1. Introduction
Social networks are currently the focus of intensive research, as they are a great source of information that can be used in multiple domains for multiple purposes. Recommender systems are one of the areas in which social data can be exploited to improve the reliability of recommendations. The adoption of streaming music services as a common way of listening to music has allowed its use in this domain since most of these platforms are, in turn, equipped with some kind of social functionality, such as establishing friendship connections. In addition, streaming systems collect user interactions, which allows implicit feedback from users to be used instead of explicit ratings as an expression of user preferences. This has promoted the development of recommender systems for these platforms. Nevertheless, the implementation of methods that take advantage of social information is scarce in the music streaming services environment, because the mechanisms of social interaction are much more limited than in social networks such as Facebook, Twitter, etc.
Currently, the methods most extensively used in recommender systems are based on Collaborative Filtering (CF). This approach requires either explicit or implicit user ratings or preferences for some products that users have already consumed. The larger is the number of ratings, the higher is the reliability of the recommendations provided by these methods. Many proposals that make use of social data are precisely aimed at minimizing the drawback of insufficient ratings, while others are just focused on improving rating prediction without dealing with problems concerning recommendation bias.
In this work, we introduce the concept of neighborhood bias that takes place in the context of collaborative filtering methods and causes a limitation in the number of potentially recommendable items. In these approaches, the recommendations made to a given user are restricted to items rated by other users with similar tastes, who are called his/her nearest neighbors. This fact prevents the user from discovering other items that he/she might like. The neighborhood bias is caused by the way neighbors are found since this process is based on the similarity of users’ ratings about the same products. For example, two users may have the same musical tastes, but those users cannot be neighbors if they have rated different artists or songs. This problem is related to popularity bias because it is more likely that the most popular items are the most rated and, therefore, the most recommended. However, the bias that we try to address in this work is not the same since the objective is to extend the range of potentially recommended items but not necessarily with the less popular items. To achieve this, we propose to extend the neighborhood by considering social factors that may have some impact on user preferences. Thus, the neighborhood of a given user is calculated not only on the basis of affinity in preferences with other users, but also on the influence received from other users in the social network. When extending the neighborhood using social factors, the number of potentially recommendable items is also extended, since the greater is the number of neighbors, the greater is the number of items with which they interact. Trust and homophily are two factors that influence users when choosing products or services, and, therefore, must be considered when predicting their interests and preferences. Trust refers to individuals who are more likely to adopt recommendations not only from opinion leaders but from their closest social context, while homophily refers to the similarity of connected users in social networks since they usually share tastes and interests. The graph of social connections between users can be the subject of structural measures that capture these two factors and allow their influence on recommendations to be considered. Many methods have been proposed in the literature for such purpose, although it has been shown that their performance depends largely on the application domain [
1] and most of them have been validated in specific domains other than music [
2,
3]. In the music area, they have not been sufficiently tested, mainly due to the difficulty of obtaining the necessary social information from streaming platforms. For instance, friendship connections are only bidirectional, and there is only one between each pair of users. This makes it impossible to apply well known graph-based metrics, such as centrality, page-rank, etc., which work with unidirectional connections, to establish two connections between each pair of users, one in each direction. In addition, that information has usually been used to improve the reliability of recommendations. It has not been exploited to deal with neighborhood bias, which is the main purpose of our work. It is therefore necessary to develop effective techniques to obtain these factors in this environment to integrate them into traditional recommendation methods and benefit from them.
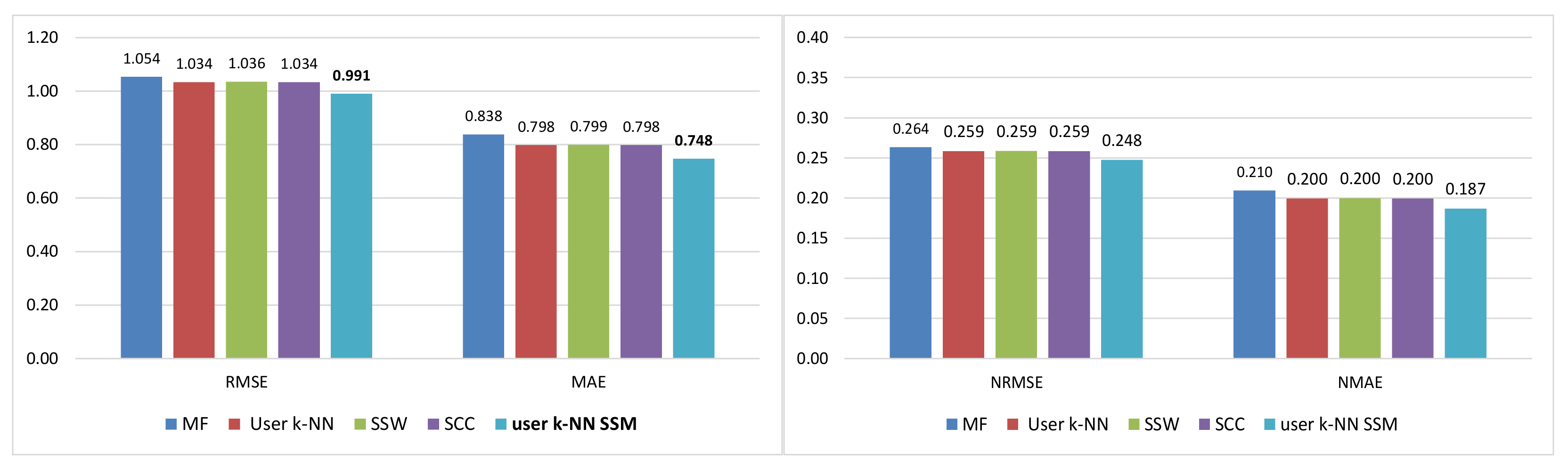
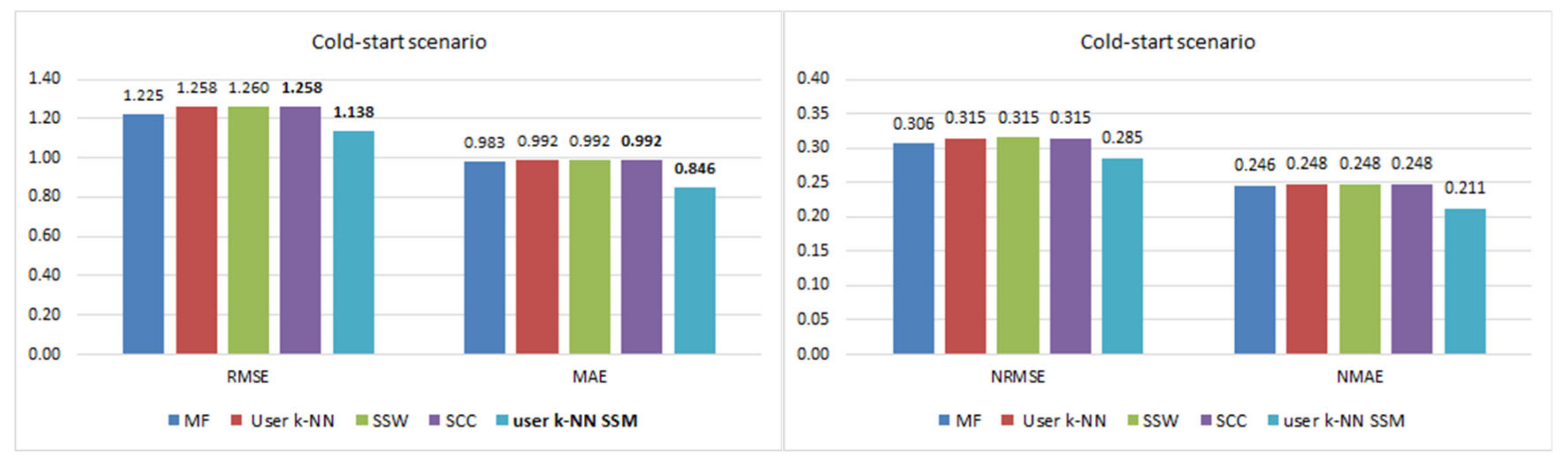
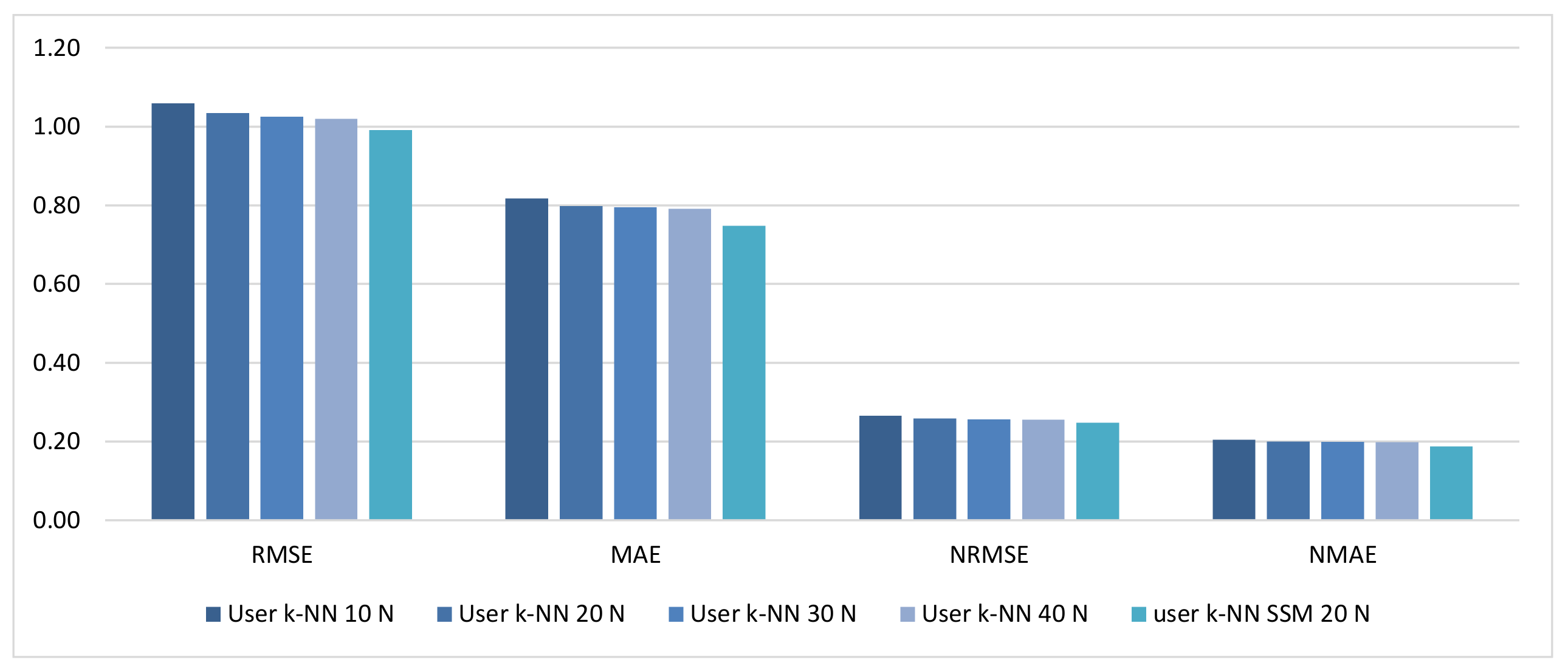
This work addresses the problem of incorporating social information obtained from music streaming systems into CF methods to improve the recommendations provided to users. Although their reliability is taken into account, the improvement is mainly focused on widening their variety by dealing with the problem of the neighborhood bias, which has great importance in this type of systems. To achieve this objective, social structure metrics that capture the concepts of trust and homophily are incorporated into the recommendation process. Our approach differs from existing ones in that social information is not used to modify the value of rating predictions but to complement them. In addition, this proposal significantly improves predictions, while most proposals focus on extending the variety of recommendations at the cost of losing accuracy or maintaining it at best. This improvement is also achieved by using only the limited social data available on streaming platforms.
Another aspect addressed in this paper is the lack of explicit ratings on music items. This inconvenience is overcome by calculating implicit ratings from the frequency of plays, recorded by streaming systems.
The rest of the paper is organized as follows.
Section 2 presents a summary of the related work. The approach to incorporate structural metrics into CF methods is described in
Section 3. The experimental study conducted to validate the proposal and the discussion of results are included in
Section 4. Finally, the conclusions are presented in
Section 5.
2. Related Work
Both the use of social information and dealing with bias is the focus of much recent research in recommender systems, but there is little work in the literature in which both topics are addressed together. The objective generally pursued in studies that exploit social information is to improve recommendations by including social data processing into the rating prediction method so that the predicted value is closer to the actual value. This is mostly done by modifying either neighborhood-based CF techniques [
4,
5] or matrix factorization methods [
6]. Regarding the work facing recommendation bias, the main proposals involve data preprocessing as resampling or clustering or postprocessing procedures as reranking, as set out below.
Bias in machine learning models is a widely studied and discussed problem that can be seen from different perspectives. Several types of bias have been studied in the recommender systems area, although most are related to unfair recommendations, from race or gender discrimination [
7] to popularity bias [
8]. In the former, the problem is usually addressed through recommendation algorithms that are sensitive to this bias and focus on the protection of discriminated groups. Burke et al. [
9] introduced the concept of a balanced neighborhood with respect to the protected and unprotected classes to enhance the fairness of recommendations without compromising personalization. In our work context, some artists in the music domain may be harmed by biased recommendations, while user satisfaction may be affected by the limited choice of items that can be recommended to them, especially to the so-called grey sheep users whose tastes are unusual. However, these unfair recommendations are not associated with any specific attribute, such as gender or race.
Popularity bias is mainly associated with neighborhood-based methods, the most frequently used, and is one of the major concerns of recent research in this field. There are proposals for facing this problem that focus on improving recommendations for grey sheep users [
10,
11], while others are focused on increasing the recommendations of the less frequently rated items and improving item diversity. This can be achieved through probabilistic models [
12], data preprocessing [
13] or postprocessing [
14,
15]. There are studies that address aggregate diversity that refers not only to diversity of individual recommendations but also across recommendations of all users [
16,
17]. The aim of these studies is to improve diversity while maintaining accuracy or with a minimum loss of it. Our proposal is different since it is a user-centered approach, which aims to expand the possibilities of the items to be recommended, but, in this case, by diversifying the user neighborhood. This is done by drawing on factors, such as trust and homophily, derived from the social network structure.
The concept of social trust is the most studied in the literature about recommender systems. It is usually used to give more relevance to the ratings of trusted users against others [
18] since it can be considered as a form of social influence that is often obtained from friendship connections, comments, messages, etc. Some systems allow users to explicitly express their trust on opinions, reviews and comments given by other users, but, in most cases, this is not possible, and it is necessary to infer it implicitly [
1].
Social trust can be used locally when only opinions of connected friends are taken into account and globally when reputed individuals in the entire network are considered [
19]. On the other hand, some approaches use social trust without considering similarity between users, while, in others, it is used jointly with similarity values [
20,
21] or even with additional factors, such as different types of interactions in social networks [
19]. There are many works in the literature where diverse factors affecting social influence are addressed, but most of them are focused on social networks such as Facebook or Twitter, from which a great variety of social information can be extracted.
Homophily and trust are two related concepts [
22]. The effect of homophily can even be used for trust prediction [
23], although homophily effects have been less studied and are often included in the general study of social influence without explicitly differentiating. Some recent work analyzes the influence of homophily on consumers’ purchasing decisions in the context of YouTube and Instagram influencers’ popularity [
24,
25]. However, in these works, homophily is treated as a complex factor that encompasses aspects such as attitude, background, morality and appearance. Therefore, it cannot only be inferred from the structure of social relations. In the area of recommender systems, the study of homophily is much scarcer. In [
3], recommendations of tourist attractions are generated by classifying users into several types, depending on factors such as homophily. This factor is determined by the membership of users in social communities.
Although trust and homophily principles have been much less studied in the field of music recommendation, we can highlight the work of Fields et al. [
26], where music recommendations are based on the social relevance of musical data obtained through complex network technologies. A different objective is pursued in [
23], in which the factors influencing the music listening homophily are analyzed. The analysis includes social information and user demographic attributes. None of these studies have addressed the problem of bias in the recommendations.
This section describes relevant work that is closely related to the proposal presented here. However, current approaches to improving recommender systems are many and varied. Among them is the promising field of cognitive computing that would allow an interaction between users and recommender systems similar to human interaction [
27]. Emotion and sentiment analysis is also being widely used in the recommendation area, especially in context-aware systems where recommendations depend on the emotional state of the user [
28]. Although social information can be used to infer emotions, it is usually textual information from comments or reviews that is not always available [
29]. Another trend in this field, although more distant from our proposal, is the research on binary codes that is focused on efficiency and storage optimization in large-scale recommender systems [
30].
3. Incorporating Social Structure Metrics into User-Based Collaborative Filtering
Collaborative filtering methods is to predict how much a user would like an item from the ratings that other users have given to that item. User-based or user-user collaborative filtering methods base the recommendations on the similarity between users, considering that two users are similar if they have similarly rated the same items.
Given a set of
m users
U = {
u1,
u2, …,
um} and a set of
n items
I = {
i1,
i2, …,
in}, each user
ui has a list of ratings that he/she has given to a set of items
Iui, where
Iui ⊆
I. In this context, a recommendation for the active user
ua ∈
U involves a set of items
Iui, where
Iui ⊆
I. In this context, a recommendation for the active user
ua ∈
U involves a set of items
Ira ⊂
I that fulfill the condition
Ira ∩
Iua = ∅, since only items not rated by
ua can be recommended. The similarity between users is computed from ratings by means of different distance-based measures such as cosine, Chebyshev and Jaccard or correlations coefficients such as Pearson, Kendall and Spearman. Among them, the most extensively used in the field of recommender systems are the Pearson coefficient and cosine similarity. The similarity between the active user
and another user
is denoted as
.
where
raj and
rij are the ratings of user
ua and user
ui for item
ij, respectively, and
and
are the average ratings of user
ua and user
ui, respectively. The Pearson coefficient can represent inverse and direct correlation with its values in the interval [−1, 1], where the value 0 corresponds to the absence of correlation.
The well-known cosine similarity metric for two given users,
ua and
ui, is computed according to Equation (2), where
and
are the vectors containing the ratings given to items by users
ua and
ui, respectively.
The items recommended to the active user are the best evaluated by the users most similar to him/her.
CF methods can be improved by introducing social information. Trust and homophily are two factors influencing the recommendations that can be inferred from the structure of relationships between users and other social network resources. However, in most music streaming services, those resources are much more limited, and the structure is restricted to bidirectional friendship relations, which does not allow centrality, page-rank and other graph-based metrics to be applied. In this work, we use the friendship structure to derive trust and homophily factors to include them in the recommendation process.
Author Contributions
Conceptualization, D.S.-M., M.N.M.-G. and V.L.B.; methodology, D.S.-M., M.D.M.V. and Á.L.S.L.; software, D.S.-M.; validation, D.S.-M., M.D.M.V. and Á.L.S.L.; formal analysis, D.S.-M. and M.N.M.-G.; investigation, D.S.-M., M.N.M.-G., V.L.B., M.D.M.V. and Á.L.S.L.; data curation, D.S.-M.; writing—original draft preparation, D.S.-M.; writing—review and editing, M.N.M.-G.; supervision, M.N.M.-G.; project administration, M.N.M.-G.; and funding acquisition, M.N.M.-G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Junta de Castilla y León, Spain, grant number SA064G19.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Aggarwal, C.C. Recommender Systems; Springer: New York, NY, USA, 2016. [Google Scholar]
- Pérez-Marcos, J.; Martín-Gómez, L.; Jimenez-Bravo, D.M.; López, V.F.; Moreno-García, M.N. Hybrid system for video game recommendation based on implicit ratings and social networks. J. Ambient Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Esmaeili, L.; Mardani, S.; Golpayegani, S.-A.H.; Madar, Z.Z. A novel tourism recommender system in the context of social commerce. Expert Syst. Appl. 2020. [Google Scholar] [CrossRef]
- Sánchez-Moreno, D.; Moreno-García, M.N.; Sonboli, N.; Mobasher, B.; Burke, R. Inferring user expertise from social tagging in music recommender systems for streaming services. In Hybrid Artificial Intelligence Systems, Lecture Notes in Artificial Intelligence; De Cos Juez, F.J., Villar, J.R., De la Cal, E.A., Herrero, A., Quintian, H., Saez, J.A., Corchado, E., Eds.; Springer: New York, NY, USA, 2018; pp. 39–49. [Google Scholar]
- Sánchez-Moreno, D.; Pérez-Marcos, J.; Gil, A.B.; López, V.F.; Moreno-García, M.N. Social influence-based similarity measures for user-user collaborative filtering applied to music recommendation. In Advances in Intelligent Systems and Computing: Distributed Computing and Artificial Intelligence, Special Sessions, 15th International, Conference, 2018; Rodríguez, S., Prieto, J., Faria, P., Klos, S., Fernandez, A., Mazuelas, S., Jimenez-Lopez, M.D., Moreno, M.N., Navarro, E.M., Eds.; Springer: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Yadav, P.; Rani, K.S.; Kumari, S. Review of social collaborative filtering recommender system’s methods. Intern. J. Eng. Comput. Sci. 2015, 4, 14927–14932. [Google Scholar]
- Mansoury, M.; Abdollahpouri, H.; Smith, J.; Dehpanah, A.; Pechenizkiy, M.; Mobasher, B. Investigating potential factors associated with gender discrimination in collaborative recommender systems. In Proceedings of the 13th FLAIRS Conference, Miami, FL, USA, 17–20 May 2020; pp. 193–196. [Google Scholar]
- Abdollahpouri, H.; Mansoury, M.; Burke, R.; Mobasher, B. The unfairness of popularity bias in recommendation. In Proceedings of the 13th ACM conference on recommender systems (RecSys), 2019, RMSE Workshop, Copenhagen, Denmark, 20 September 2019. [Google Scholar]
- Burke, R.; Sonboli, N.; Ordoñez-Gauger, A. Balanced neighborhoods for multi-sided fairness in recommendation, proceedings of machine learning research, proceedings of the 1st Conference on Fairness, Accountability, and Transparency. Proc. Mach. Learn. Res. 2018, 81, 1–13. [Google Scholar]
- Sánchez-Moreno, D.; Gil, A.B.; Muñoz, M.D.; López, V.F.; Moreno, M.N. Recommendation of songs in music streaming services. Dealing with sparsity and gray sheep problems. In Trends in Cyber-Physical Multi-Agent Systems. The PAAMS Collection–15th International Conference, PAAMS 2017. Advances in Intelligent Systems and Computing Series; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; Volume 619, pp. 206–213. [Google Scholar]
- Sánchez-Moreno, D.; Muñoz, M.D.; López, V.F.; Gil, A.B.; Moreno, M.N. A session-based song recommendation approach involving user characterization along the play power-law distribution complexity. Hindawi J. 2020. [Google Scholar] [CrossRef]
- Vargas, S.; Castells, P. Rank and relevance in novelty and diversity metrics for recommender systems. In Proceedings of the 5th ACM Conference on Recommender Systems (RecSys), Chicago, IL, USA, 23–27 October 2011; pp. 109–116. [Google Scholar] [CrossRef]
- Steck, H. Calibrated recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems (RecSys), Vancouver, BC, Canada, 2–7 October 2018; pp. 154–162. [Google Scholar]
- Adomavicius, G.; Kwon, Y. Toward more diverse recommendations: Item re-ranking methods for recommender systems. In Proceedings of the 19th Workshop on Information Technologies and Systems, Phoenix, AZ, USA, 14–15 December 2009. [Google Scholar]
- Kamishima, T.; Akaho, S.; Asoh, H.; Sakuma, J. Recommendation independence. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency (FAT), New York, NY, USA; 2018; pp. 187–201. [Google Scholar]
- Adomavicius, G.; Kwon, Y. Maximizing aggregate recommendation diversity: A graph-theoretic approach. In Proceedings of the 1st International Workshop on Novelty and Diversity in Recommender Systems (DiveRS 2011), Chicago, IL, USA; 2011; pp. 3–10. [Google Scholar]
- Mansoury, M.; Abdollahpouri, H.; Pechenizkiy, M.; Mobasher, B.; Burke, R. FairMatch: A graph-based approach for improving aggregate diversity in recommender systems. arXiv 2020, arXiv:2005.01148. [Google Scholar]
- Massa, P.; Avesani, P. Trust–aware recommender systems. In Proceedings of the ACM Conference on Recommender Systems RecSys, Minneapolis, MN, USA, 19–20 October 2007; pp. 17–24. [Google Scholar]
- Kalaï, A.; Abdelghani, W.; Zayani, C.A.; Amous, I. LoTrust: A social trust level model based on time-aware social interactions and interests similarity. In Proceedings of the 14th IEEE Fourteenth Annual Conference on Privacy, Security and Trust, Auckland, New Zeland, 12–14 December 2016; pp. 428–436. [Google Scholar]
- Akcora, C.G.; Carminati, B.; Ferrari, E. User similarities on social networks. Soc. Netw. Anal. Min. 2013, 3, 475–495. [Google Scholar] [CrossRef]
- Ziegler, C.; Golbeck, J. Investigating interactions of trust and interest similarity. Decis. Support Syst. 2006, 43, 460–475. [Google Scholar] [CrossRef]
- Zafarani, R.; Abbasi, M.A.; Liu, H. Social Media Mining; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Zhou, Z.; Xu, K.; Zhao, J. Homophily of music listening in online social networks of China. Soc. Netw. 2018, 55, 160–169. [Google Scholar] [CrossRef]
- Ladhari, R.; Massa, E.; Skandrani, H. YouTube vloggers’ popularity and influence: The roles of homophily, emotional attachment, and expertise. J. Retail. Consum. Serv. 2020, 54. [Google Scholar] [CrossRef]
- Sokolova, K.; Kefi, H. Instagram and YouTube bloggers promote it, why should I buy? How credibility and parasocial interaction influence purchase intentions. J. Retail. Consum. Serv. 2020, 53. [Google Scholar] [CrossRef]
- Fields, B.; Jacobson, K.; Rhodes, C.; Inverno, M.; Sanler, M.; Casey, M. Analysis and exploitation of musician social networks for recommendation and discovery. IEEE Trans. Multimed. 2011, 13, 674–686. [Google Scholar] [CrossRef]
- Angulo, C.; Falomir, I.Z.; Anguita, D.; Agell, N. Bridging cognitive models and recommender systems. Cogn. Comput. 2020, 12, 426–427. [Google Scholar] [CrossRef]
- Zheng, Y.; Mobasher, B.; Burke, R. Emotions in context-aware recommender systems. In Emotions and Personality in Personalized Services; Tkalčič, M., De Carolis, B., de Gemmis, M., Kosir, A., Odic, A., Eds.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Hung, B.T. Integrating sentiment analysis in recommender systems. In Reliability and Statistical Computing: Springer Series in Reliability Engineering; Pham, H., Ed.; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, Y.; Wu, J.; Wang, H. Neural binary representation learning for large-scale collaborative filtering. IEEE Access 2019, 7, 60–752. [Google Scholar] [CrossRef]
- Pacula, M. A Matrix Factorization Algorithm for Music Recommendation Using Implicit User Feedback. Available online: http://www.mpacula.com/publications/lastfm.pdf. (accessed on 11 September 2020).
- Cantador, I.; Brusilovsky, P.; Kuflik, T. 2nd Hetrec workshop. In Proceedings of the 5th ACM Conference on Recommender Systems, RecSys, New York, NY, USA, 23–27 October 2011. [Google Scholar]
- Kim, H.K.; Kim, J.K.; Ryu, Y. A local scoring model for recommendation. In Proceedings of the 20th Workshop on Information Technologies and Systems (WITS’10), Paphos, Cyprus, 27–28 March 2010. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}