
Evaluating a Taxonomy of Textual Uncertainty for Collaborative Visualisation in the Digital Humanities

 , , , and
, , , and 
Abstract
:1. Introduction
2. Related Work
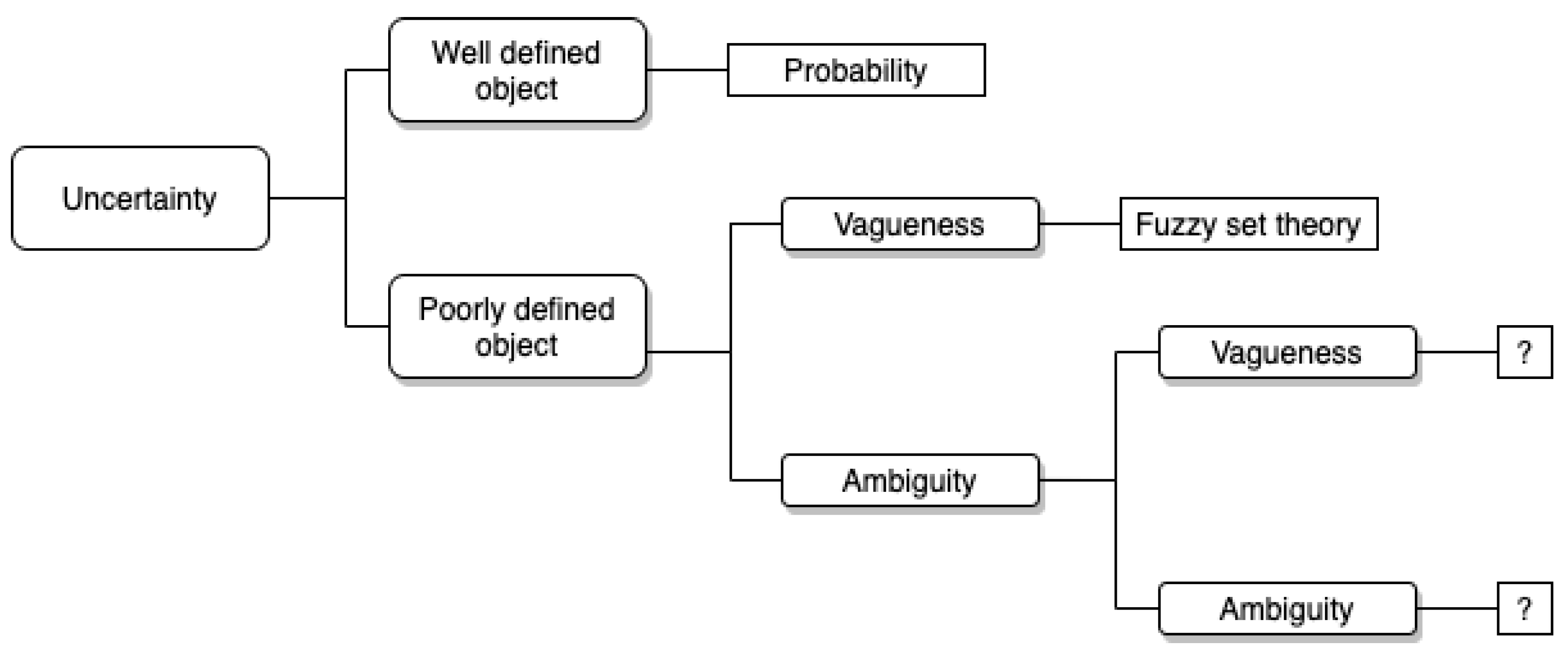
2.1. Uncertainty Taxonomies
- Aleatoric: Aleatoric uncertainty (also known as statistical or stochastic uncertainty) exists due to the random nature of physical events, and it is probabilistic in nature. Its main characteristic is that it is irreducible and thus it needs to be tackled using statistical artefacts. Aleatoric uncertainty is typically modelled with a continuous variable, and thus it is best represented by a continuous probability distribution function (CDF). In our recent work, we established that in the context of digital humanities, aleatoric uncertainty can be better understood as algorithmic uncertainty (e.g., in topic modelling, the probability of a word to be in a set of topics). We did not consider this type of uncertainty in this study.
- Epistemic: This type of uncertainty results from a lack of knowledge and it is associated with the user performing the analysis. As opposed to aleatoric uncertainty, epistemic uncertainty can be resolved if more knowledge is gathered. Furthermore, it is known in the literature as systematic, subjective, or reducible uncertainty. This is the type of uncertainty we address in this study. In this study, we aimed to capture human judgements on epistemic uncertainty. Since humans cannot emit judgements with a high level of precision (i.e., nobody says that they are 2.3575% “sure” about something), we employed a 5-point Likert scale to capture these statements, as is common practice in the literature [21]. Thus, the logical step is to employ a discrete probability distribution to represent it [22].
- (a)
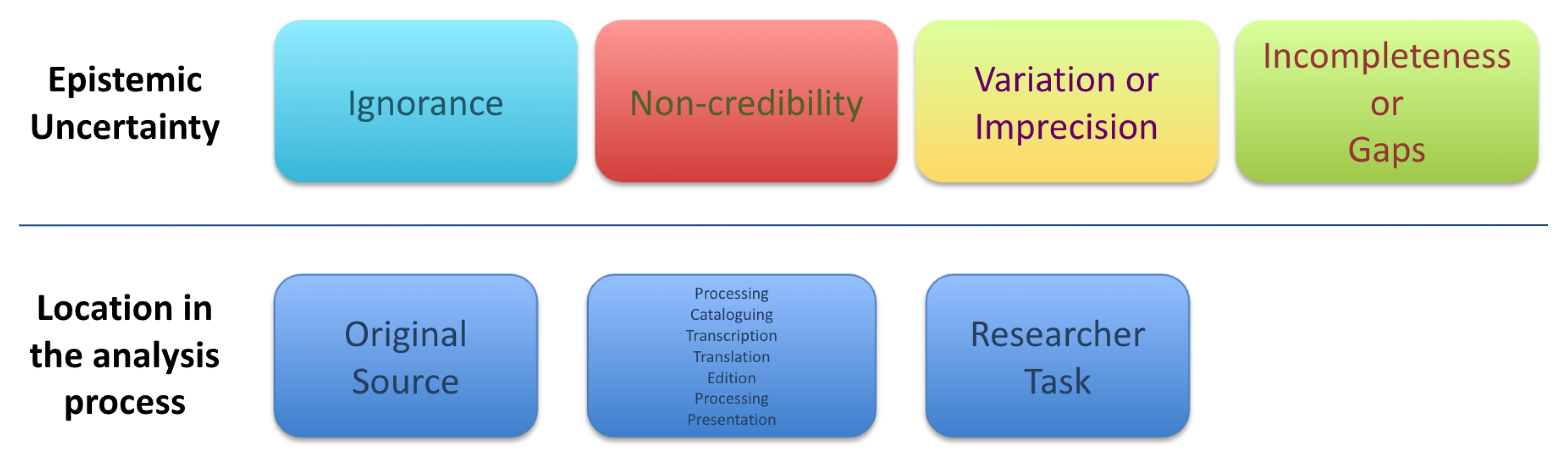
- Imprecision: Refers to the observer’s inability to pinpoint the exact value of a measure due to a lack of information (e.g., the observations made with a cheap microscope are more imprecise than those we would obtain with a better one). For example, in our context, this kind of uncertainty is often seen as imprecise statements referring to time periods (e.g., 1095–1291, the first half of 15th century, etc.).
- (b)
- Ignorance: Ignorance is related to the fact that information can be incorrectly processed by the individuals analysing it. It is a measure of the individual’s degree of confidence in their judgement, for example, when trying to interpret an old piece of text due to not being able to determine the meaning of a certain word, or lacking the necessary historical knowledge to understand a passage.
- (c)
- Credibility: This is also known as discord in the literature. This type of uncertainty is linked to the influence of personal bias when making a judgement, which can result in disparate (and sometimes even opposing) points of view from different agents when observing the same data. Credibility is also closely related to the concept of authority: for example, data that have been curated by an expert in the field are presumed to contain fewer errors by an observer. However, the concept of expertise is deeply rooted in the observer’s own previous knowledge and biases, which will lead them to (consciously or unconsciously) adjust the weight given to these judgements in their decision-making process.
- (d)
- Incompleteness: Incompleteness can be regarded as a special type of imprecision, in which it becomes impossible to know every single aspect of an event. An important point is that in this case, the agent performing the analysis is fully aware of what the data should look like to be complete (i.e., they know what the complete data should look like). Take, for example, the case of a scholar working with an old registry of people’s names. The first lines of the registry contain a summary stating that there are 1000 names listed. However, only a few pages were preserved, while others were lost, and only half of the names (500) are shown. The registry is imprecise because its exact original content cannot be retrieved, but also it is incomplete because the scholar knows it has missing information.
2.2. Uncertainty in TEI
2.3. Collaborative Visualisation
2.4. Citizen Science
3. Study Design
4. First Workshop: DH Experts
4.1. Description
4.2. Development
4.2.1. First Exercise
4.2.2. Second Exercise
4.3. Main Outcomes
4.3.1. General Remarks
4.3.2. Uncertainty in Humanities Research
4.3.3. Visual Analytics and Decision-Making in the Humanities
5. Lessons Learned
5.1. Uncertainty Modelling
5.2. Design of DH Platforms
5.3. Social Considerations
6. Second Workshop: DH Users
6.1. Description
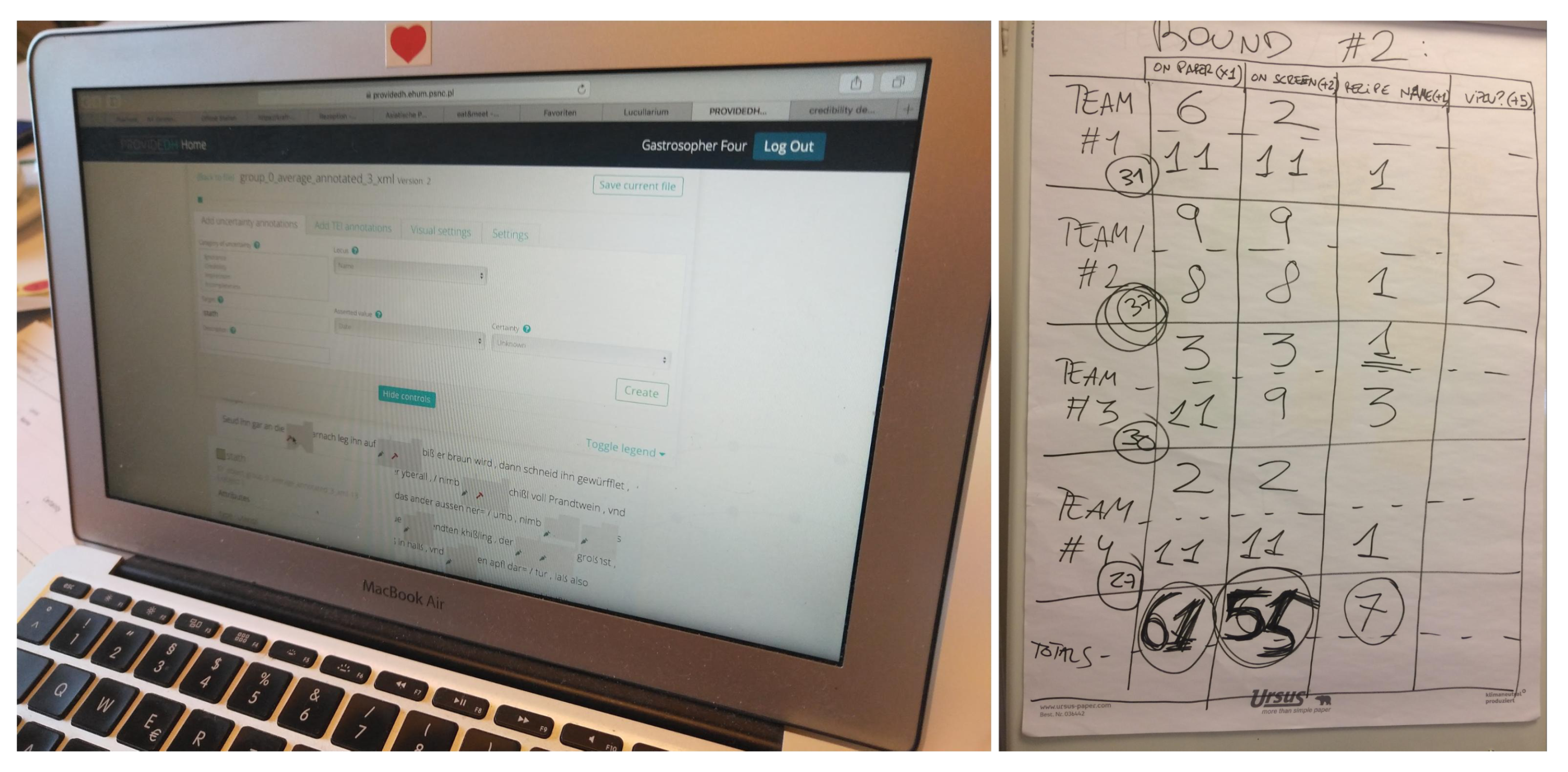
6.2. Development
6.3. Results
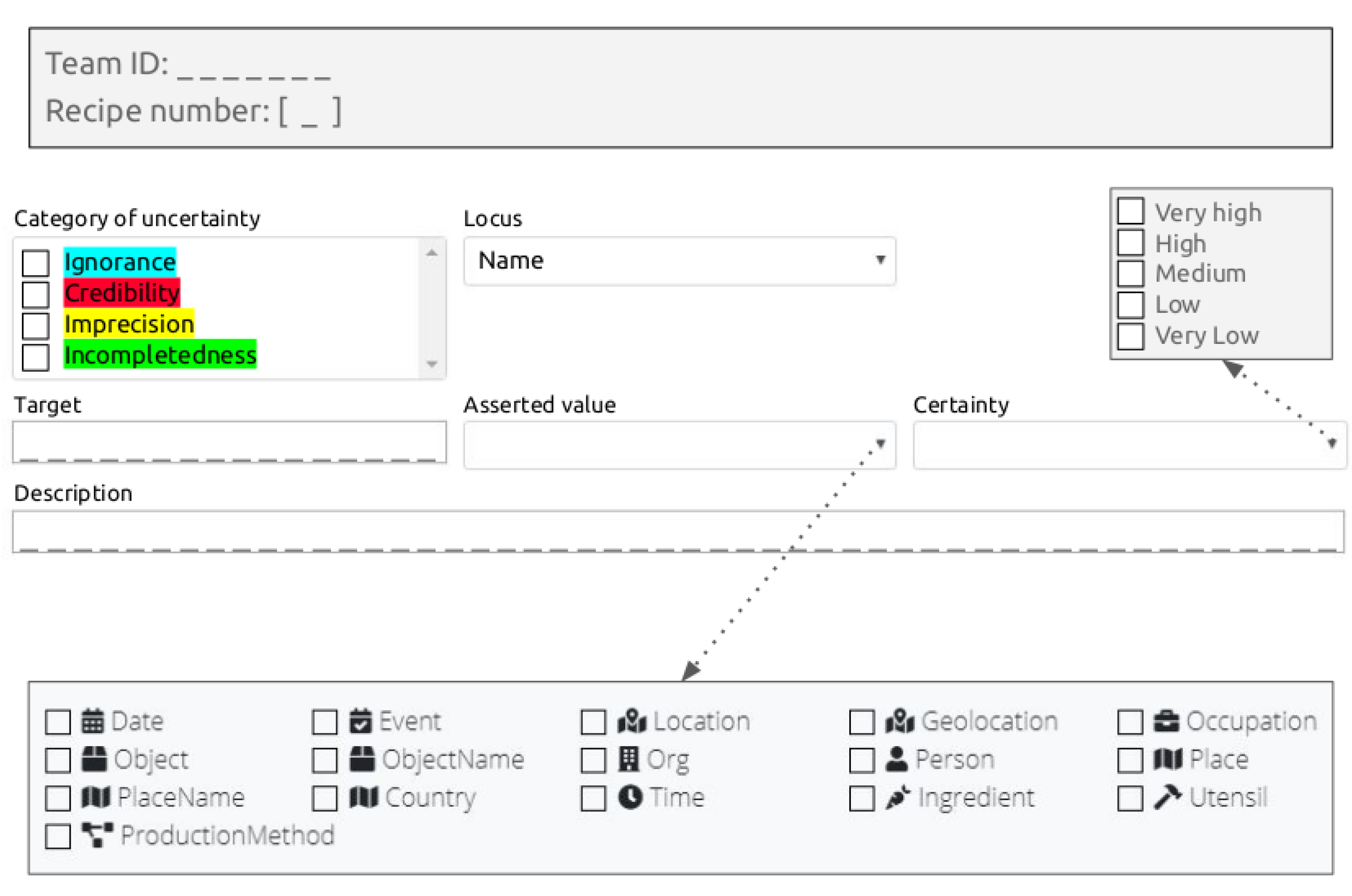
6.3.1. Categories of Uncertainty Annotations
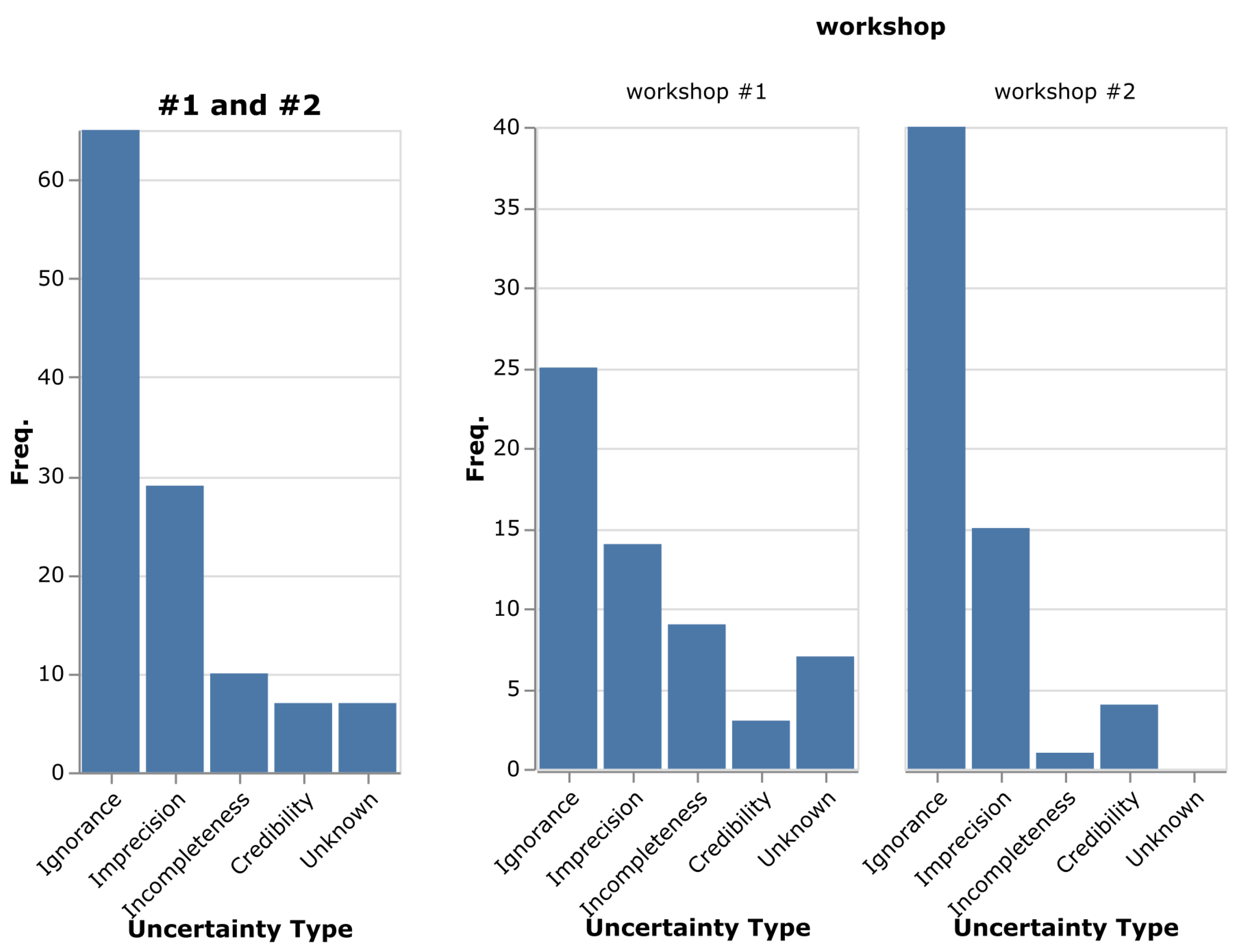
6.3.2. Category Usage
7. Discussion
7.1. On the Use of Categories
7.2. Self-Reported Confidence Levels
7.3. On the Use of a Taxonomy
7.4. Dynamic and Per-Project Taxonomies
8. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Drucker, J. Humanities Approaches to Graphical Display. Digit. Humanit. Q. 2011, 5, 1–21. [Google Scholar]
- Windhager, F.; Salisu, S.; Mayr, E. Exhibiting Uncertainty: Visualizing Data Quality Indicators for Cultural Collections. Informatics 2019, 6, 29. [Google Scholar] [CrossRef] [Green Version]
- Benito-Santos, A.; Sánchez, R.T. A Data-Driven Introduction to Authors, Readings, and Techniques in Visualization for the Digital Humanities. IEEE Comput. Graph. Appl. 2020, 40, 45–57. [Google Scholar] [CrossRef]
- Martin-Rodilla, P.; Gonzalez-Perez, C. Conceptualization and Non-Relational Implementation of Ontological and Epistemic Vagueness of Information in Digital Humanities. Informatics 2019, 6, 20. [Google Scholar] [CrossRef] [Green Version]
- Edmond, J. Strategies and Recommendations for the Management of Uncertainty in Research Tools and Environments for Digital History. Informatics 2019, 6, 36. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.M.; Tsay, M.Y. Applications of Collaborative Annotation System in Digital Curation, Crowdsourcing, and Digital Humanities. Electron. Libr. 2017, 35, 1122–1140. [Google Scholar] [CrossRef]
- Stewart, M.; Liu, W.; Cardell-Oliver, R. Redcoat: A Collaborative Annotation Tool for Hierarchical Entity Typing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations, Hong Kong, China, 3–7 November 2019; pp. 193–198. [Google Scholar] [CrossRef] [Green Version]
- Steiner, C.M.; Agosti, M.; Sweetnam, M.S.; Hillemann, E.C.; Orio, N.; Ponchia, C.; Hampson, C.; Munnelly, G.; Nussbaumer, A.; Albert, D.; et al. Evaluating a Digital Humanities Research Environment: The CULTURA Approach. Int. J. Digit. Libr. 2014, 15, 53–70. [Google Scholar] [CrossRef]
- Gius, E.; Meister, J.C.; Meister, M.; Petris, M.; Bruck, C.; Jacke, J.; Schuhmacher, M.; Gerstorfer, D.; Flüh, M.; Horstmann, J. CATMA. Zenodo. 2021. Available online: https://zenodo.org/record/5015305 (accessed on 13 October 2021). [CrossRef]
- Bradley, A.J.; El-Assady, M.; Coles, K.; Alexander, E.; Chen, M.; Collins, C.; Jänicke, S.; Wrisley, D.J. Visualization and the Digital Humanities: Moving Toward Stronger Collaborations. IEEE Comput. Graph. Appl. 2018, 38, 26–38. [Google Scholar] [CrossRef] [PubMed]
- Jänicke, S. Valuable Research for Visualization and Digital Humanities: A Balancing Act. In Proceedings of the 1st Workshop on Visualization for the Digital Humanities (VIS4DH), Baltimore, MD, USA, 24 October 2016. [Google Scholar]
- Hullman, J.; Qiao, X.; Correll, M.; Kale, A.; Kay, M. In Pursuit of Error: A Survey of Uncertainty Visualization Evaluation. IEEE Trans. Vis. Comput. Graph. 2018, 25, 903–913. [Google Scholar] [CrossRef] [PubMed]
- Hullman, J. Why Authors Don’t Visualize Uncertainty. IEEE Trans. Vis. Comput. Graph. 2020, 26, 130–139. [Google Scholar] [CrossRef] [Green Version]
- Isenberg, P.; Elmqvist, N.; Scholtz, J.; Cernea, D.; Ma, K.L.; Hagen, H. Collaborative Visualization: Definition, Challenges, and Research Agenda. Inf. Vis. 2011, 10, 310–326. [Google Scholar] [CrossRef] [Green Version]
- Cheema, M.F.; Jänicke, S.; Scheuermann, G. AnnotateVis: Combining Traditional Close Reading with Visual Text Analysis. In Proceedings of the 1st Workshop on Visualization for the Digital Humanities (VIS4DH), Baltimore, MD, USA, 24 October 2016. [Google Scholar]
- Therón, R.; Benito, A.; Santamaría, R.; Losada, A.G. Toward Supporting Decision-Making Under Uncertainty in Digital Humanities with Progressive Visualization. In Proceedings of the Sixth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 24–26 October 2018; ACM: New York, NY, USA, 2018; pp. 826–832. [Google Scholar] [CrossRef] [Green Version]
- Therón Sánchez, R.; Benito-Santos, A.; Santamaría Vicente, R.S.; Losada Gómez, A. Towards an Uncertainty-Aware Visualization in the Digital Humanities. Informatics 2019, 6, 31. [Google Scholar] [CrossRef] [Green Version]
- Fisher, P.F. Models of Uncertainty in Spatial Data. Geogr. Inf. Syst. 1999, 1, 191–205. [Google Scholar]
- Smithson, M. Ignorance and Uncertainty: Emerging Paradigms; Cognitive Science; Springer: New York, NY, USA, 1989. [Google Scholar]
- Simon, C.; Weber, P.; Sallak, M. Data Uncertainty and Important Measures; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Joshi, A.; Kale, S.; Chandel, S.; Pal, D.K. Likert Scale: Explored and Explained. Br. J. Appl. Sci. Technol. 2015, 7, 396. [Google Scholar] [CrossRef]
- Boone, H.N.; Boone, D.A. Analyzing Likert Data. J. Ext. 2012, 50, 1–5. [Google Scholar]
- Kozak, M.; Rodriguez, A.; Benito-Santos, A.; Therón, R.; Doran, M.; Dorn, A.; Edmond, J.; Wandl-Vogt, E. Analyzing and Visualizing Uncertain Knowledge: The Use of TEI Annotations in the PROVIDEDH Open Science Platform. J. Text Encoding Initiat. 2021, in press. [Google Scholar]
- Binder, F.; Entrup, B.; Schiller, I.; Lobin, H. Uncertain about Uncertainty: Different Ways of Processing Fuzziness in Digital Humanities Data. In Proceedings of the Digital Humanities, Lausanne, Switzerland, 8–12 July 2014; Volume 15. [Google Scholar]
- Mwalongo, F.; Krone, M.; Reina, G.; Ertl, T. State-of-the-Art Report in Web-Based Visualization. Comput. Graph. Forum 2016, 35, 553–575. [Google Scholar] [CrossRef]
- Badam, S.K.; Elmqvist, N. PolyChrome: A Cross-Device Framework for Collaborative Web Visualization. In Proceedings of the Ninth ACM International Conference on Interactive Tabletops and Surfaces, ITS ’14: Interactive Tabletops and Surfaces, Dresden, Germany, 16–19 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 109–118. [Google Scholar] [CrossRef]
- Bonney, R.; Cooper, C.B.; Dickinson, J.; Kelling, S.; Phillips, T.; Rosenberg, K.V.; Shirk, J. Citizen science: A developing tool for expanding science knowledge and scientific literacy. BioScience 2009, 59, 977–984. [Google Scholar] [CrossRef]
- Hecker, S.; Garbe, L.; Bonn, A. The European Citizen Science Landscape—A Snapshot; UCL Press: London, UK, 2018. [Google Scholar]
- Carletti, L.; Coughlan, T.; Christensen, J.; Gerber, E.; Giannachi, G.; Schutt, S.; Sinker, R.; Denner dos Santos, C. Structures for knowledge co-creation between organisations and the public: (cop2014). In Proceedings of the Companion Publication of the 17th ACM Conference on Computer Supported Cooperative Work & Social Computing, Baltimore, MD, USA, 15–19 February 2014; pp. 309–312. [Google Scholar]
- Conoley, J.C.; Conoley, C.W. Why Does Collaboration Work? Linking Positive Psychology and Collaboration. J. Educ. Psychol. Consult. 2010, 20, 75–82. [Google Scholar] [CrossRef]
- Lamqaddam, H.; Moere, A.V.; Abeele, V.V.; Brosens, K.; Verbert, K. Introducing Layers of Meaning (LoM): A Framework to Reduce Semantic Distance of Visualization In Humanistic Research. IEEE Trans. Vis. Comput. Graph. 2021, 27, 1084–1094. [Google Scholar] [CrossRef]
- Mühlbacher, T.; Piringer, H.; Gratzl, S.; Sedlmair, M.; Streit, M. Opening the Black Box: Strategies for Increased User Involvement in Existing Algorithm Implementations. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1643–1652. [Google Scholar] [CrossRef] [PubMed]
- Stolper, C.D.; Perer, A.; Gotz, D. Progressive Visual Analytics: User-Driven Visual Exploration of In-Progress Analytics. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1653–1662. [Google Scholar] [CrossRef]
- Mack, R.; Robinson, J.B. When Novices Elicit Knowledge: Question Asking in Designing, Evaluating, and Learning to Use Software. In The Psychology of Expertise: Cognitive Research and Empirical AI; Hoffman, R.R., Ed.; Springer: New York, NY, USA, 1992; pp. 245–268. [Google Scholar] [CrossRef]
- Ernst, M. Salzburg zu Tisch. Wie Citizen Scientists helfen, die barocke Küche zu ergründen. In Kooperationen in Den Digitalen Geisteswissenschaften Gestalten. Herausforderungen. Erfahrungen und Perspektiven; V&R Unipress: Göttingen, Germany, 2020; pp. 127–140. [Google Scholar]
- Kensing, F.; Blomberg, J. Participatory design: Issues and concerns. Comput. Support. Coop. Work (CSCW) 1998, 7, 167–185. [Google Scholar] [CrossRef]
- Benito-Santos, A.; Dorn, A.; Gómez, A.G.L.; Palfinger, T.; Sánchez, R.T.; Wandl-Vogt, E. Playing Design: A Case Study on Applying Gamification to Construct a Serious Game with Youngsters at Social Risk. J. Comput. Cult. Herit. 2021, 14, 13:1–13:19. [Google Scholar] [CrossRef]
- Ericsson, K.A.; Simon, H.A. Verbal Reports as Data. Psychol. Rev. 1980, 87, 215–251. [Google Scholar] [CrossRef]
- Zahidi, Z.; Lim, Y.P.; Woods, P.C. Understanding the user experience (UX) factors that influence user satisfaction in digital culture heritage online collections for non-expert users. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 57–63. [Google Scholar]
- Armaselu, F.; Jones, C. Towards a Digital Hermeneutics? Interpreting the User’s Response to a Visualisation Platform for Historical Documents. In Proceedings of the DH Benelux Conference 2016, Luxembourg, 9–10 June 2016. [Google Scholar]
- Lam, H.; Bertini, E.; Isenberg, P.; Plaisant, C.; Carpendale, S. Empirical Studies in Information Visualization: Seven Scenarios. IEEE Trans. Vis. Comput. Graph. 2012, 18, 1520–1536. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isenberg, T.; Isenberg, P.; Chen, J.; Sedlmair, M.; Möller, T. A Systematic Review on the Practice of Evaluating Visualization. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2818–2827. [Google Scholar] [CrossRef] [Green Version]
- Correll, M.A.; Alexander, E.C.; Gleicher, M. Quantity Estimation in Visualizations of Tagged Text. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; Association for Computing Machinery: Paris, France, 2013; pp. 2697–2706. [Google Scholar] [CrossRef] [Green Version]
- Bouckaert, R.R. Bayesian Belief Networks: From Construction to Inference. Ph.D. Thesis, Utrecht Unuversity, Utrecht, The Netherlands, 1995. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Participant | Group |
|---|---|
| Digital Humanities MSc Student | Group 1 |
| Interdisciplinary Research Assistant | Group 1 |
| French Studies Senior Researcher | Group 1 |
| Medieval History PhD Candidate | Group 1 |
| Faculty Librarian | Group 2 |
| History PhD Candidate | Group 2 |
| Creative Arts PhD Candidate | Group 2 |
| Creative Arts Research Fellow | Group 2 |
| Category | Example Annotations |
|---|---|
| Ignorance |
|
| Imprecision |
|
| Incompleteness |
|
| Credibility |
|
| Unknown |
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benito-Santos, A.; Doran, M.; Rocha, A.; Wandl-Vogt, E.; Edmond, J.; Therón, R. Evaluating a Taxonomy of Textual Uncertainty for Collaborative Visualisation in the Digital Humanities. Information 2021, 12, 436. https://doi.org/10.3390/info12110436
Benito-Santos A, Doran M, Rocha A, Wandl-Vogt E, Edmond J, Therón R. Evaluating a Taxonomy of Textual Uncertainty for Collaborative Visualisation in the Digital Humanities. Information. 2021; 12(11):436. https://doi.org/10.3390/info12110436
Chicago/Turabian StyleBenito-Santos, Alejandro, Michelle Doran, Aleyda Rocha, Eveline Wandl-Vogt, Jennifer Edmond, and Roberto Therón. 2021. "Evaluating a Taxonomy of Textual Uncertainty for Collaborative Visualisation in the Digital Humanities" Information 12, no. 11: 436. https://doi.org/10.3390/info12110436
APA StyleBenito-Santos, A., Doran, M., Rocha, A., Wandl-Vogt, E., Edmond, J., & Therón, R. (2021). Evaluating a Taxonomy of Textual Uncertainty for Collaborative Visualisation in the Digital Humanities. Information, 12(11), 436. https://doi.org/10.3390/info12110436