Large Scale Linguistic Processing of Tweets to Understand Social Interactions among Speakers of Less Resourced Languages: The Basque Case



Abstract
1. Introduction
2. Related Work
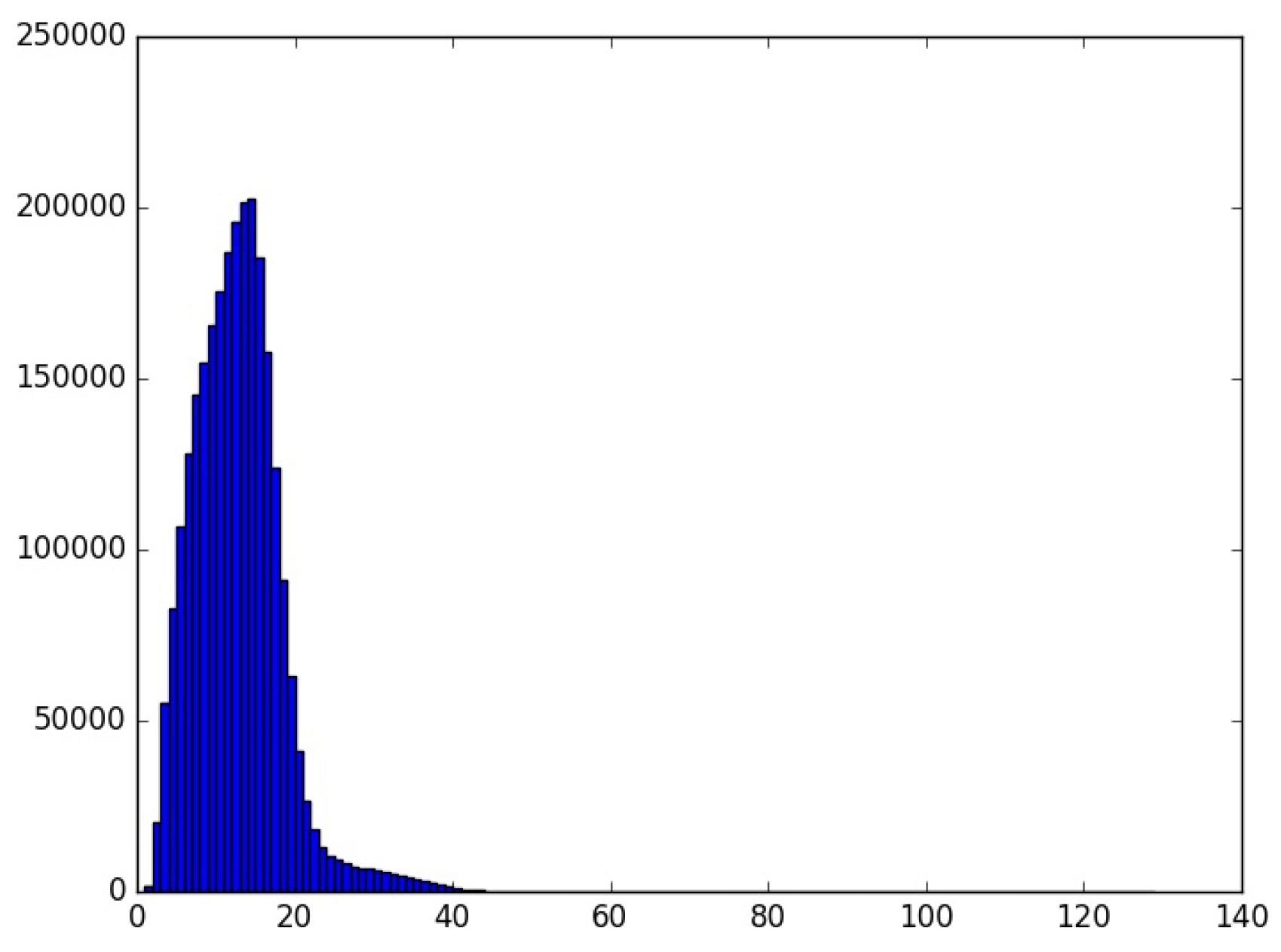
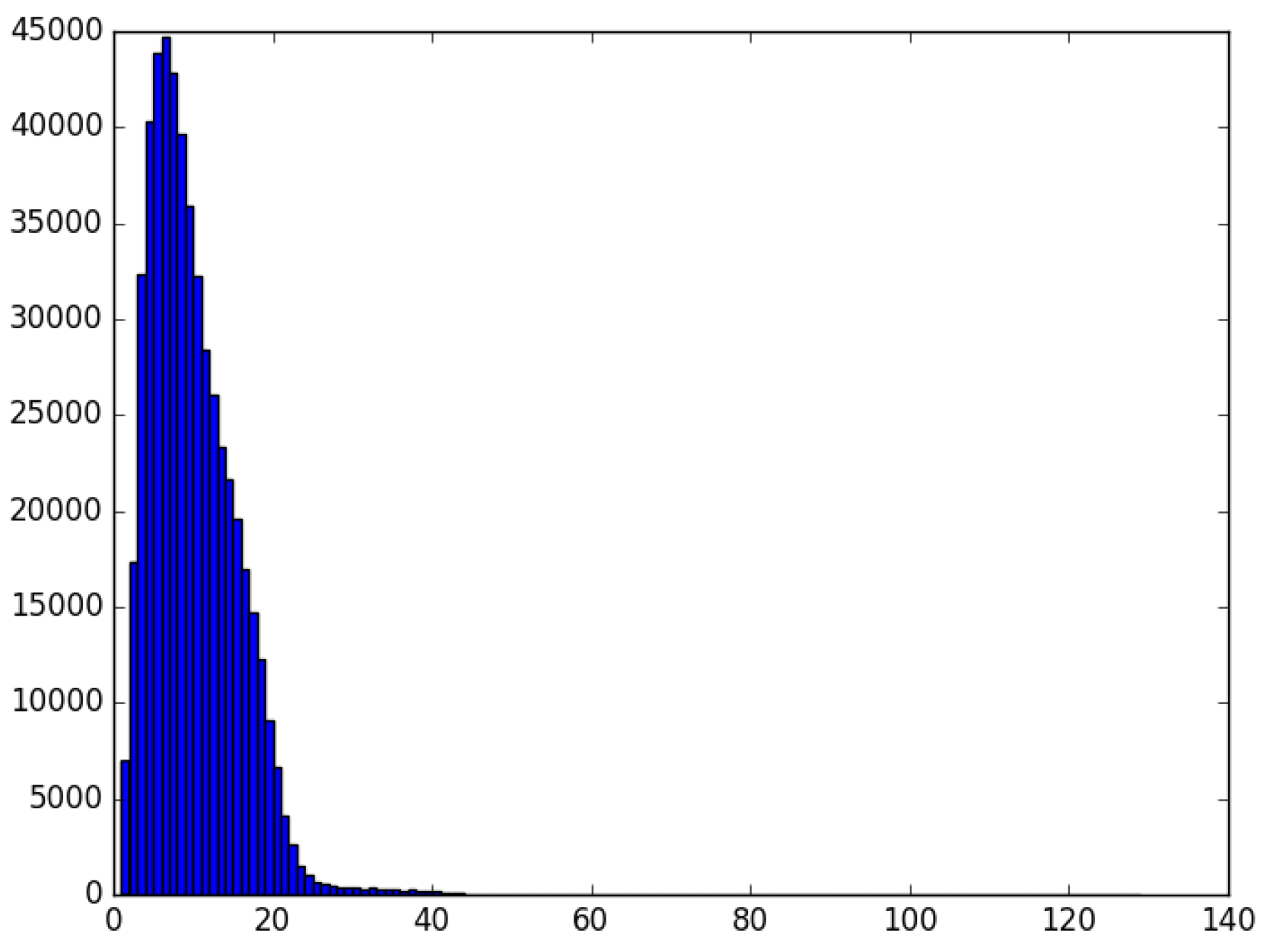
3. Extracting a Large Corpus of Tweets from Basque Users
4. Classifying Users by Age Stage
4.1. Experimental Framework
4.1.1. The Heldugazte Gold Standard Corpus
- (1)
- Informal tweet: “inoizz ezdet ein mateko examin bau au baino okerro” (Informal: This is worst exam I have ever done.).
- (2)
- Formal tweet: “killian jornet fenomenoa da zegamaaizkorri irabazi du beste behin non dago mendizale gazte honen muga” (Formal: Killian Jornet is a phenomenon he won the Zegama-Aizkorri again. Where is this mountaineer’s limit?).
4.1.2. Perplexity-Based Distance
4.1.3. Supervised Baseline
4.1.4. Pre-Trained Word Embeddings
4.1.5. IXA Pipes
4.1.6. Flair
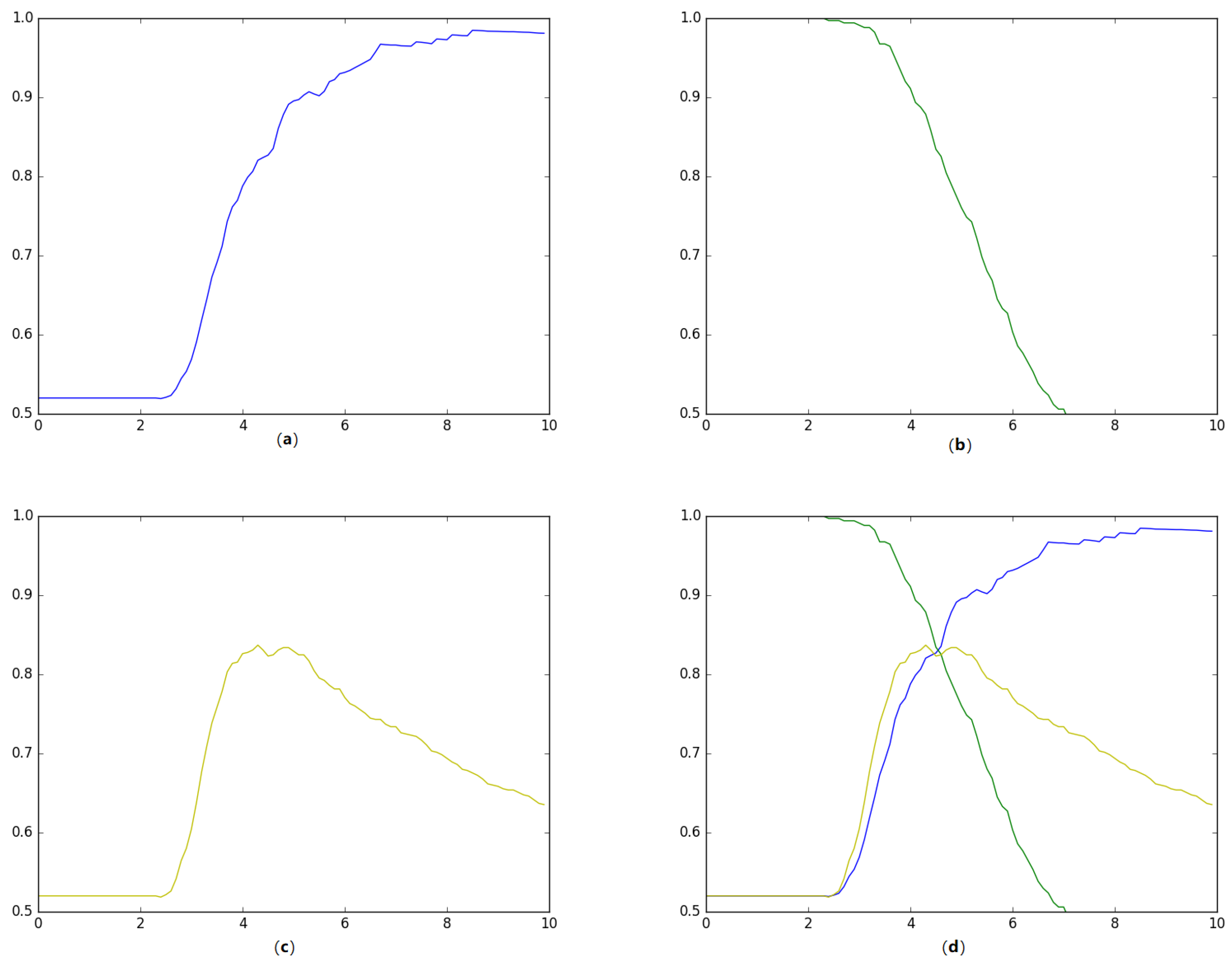
4.2. Experimental Results
4.3. Labelling the Large Corpus
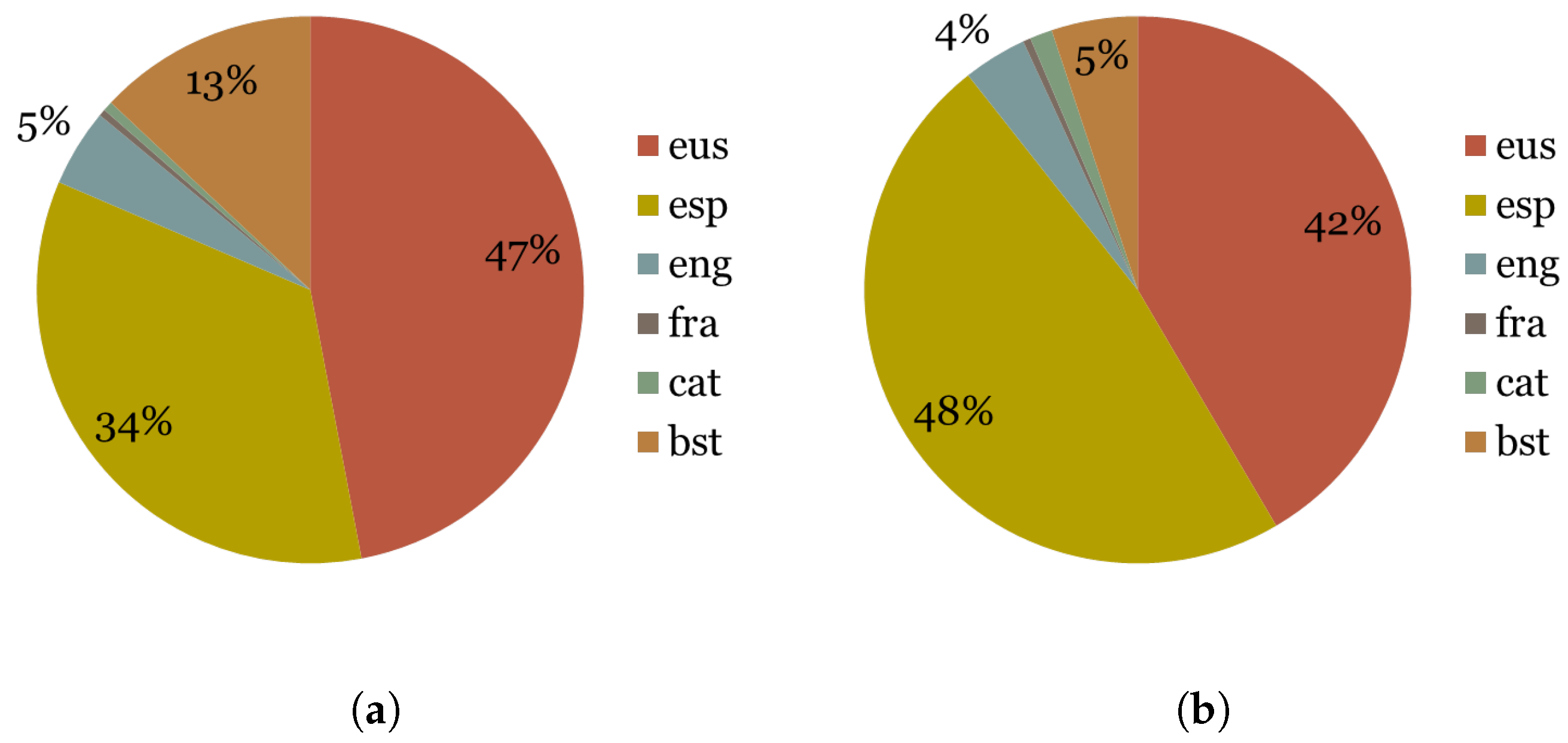
4.3.1. Analyzing Adult Twitter Users
4.3.2. Analyzing Young Twitter Users
5. Topics
6. Relations
6.1. Relationships in the Adult Graph
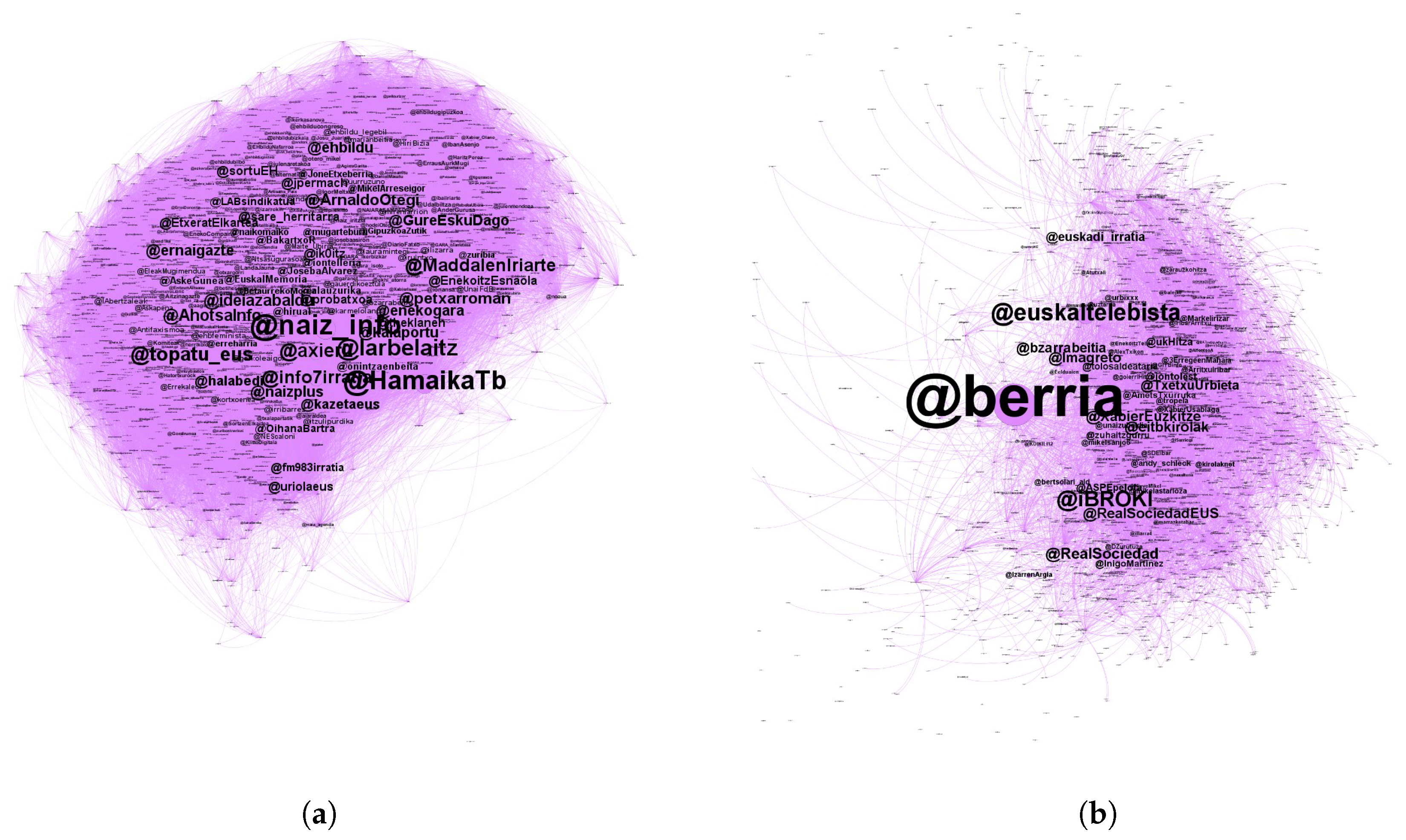
- Nationalist left (27.92%): this subgroup is made up of nodes with a specific political orientation, mostly related to members of the Nationalist Left. In addition to the users that appear in the first column of Table 14, there are also many important nodes that refer to specific users (@ArnaldoOtegi, @jpermach, @JosebaAlvarez…) or institutions (@sortuEH, @LAB…) of the Nationalist Left. This is the main group, joined by more than a quarter of all nodes that corresponds to the relationship of a certain political orientation.
- News (23.77%): this group, related to news, consists of almost a quarter of all users. Most of the nodes of this subgroup are related to the media, specially several users related to the Basque public television (EITB).
- Basque language (15.34%): in the third subgroup, there are topics related to the Basque language, such as communication media in Basque (@zuzeu, @Gaztezulo, @ArabakoALEA), associations for the promotion of the Basque language (@AEK_eus, @EHEbizi…) as well as several individuals related to the Basque language (@KikeAmonarriz, @KoldoTellitu, @MertxeMugika).
- Music and GED (13.56%): in the fourth subgroup there is a special phenomenon, since it brings together two different groups in the same subgroup. The first one is related to music, since we can appreciate different users related to the music scene (@EsneBeltza, @ZuriHidalgo, @ZeEsatek, @40minuturock, @hesiantaldea, @ItzrrSemeak…). The second one is related to the users of the social movement “Gure Esku Dago” (@GoierrikoGED, @GEDTolosaldea, @GureEskuDagoDon…).
- Basque tweeters (13.10%): in this last subgroup we can find popular Basque users of Twitter, which are important within the Basque community due to their large number of followers or retweets.
6.2. Relationships in the Young Graph
- Sports (21.61%): this subgroup, which includes most of the nodes which are considered roles models for the youths, is related to sports. The group is be made up of sports teams or organizations (@RealSociety, @RealSociedadEUS, @ASPEpelota, @SDEibar…), as well as its athletes (@InigoMartinez, @AmetsTxurruka, @XabierUsabiaga, @Markelirizar…). However, the most important nodes are sports journalists (@iBROKI, @XabierEuzkitze, @Imagreto, @bzarrabeitia, @TxetxuUbieta…) and the media (@berria, @euskaltelebista, @eitbkirolak, @euskadi_irratia…). Once again, it can be clearly seen that the newspapers and TV media are the most important nodes.
- Basque language (20.70%): a fifth of all the nodes are in this subgroup. The most important ones are those directly related to the Basque language (@EsaldiakEuskara, @euskarazEH, @Bertsotan, @bertsolaritza, @Euskeraz_Bizi…). In the adult graph it was also found a community related to this topic, although the most important nodes are markedly different.
- Nationalist left (17.12%): this third group, composed of nodes related to the nationalist left, is perhaps the most similar in both adult and young graphs. For example, media (@naiz_info, @topatu_eus, @inform7irratia, @naizplus…), organizations (@ernaigazte, @ehbildu, @sortuEH…) and individuals (@ArnaldoOtegi, @lauramintegi…) related to the nationalist left, appear in both subgroups.
- News (14.92%): as in the previous subgroup, this community is also very similar for both young and adult users. The most important nodes correspond to general news Basque media (@argia, @HamaikaTb, @eitb Albums, @zuzeu, @Gaztezulo).
- music (11.35%): In this final subgroup, although quite heterogeneous, it can be said that the most important nodes are related to music. Among these, the music related media (@gaztea, @DidaGaztea), music bands (@berritxarrak, @muguruzafm, @Glaukomaband), as well as record companies (@BagaBigaeus) are the main nodes.
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cunliffe, D. Minority Languages and Social Media. In The Palgrave Handbook of Minority Languages and Communities; Springer: Berlin, Germany, 2019; pp. 451–480. [Google Scholar]
- Leivada, E.; D’Alessandro, R.; Grohmann, K.K. Eliciting big data from small, young, or non-standard languages: 10 experimental challenges. Front. Psychol. 2019, 10, 313. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.; Doğruöz, A.S.; Rosé, C.P.; de Jong, F. Computational sociolinguistics: A survey. Comput. Linguist. 2016, 42, 537–593. [Google Scholar] [CrossRef]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 502–518. [Google Scholar]
- Baldwin, T.; de Marneffe, M.C.; Han, B.; Kim, Y.B.; Ritter, A.; Xu, W. Shared tasks of the 2015 workshop on noisy user-generated text: Twitter lexical normalization and named entity recognition. In Proceedings of the Workshop on Noisy User-generated Text, Beijing, China, 31 July 2015; pp. 126–135. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 task 6: Detecting stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). Association for Computational Linguistics, San Diego, CA, USA, 16–17 June 2016; pp. 31–41. [Google Scholar]
- Derczynski, L.; Bontcheva, K.; Liakata, M.; Procter, R.; Hoi, G.W.S.; Zubiaga, A. SemEval-2017 task 8: RumourEval: Determining rumour veracity and support for rumours. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 69–76. [Google Scholar]
- Bauman, Z. Liquid Modernity; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual string embeddings for sequence labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Morgan-Lopez, A.A.; Kim, A.E.; Chew, R.F.; Ruddle, P. Predicting age groups of Twitter users based on language and metadata features. PLoS ONE 2017, 12, e0183537. [Google Scholar] [CrossRef]
- Hu, Y.; John, A.; Wang, F.; Kambhampati, S. Et-lda: Joint topic modeling for aligning events and their twitter feedback. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Zubiaga, A.; Spina, D.; Martínez, R.; Fresno, V. Real-time classification of twitter trends. J. Assoc. Inf. Sci. Technol. 2015, 66, 462–473. [Google Scholar] [CrossRef]
- Zhao, W.X.; Jiang, J.; Weng, J.; He, J.; Lim, E.P.; Yan, H.; Li, X. Comparing twitter and traditional media using topic models. In European Conference on Information Retrieval; Springer: Berlin, Germany, 2011; pp. 338–349. [Google Scholar]
- Hong, L.; Davison, B.D. Empirical study of topic modeling in twitter. In Proceedings of the First Workshop on Social Media Analytics, Washington, DC, USA, 25–28 July 2010; pp. 80–88. [Google Scholar]
- Conover, M.D.; Ratkiewicz, J.; Francisco, M.; Gonçalves, B.; Menczer, F.; Flammini, A. Political polarization on twitter. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Pennacchiotti, M.; Popescu, A.M. Democrats, republicans and starbucks afficionados: User classification in twitter. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 430–438. [Google Scholar]
- Zubiaga, A.; Wang, B.; Liakata, M.; Procter, R. Stance classification of social media users in independence movements. Catalonia 2017, 2, 10–960. [Google Scholar]
- Villena Román, J.; Lana Serrano, S.; Martínez Cámara, E.; González Cristóbal, J.C. Tass-Workshop on Sentiment Analysis at SEPLN; The Spanish Society for Natural Language Processing: Jaén, Spain, 2013. [Google Scholar]
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 1524–1534. [Google Scholar]
- Alegria, I.; Aranberri, N.; Comas, P.R.; Fresno, V.; Gamallo, P.; Padró, L.; San Vicente, I.; Turmo, J.; Zubiaga, A. TweetNorm: A benchmark for lexical normalization of Spanish tweets. Lang. Resour. Eval. 2015, 49, 883–905. [Google Scholar] [CrossRef]
- Zubiaga, A.; San Vicente, I.; Gamallo, P.; Pichel, J.R.; Alegria, I.; Aranberri, N.; Ezeiza, A.; Fresno, V. Tweetlid: A benchmark for tweet language identification. Lang. Resour. Eval. 2016, 50, 729–766. [Google Scholar] [CrossRef]
- Rao, D.; Yarowsky, D.; Shreevats, A.; Gupta, M. Classifying latent user attributes in twitter. In Proceedings of the 2nd International Workshop on Search and Mining User-Generated Contents, Toronto, ON, Canada, 26–30 October 2010; pp. 37–44. [Google Scholar]
- Al Zamal, F.; Liu, W.; Ruths, D. Homophily and latent attribute inference: Inferring latent attributes of Twitter users from neighbors. ICWSM 2012, 270, 2012. [Google Scholar]
- Nguyen, D.; Gravel, R.; Trieschnigg, D.; Meder, T. “How old do you think I am?” A study of language and age in Twitter. In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media ICWSM, Cambridge, MA, USA, 8–11 July 2013. [Google Scholar]
- Marquardt, J.; Farnadi, G.; Vasudevan, G.; Moens, M.F.; Davalos, S.; Teredesai, A.; De Cock, M. Age and gender identification in social media. In Proceedings of the CLEF 2014 Evaluation Labs, Sheffield, UK, 15–18 September 2014; pp. 1129–1136. [Google Scholar]
- Cesare, N.; Grant, C.; Nsoesie, E.O. Detection of user demographics on social media: A review of methods and recommendations for best practices. arXiv, 2017; arXiv:1702.01807. [Google Scholar]
- Eckert, P. Age as a sociolinguistic variable. In The Handbook of Sociolinguistics; Blackwell Publishing: Hoboken, NJ, USA, 2017; pp. 151–167. [Google Scholar]
- Rosenthal, S.; McKeown, K. Age prediction in blogs: A study of style, content, and online behavior in pre-and post-social media generations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Portland, OR, USA, 2011; Volume 1, pp. 763–772. [Google Scholar]
- Gamallo, P.; Pichel, J.R.; Alegria, I. From language identification to language distance. Phys. A Stat. Mech. Appl. 2017, 484, 152–162. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; Curran Associates: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Grave, E.; Bojanowski, P.; Puhrsch, C.; Joulin, A. Advances in Pre-Training Distributed Word Representations. In Proceedings of the 11th Language Resources and Evaluation Conference, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Agerri, R.; Rigau, G. Robust multilingual Named Entity Recognition with shallow semi-supervised features. Artif. Intell. 2016, 238, 63–82. [Google Scholar] [CrossRef]
- Agerri, R.; Rigau, G. Language independent sequence labelling for Opinion Target Extraction. Artif. Intell. 2019, 268, 85–95. [Google Scholar] [CrossRef]
- González Bermúdez, M. An analysis of twitter corpora and the differences between formal and colloquial tweets. In Proceedings of the Tweet Translation Workshop 2015, Alicante, Spain, 5 September 2015; pp. 1–7. [Google Scholar]
- Chen, S.F.; Goodman, J. An empirical study of smoothing techniques for language modeling. Comput. Speech Lang. 1999, 13, 359–394. [Google Scholar] [CrossRef]
- Turian, J.; Ratinov, L.A.; Bengio, Y. Word representations: A simple and general method for semi-supervised learning. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; Association for Computational Linguistics: Uppsala, Sweden, 2010; pp. 384–394. [Google Scholar]
- Brown, P.F.; Desouza, P.V.; Mercer, R.L.; Pietra, V.J.D.; Lai, J.C. Class-based n-gram models of natural language. Comput. Linguist. 1992, 18, 467–479. [Google Scholar]
- Clark, A. Combining distributional and morphological information for part of speech induction. In Proceedings of the Tenth Conference on European Chapter of the Association for Computational Linguistics, Budapest, Hungary, 12–17 April 2003; Association for Computational Linguistics: Budapest, Hungary, 2003; Volume 1, pp. 59–66. [Google Scholar]
- Leturia, I. Evaluating different methods for automatically collecting large general corpora for Basque from the web. In Proceedings of the 24th International Conference onComputational Linguistics COLING, Mumbai, India, 8–15 December 2012; pp. 1553–1570. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Citeseer, Valletta, Malta, 22 May 2010. [Google Scholar]
- Agerri, R.; Bermudez, J.; Rigau, G. IXA pipeline: Efficient and ready to use multilingual NLP tools. LREC 2014, 2014, 3823–3828. [Google Scholar]
- Binkley, D.; Heinz, D.; Lawrie, D.; Overfelt, J. Understanding LDA in source code analysis. In Proceedings of the 22nd International Conference on Program Comprehension, Hyderabad, India, 31 May–7 June 2014; pp. 26–36. [Google Scholar]
- Steyvers, M.; Griffiths, T. Probabilistic Topic Models in Latent Semantic Analysis: A Road to Meaning; Landauer, T., Mc Namara, D., Dennis, S., Kintsch, W., Eds.; Lawrence Erlbaum Associates Publishers: Mahwah, NJ, USA, 2007. [Google Scholar]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014; pp. 63–70. [Google Scholar]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An open source software for exploring and manipulating networks. ICWSM 2009, 8, 361–362. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Jacomy, M.; Venturini, T.; Heymann, S.; Bastian, M. ForceAtlas2, a continuous graph layout algorithm for handy network visualization designed for the Gephi software. PLoS ONE 2014, 9, e98679. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Corpus Size # Users | # Labels | Language |
|---|---|---|---|
| Rao et al. (2010) | 1000 | 2 | en |
| Al Zamal et al. (2012) | 400 | 2 | en |
| Marquart et al. (2014) | 306 | 5 | es |
| Nguyen et al. (2013) | 3110 | 3 | nl |
| Morgan-Lopez et al. (2017) | 3184 | 3 | en |
| Personal Tweets in Basque | Retweets in Basque | |
|---|---|---|
| Tweets | 3,171,785 | 2,891,136 |
| Terms | 1,434,050 | 813,833 |
| Tokens | 37,350,268 | 39,329,204 |
| Total number of tweets | 1000 |
| Formal | 492 |
| Informal | 508 |
| Tokens in shortest tweet | 5 |
| Tokens in longest tweet | 34 |
| Token avg. | 9.66 |
| Label | Error | Precision | Recall | F1 |
|---|---|---|---|---|
| Informal | 48 | 0.824 | 0.858 | 0.841 |
| Formal | 62 | 0.839 | 0.801 | 0.820 |
| Machine Learning Classifier (BoW) | Accuracy |
|---|---|
| 5-NN (k-NN) | 0.614 |
| Decision Tree | 0.677 |
| Random Forest | 0.707 |
| Naive Bayes | 0.765 |
| Logistic Regression | 0.775 |
| SVM | 0.777 |
| Label | Error | Precision | Recall | F1 |
|---|---|---|---|---|
| Informal | 68 | 0.810 | 0.768 | 0.793 |
| Formal | 66 | 0.818 | 0.747 | 0.781 |
| Cluster Type | Corpus–# Clusters |
|---|---|
| Brown | EWC-3200 |
| Clark | EWC-600 & LNC-300 |
| Word2vec | EWC-300 & LNC-500 |
| Label | Error | Precision | Recall | F1 |
|---|---|---|---|---|
| Informal | 32 | 0.892 | 0.886 | 0.889 |
| Formal | 30 | 0.883 | 0.889 | 0.886 |
| Label | Error | Precision | Recall | F1 |
|---|---|---|---|---|
| Informal | 61 | 0.898 | 0.759 | 0.823 |
| Formal | 65 | 0.730 | 0.878 | 0.792 |
| System | Accuracy | Label | Error | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| Perplexity | 0.825 | Informal | 26 | 0.805 | 0.847 | 0.825 |
| Formal | 35 | 0.848 | 0.806 | 0.826 | ||
| SVM-FastText | 0.832 | Informal | 24 | 0.843 | 0.823 | 0.836 |
| Formal | 33 | 0.834 | 0.828 | 0.829 | ||
| IXA pipes | 0.886 | Informal | 20 | 0.882 | 0.881 | 0.882 |
| Formal | 20 | 0.889 | 0.888 | 0.889 | ||
| Flair | 0.866 | Informal | 22 | 0.869 | 0.858 | 0.863 |
| Formal | 24 | 0.868 | 0.877 | 0.872 |
| Adult | Young | |
|---|---|---|
| Users | 5508 | 1579 |
| Tweets (personal) | 4,046,512 | 1,128,124 |
| Retweets | 4,345,500 | 963,668 |
| Tweets in Basque (topics) | 2,634,534 | 530,226 |
| Retweets in Basque (relations) | 2,421,058 | 400,448 |
| Topics of Adult Users | Representative Words in the Topic | % of Words |
|---|---|---|
| 1 Conversation | entzun, iruditu, bizitza, pentsatu, pasatu | 10.5 |
| listen, imagine, life, think, pass | ||
| 2 Politics | Euskal Herri, espainia, politiko, estatu, eskubide | 10.0 |
| Basque Country, Spain, politics, states, rights | ||
| 3 Basque tweeters | @txargain, @berria, @boligorria, euskara, idatzi | 6.9 |
| @user, @newspaper, @user, Basque, write | ||
| 4 Cultural offer | lehiaketa, sarrera, ikastaro, erakusketa, antzerki | 6.4 |
| competition, entry, course, exhibition, theater | ||
| 5 Public administration | udal, zerbitzu, publiko, aurrekontu, euskadi | 6.1 |
| municipal, services, public, budget, euskadi | ||
| 6 Basque television | @euskaltelebista, urhanditan, @xabiermadariaga, herritxiki | 5.3 |
| @television, TV program, @journalist, TV program | ||
| 7 Tournaments | txapelketa, final, kirol, jokatu, kanporaketa | 5.0 |
| championship, final, sports, play, playoffs | ||
| 8 Basque prisoners | preso, herri, espetxe, iheslari, elkartasun | 4.9 |
| prisoner, people, prison, fugitive, solidarity | ||
| 9 Culture | liburu, literatura, filma, poesia, dokumental | 4.8 |
| books, literature, film, poetry, documentary | ||
| 10 Social movements | feminista, asanblada, gaztetxe, borroka, langile | 4.8 |
| feminist, assembly, squatted house, fight, worker | ||
| 11 Education | ikasle, hezkuntza, irakasle, ikastola, ikastetxe | 4.3 |
| students, education, teachers, Basque colleges, schools | ||
| 12 Science | euskara, artikulu, interesgarri, zientzia, teknologia | 4.1 |
| Basque, articles, interesting, science, technology | ||
| 13 Music | kontzertu, disko, talde, entzun, musika | 3.9 |
| concert, disc, group, listen, music | ||
| 14 Basque language | euskara, hizkuntza, euskaldun, euskal, ikasi | 3.8 |
| Basque language, language, Basque speaker, Basque, learn | ||
| 15 Sports | talde, real, partida, irabazi, jokatu | 3.8 |
| team, real, match, win, play | ||
| 16 Gipuzkoa (Province) | tolosa, andoain, hernani, ordizi, beasain | 3.7 |
| (Cities in the province of Gipuzkoa) | ||
| 17 Media in Basque | @berria, @euskalirratia, @argia, @zebrabidea, @iehkohitza | 3.5 |
| 18 Donostia (City) | donostia, @donostiakoudala, ezagutu, gipuzkoa | 3.5 |
| Donostia, City Hall of Donostia, meet, Gipuzkoa | ||
| 19 Nafarroa (Province) | nafarroa, baztan, altsasu, irunerri, irun | 2.7 |
| (Cities in the province of Navarre) | ||
| 20 Bizkaia (Province) | larrabetzu, lekeitio, durango, bermeo, arrasate | 2.6 |
| (Cities in the province of Bizkaia) |
| Topics of Young Users | Representative Words in the Topic | % of Words |
|---|---|---|
| 1 Gipuzkera dialect (informal chat) | in, ne, oain, atxalde, biyar | 14.7 |
| do, mine, now, late, tomorrow | ||
| 2 Express feelings | maite, amets, gau, bizi, bihotz | 11.4 |
| love, dream, night, live, heart | ||
| 3 Bizkaiera dialect (informal chat) | dau, be, ein, dot, emun, bixar | 10.8 |
| is, also, do, have, give, tomorrow | ||
| 4 Sports | partidu, irabazi, jokatu, txapeldun, etapa | 9.9 |
| match, win, play, champion, stage | ||
| 5 Cultural activities | areto, antzoki, gaztetxe, tailer, kontzertu | 9.7 |
| halls, theaters, youth clubs, workshops, concerts | ||
| 6 To congratulate | zorion, pasatu, animo, eskerrikasko, polit | 9.3 |
| congratulations, pass, courage, thank you, nice | ||
| 7 Tell the life | jajaja, bihar, ohera, partido, ikasi | 7.6 |
| Hahaha, morning, to bed, party, study | ||
| 8 Bizkaiera dialect (formal chat) | dot, dau, barri, barik, be | 7.1 |
| have, is, new, without, too | ||
| 9 Gipuzkera dialect (formal chat) | det, ne, hoi, iruditu, irakurri | 7.1 |
| do, mine, that, seem, read | ||
| 10 Basque prisoners | herri, euskal, etxe, preso, gazte | 6.4 |
| people, Basque, house, prisoner, youth | ||
| 11 Athletic CB (football team) | aupa, athletic, @athletic, san mames, bilbo | 3.3 |
| 12 Rowing | sailkapen, jardunaldi, maila, txapelketa, estropada | 2.7 |
| classification, event, level, championship, regatta |
| Nationalist Left | News | Basque Language | Music and GED | Basque Users |
|---|---|---|---|---|
| @naiz_info | @berria | @zuzeu | @XMadariagaI | @boligorria |
| @HamaikaTb | @eitbAlbisteak | @KikeAmonarriz | @gaizkapenafiel | @zaldieroa |
| @larbelaitz | @euskaltelebista | @Sustatu | @JGGarai | @urtziurkizu |
| @topatu_eus | @euskadi_irratia | @Gaztezulo | @EsneBeltza | @landergarro |
| @axierL | @tolosaldeataria | @AEK_eus | @UrHanditan | @ielortza |
| Sports | Basque Language | Nationalist Left | News | Music |
|---|---|---|---|---|
| @berria | @enekogara | @naiz_info | @argia | @berritxarrak |
| @euskaltelebista | @GureEskuDago | @larbelaitz | @HamaikaTb | @gaztea |
| @iBROKI | @EsaldiakEuskara | @topatu_eus | @eitbAlbisteak | @izanpirata |
| @RealSociedad | @ZuriHidalgo | @ArnaldoOtegi | @MaddalenIriarte | @eitbeus |
| @XabierEuzkitze | @MeriLing1 | @ernaigazte | @ielortza | @LeakoHitza |
| Subgroups in Graph of Adult Users | % of Nodes |
| Nationalist left | 27.92 |
| News | 23.77 |
| Basque language | 15.34 |
| Music and GED | 13.56 |
| Basque tweeters | 13.10 |
| Subgroups in Graph of Young Users | % of Nodes |
| Sports | 21.61 |
| Basque language | 20.70 |
| Nationalist left | 17.12 |
| News | 14.92 |
| Music | 11.35 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernandez de Landa, J.; Agerri, R.; Alegria, I. Large Scale Linguistic Processing of Tweets to Understand Social Interactions among Speakers of Less Resourced Languages: The Basque Case. Information 2019, 10, 212. https://doi.org/10.3390/info10060212
Fernandez de Landa J, Agerri R, Alegria I. Large Scale Linguistic Processing of Tweets to Understand Social Interactions among Speakers of Less Resourced Languages: The Basque Case. Information. 2019; 10(6):212. https://doi.org/10.3390/info10060212
Chicago/Turabian StyleFernandez de Landa, Joseba, Rodrigo Agerri, and Iñaki Alegria. 2019. "Large Scale Linguistic Processing of Tweets to Understand Social Interactions among Speakers of Less Resourced Languages: The Basque Case" Information 10, no. 6: 212. https://doi.org/10.3390/info10060212
APA StyleFernandez de Landa, J., Agerri, R., & Alegria, I. (2019). Large Scale Linguistic Processing of Tweets to Understand Social Interactions among Speakers of Less Resourced Languages: The Basque Case. Information, 10(6), 212. https://doi.org/10.3390/info10060212