Computation Offloading Strategy in Mobile Edge Computing


Abstract
:1. Introduction
2. Offloading Policy Model
3. Offloading Decision Model
3.1. Time-Consuming and Energy Consumption Model for Local Execution
3.2. Time-Consuming Model and Energy Consumption Model for Offloading Execution
3.3. Decision-Making Basis for Offloading
4. Server Selection Model Based on Improved AHP
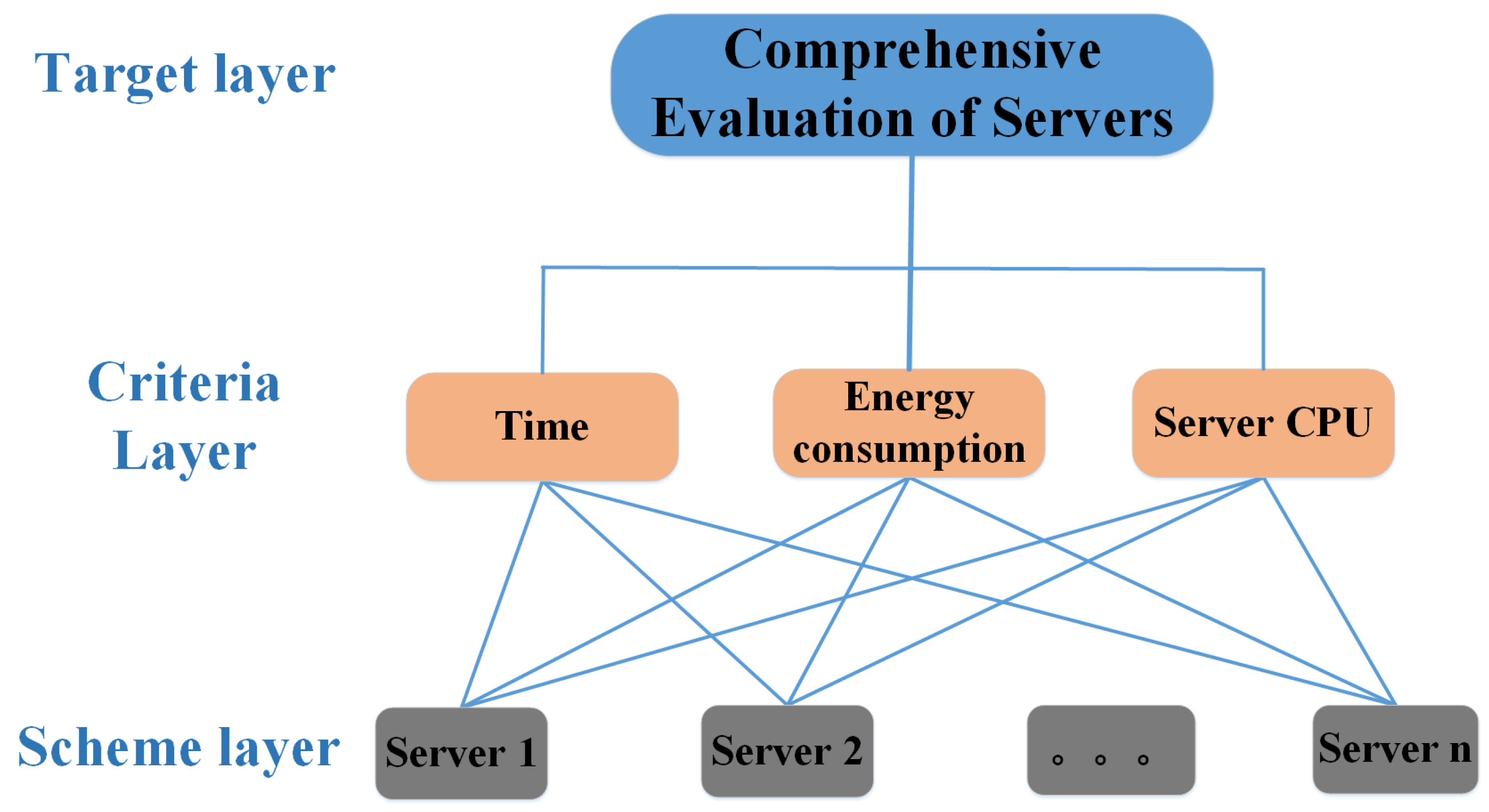
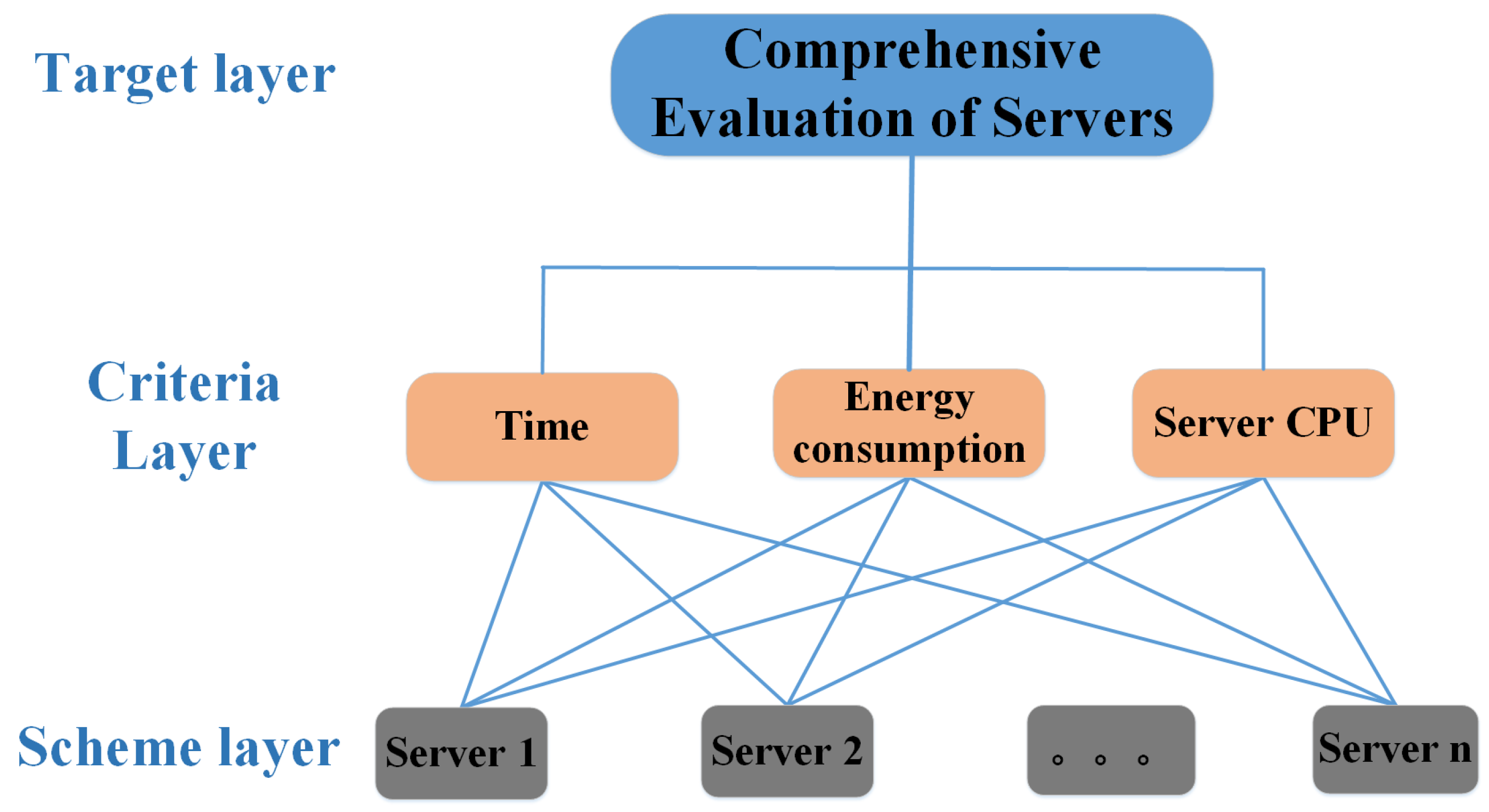
4.1. Hierarchical Model
4.2. Pairwise Comparison Matrix
4.3. Integration of Server Evaluation Indicators
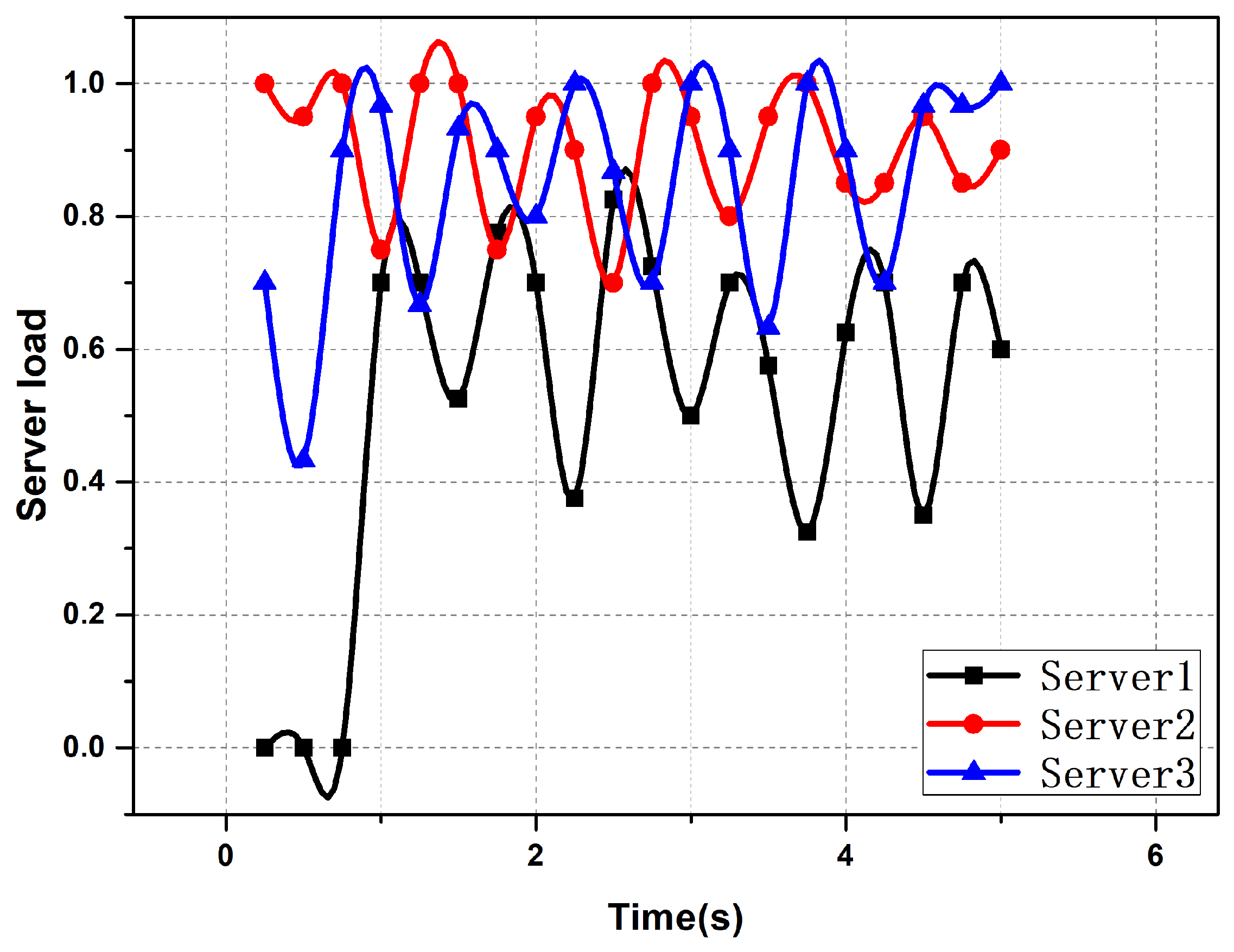
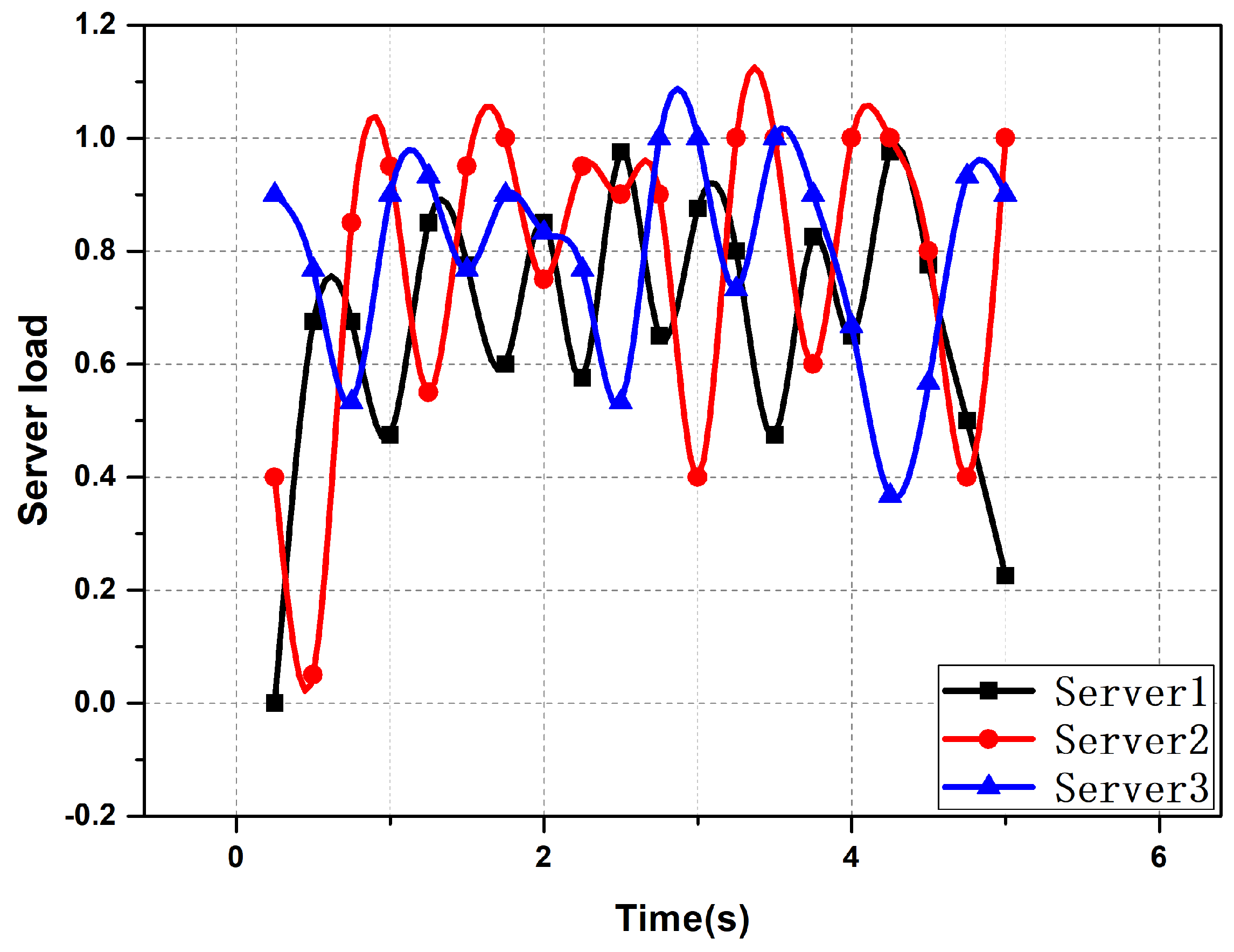
5. Task Scheduling Based on the Improved Auction Algorithm
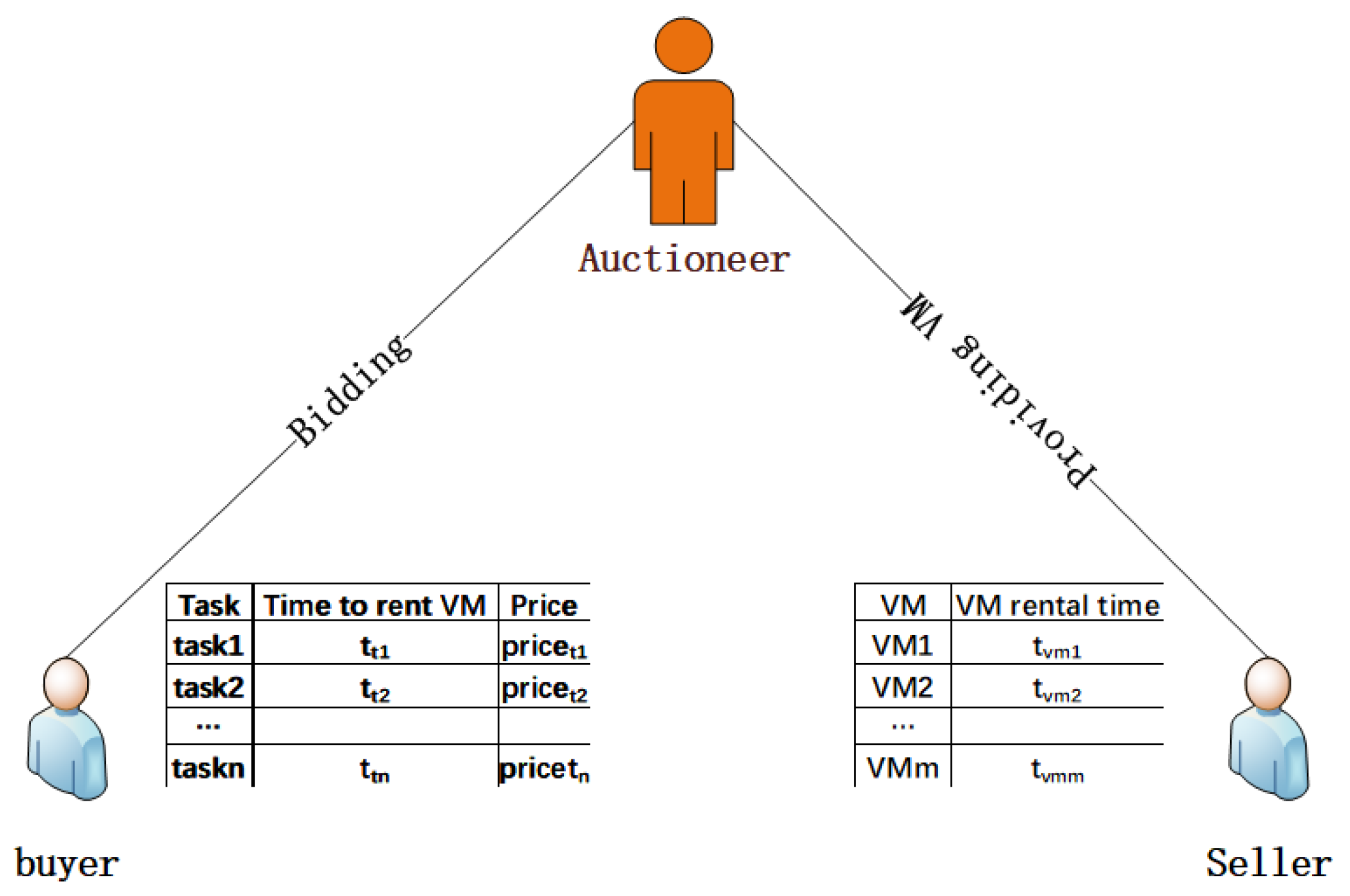
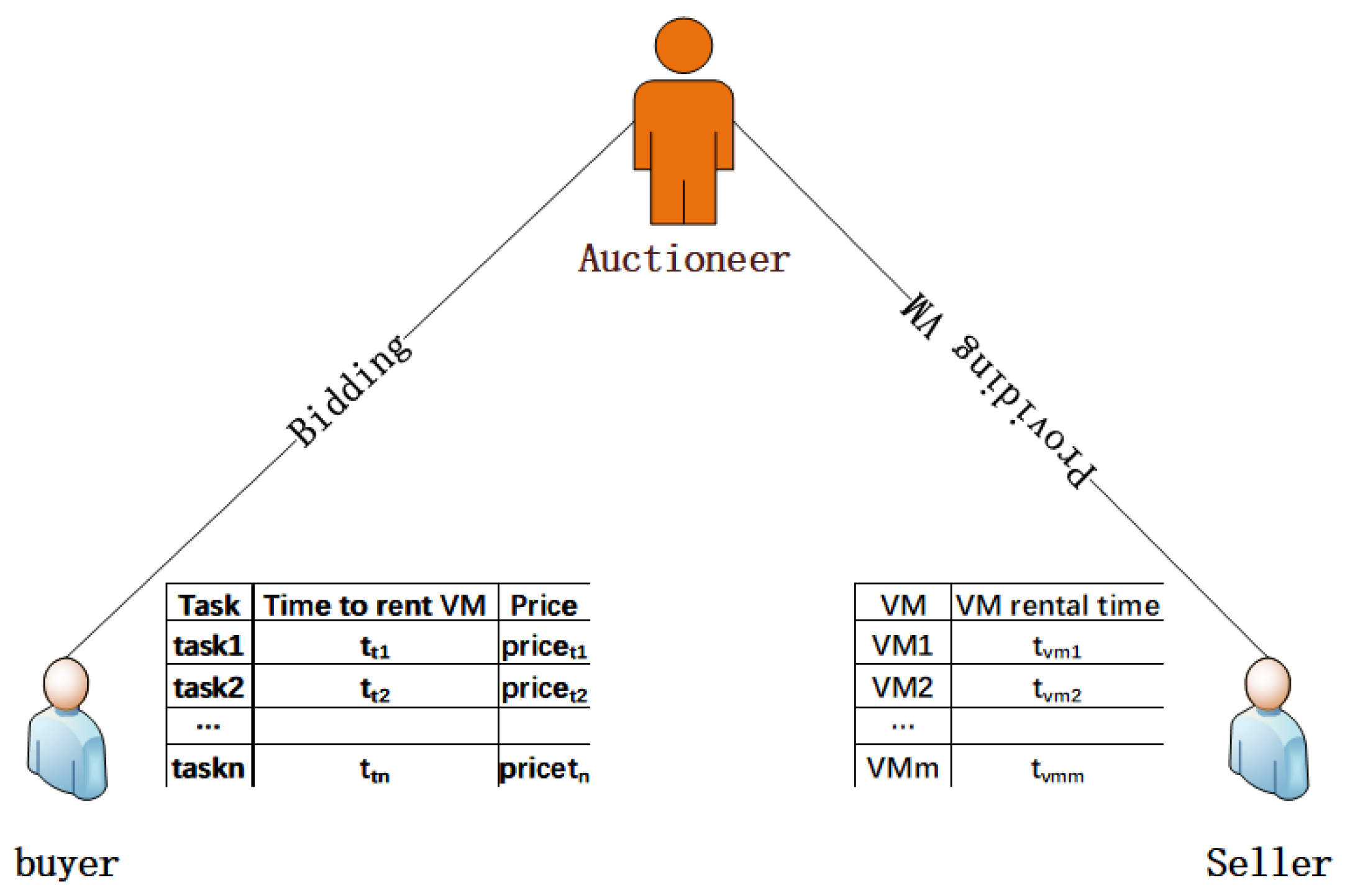
5.1. Auction Models and Formalization of Problems
5.2. Improved Auction Algorithms
5.3. Auction Compensation Strategy
| Algorithm 1 One-Round Auction Algorithms for Multi-Tasking and Multi-Virtual Machines. |
| Input: Tasks and Participating in Auctions Output: Tasks of unsuccessful bidding
|
6. Experiments and Results Analysis
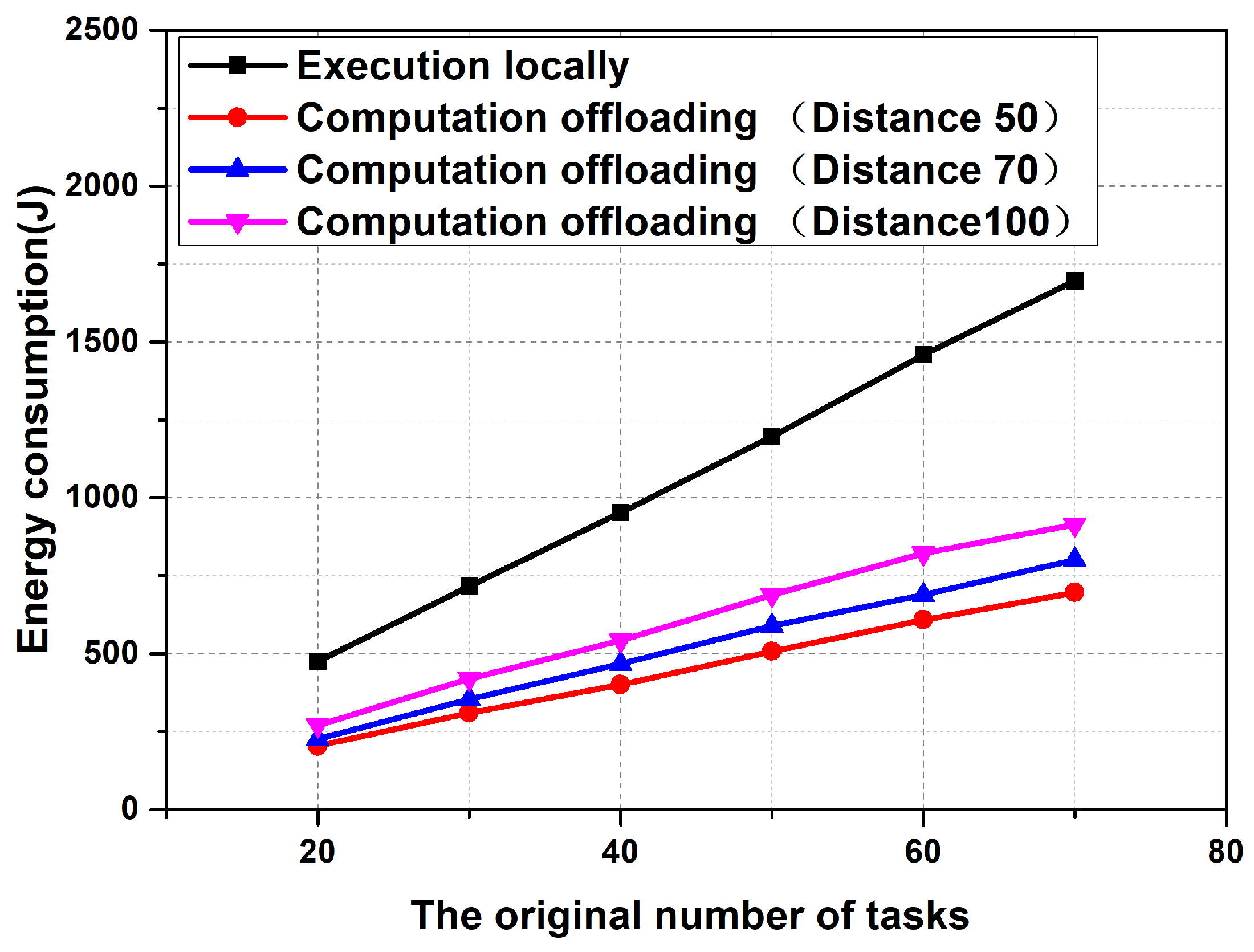
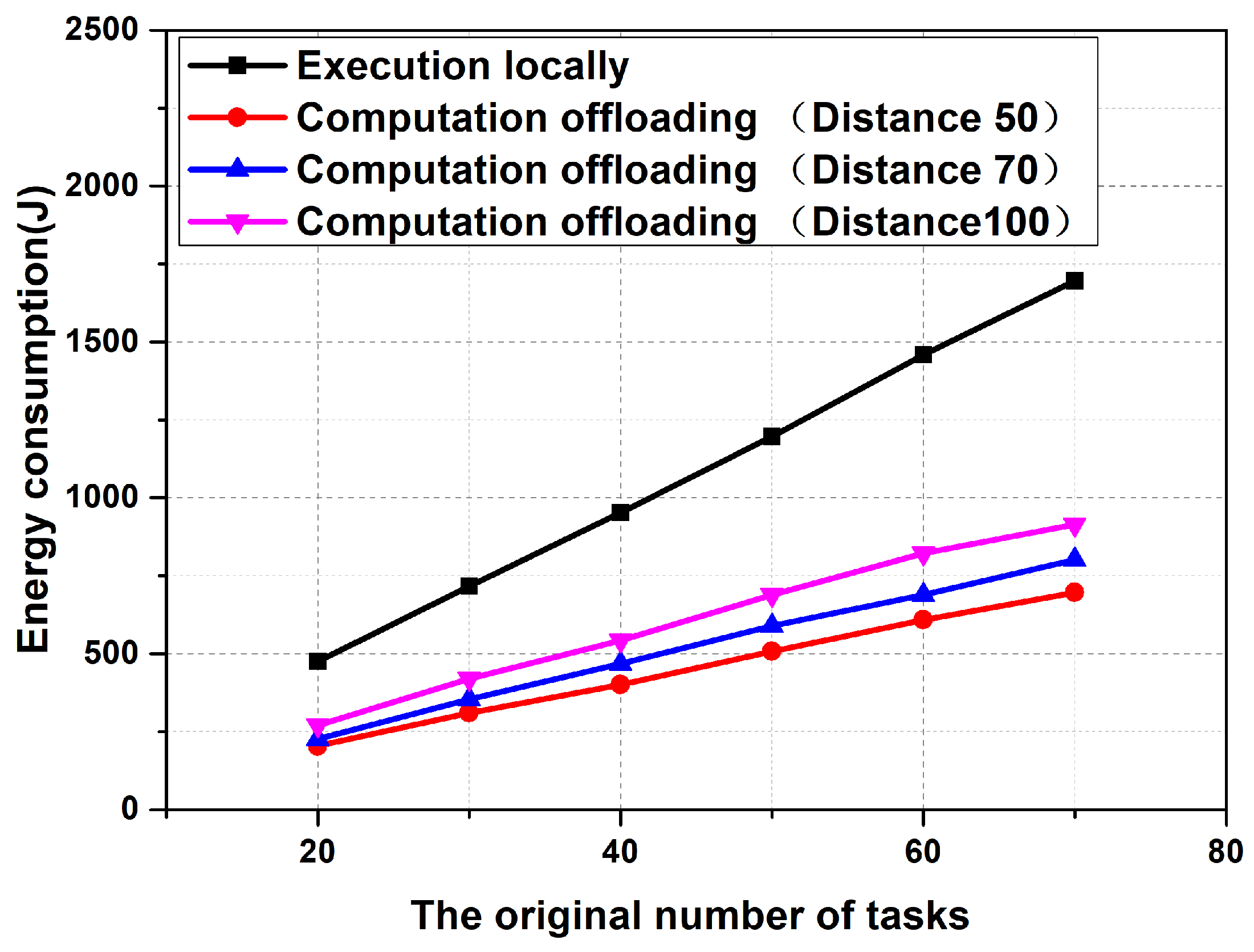
6.1. Energy Consumption Comparison between Task Offloading Computation and Local Execution
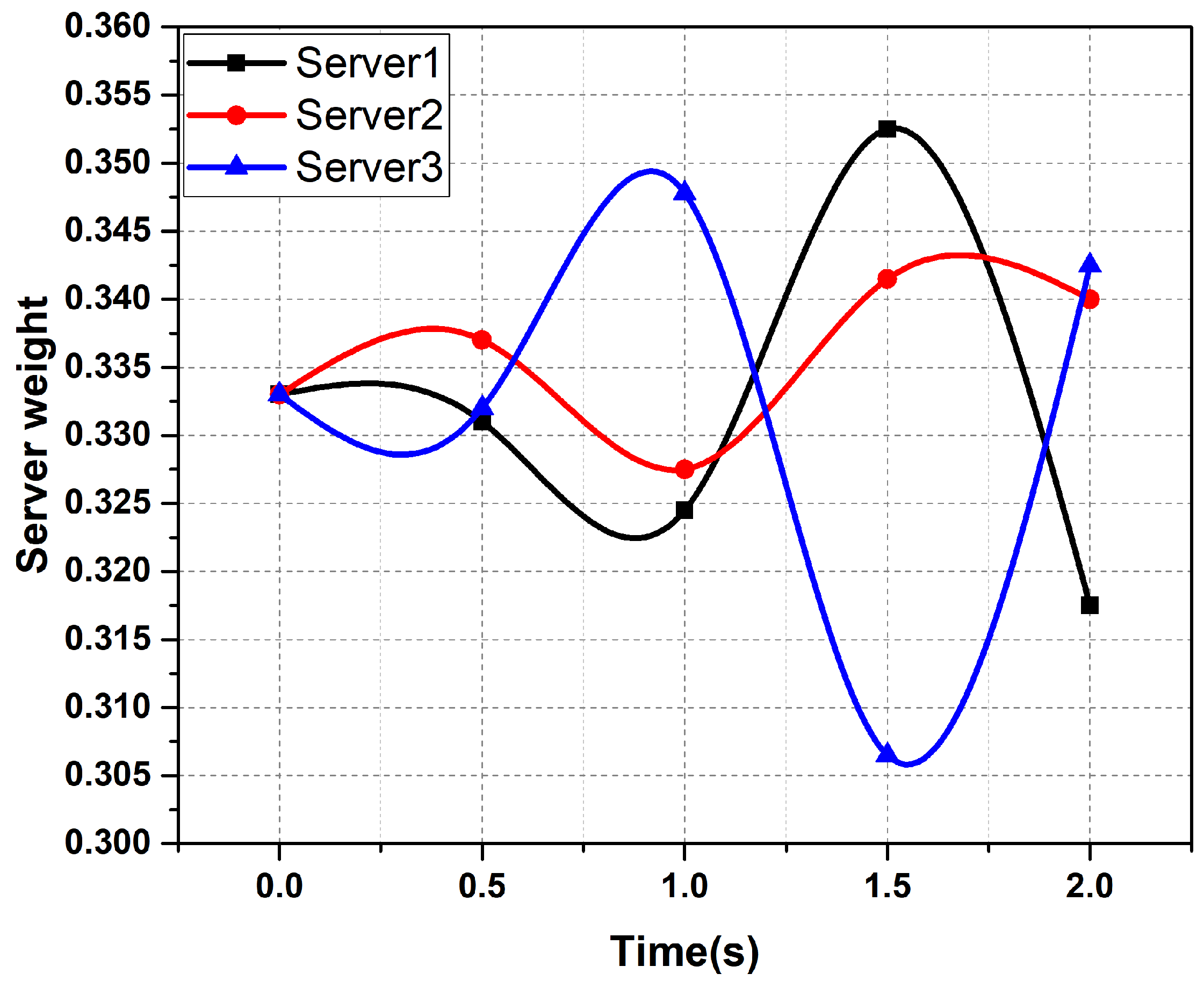
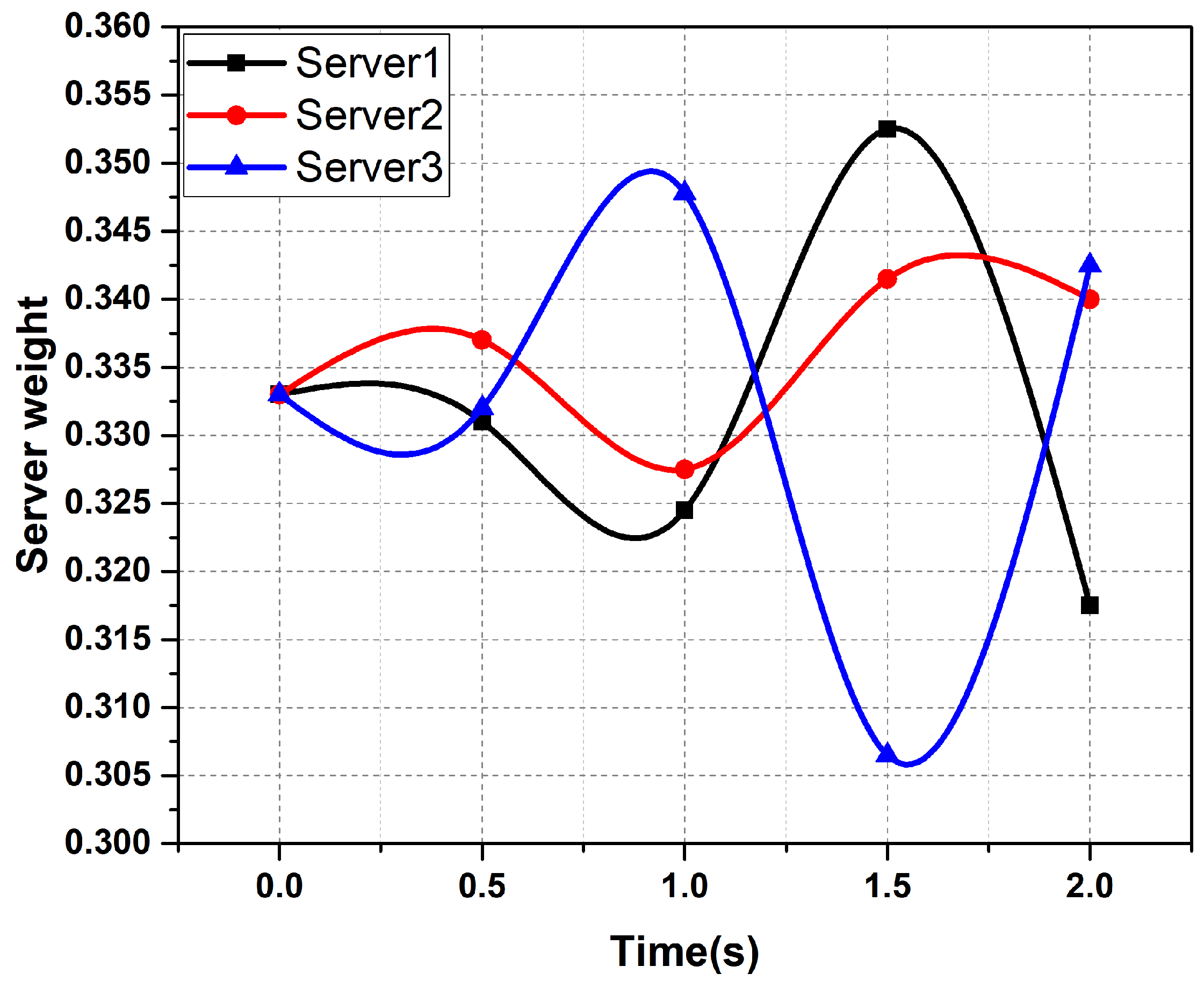
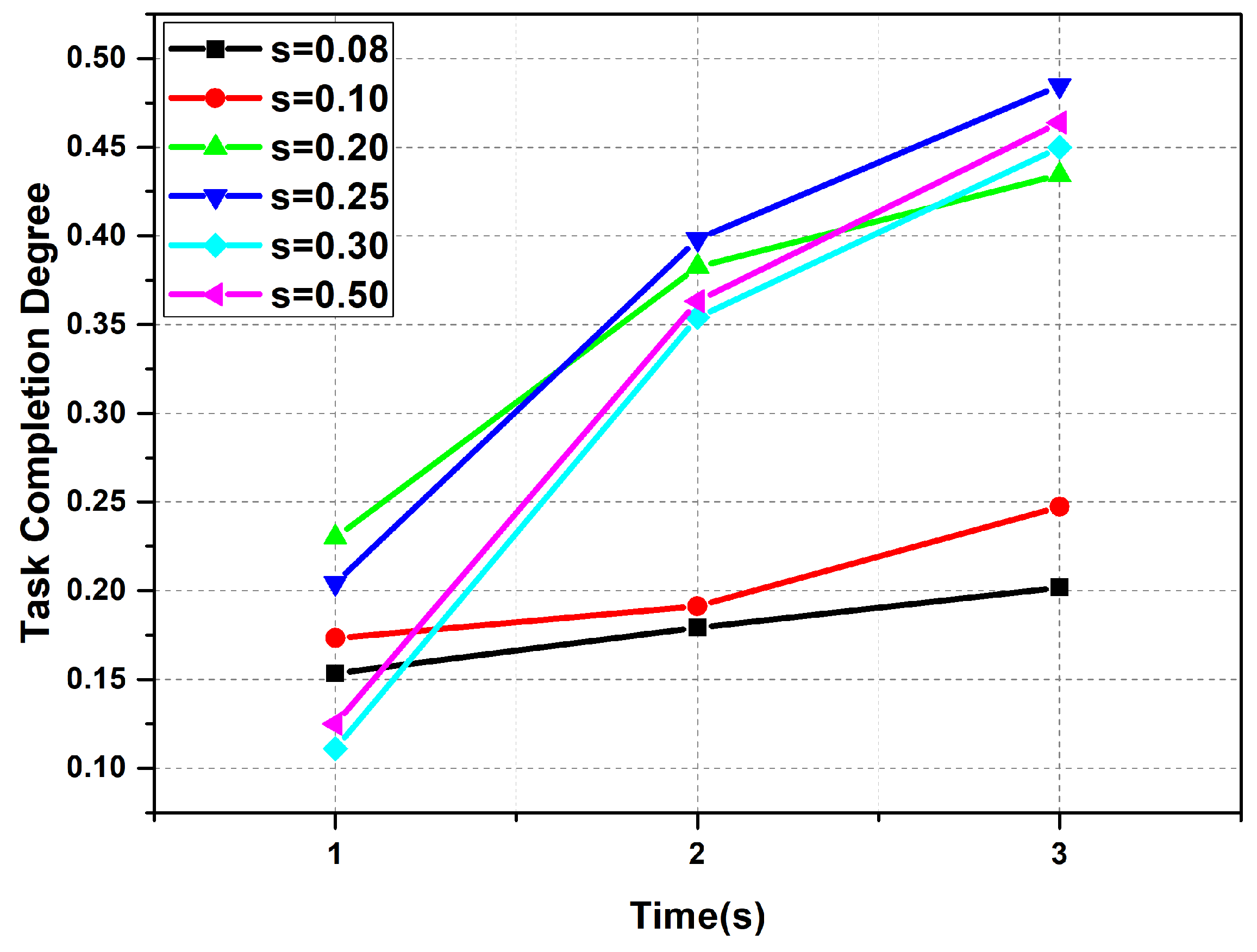
6.2. Performance Improvement of AHP Algorithms
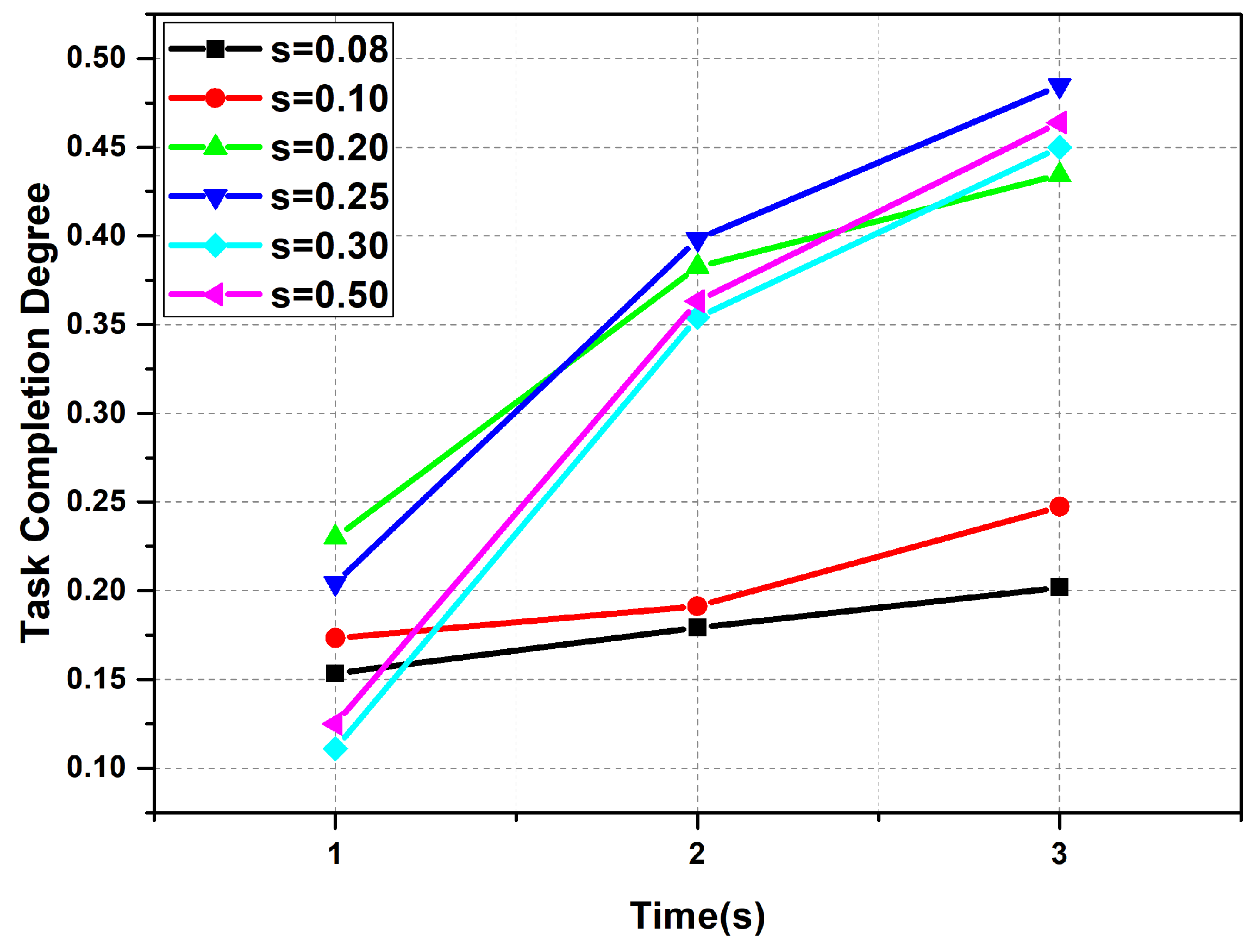
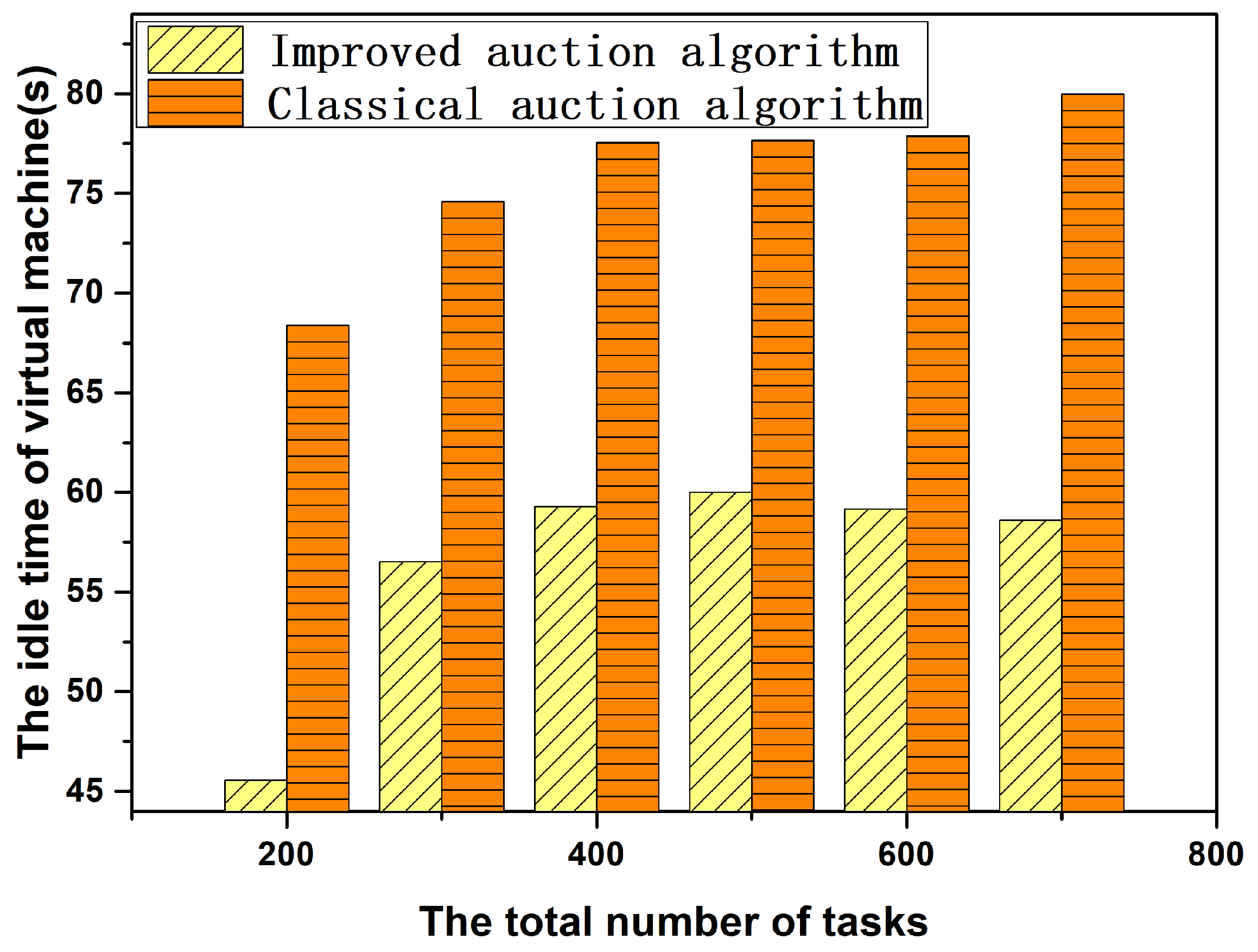
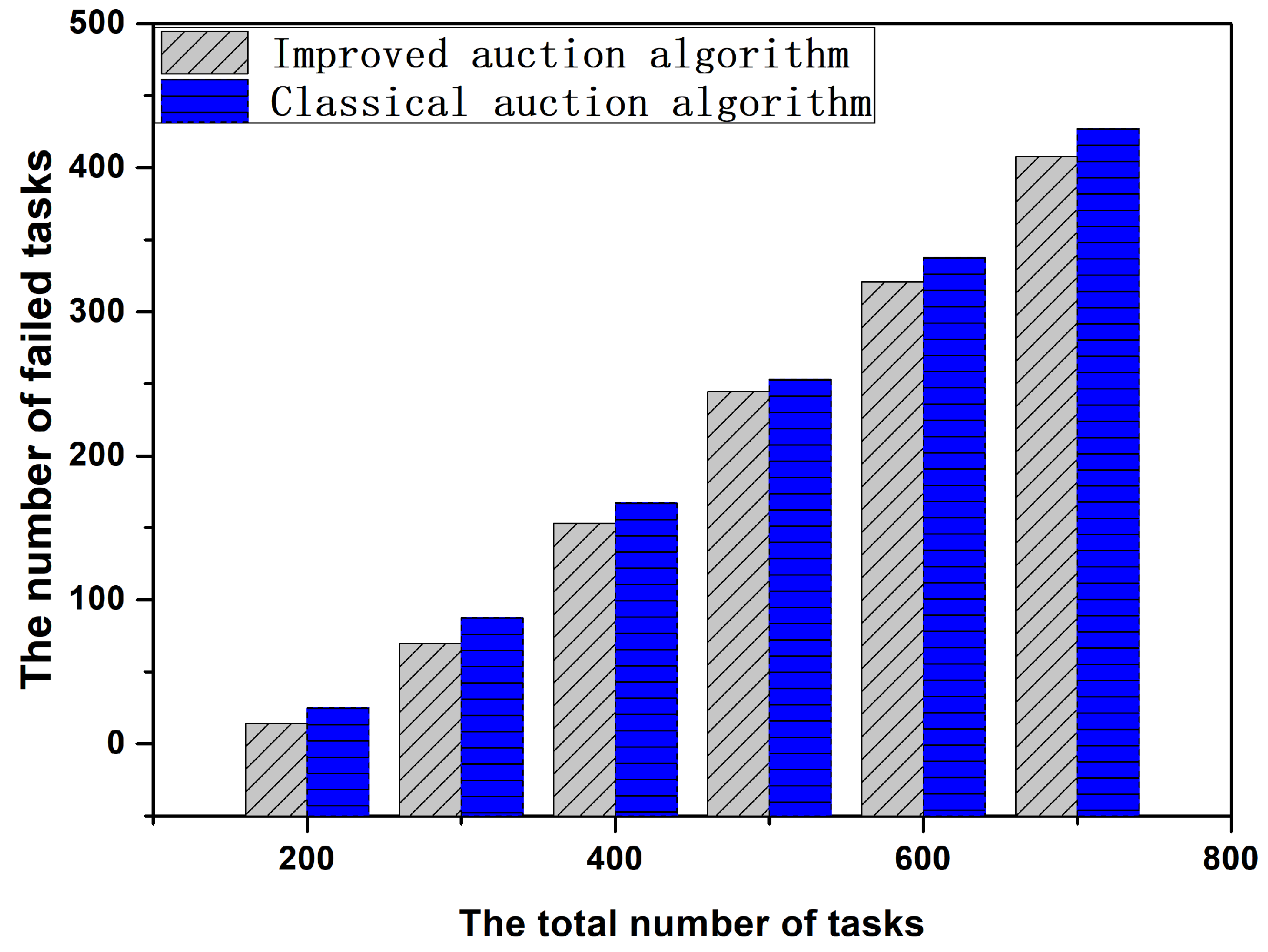
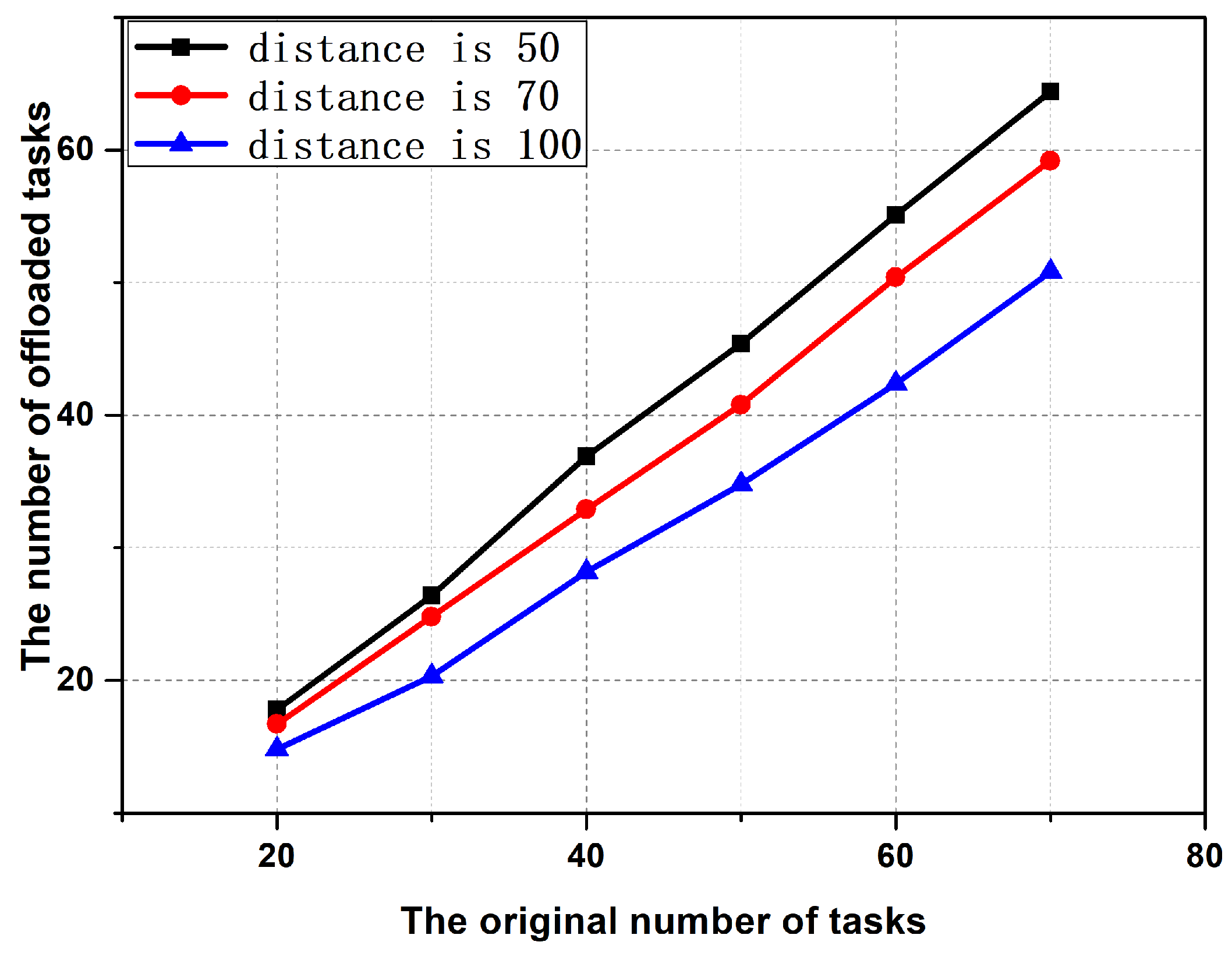
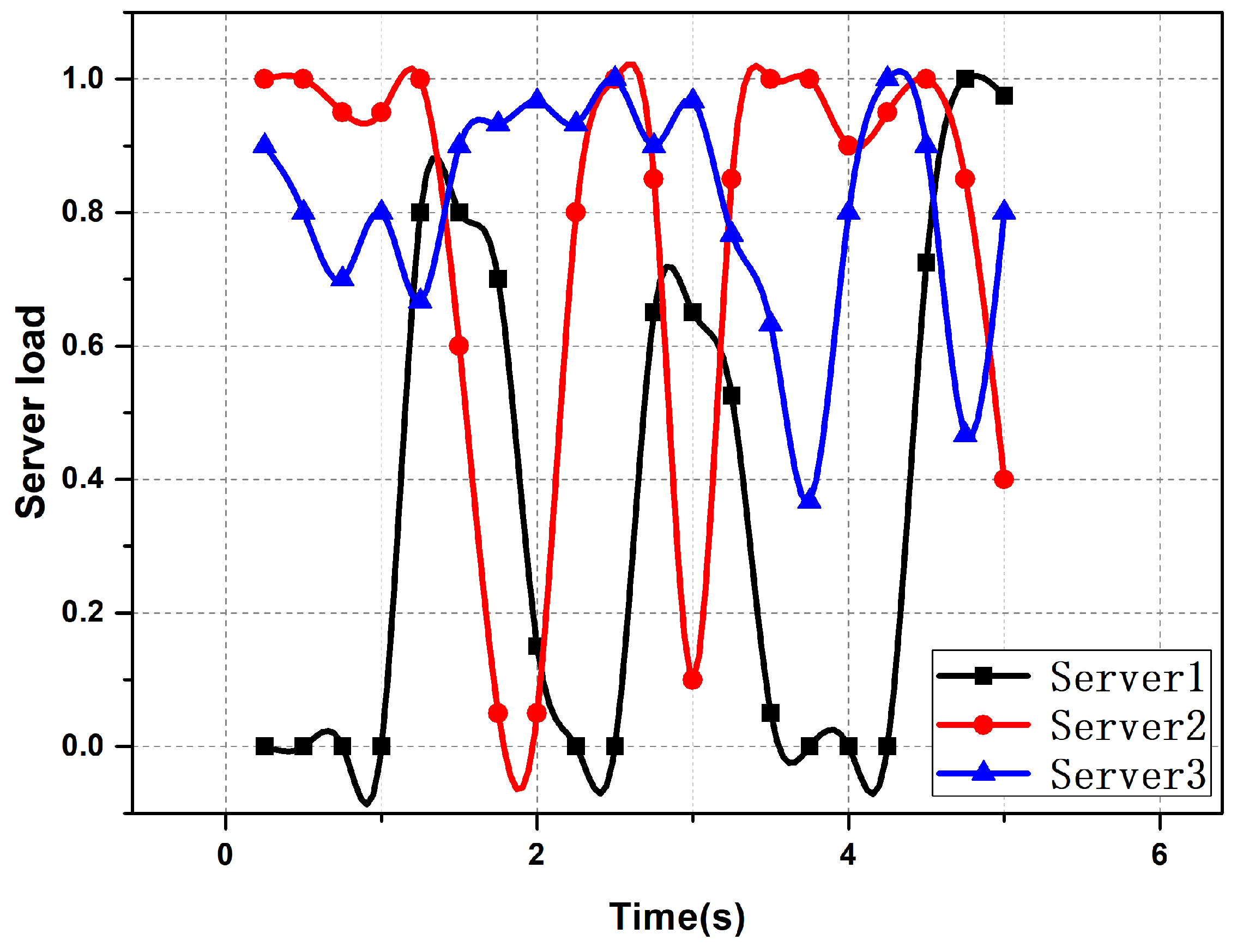
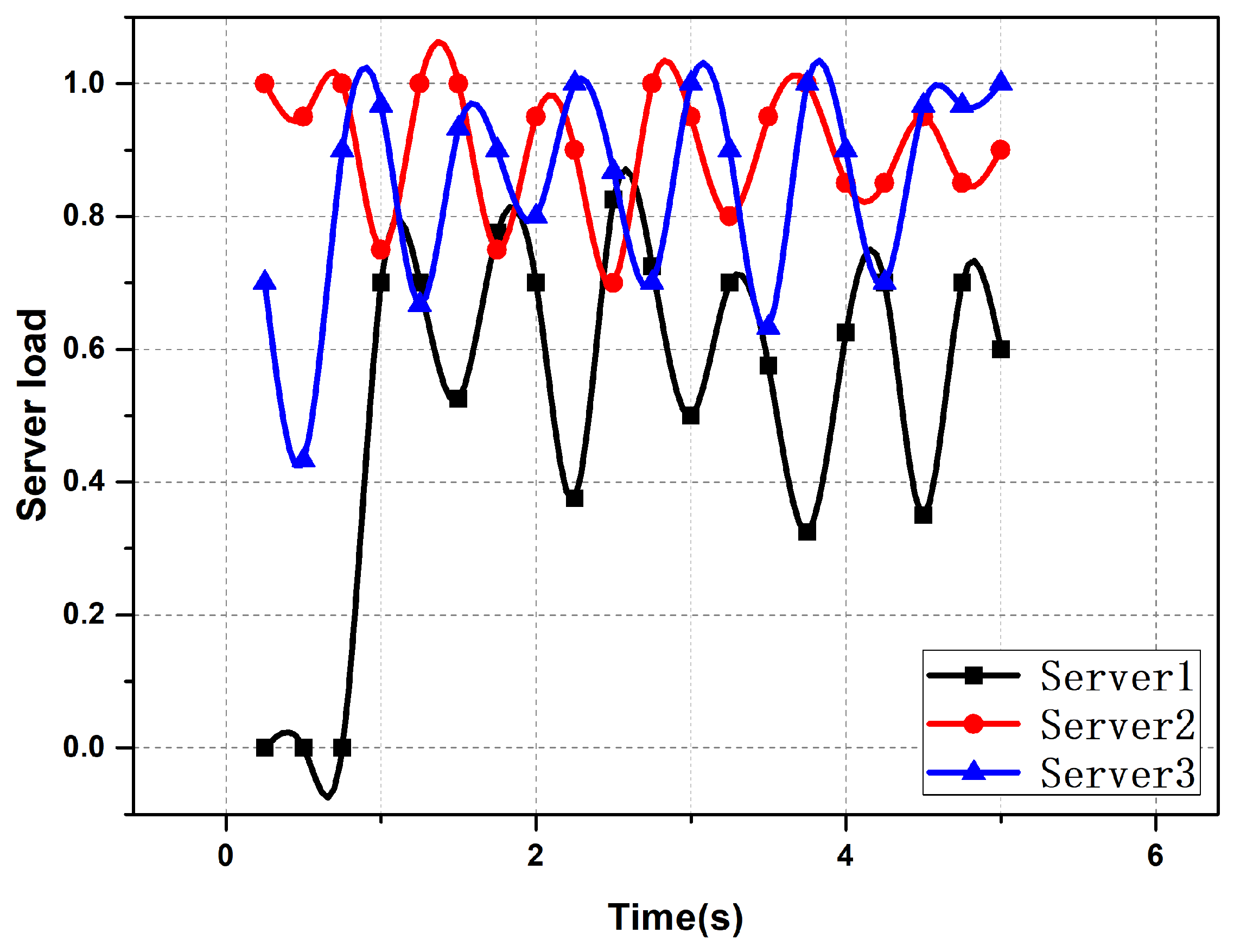
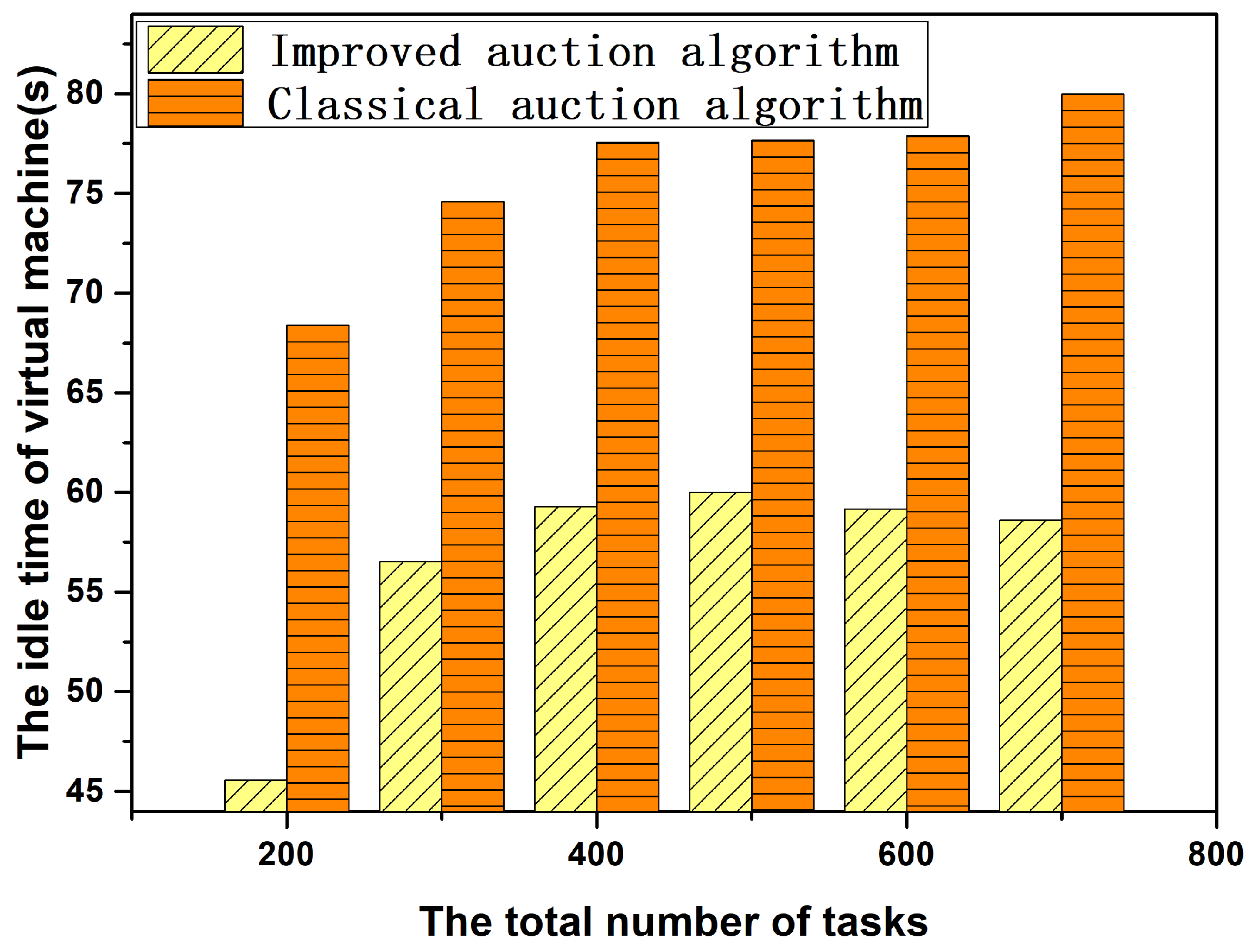
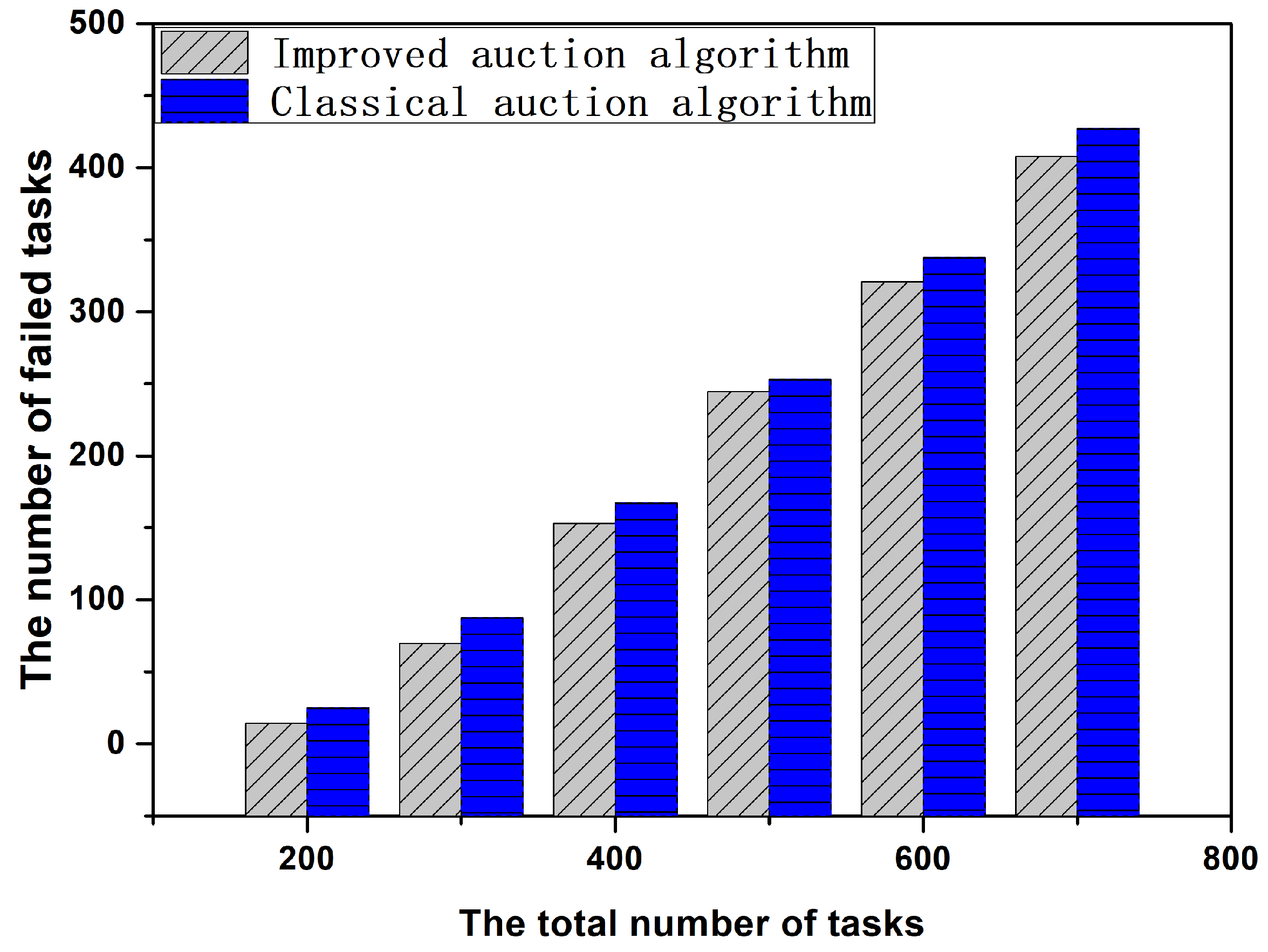
6.3. Performance Comparison between Improved Auction Algorithm and Classical Auction Algorithm
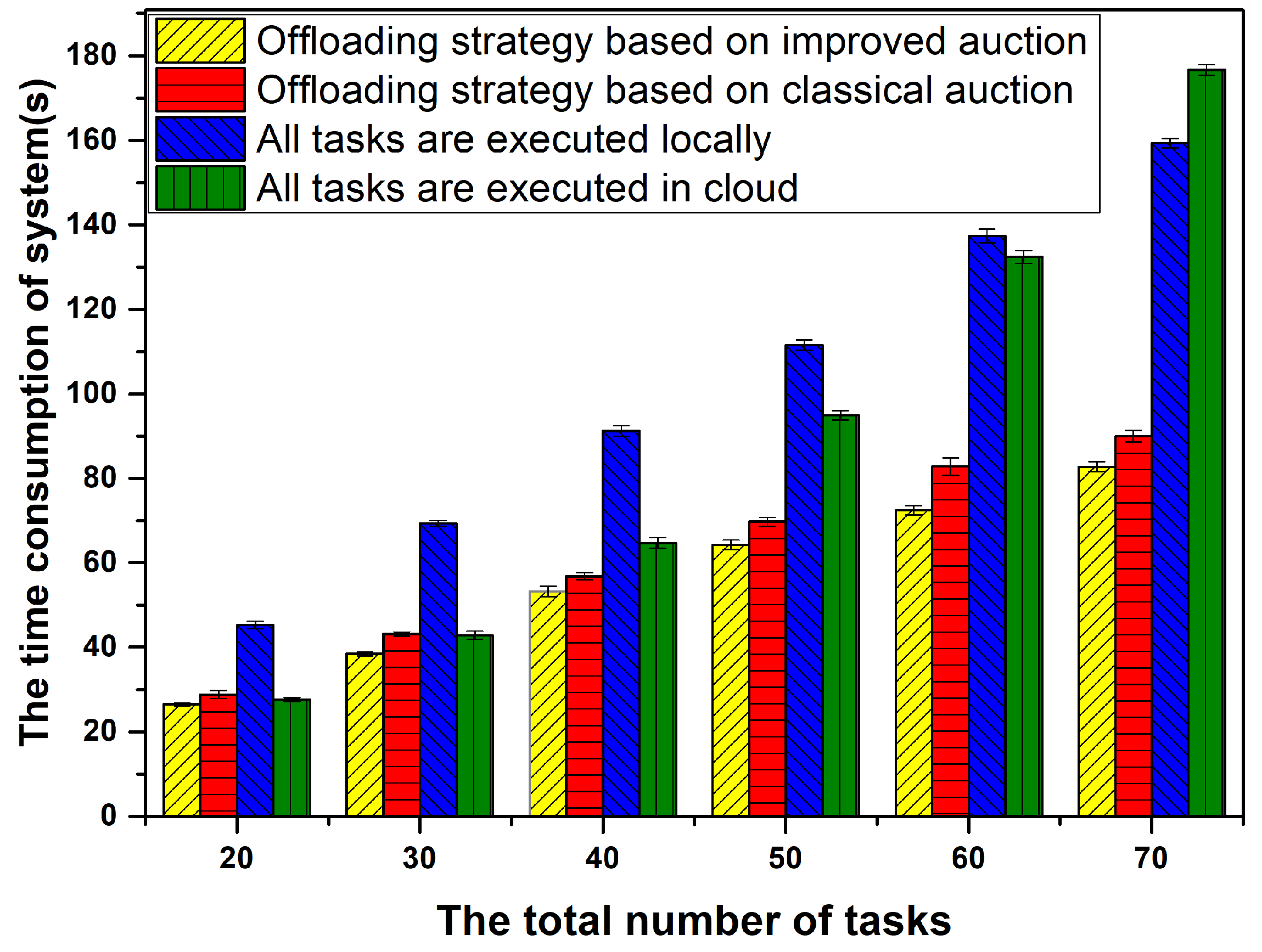
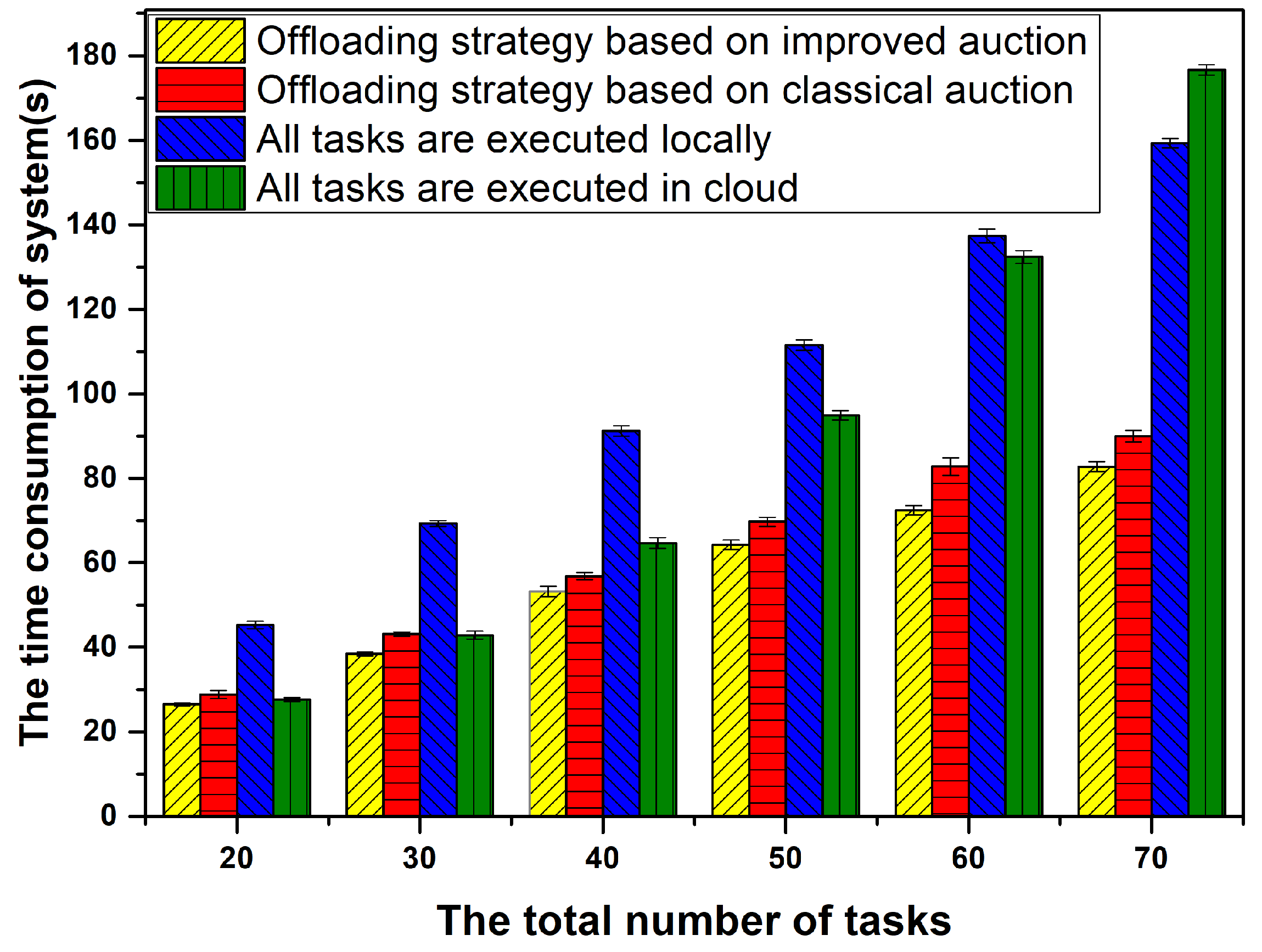
6.4. Comparison of Time Consumption between Offloading Decision Based on Improved Auction and other Methods
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kumar, K.; Liu, J.; Lu, Y.H.; Bhargava, B. A survey of computation offloading for mobile systems. Mob. Netw. Appl. 2013, 18, 129–140. [Google Scholar] [CrossRef]
- Sharifi, M.; Kafaie, S.; Kashefi, O. A survey and taxonomy of cyber foraging of mobile devices. IEEE Commun. Surv. Tutor. 2012, 14, 1232–1243. [Google Scholar] [CrossRef]
- Cuervo, E.; Balasubramanian, A.; Cho, D.; Wolman, A.; Saroiu, S.; Chandra, R. MAUI: Making smartphones last longer with code offload. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services, San Francisco, CA, USA, 15–18 June 2010. [Google Scholar]
- Kosta, S.; Aucinas, A.; Hui, P.; Mortier, R.; Zhang, X. Thinkair: Dynamic resource allocation and parallel execution in the cloud for mobile code offloading. In Proceedings of the T2012 Proceedings IEEE Infocom, Orlando, FL, USA, 25–30 March 2012; pp. 945–953. [Google Scholar]
- Xia, F.; Ding, F.; Li, J.; Kong, X.; Yang, L.T.; Ma, J. Phone2Cloud: Exploiting computation offloading for energy saving on smartphones in mobile cloud computing. Inf. Syst. Front. 2014, 16, 95–111. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- You, C.; Huang, K.; Chae, H.; Kim, B. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Trans. Wirel. Commun. 2017, 16, 1397–1411. [Google Scholar] [CrossRef]
- Deng, M.; Tian, H.; Lyu, X. Adaptive sequential offloading game for multi-cell mobile edge computing. In Proceedings of the 2016 23rd International Conference on Telecommunications (ICT), Thessaloniki, Greece, 16–18 May 2016; pp. 1–5. [Google Scholar]
- Fernando, N.; Loke, S.W.; Rahayu, W. Mobile cloud computing: A survey. Future Gener. Comput. Syst. 2013, 29, 84–106. [Google Scholar] [CrossRef]
- Rahman, M.; Gao, J.; Tsai, W.T. Energy Saving Research on Mobile Cloud Computing in 5G. Chin. J. Comput. 2017. [Google Scholar] [CrossRef]
- Sanaei, Z.; Abolfazli, S.; Gani, A.; Buyya, R. Heterogeneity in mobile cloud computing: taxonomy and open challenges. IEEE Commun. Surv. Tutor. 2014, 16, 369–392. [Google Scholar] [CrossRef]
- Orsini, G.; Bade, D.; Lamersdorf, W. Computing at the Mobile Edge: Designing Elastic Android Applications for Computation Offloading. In Proceedings of the Ifip Wireless & Mobile Networking Conference, Colmar, France, 11–13 July 2016. [Google Scholar]
- Zhang, W.; Wen, Y.; Wu, D.O. Collaborative Task Execution in Mobile Cloud Computing Under a Stochastic Wireless Channel. IEEE Trans. Wirel. Commun. 2015, 14, 81–93. [Google Scholar] [CrossRef]
- Min, C.; Hao, Y.; Yong, L.; Lai, C.F.; Di, W. On the computation offloading at ad hoc cloudlet: architecture and service modes. IEEE Commun. Mag. 2015, 53, 18–24. [Google Scholar]
- Satyanarayanan, M.; Bahl, P.; Caceres, R.; Davies, N. The case for vm-based cloudlets in mobile computing. IEEE Pervasive Comput. 2009, 8, 14–23. [Google Scholar] [CrossRef]
- Ziming, Z.; Fang, L.; Zhiping, C.; Nong, X. Edge Computing:Platforms, Applications and Challenges. J. Comput. Res. Dev. 2018, 55, 327–337. [Google Scholar]
- Sun, X.; Ansari, N. Latency Aware Workload Offloading in the Cloudlet Network. IEEE Commun. Lett. 2018, 21, 1481–1484. [Google Scholar] [CrossRef]
- Shi, Y.; Sun, H.; Cao, J. Edge Computing: A New Computing Model in the Age of Internet of Things. J. Comput. Res. Dev. 2017, 54, 907–924. [Google Scholar]
- Zhang, Y.; Niyato, D.; Wang, P. Offloading in mobile cloudlet systems with intermittent connectivity. IEEE Trans. Mob. Comput. 2015, 14, 2516–2529. [Google Scholar] [CrossRef]
- Jia, M.; Cao, J.; Liang, W. Optimal cloudlet placement and user to cloudlet allocation in wireless metropolitan area networks. IEEE Trans. Cloud Comput. 2017, 5, 725–737. [Google Scholar] [CrossRef]
- Sardellitti, S.; Scutari, G.; Barbarossa, S. Joint optimization of radio and computational resources for multicell mobile-edge computing. IEEE Trans. Signal Inf. Process. Over Netw. 2015, 1, 89–103. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Taleb, T.; Samdanis, K.; Mada, B.; Flinck, H.; Dutta, S.; Sabella, D. On Multi-Access Edge Computing: A Survey of the Emerging 5G Network Edge Architecture & Orchestration. IEEE Commun. Surv. Tutor. 2017, 19, 1657–1681. [Google Scholar]
- Yu, Y. Mobile Edge Computing Towards 5G: Vision, Recent Progress, and Open Challenges. China Commun. 2017, 13, 89–99. [Google Scholar] [CrossRef]
- Tian, H.; Fan, S.; Lyu, Y. Mobile Edge Computing for 5G Demand. J. Beijing Univ. Posts Telecommun. 2017, 42, 1–10. [Google Scholar]
- Li, W.; Wang, B.; Sheng, J.; Dong, K.; Li, Z. A resource service model in the industrial iot system based on transparent computing. Sensors 2018, 18, 981. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.; Ahmed, E. A Survey on Mobile Edge Computing. In Proceedings of the 10th IEEE International Conference on Intelligent Systems and Control, Coimbatore, India, 7–8 January 2016. [Google Scholar]
- Wang, S.; Xing, Z.; Yan, Z.; Lin, W.; Yang, J.; Wang, W. A Survey on Mobile Edge Networks: Convergence of Computing, Caching and Communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient multi-user computation offloading for mobile-edge cloud computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef]
- Cheng, K.; Teng, Y.; Sun, W.; Liu, A.; Wang, X. Energy-Efficient Joint Offloading and Wireless Resource Allocation Strategy in Multi-MEC Server Systems. In Proceedings of the IEEE ICC, Kansas City, MO, USA, 20–24 May 2018. [Google Scholar]
- Shi, C.; Habak, K.; Pandurangan, P.; Ammar, M.; Naik, M.; Zegura, E. COSMOS: Computation offloading as a service for mobile devices. In Proceedings of the IAcm Mobihoc, Philadelphia, PA, USA, 11–14 August 2014. [Google Scholar]
- Lyu, X.; Tian, H.; Zhang, P.; Sengul, C. Multiuser joint task offloading and resource optimization in proximate clouds. IEEE Trans. Veh. Technol. 2017, 66, 3435–3447. [Google Scholar] [CrossRef]
- Yu, B.; Pu, L.; Xie, Y. Research on mobile edge computing task offloading and base station association collaborative decision making problem. J. Comput. Res. Dev. 2018, 55, 537–550. [Google Scholar]
- Yang, L.; Cao, J.; Cheng, H.; Ji, Y. Multi-User Computation Partitioning for Latency Sensitive Mobile Cloud Applications. IEEE Trans. Comput. 2015, 64, 2253–2266. [Google Scholar] [CrossRef]
- Huerta-Canepa, G.; Lee, D. An Adaptable Application Offloading Scheme Based on Application Behavior. In Proceedings of the 22nd International Conference on Advanced Information Networking and Applications, Okinawa, Japan, 25–28 March 2008. [Google Scholar]
- Wen, Y.; Zhang, W.; Luo, H. Energy-optimal mobile application execution: Taming resource-poor mobile devices with cloud clones. In Proceedings of the IEEE Infocom, Orlando, FL, USA, 25–30 March 2012. [Google Scholar]
- Lin, X.; Zhang, H.; Ji, H.; Leung, V.C.M. Joint computation and communication resource allocation in mobile-edge cloud computing networks. In Proceedings of the 2016 IEEE International Conference on Network Infrastructure and Digital Content (IC-NIDC), Beijing, China, 23–25 September 2016; pp. 166–171. [Google Scholar]
- Huang, D.; Wang, P.; Niyato, D. A dynamic offloading algorithm for mobile computing. IEEE Trans. Wirel. Commun. 2012, 11, 1991–1995. [Google Scholar] [CrossRef]
- Rappaport, T.S. Wireless Communications: Principles And Practice; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Muraleedharan, R. Cloud-vision: Real-time face recognition using a mobile-cloudlet-cloud acceleration architecture. In Proceedings of the 2012 IEEE Symposium on Computers and Communications (ISCC), Cappadocia, Turkey, 1–4 July 2012; pp. 59–66. [Google Scholar]
- Zhao, T.; Zhou, S.; Zhao, Y.; Niu, Z. A cooperative scheduling scheme of local cloud and Internet cloud for delay-aware mobile cloud computing. In Proceedings of the IEEE Globecom Workshops, San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Oueis, J.; Strinati, E.C.; Barbarossa, S. Small cell clustering for efficient distributed cloud computing. IEEE Annu. 2014, 1474–1479. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scaling | Meaning |
|---|---|
| 1 | The former is more important than the latter as the numerical value increases. |
| 1.2 | |
| 1.4 | |
| 1.6 | |
| 1.8 | |
| reciprocal | If the importance ratio of factor i to factor j is , then the importance ratio of factor j to factor i is . |
| Server | CPU Computing Speed (GHZ) | Bandwidth (M) | Number of VM |
|---|---|---|---|
| Server1 | 8 | 5 | 40 |
| Server2 | 10 | 7 | 20 |
| Server3 | 12 | 4 | 30 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, J.; Hu, J.; Teng, X.; Wang, B.; Pan, X. Computation Offloading Strategy in Mobile Edge Computing. Information 2019, 10, 191. https://doi.org/10.3390/info10060191
Sheng J, Hu J, Teng X, Wang B, Pan X. Computation Offloading Strategy in Mobile Edge Computing. Information. 2019; 10(6):191. https://doi.org/10.3390/info10060191
Chicago/Turabian StyleSheng, Jinfang, Jie Hu, Xiaoyu Teng, Bin Wang, and Xiaoxia Pan. 2019. "Computation Offloading Strategy in Mobile Edge Computing" Information 10, no. 6: 191. https://doi.org/10.3390/info10060191
APA StyleSheng, J., Hu, J., Teng, X., Wang, B., & Pan, X. (2019). Computation Offloading Strategy in Mobile Edge Computing. Information, 10(6), 191. https://doi.org/10.3390/info10060191