1. Introduction
Despite the current advances in computer science and artificial intelligence, there are still some information processing problems that cannot be fully automated with obtaining results of the required quality. One of the ways to approach such problems provided by the development of global networks, is the use of the natural cognitive abilities of people, coordinated by modern information and communication technologies. This method is called crowd computing (or in a more general sense, crowdsourcing). Today, crowd computing is successfully applied to many information-processing problems in a variety of domains (see [
1,
2,
3,
4]).
However, involving a human in the information processing inevitably requires taking into account a number of factors: human’s limited productivity, the need for motivation and the possibility of error, or even purposeful distortion of information. These factors place specific requirements for crowd computing systems.
The most acute problem of crowd-driven systems is the quality of results [
5,
6,
7]. Research on methods of improving the quality paves the way for wider adoption of crowd technologies and in a broader sense to the most efficient use of human potential on a global scale. As in many crowd computing applications the only information available to the requester (or, the platform designer) is the information provided by workers (contributors) only, most of the methods developed in this area are aimed on processing only unreliable information provided by humans [
5,
6,
7]. In some cases, however, additional information is available that can also be utilized in order to improve the overall quality of the result. This information, in general, can have a form different from the one of the information provided by contributors, and there is a question about what formal basis and what techniques can be utilized to amalgamate (or, fuse) different kinds of available information to make the best use of them.
This is somewhat similar to the typical context of sensor data fusion when the true state of the observed object is deduced from a number of noisy sensor readings [
8,
9,
10]; in both cases, by involving various data describing the same object/process, an attempt is made to improve the accuracy of its description.
This paper considers community tagging of running race photos. In particular, the paper presents three contributions. First, a crowd computing application for community image tagging is proposed. Second, a user utility model is developed, allowing to identify the situations, when the use of community-based image tagging is applicable. Finally, a data fusion model is proposed making use of the location information of runners recorded in their Global Positioning System (GPS) tracks, allowing to increase the accuracy (and utility) of any unreliable tagger (not necessarily a crowd-based one).
Non-professional long distance running races are a very popular pastime activity. The number of running races registered in Running in the USA website [
11] exceeds 40,000. In Europe, there are about 10,000 running races organized annually [
12] and 50 million people are estimated to run on a regular basis, some of them occasionally taking part in running events [
13]. With today’s wide spread of digital photo equipment, most of these events are shot by many photographers, both professional and amateur. After the race, participants usually want to find photos they are in to save it as a souvenir. However, it is not an easy task, taking into account the number of photos from medium and big events (which may easily exceed 5000).
In general, the problem can be classified as an identity tagging (or identity labeling) problem, when for each photo identities of people depicted on the photo should be detected. At big races, this is usually done with a help of radio-frequency identification (RFID) tags attached to the runners, but for smaller races, it may not be the case; besides, RFID tags cannot be used to find photos in collections of amateur photographers not affiliated with the race administration.
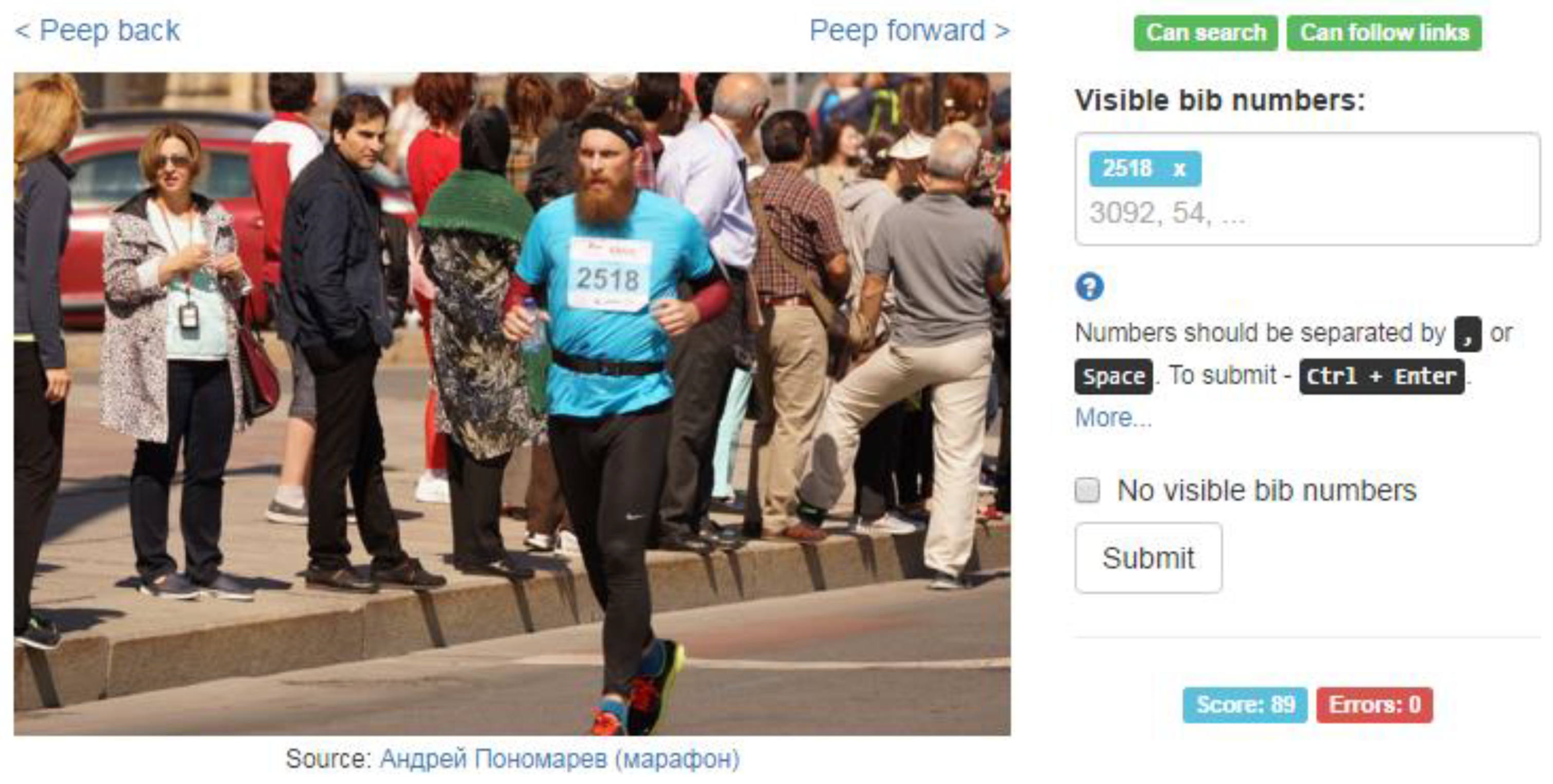
Luckily, in most races runners wear bib numbers attached to their chests (see
Figure 1), which allow transferring the task from a person who actually seeks his/her photos to anybody (or anything) who can detect numbers on photos. There are, of course, automated solutions leveraging computer vision and optical character recognition technologies (e.g., [
14,
15]), but as bib numbers are soft (and thus, can be distorted) and can be partially obscured by runners’ hands, fully automated solutions often do not allow achieving perfect results.
This paper explores a possibility to use voluntary crowdsourcing to tag race photos with bib numbers of runners depicted on them, allowing easy search of a photo by bib number. A crowd is formed (mostly) from the runners that took part in the event, usually through informing about this opportunity through social networks and official race event pages on the Internet. The incentive to take part in the tagging process is that it is significantly less time-consuming to tag a dozen photos than to wade through a thousand to find several of one’s photos.
Image labeling is probably one of the most used and studied applications of crowdsourcing, both in the commercial context (using Amazon Mechanical Turk or another platform) and non-commercial (e.g., [
16,
17,
18,
19]). However, the context of image labeling relevant to this paper is not quite the same as in popular crowdsourcing applications. First of all, the runners that actually took part in the event are more interested in watching event photos than random Amazon Mechanical Turk (AMT) workers and it creates additional motivation. Second, exploitation of one’s will to find his/her photos creates a non-monetary incentive that allows performing the tedious task at no cost (and that could be attractive to the race administration). To the best of the author’s knowledge, there are no published papers exploring this context and no such applications.
This paper presents a community-driven image tagging application and investigates the use of probabilistic graphical models (namely, Bayesian networks) to fuse different types of information about the image contents in the context of crowd-driven tagging and searching of running race photos.
Specifically, the paper presents:
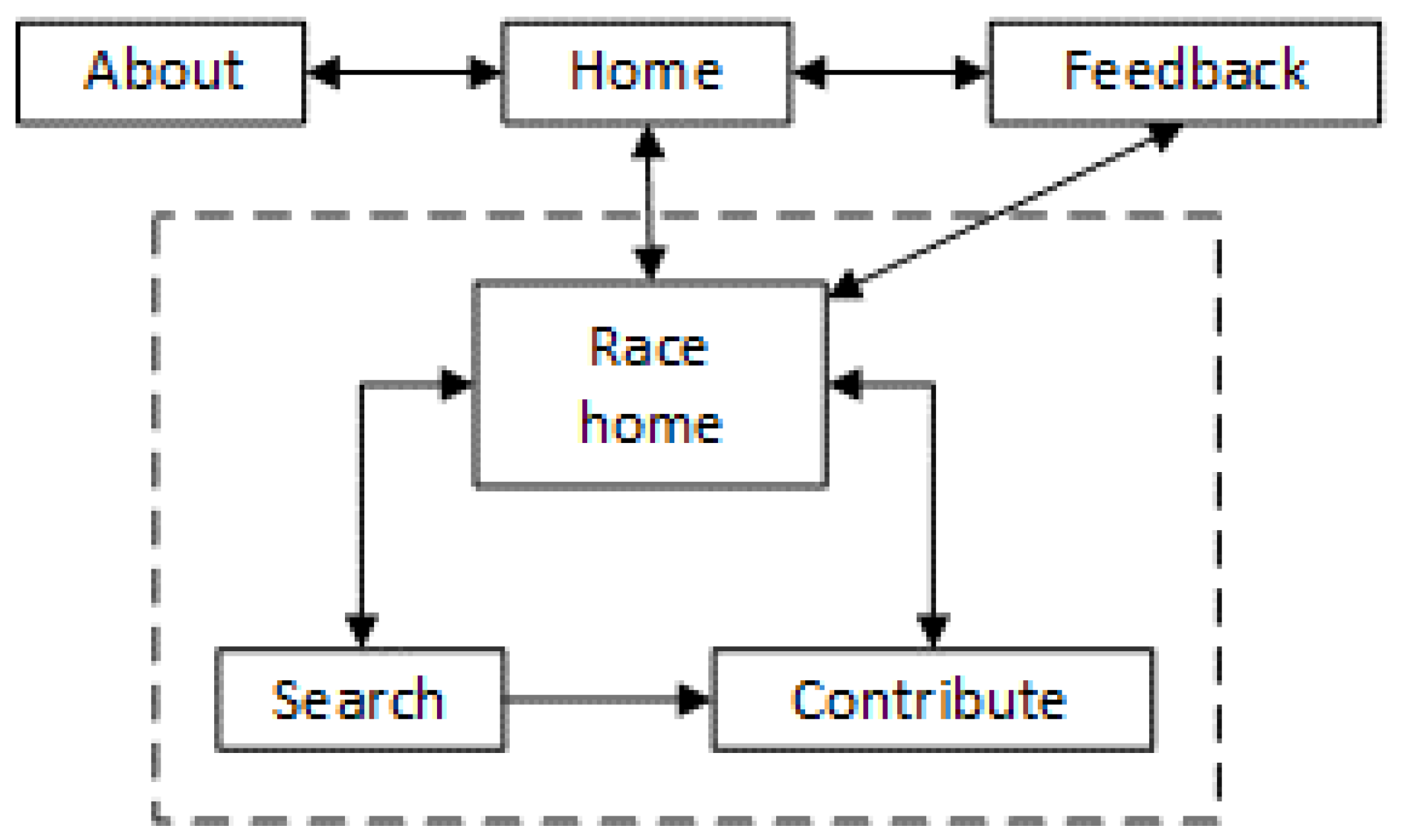
the design of crowd-driven application for photo tagging and search;
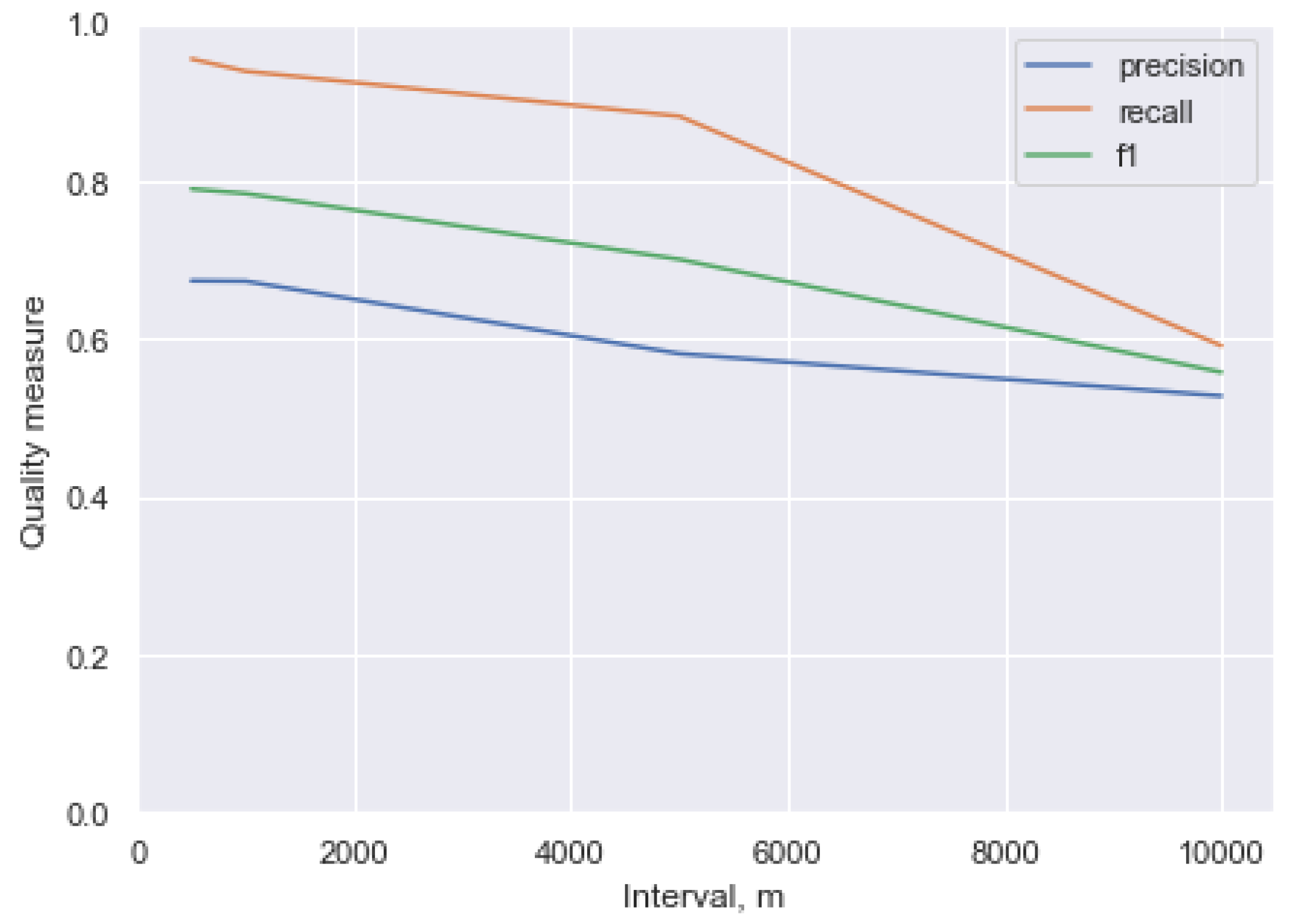
statistics showing the participation in tagging and image tagging quality;
formal model of user’s utility allowing to check if the use of the community-based system is reasonable and to analyze factors influencing the applicability;
runner’s motion model that is used as additional information to improve search quality with noisy tags;
Bayesian network-based fusion model to integrate crowd tagging with runner’s motion model;
results of (simulated) experiments showing that the proposed model actually improves the quality of search.
2. Crowd-Driven Web-Application for Running Race Photo Tagging
The purpose of the application is to allow running race participants to find their photos (taken by various photographers, not necessarily affiliated with race organizers) with minimum effort. The simplest way to do it is by using bib numbers of the participants. As the bib numbers depicted in the photos are not known in advance, in order to enable the searching functionality a user has to tag some photos with the bib numbers depicted on them. This section describes the organization of the application, as well as basic quality management techniques.
3. Participant Utility Model and Its Analysis
Like any crowd-based system, running a race photo tagging system depends heavily on participation. It becomes useful if there are enough participants to tag all the photos, and it is useful only when tagging effort is actually ‘worth it’ in that it helps the participant to achieve some goals. This section describes a participant’s model based on von Neumann–Morgenstern utility, highlighting conditions when participation in tagging becomes reasonable. In practice, this model is important in two ways: first, it allows checking if it is reasonable to start a photo tagging project for a particular race; second, it can be used to estimate possible modifications in the crowd application to verify if these modifications are beneficial for users.
Let M be the number of running race participants, and N be the number of photos taken in the race. We will assume that each photo contains only one person (actually, it is not always the case, but in many photos one runner is the center of composition, and these photos look usually more attractive). A user spends tcheck seconds to glance through a photo (in some large collection) to check if he/she is depicted on it (usually it is about 0.5 s). A user spends ttag seconds to tag a photo with the bib numbers depicted on it. The value of ttag depends on the interface of the tagging system. In the developed application, tagging takes usually about 5 s. Note that the particular values used here are reasonable estimates, and they do not constrain the applicability of the model itself. If one gets another estimate for these parameters, the model itself will still be useful, however, it may lead to slightly different results.
Let us also assume that for each photo a participant is selected randomly with equal probability; therefore, there is a probability 1/M that a particular race participant is depicted in the given photo. Then the number of photos a particular race participant is depicted in follows Bernoulli distribution B(N, 1/M).
A value of the first found photo for a user is
v. Then, the value decreases with each found photo with factor
γ. Therefore, the value of
x photos for a user is:
We consider the following strategies of a user:
search through all the photos (not using the system);
search through some subset s of the photos (not using the system). Clearly, this is a refinement of the previous strategy. It might make sense, since there are diminishing returns for each new photo;
use the system, and tag the number of photos specified by the mechanism to be able to search by bib number;
do not do anything (neither use the system, nor search by him-/herself).
The utility of these strategies is following.
The utility of searching through all the photos is:
The positive component is the utility from finding q photos of him-/herself, while the negative component is the effort required to check all the photos.
Utility of searching through a subset of photos:
Moreover, there is some optimal number of photos to examine
, maximizing this utility:
Utility of using the system is:
Here R and P are recall and precision of the tagging system, respectively, while is the number of photos a user has to tag to be able to search by bib number. The positive component is related to the utility of the number of photos, however, it is multiplied by tagging system recall, because, compared to the previous cases even if the user is present on some number of photos, it is not guaranteed that he/she will receive these photos (as they might be mislabeled). There are also two negative components: effort to tag the specified number of photos and effort to look through the search results, depending on the tagging quality characteristics.
This model allows the answer to two questions:
These two questions are addressed in the following subsections.
4. Model for Predicting Runner’s Location
Additional information that can be taken into account in the process of estimating the possibility that a runner is present in a particular photo is the location of the runner at the time the photo was taken. Normally, running races provide time measurements for the participants and the race protocol contains the finishing time of each participant (sometimes even times when the participant passed several checkpoints). Assuming that race participants move from start to finish along the known route with slightly varying speed, their location at a specific time can be predicted (with some uncertainty due to speed variation). Moreover, many participants use sports watches or smartphones with GPS trackers, therefore their position can be predicted with even greater precision. Information about the time and place of taking a photo is usually recorded in the attributes of the image file by most modern cameras. Therefore, the position of the photo (recorded by the camera) can be compared with the predicted runner’s location and if the runner was likely near the point the photo was taken the photo can be added to the result of the search query even without taking into consideration tags assigned to the photo. On the other hand, the information that the runner could not have been anywhere near the shooting point at the time the photo was taken can be used to detect tagging errors.
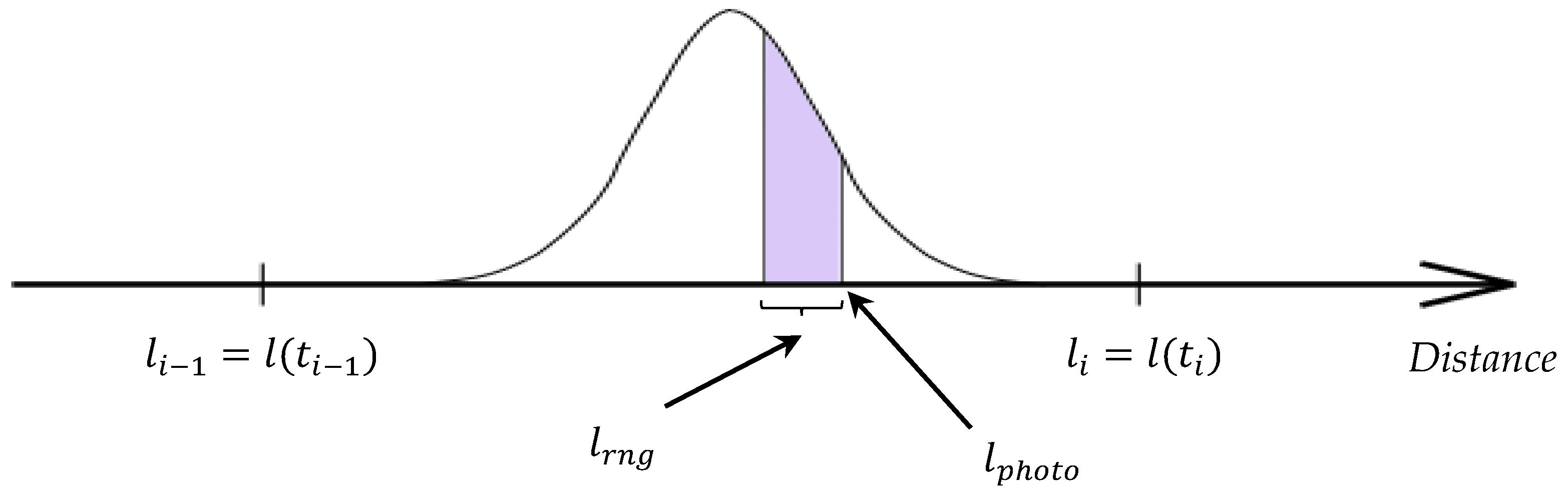
As mentioned earlier, the exact position of the race participant is known only at certain points in time (in the worst case there are two such moments: start and finish; at the best: if the participant uses a GPS tracker then his/her exact position at the distance is known at intervals of a minute or even a few seconds). Let be the moments of time at which the precise position of the participant is known, with , and corresponds to the finishing time. To denote the position of the participant at any time, we will use the functional notation . We also introduce the notation . Suppose that a participant moves only in one direction (from start to finish), with non-zero velocity, therefore, . To determine the position of the participant at times when the position is unknown (), we will use a probabilistic model based on the following assumptions:
Based on the second assumption, the position of the race participant at time
t depends only on two of his/her known locations at times
and
, such that
. A distance
, traveled in time
by a participant moving according to the assumptions above is a random variable distributed according to
, and the density of this distribution is given by:
It can be shown that probability of the particular location of a race participant conditioned on his/her known locations is given by the following expression:
Notice, that
is
and
is
. Therefore, the probability density of the position
in the route segment
for
is given by the following expression:
for
, the probability density is 0.
The obtained probability density is used to determine the probability that a participant is in the field of view of the camera at the time the picture was taken. Let the photo be made at the time
by a camera located at
, and the distance from the camera to the object within which a high-quality image can be obtained is
. For simplicity, we also assume that
. Then the probability that the participant will be in the field of view of the camera at the time
:
Thus, the proposed algorithm for estimating the probability of finding a race participant near the location of the photographer at the time of taking the photo is as follows (see
Figure 5):
Check if the position of a race participant at the time of taking a photo is known exactly, i.e., if there exists an index , s.t., . If such index exists, then the position is known exactly, and the required probability is 1.0 if and 0.0 otherwise. If there is no such index, go to Step 2.
Determine the segment of the route at which the participant is at the time of taking the photo, i.e., find an index , s.t. .
Find the probability density function of the runner’s position on this segment according to Equation (1).
Calculate the probability according to Equation (2).
5. Data Fusion Model
Probabilistic models of contributors are widely used for processing the results obtained from the crowd. These models numerically describe the propensity of contributors to make various kinds of errors (e.g., [
25]). Specifically, during tagging photos with bib numbers two types of errors are possible: (1) the image is not tagged with a number actually present in the image, and (2) the image is tagged with a bib number that is not actually present in the image. The tagging quality analysis has shown that errors of type (1) are more popular. This is explained by the fact that missing a number is usually caused by a lack of diligence, which is natural for crowdsourcing environments, while adding non-existent numbers requires some additional effort which is non-typical. In fact, errors of type (2) are mostly associated, with incorrect reading of the (often distorted) number or its incorrect input.
Thus, it is proposed to describe participant u of the tagging process with two parameters: (“attentiveness” or “diligence”—the probability that the number present in the image will be found and included in the annotation) and (the probability that an image is tagged with some number that is not present on the image).
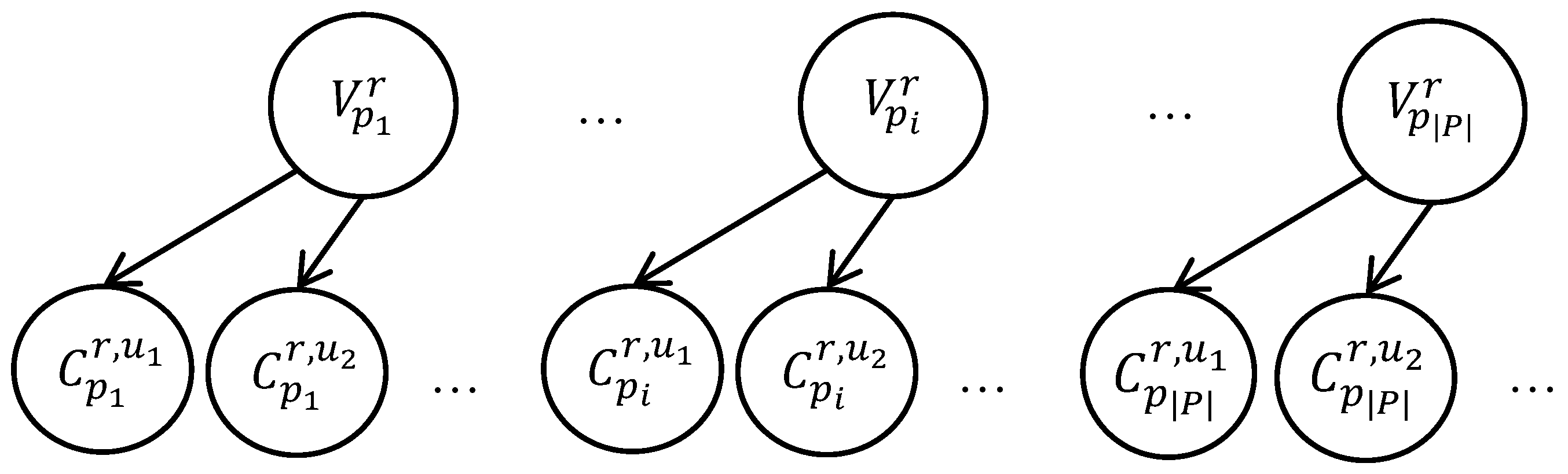
The unified representation of different types of uncertainty (uncertainty associated with the actions and errors of a contributor performing tagging, and uncertainty associated with the position of race participants on the track) using the probability allows to employ probabilistic inference to integrate (or, fuse) this information. The proposed fusion model can be visualized in the form of a Bayesian network, as shown in
Figure 6.
A network of this layout is formed to search for images of each race participant r. The binary variables , are unobservable variables, each of which corresponds to the presence of a race participant r in the image pi. The a priori probability is determined by the probability of the presence of the participant in the camera’s field of view, calculated using Equation (2). The variables are observable and correspond to the results of the tagging; according to the tag contributor u the race participant with the bib number r is present on the image pi. Conditional distribution table for the variables is formed as follows. If r is indeed present in the image, the probability that it will be indicated by the contributor u is, by definition, equal to . If r is not in the image, but the contributor u indicated that r is present, it means that when reading or entering one of the numbers u made an error, replacing the correct number with r. The probability of making an error by definition , the probability of a particular error: , where is the set of bib numbers specified by u for the image pi and R is the set of valid bib numbers.
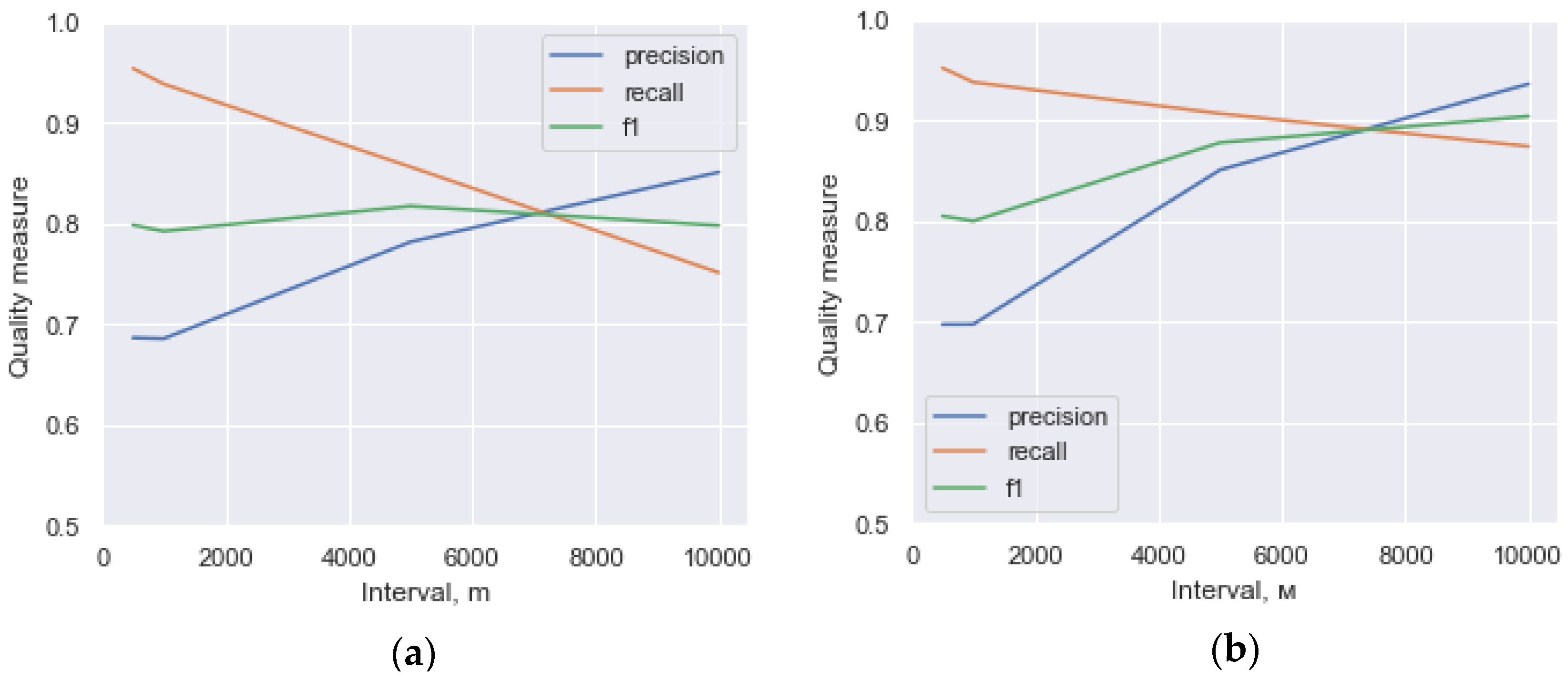
The process of searching photos containing certain bib numbers relies on estimating posterior probabilities with known tagging data, and forming a set of photos for which this a posterior probability exceeds a certain threshold value.
The advantage of using probabilistic graphical models for data integration is the modularity of the fusion scheme. Indeed, in the future, the proposed scheme may be expanded and supplemented with a more elaborate user error model, for example, one taking into account the fact that some types of errors (confusing digits 7 and 1, or 8 and 9) occur more frequently than others.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}