1. Introduction
This paper is an extension of an already published conference paper [
1], where we investigated how to extract social networks from Linked Open Data. In recent years, the Web has evolved from a network of linked documents to one where both documents and data are linked, resulting in what is commonly known as the Web of Data. Underpinning this evolution is a set of best practices known as Linked Open Data (LOD) [
2], which provide mechanisms for publishing and connecting structured data on the Web in a machine-readable form with explicit semantics. Recently, Linked Open Data has evolved from an academic endeavor into one that has been embraced by numerous governments and industrial stakeholders.
Due to the creation of an increasing number of publicly available Linked Open Data resources, the Web of Data has become a major application area for semantic technologies. Currently, the so-called LOD cloud contains over 1200 datasets, with billions of facts from many different domains like geography, media, biology, chemistry, economy, energy, etc., and millions of links among entities (
http://lod-cloud.net). Examples of large LOD datasets are DBpedia [
3,
4] (3.4 million entities, 1 billion facts), and YAGO [
5] (17 million entities, 150 million facts).
All such data are typically represented using the Resource Description Framework (RDF) which is the World Wide Web Consortium’s (W3C) standard language for representing information in the Semantic Web [
6,
7]. RDF is based on a directed graph data model, where both nodes and edges are labeled. An RDF graph is a set of triples of the form
, which can be interpreted as edges labeled by
p (the predicate) from nodes labeled by
s (the subject) to nodes labeled by
o (the object). The elements of a triple are typically Internationalized Resource Identifiers (IRIs)-global names that uniquely identify resources on the Web. SPARQL, which became a W3C recommendation in 2008, is the standard query language for RDF [
8,
9]. Recently, a new version of the SPARQL query language, called SPARQL 1.1, has been standardized by W3C. It addresses some of the limitations of the original language by introducing a wide range of constructs [
10].
The increasing adoption of Linked Open Data is turning the Web into a global data space that connects data from diverse domains and enables genuinely novel applications. The richness and openness of Linked Open Data make it an invaluable resource of information, and creates new opportunities for many areas of application. For instance, in this present work, we address the exploitation of Linked Open Data in order to extract social networks among entities. This will enable the application of de-facto techniques from Social Network Analysis to study social relations and interactions among entities, providing deep insights into their latent social structure.
Social Network Analysis (SNA) refers to the collection of methods, techniques, and tools in sociometry aiming at the analysis of social networks. There is an abundance of tools allowing for the analysis and visualization of such networks. A social network may be dense or not, the “social distances” among individuals may be short or long, etc. An individual may be “central” (directly linked to many other individuals) or an “isolate” (not linked to others). However, more subtle notions are also possible, e.g., an individual who is only linked to people having many relationships is considered to be a more powerful node in the network than an individual having many connections to less connected individuals.
The work presented in this paper is an attempt to bring together the two research areas of Linked Open Data and Social Network Analysis. The main idea is to derive social networks from large datasets of linked open data, such that extracted networks become a fresh material for study and analysis, while at the same time forming an additional asset of knowledge added to linked open data.
The main contributions of this present paper are the following:
We propose several techniques to extract social networks from linked open data.
We express those techniques in a formal way using SPARQL algebra.
We present formal translations into social networks.
We present several case studies that apply some of the presented techniques.
The paper is organized as follows.
Section 2 presents a motivation example that demonstrates the importance of the proposed approach, while
Section 3 gives an overview of relevant previous work.
Section 4 provides a background on social networks and SPARQL algebra.
Section 5 and
Section 6 are the core of this paper, introducing network extraction patterns for complete networks as SPARQL queries. Then, a generic translation method that transforms query results into networks is presented in
Section 7.
Section 8 concludes the paper with an overall discussion.
3. Related Work
The richness and openness of Linked Open Data, as well as the inter-linking of the many datasets, known as LOD cloud, make it an invaluable resource of information, and create new opportunities for many areas of application. This leads to an increasing adoption of LOD by the scientific community, and several sectors of industry [
13]. Among others, one of the major factors that foster the evolution and adoption of LOD is the semantic technologies (RDF [
7], OWL [
14], and SPARQL [
10]) standardized by W3C. Being structured using a standard data format (RDF), the consumption of Linked Open Data is facilitated with SPARQL, a standard query language, and protocol to access RDF datasets. SPARQL is based on a solid background with respect to its syntax and semantics [
9] (see
Section 4.2 below). The large amount of RDF data available on the Web is exposed by means of (a) Linked Data-enabled dereferenceable URIs in various formats (such as RDF/XML, Turtle, RDFa, etc.) and by (b) SPARQL endpoints (SPARQL endpoints are RESTful web services that accept SPARQL queries over HTTP adhering to the SPARQL protocol, as defined by the respective W3C recommendations [
15]). Most of the LOD datasets are interlinked, which allows navigating through them and facilitates building complex queries by combining data from different, sometimes heterogeneous and often physically distributed datasets. To address this use case, the W3C recommendation defines a federation extension [
16] for SPARQL 1.1 [
10], which allows for combining graph patterns that can be evaluated over several endpoints within a single query [
15].
Several areas of application are increasingly benefiting from the large amount of RDF data available in the Web of Data, and exploiting their potential power. For instance, Recommender Systems are among such applications consuming Linked Open Data. Passant [
17] proposes a Music recommender system, called
drec, which is built on top of DBpedia. Di Noia et al. [
18] develop a content-based recommender system that leverages the data available within Linked Open Data datasets in order to recommend movies to the end users.
Some works seek to combine social analytics with the Linked Open Data (LOD) cloud. De Vocht et al. [
19] propose a semantically driven aggregation of social data, where they use semantic technologies, common vocabularies, and Linked Open Data to extract and mine the data about scientific events out of context of microblogs (e.g., Twitter). As a proof-of-concept, they implement and evaluate a researcher profiling use case. Razis et al. [
20,
21] propose an ontology schema towards linking semantified Twitter social analytics with the Linked Open Data cloud. The ontology is deployed over a publicly available service that measures how influential a Twitter account is by combining its social activity in Twitter. They also introduce in [
22] a methodology for discovering and suggesting similar Twitter accounts, based entirely on their disseminated content in terms of used Twitter entities (mentions, replies, hashtags, URLs). The methodology is based on semantic representation protocols and related technologies. An ontological schema is also described towards the semantification of the Twitter accounts and their entities.
Several works in the literature have already attempted to combine Social Network Analysis with semantic technologies. For instance, Flink [
23] is an early system for the extraction, aggregation, and visualization of online social networks. Flink employs semantic technology for reasoning with social information aggregated from disparate sources: web pages, emails, publication archives, and FOAF profiles. Martin et al. [
24] propose a model to represent social networks in RDF and show how SPARQL can be used to query and transform networks. However, the proposed data model is unnecessarily complex as relations among nodes are represented as RDF resources, hence additional predicates are introduced to link nodes to the relations. Moreover, at that time, aggregation was missing in SPARQL, therefore SQL is used in the model. Other works have been proposed to use SPARQL and other semantic technologies not only to represent social networks, but also to perform social network analysis [
25,
26,
27]. However, all the aforementioned works use semantic technologies to represent social networks and/or to perform social network analysis. Unlike our work, none of them extract social networks from RDF datasets (LOD). Our work focuses on network extraction patterns from RDF, not on representing the networks themselves.
Groth and Gil [
28] present an approach for extracting networks from Linked Data, where extracted networks can then be analyzed through network analysis algorithms, and the results of these analyses can be published back as Linked Data. Zehetner [
29] proposes in his dissertation a framework, called
SocioCatcher, to extract and analyze social networks from DBpedia. However, both of these works focus on the system and its computational workflows, without a solid theoretical basis and formalism of extraction patterns as we do in our present work.
8. Discussion
This paper proposes several techniques to extract social networks from Linked Open Data. The proposed techniques have the form of extraction patterns that can be expressed using SPARQL queries whose results make up the target social network. The importance of the proposed approach comes from (1) the importance of Linked Open Data as a rich source of information, and (2) the role of extraction patterns as guidelines for the process of deriving new latent knowledge (social networks) from existing one (linked open data).
Linked Open Data is structured information in a machine-processable format, openly published on the Web, and linked to other datasets. Those properties of LOD make it an invaluable resource of information, and create new opportunities for many areas of application. Thus, LOD is being increasingly adopted, not only by the scientific community, but also by several groups of stakeholders such as media, industry, and governmental organizations and NGOs. LOD is already widely available in several industries, including libraries, bio-medicine, and government data. “Linking information from different sources is key for further innovation. If data can be placed in a new context, more and more valuable applications—and therefore knowledge—will be generated” [
13].
From this point of view comes our proposal of mining new information i.e., social networks, from LOD, and then turning it into knowledge, through social network analysis. Hence, the extraction techniques/patterns proposed in this paper come to facilitate this process.
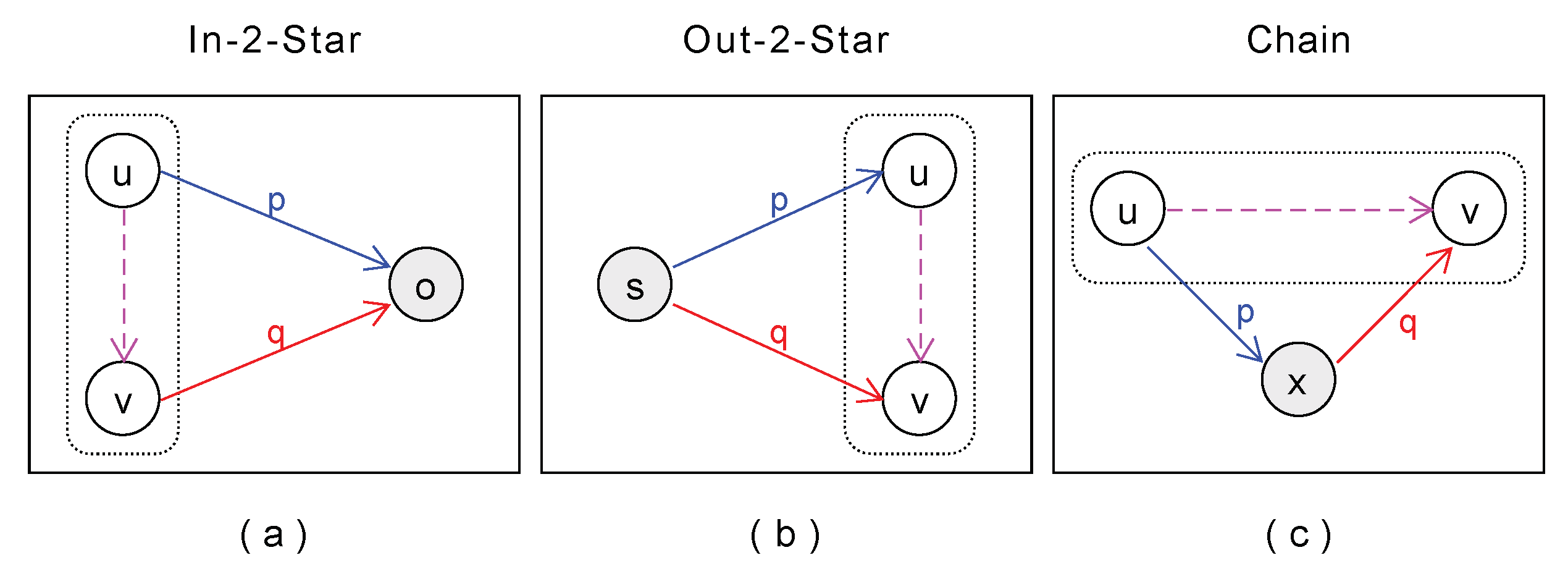
Extraction patterns can be considered as guidelines to help the user figure out the appropriate formulation of the query to extract a desired network, and to understand the outcomes of different design choices: which predicates are needed, how many triple patterns, which direction of predicate of each triple pattern (subject-object) is the appropriate, etc. Extraction patterns are used as building blocks to establish more complex patterns that can be used to extract complex networks (e.g., as in 3-triple and 4-triple patterns). Moreover, they can also be used as building blocks to design extraction patterns for other types of social networks, such as contextual networks and ego-centered networks.
A contextual social network differs from a complete network in that it covers a subset of the population defined by means of a specific context, e.g., entity type, time, location, or gender (e.g., a co-acting network of Indian actors, or influence network of intellectuals in a specific era). Given the general extraction patterns presented in this paper, specialized extraction patterns for contextual social networks can be constructed by applying additional triple patterns and/or filters that specify the desired context of a target partial network.
On the other hand, an ego-centered network is centered around a specific entity and includes its surrounding environment, e.g., a co-acting network centered around Jodie Foster, or an influence network centered around Isaac Newton. Hence, specialized extraction patterns for ego-centered social networks can be built on top of the general extraction patterns, taking into account whether the network is directed or not, and considering both ego-alter ties and alter-alter ties, as we demonstrated in a previous work [
34].
In this paper, the focus has been on the case where a single dataset is being queried at a time, that is, the described patterns have a limited scope to one dataset only (e.g., from a movie subset, or from a bibliographic resource). However, this work can be extended to tackle the case where multiple datasets can be used to extract a target social network. This can be done using the interlinking among LOD datasets, as well as using federated SPARQL queries. One of the main objectives of Linked Open Data is linking and integration among the LOD cloud datasets. “Connectivity among two or more datasets can be achieved through common
Entities,
Triples,
Literals, and
Schema Elements, while more connections can occur due to equivalence relationships between URIs, such as
owl:sameAs,
owl:equivalentProperty and
owl:equivalentClass, since many publishers use such equivalence relationships, for declaring that their URIs are equivalent with URIs of other datasets” [
35]. As most of LOD datasets are interlinked, there are considerable amounts of overlap of RDF resources within datasets in the whole LOD cloud. Thus, such overlap is also reflected onto the social networks extracted from different datasets.
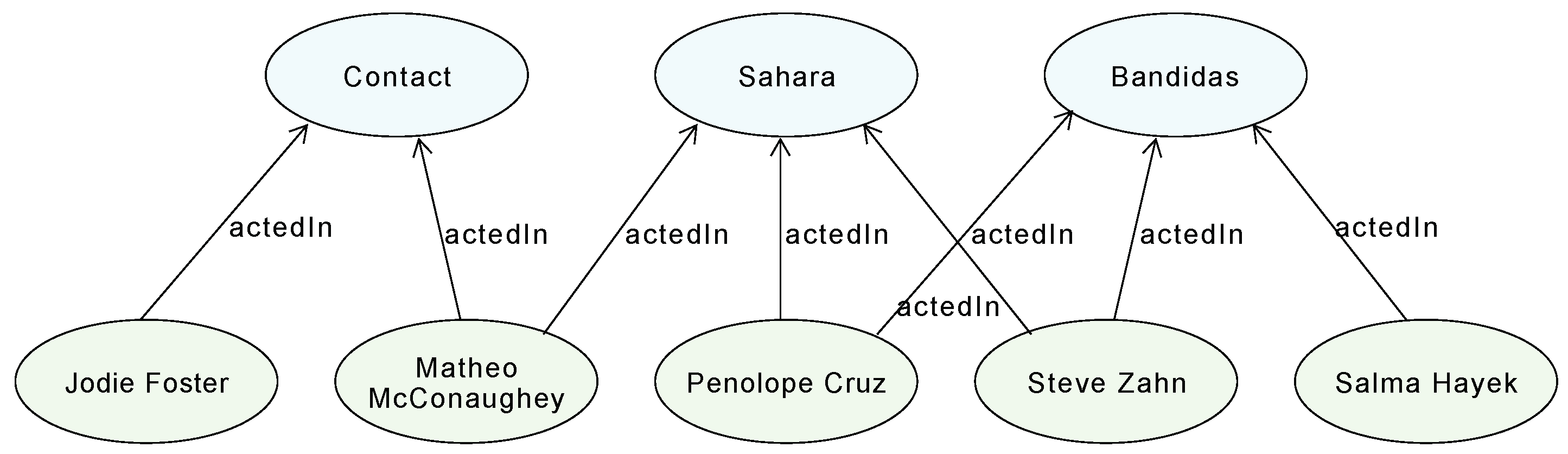
For example, consider the co-acting social network as described in the motivation example (
Section 2). This network can be extracted from YAGO dataset using the predicate
yago:actedIn (which relates an actor to a movie) with the in-2-star extraction pattern (
Section 5.3.1) as demonstrated in Example 3. In this case, the size of the network is 225,790 edges, connecting 26,544 nodes (actors).
It is also possible to extract such a network from DBpedia using the predicate
dbo:starring (which relates a movie to an actor) with the out-2-star extraction pattern (
Section 5.3.2) as mentioned in Example 4. The SPARQL query is shown in
Figure 8. In this case, the size of the network is 829,887 edges. This network is different from the one extracted from YAGO, not only in terms of the number of entities and edges, but also in terms of the entities themselves (RDF resources), as the entities in YAGO belong to the namespace
http://yago-knowledge.org/resource/, whereas the entities in DBpedia belong to the namespace
http://dbpedia.org/resource/.
Despite the differences between the two extracted networks, there are certainly many overlaps between them. For instance, the entity
yago:Brad_Pitt from yago is the same as the entity
dbr:Brad_Pitt from DBpedia (Here, the prefix
dbr refers to DBpedia resources namespace:
http://dbpedia.org/resource/). The good news is that, thanks to the interlinking of DBpedia and YAGO, such equivalences of entities are available via the OWL property
owl:sameAs. Thus, the overlap between the two co-acting social networks (from YAGO and DBpedia) can be easily detected.
Figure 9 shows another version of the previous SPARQL query (to extract the network from DBpedia) where each entity from DBpedia is associated with its equivalent entity from YAGO. The results of this query consist of 94,311 ties/edges that correspond to the intersection of the the two social networks.
It is also possible to perform such an overlap investigation using federated SPARQL queries [
16] (through
SERVICE operator) which allow for combining graph patterns that can be evaluated over several endpoints within a single query [
15].
Overall, extracting social networks from linked open data enables us to visualize those networks and study them using prominent tools of social network analysis. Besides usual types of analysis, such as connectivity and centrality, advanced analysis can be applied on extracted social networks, including e.g., community detection, diffusion dynamics, and link prediction, etc. Moreover, being extracted from linked open data, the nodes of an extracted network are LOD entities and thus can be enriched with their attributes that are readily available in the source LOD dataset. This process will turn the extracted network into a content-rich network whose nodes are associated with rich content information. For instance, consider the co-acting network when each actor is associated with extra metadata, such as country, birth date, and gender. As another example, consider the influence network of intellectuals when we associate each node (scholar) with the historical period in which he/she lived; this makes the influence network into a dynamic network and hence enables longitudinal network studies, i.e., to study how a social network develops or changes over time. In all cases, new knowledge is being generated which would be of a great interest.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}