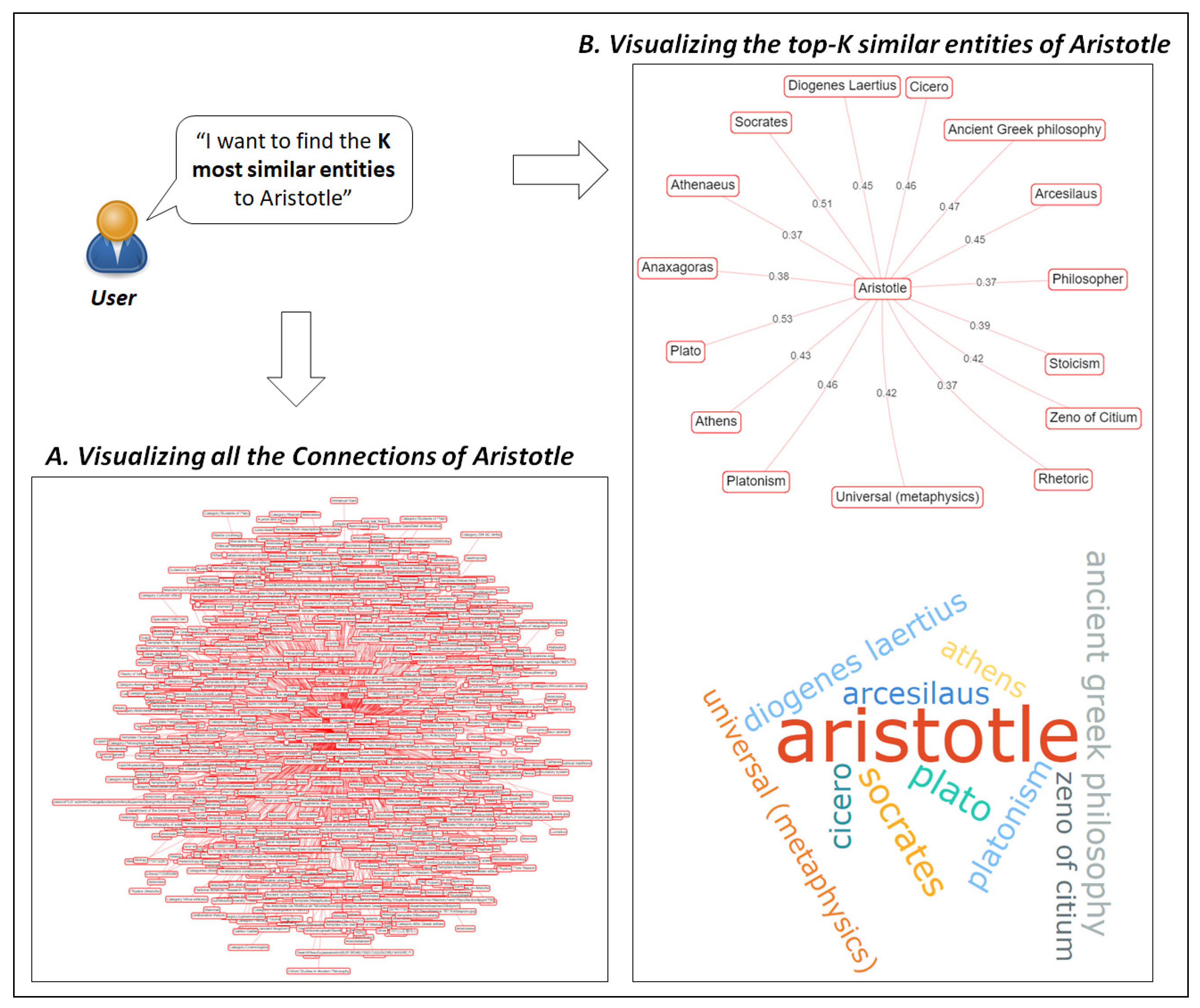
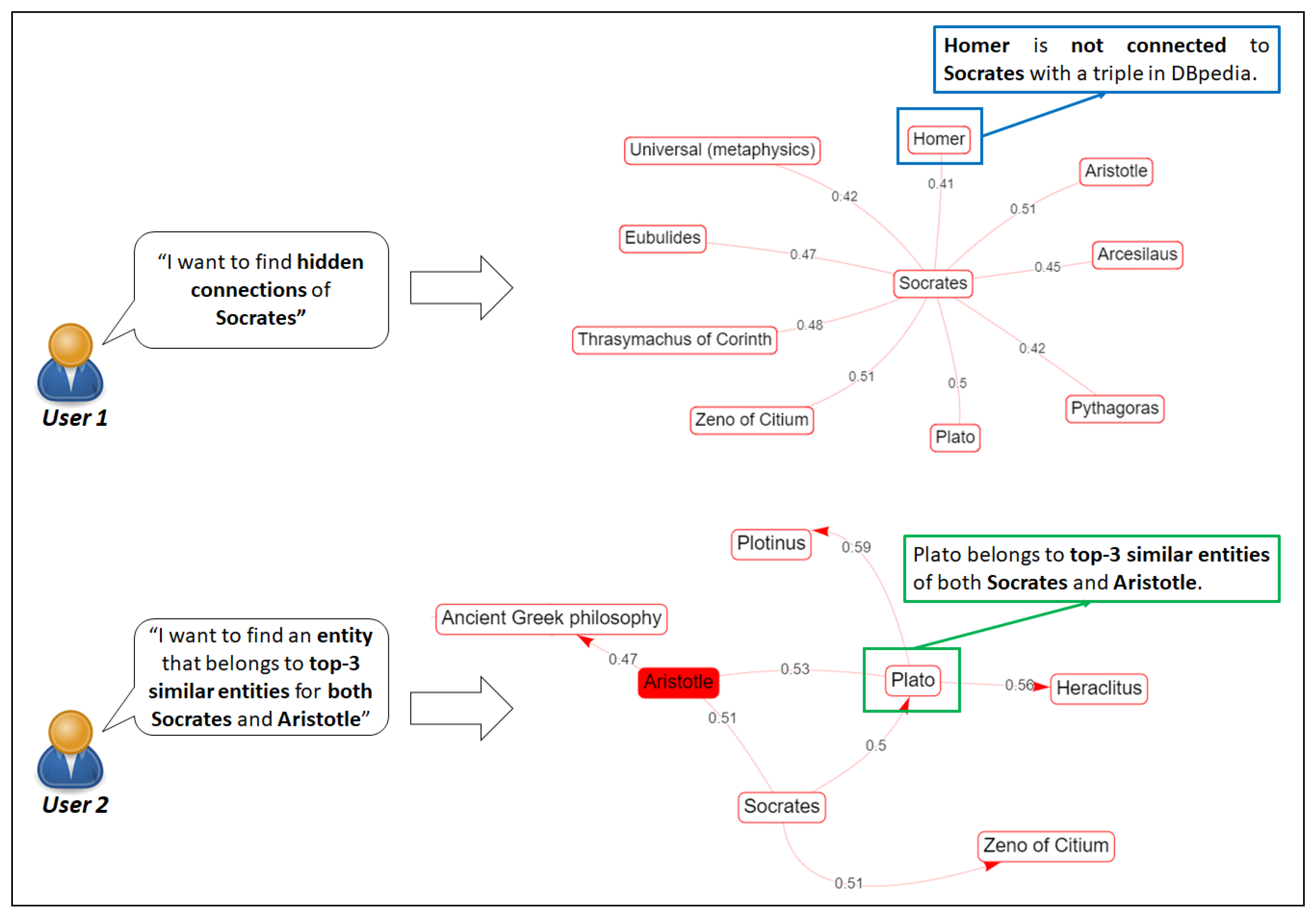
6.2. Use Case 2. Finding the Most Similar Entities of a Popular Entity
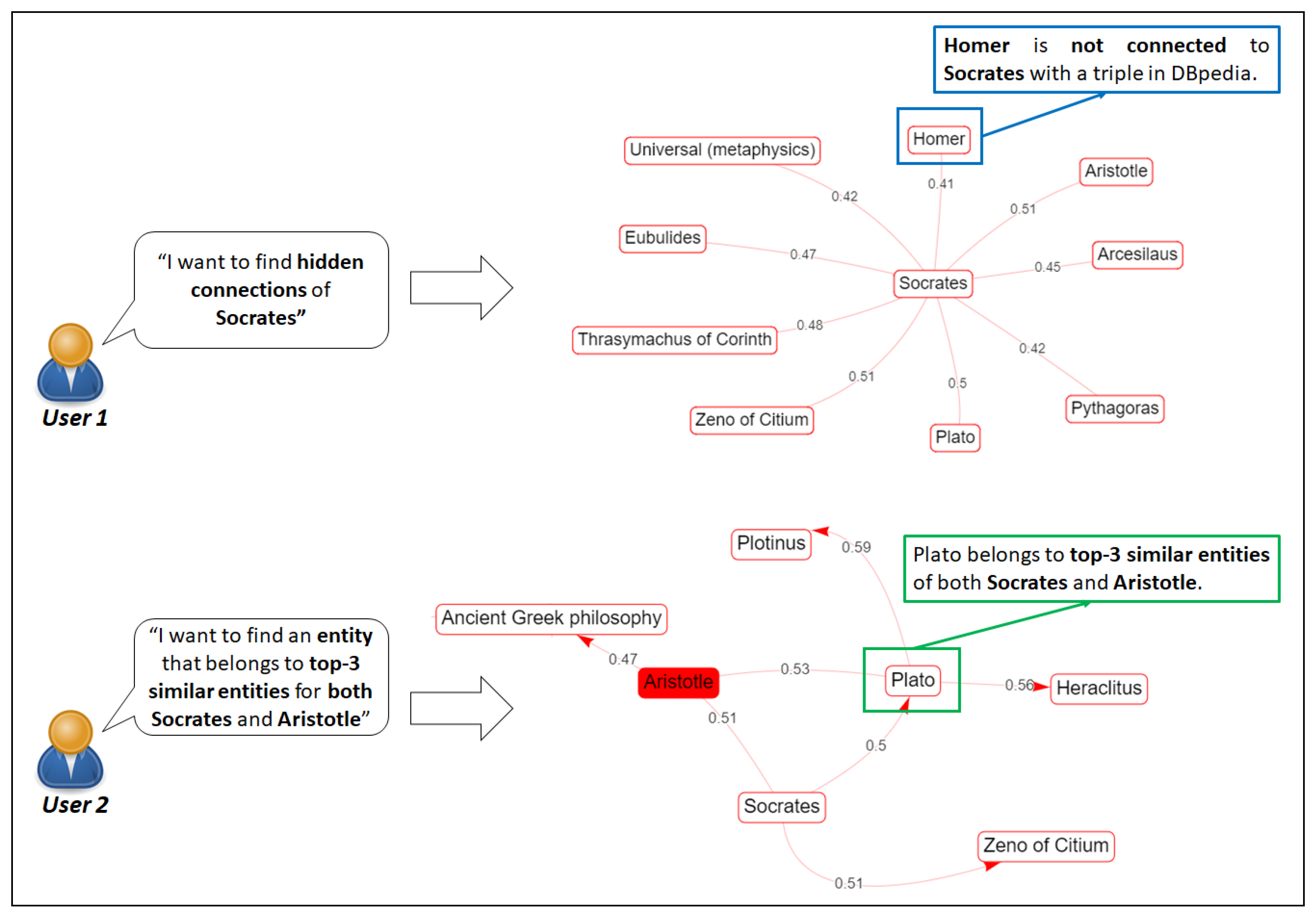
6.3. Use Case 3. Discovering “Hidden” Similarity-Based Connections between Entities
7. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Nikas, C.; Kadilierakis, G.; Fafalios, P.; Tzitzikas, Y. Keyword Search over RDF: Is a Single Perspective Enough? Big Data Cogn. Comput. 2020, 4, 22. [Google Scholar] [CrossRef]
- Ilievski, F.; Beek, W.; van Erp, M.; Rietveld, L.; Schlobach, S. LOTUS: Adaptive text search for big linked data. In Proceedings of the European Semantic Web Conference, Kobe, Japan, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 470–485. [Google Scholar]
- Camarda, D.V.; Mazzini, S.; Antonuccio, A. LodLive, exploring the web of data. In Proceedings of the 8th International Conference on Semantic Systems, Graz, Austria, 5–7 September 2012; pp. 197–200. [Google Scholar]
- Micsik, A.; Turbucz, S.; Györök, A. Lodmilla: A linked data browser for all. Information 2014, 31–34. [Google Scholar]
- Atzori, M.; Mazzeo, G.M.; Zaniolo, C. QA3: A natural language approach to question answering over RDF data cubes. Semant. Web 2019, 10, 587–604. [Google Scholar] [CrossRef]
- Arenas, M.; Grau, B.C.; Kharlamov, E.; Marciuška, Š.; Zheleznyakov, D. Faceted search over RDF-based knowledge graphs. J. Web Semant. 2016, 37, 55–74. [Google Scholar] [CrossRef]
- Tzitzikas, Y.; Manolis, N.; Papadakos, P. Faceted exploration of RDF/S datasets: A survey. J. Intell. Inf. Syst. 2017, 48, 329–364. [Google Scholar] [CrossRef]
- Kritsotakis, V.; Roussakis, Y.; Patkos, T.; Theodoridou, M. Assistive Query Building for Semantic Data. In Proceedings of the SEMANTICS Posters & Demos, Vienna, Austria, 10–13 September 2018. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. Dbpedia—A large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Ristoski, P.; Rosati, J.; Di Noia, T.; De Leone, R.; Paulheim, H. RDF2Vec: RDF graph embeddings and their applications. Semant. Web 2019, 10, 721–752. [Google Scholar] [CrossRef] [Green Version]
- Portisch, J.; Hladik, M.; Paulheim, H. KGvec2go–Knowledge Graph Embeddings as a Service. arXiv 2020, arXiv:2003.05809. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. Knowledge Graph Embeddings over Hundreds of Linked Datasets. In Proceedings of the Research Conference on Metadata and Semantics Research, Rome, Italy, 28–31 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 150–162. [Google Scholar]
- Moreno-Vega, J.; Hogan, A. GraFa: Scalable faceted browsing for RDF graphs. In Proceedings of the International Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 301–317. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Wylot, M.; Hauswirth, M.; Cudré-Mauroux, P.; Sakr, S. RDF data storage and query processing schemes: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Elbassuoni, S.; Blanco, R. Keyword search over RDF graphs. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Scotland, UK, 24–28 October 2011; pp. 237–242. [Google Scholar]
- Delbru, R.; Rakhmawati, N.A.; Tummarello, G. Sindice at semsearch 2010. In Proceedings of the 19th International World Wide Web Conference, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Liu, X.; Fang, H. A study of entity search in semantic search workshop. In Proceedings of the 3rd International Semantic Search Workshop, Raleigh, NC, USA, 26 April 2010. [Google Scholar]
- Kadilierakis, G.; Nikas, C.; Fafalios, P.; Papadakos, P.; Tzitzikas, Y. Elas4RDF: Multi-perspective triple-centered keyword search over RDF using elasticsearch. In Proceedings of the European Semantic Web Conference, Virtual online, 1–6 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 122–128. [Google Scholar]
- Vega-Gorgojo, G.; Slaughter, L.; Von Zernichow, B.M.; Nikolov, N.; Roman, D. Linked data exploration with RDF surveyor. IEEE Access 2019, 7, 172199–172213. [Google Scholar] [CrossRef]
- Papadaki, M.E.; Spyratos, N.; Tzitzikas, Y. Towards Interactive Analytics over RDF Graphs. Algorithms 2021, 14, 34. [Google Scholar] [CrossRef]
- Colazzo, D.; Goasdoué, F.; Manolescu, I.; Roatiş, A. RDF analytics: Lenses over semantic graphs. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 467–478. [Google Scholar]
- Zou, L.; Huang, R.; Wang, H.; Yu, J.X.; He, W.; Zhao, D. Natural language question answering over RDF: A graph data driven approach. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 313–324. [Google Scholar]
- Bast, H.; Haussmann, E. More accurate question answering on freebase. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, VIC, Australia, 19–23 October 2015; pp. 1431–1440. [Google Scholar]
- Shekarpour, S.; Marx, E.; Ngomo, A.C.N.; Auer, S. Sina: Semantic interpretation of user queries for question answering on interlinked data. J. Web Semant. 2015, 30, 39–51. [Google Scholar] [CrossRef]
- Dimitrakis, E.; Sgontzos, K.; Tzitzikas, Y. A survey on question answering systems over linked data and documents. J. Intell. Inf. Syst. 2019, 55, 1–27. [Google Scholar] [CrossRef]
- Nikas, C.; Fafalios, P.; Tzitzikas, Y. Open Domain Question Answering over Knowledge Graphs using Keyword Search, Answer Type Prediction, SPARQL and Pre-trained Neural Models. In Proceedings of the 20th International Semantic Web Conference, Virtual online, 24–28 October 2021; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Chandrasekaran, D.; Mago, V. Evolution of Semantic Similarity—A Survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Albertoni, R.; De Martino, M. Asymmetric and context-dependent semantic similarity among ontology instances. In Journal on Data Semantics X; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–30. [Google Scholar]
- Hickson, M.; Kargakis, Y.; Tzitzikas, Y. Similarity-based browsing over linked open data. arXiv 2011, arXiv:1106.4176. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. Applying cross-data set identity reasoning for producing URI embeddings over hundreds of RDF data sets. Int. J. Metadata Semant. Ontol. 2021, 15, 1–22. [Google Scholar] [CrossRef]
- Nielsen, F.Å. Wembedder: Wikidata entity embedding web service. arXiv 2017, arXiv:1710.04099. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. Content-based union and complement metrics for dataset search over RDF knowledge graphs. J. Data Inf. Qual. (JDIQ) 2020, 12, 1–31. [Google Scholar] [CrossRef]
- Gesese, G.A.; Biswas, R.; Alam, M.; Sack, H. A survey on knowledge graph embeddings with literals: Which model links better literal-ly? Semant. Web 2019, 12, 617–647. [Google Scholar] [CrossRef]
- Kastrinakis, D.; Tzitzikas, Y. Advancing search query autocompletion services with more and better suggestions. In Proceedings of the International Conference on Web Engineering, Vienna, Austria, 5–9 July 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 35–49. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Tzitzikas, Y.; Papadaki, M.; Chatzakis, M. A Spiral-like Method to Place in the Space (and Interact with) too Many Values. J. Intell. Inf. Syst. 2021, in press. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Browsing System | Data Import | User Input | Output | HTML pages | Datasets Supported | Paths | Based on Data | Facets |
|---|---|---|---|---|---|---|---|---|
| RDFsim | SPARQL query | URI + Keywords | Tables + Visual | Dynamic | DBpedia | Triples + Larger Paths | KB-Data, embeddings | No |
| DBpedia [9] Browser | SPARQL query | URI | Tables | Dynamic | DBpedia | Triples | KB-Data | No |
| Wikidata [41] Browser | SPARQL query | URI | Tables | Dynamic | Wikidata | Triples | KB-Data | No |
| LODlive [3] | SPARQL query | URI + Keywords | Tables + Visual. | Dynamic | Any Dataset | Triples + Larger Paths | KB-Data | Yes |
| LODmilla [4] | SPARQL query | URI + Keywords | Tables + Visual. | Dynamic | Any Dataset | Triples + Larger Paths | KB-Data | Yes |
| RDF surveyor [21] | SPARQL query | Keywords | Tables + Visual. | Dynamic | Any Dataset | Triples | KB-Data | Yes |
| DBpedia Dataset | Number of Triples | Triples Size (MB) | Number of Entity Index Entries | Entity Index Size (MB) |
|---|---|---|---|---|
| Philosophers | 47,425 | 6.1 MB | 804 | 1.8 MB |
| Programming Languages | 100,070 | 13.2 MB | 2661 | 5.2 MB |
| Video Games | 3,089,559 | 423.0 MB | 58,257 | 118.0 MB |
| Movies | 13,512,335 | 1780.0 MB | 284,062 | 574.0 MB |
| Total | 16,749,389 | 2222.3 MB | 345,784 | 699.0 MB |
| DBpedia Dataset | Embeddings Creation Time | Indexing Creation Time | Total Time |
|---|---|---|---|
| Philosophers | 5.8 s | 5.3 s | 11.1 s |
| Programming Languages | 11.1 s | 16.6 s | 27.1 s |
| Video Games | 535.8 s | 1408.4 s | 1944.2 s |
| Movies | 2338.3 s | 27,716.6 s | 30,054.9 s |
| Total | 2891.0 s | 29,146.9 s | 32,037.3 s |
| DBpedia Dataset | Browse Entity-Sequential Access | Browse Entity-Random Access | Speedup from Random Access |
|---|---|---|---|
| Philosophers | 0.00502 s | 0.00044 s | 11.40× |
| Programming Languages | 0.01756 s | 0.00132 s | 13.30× |
| Video Games | 0.37720 s | 0.02257 s | 16.71× |
| Movies | 1.98209 s | 0.13247 s | 14.96× |
| Position | Entity | Sim. Score | Belongs to | |
|---|---|---|---|---|
| 1 | Plato | 0.53 | ✓ | 3084 |
| 2 | Socrates | 0.51 | ✓ | 984 |
| 3 | Ancient Greek philosophy | 0.47 | ✓ | 586 |
| 4 | Cicero | 0.46 | ✓ | 810 |
| 5 | Platonism | 0.46 | ✓ | 304 |
| 6 | Arcesilaus | 0.45 | 50 | |
| 7 | Diogenes Laertius | 0.45 | 173 | |
| 8 | Athens | 0.43 | √ | 710 |
| 9 | Zeno of Citium | 0.42 | 158 | |
| 10 | Universal (metaphysics) | 0.42 | 114 |
| Position | Entity | Sim. Score | Belongs to | |
|---|---|---|---|---|
| 1 | Java | 0.59 | ✓ | 2386 |
| 2 | Ruby | 0.57 | ✓ | 1450 |
| 3 | Compiler | 0.56 | ✓ | 478 |
| 4 | Open-source software | 0.55 | 1048 | |
| 5 | Object-oriented programming | 0.55 | ✓ | 502 |
| 6 | C++ | 0.54 | ✓ | 1508 |
| 7 | C Sharp | 0.54 | √ | 1270 |
| 8 | Graphical user interface | 0.53 | ✓ | 602 |
| 9 | Reflective programming | 0.53 | ✓ | 124 |
| 10 | BASIC | 0.50 | 260 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatzakis, M.; Mountantonakis, M.; Tzitzikas, Y. RDFsim: Similarity-Based Browsing over DBpedia Using Embeddings. Information 2021, 12, 440. https://doi.org/10.3390/info12110440
Chatzakis M, Mountantonakis M, Tzitzikas Y. RDFsim: Similarity-Based Browsing over DBpedia Using Embeddings. Information. 2021; 12(11):440. https://doi.org/10.3390/info12110440
Chicago/Turabian StyleChatzakis, Manos, Michalis Mountantonakis, and Yannis Tzitzikas. 2021. "RDFsim: Similarity-Based Browsing over DBpedia Using Embeddings" Information 12, no. 11: 440. https://doi.org/10.3390/info12110440
APA StyleChatzakis, M., Mountantonakis, M., & Tzitzikas, Y. (2021). RDFsim: Similarity-Based Browsing over DBpedia Using Embeddings. Information, 12(11), 440. https://doi.org/10.3390/info12110440