TEEDA: An Interactive Platform for Matching Data Providers and Users in the Data Marketplace


Abstract
1. Introduction
- Description items of the users’ calls for data as data requests;
- A platform where the data information (users’ data requests and providable data of data providers) converges.
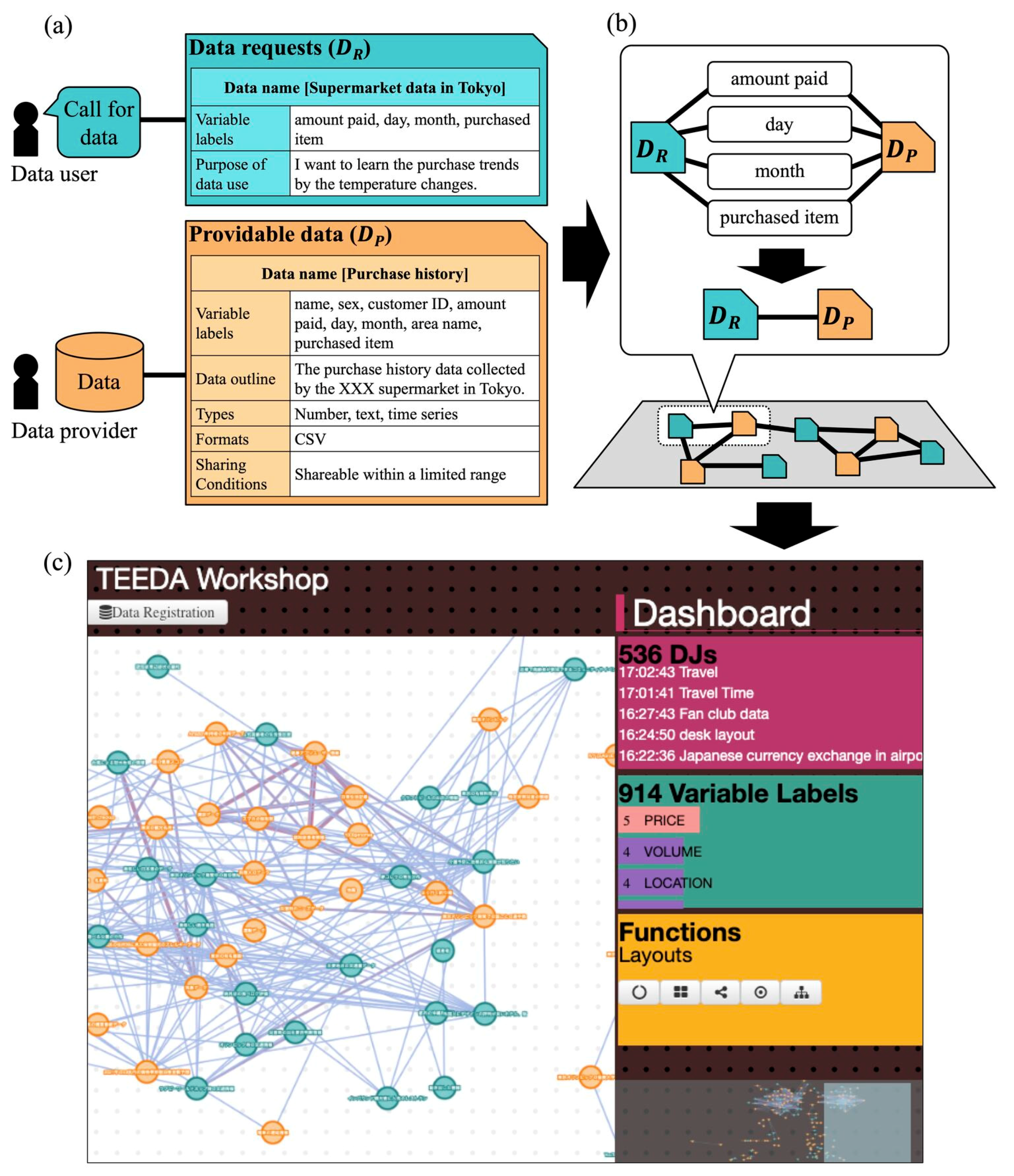
2. Design and Implementation
2.1. Description Items to Share Data Requests
2.2. A Platform to Match Data Requests and Providable Data
3. Experimental Details
4. Results and Discussion
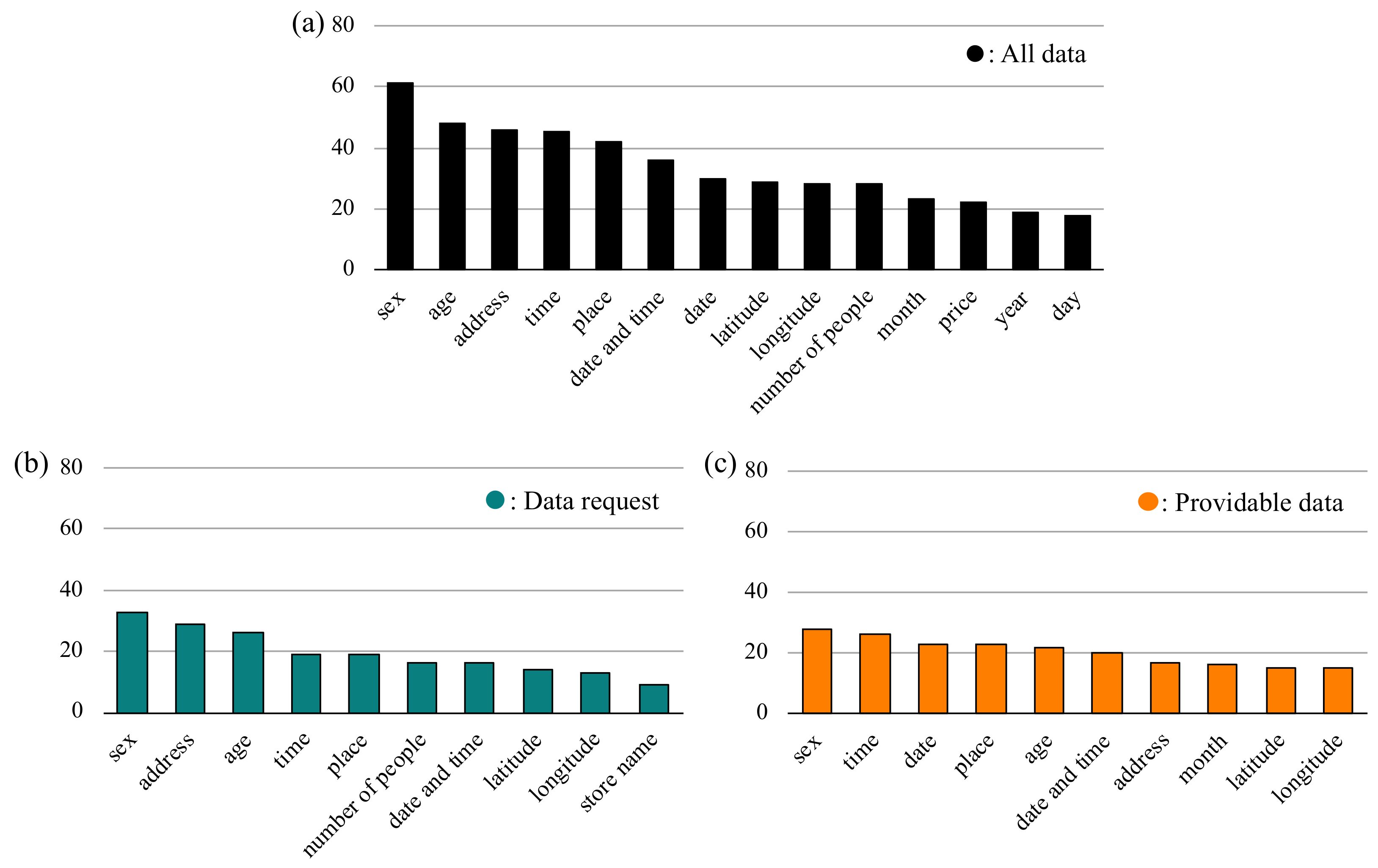
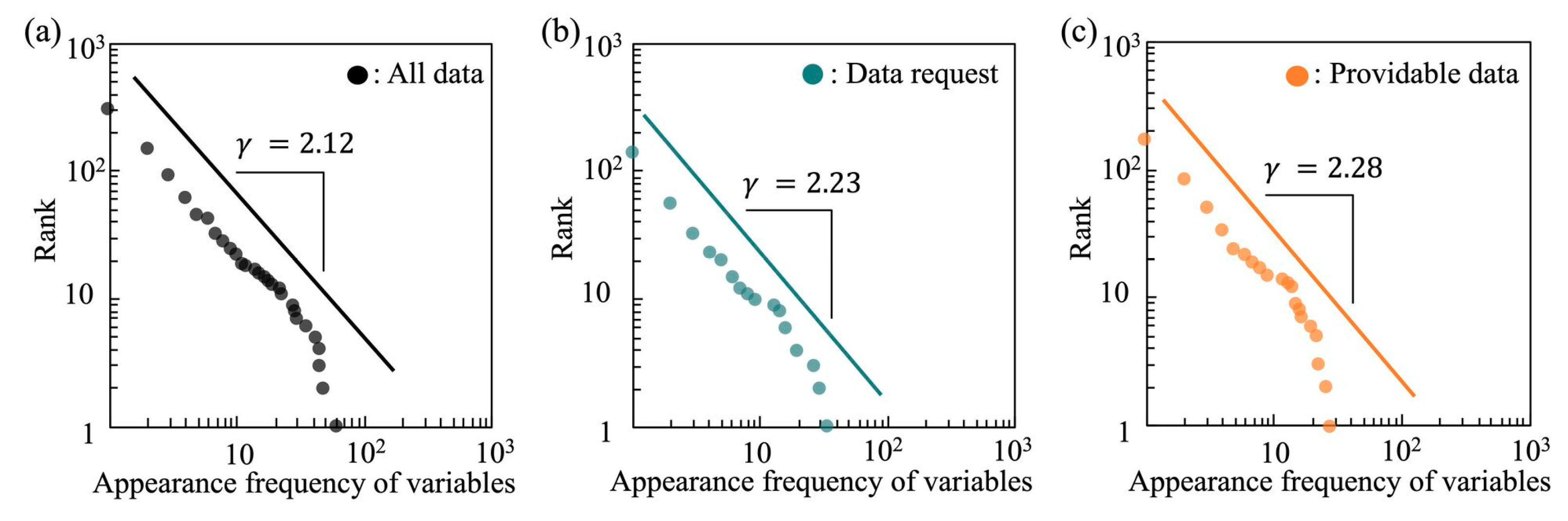
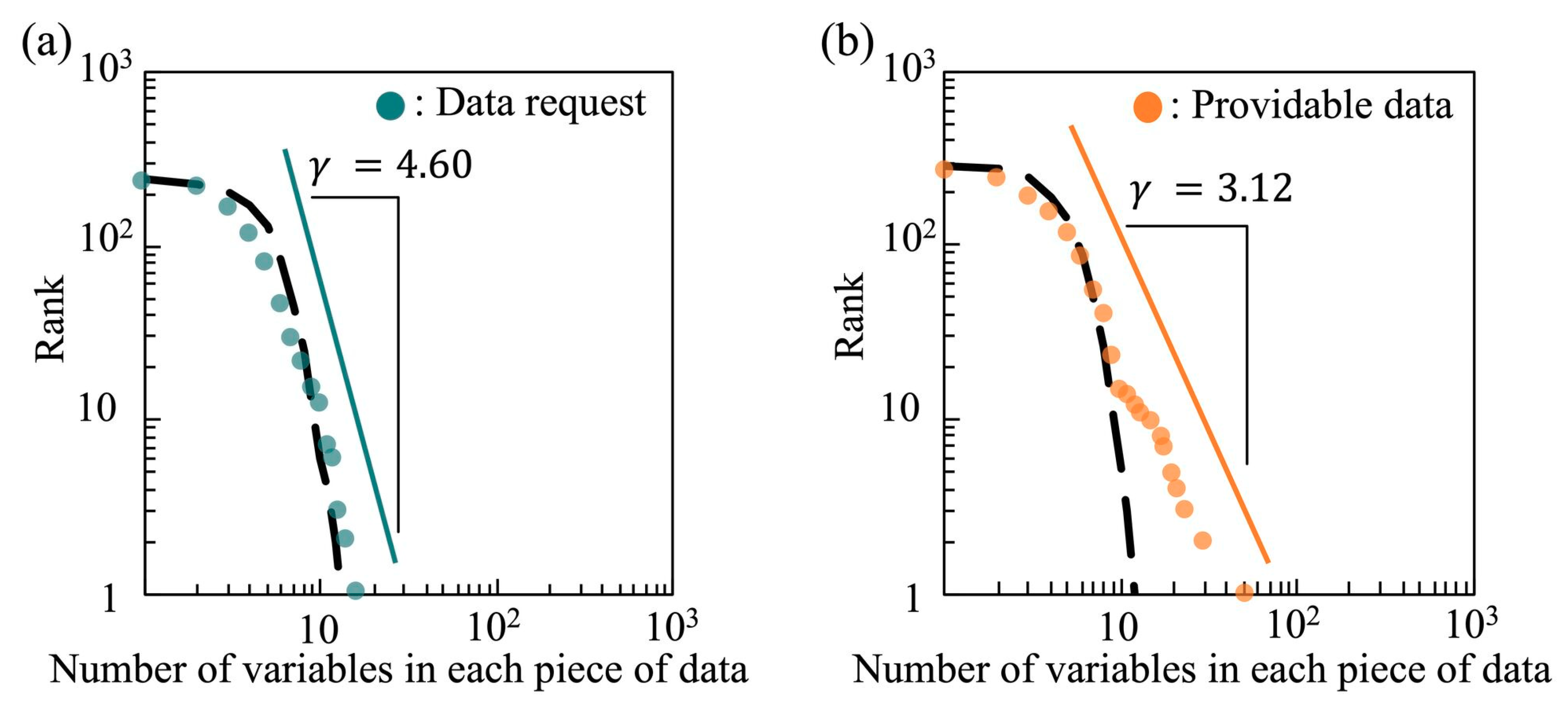
4.1. Structural Characteristics of Data Requests and Providable Data
4.2. Distributions and Matching Possibility
4.3. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, H.A. Big Data: The Next Frontier for Innovation, Competition and Productivity; McKinsey Global Institute: Washington, DC, USA, 2011. [Google Scholar]
- Chui, M.; Manyika, J.; Miremadi, M.; Henke, N.; Chung, R.; Nel, P.; Malhotra, S. Notes from the AI Frontier: Applications and Value of Deep Learning; McKinsey Global Institute: Washington, DC, USA, 2018. [Google Scholar]
- Balazinska, M.; Howe, B.; Suciu, D. Data markets in the cloud: An opportunity for the database community. Proc. VLDB Endow. 2011, 4, 1482–1485. [Google Scholar]
- Ellram, M.L.; Tate, L.W. The use of secondary data in purchasing and supply management (P/SM) research. J. Purch. Supply Manag. 2016, 22, 250–254. [Google Scholar] [CrossRef]
- Ohsawa, Y.; Hayashi, T.; Kido, H. Restructuring incomplete models in innovators marketplace on data jackets. In Springer Handbook of Model-Based Science; Springer: Cham, Switzerland, 2017; pp. 1015–1031. [Google Scholar] [CrossRef]
- Short, E.J.; Todd, S. What’s your data worth? MIT Sloan Manag. Rev. 2017, 58, 17–19. [Google Scholar]
- Liang, F.; Yu, W.; An, D.; Yang, Q.; Fu, X.; Zhao, W. A survey on big data market: Pricing, trading and protection. IEEE Access 2018, 6, 15132–15154. [Google Scholar] [CrossRef]
- Mano, H. EverySense: An end-to-end IoT market platform. In Proceedings of the 13th International Conference on Mobile and Ubiquitous Systems: Computing Networking and Services, Hiroshima, Japan, 28 November–1 December 2016; ACM: New York, NY, USA, 2016; pp. 1–5. [Google Scholar]
- Ejiri, Y.; Ikeda, E.; Sasaki, H. Realization of data exchange and utilization society by blockchain and data jacket: Merit of consortium to accelerate co-creation. In Proceedings of the IEEE International Conference on Data Mining Workshops, Singapore, 17–20 November 2018; pp. 180–182. [Google Scholar] [CrossRef]
- Dai, W.; Daia, C.; Choo, R.K.; Cui, C.; Zou, D.; Jin, H. SDTE: A secure blockchain-based data trading ecosystem. IEEE Trans. Inf. Forensics Secur. 2019, 45–48. [Google Scholar] [CrossRef]
- Yagihashi, T. Social Data Platform, D-Ocean. In Proceedings of the IEEE International Conference on Data Mining Workshops, Beijing, China, 8–11 November 2019; pp. 45–48. [Google Scholar] [CrossRef]
- Zhao, L.; Ichise, R. Ontology integration for linked data. J. Data Semant. 2014, 3, 237–254. [Google Scholar] [CrossRef]
- Euzenat, J.; Shvaiko, P. Ontology Matching; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Hayashi, T.; Ohsawa, Y. Retrieval system for data utilization knowledge integrating stakeholders’ interests. In Proceedings of the AAAI Spring Symposium Series, Beyond Machine Intelligence: Understanding Cognitive Bias and Humanity for Well-being AI, Palo Alto, CA, USA, 26–28 March 2018. [Google Scholar]
- Iwasa, D.; Hayashi, T.; Ohsawa, Y. Development and evaluation of a new platform for accelerating cross-domain data exchange and cooperation. New Gener. Comput. 2019, 1–32. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Deshpande, A.; Elmore, J.A.; Karger, D.; Madden, S.; Parameswaran, A.; Subramanyam, H.; Wu, E.; Zhang, R. Collaborative data analytics with DataHub. In Proceedings of the 41st International Conference on Very Large Data Bases, Kohala Coast, HI, USA, 31 August–4 September 2015; Volume 8, pp. 1916–1919. [Google Scholar] [CrossRef]
- Kandogan, E.; Roth, M.; Schwarz, P.; Hui, J.; Terrizzano, I.; Christodoulakis, C.; Miller, J.R. Labbook: Metadata-driven social collaborative data analysis. In Proceedings of the IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015. [Google Scholar] [CrossRef]
- Boisot, M.; Canals, A. Data, Information and knowledge: Have we got it right? J. Evol. Econ. 2004, 14, 43–67. [Google Scholar] [CrossRef]
- Spiekermann, M. Data marketplaces: Trends and monetisation of data goods. Intereconomics 2019, 54, 208–216. [Google Scholar] [CrossRef]
- Sooksatra, K.; Li, W.; Mei, B.; Alrawais, A.; Wang, S.; Yu, J. Solving data trading dilemma with asymmetric incomplete information using zero-determinant strategy. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Tianjin, China, 20–22 June 2018; pp. 425–437. [Google Scholar] [CrossRef]
- Aperjis, C.; Huberman, A.B. A market for unbiased private data: Paying individuals according to their privacy attitudes. SSRN Electron. J. 2012. [Google Scholar] [CrossRef]
- Niu, C.; Zheng, Z.; Wu, F.; Gao, X.; Chen, G. Achieving data truthfulness and privacy preservation in data markets. IEEE Trans. Knowl. Data Eng. 2019, 31, 105–119. [Google Scholar] [CrossRef]
- Zheng, Z.; Peng, Y.; Wu, F.; Tang, S.; Chen, G. An online pricing mechanism for mobile crowdsensing data markets. In Proceedings of the 18th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Chennai, India, 10–14 July 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Shen, Y.; Guo, B.; Shen, Y.; Duan, X.; Dong, X.; Zhang, H. A pricing model for big personal data. Tsinghua Sci. Tech. 2016, 21, 482–490. [Google Scholar] [CrossRef]
- Hayashi, T.; Ohsawa, Y. Understanding the structural characteristics of data platforms using metadata and a network approach. IEEE Access 2020, 8, 35469–35481. [Google Scholar] [CrossRef]
- Christen, P. Data Matching; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Gale, D.; Shapley, L. College administrations and the stability of marriage. Am. Math. Mon. 1962, 69, 9–15. [Google Scholar] [CrossRef]
- Cao, X.; Chen, Y.; Liu, J.K. Data trading with multiple owners, collectors, and users: An iterative auction mechanism. IEEE Trans. Signal Inf. Process. Netw. 2017, 3, 268–281. [Google Scholar] [CrossRef]
- Katz, M.L. Multisided platforms, big data, and a little antitrust policy. Rev. Ind. Organ. 2019, 54, 695–716. [Google Scholar] [CrossRef]
- Nie, Y.; Han, X. Research on consumers’ protection in advantageous operation of big data brokers. Clust. Comput. 2019, 22, 8387–8400. [Google Scholar] [CrossRef]
- Ostrovsky, M. Stability in supply chain networks. Am Econ Rev. 2008, 98, 897–923. [Google Scholar] [CrossRef]
- Crawford, P.V.; Knoer, M.E. Job matching with heterogeneous firms and workers. Econometrica 1981, 49, 437–450. [Google Scholar] [CrossRef]
- Babbie, E. The Basics of Social Research, 7th ed.; Cengage Learning: Boston, MA, USA, 2016. [Google Scholar]
- Hayashi, T.; Ohsawa, Y. Inferring variable labels using outlines of data in data jackets by considering similarity and co-occurrence. Int. J. Data Sci. Anal. 2018, 6, 351–361. [Google Scholar] [CrossRef]
- Ohsawa, Y.; Kido, H.; Hayashi, T.; Liu, C. Data jackets for synthesizing values in the market of data. In Proceedings of the 17th International Conference in Knowledge Based and Intelligent Information and Engineering Systems, Procedia Computer Science, Kitakyushu, Japan, 9–11 September 2013; Volume 22, pp. 709–716. [Google Scholar]
- Poggi, A.; Lembo, D.; Calvanese, D.; De Giacomo, G.; Lenzerini, M.; Rosati, R. Linking data to ontologies. J. Data Semant. X 2008, 4900, 133–173. [Google Scholar]
- Nikolaou, C.; Grau, C.B.; Kostylev, V.E.; Kaminski, M.; Horrocks, I. Satisfaction and implication of integrity constraints in ontology-based data access. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macau, China, 10–16 August 2019; pp. 1829–1835. [Google Scholar] [CrossRef]
- Cima, G.; Lenzerini, M.; Poggi, A. Semantic characterization of data services through ontologies. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macau, China, 10–16 August 2019; pp. 1647–1653. [Google Scholar] [CrossRef]
- Newman, M.E.J. Power laws, Pareto distributions and Zipf’s law. Contem Phys. 2007, 46, 323–351. [Google Scholar] [CrossRef]
- Shapiro, S.; Wilk, M. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Hayashi, T.; Ohsawa, Y. Growth processes of variable-and context-based data networks using data jackets. In Proceedings of the 3rd International Workshop on Language Sense on Computer in IJCAI2019, Macau, China, 19–20 August 2019. [Google Scholar]
- Uehara, N.; Hayashi, T.; Ohsawa, Y. Evaluation of the similarity of data using data jackets based on users’ recognition. In Proceedings of the 23rd International Conference on Knowledge Based and Intelligent Information and Engineering System (KES2019), Budapest, Hungary, 4–6 September 2019. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Field Name | Description |
|---|---|---|
| Data request | Data name * | The name of requested data |
| Variables * | A set of variables in requested data | |
| Purpose of data use | Intended use or purpose of requested data | |
| Providable data | Data name * | The name of providable data |
| Variables * | A set of variables in the providable data | |
| Data outline | Detailed information on the providable data | |
| Types | The types of data (e.g., text, number, table) | |
| Formats | The formats of data (e.g., CSV, PDF, JSON) | |
| Sharing conditions | The conditions for data providers to exchange data with, or provide data to, other parties |
| Data Request | Providable Data | |
|---|---|---|
| No. of data items | 248 | 288 |
| No. of variables | 1181 | 1606 |
| Types of variables | 779 | 1081 |
| Maximum no. of variables in data | 16 | 52 |
| Minimum no. of variables in data | 1 | 1 |
| Average no. of variables in data | 4.76 | 5.58 |
| Data Request | Providable Data | No. of Variables in Common |
|---|---|---|
| Human-related data | Human data | 5 |
| Laptop performance data | Laptop performance data | 5 |
| Stock information of convenience stores | Stock information of shops | 5 |
| Health conditions of employees | Human data | 5 |
| Brand image of products | Customers’ media contact data | 4 |
| Type of Data Combination | No. of Links | |
|---|---|---|
| Data request | Data request | 1992 |
| Providable data | Providable data | 2345 |
| Data request | Providable data | 4336 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hayashi, T.; Ohsawa, Y. TEEDA: An Interactive Platform for Matching Data Providers and Users in the Data Marketplace. Information 2020, 11, 218. https://doi.org/10.3390/info11040218
Hayashi T, Ohsawa Y. TEEDA: An Interactive Platform for Matching Data Providers and Users in the Data Marketplace. Information. 2020; 11(4):218. https://doi.org/10.3390/info11040218
Chicago/Turabian StyleHayashi, Teruaki, and Yukio Ohsawa. 2020. "TEEDA: An Interactive Platform for Matching Data Providers and Users in the Data Marketplace" Information 11, no. 4: 218. https://doi.org/10.3390/info11040218
APA StyleHayashi, T., & Ohsawa, Y. (2020). TEEDA: An Interactive Platform for Matching Data Providers and Users in the Data Marketplace. Information, 11(4), 218. https://doi.org/10.3390/info11040218