Study on Unknown Term Translation Mining from Google Snippets

Abstract
1. Introduction
2. Related Works
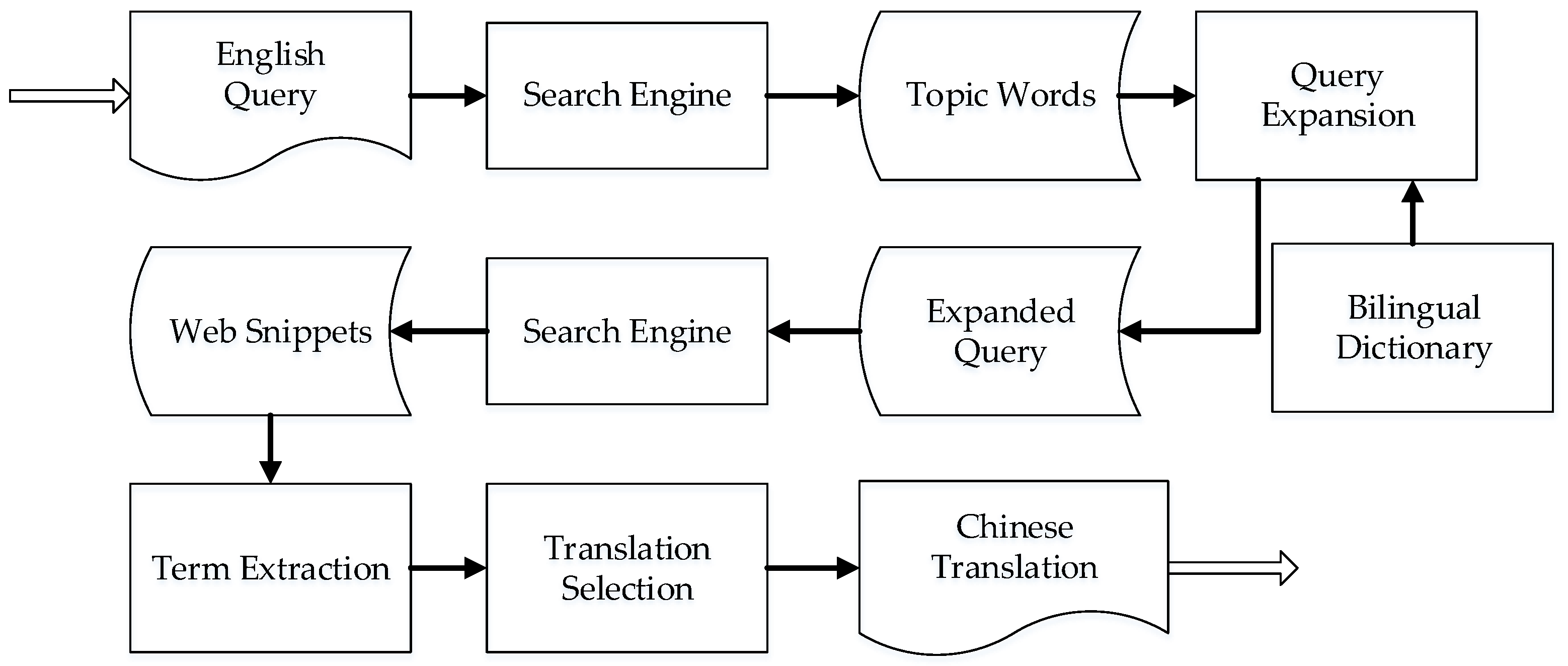
3. Web-Based Term Translation Mining System
3.1. Architecture of the System
- Collection of bilingual snippets. Retrieve bilingual snippets containing source terms in English together with translations in Chinese via a search engine, and download the snippets as bilingual resources. Effective techniques for obtaining highly related snippets lay the foundation for the extraction of translations.
- Extraction of candidate terms. Extract valid lexical and multi-lexical units (MLUs) from the returned set of snippets in step 1. However, this process is indirect. To begin with, no spaces exist between characters in Chinese texts, so a snippet of two or three sentences is smaller relative to authoritative corpora. Second, OOV terms are usually contained in snippets. Thus, specific research remains to be conducted for the extraction of terms from returned snippets.
- Selection of proper translations. Rank and sort the translation candidates yielded in step 2. As a candidate set is probably extremely large, the most suitable translations are expected to be chosen therefrom.
3.2. Collection of Bilingual Snippets
3.3. Extraction of Candidate Terms
| Algorithm 1 FCMAI |
| Input: s = a_1, a_2, …, a_n, which is an English string containing n characters |
| Output: M, which is an assembly of MLUs. /* M is the assembly of candidate translation terms. */ |
| BEGIN Procedure FCMAI |
| Use symbol “+” in s to replace English stop words like “the”, “is”, “are”, “a”, etc. and split s to substrings according to “+” and punctuation marks. In this way, s contains several substrings: s_1, s_2, …, s_m. |
| M = None, Threshold = 0.5, ω = 7 /* The value of Threshold is chosen empirically. */ |
| For each substring s_i in s |
| Let b = 1, e = 1, first-term = true |
| LOOP: Let t1 = a_b, a_2, …a_e, t2 = a_b, a_2, …a_(e+1) |
| If > and > Threshold then M = M∪{t1} /* Add substring t1 to M */ |
| If first-term = true, then |
| first-position = e and first-term = false |
| If e – b + 1 > =ω, then |
| e = first-position, b = e + 1, first-term = true |
| e = e + 1 |
| If e + 1 <= length of s_i then goto LOOP. |
| END For. |
| Return M. |
| END Procedure FCMAI |
3.4. Selection of Translations
3.4.1. Frequency–Distance Model
3.4.2. Match Modeling of Surface Patterns
3.4.3. The Transliteration Model
3.4.4. Combination of Features
4. Experimental Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ballesteros, L.; Croft, W.B. Phrasal Translation and Query Expansion Techniques for Cross-language Information Retrieval. In Proceedings of the 20th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Philadelphia, PA, USA, 27–31 July 1997; pp. 84–91. [Google Scholar]
- Pirkola, A.; Hedlund, T.; Keskustalo, H.; Järvelin, K. Dictionary-based Cross-language Information Retrieval: Problems, Methods, and Research Findings. Inf. Retr. 2001, 4, 209–230. [Google Scholar] [CrossRef]
- Pirkola, A.; Toivonen, J.; Keskustalo, H.; Järvelin, K. FITE-TRT: A High Quality Translation Technique for OOV Words. In Proceedings of the 2006 ACM symposium on Applied computing, Dijon, France, 23–27 April 2006; pp. 1043–1049. [Google Scholar]
- Sharma, V.K.; Mittal, N. Cross-Lingual Information Retrieval: A Dictionary-Based Query Translation Approach. In Advances in Computer and Computational Sciences; Springer: Singapore, 2018; Volume 2, pp. 611–618. [Google Scholar]
- Tufiş, D.; Barbu, A.M.; Ion, R. Extracting Multilingual Lexicons from Parallel Corpora. Comput. Hum. 2004, 38, 163–189. [Google Scholar] [CrossRef]
- Piperidis, S.; Harlas, I. Mining Bilingual Lexical Equivalences out of Parallel Corpora. In Proceedings of the 4th Hellenic Conference on Artificial Intelligence, Heraklion, Greece, 18–20 May 2006; pp. 311–322. [Google Scholar]
- Liu, L.; Ge, Y.D.; Yan, Z.X.; Yao, J.M. A CLIR-oriented OOV Translation Mining Method from Bilingual Webpages. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics, Guilin, China, 10–13 July 2011; pp. 1872–1877. [Google Scholar]
- Macken, L.; Lefever, E.; Hoste, V. TExSIS: Bilingual Terminology Extraction from Parallel Corpora Using Chunk-based Alignment. Terminology 2013, 19, 1–30. [Google Scholar] [CrossRef]
- Widdows, D.; Dorow, B.; Chan, C.K. Using Parallel Corpora to enrich Multilingual Lexical Resource. In Proceedings of the Third International Conference on Language Resources and Evaluation, Las Palmas, Spain, 29–31 May 2002; pp. 240–245. [Google Scholar]
- Morin, E.; Hazem, A. Looking at Unbalanced Specialized Comparable Corpora for Bilingual Lexicon Extraction. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; pp. 1284–1293. [Google Scholar]
- Otero, P.G.; José, R.P.C. An Approach to Acquire Word Translations from Non-parallel Texts. In Proceedings of the 12th Portuguese Conference on Progress in Artificial Intelligence, Covilha, Portugal, 5–8 December 2005; pp. 600–610. [Google Scholar]
- Kwon, H.; Seo, H.; Kim, J. Bilingual Lexicon Extraction via Pivot Language and Word Alignment Tool. In Proceedings of the Sixth Workshop on Building and Using Comparable Corpora, Sofia, Bulgaria, 8 August 2013; pp. 11–15. [Google Scholar]
- Linard, A.; Daille, B.; Morin, E. Attempting to Bypass Alignment from Comparable Corpora via Pivot Language. In Proceedings of the Eighth Workshop on Building and Using Comparable Corpora, Beijing, China, 30 July 2015; pp. 32–37. [Google Scholar]
- Vulić, I.; Moens, M.F. Bilingual Word Embeddings from Non-Parallel Document-Aligned Data Applied to Bilingual Lexicon Induction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 719–725. [Google Scholar]
- Vulić, I.; Moens, M.F. Bilingual Distributed Word Representations from Document-Aligned Comparable Data. J. Artif. Intell. Res. 2016, 55, 953–994. [Google Scholar] [CrossRef]
- Hazem, A.; Morin, E. Efficient Data Selection for Bilingual Terminology Extraction from Comparable Corpora. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 3401–3411. [Google Scholar]
- Hazem, A.; Daille, B. Word Embedding Approach for Synonym Extraction of Multi-Word Terms. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 297–303. [Google Scholar]
- Hazem, A.; Daille, B. Semi-Compositional Method for Synonym Extraction of Multi-Word Terms. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 1201–1207. [Google Scholar]
- Rigouts, T.A.; Hoste, V.; Lefever, E. A Gold Standard for Multilingual Automatic Term Extraction from Comparable Corpora: Term Structure and Translation Equivalents. In Proceedings of the 11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 1803–1808. [Google Scholar]
- Nagata, M.; Saito, T.; Suzuki, K. Using the Web as a Bilingual Dictionary. In Proceedings of the Workshop on Data-Driven Methods in Machine Translation, Toulouse, France, 7 July 2001; pp. 1–8. [Google Scholar]
- Lu, W.H.; Chien, L.F.; Lee, H.J. Translation of Web Queries Using Anchor Text Mining. ACM TALIP 2002, 1, 159–172. [Google Scholar] [CrossRef]
- Cheng, P.J.; Teng, J.W.; Chen, R.C.; Wang, J.H.; Lu, W.H.; Chien, L.F. Translating Unknown Queries with Web Corpora for Cross-language Information Retrieval. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 146–153. [Google Scholar]
- Huang, F.; Zhang, Y.; Vogel, S. Mining Key Phrase Translations from Web Corpora. In Proceedings of the Conference on Human Language Technology & Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 483–490. [Google Scholar]
- Fang, G.; Yu, H.; Nishino, F. Chinese-English Term Translation Mining Based on Semantic Prediction. In Proceedings of the COLING/ACL on Main Conference Poster Session, Sydney, Australia, 17–18 July 2006; pp. 199–206. [Google Scholar]
- Sun, J.; Yao, J.; Zhang, J.; Zhu, Q. Web Mining of OOV Translations. J. Inf. Comput. Sci. 2008, 6, 97–103. [Google Scholar]
- Ge, Y.D.; Hong, Y.; Yao, J.M.; Zhu, Q.M. Improving Web-Based OOV Translation Mining for Query Translation. In Proceedings of the Asia Information Retrieval Symposium, Taipei, China, 1–3 December 2010; pp. 576–587. [Google Scholar]
- Pal, S.; Naskar, S.K.; Zampieri, M.; Nayak, T.; Van, G.J. Catalog Online: A Web-based CAT Tool for Distributed Translation with Data Capture for Ape and Translation Process Research. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 98–102. [Google Scholar]
- Berger, A.; Lafferty, J. Information Retrieval as Statistical Translation. In ACM SIGIR Forum; ACM: New York, NY, USA, 2017; Volume 51, pp. 219–226. [Google Scholar]
- Lu, C.; Xu, Y.; Geva, S. Web-based Query Translation for English-Chinese CLIR. Comput. Linguist. Chin. Languist. Process. 2008, 13, 61–90. [Google Scholar]
- Lin, D.; Zhao, S.; Van Durme, B.; Paşca, M. Mining Parenthetical Translations from the Web by Word Alignment. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 16–18 June 2008; pp. 994–1002. [Google Scholar]
- Lam, W.; Huang, R.; Cheung, P.S. Learning Phonetic Similarity for Matching Named Entity Translations and Mining New Translations. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 289–296. [Google Scholar]


{kind=link}
| No. | Surface Patterns |
|---|---|
| 1 | E (C, C(E, E (C, C (E |
| 2 | E [C, C[E, E [C, C [E |
| 3 | E.C, C.E |
| 4 | E,C C,E |
| 5 | E>>(C |
| 6 | E』(C |
| 7 | E|C |
| 8 | E-C |
| No. | Method | Top 1 | Top 3 | Top 5 | Top 10 |
|---|---|---|---|---|---|
| 50 | Baseline | 45.8% | 68.2% | 75.2% | 89.1% |
| Our approach | 58.1% | 77.5% | 80.6% | 89.1% | |
| 100 | Baseline | 66.7% | 80.6% | 82.2% | 91.5% |
| Our approach | 73.6% | 87.6% | 89.1% | 94.6% | |
| 150 | Baseline | 66.7% | 77.5% | 82.9% | 90.7% |
| Our approach | 73.6% | 82.2% | 87.6% | 91.5% |
| Method | Top 1 | Top 3 | Top 5 | Top 10 |
|---|---|---|---|---|
| BabelFish | 41.9% | N/A | N/A | N/A |
| Chi-squared and context vector | 30.2% | 44.2% | 55.8% | 79.1% |
| Combined method in [26] | 61.2% | 74.4% | 82.2% | 90.7% |
| Our approach | 73.6% | 87.6% | 89.1% | 94.6% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Yao, J. Study on Unknown Term Translation Mining from Google Snippets. Information 2019, 10, 267. https://doi.org/10.3390/info10090267
Li B, Yao J. Study on Unknown Term Translation Mining from Google Snippets. Information. 2019; 10(9):267. https://doi.org/10.3390/info10090267
Chicago/Turabian StyleLi, Bin, and Jianmin Yao. 2019. "Study on Unknown Term Translation Mining from Google Snippets" Information 10, no. 9: 267. https://doi.org/10.3390/info10090267
APA StyleLi, B., & Yao, J. (2019). Study on Unknown Term Translation Mining from Google Snippets. Information, 10(9), 267. https://doi.org/10.3390/info10090267