Attentional Colorization Networks with Adaptive Group-Instance Normalization

Abstract
1. Introduction
- We proposed a novel end-to-end framework for colorization with attention mechanism and AGIN which is a learnable normalization function.
- Our framework is guided by attention maps produced by the auxiliary classifier to know where the salient area is and to give more delicate color.
- AGIN is a learnable normalization function which helps our framework generate reasonable color flexibly and freely without transforming the network.
2. Related Works
2.1. Networks
2.2. Colorization
2.3. Class Activation Mapping
2.4. Normalization
3. Network
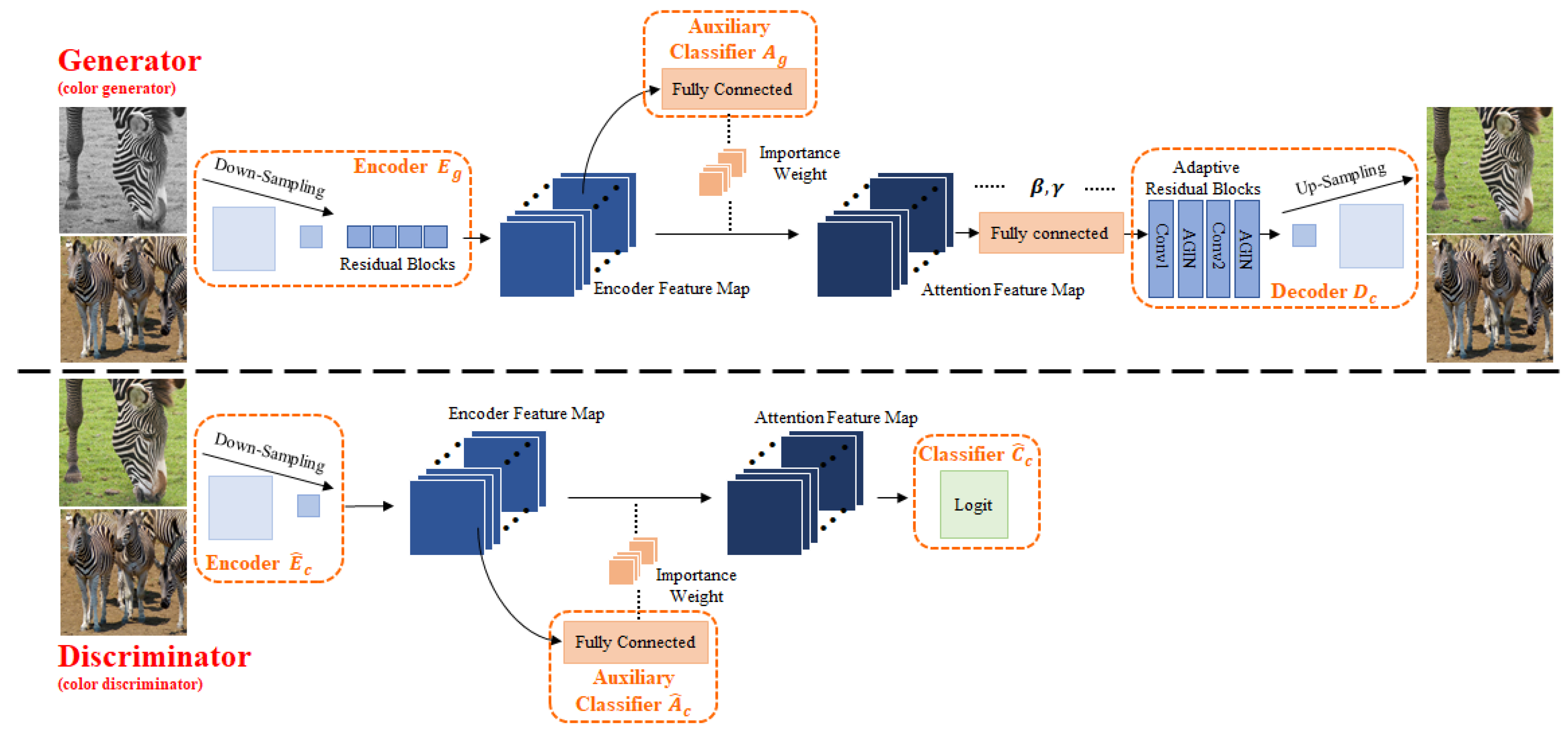
3.1. Model
3.1.1. Generator
3.1.2. Discriminator
3.2. Loss
3.2.1. Adversarial Loss
3.2.2. Cycle Consistency Loss
3.2.3. Content Loss
3.2.4. CAM Loss
3.2.5. Full Function
4. Implementation
4.1. Architecture
4.2. Training
5. Experiments
5.1. Dataset
5.2. Comparisons with State-of-the-Art
5.3. CAM Ablation Experiment
5.4. AGIN Ablation Experiment
5.5. Qualitative and Quantitative Evaluations
6. Limitations and Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation. arXiv 2019, arXiv:1907.10830. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the Computer Vision—ECCV 2018—5th European Conference, Part XIII, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Koleini, M.; Monadjemi, S.A.; Moallem, P. Film Colorization Using Texture Feature Coding and Artificial Neural Networks. J. Multim. 2009, 4, 240–247. [Google Scholar] [CrossRef]
- Cheng, Z.; Yang, Q.; Sheng, B. Deep Colorization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 415–423. [Google Scholar]
- Putri, V.K.; Fanany, M.I. Sketch plus colorization deep convolutional neural networks for photos generation from sketches. In Proceedings of the 2017 4th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Yogyakarta, Indonesia, 19–21 September 2017; pp. 1–6. [Google Scholar]
- Vitynskyi, P.; Tkachenko, R.; Izonin, I.; Kutucu, H. Hybridization of the SGTM neural-like structure through inputs polynomial extension. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 386–391. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. Colorization using optimization. ACM Trans. Graph. 2004, 23, 689–694. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, J.; Isola, P.; Geng, X.; Lin, A.S.; Yu, T.; Efros, A.A. Real-time user-guided image colorization with learned deep priors. arXiv 2017, arXiv:1705.02999. [Google Scholar] [CrossRef]
- Sangkloy, P.; Lu, J.; Fang, C.; Yu, F.; Hays, J. Scribbler: Controlling Deep Image Synthesis with Sketch and Color. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6836–6845. [Google Scholar]
- Welsh, T.; Ashikhmin, M.; Mueller, K. Transferring color to greyscale images. ACM Trans. Graph. 2002, 21, 277–280. [Google Scholar] [CrossRef]
- Tai, Y.; Jia, J.; Tang, C. Local Color Transfer via Probabilistic Segmentation by Expectation-Maximization. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 747–754. [Google Scholar]
- He, M.; Chen, D.; Liao, J.; Sander, P.V.; Yuan, L. Deep exemplar-based colorization. ACM Trans. Graph. 2018, 37, 1–16. [Google Scholar] [CrossRef]
- Zhang, B.; He, M.; Liao, J.; Sander, P.V.; Yuan, L.; Bermak, A.; Chen, D. Deep Exemplar-Based Video Colorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 8052–8061. [Google Scholar]
- Yoo, S.; Bahng, H.; Chung, S.; Lee, J.; Chang, J.; Choo, J. Coloring With Limited Data: Few-Shot Colorization via Memory Augmented Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 11283–11292. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Learning Representations for Automatic Colorization. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Part IV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 577–593. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Let there be color!: Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification. ACM Trans. Graph. 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Part III, Amsterdam, The Netherlands, 11–14 October 2016; pp. 649–666. [Google Scholar]
- Messaoud, S.; Forsyth, D.A.; Schwing, A.G. Structural Consistency and Controllability for Diverse Colorization. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Part VI, Munich, Germany, 8–14 September 2018; pp. 603–619. [Google Scholar]
- Cao, Y.; Zhou, Z.; Zhang, W.; Yu, Y. Unsupervised Diverse Colorization via Generative Adversarial Networks. In Proceedings of the Machine Learning and Knowledge Discovery in Databases—European Conference (ECML PKDD 2017), Part I, Skopje, Macedonia, 18–22 September 2017; pp. 151–166. [Google Scholar]
- Zhao, J.; Han, J.; Shao, L.; Snoek, C.G.M. Pixelated Semantic Colorization. arXiv 2019, arXiv:1901.10889. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, À.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ba, L.J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Nam, H.; Kim, H. Batch-Instance Normalization for Adaptively Style-Invariant Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 2563–2572. [Google Scholar]
- Huang, X.; Belongie, S.J. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 1510–1519. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A Learned Representation For Artistic Style. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. ECCV (5). Lect. Notes Comput. Sci. 2014, 8693, 740–755. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | COCO | VisualGenome | Landscape | |
|---|---|---|---|---|
| Method | ||||
| Zhang et al. [22] | 15.74% | 13.20% | 10.15% | |
| Larsson et al. [20] | 8.12% | 4.06% | 5.58% | |
| Iizuka et al. [21] | 7.11% | 9.64% | 7.61% | |
| Ours | 69.04% | 73.10% | 77.65% | |
| Dataset | COCO | VisualGenome | Landscape | |
|---|---|---|---|---|
| Method | ||||
| CycleGAN | 16.75% | 14.72% | 11.68% | |
| DCGAN | 10.65% | 10.15% | 10.66% | |
| Pix2Pix | 8.62% | 7.11% | 7.11% | |
| Ours | 63.95% | 68.02% | 70.56% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Ding, Y.; Wang, F.; Liang, H. Attentional Colorization Networks with Adaptive Group-Instance Normalization. Information 2020, 11, 479. https://doi.org/10.3390/info11100479
Gao Y, Ding Y, Wang F, Liang H. Attentional Colorization Networks with Adaptive Group-Instance Normalization. Information. 2020; 11(10):479. https://doi.org/10.3390/info11100479
Chicago/Turabian StyleGao, Yuzhen, Youdong Ding, Fei Wang, and Huan Liang. 2020. "Attentional Colorization Networks with Adaptive Group-Instance Normalization" Information 11, no. 10: 479. https://doi.org/10.3390/info11100479
APA StyleGao, Y., Ding, Y., Wang, F., & Liang, H. (2020). Attentional Colorization Networks with Adaptive Group-Instance Normalization. Information, 11(10), 479. https://doi.org/10.3390/info11100479