Early Prediction of Quality Issues in Automotive Modern Industry

 , ,
, ,  and
and
Abstract
1. Introduction
2. Related Work
3. Data Presentation
3.1. Logged Vehicle Data (LVD)
3.2. Claim Data
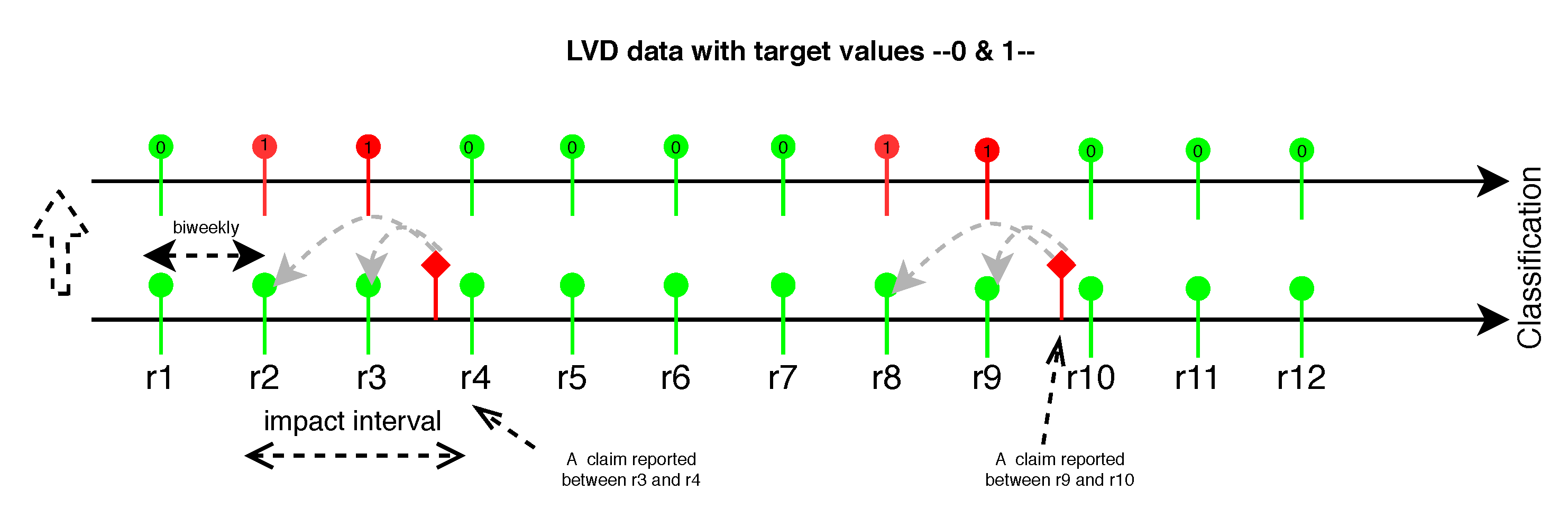
4. Problem Formulation
- First we use only claim data, without LVD, to predict the future ratio of the vehicles’ failure over time, based on how it looked in the past. The approach is based on the assumption that the patterns of reported claims that happened in the past will also continue in the future.
- Second, we have investigated the combination of the LVD and claim data, formulating it as a classification task to predict the failure ratio. Basically, the model acts based on the knowledge that can be extracted from vehicle usage to predict the upcoming failures. In this formulation, individual fault predictions are aggregated for the whole population into the failure ratio over time.
5. Approach
5.1. Approach 1: Forecasting Claim Rate Using Claim Data
5.2. Approach 2: Data Integration and Feature Engineering
5.2.1. Data Integration
5.2.2. Feature Engineering
Feature Selection
Feature Extraction
5.3. Approach 2: Forecasting Failure Rate Using LVD and Claim Data
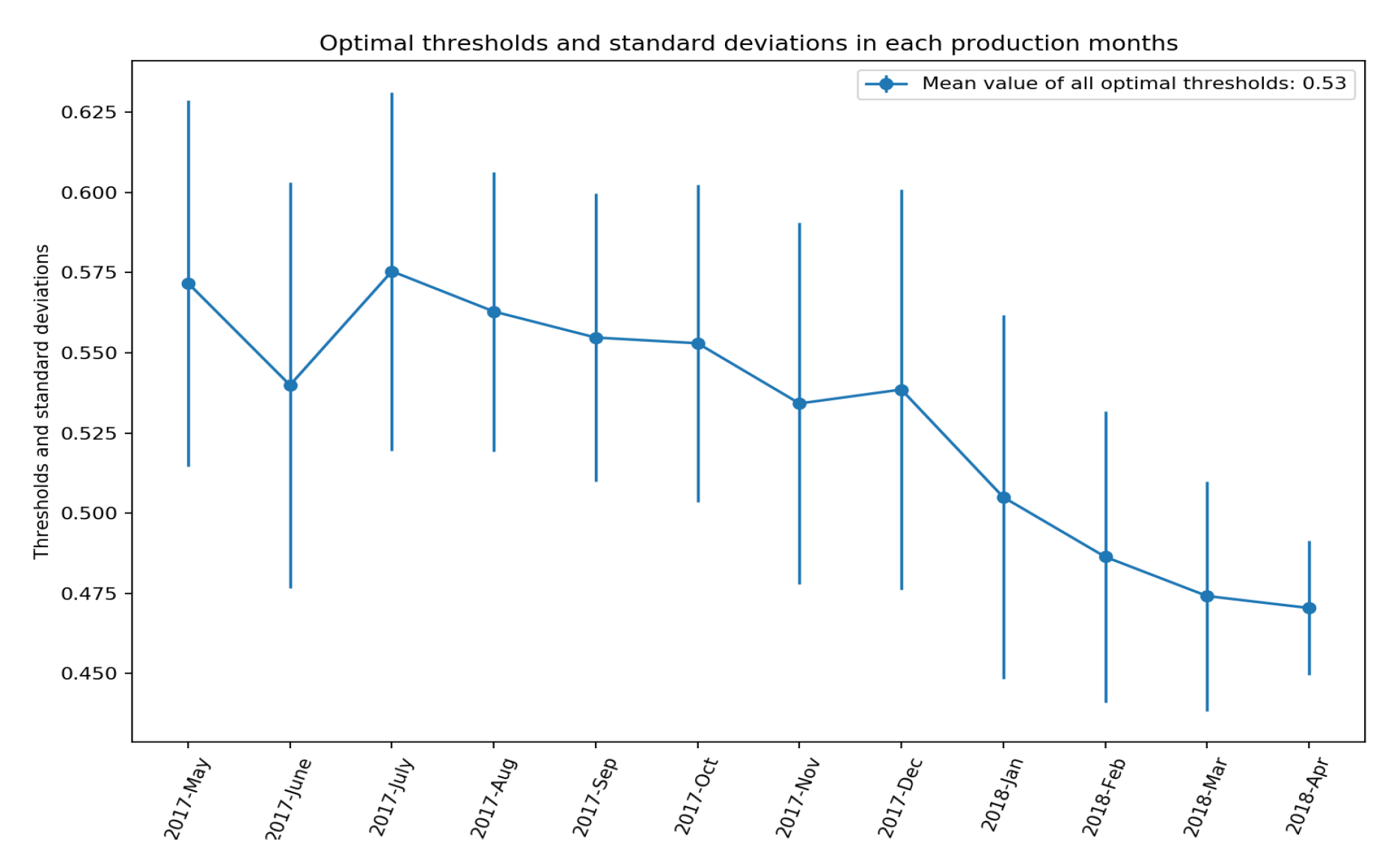
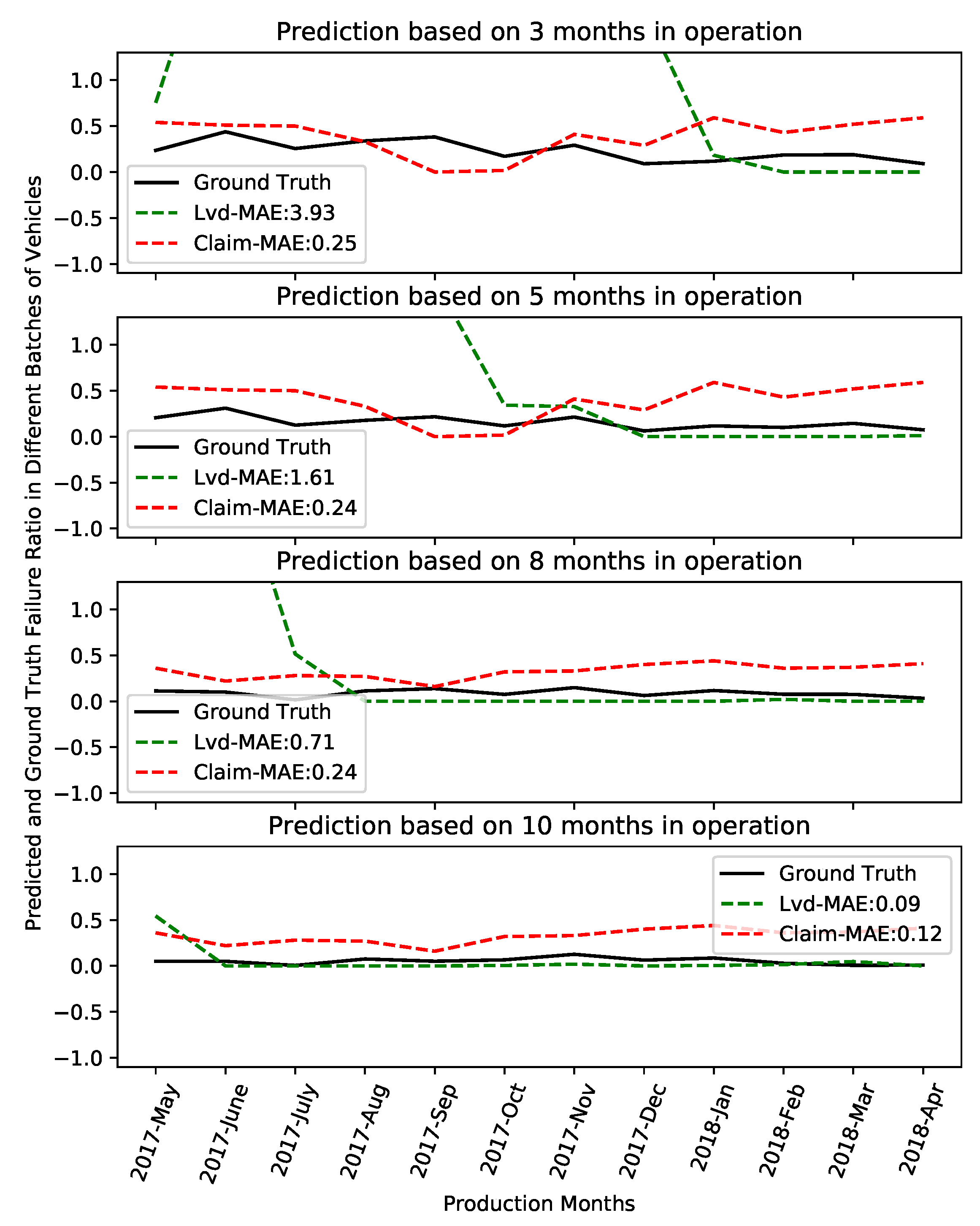
6. Experimental Evaluation and Results
7. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pickett, A.K.; Pyttel, T.; Payen, F.; Lauro, F.; Petrinic, N.; Werner, H.; Christlein, J. Failure prediction for advanced crashworthiness of transportation vehicles. Int. J. Impact Eng. 2004, 30, 853–872. [Google Scholar] [CrossRef]
- Sobie, C.; Freitas, C.; Nicolai, M. Simulation-driven machine learning: Bearing fault classification. Mech. Syst. Signal Process. 2018, 99, 403–419. [Google Scholar] [CrossRef]
- Hirschmann, D.; Tissen, D.; Schroder, S.; De Doncker, R.W. Reliability prediction for inverters in hybrid electrical vehicles. IEEE Trans. Power Electron. 2007, 22, 2511–2517. [Google Scholar] [CrossRef]
- Fink, O.; Zio, E.; Weidmann, U. Predicting component reliability and level of degradation with complex-valued neural networks. Reliab. Eng. Syst. Saf. 2014, 121, 198–206. [Google Scholar] [CrossRef]
- Boss, G.J.; Jones, A.R.; Lingafelt, C.S.; McConnell, K.C.; Moore, J.E. Predicting Vehicular Failures Using Autonomous Collaborative Comparisons to Detect Anomalies. U.S. Patent 10,109,120, 6 July 2020. [Google Scholar]
- Yang, C.; Liu, J.; Zeng, Y.; Xie, G. Prediction of components degradation using support vector regression with optimized parameters. Energy Procedia 2017, 127, 284–290. [Google Scholar] [CrossRef]
- Ding, Z.; Zhou, Y.; Pu, G.; Zhou, M. Online failure prediction for railway transportation systems based on fuzzy rules and data analysis. IEEE Trans. Reliab. 2018, 67, 1143–1158. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef]
- Jegadeeshwaran, R.; Sugumaran, V. Fault diagnosis of automobile hydraulic brake system using statistical features and support vector machines. Mech. Syst. Signal Process. 2015, 52, 436–446. [Google Scholar] [CrossRef]
- Malhotra, R.; Jain, A. Fault prediction using statistical and machine learning methods for improving software quality. J. Inf. Process. Syst. 2012, 8, 241–262. [Google Scholar] [CrossRef]
- Kalbfleisch, J.; Lawless, J.; Robinson, J. Methods for the analysis and prediction of warranty claims. Technometrics 1991, 33, 273–285. [Google Scholar] [CrossRef]
- Kleyner, A.; Sanborn, K. Modelling automotive warranty claims with build-to-sale data uncertainty. Int. J. Reliab. Saf. 2008, 2, 179–189. [Google Scholar] [CrossRef]
- Corbu, D.; Chukova, S.; O’Sullivan, J. Product warranty: Modelling with 2D-renewal process. Int. J. Reliab. Saf. 2008, 2, 209–220. [Google Scholar] [CrossRef]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; Technical Report; Advance Publication: Chapel Hill, NC, USA, 1995. [Google Scholar]
- Wasserman, G.S. An application of dynamic linear models for predicting warranty claims. Comput. Ind. Eng. 1992, 22, 37–47. [Google Scholar] [CrossRef]
- Chen, J.; Lynn, N.; Singpurwalla, N. Forecasting Warranty Claims; Advance Publication: Cranfield, UK, 1996. [Google Scholar]
- Fredette, M.; Lawless, J.F. Finite-horizon prediction of recurrent events, with application to forecasts of warranty claims. Technometrics 2007, 49, 66–80. [Google Scholar] [CrossRef]
- Singpurwalla, N.D.; Wilson, S.P. Failure models indexed by two scales. Adv. Appl. Probab. 1998, 30, 1058–1072. [Google Scholar] [CrossRef]
- Chukova, S.; Robinson, J. Estimating mean cumulative functions from truncated automotive warranty data. Mod. Stat. Math. Methods Reliab. 2005, 10, 121. [Google Scholar]
- Kleyner, A.; Sandborn, P. A warranty forecasting model based on piecewise statistical distributions and stochastic simulation. Reliab. Eng. Syst. Saf. 2005, 88, 207–214. [Google Scholar] [CrossRef]
- Wasserman, G.; Sudjianto, A. Neural networks for forecasting warranty claims. In Intelligent Engineering Systems Through Artificial Neural Networks; ASME Press: New York, NY, USA, 1996; pp. 901–906. [Google Scholar]
- Wasserman, G.S.; Sudjianto, A. A comparison of three strategies for forecasting warranty claims. IIE Trans. 1996, 28, 967–977. [Google Scholar] [CrossRef]
- Rai, B.; Singh, N. Forecasting warranty performance in the presence of the ‘maturing data’phenomenon. Int. J. Syst. Sci. 2005, 36, 381–394. [Google Scholar] [CrossRef]
- Elforjani, M.; Shanbr, S. Prognosis of bearing acoustic emission signals using supervised machine learning. IEEE Trans. Ind. Electron. 2017, 65, 5864–5871. [Google Scholar] [CrossRef]
- Teng, W.; Zhang, X.; Liu, Y.; Kusiak, A.; Ma, Z. Prognosis of the remaining useful life of bearings in a wind turbine gearbox. Energies 2017, 10, 32. [Google Scholar] [CrossRef]
- He, Y.; Han, X.; Gu, C.; Chen, Z. Cost-oriented predictive maintenance based on mission reliability state for cyber manufacturing systems. Adv. Mech. Eng. 2018, 10, 1687814017751467. [Google Scholar] [CrossRef]
- Louhichi, R.; Sallak, M.; Pelletan, J. A Cost Model for Predictive Maintenance Based on Risk-Assessment; Advance Publication: Paris, France, 2019. [Google Scholar]
- Ran, Y.; Zhou, X.; Lin, P.; Wen, Y.; Deng, R. A Survey of Predictive Maintenance: Systems, Purposes and Approaches. arXiv 2019, arXiv:1912.07383. [Google Scholar]
- Noorsuhada, M. An overview on fatigue damage assessment of reinforced concrete structures with the aid of acoustic emission technique. Constr. Build. Mater. 2016, 112, 424–439. [Google Scholar] [CrossRef]
- Remaining useful life estimation based on nonlinear feature reduction and support vector regression. Eng. Appl. Artif. Intell. 2013, 26, 1751–1760. [CrossRef]
- Bearing fault prognostics using Rényi entropy based features and Gaussian process models. Mech. Syst. Signal Process. 2015, 52–53, 327–337. [CrossRef]
- Kalbfleisch, J.; Lawless, J. Statistical analysis of warranty claims data. In Product Warranty Handbook; CRC Press: Boca Raton, FL, USA, 1996; pp. 231–259. [Google Scholar]
- Karim, R.; Suzuki, K. Analysis of warranty claim data: A literature review. In Advanced Reliability Modeling; World Scientific: Singapore, 2004; pp. 229–236. [Google Scholar]
- Lawless, J. Statistical analysis of product warranty data. Int. Stat. Rev. 1998, 66, 41–60. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Gontarz, S.; Lin, J.; Radkowski, S.; Dybala, J. A model-based method for remaining useful life prediction of machinery. IEEE Trans. Reliab. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- You, M.Y.; Liu, F.; Wang, W.; Meng, G. Statistically planned and individually improved predictive maintenance management for continuously monitored degrading systems. IEEE Trans. Reliab. 2010, 59, 744–753. [Google Scholar] [CrossRef]
- Nowaczyk, S.; Prytz, R.; Rögnvaldsson, T.; Byttner, S. Towards a machine learning algorithm for predicting truck compressor failures using logged vehicle data. In Proceedings of the 12th Scandinavian Conference on Artificial Intelligence, Aalborg, Denmark, 20–22 November 2013; IOS Press: Amsterdam, The Netherlands, 2013; pp. 205–214. [Google Scholar]
- Prytz, R.; Nowaczyk, S.; Rögnvaldsson, T.; Byttner, S. Predicting the need for vehicle compressor repairs using maintenance records and logged vehicle data. Eng. Appl. Artif. Intell. 2015, 41, 139–150. [Google Scholar] [CrossRef]
- Khoshkangini, R.; Pashami, S.; Nowaczyk, S. Warranty Claim Rate Prediction Using Logged Vehicle Data. In EPIA Conference on Artificial Intelligence; Springer: Berlin, Germany, 2019; pp. 663–674. [Google Scholar]
- Behrens, T.; Zhu, A.X.; Schmidt, K.; Scholten, T. Multi-scale digital terrain analysis and feature selection for digital soil mapping. Geoderma 2010, 155, 175–185. [Google Scholar] [CrossRef]
- Yang, Y.; Pedersen, J.O. A comparative study on feature selection in text categorization. ICML 1997, 97, 35. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Rögnvaldsson, T.; Nowaczyk, S.; Byttner, S.; Prytz, R.; Svensson, M. Self-monitoring for maintenance of vehicle fleets. Data Min. Knowl. Discov. 2018, 32, 344–384. [Google Scholar] [CrossRef]
- Khoshkangini, R.; Berck, P.; Gholami, S.; Pashami, S.; Nowaczyk, S. Prediction of Field Reliability Deviation from Logged Vehicle Data; Submitted ICDM; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Schein, A.I.; Popescul, A.; Ungar, L.H.; Pennock, D.M. Methods and metrics for cold-start recommendations. In Proceedings of the 25th Annual International ACM SIGIR Conference On Research and Development in Information Retrieval, Tampere, Finland, 11–15 August 2002; ACM: New York, NY, USA, 2002; pp. 253–260. [Google Scholar]
- Hahn, P.R.; Murray, J.S.; Carvalho, C.M. Bayesian regression tree models for causal inference: Regularization, confounding, and heterogeneous effects. In Bayesian Analysis; Advance Publication: Staten Island, NY, USA, 2020. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Three Months | Five Months | Eight Months | Ten Months | ||
|---|---|---|---|---|---|
| Claim | MAE | 0.25 | 0.24 | 0.24 | 0.12 |
| LVD | MAE | 3.9 | 1.61 | 0.70 | 0.08 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khoshkangini, R.; Sheikholharam Mashhadi, P.; Berck, P.; Gholami Shahbandi, S.; Pashami, S.; Nowaczyk, S.; Niklasson, T. Early Prediction of Quality Issues in Automotive Modern Industry. Information 2020, 11, 354. https://doi.org/10.3390/info11070354
Khoshkangini R, Sheikholharam Mashhadi P, Berck P, Gholami Shahbandi S, Pashami S, Nowaczyk S, Niklasson T. Early Prediction of Quality Issues in Automotive Modern Industry. Information. 2020; 11(7):354. https://doi.org/10.3390/info11070354
Chicago/Turabian StyleKhoshkangini, Reza, Peyman Sheikholharam Mashhadi, Peter Berck, Saeed Gholami Shahbandi, Sepideh Pashami, Sławomir Nowaczyk, and Tobias Niklasson. 2020. "Early Prediction of Quality Issues in Automotive Modern Industry" Information 11, no. 7: 354. https://doi.org/10.3390/info11070354
APA StyleKhoshkangini, R., Sheikholharam Mashhadi, P., Berck, P., Gholami Shahbandi, S., Pashami, S., Nowaczyk, S., & Niklasson, T. (2020). Early Prediction of Quality Issues in Automotive Modern Industry. Information, 11(7), 354. https://doi.org/10.3390/info11070354