A Frequent Pattern Conjunction Heuristic for Rule Generation in Data Streams




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- 1
- An algorithm (FGRI) that can incrementally induce a set of generalised rules from a data stream in real-time, responsive to new data instances as these become available. The rules are explainable, expressive and can be applied on data streams with both, numerical and categorical features;
- 2
- A method in FGRI that is able to adapt the induced rule-set to concept drifts, i.e., changes of the pattern encoded in the data stream that occur in real-time. The method does not require a complete retraining of the rule-set but focuses on parts of the rule-set that are affected. It does this by removing rules that have become obsolete and adding rules for newly emerged concepts;
- 3
- A thorough evaluation of FGRI. This comprises: (i) an empirical evaluation on various data streams to examine the ability of FGRI to learn concepts in real-time and to adapt to concept drifts; (ii) a qualitative evaluation using real data to demonstrate the FGRI capability to produce explainable rule-sets; (iii) a theoretical complexity analysis to examine the FGRI scalability to larger and faster data streams.
2. Related State-Of-The-Art
- –
- Data instances which arrive in real-time in any arbitrary sequence are to be processed in the order of their arrival; there is often no control over the order in which data instances arriving have to be seen, either within a data stream or across data streams.
- –
- Unbounded, the data instances are constantly arriving, and the exact quantity of the data instances is not known, also it is not known whether the stream would fit in the designated buffer or available hard drive space over time.
- –
- The concept in the data may change over time (concept drift).
- –
- Popular on-line social networking sites such as Facebook, Twitter, and LinkedIn, offer their content tailored for each individual user. In order to do so, these services need to analyse huge amounts of data generated by the users in real-time to keep the content up to date [7].
- –
- Sensor Monitoring is a good example of applications in data stream mining [8]. More and more sensors are used in our personal daily lives and in industry. These sensors behave differently from traditional data sources because the data is periodically collected and discarded immediately, thus, the sensors do not keep a record of historical information. These unique challenges render traditional mining techniques and approaches inappropriate for mining real-time sensor data.
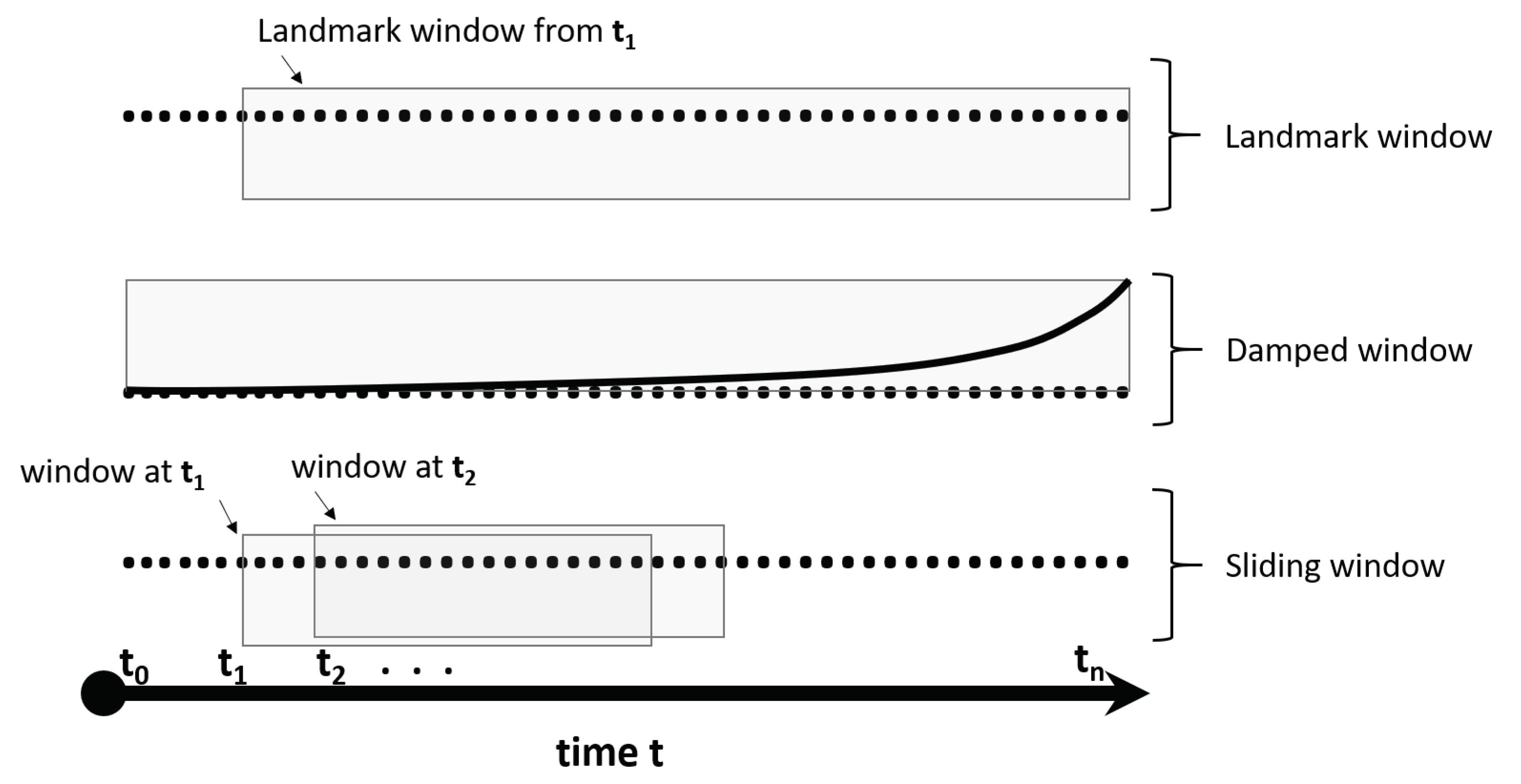
2.1. Windowing Techniques
2.2. Concept Drift Detection Techniques
2.3. Predictive Adaptive DSM Algorithms
2.4. Descriptive Adaptive DSM Algorithms
2.5. Neural Networks for Data Stream Mining
2.6. Discussion
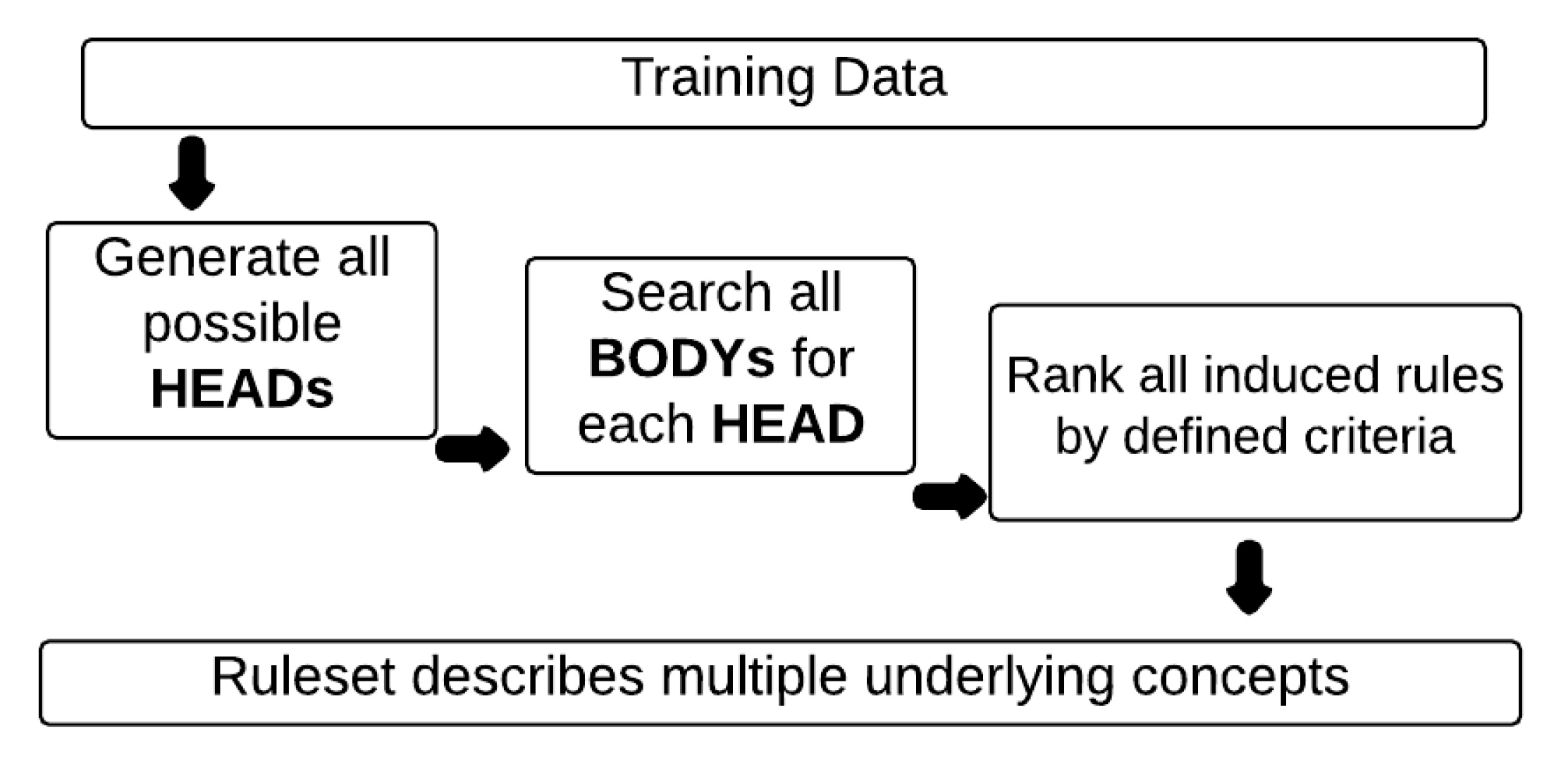
3. Generalised Rule Induction
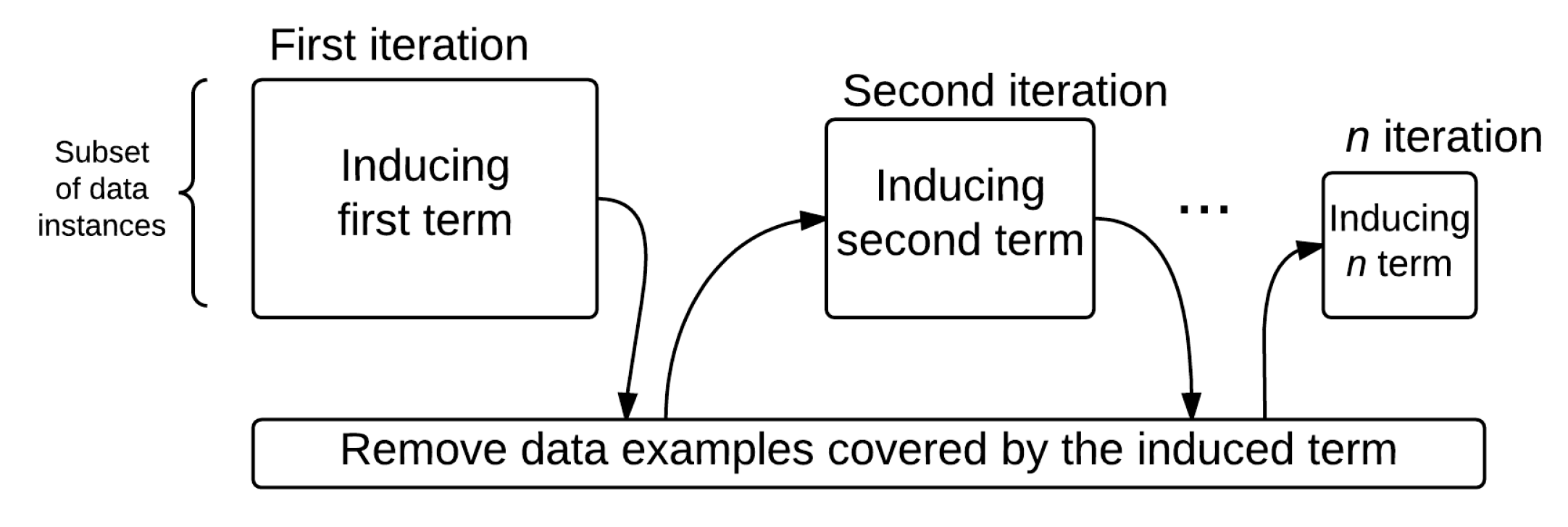
3.1. Inducing Generalised Rules Using Separate and Conquer Strategy
- –
- Separate part—Induce a rule that covers a part of the training data instances and remove the covered data instances from the training set.
- –
- Conquer part—Recursively learn another rule that covers some of the remaining data instances until no more data instances remain.
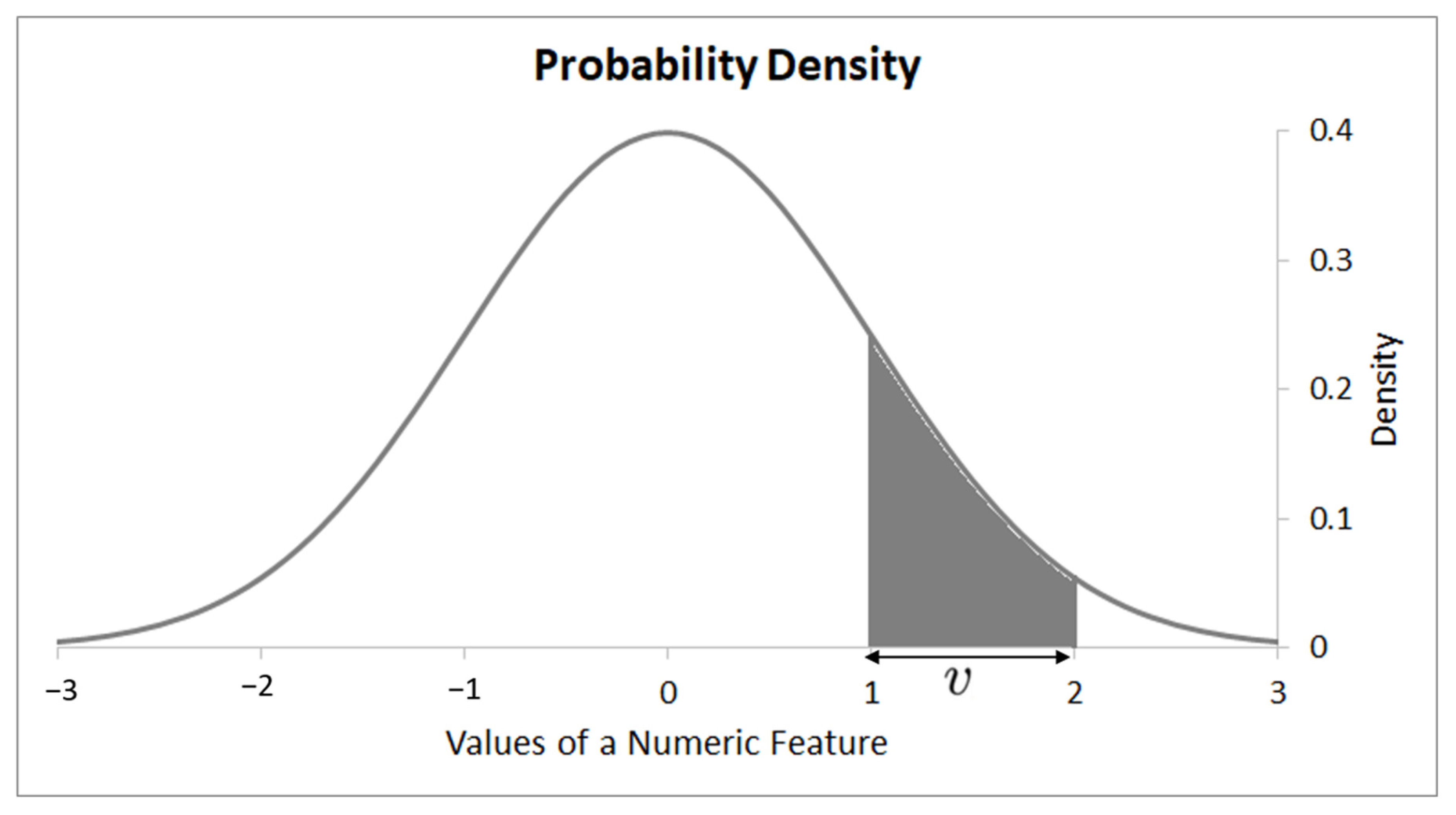
3.2. Inducing Rule Terms for Numerical Features Using Gaussian Distribution
3.3. Inducing the HEAD of a Generalised Rule
| Algorithm 1: Generate all possible HEAD conjunctions. |
D: original training data instances; : all possible terms (feature-value) from all features; : a collection of all possible conjunctions for HEAD; : number of maximum terms for conjunction; : a Head, represented by a conjunction of terms; : a collection of terms used for induced HEADs; Let ; Let
;  |
3.4. Inducing Rule BODYs for a HEAD
- –
- Rule 1: IF AND THEN AND (covers 100%)
- –
- Rule 2: IF AND THEN AND (covers 98%)
- –
- Rule 3: IF AND THEN AND (covers 2%)
| Algorithm 2: Induce complete rules for each HEAD |
D: original training data instances; : The collection of all possible HEAD were generated in Algorithm 1; : A collection of all complete rules; : A list of all features in the dataset; : A list of used features;  |
3.5. Pruning of Rules
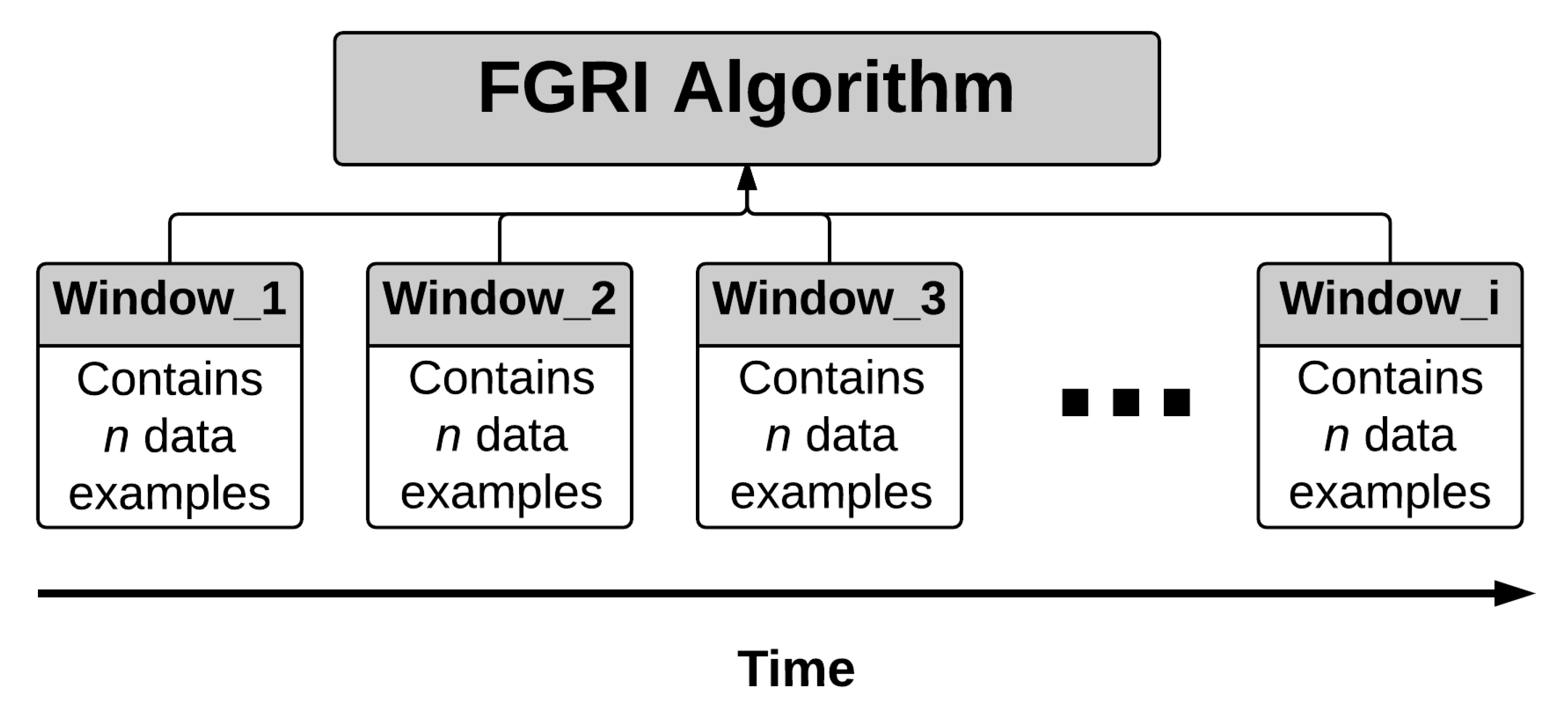
4. FGRI: Fast Generalised Rule Induction from Streaming Data
4.1. Real-Time Generalised Rules Induction from Streaming Data
- –
- To detect change/concept drift detection by using a statistic test to compare the underlying model between two different sub-windows.
- –
- To obtain updated statistics from recent data instances.
- –
- To rebuild or revise the learnt model after data has changed.
4.2. Inducing Generalised Rules from a Dynamically Sized Sliding Window
| Algorithm 3: Fast Generalised Rules Induction from streaming data |
 |
4.3. Removing Obsolete Rules
- –
- True Positive Rate;
- –
- False Positive Rate;
- –
- Precision;
- –
- Recall;
- –
- F1-Score.
5. Evaluation
5.1. Datasets
5.2. Complexity Analysis of FGRI
5.3. The Expressiveness of Generalised Induced Rules
- –
- True Positive ()—Both HEAD and BODY cover the data instance.
- –
- Abstained (A)—Neither HEAD nor BODY of a rule cover the data instance.
- –
- False Positive ()—BODY covers the data instance but the HEAD does not cover the data instance.
- –
- False Negative ()—BODY does not cover the data instance but the HEAD covers the data instance correctly.
- –
- Rule 1: IF Delay THEN DayOfWeek .
- –
- Rule 2: IF Airline THEN Delay .
- –
- Rule 3: IF Airline THEN DayOfWeek .
- –
- Rule 4: IF Length THEN DayOfWeek .
- –
- Rule 5: IF AirportTo THEN Airline .
- –
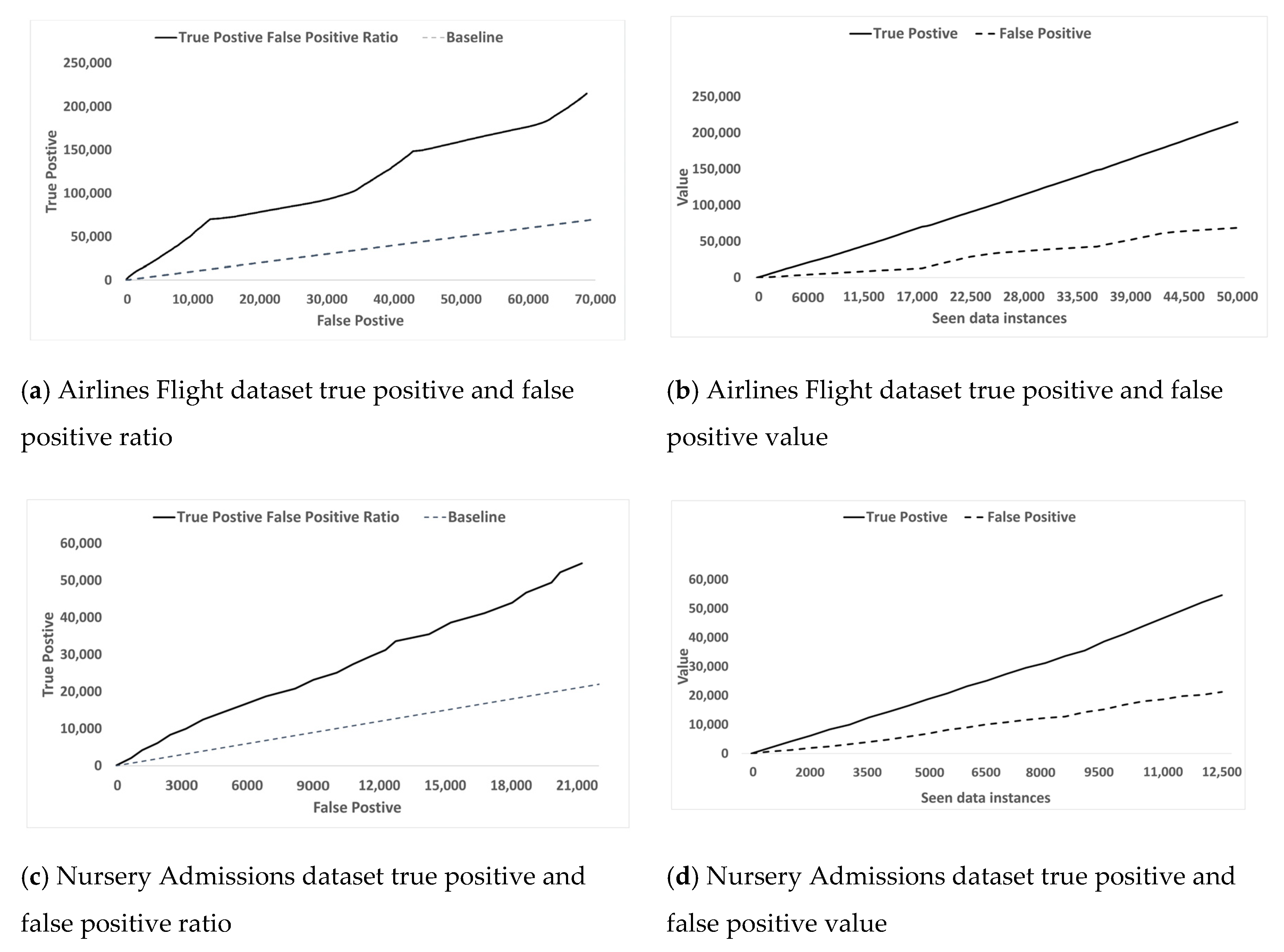
- Rule 1: After first 10,000 data instance, out of 10,000 flights records are not delayed which is correctly suggested by this rule.
- –
- Rule 2: After first 10,000 data instances, 1139 records out of 1816, or 62, seen records for ‘WN’ airline are delayed.
- –
- Rule 3: The Airlines Flight dataset is sorted by ‘DayOfWeek’, so data for each day of the week is appended to each other. The first 10,000 records contain just records for all flights with ‘DayOfWeek = 3’.
- –
- Rule 4: Most of the flights have duration between 118 to 141 min. The first 10,000 records.
- –
- Rule 5: The majority of flights with destination as LAS are operated by WN airline. The first 10,000 records confirmed this.
- –
- Rule 1: IF class = not_recom THEN health = not_recom.
- –
- Rule 2: IF parents = professional THEN has_nurs = very_crit.
- –
- Rule 3: IF health = priority THEN class = spec_prior.
- –
- Rule 4: IF form = complete THEN has_nurs = very_crit.
- –
- Rule 5: IF finance = convenient THEN parents = great_profession.
- –
- Rule 1: In a significant number of cases when the applications were not recommended then the main reason (THEN part) was because the health of the child was not recommended.
- –
- Rule 2: If the parent(s) had a professional job then the need for a nursery place is very high.
- –
- Rule 3: As a corollary of Rule 1, it was revealed that many accepted applications for a nursery place had an assigned priority value because of the health condition of the child.
- –
- Rule 4: In most completed/submitted applications, the child had a very critical need for a place.
- –
- Rule 5: When the financial standing of a family was comfortable then the parents’ occupation was likely to be a highly demanding professional position.
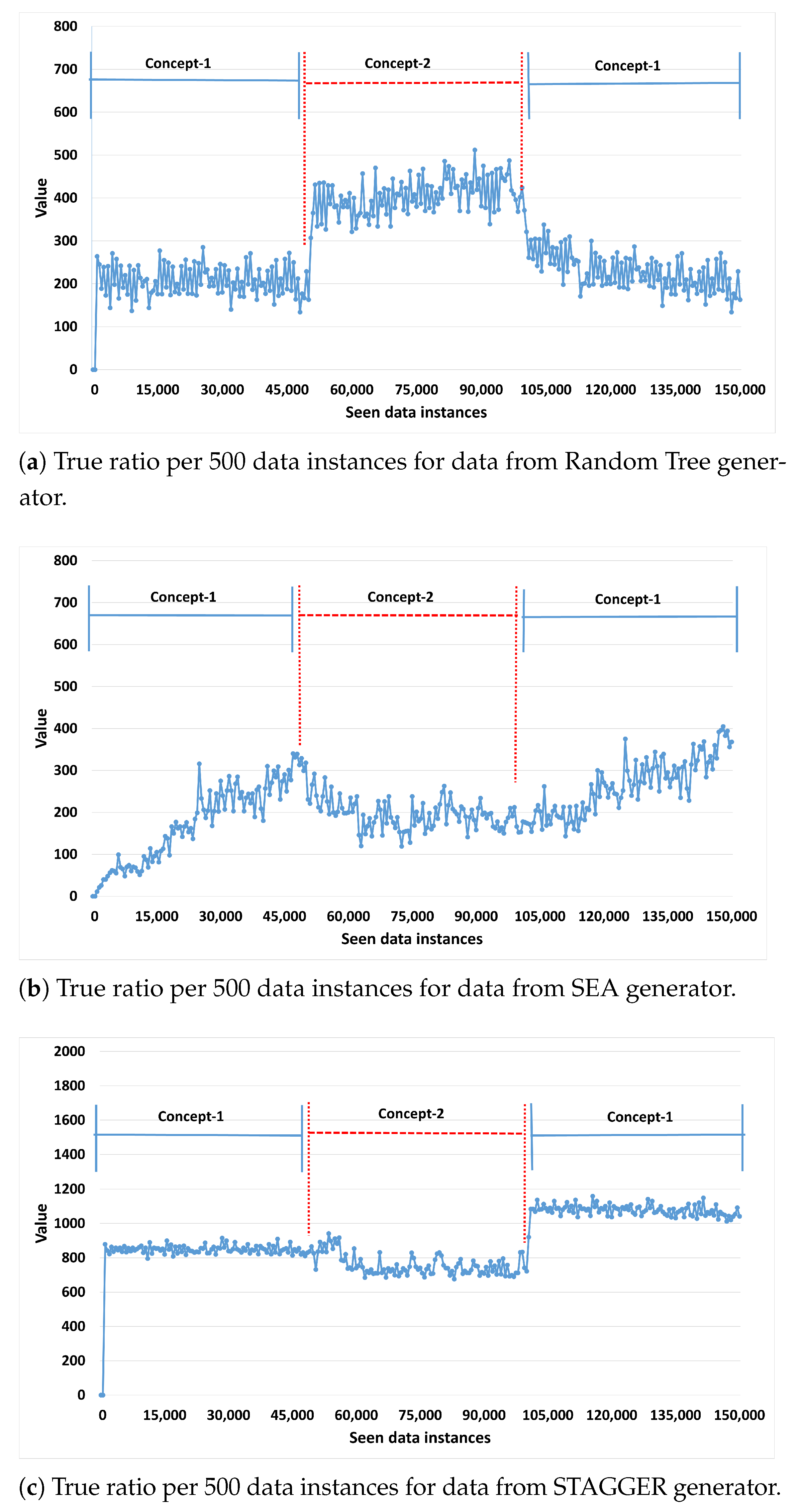
5.4. Real-Time Learning and Adaptation to Concept Drift
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Borgelt, C. Frequent item set mining. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 437–456. [Google Scholar] [CrossRef]
- Liu, B.; Hsu, W.; Ma, Y.; Ma, B. Integrating Classification and Association Rule Mining. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998. [Google Scholar]
- Agrawal, R.; Mannila, H.; Srikant, R.; Toivonen, H.; Verkamo, A.I. Fast Discovery of Association Rules. Adv. Knowl. Discov. Data Min. 1996, 12, 307–328. [Google Scholar]
- Wrench, C.; Stahl, F.; Fatta, G.D.; Karthikeyan, V.; Nauck, D. A Rule Induction Approach to Forecasting Critical Alarms in a Telecommunication Network. In Proceedings of the 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 480–489. [Google Scholar]
- Nixon, M.J.; Blevins, T.; Christensen, D.D.; Muston, P.R.; Beoughter, K. Big Data in Process Control Systems. U.S. Patent App 15/398,882, 31 January 2017. [Google Scholar]
- Aggarwal, C. Data Streams: Models and Algorithms; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- Noyes, D. The Top 20 Valuable Facebook Statistics-Updated February 2014. 2014. Available online: https://zephoria.com/social-media/top-15-valuable-facebook-statistics (accessed on 6 January 2021).
- De Francisci Morales, G.; Bifet, A.; Khan, L.; Gama, J.; Fan, W. IoT Big Data Stream Mining. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD ’16, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Motwani, R.; Babcock, B.; Babu, S.; Datar, M.; Widom, J. Models and issues in data stream systems. Invit. Talk. PODS 2002, 10, 543613–543615. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Jin, R.; Agrawal, G. An algorithm for in-core frequent itemset mining on streaming data. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005. [Google Scholar]
- Youn, J.; Shim, J.; Lee, S.G. Efficient data stream clustering with sliding windows based on locality-sensitive hashing. IEEE Access 2018, 6, 63757–63776. [Google Scholar] [CrossRef]
- Ibrahim, S.S.; Pavithra, M.; Sivabalakrishnan, M. Pstree based associative classification of data stream mining. Int. J. Pure Appl. Math. 2017, 116, 57–65. [Google Scholar]
- Nam, H.; Yun, U.; Vo, B.; Truong, T.; Deng, Z.H.; Yoon, E. Efficient approach for damped window-based high utility pattern mining with list structure. IEEE Access 2020, 8, 50958–50968. [Google Scholar] [CrossRef]
- Yun, U.; Kim, D.; Yoon, E.; Fujita, H. Damped window based high average utility pattern mining over data streams. Knowl. Based Syst. 2018, 144, 188–205. [Google Scholar] [CrossRef]
- Li, S.; Zhou, X. An intrusion detection method based on damped window of data stream clustering. In Proceedings of the 2017 9th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 26–27 August 2017; Volume 1, pp. 211–214. [Google Scholar]
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- Le, T.; Stahl, F.; Gaber, M.M.; Gomes, J.B.; Di Fatta, G. On expressiveness and uncertainty awareness in rule-based classification for data streams. Neurocomputing 2017, 265, 127–141. [Google Scholar] [CrossRef]
- Floyd, S.L.A. Semi-Supervised Hybrid Windowing Ensembles for Learning from Evolving Streams. Ph.D. Thesis, Université d’Ottawa/University of Ottawa, Ottawa, ON, Canada, 2019. [Google Scholar]
- Yun, U.; Lee, G.; Yoon, E. Advanced approach of sliding window based erasable pattern mining with list structure of industrial fields. Inf. Sci. 2019, 494, 37–59. [Google Scholar] [CrossRef]
- Yun, U.; Lee, G.; Yoon, E. Efficient high utility pattern mining for establishing manufacturing plans with sliding window control. IEEE Trans. Ind. Electron. 2017, 64, 7239–7249. [Google Scholar] [CrossRef]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with Drift Detection. Brazilian Symposium on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2004; pp. 286–295. [Google Scholar]
- Baena-Garcıa, M.; del Campo-Ávila, J.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales-Bueno, R. Early drift detection method. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Data Streams, Berlin, Germany, 18–22 September 2006; Volume 6, pp. 77–86. [Google Scholar]
- Hammoodi, M.S.; Stahl, F.; Badii, A. Real-time feature selection technique with concept drift detection using adaptive micro-clusters for data stream mining. Knowl. Based Syst. 2018, 161, 205–239. [Google Scholar] [CrossRef]
- De Mello, R.F.; Vaz, Y.; Grossi, C.H.; Bifet, A. On learning guarantees to unsupervised concept drift detection on data streams. Expert Syst. Appl. 2019, 117, 90–102. [Google Scholar] [CrossRef]
- Hulten, G.; Domingos, P. VFML–A Toolkit for Mining High-Speed Time-Changing Data Streams. Software Toolkit. 2003, p. 51. Available online: http://www.cs.washington.edu/dm/vfml (accessed on 6 January 2021).
- Domingos, P.; Hulten, G. Mining high-speed data streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD ’00, Boston, MA, USA, 20–23 August 2000; pp. 71–80. [Google Scholar] [CrossRef]
- Hulten, G.; Spencer, L.; Domingos, P. Mining time-changing data streams. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 97–106. [Google Scholar]
- Gama, J.; Kosina, P. Learning decision rules from data streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000. [Google Scholar]
- Cano, A.; Krawczyk, B. Evolving rule-based classifiers with genetic programming on GPUs for drifting data streams. Pattern Recognit. 2019, 87, 248–268. [Google Scholar] [CrossRef]
- Nagaraj, S.; Mohanraj, E. A novel fuzzy association rule for efficient data mining of ubiquitous real-time data. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4753–4763. [Google Scholar] [CrossRef]
- Leite, D.; Andonovski, G.; Skrjanc, I.; Gomide, F. Optimal rule-based granular systems from data streams. IEEE Trans. Fuzzy Syst. 2019, 28, 583–596. [Google Scholar] [CrossRef]
- Ghomeshi, H.; Gaber, M.M.; Kovalchuk, Y. EACD: Evolutionary adaptation to concept drifts in data streams. Data Min. Knowl. Discov. 2019, 33, 663–694. [Google Scholar] [CrossRef]
- Barddal, J.P.; Gomes, H.M.; Enembreck, F. SFNClassifier: A scale-free social network method to handle concept drift. In Proceedings of the 29th Annual ACM Symposium on Applied Computing, Gyeongju, Korea, 24–28 March 2014; pp. 786–791. [Google Scholar]
- Idrees, M.M.; Minku, L.L.; Stahl, F.; Badii, A. A heterogeneous online learning ensemble for non-stationary environments. Knowl. Based Syst. 2020, 188, 104983. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Philip, S.Y.; Han, J.; Wang, J. A framework for clustering evolving data streams. In Proceedings 2003 VLDB Conference; Elsevier: Amsterdam, The Netherlands, 2003; pp. 81–92. [Google Scholar]
- Cao, F.; Estert, M.; Qian, W.; Zhou, A. Density-based clustering over an evolving data stream with noise. In Proceedings of the 2006 SIAM International Conference on Data Mining, Bethesda, MD, USA, 20–22 April 2006; pp. 328–339. [Google Scholar]
- Kranen, P.; Assent, I.; Baldauf, C.; Seidl, T. The ClusTree: Indexing micro-clusters for anytime stream mining. Knowl. Inf. Syst. 2011, 29, 249–272. [Google Scholar] [CrossRef]
- Carnein, M.; Trautmann, H. evostream–evolutionary stream clustering utilizing idle times. Big Data Res. 2018, 14, 101–111. [Google Scholar] [CrossRef]
- Shao, J.; Tan, Y.; Gao, L.; Yang, Q.; Plant, C.; Assent, I. Synchronization-based clustering on evolving data stream. Inf. Sci. 2019, 501, 573–587. [Google Scholar] [CrossRef]
- Din, S.U.; Shao, J. Exploiting evolving micro-clusters for data stream classification with emerging class detection. Inf. Sci. 2020, 507, 404–420. [Google Scholar] [CrossRef]
- Adedoyin-Olowe, M.; Gaber, M.M.; Dancausa, C.M.; Stahl, F.; Gomes, J.B. A rule dynamics approach to event detection in twitter with its application to sports and politics. Expert Syst. Appl. 2016, 55, 351–360. [Google Scholar] [CrossRef]
- Hong, T.P.; Wu, J.M.T.; Li, Y.K.; Chen, C.H. Generalizing concept-drift patterns for fuzzy association rules. J. Netw. Intell. 2018, 3, 126–137. [Google Scholar]
- Tang, F.; Huang, D.T.J.; Koh, Y.S.; Fournier-Viger, P. Adaptive Self-Sufficient Itemset Miner for Transactional Data Streams. In Pacific Rim International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2019; pp. 419–430. [Google Scholar]
- Lobo, J.L.; Laña, I.; Del Ser, J.; Bilbao, M.N.; Kasabov, N. Evolving spiking neural networks for online learning over drifting data streams. Neural Netw. 2018, 108, 1–19. [Google Scholar] [CrossRef]
- Schliebs, S.; Kasabov, N. Evolving spiking neural network—A survey. Evol. Syst. 2013, 4, 87–98. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Angelov, P.; Soares, E. Towards explainable deep neural networks (xDNN). Neural Netw. 2020, 130, 185–194. [Google Scholar] [CrossRef]
- Vaughan, J.; Sudjianto, A.; Brahimi, E.; Chen, J.; Nair, V.N. Explainable neural networks based on additive index models. arXiv 2018, arXiv:1806.01933. [Google Scholar]
- Zliobaite, I.; Bifet, A.; Gaber, M.; Gabrys, B. Next challenges for adaptive learning systems. SIGKDD Explor. 2012, 14, 48–55. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Gamberger, D.; Lavrač, N. Foundations of Rule Learning; Springer: Berlin, Germany, 2003; p. 334. [Google Scholar] [CrossRef]
- Michalski, R.S. On the Quasi-Minimal Solution of the General Covering Problem. 1969. Available online: http://ebot.gmu.edu/bitstream/handle/1920/1507/69-02.pdf?sequence=2&isAllowed=y (accessed on 6 January 2021).
- Bagallo, G.; Haussler, D. Boolean feature discovery in empirical learning. Mach. Learn. 1990, 5, 71–99. [Google Scholar] [CrossRef]
- Altman, D.G.; Bland, J.M. Statistics notes: The normal distribution. BMJ 1995, 310, 298. [Google Scholar] [CrossRef] [PubMed]
- Elliott, A.C.; Woodward, W.A. Statistical Analysis Quick Reference Guidebook: With SPSS Example; SAGE Publications: Thousand Oaks, CA, USA, 2007. [Google Scholar] [CrossRef]
- Ribeiro, M.I. Gaussian Probability Density Functions: Properties Furthermore, Error Characterization; Institute for Systems and Robotics: Lisboa, Portugal, 2004. [Google Scholar]
- Bramer, M. An information-theoretic approach to the pre-pruning of classification rules. In International Conference on Intelligent Information Processing; Springer: Berlin/Heidelberg, Germany, 2002; pp. 201–212. [Google Scholar]
- Bifet, A.; Holmes, G.; Pfahringer, B.; Kranen, P.; Kremer, H.; Jansen, T.; Seidl, T. MOA: Massive Online Analysis, a Framework for Stream Classification and Clustering. 2010. Available online: ebot.gmu.edu/bitstream/handle/1920/1507/69-02.pdf?sequence=2&isAllowed=y (accessed on 6 January 2021).
- Muthukrishnan, S. Data Streams: Algorithms and Applications; Now Publishers Inc.: Hanover, MA, USA, 2005. [Google Scholar]
- Babcock, B.; Babu, S.; Datar, M.; Motwani, R.; Widom, J. Models and issues in data stream systems. In Proceedings of the Twenty-First ACM SIGMODSIGACTSIGART Symposium on Principles of Database Systems PODS 02, Madiso, WI, USA, 3–5 June 2002; pp. 1–16. [Google Scholar]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. J. Am. Stat. Assoc. 1963, 58, 13–30. [Google Scholar] [CrossRef]
- Haussler, D. Decision theoretic generalizations of the PAC model for neural net and other learning applications. Inf. Comput. 1992, 100, 78–150. [Google Scholar] [CrossRef]
- Maron, O.; Moore, A. Hoeffding Races: Accelerating Model Selection Search for Classification and Function Approximation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 28 November–1 December 1994; pp. 59–66. [Google Scholar]
- Gama, J.; Sebastião, R.; Rodrigues, P.P. On evaluating stream learning algorithms. Mach. Learn. 2013, 90, 317–346. [Google Scholar] [CrossRef]
- Street, W.N.; Kim, Y. A streaming ensemble algorithm (SEA) for large-scale classification. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; Volume 4, pp. 377–382. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Pfahringer, B.; Kirkby, R.; Gavaldà, R. New ensemble methods for evolving data streams. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 139–148. [Google Scholar]
- Stahl, F.; Gaber, M.M.; Salvador, M.M. eRules: A Modular Adaptive Classification Rule Learning Algorithm for Data Streams. In International Conference on Innovative Techniques and Applications of Artificial Intelligence; Bramer, M., Petridis, M., Eds.; Springer: London, UK, 2012; pp. 65–78. [Google Scholar]
- Widmer, G.; Kubat, M. Learning in the presence of concept drift and hidden contexts. Mach. Learn. 1996, 23, 69–101. [Google Scholar] [CrossRef]
- Narasimhamurthy, A.; Kuncheva, L.I. A Framework for Generating Data to Simulate Changing Environments. In Proceedings of the 25th IASTED International Multi-Conference: Artificial Intelligence and Applications, AIAP’07, Phuket, Thailand, 2–4 April 2007; pp. 384–389. [Google Scholar]
- Delany, S.J.; Cunningham, P.; Tsymbal, A. A Comparison of Ensemble and Case-Base Maintenance Techniques for Handling Concept Drift in Spam Filtering. In Proceedings of the FLAIRS Conference, Melbourne Beach, FL, USA, 11–13 May 2006; pp. 340–345. [Google Scholar]
- Kuncheva, L.I. Classifier ensembles for changing environments. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–15. [Google Scholar]
- Ikonomovska, E.; Gama, J.; Džeroski, S. Learning model trees from evolving data streams. Data Min. Knowl. Discov. 2010, 23, 128–168. [Google Scholar] [CrossRef]
- Olave, M.; Rajkovic, V.; Bohanec, M. An application for admission in public school systems. Expert Syst. Public Adm. 1989, 1, 145–160. [Google Scholar]
- Su, L.; Liu, H.Y.; Song, Z.H. A new classification algorithm for data stream. IJ Mod. Educ. Comput. Sci. 2011, 4, 32–39. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Flach, P.A. ROC n’ rule learning-Towards a better understanding of covering algorithms. Mach. Learn. 2005, 58, 39–77. [Google Scholar] [CrossRef]
- Hernando, A.; Villuendas, D.; Vesperinas, C.; Abad, M.; Plastino, A. Unravelling the size distribution of social groups with information theory in complex networks. Eur. Phys. J. B 2010, 76, 87–97. [Google Scholar] [CrossRef]
- Bohanec, M.; Rajkovič, V. DEX: An expert system shell for decision support. Sistemica 1990, 1, 145–157. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stahl, F.; Le, T.; Badii, A.; Gaber, M.M. A Frequent Pattern Conjunction Heuristic for Rule Generation in Data Streams. Information 2021, 12, 24. https://doi.org/10.3390/info12010024
Stahl F, Le T, Badii A, Gaber MM. A Frequent Pattern Conjunction Heuristic for Rule Generation in Data Streams. Information. 2021; 12(1):24. https://doi.org/10.3390/info12010024
Chicago/Turabian StyleStahl, Frederic, Thien Le, Atta Badii, and Mohamed Medhat Gaber. 2021. "A Frequent Pattern Conjunction Heuristic for Rule Generation in Data Streams" Information 12, no. 1: 24. https://doi.org/10.3390/info12010024
APA StyleStahl, F., Le, T., Badii, A., & Gaber, M. M. (2021). A Frequent Pattern Conjunction Heuristic for Rule Generation in Data Streams. Information, 12(1), 24. https://doi.org/10.3390/info12010024