Short-Term Solar Irradiance Forecasting Based on a Hybrid Deep Learning Methodology



Abstract
1. Introduction
2. Materials and Methods
2.1. Introduction to the Comparison Model
2.2. Gated Recurrent Unit (GRU) with an Attention Mechanism
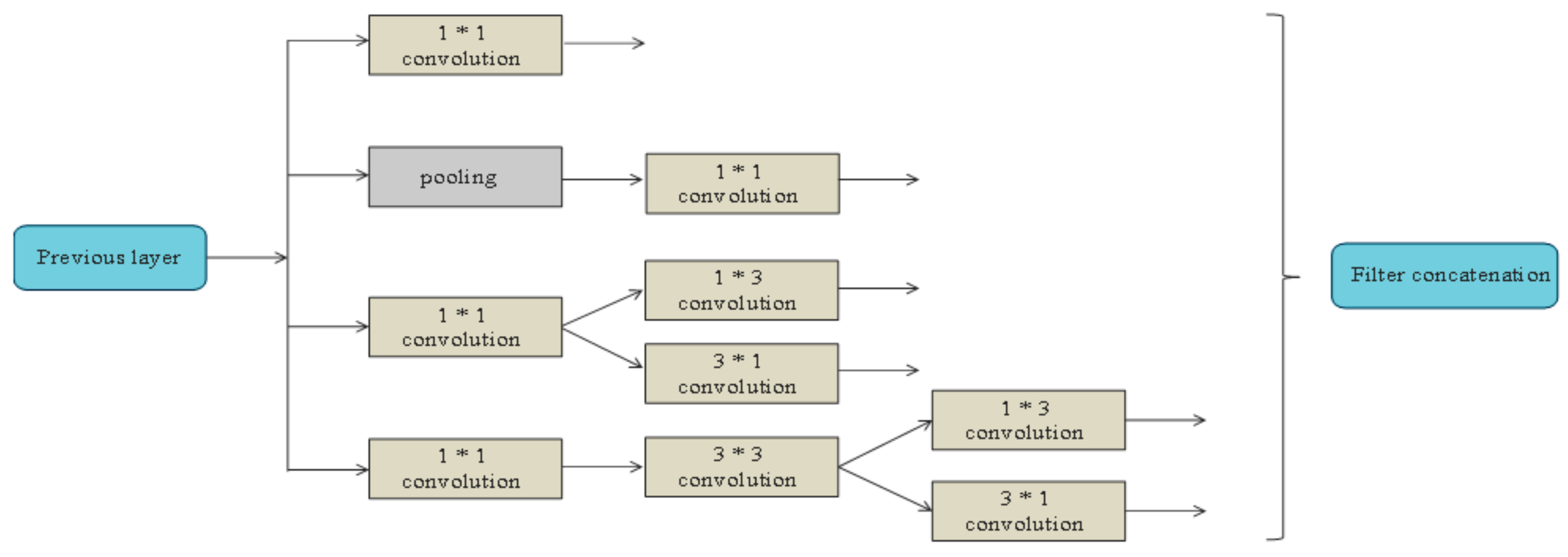
2.2.1. Inception Network
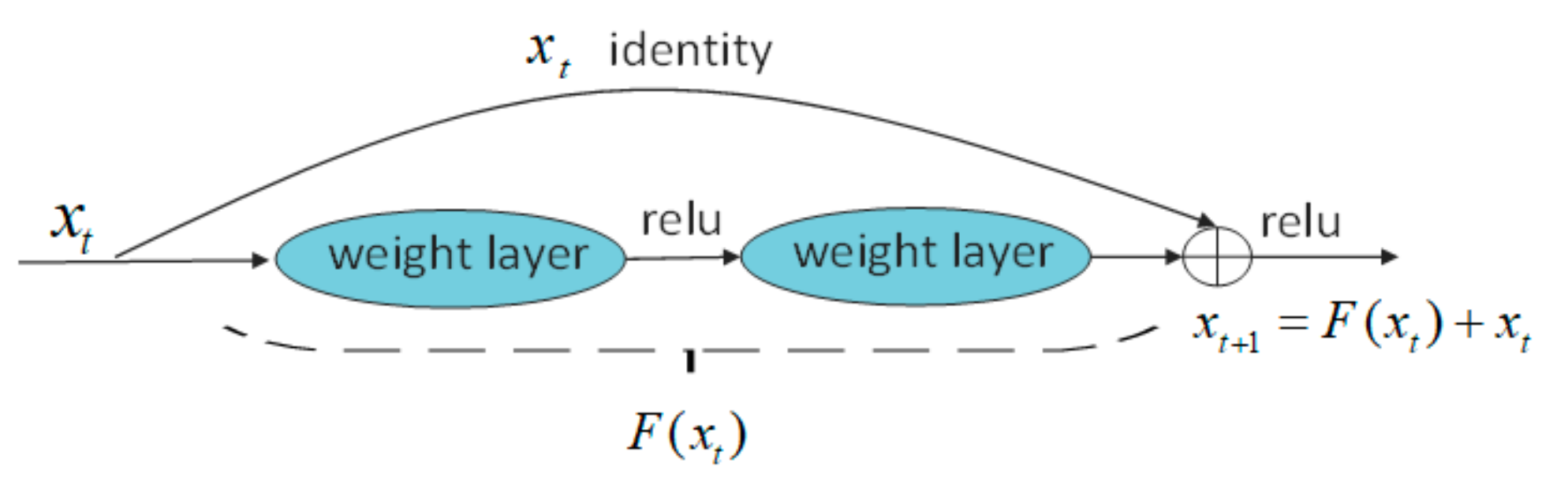
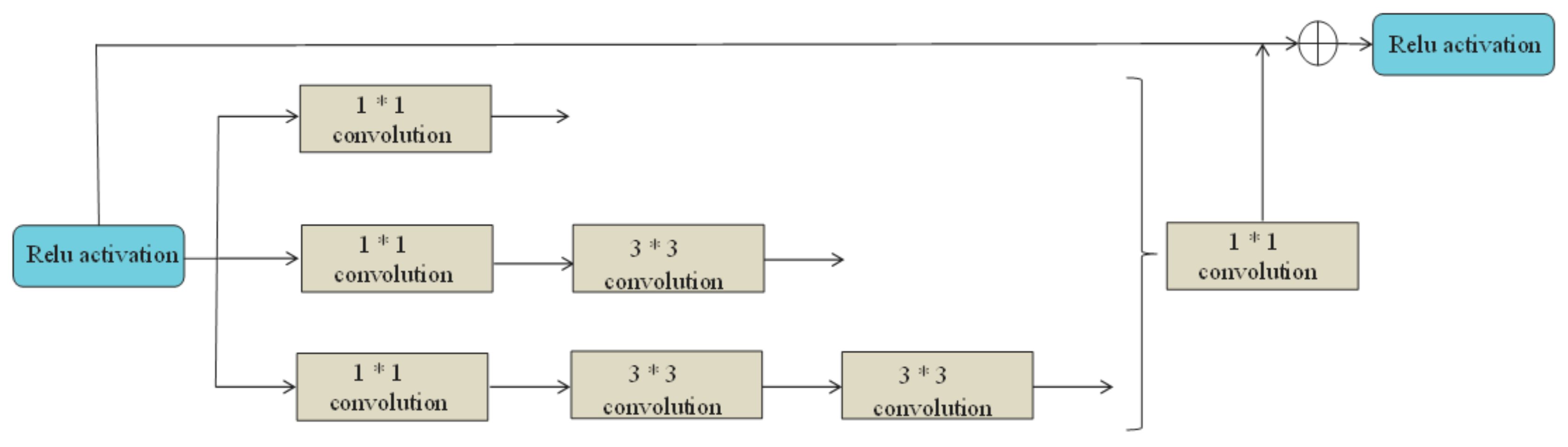
2.2.2. ResNet Network
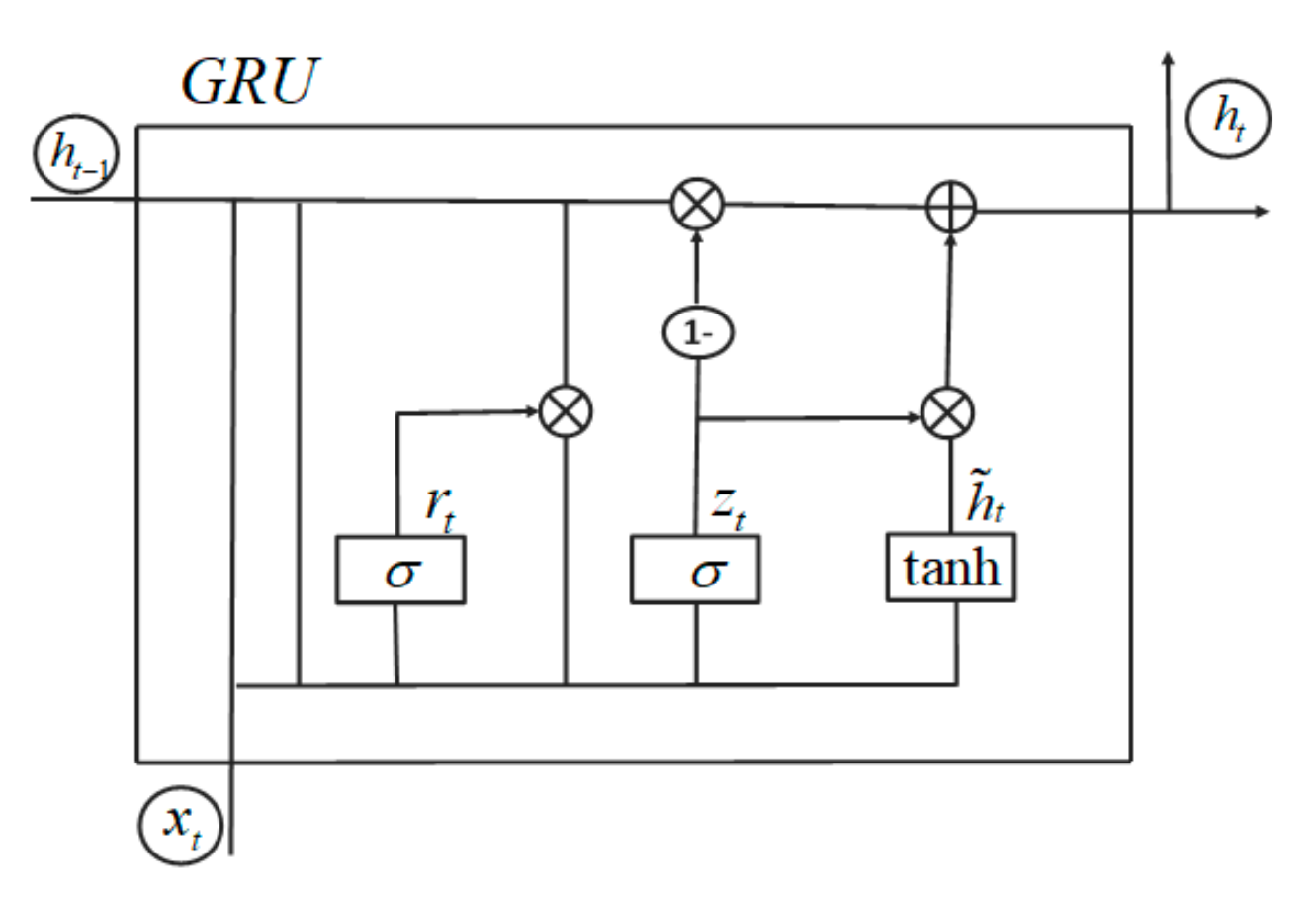
2.2.3. GRU-Gated Cyclic Neural Network
2.2.4. The Attention Mechanism
2.3. Model Structure
2.4. Data Preprocessing
2.5. Experimental Simulation Platform
2.6. Evaluation Criteria
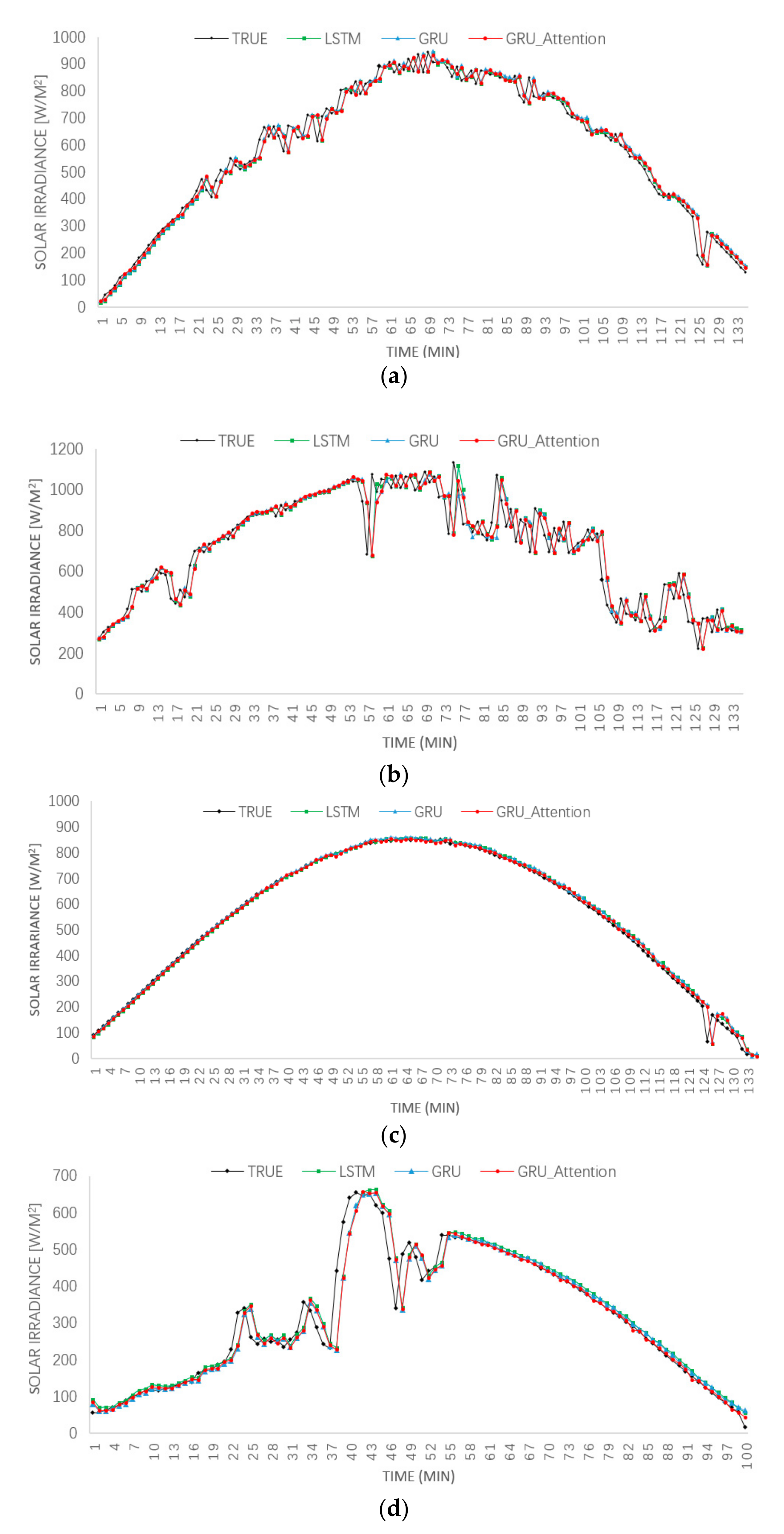
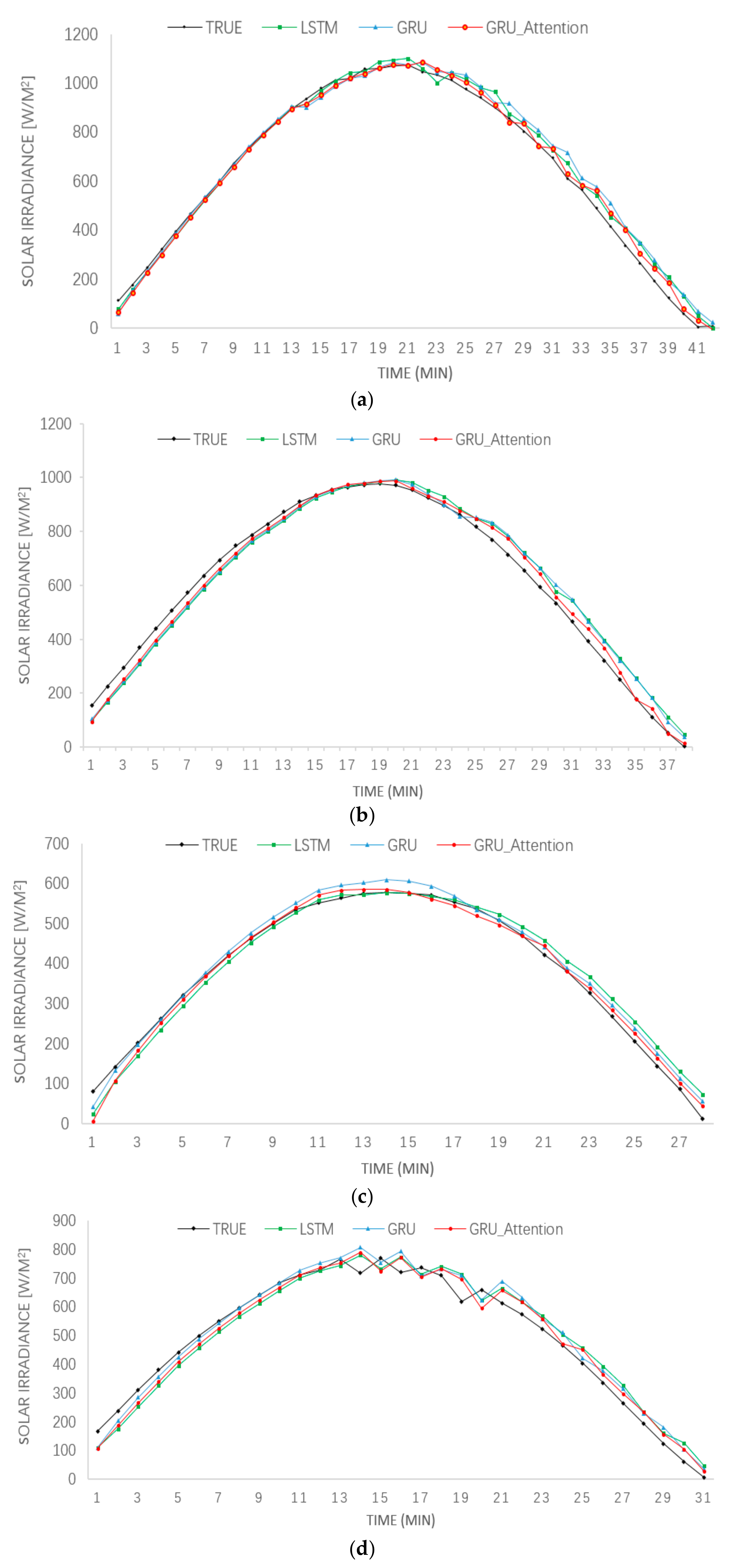
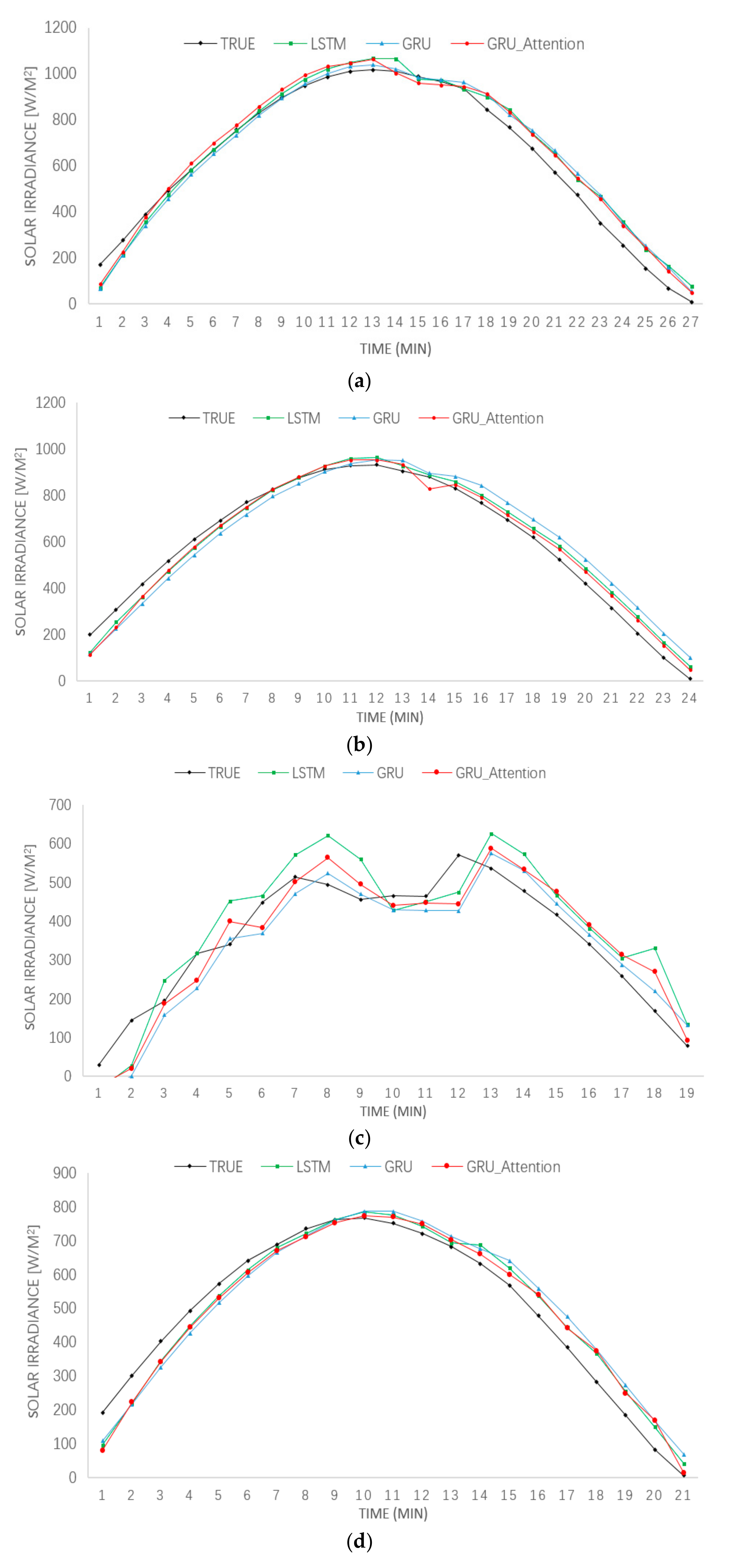
3. Results
4. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Serrano, M.; Sanz, L.; Puig, J.; Pons, J. Landscape fragmentation caused by the transport network in Navarra (Spain): Two-scale analysis and landscape integration assessment. Landsc. Urban Plan. 2002, 58, 113–123. [Google Scholar] [CrossRef]
- Kabir, E.; Kumar, P.; Kumar, S.; Adelodun, A.A.; Kim, K.H. Solar energy: Potential and future prospects. Renew. Sustain. Energy Rev. 2018, 82, 894–900. [Google Scholar] [CrossRef]
- Yan, K.; Du, Y.; Ren, Z. MPPT perturbation optimization of photovoltaic power systems based on solar irradiance data classification. IEEE Trans. Sustain. Energy 2018, 10, 514–521. [Google Scholar] [CrossRef]
- Du, Y.; Yan, K.; Ren, Z.; Xiao, W. Designing localized MPPT for PV systems using fuzzy-weighted extreme learning machine. Energies 2018, 11, 2615. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, Y.; Yang, L.; Liu, Q.; Yan, K.; Du, Y. Short-Term Photovoltaic Power Forecasting Based on Long Short Term Memory Neural Network and Attention Mechanism. IEEE Access 2019, 7, 78063–78074. [Google Scholar] [CrossRef]
- Yan, K.; Dai, Y.; Xu, M.; Mo, Y. Tunnel Surface Settlement Forecasting with Ensemble Learning. Sustainability 2020, 12, 232. [Google Scholar] [CrossRef]
- Yan, K.; Wang, X.; Du, Y.; Jin, N.; Huang, H.; Zhou, H. Multi-Step short-term power consumption forecasting with a hybrid deep learning strategy. Energies 2018, 11, 3089. [Google Scholar] [CrossRef]
- Vaz, A.G.R.; Elsinga, B.; Van Sark, W.G.J.H.M.; Brito, M.C. An artificial neural network to assess the impact of neighbouring photovoltaic systems in power forecasting in Utrecht, The Netherlands. Renew. Energy 2016, 85, 631–641. [Google Scholar] [CrossRef]
- Liu, B.; Pan, Y.; Xu, B.; Liu, W.; Li, H.; Wang, S. Short-term output prediction of photovoltaic power station based on improved grey neural network combination model. Guangdong Electr. Power 2017, 30, 55–60. [Google Scholar]
- Yan, K.; Ji, Z.; Shen, W. Online fault detection methods for chillers combining extended kalman filter and recursive one-class SVM. Neurocomputing 2017, 228, 205–212. [Google Scholar] [CrossRef]
- Hu, M.; Li, W.; Yan, K.; Ji, Z.; Hu, H. Modern machine learning techniques for univariate tunnel settlement forecasting: A comparative study. Math. Probl. Eng. 2019, 2019. [Google Scholar] [CrossRef]
- Aghajani, A.; Kazemzadeh, R.; Ebrahimi, A. A novel hybrid approach for predicting wind farm power production based on wavelet transform, hybrid neural networks and imperialist competitive algorithm. Energy Convers. Manag. 2016, 121, 232–240. [Google Scholar] [CrossRef]
- Yan, K.; Huang, J.; Shen, W.; Ji, Z. Unsupervised Learning for Fault Detection and Diagnosis of Air Handling Units. Energy Build. 2019, 2019, 109689. [Google Scholar] [CrossRef]
- Yan, K.; Zhong, C.; Ji, Z.; Huang, J. Semi-supervised learning for early detection and diagnosis of various air handling unit faults. Energy Build. 2018, 181, 75–83. [Google Scholar] [CrossRef]
- Bao, A. Short-term optimized prediction and simulation of solar irradiance in photovoltaic power generation. Comput. Simul. 2017, 34, 69–72. [Google Scholar]
- Wang, K.; Qi, X.; Liu, H. Photovoltaic power forecasting based LSTM-Convolutional. Netw. Energy 2019, 189, 116225. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Xu, Y.; Lu, Y.; Zhu, B.; Wang, B.; Deng, Z.; Wan, Z. Short-term load forecasting method based on FFT optimized ResNet model. Control Eng. 2019, 26, 1085–1090. [Google Scholar]
- Wang, Y.; Liao, W.; Chang, Y. Gated Recurrent Unit Network-Based Short-Term Photovoltaic Forecasting. Energies 2018, 11, 2163. [Google Scholar] [CrossRef]
- Stoffel, T.; Andreas, A. University of Nevada (UNLV): Las Vegas, Nevada (Data); No. NREL/DA-5500–56509; National Renewable Energy Laboratory (NREL): Golden, CO, USA, 2006. [Google Scholar]
- Ssekulima, E.B.; Anwar, M.B.; Al Hinai, A.; El Moursi, M.S. Wind speed and solar irradiance forecasting techniques for enhanced renewable energy integration with the grid: A review. IET Renew. Power Gener. 2016, 10, 885–989. [Google Scholar] [CrossRef]
- Chen, X.; Du, Y.; Lim, E.; Wen, H.; Jiang, L. Sensor network based PV power nowcasting with spatio-temporal preselection for grid-friendly control. Appl. Energy 2019, 255, 113760. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spring | Summer | Autumn | Winter | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | ||
| 5 min | LSTM | 26.95 | 36.67 | 6.01 | 59.20 | 89.91 | 9.46 | 13.13 | 18.85 | 7.01 | 21.58 | 44.24 | 9.10 |
| GRU | 27.18 | 36.82 | 6.13 | 59.70 | 89.77 | 9.63 | 16.03 | 20.75 | 10.34 | 23.60 | 43.66 | 10.05 | |
| GRU_Attention | 26.49 | 36.23 | 5.80 | 57.76 | 88.05 | 9.19 | 11.32 | 17.41 | 6.33 | 20.69 | 43.09 | 8.46 | |
| 10 min | LSTM | 29.65 | 41.02 | 11.08 | 32.96 | 42.23 | 11.11 | 33.62 | 53.01 | 8.52 | 11.09 | 14.20 | 11.43 |
| GRU | 34.42 | 44.71 | 15.04 | 30.92 | 41.08 | 12.66 | 38.35 | 55.00 | 9.92 | 12.83 | 15.20 | 13.21 | |
| GRU_Attention | 28.44 | 39.72 | 10.29 | 25.52 | 38.82 | 10.44 | 27.28 | 49.49 | 7.85 | 9.48 | 11.44 | 11.89 | |
| 20 min | LSTM | 49.09 | 56.22 | 53.85 | 40.58 | 46.31 | 58.06 | 28.11 | 33.86 | 33.55 | 39.10 | 43.54 | 29.38 |
| GRU | 36.78 | 45.23 | 49.33 | 47.44 | 53.97 | 61.41 | 24.55 | 29.58 | 29.14 | 37.09 | 41.03 | 26.56 | |
| GRU_Attention | 21.64 | 27.17 | 22.50 | 30.00 | 36.72 | 21.71 | 14.95 | 20.22 | 18.48 | 28.37 | 34.77 | 16.87 | |
| 30 min | LSTM | 47.54 | 58.77 | 45.57 | 47.82 | 58.00 | 50.60 | 59.08 | 81.75 | 47.43 | 52.29 | 61.68 | 48.61 |
| GRU | 49.65 | 60.42 | 49.52 | 50.52 | 55.29 | 42.39 | 60.71 | 82.12 | 40.22 | 54.13 | 62.33 | 52.12 | |
| GRU_Attention | 33.20 | 41.85 | 26.96 | 38.33 | 44.15 | 28.31 | 56.33 | 84.35 | 27.05 | 33.66 | 41.69 | 28.96 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, K.; Shen, H.; Wang, L.; Zhou, H.; Xu, M.; Mo, Y. Short-Term Solar Irradiance Forecasting Based on a Hybrid Deep Learning Methodology. Information 2020, 11, 32. https://doi.org/10.3390/info11010032
Yan K, Shen H, Wang L, Zhou H, Xu M, Mo Y. Short-Term Solar Irradiance Forecasting Based on a Hybrid Deep Learning Methodology. Information. 2020; 11(1):32. https://doi.org/10.3390/info11010032
Chicago/Turabian StyleYan, Ke, Hengle Shen, Lei Wang, Huiming Zhou, Meiling Xu, and Yuchang Mo. 2020. "Short-Term Solar Irradiance Forecasting Based on a Hybrid Deep Learning Methodology" Information 11, no. 1: 32. https://doi.org/10.3390/info11010032
APA StyleYan, K., Shen, H., Wang, L., Zhou, H., Xu, M., & Mo, Y. (2020). Short-Term Solar Irradiance Forecasting Based on a Hybrid Deep Learning Methodology. Information, 11(1), 32. https://doi.org/10.3390/info11010032