
Quality Assessment Methods for Textual Conversational Interfaces: A Multivocal Literature Review



Abstract
1. Introduction
- Section 2 presents the background about the evaluation processes of chatbots and compares this work to existing secondary studies in the field;
- Section 3 describes the adopted research methods by specifying its goals, research questions, search criteria, and analysis methods;
- Section 4 presents the results of the MLR;
- Section 5 discusses the implications of the results and the threats to the validity of our study;
- Finally, Section 6 concludes the study and presents possible future avenues for this work.
2. Background
2.1. Overview of Quality Assessment Methods for Conversational Interfaces
2.2. Multivocal Literature Reviews
2.3. Related Work
3. Research Method
- 1.
- Planning: in this phase, the need for conducting an MLR on a given topic is established, and the goals and research questions of the MLR are specified;
- 2.
- Conducting: in this phase, the MLR is conducted entailing five different sub-steps: definition of the search process, source selection, assessment of the quality of the selected studies, data extraction, and data synthesis;
- 3.
- Reporting: in this phase, the review results are reported and tailored to the selected destination audience (e.g., researchers or practitioners from the industry).
3.1. Planning
3.1.1. Motivation behind Conducting an MLR
- 1.
- The subject is not addressable only with evidence from formal literature, since typically real-world limitations of the conversational interfaces are addressed by white literature only to a certain extent;
- 2.
- Many studies in the literature do provide methods for the evaluation of conversational interfaces with small controlled experiments, which may not reflect the dynamics of the usage of such technologies by practitioners;
- 3.
- The context where they are applied is of crucial importance for conversational interfaces, and grey literature is supposed to provide more information of this kind since they it is more strictly tied to actual practice;
- 4.
- Practical experiences reported in grey literature can indicate whether the metrics or approaches proposed in the formal literature are feasible or beneficial in real-world scenarios;
- 5.
- Grey literature can reveal the existence of more evaluation methodologies and metrics than those that could be deduced from white literature only;
- 6.
- Observing the outcomes of measurements on commercial products can provide researchers with relevant insights regarding where to focus research efforts; conversely, practitioners can deduce new areas in which to invest from the white literature;
- 7.
- Conversational interfaces and their evaluation are prevalent in the software engineering area, which accounts for many sources of reliable grey literature.
3.1.2. Goals
- Goal 1: Providing a mapping of the studies regarding the evaluation of the quality of conversational interfaces.
- Goal 2: Describing the methods, frameworks, and datasets that have been developed in the last few years for the evaluation of the quality of conversational interfaces.
- Goal 3: Quantifying the contribution of grey and practitioners’ literature to the subject.
3.1.3. Review Questions
- RQ1.1 What are the different categories of contributions of the considered sources?
- RQ1.2 How many sources present metrics, guidelines, frameworks, and datasets to evaluate textual conversational interfaces?
- RQ1.3 Which research methods have been used in the considered sources?
- RQ2.1 Which are the metrics used for the quality evaluation of textual conversational interfaces?
- RQ2.2 Which are the proposed frameworks for evaluating the quality of textual conversational interfaces?
- RQ2.3 Which are the datasets used to evaluate textual conversational interfaces?
- RQ3.1 Which technological contributions from the industry and practitioner community are leveraged by white literature?
- RQ3.2 How much attention has this topic received from the practitioner and industrial community compared to the research community?
3.2. Conducting the MLR
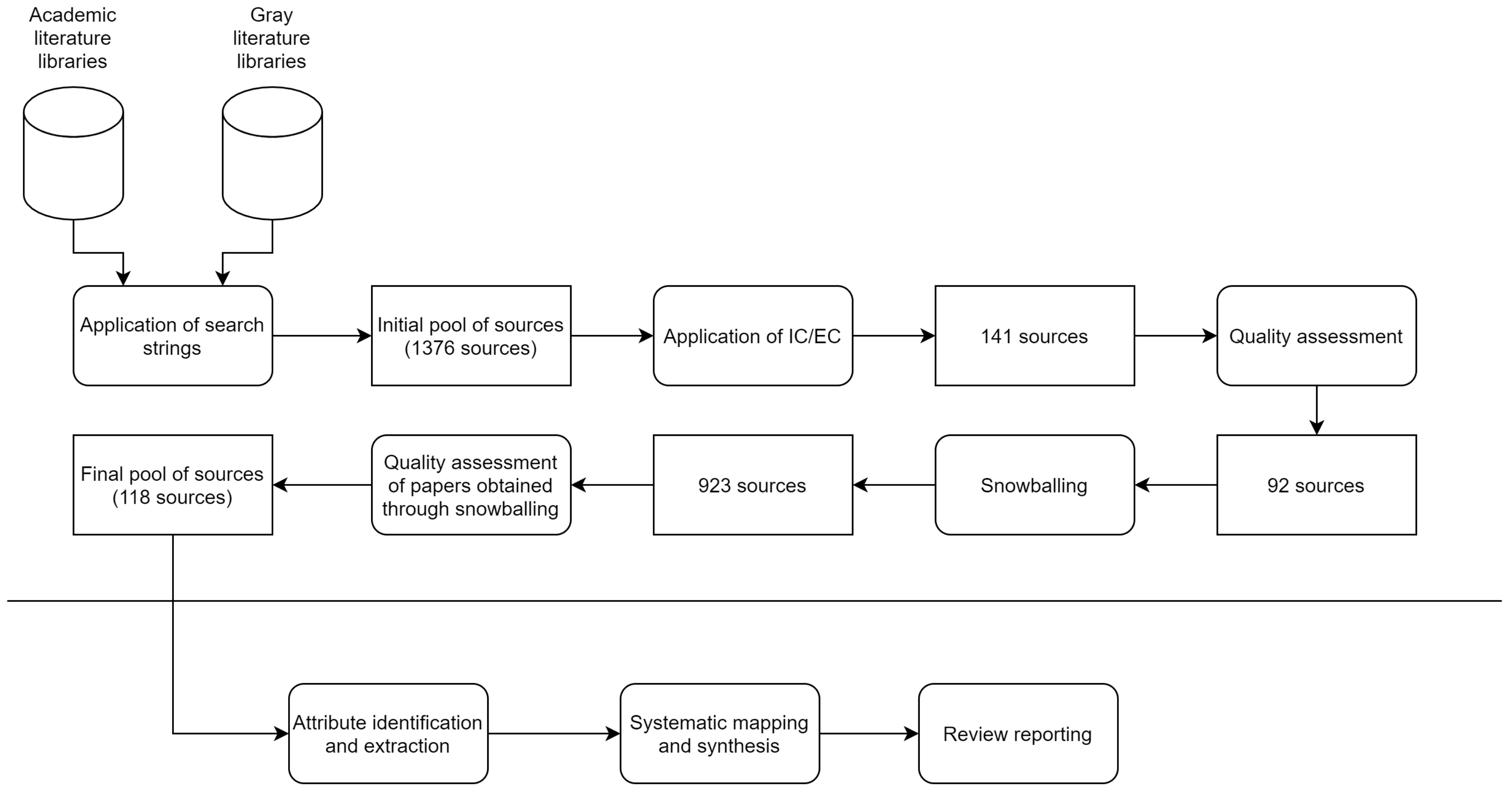
3.2.1. Search Approach
- Application of the search strings: the specific strings were applied to the selected online libraries (for the white literature search) and on the Google search engine (for the grey literature search);
- Search bounding: To stop the searching of grey literature and to limit the number of sources to a reasonable number, we applied the Effort Bounded strategy, i.e., we limited our effort to the first 100 Google search hits;
- Removal of duplicates: in our pool of sources, we consider a single instance for each source that is present in multiple repositories;
- Application of inclusion and exclusion criteria: we defined and applied the inclusion and exclusion criteria directly to the sources extracted from the online repositories, based on an examination of titles, keywords, and abstracts of the papers;
- Quality assessment: every source from the pool was entirely read and evaluated in terms of the quality of the contribution.
- Backward Snowballing [36]: all the articles in the reference lists of all sources were added to the preliminary pool and evaluated through the application of the previous steps. We also added to the pool of grey literature the grey literature sources cited by white literature;
- Documentation and analysis: the information about the final pool of paper was collected in a form including fields for all the information needed to answers the formulated research questions.
3.2.2. Selected Digital Libraries
- 1.
- ACM Digital Library: https://dl.acm.org/ (accessed on 18 October 2021);
- 2.
- IEEE Xplore: http://www.ieeexplore.ieee.org (accessed on 18 October 2021);
- 3.
- Springer Link: https://link.springer.com/ (accessed on 18 October 2021);
- 4.
- Science Direct Elsevier: https://www.sciencedirect.com/ (accessed on 18 October 2021);
- 5.
- Google Scholar: http://www.scholar.google.com (accessed on 18 October 2021);
3.2.3. Search Strings
- conversational [agent, assistant, system, interface, AI, artificial intelligence*, bot*, ...], dialog [system*, ...], chatbot [system*, ...], virtual [agent*, assistant*, ...], personal digital assistant, ...
- evaluat*, measur*, check*, metric*, quality, quality assessment, quality attribute*, criteria, analys*, performance, rank*, assess*, benchmark, diagnostic, test*, compar*, scor*, framework, dataset...
- user [interaction, experience, satisfaction, ...], customer [interaction, experience, satisfaction, ...], engagement, intent, psychometric, usability, perception, QoE, naturalness, personal*, QoS, ...
3.2.4. Inclusion/Exclusion Criteria
- IC1 The source is directly related to the topic of chatbot evaluation. We include papers that explicitly propose, discuss or improve an approach regarding evaluation of conversational interfaces.
- IC2 The source addresses the topics covered by the research questions. This means including papers using or proposing metrics, datasets, and instruments for the evaluation of conversational interfaces.
- IC3 The literature item is written in English;
- IC4 The source is an item of white literature available for download and is published in a peer-reviewed journal or conference proceedings; or, the source is an item of 1st tier Grey Literature;
- IC5 The source is related (not exclusively) to text-based conversational interfaces.
- EC1 The source does not perform any investigation nor reports any result related to chatbots, corresponding evaluation metrics, datasets used to evaluate chatbots.
- EC2 The source is not in a language directly comprehensible by the authors.
- EC3 The source is not peer-reviewed; or, the paper is Grey Literature of 2nd or 3rd tier.
- EC4 The source is related exclusively to a different typology of conversational interface.
3.2.5. Quality Assessment of Sources
3.2.6. Data Extraction and Synthesis
3.2.7. Final Pool of Sources
4. Results
4.1. RQ1—Mapping
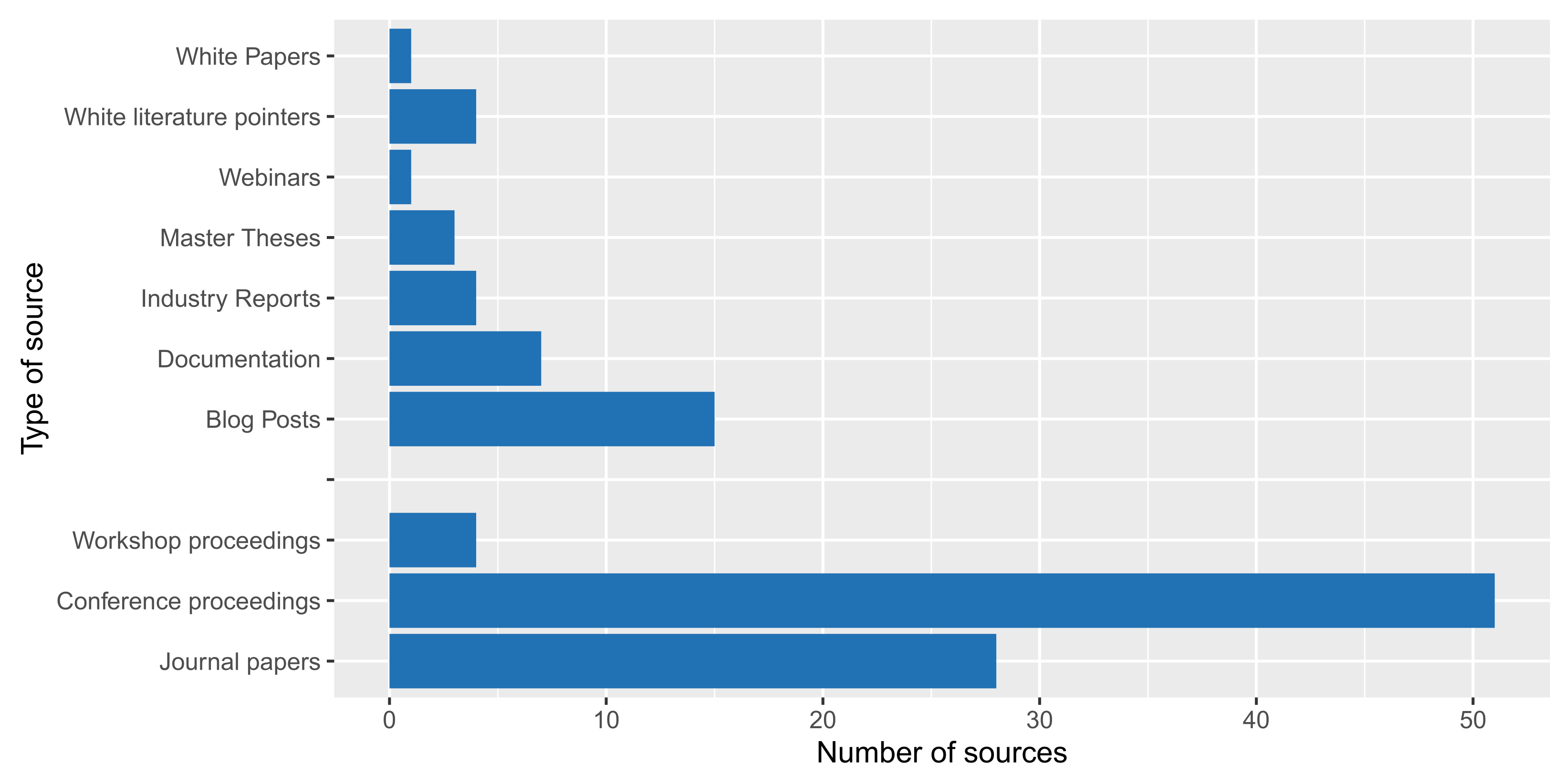
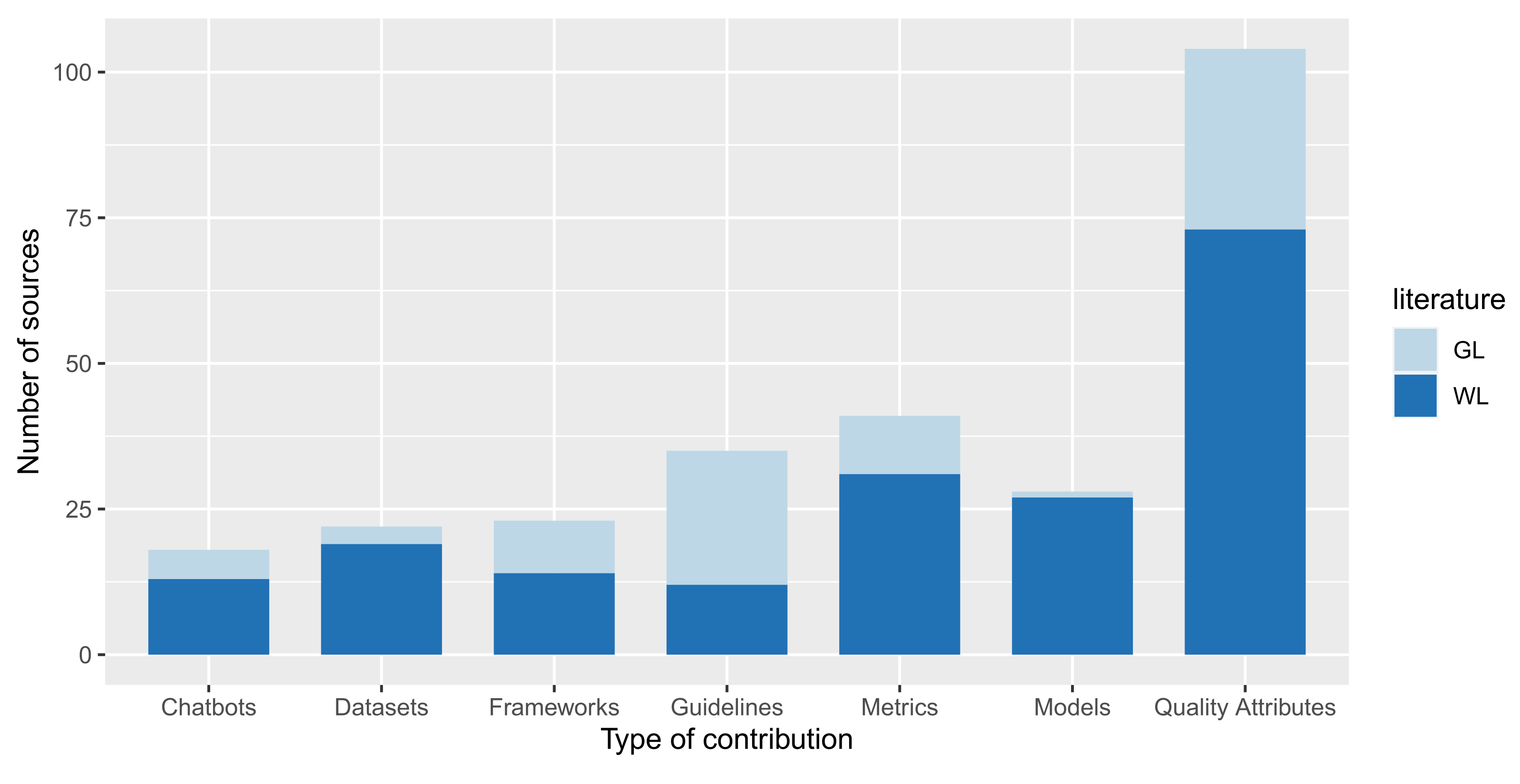
4.1.1. Types of Contributions (RQ1.1)
- Chatbot description: sources whose primary focus is the description of the implementation of a novel conversational interface.
- Guidelines: sources (typically more descriptive and high-level) that list sets of best practices that should be adopted by chatbot developers and/or researchers to enhance their quality. Sources discussing guidelines do not need to explicitly adopt or measure quality attributes or metrics for chatbot evaluation.
- Quality attributes: sources that discuss explicitly or implicitly one or more qualitative attributes for evaluating textual conversational interfaces.
- Metrics: sources that explicitly describe metrics—with mathematical formulas—for the quantitative evaluation of the textual conversational interfaces.
- Model: sources whose main contribution is a presentation or discussion of machine learning modules finalized to enhance one or more quality attributes of textual conversational interfaces. Regarding models, many different models were mentioned in the analyzed studies. Some examples are: Cuayáhuitl et al., who adopt a 2-layer Gated Recurrent Unit (GRU) neural network in their experiments [40]; Nestorovic also adopts a two-layered model, with the intentions of separating the two components contained in each task-oriented dialogue, i.e., intentions of the users and passive data of the dialogue [41]; Campano et al. use a binary decision tree, which allows for a representation of a conditional rule-based decision process [42].
- Framework: sources that explicitly describe an evaluation framework for textual conversational interfaces, or that select a set of parameters to be used for the evaluation of chatbots. In all cases, this typology of sources clearly defines the selected attributes deemed essential to evaluate chatbots. The difference between this category and Quality attributes and Metrics lies in the combination of multiple quality attributes or metrics into a single comprehensive formula for evaluating chatbots.
- Dataset: sources that describe, make available, or explicitly utilize publicly available datasets that can be used to evaluate textual conversational interfaces.
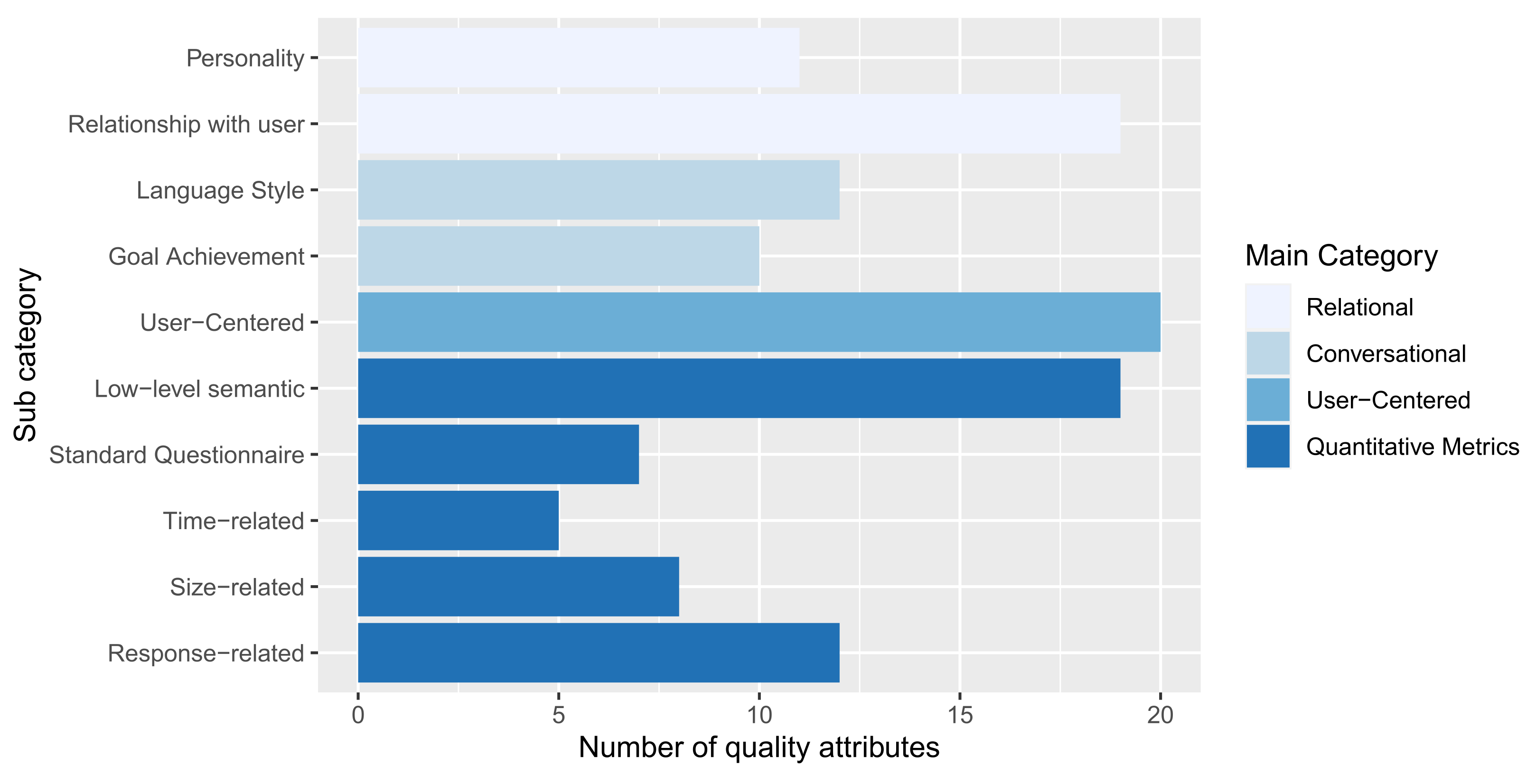
4.1.2. Distribution of Sources per Type of Contribution (RQ1.2)
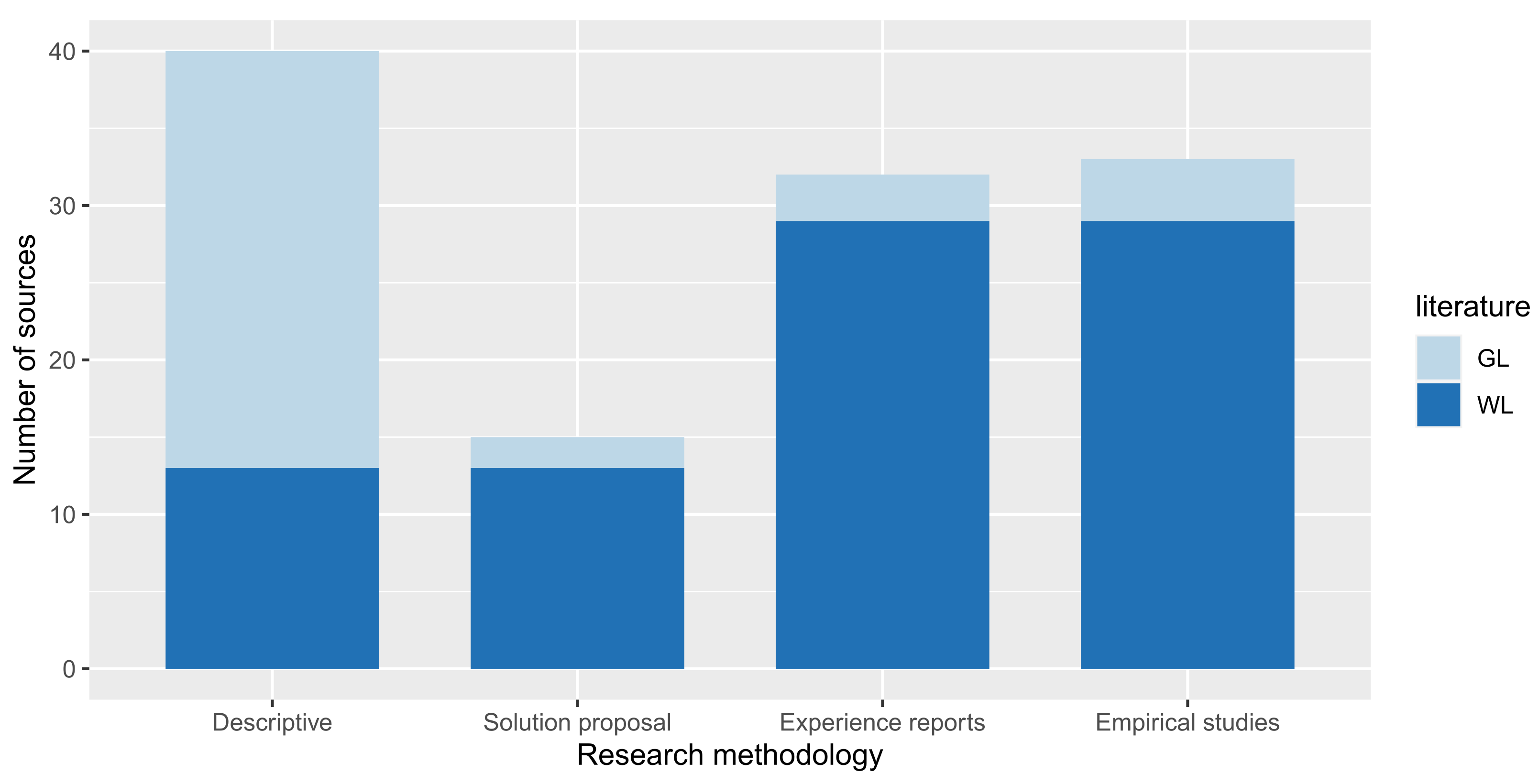
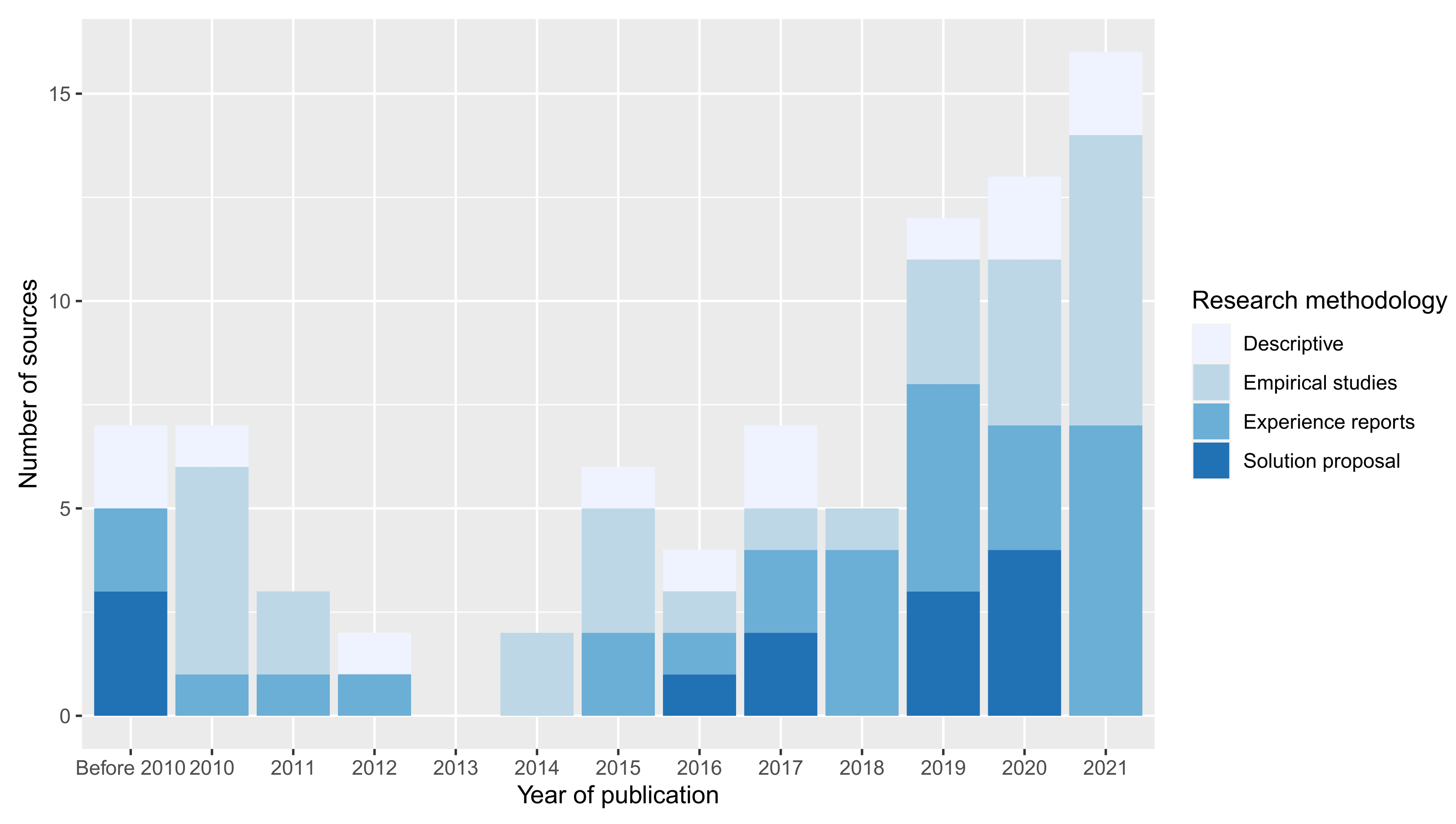
4.1.3. Mapping of Sources by Research Methodology (RQ1.3)
- Descriptive and opinion studies: Studies that discuss issues about conversational interface validation and measurement and that propose metrics and frameworks for their evaluation from a theoretical perspective. This category’s studies do not propose technical solutions to improve conversational interfaces or compute quality attributes upon them. Neither do they set up and describe experiments to measure and/or compare them.
- Solution proposals: Studies proposing technical solutions (e.g., new chatbot technologies, machine learning models, and metric frameworks) to solve issues in the field of conversational interfaces, and that explicitly mention quality attributes for chatbots. However, the studies only propose solutions without performing measurements, case studies, or empirical studies about them.
- Experience reports and case studies: Studies in which quality attributes and metrics about conversational interfaces are explicitly measured and quantified, in small-scale experiments that do not involve formal empirical methods (e.g., the definition of controlled experiments, formulation of research questions, and hypothesis testing).
- Empirical studies: Studies in which quality attributes and metrics about conversational interfaces are explicitly measured and quantified through the description and reporting of the results of formal empirical studies.
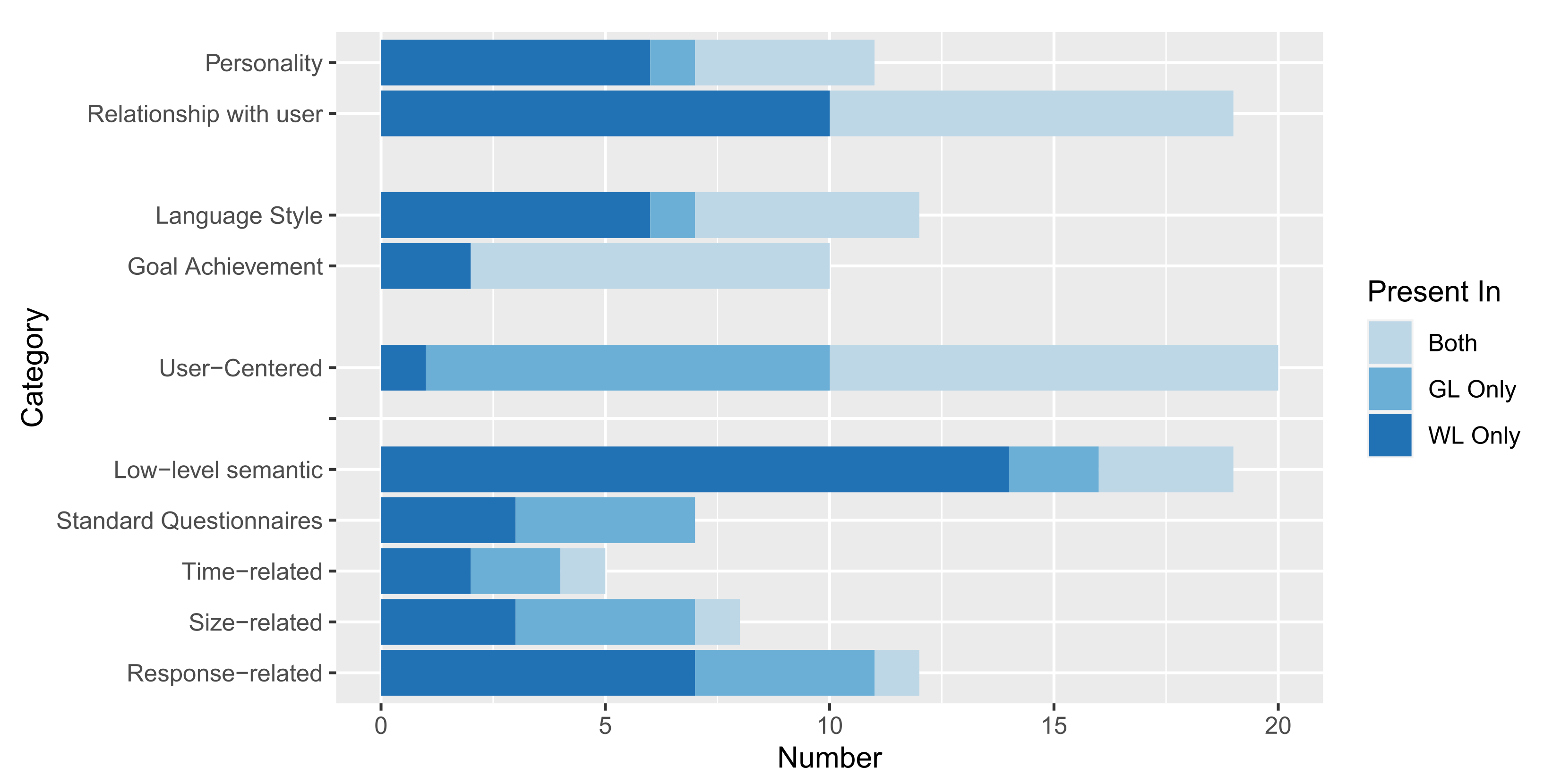
4.2. RQ2—Quality Evaluation of Textual Conversational Interfaces
4.2.1. Proposed Quality Metrics (RQ2.1)
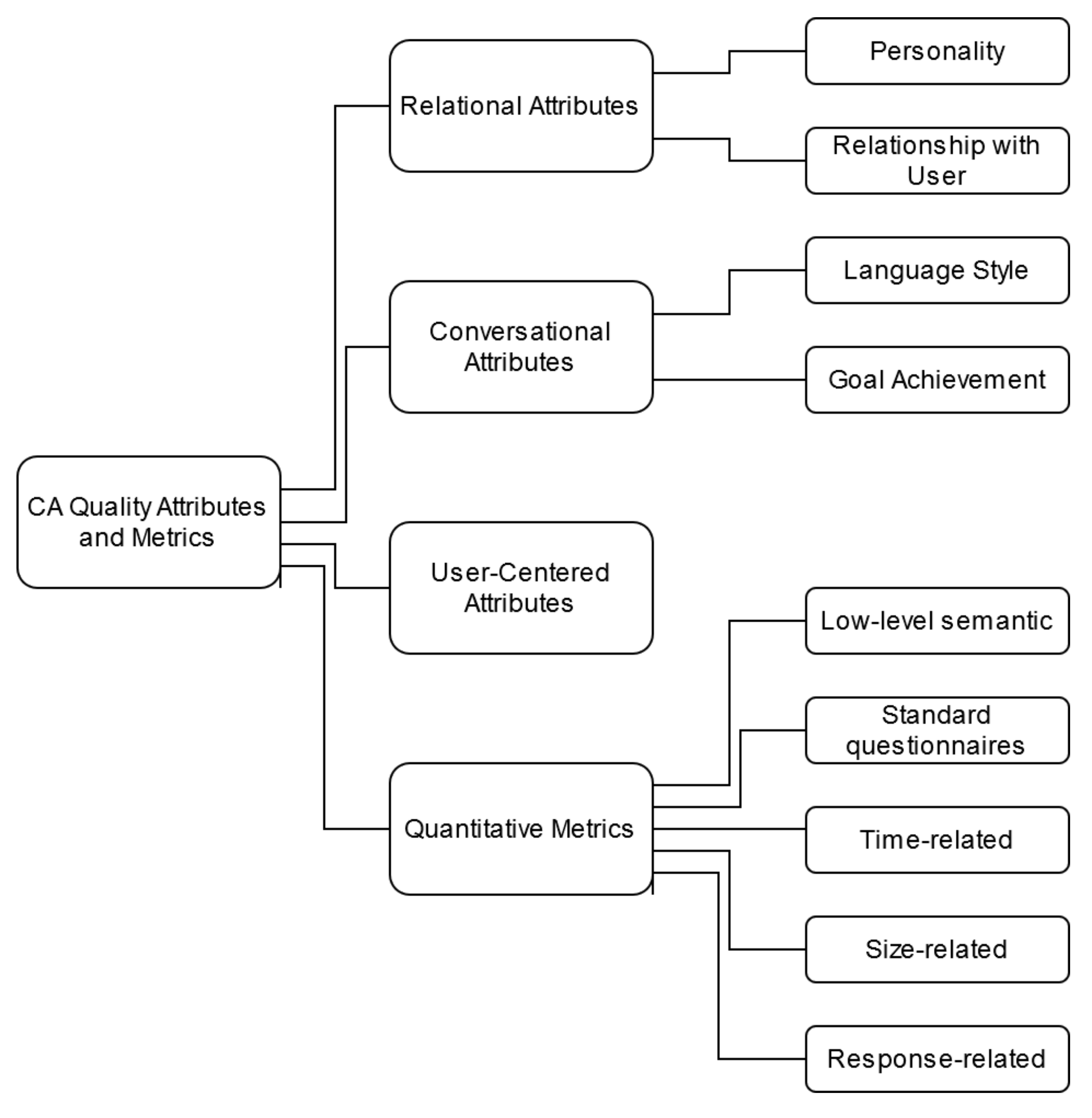
- Relational attributes. Quality attributes that measure the relationship with the user on human-related aspects or describe the human characteristics of a chatbot. Relational aspects do not directly affect the communication correctness but rather enrich it by creating emotional bonds between the user and the chatbot.These attributes cannot always be clearly separated from functionality, since in various applications establishing a human connection with the user is the main functional goal for which the conversational agent is used (e.g., in the medical field). As an example, Looije et al. report that “Research on persuasive technology and affective computing is providing technological (partial) solutions for the development of this type of assistance, e.g., for the realization of social behavior, such as social talk and turn-taking, and empathic behavior, such as attentiveness and compliments” [48].Among Relational Attributes, we identify two sub-categories:
- -
- Personality: Attributes that are related to the perceived humanness of the chatbot, which are generally reserved to describe essential and distinctive human traits.In this category, the most prominent attribute considered is the Social Capacity of the Conversational Agent. Chen et al., for instance, [46] identify several attributes that can all be considered as expressions of the social capacity of an agent working in a smart home, and that they translate into several guidelines for the behavior of a chatbot (e.g., ”Be Friendly”, ”Be Humorous”, ”Have an adorable persona”). Several manuscripts also refer to the Empathy of chatbots, which implies the ability of the chatbot to correctly understand the emotional tone of the user and avoid being perceived as rude.Another frequently mentioned attribute is the Common Sense of the Conversational Agent, also defined as the context sensitiveness of the agent [49], or the match between the system and the real world [50].Many studies in the pool have also mentioned the ethics of the Conversational Agents: in a grey literature source about the faults of a commercial chatbot, the concept is defined as as "the need to teach a system about what is not appropriate like we do with children" [51].
- -
- Relationship with the user: quality attributes that directly affect the relationship between the chatbot and the user. Trust [52] and Self-Disclosure [53], for instance, are essential to triggering rich conversations. Memory (also defined as User History) is a basic principle to keep alive the relationship with the user over time. Customization (also defined as Personalization, User-Tailored content [47], Personalized experience [54]) is an important parameter to improve the uniqueness of the conversation for each specific user. Finally, Engagement [46] and Stimulating Companionship [55] are relevant attributes to measure the positive impact on the user.
- Conversational attributes. Quality attributes are related to the content of the conversation happening between the chatbot and the user. We can identify two sub-categories of Conversational attributes:
- -
- Language Style: attributes related to the linguistic qualities of the Conversational Agents’ language.The most mentioned language style attribute is Naturalness, defined by Cuaydhuitl et al., as the fact that the dialogue is "naturally articulated as written by a human", [40], also referred to as Human-like Tone and Fluency.Relevance refers to the capability of the system to convey the information in a way that is relevant to the specific context of application [56], to keep the answers simple and strictly close to the subjects [57], and to avoid providing information overload to the users [58].Diversity refers to the capability of the chatbot to use a varied lexicon to provide information to the users and the capability to correctly manage homonymy and polysemy [59].Conciseness is a quality attribute that takes into account the elimination of redundancy without removing any important information (a dual metric is Repetitiveness).
- -
- Goal Achievement: attributes related to the way the chatbot provides the right responses to the users’ goal. They measure the correctness of the output given by the chatbot in response to specific inputs.The most cited quality attribute for this category is the Informativeness of the chatbot, i.e., the chatbot capability to provide the desired information to the user in a given task. Informativeness is also defined as Usefulness, measured in terms of the quantity of the content of the answers given to the users [60], or Helpfulness [61].Correctness instead evaluates the quality of the output provided by the chatbot measured in terms of the correct answers provided to the users [62], and the accuracy of the provided content.Proactiveness (in some sources referred to as Control of topic transfer [63], Initiate a new topic appropriately [46], Topic Switching [64] and Intent to Interact [65]), is the capability of the chatbot to switch or initiate new topics autonomously.Richness is defined as the capability of the chatbot to convey rich conversations with a high diversity of topics [66].
- User-centered Attributes: attributes related to the user’s perception of a chatbot. These attributes are mostly compatible with traditional Usability software non-functional requirements.The most-frequently cited user-centered attributes are Aesthetic Appearance, User Intention to Use, and User Satisfaction.Aesthetic Appearance refers to the interface that is offered to the user for the conversation. Bosse and Provost mentions the benefits of having photorealistic animations [69]; Pontier et al. performed a study in which the aesthetic perception of the participants was evaluated in a scale going from attractive to bad-looking [70].User Satisfaction is defined as the capability of a conversational agent to convey competent and trustworthy information [71], or the capability of the chatbot to answer questions and solve customer issues [72].User Intention to Use is defined as the intention of a user to interact with a specific conversational agent [65]. Jain et al. measured the user’s intention to use the chatbot again in the future as an indicator of the quality of the interaction [73].Ease of Use is defined as the capability of the chatbot to offer easy interaction to the user [57], i.e., the capability of the chatbot to allow the users to write easy questions that are correctly understood [58], and to keep the conversation going with low effort [74]. The ease of use of a chatbot can be enhanced, for instance, by providing routine suggestions during the conversation [75].
- Quantitative Metrics. Quantitative metrics can be objectively computed with mathematical formulas. Metrics are generally combined to provide measurements of the quality attributes described in the other categories.We can divide this category of quality attributes into the following sub-categories:
- -
- Low-Level Semantic: grey box metrics that evaluate how the conversational agent’s models correctly interpret and classify the input provided by the user.Several papers, especially those based on the machine learning approaches, report metrics related to these fields, e.g., the use of word embeddings metrics [76] or confusion matrices [77].The most cited metrics of the category are common word-overlap-based metrics (i.e., they rely on frequencies and position of words with respect to ground truth, e.g., a human-annotated dataset), BLEU, ROUGE, METEOR, CIDEr, and word-embedding-based metrics like Skip-Thought, Embedding Average, Vector Extrema and Greedy Matching [60].Low-level Semantic metrics are typically employed to evaluate the learning models adopted by the chatbots and to avoid common issues like underfitting (i.e., the inability to model either training data or new data) which translates to a very low BLEU metric, or overfitting (i.e., poor performance on new data and hence small generalizability of the algorithm) which translates to a very high BLEU metric.In this category of metric we also include traditional metrics used to evaluate the prediction of Semantic Textual Similarity based on Regression Models. Examples are the Mean Squared Error (MSE), defined as the average of sum of squared difference between actual value and the predicted or estimated value; Root Mean Squared Error (RMSE) that considers whether the values of the response variable are scaled or not; and R-Squared metric (or R2), defined as the ratio of Sum of Squares Regression (SSR) and Sum of Squares Total (SST). Values closer to 0 for (R)MSE, or closer to 100% for R2, indicate optimum correlation.
- -
- Standard Questionnaires: sets of standard questions to be answered using a Likert scale, and that can be used to quantify abstract quality attributes defined in the previous categories.Edwards et al. list three instruments belonging to this category: the Measure of Source Credibility, an 18-item instrument designed to assess perceptions of an individual’s credibility across three dimensions of competence, character and caring; the Measure of interpersonal attraction, to assess attraction to another along two dimensions, task and social; and the Measure of computer-mediated Communication Competence, to examine how competent the target was perceived as in the communication by the participants [65].Valtolina et al., in the context of an evaluation of the usability of chatbots for healthcare and smart home domains, leveraged three standard questionnaires for general-purpose software: SUS (System Usability Scale), CSUQ (Computer System Usability Questionnaire), and UEQ (User Experience Questionnaire) [78].
- -
- Time-related metrics: time and frequency of various aspects of the interaction between the user and the chatbot. The most mentioned metric is the Response Time, i.e., the time employed by the chatbot to respond to a single request by the user [79]. Other manuscripts report the time to complete a task (i.e., a full conversation leading to a result) or the frequency of requests and conversations initiated by the users.
- -
- Size-related metrics: quantitative details about the length of the conversation between the human user and the chatbot. The most common is the number of messages, also referred to as the number of interactions or utterances, with several averaged variations (e.g., the number of messages per user [41] or per customer [80]).
- -
- Response-related metrics: measures of the number of successful answers provided by the chatbot to meet the users’ requests. Examples of this category of metrics are the frequency of responses (among the possible responses given by the chatbot) [81], the task success rate (i.e., entire conversations leading to a successful according to the user’s point of view) [82], the number of correct (individual) responses, the number of successful (or, vice-versa, of incomplete) sessions [83].
4.2.2. Proposed Frameworks for the Evaluation of Conversational Agents (RQ2.2)
- ADEM: an automated dialogue evaluation model that learns to predict human-like scores to responses provided as input, based on a dataset of human responses collected using the crowdsourcing platform Amazon Mechanical Turk (AMT).The ADEM framework computes versions of the Response Satisfaction Score and Task Satisfaction Score metrics. According to empirical evidence provided by Lowe et al. [84] the framework outperforms available word-overlap-based metrics like BLEU.
- Botest: a framework to test the quality of conversational agents using divergent input examples. These inputs are based on known utterances for which the right outputs are known. The Botest framework computes as principal metrics the size of the utterances and the conversations and the quality of the responses.The quality of responses is evaluated at syntactical level by identifying several possible errors, e.g., word order errors, incorrect verb tenses, and wrong synonym usage.
- Bottester: a framework to evaluate conversational agents through their GUIs. The tool computes time and size metrics (mean answer size, answer frequency, word frequency, response time per question, mean response time) and response-based metrics, i.e., the number and percentage of correct answers given by the conversational interface. The tool receives the files with all questions submitted, the expected answers, and configuration parameters for the specific agent to test to give an evaluation of the proportion of correct answers. The evaluation provided by the tool is focused on the user perspective.
- ParlAI: a unified framework for testing dialog models. It is based on many popular datasets and allows seamless integration of Amazon Mechanical Turk for data collection and human evaluation, and is integrated with chat services like Facebook Messenger. The framework computes accuracy and efficiency metrics for the conversation with the chatbot.
- LEGOEval: an open-source framework to enable researchers to evaluate dialogue systems by means of the online crowdsourced platform Amazon Mechanical Turk. The toolkit provides a Python API that allows the personalization of the chatbot evaluation procedures.
4.2.3. Proposed Datasets for the Evaluation of Conversational Agents (RQ2.3)
- Forums and FAQs. Since forums and FAQ pages are based on a question and answer, conversational nature, they can be leveraged as sources of dialogue to train and test chatbots.The datasets of this category used in the examined sources are the following:
- -
- IMDB Movie Review Data: a dataset of 50K movie reviews, containing 25,000 reviews for training and 25,000 for testing, with a label (polarity) for sentiment classification. The dataset is used, for instance, by Kim et al. to address common sense end ethics through a neural network for text generation [90].
- -
- Ubuntu Dialog Corpora: a dataset of 1 million non-labeled multi-turn dialogues (more than 7 million utterances and 100 million words). The dataset is oriented to machine learning and deep learning algorithms and models.
- -
- Yahoo! Answers: datasets hosted on GitHub repositories, containing scrapings of the questions and answers on the popular community-driven website.
- -
- 2channel: a popular Japanese bulletin board that can be used as a source for natural, colloquial utterances, containing many boards related to diverse topics.
- -
- Slashdot: a social news website featuring news stories on science, technology, and politics, that are submitted and evaluated by site users and editors.
- Social Media. Social media are sources of continuous, updated information and dialogue. It is often possible to model the users and access their history and metadata (e.g., preferences, habits, geographical position, personality, and language style). It is also possible to reconstruct the social graphs, i.e., the social relations between users and how they are connected. Several social media, to maximize the exploitation of data and render a higher amount of analyses possible, make their data available through APIs, allowing developers to extract datasets.
- -
- Twitter: it provides simple and accessible tools and API to download tweets and related metadata. Moreover, it allows performance of data scraping.
- Customer Service: collections of technical dialogues for customer service coming from multiple sources, such as private and company channels, social platforms, or e-commerce platforms. Some examples are the following:
- -
- Twitter Customer Service Corpus: a large corpus of tweets and replies to and from customer service accounts on Twitter.
- -
- Didi Customer Service Corpus: a dataset of 11,102 Facebook wall posts, 6507 wall comments, and 22,218 private messages from 136 South Tyrolean users who participated in the “DiDi” project in the year 2013.
- Movies and Subtitles. Subtitles can be used to collect dialogues by modeling the characters and, virtually, the users, if metadata are present.
- -
- Open Subtitles Corpus: A dataset composed of movie and television subtitle data from OpenSubtitles, in 62 languages [148]. Consecutive lines in the subtitle data could be used as conversational dialogues.
- -
- Cornell Movie Dialog Corpus 3: an extensive collection of fictional conversations extracted from raw movie scripts. There are 220,579 conversations between 10,292 pairs of movie characters, 9035 characters from 617 movies.
- -
- Movie-DiC: a dataset comprising 132,229 dialogues containing a total of 764,146 turns that have been extracted from 753 movies.
- -
- HelloE: a dialogue dataset containing around 9K conversations from about 921 movies.
- -
- CMU_DoG: a conversation dataset where each conversation is followed by documents about popular movies from Wikipedia articles. The dataset contains around 4K conversations.
- -
- DuConv: a conversation dataset where each conversation is grounded with a factoid knowledge graph, containing 270K sentences within 30K conversations.
- Challenges. Chatbot competitions are regularly held by both research and industry. Generally, datasets are given and left available for these competitions even after their conclusion; these datasets are often annotated by humans. The transcripts of the competitions are usually made available by the authors or organizers and can be utilized for further comparisons.
- -
- Persona-Chat dataset: a dataset consisting of conversations between crowd-workers who were paired and asked to act as a given provided persona. The dataset is oriented to machine learning and deep learning algorithms and models.
- -
- Dialog State Tracking Challenge datasets: a corpus collecting multi-turn dialogues from Amazon Mechanical Turk.
- -
- Dialog System Technology Challenges (DSTC6) Track 2: a dataset composed of customer service conversations scraped from Twitter.
- -
- NTCIR-13 Short Text Conversation: a dataset used in the NTCIR conference context to clarify the effectiveness and limitations of retrieval-based and generation-based methods and to advance the research on automatic evaluation of natural language conversation.
- External Knowledge. Sources of high interest for those chatbots that require specific knowledge in a specialized domain. They are also often represented as knowledge graphs and are useful for semantic and conceptual abstraction. Prominent examples of this category are medical knowledge bases. In our pool of sources, the following examples are used:
- -
- WordNet: a lexical database of English, where nouns, verbs, adjectives, and adverbs are grouped into sets of cognitive synonyms, each expressing a distinct concept interlinked in a network utilizing conceptual–semantic and lexical relations.
- -
- Wikipedia and related projects: the content of the free crowd-based online encyclopedia and its related projects, as Wikidata, the open knowledge base that acts as central storage for the structured data of other Wikimedia projects.
- -
- Wizard of Wikipedia: an open-domain dialogue benchmark containing 22K conversations linked to knowledge retrieved from Wikipedia.
- -
- OpenDialKG: a human-to-human dialogue dataset containing 91K utterances across 15K dialog sessions about varied topics.
- -
- Unified Medical Language System (UMLS): created by MedLine (the U.S. National Library of Medicine bibliographic database), the UMLS, or Unified Medical Language System, it brings together many health and biomedical vocabularies and standards.
- -
- SNOMED CT: a dataset of clinical terminology for Electronic Health records to be used in electronic clinical decision support, disease screening and enhanced patient safety.
- -
- Bioportal: a dataset released by NCBO (National Center for Biomedical Ontology) and accessible through a web portal that provides access to a library of biomedical ontologies and terminologies.
- -
- CISMEF: Catalogue et Index des Sites Médicaux de langue Française, a French database dedicated to teaching and research.
- -
- Schema.org: founded by Google, Microsoft, Yahoo, and Yandex, and maintained by an open community process, Schema.org has the purpose of creating, maintaining, and promoting schemas for structured data on the Internet, on web pages, and other applications.
- Others:. Some heterogeneous datasets cannot be filed under the previous categories. We report the following example mentioned in one source of our set:
- -
- Debate Chat Contexts Wang et al. reported the creation of chat contexts spanning a range of topics in politics, science, and technology [67]. These chats can be considered examples of typical conversations between humans and can be used to train the chatbots to improve their evaluation regarding Conversational Quality Attributes.
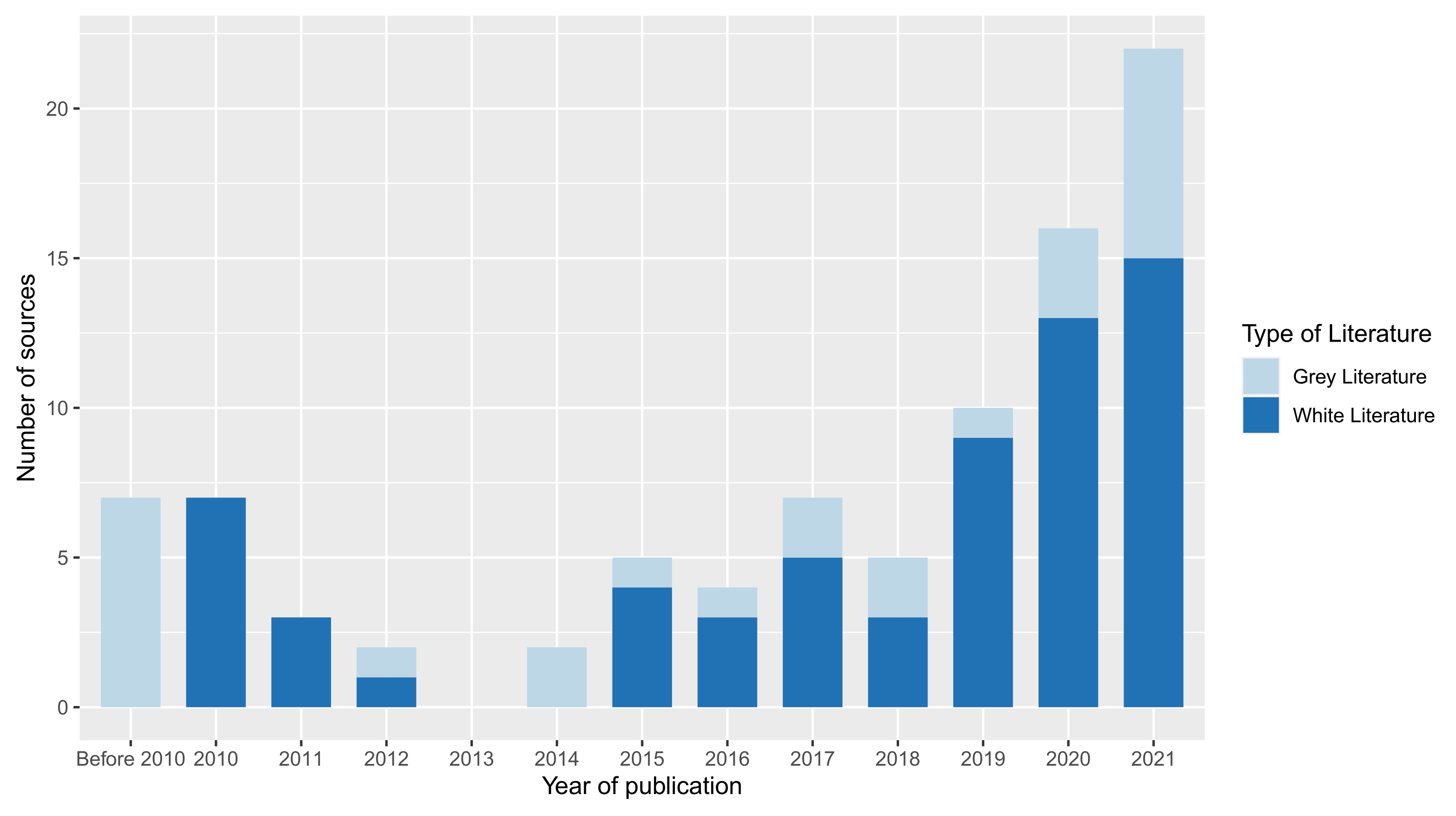
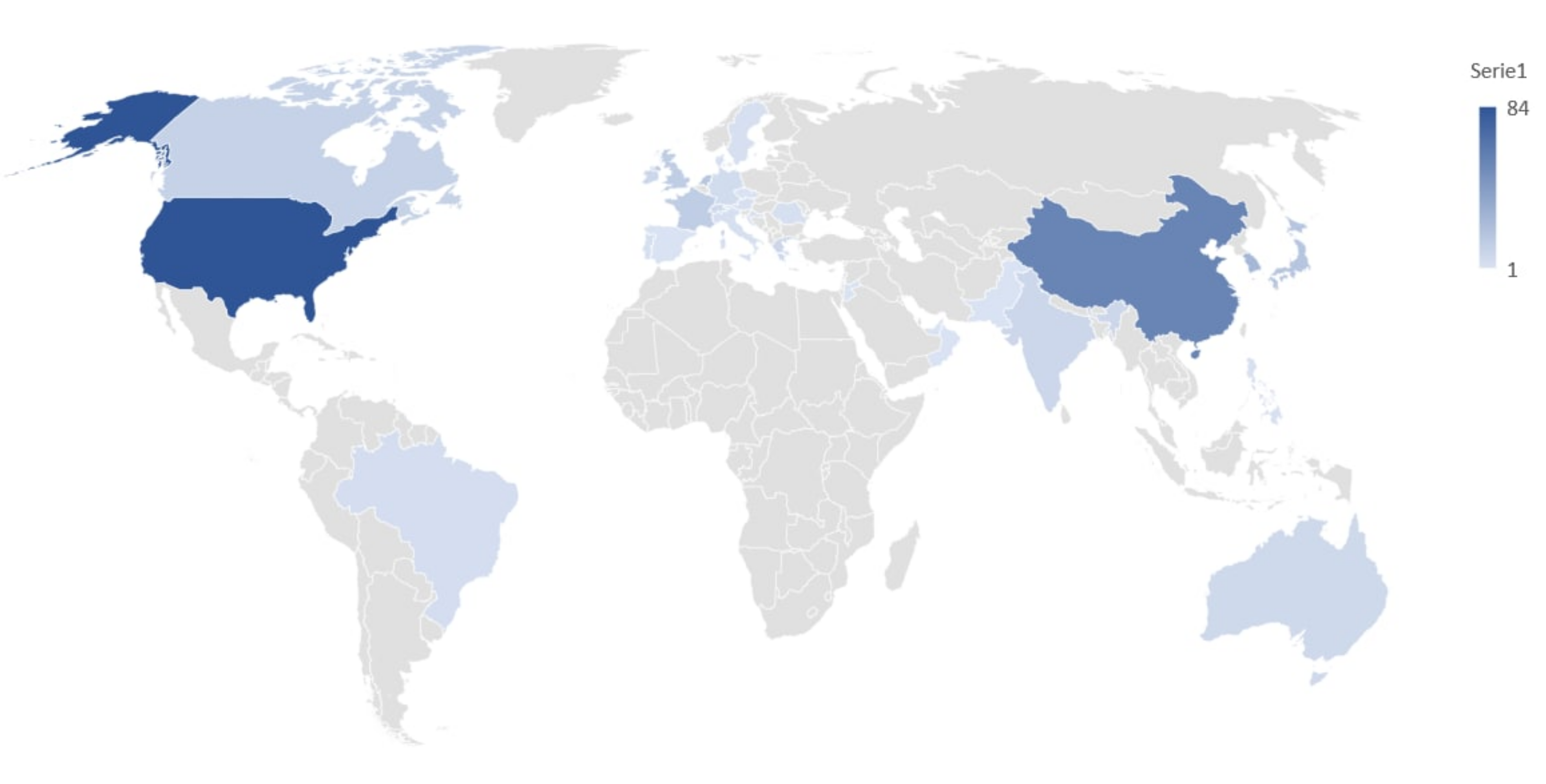
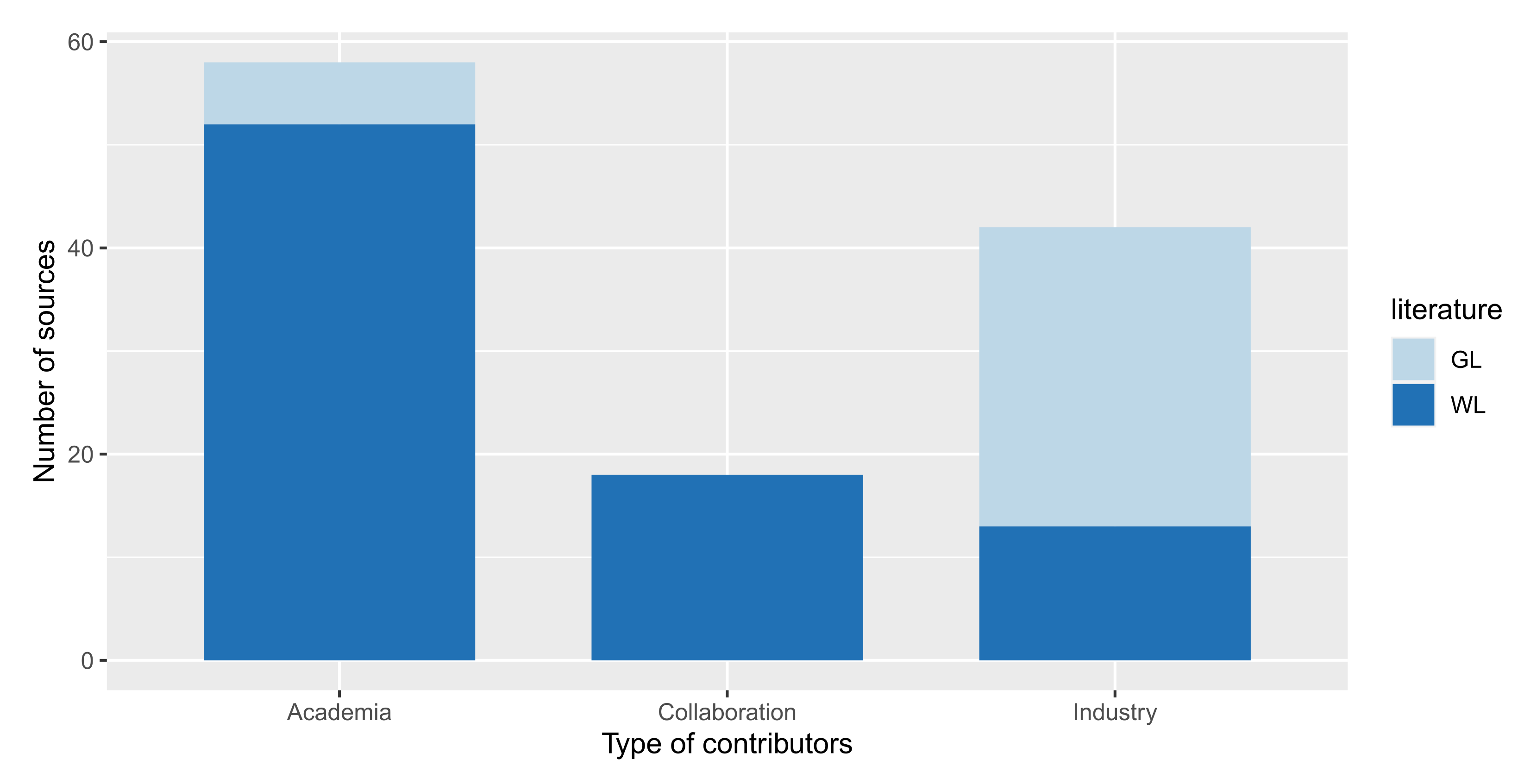
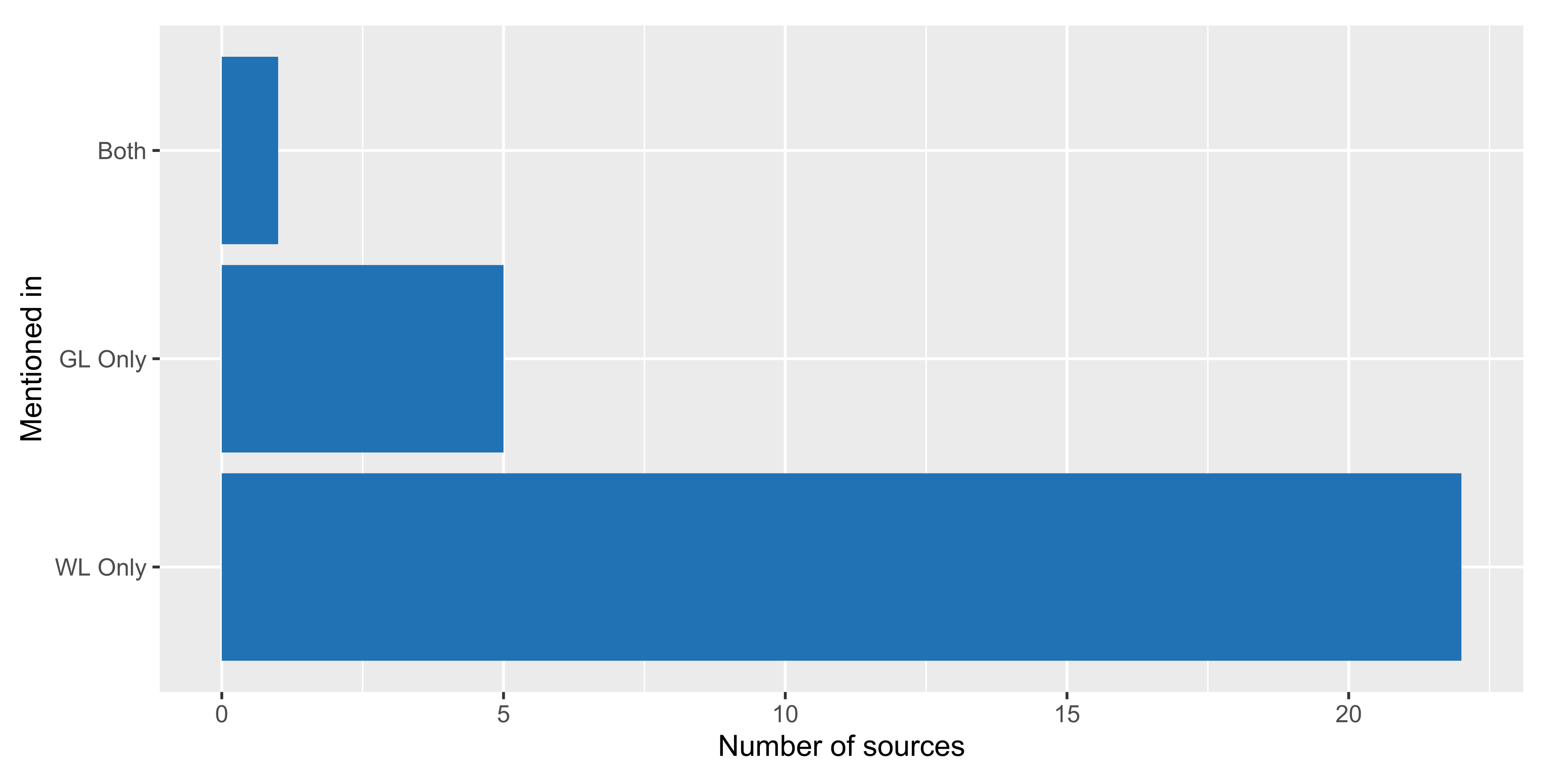
4.3. RQ3—Comparison between Formal and Grey Literature
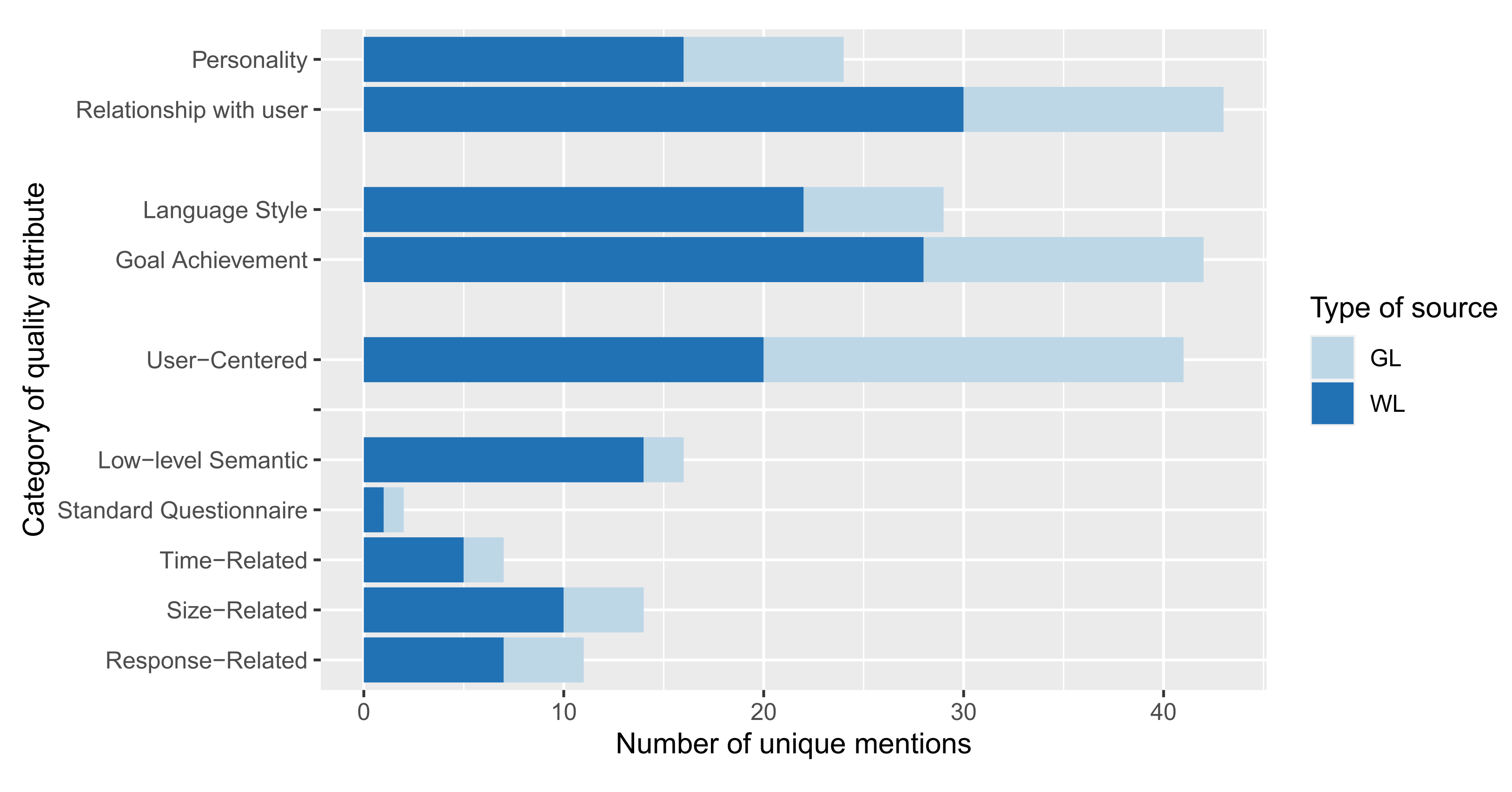
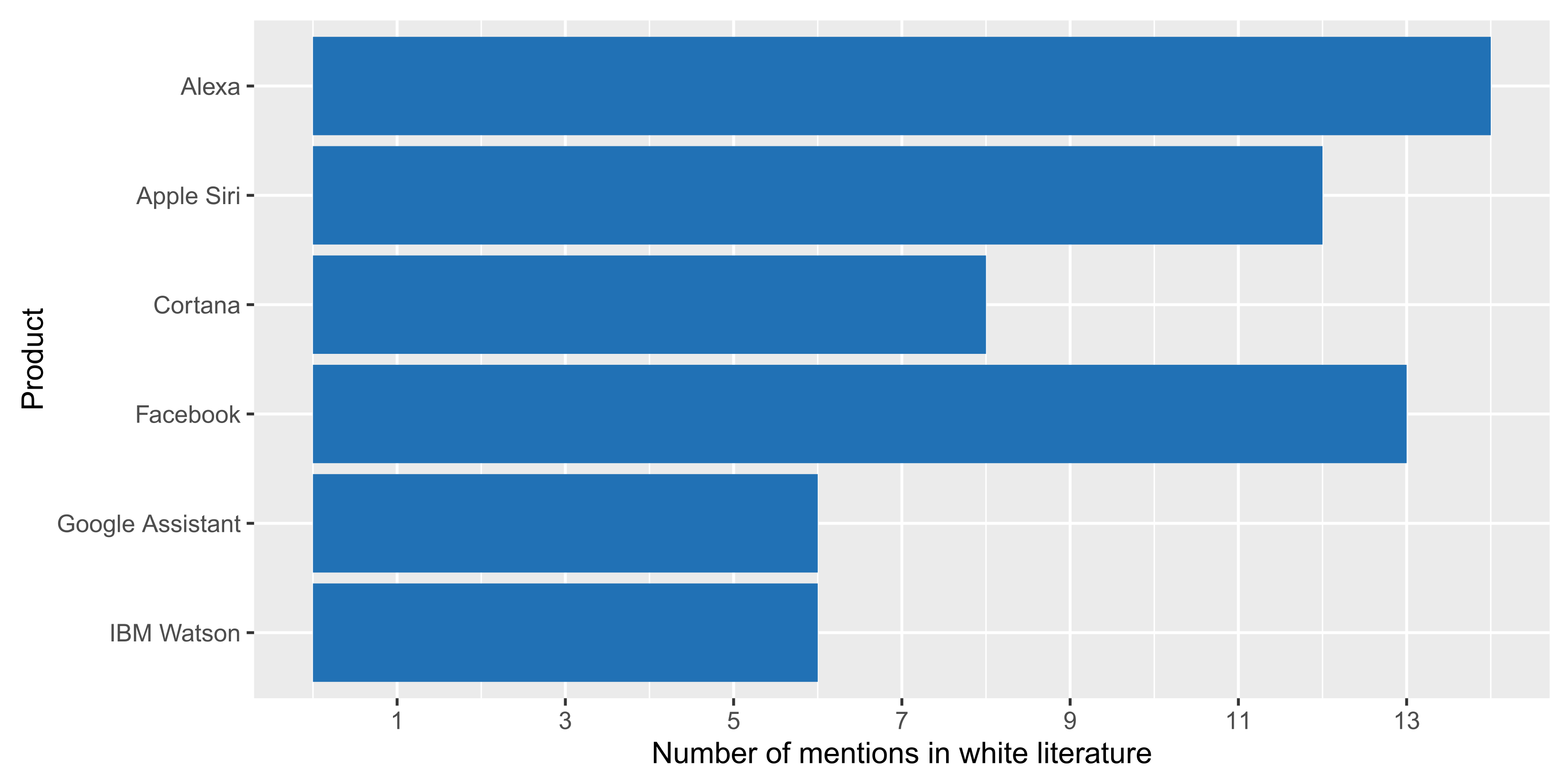
4.3.1. Industrial Contributions Leveraged by White Literature (RQ3.1)
4.3.2. Attention from Formal and Grey Literature (RQ3.2)
5. Discussion
5.1. Summary of Findings
5.2. Threats to Validity
6. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Radziwill, N.M.; Benton, M.C. Evaluating quality of chatbots and intelligent conversational agents. arXiv 2017, arXiv:1704.04579. [Google Scholar]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Colby, K.M. Modeling a paranoid mind. Behav. Brain Sci. 1981, 4, 515–534. [Google Scholar] [CrossRef]
- Klopfenstein, L.C.; Delpriori, S.; Malatini, S.; Bogliolo, A. The Rise of Bots: A Survey of Conversational Interfaces, Patterns, and Paradigms; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar]
- Dale, R. The return of the chatbots. Nat. Lang. Eng. 2016, 22, 811–817. [Google Scholar] [CrossRef]
- Følstad, A.; Brandtzæg, P.B. Chatbots and the New World of HCI. Interactions 2017, 24, 38–42. [Google Scholar] [CrossRef]
- Shanhong, L. Chatbot Market Revenue Worldwide 2017 and 2024. 2019. Available online: https://www.statista.com/statistics/966893/worldwide-chatbot-market-value (accessed on 18 October 2021).
- Brandtzaeg, P.B.; Følstad, A. Why People Use Chatbots. In Internet Science; Kompatsiaris, I., Cave, J., Satsiou, A., Carle, G., Passani, A., Kontopoulos, E., Diplaris, S., McMillan, D., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 377–392. [Google Scholar]
- Müller, L.; Mattke, J.; Maier, C.; Weitzel, T.; Graser, H. Chatbot Acceptance: A Latent Profile Analysis on Individuals’ Trust in Conversational Agents. In Proceedings of the SIGMIS-CPR’19: 2019 on Computers and People Research Conference, Nashville, TN, USA, 20–22 June 2019; pp. 35–42. [Google Scholar] [CrossRef]
- A Taxonomy of Social Cues for Conversational Agents. Int. J. Hum. Comput. Stud. 2019, 132, 138–161. [CrossRef]
- Yu, Z.; Xu, Z.; Black, A.W.; Rudnicky, A. Chatbot evaluation and database expansion via crowdsourcing. In Proceedings of the chatbot workshop of LREC; International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016; Volume 63, p. 102. [Google Scholar]
- Maroengsit, W.; Piyakulpinyo, T.; Phonyiam, K.; Pongnumkul, S.; Chaovalit, P.; Theeramunkong, T. A Survey on Evaluation Methods for Chatbots. In Proceedings of the 2019 7th International Conference on Information and Education Technology, Aizu-Wakamatsu, Japan, 29–31 March 2019; pp. 111–119. [Google Scholar]
- Jokinen, K. Natural Language and Dialogue Interfaces. Journal of Human Factors and Ergonomics. 2009. Available online: http://www.ling.helsinki.fi/~kjokinen/Publ/200906UAIHandbookCh41_NaturalLanguage_Jokinen_Final.pdf (accessed on 18 October 2021).
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for Human-AI Interaction. In Proceedings of the CHI’19: 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–13. [Google Scholar] [CrossRef]
- Nuruzzaman, M.; Hussain, O.K. A Survey on Chatbot Implementation in Customer Service Industry through Deep Neural Networks. In Proceedings of the 2018 IEEE 15th International Conference on e-Business Engineering (ICEBE), Xi’an, China, 12–14 October 2018; pp. 54–61. [Google Scholar] [CrossRef]
- Kocaballi, A.B.; Laranjo, L.; Coiera, E. Measuring User Experience in Conversational Interfaces: A Comparison of Six Questionnaires. In Proceedings of the HCI ’18: 32nd International BCS Human Computer Interaction Conference, Belfast, UK, 4–6 July 2018; BCS Learning & Development Ltd.: Swindon, UK, 2018. [Google Scholar] [CrossRef]
- Jain, M.; Kumar, P.; Kota, R.; Patel, S.N. Evaluating and Informing the Design of Chatbots; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar]
- Hingston, P. A turing test for computer game bots. IEEE Trans. Comput. Intell. AI Games 2009, 1, 169–186. [Google Scholar] [CrossRef]
- Liu, D.; Bias, R.G.; Lease, M.; Kuipers, R. Crowdsourcing for usability testing. Proc. Am. Soc. Inf. Sci. Technol. 2012, 49, 1–10. [Google Scholar] [CrossRef]
- Tung, Y.H.; Tseng, S.S. A novel approach to collaborative testing in a crowdsourcing environment. J. Syst. Softw. 2013, 86, 2143–2153. [Google Scholar] [CrossRef]
- Ogawa, R.T.; Malen, B. Towards rigor in reviews of multivocal literatures: Applying the exploratory case study method. Rev. Educ. Res. 1991, 61, 265–286. [Google Scholar] [CrossRef]
- Higgins, J.P.; Thomas, J.; Chandler, J.; Cumpston, M.; Li, T.; Page, M.J.; Welch, V.A. Cochrane Handbook for Systematic Reviews of Interventions; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Adams, R.J.; Smart, P.; Huff, A.S. Shades of grey: Guidelines for working with the grey literature in systematic reviews for management and organizational studies. Int. J. Manag. Rev. 2017, 19, 432–454. [Google Scholar] [CrossRef]
- Garousi, V.; Felderer, M.; Mäntylä, M.V. Guidelines for including grey literature and conducting multivocal literature reviews in software engineering. Inf. Softw. Technol. 2019, 106, 101–121. [Google Scholar] [CrossRef]
- Garousi, V.; Felderer, M.; Mäntylä, M.V. The Need for Multivocal Literature Reviews in Software Engineering: Complementing Systematic Literature Reviews with Grey Literature. In Proceedings of the 20th International Conference on Evaluation and Assessment in Software Engineering, New York, NY, USA, 1–3 June 2016. [Google Scholar]
- Garousi, V.; Mäntylä, M.V. When and what to automate in software testing? A multi-vocal literature review. Inf. Softw. Technol. 2016, 76, 92–117. [Google Scholar] [CrossRef]
- Garousi, V.; Felderer, M.; Hacaloğlu, T. Software test maturity assessment and test process improvement: A multivocal literature review. Inf. Softw. Technol. 2017, 85, 16–42. [Google Scholar] [CrossRef]
- Myrbakken, H.; Colomo-Palacios, R. DevSecOps: A multivocal literature review. In International Conference on Software Process Improvement and Capability Determination; Springer: New York, NY, USA, 2017; pp. 17–29. [Google Scholar]
- Putta, A.; Paasivaara, M.; Lassenius, C. Benefits and Challenges of Adopting the Scaled Agile Framework (SAFe): Preliminary Results from a Multivocal Literature Review. In Product-Focused Software Process Improvement; Kuhrmann, M., Schneider, K., Pfahl, D., Amasaki, S., Ciolkowski, M., Hebig, R., Tell, P., Klünder, J., Küpper, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 334–351. [Google Scholar]
- Tripathi, N.; Klotins, E.; Prikladnicki, R.; Oivo, M.; Pompermaier, L.B.; Kudakacheril, A.S.; Unterkalmsteiner, M.; Liukkunen, K.; Gorschek, T. An anatomy of requirements engineering in software startups using multi-vocal literature and case survey. J. Syst. Softw. 2018, 146, 130–151. [Google Scholar] [CrossRef]
- Tom, E.; Aurum, A.; Vidgen, R. An exploration of technical debt. J. Syst. Softw. 2013, 86, 1498–1516. [Google Scholar] [CrossRef]
- Ampatzoglou, A.; Ampatzoglou, A.; Chatzigeorgiou, A.; Avgeriou, P. The financial aspect of managing technical debt: A systematic literature review. Inf. Softw. Technol. 2015, 64, 52–73. [Google Scholar] [CrossRef]
- Ren, R.; Castro, J.W.; Acuña, S.T.; de Lara, J. Usability of Chatbots: A Systematic Mapping Study. In Proceedings of the 31st International Conference on Software Engineering and Knowledge Engineering, SEKE 2019, Hotel Tivoli, Lisbon, Portugal, 10–12 July 2019; Perkusich, A., Ed.; KSI Research Inc. and Knowledge Systems Institute Graduate School: Singapore, 2019; pp. 479–617. [Google Scholar]
- Kitchenham, B.A.; Budgen, D.; Brereton, P. Evidence-Based Software Engineering and Systematic Reviews; CRC Press: Boca Raton, FL, USA, 2015; Volume 4. [Google Scholar]
- Benzies, K.M.; Premji, S.; Hayden, K.A.; Serrett, K. State-of-the-evidence reviews: Advantages and challenges of including grey literature. Worldviews Evid.-Based Nurs. 2006, 3, 55–61. [Google Scholar] [CrossRef]
- Jalali, S.; Wohlin, C. Systematic literature studies: Database searches vs backward snowballing. In In Proceedings of the 2012 ACM-IEEE International Symposium on Empirical Software Engineering and Measurement, Lund, Sweden, 20–21 September 2012; IEEE Computer Society: Los Alamitos, CA, USA, 2012; pp. 29–38. [Google Scholar]
- Corbin, J.M.; Strauss, A. Grounded theory research: Procedures, canons, and evaluative criteria. Qual. Sociol. 1990, 13, 3–21. [Google Scholar] [CrossRef]
- Khandkar, S.H. Open coding. Univ. Calg. 2009, 23, 2009. [Google Scholar]
- Scott, C.; Medaugh, M. Axial Coding. Int. Encycl. Commun. Res. Methods 2017, 1, 1–2. [Google Scholar]
- Cuayáhuitl, H.; Lee, D.; Ryu, S.; Cho, Y.; Choi, S.; Indurthi, S.; Yu, S.; Choi, H.; Hwang, I.; Kim, J. Ensemble-based deep reinforcement learning for chatbots. Neurocomputing 2019, 366, 118–130. [Google Scholar] [CrossRef]
- Nestorovič, T. Creating a general collaborative dialogue agent with lounge strategy feature. Expert Syst. Appl. 2012, 39, 1607–1625. [Google Scholar] [CrossRef]
- Campano, S.; Langlet, C.; Glas, N.; Clavel, C.; Pelachaud, C. An ECA Expressing Appreciations; IEEE Computer Society: Washington, DC, USA, 2015. [Google Scholar]
- Glass, R.L.; Vessey, I.; Ramesh, V. Research in software engineering: An analysis of the literature. Inf. Softw. Technol. 2002, 44, 491–506. [Google Scholar] [CrossRef]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic Mapping Studies in Software Engineering; EASE’08; BCS Learning & Development Ltd.: Swindon, UK, 2008; pp. 68–77. [Google Scholar]
- Ralph, P. Toward methodological guidelines for process theories and taxonomies in software engineering. IEEE Trans. Softw. Eng. 2018, 45, 712–735. [Google Scholar] [CrossRef]
- Chen, X.; Mi, J.; Jia, M.; Han, Y.; Zhou, M.; Wu, T.; Guan, D. Chat with Smart Conversational Agents: How to Evaluate Chat Experience in Smart Home; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Ly, K.H.; Ly, A.M.; Andersson, G. A fully automated conversational agent for promoting mental well-being: A pilot RCT using mixed methods. Internet Interv. 2017, 10, 39–46. [Google Scholar] [CrossRef]
- Looije, R.; Neerincx, M.A.; Cnossen, F. Persuasive robotic assistant for health self-management of older adults: Design and evaluation of social behaviors. Int. J. Hum.-Comput. Stud. 2010, 68, 386–397. [Google Scholar] [CrossRef]
- Kuligowska, K. Commercial chatbot: Performance evaluation, usability metrics and quality standards of embodied conversational agents. Prof. Cent. Bus. Res. 2015, 2, 1–16. [Google Scholar] [CrossRef]
- Earley, S. Chatbot Best Practices—Webinar Overflow Questions Answered. Available online: https://www.earley.com/blog/chatbot-best-practices-webinar-overflow-questions-answered (accessed on 23 September 2021).
- Reese, H. Why Microsoft’s ’Tay’ AI Bot Went Wrong. Available online: https://www.techrepublic.com/article/why-microsofts-tay-ai-bot-went-wrong/ (accessed on 23 September 2021).
- Luthra, V.; Sethia, A.; Ghosh, S. Evolving Framework for Building Companionship Among Human and Assistive Systems. In Human-Computer Interaction. Novel User Experiences; Kurosu, M., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 138–147. [Google Scholar]
- Lee, S.; Choi, J. Enhancing user experience with conversational agent for movie recommendation: Effects of self-disclosure and reciprocity. Int. J. Hum. Comput. Stud. 2017, 103, 95–105. [Google Scholar] [CrossRef]
- Reply. Chatbot in the Travel Industry|Reply Solutions. Available online: https://www.reply.com/en/travel-with-a-bot (accessed on 23 September 2021).
- Abdulrahman, A.; Richards, D. Modelling Therapeutic Alliance Using a User-Aware Explainable Embodied Conversational Agent to Promote Treatment Adherence. In Proceedings of the 19th ACM International Conference on Intelligent Virtual Agents, Paris, France, 2–5 July 2019. [Google Scholar]
- Götzer, J. Engineering and User Experience of Chatbots in the Context of Damage Recording for Insurance Companies. 2018. Available online: https://shorturl.at/yBEQZ (accessed on 18 October 2021).
- Slesar, M. How to Design a Chatbot: Creating a Conversational Interface. Available online: https://onix-systems.com/blog/how-to-design-a-chatbot-creating-a-conversational-interface (accessed on 23 September 2021).
- Linh, P.N. Want to Design a World-Class Customer Service Chatbot? Not without UX Testing! Available online: https://in.solvemate.com/blog/want-to-design-a-world-class-customer-service-chatbot-not-without-ux-testing (accessed on 23 September 2021).
- Sanofi. Healthcare Chatbots. Available online: https://www.sanofi.fr/fr/-/media/Project/One-Sanofi-Web/Websites/Europe/Sanofi-FR/Newsroom/nos-publications/Livre-blanc-BOT-ENG-HD.pdf (accessed on 23 September 2021).
- Xu, Z.; Sun, C.; Long, Y.; Liu, B.; Wang, B.; Wang, M.; Zhang, M.; Wang, X. Dynamic Working Memory for Context-Aware Response Generation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1419–1431. [Google Scholar] [CrossRef]
- Okanović, D.; Beck, S.; Merz, L.; Zorn, C.; Merino, L.; van Hoorn, A.; Beck, F. Can a Chatbot Support Software Engineers with Load Testing? Approach and Experiences. In Proceedings of the ACM/SPEC International Conference on Performance Engineering, Edmonton, AB, Canada, 20–24 April 2020. [Google Scholar]
- Mimoun, M.S.B.; Poncin, I. A valued agent: How ECAs affect website customers’ satisfaction and behaviors. J. Retail. Consum. Serv. 2015, 26, 70–82. [Google Scholar] [CrossRef]
- Chang, J.; He, R.; Xu, H.; Han, K.; Wang, L.; Li, X.; Dang, J. NVSRN: A Neural Variational Scaling Reasoning Network for Initiative Response Generation. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 51–60. [Google Scholar]
- Solutions, A. Chatbots: The Definitive Guide. Available online: https://www.artificial-solutions.com/chatbots (accessed on 23 September 2021).
- Edwards, C.; Edwards, A.; Spence, P.R.; Shelton, A.K. Is that a bot running the social media feed? Testing the differences in perceptions of communication quality for a human agent and a bot agent on Twitter. Comput. Hum. Behav. 2014, 33, 372–376. [Google Scholar] [CrossRef]
- Chalaguine, L.A.; Hunter, A.; Potts, H.; Hamilton, F. Impact of argument type and concerns in argumentation with a chatbot. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, USA, 4–6 November 2019; pp. 1557–1562. [Google Scholar]
- Wang, D.; Jojic, N.; Brockett, C.; Nyberg, E. Steering Output Style and Topic in Neural Response Generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Inoue, M.; Matsuda, T.; Yokoyama, S. Web Resource Selection for Dialogue System Generating Natural Responses. In HCI International 2011—Posters’ Extended Abstracts; Stephanidis, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 571–575. [Google Scholar]
- Bosse, T.; Provoost, S. Integrating Conversation Trees and Cognitive Models Within an ECA for Aggression De-escalation Training. In PRIMA 2015: Principles and Practice of Multi-Agent Systems; Chen, Q., Torroni, P., Villata, S., Hsu, J., Omicini, A., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 650–659. [Google Scholar]
- Pontier, M.; Siddiqui, G.; Hoorn, J.F. Speed Dating with an Affective Virtual Agent—Developing a Testbed for Emotion Models. In Intelligent Virtual Agents; Allbeck, J., Badler, N., Bickmore, T., Pelachaud, C., Safonova, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 91–103. [Google Scholar]
- Chatbot e-service and customer satisfaction regarding luxury brands. J. Bus. Res. 2020, 117, 587–595. [CrossRef]
- Arthur, R. Louis Vuitton Becomes Latest Luxury Brand to Launch a Chatbot. Available online: https://www.forbes.com/sites/rachelarthur/2017/12/08/louis-vuitton-becomes-latest-luxury-brand-to-launch-a-chatbot/#46b9941afe10 (accessed on 23 September 2021).
- Jain, M.; Kota, R.; Kumar, P.; Patel, S.N. Convey: Exploring the Use of a Context View for Chatbots. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 21–26 April 2018. [Google Scholar]
- Ali, M.R.; Crasta, D.; Jin, L.; Baretto, A.; Pachter, J.; Rogge, R.D.; Hoque, M.E. LISSA—Live Interactive Social Skill Assistance; IEEE Computer Society: Washington, DC, USA, 2015. [Google Scholar]
- Google. User Engagement. Available online: https://developers.google.com/assistant/engagement (accessed on 23 September 2021).
- Liu, C.W.; Lowe, R.; Serban, I.V.; Noseworthy, M.; Charlin, L.; Pineau, J. How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Volume 1, pp. 2122–2132. [Google Scholar]
- Hwang, S.; Kim, B.; Lee, K. A Data-Driven Design Framework for Customer Service Chatbot. In Design, User Experience, and Usability. Design Philosophy and Theory; Marcus, A., Wang, W., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 222–236. [Google Scholar]
- Valtolina, S.; Barricelli, B.R.; Di Gaetano, S. Communicability of traditional interfaces VS chatbots in healthcare and smart home domains. Behav. Inf. Technol. 2020, 39, 108–132. [Google Scholar] [CrossRef]
- Vasconcelos, M.; Candello, H.; Pinhanez, C.; dos Santos, T. Bottester: Testing Conversational Systems with Simulated Users. In Proceedings of the IHC 2017: XVI Brazilian Symposium on Human Factors in Computing Systems, Joinville, Brazil, 23–27 October 2017. [Google Scholar] [CrossRef]
- Amazon. Alexa Skills Kit, Alexa Skills. Available online: https://developer.amazon.com/it-IT/blogs/alexa/alexa-skills-kit (accessed on 23 September 2021).
- Zhang, R.; Guo, J.; Fan, Y.; Lan, Y.; Xu, J.; Cheng, X. Learning to Control the Specificity in Neural Response Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Benvie, A.; Eric Wayne, M.A. Watson Assistant Continuous Improvement Best Practices. 2019. Available online: https://www.ibm.com/downloads/cas/V0XQ0ZRE (accessed on 20 October 2021).
- Amazon. Alexa Skills Kit Metrics API. Available online: https://developer.amazon.com/it-IT/docs/alexa/smapi/metrics-api.html (accessed on 23 September 2021).
- Lowe, R.; Noseworthy, M.; Serban, I.V.; Angelard-Gontier, N.; Bengio, Y.; Pineau, J. Towards an Automatic Turing Test: Learning to Evaluate Dialogue Responses. arXiv 2017, arXiv:1708.07149. [Google Scholar]
- Niewiadomski, R.; Demeure, V.; Pelachaud, C. Warmth, competence, believability and virtual agents. In International Conference on Intelligent Virtual Agents; Springer: New York, NY, USA, 2010; pp. 272–285. [Google Scholar]
- Thaler, M.; Schlögl, S.; Groth, A. Agent vs Avatar: Comparing Embodied Conversational Agents Concerning Characteristics of the Uncanny Valley. In In Proceedings of the 2020 IEEE International Conference on Human-Machine Systems (ICHMS), Rome, Italy, 7–9 September 2020; pp. 1–6. [Google Scholar]
- Herath, D.C.; Binks, N.; Grant, J.B. To Embody or Not: A Cross Human-Robot and Human-Computer Interaction (HRI/HCI) Study on the Efficacy of Physical Embodiment. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 848–853. [Google Scholar]
- Grimes, G.M.; Schuetzler, R.M.; Giboney, J.S. Mental models and expectation violations in conversational AI interactions. Decis. Support Syst. 2021, 144, 113515. [Google Scholar] [CrossRef]
- Knidiri, H. How Artificial Intelligence Impacts the Customer Experience. 2021. Available online: https://matheo.uliege.be/bitstream/2268.2/13565/8/ISU_Template_with_Journal_Article_Format__ver_3_01_2021_%20%284%29.pdf (accessed on 18 October 2021).
- Kim, W.; Lee, K. A Data-Driven Strategic Model of Common Sense in Machine Ethics of Cares. In Human-Computer Interaction. Perspectives on Design; Kurosu, M., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 319–329. [Google Scholar]
- Iwase, K.; Gushima, K.; Nakajima, T. “Relationship Between Learning by Teaching with Teachable Chatbots and the Big 5. In Proceedings of the 2021 IEEE 3rd Global Conference on Life Sciences and Technologies (LifeTech), Nara, Japan, 9–11 March 2021; pp. 191–194. [Google Scholar]
- Vukovac, D.P.; Horvat, A.; Čižmešija, A. Usability and User Experience of a Chat Application with Integrated Educational Chatbot Functionalities. In International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2021; pp. 216–229. [Google Scholar]
- Komori, M.; Fujimoto, Y.; Xu, J.; Tasaka, K.; Yanagihara, H.; Fujita, K. Experimental Study on Estimation of Opportune Moments for Proactive Voice Information Service Based on Activity Transition for People Living Alone. In Human-Computer Interaction. Perspectives on Design; Kurosu, M., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 527–539. [Google Scholar]
- Pelau, C.; Dabija, D.C.; Ene, I. What makes an AI device human-like? The role of interaction quality, empathy and perceived psychological anthropomorphic characteristics in the acceptance of artificial intelligence in the service industry. Comput. Hum. Behav. 2021, 122, 106855. [Google Scholar] [CrossRef]
- Verstegen, C. The Pros and Cons of Chatbots. Available online: https://www.chatdesk.com/blog/pros-and-cons-of-chatbots (accessed on 23 September 2021).
- Ishida, Y.; Chiba, R. Free Will and Turing Test with Multiple Agents: An Example of Chatbot Design. Procedia Comput. Sci. 2017, 112, 2506–2518. [Google Scholar] [CrossRef]
- Ruane, E.; Farrell, S.; Ventresque, A. User Perception of Text-Based Chatbot Personality. In International Workshop on Chatbot Research and Design; Springer: Berlin/Heidelberg, Germany, 2020; pp. 32–47. [Google Scholar]
- Langevin, R.; Lordon, R.J.; Avrahami, T.; Cowan, B.R.; Hirsch, T.; Hsieh, G. Heuristic Evaluation of Conversational Agents. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–15. [Google Scholar]
- Morgan, B. How Chatbots Improve Customer Experience in Every Industry: An Infograph. Available online: https://www.forbes.com/sites/blakemorgan/2017/06/08/how-chatbots-improve-customer-experience-in-every-industry-an-infograph/#2162528867df (accessed on 23 September 2021).
- Max, D. The 13 Best AI Chatbots for Business in 2021 and Beyond [Review and Key Features]. Available online: https://www.netomi.com/best-ai-chatbot (accessed on 23 September 2021).
- TechLabs, M. Your Go-To Chatbot Guide 101—All You Need to Know About Chatbots. Available online: https://marutitech.com/complete-guide-chatbots/ (accessed on 23 September 2021).
- Hu, P.; Lu, Y. Dual humanness and trust in conversational AI: A person-centered approach. Comput. Hum. Behav. 2021, 119, 106727. [Google Scholar] [CrossRef]
- Ameen, N.; Tarhini, A.; Reppel, A.; Anand, A. Customer experiences in the age of artificial intelligence. Comput. Hum. Behav. 2021, 114, 106548. [Google Scholar] [CrossRef]
- Raunio, K. Chatbot Anthropomorphism: Adoption and Acceptance in Customer Service. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2021. [Google Scholar]
- Shin, D. How do people judge the credibility of algorithmic sources? 2021. Available online: https://philpapers.org/rec/SHIHDP-2 (accessed on 18 October 2021).
- Ashfaq, M.; Yun, J.; Yu, S.; Loureiro, S.M.C. I, Chatbot: Modeling the determinants of users’ satisfaction and continuance intention of AI-powered service agents. Telemat. Inform. 2020, 54, 101473. [Google Scholar] [CrossRef]
- Li, Y.; Arnold, J.; Yan, F.; Shi, W.; Yu, Z. LEGOEval: An Open-Source Toolkit for Dialogue System Evaluation via Crowdsourcing. arXiv 2021, arXiv:2105.01992. [Google Scholar]
- Wang, Z.; Wang, Z.; Long, Y.; Wang, J.; Xu, Z.; Wang, B. Enhancing generative conversational service agents with dialog history and external knowledge. Comput. Speech Lang. 2019, 54, 71–85. [Google Scholar] [CrossRef]
- Campos, J.; Paiva, A. A Personal Approach: The Persona Technique in a Companion’s Design Lifecycle. In Human-Computer Interaction—INTERACT 2011; Campos, P., Graham, N., Jorge, J., Nunes, N., Palanque, P., Winckler, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 73–90. [Google Scholar]
- Dušan, O.; Samuel, B.; Lasse, M.; Christoph, Z.; Leonel, M.; André, v.H.; Fabian, B. Can a Chatbot Support Software Engineers with Load Testing? Approach and Experiences. 2020. Available online: https://www.vis.wiwi.uni-due.de/uploads/tx_itochairt3/publications/2020_ICPE_IndustryTrack_Chatbots.pdf (accessed on 18 October 2021).
- Reeves, L.M.; Lai, J.; Larson, J.A.; Oviatt, S.; Balaji, T.; Buisine, S.; Collings, P.; Cohen, P.; Kraal, B.; Martin, J.C.; et al. Guidelines for multimodal user interface design. Commun. ACM 2004, 47, 57–59. [Google Scholar] [CrossRef]
- Zhang, L. Exploration on Affect Sensing from Improvisational Interaction. In Intelligent Virtual Agents; Allbeck, J., Badler, N., Bickmore, T., Pelachaud, C., Safonova, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 385–391. [Google Scholar]
- Bührke, J.; Brendel, A.B.; Lichtenberg, S.; Greve, M.; Mirbabaie, M. Is Making Mistakes Human? In On the Perception of Typing Errors in Chatbot Communication. In Proceedings of the 54th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5 January 2021; p. 4456. [Google Scholar]
- Krommyda, M.; Kantere, V. Improving the Quality of the Conversational Datasets through Extensive Semantic Analysis. In Proceedings of the 2019 IEEE International Conference on Conversational Data & Knowledge Engineering (CDKE), San Diego, CA, USA, 9–11 December 2019; pp. 1–8. [Google Scholar]
- Hijjawi, M.; Bandar, Z.; Crockett, K. A general evaluation framework for text based conversational agent. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 23–33. [Google Scholar] [CrossRef]
- Crutzen, R.; Peters, G.J.Y.; Portugal, S.D.; Fisser, E.M.; Grolleman, J.J. An artificially intelligent chat agent that answers adolescents’ questions related to sex, drugs, and alcohol: An exploratory study. J. Adolesc. Health 2011, 48, 514–519. [Google Scholar] [CrossRef]
- Guichard, J.; Ruane, E.; Smith, R.; Bean, D.; Ventresque, A. Assessing the robustness of conversational agents using paraphrases. In Proceedings of the 2019 IEEE International Conference On Artificial Intelligence Testing (AITest), Newark, CA, USA, 4–9 April 2019; pp. 55–62. [Google Scholar]
- Jordan, P.; Albacete, P.; Katz, S. Exploring the effects of redundancy within a tutorial dialogue system: Restating students’ responses. In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Prague, Czech Republic, 2–4 September 2015; pp. 51–59. [Google Scholar]
- Michelsen, J. Chatbots: Tip of the Intelligent Automation Iceberg. Available online: https://kristasoft.com/chatbots-tip-of-the-intelligent-automation-iceberg/ (accessed on 23 September 2021).
- Microsoft. Bot Analytics. Available online: https://docs.microsoft.com/it-it/azure/bot-service/bot-service-manage-analytics?view=azure-bot-service-4.0 (accessed on 23 September 2021).
- Ogara, S.O.; Koh, C.E.; Prybutok, V.R. Investigating factors affecting social presence and user satisfaction with mobile instant messaging. Comput. Hum. Behav. 2014, 36, 453–459. [Google Scholar] [CrossRef]
- Casas, J.; Tricot, M.O.; Abou Khaled, O.; Mugellini, E.; Cudré-Mauroux, P. Trends & Methods in Chatbot Evaluation. In Proceedings of the Companion Publication of the 2020 International Conference on Multimodal Interaction, Virtual, 25–29 October 2020; pp. 280–286. [Google Scholar]
- Piao, M.; Kim, J.; Ryu, H.; Lee, H. Development and Usability Evaluation of a Healthy Lifestyle Coaching Chatbot Using a Habit Formation Model. Healthc. Inform. Res. 2020, 26, 255–264. [Google Scholar] [CrossRef]
- Mavridis, P.; Huang, O.; Qiu, S.; Gadiraju, U.; Bozzon, A. Chatterbox: Conversational interfaces for microtask crowdsourcing. In Proceedings of the 27th ACM Conference on User Modeling, Adaptation and Personalization, Larnaca, Cyprus, 9–12 June 2019; pp. 243–251. [Google Scholar]
- Epstein, M.; Ramabhadran, B.; Balchandran, R. Improved language modeling for conversational applications using sentence quality. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; IEEE: New York, NY, USA, 2010; pp. 5378–5381. [Google Scholar]
- Walker, M.; Langkilde, I.; Wright, J.; Gorin, A.; Litman, D. Learning to Predict Problematic Situations in a Spoken Dialogue System: Experiments with How May I Help You? In Proceedings of the 1st Meeting of the North American Chapter of the Association for Computational Linguistics, Seattle, WA, USA, 29 April–4 May 2000; pp. 210–217. [Google Scholar]
- Shalaby, W.; Arantes, A.; GonzalezDiaz, T.; Gupta, C. Building chatbots from large scale domain-specific knowledge bases: Challenges and opportunities. In Proceedings of the 2020 IEEE International Conference on Prognostics and Health Management (ICPHM), Detroit, MI, USA, 8–10 June 2020; pp. 1–8. [Google Scholar]
- Teixeira, M.S.; da Costa Pereira, C.; Dragoni, M. Information Usefulness as a Strategy for Action Selection in Health Dialogues. In Proceedings of the 2020 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Melbourne, Australia, 14–17 December 2020; pp. 323–330. [Google Scholar]
- Zhang, Y.; Song, D.; Li, X.; Zhang, P.; Wang, P.; Rong, L.; Yu, G.; Wang, B. A quantum-like multimodal network framework for modeling interaction dynamics in multiparty conversational sentiment analysis. Inf. Fusion 2020, 62, 14–31. [Google Scholar] [CrossRef]
- Wang, W.; Huang, M.; Xu, X.S.; Shen, F.; Nie, L. Chat more: Deepening and widening the chatting topic via a deep model. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 255–264. [Google Scholar]
- Wang, H.; Guo, B.; Wu, W.; Liu, S.; Yu, Z. Towards information-rich, logical dialogue systems with knowledge-enhanced neural models. Neurocomputing 2021, 465, 248–264. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Fergencs, T.; Meier, F.M. Engagement and Usability of Conversational Search–A Study of a Medical Resource Center Chatbot. In Proceedings of iConference 2021, Beijing, China, 17–31 March 2021; Available online: https://vbn.aau.dk/en/publications/engagement-and-usability-of-conversational-search-a-study-of-a-me (accessed on 18 October 2021).
- Karakostas, A.; Nikolaidis, E.; Demetriadis, S.; Vrochidis, S.; Kompatsiaris, I. colMOOC–an Innovative Conversational Agent Platform to Support MOOCs A Technical Evaluation. In Proceedings of the 2020 IEEE 20th International Conference on Advanced Learning Technologies (ICALT), Tartu, Estonia, 6–9 July 2020; pp. 16–18. [Google Scholar]
- Firdaus, M.; Thangavelu, N.; Ekba, A.; Bhattacharyya, P. Persona aware Response Generation with Emotions. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Beredo, J.; Ong, E. Beyond the Scene: A Comparative Analysis of Two Storytelling-based Conversational Agents. In Proceedings of the Asian CHI Symposium 2021, Yokohama, Japan, 8–13 May 2021; pp. 189–195. Available online: https://dl.acm.org/doi/abs/10.1145/3429360.3468208 (accessed on 18 October 2021).
- Chug, P. 12 Experts Share The Biggest Chatbot Trends For 2020! Available online: https://botcore.ai/blog/12-experts-share-the-biggest-chatbot-trends-for-2020/ (accessed on 23 September 2021).
- Bailey, D.; Almusharraf, N. Investigating the Effect of Chatbot-to-User Questions and Directives on Student Participation. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 85–90. [Google Scholar]
- Schumaker, R.P.; Chen, H. Interaction analysis of the alice chatterbot: A two-study investigation of dialog and domain questioning. IEEE Trans. Syst. Man Cybern. Part A Syst. Humans 2009, 40, 40–51. [Google Scholar] [CrossRef]
- Ruane, E.; Faure, T.; Smith, R.; Bean, D.; Carson-Berndsen, J.; Ventresque, A. Botest: A framework to test the quality of conversational agents using divergent input examples. In Proceedings of the 23rd International Conference on Intelligent User Interfaces Companion, Tokyo, Japan, 7–11 March 2018; pp. 1–2. Available online: https://researchrepository.ucd.ie/handle/10197/9305?mode=full (accessed on 18 October 2021).
- Miller, A.; Feng, W.; Batra, D.; Bordes, A.; Fisch, A.; Lu, J.; Parikh, D.; Weston, J. ParlAI: A Dialog Research Software Platform. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Copenhagen, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.; Pineau, J. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems. In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue; Association for Computational Linguistics: Prague, Czech Republic, 2–4 September 2015. [Google Scholar]
- Hori, C.; Perez, J.; Higashinaka, R.; Hori, T.; Boureau, Y.L.; Inaba, M.; Tsunomori, Y.; Takahashi, T.; Yoshino, K.; Kim, S. Overview of the sixth dialog system technology challenge: DSTC6. Comput. Speech Lang. 2019, 55, 1–25. [Google Scholar] [CrossRef]
- TheBotForge. How Much Does It Cost to Build a Chatbot in 2020? 2020. Available online: https://www.thebotforge.io/how-much-does-it-cost-to-build-a-chatbot-in-2020/ (accessed on 18 October 2021).
- Banchs, R.E. On the construction of more human-like chatbots: Affect and emotion analysis of movie dialogue data. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), New York, NY, USA, 12–15 December 2017; pp. 1364–1367. [Google Scholar]
- Mairesse, F.; Walker, M. PERSONAGE: Personality generation for dialogue. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics; Association for Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 496–503. [Google Scholar]
- Neff, M.; Wang, Y.; Abbott, R.; Walker, M. Evaluating the Effect of Gesture and Language on Personality Perception in Conversational Agents. In Intelligent Virtual Agents; Allbeck, J., Badler, N., Bickmore, T., Pelachaud, C., Safonova, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 222–235. [Google Scholar]
- Lison, P.; Tiedemann, J. OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16); European Language Resources Association (ELRA), Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Microsoft. Analyze Your Bot’s Telemetry Data. Available online: https://docs.microsoft.com/en-us/azure/bot-service/bot-builder-telemetry-analytics-queries?view=azure-bot-service-4.0 (accessed on 23 September 2021).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Title | Research Methodology | # of Primary Studies | Description |
|---|---|---|---|---|---|
| [1] | 2017 | Evaluating Quality of Chatbots and Intelligent Conversational Agents | MLR | 46 | This paper presents a literature review of quality issues and attributes as they relate to the contemporary issue of chatbot development and implementation. The quality assessment approaches are reviewed and based on these attributes a quality assessment method is proposed and examined. |
| [12] | 2019 | A Survey on Evaluation Methods for Chatbots | SLR | 30 | This work presents a survey starting from a literature review, evaluation methods/criteria and comparison of evaluation methods. It is conducted with classication of chatbot evaluation methods and their analysis according to chatbot types and the three main evaluation schemes: content evaluation, user satisfaction and chat function. |
| [33] | 2019 | Usability of Chatbots: A Systematic Mapping Study | SLR | 19 | This paper is focused on identifying the state of the art in chatbot usability and applied human–computer interaction techniques and to analyze how to evaluate chatbots usability. The works were categorized according to four criteria: usability techniques, usability characteristics, research methods and type of chatbots. |
| # | Question | Answer |
|---|---|---|
| 1 | Is the subject ”complex” and not solvable by considering only the formal literature? | Yes |
| 2 | Is there a lack of volume or quality of evidence, or a lack of consensus of outcome measurement in the formal literature? | Yes |
| 3 | Is the contextual information important in the subject under study? | Yes |
| 4 | Is it the goal to validate or corroborate scientific outcomes with practical experiences? | Yes |
| 5 | Is it the goal to challenge assumptions or falsify results from practice using academic research or vice versa? | Yes |
| 6 | Would a synthesis of insights and evidence from the industrial and academic community be useful to one or even both communities? | Yes |
| 7 | Is there a large volume of practitioner sources indicating high practitioner interest in a topic? | Yes |
| # | Search String |
|---|---|
| IEEE Xplore | (((chatbot* OR conversational) AND (interface* OR agent*)) AND (metric* OR evaluat* OR “quality assessment” OR analysis OR measur*)) |
| Elsevier Science Direct | (((chatbot OR conversational) AND (interface OR agent)) AND (metric OR evaluation OR “quality assessment” OR analysis OR measurement)) |
| ACM Digital Library | (((chatbot* OR conversational) AND (interface* OR agent*)) AND (metric* OR evaluat* OR “quality assessment” OR analysis OR measur*)) |
| Springer Link | ((chatbot* OR conversational) AND (interface* OR agent*)) AND (metric* OR evaluat* OR “quality assessment” OR analysis OR measur*) |
| Google Scholar | metric OR evaluation OR “quality assessment” OR analysis OR measurement “chatbot interface” |
| metric OR evaluation OR “quality assessment” OR analysis OR measurement “chatbot interface” |
| Repository | Number of Sources |
|---|---|
| IEEE Xplore | 18 |
| Elsevier Science Direct | 17 |
| ACM Digital Library | 4 |
| Springer Link | 14 |
| Google Scholar | 12 |
| 23 | |
| Snowballing WL | 18 |
| Snowballing GL | 12 |
| Final Pool | 118 |
| Macro-Category | Sub-Category | Attribute | WL Refs. | GL Refs. | Refs. |
|---|---|---|---|---|---|
| Relational | Personality | Social Capacities | [46,48,69,85,86,87,88] | [49,58,59,64,89] | 12 |
| Common Sense | [90,91,92] | [49,51,56,59] | 7 | ||
| Ethics | [70,91,93] | [49,51] | 5 | ||
| Empathy | [47,48,94] | [59,95] | 5 | ||
| Freewill | [92,96] | - | 2 | ||
| Extraversion | [91,97] | - | 2 | ||
| Warmth | [85] | - | 1 | ||
| Judgement | - | [51] | 1 | ||
| Perceived Intelligence | [87] | - | 1 | ||
| Neuroticism | [91] | - | 1 | ||
| Openness | [91] | - | 1 | ||
| Relationship with user | Customization | [47,52,71,98] | [49,54,72,99,100,101] | 10 | |
| Trust | [48,52,53,62,87,102,103] | [59,104] | 9 | ||
| Believability | [42,65,69,71,96,97,105] | [59] | 8 | ||
| Engagingness | [40,42,70,87,106,107] | [57,89] | 7 | ||
| Memory | [47,60,108] | [54,58,64] | 6 | ||
| Companionship | [46,55,105,109] | [54,110] | 6 | ||
| Adaptability | [47,55,87,111] | - | 4 | ||
| Playfulness | [62,71,77,87] | - | 4 | ||
| Utilitarian Value | [62], | [72,99,104] | 4 | ||
| Affect Understanding | [102,105,112] | [57] | 4 | ||
| Reliability | [55,92,109] | - | 3 | ||
| Intimacy | [53,109] | - | 2 | ||
| Modeling Capability | [55] | [54] | 2 | ||
| Persuasiveness | [48] | - | 1 | ||
| Reciprocity | [53] | - | 1 | ||
| Self-Disclosure | [53] | - | 1 | ||
| Perceived Sacrifice | [103] | - | 1 | ||
| Transparency | [105] | - | 1 | ||
| Clarity | [105] | - | 1 | ||
| Conversational | Language Style | Naturalness | [40,63,68,87,91,102] | [58,59,95,101], | 16 |
| [92,94,98,103,107,113] | |||||
| Diversity | [46,114,115] | [59] | 4 | ||
| Interaction Style | [67,69] | [56,59] | 4 | ||
| Language Relevance | [73] | [56,57,58] | 4 | ||
| Conciseness | [116] | [57] | 2 | ||
| Repetitiveness | [42,47] | - | 2 | ||
| Colloquiality | [46] | - | 1 | ||
| Initiative to User | [41] | - | 1 | ||
| Lexical Performance | [117] | - | 1 | ||
| Politeness | - | [54] | 1 | ||
| Restatement | [118] | - | 1 | ||
| Shallowness | [47] | - | 1 | ||
| Goal Achievement | Informativeness | [46,60,63,108,116], | [54,56,57,64,110] | ||
| [62,73,87,109,111] | 16 | ||||
| Correctness | [46,62,65,69,71,85,103] | [100,119] | 12 | ||
| Context Understanding | [46,60,67,68,98] | [49,57] | 7 | ||
| Proactiveness | [47,63,65,93] | [58,64] | 6 | ||
| Richness | [46,60,108,114] | [49,120] | 6 | ||
| Consistency | [40,46,111] | [56,57] | 5 | ||
| Clarity | [47,55,98] | [59,110] | 5 | ||
| Relevance | [46,60,70] | [59] | 4 | ||
| Robustness | [117] | [51] | 2 | ||
| User Understanding | [117,121] | - | 2 | ||
| User-Centered Attributes | Aesthetic Appearance | [47,69,70,86,87,92,98] | [49,50,56,57,58,89] | 13 | |
| User Satisfaction | [53,62,71,103,106,122] | [54,57,59,82,95,99,104] | 13 | ||
| Ease of Use | [62,74,87,116,123] | [57,58,99,104,124] | 10 | ||
| User Intention to Use | [53,62,65,70,73] | [57,82,124] | 8 | ||
| Mental Demand | [62,73,87] | [50,54,56,58,99] | 8 | ||
| Availability | [47] | [54,64,72,95,99] | 6 | ||
| Acceptability | [48,93] | [59,124] | 4 | ||
| Presence of Notifications | [47,74] | [75,100] | 4 | ||
| Protection of Sensitive Data | [116] | [59,101] | 3 | ||
| Number of Channels | - | [100,101] | 2 | ||
| Physical Demand | [73] | [99] | 2 | ||
| Presence of Documentation | - | [56,78] | 2 | ||
| Hedonic Value | [62,103] | - | 2 | ||
| Information Presentation | - | [49] | 1 | ||
| Integration in External Channels | - | [99] | 1 | ||
| Presence of Ratings | - | [49] | 1 | ||
| Responsiveness (Graphical) | - | [80] | 1 | ||
| Integration with multiple systems | - | [119] | 1 | ||
| Human Escalation | - | [100] | 1 | ||
| Number of Languages | - | [100] | 1 | ||
| Quantitative | Low-level semantic | ML Accuracy | [63,90,125,126,127,128,129] | [82] | 8 |
| BLEU | [60,63,76,81,108,130,131] | - | 7 | ||
| ML Precision | [63,90,125,126,128] | [82] | 6 | ||
| ML Recall | [63,90,125,126] | [82] | 5 | ||
| Distinct-1 | [63,81,130,131] | - | 4 | ||
| METEOR | [60,76,108,132] | - | 4 | ||
| ROUGE | [60,76,108,131] | - | 4 | ||
| CIDEr | [60,108] | - | 2 | ||
| Skip-Thought | [76,108] | - | 2 | ||
| Embedding Average | [76,108] | - | 2 | ||
| Vector Extrema | [76,81] | - | 2 | ||
| Perplexity (PPL) | [130,131] | - | 2 | ||
| Greedy Matching | [76,108] | - | 1 | ||
| Distinct-2 | [81] | - | 1 | ||
| ASR Confidence Score | - | [120] | 1 | ||
| NLU Confidence Score | - | [120] | 1 | ||
| Semantic Similarity Metrics | [108] | - | 1 | ||
| MRR | [67] | - | 1 | ||
| P1 | [67] | - | 1 | ||
| Standard Questionnaires | Measure of Source Credibility | [65] | - | 1 | |
| Measure of interpersonal attraction | [65] | - | 1 | ||
| Measure of computer-mediated Communication Competence | [65] | - | 1 | ||
| Communicability Evaluation Method (CEM) | - | [78] | 1 | ||
| System Usability Scale (SUS) | - | [78] | 1 | ||
| Computer System Usability Questionnaire (CSUQ) | - | [78] | 1 | ||
| User Experience Questionnaire (UEQ) | - | [78] | 1 | ||
| Time-Related Metrics | Response Time | [79,116,133] | [57] | 4 | |
| Task Completion Time | [73,97,116,133] | - | 4 | ||
| Peak Usage Time | - | [80] | 1 | ||
| Frequency of Requests | - | [120] | 1 | ||
| Frequency of Conversations | [116] | - | 1 | ||
| Size-Related Metrics | Number of messages/utterances | [73,97,115,127,134,135,136] | [54,64] | 9 | |
| Number of conversations | [133,134,135] | [54,64] | 5 | ||
| Number of Keywords | [68,77,135] | - | 3 | ||
| Number of users | [134] | [54,57,119] | 4 | ||
| Mean Answer Size | [79,97,135] | - | 3 | ||
| Number of user ended sessions | - | [54] | 1 | ||
| Number of system ended sessions | - | [54] | 1 | ||
| Number of emotions per dialogue | [135] | - | 1 | ||
| Response-Related Metrics | Response Frequency | [79,81] | - | 2 | |
| Number of successful sessions | - | [83,137] | 2 | ||
| Number of correct responses | - | [64,83] | 2 | ||
| Topic Diversity | [138] | [120] | 2 | ||
| Word Frequency | [81] | - | 1 | ||
| Number of queries related to the topic | [116] | - | 1 | ||
| Number of utterances with poor understanding | - | [82] | 1 | ||
| Response Satisfaction Score | [139] | - | 1 | ||
| Task Success Rate | [79] | - | 1 | ||
| Reliability Coefficient | [65] | - | 1 | ||
| User Satisfaction Estimate (USE) | - | [120] | 1 | ||
| Response Specificity | [81] | - | 1 | ||
| Framework | References | Language | License |
|---|---|---|---|
| ADEM | [12,84] | Python | - |
| BoTest | [140] | Python | Open Source |
| Bottester | [79] | Mocha/chai | MIT License |
| ParlAI | [141] | Python | MIT License |
| LEGOEval | [107] | Python | Open Source |
| Type of Source | Source Examples | WL References | GL References |
|---|---|---|---|
| Forums | IMDB Movie Review Data | [90] | - |
| Ubuntu Dialog corpora | [108,142] | - | |
| Yahoo! Answer | [67,114] | - | |
| 2channel Internet bulletin board | [68] | - | |
| Slashdot | [68] | ||
| Social Media | [46,47,60,68,71,76,90,96,108,114,117,121,130,142,143] | [64,144] | |
| Customer Service | Twitter Customer Service Corpus | [60] | |
| Didi Customer Service Corpus | [63] | - | |
| Movies and Subtitles | OpenSubtitles | [60] | - |
| Cornell Movie Dialog Corpus 3 | [63,67] | - | |
| Movie-DiC | [67,145] | - | |
| Hello-E | [131] | - | |
| CMU_DoG | [131] | - | |
| DuConv | [131] | - | |
| Challenges | Persona-Chat dataset | [40] | - |
| Dialog State Tracking Challenge datasets | [81,130,143] | - | |
| Dialog System Technology Challenges (DSTC6) Track 2 | [60,108,143] | - | |
| NTCIR-13 Short Text Conversation | [81] | ||
| External Knowledge | WordNet, WordNet Affect | [76,112,114,115,117,118,139,146,147] | - |
| Wikipedia | [68,90,114,141] | - | |
| Wizard of Wikipedia | [131] | - | |
| OpenDialKG | [131] | - | |
| Unified Medical Language System (UMLS) | - | [59] | |
| SNOMED CT® (Clinical Terms) | - | [59] | |
| Bioportal | - | [59] | |
| CISMEF | - | [59] | |
| Schema.org | - | [50] | |
| Others | Debate Chat Contexts | [67] | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coppola, R.; Ardito, L. Quality Assessment Methods for Textual Conversational Interfaces: A Multivocal Literature Review. Information 2021, 12, 437. https://doi.org/10.3390/info12110437
Coppola R, Ardito L. Quality Assessment Methods for Textual Conversational Interfaces: A Multivocal Literature Review. Information. 2021; 12(11):437. https://doi.org/10.3390/info12110437
Chicago/Turabian StyleCoppola, Riccardo, and Luca Ardito. 2021. "Quality Assessment Methods for Textual Conversational Interfaces: A Multivocal Literature Review" Information 12, no. 11: 437. https://doi.org/10.3390/info12110437
APA StyleCoppola, R., & Ardito, L. (2021). Quality Assessment Methods for Textual Conversational Interfaces: A Multivocal Literature Review. Information, 12(11), 437. https://doi.org/10.3390/info12110437