2. Related Works
Process discovery is a growing and promising scientific area, which concentrates on the development of theory and techniques of gathering and representing knowledge about real processes execution and the other rules driving the organization activity. The recent twenty years were fruitful in novel research in this area [
10]. A systematic survey presented in Reference [
10] shows that most active research subjects are focused on process mining algorithms working out and optimization, with the conformance checking techniques and software architecture and tools enhancement. As regards the domains where those efforts are applied, the health segment is very significant and then communication, IT, manufacture, education, logistics, and finances. Our research domain is the finance domain, wherein we have a long time experience and constant access to extensive real-world data.
The authors of Reference [
11], after analysis of 705 papers, showed that the primary type of process mining activity studied is “discovery” (71%) and “categorical prediction” is the challenge most often taken (25%). They also report that the “graph structure-based” technique is the most frequently used one (38%) and they concluded that computational intelligence and machine learning techniques are still rather loosely tied with the process mining discipline. “Evolutionary computation” (9%) and “decision tree” (6%) are the most applied. Many authors, e.g. Reference [
12], prove that the process representation most often used is the Petri net because of its well-grounded theory and its computability, and then the Business Process Model and Notation (BPMN) because of its broad application in tools and its everyday use in the business world. Some authors present the discussion on abstractions and process representations to reflect on the gap between process mining literature and commercial process mining tools [
12]. That discussion facilitates users to select an appropriate process discovery technique.
In References [
3,
6,
13], the authors present some of the essential methodologies of process model generation. The first group is a set of methods which use the up-front design of the process model. As an example, the technique which allows the generation of process models from text descriptions based on natural language or methods which allow for creation of new models from existing models, and in particular from a set of existing process diagram or through translation from other representations, such as UML, data models, or other diagrams, may be used. Those methods require additional investment to design other intermediate models. The authors also distinguish methods for generating imperative process models (focusing on explicit process definition) based on declarative models (implicit definitions, which are described by directives and policies), as well as hybrid solutions in which a hybrid process model combines data-oriented declarative specification and flow-oriented imperative control.
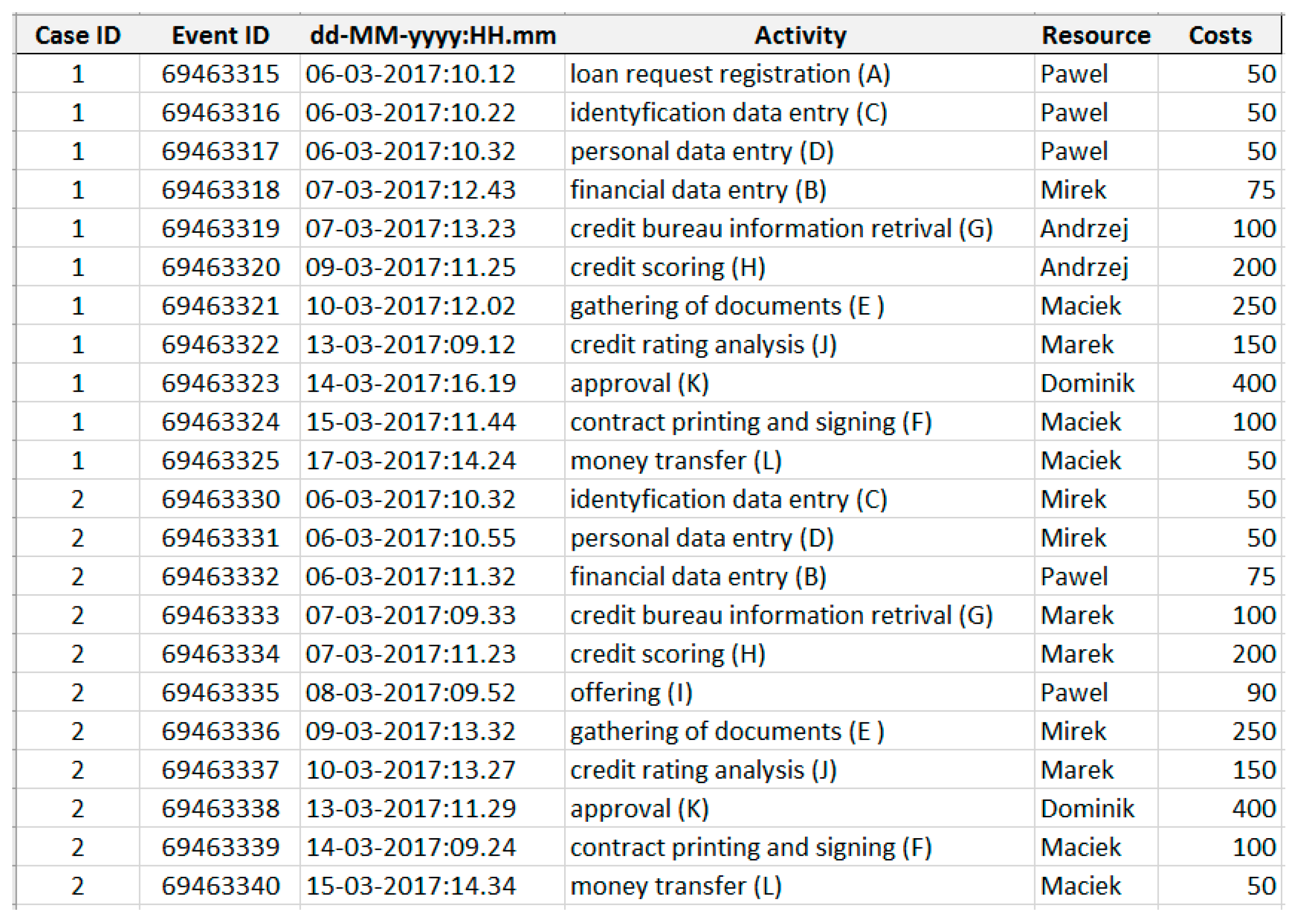
The second group mentioned by the same authors contains methods based on event log analysis. The event log includes a set of execution sequences, based on which the relationship between the different activities may be determined. Such real data can be used to build a process model directly from its working implementation. Based on isolated use cases, archival data, and negative logs (which represent workflow sequences not allowed during the process execution), such method allows for optimal redesign of the initial business process model. One of the first steps in this method is for the developer to determine the initial and final state of the process and the variants of transitions performed by actors on specific resources. A particular business process consists of multiple use cases. Such a structure can be defined by a set of n-element vectors that describe the order and number of executions for each task. Then, the event log is generated and analyzed. The event log is a set of traces of events that can be defined as an ordered sequence of activities in the process. Traces are described by the use case identifier, the event identifier, the timestamp, the activity name, the resource, and the cost. Based on such a record, it is possible to determine many useful statistics, such as the number of events in use cases, the duration of the case, etc. Next, the mining-driven approach may be applied to generate a BPMN diagram using the event log generated from the business process model; in our case, it is a cash loan process. There are many process discovery algorithms which can be used in the BPMN diagram building process, for example, the α-algorithm (abstraction-based algorithm), the heuristic miner (heuristic-based algorithm), the ILP Miner (language-based algorithm), or the inductive miner (inductive-based algorithm).
Some authors (e.g., Reference [
14]) raise the significant problem of the quality of event logs. They notice that processes discovered using logs of low quality will also be of low quality, resulting in incorrect business decisions taken upon them. Authors of Reference [
14] propose the use of methods based on autoencoders, which are a class of neural networks, to reconstruct the leaking values in logs. They report a significant improvement of the model quality after applying that method.
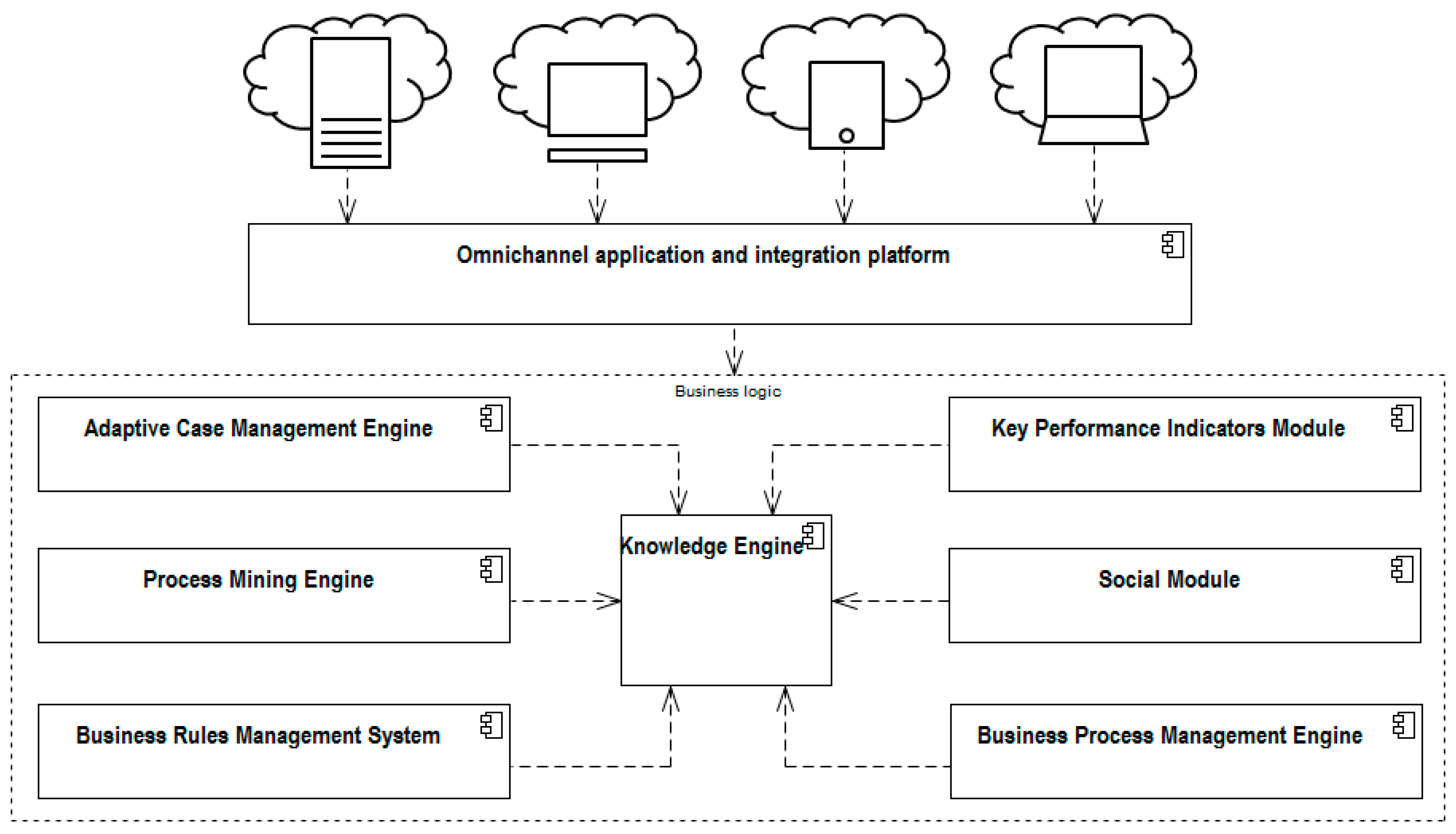
A considerable amount of research in the process discovery area is done under the adaptive case management (ACM) umbrella. ACM [
15,
16] is a relatively novel approach in the BPM world, which operates in many connected areas such as knowledge extraction, knowledge storage and sharing, empowerment of workers, advanced collaboration, adaptability, and guidance techniques [
17]. Our work supports a few of them, especially knowledge extraction and storage, and superior collaboration done by our omnichannel business model (OBM). The great challenge of today’s systems is the multichannel access to shared data with the growing significance of mobile channels. This question is increasingly raised by researchers, e.g., Reference [
18]. Social network aspects of process management are studied in Reference [
18], where the authors introduce a framework for supporting case management in social networking environments. The structure can capture and formalize communication acts between cooperating people, making them usable in future processes.
Since the business process is recognized as a set of related events and decisions, trying to respond to the increasingly demanding expectations of the markets, it is necessary to implement mechanisms of the dynamic redesign of basic workflows in business processes to improve performance indicators. Many authors focus their work on the possibility of introducing business process redesign (BPR) mechanisms [
19]. For example, in Reference [
5], the authors focus on the presentation of the evaluation mechanism that measures the effectiveness of the BPMN model and its ability to effectively transform it into a directed acyclic graph and to determine the average efficiency of process execution. The proposed mechanism evaluates the model type, complexity indicators, and the ability to standardize and optimize candidate process models, while at the same time allowing users to set the desired complexity thresholds. The authors of Reference [
20] propose process reengineering ontology—based knowledge map methodology (PROM) to reduce the failure ratio and solve BPR problems. They use analytical hierarchy processing to identify and prioritize the processes of the business to be re-designed. That technique enables creation of process-aware software and process-driven applications (PDA) based on the ontology and knowledge maps.
As an alternative to the classical process model-driven approach, some authors propose activity modeling and simulation based on agents (agent-based simulation, ABS). According to Reference [
21], ABS will get more attention in the field of BPM similarly to other areas like, e.g., social sciences. Following non-standard solutions, some authors use the axiomatic fuzzy set (AFS) theory to convert event logs into fuzzy sets, resulting in a powerful tool to model and store human knowledge and behavior [
22]. In recent years, such an approach is more and more often applied in various disciplines—business intelligence, financial analysis, clinical tests, etc. The still existing drawback of that direction is the complicated implementation, especially in systems where performance requirements are high. Similarly, the adaptation of latent Dirichlet allocation (LDA), proposed by the authors of Reference [
23] as an unsupervised machine learning technique to automatically detect and assign labels to activities, encountered difficulties in an implementation, but it seems to be a promising direction since this framework does not require any human intervention.
Our work combines a few techniques described above and a few of them we consider to embed into our framework in the future. First of all, we use well-grounded methods of process mining as the primary source of knowledge in the system. We connect them with existing BPM and ACM tools used in enterprises and an omnichannel cooperation platform, obtaining the solution called the omnichannel business model (OBM). The solution (a) allows catching and storage of the knowledge from the cloud of information hidden in the enterprise resources and (b) can automate future processes and general enterprise activity using the unhidden knowledge and BPR techniques.
4. Modeling the Process of a Cash Loan Sale
In this paper, we present means of data mining discovery in terms of the omnichannel business model, an emergent system class which is characterized by a self-organization feature. We create a model of the real business process of a cash loan and then we discuss key steps of process mining and cost estimation. The cash credit sale process is usually tied with high levels of some efficiency indicators, such as cost efficiency or the speed of decisions. This requirement has a critical impact on the level of automation offered by the system [
1,
6,
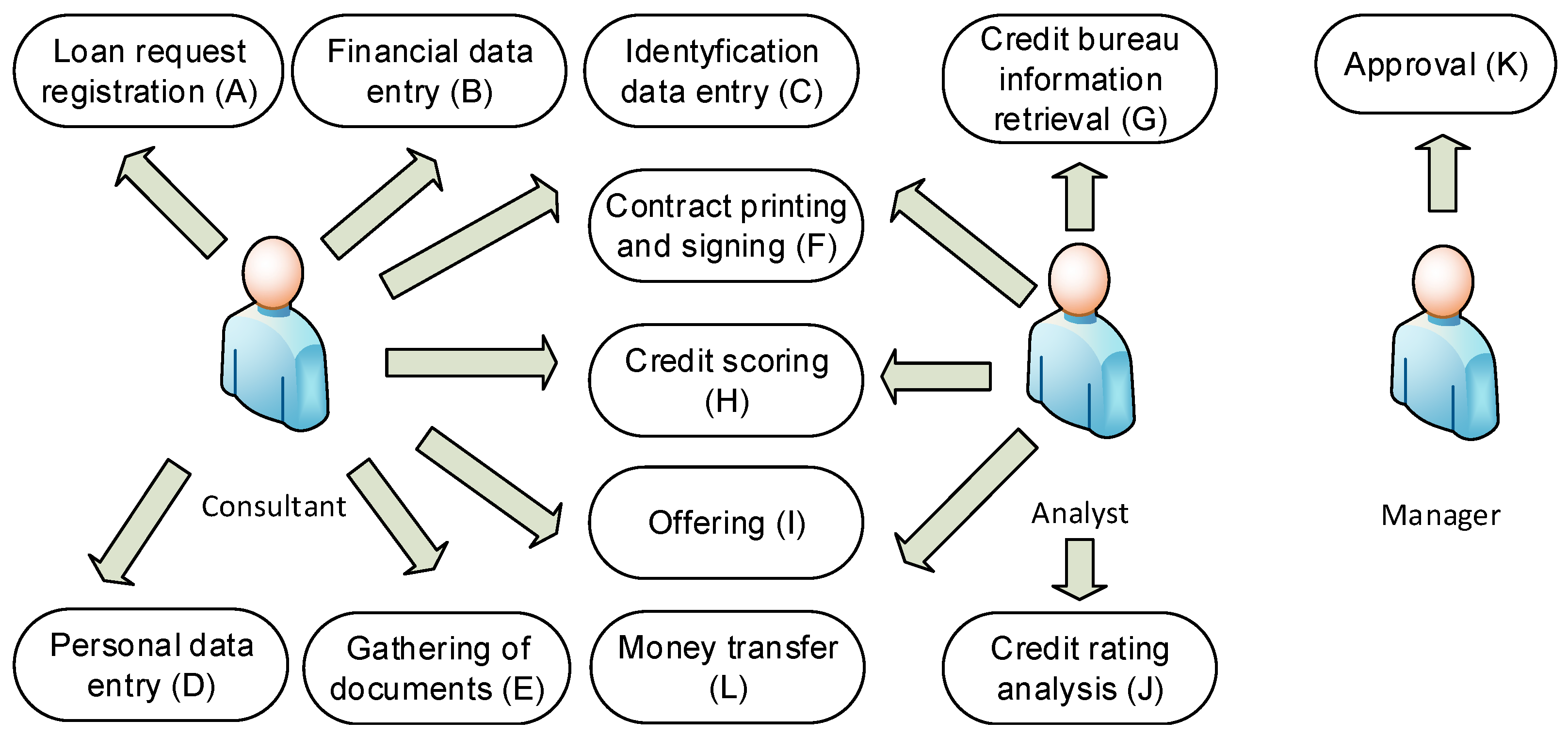
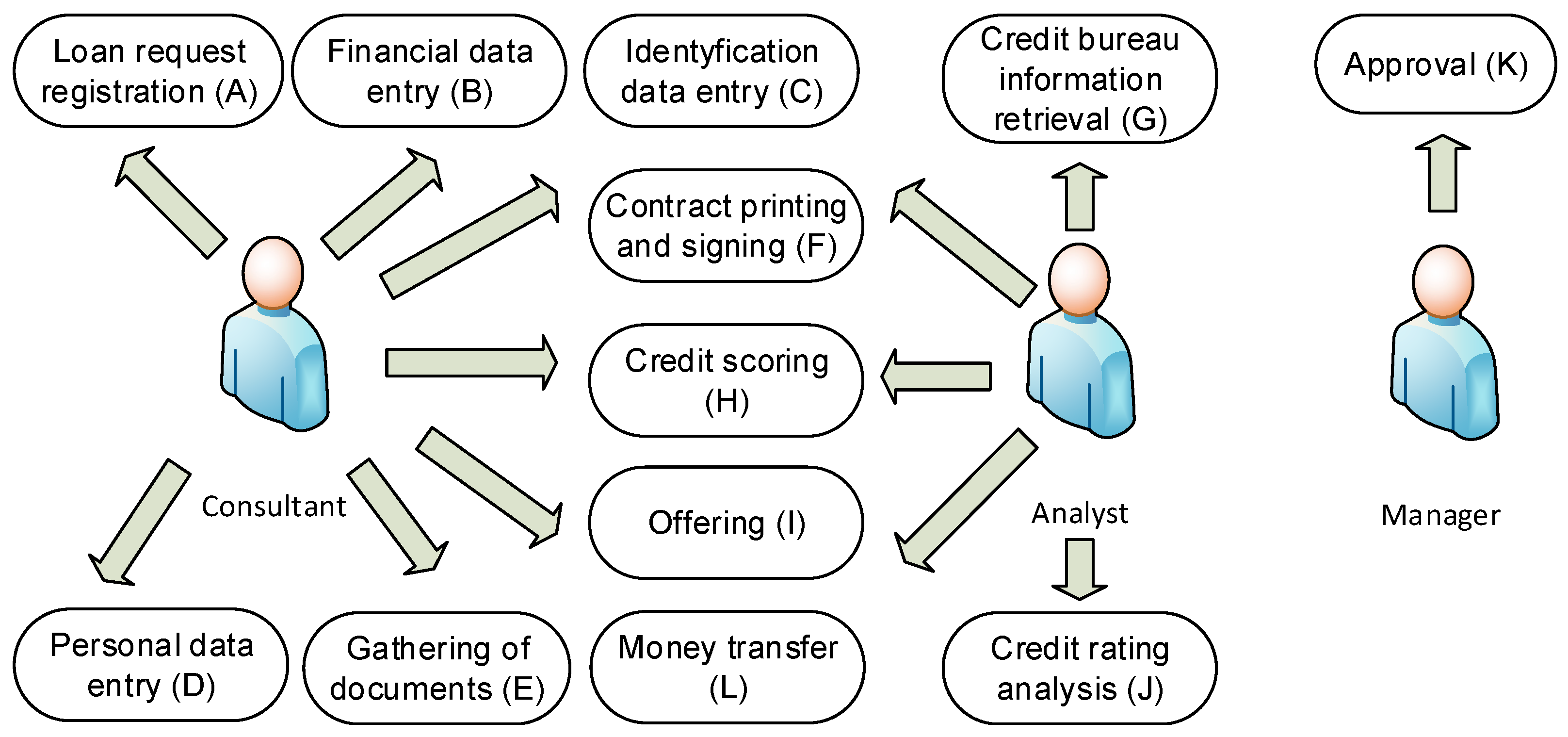
7]. The discussed process is built on the set of use cases (UC), shown in
Figure 2. Each use case may be performed by one on more business roles fulfilled by one or more persons (connections between actors and use cases do not unambiguously appoint who is responsible for the use case; e.g., in the figure, some of them may be performed by two roles). The model also neither orders use cases nor defines which are necessary to achieve the goal of the process.
In the real business environment, many possible traces may be used to move from the starting point of the process to its final state. Even many of the use cases have constraints disabling their use in some circumstances. Typically, a few of them may be used in a different order, resulting in hundreds of possible solutions as regards the whole population of process traces. Usually, this puzzle is solved (better or worse) by business analysts, process engineers, or other highly skilled workers.
In our model, we propose discussion of three main event paths. A first variant called passive-defensive (
), the second is called active-defensive (
), and the third is called active-offensive (
), where the first part of the name concerns level of pro-active behavior of sellers (the passive seller only follows customer needs, the active seller tries to maximize transaction) and the second part concerns the level of the financial risk involved (the offensive variant involves higher risk expecting higher sale) These variants are defined as follows:
In the literature, many different notations for process models may be found. At the first step of the analysis, Petri nets are used, especially its subclass known as WorkFlow nets (WF-nets) [
3,
4,
5,
6,
13,
24,
25,
26]. A WF-net is a Petri net with a defined starting point for the process and a separate ending point for the process [
2,
4]. All nodes are on a path from source to sink.
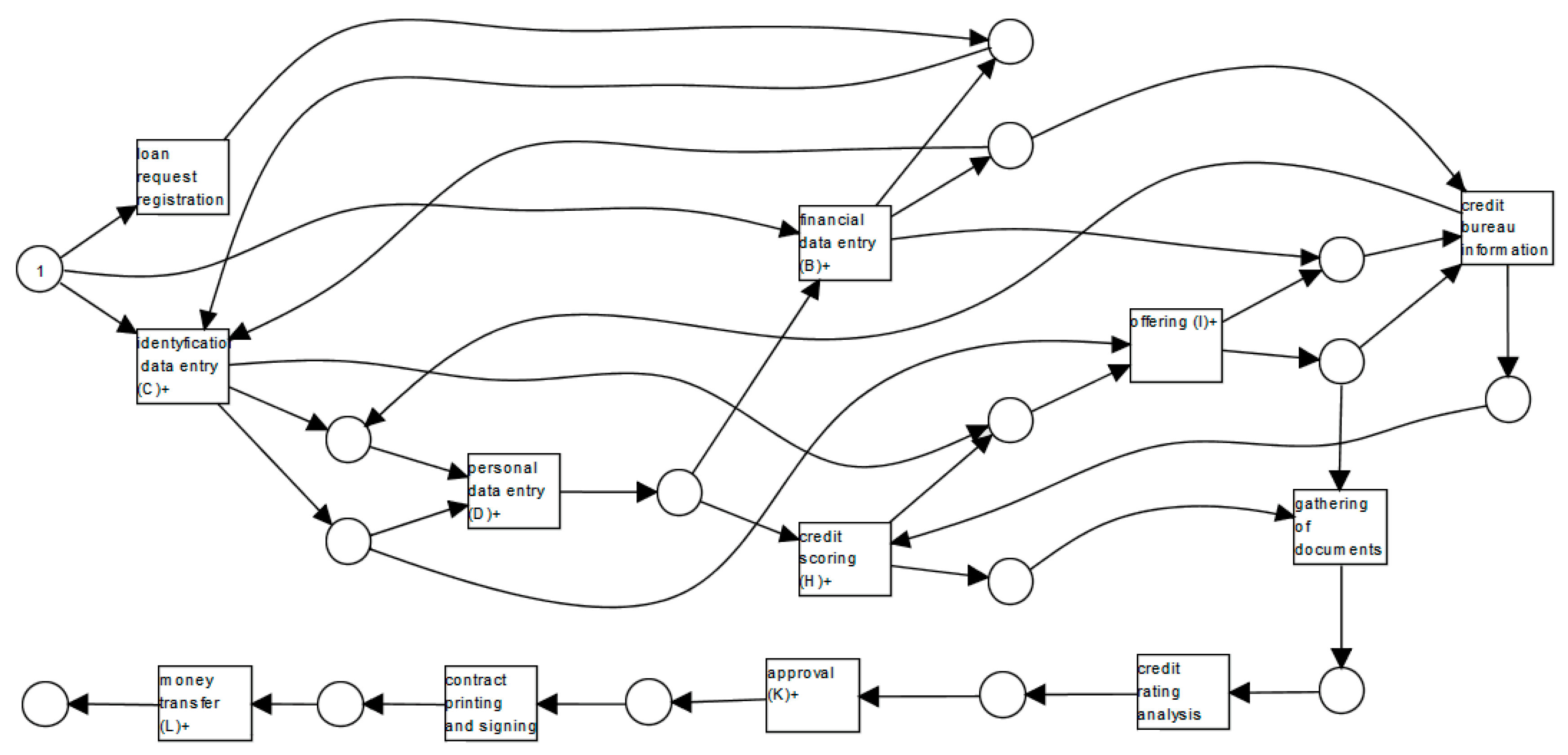
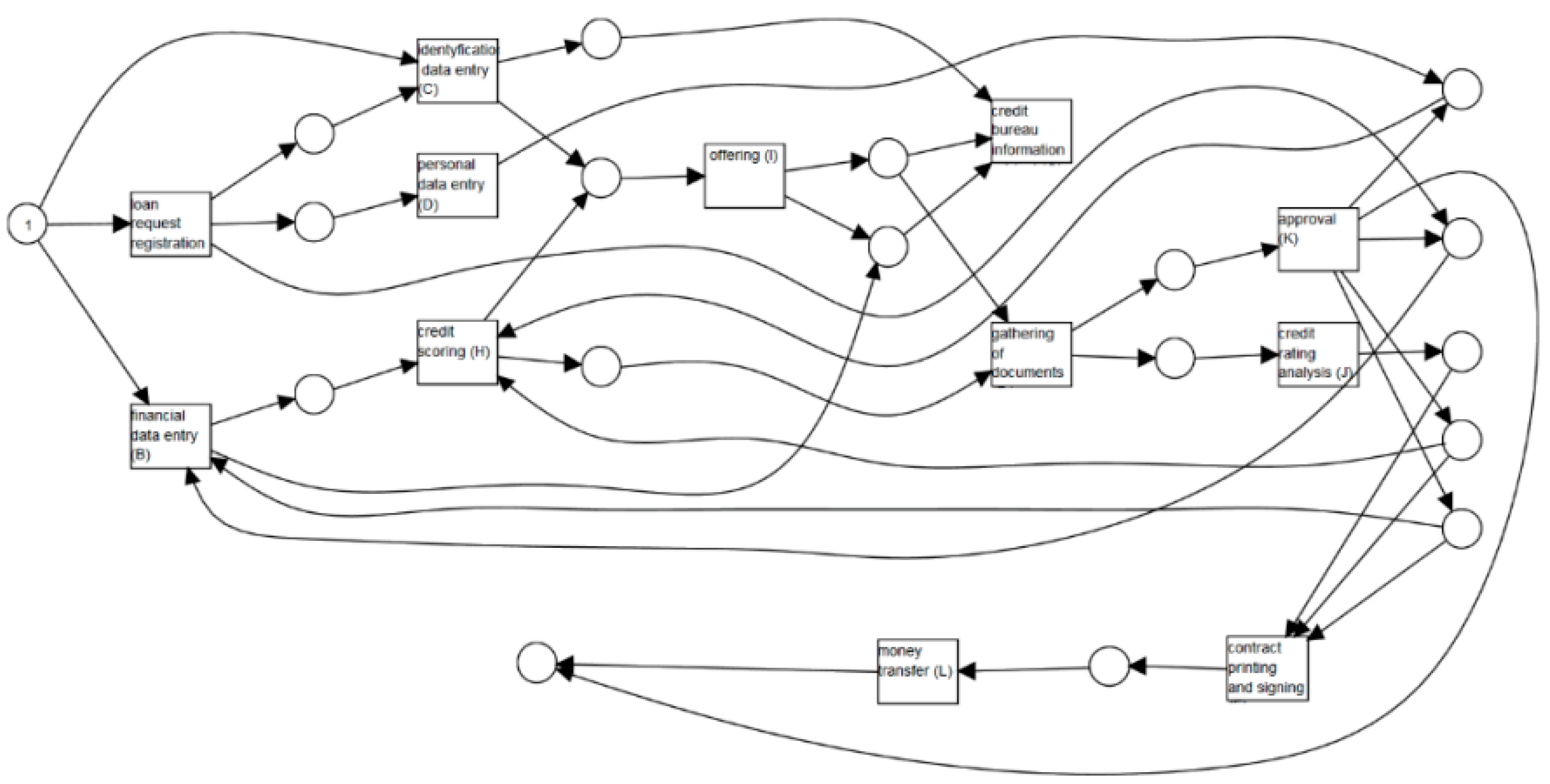
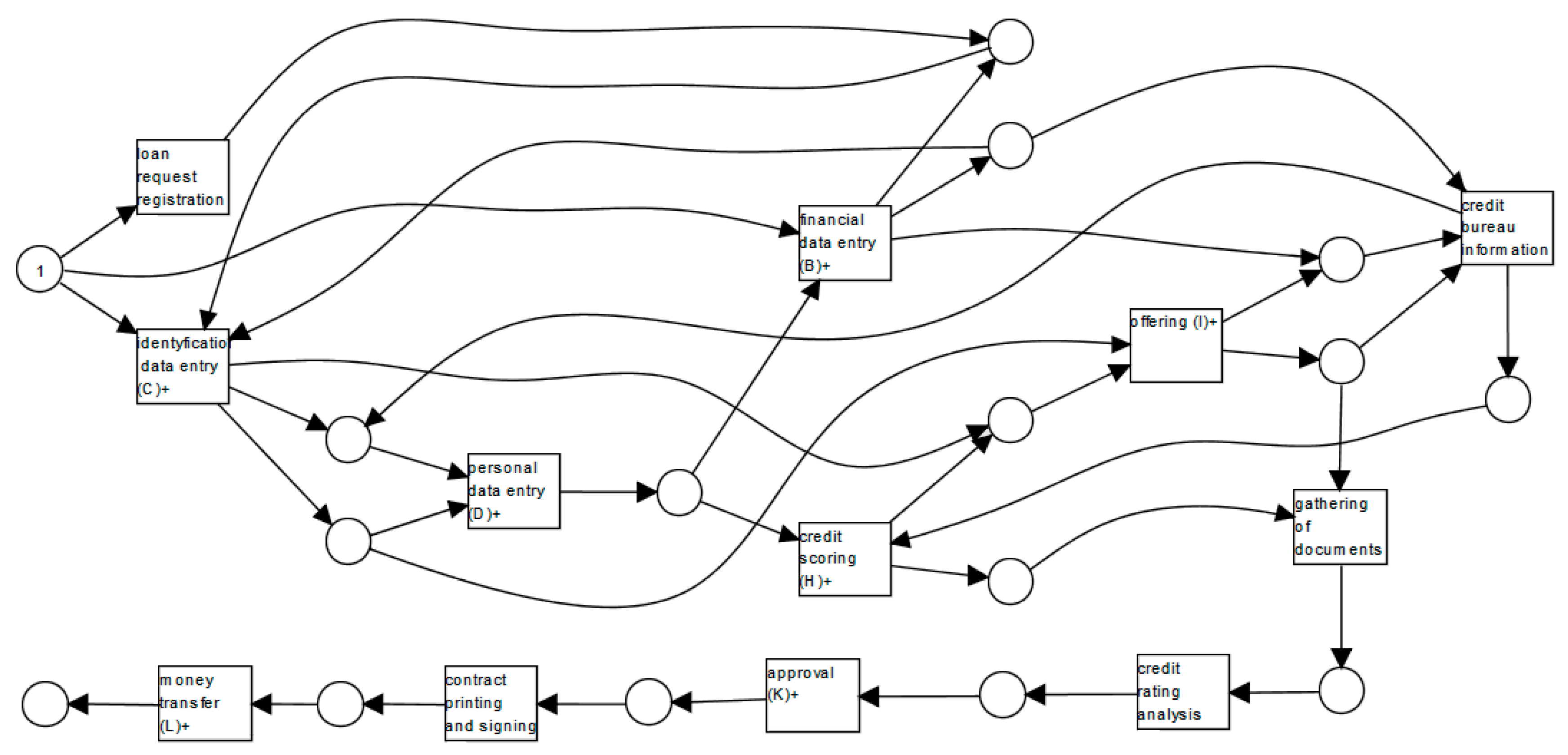
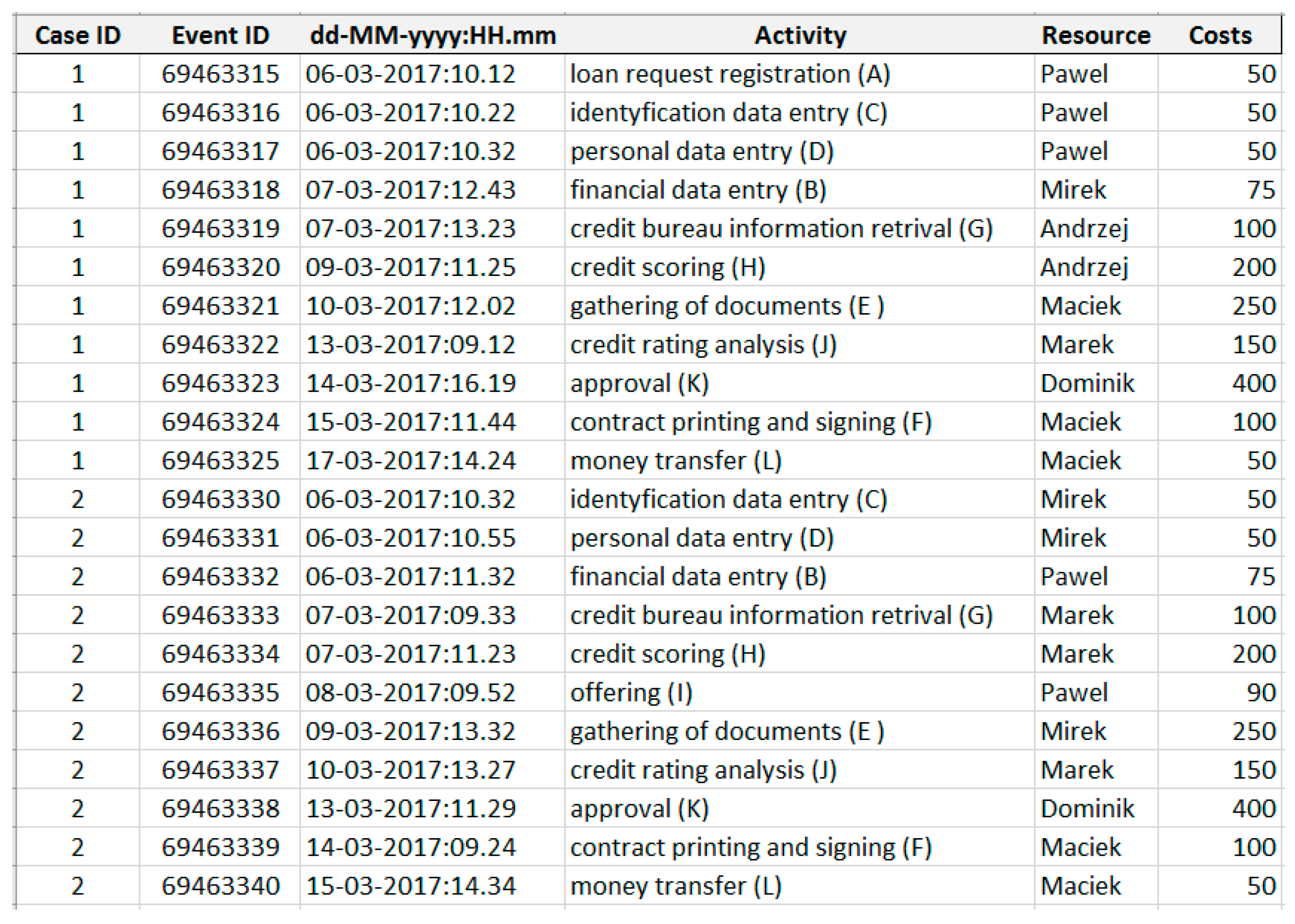
Figure 3 presents a WF-net generated for our model of the cash loan process. The model is designed to describe the handling of an application for a new cash loan where customers may apply for a money transfer from a bank. As
Figure 3 shows, the process may start by a loan request registration (A) request or other activities like financial data entry (B) or identification data entry (C). Each action is represented by a transition that is a square. Transitions are interconnected by points that model the potential process status. Each point is defended by a circle. In a Petri net, a transition is activated, i.e., a proper action may be performed if all input points have a token. Transition loan request registration (A) has only one input point (start), and this point initially includes a token to represent the request for compensation. Other transitions like financial data entry (B) or identification data entry (C) have two input points. The transition uses one token from each of its input points and creates one token for each of its output points.
Therefore, starting the transition, i.e., loan request registration (A), causes the termination of the token from the initial point of entry and the creation of the token for the output place. Tokens are presented as black dots. The setting of tokens in specific points, in this case, the request state, is defined as marking. In our WF-net model, we can distinguish activities which may be processed by different job roles, i.e., consultant, analyst, and manager. At many use cases, the same activity may also be processed by a different person with the same job role. Additionally, some activities like contract printing and signing (F), credit scoring (H), and offering (I) may be realized by the consultant job role as an analyst. Let us notice that the activity approval (K) is assigned only to the manager. The process ends after paying the money transfer (L) activity of the cash loan request.
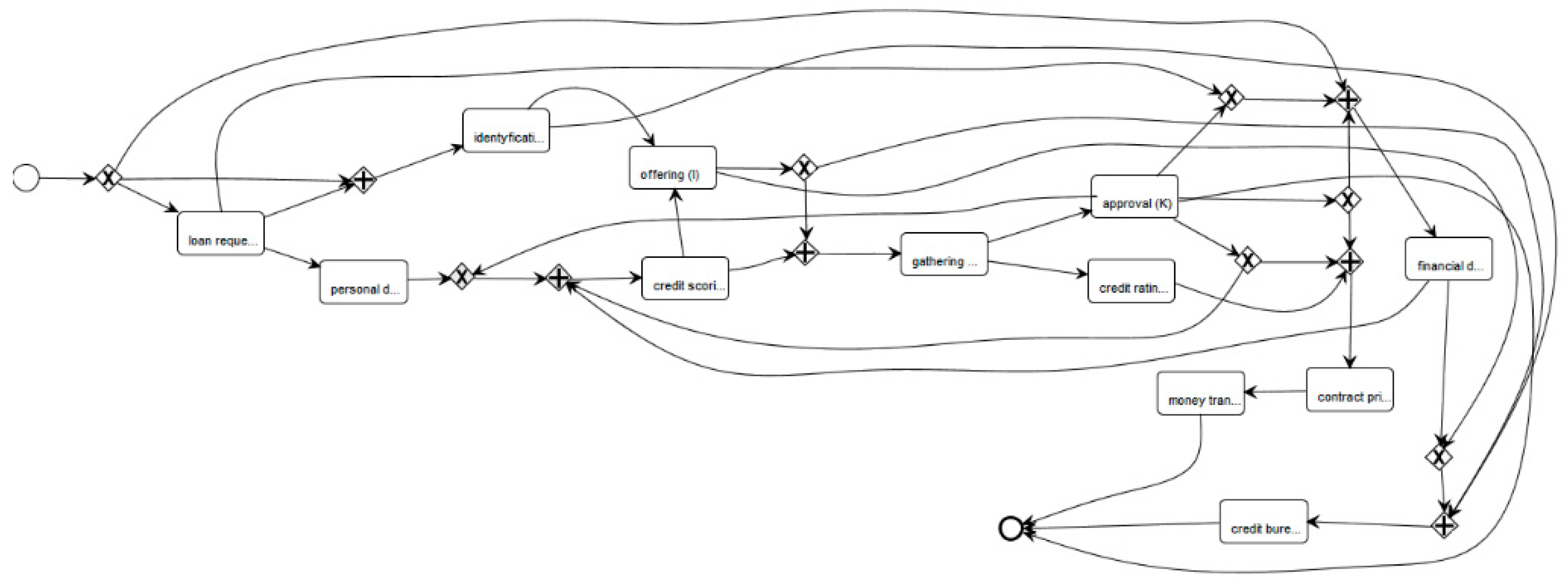
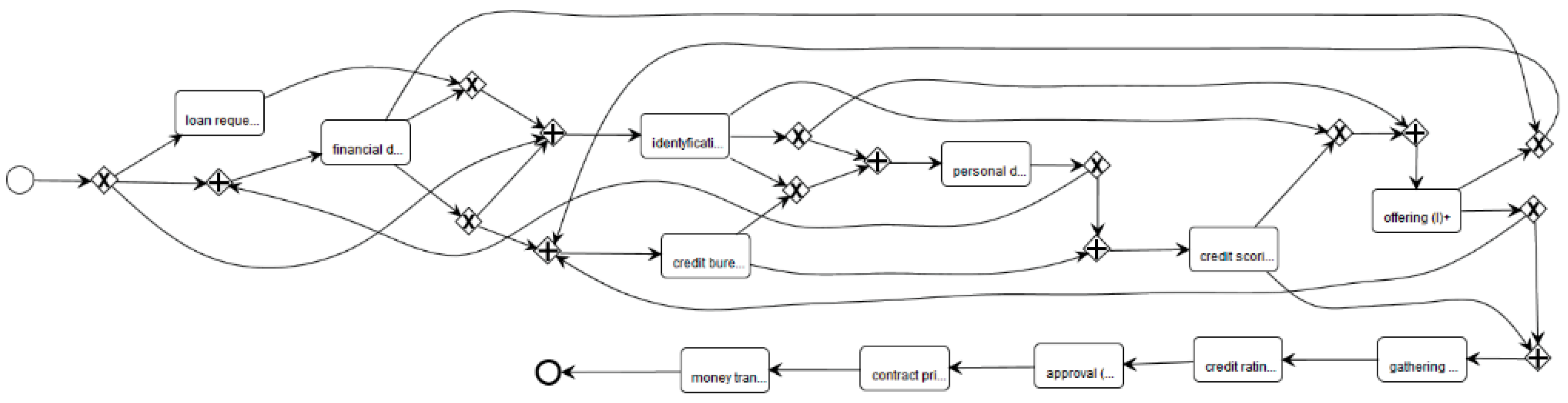
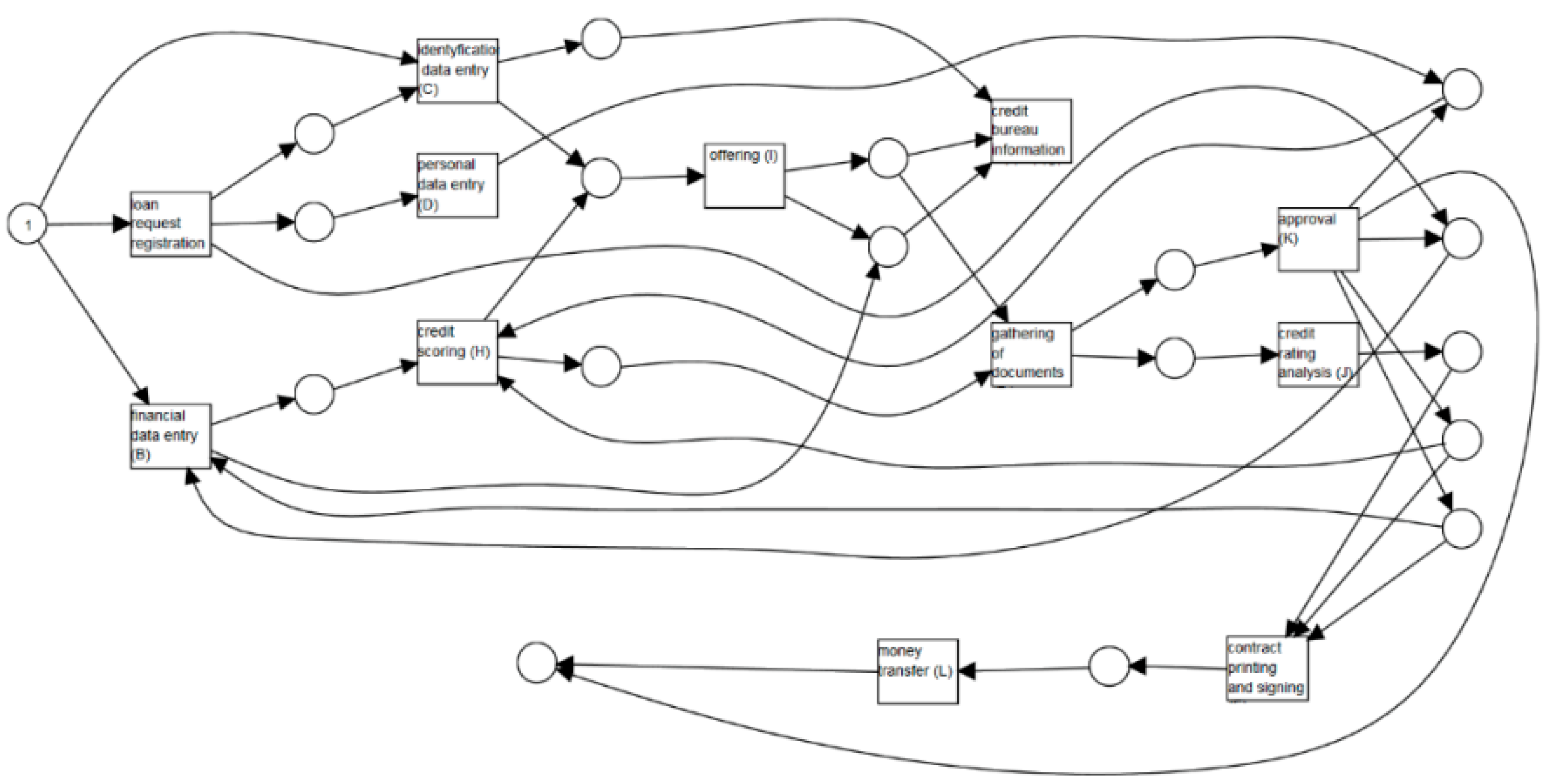
In
Figure 4, we present the same process model in terms of the BPMN diagram [
1,
2,
3]. The business process model and notation (BPMN) uses explicit gateways instead of points for simulating the logic of control flow. The diamonds with an “×” mark indicate XOR split/join gateways, whereas diamonds with a “+” mark indicate AND split/join gateways. The presented graphs were obtained with the use of RapidMiner Studio, a popular mining tool, with the ProM extension (RapidProM). This software is an upgradeable structure that handles a large number of process mining techniques, which are prepared and distributed as extensions and plug-ins [
2,
3,
4,
5,
6,
7,
13,
26].
6. Results
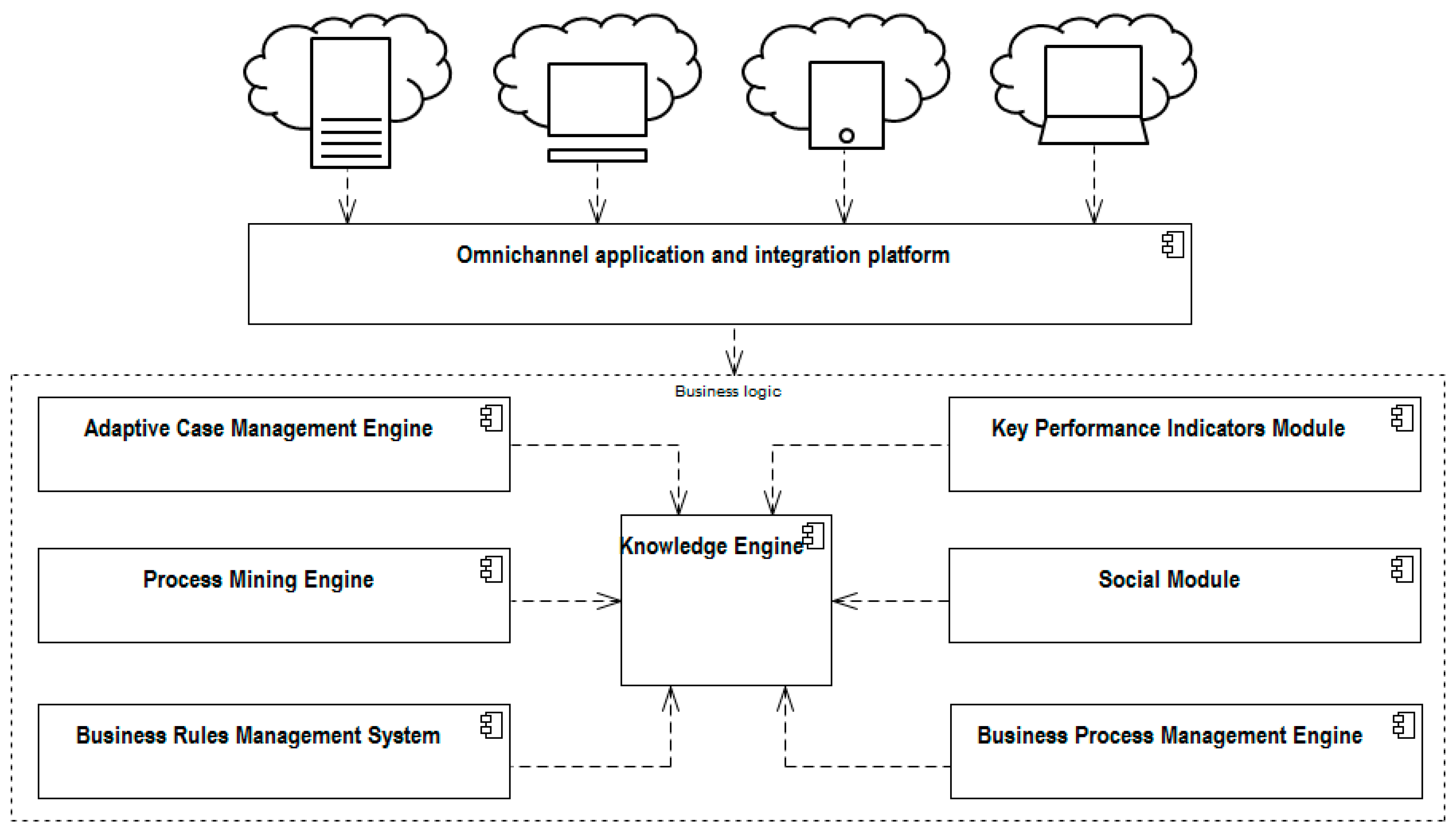
In the accordance with the conceptual model of the system presented in the
Figure 1, where the process mining engine is one of its modules, the critical responsibility of the system is to improve business processes using process mining as a tool that gives continuous insight into actors’ behavior and enables the opportunity for online improvement [
1,
2,
7].
In the beginning, we assumed that in our example, only three main processing paths would be used, as the outcome of process engineer work told us. After system implementation in the real banking environment, we logged system events in order to obtain hidden information about actual activity flows and other system business parameters. Next, we performed a sophisticated analysis of the event log (which refers to the process mining engine functions in
Figure 1). After execution of the Alpha algorithm in a RapidProM environment, which provides a Petri net and a marking [
2,
4,
13,
24,
26], we discovered some new activity traces (
Figure 6).
We can now update our first model with the obtained knowledge. Furthermore, on the base of the Petri net, with the use of the Petri net to BPMN framework in the RapidProM tool, we created the BPMN graph for a cash loan process recorded in the event log (
Figure 7) [
13,
26].
The efficiency of processes in an organization can be determined in various ways. Usually, three dimensions are identified, as follows: Time, cost, and quality. Each of these efficiency dimensions can be assigned different key performance indicators (KPIs) [
2,
7,
25]. For further analyses, we should determine the activity costs using a causal activity matrix. To do that, we must discover activity clusters based on the cash loan process recorded in the event log. The clustered view of the event log is a product of that step. Clustering algorithms cause partitioning or hierarchical division of objects, in which the most different objects are distinguished in each grouping [
2,
3,
24]. Most clustering algorithms expect a distinction that defines how the two objects are dissimilar. Such a dissimilarity measure is implemented using a distance function. By clustering an event log, a more consistent group of tracks can be achieved. This results in more intelligible exploration of process models. In this process, clusters are created for and associated with every activity in the event log. All direct predecessors and successors of activity will be added to the associated cluster. Clustering refers to building groups of entities that are comparable to each other and not equivalent to entities from other clusters. This mechanism is a technique for identifying information from untagged data. Clustering may be very helpful in many scenarios, e.g., to find groups of resources with similar job behavior [
2,
7,
24].
After clustering, we discovered a causal activity matrix from an event log. Every single cell in the matrix may obtain a value from 1 or −1. A value of 1 indicates that there is a causal relationship between the row-activity to the column-activity. A value of −1 indicates that there is no causal relation. A value of 0 indicates that we cannot find any correlation (indefinite state). Any other positive values from this range indicate a connection [
4,
5]. For our cash loan process in
Table 2, we present the causal activity matrix.
In
Table 3, some main activity statistics in the event log are presented. We can analyze the activity total and the relative occurrences in the event log of the cash loan process. A vital activity attribute shown in
Table 3 is an activity replay cost factor. Having a causal activity matrix, we may now determine the activity replay cost factor. The algorithm creates a replay cost factor for the given activity cluster array. The cost factor for an activity is correlated with the number of clusters that include this activity. The total replay factor value is 60 [
2,
7,
28].
Creating useful and understandable visualizations of data is an extremely significant area for research purposes. To a large extent, it enables analysts to discover information from data using visual artifacts. BPM is committed to managing business processes using a variety of artifacts and the relationship between people and business processes plays an essential role in managing processes. Such a set of tools enables the effective discovery of social networks from the data of executed processes and can simplify the management of business processes to make them more productive and successful [
2,
3,
29].
The social network in BPM is a concept that describes processes developing jointly and that are cyclically iterated. In literature, it is also known as "socially active processes." These socially supported processes emulate the way work is done from the end-users’ perspective and how it is experienced from the user’s perspective in order to harness the power of continuous cooperation. Social BPM is at the interface between business processes and joint activities. The combination of BPM and social media complements the interpersonal interactions at work by supporting social networks, cooperation, and communication. Several techniques can be used to analyze social networks, e.g., to identify patterns of interactivity, to assess the role of the individual in the organization, etc. [
2,
3,
29]. In the process instance (case), the work is transferred from one resource (actor) to another. Therefore, knowledge about the structure of the process can be used to detect whether there is a causal relationship between the two actions. It is also possible not only to consider direct and indirect inheritance, to obtain which activity was first completed or not, but also to find hierarchical relations. There are also events such as changing the assignment of an action from one person to another (work delegation). This is an excellent subcontracting metric, which is obtained through social networks. The main idea of this metric is to aggregate the number of cases in which one person performed an action before another activity performed by another person. It could be evidence that the work has been commissioned between these individuals [
28,
29].
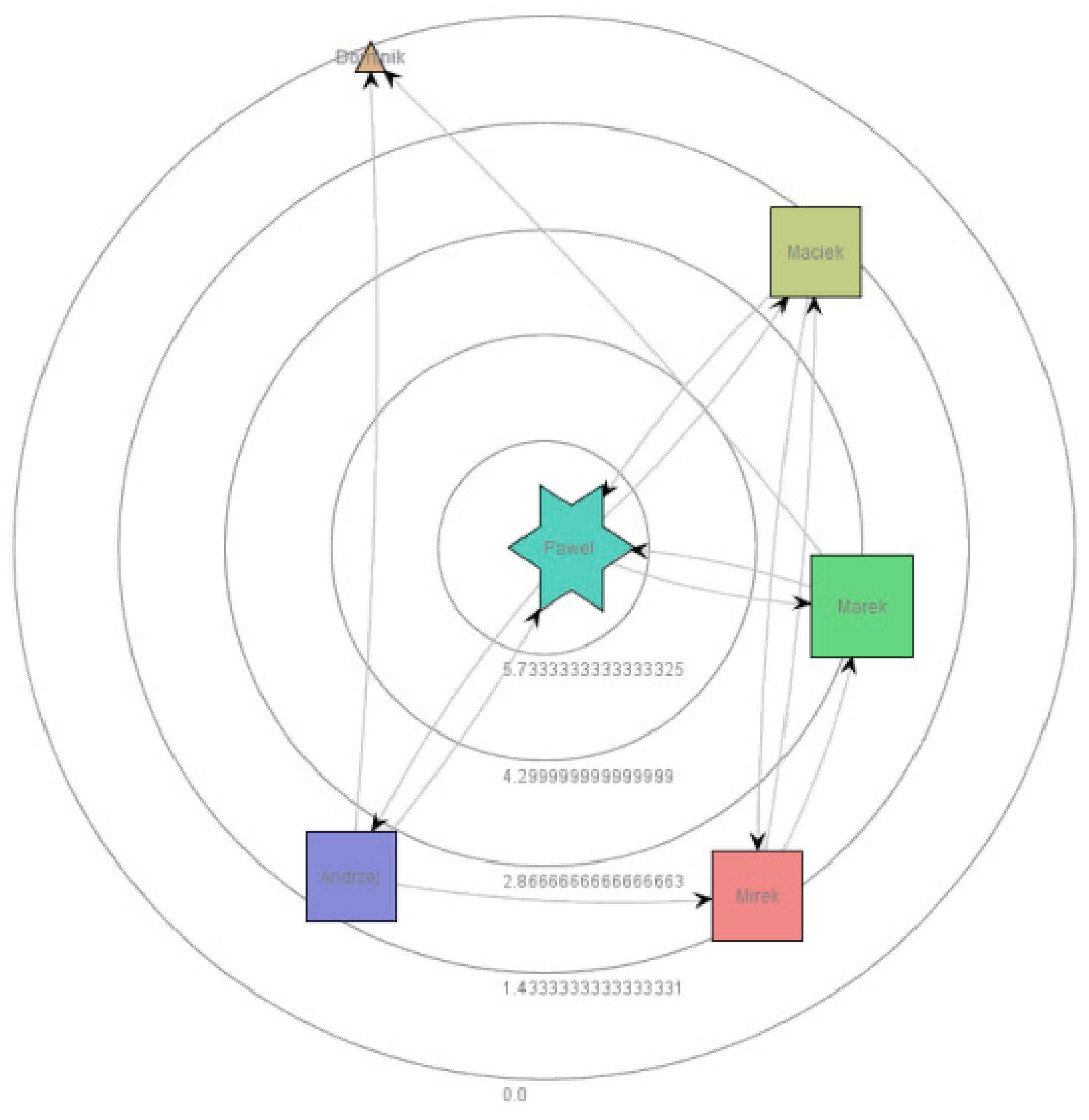
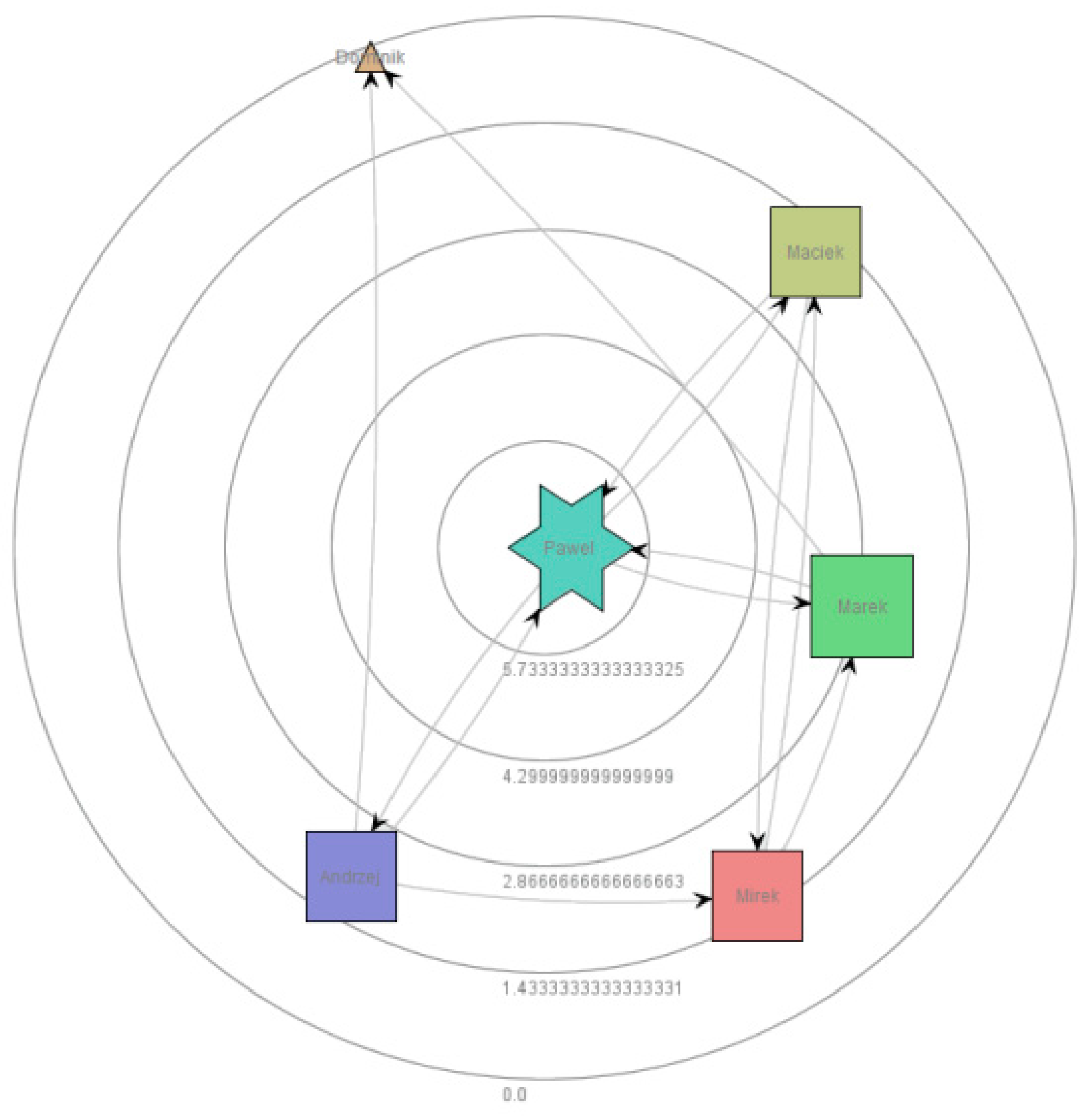
Active communication between actors (resources) is one of the conditions of emergence. With the social network, we can judge the degree of correctness of communication in the data flow processes.
Figure 8 shows a social network of interrelations between the main actors in our processes. The individual resources are placed in circles denoting the between ranking view and are connected with an arc indicating the actors’ common correlation. The shape of the presented resources is correlated with the degree and size of the node and is correlated with the resource ranking. In addition, we can set the KPI of mutual cooperation [
3,
6,
25,
29]. Reciprocal relationships between actors were possible to obtain by generating the causal resource matrix.
A significant benefit of social BPM is that it helps to eliminate the barrier between BPM decision-makers and the users affected by their decisions. Compared to conventional approaches to process modeling and management, social BPM engages a larger and more heterogeneous set of actors and aims to achieve a higher quantity, quality, variety, and timeliness of contributions [
8,
28].
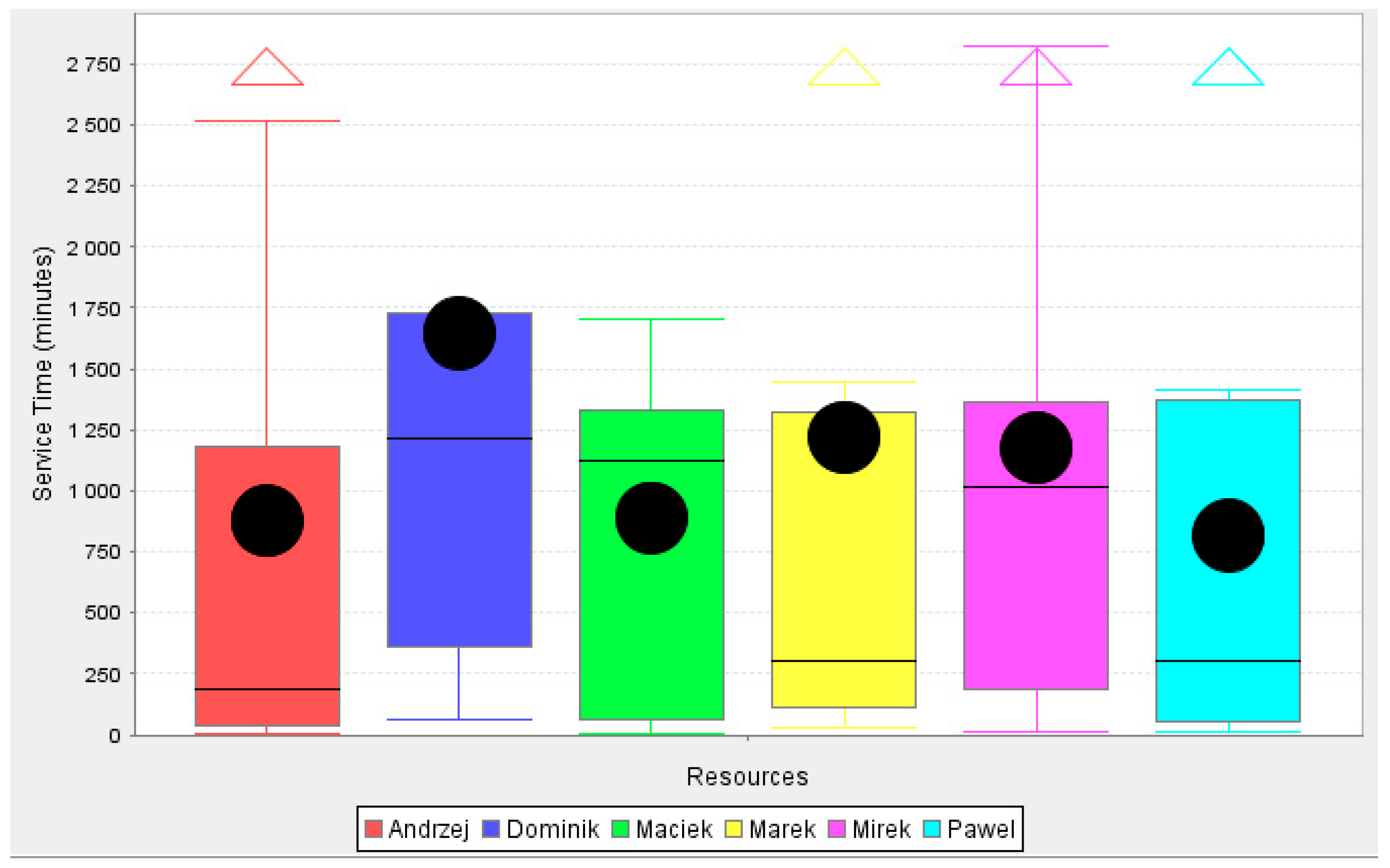
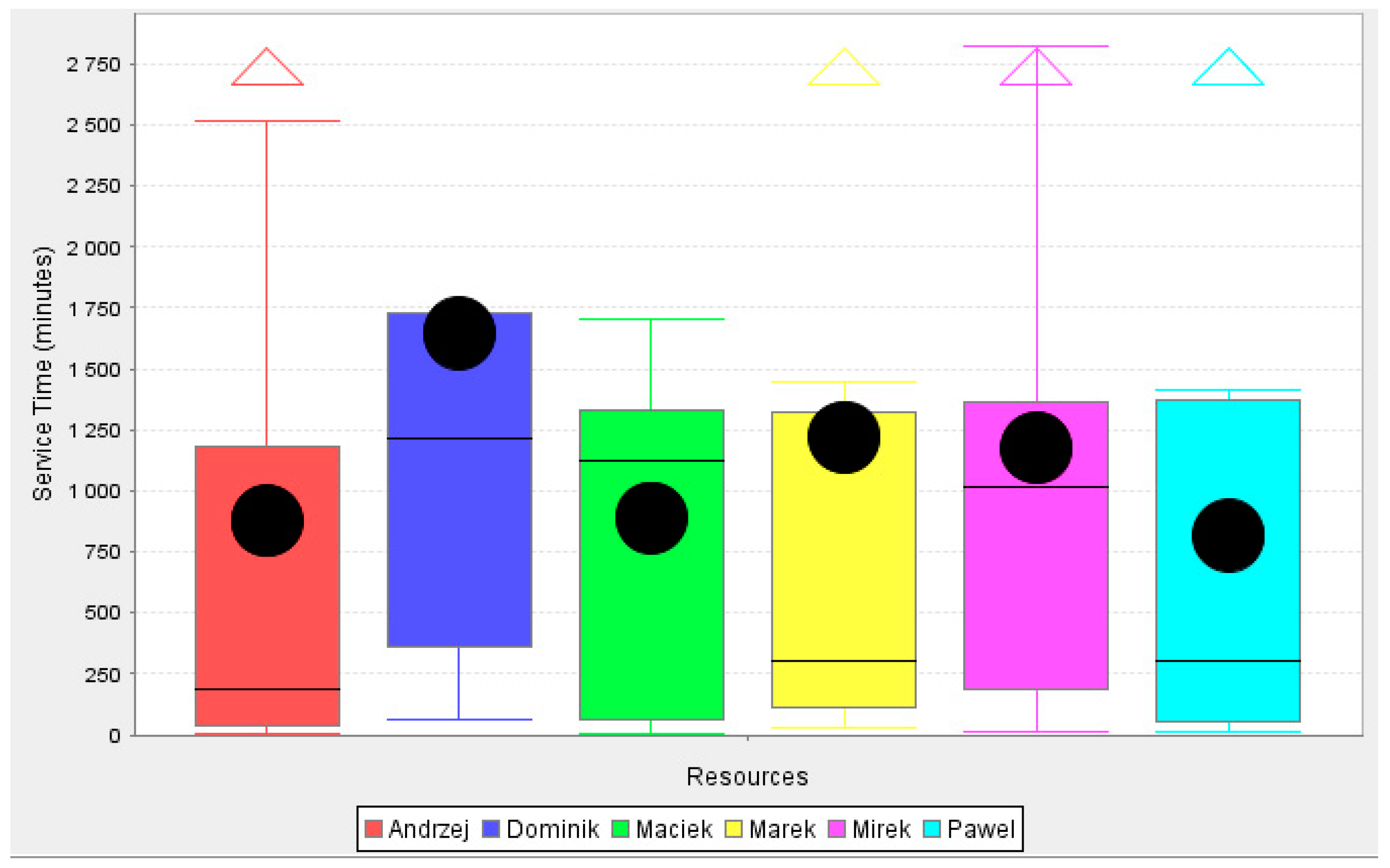
Table 4 demonstrates the participation of each actor in the decision-making process. In addition, the relative frequency of each actor and the resource replay cost factors were determined (as in activity analysis). The total factor for the resources (actors) is 6.
Details of the actors involved in the process of the cash loan are shown in
Figure 9. Process discovery in BPM allows us to estimate the total commitment of each resource and service time. The identification and analysis of similarities and differences in a large amount of data have been addressed by involving RapidMiner with ProM extension [
13,
26]. This diagram has been used widely in different areas to support the identification and analysis of a large amount of data.
Author Contributions
Conceptualization, P.D. and M.K.; methodology, P.D., M.K., and M.M.; software—formal analysis and investigation, P.D., M.K., and M.M.; resources, P.D., M.K., and M.M.; writing—original draft preparation, P.D., M.K., and M.M.; writing—review and editing, P.D. and M.M.; visualization, P.D., M.K., and M.M.; supervision, P. D.; project administration, P.D. and M.M.
Funding
This project is financed by the Minister of Science and Higher Education of the Republic of Poland within the "Regional Initiative of Excellence" program for years 2019 – 2022. Project number 027/RID/2018/19, amount granted 11 999 900 PLN.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Meidan, A.; Garcia-Garcia, J.A.; Escalona, M.J.; Ramos, I. A survey on business processes management suites. Comput. Stand. Interfaces 2017, 51, 71–86. [Google Scholar] [CrossRef]
- Wiśniewski, P.; Kluza, K.; Ligęza, A. An approach to participatory business process modeling: BPMN model generation using constraint programming and graph composition. Appl. Sci. 2018, 8, 1428. [Google Scholar] [CrossRef]
- Wert, A.; Schulz, H.; Heger, C. AIM: Adaptable Instrumentation and Monitoring for automated software performance analysis. In Proceedings of the 10th International Workshop on Automation of Software Test, Florence, Italy, 16–24 May 2015; pp. 38–42. [Google Scholar]
- Van der Aalst, W.M.P. Process Mining: Data Science in Action; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Tsakalidis, G.; Vergidis, K.; Kougka, G.; Gounaris, A. Eligibility of BPMN models for business process redesign. Information 2019, 10, 225. [Google Scholar] [CrossRef]
- Hoang, H.H.; Jung, J.J.; Tran, C.P. Ontology-based approaches for cross-enterprise collaboration: A literature review on semantic business process management. Enterp. Inf. Syst. 2014, 8, 648–664. [Google Scholar] [CrossRef]
- De Medeiros, A.K.A.; Guzzo, A.; Greco, G.; Van Der Aalst, W.M.; Weijters, A.J.M.M.; Van Dongen, B.F.; Saccà, D. Process mining based on clustering: A quest for precision. In International Conference on Business Process Management; Springer: Berlin/Heidelberg, Germany, 2008; pp. 17–29. [Google Scholar]
- Dymora, P.; Mazurek, M. Network anomaly detection based on the statistical self-similarity factor. In Analysis and Simulation of Electrical and Computer Systems; Springer: Berlin/Heidelberg, Germany, 2015; Volume 324, pp. 271–287. [Google Scholar]
- Motahari-Nezhad, H.R.; Swenson, K. Adaptive case management: overview and research challenges. In Proceedings of the IEEE International Conference on Business Informatics, Vienna, Austria, 15–18 July 2013. [Google Scholar]
- Dos Santos Garcia, C.; Meincheim, A.; Junior, E.R.F.; Dallagassa, M.R.; Sato, D.M.V.; Carvalho, D.R.; Santos, E.A.P.; Scalabrin, E.E. Process mining techniques and applications—A systematic mapping study. Expert Syst. Appl. 2019, 133, 260–295. [Google Scholar] [CrossRef]
- Maita, A.R.C.; Martins, L.C.; Lopez Paz, C.R.; Rafferty, L.; Hung, P.C.; Peres, S.M.; Fantinato, M. A systematic mapping study of process mining. Enterp. Inf. Syst. 2018, 12, 505–549. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P. Process discovery from event data: Relating models and logs through abstractions. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1244. [Google Scholar] [CrossRef]
- Koryl, M.; Mazur, M. Towards emergence phenomenon in business process management. Arch. Control Sci. 2017, 27, 263–277. [Google Scholar] [CrossRef]
- Nguyen, H.T.C.; Lee, S.; Kim, J.; Ko, J.; Comuzzi, M. Autoencoders for improving quality of process event logs. Expert Syst. Appl. 2019, 131, 132–147. [Google Scholar] [CrossRef]
- Hauder, M.; Pigat, S.; Matthes, F. Research challenges in adaptive case mangement: A literature review. In Proceedings of the 2014 IEEE 18th International Enterprise Distributed Object Computing Conference Workshops and Demonstrations, Ulm, Germany, 1–2 September 2014; pp. 98–107. [Google Scholar]
- Motahari-Nezhad, H.R.; Bartolini, C.; Graupner, S.; Spence, S. Adaptive case management in the social enterprise. In International Conference on Service-Oriented Computing; Springer: Berlin/Heidelberg, Germany, 2012; pp. 550–557. [Google Scholar]
- Lantow, B. Adaptive case management—A review of method support. In IFIP Working Conference on The Practice of Enterprise Modeling; Springer: Berlin/Heidelberg, Germany, 2018; pp. 157–171. [Google Scholar]
- Moore, C. The Process-Driven Business Of 2020; Future Strategies Inc.: Lighthouse Point, FL, USA, 2012. [Google Scholar]
- Abdi, N.; Zarei, B.; Vaisy, J.; Parvin, B. Innovation models and business process redesign. Int. Bus. Manag. 2011, 3, 147–152. [Google Scholar]
- AbdEllatif, M.; Farhan, M.S.; Shehata, N.S. Overcoming business process reengineering obstacles using ontology-based knowledge map methodology. Future Comput. Inform. J. 2018, 3, 7–28. [Google Scholar] [CrossRef]
- Halaska, M.; Sperka, R. Is there a need for agent-based modelling and simulation in business process management? Organizacija 2018, 51, 255–269. [Google Scholar] [CrossRef]
- Liu, X.; Jia, W.; Wang, Y.; Guo, H.; Ren, Y.; Li, Z. Knowledge discovery and semantic learning in the framework of axiomatic fuzzy set theory. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1268. [Google Scholar] [CrossRef]
- Banziger, R.B.; Basukoski, A.; Chaussalet, T. Discovering business processes in CRM systems by leveraging unstructured text data. In Proceedings of the IEEE 20th International Conference on High Performance Computing and Communications/IEEE 16th International Conference on Smart City/IEEE 4th International Conference on Data Science and Systems (HPCC/SMARTCITY/DSS), Exeter, UK, 28–30 June 2018; pp. 1571–1577. [Google Scholar]
- Burattin, A. Heuristics Miner for Time Interval. In Process Mining Techniques in Business Environments; Springer: Berlin/Heidelberg, Germany, 2015; Volume 207, pp. 85–95. [Google Scholar]
- Dumas, M.; La Rosa, M.; Mendling, J.; Reijers, H. Fundamentals of Business Process Management; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Mans, R.S.; van der Aalst, W.M.P.; Verbeek, H.M.W. Supporting process mining workflows with RapidProM. In BPM Demo Sessions 2014; Limonad, L., Weber, B., Eds.; CEUR Workshop Proceedings: Eindhoven, The Netherlands, 2014; Volume 1295, pp. 56–60. [Google Scholar]
- ProM Tool 6.6–6.9. Available online: http://www.promtools.org (accessed on 25 May 2019).
- Holland, J.H. Emergence: From Chaos to Order; Perseus Publishing: New York, NY, USA, 1999. [Google Scholar]
- Grigori, D.; Casati, F.; Dayal, U.; Shan, M. Improving business process quality through exception understanding, prediction, and prevention. In VLDB; Morgan Kaufmann: Burlington, MA, USA, 2001; pp. 159–168. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}