
Emotion Classification in Spanish: Exploring the Hard Classes


Abstract
:1. Introduction
2. Related Work
2.1. Lexicons for Emotion Analysis
2.2. Annotated Corpora for Emotion Classification
2.3. Automatic Emotion Classification
3. Materials and Methods
3.1. Corpora
3.2. Preprocessing
3.3. Experiments
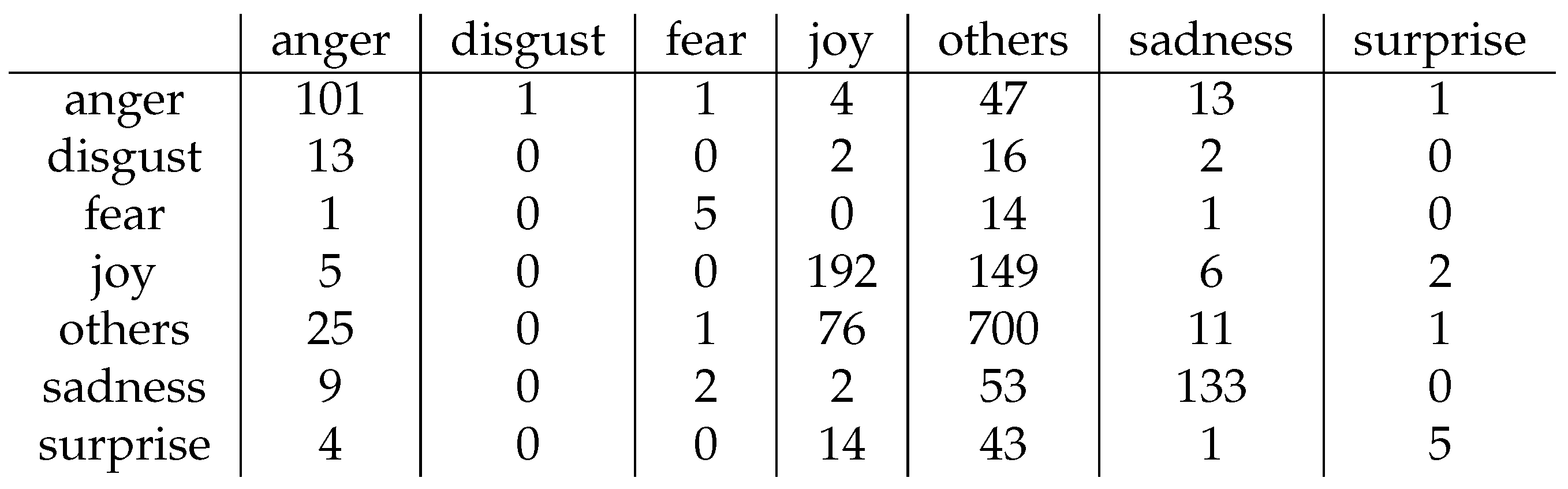
4. Results and Discussion
- A sad tweet: Guardaré en mis ojos tu última mirada… #notredame #paris #francia #photography #streetphotography;
- A clearly positive tweet, that could even have been annotated as joy: Que clase táctica están dando estos dos Equipos… bendita #ChampionsLeague;
- An informative tweet, with no emotion: El escrutinio en el Senado va mucho más lento. Solo el 14.85% del voto escrutado #28A #ElecccionesGenerales28A.
4.1. The Disgust Class
- Tweet transmitting a very low level of dislike: Me cuesta mucho entender la fiesta de Ciudadanos…#ElecccionesGenerales28A;
- Tweet transmitting a very high level of dislike Caterva de hijueputas venezolanos que le hacen juego al pilche golpe. Háganse los valientes en #Venezuela y no jodan en Ecuador. Dan asco….;
- Informative tweet: Los gobiernos de #Argentina #Brasil #Canada #Chile #Colombia #CostaRica #Guatemala #Honduras #Panamá #Paraguay #Peru y #Venezuela, miembros del #GrupoDeLima, “conminan a USER a cesar la usurpación, para que pueda empezar la transición democrática” en #Venezuela;
- Tweet that could have been annotated as anger: Si no fuésemos estúpidos/as, los gestores de nuestro sistema alimentario estarían en prisión, por actos criminales contra la naturaleza y la salud pública. #ExtinctionRebellion #GretaThunberg.
4.2. The Fear Class
- Ansiedad;
- Ansiosa;
- Ansioso;
- Asustada;
- Asustado;
- Asustar;
- Co;
- https;
- Miedo;
- Nerviosa;
- Nervioso;
- Peligroso;
- Pesadilla;
- Preocupación;
- Preocupada;
- Pánico;
- Susto;
- Temblor;
- Temor;
- Terror.
4.3. The Surprise Class
- Liverpool está paseando al barcelona, hace tiempo no lo veía tan presionado al barca…!! #ChampionsLeague;
- Tremendo liderazgo de #GretaThunberg!! Tiene 16 años y nos está haciendo a TODOS mirar el mundo con otros ojos! Entremos en pánico, salvemos el planeta!! #CambioClimatico;
- El Messi de hoy deslumbra! Que nivel #ChampionsLeague;
- Primera vez que veo a Messi exagerar una falta. #ChampionsLeague;
- El único episodio que me ha dejado sin palabras. #JuegoDeTronos #GameofThrones;
- Menudo sorpresón final. Eso sí que no me lo esperaba. #JuegoDeTronos;
- Lo que vino a sacarles #NotreDame, es TODA su amargura. A la madere, me tienen sorprendida.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| BOW | Bag of Words |
| ANEW | Affective Norms for English Words |
| LSTM | Long Short-Term Memory |
| SEL | Spanish Emotion Lexicon |
| SVM | Support Vector Machine |
References
- Liu, B. Sentiment Analysis. Mining Opinions, Sentiments, and Emotions, 2nd ed.; Cambridge University Press: New York, NY, USA, 2020. [Google Scholar]
- Wundt, W. Grundriss der Psychologie (Outlines of Psychology); Engelmann: Leibzig, Germany, 1874. [Google Scholar]
- Osgood, C.; Suci, G.; Tenenbaum, P. The Measurement of Meaning; University of Illinois Press: Urbana, IL, USA, 1957. [Google Scholar]
- Mehrabian, A.; Russell, J. An Approach to Environmental Psychology; The MIT Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Ekman, P. Facial Expressions of Emotion: New Findings, New Questions. Psychol. Sci. 1992, 3, 34–38. [Google Scholar] [CrossRef]
- Plutchik, R. A psychoevolutionary theory of emotions. Soc. Sci. Inf. 1982, 21, 529–553. [Google Scholar] [CrossRef]
- Chiruzzo, L.; Rosá, A. RETUYT-InCo at EmoEvalEs 2021: Multiclass Emotion Classification in Spanish. In Proceedings of the Iberian Languages Evaluation Forum Co-Located with the XXXVII International Conference of the Spanish Society for Natural Language Processing (SEPLN 2021), Málaga, Spain, 21–24 September 2021. [Google Scholar]
- Plaza-del-Arco, F.M.; Jiménez-Zafra, S.M.; Montejo-Ráez, A.; Molina-González, M.D.; Ureña-López, L.A.; Martín-Valdivia, M.T. Overview of the EmoEvalEs task on emotion detection for Spanish at IberLEF 2021. Proces. Leng. Nat. 2021, 67, 155–161. [Google Scholar]
- Bradley, M.; Lang, P. Affective Norms for English Words (ANEW): Instruction Manual and Affective Ratings; Technical Report; Center for Research in Psychophysiology, University of Florida: Gainesville, FL, USA, 1999. [Google Scholar]
- Redondo, J.; Fraga, I.; Padrón, I.; Comesaña, M. The Spanish adaptation of ANEW (Affective Norms for English Words). Behav. Res. Methods 2007, 39, 600–605. [Google Scholar] [CrossRef] [PubMed]
- Warriner, A.B.; Kuperman, V.; Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 2013, 45, 1191–1207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shaikh, S.; Cho, K.; Strzalkowski, T.; Feldman, L.; Lien, J.; Liu, T.; Broadwell, G.A. ANEW+: Automatic Expansion and Validation of Affective Norms of Words Lexicons in Multiple Languages. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 1127–1132. [Google Scholar]
- Mohammad, S.; Turney, P.D. Crowdsourcing a Word-Emotion Association Lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef] [Green Version]
- Rangel, I.; Sidorov, G.; Guerra, S. Creación y evaluación de un diccionario marcado con emociones y ponderado para el español. Onomázein 2014, 29, 31–46. [Google Scholar] [CrossRef] [Green Version]
- Plaza-del-Arco, F.M.; Molina-González, M.D.; Jiménez-Zafra, S.M.; Martín-Valdivia, M.T. Lexicon Adaptation for Spanish Emotion Mining. Proces. Leng. Nat. 2018, 61, 117–124. [Google Scholar]
- Mohammad, S.M.; Bravo-Marquez, F.; Salameh, M.; Kiritchenko, S. SemEval-2018 Task 1: Affect in Tweets. In Proceedings of the International Workshop on Semantic Evaluation (SemEval-2018), New Orleans, LA, USA, 5–6 June 2018. [Google Scholar]
- Strapparava, C.; Mihalcea, R. SemEval-2007 Task 14: Affective Text. In Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), Prague, Czech Republic, 23–24 June 2007; pp. 70–74. [Google Scholar]
- Mohammad, S.; Bravo-Marquez, F. Emotion Intensities in Tweets. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (*SEM 2017), Vancouver, QC, Canada, 3–4 August 2017; pp. 65–77. [Google Scholar] [CrossRef] [Green Version]
- Mohammad, S.M.; Bravo-Marquez, F. WASSA-2017 Shared Task on Emotion Intensity. In Proceedings of the Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis (WASSA), Copenhagen, Denmark, 8 September 2017. [Google Scholar]
- Mohammad, S.; Kiritchenko, S. Understanding Emotions: A Dataset of Tweets to Study Interactions between Affect Categories. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Plaza-del-Arco, F.; Strapparava, C.; Ureña-López, L.A.; Martín-Valdivia, M.T. EmoEvent: A Multilingual Emotion Corpus based on different Events. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1492–1498. [Google Scholar]
- García-Vega, M.; Díaz-Galiano, M.C.; García-Cumbreras, M.A.; del Arco, F.M.P.; Montejo-Ráez, A.; Jiménez-Zafra, S.M.; Martínez Cámara, E.; Aguilar, C.A.; Cabezudo, M.A.S.; Chiruzzo, L.; et al. Overview of TASS 2020: Introducing Emotion Detection. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020) Co-Located with 36th Conference of the Spanish Society for Natural Language Processing (SEPLN 2020), Málaga, Spain, 23 September 2020; pp. 163–170. [Google Scholar]
- Montes, M.; Rosso, P.; Gonzalo, J.; Aragón, E.; Agerri, R.; Álvarez-Carmona, M.Á.; Álvarez Mellado, E.; Carrillo-de Albornoz, J.; Chiruzzo, L.; Freitas, L.; et al. Iberian Languages Evaluation Forum 2021. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2021), Málaga, Spain, 21–24 September 2021; Available online: http://ceur-ws.org/Vol-2943/ (accessed on 17 October 2021).
- Acheampong, F.A.; Wenyu, C.; Nunoo-Mensah, H. Text-based emotion detection: Advances, challenges, and opportunities. Eng. Rep. 2020, 2, e12189. [Google Scholar] [CrossRef]
- González, J.Á.; Hurtado, L.F.; Pla, F. ELiRF-UPV at SemEval-2018 Tasks 1 and 3: Affect and Irony Detection in Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation, New Orleans, LA, USA, 5–6 June 2018; pp. 565–569. [Google Scholar] [CrossRef]
- Ángel González, J.; Moncho, J.A.; Hurtado, L.F.; Pla, F. ELiRF-UPV at TASS 2020: TWilBERT for Sentiment Analysis and Emotion Detection in Spanish Tweets. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020) Co-Located with 36th Conference of the Spanish Society for Natural Language Processing (SEPLN 2020), Málaga, Spain, 23 September 2020; pp. 179–186. [Google Scholar]
- Gonzalez, J.A.; Hurtado, L.F.; Pla, F. TWilBert: Pre-trained deep bidirectional transformers for Spanish Twitter. Neurocomputing 2021, 426, 58–69. [Google Scholar] [CrossRef]
- Plaza-del-Arco, F.; Martín-Valdivia, M.T.; Ureña-López, L.A.; Mitkov, R. Improved emotion recognition in Spanish social media through incorporation of lexical knowledge. Future Gener. Comput. Syst. 2020, 110, 1000–1008. [Google Scholar] [CrossRef]
- Cañete, J.; Chaperon, G.; Fuentes, R.; Ho, J.H.; Kang, H.; Pérez, J. Spanish Pre-Trained BERT Model and Evaluation Data. PML4DC at ICLR 2020. 2020. Available online: https://users.dcc.uchile.cl/~jperez/papers/pml4dc2020.pdf (accessed on 17 October 2021).
- Vera, D.; Araque, O.; Iglesias, C.A. GSI-UPM at IberLEF2021: Emotion Analysis of Spanish Tweets by Fine-tuning the XLM-RoBERTa Language Model. In Proceedings of the Iberian Languages Evaluation Forum Co-Located with the XXXVII International Conference of the Spanish Society for Natural Language Processing (SEPLN 2021), Málaga, Spain, 21–24 September 2021. [Google Scholar]
- Tafreshi, S.; De Clercq, O.; Barriere, V.; Buechel, S.; Sedoc, J.; Balahur, A. WASSA 2021 Shared Task: Predicting Empathy and Emotion in Reaction to News Stories. In Proceedings of the Eleventh Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Online, 19 April 2021; pp. 92–104. [Google Scholar]
- Deng, J.; Ren, F. Multi-label Emotion Detection via Emotion-Specified Feature Extraction and Emotion Correlation Learning. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Ahmad, Z.; Jindal, R.; Ekbal, A.; Bhattachharyya, P. Borrow from rich cousin: Transfer learning for emotion detection using cross lingual embedding. Expert Syst. Appl. 2020, 139, 112851. [Google Scholar] [CrossRef]
- Abdul-Mageed, M.; Ungar, L. EmoNet: Fine-Grained Emotion Detection with Gated Recurrent Neural Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, QC, Canada, 7–12 August 2017; pp. 718–728. [Google Scholar] [CrossRef] [Green Version]
- Colnerič, N.; Demšar, J. Emotion Recognition on Twitter: Comparative Study and Training a Unison Model. IEEE Trans. Affect. Comput. 2020, 11, 433–446. [Google Scholar] [CrossRef]
- Wadhawan, A.; Aggarwal, A. Towards Emotion Recognition in Hindi-English Code-Mixed Data: A Transformer Based Approach. In Proceedings of the Eleventh Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Online, 19 April 2021; pp. 195–202. [Google Scholar]
- Chiruzzo, L.; Etcheverry, M.; Rosá, A. Sentiment analysis in Spanish tweets: Some experiments with focus on neutral tweets. Rev. Proces. Leng. Nat. 2020, 64, 109–116. [Google Scholar]


{kind=link}
{kind=link}
| Emotion | Train | Dev | Test |
|---|---|---|---|
| Anger | 589 | 85 | 168 |
| Disgust | 111 | 16 | 33 |
| Fear | 65 | 9 | 21 |
| Joy | 1227 | 181 | 354 |
| Sadness | 693 | 104 | 199 |
| Surprise | 238 | 35 | 67 |
| Others | 2800 | 414 | 814 |
| Total | 5723 | 844 | 1656 |
| Emotion | Tweets |
|---|---|
| Anger | 2872 |
| Disgust | 1153 |
| Fear | 810 |
| Joy | 3388 |
| Sadness | 2325 |
| Surprise | 566 |
| Others | 3816 |
| Total | 14,930 |
| Training Corpus | Acc on Dev | W-F1 on Dev | Acc on Test | W-F1 on Test |
|---|---|---|---|---|
| EmoEvent | ||||
| EmoEvent + SemEval |
| System | Acc | W-P | W-R | W-F1 |
|---|---|---|---|---|
| GSI-UPM | 0.7276 | 0.7094 | 0.7276 | 0.7170 |
| EmoEvent + SemEval | 0.6860 | 0.6683 | 0.6860 | 0.6620 |
| RETUYT-InCo (EmoEvent) | 0.6781 | 0.6583 | 0.6781 | 0.6573 |
| qu | 0.4498 | 0.6188 | 0.4498 | 0.4469 |
| Corpus Version | Class | F1 on Test |
|---|---|---|
| With others | anger | 0.6196 |
| disgust | 0.0000 | |
| fear | 0.3333 | |
| joy | 0.5963 | |
| sadness | 0.7268 | |
| surprise | 0.1316 | |
| others | 0.7625 | |
| Accuracy: | 0.6860 | |
| Weighted-F1: | 0.6620 | |
| Without others | anger | 0.7049 |
| disgust | 0.0000 | |
| fear | 0.5500 | |
| joy | 0.8475 | |
| sadness | 0.7749 | |
| surprise | 0.2917 | |
| Accuracy: | 0.7447 | |
| Weighted-F1: | 0.7170 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosá, A.; Chiruzzo, L. Emotion Classification in Spanish: Exploring the Hard Classes. Information 2021, 12, 438. https://doi.org/10.3390/info12110438
Rosá A, Chiruzzo L. Emotion Classification in Spanish: Exploring the Hard Classes. Information. 2021; 12(11):438. https://doi.org/10.3390/info12110438
Chicago/Turabian StyleRosá, Aiala, and Luis Chiruzzo. 2021. "Emotion Classification in Spanish: Exploring the Hard Classes" Information 12, no. 11: 438. https://doi.org/10.3390/info12110438
APA StyleRosá, A., & Chiruzzo, L. (2021). Emotion Classification in Spanish: Exploring the Hard Classes. Information, 12(11), 438. https://doi.org/10.3390/info12110438