A Novel Method for Twitter Sentiment Analysis Based on Attentional-Graph Neural Network


Abstract
1. Introduction
- AGN-TSA is a neural-network-based method which takes both the tweet-text data and the user-connection data into account, which to the best of our knowledge is the first time such an attempt has been made.
- We bridge the gap between graph neural networks (GNN) and TSA by designing a three-layered network with an integrated loss function for regularization, which guarantees the structural-controllability to satisfy different needs for analysis.
- AGN-TSA is tested extensively based on a real-world Twitter dataset concerning the 2016 presidential election in America, where empirically-optimized settings for parameters are given.
2. Related Works
2.1. Related Works Regarding Twitter Sentiment Analysis
2.2. Related Works Regarding Graph Neural Network
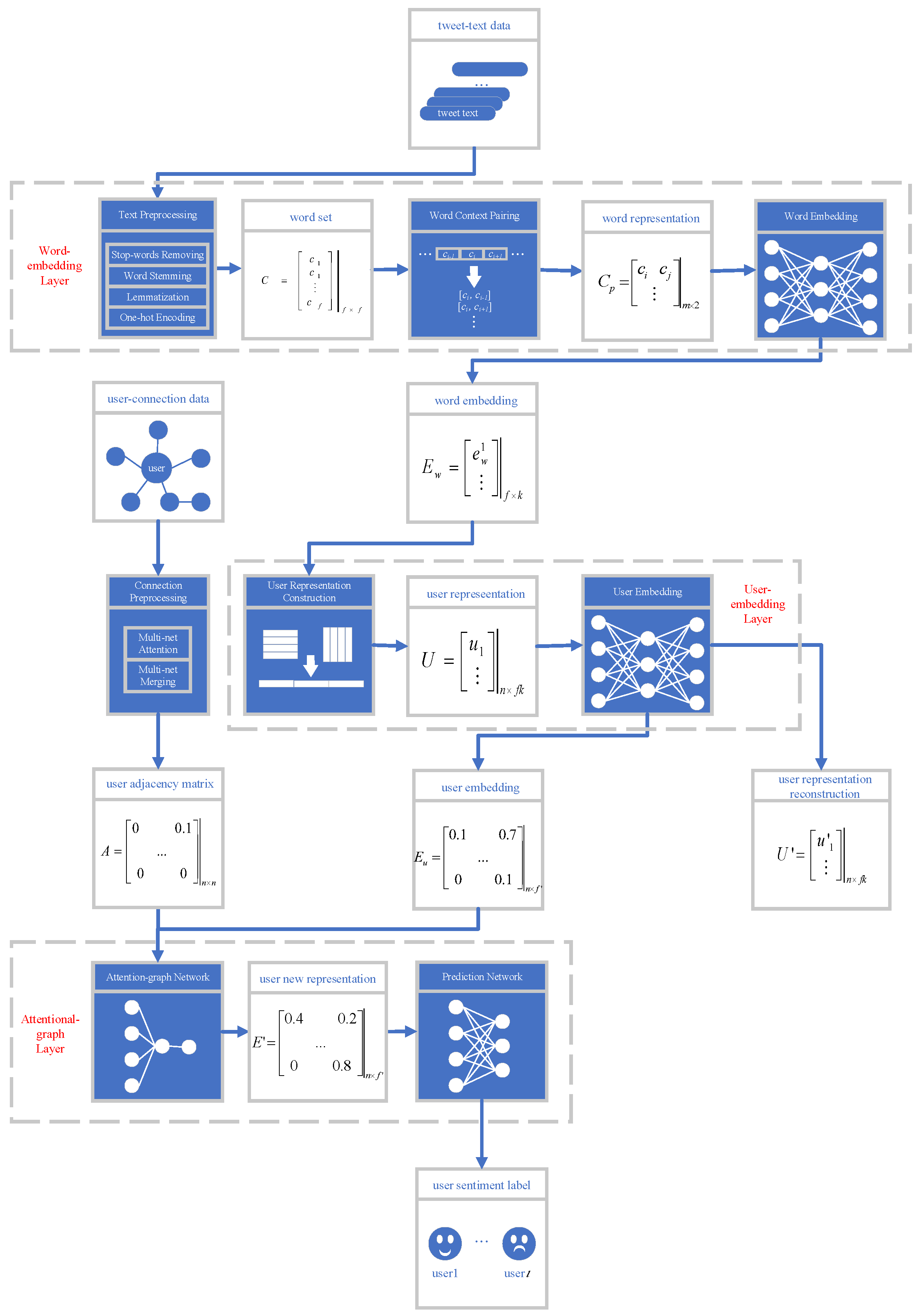
3. Methodology Explanation
3.1. Method Viability
3.2. AGN-TSA Structure
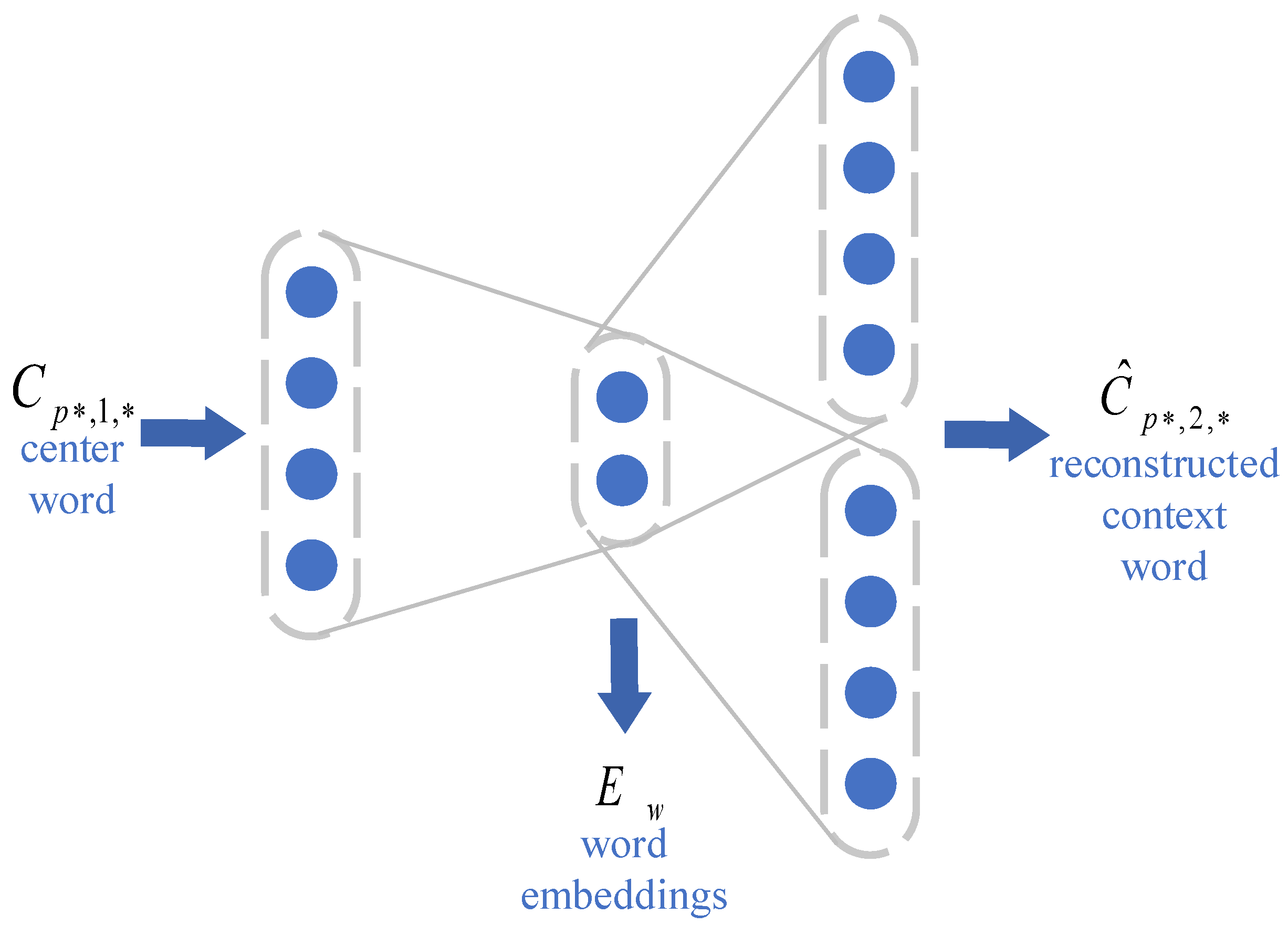
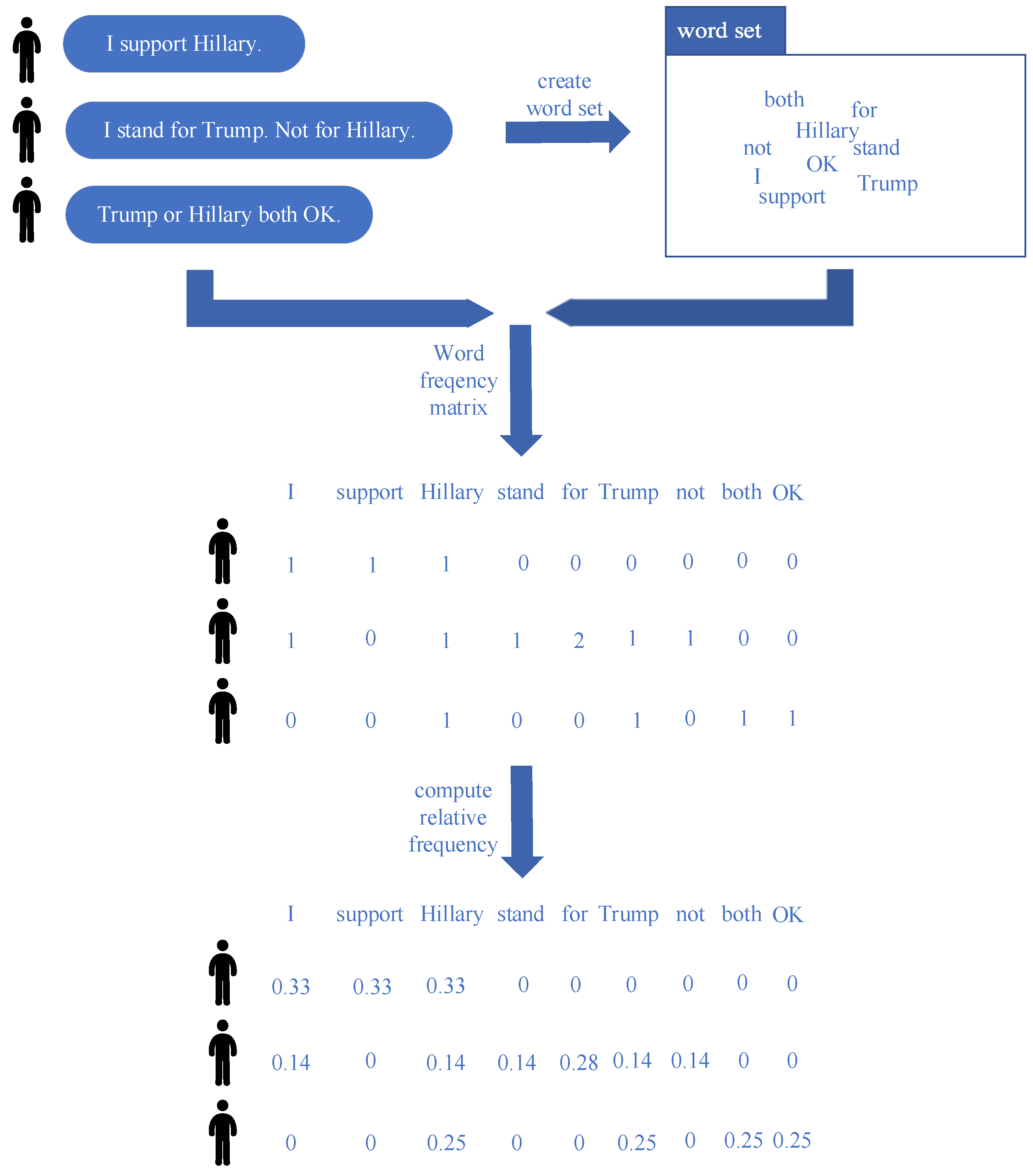
3.2.1. The Word-Embedding Layer
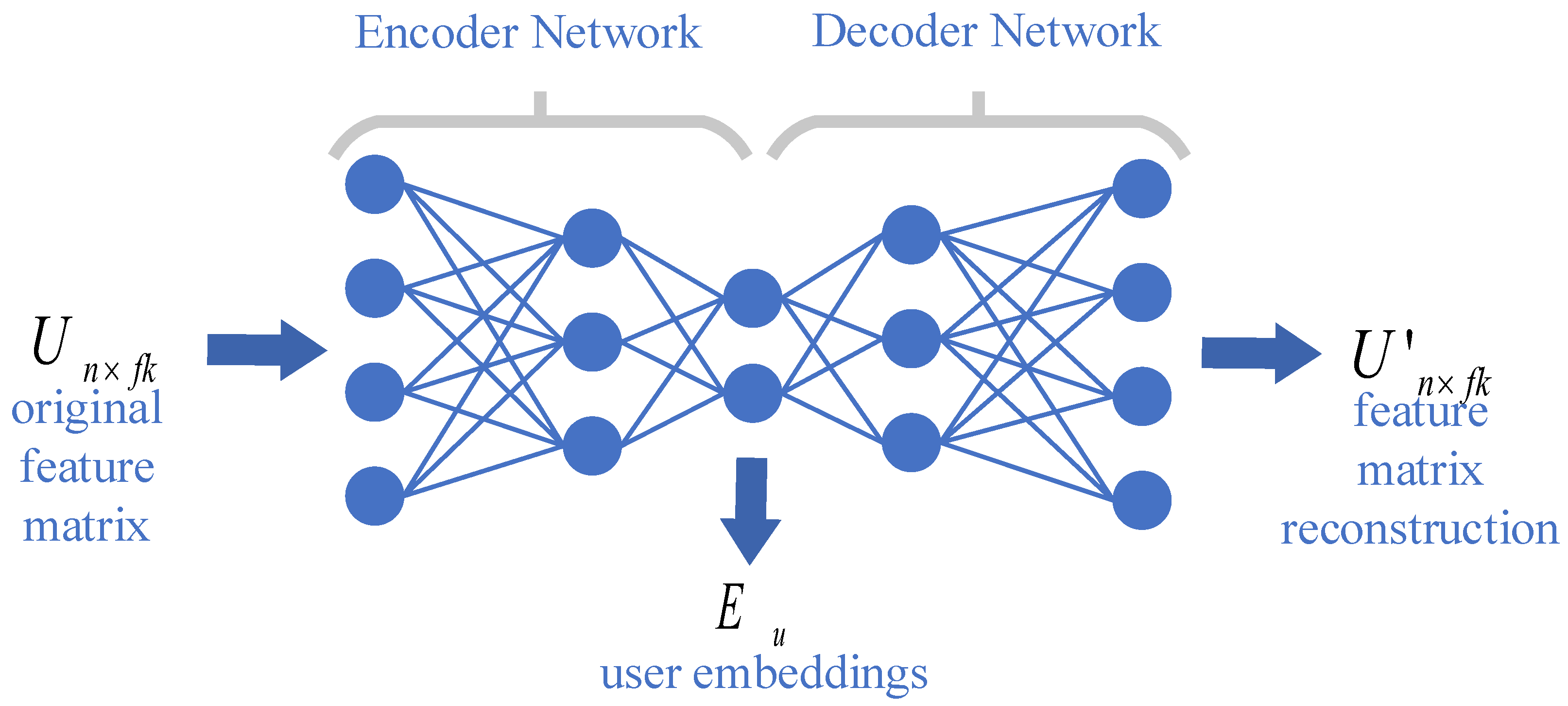
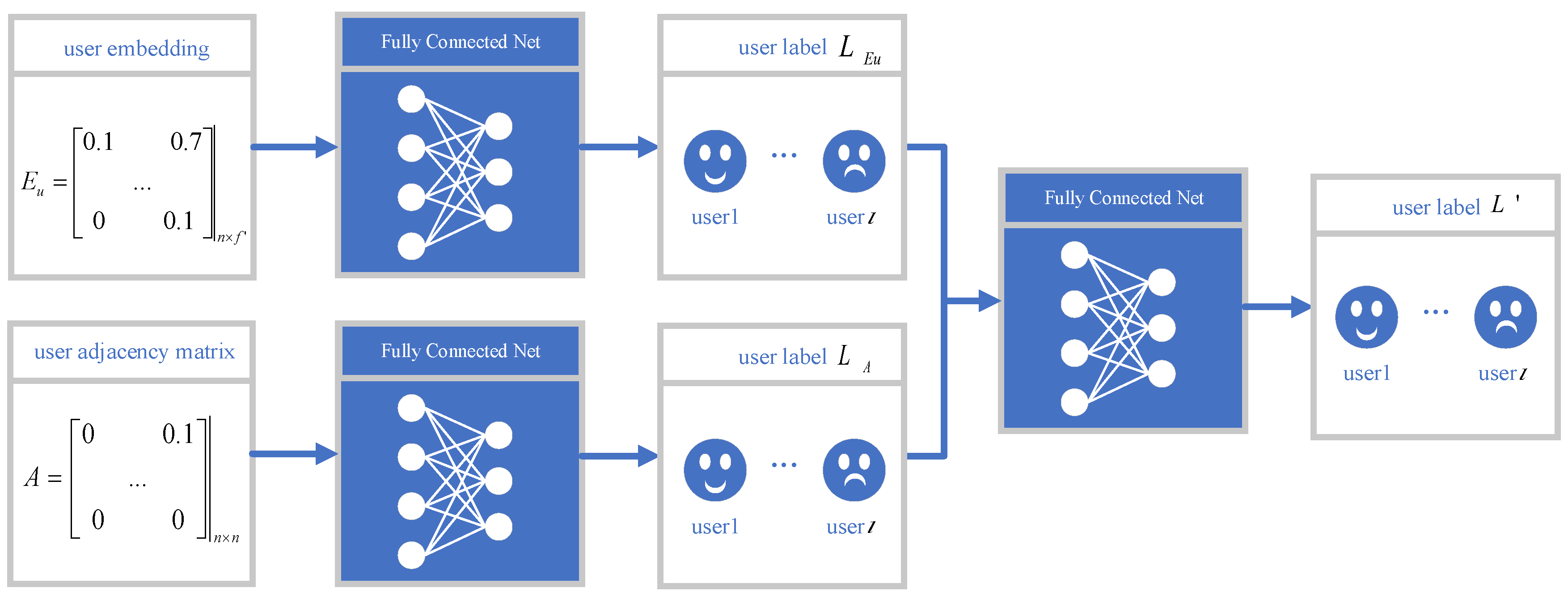
3.2.2. The User-Embedding Layer
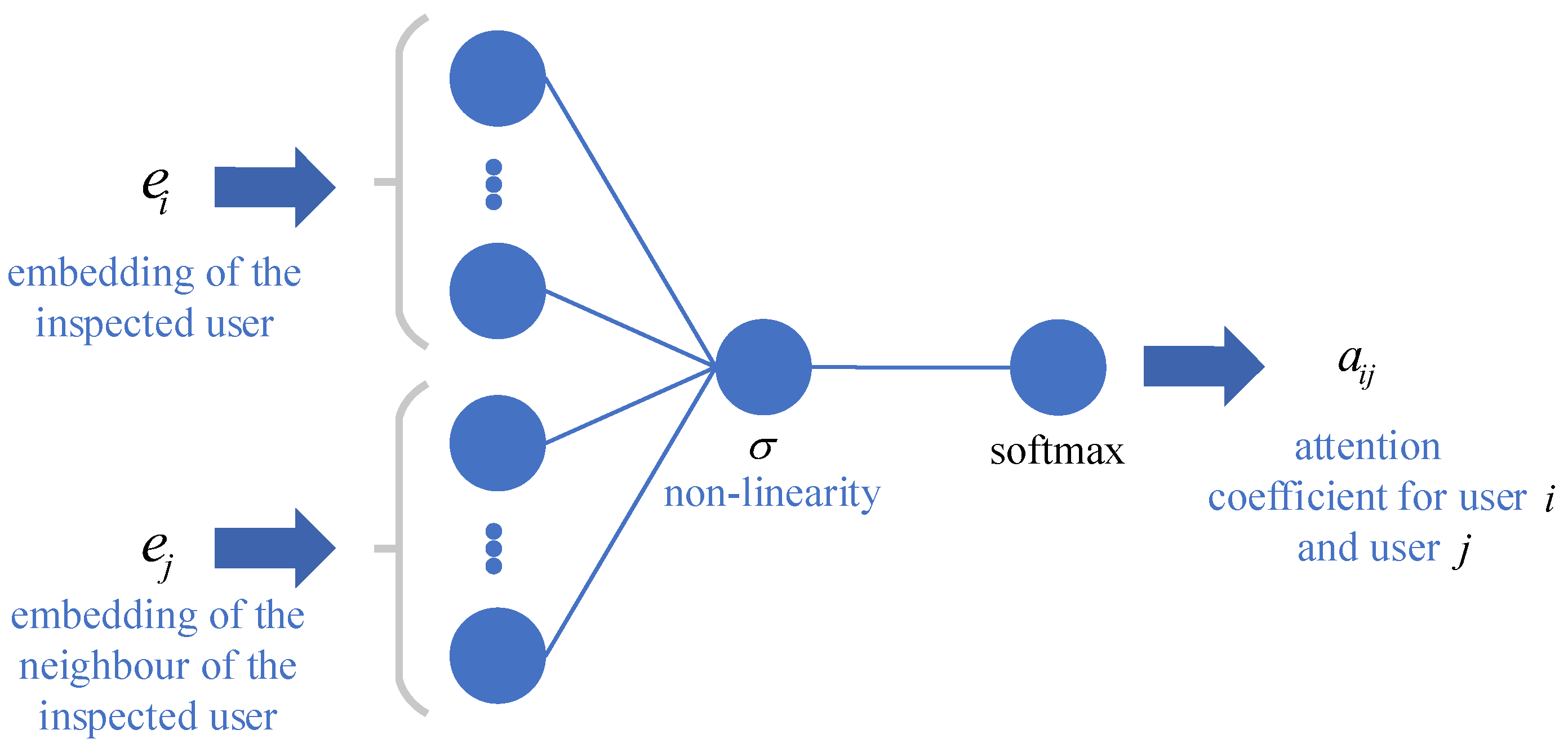
3.2.3. The Attentional-Graph Layer
3.3. The Back Propagation Process
4. Experiments and Analysis
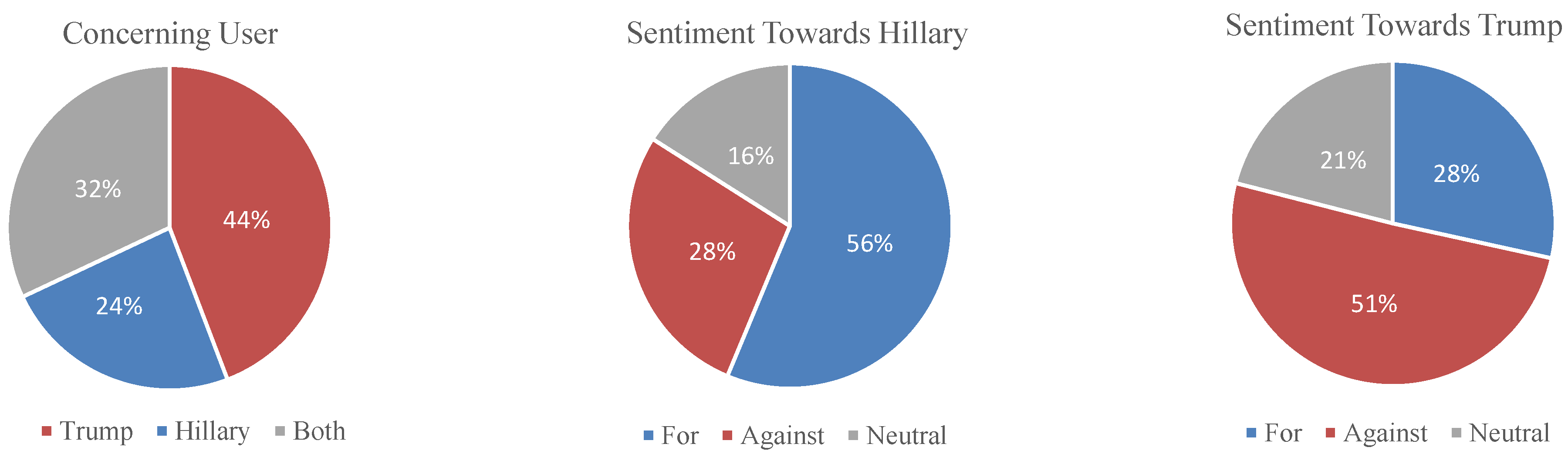
4.1. Experiment Configuration
4.2. Experiment Results and Analysis
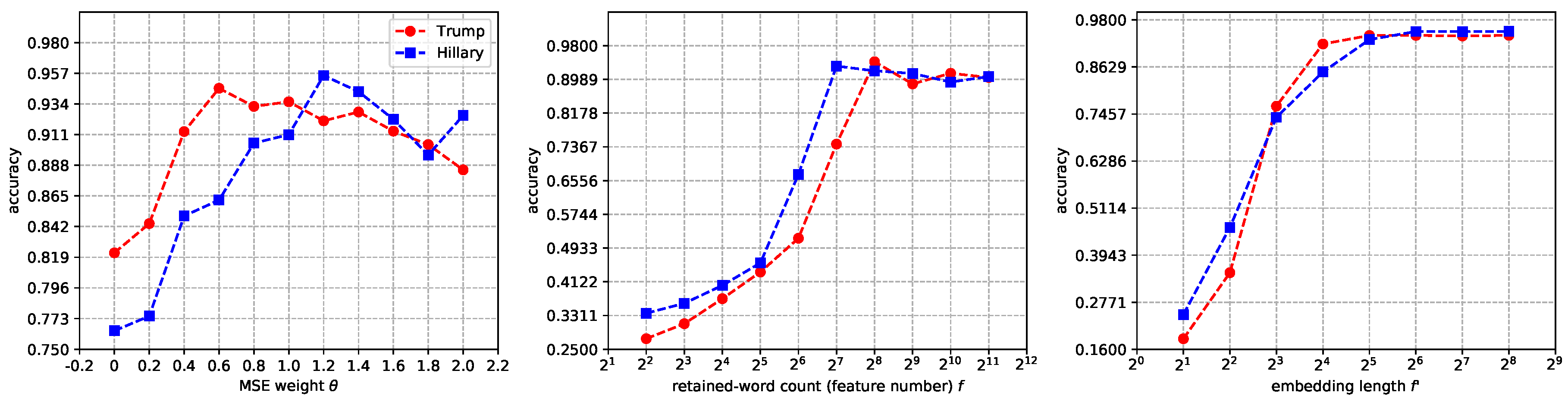
4.2.1. Parameter Rotation Experiment
4.2.2. Word-Embedding Method Experiment
4.2.3. Method Contrasting Experiment
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| TSA | Twitter Sentiment Analysis |
| AGN-TSA | Twitter Sentiment Analyzer base on Attentional-graph Neural Network |
| CNN | Convolutional Neural Network |
| GNN | Graph Neural Network |
| GAT | Graph Attention Network |
| SGD | Stochastic Gradient Descent |
| ReLU | Rectified Linear Unit |
| NBC | Naïve Bayes Classifier |
| DCT | Decision Tree |
| SVM | Support Vector Machine |
| RDF | Random Forest |
| DSF | Decision-stage-fusion Framework |
Appendix A. Autoencoder for Word-Embedding Layer

Appendix B. Decision-Stage-Fusion Framework

References
- Twitter Transparency Report. Available online: https://transparency.twitter.com (accessed on 2 January 2020).
- Tumasjan, A.; Sprenger, T.O.; Sandner, P.G.; Welpe, I.M. Predicting elections with twitter: What 140 characters reveal about political sentiment. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Maynard, D.; Funk, A. Automatic detection of political opinions in tweets. In Proceedings of the Extended Semantic Web Conference, Crete, Greece, 29 May–2 June 2011. [Google Scholar]
- Twitter Developer Webpage. Available online: https://developer.twitter.com (accessed on 2 January 2020).
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine learning-based sentiment analysis for twitter accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef]
- Severyn, A.; Moschitti, A. Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 959–962. [Google Scholar]
- Zhang, Z.; Zou, Y.; Gan, C. Textual sentiment analysis via three different attention convolutional neural networks and cross-modality consistent regression. Neurocomputing 2018, 275, 1407–1415. [Google Scholar] [CrossRef]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Loria, S. Textblob Documentation. Technical Report; Release 0.15.2. 2018. Available online: https://buildmedia.readthedocs.org/media/pdf/textblob/latest/textblob.pdf (accessed on 7 February 2020).
- Farooq, U.; Dhamala, T.P.; Nongaillard, A.; Ouzrout, Y.; Qadir, M.A. A word sense disambiguation method for feature level sentiment analysis. In Proceedings of the 2015 9th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Kathmandu, Nepal, 15–17 December 2015; pp. 1–8. [Google Scholar]
- Khan, F.H.; Qamar, U.; Bashir, S. SentiMI: Introducing point-wise mutual information with SentiWordNet to improve sentiment polarity detection. Appl. Soft Comput. 2016, 39, 140–153. [Google Scholar] [CrossRef]
- Russell, I.; Markov, Z. An introduction to the Weka data mining system. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education, Seattle, WA, USA, 8–11 March 2017. [Google Scholar]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4 August 2001; pp. 41–46. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Xing, F.Z.; Cambria, E.; Welsch, R.E. Intelligent asset allocation via market sentiment views. IEEE Comput. Intell. Mag. 2018, 13, 25–34. [Google Scholar] [CrossRef]
- Chung, F.R.; Graham, F.C. Spectral Graph Theory (No. 92); American Mathematical Society: Providence, RI, USA, 1997. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep convolutional networks on graph-structured data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Yang, Y.; Wilbur, J. Using corpus statistics to remove redundant words in text categorization. J. Am. Soc. Inf. Sci. 1996, 47, 357–369. [Google Scholar] [CrossRef]
- Jivani, A.G. A comparative study of stemming algorithms. Int. J. Comp. Technol. Appl. 2011, 2, 1930–1938. [Google Scholar]
- Plisson, J.; Lavrac, N.; Mladenic, D. A rule based approach to word lemmatization. Proc. IS 2004, 3, 83–86. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category Name | Category Explanation |
|---|---|
| Hillary_for | Most of the user’s tweets have positive attitude towards Hillary Clinton. |
| Hillary_neutral | No prominent attitude towards Hillary Clinton has been found. |
| Hillary_against | Most of the user’s tweets have negative attitude towards Hillary Clinton. |
| Trump_for | Most of the user’s tweets have positive attitude towards Donald Trump. |
| Trump_neutral | No prominent attitude towards Donald Trump has been found. |
| Trump_against | Most of the user’s tweets have negative attitude towards Donald Trump. |
| Method | Sentiment Towards Trump | Sentiment Towards Hillary | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| autoencoder | 0.7692 | 0.7705 | 0.7692 | 0.7697 | 0.7462 | 0.7486 | 0.7462 | 0.7471 |
| CBOW | 0.8615 | 0.8645 | 0.8615 | 0.8615 | 0.8692 | 0.8696 | 0.8692 | 0.8682 |
| Skip-Gram | 0.9462 | 0.9467 | 0.9462 | 0.9457 | 0.9539 | 0.9557 | 0.9539 | 0.9536 |
| Method | Sentiment Towards Trump | Sentiment Towards Hillary | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| NBC | 0.8385 | 0.8391 | 0.8385 | 0.8387 | 0.8076 | 0.8107 | 0.8077 | 0.8082 |
| DCT | 0.8769 | 0.8782 | 0.8769 | 0.8773 | 0.8462 | 0.8491 | 0.8462 | 0.8460 |
| SVM | 0.8923 | 0.8934 | 0.8923 | 0.8926 | 0.8692 | 0.8704 | 0.8692 | 0.8686 |
| RDF | 0.8846 | 0.8885 | 0.8846 | 0.8852 | 0.8769 | 0.8799 | 0.8769 | 0.8765 |
| DSF | 0.9077 | 0.9080 | 0.9077 | 0.9076 | 0.9154 | 0.9168 | 0.9153 | 0.9158 |
| AGN-TSA | 0.9462 | 0.9476 | 0.9462 | 0.9463 | 0.9539 | 0.9550 | 0.9539 | 0.9538 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Hu, G. A Novel Method for Twitter Sentiment Analysis Based on Attentional-Graph Neural Network. Information 2020, 11, 92. https://doi.org/10.3390/info11020092
Wang M, Hu G. A Novel Method for Twitter Sentiment Analysis Based on Attentional-Graph Neural Network. Information. 2020; 11(2):92. https://doi.org/10.3390/info11020092
Chicago/Turabian StyleWang, Mingda, and Guangmin Hu. 2020. "A Novel Method for Twitter Sentiment Analysis Based on Attentional-Graph Neural Network" Information 11, no. 2: 92. https://doi.org/10.3390/info11020092
APA StyleWang, M., & Hu, G. (2020). A Novel Method for Twitter Sentiment Analysis Based on Attentional-Graph Neural Network. Information, 11(2), 92. https://doi.org/10.3390/info11020092