A Two-Stage Household Electricity Demand Estimation Approach Based on Edge Deep Sparse Coding



Abstract
1. Introduction
- (1)
- A deep non-negative K-SVD algorithm, with an initial dictionary that consists of household electricity load, was proposed. This algorithm can extract deeper and more valid usage patterns that are conducive to the analysis and estimation of consumer behavior.
- (2)
- An edge sparse coding architecture was proposed to address the data deluge issue. In this architecture, deep sparse coding was completed in the edge nodes and then DUBPs or the coefficient matrix were uploaded to the cloud computing center for storage and estimation. This scheme considerably reduced the amount of data and effectively alleviated the communication and storage burden of the data link.
- (3)
- A novel two-stage estimation method for short-term household electricity consumption based on a LSTM network was proposed. Actual meter data were used for verification and simulation, and the results indicated that the proposed method achieved the best overall performance. It provided a considerable and stable improvement in load forecasting accuracy.
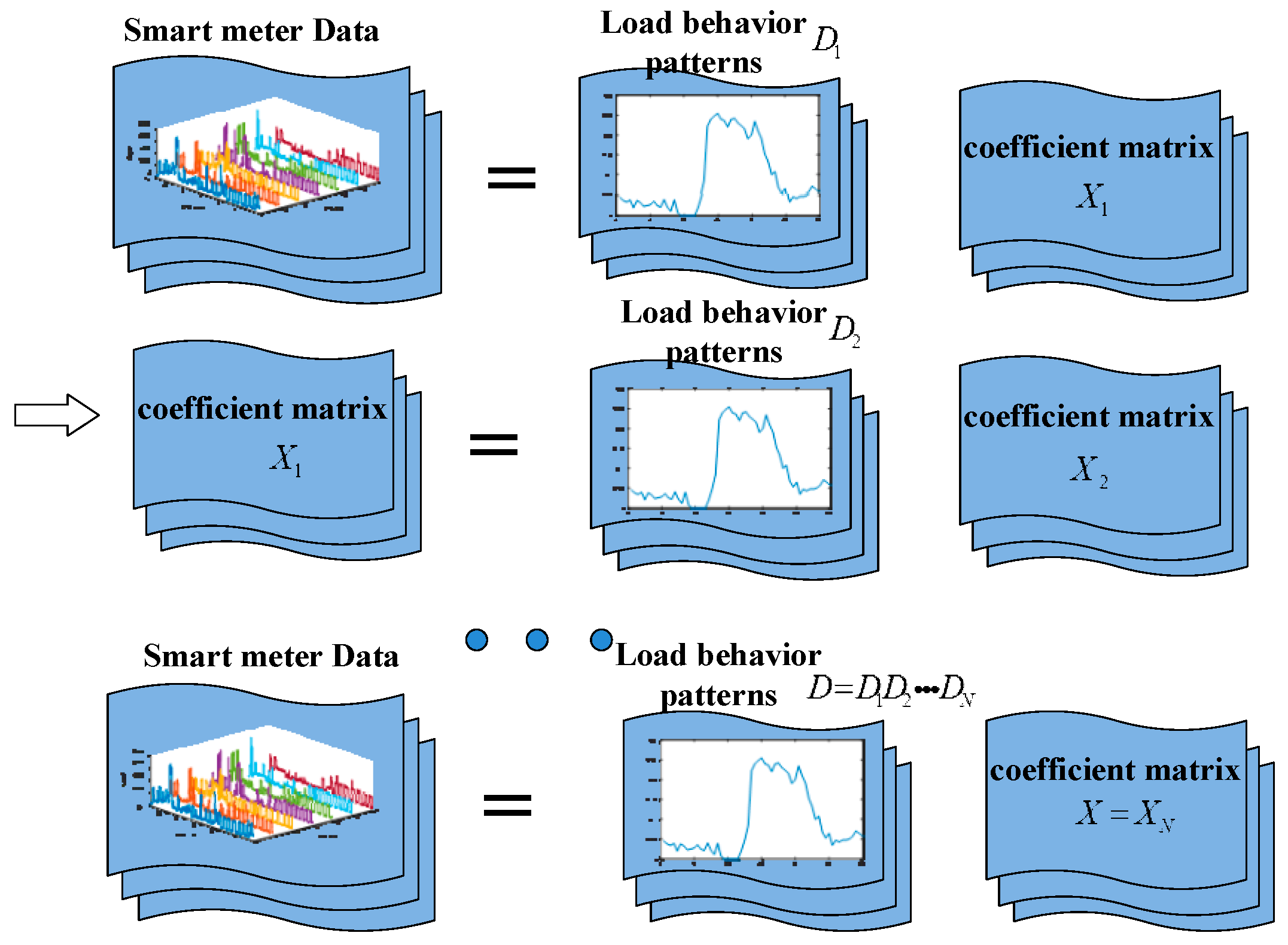
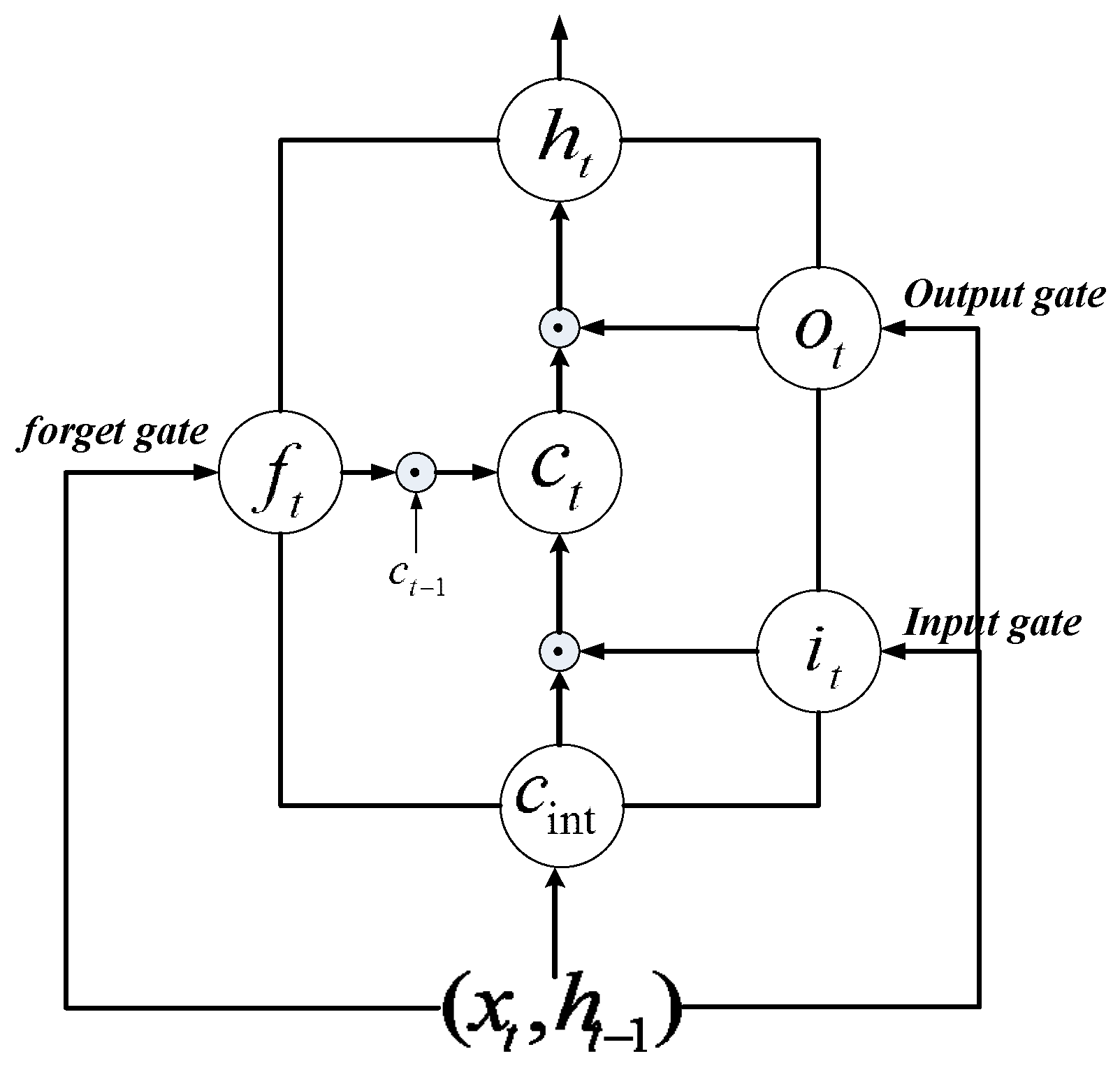
2. Deep K-SVD Algorithm
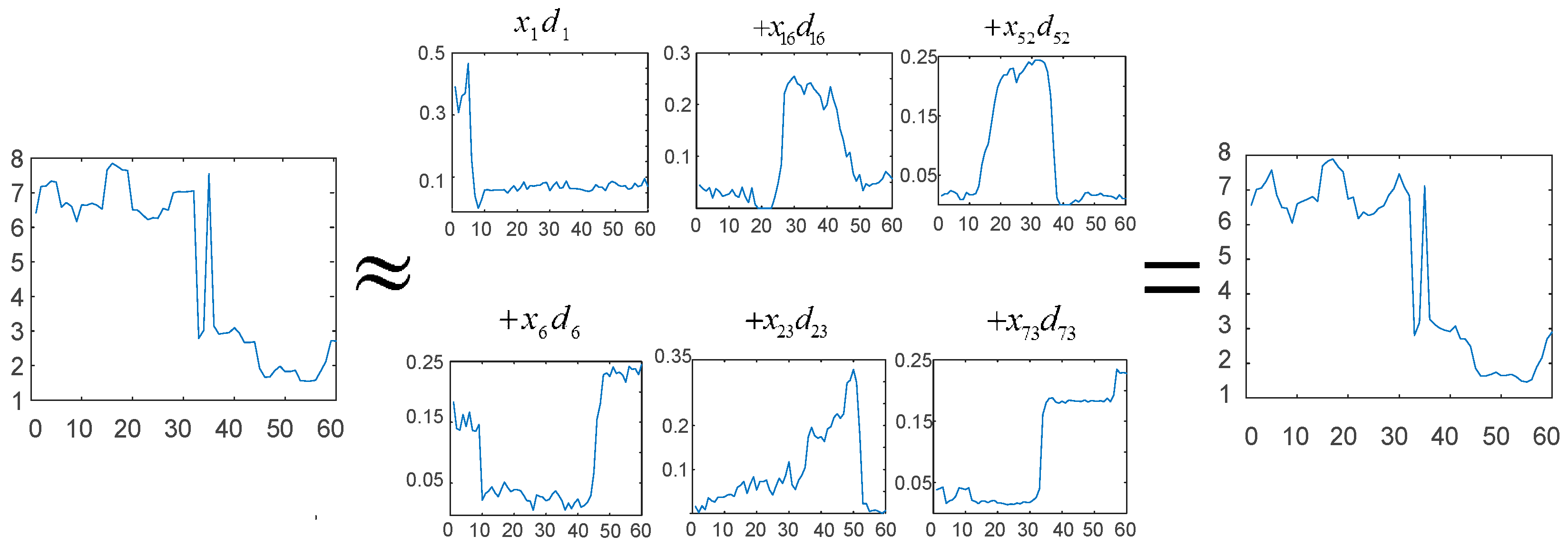
2.1. Basic K-SVD Algorithm
- (1)
- Sparse coding: The orthogonal matching pursuit (OMP) algorithms are introduced to obtain the approximate solution of the sparse coefficient vector that corresponds to each load profile .
- (2)
- Dictionary updating: The dictionary vector is updated with fixed coefficient vectors.
2.2. Deep K-SVD Algorithm
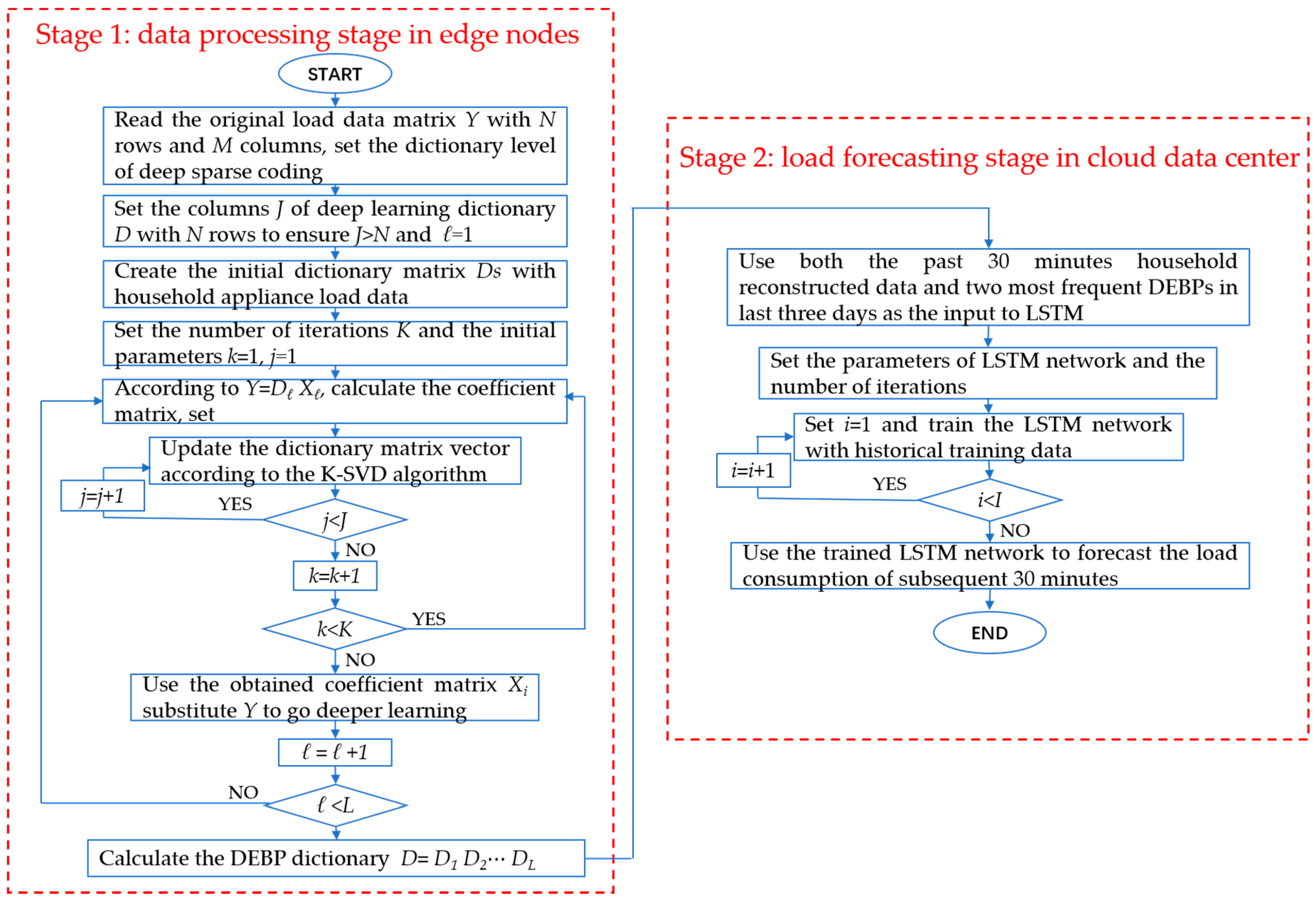
3. Proposed Methodology
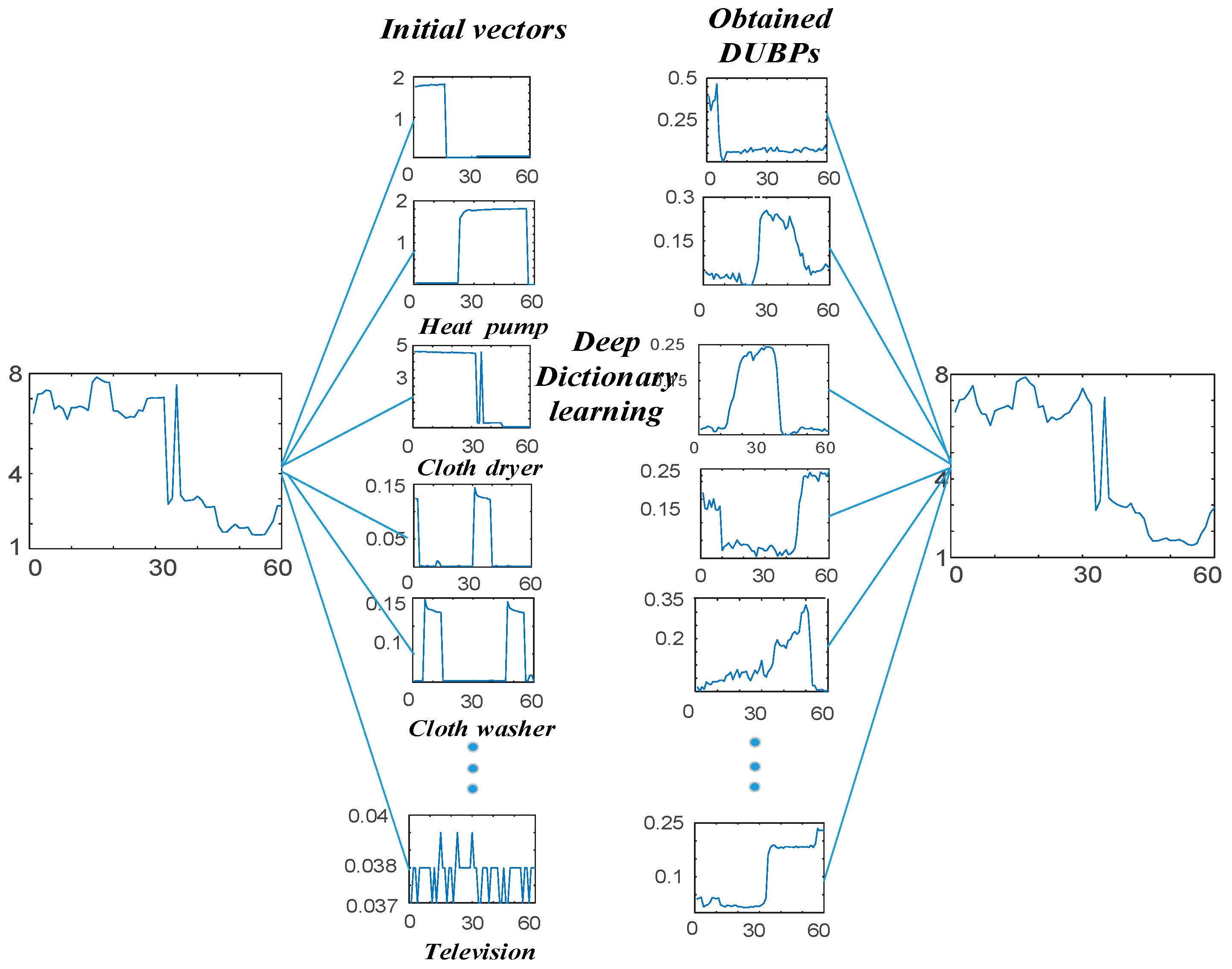
3.1. Stage 1: Deep K-SVD Algorithm with Household Appliance Data
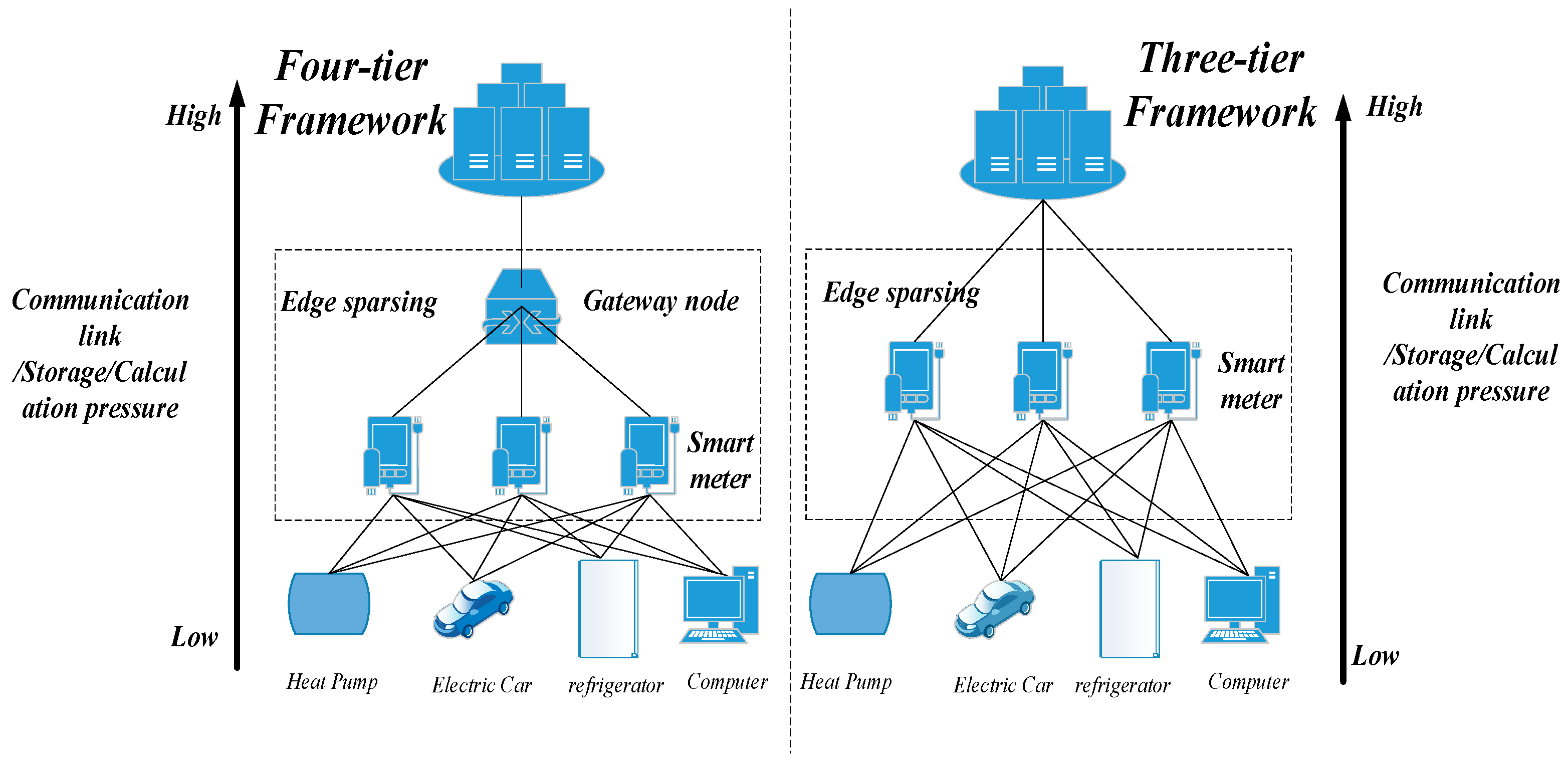
3.2. Edge Sparse Coding Architecture
3.3. Stage 2: DUBPs-Based Electricity Demand Estimation Using LSTM
4. Results
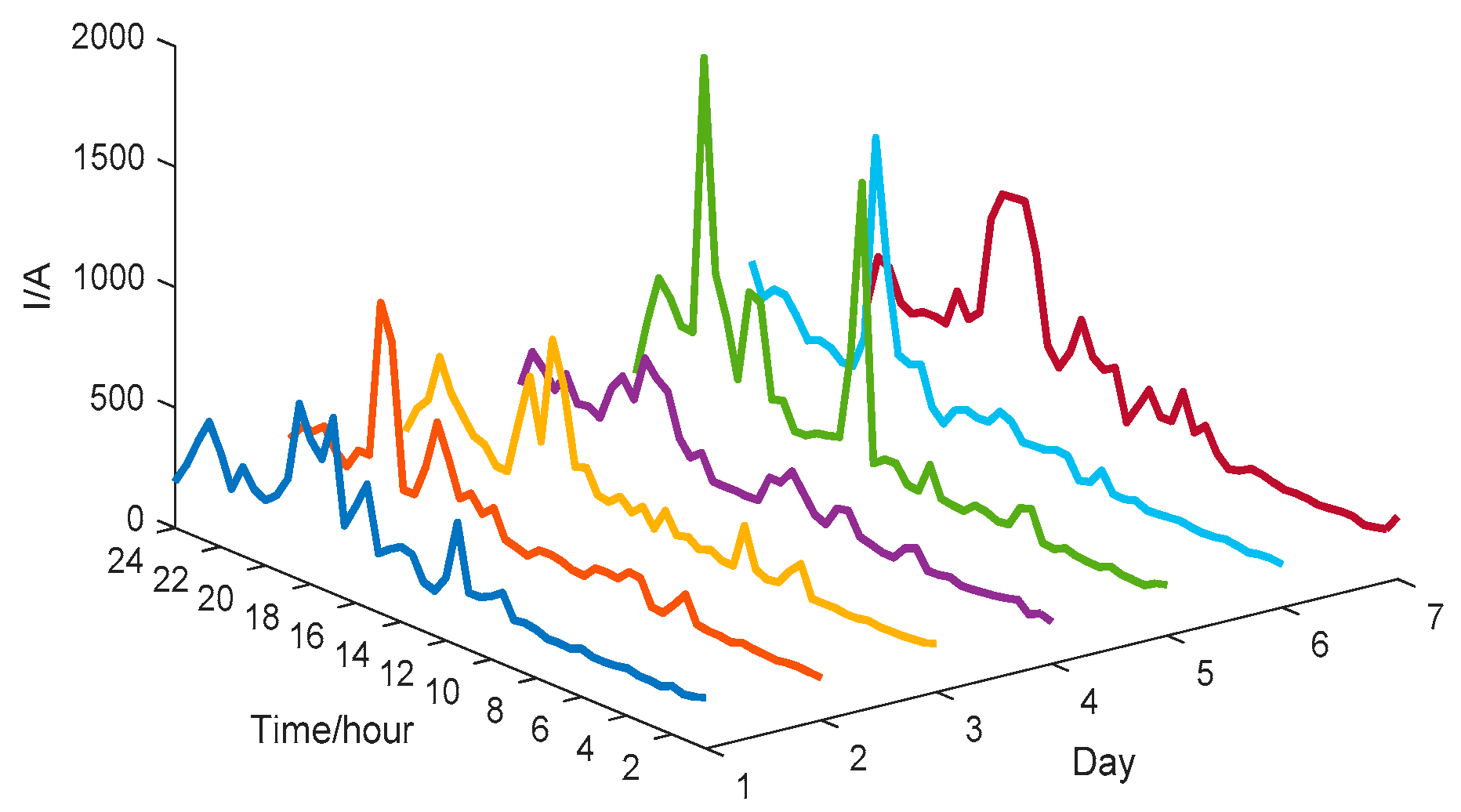
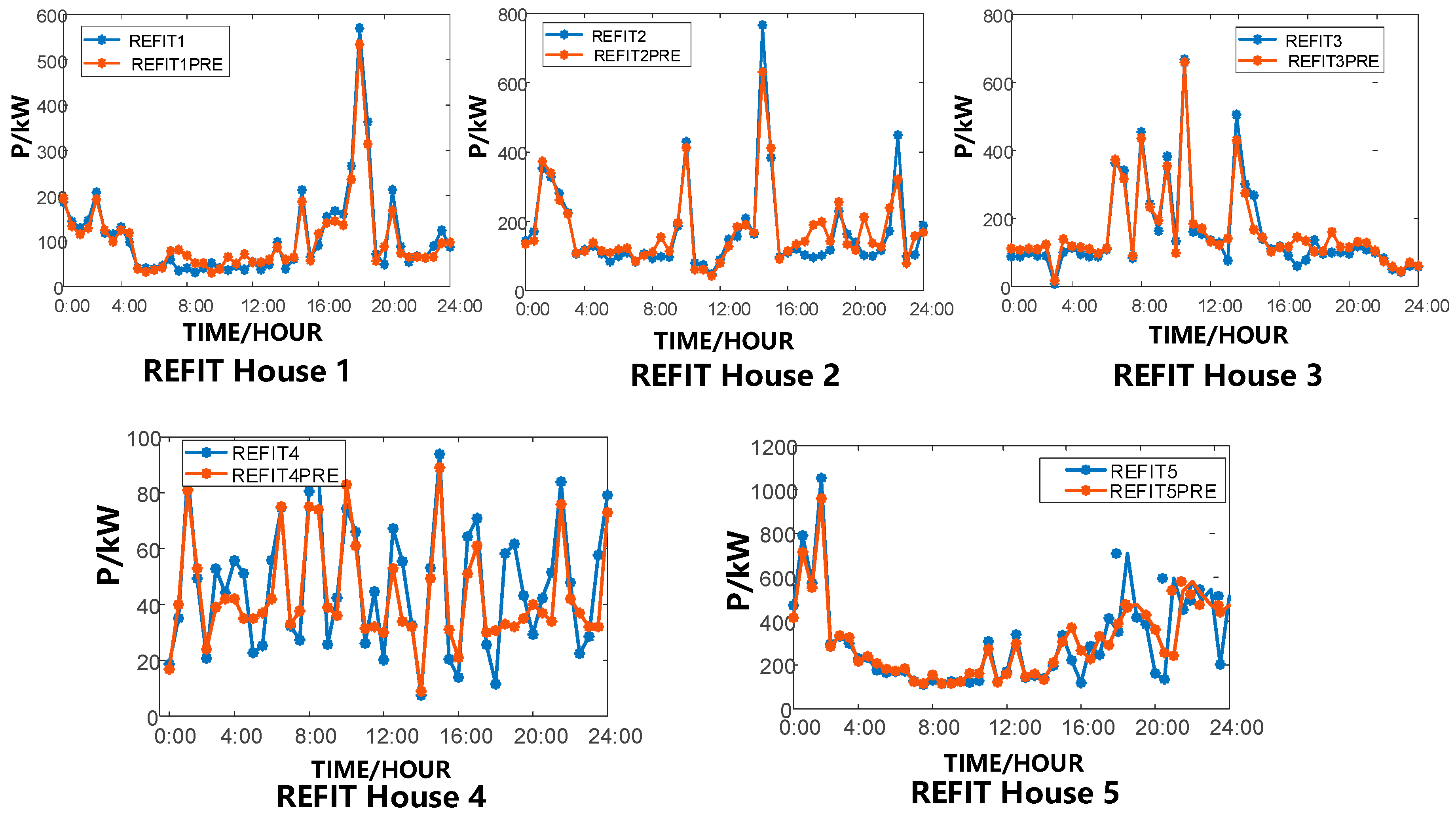
4.1. Description of The Dataset
4.2. Test Cases and Results
4.2.1. Effect of Adding Appliance Status into the Initial Dictionary
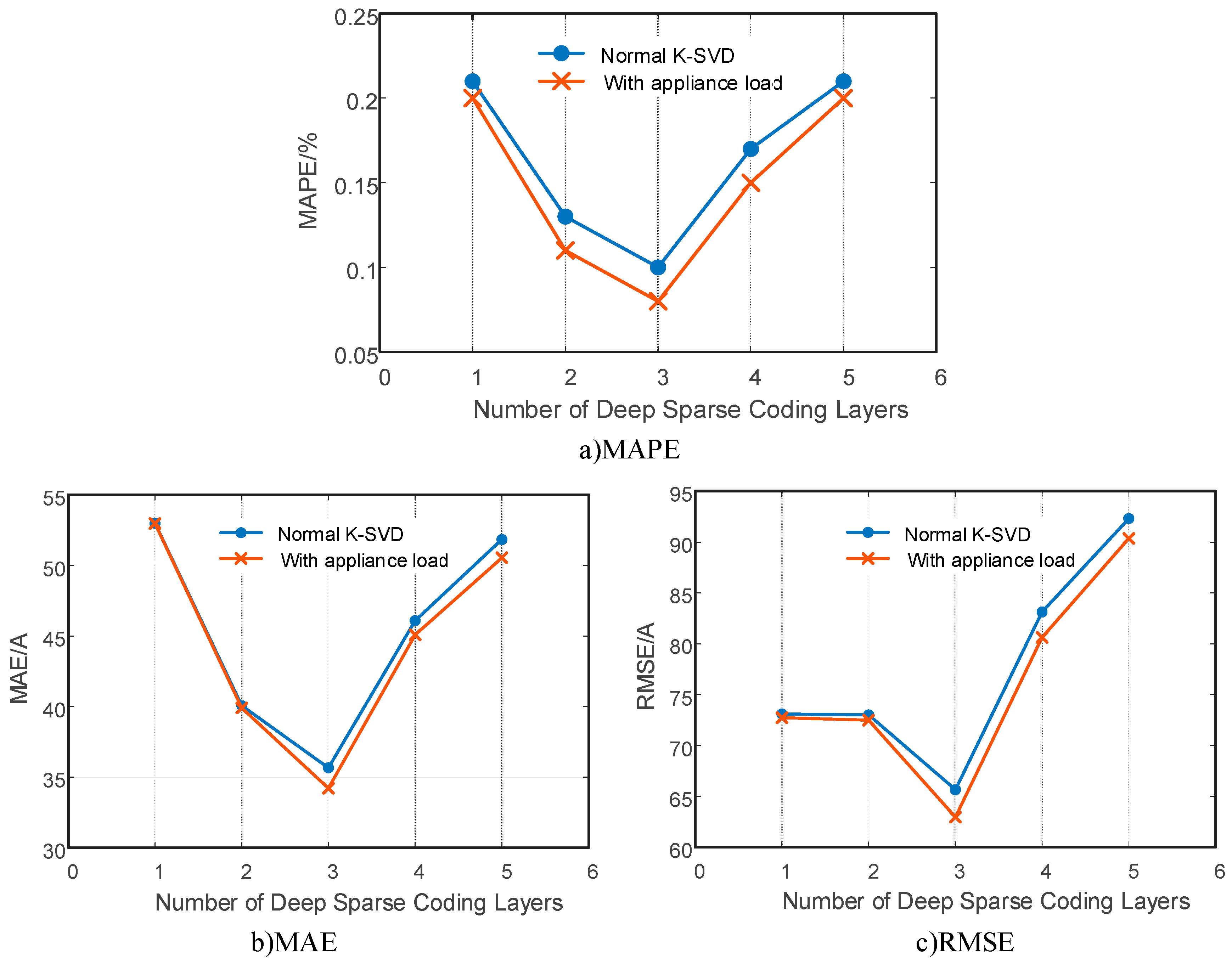
4.2.2. Effect from Shallow to Deep
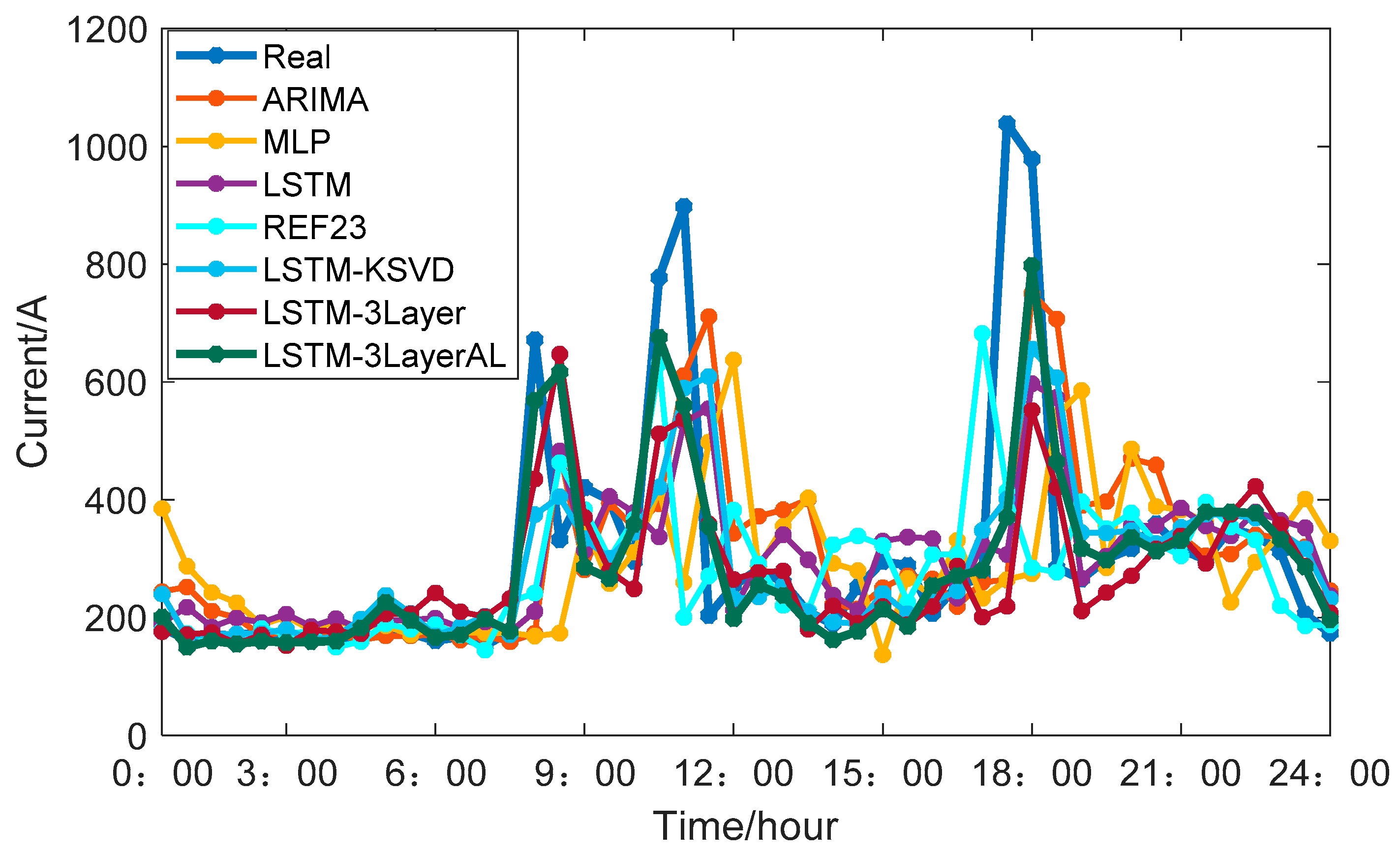
4.2.3. Benchmarking of Load Demand Estimation Methods in Households
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Saputro, N.; Akkaya, K.; Uludag, S. A survey of routing protocols for smart grid communications. Comput. Netw. 2012, 56, 2742–2771. [Google Scholar] [CrossRef]
- Peppanen, J.; Reno, M.J.; Thakkar, M.; Grijalva, S.; Harley, R.G. Leveraging AMI Data for Distribution System Model Calibration and Situational Awareness. IEEE Trans. Smart Grid 2015, 6, 2050–2059. [Google Scholar] [CrossRef]
- Godina, R.; Rodrigues, E.M.G.; Pouresmaeil, E.; Matias, J.C.O.; Catalao, J.P.S. Model Predictive Control Home Energy Management and Optimization Strategy with Demand Response. Appl. Sci. 2018, 8, 408. [Google Scholar] [CrossRef]
- Kwac, J.; Flora, J.; Rajagopal, R. Household Energy Consumption Segmentation Using Hourly Data. IEEE Trans. Smart Grid 2014, 5, 420–430. [Google Scholar] [CrossRef]
- Mahmoudi-Kohan, N.; Moghaddam, M.P.; Sheikh-El-Eslami, M.K.; Shayesteh, E. A three-stage strategy for optimal price offering by a retailer based on clustering techniques. Int. J. Electr. Power Energy Syst. 2010, 32, 1135–1142. [Google Scholar] [CrossRef]
- Rhodes, J.D.; Cole, W.J.; Upshaw, C.R.; Edgar, T.F.; Webber, M.E. Clustering analysis of residential electricity demand profiles. Appl. Energy 2014, 135, 461–471. [Google Scholar] [CrossRef]
- Sun, G.; Cong, Y.; Hou, D.; Fan, H.; Xu, X.; Yu, H. Joint Household Characteristic Prediction via Smart Meter Data. IEEE Trans. Smart Grid 2017, 10, 1834–1844. [Google Scholar] [CrossRef]
- Wang, Y.; Gan, D.; Sun, M.; Zhang, N.; Lu, Z.; Kang, C. Probabilistic individual load forecasting using pinball loss guided LSTM. Appl. Energy 2019, 235, 10–20. [Google Scholar] [CrossRef]
- Ramchurn, S.; Vytelingum, P.; Rogers, A.; Jennings, N.R. Putting the “smarts” into the smart grid: A grand challenge for artificial intelligence. Commun. ACM 2012, 55, 86–97. [Google Scholar] [CrossRef]
- Zehir, M.A.; Batman, A.; Bagriyanik, M. Review and comparison of demand response options for more effective use of renewable energy at consumer level. Renew. Sustain. Energy Rev. 2016, 56, 631–642. [Google Scholar] [CrossRef]
- Zhou, K.-L.; Yang, S.-L.; Shen, C. A review of electric load classification in smart grid environment. Renew. Sustain. Energy Rev. 2013, 24, 103–110. [Google Scholar] [CrossRef]
- Notaristefano, A.; Chicco, G.; Piglione, F. Data size reduction with symbolic aggregate approximation for electrical load pattern grouping. IET Gener. Transm. Distrib. 2013, 7, 108–117. [Google Scholar] [CrossRef]
- Zordan, D.; Martinez, B.; Vilajosana, I.; Rossi, M. On the performance of lossy compression schemes for energy constrained sensor networking. ACM Trans. Sens. Netw. 2014, 11, 15. [Google Scholar] [CrossRef]
- Yu, C.-N.; Mirowski, P.; Ho, T.K. A Sparse Coding Approach to Household Electricity Demand Forecasting in Smart Grids. IEEE Trans. Smart Grid 2016, 8, 1–11. [Google Scholar] [CrossRef]
- Tong, X.; Kang, C.; Xia, Q. Smart Metering Load Data Compression Based on Load Feature Identification. IEEE Trans. Smart Grid 2016, 7, 1. [Google Scholar] [CrossRef]
- Tcheou, M.P.; Lovisolo, L.; Ribeiro, M.V.; Da Silva, E.A.; Rodrigues, M.A.; Romano, J.M.; Diniz, P.S. The compression of electric signal waveforms for smart grids: State of the art and future trends. IEEE Trans. Smart Grid 2013, 5, 291–302. [Google Scholar] [CrossRef]
- Mehra, R.; Bhatt, N.; Kazi, F.; Singh, N.M. Analysis of PCA based compression and denoising of smart grid data under normal and fault con-ditions. In Proceedings of the 2013 IEEE International Conference on Electronics, Computing and Communication Technologies, Bangalore, India, 17–19 January 2013; pp. 1–6. [Google Scholar]
- de Souza JC, S.; Assis TM, L.; Pal, B.C. Data compression in smart distribution systems via singular value decomposition. IEEE Trans. Smart Grid 2015, 8, 275–284. [Google Scholar] [CrossRef]
- Unterweger, A.; Engel, D. Resumable load data compression in smart grids. IEEE Trans. Smart Grid 2014, 6, 919–929. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Kang, C.; Xia, Q.; Luo, M. Sparse and redundant representation-based smart meter data compression and pattern extraction. IEEE Trans. Power Syst. 2016, 32, 2142–2151. [Google Scholar] [CrossRef]
- Ahmad, A.; Javaid, N.; Alrajeh, N.; Khan, Z.A.; Qasim, U.; Khan, A. A Modified Feature Selection and Artificial Neural Network-Based Day-Ahead Load Forecasting Model for a Smart Grid. Appl. Sci. 2015, 5, 1756–1772. [Google Scholar] [CrossRef]
- Xie, J.; Chen, Y.; Hong, T.; Laing, T.D. Relative humidity for load forecasting models. IEEE Trans. Smart Grid 2018, 9, 191–198. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Hill, D.J.; Luo, F.; Xu, Y. Short-term residential load forecasting based on resident behaviour learning. IEEE Trans. Power Syst. 2017, 3, 1087–1088. [Google Scholar] [CrossRef]
- Yu, C.-N.; Mirowski, P.; Ho, T.K. A sparse coding approach to household electricity demand estimation in smart grids. IEEE Trans. Smart Grid 2017, 8, 738–748. [Google Scholar]
- Quilumba, F.L.; Lee, W.-J.; Huang, H.; Wang, D.Y.; Szabados, R.L. Using smart meter data to improve the accuracy of intraday load forecasting considering customer behavior similarities. IEEE Trans. Smart Grid 2015, 6, 911–918. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Hong, T.; Kang, C. Review of smart meter data analytics: Applications, methodologies, and challenges. IEEE Trans. Smart Grid 2019, 10, 3125–3148. [Google Scholar] [CrossRef]
- Bruckstein, A.M.; Aharon, M.; Elad, M. K-SVD and its non-negative variant for dictionary design. Opt. Photonics 2005, 5914, 591411. [Google Scholar]
- Tariyal, S.; Majumdar, A.; Singh, R.; Vatsa, M. Deep dictionary learning. IEEE Access 2016, 4, 10096–10109. [Google Scholar] [CrossRef]
- Bhotto, M.Z.A.; Makonin, S.; Bajić, I.V. Load disaggregation based on aided linear integer programming. IEEE Trans. Circuits Syst. II Express Briefs 2017, 64, 792–796. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 1. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Makonin, S.; Popowich, F.; Bartram, L.; Gill, B.; Bajić, I.V. AMPds: A Public Dataset for Load Disaggregation and Eco-Feedback Research. In Proceedings of the 2013 IEEE Electrical Power & Energy Conference, Halifax, NS, Canada, 21–23 August 2013; Wadsworth: Belmont, CA, USA, 1993; pp. 123–135. [Google Scholar]
- REFIT: Personalised Retrofit Decision Support Tools for UK Homes Using Smart Home Technology. Available online: http://www.refitsmarthomes.org/index.php/refit-launches (accessed on 26 June 2019).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CR | Algorithm | RMSE (A) | MAE (A) | MAPE (%) |
|---|---|---|---|---|
| 0.1250 | 3-layer K-SVD | 57.37 | 31.77 | 0.07% |
| 3-layer K-SVD with appliance load | 54.74 | 30.07 | 0.06% | |
| 0.1042 | 3-layer K-SVD | 65.66 | 35.67 | 0.10% |
| 3-layer K-SVD with appliance load | 62.96 | 33.22 | 0.08% | |
| 0.0833 | 3-layer K-SVD | 71.74 | 39.04 | 0.14% |
| 3-layer K-SVD with appliance load | 69.49 | 37.73 | 0.13% |
| Algorithm | MAPE (%) | MAE (A) | RMSE (A) |
|---|---|---|---|
| ARIMA | 31.84% | 109.63 | 192.80 |
| MLP | 41.41% | 143.49 | 233.54 |
| LSTM | 27.62% | 100.51 | 180.55 |
| Ref. [23] | 23.92% | 99.42 | 198.00 |
| LSTM-KSVD (with normal K-SVD) | 24.14% | 88.50 | 167.28 |
| LSTM-3Layer (with 3-layer K-SVD) | 22.67% | 87.71 | 157.07 |
| LSTM-3LayerAL (with 3-layer appliance load based K-SVD) | 20.18% | 78.42 | 147.76 |
| Improvement from LSTM-KSVD to LSTM-3LayerAL | 16.4% | 11.38% | 18.16% |
| Improvement from ARIMA to LSTM-3LayerAL | 36.62% | 28.47% | 23.36% |
| Improvement from MLP to LSTM-3LayerAL | 51.26% | 53.95% | 36.73% |
| REFIT | Sociodemographic Information | RMSE (kW) | MAE (kW) | MAPE (%) |
|---|---|---|---|---|
| REFIT House1 | 2 people 3 bedrooms 27 equipment | 21.30 | 17.27 | 24.14% |
| REFIT House2 | 2 people 4 bedrooms 33 equipment | 43.26 | 28.84 | 20.58% |
| REFIT House3 | 3 people 3 bedrooms 26 equipment | 31.75 | 22.66 | 22.79% |
| REFIT House4 | 1 people 3 bedrooms 19 equipment | 11.87 | 9.74 | 26.53% |
| REFIT House5 | 4 people 4 bedrooms 44 equipment | 93.21 | 57.26 | 21.76% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Sun, Y.; Li, B. A Two-Stage Household Electricity Demand Estimation Approach Based on Edge Deep Sparse Coding. Information 2019, 10, 224. https://doi.org/10.3390/info10070224
Liu Y, Sun Y, Li B. A Two-Stage Household Electricity Demand Estimation Approach Based on Edge Deep Sparse Coding. Information. 2019; 10(7):224. https://doi.org/10.3390/info10070224
Chicago/Turabian StyleLiu, Yaoxian, Yi Sun, and Bin Li. 2019. "A Two-Stage Household Electricity Demand Estimation Approach Based on Edge Deep Sparse Coding" Information 10, no. 7: 224. https://doi.org/10.3390/info10070224
APA StyleLiu, Y., Sun, Y., & Li, B. (2019). A Two-Stage Household Electricity Demand Estimation Approach Based on Edge Deep Sparse Coding. Information, 10(7), 224. https://doi.org/10.3390/info10070224