A Model for the Frequency Distribution of Multi-Scale Phenomena


Abstract
1. Introduction
2. The Frequency Distribution Model
2.1. The Structure of Datasets
2.2. The Model
2.3. The Discrete-Time Stochastic Process
- If the item is new, different from any item already existing in the set, it is added to the set and it is given degree 1. Let , with , be the probability of this event, i.e., . Hence, .
- If the item already exists in the set, its degree is increased by 1. In this case, we assume that the event has a probability which is proportional to the ratio , i.e.,where does not depend on t. Hence,
2.4. The Linear Case
- (a1)
- With probability , , the index k is chosen accordingly to its degree j (this policy is known as preferential attachment), and
- (a2)
- with probability , the index k is chosen at random (this policy is known as uniform attachment).
2.5. The General Case
- The power law model, in which log-log function is a straight line
- The log-normal model, in which log-log function is a parabola
- The cut-off model, in which log-log function is an exponential
- We suggest a unifying approach: the function is
3. Treatment of the Data
- The crawling process through which data are acquired can produce complete or partial datasets. English Wikipedia-2018 is an example of a complete crawling, whereas English Web must inevitably be partially crawled.
- For the visualization of multi-scale data, a log-log plot is required, in order to better evidence the properties of the data and the possible correspondence with the chosen model. For example, if the chosen model is the power law, the log-log data should have a straight line representation.
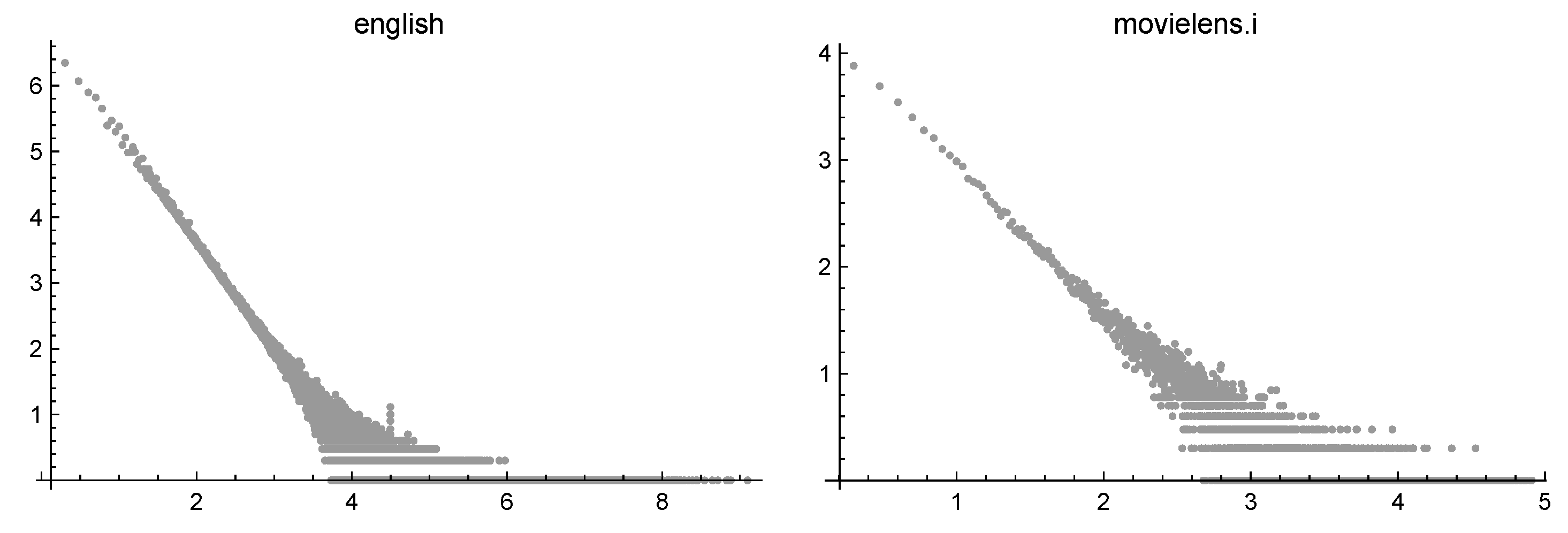
- In the previous sections, we looked for approximations of a function verifying for t large enough. Actually, when real-world phenomena (such as the web or the whole English language) are considered, t is so large that it can be assumed infinite. In practice, we deal with J samples , and, typically, the quantity is much smaller than t. So, we assumewhere d is a suitable scaling factor. Note that , being the number of items having degree j, is a nonnegative integer, while is a real number which can be very small. The quantization phenomenon cannot be considered statistical noise (as done by some authors) but is an intrinsic characteristic of the sampled data. For example, if , the corresponding values are mostly 0 but sometimes 1 or 2. Obviously, the zeros become more and more probable until the last data are reached.In the log-log scale, the values are gathered in plateaus on the tail of the dataset. Figure 3 shows the base 10 log-log representation of the frequencies of two datasets described in the next section: a set of English words and a set of MovieLens ratings. The quantization phenomenon is evident.
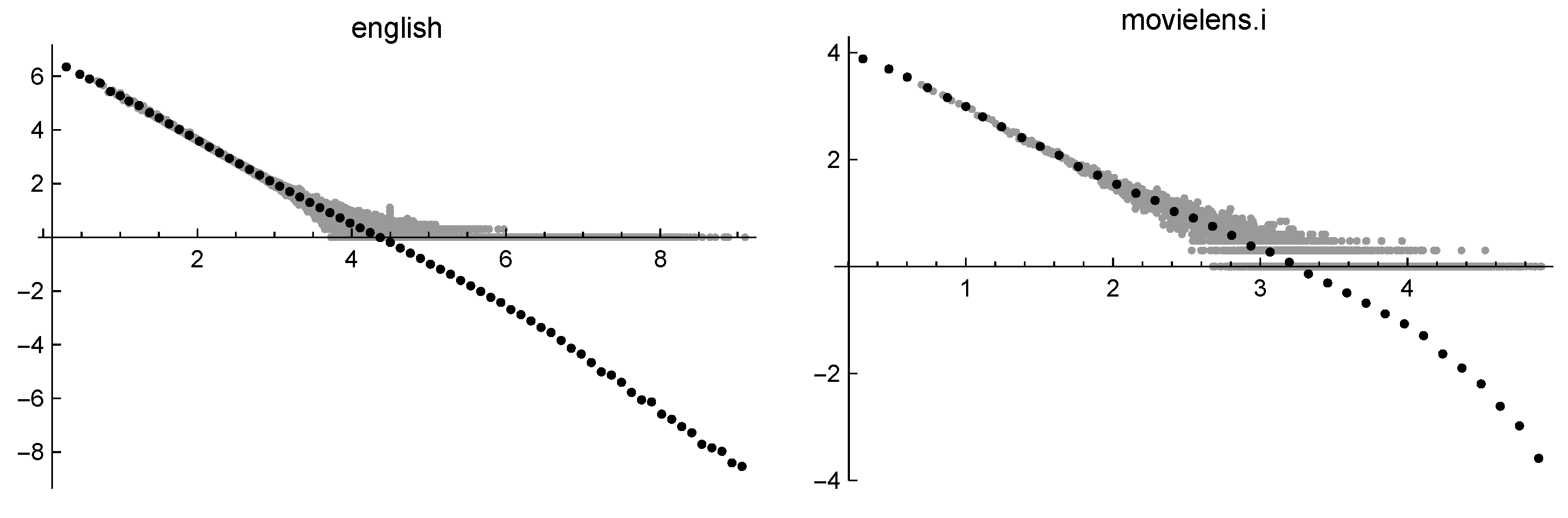
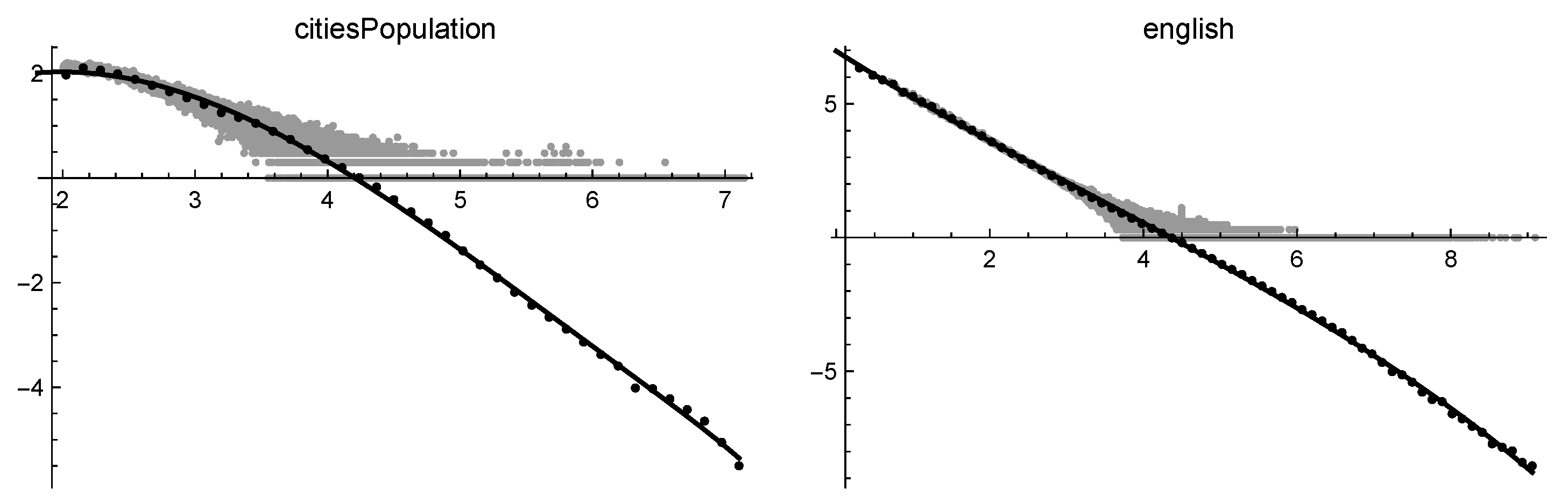
- A dequantization process can be accomplished by binning the data: the data values belonging to a given small interval (called a bin) are replaced by a value representative of that interval. When the binning is performed in the log-log scale, negative values might be generated. This procedure is essential to recover the asymptotic properties of the phenomenon and allows to reduce the size of data while performing some sort of smoothing. In Figure 4, the same data of Figure 3 are presented, together with the result of binning. It is clear that the binning reveals the different asymptotic behavior of the two data sets.
3.1. The Binning
3.2. The Fitting
3.3. The Attachment Rule
3.4. Performance Indices
- the Beta function defined in (16),
- the power law function defined in (17),
- the log-normal function defined in (18),
- the cut-off function defined in (19),
- the cubic-cut-off function defined in (21).
- (1)
- The quality of the approximation of by is measured by the NRMSEwhere and are the minimum and the maximum of the values for .
- (2)
- A too large discrepancy between and suggests that the similarity of the bases used for , and cannot be assumed. This is measured by the NRMSEwhere and are the minimum and the maximum of the values for .
4. Experiments
4.1. Scalar Phenomena
- cities population [14]. The population of N cities obtained by Mathematica CityData feature on February 2020. , and .
- english [15]. A large collection of English words obtained by joining a collection of Project Gutenberg texts and a collection of public USENET postings collected between October 2005 and January 2011. , and .
- hollywood-2011 [16]. One of the most popular social dataset: the graph of movie actors. Nodes are actors, and two actors are joined by a link whenever they appeared in a movie together. Since outdegree and indegree coincide, from the point of view of the frequency analysis, this is considered a scalar phenomenon. , and .
4.2. Directed Graphs
- clueweb12 [19]. The web graph underlying the ClueWeb12, a dataset created to support research on information retrieval and related human language technologies. , and .
- eu-2015 [20] The web graph of a large snapshot of the EU countries taken in 2015 by BUbiNG starting from the site http://europa.eu/. The maximum number of nodes per host was set to 10M (and never reached). , and .
- Wikipedia graphs [21]. The node connections for the following versions of Wikipedia: English (enwiki-2018) and , German (dewiki-2013) and , French (frwiki-2013) and , Spanish (eswiki-2013) and , and Italian (itwiki-2013) , and .
- hu-tel-2006 [16]. The social graph built from the detailed call record of Hungarian Telekom for an eight-month time frame in 2006. Measurements were performed by the Hungarian Academy of Sciences. , and .
- steemit [22]. The relations graph of Steemit, a blockchain-based blogging and social media website. , and .
- twitter-2010 [23]. The website, owned and operated by Twitter, Inc., which offers a social networking and microblogging service. Nodes are users, and there is an arc from x to y if y is a follower of x, i.e., the arcs follow the direction of the tweet transmission. , and .
4.3. Bipartite Graphs
- book crossing [24]. Collected by Ziegler in a 4-week crawl (August/September 2004) from the Book-Crossing community. It contains the ratings about 271,379 books. , and .
- fine foods [25]. The dataset of the reviews of fine foods from Amazon. The data span a period of more than 10 years, up to October 2012. , and .
- last.fm. A large database of listening data crawled by [26] using the last.fm API. There were considered both relations user-song ( and ) and relations user-song weighted with the number of plays (, and ).
- movielens [27]. The dataset describes 5-star rating and free-text tagging activity from MovieLens, a movie recommendation service. It contains 25 M ratings. These data were created between 9 January 1995 and 21 November 2019. , and .
- supermarket. A small database of supermarket purchases collected by [28]. There were considered both relations user-product ( and ) and the relations user-product weighted with the number of purchases (, and ).
- Yahoo! artists [29]. The artists ratings collected from the Yahoo! Webscope dataset R1. This dataset represents a (anonymized) snapshot of the Yahoo! Music community’s preferences for various musical artists, collected in one month sometime prior to March 2004. , and .
4.4. Comments
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Barabasi, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar] [CrossRef]
- Mitzenmacher, M. A Brief History of Generative Models for Power Law and Lognormal Distributions. Internet Math. 2003, 1, 226–251. [Google Scholar] [CrossRef]
- Adamic, L.A. Zipf, Power-Laws, and Pareto—A Ranking Tutorial; Information Dynamics Lab, HP Labs: Palo Alto, CA, USA, 2012; Available online: http://www.hpl.hp.com/research/idl/papers/ranking/ranking.html (accessed on 2 December 2020).
- Caldarelli, G.; De Los Rios, P.; Laura, L.; Leonardi, S.; Millozzi, S. A Study of Stochastic Models for the Web Graph; Technical Report 04-03; Dip. di Informatica e Sistemistica, Universita’ di Roma “La Sapienza”: Rome, Italy, 2003. [Google Scholar]
- Simon, H.A. On a Class of Skew Distribution Functions. Biometrika 1955, 42, 425–440. [Google Scholar] [CrossRef]
- Cooper, C.; Frieze, A.M. A general model of undirected web graphs. In European Symposium on Algorithms; Springer: Berlin/Heidelberg, Germany, 2001; pp. 500–511. [Google Scholar]
- Dorogovtsev, S.; Mendes, J.; Samukhin, A. Structure of Growing Networks: Exact Solution of the Barabasi-Albert’s model. Phys. Rev. Lett. 2000, 85, 4633–4636. [Google Scholar] [CrossRef]
- Pennock, D.M.; Flake, G.W.; Lawrence, S.; Glover, E.J.; Giles, C.L. Winners don’t take all: Characterizing the competition for links on the web. Proc. Natl. Acad. Sci. USA 2002, 99, 5207–5211. [Google Scholar] [CrossRef] [PubMed]
- Dereich, S.; Mörters, P. Random Networks with Sublinear Preferential Attachment: Degree Evolutions. Electron. J. Probab. 2009, 14, 1222–1267. Available online: https://projecteuclid.org/euclid.ejp/1464819504 (accessed on 11 December 2020). [CrossRef]
- Kunegis, J.; Blattner, M.; Moser, C. Preferential Attachment in Online Networks: Measurement and Explanations. arXiv 2013, arXiv:1303.6271. [Google Scholar]
- Abramowitz, M.; Stegun, I. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, National Bureau of Standards, 10th Printing; National Bureau of Standards (DOC): Washington, DC, USA, 1972.
- Beta Function. Available online: https://en.wikipedia.org/wiki/Beta_function (accessed on 2 December 2020).
- Supplementary Data for This Paper. Available online: http://pages.di.unipi.it/romani/MDPIdata.zip (accessed on 9 December 2020).
- Wolfram Language & System Documentation Center. Available online: https://reference.wolfram.com/language/ref/CityData.html (accessed on 4 December 2020).
- Project Gutenberg Literary Archive. Available online: ftp://mirrors.pglaf.org/mirrors/gutenberg-iso/pgdvd042010.iso (accessed on 4 December 2020).
- Laboratory for Web Algorithmics. Available online: http://law.di.unimi.it/datasets.php (accessed on 4 December 2020).
- Boldi, P.; Vigna, S. The Web Graph Framework I: Compression Techniques. In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17–20 May 2004; ACM Press: New York, NY, USA, 2004; Volume 99, pp. 595–601. Available online: http://law.di.unimi.it/datasets.php (accessed on 4 December 2020).
- Boldi, P.; Rosa, M.; Santini, M.; Vigna, S. Layered Label Propagation: A MultiResolution Coordinate-Free Ordering for Compressing Social Networks. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; Srinivasan, S., Ramamritham, K., Kumar, A., Ravindra, M.P., Bertino, E., Kumar, R., Eds.; ACM Press: New York, NY, USA, 2011; pp. 587–596. [Google Scholar]
- ClueWeb12 Web Graph. Available online: http://www.lemurproject.org/clueweb12/webgraph.php/ (accessed on 4 December 2020).
- Boldi, P.; Marino, A.; Santini, M.; Vigna, S. BUbiNG: Massive Crawling for the Masses. In Proceedings of the Companion Publication of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 227–228. [Google Scholar]
- Boldi, P.; Codenotti, B.; Santini, M.; Vigna, S. Ubicrawler: A Scalable Fully Distributed Web Crawler. Software Pract. Exp. 2004, 34, 711–726. [Google Scholar] [CrossRef]
- Guidi, B.; Michienzi, A.; Ricci, L. A graph-based socio-economic analysis of Steemit. IEEE Trans. Comput. Soc. Syst. Submitted to.
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a Social Network or a News Media? In Proceedings of the 19th International World Wide Web (WWW) Conference, Raleigh, NC, USA, 26–30 April 2010; ACM Press: New York, NY, USA, 2010; pp. 591–600. [Google Scholar] [CrossRef]
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving Recommendation Lists Through Topic Diversification. In Proceedings of the 14th International World Wide Web Conference (WWW ’05), Chiba, Japan, 10–14 May 2005. [Google Scholar]
- McAuley, J.; Leskovec, J. From Amateurs to Connoisseurs: Modeling the Evolution of User Expertise through Online Reviews. WWW 2013. Available online: https://snap.stanford.edu/data/web-FineFoods.html (accessed on 4 December 2020).
- Bradan, A.L. Forecast Emerging Artists Success on Last.fm Music Service: A Data-Driven Study. Master’s Thesis, University of Pisa, Pisa, Italy, 2020. [Google Scholar]
- Movie Lens. Available online: https://grouplens.org/datasets/movielens/ (accessed on 4 December 2020).
- Pennacchioli, D.; Coscia, M.; Rinzivillo, S.; Pedreschi, D.; Giannotti, F. Explaining the product range effect in purchase data. In Proceedings of the 2013 IEEE International Conference on Big Data, Big Data 2013, Santa Clara, CA, USA, 6–9 October 2013; pp. 648–656. [Google Scholar] [CrossRef]
- Yahoo! Webscope Dataset ydata-ymusic-user-artist-ratings-v1_0 Yahoo! Music User Ratings of Musical Artists, Version 1.0. Available online: http://webscope.sandbox.yahoo.com/catalog.php?datatype=r (accessed on 11 December 2020).
- Caron, F.; Fox, E.B. Sparse Graphs using Exchangeable Random Measures. J. R. Stat. Soc. Ser. B 2017, 79, 1295–1366. Available online: https://rss.onlinelibrary.wiley.com/doi/full/10.1111/rssb.12233 (accessed on 4 December 2020). [CrossRef] [PubMed]










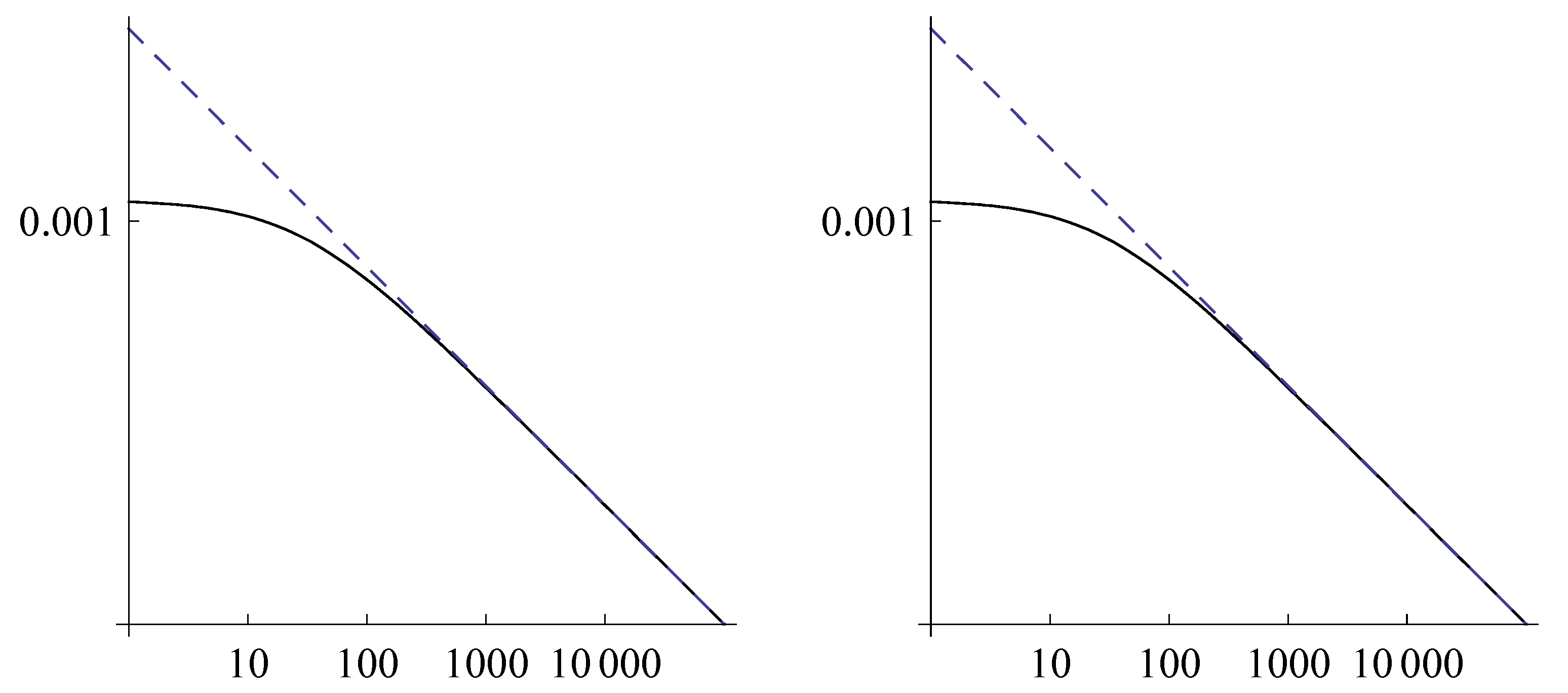{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File | ||||||||
|---|---|---|---|---|---|---|---|---|
| citiesPopulation | 0.015 | ∞ | 0.017 | * | 0.010 | 0.081 | 0.026 | 2.71 |
| english | * | ∞ | 0.010 | 0.012 | 0.005 | 0.016 | 0.004 | 1.17 |
| hollywood2011 | * | ∞ | * | * | 0.007 | 0.043 | 0.037 | 1.28 |
| citiesPopulation | |
| english |
| File | ||||||||
|---|---|---|---|---|---|---|---|---|
| clueweb12.i | 0.024 | 0.026 | 0.026 | ∞ | 0.018 | 0.011 | 0.058 | 1.09 |
| clueweb12.o | 0.065 | 0.098 | 0.048 | 0.039 | 0.033 | 0.047 | 0.051 | 1.12 |
| eu2015.i | 0.033 | 0.044 | 0.018 | 0.041 | 0.018 | 0.001 | 0.019 | 1.18 |
| eu2015.o | 0.065 | * | 0.043 | 0.051 | 0.034 | 0.019 | 0.011 | 1.34 |
| enwiki2018.i | 0.013 | * | 0.008 | * | 0.006 | 0.009 | 0.016 | 1.03 |
| enwiki2018.o | 0.020 | * | 0.022 | * | 0.009 | 0.060 | 0.026 | 0.96 |
| dewiki2013.i | 0.014 | * | 0.012 | 0.025 | 0.011 | 0.004 | 0.011 | 1.04 |
| dewiki2013.o | 0.027 | * | 0.026 | * | 0.018 | 0.063 | 0.037 | 0.96 |
| frwiki2013.i | 0.012 | * | 0.011 | 0.020 | 0.009 | 0.010 | 0.016 | 1.03 |
| frwiki2013.o | 0.023 | * | 0.028 | * | 0.012 | 0.071 | 0.031 | 1.01 |
| eswiki2013.i | 0.012 | 0.019 | 0.012 | 0.014 | 0.009 | 0.019 | 0.019 | 1.00 |
| eswiki2013.o | 0.073 | 0.115 | 0.060 | 0.087 | 0.050 | 0.108 | 0.061 | 0.90 |
| itwiki2013.i | 0.016 | 0.026 | 0.014 | 0.017 | 0.011 | 0.014 | 0.015 | 1.01 |
| itwiki2013.o | 0.044 | * | 0.023 | * | 0.017 | 0.056 | 0.030 | 0.98 |
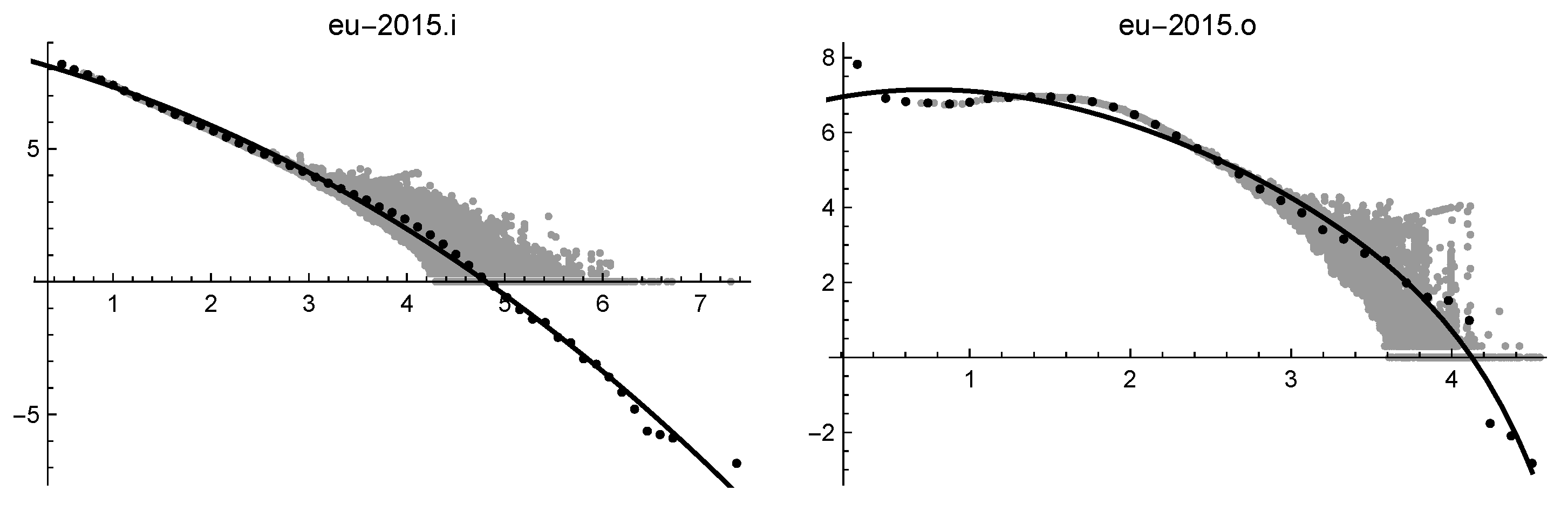
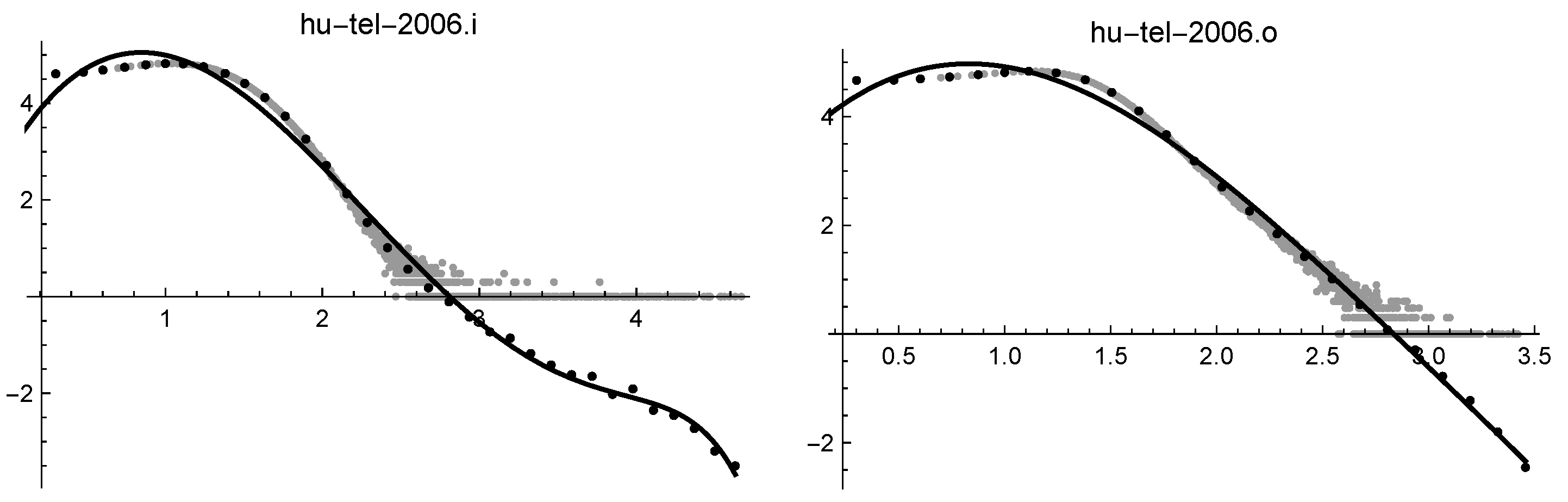
| hutel2006.i | 0.060 | * | * | ∞ | 0.022 | 0.092 | 0.055 | |
| hutel2006.o | 0.028 | * | 0.033 | * | 0.019 | 0.072 | 0.046 | 0.91 |
| steemit.i | 0.026 | ∞ | 0.014 | * | 0.013 | 0.001 | 0.001 | 1.24 |
| steemit.o | 0.022 | ∞ | 0.017 | 0.023 | 0.015 | 0.013 | 0.019 | 1.19 |
| twitter2010.i | 0.025 | 0.043 | 0.018 | 0.037 | ∞ | – | – | – |
| twitter2010.o | 0.019 | 0.025 | 0.023 | 0.025 | 0.017 | 0.016 | 0.042 | 1.04 |
| eu2015.i | |
| eu2015.o | |
| hutel2006.i | |
| hutel2006.o |
| File | ||||||||
|---|---|---|---|---|---|---|---|---|
| bookCrossing.i | 0.030 | 0.038 | 0.028 | 0.035 | 0.028 | 0.001 | 0.001 | 0.90 |
| bookCrossing.o | 0.026 | 0.035 | 0.021 | 0.027 | 0.020 | 0.006 | 0.003 | 1.06 |
| fineFoods.i | 0.039 | 0.043 | 0.040 | 0.041 | 0.038 | 0.013 | 0.016 | 0.87 |
| fineFoods.o | 0.040 | * | 0.034 | 0.023 | 0.014 | 0.028 | 0.057 | 0.99 |
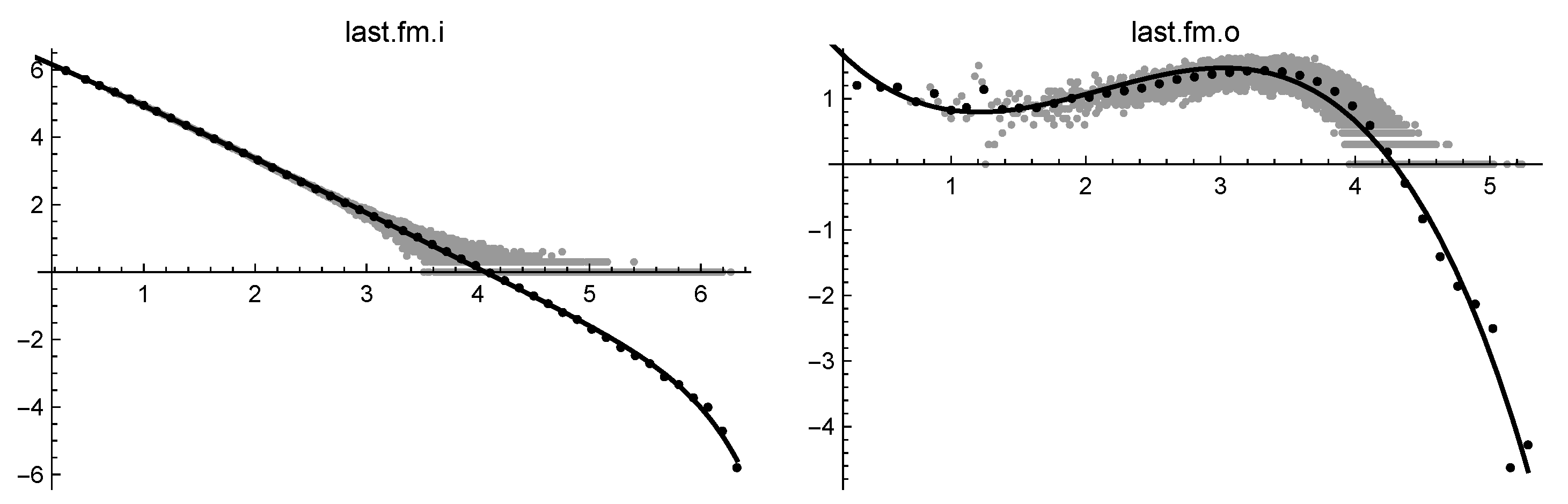
| last.fm.i | * | ∞ | * | 0.006 | 0.005 | 0.029 | 0.020 | 1.15 |
| last.fm.o | * | ∞ | 0.105 | 0.070 | 0.035 | 0.260 | 0.168 | 3.33 |
| last.fm W.i | * | ∞ | * | * | 0.002 | 0.025 | 0.026 | 1.22 |
| last.fm W.o | 0.136 | ∞ | 0.086 | 0.141 | 0.063 | 0.183 | 0.064 | 3.34 |
| movieLens.i | * | ∞ | * | 0.006 | 0.004 | 0.012 | 0.007 | 1.33 |
| movieLens.o | 0.029 | 0.065 | 0.034 | 0.056 | ∞ | – | – | – |
| supermarket.i | * | ∞ | 0.030 | 0.027 | 0.013 | 0.009 | 0.012 | 1.99 |
| supermarket.o | * | ∞ | * | * | 0.017 | 0.134 | 0.147 | 2.03 |
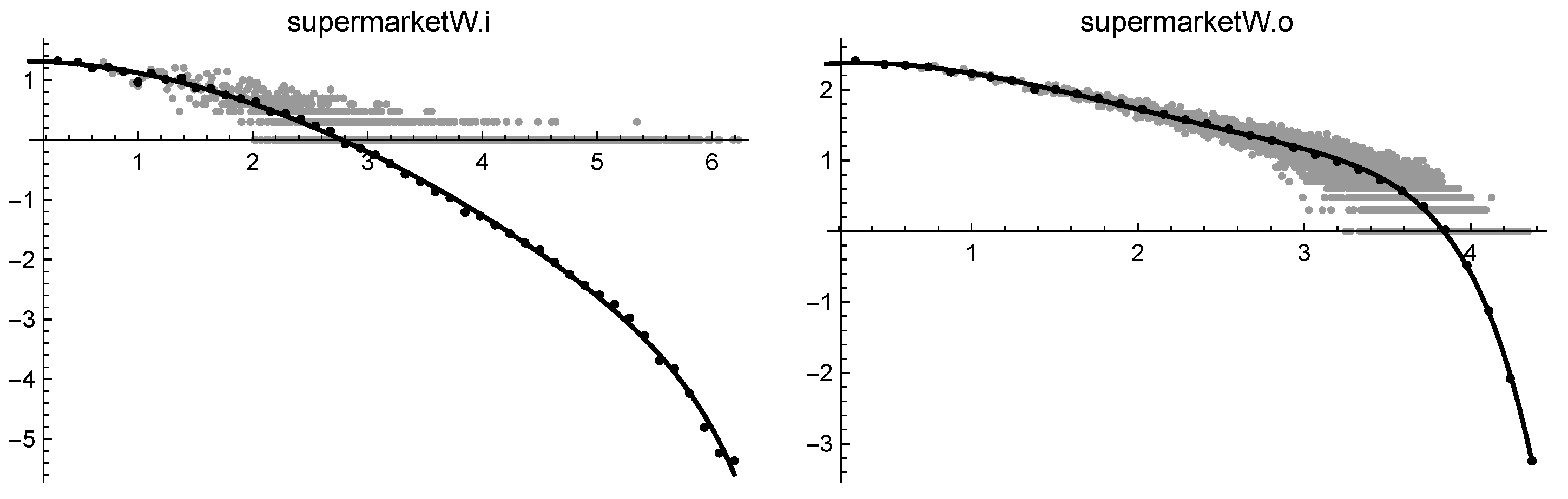
| supermarketW.i | * | ∞ | 0.022 | * | 0.011 | 0.011 | 0.010 | 2.02 |
| supermarketW.o | * | ∞ | * | 0.012 | 0.004 | 0.038 | 0.048 | 2.06 |
| yahooArtists.i | 0.036 | ∞ | 0.032 | 0.021 | 0.018 | 0.018 | 0.016 | 1.34 |
| yahooArtists.o | 0.081 | 0.097 | 0.084 | 0.092 | 0.077 | 0.074 | 0.024 | 1.09 |
| last.fm.i | |
| last.fm.o | |
| supermarketW.i | |
| supermarketW.o |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Favati, P.; Lotti, G.; Menchi, O.; Romani, F. A Model for the Frequency Distribution of Multi-Scale Phenomena. Information 2020, 11, 580. https://doi.org/10.3390/info11120580
Favati P, Lotti G, Menchi O, Romani F. A Model for the Frequency Distribution of Multi-Scale Phenomena. Information. 2020; 11(12):580. https://doi.org/10.3390/info11120580
Chicago/Turabian StyleFavati, Paola, Grazia Lotti, Ornella Menchi, and Francesco Romani. 2020. "A Model for the Frequency Distribution of Multi-Scale Phenomena" Information 11, no. 12: 580. https://doi.org/10.3390/info11120580
APA StyleFavati, P., Lotti, G., Menchi, O., & Romani, F. (2020). A Model for the Frequency Distribution of Multi-Scale Phenomena. Information, 11(12), 580. https://doi.org/10.3390/info11120580