A Review Structure Based Ensemble Model for Deceptive Review Spam

 ,
,
Abstract
1. Introduction
2. Related Work
2.1. Classification of Deceptive Reviews
2.2. Ensemble Learning
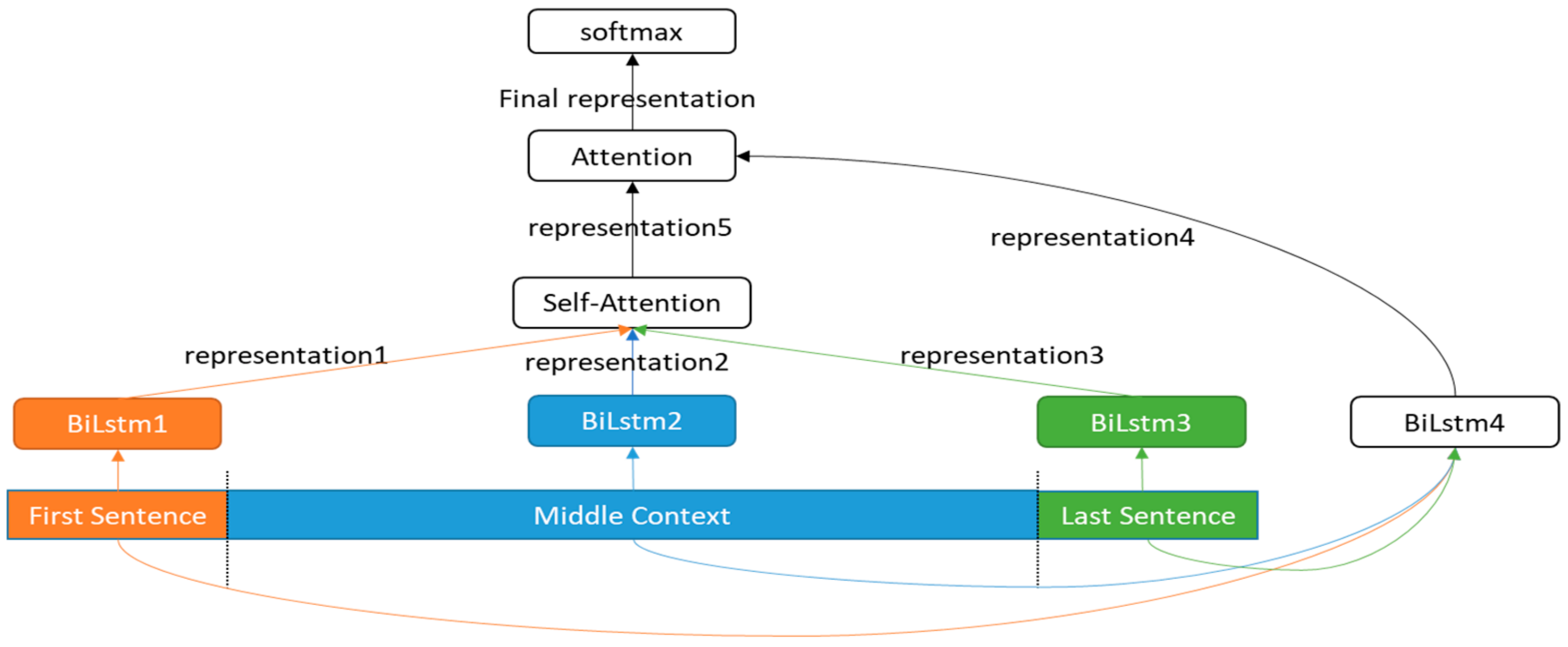
3. Materials and Methods
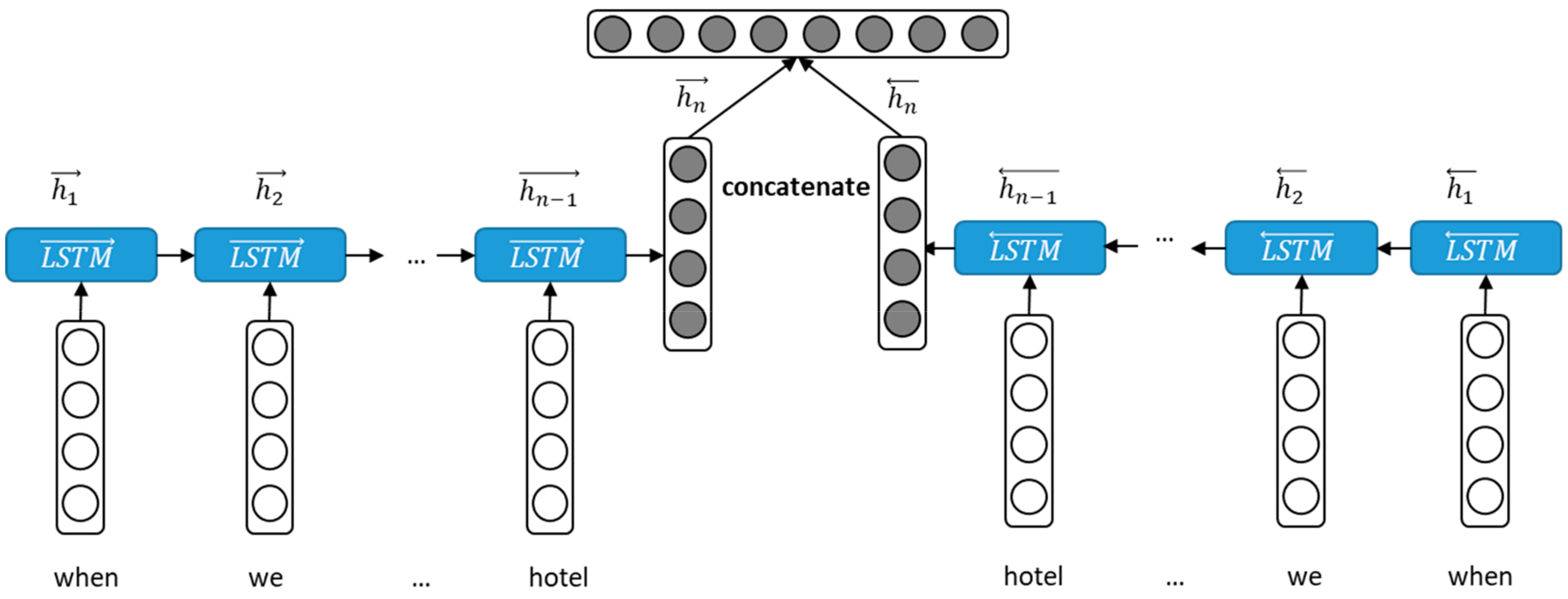
3.1. Bidirectional LSTM Encoder
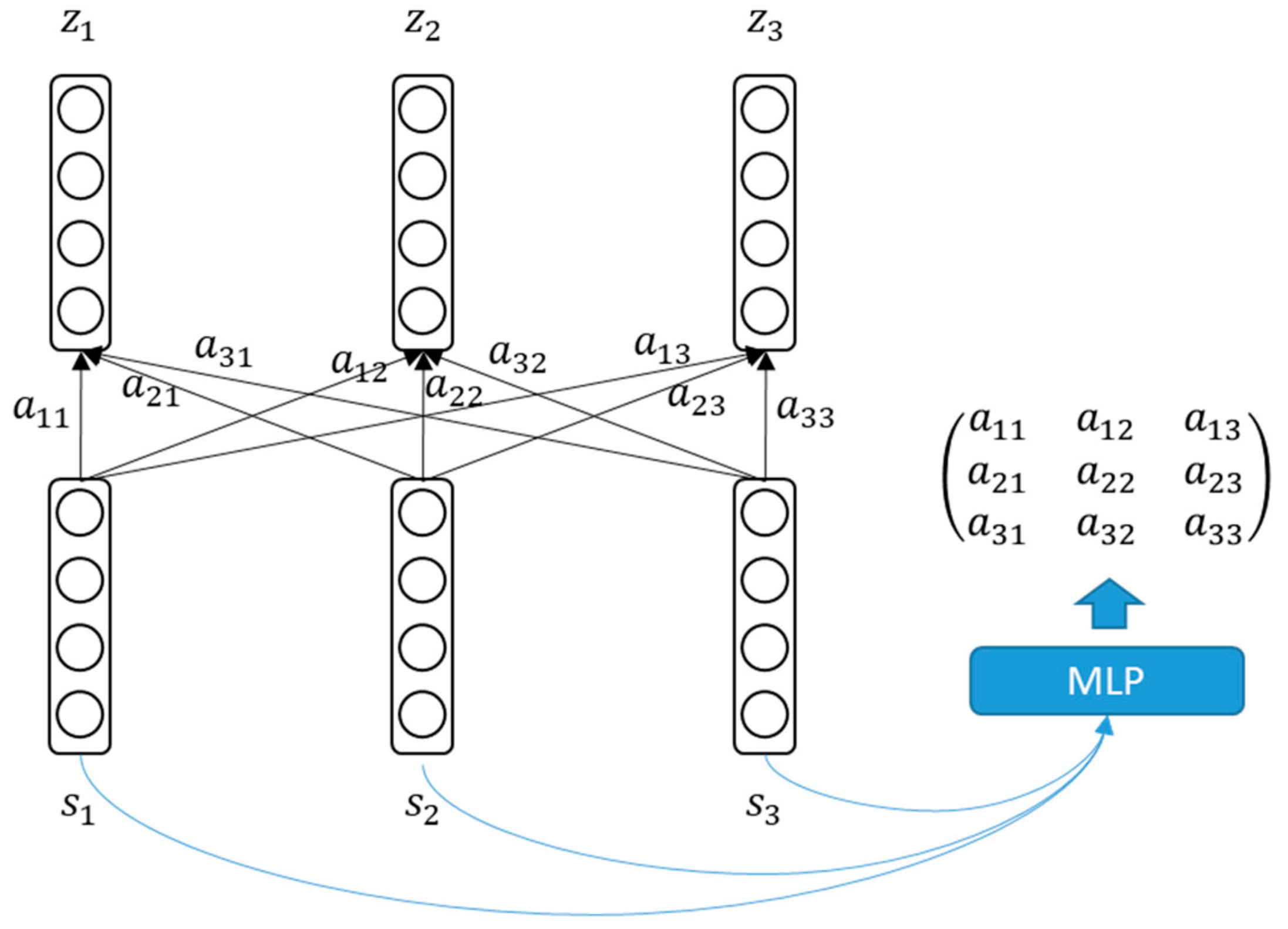
3.2. Self-Attention Mechanism
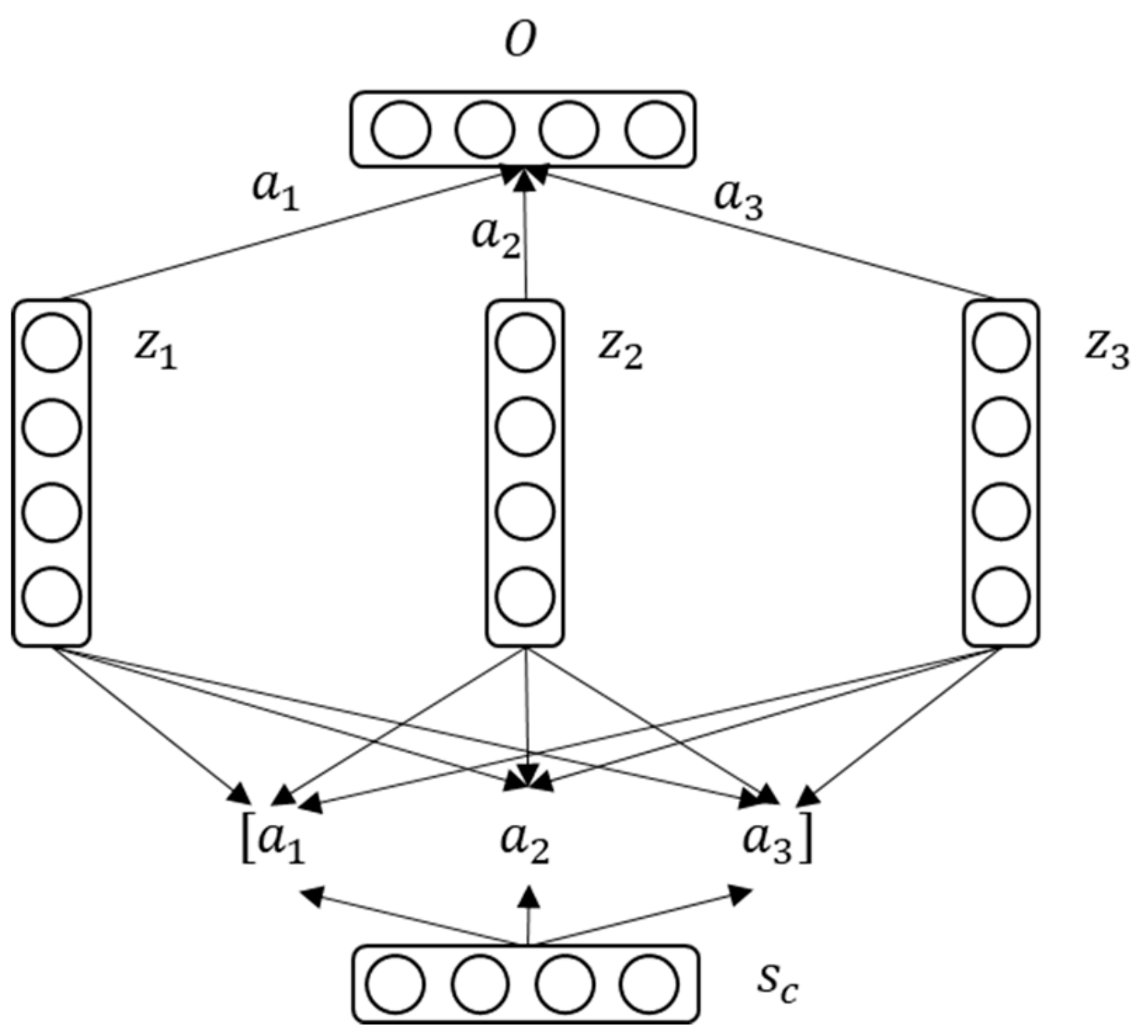
3.3. Attention Mechanism
3.4. Classifier
4. Results
4.1. Datasets and Evaluation Metrics
4.2. In-Domain Experiments
4.3. Mix-Domain Experiments
4.4. Cross-Domain Experiments
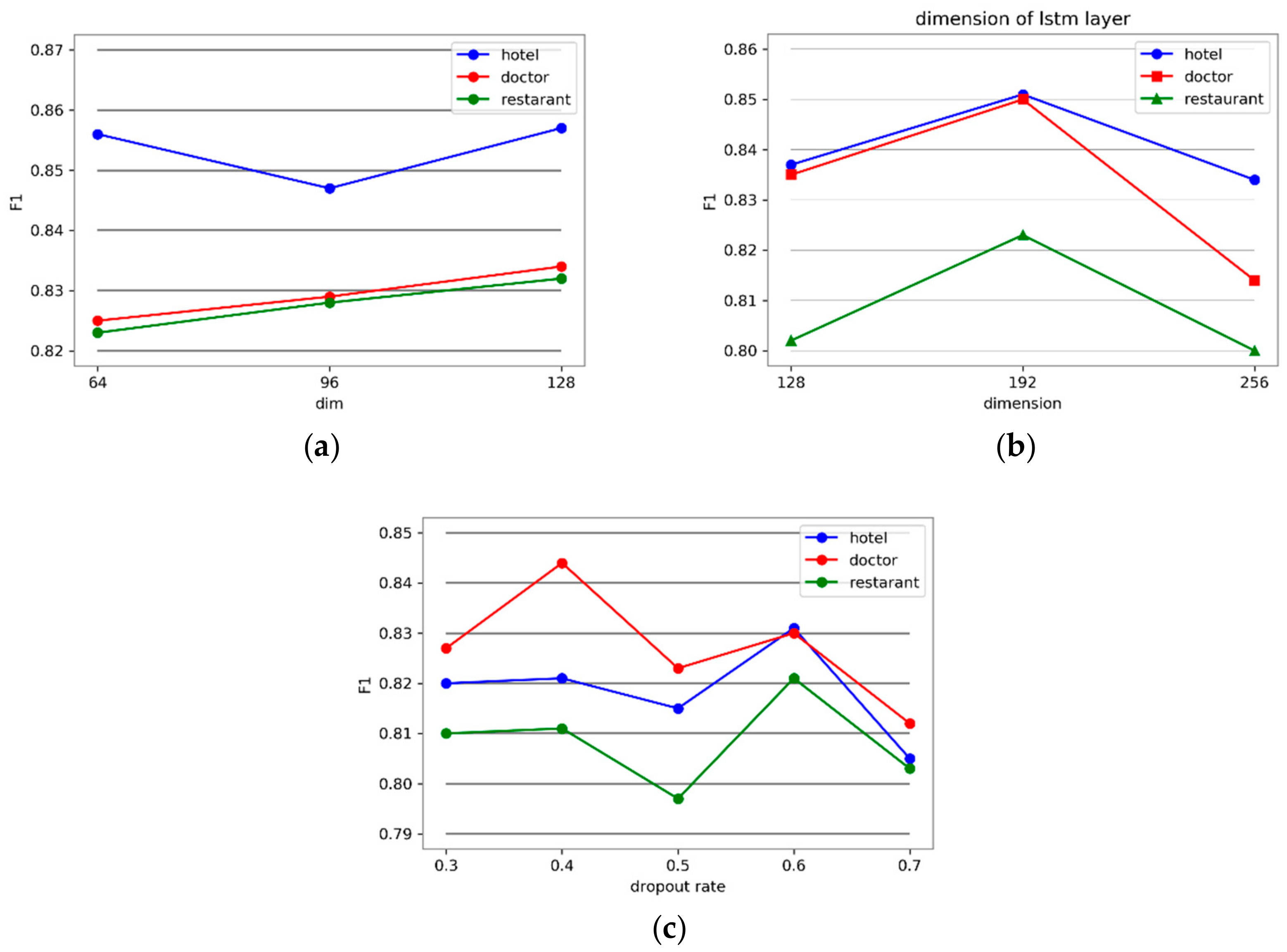
4.5. Hyper-Parameters Tuning
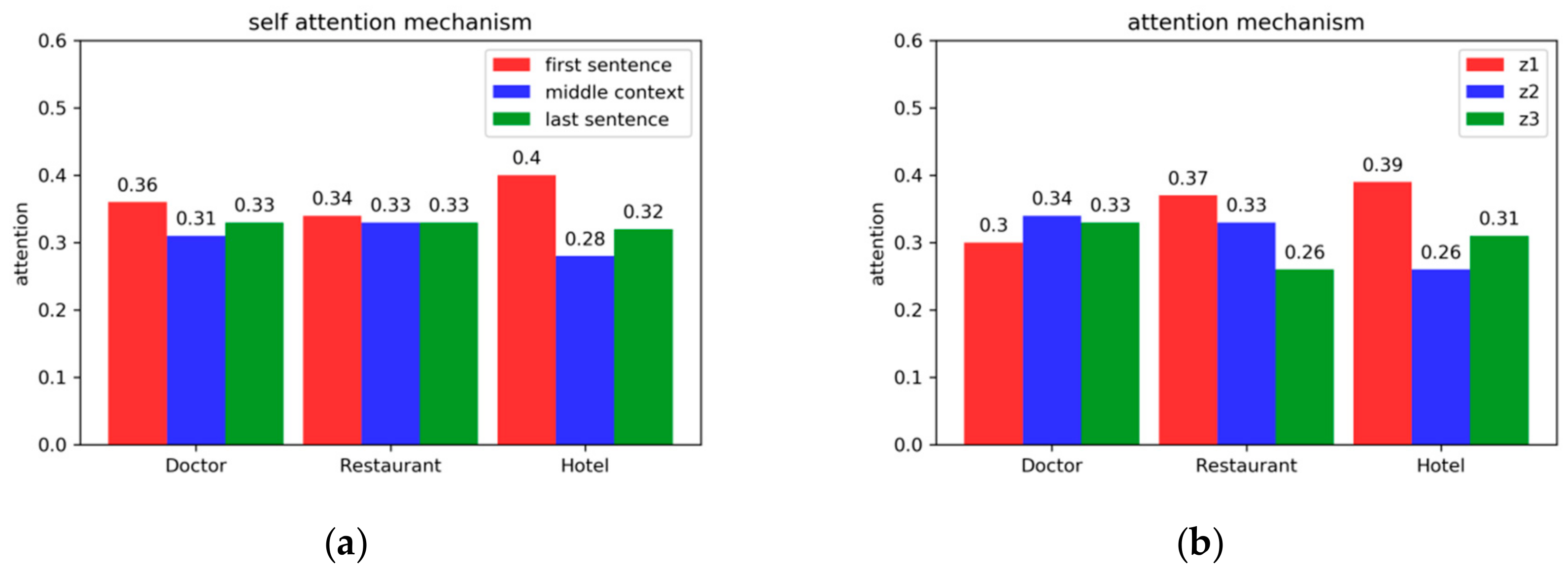
4.6. Visualization of Attention
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jindal, N.; Liu, B. Opinion spam and analysis. In Proceedings of the 2008 International Conference on Web Search and Data Mining (WSDM ’08), Palo Alto, CA, USA, 11–12 February 2008; pp. 219–230. [Google Scholar]
- Ott, M.; Choi, Y.; Cardie, C.; Hancock, J.T. Finding Deceptive Opinion Spam by Any Stretch of the Imagination. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (HLT ’11), Portland, OR, USA, 19–24 June 2011; pp. 309–319. [Google Scholar]
- Ott, M.; Cardie, C.; Hancock, J.T. Estimating the prevalence of deception in online review communities. In Proceedings of the 21st international conference on World Wide Web (WWW ’12), Lyon, France, 16–20 April 2012; pp. 201–210. [Google Scholar]
- Li, J.; Ott, M.; Cardie, C.; Hovy, E.H. Towards a General Rule for Identifying Deceptive Opinion Spam. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; pp. 1566–1576. [Google Scholar]
- Li, J.; Cardie, C.; Li, S. Topics pam: A topic-model based approach for spam detection. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 217–221. [Google Scholar]
- Li, L.; Qin, B.; Ren, W.; Liu, T. Document representation and feature combination for deceptive spam review detection. Neurocomputing 2017, 254, 33–41. [Google Scholar] [CrossRef]
- Ren, Y.; Ji, D. Neural networks for deceptive opinion spam detection: An empirical study. Inf. Sci. 2017, 385–386, 213–224. [Google Scholar] [CrossRef]
- Shang, Y. Resilient consensus of switched multi-agent systems. Syst. Control Lett. 2018, 122, 12–18. [Google Scholar] [CrossRef]
- Shang, Y. Resilient Multiscale Coordination Control against Adversarial Nodes. Energies 2018, 11, 1844. [Google Scholar] [CrossRef]
- Shang, Y. Hybrid consensus for averager–copier–voter networks with non-rational agents. Chaos Solit. Fract. 2018, 110, 244–251. [Google Scholar] [CrossRef]
- Feng, S.; Banerjee, R.; Choi, Y. Syntactic stylometry for deception detection. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22 June 2014; pp. 171–175. [Google Scholar]
- Xu, Q.; Zhao, H. Using deep linguistic features for finding deceptive opinion spam. In Proceedings of the COLING, Mumbai, India, 8–15 December 2012; pp. 1341–1350. [Google Scholar]
- Banerjee, S.; Chua, A.Y. A linguistic framework to distinguish between genuine and deceptive online reviews. In Proceedings of the International Conference on Internet Computing and Web Services, Baltimore, MD, USA, 22 June 2014. [Google Scholar]
- Fusilier, D.H.; Montesygomez, M.; Rosso, P.; Cabrera, R.G. Detection of opinion spam with character n-grams. In Proceedings of the Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; pp. 285–294. [Google Scholar]
- Fusilier, D.H.; Montesygomez, M.; Rosso, P.; Cabrera, R.G. Detecting positive and negative deceptive opinions using PU-learning. Inf. Process. Manag. 2015, 51, 433–443. [Google Scholar] [CrossRef]
- Hai, Z.; Zhao, P.; Cheng, P.; Yang, P.; Li, X.; Li, G. Deceptive Review Spam Detection via Exploiting Task Relatedness and Unlabeled Data. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1817–1826. [Google Scholar]
- Feng, S.; Xing, L.; Gogar, A.; Choi, Y. Distributional Footprints of Deceptive Product Reviews. In Proceedings of the International Conference on Weblogs and Social Media, Dublin, Ireland, 4–7 June 2012. [Google Scholar]
- Liu, Y.; Pang, B. Spam Detection based on Annotation Extension and Neural Networks. Comp. Inf. Sci. 2019. Available online: https://pdfs.semanticscholar.org/a312/7f6c118a6e29be12679cefda14a363f9028e.pdf (accessed on 3 June 2019).
- Sun, C.; Du, Q.; Tian, G. Exploiting Product Related Review Features for Fake Review Detection. Math. Probl. Eng. 2016, 1–7. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Schapire, R.E. The strength of weak learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kégl, B. The return of AdaBoost. MH: Multi-class Hamming trees. arXiv 2013, arXiv:1312.6086. [Google Scholar]
- Perrone, M.P.; Cooper, L.N. When Networks Disagree: Ensemble Methods for Hybrid Neural Networks. 1992. Available online: https://pdfs.semanticscholar.org/5956/40253ffdfd12e04ac57bd78753f936a7cfad.pdf?_ga=2.149320566.1196925254.1559288762-513896128.1544690129 (accessed on 3 June 2019).
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 10, 993–1001. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Williams, R.J.; Zipser, D. A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1989, 1, 270–280. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is All You Need. In Proceedings of the 2017 Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Gal, Y.; Ghahramani, Z. A theoretically grounded application of dropout in recurrent neural networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 4–9 December 2016; pp. 1019–1027. [Google Scholar]
- Palatucci, M.; Pomerleau, D.A.; Hinton, G.E.; Mitchell, T.M. Zero-shot Learning with Semantic Output Codes. In Proceedings of the 22nd International Conference on Neural Information Processing Systems (NIPS’09), Vancouver, BC, Canada, 7–10 December 2009; pp. 1410–1418. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Peng, M.; Zhang, Q.; Jiang, Y.; Huang, X. Cross-Domain Sentiment Classification with Target Domain Specific Information. In Proceedings of the Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 2505–2513. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Similar Beginnings | My husband and I arrived for a 3-night stay for our 10th wedding anniversary. |
| My husband and I stayed there when we went to visit my sister. | |
| My wife and I checked in to this hotel after a rough flight from Los Angeles. | |
| Similar Endings | I look forward to many visits to Joe’s in the future. |
| I am looking forward to my next visit to Mike Ditka’s—Chicago. | |
| We definitely will be returning to this restaurant in the near future. |
| Domain | Turker | Expert | User |
|---|---|---|---|
| Hotel | 800 | 280 | 800 |
| Restaurant | 200 | 0 | 200 |
| Doctor | 356 | 0 | 200 |
| Domain | Method | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Hotel | SAGE | 81.8% | 81.2% | 84.0% | 82.6% |
| SWNN | - | 84.1% | 83.3% | 83.7% | |
| RSBE | 85.7% | 85.5% | 86.1% | 85.7% | |
| Restaurant | SAGE | 81.7% | 84.2% | 81.6% | 82.8% |
| SWNN | - | 87.0% | 88.2% | 87.6% | |
| RSBE | 85.5% | 84.1% | 88.5% | 85.8% | |
| Doctor | SAGE | 74.5% | 77.2% | 70.1% | 73.5% |
| SWNN | - | 85.0% | 81.0% | 82.9% | |
| RSBE | 84.7% | 83.6% | 86.5% | 85.0% |
| Method | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| SWNN | 80.1% | 80.0% | 87.3% | 83.4% |
| Basic LSTM | 55% | 59% | 72% | 72% |
| Hier-LSTM | 62% | 61% | 95% | 74% |
| Basic CNN | 71% | 69% | 88% | 78% |
| RSBE | 83.4% | 82.5% | 82.1% | 82.3% |
| Domain | Method | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Restaurant | SAGE | 7850.0% | 81.3% | 74.2% | 77.8% |
| SWNN | 69.0% | 64.4% | 85.0% | 73.3% | |
| RSBE | 71.6% | 69.4% | 77.2% | 72.9% | |
| Doctor | SAGE | 5500.0% | 57.3% | 72.5% | 6170.0% |
| SWNN | 61.0% | 57.3% | 86.0% | 68.8% | |
| RSBE | 60.5% | 60.0% | 65.7% | 62.3% |
| Hyper-Parameters | Hotel | Restaurant | Doctor |
|---|---|---|---|
| Dropout rate | 0.6 | 0.6 | 0.4 |
| Recurrent Dropout rate | 0.2 | 0.2 | 0.2 |
| Output Dimension of BiLSTM layer | 192 | 192 | 192 |
| Output Dimension of fully-connected layer | 128 | 128 | 128 |
| Hyper-Parameters | Hotel | Restaurant | Doctor | Standard Deviation | |
|---|---|---|---|---|---|
| Dropout rate | 0.3 | 0.820 | 0.810 | 0.827 | 0.006 |
| 0.4 | 0.821 | 0.811 | 0.844 | 0.013 | |
| 0.5 | 0.815 | 0.797 | 0.823 | 0.010 | |
| 0.6 | 0.831 | 0.821 | 0.830 | 0.004 | |
| 0.7 | 0.805 | 0.803 | 0.812 | 0.004 | |
| standard deviation | 0.008 | 0.008 | 0.010 | - | |
| Dimension of fully-connected layer | 64 | 0.856 | 0.823 | 0.825 | 0.015 |
| 96 | 0.847 | 0.828 | 0.829 | 0.008 | |
| 128 | 0.857 | 0.832 | 0.834 | 0.011 | |
| standard deviation | 0.004 | 0.003 | 0.003 | - | |
| Dimension of LSTM layer | 128 | 0.837 | 0.802 | 0.835 | 0.016 |
| 192 | 0.851 | 0.823 | 0.850 | 0.012 | |
| 256 | 0.834 | 0.801 | 0.814 | 0.013 | |
| standard deviation | 0.007 | 0.01 | 0.014 | - | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, Z.-Y.; Lin, J.-J.; Chen, M.-S.; Chen, M.-H.; Lan, Y.-Q.; Liu, J.-L. A Review Structure Based Ensemble Model for Deceptive Review Spam. Information 2019, 10, 243. https://doi.org/10.3390/info10070243
Zeng Z-Y, Lin J-J, Chen M-S, Chen M-H, Lan Y-Q, Liu J-L. A Review Structure Based Ensemble Model for Deceptive Review Spam. Information. 2019; 10(7):243. https://doi.org/10.3390/info10070243
Chicago/Turabian StyleZeng, Zhi-Yuan, Jyun-Jie Lin, Mu-Sheng Chen, Meng-Hui Chen, Yan-Qi Lan, and Jun-Lin Liu. 2019. "A Review Structure Based Ensemble Model for Deceptive Review Spam" Information 10, no. 7: 243. https://doi.org/10.3390/info10070243
APA StyleZeng, Z.-Y., Lin, J.-J., Chen, M.-S., Chen, M.-H., Lan, Y.-Q., & Liu, J.-L. (2019). A Review Structure Based Ensemble Model for Deceptive Review Spam. Information, 10(7), 243. https://doi.org/10.3390/info10070243