1. Introduction
Machine learning (ML) is a broad church. Supervised ML is very popular for exploring the relationship between clearly defined input and output variables. ML methods include: linear regression which handles continuous output by finding a line or plane that best fits the data, logistic regression which makes classification predictions for binary output, and support vector machines which classify by finding a hyperplane or boundary that maximises the margin between two or more classes. As an example, a supervised ML algorithm, or model, might be trained to classify incoming email based on the sender, subject line, or message content (input) that are accurately labelled as SPAM or NOT-SPAM (output). In contrast, unsupervised ML models attempt to draw inferences and find patterns from unlabelled data sets, such as finding neighbourhood clusters within demographic information. Common clustering methods include k-means clustering, which groups input into a pre-determined k number of groups, and hierarchical clustering, which arranges observations into tree-like graphs called dendrograms. For instance, an unsupervised ML model might be asked to classify research articles into disciplines according to their similarity. There are also semi-supervised approaches to machine learning, so the distinction is not always clear-cut.
ML models and tasks are diverse, but there are some general features that make some ML models useful for some tasks. For example, supervised ML can automatically classify items when the volume or complexity exceeds the capacity of manual classification or non-learning algorithmic exploration [
1,
2]. Similarly, unsupervised ML models are extremely useful for real-time data exploration and pattern detection in data that changes too quickly or too unpredictably for conventional exploration. ML (supervised and unsupervised) are often understood to perform better with more data. Nevertheless, there are trade-offs as unrepresentative data can lead to ‘over-fitting’ and poor generalisability, which is when a ML model performs very well on the training data but poorly on other data. ML is also typically understood to tolerate errors in the data, with some approaches showing acceptable performance despite error rates of up to 39 percent [
1,
2]. ML methods usually require substantial calculation, but this can be managed through careful selection of models and setups [
3]. For these reasons, ML is understood to be a good tool for the large, complex, and messy data that are ballooning too rapidly for manual or conventional means of exploration, classification, or analysis.
This paper begins with some background on time, machine learning, and the intersection of the two. Following this is a clear description of the research question to be addressed and the methods and data used to address it. Next are the research results and a discussion of how the results relate to the research question. Finally, there is a brief discussion of what the results might mean for the wider ML research context and what potential next steps for this research topic.
1.1. The Arrow of “Time”
The “arrow of time” concept comes from 1927 theoretical physics lecture and describes the apparent one-way flow of time observed in irreversible processes at macroscopic levels. Although concluding that the arrow of time is a consequence of entropy, it was also described as a matter of perception, reasoning and statistical approaches [
4]. Put another way, the one-way flow of time was understood to have a thermodynamic origin and psychological consequences. Thus, the arrow of time applies to irreversible processes that are both physical (e.g., an egg cannot be unscrambled) and economic or social (e.g., decisions cannot be undone and done differently instead), often known as path dependency or lock-in [
5] as illustrated in
Figure 1.
More recent work on the arrow of time maintains that people perceive and experience time as flowing in one direction, but highlights how the concept has continued to develop. Entropy is now linked to information and complexity [
6] although the concepts and their applications are not interchangeable [
7]. Currently, time’s arrow is thought to be a key driver of thermodynamic processes, biochemical processes like evolution via natural selection, and informational processes in both the natural world and cultural systems like language [
6,
8].
Setting aside the complicated concepts of information (especially as they related to entropy and thermodynamics), the arrow of time can be found in language; utterances (utterances are usually understood to be exclusively spoken, but this research counts tweets as utterances.) are spoken or written at a specific point in time. Further, language sequentially orders its components (symbols, semantic features, words, etc.) These temporal aspects of language are not always strict, allowing some meaning to be communicated ‘out of order’. Still, exactly what is communicated may not be “the same” as what would have been communicated if the utterances had been experienced at a different time or in another order. For example, classic literature is read and reread continuously with frequent new interpretations, all of which are probably unlike the contemporary interpretations from when the literature was originally available. Another example would be how readers may or may not struggle to understand the plot of a book series were they to read the sequel before the original. Likewise, some sentences can be understood more clearly than others when the words are jumbled; ‘eats mouse cheese’ is relatively clear while ‘eats man shark’ remains ambiguous.
The difference in interpretations or in interpretability described above derives from shared knowledge or common ground, which accumulates gradually as a consequence of experience [
9]. Once learned, common ground allows communicators to recruit previously gained knowledge into helping interpret current utterances. Thus, books in a series can be read out of order if they deal with well-known topics, plots, tropes, events, or characters, even if they are not always interpreted in the same way. Likewise, individuals could use common ground to assume that the mouse is eating the cheese in the first jumbled sentence (rather than the cheese eating the mouse) but might not be able to make assumptions about the second without more context (as humans and sharks are both capable of eating each other).
However, common ground is also built between individuals through repeated interactions [
9] and within a single interaction as participants take turns to speak and check their understanding [
10]. Meaning is even built within a single utterance as linguistic input is incrementally processed word-by-word [
10], which can create problems when an incremental understanding is violated by a ‘garden path’ sentence [
11]. As a consequence, language use and comprehension are affected by prior exposure to language, most obviously in childhood language development where studies show neurological differences as a result of language exchanges and linguistic turn-taking [
12].
1.2. Time in ML
ML includes supervised and unsupervised methods and can perform tasks such as prediction, classification, clustering, search and retrieval, or pattern discovery [
13]. Some ML tasks, such as auto-complete word suggestions or weather warning systems, rely on using explicitly ordered or temporal data. Comparative studies have found that different ML models perform differently on time-series classification [
14] and explicitly temporal tasks [
15]; neural networks outperformed classic linear analysis techniques and multi-layer perceptron (followed by Gaussian processes) performing best across a range of categories and data features [
16]. Clearly, ML can be very sensitive to time, with some ML models working with time better than others. Consequently, there are well-established data sets, benchmarks, and approaches for using ML models on tasks and with data that have an explicit order or temporal nature.
Many of the ML models that can deal with ordered or temporal data to address explicitly order- or time-sensitive tasks have problems or weaknesses that other ML methods can avoid. The problems of over-fitting and generalisability are more complicated because order/time is another dimension on which the data must be representative and which leaves the model relatively less tolerant of errors or missing values. Consequently, time-sensitive ML models typically have additional data requirements, including that the data must be organised into uniformly sized time intervals. Although not insurmountable, the stricter data requirements mean that time-sensitive ML is more difficult to apply or use. For tasks that do not require the specific use of time-sensitive methods, many researchers opt for ML models that assume the data to be time-independent and/or time-symmetrical.
Most of the data of interest for ML exploration and analysis are vast, complex, and messy because they are automatically generated by diverse digital technologies or practices. This means that the data of interest for ML usually have a temporal context. First, much of the data are time-stamped or otherwise ordered, although this is not always seen as important. Second, data are unevenly distributed over time as users, platforms, and records are added or shared, seriously complicating temporal representativeness. Additionally, features within these data are also unevenly distributed over time. To illustrate, 10–15% of medical diagnoses at any given point in time are estimated to be wrong [
17], although which ones are erroneous is not known at the time. Some incorrect diagnoses are identified through later testing, condition progression, and medical innovations or discoveries, but the re-diagnosis is also subject to the 10–15% misdiagnosis rate. Further complicating the issue, a correct diagnosis according to the diagnostic criteria of the time could be a misdiagnosis according to later criteria. This becomes clear when we recognise that autism is not childhood schizophrenia [
18] or that status lymphaticus is not a real condition [
19]. Third, and perhaps most importantly, new data are not created independently of existing data. Instead, data are often generated as the result of learning from previously generated data. For example, users might change what content they share on a social media platform after observing what content is popular or well-received. When considered together, all of this suggests that the data that invite ML analysis are likely to be time-asymmetrical in ways to which many ML models are not well suited.
Researchers have begun to ask how time and ML models interact, both to correct for problems caused by temporal features, as well as to capitalise on these features. For example, sentiment analysis of Twitter data is well-established as a ML problem of interest, but accounting for temporal aspects of the data allowed researchers to analyse sentiment in ‘real-time’ tweets [
20,
21] while combining sentiment analysis of tweets with geo-tagging enabled researchers to build a spatial and temporal map of New York [
22]. Further, using social interactions with temporal features allowed researchers to significantly improve stress detection in young people [
23], potentially allowing problems to be detected early enough for effective intervention. Researchers have clearly noticed the ways that time is relevant to some ML models and some tasks and are beginning to investigate these interactions and even to put them to practical use. Thus, it is important to understand which models, tasks, or model–task pairs are sensitive to implicit temporal features and in what ways these temporal sensitivities affect the ML performance.
1.3. Research Question
This research addresses several related questions. First, will ML models performing automatic classification tasks be influenced, biased, or complicated by data with subtle or implicit representations of the flow of time? Put another way, how will ML models sort data differently when the assumption of time independence is violated? This could have consequences for how appropriate ML models are chosen according to the data available or the task to be performed.
A second problem would revolve around identifying, quantifying, or managing the ML model effects on typically non-temporal tasks when the data implicitly capture the one-directional flow of time. Researchers could always discard or reshape the data to meet the more stringent requirements of explicitly time-sensitive ML methods, weighting the data, presenting the data differently during training, or other possible modifications. While these may help balance the risks between over-fitting and implicit temporal distortion, it would leave the models relatively slow, fussy, and complicated which seems to lose many of the benefits of ML as it is currently understood. Alternatively, iterative learning could be introduced so that models learn from already-trained models, as well as from the data. By approximating the way that the people generating the data learn from past data, such iterative learning may account for the time-asymmetry of the data. Still, such potential changes may detract from the benefits of ML as it is currently understood or used.
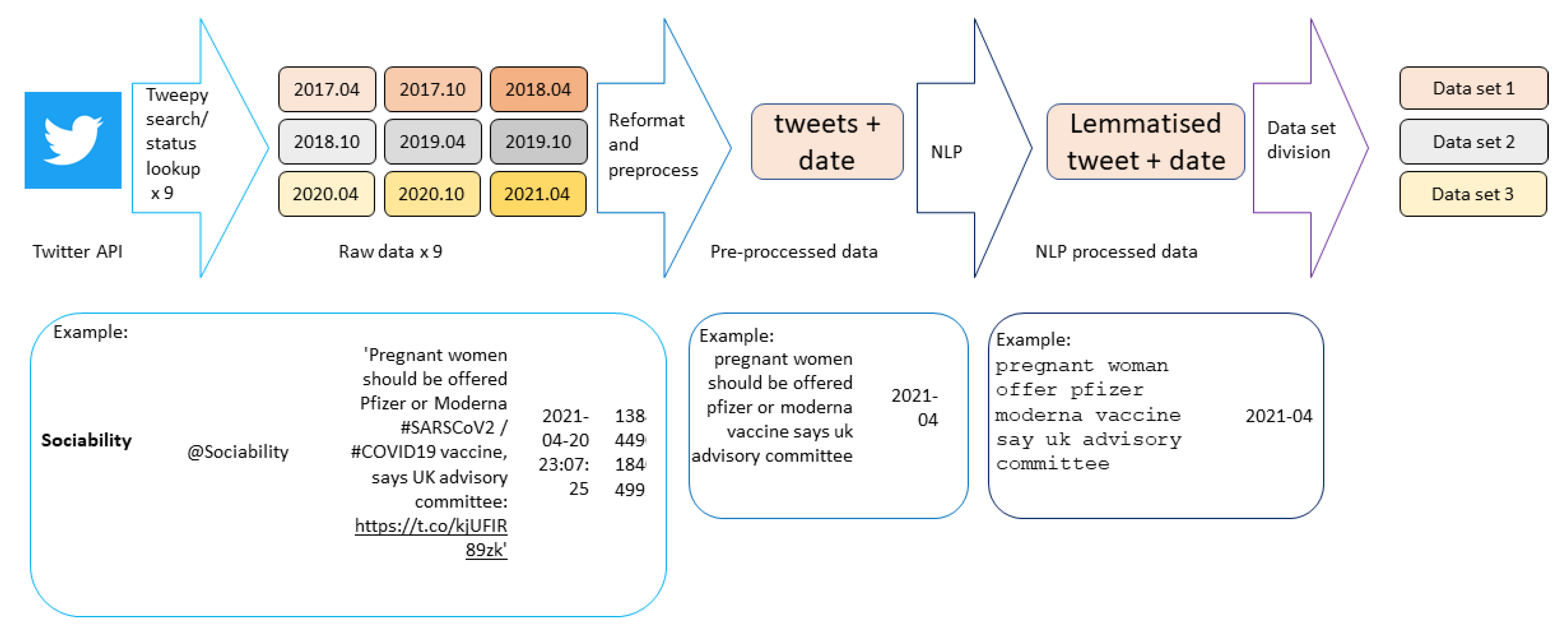
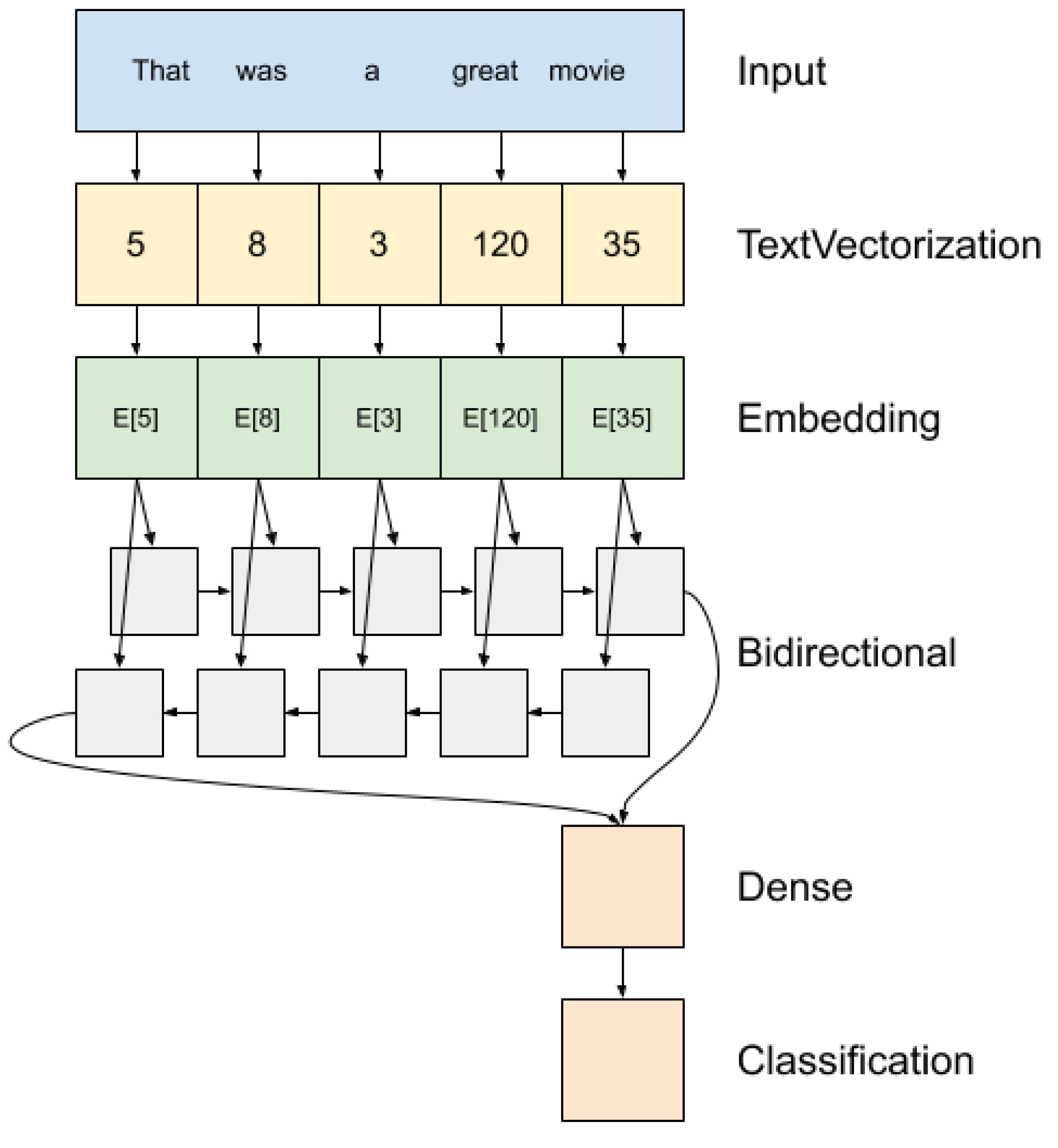
The research seeks to answer whether or not the ‘arrow of time’ can be observed in the performance of naive Bayes classification and recurrent neural networks ML models (both are commonly used) as they perform automatic classification tasks (very common) with Twitter data (a popular data source). Neither of these ML models are explicitly time-sensitive and so they do not have the sort of strict temporal representative measures of time-series prediction. Further, automatic classification tasks (e.g., sorting pictures into classes of ‘picture of a dog’ or ‘not a picture of a dog’) are not considered to be time-sensitive. The model will either accurately classify the pictures or not, regardless of when the picture was taken, when the classification happens, or how many pictures the ML model has been asked to classify. Finally, time is included in this data set, but not in a way that can be accessed directly. The model only has access to and learns from language and classifies purely based on the tweet text. This combination of model, task, and data are deliberately have no explicit access to or instruction to use time as a feature.
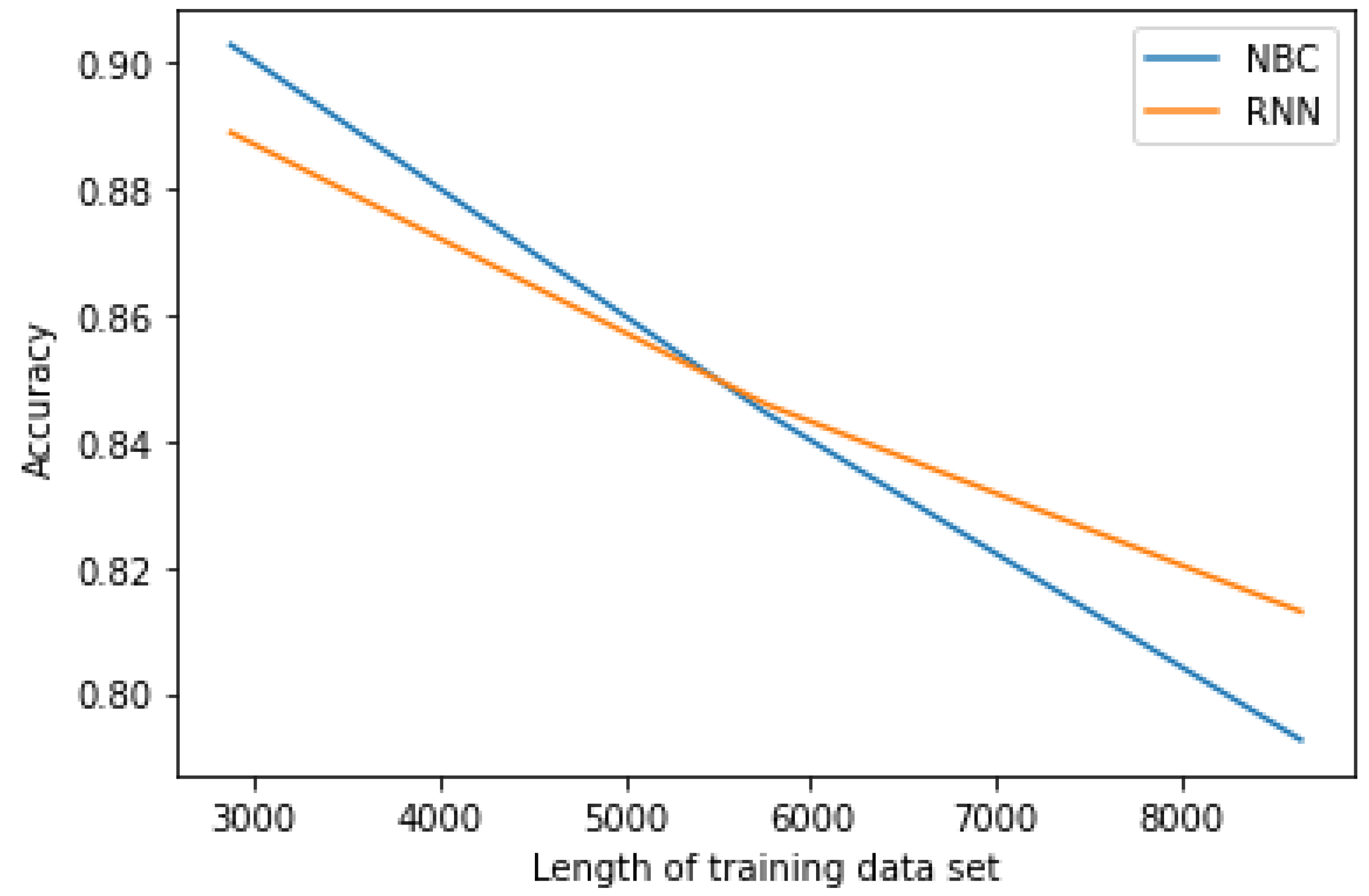
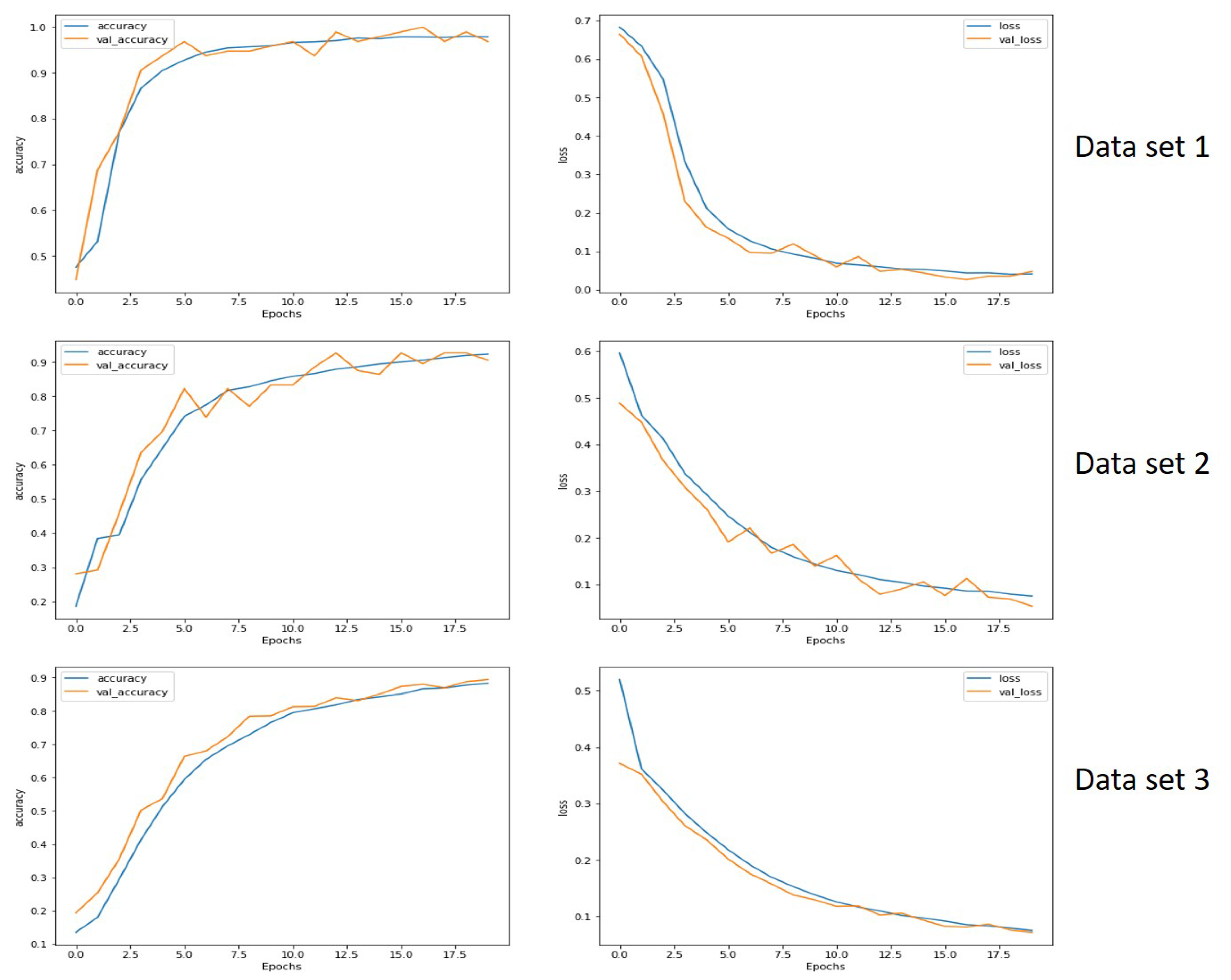
For extremely such common model–task–data combinations, more data are typically considered to be ‘better’ but that assumes that the data will not be complicated by an implicit arrow of time. The data in this case come from 9 searches, each of which covers a different time frame. The ML models are trained to classify by which search produced them, but are trained on 3 searches, 6 searches, and all 9 searches and which differ according to the time frame searched. If ‘more training data is always better’ then the performance should be equal or better when the models are trained on 6 or 9 searches in comparison to when they are trained on only 3. However, if the mode–task–data combination includes implicit temporal features that disrupt learning, then the performance should be worse on the models trained with more data than those trained with less. In essence, the research question can be rephrased as ‘is the performance of non-temporal ML models carrying out non-temporal tasks influenced by purely implicit temporal features of the data?’
Author Contributions
Conceptualisation, J.K. and A.Z.; methodology, J.K. and A.Z.; software, A.Z.; validation, J.K. and A.Z.; formal analysis, A.Z.; writing—original draft preparation, J.K.; writing—review and editing, J.K. and A.Z.; visualisation, J.K. and A.Z. All authors have read and agreed to the published version of the manuscript.
Funding
Funded by UKRI through the ESRC under grant number ES/P008437/1, with contributions from our partners.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
The authors thankfully acknowledge colleagues at the UK Data Service and the Cathie Marsh Institute at the University of Manchester. We are especially grateful to Joe Allen for the time he spent reviewing drafts, discussing ideas, suggesting code fixes and generally be a legend, to Vanessa Higgins for her patient support with our difficult ideas, and to Gill Meadows for her almost omniscient professional service support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Brunk, C.A.; Pazzani, M.J. An investigation of noise-tolerant relational concept learning algorithms. In Machine Learning Proceedings 1991; Elsevier: Amsterdam, The Netherlands, 1991; pp. 389–393. [Google Scholar]
- Kaiser, T.M.; Burger, P.B. Error tolerance of machine learning algorithms across contemporary biological targets. Molecules 2019, 24, 2115. [Google Scholar] [CrossRef] [PubMed]
- Baştanlar, Y.; Özuysal, M. Introduction to machine learning. In miRNomics: MicroRNA Biology and Computational Analysis; Springer: Berlin/Heidelberg, Germany, 2014; pp. 105–128. [Google Scholar]
- Eddington, A. The Nature of the Physical World: The Gifford Lectures 1927; Books on Demand: Norderstedt, Germany, 2019; Volume 23. [Google Scholar]
- Page, S.E. Path dependence. Q. J. Political Sci. 2006, 1, 87–115. [Google Scholar] [CrossRef]
- Mikhailovsky, G.E.; Levich, A.P. Entropy, information and complexity or which aims the arrow of time? Entropy 2015, 17, 4863–4890. [Google Scholar] [CrossRef]
- Ben-Naim, A. Entropy, Shannon’s measure of information and Boltzmann’s H-theorem. Entropy 2017, 19, 48. [Google Scholar] [CrossRef]
- Febres, G.; Jaffe, K. A fundamental scale of descriptions for analyzing information content of communication systems. Entropy 2015, 17, 1606–1633. [Google Scholar] [CrossRef]
- CLARK, E. Common Ground; Wiley: Hoboken, NJ, USA, 2015; Volume 87. [Google Scholar]
- Eshghi, A.; Howes, C.; Gregoromichelaki, E.; Hough, J.; Purver, M. Feedback in conversation as incremental semantic update. In Proceedings of the 11th International Conference on Computational Semantics, London, UK, 15–17 April 2015; pp. 261–271. [Google Scholar]
- Ferreira, F.; Henderson, J.M. Recovery from misanalyses of garden-path sentences. J. Mem. Lang. 1991, 30, 725–745. [Google Scholar] [CrossRef]
- Romeo, R.R.; Leonard, J.A.; Robinson, S.T.; West, M.R.; Mackey, A.P.; Rowe, M.L.; Gabrieli, J.D. Beyond the 30-million-word gap: Children’s conversational exposure is associated with language-related brain function. Psychol. Sci. 2018, 29, 700–710. [Google Scholar] [CrossRef] [PubMed]
- Laxman, S.; Sastry, P.S. A survey of temporal data mining. Sadhana 2006, 31, 173–198. [Google Scholar] [CrossRef]
- Bagnall, A.; Bostrom, A.; Large, J.; Lines, J. The great time series classification bake off: An experimental evaluation of recently proposed algorithms. Extended version. arXiv 2016, arXiv:1602.01711. [Google Scholar]
- Wang, S.; Cao, J.; Yu, P. Deep learning for spatio-temporal data mining: A survey. IEEE Trans. Knowl. Data Eng. 2020. early access. [Google Scholar] [CrossRef]
- Ahmed, N.K.; Atiya, A.F.; Gayar, N.E.; El-Shishiny, H. An empirical comparison of machine learning models for time series forecasting. Econom. Rev. 2010, 29, 594–621. [Google Scholar] [CrossRef]
- Graber, M.L. The incidence of diagnostic error in medicine. BMJ Qual. Saf. 2013, 22, ii21–ii27. [Google Scholar] [CrossRef] [PubMed]
- Kanner, L. Autistic disturbances of affective contact. Nerv. Child 1943, 2, 217–250. [Google Scholar]
- Dodwell, H. “Status Lymphaticus,” the Growth of a Myth. Br. Med J. 1954, 1, 149. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Goel, A.; Gautam, J.; Kumar, S. Real time sentiment analysis of tweets using Naive Bayes. In Proceedings of the 2016 2nd International Conference on Next Generation Computing Technologies (NGCT), Dehradun, India, 14–16 October 2016; pp. 257–261. [Google Scholar] [CrossRef]
- Prakruthi, V.; Sindhu, D.; Anupama Kumar, D.S. Real Time Sentiment Analysis Of Twitter Posts. In Proceedings of the 2018 3rd International Conference on Computational Systems and Information Technology for Sustainable Solutions (CSITSS), Bengaluru, India, 20–22 December 2018; pp. 29–34. [Google Scholar] [CrossRef]
- Bertrand, K.Z.; Bialik, M.; Virdee, K.; Gros, A.; Bar-Yam, Y. Sentiment in new york city: A high resolution spatial and temporal view. arXiv 2013, arXiv:1308.5010. [Google Scholar]
- Zhao, L.; Jia, J.; Feng, L. Teenagers’ stress detection based on time-sensitive micro-blog comment/response actions. In Proceedings of the IFIP International Conference on Artificial Intelligence in Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2015; pp. 26–36. [Google Scholar]
- Zhao, A.; Kasmire, J. ICTeSSH-Arrow-of-Time, GitHub, 2021. Available online: https://assets.pubpub.org/cbyfgra4/51626784796909.pdf (accessed on 12 October 2021).
- Roesslein, J. Tweepy: Twitter for Python! 2020. Available online: https://github.com/tweepy/tweepy (accessed on 1 May 2021).
- Python Package Index-PyPI. Available online: https://docs.python.org/3/distutils/packageindex.html (accessed on 1 May 2021).
- Van Rossum, G. The Python Library Reference, Release 3.8.2; Python Software Foundation: Wilmington, DE, USA, 2020. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Newton, MA, USA, 2009. [Google Scholar]
- Zhang, H. The optimality of naive Bayes. In Proceedings of the 17th International Florida Artificial Intelligence Research Society Conference, Miami Beach, FL, USA, 12–14 May 2004. [Google Scholar]
- Wang, S.I.; Manning, C.D. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; Volume 2, pp. 90–94. [Google Scholar]
- Loria, S. Textblob Documentation. Python Package, Release 0.15. 2018. Available online: https://textblob.readthedocs.io/en/dev/ (accessed on 12 October 2021).
- Lewis, D.D. Naive (Bayes) at forty: The independence assumption in information retrieval. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1998; pp. 4–15. [Google Scholar]
- Lee, S.H.; Levin, D.; Finley, P.D.; Heilig, C.M. Chief complaint classification with recurrent neural networks. J. Biomed. Inform. 2019, 93, 103158. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. LSTM can solve hard long time lag problems. In Proceedings of the Advances in Neural Information Processing Systems 9, NIPS, Denver, CO, USA, 2–5 December 1996; pp. 473–479. [Google Scholar]
- Wang, F.; Xuan, Z.; Zhen, Z.; Li, K.; Wang, T.; Shi, M. A day-ahead PV power forecasting method based on LSTM-RNN model and time correlation modification under partial daily pattern prediction framework. Energy Convers. Manag. 2020, 212, 112766. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 12 October 2021).
- The Pandas Development Team. Pandas-Dev/Pandas: Pandas. Zenodo, February 2020. Available online: https://pandas.pydata.org/about/citing.html (accessed on 12 October 2021).
- Chollet, F. Keras, GitHub, 2015. Available online: https://www.scirp.org/(S(351jmbntvnsjt1aadkposzje))/reference/ReferencesPapers.aspx?ReferenceID=1887532 (accessed on 12 October 2021).
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum Learning. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML’09, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}