Combating Fake News in “Low-Resource” Languages: Amharic Fake News Detection Accompanied by Resource Crafting




Abstract
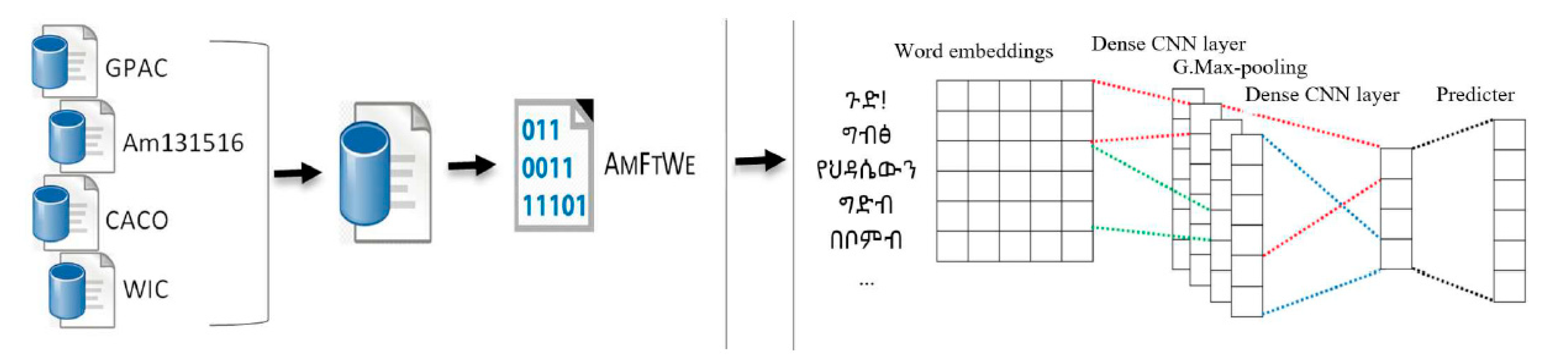
1. Introduction
- We collected and organized a huge Amharic general purpose corpus.
- We created Amharic fasttext word embedding.
- We prepared a novel fake news detection dataset for the Amharic language.
- We introduced a deep learning-based model for Amharic fake news detection.
- We performed a series of experiments to evaluate the word embedding and fake news detection model.
2. GPAC: General-Purpose Amharic Corpus
2.1. Data Collection
2.2. Data Processing
3. Amharic Fasttext Word Embedding (AmFtWe)
4. ETH_FAKE: A Novel Amharic Fake News Dataset
4.1. Data Collection
4.2. Preprocessing
5. Automatic Fake News Detection: Model, Experiments, and Evaluation
5.1. Evaluation Metrics
5.2. Experimental Setup
5.3. Results and Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bajaj, S. The Pope Has a New Baby! Fake News Detection Using Deep Learning; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Ferreira, W.; Vlachos, A. Emergent: A novel data-set for stance classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; ACM: New York, NY, USA, 2016; pp. 1163–1168. [Google Scholar]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16), New York, NY, USA, 9–15 July 2016; Association for the Advancement of Artificial Intelligence: Palo Alto, CA, USA, 2016; pp. 3818–3824. [Google Scholar]
- Shu, K.; Slivaz, A.; Wangy, S.; Tang, J.; Liuy, H. Fake news detection on social media: A data mining perspective. SIGKDD 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Zhou, X.; Zafarani, R. 2018 A survey of fake news: Fundamental theories, detection methods, and opportunities. ACM Comput. Surv. 2020, 53. [Google Scholar] [CrossRef]
- Gereme, F.B.; William, Z. Fighting fake news using deep learning: Pre-trained word embeddings and the embedding layer investigated. In Proceedings of the 3rd International Conference on Computational Intelligence and Intelligent Systems (CIIS 2020), Tokyo, Japan, 13–15 November 2020; ACM: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Sobhani, P.; Kiritchenko, S. Stance and sentiment in tweets. ACM Trans. Internet Technol. 2017, 17, 1–23. [Google Scholar] [CrossRef]
- District of Columbia Language Access Act Fact Sheet 2004. Available online: https://ohr.dc.gov/publication/know-your-rights-cards-amharic (accessed on 6 January 2021).
- Karimi, H.; Tanh, J. Learning hierarchical discourse-level structure for fake news detection. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3432–3442. [Google Scholar]
- Khan, J.Y.; Khondaker, T.I.; Iqbal, A.; Afroz, S. A benchmark study on machine learning methods for fake news detection. arXiv 2019, arXiv:1905.04749. [Google Scholar]
- Singhania, S.; Fernandez, N.; Rao, S. 3HAN: A deep neural network for fake news detection. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Tagami, T.; Ouchi, H.; Asano, H.; Hanawa, K.; Uchiyama, K.; Suzuki, K.; Inui, K.; Komiya, A.; Fujimura, A.; Yanai, H.; et al. Suspicious news detection using micro blog text. In Proceedings of the 32nd Pacific Asia Conference on Language, Information and Computation, Hong Kong, China, 1–3 December 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018. [Google Scholar]
- Thota, A.; Tilak, P.; Ahluwalia, S.; Lohia, N. Fake news detection: A deep learning approach. SMU Data Sci. Rev. 2018, 1, 10. [Google Scholar]
- Wang, W.Y. Liar-Liar pants on fire: A new benchmark dataset for fake news detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 6 February 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 422–426. [Google Scholar]
- Yang, Y.; Zheng, L.; Zhang, J.; Cui, Q.; Li, Z.; Yu, P. TI-CNN: Convolutional neural networks for fake news detection. arXiv 2018, arXiv:1806.00749. [Google Scholar]
- Ronny, M. Amharic as lingua franca in Ethiopia. Lissan J. Afr. Lang. Linguist. 2006, 20, 117–131. [Google Scholar]
- Anbessa, T. Amharic: Political and social effects on English loan words. In Globally Speaking: Motives for Adopting English Vocabulary in Other Languages; Rosenhouse, J., Kowner, R., Eds.; Multilingual Matters: Bristol, UK, 2008; p. 165. [Google Scholar]
- Demeke, G.A.; Getachew, M. Manual annotation of Amharic news items with part-of-speech tags and its challenges. In Ethiopian Languages Research Center Working Papers; Ethiopian Languages Research Center: Addis Ababa, Ethiopia, 2016; Volume 2, pp. 1–16. [Google Scholar]
- Rychlý, P.; Suchomel, V. Annotated Amharic Corpora. In Proceedings of the International Conference on Text, Speech, and Dialogue(TSD2016), Brno, Czech Republic, 12–16 September 2016; Springer: Cham, Switzerland, 2016; pp. 295–302. [Google Scholar]
- Scannell, K.P. The Crúbadán Project: Corpus building for under-resourced languages. Cah. Cental 2007, 5, 1. [Google Scholar]
- Gezmu, A.M.; Seyoum, B.E.; Gasser, M.; Nürnberger, A. Contemporary Amharic Corpus: Automatically Morpho-Syntactically Tagged Amharic Corpus. In Proceedings of the First Workshop on Linguistic Resources for Natural Language Processing, Santa Fe, NM, USA, 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, August 2018; pp. 65–70. [Google Scholar]
- Gereme, F.B.; William, Z. Early detection of fake news, before it flies high. In Proceedings of the 2nd International Conference on Big Data Technologies (ICBDT2019), Jinan, China, 28–30 August 2019; ACM: New York, NY, USA, 2019; pp. 142–148. [Google Scholar] [CrossRef]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning sentiment-specific word embedding for twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics 1, Baltimore, MD, USA, 23–25 June 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1555–1565. [Google Scholar]
- Ouchi, H.; Duh, K.; Shindo, H.; Matsumoto, Y. Transition-Based dependency parsing exploiting supertags. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2059–2068. [Google Scholar] [CrossRef]
- Chen, K.; Zhao, T.; Yang, M.; Liu, L.; Tamura, A.; Wang, R.; Utiyama, M.; Sumita, E. A neural approach to source dependence based context model for statistical machine translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 266–280. [Google Scholar] [CrossRef]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning word vectors for 157 languages. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; European Language Resources Association (ELRA): Paris, France, 2018. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations (ICLR 2013), Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2, Lake Tahoe, SN, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe-Global Vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. TACL 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Bairong, Z.; Wenbo, W.; Zhiyu, L.; Chonghui, Z.; Shinozaki, T. Comparative analysis of word embedding methods for DSTC6 end-to-end Conversation Modeling Track. In Proceedings of the 6th Dialog System Technology Challenges (DSTC6) Workshop, Long Beach, CA, USA, 10 December 2017. [Google Scholar]
- Li, H.; Li, X.; Caragea, D.; Caragea, C. Comparison of word embeddings and sentence encodings as generalized representations for crisis tweet classification tasks. In Proceedings of the ISCRAM Asian Pacific Conference, Wellington, New Zealand, 4–7 November 2018. [Google Scholar]
- Wang, B.; Wang, A.; Chen, F.; Wang, Y.; Kuo, C.J. Evaluating word embedding models: Methods and experimental results. APSIPA Trans. Signal Inf. Process. 2019, 8. [Google Scholar] [CrossRef]
- Schnabel, T.; Labutov, I.; Mimno, D.; Joachims, T. Evaluation methods for unsupervised word embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 298–307. [Google Scholar]
- Allcott, H.; Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]


{kind=link}
| Corpus | Documents | Tokens | Remark |
|---|---|---|---|
| The Walta Information Center (WIC) | 1065 | 210,000 | |
| The HaBit project (am131516) | 75,509 | 25,975,846 | |
| The Crúbadán | 9999 | 16,970,855 | Just a list of words and frequencies |
| Contemporary Amharic Corpus (CACO) | 25,199 | 21,863,015 | |
| General-Purpose Amharic Corpus (GPAC) | 121,071 | 40,601,139 |
| Sources Types | Instances |
|---|---|
| News Papers | AddisAdmass, Reporter, Goolgule |
| Government communication offices pages (Federal, Regional, Zonal, Woreda), university pages, think tank groups pages, media pages, etc. | |
| Portals | EthiopiaNege, EthiopiaZare, Satenaw, ECADF |
| Forums | Ethiopian Review |
| Media | ESAT, Walta Information Center, BBC News Amharic |
| Books | Academic, fiction, historical, etc. |
| Religious Books | The Holy Bible, newspapers, others |
| Embedding Name | Corpus | Dimension | Size of the .vec File | Size of the .bin File |
|---|---|---|---|---|
| amftwe_300.bin/.vec | GPAC_CACO_WIC_am131516 | 300 | 1.91 gb | 4.2 gb |
| amftwe_200.bin/.vec | 200 | 1.27 gb | 2.2 gb | |
| amftwe_100.bin/vec | 100 | 620 mb | 1.2 gb | |
| amftwe_50.bin/vec | 50 | 312 mb | 620 mb |
| News Group | Number of Articles | News Sources | News Domain |
|---|---|---|---|
| Real News | 3417 | Facebook, Addis Admass newspaper, Reporter newspaper | Sport, politics, art, social, religion, education, economics, history |
| Fake News | 3417 | Facebook, Addis Admass newspaper, Reporter newspaper | Sport, politics, art, social, religion, education, economics, history |
| Word Embedding | Dataset | Embedding Dim | Model Performance | |||
|---|---|---|---|---|---|---|
| Acc | Pre | Rec | F1 | |||
| cc_am_300 | ETH_FAKE | 300 | .9883 | .9850 | .9882 | .9866 |
| AmFtWe | ETH_FAKE | 50 | .9715 | .9631 | .9713 | .9672 |
| AmFtWe | ETH_FAKE | 100 | .9890 | .9898 | .9847 | .9872 |
| AmFtWe | ETH_FAKE | 200 | .9921 | .9910 | .9930 | .9920 |
| AmFtWe | ETH_FAKE | 300 | .9936 | .9930 | .9941 | .9935 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gereme, F.; Zhu, W.; Ayall, T.; Alemu, D. Combating Fake News in “Low-Resource” Languages: Amharic Fake News Detection Accompanied by Resource Crafting. Information 2021, 12, 20. https://doi.org/10.3390/info12010020
Gereme F, Zhu W, Ayall T, Alemu D. Combating Fake News in “Low-Resource” Languages: Amharic Fake News Detection Accompanied by Resource Crafting. Information. 2021; 12(1):20. https://doi.org/10.3390/info12010020
Chicago/Turabian StyleGereme, Fantahun, William Zhu, Tewodros Ayall, and Dagmawi Alemu. 2021. "Combating Fake News in “Low-Resource” Languages: Amharic Fake News Detection Accompanied by Resource Crafting" Information 12, no. 1: 20. https://doi.org/10.3390/info12010020
APA StyleGereme, F., Zhu, W., Ayall, T., & Alemu, D. (2021). Combating Fake News in “Low-Resource” Languages: Amharic Fake News Detection Accompanied by Resource Crafting. Information, 12(1), 20. https://doi.org/10.3390/info12010020