Artificial Intelligence-Enhanced Decision Support for Informing Global Sustainable Development: A Human-Centric AI-Thinking Approach

 ,
, 


Abstract
1. Introduction
1.1. Gaining Insights from Unified Analysis of Data Related to the Environmental Performance Index (EPI) and the Sustainable Development Goals Index (SDGI)
1.1.1. Environmental Performance Index (EPI)
1.1.2. Sustainable Development Goals Index (SDGI)
1.2. How Unified Analytics of Sustainability Indicators Related to EPI and SDGI Can Inform Education and Policy-Making
1.3. The Theoretical Basis of AI-Thinking
1.4. The Democratization of the Use of AI by Analysts Who Are Not Computer Scientists
2. Research Problem and Research Questions
2.1. Research Problem
2.2. Research Questions
- RQ1: From descriptive analytics of the dataset, what is the overall characterization of the sustainability variables and the EPI?
- RQ2: From predictive analytics of the dataset, what are the conditions in the best-case scenario that could result in high EPI?
- RQ3: From predictive analytics of the dataset, what are the conditions in the worst-case scenario that could result in low EPI?
3. Methods
3.1. Rationale for Using the AI-Based Bayesian Network Approach in Sustainability Research
3.2. The Bayesian Theorem
3.3. The Research Model
3.3.1. Descriptive Analytics of “What Has Already Happened?”
3.3.2. Predictive Analytics Using “What-If?” Hypothetical Scenarios
3.4. Data Source
3.5. AI-Based BN Software Used and Pre-Processing of the Data
3.6. Overview of the BN Approach Used to Machine-Learn the Data
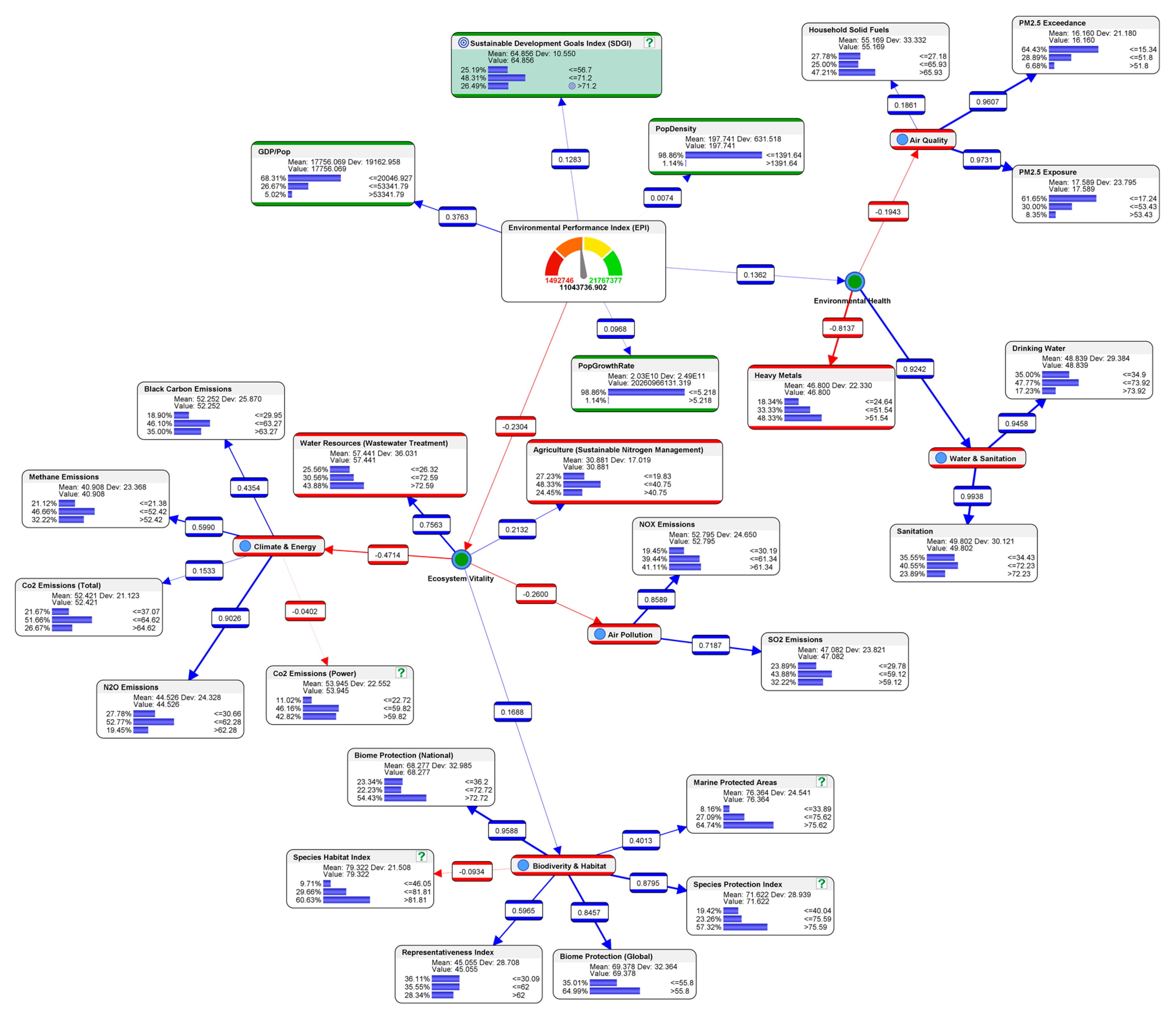
4. Results
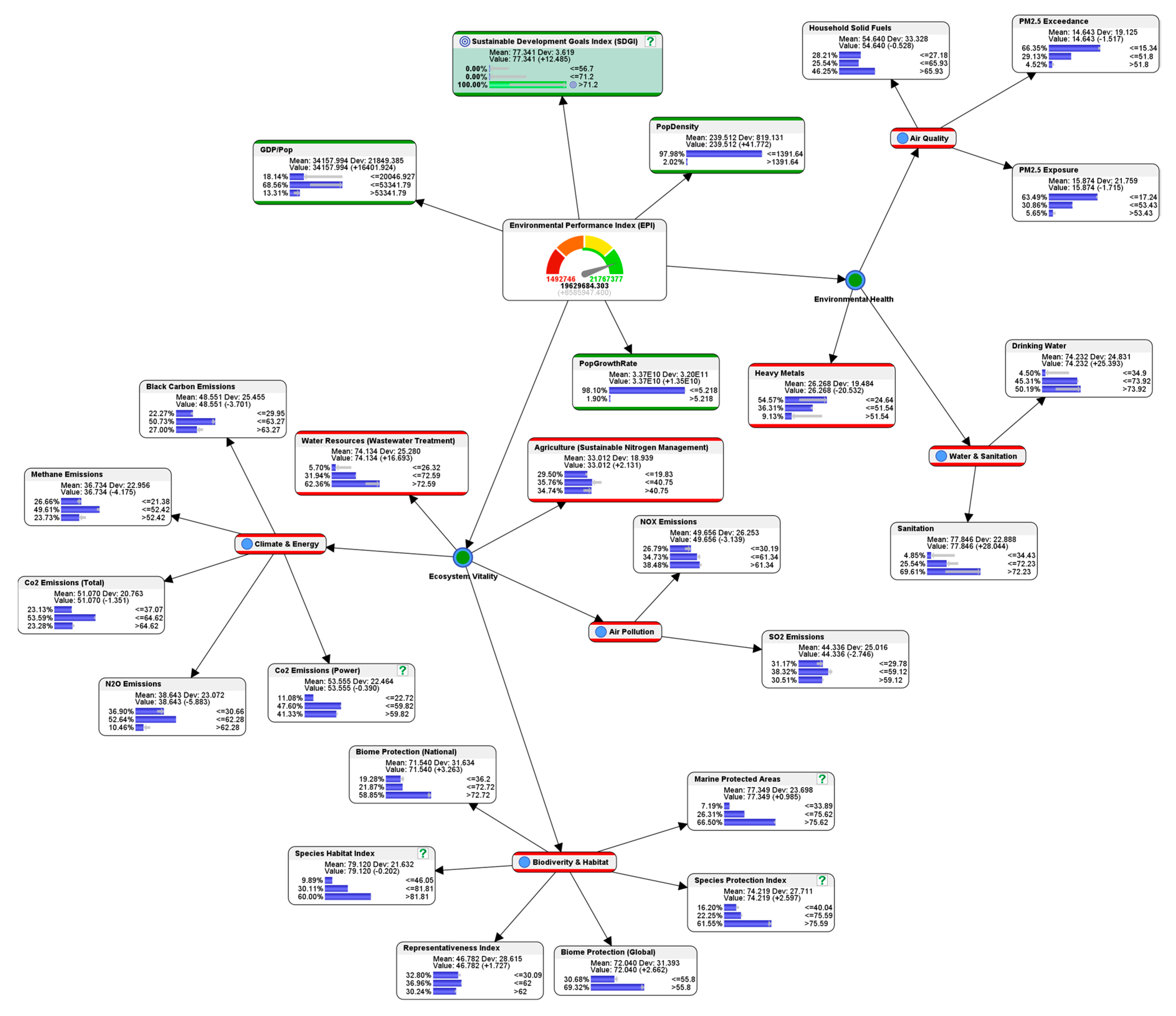
4.1. Descriptive Analytics: Current State of Global Environmental Performance
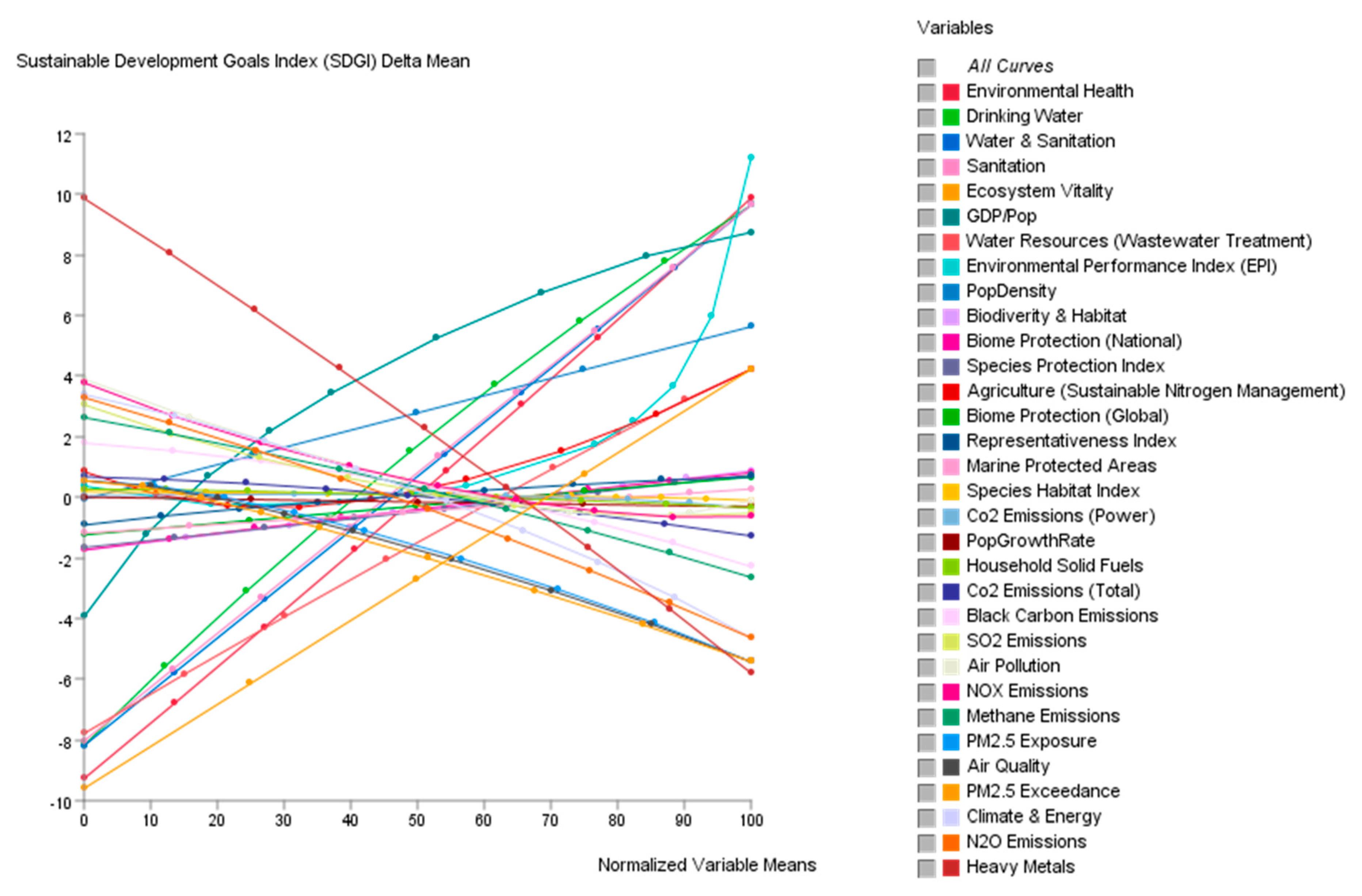
4.2. Mean-Target Total Effects Analysis
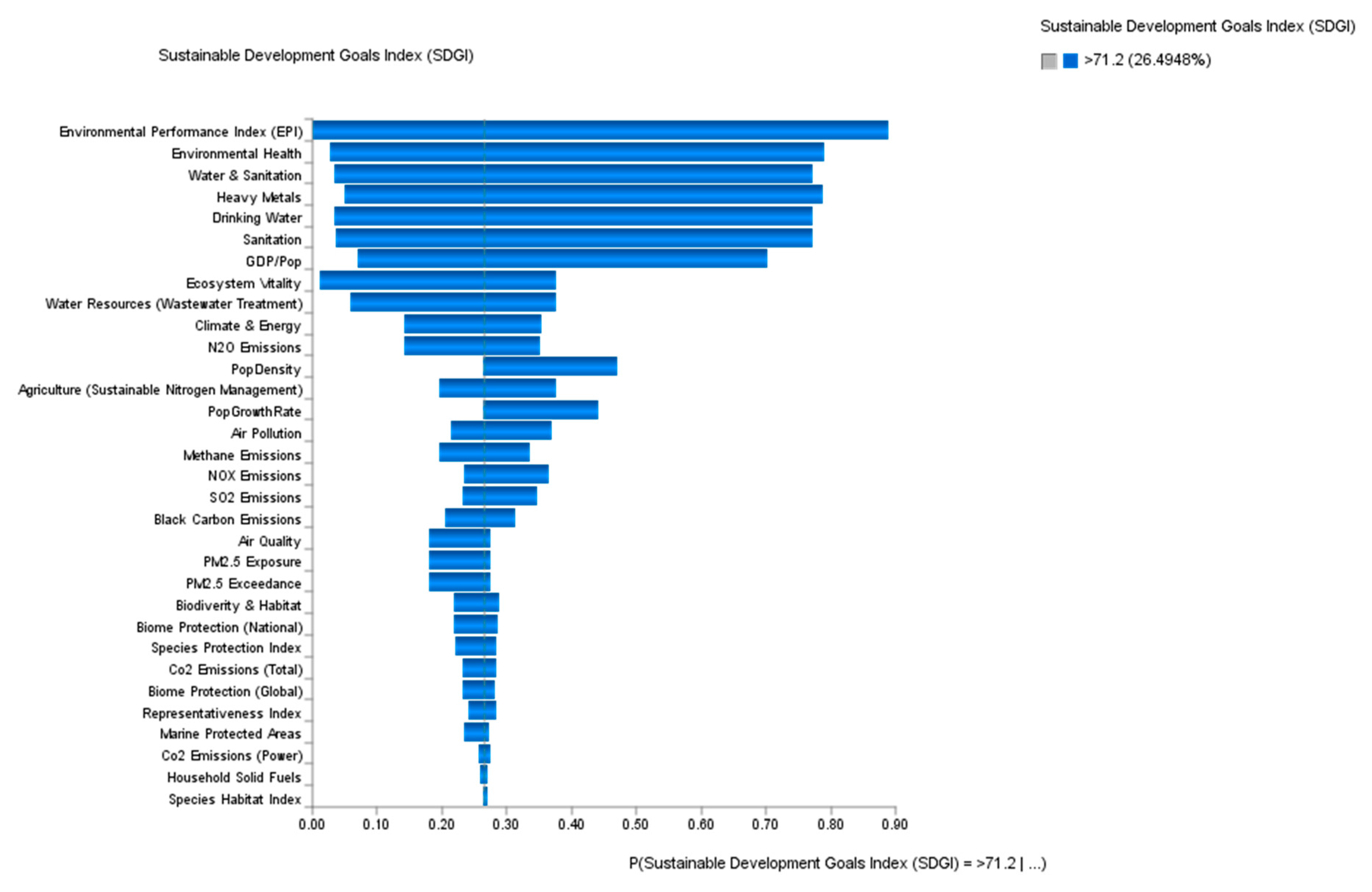
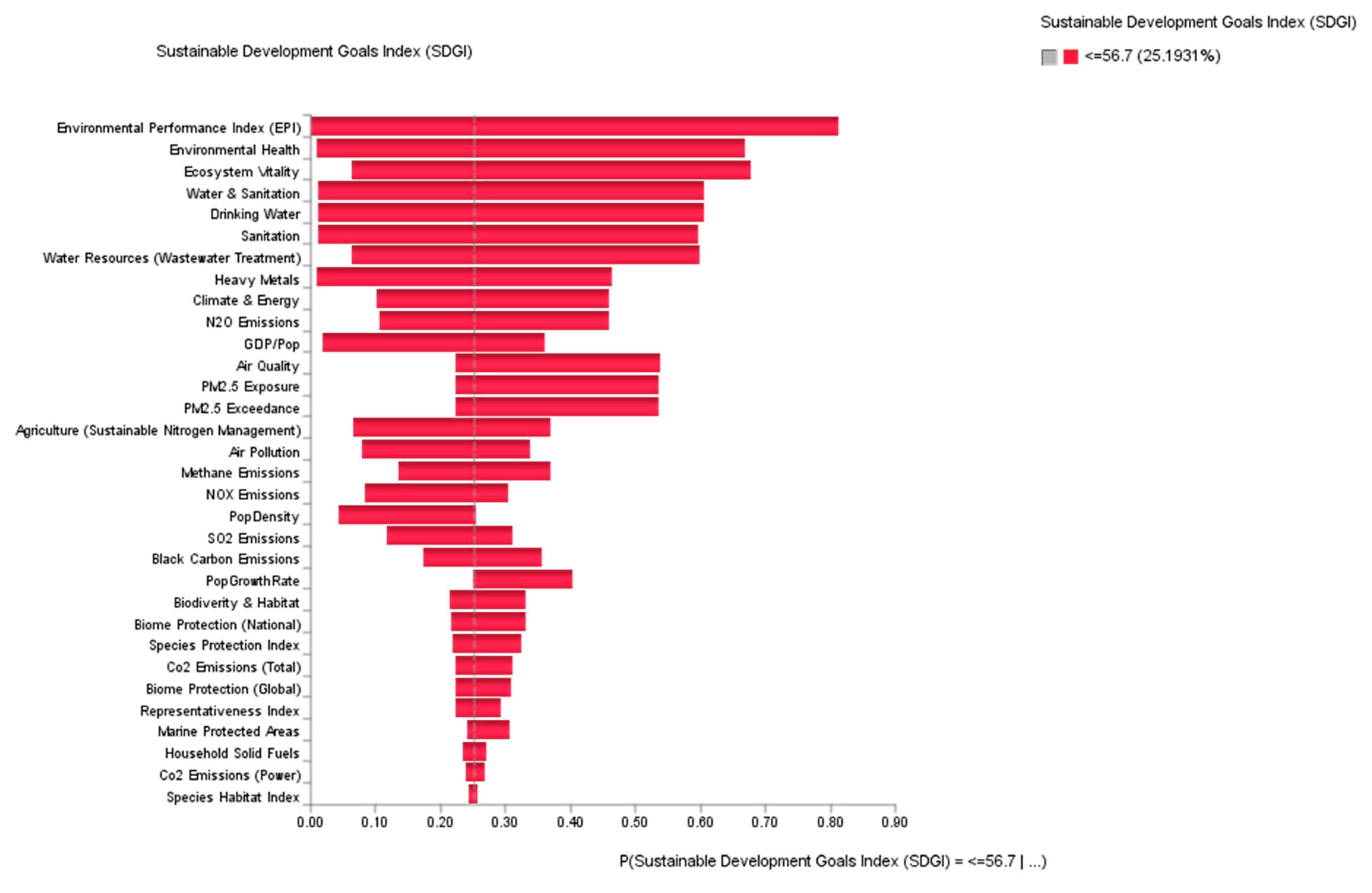
4.3. Sensitivity Analysis
4.4. Predictive Analytics: What If We Want to Achieve High-Level SGDI?
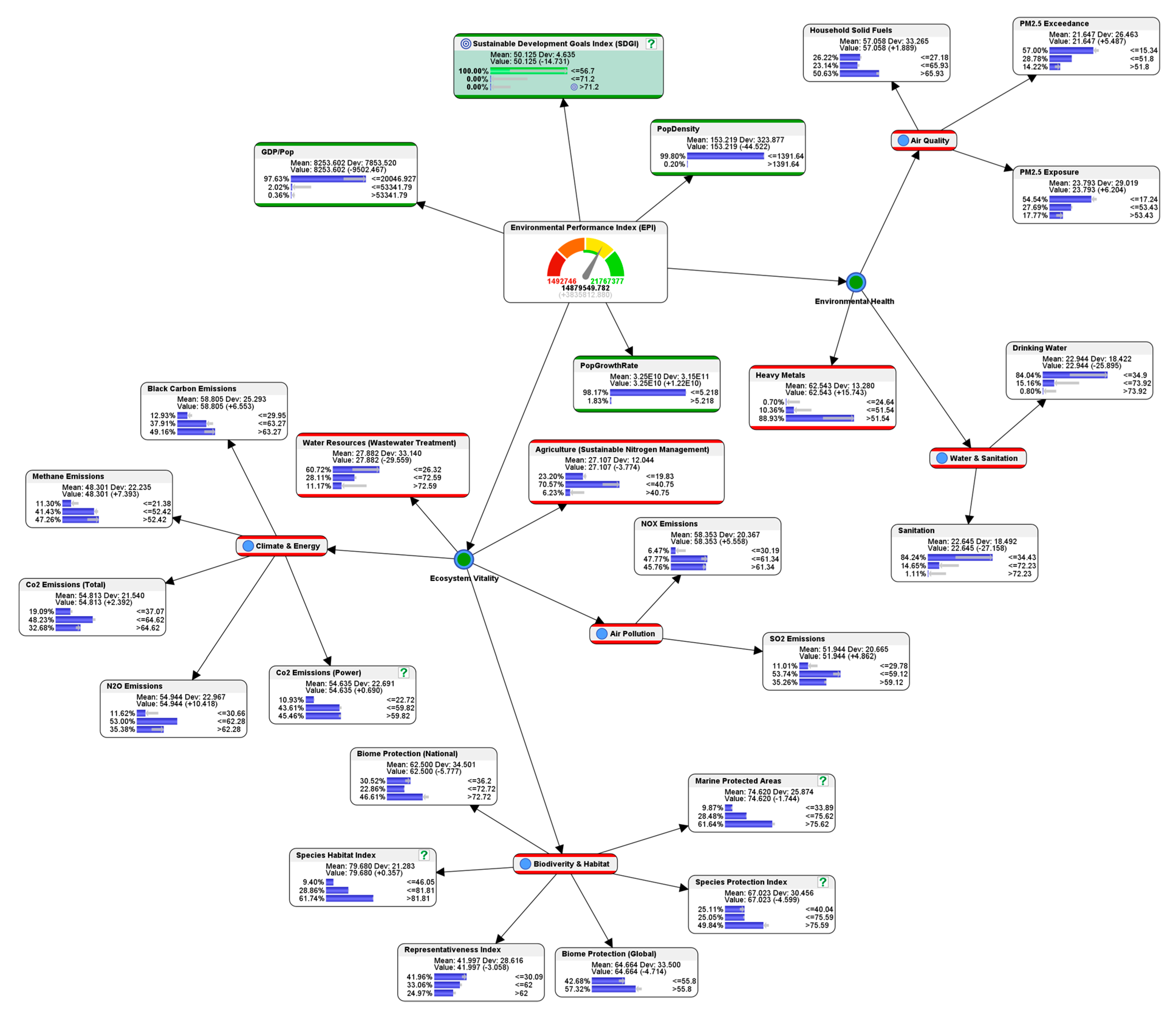
4.5. Predictive Analytics: What Are the Conditions to Avoid in Order to Prevent the Worst-Case Scenario from Happening?
4.6. Evaluation of the Predictive Performance of the Bayesian Network Model
4.6.1. Evaluation of the Predictive Performance Using Target Evaluation Cross-Validation by K-Folds
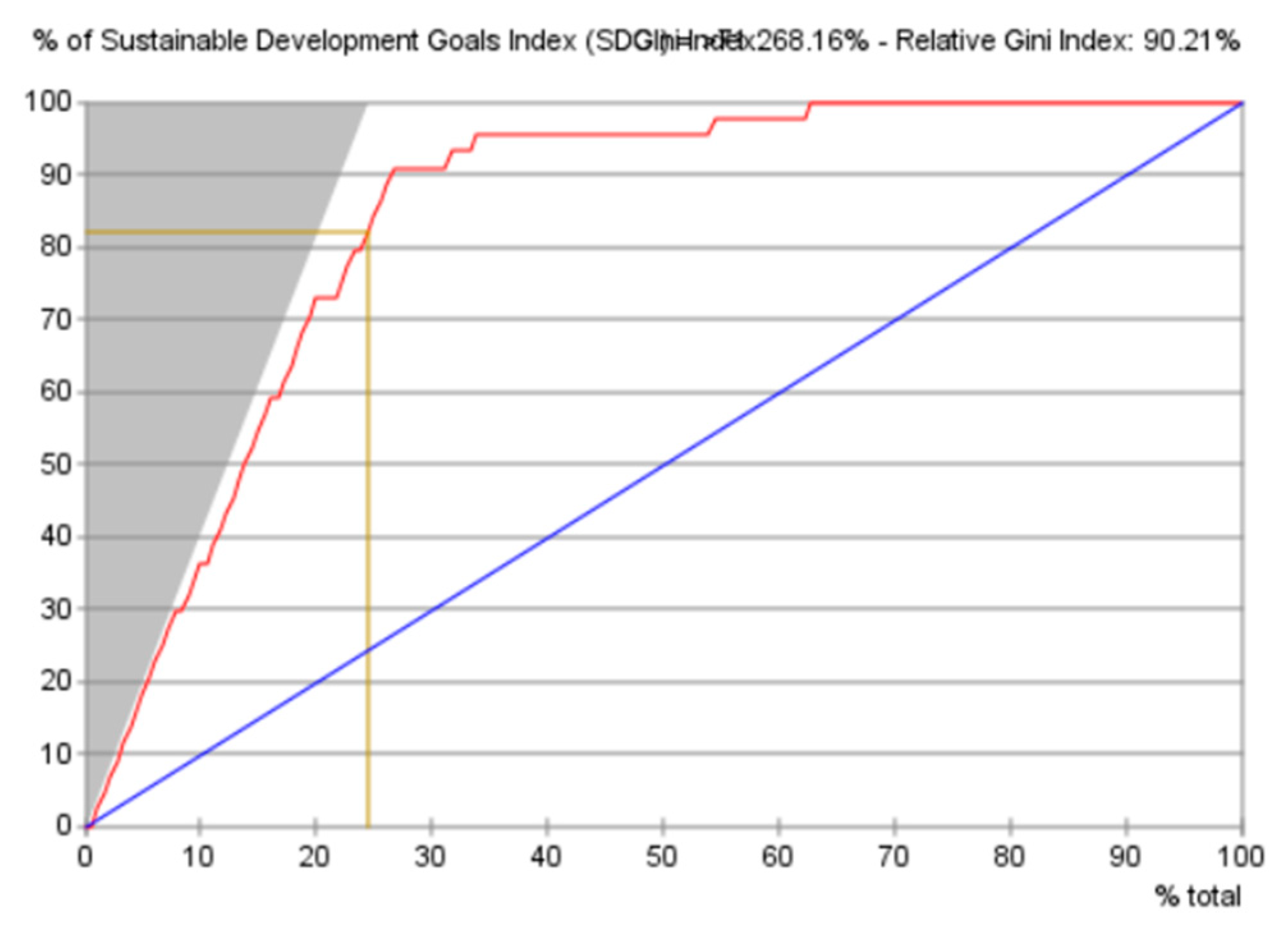
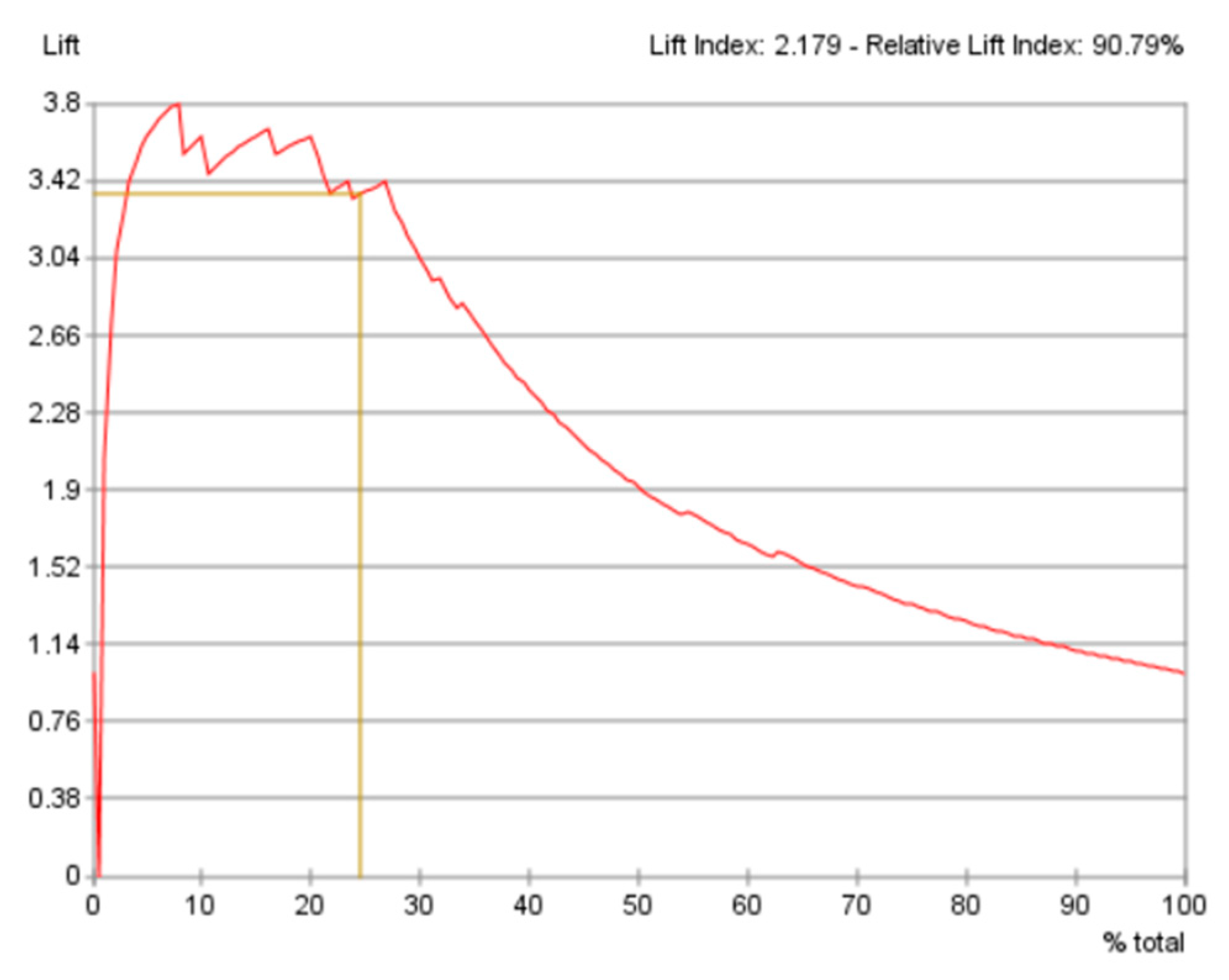
4.6.2. Evaluation of the Predictive Performance Using the Gains Curve, Lift Curve and ROC Curve
4.6.3. Limitations of the Study
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wendling, Z.; Esty, D.; Emerson, J.; Levy, M.; de Sherbinin, A. The 2018 Environmental Performance Index Report; Yale Center for Environmental Law and Policy: New Haven, CT, USA, 2018. [Google Scholar]
- Sachs, J.; Kroll, C.; Schmidt-Traub, G.; Lafortune, G.; Fuller, G.; Woelm, F. The Sustainable Development Report 2019: Transformations to Achieve the Sustainable Development Goals; Bertelsmann Stiftung and Sustainable Development Solutions Network (SDSN): New York, NY, USA, 2019. [Google Scholar]
- The World Bank. The World Bank Logistics Performance Index. Available online: https://lpi.worldbank.org/about (accessed on 13 December 2019).
- Arvis, J.-F.; Ojala, L.; Wiederer, C.; Shepherd, B.; Raj, A.; Dairabayeva, K.; Kiiski, T. Connecting to Compete 2018: Trade Logistics in the Global Economy: The Logistics Performance Index and Its Indicators; The International Bank for Reconstruction and Development/The World Bank: Washington, DC, USA, 2018. [Google Scholar]
- Hsu, A.; Lloyd, A.; Emerson, J.W. What progress have we made since Rio? The 2012 Environmental Performance Index (EPI) and Pilot Trend EPI. Environ. Sci. Policy 2013, 33, 171–185. [Google Scholar] [CrossRef]
- Kraemer, R.A.; Peichert, H. Analysis of the Yale Environmental Performance Index (EPI); German Federal Environment Agency: Dessau, Germany, 2008. [Google Scholar]
- Kulin, J.; Sevä, I.J. The Role of Government in Protecting the Environment: Quality of Government and the Translation of Normative Views about Government Responsibility into Spending Preferences. Int. J. Sociol. 2019, 49, 110–129. [Google Scholar] [CrossRef]
- Association of Computing Machinery, A.M. Turing Award Laureate Dr. McCarthy’s Lecture “The Present State of Research on Artificial Intelligence”. Available online: https://amturing.acm.org/award_winners/mccarthy_1118322.cfm (accessed on 10 July 2019).
- Holzinger, A. From Machine Learning to Explainable AI. In Proceedings of the 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Kosice, Slovakia, 23–25 August 2018; pp. 55–66. [Google Scholar]
- Zeng, D. From Computational Thinking to AI Thinking [A letter from the editor]. IEEE Intell. Syst. 2013, 28, 2–4. [Google Scholar] [CrossRef]
- Gadanidis, G. Artificial intelligence, computational thinking, and mathematics education. Int. J. Inf. Learn. Technol. 2017, 34, 133–139. [Google Scholar] [CrossRef]
- Rad, P.; Roopaei, M.; Beebe, N.; Shadaram, M.; Au, Y. AI Thinking for Cloud Education Platform with Personalized Learning. In Proceedings of the 51st Hawaii International Conference on System Sciences, Waikoloa Village, HI, USA, 3–6 January 2018; pp. 3–12. [Google Scholar]
- Klebanov, B.B.; Burstein, J.; Harackiewicz, J.M.; Priniski, S.J.; Mulholland, M. Reflective Writing About the Utility Value of Science as a Tool for Increasing STEM Motivation and Retention—Can AI Help Scale Up? Int. J. Artif. Intell. Educ. 2017, 31, 151. [Google Scholar]
- Rosenberg, L. Artificial Swarm Intelligence, a Human-in-the-Loop Approach to A.I. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AR, USA, 12–17 February 2016; pp. 4381–4382. [Google Scholar]
- Davis, B. Complexity and Education: Vital simultaneities. Educ. Philos. Theory 2008, 40, 50–65. [Google Scholar] [CrossRef]
- Gherheș, V.; Obrad, C. Technical and Humanities Students’ Perspectives on the Development and Sustainability of Artificial Intelligence (AI). Sustainability 2018, 10, 3066. [Google Scholar] [CrossRef]
- Khakurel, J.; Penzenstadler, B.; Porras, J.; Knutas, A.; Zhang, W. The Rise of Artificial Intelligence under the Lens of Sustainability. Technology 2018, 6, 100. [Google Scholar] [CrossRef]
- Hill, P.; Barber, M. Preparing for a Renaissance in Assessment; Pearson: London, UK, 2014. [Google Scholar]
- Correa, M.; Bielza, C.; Teixeira, J.P. Comparison of Bayesian networks and artificial neural networks for quality detection in a machining process. Expert Syst. Appl. 2009, 36, 7270–7279. [Google Scholar] [CrossRef]
- Georgiopoulos, M.; Demara, R.F.; Gonzalez, A.J.; Wu, A.S.; Mollaghasemi, M.; Gelenbe, E.; Kysilka, M.; Secretan, J.; Sharma, C.A.; Alnsour, A.J. A Sustainable Model for Integrating Current Topics in Machine Learning Research Into the Undergraduate Curriculum. IEEE Trans. Educ. 2009, 52, 503–512. [Google Scholar] [CrossRef][Green Version]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2010; ISBN 978-0-521-89560-6. [Google Scholar]
- Pearl, J. Causes of Effects and Effects of Causes. Sociol. Methods Res. 2015, 44, 149–164. [Google Scholar] [CrossRef]
- Pearl, J. Fusion, propagation, and structuring in belief networks. Artif. Intell. 1986, 29, 241–288. [Google Scholar] [CrossRef]
- Loveland, D.W. Automated Theorem Proving: A logical Basis; Elsevier North-Holland, Inc.: New York, NY, USA, 1978; ISBN 0-7204-0499-1. [Google Scholar]
- Moore, R.C. Logic and Representation; Center for the Study of Language (CSLI); Stanford University: Main Quad, CA, USA, 1995; Volume 39. [Google Scholar]
- Domingos, P.; Pazzani, M. On the Optimality of the Simple Bayesian Classifier under Zero-One Loss. Mach. Learn. 1997, 29, 103–130. [Google Scholar] [CrossRef]
- Hand, D.; You, K. Idiot’s Bayes–Not so stupid after all? Int. Stat. Rev. 2001, 69, 385–398. [Google Scholar]
- Bayes, T. A Letter from the Late Reverend Mr. Thomas Bayes, F.R.S. to John Canton, M.A. and F. R. S. In The Royal Society, Philosophical Transactions (1683–1775); The Royal Society Publishing: London, UK, 1763; Volume 53, pp. 269–271. [Google Scholar]
- van de Schoot, R.; Kaplan, D.; Denissen, J.; Asendorpf, J.B.; Neyer, F.J.; van Aken, M.A.G. A Gentle Introduction to Bayesian Analysis: Applications to Developmental Research. Child Dev. 2014, 85, 842–860. [Google Scholar] [CrossRef] [PubMed]
- Hox, J.; van de Schoot, R.; Matthijsse, S. How few countries will do? Comparative survey analysis from a Bayesian perspective. Surv. Res. Methods 2012, 6, 87–93. [Google Scholar]
- Lee, S.-Y.; Song, X.-Y. Evaluation of the Bayesian and Maximum Likelihood Approaches in Analyzing Structural Equation Models with Small Sample Sizes. Multivar. Behav. Res. 2004, 39, 653–686. [Google Scholar] [CrossRef]
- Button, K.S.; Ioannidis, J.P.A.; Mokrysz, C.; Nosek, B.A.; Flint, J.; Robinson, E.S.J.; Munafò, M.R. Power failure: Why small sample size undermines the reliability of neuroscience. Nat. Rev. Neurosci. 2013, 14, 365–376. [Google Scholar] [CrossRef]
- Kaplan, D.; Depaoli, S. Bayesian structural equation modeling. In Handbook of Structural Equation Modeling; Hoyle, R., Ed.; Guilford Press: New York, NY, USA, 2012; pp. 650–673. [Google Scholar]
- Walker, L.J.; Gustafson, P.; Frimer, J.A. The application of Bayesian analysis to issues in developmental research. Int. J. Behav. Dev. 2007, 31, 366–373. [Google Scholar] [CrossRef]
- Zhang, Z.; Hamagami, F.; Wang, L.L.; Nesselroade, J.R.; Grimm, K.J. Bayesian analysis of longitudinal data using growth curve models. Int. J. Behav. Dev. 2007, 31, 374–383. [Google Scholar] [CrossRef]
- Zou, L.; Kent, J.; Lam, N.S.-N.; Cai, H.; Qiang, Y.; Li, K. Evaluating Land Subsidence Rates and Their Implications for Land Loss in the Lower Mississippi River Basin. Water 2015, 8, 10. [Google Scholar] [CrossRef]
- Seydehmet, J.; Lv, G.H.; Nurmemet, I.; Aishan, T.; Abliz, A.; Sawut, M.; Abliz, A.; Eziz, M. Model Prediction of Secondary Soil Salinization in the Keriya Oasis, Northwest China. Sustainability 2018, 10, 656. [Google Scholar] [CrossRef]
- Shannon, C. The lattice theory of information. Trans. IRE Prof. Group Inf. Theory 1953, 1, 105–107. [Google Scholar] [CrossRef]
- Lleo, S.; Ziemba, B. The Swiss black swan bad scenario: Is Switzerland another casualty of the Eurozone crisis. IJFS 2015, 3, 351–380. [Google Scholar] [CrossRef]
- Chang, W.; Xu, Z.; You, M.; Zhou, S.; Xiao, Y.; Cheng, Y. A Bayesian Failure Prediction Network Based on Text Sequence Mining and Clustering. Entropy 2018, 20, 923. [Google Scholar] [CrossRef]
- Sperotto, A.; Molina, J.L.; Torresan, S.; Critto, A.; Pulido-Velazquez, M.; Marcomini, A. Water Quality Sustainability Evaluation under Uncertainty: A Multi-Scenario Analysis Based on Bayesian Networks. Sustainability 2019, 11, 4764. [Google Scholar] [CrossRef]
- Cowell, R.G.; Dawid, A.P.; Lauritzen, S.L.; Spieglehalter, D.J. Probabilistic Networks and Expert Systems: Exact Computational Methods for Bayesian Networks; Springer: New York, NY, USA, 1999; ISBN 978-0-387-98767-5. [Google Scholar]
- Jensen, F.V. An Introduction to Bayesian Networks; Springer: New York, NY, USA, 1999; ISBN 0-387-91502-8. [Google Scholar]
- Korb, K.B.; Nicholson, A.E. Bayesian Artificial Intelligence; Chapman & Hall/CRC: London, UK, 2010; ISBN 978-1-4398-1591-5. [Google Scholar]
- Tsamardinos, I.; Aliferis, C.F.; Statnikov, A. Time and sample efficient discovery of Markov blankets and direct causal relations. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD, New York, NY, USA, 3 August 2003; p. 673. [Google Scholar]
- Chi, G.; Hu, S.; Yang, Y.; Chen, T. Response surface methodology with prediction uncertainty: A multi-objective optimisation approach. Chem. Eng. Res. Des. 2012, 90, 1235–1244. [Google Scholar] [CrossRef]
- Fox, R.J.; Elgart, D.; Davis, S.C. Bayesian credible intervals for response surface optima. J. Stat. Plan. Inference 2009, 139, 2498–2501. [Google Scholar] [CrossRef]
- Miró-Quesada, G.; Del Castillo, E.; Peterson, J.J. A Bayesian Approach for Multiple Response Surface Optimization in the Presence of Noise Variables. J. Appl. Stat. 2004, 31, 251–270. [Google Scholar] [CrossRef]
- Myers, R.H.; Montgomery, D.C.; Anderson-Cook, C.M. Response Surface Methodology: Process and Product Optimization Using Designed Experiments, 3th ed.; Wiley and Sons, Inc.: Somerset, NJ, USA, 2009; ISBN 978-0-470-17446-3. [Google Scholar]
- Socioeconomic Data and Applications Center (sedac) Environmental Performance Index, 2018 Release. Available online: https://sedac.ciesin.columbia.edu/data/set/epi-environmental-performance-index-2018/data-download (accessed on 5 January 2020).
- Yale University Subset of the Environment Performance Index Dataset. Available online: https://figshare.com/articles/Educing_AI-Thinking_in_Global_Sustainability_Development_Education_Dataset/11330645 (accessed on 3 January 2020).
- Yale University Full Dataset of the Environment Performance Index. Available online: https://sedac.ciesin.columbia.edu/data/set/epi-environmental-performance-index-2018/data-download (accessed on 3 January 2020).
- Conrady, S.; Jouffe, L. Bayesian Networks & BayesiaLab: A Practical Introduction for Researchers; Bayesia: Franklin, TN, USA, 2015; ISBN 0-9965333-0-3. [Google Scholar]
- Bayesia, S.A.S. BayesiaLab: Missing Values Processing. Available online: http://www.bayesia.com/bayesialab-missing-values-processing (accessed on 2 June 2019).
- How, M.-L.; Hung, W.L.D. Harnessing Entropy via Predictive Analytics to Optimize Outcomes in the Pedagogical System: An Artificial Intelligence-Based Bayesian Networks Approach. Educ. Sci. 2019, 9, 158. [Google Scholar] [CrossRef]
- Bayesia, S.A.S. R2-GenOpt* Algorithm. Available online: https://library.bayesia.com/pages/viewpage.action?pageId=35652439#6c939073de75493e8379c0fff83e1384 (accessed on 19 March 2019).
- Lauritzen, S.L.; Spiegelhalter, D.J. Local Computations with Probabilities on Graphical Structures and Their Application to Expert Systems. J. R. Stat. Soc. Ser. B 1988, 50, 157–194. [Google Scholar] [CrossRef]
- Kschischang, F.; Frey, B.; Loeliger, H.-A. Factor graphs and the sum-product algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Bonilla, S.H.; Silva, H.R.O.; Da Silva, M.T.; Gonçalves, R.F.; Sacomano, J.B. Industry 4.0 and Sustainability Implications: A Scenario-Based Analysis of the Impacts and Challenges. Sustainability 2018, 10, 3740. [Google Scholar] [CrossRef]
- Valero, L.G.; Pajares, E.M.; Sánchez, I.R. The Tax Burden on Wastewater and the Protection of Water Ecosystems in EU Countries. Sustainability 2018, 10, 212. [Google Scholar] [CrossRef]
- Hou, Y.; Iqbal, W.; Shaikh, G.M.; Iqbal, N.; Solangi, Y.A.; Fatima, A. Measuring Energy Efficiency and Environmental Performance: A Case of South Asia. Processes 2019, 7, 325. [Google Scholar] [CrossRef]
- Kim, J.; Jun, S.; Jang, D.; Park, S. Sustainable Technology Analysis of Artificial Intelligence Using Bayesian and Social Network Models. Sustainability 2018, 10, 115. [Google Scholar] [CrossRef]
- Liu, G.; Brown, M.T.; Casazza, M. Enhancing the Sustainability Narrative through a Deeper Understanding of Sustainable Development Indicators. Sustainability 2017, 9, 1078. [Google Scholar] [CrossRef]
- Rodríguez-Martínez, C.C.; García-Sánchez, I.M.; Vicente-Galindo, P.; Galindo-Villardón, P. Exploring Relationships between Environmental Performance, E-Government and Corruption: A Multivariate Perspective. Sustainability 2019, 11, 6497. [Google Scholar]
- How, M.-L.; Hung, W.L.D. Educational Stakeholders’ Independent Evaluation of an Artificial Intelligence-Enabled Adaptive Learning System Using Bayesian Network Predictive Simulations. Educ. Sci. 2019, 9, 110. [Google Scholar] [CrossRef]
- Shen, K.-Y.; Tzeng, G.-H. Advances in Multiple Criteria Decision Making for Sustainability: Modeling and Applications. Sustainability 2018, 10, 1600. [Google Scholar] [CrossRef]
- Sun, Z.; An, C.; Sun, H. Regional Differences in Energy and Environmental Performance: An Empirical Study of 283 Cities in China. Sustainability 2018, 10, 2303. [Google Scholar] [CrossRef]
- How, M.-L. Future-Ready Strategic Oversight of Multiple Artificial Superintelligence-Enabled Adaptive Learning Systems via Human-Centric Explainable AI-Empowered Predictive Optimizations of Educational Outcomes. Big Data Cogn. Comput. 2019, 3, 46. [Google Scholar] [CrossRef]
- How, M.-L.; Hung, W.L.D. Educing AI-Thinking in Science, Technology, Engineering, Arts, and Mathematics (STEAM) Education. Educ. Sci. 2019, 9, 184. [Google Scholar] [CrossRef]
- Bayesia, S.A.S. Bayesialab. Available online: https://www.bayesialab.com/ (accessed on 18 March 2019).
- Bayes Fusion LLC. GeNie. Available online: https://www.bayesfusion.com/genie/ (accessed on 18 March 2019).
- Norsys Software Corp. FigurNetica. Available online: https://www.norsys.com/netica.html (accessed on 18 March 2019).
- Bayes Server LLC. Bayes Server. Available online: https://www.bayesserver.com/ (accessed on 18 March 2019).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Policy Objective | Issue Category | Indicator | |
|---|---|---|---|
| EPI | Environmental Health | Air Quality | Household Solid Fuels |
| PM2.5 Exposure | |||
| PM2.5 Exceedance | |||
| Water and Sanitation | Drinking Water | ||
| Sanitation | |||
| Heavy Metals | Lead Exposure | ||
| Ecosystem Vitality | Biodiversity and Habitat | Marine Protected Areas | |
| Biome Protection (National) | |||
| Biome Protection (Global) | |||
| Species Protection Index | |||
| Protected Area Representativeness Index | |||
| Species Habitat Index | |||
| Climate and Energy | CO2 Emissions—Total | ||
| CO2 Emissions—Power | |||
| Methane Emissions | |||
| N2O Emissions | |||
| Black Carbon Emissions | |||
| Air Pollution | SO2 Emissions | ||
| NOX Emissions | |||
| Water Resources | Wastewater Treatment | ||
| Agriculture | Sustainable Nitrogen Management |
| Variable | Low Level | Mid-Level | High Level | |||
|---|---|---|---|---|---|---|
| Range | Probability | Range | Probability | Range | Probability | |
| Sustainable Development Goals Index (SDGI) | ≤56.7 | 25.19% | 56.8–71.2 | 48.31% | >71.2 | 26.49% |
| Household Solid Fuels | e.g., 27.18 | 27.78% | 27.19–65.93 | 25.00% | >65.93 | 47.21% |
| PM2.5 Exposure | e.g., 17.24 | 61.65% | 17.25–53.43 | 30.00% | >53.43 | 8.35% |
| PM2.5 Exceedance | e.g., 15.34 | 64.43% | 15.35–51.8 | 28.89% | >51.8 | 6.68% |
| Drinking Water | e.g., 34.9 | 35.00% | 35.0–73.92 | 47.77% | >73.92 | 17.23% |
| Sanitization | e.g., 34.43 | 35.55% | 34.44–72.23 | 40.55% | >72.23 | 23.89% |
| Lead Exposure | e.g., 24.64 | 18.34% | 24.65–51.54 | 33.33% | >51.54 | 48.33% |
| Marine Protected Areas | e.g., 33.89 | 8.16% | 33.9–75.62 | 27.09% | >75.62 | 64.74% |
| Biome Protection (National) | e.g., 36.2 | 23.34% | 36.3–72.72 | 22.23% | >72.72 | 54.43% |
| Biome Protection (Global) | e.g., 55.8 | 35.01% | - | - | >55.8 | 64.99% |
| Species Protection Index | e.g., 40.04 | 19.42% | 40.05–75.59 | 23.26% | >75.59 | 57.32% |
| Protected Area Representiveness Index | e.g., 30.09 | 36.11% | 30.1–62 | 35.55% | >62 | 28.34% |
| Species Habitat Index | e.g., 46.05 | 9.71% | 46.06–81.81 | 29.66% | >81.81 | 60.63% |
| CO2 Emissions (Total) | e.g., 37.07 | 21.67% | 37.08–64.62 | 51.66% | >64.62 | 26.67% |
| CO2 Emissions (Power) | e.g., 22.72 | 11.02% | 22.73–59.82 | 46.16% | >59.82 | 42.82% |
| Methane Emissions | e.g., 21.38 | 21.12% | 21.39–52.42 | 46.66% | e.g., 52.42 | 32.33% |
| N2O Emissions | e.g., 30.66 | 27.78% | 30.67–62.28 | 52.77% | >62.28 | 19.45% |
| Black Carbon Emissions | e.g., 29.95 | 18.90% | 29.96–63.27 | 46.10% | >63.27 | 35.00% |
| SO2 Emissions | e.g., 29.78 | 23.89% | 29.79–59.12 | 43.88% | >59.12 | 32.22% |
| NOX Emissions | e.g., 30.19 | 19.45% | 30.2–61.34 | 39.44% | >61.34 | 41.11% |
| Wastewater Treatment | e.g., 26.32 | 25.56% | 26.33–72.59 | 30.56% | >72.59 | 43.88% |
| Sustainable Nitrogen Management | e.g., 19.83 | 27.23% | 19.84–40.75 | 48.33% | >40.75 | 24.45% |
| Variable/Node | Low Level | Mid-Level | High Level | |||
|---|---|---|---|---|---|---|
| Base | Best-Case | Base | Best-Case | Base | Best-Case | |
| Household Solid Fuels | 27.78% | 28.21% | 25.00% | 25.54% | 47.21% | 46.35% |
| PM2.5 Exposure | 64.43% | 63.49% | 30.00% | 30.86% | 8.35% | 5.65% |
| PM2.5 Exceedance | 64.43% | 66.35% | 28.89% | 29.13% | 6.68% | 4.52% |
| Drinking Water | 35.00% | 4.50% | 47.77% | 45.31% | 17.23% | 50.19% |
| Sanitization | 35.55% | 4.85% | 40.55% | 25.54% | 23.89% | 69.61% |
| Lead Exposure | 18.34% | 54.57% | 33.33% | 36.31% | 48.33% | 9.13% |
| Marine Protected Areas | 8.16% | 7.19% | 27.09% | 26.31% | 64.74% | 66.50% |
| Biome Protection (National) | 23.34% | 19.28% | 22.23% | 21.87% | 54.43% | 58.85% |
| Biome Protection (Global) | 35.01% | 30.68% | - | - | 64.99% | 69.32% |
| Species Protection Index | 19.42% | 16.20% | 75.59% | 22.25% | 57.32% | 61.55% |
| Protected Area Representiveness Index | 36.11% | 32.80% | 35.55% | 36.96% | 28.34% | 30.24% |
| Species Habitat Index | 9.71% | 9.89% | 29.66% | 30.11% | 60.63% | 60.00% |
| CO2 Emissions (Total) | 21.67% | 23.13% | 51.66% | 53.59% | 26.67% | 23.28% |
| CO2 Emissions (Power) | 11.02% | 11.08% | 46.16% | 47.60% | 42.82% | 41.33% |
| Methane Emissions | 21.12% | 26.66% | 46.66% | 49.61% | 32.33% | 23.73% |
| N2O Emissions | 27.78% | 36.90% | 52.77% | 52.64% | 19.45% | 10.46% |
| Black Carbon Emissions | 18.90% | 22.27% | 46.10% | 50.73% | 35.00% | 27.00% |
| SO2 Emissions | 23.89% | 31.17% | 43.88% | 38.32% | 32.22% | 30.51% |
| NOX Emissions | 19.45% | 26.79% | 39.44% | 34.73% | 41.11% | 38.48% |
| Wastewater Treatment | 25.56% | 5.70% | 30.56% | 31.94% | 43.88% | 62.36% |
| Sustainable Nitrogen Management | 27.23% | 29.50% | 48.33% | 35.76% | 24.45% | 34.74% |
| Variable/Node | Low Level | Mid-Level | High Level | |||
|---|---|---|---|---|---|---|
| Worst-Case | Base | Worst-Case | Base | Worst-Case | Base | |
| Household Solid Fuels | 26.22% | 27.78% | 23.14% | 25.00% | 50.63% | 47.21% |
| PM2.5 Exposure | 54.54% | 61.65% | 27.69% | 30.00% | 17.77% | 8.35% |
| PM2.5 Exceedance | 57.00% | 64.43% | 28.78% | 28.89% | 14.22% | 6.68% |
| Drinking Water | 84.04% | 35.00% | 15.16% | 47.77% | 0.80% | 17.23% |
| Sanitization | 84.24% | 35.55% | 14.65% | 40.55% | 1.11% | 23.89% |
| Lead Exposure | 0.70% | 18.34% | 10.36% | 33.33% | 88.93% | 48.33% |
| Marine Protected Areas | 9.87% | 8.16% | 28.48% | 27.09% | 61.64% | 64.74% |
| Biome Protection (National) | 30.52% | 23.34% | 22.86% | 22.23% | 46.61% | 54.43% |
| Biome Protection (Global) | 42.68% | 35.01% | - | - | 57.32% | 64.99% |
| Species Protection Index | 25.11% | 19.42% | 25.05% | 75.59% | 49.84% | 57.32% |
| Protected Area Representiveness Index | 41.96% | 36.11% | 33.06% | 35.55% | 35.55% | 28.34% |
| Species Habitat Index | 9.40% | 9.71% | 28.86% | 29.66% | 61.74% | 60.63% |
| CO2 Emissions (Total) | 19.09% | 21.67% | 48.23% | 51.66% | 32.68% | 26.67% |
| CO2 Emissions (Power) | 10.93% | 11.02% | 43.61% | 46.16% | 45.46% | 42.82% |
| Methane Emissions | 11.30% | 21.12% | 41.43% | 46.66% | 47.26% | 32.33% |
| N2O Emissions | 11.62% | 27.78% | 53.00% | 52.77% | 35.38% | 19.45% |
| Black Carbon Emissions | 12.93% | 18.90% | 37.91% | 46.10% | 49.16% | 35.00% |
| SO2 Emissions | 11.01% | 23.89% | 53.74% | 43.88% | 35.26% | 32.22% |
| NOX Emissions | 6.47% | 19.45% | 47.77% | 39.44% | 45.76% | 41.11% |
| Wastewater Treatment | 60.72% | 25.56% | 28.11% | 30.56% | 11.17% | 43.88% |
| Sustainable Nitrogen Management | 23.20% | 27.23% | 70.57% | 48.33% | 6.23% | 24.45% |
| Variable/Node | Low Level | Mid-Level | High Level | |||
|---|---|---|---|---|---|---|
| Worst-Case | Best-Case | Worst-Case | Best-Case | Worst-Case | Best-Case | |
| Household Solid Fuels | 26.22% | 28.21% | 23.14% | 25.54% | 50.63% | 46.35% |
| PM2.5 Exposure | 54.54% | 63.49% | 27.69% | 30.86% | 17.77% | 5.65% |
| PM2.5 Exceedance | 57.00% | 66.35% | 28.78% | 29.13% | 14.22% | 4.52% |
| Drinking Water | 84.04% | 4.50% | 15.16% | 45.31% | 0.80% | 50.19% |
| Sanitization | 84.24% | 4.85% | 14.65% | 25.54% | 1.11% | 69.61% |
| Lead Exposure | 0.70% | 54.57% | 10.36% | 36.31% | 88.93% | 9.13% |
| Marine Protected Areas | 9.87% | 7.19% | 28.48% | 26.31% | 61.64% | 66.50% |
| Biome Protection (National) | 30.52% | 19.28% | 22.86% | 21.87% | 46.61% | 58.85% |
| Biome Protection (Global) | 42.68% | 30.68% | - | - | 57.32% | 69.32% |
| Species Protection Index | 25.11% | 16.20% | 25.05% | 22.25% | 49.84% | 61.55% |
| Protected Area Representiveness Index | 41.96% | 32.80% | 33.06% | 36.96% | 35.55% | 30.24% |
| Species Habitat Index | 9.40% | 9.89% | 28.86% | 30.11% | 61.74% | 60.00% |
| CO2 Emissions (Total) | 19.09% | 23.13% | 48.23% | 53.59% | 32.68% | 23.28% |
| CO2 Emissions (Power) | 10.93% | 11.08% | 43.61% | 47.60% | 45.46% | 41.33% |
| Methane Emissions | 11.30% | 26.66% | 41.43% | 49.61% | 47.26% | 23.73% |
| N2O Emissions | 11.62% | 36.90% | 53.00% | 52.64% | 35.38% | 10.46% |
| Black Carbon Emissions | 12.93% | 22.27% | 37.91% | 50.73% | 49.16% | 27.00% |
| SO2 Emissions | 11.01% | 31.17% | 53.74% | 38.32% | 35.26% | 30.51% |
| NOX Emissions | 6.47% | 26.79% | 47.77% | 34.73% | 45.76% | 38.48% |
| Wastewater Treatment | 60.72% | 5.70% | 28.11% | 31.94% | 11.17% | 62.36% |
| Sustainable Nitrogen Management | 23.20% | 29.50% | 70.57% | 35.76% | 6.23% | 34.74% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
How, M.-L.; Cheah, S.-M.; Chan, Y.-J.; Khor, A.C.; Say, E.M.P. Artificial Intelligence-Enhanced Decision Support for Informing Global Sustainable Development: A Human-Centric AI-Thinking Approach. Information 2020, 11, 39. https://doi.org/10.3390/info11010039
How M-L, Cheah S-M, Chan Y-J, Khor AC, Say EMP. Artificial Intelligence-Enhanced Decision Support for Informing Global Sustainable Development: A Human-Centric AI-Thinking Approach. Information. 2020; 11(1):39. https://doi.org/10.3390/info11010039
Chicago/Turabian StyleHow, Meng-Leong, Sin-Mei Cheah, Yong-Jiet Chan, Aik Cheow Khor, and Eunice Mei Ping Say. 2020. "Artificial Intelligence-Enhanced Decision Support for Informing Global Sustainable Development: A Human-Centric AI-Thinking Approach" Information 11, no. 1: 39. https://doi.org/10.3390/info11010039
APA StyleHow, M.-L., Cheah, S.-M., Chan, Y.-J., Khor, A. C., & Say, E. M. P. (2020). Artificial Intelligence-Enhanced Decision Support for Informing Global Sustainable Development: A Human-Centric AI-Thinking Approach. Information, 11(1), 39. https://doi.org/10.3390/info11010039