Text Filtering through Multi-Pattern Matching: A Case Study of Wu–Manber–Uy on the Language of Uyghur


Abstract
:1. Introduction and Motivation
2. Related Work
3. Our Proposed Method for Uyghur Multi-Pattern Matching and Text Filtering
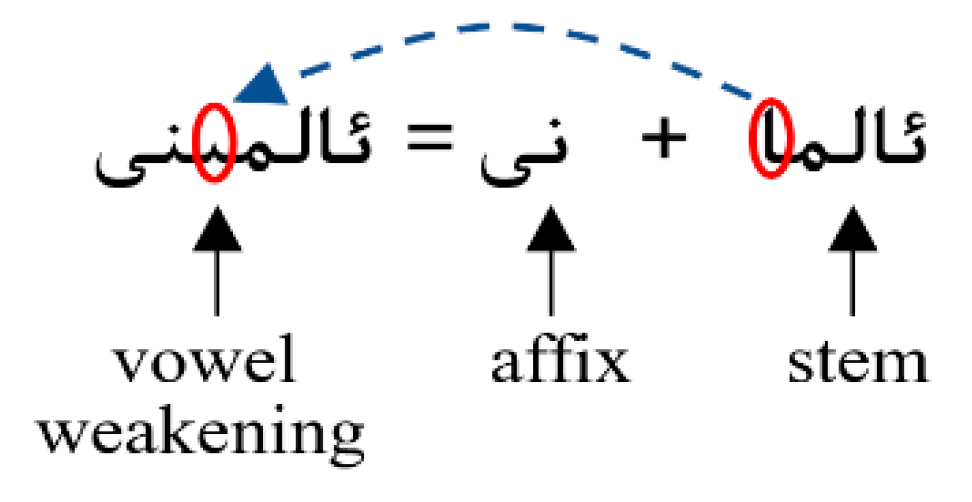
3.1. The Deficiency of Wu–Manber Algorithm in Uyghur
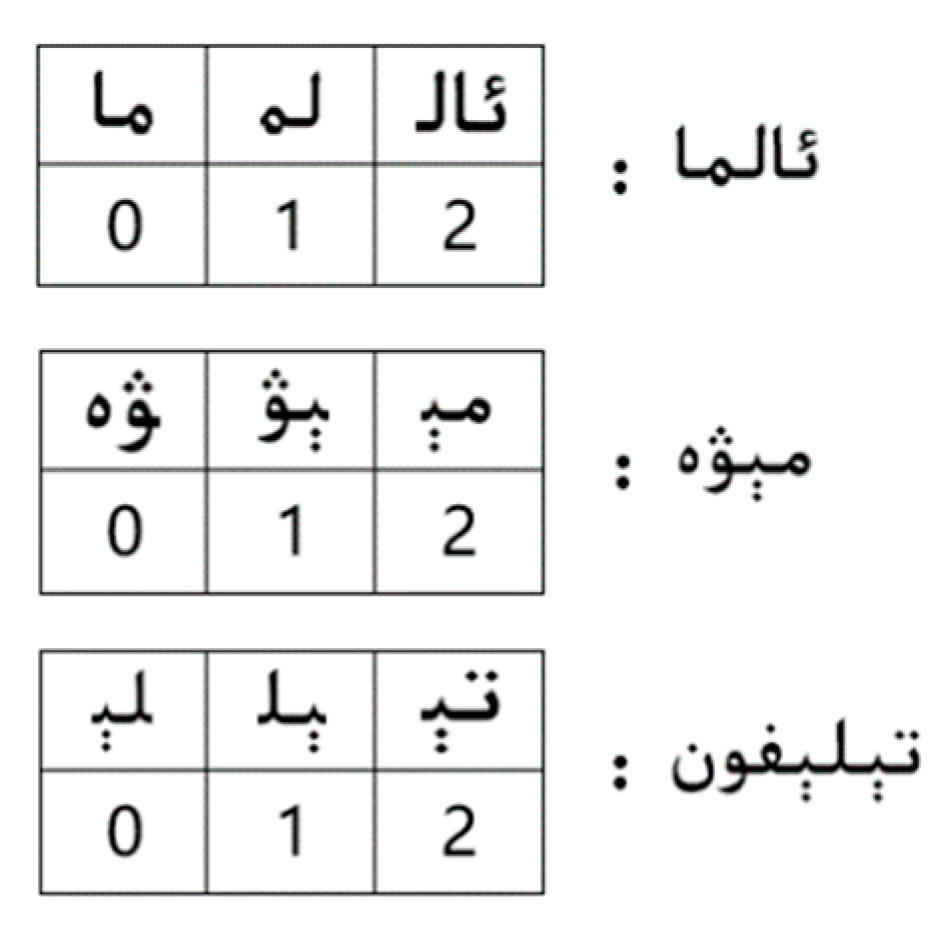
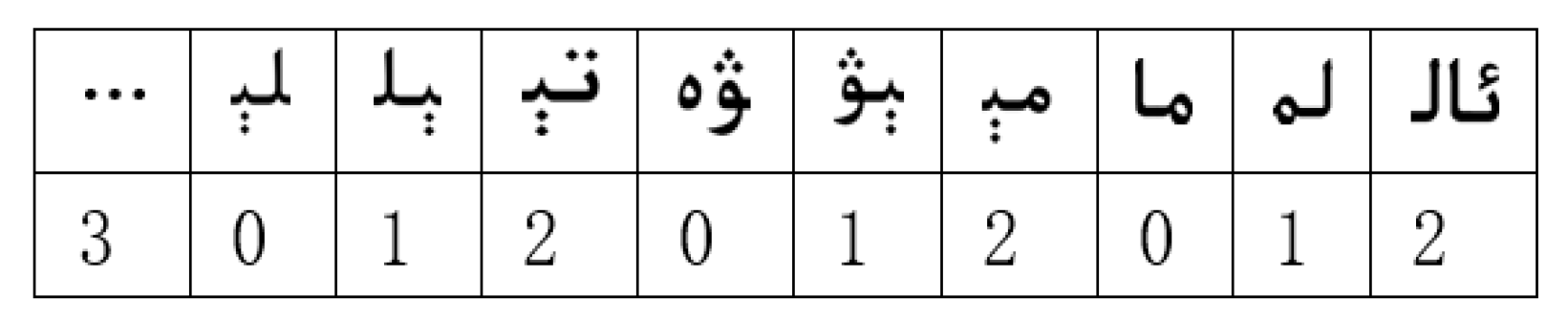
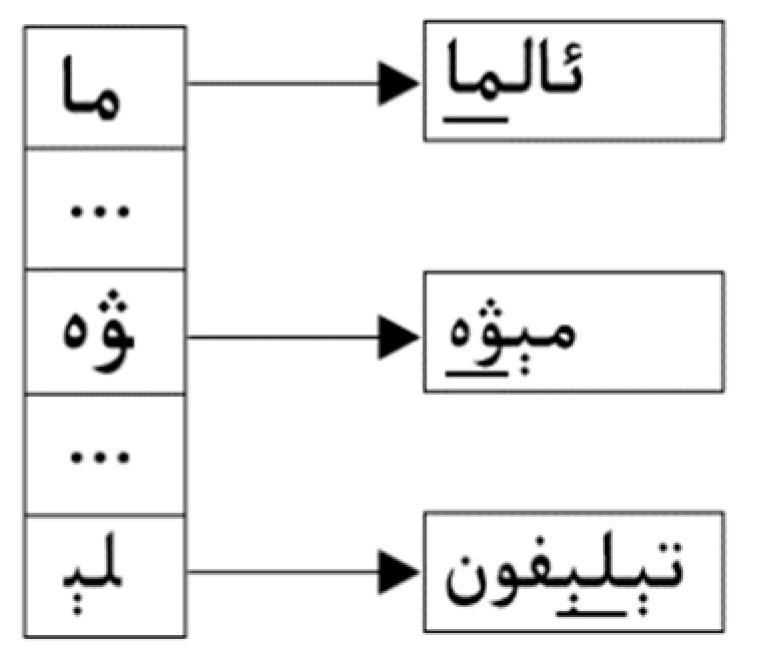
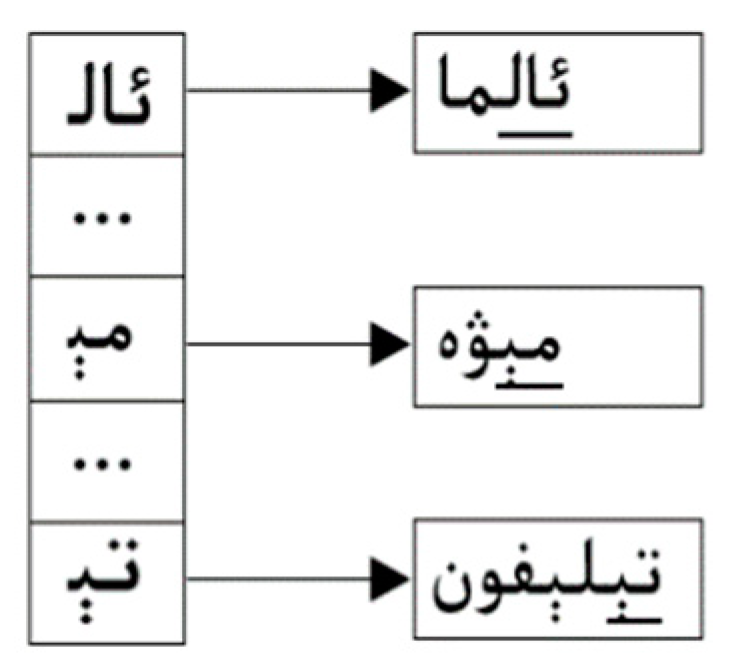
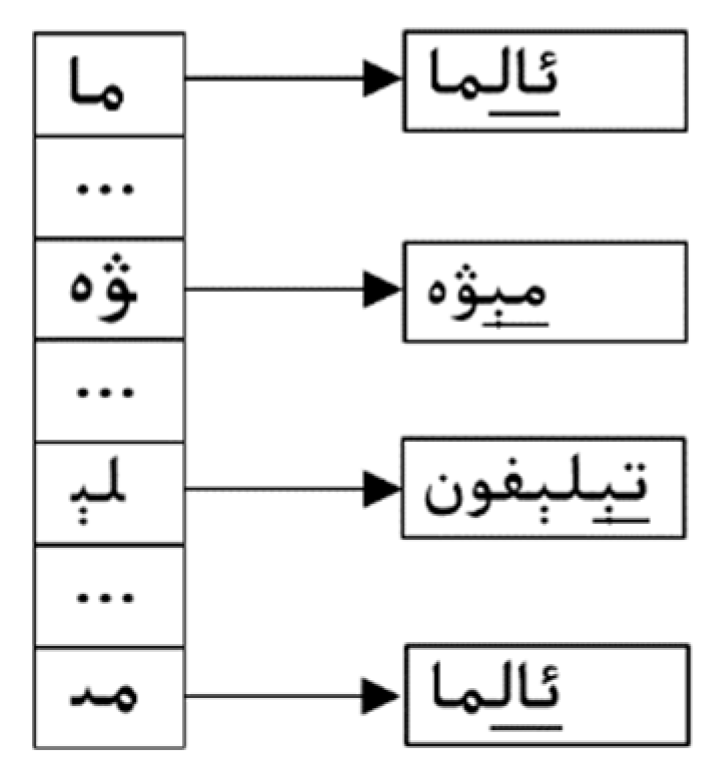
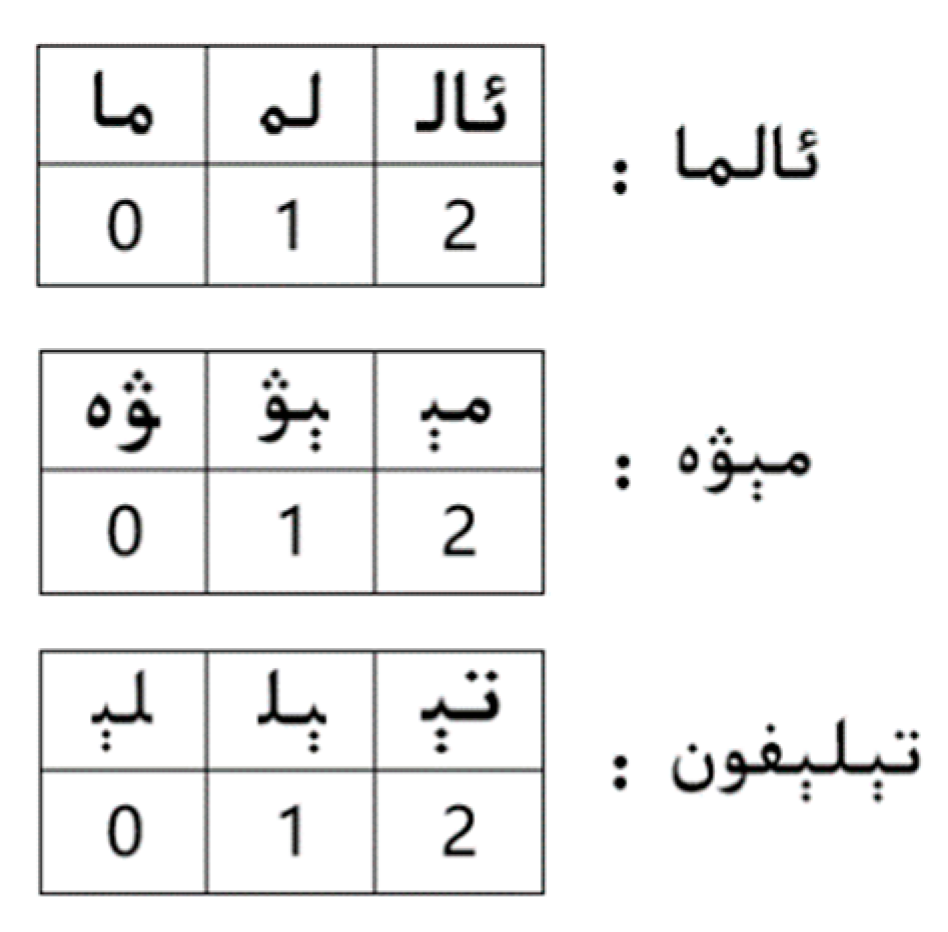
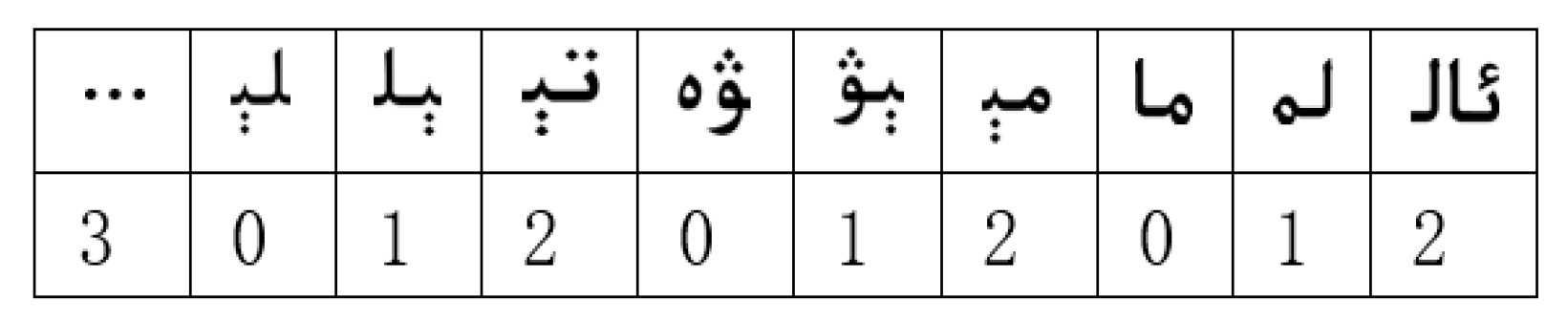
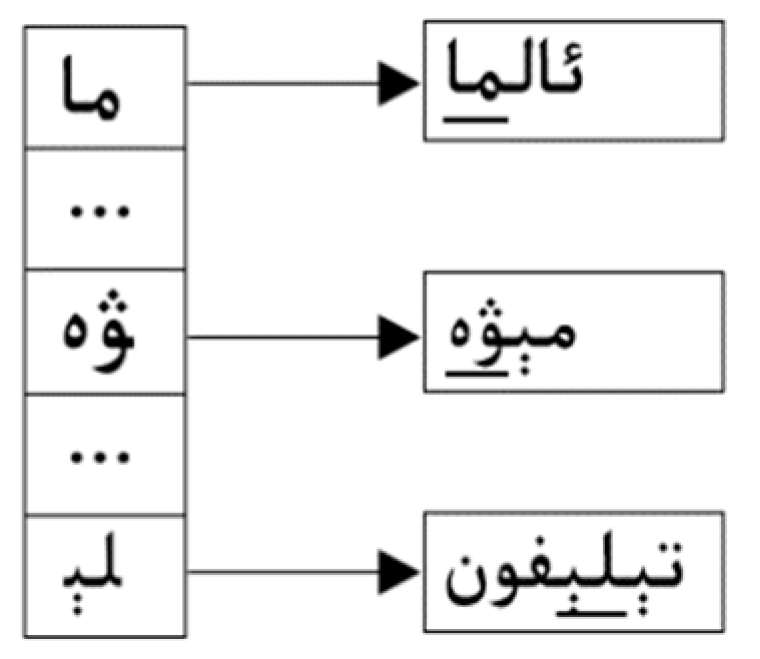
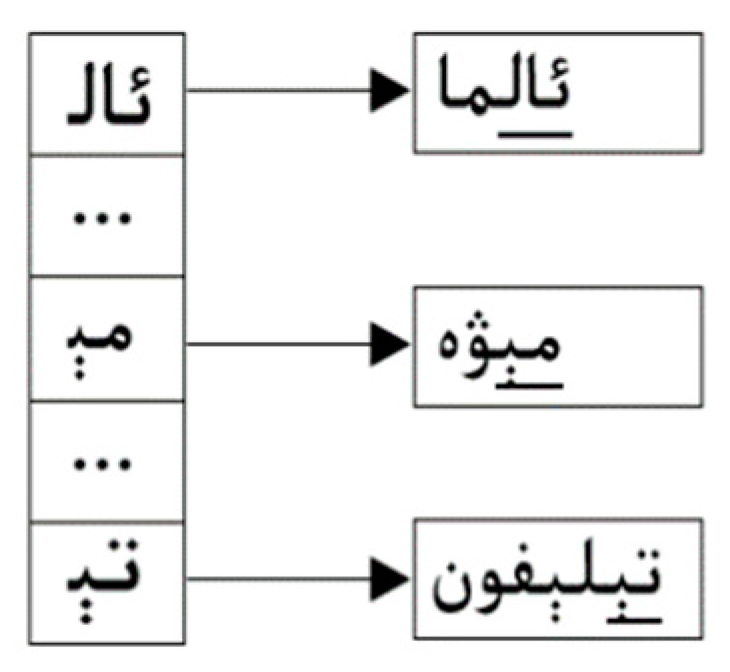
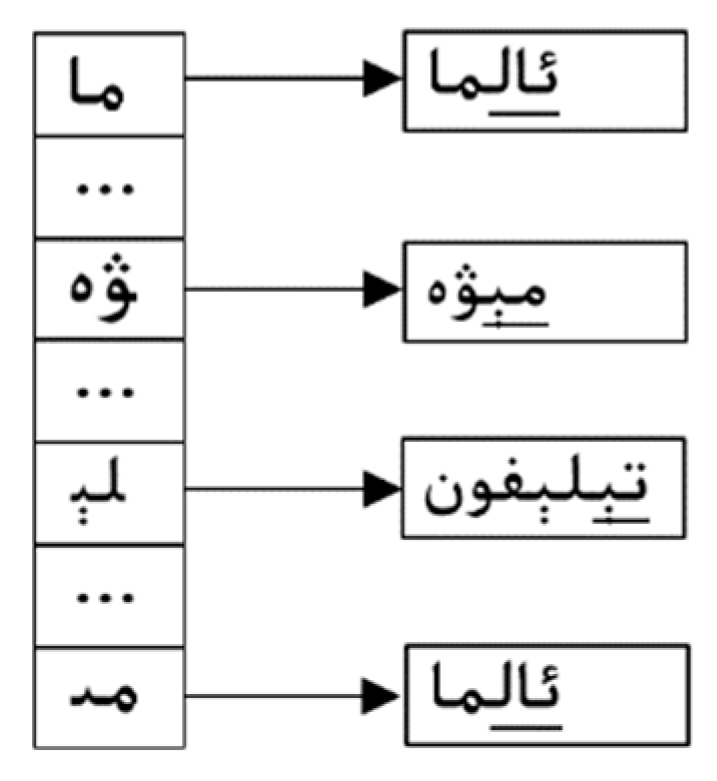
3.2. Our Multi-Pattern Matching Algorithm: Wu–Manber–Uy
| (the apple) | ئالمىنى | = | (word-forming affix) | نى | + | (apple) | ئالما |
| (of the apple) | ئالمىنڭ | = | (word-forming affix) | نىڭ | + | (apple) | ئالما |
| (apple orchard) | ئالمىزار | = | (word-building affix) | زار | + | (apple) | ئالما |
| (person name) | ئالمىخان | = | (word-building affix) | خان | + | (apple) | ئالما |
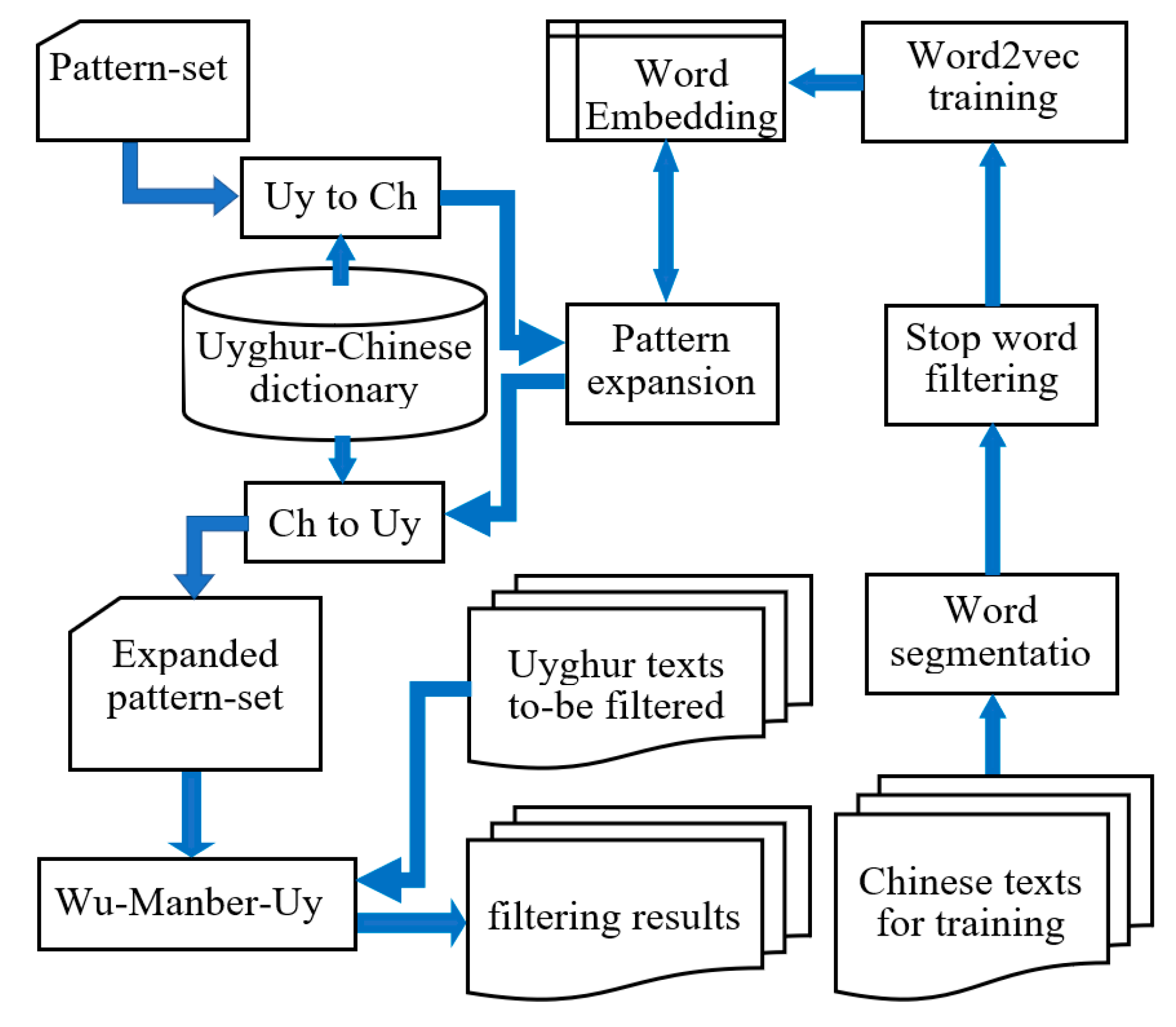
3.3. Our Proposed Method for Uyghur Text Filtering
4. Experiments and Analysis
4.1. Data Sets
4.2. Performance of Multi-Pattern Matching Algorithms
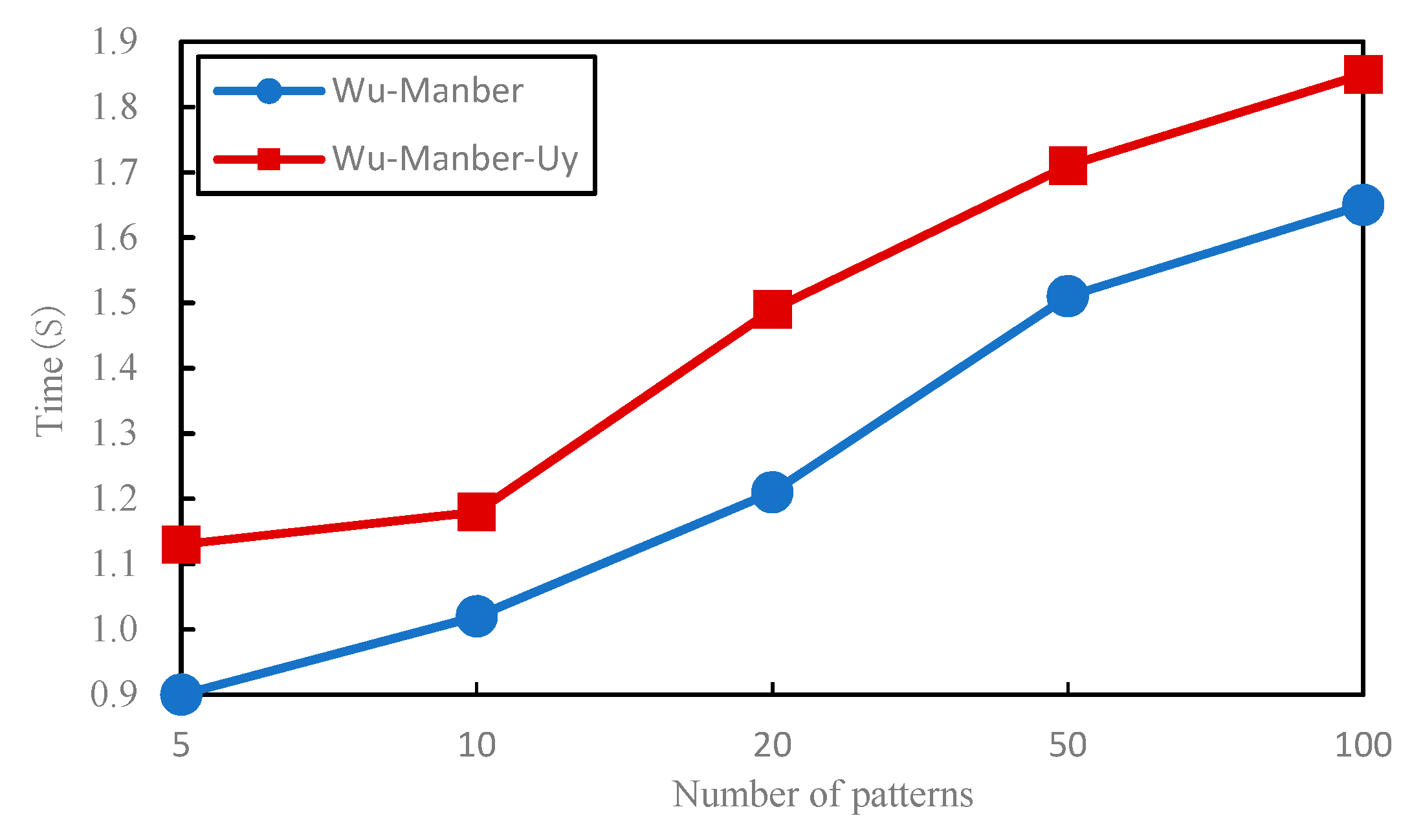
4.2.1. Comparison of Time Performance
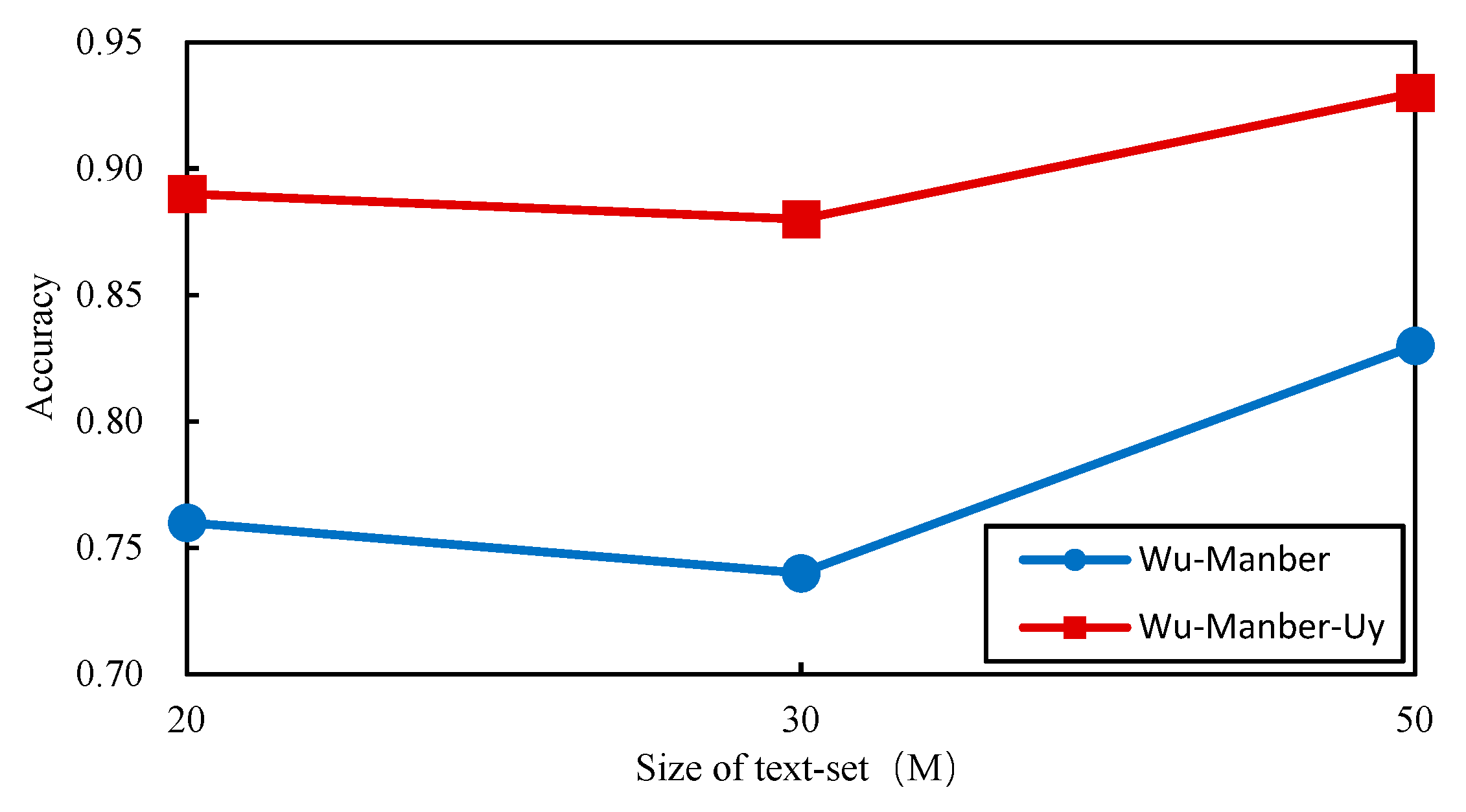
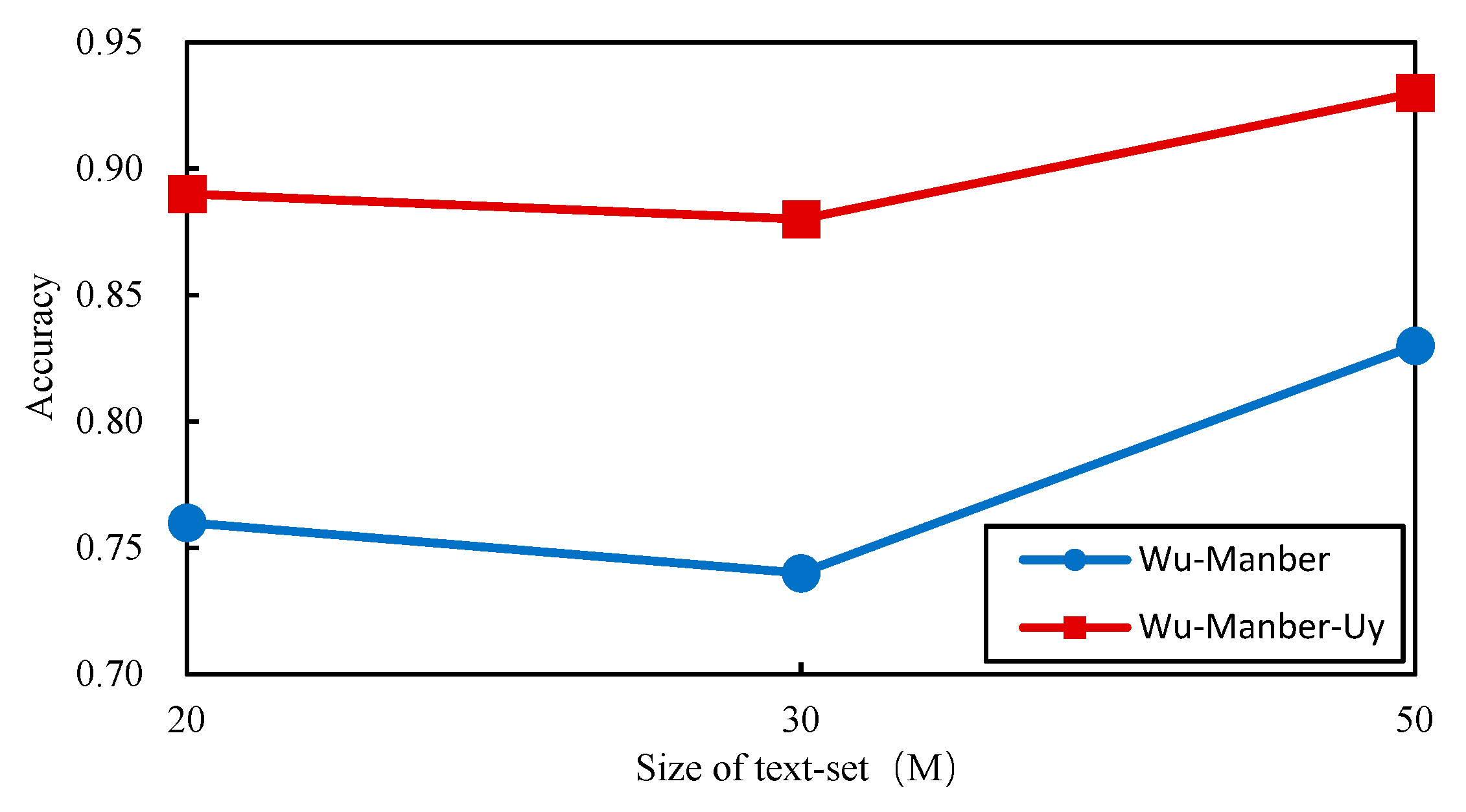
4.2.2. Comparison of Matching Accuracy
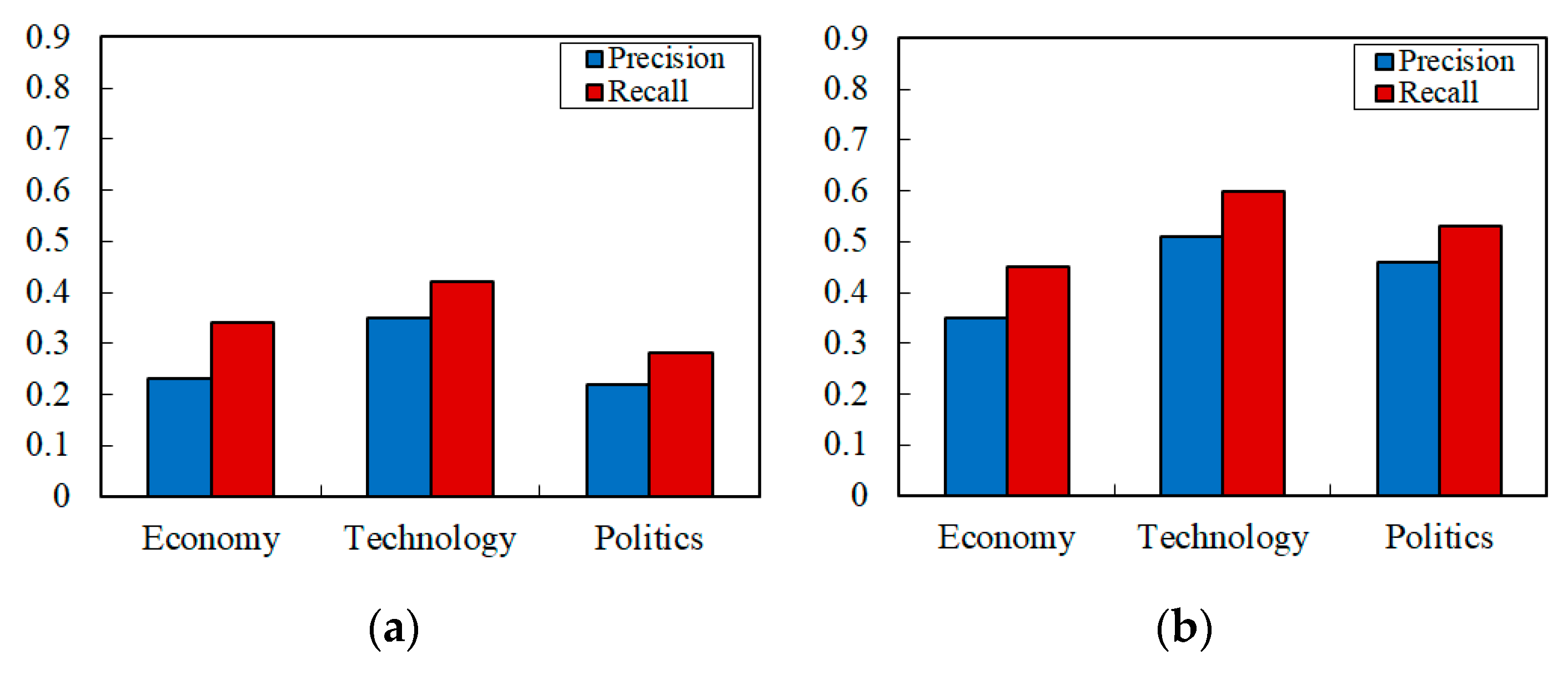
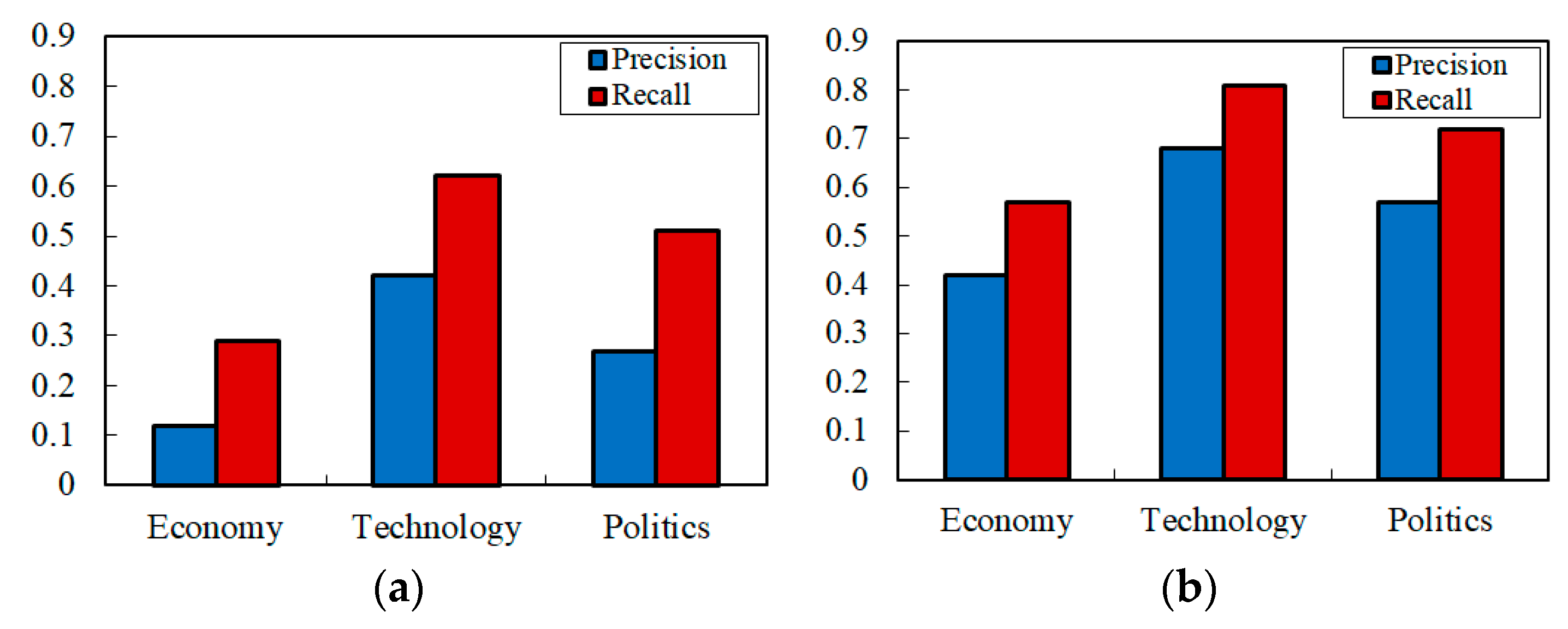
4.3. Text Filtering Experiments
4.4. Further Discussion and Analysis
4.5. Impact of the Proposed Methods
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Khurshid, S.; Khan, S.; Bashir, S. Text-Based Intelligent Content Filtering on Social Platforms. In Proceedings of the International Conference on Frontiers of Information Technology, Islamabad, Pakistan, 17–19 December 2014; pp. 232–237. [Google Scholar]
- Bertino, E.; Ferrari, E.; Perego, A. A General Framework for Web Content Filtering. World Wide Web-Internet Web Inf. Syst. 2010, 13, 215–249. [Google Scholar] [CrossRef]
- Renugadevi, S.; Geetha, T.V.; Murugavel, N. Information Retrieval Using Collaborative Filtering and Item Based Recommendation. Adv. Nat. Appl. Sci. 2015, 9, 344–349. [Google Scholar]
- Wang, X.C.; Li, S.; Yang, M.Y.; Zhao, T.J. Personalized Search by Combining Long-term and Short-term User Interests. J. Chin. Inf. Process. 2016, 30, 172–177. [Google Scholar]
- Wei, L.L.; Yang, W. The Study of Network Information Security Based on Information Filtering Technology. Appl. Mech. Mater. 2014, 644–650, 2978–2980. [Google Scholar] [CrossRef]
- Kodialam, M.; Lakshman, T.V.; Sengupta, S. Configuring networks with content filtering nodes with applications to network security. In Proceedings of the 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; pp. 2395–2404. [Google Scholar]
- Qiao, L.; Zhang, R.T.; Zhu, C.Y. personalized recommendation algorithm based on situation awareness. In Proceedings of the International Conference on Logistics, Informatics and Service Sciences, Barcelona, Spain, 27–29 July 2015; pp. 1–4. [Google Scholar]
- Thorat, P.B.; Goudar, R.M.; Barve, S. Survey on Collaborative Filtering, Content-based Filtering and Hybrid Recommendation System. Int. J. Comput. Appl. 2015, 110, 31–36. [Google Scholar]
- Kohei, H.; Takanori, M.; Masashi, T.; Kawarabayashi, K.I. Real-time Top-R topic detection on twitter with topic hijack filtering. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 417–426. [Google Scholar]
- Lever, J.; Gakkhar, S.; Gottlieb, M.; Rashnavadi, T.; Lin, S.; Siu, C.; Smith, M.; Jones, M.R.; Krzywinski, M.; Jones, S.J.M.; et al. A collaborative filtering-based approach to biomedical knowledge discovery. Bioinformatics 2017, 34, 652–659. [Google Scholar] [CrossRef]
- Shen, Y.F.; Shen, Y.W. Typed N-gram for Online SVM Based Chinese Spam Filtering. J. Chin. Inf. Process. 2015, 29, 126–132. [Google Scholar]
- Huang, W.M.; Mo, Y. Chinese Spam message filtering based on text weighted KNN algorithm. Comput. Eng. 2017, 43, 193–199. [Google Scholar]
- Chang, C.Y.; Lee, S.J.; Lai, C.C. Weighted word2vec based on the distance of words. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics, Ningbo, China, 9–12 July 2017; pp. 563–568. [Google Scholar]
- Almas, Y.; Abdureyim, H.; Yang, C. Uyghur Text Filtering Based on Vector Space Model. J. Xinjiang Univ. (Nat. Sci. Ed.) 2015, 32, 221–226. [Google Scholar]
- Zhao, X.D.; Aizezi, Y. A Uyghur bad text information filtering scheme based on mutual information and Cosine similarity. Electron. Des. Eng. 2016, 24, 109–112. [Google Scholar]
- Dharmapurikar, S. Fast and scalable pattern matching for content filtering. In Proceedings of the ACM/IEEE Symposium on Architecture for Networking & Communications Systems, Princeton, NJ, USA, 26–28 October 2005; pp. 183–192. [Google Scholar]
- Sherkat, E.; Farhoodi, M.; Yari, A. A new approach for multi-pattern string matching in large text corpora. In Proceedings of the International Symposium on Telecommunications, Tehran, Iran, 9–11 September 2014; pp. 72–77. [Google Scholar]
- Hung, C.L.; Lin, C.Y.; Wu, P.C. An Efficient GPU-Based Multiple Pattern Matching Algorithm for Packet Filtering. J. Signal Process. Syst. 2017, 86, 1–12. [Google Scholar] [CrossRef]
- Dawut, Y.; Abdureyim, H.; Yang, N.N. Research on Multiple Pattern Matching Algorithm for Uyghur. Comput. Eng. 2015, 41, 143–148. [Google Scholar]
- Xue, P.Q.; Xian, Y.; Nurbol; Silamu, W. Sensitive information filtering algorithm based on Uyghur text information network research. Comput. Eng. Appl. 2018, 54, 236–241. [Google Scholar]
- Song, H.; Shi, N.S. Comment Object Extraction Based on Pattern Matching and Semi-supervised Learning. Comput. Eng. 2013, 39, 221–226. [Google Scholar]
- Shao, K.; Yang, C.L.; Qian, L.B.; Fang, S. Structured Information Extraction Based on Pattern Matching. Pattern Recognit. Artif. Intell. 2014, 27, 758–768. [Google Scholar]
- Sonal, G.; Christopher, D.M. Improved Pattern Learning for Bootstrapped Entity Extraction. In Proceedings of the Eighteenth Conference on Computational Language Learning, Baltimore, MD, USA, 26–27 June 2014; pp. 98–108. [Google Scholar]
- Hojjat, E.; Hossein, S.; Ahmad, A.B.; Maryam, H. A Pattern-Matching Method for extracting Personal Information in Farsi Content. U.P.B. Sci. Bull. Ser. C 2016, 78, 125–138. [Google Scholar]
- Cheng, C.; Yin, H.; Wang, L.S. A study of opinion question sentence classification in Question & Answering system. Microcomput. Inf. 2009, 25, 166–168. [Google Scholar]
- Yu, Z.T.; Han, L.; Mao, C.L.; Deng, J.H.; Zhang, C. Answer extracting based on pattern learning and pattern matching in Chinese question answering system. J. Comput. Inf. Syst. 2007, 3, 957–964. [Google Scholar]
- Tian, W.D.; Zu, Y.L. Answer extraction scheme based on answer pattern and semantic feature fusion. Comput. Eng. Appl. 2011, 47, 127–130. [Google Scholar]
- Tohti, T.; Musajan, W.; Hamdulla, A. Uyghur Semantic String Extraction Based on Statistical Model and Shallow Linguistic Parsing. J. Chin. Inf. Process. 2017, 31, 70–79. [Google Scholar]
- Achar, A.; Ibrahim, A.; Sastry, P.S. Pattern-growth based frequent serial episode discovery. Data Knowl. Eng. 2013, 87, 91–108. [Google Scholar] [CrossRef]
- Muhammad, J.; Ibrahim, T.; Omar, H. Research of Uyghur Person Names Recognition Based on Statistics and Rules. J. Xinjiang Univ. (Nat. Sci. Ed.) 2014, 31, 319–324. [Google Scholar]
- Yusuf, H.; Zhang, J.J.; Zong, C.Q.; Hamdulla, A. Name Recognition in the Uyghur Language Based on Fuzzy Matching and Syllable -character Conversion. J. Tsinghua Univ. (Sci. Technol.) 2017, 57, 188–196. [Google Scholar]
- Zhang, L.; Wang, D.W.; He, L.T.; Wang, W. Improvement on Wu-manber multi-pattern matching algorithm. In Proceedings of the 3rd International Conference on Computer Science and Network Technology, Dalian, China, 12–13 October 2013; pp. 608–611. [Google Scholar]
- Enwer, S.; Xiang, L.; Zong, C.Q.; Pattar, A.; Hamdulla, A. A Multi-strategy Approach to Uyghur Stemming. J. Chin. Inf. Process. 2015, 29, 204–210. [Google Scholar]
- Abulimiti, M.; Aimudula, A. Morphological Analysis Based Algorithm for Uyghur Vowel Weakening Identification. J. Chin. Inf. Process. 2008, 22, 43–47. [Google Scholar]
- Jiang, W.B.; Wang, Z.Y.; Yibulayin, T.; Liu, Q. Directed Graph Model of Uyghur Morphological Analysis. J. Softw. 2012, 23, 3115–3129. [Google Scholar]
- Jiang, W.B.; Wang, Z.Y.; Yibulayin, T. Lemmatization of Uyghur Inflectional Words. J. Chin. Inf. Process. 2012, 26, 91–96. [Google Scholar]
- Vasudha, B.; Vikram, G. Efficient Wu Manber String Matching Algorithm for Large Number of Patterns. Int. J. Comput. Appl. 2015, 132, 29–33. [Google Scholar]
- Yan, J.J. Mechanism of ontology semantic extension with constraints for information filtering. J. Comput. Appl. 2011, 31, 1751–1755. [Google Scholar]
- Li, X.; Xie, H.; Li, L.J. Research on Sentence Semantic Similarity Calculation Based on Word2vec. Comput. Sci. 2017, 44, 256–260. [Google Scholar]
- Yibulayin, M.; Abulimiti, M.; Hamdulla, A. A Minimum Edit Distance Based Uighur Spelling Check. J. Chin. Inf. Process. 2008, 22, 110–114. [Google Scholar]
- Maihefureti; Wumaier, A.; Aili, M.; Yibulayin, T.; Zhang, J. Spelling Check Method of Uyghur Languages Based on Dictionary and Statistics. J. Chin. Inf. Process. 2014, 28, 66–71. [Google Scholar]
- Luo, Y.G.; Li, X.; Jiang, T.H.; Yang, Y.T.; Zhou, X.; Wang, L. Uyghur Lexicon Normalization Method Based on Word Vector. Comput. Eng. 2018, 44, 220–225. [Google Scholar]
- Liu, Y.B.; Shao, Y.; Wang, Y.; Liu, Q.Y.; Guo, L. A Multiple String Matching Algorithm for Large-Scale URL Filtering. Chin. J. Comput. 2014, 37, 1159–1169. [Google Scholar]
- Shen, F.X.; Zhu, Q.M. Text Information Filtering System Based on Adaptive Learning. Comput. Appl. Softw. 2010, 27, 9–10. [Google Scholar]
- Li, Q.X.; Wei, H.P. Research of the Information Filtering Based on clustering Launched Classification. Electron. Des. Eng. 2014, 22, 14–16. [Google Scholar]
- Li, Z.X.; Ma, Z.T. Research on Big Data Retrieve Filter Model for Batch Processing. Comput. Sci. 2015, 42, 183–190. [Google Scholar]
- Tohti, T.; Hamdulla, A.; Musajan, W. Research on Web Text Representation and the Similarity Based on Improved VSM in Uyghur Web Information Retrieval. In Proceedings of the Chinese Conference on Pattern Recognition, Chongqing, China, 21–23 October 2010; pp. 984–988. [Google Scholar]
- Tohti, T.; Musajan, W.; Hamdulla, A. Semantic String-Based Topic Similarity Measuring Approach for Uyghur Text Classification. J. Chin. Inf. Process. 2017, 31, 100–107. [Google Scholar]
- Cheng, Z.; Zheng, D.; Li, S. Multi-pattern fusion based semi-supervised Name Entity Recognition. In Proceedings of the International Conference on Machine Learning & Cybernetics, Tianjin, China, 14–17 July 2013; pp. 45–50. [Google Scholar]
- Xia, W.; Zhu, W.; Liao, B.; Chen, M.; Cai, L.J.; Huang, L. Novel architecture for long short-term memory used in question classification. Neurocomputing 2018, 299, 20–31. [Google Scholar] [CrossRef]
- Rao, J.; He, H.; Lin, J. Experiments with Convolutional Neural Network Models for Answer Selection. In Proceedings of the International ACM Sigir Conference on Research & Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; pp. 1217–1220. [Google Scholar]
- Ravichandran, D.; Hovy, E. Learning surface text patterns for a question answering system. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 7–12 July 2002; pp. 41–47. [Google Scholar]
- Kosseim, L.; Yousefi, J. Improving the performance of question answering with semantically equivalent answer patterns. Data Knowl. Eng. 2008, 66, 53–67. [Google Scholar] [CrossRef]
- Zhang, C.X.; Gao, X.Y.; Lu, Z.M. Extract Reordering Templates for Statistical Machine Translation. Int. J. Digit. Content Technol. Appl. 2011, 5, 55–62. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Affix | Type |
|---|---|
 | wf |
 | wf |
 | wb |
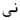 | wf |
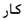 | wb |
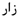 | wb |
| … | … |
| Stem | Correct Deformations | Documents Found | Misspelled Deformations | Documents Found |
|---|---|---|---|---|
| شىركەت (company) | شىركىتى | 351,000 | شىركېتى | 83 |
| خەتەر (danger) | خەتىرى | 42,300 | خەتېرى | 77 |
| مەشئەل (torch) | مەشئىلى | 3660 | مەشئېلى | 97 |
| مۇھاببەت (love) | مۇھاببىتى | 2010 | مۇھاببېتى | 72 |
| ھۆكۈمەت (government) | ھۆكۈمىتى | 208,000 | ھۆكۆمېتى | 272 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tohti, T.; Huang, J.; Hamdulla, A.; Tan, X. Text Filtering through Multi-Pattern Matching: A Case Study of Wu–Manber–Uy on the Language of Uyghur. Information 2019, 10, 246. https://doi.org/10.3390/info10080246
Tohti T, Huang J, Hamdulla A, Tan X. Text Filtering through Multi-Pattern Matching: A Case Study of Wu–Manber–Uy on the Language of Uyghur. Information. 2019; 10(8):246. https://doi.org/10.3390/info10080246
Chicago/Turabian StyleTohti, Turdi, Jimmy Huang, Askar Hamdulla, and Xing Tan. 2019. "Text Filtering through Multi-Pattern Matching: A Case Study of Wu–Manber–Uy on the Language of Uyghur" Information 10, no. 8: 246. https://doi.org/10.3390/info10080246
APA StyleTohti, T., Huang, J., Hamdulla, A., & Tan, X. (2019). Text Filtering through Multi-Pattern Matching: A Case Study of Wu–Manber–Uy on the Language of Uyghur. Information, 10(8), 246. https://doi.org/10.3390/info10080246