1. Introduction
Internet of Things (IoT) [
1] solutions have emerged as highly distributed environments in which large amounts of data are generated by devices and transferred toward centralised datacentres. This fact causes not only inefficient utilisation of network bandwidth and computing resources, but also a high-latency response time for IoT applications. Nowadays, in order to decrease both service response time and network traffic load over the Internet, computing platforms are extended from centralised cloud-based infrastructures [
2] across the cloud continuum and down to fog resources in close proximity to IoT devices.
A fog node may be referred to communication service providers (e.g., ISP providers, cable or mobile operators), switches, routers or industrial controllers. It could be even a small computing resource at the extreme edge of the network that has a single or multi-processor on-board system (e.g., Raspberry Pi [
3], BeagleBoard [
4] and PCDuino [
5]. In this case, various lightweight operating systems such as CoreOS [
6] and RancherOS [
7] have been offered so far to exploit such fog computing infrastructures.
In a computing environment that exploits resources available in the cloud continuum, the prominent trend in software engineering is the microservices architecture aimed at an efficient execution of IoT applications [
8,
9]. Advanced software engineering IoT workbenches such as PrEstoCloud [
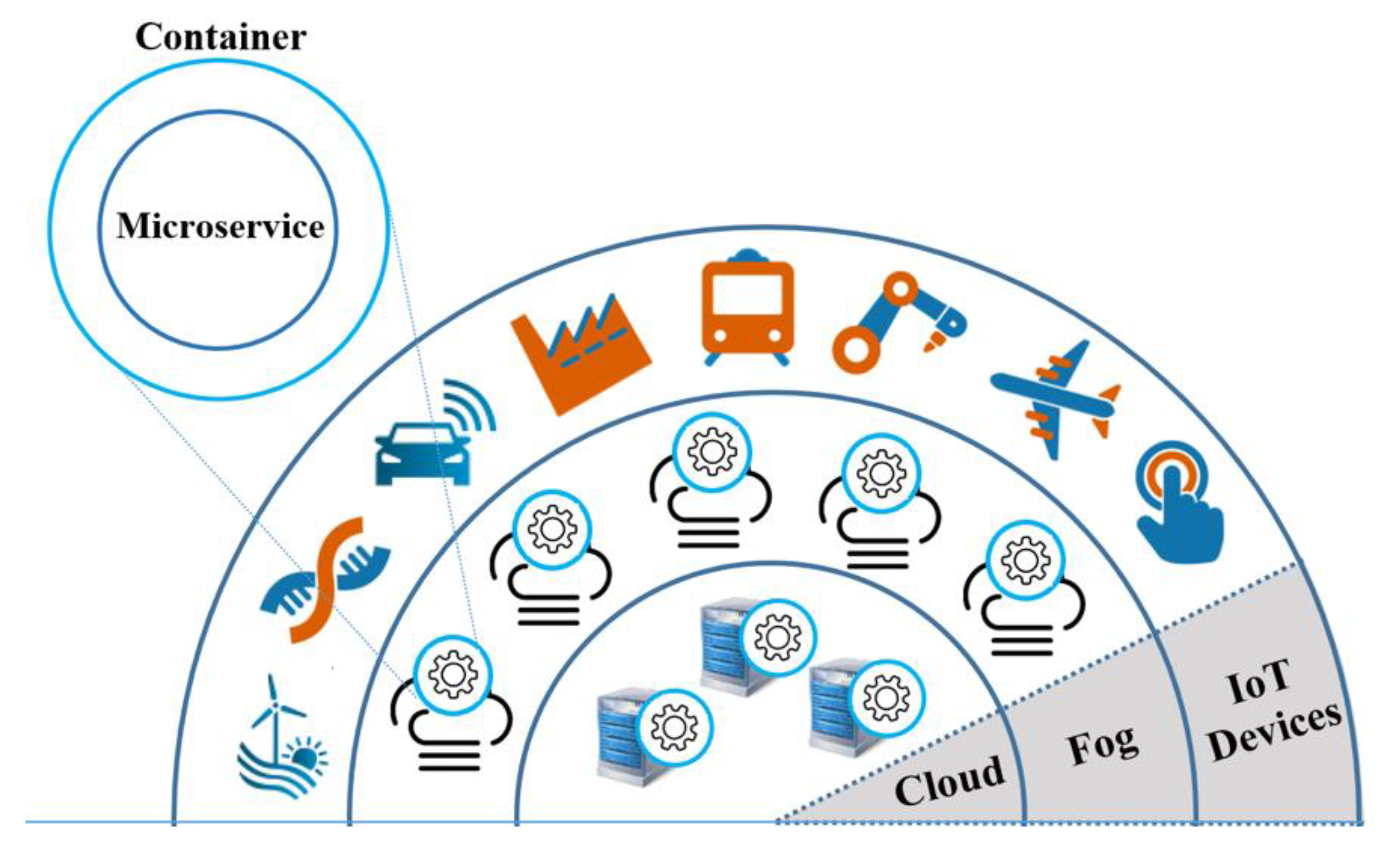
10] may exploit small, discrete, reusable, elastic microservices generally packaged into lightweight containers, shown in
Figure 1. The depicted three-layer cloud continuum computing framework comprises:
IoT Devices: They are simple networked devices such as sensors, actuators and objects which are connected to fog nodes via a wide range of interfaces, for example, 3G, 4G, 5G, Wi-Fi, PCIe, USB or Ethernet.
Fog nodes: These resources provide limited processing, storage and networking functions. Fog nodes may be installed in the end-users’ premises. At the edge of the network, fog nodes are typically aimed at sensor data acquisition, collection, aggregation, filtering, compression, as well as the control of sensors and actuators. In comparison to the cloud, which always benefits from an enormous computation and storage capacity, fog nodes still may suffer from the resource limitation. The location of IoT devices may change over time, and hence migrating microservices from one fog node in a specific geographic region to another one needs to be offered to deliver always-on services. Various situations may also arise in which case computation provided on a fog node has to be offloaded to the cloud. A reason for this may include a sudden computational workload, particularly when the number of IoT devices in one geographic location increases at runtime.
Cloud resources: Cloud-based infrastructure provides a powerful central storage and processing capability for IoT use cases. It should be noted that the centralised cloud computing continues to be a significant part of the fog computing model. Cloud resources and fog nodes complement each other to provide a mutually beneficial and interdependent service continuum. Since not all of the data could be processed on the fog nodes itself, further demanding processing tasks such as offline data analytics or long-term storage of data may be performed on the cloud side.
Microservices [
11] are small, highly decoupled processes which communicate with each other through language independent application programming interfaces (APIs) to form complex applications. Decomposing a single application into smaller microservices allows application providers to distribute the computational load of services among different resources, e.g., fog nodes located in various geographic locations.
In comparison with the service-oriented architecture (SOA) [
12], microservices are usually organised around business priorities and capabilities, and they have the capability of independent deployability [
13] and often use simplified interfaces, such as representational state transfer (REST). Resilience to failure could be the next characteristic of microservices since every request will be separated and translated to various service calls in this modern architecture. For instance, a bottleneck in one service brings down only that service and not the entire system. In such a situation, other services will continue handling requests in a normal manner. Therefore, the microservices architecture is able to support requirements, namely, modularity, distribution, fault-tolerance and reliability [
14]. The microservices architecture also supports the efficiency of re-usable functionality. In other words, a microservice is a re-usable and well-tested unit that means a single service can be re-used or shared in various applications or even in separate areas of the same application.
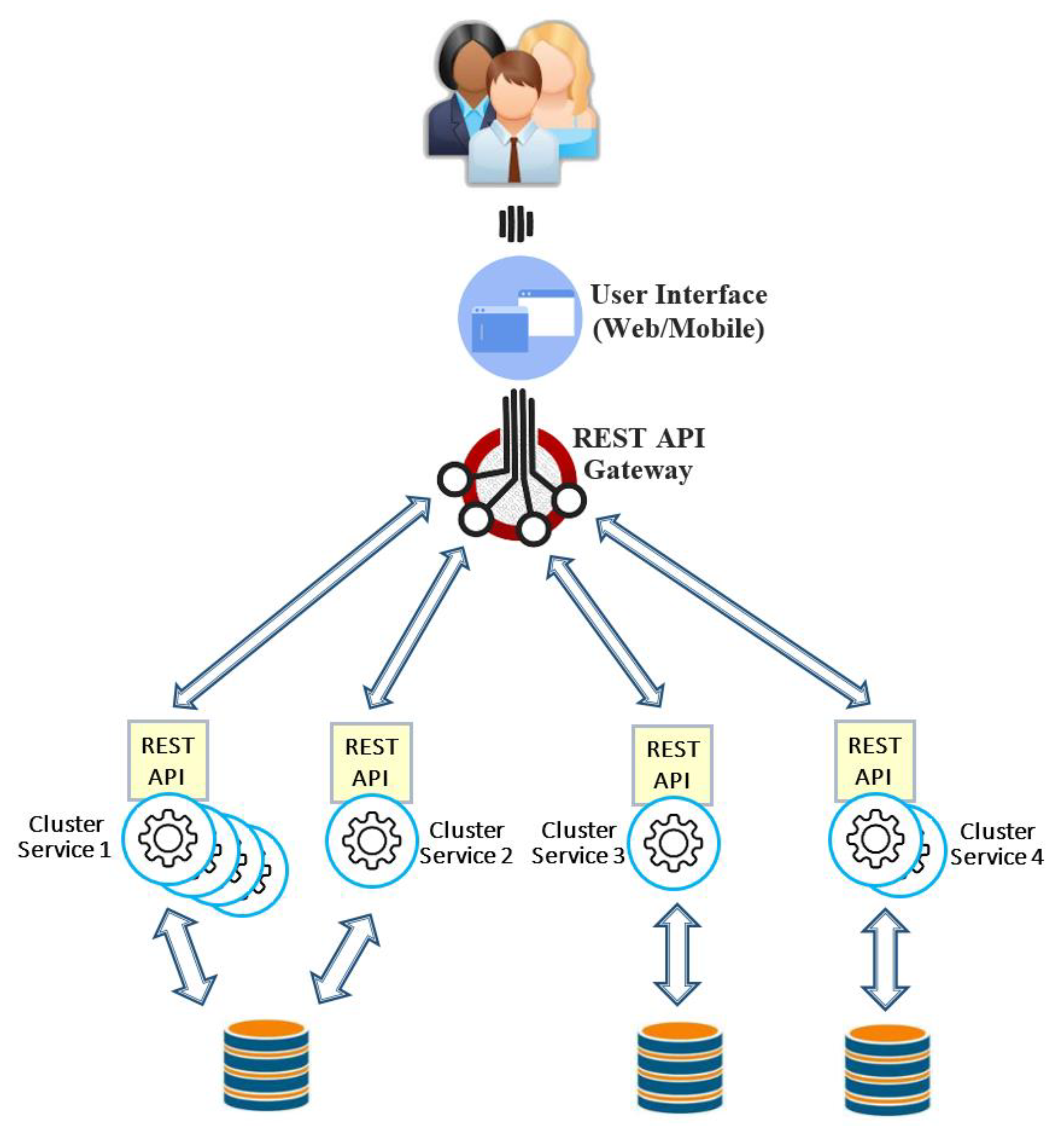
Figure 2 shows an example of the microservices architecture in which different services have a varying amount of demands to process their own specific tasks at runtime, and hence it is possible to dynamically scale each service at different level. Due to various demands for different services, for example, cluster service 1 includes four microservice instances, whereas cluster service 2 includes only one microservice instance. This fact indicates a heavy workload sent to cluster service 1 and the lowest level of cluster service 2. The REST API gateway is basically a proxy to microservices, and it acts as a single-entry point into the system. It should be noted that the REST API gateway can be seen as another service like other microservices in the system, and hence it is an elastic component which can be scaled up or down according to the amount of workloads. The REST API gateway is also aimed at addressing some other functionalities such as dealing with security, caching and monitoring at one place. Moreover, it may be capable of satisfying the needs of heterogeneous clients.
The current focus of cloud continuum platforms is on the dynamic orchestration of microservices to support quality of service (QoS) under varied amounts of workload, while IoT devices move dynamically from one geographic area to another. In order to implement such systems, a wide variety of different technologies should be exploited to develop, deploy, execute, monitor and adapt services. However, interrelations among such various technologies have always been ambiguous, and hence the feasibility of their interoperability is currently uncertain. Besides that, the state-of-the-art in this research domain lacks a systematic classification of technologies used in modern cloud continuum computing environments, and also their interdependency. Each provider of such isolated computing technologies has different interface characteristics and employs a distinct access features. This situation makes a user dependent on a specific microservice provider, unable to exploit another provider without substantial switching costs. Along this line, the EU general data protection regulation (GDPR) encourages more portability of own data, with the aim of making it simpler to transmit this data from one application or service vendor to another who defines purposes and means of data processing.
To overcome the aforementioned interoperability problems, the primary goal of this paper is to present a new semantic model which clarifies all components necessary to exploit microservices within cloud continuum applications. This model allows both the professional and scientific communities to gain a comprehensive understanding of all technologies which are required to be employed in IoT environments. Beyond only a model, we also highlight widely used tools which can be currently involved in building each component defined in our proposed model. Moreover, we discusses several solutions proposed by research and industry which enable data portability from one microservice to another.
The rest of the paper is organised as follows.
Section 2 discusses related work on existing models for fog computing environments.
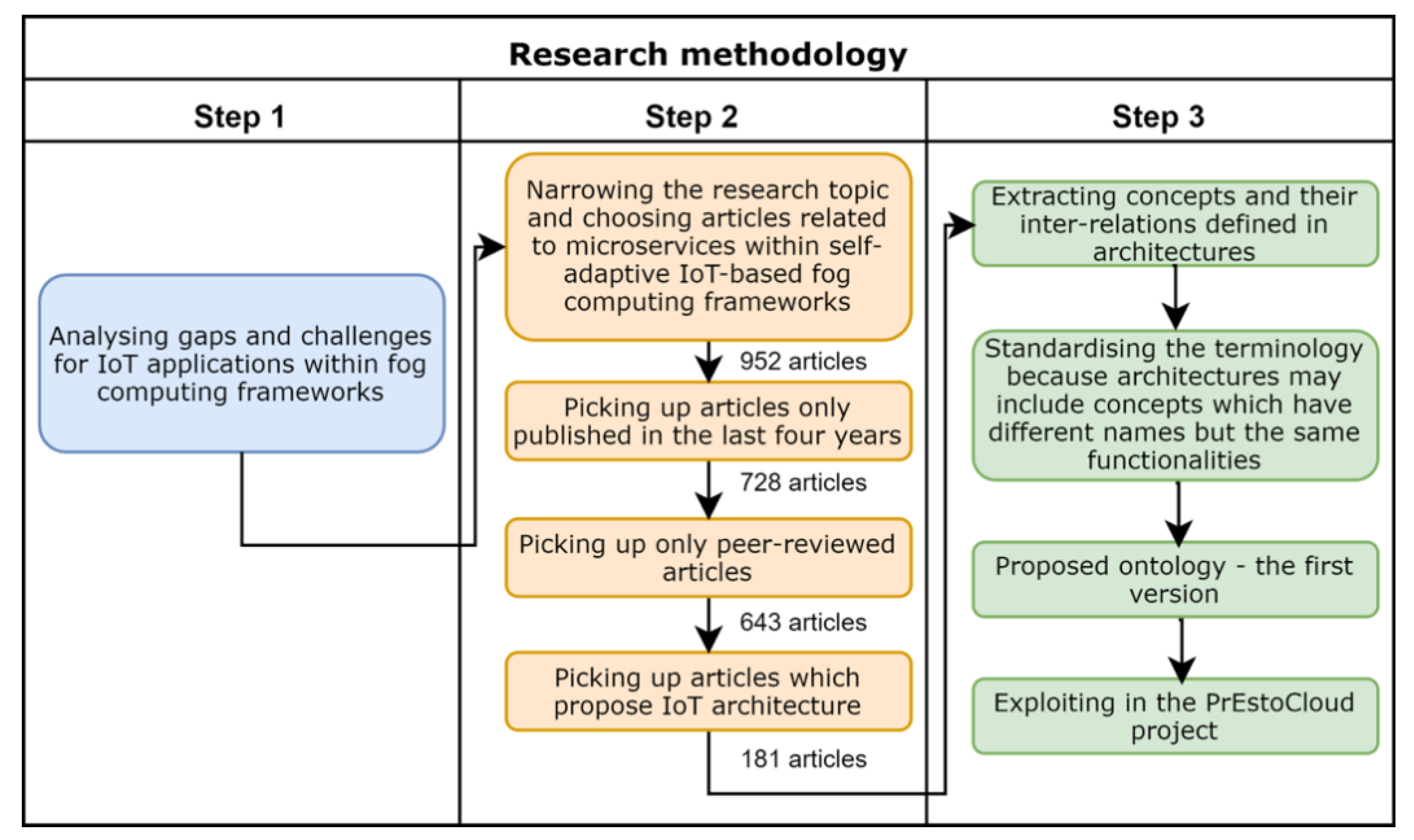
Section 3 describes the research methodology employed to generate the proposed semantic model.
Section 4 presents our proposed model in detail.
Section 5 outlines available data portability solutions and how they address GDPR requirements. Finally, conclusions appear in
Section 6.
2. Related Work
Despite all benefits of cloud continuum computing frameworks, interoperability problem is a key unsolved challenge which needs to be addressed. This is because in light of emerging IoT solutions addressing the needs of domains such as intelligent energy management [
15], smart cities [
16], lighting [
17,
18] and healthcare [
19], many different technologies and techniques offered by various providers have to be integrated with each other and even customised in most cases. In this regards, very limited research works [
20,
21,
22,
23,
24,
25], which concentrate on heterogeneous modern computing environments and the related interoperability issues have been conducted. Key members of fog computing community have recognised that they need to work on open standards, specifications and open-source platforms in order to overcome this challenge.
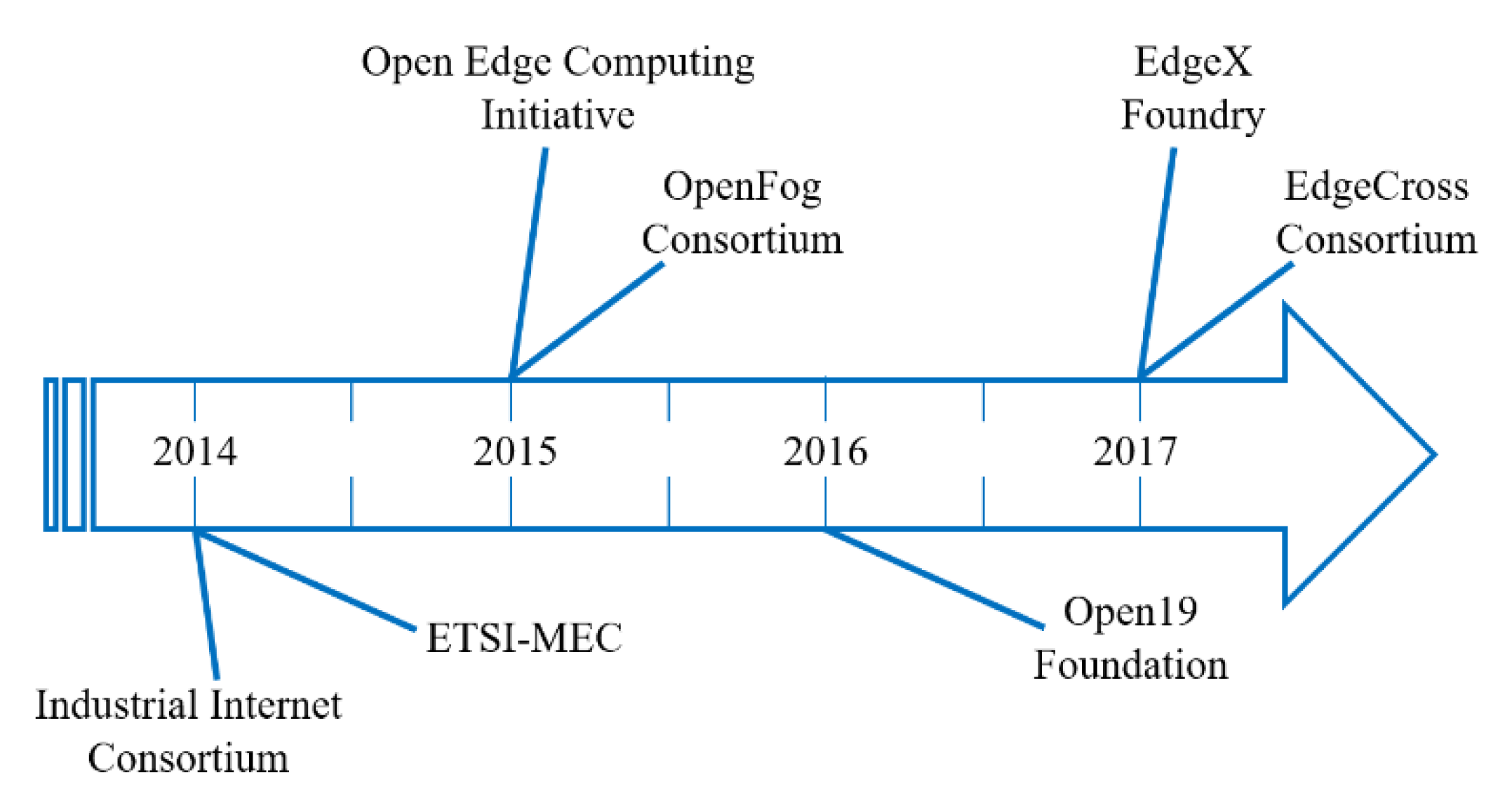
Figure 3 shows a number of large foundations and consortiums aiming at such an objective.
The Industrial Internet Consortium [
26], founded by Cisco, IBM, AT\&T, Intel and GE, was established in 2014. This consortium is aimed at pushing the standardisation for the industrial IoT. The Industrial Internet Consortium published the latest version of their industrial IoT reference architecture in 2017. The European Telecommunications Standards Institute (ETSI) is an independent standardisation organization in the telecommunications industry. Multi-Access edge computing (MEC) [
27], which is an industry specification group within ETSI, is aimed at creating a standardised, open environment for the efficient and seamless integration of IoT technologies from service providers, vendors and third parties. The key objective of the Open Edge Computing Initiative [
28] is to make all nearby components such as access points, WiFi, DSL-boxes and base stations able to act as computing resources at the edge of the network via standardised, open mechanisms for IoT applications. Members of this initiative are Intel, Nokia, Telekom, Vodafone, NTT, Crown Castle along with Carnegie Mellon University.
The OpenFog consortium [
29] was founded by high-tech industry companies, namely, Cisco, Dell, Intel, ARM and Microsoft together with Princeton University in order to drive standardisation of fog computing. This consortium aims to promote fog computing to improve IoT scenarios. The OpenFog consortium released its reference architecture for fog computing in 2017. The Open19 Foundation [
30] was launched in 2016 by LinkedIn, VaporIO and Hewlett Packard Enterprise. This fast-growing project offers an open standard technology able to create a flexible and economic edge solution for operators and datacentres of all sizes with wide levels of adoption. The open-source EdgeX Foundry [
31], which is supported by the Linux Foundation, started in 2017. This project is aimed at developing a vendor-neutral framework for IoT edge computing. The EdgeX Foundry allows developers to build, deploy, run and scale IoT solutions for enterprise, industrial and consumer applications. The EdgeCross Consortium [
32], established by Oracle, IBM, NEC, Omron and Advantec in Japan, provides an open edge computing software platform. This project stands for addressing the need for edge computing standardisation across industries on a global scale.
One of the significant efforts to improve the cloud interoperability has been made by the mOSAIC project [
33] within the European framework FP7. The mOSAIC project has developed an ontology which offers a comprehensive collection of cloud computing concepts. In other words, the mOSAIC ontology provides a unified formal description of different cloud computing components, resources, requirements, APIs, interfaces, service-level agreements (SLAs), etc. Han et al. [
34] provided an ontology which includes a taxonomy of cloud-related concepts in order to support cloud service discovery. The proposed cloud ontology can be used to assess the similarity between cloud services and return a list of results matching the user’s query. In essence, they presented a discovery system using ontology for VM services according to different search parameters, for example, CPU architecture, CPU frequency, storage capacity, memory size, operating system, and so on.
Bassiliades et al. [
35] presented an ontology named PaaSport which is an extension of the DOLCE+DnS Ultralite ontology [
36]. The PaaSport ontology is exploited to represent Platform-as-a-Service (PaaS) offering capabilities as well as requirements of cloud-based applications to be deployed. In other words, this ontology is able to support a semantic ranking algorithm which primarily recommends the best-matching PaaS offering to the application developers. However, this ontology could be extended to consider the perspective of modern distributed models such as the microservices architecture which is currently one of the state-of-the-art concept in the cloud. Sahlmann and Schwotzer [
37] proposed the usage of the oneM2M ontology descriptions [
38] enabling automatic resource management as well as service discovery and aggregation. They employed these semantic descriptions for the automatic deployment of virtual IoT edge devices settled at the edge of network. Androcec and Vrcek [
39] developed a cloud ontology as a key solution to cope with interoperability issues among different parts of an IoT system, such as service instances, resources, agents, etc. The authors claimed that their ontology, which can be considered as sharable information among different partners, is a tool able to explicitly specify various semantics. The main aim in this work is to clearly describe and categorise the existing features, functionalities and specificities of commercial PaaS offers.
Although existing standards and proposed ontologies address various aspects of the cloud continuum (from centralized clouds, to fog and the extreme edge), they do not provide a comprehensive account of the various aspects of microservices and their emerging role in the cloud continuum. Our work aims to capture the essential concepts and entities of microservices and their relations, focusing mainly on microservices used in self-adaptive IoT applications. Therefore, the focus of our proposed semantic model lies in directions, such as what components need to be defined in a microservice-based IoT fog computing architecture, what parameters have to be taken into consideration for each component, how to best serve relationships among various entities of a microservice-based IoT environment, how each entity can be characterised, what aspects should be monitored, etc.
Author Contributions
Data curation, S.T., D.A., Y.V., M.G. and G.M.; Microservices overview S.T., D.A., Y.V.; Related work analysis, S.T., D.A., G.M.; Research methodology S.T., D.A., M.G.; Microservice semantic model S.T., D.A., Y.V., M.G. and G.M.; Microservice data portability S.T., D.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Matheu-Garcia, S.N.; Hernandez-Ramos, J.L.; Skarmeta, A.F.; Baldini, G. Risk-based automated assessment and testing for the cybersecurity certification and labelling of iot devices. Comput. Stand. Interfaces 2019, 62, 64–83. [Google Scholar] [CrossRef]
- Bounagui, Y.; Mezrioui, A.; Hafiddi, H. Toward a unified framework for cloud computing governance: An approach for evaluating and integrating it management and governance models. Comput. Stand. Interfaces 2019, 62, 98–118. [Google Scholar] [CrossRef]
- Gupta, V.; Kaur, K.; Kaur, S. Developing small size low-cost software- defined networking switch using raspberry pi. Next Gener. Netw. 2018, 147–152. [Google Scholar] [CrossRef]
- Adam, G.; Kontaxis, P.; Doulos, L.; Madias, E.-N.; Bouroussis, C.; Topalis, F. Embedded microcontroller with a ccd camera as a digi- tal lighting control system. Electronics 2019, 8, 33. [Google Scholar] [CrossRef]
- Madumal, P.; Atukorale, A.S.; Usoof, H.A. Adaptive event tree- based hybrid cep computational model for fog computing architecture. In Proceedings of the 2016 Sixteenth International Conference on Advances in ICT for Emerging Regions (ICTer), IEEE, Negombo, Sri Lanka, 1–3 September 2016; pp. 5–12. [Google Scholar]
- Casalicchio, E. Container orchestration: A survey. In Systems Modeling: Methodologies and Tools; Springer: Cham, Switzerland, 2019; pp. 221–235. [Google Scholar]
- Kakakhel, S.R.U.; Mukkala, L.; Westerlund, T.; Plosila, J. Virtualization at the network edge: A technology perspective. In Proceedings of the 2018 Third International Conference on Fog and Mobile Edge Computing (FMEC), Barcelona, Spain, 23–26 April 2018; pp. 87–92. [Google Scholar]
- Fernandez-Garcia, L.I.A.C.J.C.; Jesus, A.; Wang, J.Z. A flexible data acquisition system for storing the interactions on mashup user interfaces. Comput. Stand. Interfaces 2018, 59, 10–34. [Google Scholar] [CrossRef]
- Donassolo, B.; Fajjari, I.; Legrand, A.; Mertikopoulos, P. Fog based framework for iot service orchestration. In Proceedings of the 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–2. [Google Scholar]
- Papageorgiou, N.; Apostolou, D.; Verginadis, Y.; Tsagkaropoulos, A.; Mentzas, G. Situation detection on the edge. In Proceedings of the Workshops of the International Conference on Advanced Information Networking and Applications, Matsue, Japan, 27–29 March 2019; Springer: Cham, Switzerland, 2019; pp. 985–995. [Google Scholar]
- Thönes, J. Microservices. IEEE Softw. 2015, 32, 116. [Google Scholar] [CrossRef]
- Tsakos, K.; Petrakis, E.G. Service oriented architecture for interconnecting lora devices with the cloud. In Proceedings of the International Conference on Advanced Information Networking and Applications, Matsue, Japan, 27–29 March 2019; Springer: Cham, Switzerland, 2019; pp. 1082–1093. [Google Scholar]
- Todoli-Ferrandis, D.; Silvestre-Blanes, J.; Santonja-Climent, S.; Sempere-Paya, V.; Vera-Perez, J. Deploy & forget wireless sensor networks for itinerant applications. Comput. Stand. Interfaces 2018, 56, 27–40. [Google Scholar]
- Stubbs, J.; Moreira, W.; Dooley, R. Distributed systems of microservices using docker and serfnode. In Proceedings of the 2015 7th International Workshop on Science Gateways, Budapest, Hungary, 3–5 June 2015; pp. 34–39. [Google Scholar]
- Marinakis, V.; Doukas, H. An advanced IoT-based system for intelligent energy management in buildings. Sensors 2018, 18, 610. [Google Scholar] [CrossRef]
- Lavalle, A.; Teruel, M.A.; Maté, A.; Trujillo, J. Improving Sustainability of Smart Cities through Visualization Techniques for Big Data from IoT Devices. Sustainability 2020, 12, 5595. [Google Scholar] [CrossRef]
- Durmus, D. Real-Time Sensing and Control of Integrative Horticultural Lighting Systems. J. Multidiscip. Sci. J. 2020, 3, 266–274. [Google Scholar] [CrossRef]
- Gagliardi, G.; Lupia, M.; Cario, G.; Tedesco, F.; Cicchello Gaccio, F.; Lo Scudo, F.; Casavola, A. Advanced Adaptive Street Lighting Systems for Smart Cities. Smart Cities 2020, 3, 1495–1512. [Google Scholar] [CrossRef]
- He, Y.; Fu, B.; Yu, J.; Li, R.; Jiang, R. Efficient Learning of Healthcare Data from IoT Devices by Edge Convolution Neural Networks. Appl. Sci. 2020, 10, 8934. [Google Scholar] [CrossRef]
- Noura, M.; Atiquzzaman, M.; Gaedke, M. Interoperability in internet of things: Taxonomies and open challenges. Mob. Netw. Appl. 2018, 1–14. [Google Scholar] [CrossRef]
- Koo, J.; Oh, S.-R.; Kim, Y.-G. Device identification interoperability in heterogeneous iot platforms. Sensors 2019, 19, 1433. [Google Scholar] [CrossRef] [PubMed]
- Kalatzis, N.; Routis, G.; Marinellis, Y.; Avgeris, M.; Roussaki, I.; Papavassiliou, S.; Anagnostou, M. Semantic interoperability for iot plat-forms in support of decision making: An experiment on early wild fire detection. Sensors 2019, 19, 528. [Google Scholar] [CrossRef]
- Ahmad, A.; Cuomo, S.; Wu, W.; Jeon, G. Intelligent algorithms and standards for interoperability in internet of things. Future Gener. Comput. Syst. 2018. [Google Scholar] [CrossRef]
- Fortino, G.; Savaglio, C.; Palau, C.E.; de Puga, J.S.; Ganzha, M.; Paprzycki, M.; Montesinos, M.; Liotta, A.; Llop, M. Towards multi-layer interoperability of heterogeneous iot platforms: The interiot approach. In Integration, Interconnection, and Interoperability of IoT Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 199–232. [Google Scholar]
- Garcia, A.L.; del Castillo, E.F.; Fernandez, P.O. Standards for enabling heterogeneous iaas cloud federations. Comput. Stand. Interfaces 2016, 47, 19–23. [Google Scholar] [CrossRef][Green Version]
- Kemppainen, P. Pharma industrial internet: A reference model based on 5g public private partnership infrastructure, industrial internet consortium reference architecture and pharma industry standards. Nord. Balt. J. Inf. Commun. Technol. 2016, 2016, 141–162. [Google Scholar]
- Yang, S.-R.; Tseng, Y.-J.; Huang, C.-C.; Lin, W.-C. Multi-access edge computing enhanced video streaming: Proof-of-concept implementation and prediction/qoe models. IEEE Trans. Veh. Technol. 2019, 68, 1888–1902. [Google Scholar] [CrossRef]
- Open Edge Computing Initiative 2019. Available online: http://openedgecomputing.org/ (accessed on 15 April 2019).
- Yannuzzi, M.; Irons-Mclean, R.; Van-Lingen, F.; Raghav, S.; Somaraju, A.; Byers, C.; Zhang, T.; Jain, A.; Curado, J.; Carrera, D.; et al. Toward a converged openfog and etsi mano architecture. In Proceedings of the 2017 IEEE Fog World Congress (FWC), Santa Clara, CA, USA, 30 October–1 November 2017; pp. 1–6. [Google Scholar]
- Open19 Foundation 2019. Available online: https://www.open19.org/ (accessed on 15 April 2019).
- EdgeX Foundry 2019. Available online: https://www.edgexfoundry.org/ (accessed on 15 April 2019).
- EdgeCross Consortium 2019. Available online: https://www.edgecross.org/en/ (accessed on 15 April 2019).
- Cretella, G.; Martino, B.D. A semantic engine for porting applications to the cloud and among clouds. Softw. Pract. Exp. 2015, 45, 1619–1637. [Google Scholar] [CrossRef]
- Han, T.; Sim, K.M. An ontology-enhanced cloud service discovery system. In Proceedings of the International Multi Conference of Engineers and Computer Scientists, Hong Kong, China, 17–19 March 2010; Volume 1, pp. 17–19. [Google Scholar]
- Bassiliades, N.; Symeonidis, M.; Gouvas, P.; Kontopoulos, E.; Med-itskos, G.; Vlahavas, I. Paasport semantic model: An ontology for a platform-as-a-service semantically interoperable marketplace. Data Knowl. Eng. 2018, 113, 81–115. [Google Scholar] [CrossRef]
- Agarwal, R.; Fernandez, D.G.; Elsaleh, T.; Gyrard, A.; Lanza, J.; Sanchez, L.; Georgantas, N.; Issarny, V. Unified iot ontology to enable interoperability and federation of testbeds. In Proceedings of the 2016 IEEE 3rd World Forum on Internet of Things (WF-IoT), Reston, VA, USA, 12–14 December 2016; pp. 70–75. [Google Scholar]
- Sahlmann, K.; Schwotzer, T. Ontology-based virtual iot devices for edge computing. In Proceedings of the 8th International Conference on the Internet of Things, Santa Barbara, CA, USA, 15–18 October 2018; p. 15. [Google Scholar]
- Sahlmann, K.; Scheffler, T.; Schnor, B. Ontology-driven device descriptions for iot network management. In Proceedings of the 2018 Global Internet of Things Summit (GIoTS), Bilbao, Spain, 4–7 June 2018; pp. 1–6. [Google Scholar]
- Androcec, D.; Vrcek, N. Ontologies for platform as service apis inter-operability. Cybern. Inf. Technol. 2016, 16, 29–44. [Google Scholar]
- Naqvi, S.N.Z.; Yfantidou, S.; Zimanyi, E. Time series databases and influxdb. In Studienarbeit; Université Libre de Bruxelles: Brussels, Belgium, 17 December 2017. [Google Scholar]
- Kumari, M.; Vishwanathan, A.; Dash, D. Real-time cloud monitoring solution using prometheus tool and predictive analysis using arimamodel. Int. J. Eng. Sci. 2018, 8, 18338. [Google Scholar]
- Scout 2019. Available online: https://scoutapp.com/ (accessed on 15 April 2019).
- Taherizadeh, S.; Stankovski, V. Dynamic multi-level auto-scaling rules for containerized applications. Comput. J. 2018, 62, 174–197. [Google Scholar] [CrossRef]
- The StatsD protocol 2019. Available online: https://github.com/etsy/statsd/wiki (accessed on 15 April 2019).
- Netdata 2019. Available online: https://my-netdata.io/ (accessed on 15 April 2019).
- Petruti, C.-M.; Puiu, B.-A.; Ivanciu, I.-A.; Dobrota, V. Automatic management solution in cloud using ntopng and Zabbix. In Proceedings of the 2018 17thRoEduNet Conference: Networking in Education and Research (RoE-duNet), Cluj-Napoca, Romania, 6–8 September 2018; pp. 1–6. [Google Scholar]
- Taherizadeh, S.; Jones, A.C.; Taylor, I.; Zhao, Z.; Stankovski, V. Monitoring self-adaptive applications within edge computing frameworks: A state-of-the-art review. J. Syst. Softw. 2018, 136, 19–38. [Google Scholar] [CrossRef]
- Bader, A.; Kopp, O.; Falkenthal, M. Survey and comparison of opensource time series databases. In Datenbanksysteme für Business, Technologie und Web (BTW 2017)-Workshopband; Gesellschaft für Informatik e.V.: Bonn, Germany, 2017; pp. 249–268. [Google Scholar]
- Jeyakumar, V.; Madani, O.; Parandeh, A.; Kulshreshtha, A.; Zeng, W.; Yadav, N. Explainit!—A declarative root-cause analysis engine for timeseries data (extended version). arXiv 2019, arXiv:1903.08132. [Google Scholar]
- Bizer, C.; Schultz, A. The berlin sparql benchmark. Int. J. Semant. Web Inf. Syst. (IJSWIS) 2009, 5, 1–24. [Google Scholar] [CrossRef]
- Taherizadeh, S.; Stankovski, V.; Grobelnik, M. A capillary computing architecture for dynamic internet of things: Orchestration of microservices from edge devices to fog and cloud providers. Sensors 2018, 18, 2938. [Google Scholar] [CrossRef]
Figure 1.
Container-based microservices within a fog computing framework.
Figure 2.
Microservices architecture.
Figure 3.
Interoperable open standard projects for fog computing.
Figure 4.
Methodology for developing the semantic model for microservices.
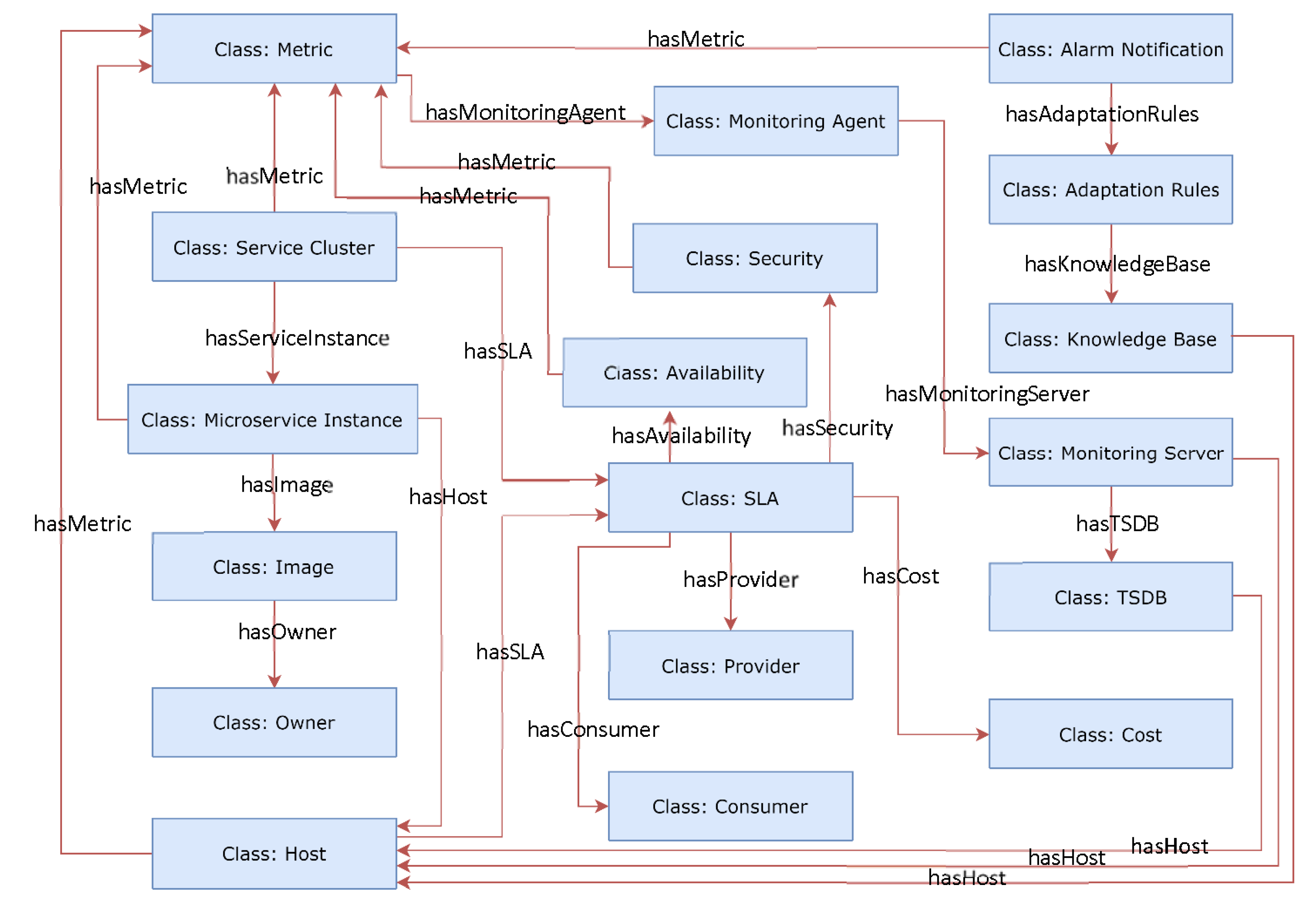
Figure 5.
Microservice semantic model depicting classes and interrelations between classes.
Table 1.
Service cluster class.
| Property Name | Range (Type) | Rationale |
|---|
| Service Cluster ID | unsignedInt | This property allows a unique number to be generated when a new individual service cluster is inserted into the system. |
| Service Cluster Name | string | This property implies the service cluster’s name. |
| Service Cluster Description | string | This property is an explanation which describes the service cluster. |
| hasMetric | Metric ID | This relation includes one or more service-level metrics which represent the information about the status of the service cluster as a whole and its performance, such as the aggregated service response time or the aggregated application throughput. |
| hasMicroserviceInstance | Microservice Instance ID | This relation includes one or more microservice Instances which belong to the service cluster in order to process the tasks. |
| hasSLA | SLA ID | This relation includes the SLA which applies to the service cluster. |
Table 2.
Microservice instance class.
| Property Name | Range (Type) | Rationale |
|---|
| Microservice Instance ID | unsignedInt | This property allows a unique number to be generated when a new individual microservice instance is inserted into the system. |
| Microservice Instance Port Number | unsignedInt | The task provided by the microservice instance uses a set of ports which need to be exposed. |
| Microservice Instance CPU Portion | decimal | Each microservice instance located on a host achieves a proportion of CPU cycles through an assigned relative weight. |
| Microservice Instance Memory Limit | decimal | Each microservice instance located on a host has its own limit at the use of memory. |
| Microservice Instance Type | string | A microservice instance is usually packaged into containers. Besides that, it could be also based on VM. |
| hasMetric | Metric ID | This relation includes one or more service-level metrics which represent the information about the status of an individual microservice instance, such as the its response time or application throughput. |
| hasHost | Host ID | This relation includes the host where the microservice Instance is located. |
| hasImage | Image ID | This relation includes the container or VM Image based on which the microservice instance is instantiated. |
Table 3.
Image class.
| Property Name | Range (Type) | Rationale |
|---|
| Image ID | unsignedInt | This property allows a unique number to be generated when a new individual image is inserted into the system. |
| Image Name | string | Each image stored in a local repository or a public registry such as the Docker hub has its own name. |
| Image Description | string | This property is used to display the description about the image. |
| Image Title | string | Title is a short and keywords-relevant description of the image. |
| Image Functionality | string | This property implies the functionality which is provided by the service included in the image. |
| Image Version | string | During the application lifecycle, Images may be upgraded several times, and each one has its own version. |
| Image Instruction Set | string | Different types of image instruction set can be, for example, ARM or X86. |
| Image Creation Time | dateTime | This property specifies the time when the image was generated or upgraded. |
| Image File Format | string | This property is used to define the file format of the Image. |
| Image IRI | anyURI | Images need to be properly indexed through the URI (Uniform resource identifier), the geographic location, and other details for the search facility. |
| Image License | string | This property specifies the license based on which the image is published. |
| hasOwner | Owner ID | This relation includes the owner of the image that can be for example the application developer, the service provider, or anyone else. |
Table 4.
Host class.
| Property Name | Range (Type) | Rationale |
|---|
| Host ID | unsignedInt | This property allows a unique number to be generated when a new individual host is inserted into the system. |
| Host Type | string | Different types of host can be, for example, a fog node or a cloud resource. |
| Host IP | string | Each host has its own IP address to use the Internet Protocol for communication. |
| Host Location | string | Each host has its own particular geographic location. |
| Host Network Interface | string | Each host has its own network adapter to transmit and receive data such as eth0. |
| Host Network Speed | unsignedInt | This property shows how much bandwidth is assigned to the host. |
| Host Subnet Mask | string | Each host has its own subnet mask address in the network area. |
| Host Default Gateway | string | Default gateway is the node that is assumed to know how to forward packets to other networks. |
| Host OS | string | Each host has an operating system (OS). |
| Host Storage Size | decimal | Each host has its own particular storage size. |
| Host Memory Size | decimal | This is a parameter to define the size of an individual host’s memory. |
| Host CPU Count | unsignedInt | This property indicates the number of cores called processors that belong to the host. |
| Host CPU Clock Rate | decimal | This property indicates the hertz which is the measure of frequency in cycles per second. |
| Host GPU | string | This property indicates the graphics processing unit (GPU) which is a specialised electronic circuit developed to accomplish rapid mathematical calculations, principally for the purpose of rendering images. |
| Host Root Username | string | This property indicates the username assigned for the root user employed to connect to the host. |
| Host Root Password | string | This property indicates the password assigned for the root user employed to connect to the host. |
| hasMetric | Metric ID | This relation includes one or more host-related metrics which represent the information about the status of an individual infrastructure, such as its current CPU or memory utilisation. |
| hasSLA | SLA ID | This relation includes the ID of the SLA which applies to the host. |
Table 5.
Comparison of popular single-board computers.
| Specification | Raspberry Pi Model B | BeagleBoard-X15 | pcDuino3 Nano |
|---|
| Chip | BCM2837 | Sitara AM5728 | Allwinner A20 |
| Core | 4 | 1 | 2 |
| CPU | 1.4 GHz | 1.5 GHz | 1 GHz |
| GPU | VideoCore IV | PowerVR SGX544 | Mali-400MP2 |
| Memory | 1 GB RAM | 2 GB RAM | 1 GB RAM |
| SD Card | Minimum of 4 GB | Minimum of 4 GB | Minimum of 4 GB |
| Operating System | Linux | Linux + Android | Linux + Android |
| Dimensions | 85.60 mm × 53.98 mm | 107 mm × 102 mm | 96 mm × 64 mm |
Table 6.
Metric class.
| Property Name | Range (Type) | Rationale |
|---|
| Metric ID | unsignedInt | This property allows a unique number to be generated when a new individual monitoring metric is inserted into the system. |
| Metric Name | string | This property implies the name of the monitoring metric. |
| Metric Description | string | This is a freestyle textual description of the monitoring metric. |
| Metric Group | string | For example, all metrics such as memTotal, memFree, memUsed and memUsedPerecent may belong to a group named ‘memory’. |
| Metric Level | unsignedInt | Metrics can be monitored as (i) host-level parameters related to the infrastructure utilisation such as CPU, memory, etc., (ii) service-level parameters related to the application performance such as response time, etc., or (iii) SLA-level parameters such as availability, cost, etc. |
| Metric Unit | string | Metric units can be, for example, (i) percentage, (ii) KBps, (iii) MBps, (iv) Bps, (vi) Yes/No, etc. |
| Metric Data Type | string | Metric data types can be (i) integer, (ii) long, (iii) double, etc. |
| Metric Collecting Interval | unsignedInt | The collecting period is an important parameter specially for the time-critical environment. It indicates the monitoring frequency which represents the interval between each measurement for the metric. |
| Metric History | unsignedInt | This property implies how many days the monitoring system keeps measured values of the metric. |
| Metric Upper Limit | decimal | This property implies the maximum value of the metric that can be observed. |
| Metric Lower Limit | decimal | This property implies the minimum value of the metric that can be observed. |
| Metric Threshold | decimal | This property implies the threshold value of the metric that should be continuously checked. |
| hasMonitoringAgent | Monitoring Agent ID | This relation includes the monitoring agent which measures the metric instance. |
Table 7.
Monitoring agent class.
| Property Name | Range (Type) | Rationale |
|---|
| Monitoring Agent ID | unsignedInt | This property allows a unique number to be generated when a new individual monitoring agent is inserted into the system. |
| Monitoring Agent Logging | boolean | When this property is set to true, abnormal situations associated to the monitoring agent will be logged. |
| Monitoring Agent Port | unsignedInt | This is a port which the monitoring agent uses to distribute metrics to monitoring server. It should be identical to the one defined for the monitoring server. |
| hasMonitoringServer | Monitoring Server ID | This relation includes the ID of the monitoring server to which the monitoring agent distributes measured values of metrics. |
Table 8.
Monitoring server class.
| Property Name | Range (Type) | Rationale |
|---|
| Monitoring Server ID | unsignedInt | This property allows a unique number to be generated when a new individual monitoring server is inserted into the system. |
| Monitoring Server Logging | boolean | When this property is set to true, abnormal situations associated to the monitoring server will be logged. |
| Monitoring Server Bind Interface | string | The network interface such as eth0 to which the monitoring server’s listener will bind. |
| Monitoring Server Port | unsignedInt | Monitoring server will bind to this port and listen for metric messages distributed by monitoring agents. This property should be identical to the one defined for monitoring agents. |
| Monitoring Server Heart Beat | unsignedInt | This property implies the intensity based on which the monitoring server’s heartbeat should check monitoring agents’ availability. |
| Monitoring Server Heart Retry | unsignedInt | The number of iterations for which the monitoring server heartbeat will allow a monitoring agent to be down until it is declared as dead. |
| hasTSDB | TSDB ID | This relation includes the ID of TSDB which will be used to store all measured monitoring metrics. |
| hasHost | Host ID | This relation includes the host where the monitoring server is located. |
Table 9.
Comparison of monitoring tools widely used within fog environments.
| Monitoring Server | Open Source | License | Scalability | Alerting |
|---|
| InfluxDB | Yes | MIT | Yes | No |
| Prometheus | Yes | Apache 2 | No | Yes |
| Scout | Yes | Commercial | No | Yes |
| SWITCH | Yes | Apache 2 | Yes | Yes |
| NetData | Yes | GPL | Yes | Yes |
| Zabbix | Yes | GPL | Yes | Yes |
Table 10.
Time series database (TSDB) class.
| Property Name | Range (Type) | Rationale |
|---|
| TSDB ID | unsignedInt | This property allows a unique number to be generated when a new individual TSDB is inserted into the system. |
| TSDB DB Username | string | The DB username of the TSDB backend. |
| TSDB DB Password | string | The DB password of the TSDB backend. |
| TSDB DB Name | string | The DB name of the TSDB backend. |
| hasHost | Host ID | This relation includes the Host where the TSDB is located. |
Table 11.
Comparison of widely used TSDB databases.
| TSDB | Open Source | License | Scalability | High Availability |
|---|
| InfluxDB | Yes | MIT | Yes | Yes |
| Prometheus | Yes | Apache2 | No | No |
| OpenTSDB | Yes | LGPL | Yes | Yes |
| Druid | Yes | Apache2 | Yes | Yes |
| Elasticsearch | Yes | Apache2 | Yes | Yes |
| Cassandra | Yes | Apache2 | Yes | Yes |
Table 12.
Alarm notification class.
| Property Name | Range (Type) | Rationale |
|---|
| Alarm Notification ID | unsignedInt | This property allows a unique number to be generated when a new individual alarm notification is inserted into the system. |
| Alarm Notification Date | dateTime | This property specifies the date when a particular alarm notification is triggered. |
| Alarm Notification Time | dateTime | This property specifies the time when a particular alarm notification is triggered. |
| Alarm Notification Value | decimal | This property implies the current value of the metric which violates the threshold. |
| hasMetric | Metric ID | Each alarm notification is associated to the violation of a specific monitoring metric. |
| hasAdaptationRules | Adaptation Rule ID | For each predefined condition when a particular alarm notification is triggered, specific adaptation rules need to be performed. |
Table 13.
Adaptation rules class.
| Property Name | Range (Type) | Rationale |
|---|
| Adaptation Rule ID | unsignedInt | This property allows a unique number to be generated when a new individual adaptation rule is inserted into the system. |
| Adaptation Rule Action | string | This property indicates a specific action defined by the adaptation rule to be accomplished when a particular condition happens at runtime. |
| Adaptation Rule Condition | string | This property indicates a specific condition when the adaptation rule has to be performed. |
| hasKnowledgeBase | KB ID | This relation includes the knowledge base (KB) which will be used to store all information about the environment when the adaptation rule is performed. |
Table 14.
Knowledge base class.
| Property Name | Range (Type) | Rationale |
|---|
| KB ID | unsignedInt | This property allows a unique number to be generated when a new individual KB is inserted into the system. |
| KB Username | string | The username of the KB backend. |
| KB Password | string | The password of the KB backend. |
| KB Name | string | The name of the KB backend. |
| hasHost | Host ID | This relation includes the host where the KB is located. |
Table 15.
Overview of widely used RDF triple stores.
| Name | Source | License | Supported Query Language |
|---|
| AllegroGraph | No | Commercial | SPARQL |
| Virtuoso | Yes | Commercial | SPARQL |
| Sesame | Yes | BSD | SPARQL + SeRQL |
| Open Anzo | Yes | Eclipse Public | SPARQL |
| BigData | Yes | GPL | SPARQL |
| OWLIM-Lite | No | GPL | SPARQL + SeRQL |
| Jena Fuseki | Yes | Apache 2 | SPARQL + SeRQL |
Table 16.
Service-level agreement class.
| Property Name | Range (Type) | Rationale |
|---|
| SLA ID | unsignedInt | This property allows a unique number to be generated when a new individual SLA is inserted into the system. |
| SLA Description | string | This is a freestyle textual description of the SLA. |
| SLA Start Time | dateTime | This property specifies the time when the SLA operation starts. |
| SLA Support Time Period | unsignedInt | This property specifies the time period when the SLA operation should be supported. |
| SLA Recovery Time | unsignedInt | This property specifies the time period by which the system must be recovered after an unplanned disruption in the SLA. |
| hasAvailability | Availability ID | This relation includes the level of availability agreed between provider and consumer in the SLA. |
| hasSecurity | Security ID | This relation includes the level of security agreed between provider and consumer in the SLA. |
| hasCost | Cost ID | This relation includes the cost plan agreed between provider and consumer in the SLA. |
| hasProvider | Provider ID | This relation includes the ID of provider who is primarily responsible for delivering the SLA. |
| hasConsumer | Consumer ID | This relation includes the ID of consumers who mainly select the SLA definition that best fits their requirement. |
Table 17.
Availability class.
| Property Name | Range (Type) | Rationale |
|---|
| Availability ID | unsignedInt | This property allows a unique number to be generated when a new individual availability is inserted into the system. |
| Availability Description | string | This is a freestyle textual description of the availability defined in SLA. |
| Availability Logging | boolean | When this property is set to true, abnormal situations associated to the availability defined in SLA will be logged. |
| Availability Mechanism | string | This property specifies the mechanism exploited to provide the availability defined in SLA. |
| Availability Standard | string | This property specifies the standard of mechanism exploited to provide the availability defined in SLA. |
| Availability Requirement | string | This property specifies the requirement for the availability defined in SLA. |
| hasMetric | Metric ID | This relation includes the monitoring metric based on which the availability is defined in SLA. |
Table 18.
Security class.
| Property Name | Range (Type) | Rationale |
|---|
| Security ID | unsignedInt | This property allows a unique number to be generated when a new individual security is inserted into the system. |
| Security Description | string | This is a freestyle textual description of the security defined in SLA. |
| Security Logging | boolean | When this property is set to true, abnormal situations associated to the security defined in SLA will be logged. |
| Security Mechanism | string | This property specifies the mechanism exploited to provide the security defined in SLA. |
| Security Standard | string | This property specifies the standard of mechanism exploited to provide the security defined in SLA. |
| Security Requirement | string | This property specifies the requirement for the security defined in SLA. |
| hasMetric | Metric ID | This relation includes the monitoring metric based on which the security is defined in SLA. |
Table 19.
Cost class.
| Property Name | Range (Type) | Rationale |
|---|
| Cost ID | unsignedInt | This property allows a unique number to be generated when a new individual cost is inserted into the system. |
| Cost Description | string | This is a freestyle textual description of the cost defined in SLA. |
| Cost Currency | currency | This property specifies the currency used in SLA. |
| Cost Pricing Model | string | This property specifies the pricing model exploited in SLA. It can be (i) free, (ii) pay-per-use, (iii) flat fee, or any other option. |
| Cost Penalty | string | This property specifies the penalty which can be taken into account if the provider violates any terms of SLA. |
Table 20.
Overview of challenges in relation to data portability methods.
| | Common Open API | Centralised Framework | Standard Formats | Core Vocabularies and Ontologies |
|---|
| Data controllers incur data conversion overhead | Yes | No | No | No |
| Redundant temporary data storage is required on data controllers | Yes | No | No | No |
| Data controllers get involved in any upgrade in data portability method | Yes | No | No | No |
| Storage size is drastically increased on data controllers | No | No | Yes | Yes |
| Poor hardware prefetching performance may impact data controllers | No | No | No | Yes |
| Significant investment is required by data controllers | No | No | No | Yes |
| Long conversion time is required within data controllers | Yes | No | No | No |
| Difficult to be consensual by all data controllers | Yes | Yes | Yes | Yes |
| Limiting the freedom and right of data controllers | No | No | No | No |
| Large effort in data structure design is required by all data controllers | No | No | No | Yes |
| Single point of failure intrinsic to data portability framework | No | Yes | No | No |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}